introduction to legal technology, lecture 5 (2015)
TRANSCRIPT

TLS0070 Introduction to Legal Technology
Lecture 5 Applications I: Information retrieval, knowledge management, e-discovery University of Turku Law School 2015-02-10 Anna Ronkainen @ronkaine [email protected]

First a little digression (guess why...)
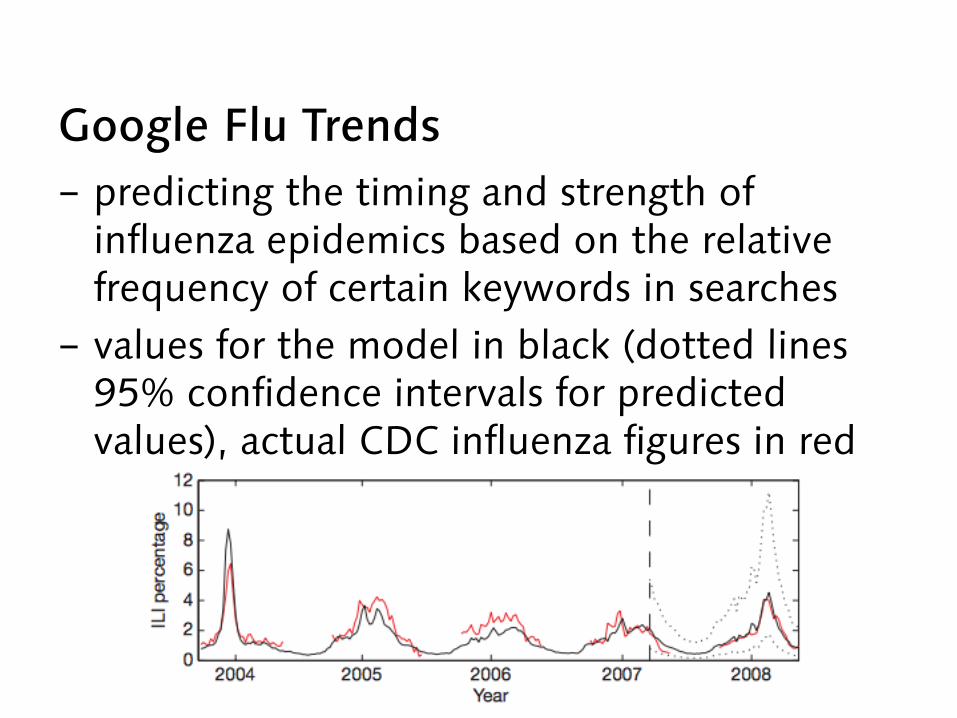
Google Flu Trends - predicting the timing and strength of
influenza epidemics based on the relative frequency of certain keywords in searches
- values for the model in black (dotted lines 95% confidence intervals for predicted values), actual CDC influenza figures in red

But...
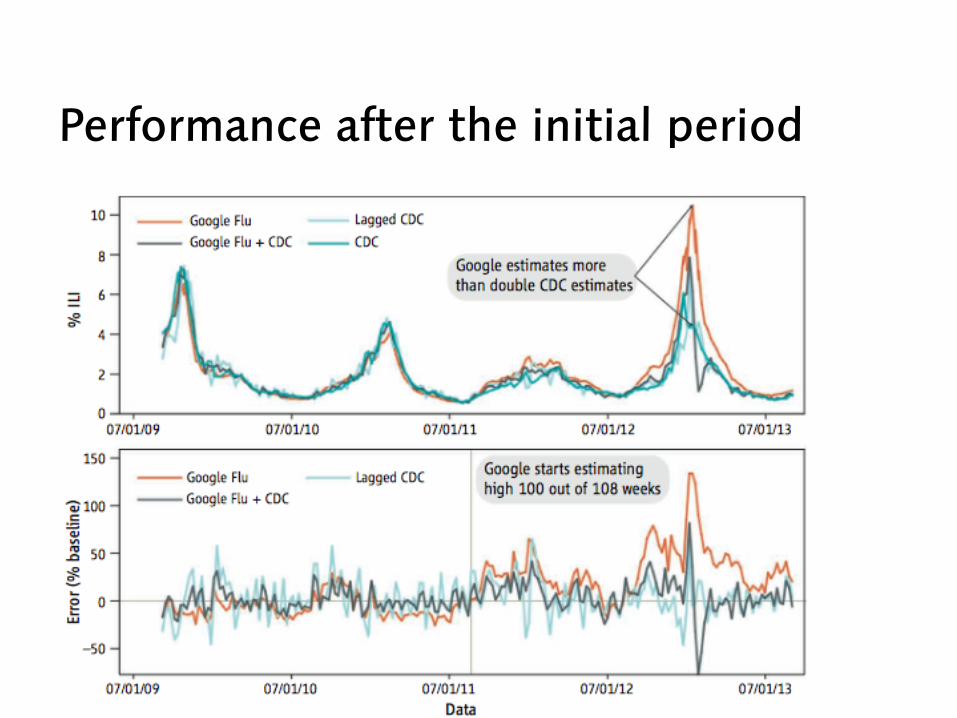
Performance after the initial period

Lessons worth learning (also for legal applications) - transparency and replicability - use big data for understanding the unknown - study the algorithm - it’s not just about the size of the data (from Lazer et al 2014)

Applications (general)

Application lectures overview Applications I (this week): - information retrieval - e-discovery (e-disclosure) - knowledge management Applications II (next week, 1st half): - case management - online dispute resolution - access to justice solutions Applications III (next week, 2nd half): - decision support - prediction - automation - self-service

Legal tech applications not covered here - general-purpose applications (like Office®/
office software) - legislative drafting applications - docket management (and other applications
for use within the judiciary) - courtroom visualization (etc.) software - ... and probably a ton of other things I don’t
even know existed

Information retrieval

Information retrieval (IR) - the granddaddy of legal tech applications - the only form of legal tech available in all
(industrial) countries at least in some form - making different types of static legal content
available for human consumption - statute law (+ commentaries) - case law - doctrine: journal articles and books

Information retrieval users - types of users: - lawyers in general - subgroups of lawyers (e.g. IP lawyers) - legal/admin support staff (e.g. tax
administrators, paralegals, informaticians) - other non-law professionals - ordinary citizens
- different users have different needs in terms of - type and quantity of content required - terminology used - user interface in general

First-generation information retrieval - take whatever text you have (on paper) and
put it into a database - full-text search (exact match or wildcards) - structured search (in whatever fields are
available) - Boolean search with AND, OR, NOT - some metadata enhancements like keywords
(typically same as on paper)
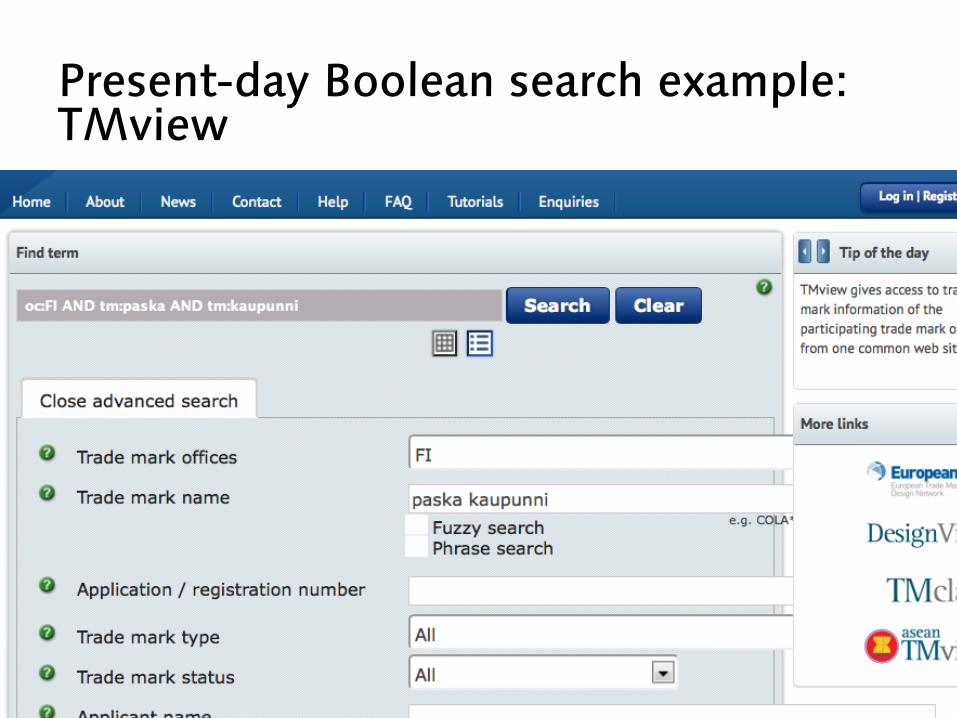
Present-day Boolean search example: TMview

Further developments - hypertext (links) - better search capabilities with language
technology (try searching for “back” as a noun)
- relevancy ranking - recommendations for further reading - morebetter metadata

An example: WestlawNext - natural-language and Boolean search - relevancy ranking of sources of law, using
(among others) a network of links between cases
- (commercial break, text version: http://info.legalsolutions.thomsonreuters.com/pdf/wln2/L-355700_v2.pdf)

On the horizon - natural-language query interfaces and
advanced text understanding (think Watson/Siri)
- merging relevancy ranking with predictive legal analytics (like a certain trademark platform)
- even more polarization between biggest markets (esp. US) and others (e.g. Finland, let alone developing countries)

Knowledge management

Knowledge management - taking (and improving upon!) the knowledge
(explicit and tacit!) of an organization and putting it into optimal use
- by no means just tech: creating and developing processes within the organization is equally important
- can take different forms: - internal: e.g. making work product (memos,
contracts etc.) electronically searchable - external: creating digital legal content for use
by law firm customers

Knowledge management advantages - higher efficiency -> better service - higher quality (better dissemination of
expertise) - makes life easier for lawyers (increased
productivity, reduced stress) - keeps knowledge in the firm even if individuals
leave - helps with the training of new lawyers - necessary for good risk management (after Kay 2003)

One knowledge management example: contract management - the default solution that’s still used by many
(most?) companies: paper + binders - low overhead; manageable with low volumes - doesn’t scale (cope with large volumes) well,
e.g. finding information becomes difficult - particularly kludgy when documents needed
externally (due diligence, anyone?) - error-prone and fragile - still need to manage templates somewhere
(lack of central storage leads to inconsistencies)

Low-tech electronic contract management - establish a central organization-wide repository for
signed contracts and official templates - doesn’t need proprietary software, any LAN or
cloud based (private) file sharing solution works - electronically searchable, at least if word processing
documents and scans are kept together - works well (enough) if there are good processes
(e.g. regarding file naming and organization of files) and they are (always!) consistently adhered to
- ...which this solution obviously cannot enforce - no built-in workflow management

Dedicated contract lifecycle management (CLM) solutions - hundreds of providers, including two from Finland (that I
know of: M-Files and Sopima) - functionalities of varying sophistication for different stages
in the contract lifecycle: - contract and clause template libraries - platform and history for internal review - platform and history for negotiations and external
review - electronic signing / import of scanned definitive paper
originals - archiving, retrieval etc. - workflow management, managing access privileges etc.

Exhibit A: Sopima

Exhibit B: M-Files https://www.youtube.com/watch?v=0b0xSVHOFIg

Electronic signing - real electronic signing not widespread
(outside Estonia, anyway), to a great deal due to a lack of standards internationally (and esp. for identifying legal persons)
- pseudo-electronic signing (images manually written signatures stored electronically) now quite widespread, dedicated solutions and support in CLM systems also available
- the latter raises some obvious questions about probative value
Heck, even Apple does it:

In summary: Levels of contract management adoption
(via Juntunen 2013)
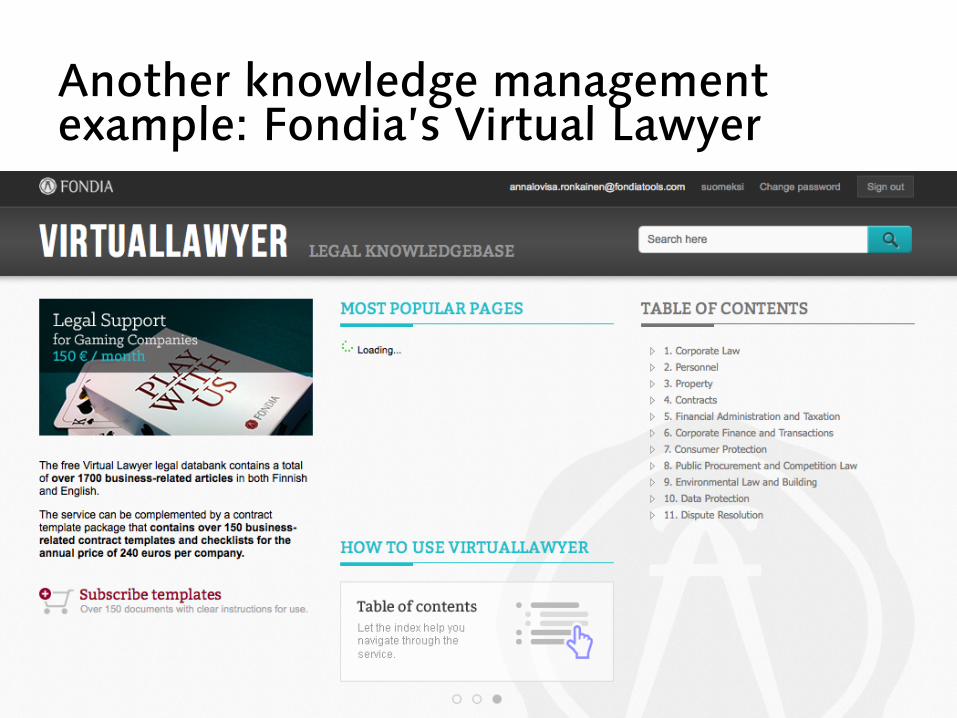
Another knowledge management example: Fondia’s Virtual Lawyer
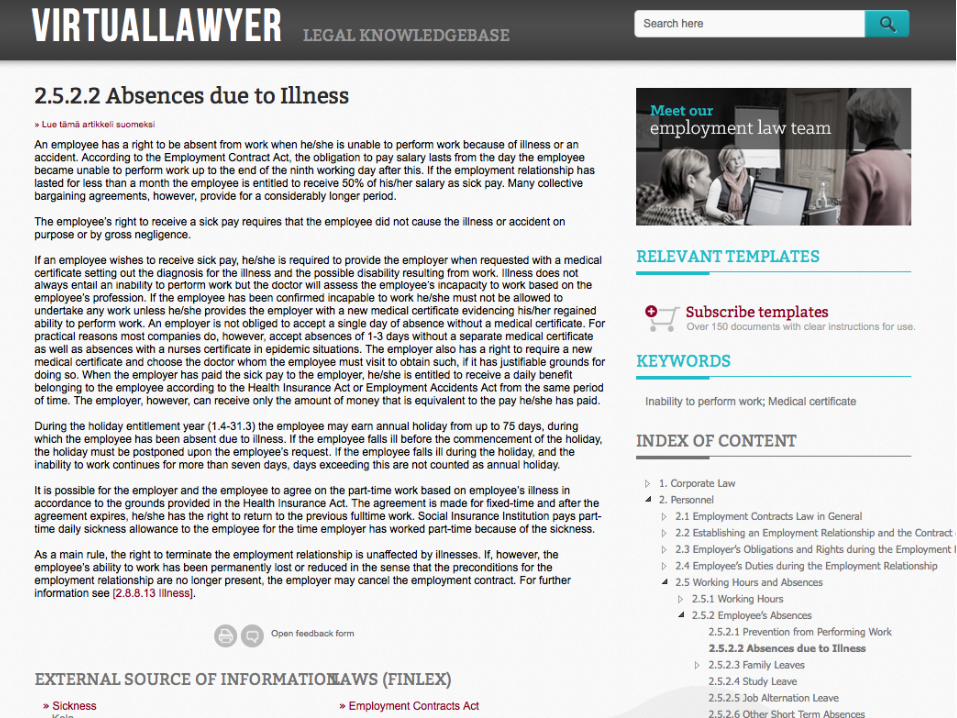

Fondia’s Virtual Lawyer - a collection of ~1700 short documents made
by Fondia staff describing the legal aspects of particular situations
- for external use (self-help by Fondia clients etc.), AFAIK also used internally in an enhanced version
- not for total novices - available at virtuallawyer.fi for free,
registration required, document template library additionally available for a fee

Electronic discovery (disclosure)

Discovery in electronically stored information (e-discovery) - emerged out of nowhere a dozen years ago - now a multi-billion-dollar industry (mostly US),
hundreds of providers - roots in more general-purpose language tech
(outside the AI & law community) - Enron corpus, Sedona Conference, TREC, DESI - storage requirements for e-mail etc. introduced
(US) by amendments to Federal Rules of Civil Procedure in 2006

...and now* it’s already this much widespread (in the US, anyway):
*: actually this book is from 2009

Zubulake v. UBS Warburg - employment law case in District Court for
Southern NY, heard 2003–2005 - led to four groundbreaking rulings which set
the basic standards for e-discovery (before 2006 FRCP revisions), widely referred to as Zubulake I, III, IV, V

Zubulake I and III - what data is considered accessible ESI
- yes: online data/hard disks, optical disks, offline magnetic tapes - no: backup tapes, damaged/deleted/... data
- no -> yes if considerable evidentiary value can be demonstrated, for which a 7-factor test was introduced: - The extent to which the request is specifically tailored to discover
relevant information; - The availability of such information from other sources; - The total cost of production, compared to the amount in
controversy; - The total cost of production, compared to the resources available to
each party; - The relative ability of each party to control costs and its incentive to
do so; - The importance of the issues at stake in the litigation; and - The relative benefits to the parties of obtaining the information.

Zubulake IV - some backups no longer available - relevant emails (created after the start of the
proceedings) had been deleted - defendant had a duty to preserve evidence
(since relevant for ongoing/future litigation) - plaintiff got access to the information - however, plaintiff couldn’t show adverse
interference (at this stage) and was ordered to pay the costs

Zubulake V - upon the plaintiff’s motion, the court
concluded that the defendant (and defence counsel) had failed to safeguard and produce evidence in an adequate manner
- defendant sanctioned and ordered to pay plaintiff’s costs for producing evidence (witness re-examination etc.) necessary due to plaintiff’s late (or non-)production of relevant evidence

Outcome - active interference (intentional destruction
or hiding of evidence) ruled by the judge - jury found in favour of the plaintiff,
compensatory and punitive damages - reimbursement of even more costs to the
plaintiff (generally a lot more unusual in US)

E-discovery workflow - establish an ESI retention policy, stick to it when
creating and storing data - identify relevant ESI, create authentic snapshot and
collect it for further processing - process and filter ESI (e.g. removal of duplicates) - review and analyze ESI for privileged information - produce ESI after filtering out irrelevant, duplicated
or privileged materials - possibly clawback if too much produced in error - present at trial (if it ever goes that far)

First-generation e-discovery - based on lists of specific search terms (or
phrases) proposed by the plaintiff and approved or modified by the judge
- a bit sketchy, not even real consensus about whether keywords cover all inflections?
- no longer considered acceptable by many of the most influential US judges for this field

Predictive coding - based on coding a (very) small subset of the
relevant document mass as responsive or not (should/n’t be released)
- then using that as the teaching set for a machine learning algorithm
- performance comparable to (or better than) human reviewers at a fraction of the cost

E-discovery output - native (original) formats (e.g.: .docx) - usually better for the plaintiff: electronically
searchable - native file formats for proprietary software not
necessarily openable without that software - “petrified” formats (tiff, pdf) - often better for the defendant: almost the same
as handing out the data on paper - general-purpose tools enough for viewing - easier to redact

What’s the status with e-discovery - very widespread in the US (because it’s the
law!) - gaining popularity in the rest of Anglophonia
(because common law; tech readily available for English)
- some providers also support major European and Asian languages (mostly for international companies operating in the US)
- rest of the world: is there even a word for this? (then again: discovery in the common-law sense doesn’t exist in most civil-law countries (incl. Finland) in general)

No concrete examples - (because, frankly, I understand neither the field
nor the legal issue well enough) - but e-discovery in itself is an interesting
example of legal tech for many reasons - first real big data application for law - came out of nowhere in the early 2000s - now a multi-billion-dollar industry (US) - many startups, some notable exits (e.g.
Cataphora’s e-discovery ops to EY) - also continuously new funding rounds (even
$100M+) to more and more companies

Questions?