introduction to hadoop - duratechsolutions.in · introduction to hadoop. •hadoop was created by...
TRANSCRIPT

Introduction to Hadoop
www.duratechsolutions.in
8940003640
0422 4200383

Agenda
1. Big Data?
2. Introduction to Hadoop.
3. Hadoop Distributed File System.
4. MapReduce and Hadoop MapReduce.
5. Single Node Hadoop(Pseudo Distributed)

What is Big Data?
• Large datasets – Big Data has to deal with large and complex datasets
– structured, semi-structured, or unstructured.
– Five exabytes of data are generated every days!! ”Eric Schmidt”. • How to explore, analyze such large datasets?
• Facebook – > 800 million active users in Facebook.
– interacting with > 1 billion objects.
– 2.5 petabytes of userdata per day!

What is Big Data?

Introduction to Hadoop.
• Hadoop was created by Doug Cutting and Mike Cafarella in 2005.
• Apache Hadoop is an open source Java framework for processing and
• querying vast amounts of data on large clusters of commodity hardware.
• Supports applications under a free license. • Operates on unstructured and structured data. • A large and active ecosystem. • Handles thousands of nodes and petabytes of data. • Hadoop enables scalable, cost-effective, flexible, fault-
tolerant solutions.

Introduction to Hadoop
• Studying Hadoop components
• Mahout
• Pig
• Hive
• HBase
• Sqoop
• ZooKeper
• Ambari

Introduction to Hadoop
• Hadoop Common: common utilities package.
• HDFS: Hadoop Distributed File System with high throughput access to application data.
• MapReduce: A software framework for distributed processing of large data sets on computer clusters.
• Hadoop YARN: a resource-management platform responsible for managing compute resources in clusters and using them for scheduling the applications of users.

Hadoop Distributed File System
• HDFS components
– NameNode.
– DataNode.
– Secondary NameNode. • Hadoop Distributed File System (HFDS)
– Is a distributed, scalable, and portable file-system written in Java for the Hadoop framework.
• The characteristics of HDFS:
– Fault tolerant.
– Runs with commodity hardware.
– Able to handle large datasets.
– Master slave paradigm.
– Write once file access only.

MapReduce and Hadoop MapReduce
• MapReduce
– Is derived from Google MapReduce.
– Is a programming model for processing large datasets distributed on a
– large cluster.
– MapReduce is the heart of Hadoop.

MapReduce paradigm
• Map phase: Once divided, datasets are assigned to the task tracker to perform the Map phase. The data functional operation will be performed over the data, emitting the mapped key and value pairs as the output of the Map phase, (i.e data processing).
• Reduce phase: The master node then collects the answers to all the subproblems and combines them in some way to form the output; the answer to the problem it was originally trying to solve, (i.e data collection and digesting).

MapReduce Goals
• Scalability to large data volumes:
– Scan 100 TB on 1 node @ 50 MB/s = 24 days.
– Scan on 1000-node cluster = 35 minutes.
• Cost-efficiency:
– Commodity nodes (cheap, but unreliable).
– Commodity network.
– Automatic fault-tolerance (fewer admins).
– Easy to use (fewer programmers).

Challenges
Cheap nodes fail, especially if you have many:
– Mean time between failures for 1 node = 3 years.
– MTBF for 1000 nodes = 1 day.
– Solution: Build fault-tolerance into system.
• Programming distributed systems is hard:
– Solution: Users write data-parallel ”map” and ”reduce” functions, system
– handles work distribution and faults.
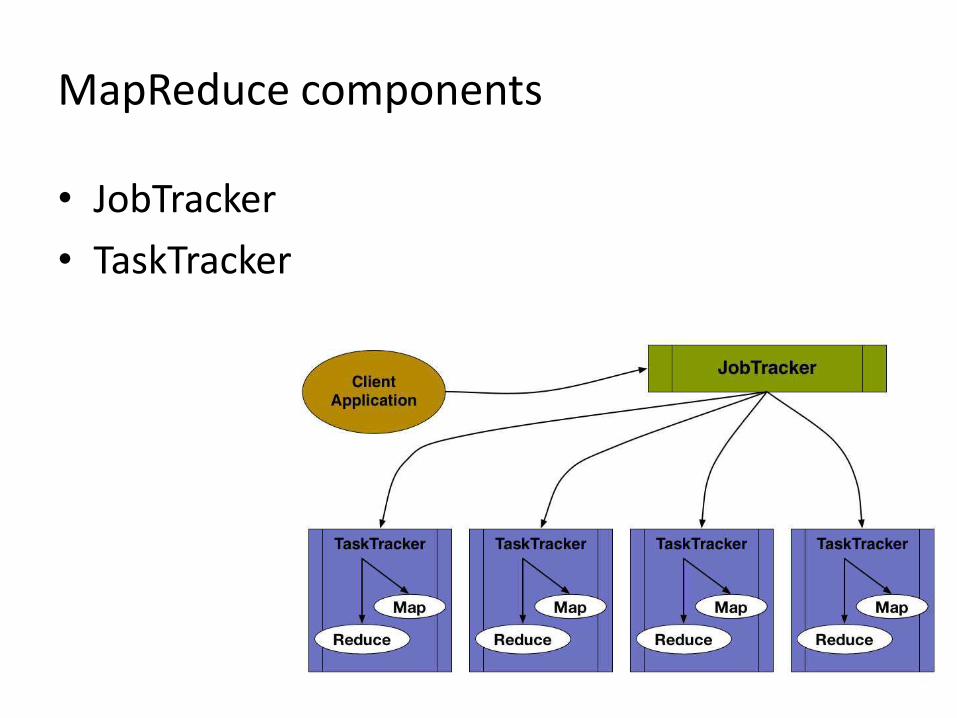
MapReduce components
• JobTracker
• TaskTracker


Hadoop Distributed Architecture

Hadoop File System Deployment
N1, N3, N5 N2, N4, N5 N2, N3, N4 N3, N4, N5 N1, N2, N3

Hadoop Deployment Architecture

Mapreduce job sequence
1. Cleint submits job to Job Tracker
2. Job Tracker talks to Name node
3. Job Tracker creates execution plan
4. Job Tracker submits work to task tracker
5. Task tracker reports progress via Heartbeats
6. Job Tracker manages phases
7. Job tracker updates status

Hadoop Implementation

Hadoop MapReduce scenario • The loading of data into HDFS.
• The execution of the Map phase.
• Shuffling and sorting.
• The execution of the Reduce phase.

MapReduce Example: Word Count

Hadoop Instllation

Prerequisites
• 1. Java compatible version installation
sudo apt-get install openjdk-7-jdk
• 2. SSH Passwrodless authentication
ssh-keygen
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

Environment Configuration:
• 3. Set the environment variables in .bashrc export HADOOP_PREFIX=/usr/local/hadoop
export PATH=$PATH:$HADOOP_PREFIX/bin
• 4. exec bash
• 5. Copy hadoop binaries locally to target location • /usr/hadoop
• 6. Change the ownership to user1 chown -R user1 /usr/hadoop
• 7. hadoop/conf/hadoop-env.sh export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-amd64 export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true

Hadoop Configuration
• 8. /hadoop/conf/core-site.xml <configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/tmp</value> </property> </configuration>

Hadoop Configuration
• 9. hadoop/conf/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>

Hadoop Configuration
• 10. mkdir /usr/hadoop/tmp
• 11. hadoop namenode –format
• 12. start-all.sh
• 13. Issue jps command to test running services
jps
• 14. Open a browser and visit the following Web UIs
localhost:50030
localhost:50070
localhost:50060
localhost:50075

Executing Wordcount Program
• List files in the HDFS
hadoop fs –ls
• Create a dir in HDFS
hadoop fs -mkdir /data
• Copy the input file into HDFS
hadoop fs -copyFromLocal words.txt /data
• Execute the wordcount program
hadoop jar hadoop-examples-*.jar wordcount /data/words.txt /data/results

Hadoop Benchmarking
• Generate 500MB of random data
hadoop-*examples*.jar teragen 5242880 /data/input
• Sort the data generated above using terasort
hadoop-*examples*.jar terasort /data/input /data/output
