introduction to databases - query optimizations for mysql
TRANSCRIPT

DatabasesKodok Márton
■ simb.ro■ kodokmarton.eu■ twitter.com/martonkodok■ facebook.com/marton.kodok■ stackoverflow.com/users/243782/pentium10
23 May, 2013 @Sapientia
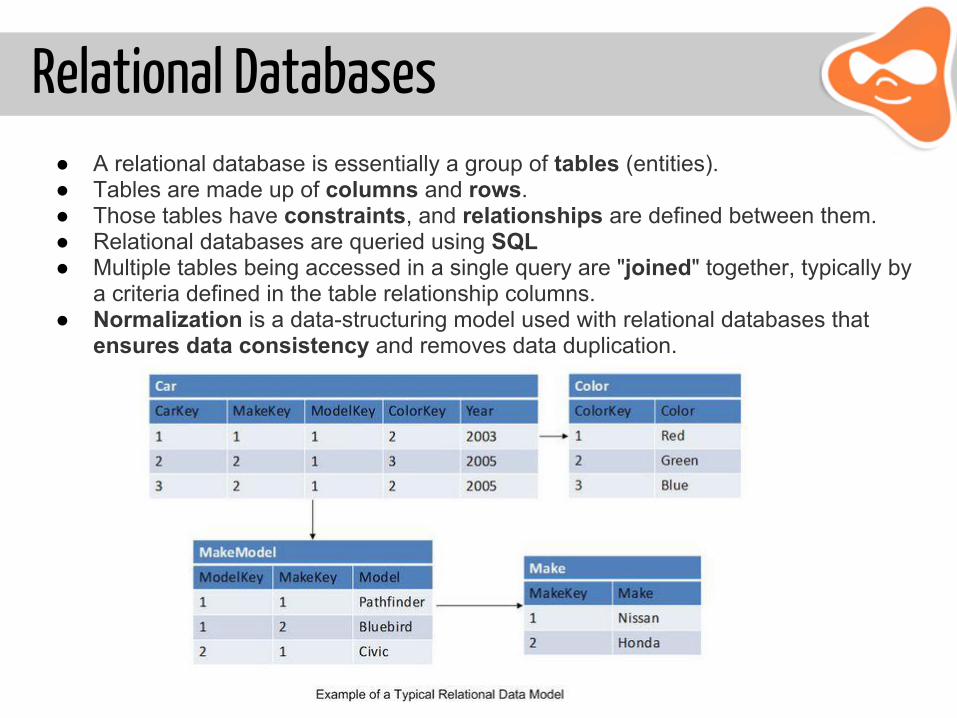
Relational Databases● A relational database is essentially a group of tables (entities). ● Tables are made up of columns and rows. ● Those tables have constraints, and relationships are defined between them.● Relational databases are queried using SQL● Multiple tables being accessed in a single query are "joined" together, typically by
a criteria defined in the table relationship columns. ● Normalization is a data-structuring model used with relational databases that
ensures data consistency and removes data duplication.

Non-Relational Databases (NoSQL)● Key-value stores are the simplest NoSQL
databases. Every single item in the database is
stored as an attribute name, or key, together with its
value. Examples of key-value stores are Riak and
MongoDB. Some key-value stores, such as Redis,
allow each value to have a type, such as "integer",
which adds functionality.
● Document databases can contain many different
key-value pairs, or key-array pairs, or even nested
documents
● Graph stores are used to store information about
networks, such as social connections
● Wide-column stores such as Cassandra and
HBase are optimized for queries over large datasets,
and store columns of data together, instead of rows.

SQL vs NoSQL
The purpose of this presentation is NOT about SQL vs NoSQL.
Let’s be blunt: none of them are difficult, we need both of them. We evolve.

Spreadsheets/Frontends
Excel and Access are not a database.
Let’s be blunt: Excel does not need more than 256 columns and 65 536 rows.

DDL (Data Definition Language)
CREATE TABLE employees ( id INTEGER(11) PRIMARY KEY, first_name VARCHAR(50) NULL, last_name VARCHAR(75) NOT NULL, dateofbirth DATE NULL);
ALTER TABLE sink ADD bubbles INTEGER;ALTER TABLE sink DROP COLUMN bubbles;
DROP TABLE employees;
RENAME TABLE My_table TO Tmp_table;
TRUNCATE TABLE My_table;
CREATE, ALTER, DROP, RENAME, TRUNCATE

SQL (Structured Query Language)
INSERT INTO My_table (field1, field2, field3) VALUES ('test', 'N', NULL);
SELECT Book.title AS Title, COUNT(*) AS Authors FROM Book JOIN Book_author ON Book.isbn = Book_author.isbn GROUP BY Book.title;
UPDATE My_table SET field1 = 'updated value' WHERE field2 = 'N';
DELETE FROM My_table WHERE field2 = 'N';
CRUD (CREATE, READ, UPDATE, DELETE)

Indexes (fast lookup + constraints)
Constraint:
a. PRIMARYb. UNIQUEc. FOREIGN KEY
● Index reduce the amount of data the server has to examine ● can speed up reads but can slow down inserts and updates ● is used to enforce constraints
Type:
1. BTREE- can be used for look-ups and sorting- can match the full value- can match a leftmost prefix ( LIKE 'ma%' )
2. HASH- only supports equality comparisons: =, IN()- can't be used for sorting
3. FULLTEXT- only MyISAM tables- compares words or phrases- returns a relevance value

Some Queries That Can Use BTREE Index● point look-up
SELECT * FROM students WHERE grade = 100; ● open range
SELECT * FROM students WHERE grade > 75; ● closed range
SELECT * FROM students WHERE 70 < grade < 80; ● special range
SELECT * FROM students WHERE name LIKE 'ma%';
Multi Column Indexes Useful for sorting/where
CREATE INDEX `salary_name_idx` ON emp(salary, name);
SELECT salary, name FROM emp ORDER BY salary, name;
(5000, 'john') < (5000, 'michael') (9000, 'philip') < (9999, 'steve')

Indexing InnoDB Tables
● data is clustered by primary key ● primary key is implicitly appended to all indexes
CREATE INDEX fname_idx ON emp(firstname); actually creates KEY(firstname, id) internally
Avoid long primary keys! TS-09061982110055-12345 349950002348857737488334 supercalifragilisticexpialidocious
How MySQL Uses Indexes
● looking up data● joining tables● sorting● avoiding reading data
MySQL chooses only ONE index per table.

DON'Ts● don't follow optimization rules blindly ● don't create an index for every column in your table
thinking that it will make things faster ● don't create duplicate indexes
ex. BAD:create index firstname_ix on Employee(firstname); create index lastname_ix on Employee(lastname);
GOOD:create index first_last_ix on Employee(firstname, lastname); create index id_ix on Employee(id);

DOs
● use index for optimizing look-ups, sorting and retrieval of data
● use short primary keys if possible when using the InnoDB storage engine
● extend index if you can, instead of creating new indexes ● validate performance impact as you're doing changes ● remove unused indexes

Speeding it up
● proper table design (3nf)● understand query cache (internal of MySQL)● EXPLAIN syntax● proper indexes● MySQL server daemon optimization● Slow Query Logs● Stored Procedures● Profiling● Redundancy -> Master : Slave● Sharding● mix database servers based on business logic
-> Memcache, Redis, MongoDB
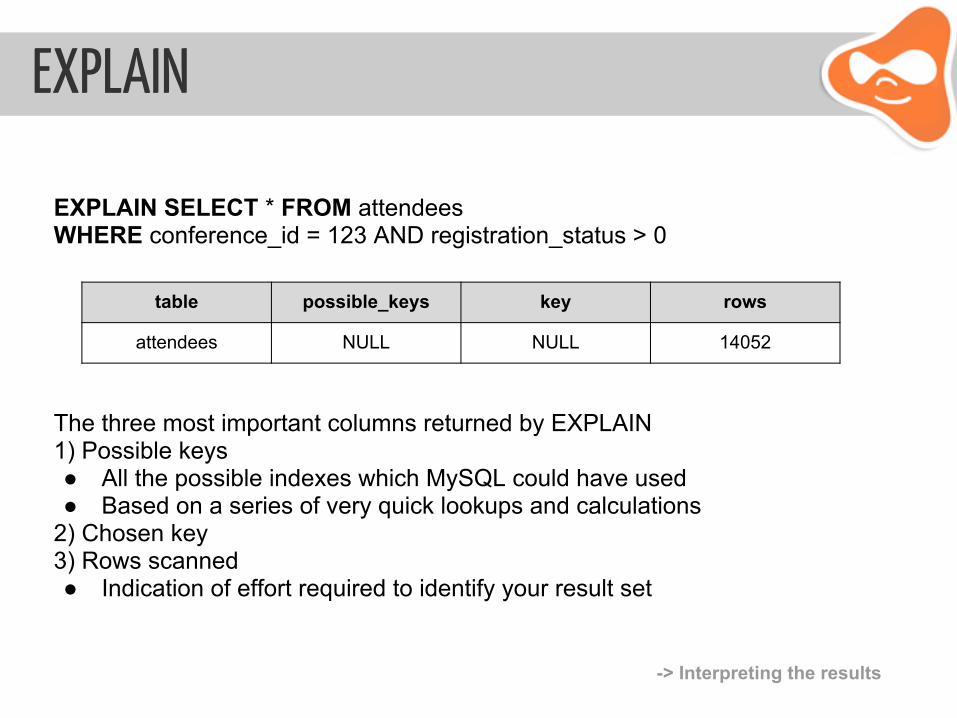
EXPLAIN
EXPLAIN SELECT * FROM attendees WHERE conference_id = 123 AND registration_status > 0
table possible_keys key rows
attendees NULL NULL 14052
The three most important columns returned by EXPLAIN 1) Possible keys● All the possible indexes which MySQL could have used ● Based on a series of very quick lookups and calculations
2) Chosen key 3) Rows scanned ● Indication of effort required to identify your result set
-> Interpreting the results
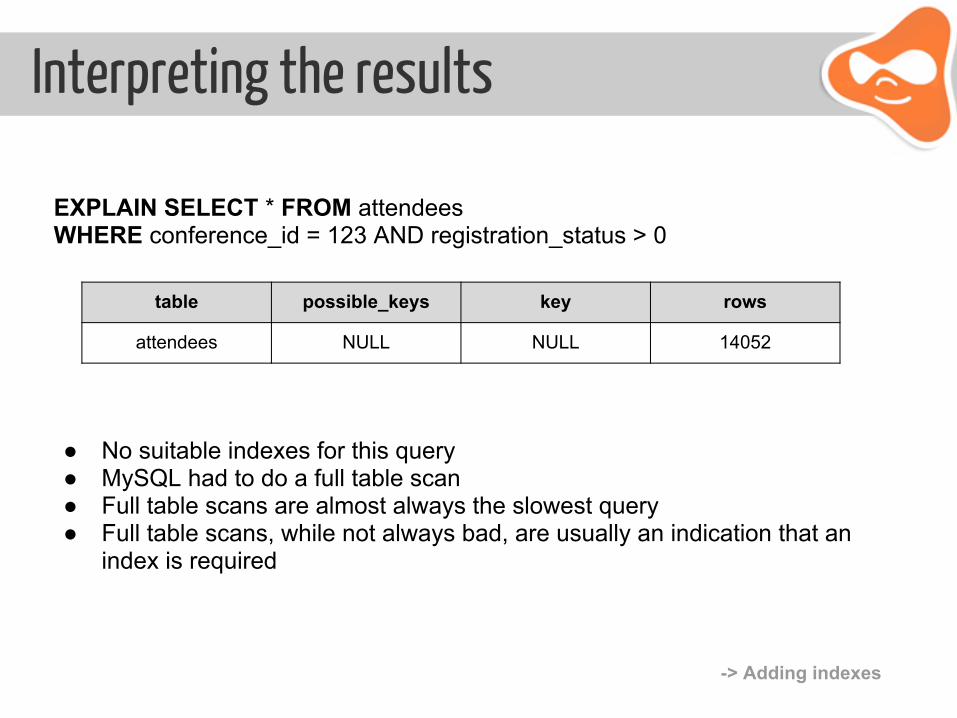
Interpreting the results
EXPLAIN SELECT * FROM attendees WHERE conference_id = 123 AND registration_status > 0
table possible_keys key rows
attendees NULL NULL 14052
● No suitable indexes for this query ● MySQL had to do a full table scan ● Full table scans are almost always the slowest query ● Full table scans, while not always bad, are usually an indication that an
index is required
-> Adding indexes
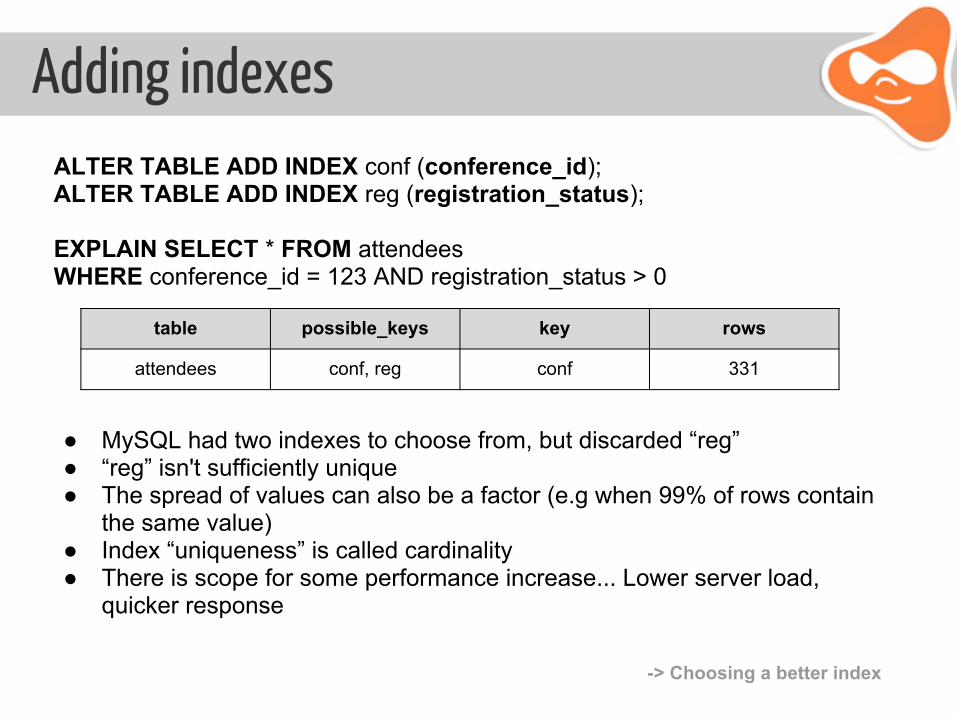
Adding indexesALTER TABLE ADD INDEX conf (conference_id); ALTER TABLE ADD INDEX reg (registration_status);
EXPLAIN SELECT * FROM attendees WHERE conference_id = 123 AND registration_status > 0
table possible_keys key rows
attendees conf, reg conf 331
● MySQL had two indexes to choose from, but discarded “reg” ● “reg” isn't sufficiently unique ● The spread of values can also be a factor (e.g when 99% of rows contain
the same value)● Index “uniqueness” is called cardinality ● There is scope for some performance increase... Lower server load,
quicker response
-> Choosing a better index
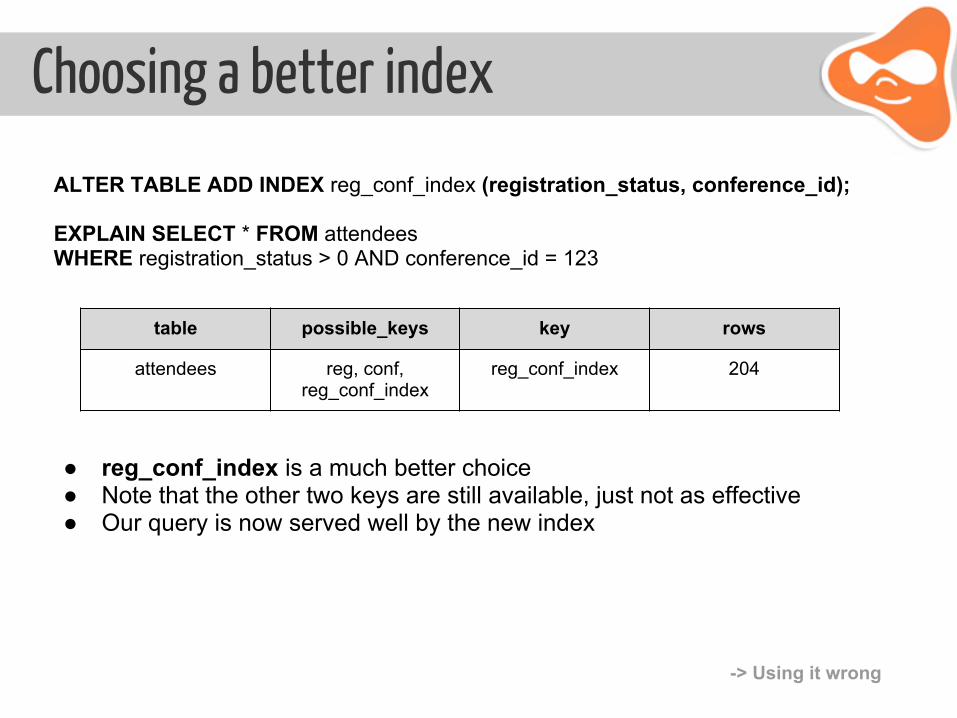
Choosing a better index
ALTER TABLE ADD INDEX reg_conf_index (registration_status, conference_id);
EXPLAIN SELECT * FROM attendees WHERE registration_status > 0 AND conference_id = 123
table possible_keys key rows
attendees reg, conf, reg_conf_index
reg_conf_index 204
● reg_conf_index is a much better choice ● Note that the other two keys are still available, just not as effective ● Our query is now served well by the new index
-> Using it wrong
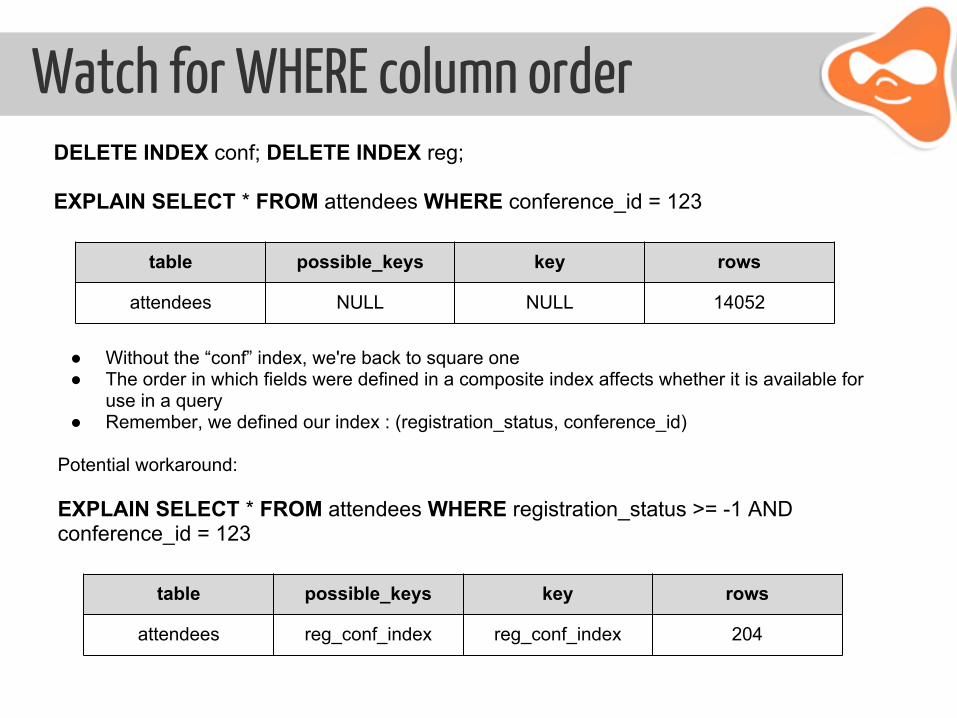
Watch for WHERE column orderDELETE INDEX conf; DELETE INDEX reg;
EXPLAIN SELECT * FROM attendees WHERE conference_id = 123
table possible_keys key rows
attendees NULL NULL 14052
● Without the “conf” index, we're back to square one ● The order in which fields were defined in a composite index affects whether it is available for
use in a query ● Remember, we defined our index : (registration_status, conference_id)
Potential workaround:
EXPLAIN SELECT * FROM attendees WHERE registration_status >= -1 AND conference_id = 123
table possible_keys key rows
attendees reg_conf_index reg_conf_index 204

JOINs
● JOINing together large data sets (>= 10,000) is really where EXPLAIN becomes useful
● Each JOIN in a query gets its own row in EXPLAIN ● Make sure each JOIN condition is FAST ● Make sure each joined table is getting to its result set as quickly as possible ● The benefits compound if each join requires less effort

Simple JOIN exampleEXPLAIN SELECT * FROM conferences cJOIN attendees a ON c.conference_id = a.conference_id WHERE conferences.location_id = 2 AND conferences.topic_id IN (4,6,1) AND attendees.registration_status > 1
table type possible_keys key rows
conferences ref conference_topic conference_topic 15
attendees ALL NULL NULL 14052
● Looks like I need an index on attendees.conference_id ● Another indication of effort, aside from rows scanned ● Here, “ALL” is bad – we should be aiming for “ref” ● There are 13 different values for “type” ● Common values are:
const, eq_ref, ref, fulltext, index_merge, range, all
http://dev.mysql.com/doc/refman/5.0/en/using-explain.html
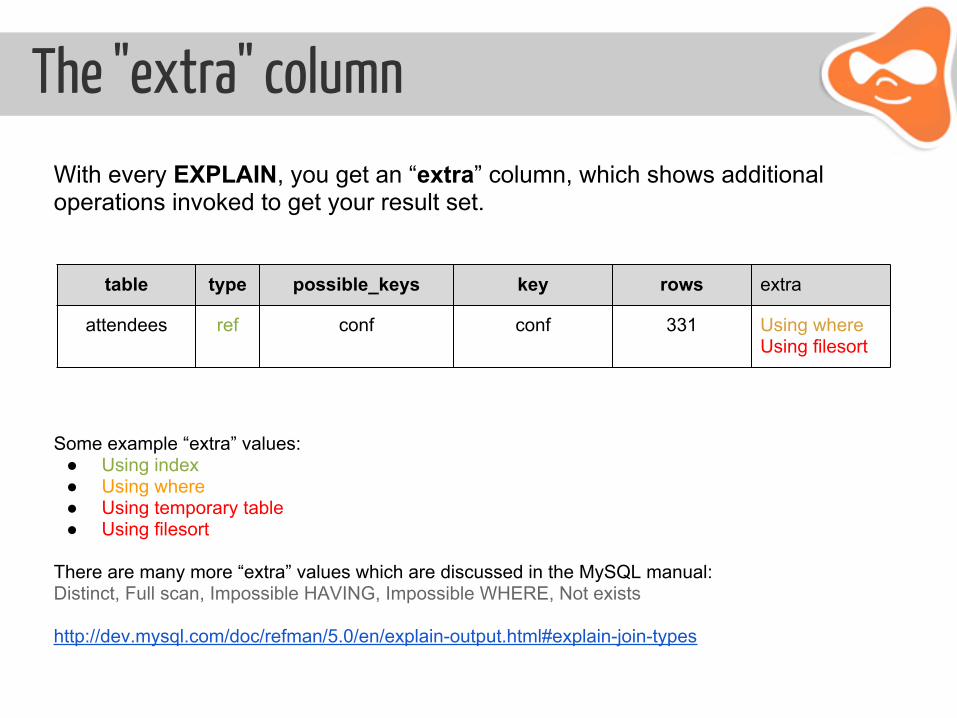
The "extra" columnWith every EXPLAIN, you get an “extra” column, which shows additional operations invoked to get your result set.
Some example “extra” values: ● Using index ● Using where ● Using temporary table ● Using filesort
There are many more “extra” values which are discussed in the MySQL manual:Distinct, Full scan, Impossible HAVING, Impossible WHERE, Not exists
http://dev.mysql.com/doc/refman/5.0/en/explain-output.html#explain-join-types
table type possible_keys key rows extra
attendees ref conf conf 331 Using whereUsing filesort

Using filesort
Avoid, because: ● Doesn't use an index ● Involves a full scan of your result set ● Employs a generic (i.e. one size fits all) algorithm ● Creates temporary tables● Uses the filesystem (seek) ● Will get slower with more data
It's not all bad... ● Perfectly acceptable provided you get to your ● result set as quickly as possible, and keep it predictably small ● Sometimes unavoidable - ORDER BY RAND() ● ORDER BY operations can use indexes to do the sorting!
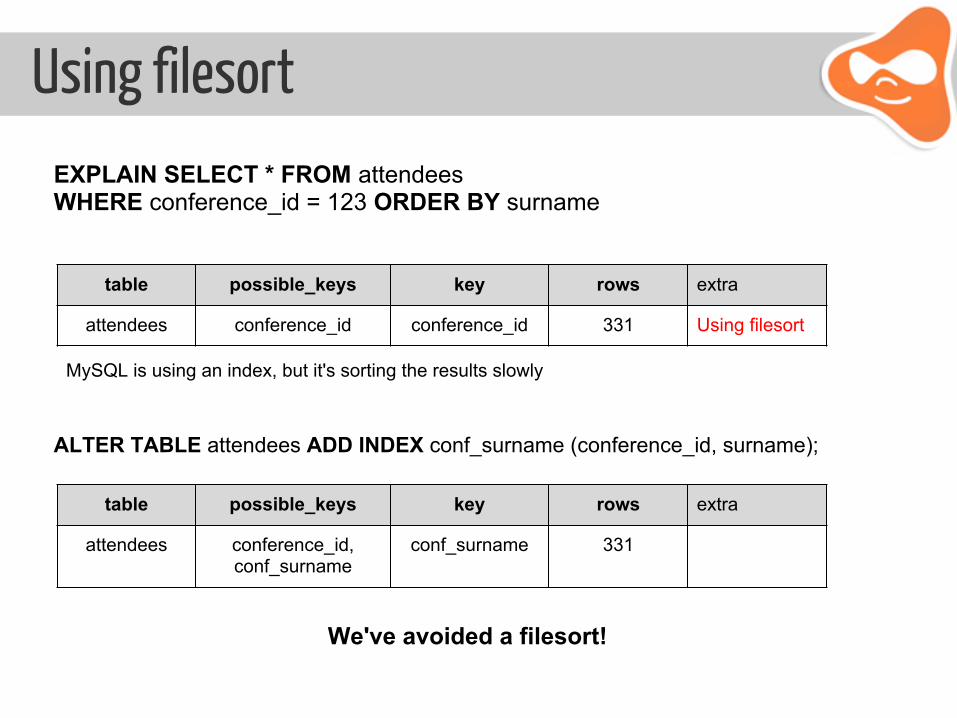
Using filesortEXPLAIN SELECT * FROM attendees WHERE conference_id = 123 ORDER BY surname
ALTER TABLE attendees ADD INDEX conf_surname (conference_id, surname);
We've avoided a filesort!
table possible_keys key rows extra
attendees conference_id conference_id 331 Using filesort
MySQL is using an index, but it's sorting the results slowly
table possible_keys key rows extra
attendees conference_id,conf_surname
conf_surname 331

NoSQL engines
● Redis● MongoDB● Cassandra● CouchDB● DynamoDB● Riak● Membase● HBase
Data is created, updated, deleted, retrieved using API calls.All application and data integrity logic is contained in the application code.

Redis
● Written In: C/C++● Main point: Blazing fast● License: BSD● Protocol: Telnet-like● Disk-backed in-memory database,● Master-slave replication● Simple values or hash tables by keys,● but complex operations like ZREVRANGEBYSCORE.● INCR & co (good for rate limiting or statistics)● Has sets (also union/diff/inter)● Has lists (also a queue; blocking pop)● Has hashes (objects of multiple fields)● Sorted sets (high score table, good for range queries)● Redis has transactions (!)● Values can be set to expire (as in a cache)● Pub/Sub lets one implement messaging (!)
Best used: For rapidly changing data with a foreseeable database size (should fit mostly in memory).
For example: Stock prices. Analytics. Real-time data collection. Real-time communication.
SET uid:1000:username antirezr
uid:1000:followers
uid:1000:following
GET foo => bar
INCR foo => 11
LPUSH mylist a (now mylist holds one element list 'a')
LPUSH mylist b (now mylist holds 'b,a')
LPUSH mylist c (now mylist holds 'c,b,a')
SADD myset a
SADD myset b
SADD myset foo
SADD myset bar
SCARD myset => 4
SMEMBERS myset => bar,a,foo,b

MongoDB
● Written In: C++● Main point: Retains some friendly properties of SQL. (Query, index)● License: AGPL (Drivers: Apache)● Protocol: Custom, binary (BSON)● Master/slave replication (auto failover with replica sets)● Sharding built-in● Queries are javascript expressions / Run arbitrary javascript functions server-side● Uses memory mapped files for data storage● Performance over features● Journaling (with --journal) is best turned on● On 32bit systems, limited to ~2.5Gb● An empty database takes up 192Mb● Has geospatial indexing
Best used: If you need dynamic queries. If you prefer to define indexes, not map/reduce functions. If you need good performance on a big DB.
For example: For most things that you would do with MySQL or PostgreSQL, but having predefined columns really holds you back.

MongoDB -> JSON
The MongoDB examples assume a collection named users that contain
documents of the following prototype:
{ _id: ObjectID("509a8fb2f3f4948bd2f983a0"), user_id: "abc123", age: 55, status: 'A'}

MongoDB -> insert
SQL MongoDB
CREATE TABLE users ( id MEDIUMINT NOT NULL AUTO_INCREMENT, user_id Varchar(30), age Number, status char(1), PRIMARY KEY (id))
db.users.insert( { user_id: "abc123", age: 55, status: "A" } )
Implicitly created on first insert operation. The primary key _id is automatically added if _id field is not specified.

MongoDB -> Alter, Index, Select
SQL MongoDB
ALTER TABLE usersADD join_date DATETIME
db.users.update( { }, { $set: { join_date: new Date() } }, { multi: true })
CREATE INDEX idx_user_id_ascON users(user_id)
db.users.ensureIndex( { user_id: 1 } )
SELECT user_id, statusFROM usersWHERE status = "A"
db.users.find( { status: "A" }, { user_id: 1, status: 1, _id: 0 })
SELECT *FROM usersWHERE status = "A"OR age = 50
db.users.find( { $or: [ { status: "A" } , { age: 50 } ] })
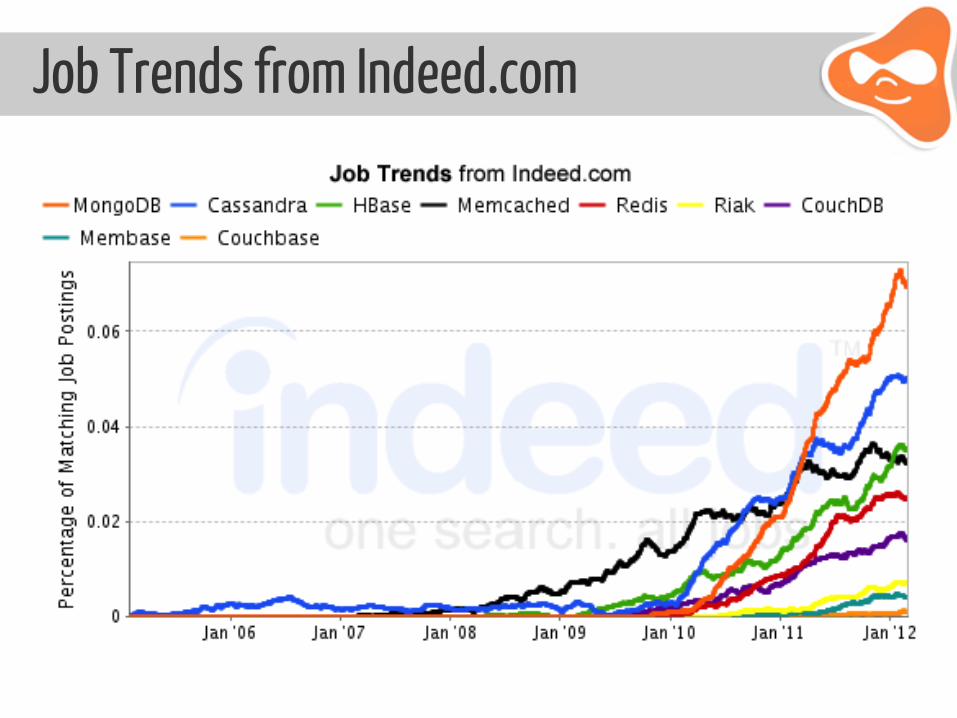
Job Trends from Indeed.com

Thank you.
Questions?