introduction to data analysis why do we analyze data? make sense of data we have collected basic...
TRANSCRIPT

Introduction to Data Analysis
Why do we analyze data? Make sense of data we have collected
Basic steps in preliminary data analysis Editing Coding Tabulating

Introduction to Data Analysis
Editing of data Impose minimal quality standards on the raw data
Field Edit -- preliminary edit, used to detect glaring omissions and inaccuracies (often involves respondent follow up) Completeness Legibility Comprehensibility Consistency Uniformity

Introduction to Data Analysis
Central office edit More complete and exacting edit
Best performed by a number of editors, each looking at one part of the data
Decision on how to handle item non-response and other omissions need to be made List-wise deletion (drop for all analyses) vs. case-wise
deletion (drop only for present analysis)

Introduction to Data Analysis
Coding -- transforming raw data into symbols (usually numbers) for tabulating, counting, and analyzing Must determine categories
Completely exhaustive Mutually exclusive
Assign numbers to categories Make sure to code an ID number for each
completed instrument

Introduction to Data Analysis
Tabulation -- counting the number of cases that fall into each category Initial tabulations should be preformed for each
item One-way tabulations
Determines degree of item non-response Locates errors Locates outliers Determines the data distribution

Preliminary Data Analysis
Tabulation Simple Counts For example
74 families in the study own 1 car
2 families own 3
Missing data (9) 1 Family did not report Not useful for further
analysis
Number of Cars
Number of Families
1 75
2 23
3 2
9 1
Total 101
Preliminary Data Analysis
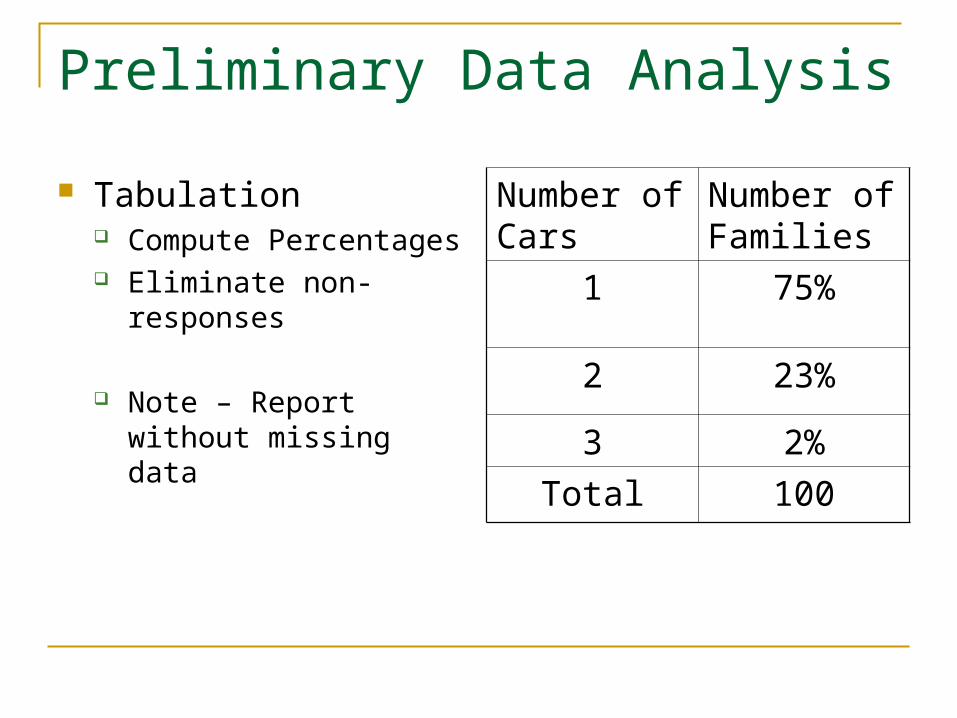
Tabulation Compute Percentages Eliminate non-responses
Note – Report without missing data
Number of Cars
Number of Families
1 75%
2 23%
3 2%
Total 100
Preliminary Data Analysis
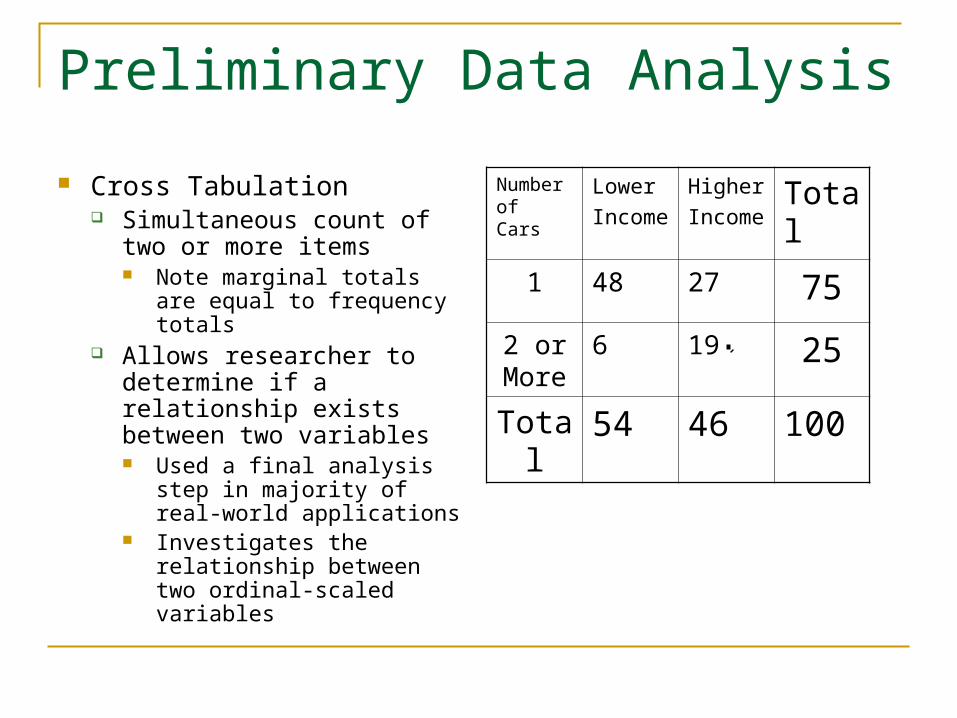
Cross Tabulation Simultaneous count of two
or more items Note marginal totals are
equal to frequency totals Allows researcher to
determine if a relationship exists between two variables Used a final analysis step in
majority of real-world applications
Investigates the relationship between two ordinal-scaled variables
Number of Cars
Lower
Income
Higher
IncomeTotal
1 48 27 75
2 or More
6 19 25
Total 54 46 100
Preliminary Data Analysis
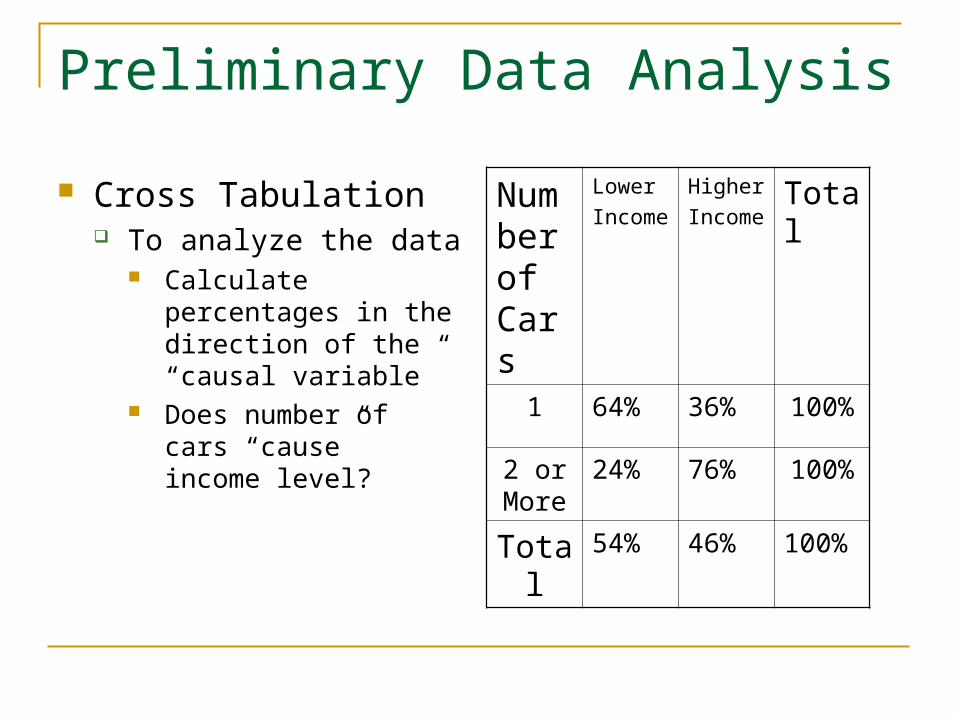
Cross Tabulation To analyze the data
Calculate percentages in the direction of the “causal variable”
Does number of cars “cause” income level?
Number of Cars
Lower
Income
Higher
IncomeTotal
1 64% 36% 100%
2 or More
24% 76% 100%
Total 54% 46% 100%
Preliminary Data Analysis
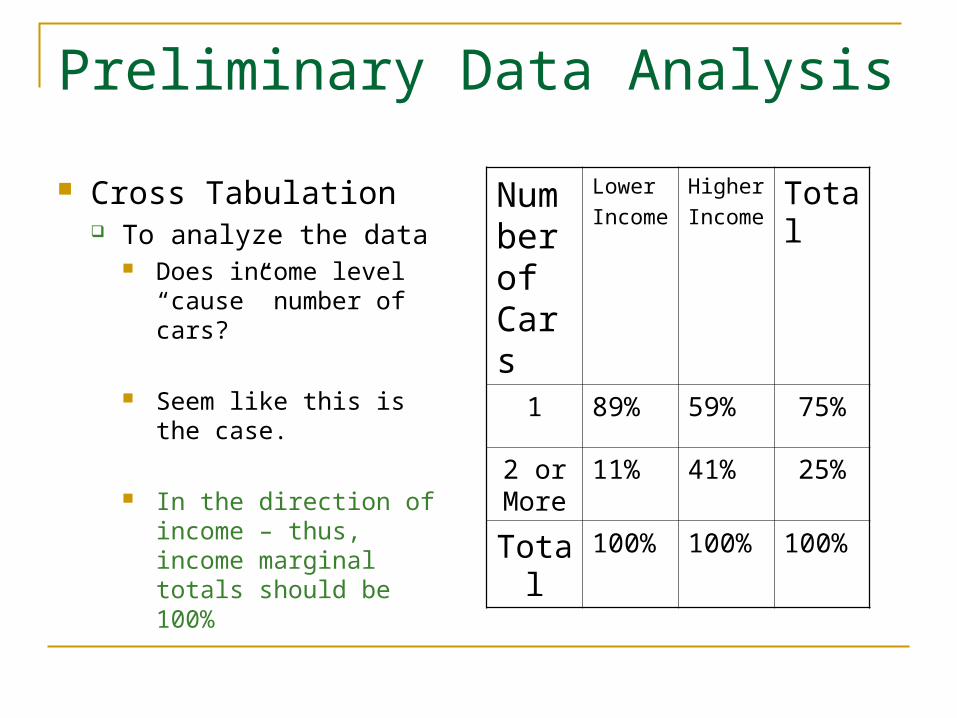
Cross Tabulation To analyze the data
Does income level “cause” number of cars?
Seem like this is the case.
In the direction of income – thus, income marginal totals should be 100%
Number of Cars
Lower
Income
Higher
IncomeTotal
1 89% 59% 75%
2 or More
11% 41% 25%
Total 100% 100% 100%

Preliminary Data Analysis
Cross Tabulation allows the development of hypotheses Develop by comparing percentages across
Lower income more likely to have one car (89%) than the higher income group (59%)
Higher income more likely to have multiple cars (41%) than the lower income group (11%)
Are results statistically significant? To test must employ chi-square analysis

Preliminary Data Analysis
Chi-square analysis Tests the hypothesis that two or more nominally-
scaled variables are NOT independent Null hypothesis (HO) is that the variables are
independent (i.e., no relationship exists) Alternative hypothesis (HA) is that a statistical
relationship exists among the variables Present example
HO: Income level will have no affect on the number of cars that a family owns
HA: Income level will affect the number of cars that a family owns
Preliminary Data Analysis
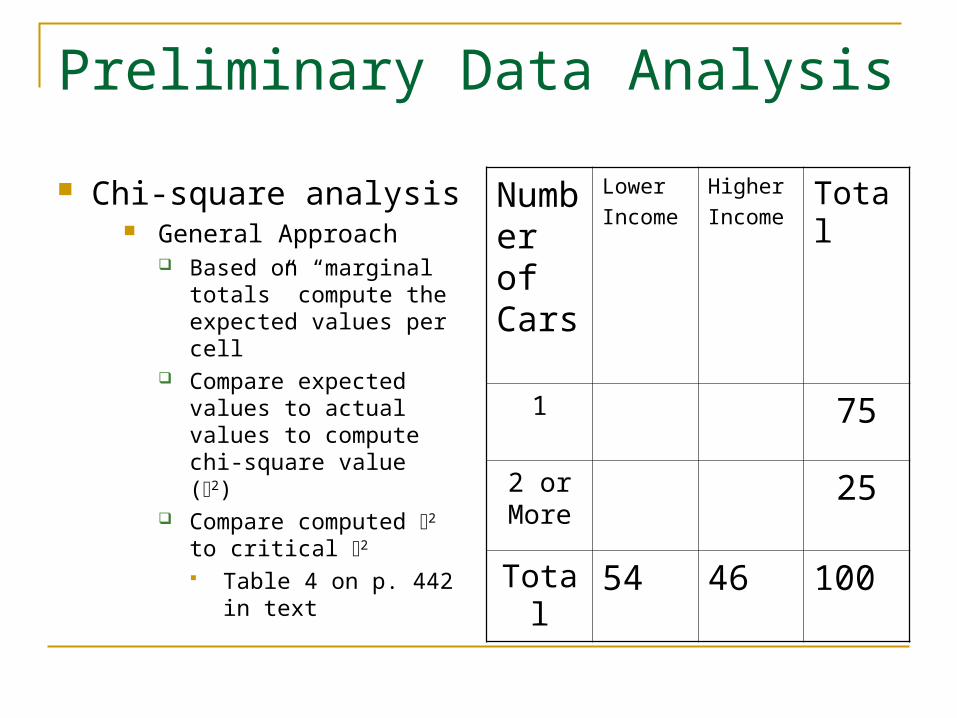
Chi-square analysis General Approach
Based on “marginal totals” compute the expected values per cell
Compare expected values to actual values to compute chi-square value (2)
Compare computed 2 to critical 2
Table 4 on p. 442 in text
Number of Cars
Lower
Income
Higher
IncomeTotal
1 75
2 or More
25
Total 54 46 100

Preliminary Data Analysis
Chi-square analysis Compute Expected
Values E1 = (75 * 54)/100 E1 = 40.5
E2 = (75 * 46)/100 E2 = 34.5
Note E1 + E2 = 75
E3 = ? E4 = ?
Number of Cars
Lower
Income
Higher
IncomeTotal
1 E1 E2 75
2 or More
E3 E4 25
Total 54 46 100

Preliminary Data Analysis
Compute 2 value
2 = (Oi – Ei)2/Ei Computed 2 = 12.08
df = (rows - 1) x (cols. - 1) = 1 x 1 =1
= .05 Critical 2 = 3.84
12.08 > 3.84: Reject the Null Hypothesis (reject if Computed > Critical)
Cell Oi EiOi - Ei
(Oi – Ei)2 (Oi – Ei)2/Ei
E1 48 40.5 7.5 56.25 1.39
E2 27 34.5 -7.5 56.25 1.63
E3 6 13.5 -7.5 56.25 4.17
E4 19 11.5 7.5 56.25 4.89
2 12.08

Preliminary Data Analysis
Conclusion Income has an influence on number of cars in a
family