introduction to machine learning with h2o and python
TRANSCRIPT

Introduction to Machine Learning with H2O and Python
Jo-fai (Joe) Chow
Data Scientist
@matlabulous
H2O Tutorial at Analyx20th April, 2017

Slides and Code Examples:
bit.ly/joe_h2o_tutorials
2

About Me
• Civil (Water) Engineer• 2010 – 2015
• Consultant (UK)• Utilities
• Asset Management
• Constrained Optimization
• Industrial PhD (UK)• Infrastructure Design Optimization
• Machine Learning + Water Engineering
• Discovered H2O in 2014
• Data Scientist• 2015
• Virgin Media (UK)
• Domino Data Lab (Silicon Valley, US)
• 2016 – Present
• H2O.ai (Silicon Valley, US)
3

About Me
4

Side Project #1 – Crime Data Visualization
5
https://github.com/woobe/rApps/tree/master/crimemaphttp://insidebigdata.com/2013/11/30/visualization-week-crimemap/

Side Project #2 – Data Visualization Contest
6
https://github.com/woobe/rugsmaps http://blog.revolutionanalytics.com/2014/08/winner-for-revolution-analytics-user-group-map-contest.html


About Me
8
R + H2O + Domino for KaggleGuest Blog Post for Domino & H2O (2014)
• The Long Story• bit.ly/joe_kaggle_story

Agenda
• About H2O.ai• Company
• Machine Learning Platform
• Tutorial• H2O Python Module
• Download & Install
• Step-by-Step Examples:• Basic Data Import / Manipulation
• Regression & Classification (Basics)
• Regression & Classification (Advanced)
• Using H2O in the Cloud
9

Agenda
• About H2O.ai• Company
• Machine Learning Platform
• Tutorial• H2O Python Module
• Download & Install
• Step-by-Step Examples:• Basic Data Import / Manipulation
• Regression & Classification (Basics)
• Regression & Classification (Advanced)
• Using H2O in the Cloud
10
Background Information
For beginners
As if I am working onKaggle competitions
Short Break

About H2O.ai
11

Company OverviewFounded 2011 Venture-backed, debuted in 2012
Products • H2O Open Source In-Memory AI Prediction Engine• Sparkling Water• Steam
Mission Operationalize Data Science, and provide a platform for users to build beautiful data products
Team 70 employees• Distributed Systems Engineers doing Machine Learning• World-class visualization designers
Headquarters Mountain View, CA
12

13
Our Team
Joe

Scientific Advisory Council
14

15

0
10000
20000
30000
40000
50000
60000
70000
1-Jan-15 1-Jul-15 1-Jan-16 1-Oct-16
# H2O Users
H2O Community GrowthTremendous Momentum Globally
65,000+ users globally (Sept 2016)
• 65,000+ users from ~8,000 companies in 140 countries. Top 5 from:
Large User Circle
* DATA FROM GOOGLE ANALYTICS EMBEDDED IN THE END USER PRODUCT 16
0
2000
4000
6000
8000
10000
1-Jan-15 1-Jul-15 1-Jan-16 1-Oct-16
# Companies Using H2O ~8,000+ companies(Sept 2016)
+127%
+60%

#AroundTheWorldWithH2Oai
17

H2O for Kaggle Competitions
18

H2O for Academic Research
19
http://www.sciencedirect.com/science/article/pii/S0377221716308657
https://arxiv.org/abs/1509.01199

Users In Various Verticals Adore H2O
Financial Insurance MarketingTelecom Healthcare
20

22
Check out our websiteh2o.ai

H2O Machine Learning Platform
23

24

25

H2O Overview
26

HDFS
S3
NFS
DistributedIn-Memory
Load Data
Loss-lessCompression
H2O Compute Engine
Production Scoring Environment
Exploratory &Descriptive
Analysis
Feature Engineering &
Selection
Supervised &Unsupervised
Modeling
ModelEvaluation &
Selection
Predict
Data & ModelStorage
Model Export:Plain Old Java Object
YourImagination
Data Prep Export:Plain Old Java Object
Local
SQL
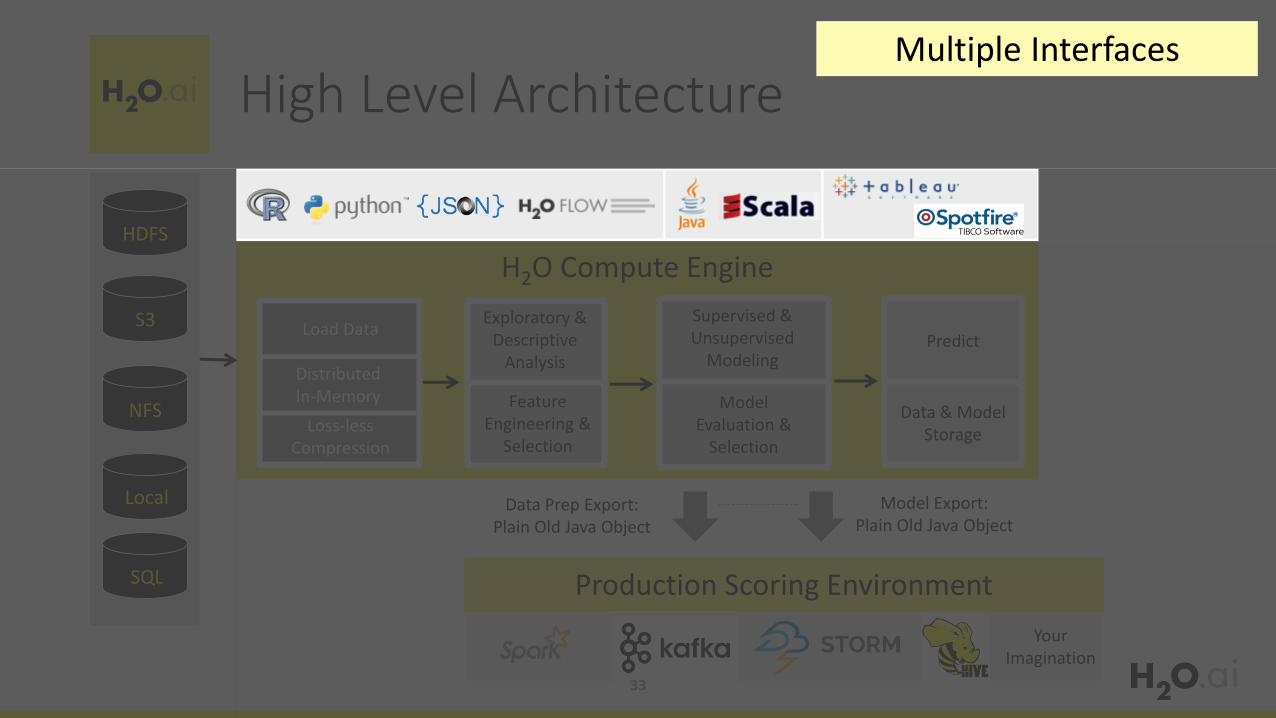
High Level Architecture
27

HDFS
S3
NFS
DistributedIn-Memory
Load Data
Loss-lessCompression
H2O Compute Engine
Production Scoring Environment
Exploratory &Descriptive
Analysis
Feature Engineering &
Selection
Supervised &Unsupervised
Modeling
ModelEvaluation &
Selection
Predict
Data & ModelStorage
Model Export:Plain Old Java Object
YourImagination
Data Prep Export:Plain Old Java Object
Local
SQL
High Level Architecture
28
Import Data from Multiple Sources

HDFS
S3
NFS
DistributedIn-Memory
Load Data
Loss-lessCompression
H2O Compute Engine
Production Scoring Environment
Exploratory &Descriptive
Analysis
Feature Engineering &
Selection
Supervised &Unsupervised
Modeling
ModelEvaluation &
Selection
Predict
Data & ModelStorage
Model Export:Plain Old Java Object
YourImagination
Data Prep Export:Plain Old Java Object
Local
SQL
High Level Architecture
29
Fast, Scalable & Distributed Compute Engine Written in
Java

HDFS
S3
NFS
DistributedIn-Memory
Load Data
Loss-lessCompression
H2O Compute Engine
Production Scoring Environment
Exploratory &Descriptive
Analysis
Feature Engineering &
Selection
Supervised &Unsupervised
Modeling
ModelEvaluation &
Selection
Predict
Data & ModelStorage
Model Export:Plain Old Java Object
YourImagination
Data Prep Export:Plain Old Java Object
Local
SQL
High Level Architecture
30
Fast, Scalable & Distributed Compute Engine Written in
Java

Supervised Learning
• Generalized Linear Models: Binomial, Gaussian, Gamma, Poisson and Tweedie
• Naïve Bayes
Statistical Analysis
Ensembles
• Distributed Random Forest: Classification or regression models
• Gradient Boosting Machine: Produces an ensemble of decision trees with increasing refined approximations
Deep Neural Networks
• Deep learning: Create multi-layer feed forward neural networks starting with an input layer followed by multiple layers of nonlinear transformations
Algorithms OverviewUnsupervised Learning
• K-means: Partitions observations into k clusters/groups of the same spatial size. Automatically detect optimal k
Clustering
Dimensionality Reduction
• Principal Component Analysis: Linearly transforms correlated variables to independent components
• Generalized Low Rank Models: extend the idea of PCA to handle arbitrary data consisting of numerical, Boolean, categorical, and missing data
Anomaly Detection
• Autoencoders: Find outliers using a nonlinear dimensionality reduction using deep learning
31

H2O Deep Learning in Action
32
HDFS
S3
NFS
DistributedIn-Memory
Load Data
Loss-lessCompression
H2O Compute Engine
Production Scoring Environment
Exploratory &Descriptive
Analysis
Feature Engineering &
Selection
Supervised &Unsupervised
Modeling
ModelEvaluation &
Selection
Predict
Data & ModelStorage
Model Export:Plain Old Java Object
YourImagination
Data Prep Export:Plain Old Java Object
Local
SQL
High Level Architecture
33
Multiple Interfaces

H2O + Python
34

H2O + R
35

36
H2O Flow (Web) Interface

HDFS
S3
NFS
DistributedIn-Memory
Load Data
Loss-lessCompression
H2O Compute Engine
Production Scoring Environment
Exploratory &Descriptive
Analysis
Feature Engineering &
Selection
Supervised &Unsupervised
Modeling
ModelEvaluation &
Selection
Predict
Data & ModelStorage
Model Export:Plain Old Java Object
YourImagination
Data Prep Export:Plain Old Java Object
Local
SQL
High Level Architecture
37
Export Standalone Models for Production

38
docs.h2o.ai

H2O + Python Tutorial
39

Learning Objectives
• Start and connect to a local H2O cluster from Python.
• Import data from Python data frames, local files or web.
• Perform basic data transformation and exploration.
• Train regression and classification models using various H2O machine learning algorithms.
• Evaluate models and make predictions.
• Improve performance by tuning and stacking.
• Connect to H2O cluster in the cloud.
40

41

Install H2Oh2o.ai -> Download -> Install in Python
42

43

Start and Connect to a Local H2O Clusterpy_01_data_in_h2o.ipynb
44

Local H2O Cluster
45
Import H2O module
Start a local H2O clusternthreads = -1 means
using ALL CPU resources

46
Information of Cluster

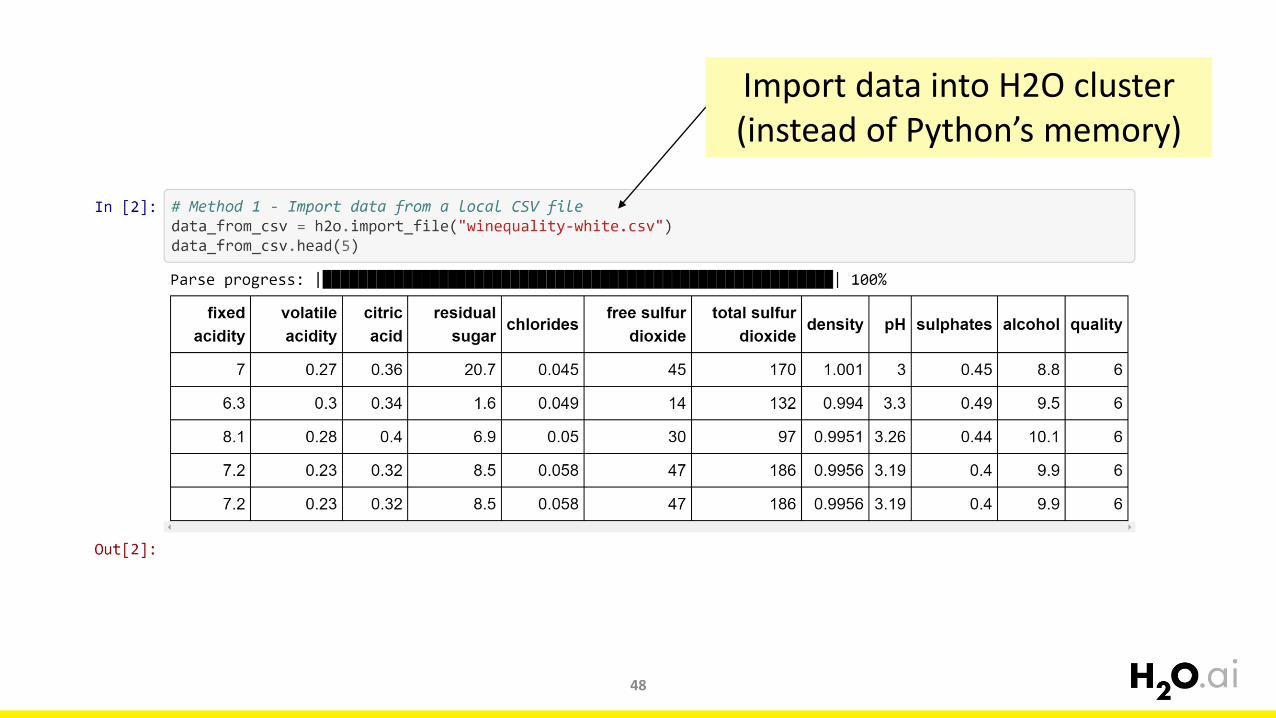
Importing Data into H2Opy_01_data_in_h2o.ipynb
47
48
Import data into H2O cluster(instead of Python’s memory)

49
Directly from data on the web

50
Convert from Pandas to H2O data frame

Basic Data Transformation & Explorationpy_02_data_manipulation.ipynb
(see notebooks)
51

52
The Classic Titanic Dataset

53
Only two unique values(0 or 1)

54
“enum” is the data type of categorical data in Java
Convert numerical to categorical values

55
Only three unique values(1, 2 or 3)

Regression Models (Basics)py_03a_regression_basics.ipynb
56

Supervised Learning
• Generalized Linear Models: Binomial, Gaussian, Gamma, Poisson and Tweedie
• Naïve Bayes
Statistical Analysis
Ensembles
• Distributed Random Forest: Classification or regression models
• Gradient Boosting Machine: Produces an ensemble of decision trees with increasing refined approximations
Deep Neural Networks
• Deep learning: Create multi-layer feed forward neural networks starting with an input layer followed by multiple layers of nonlinear transformations
Algorithms OverviewUnsupervised Learning
• K-means: Partitions observations into k clusters/groups of the same spatial size. Automatically detect optimal k
Clustering
Dimensionality Reduction
• Principal Component Analysis: Linearly transforms correlated variables to independent components
• Generalized Low Rank Models: extend the idea of PCA to handle arbitrary data consisting of numerical, Boolean, categorical, and missing data
Anomaly Detection
• Autoencoders: Find outliers using a nonlinear dimensionality reduction using deep learning
57

58
docs.h2o.ai

59
11 Numerical Features
Target

60
Define 11 Numerical Features using their
Column Names

61
Split dataset so we can measure out-of-bag performance later

62
Basic H2O Usage for GLM

63
Regression Performance – MSE
Lower the better

64
Model Summary

65
Evaluate model performance using test set

66
67
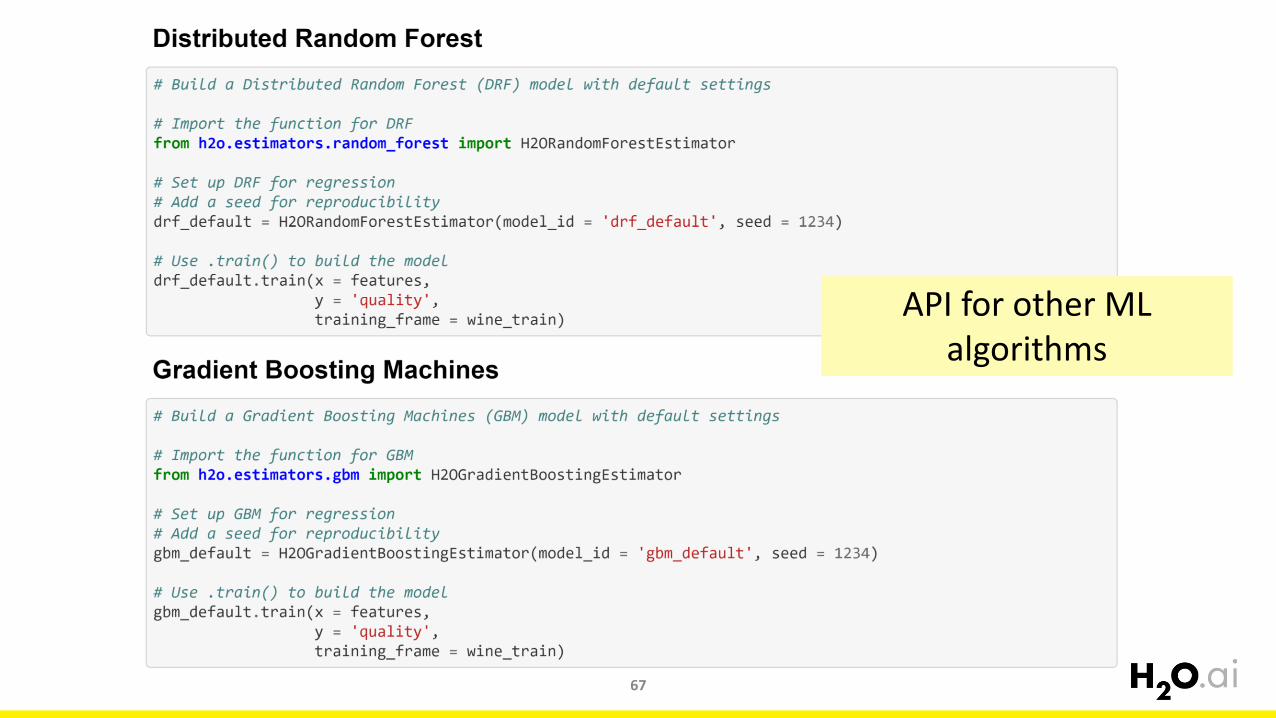
API for other ML algorithms

68
API for other ML algorithms

Classification Models (Basics)py_04_classification_basics.ipynb
69

70
Target

71
Convert numerical to categorical values

72
Define features manually
Split dataset so we can measure out-of-bag performance later

73
Basic H2O Usage for GLM
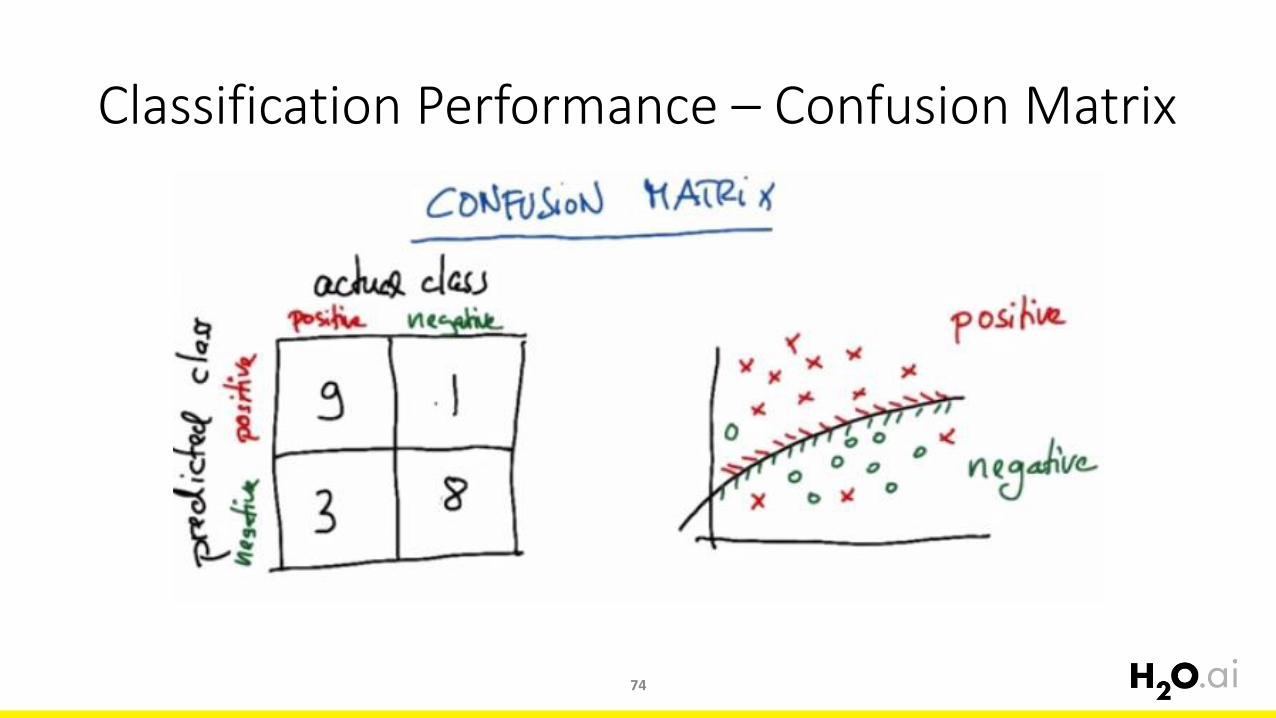
Classification Performance – Confusion Matrix
74

Confusion Matrix
75
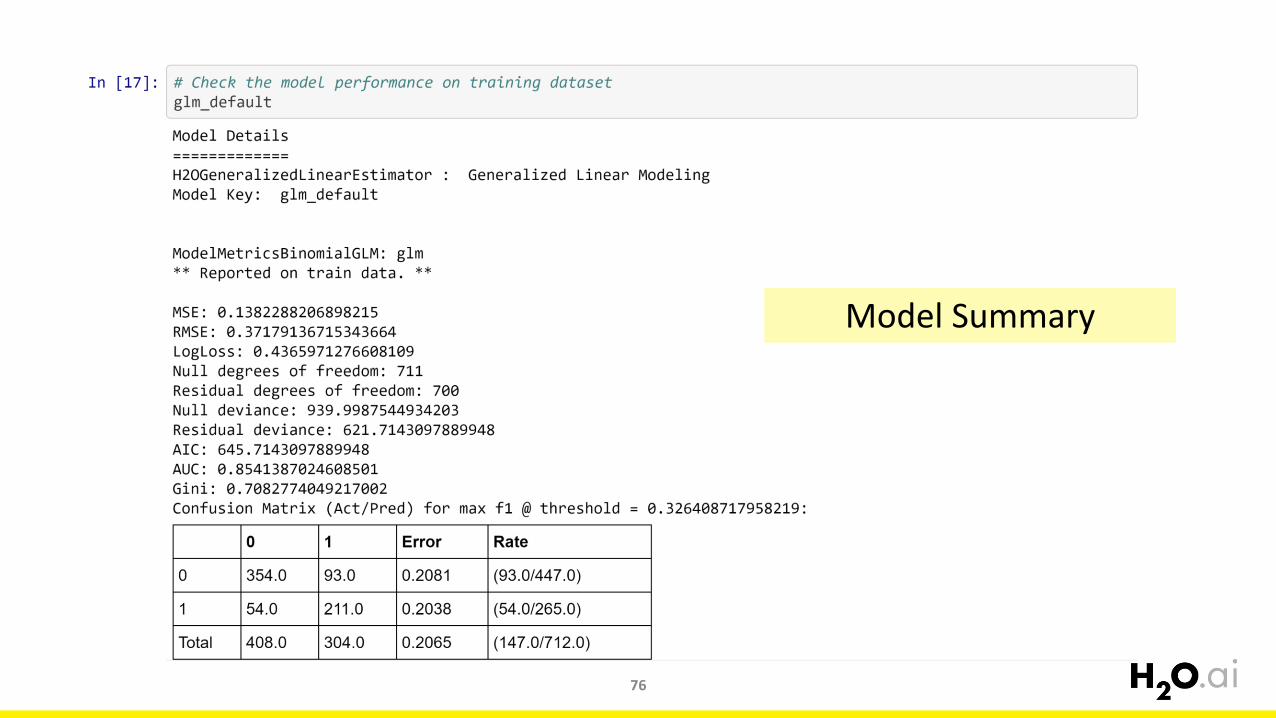
76
Model Summary

77
Evaluate model performance using test set

78
Predicted Class
Probabilities of Each Class

79
API for other ML algorithms

80
API for other ML algorithms

End of BasicsLet’s have a break ☺
81

Regression Models (Tuning)py_03b_regression_grid_search.ipynb
82

Improving Model Performance (Step-by-Step)
83
Model Settings MSE (CV) MSE (Test)
GBM with default settings N/A 0.4551
GBM with manual settings N/A 0.4433
Manual settings + cross-validation 0.4502 0.4433
Manual + CV + early stopping 0.4429 0.4287
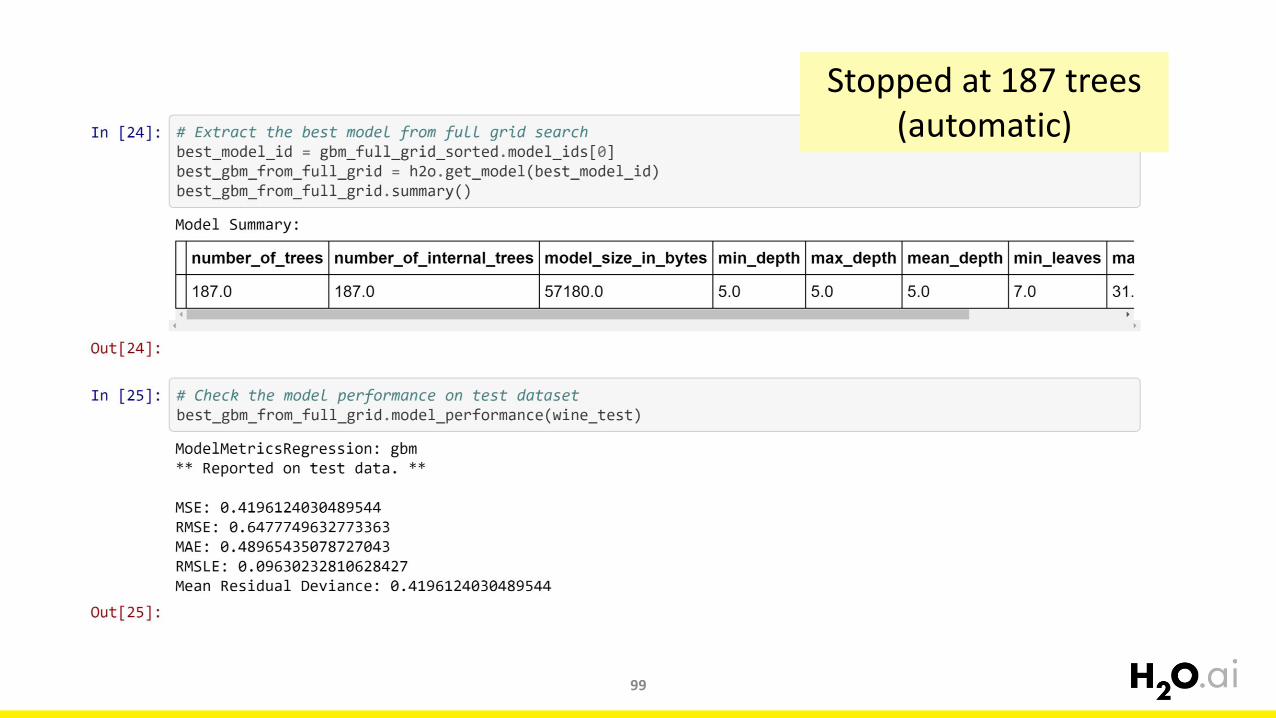
CV + early stopping + full grid search 0.4378 0.4196
CV + early stopping + random grid search 0.4227 0.4047
Stacking models from random grid search N/A 0.3969
Lower Mean Square Error
=Better
Performance

84
Using same dataset and split as previous tutorial

85
Baseline Model
Write down MSE on Test set

Improving Model Performance (Step-by-Step)
86
Model Settings MSE (CV) MSE (Test)
GBM with default settings N/A 0.4551
GBM with manual settings N/A 0.4433
Manual settings + cross-validation 0.4502 0.4433
Manual + CV + early stopping 0.4429 0.4287
CV + early stopping + full grid search 0.4378 0.4196
CV + early stopping + random grid search 0.4227 0.4047
Stacking models from random grid search N/A 0.3969

87
Manual settings based on experience

Improving Model Performance (Step-by-Step)
88
Model Settings MSE (CV) MSE (Test)
GBM with default settings N/A 0.4551
GBM with manual settings N/A 0.4433
Manual settings + cross-validation 0.4502 0.4433
Manual + CV + early stopping 0.4429 0.4287
CV + early stopping + full grid search 0.4378 0.4196
CV + early stopping + random grid search 0.4227 0.4047
Stacking models from random grid search N/A 0.3969
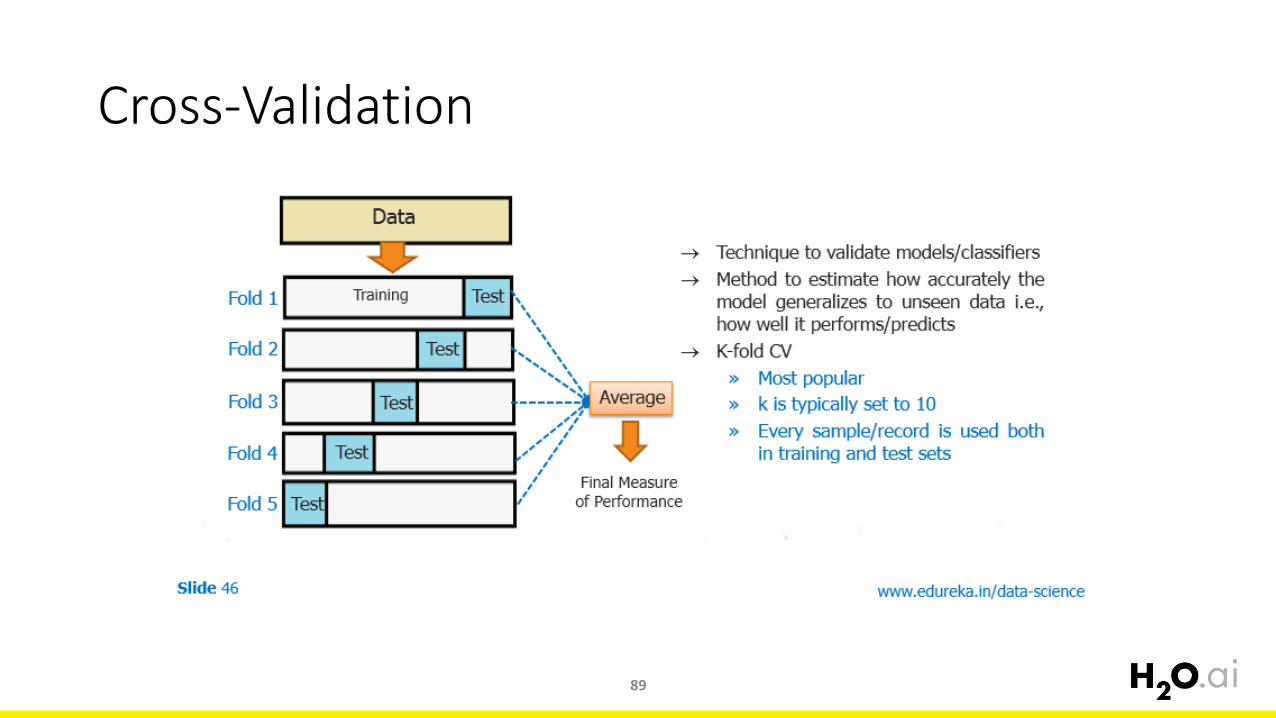
Cross-Validation
89

90
Manual settings based on experience
+5-fold CV
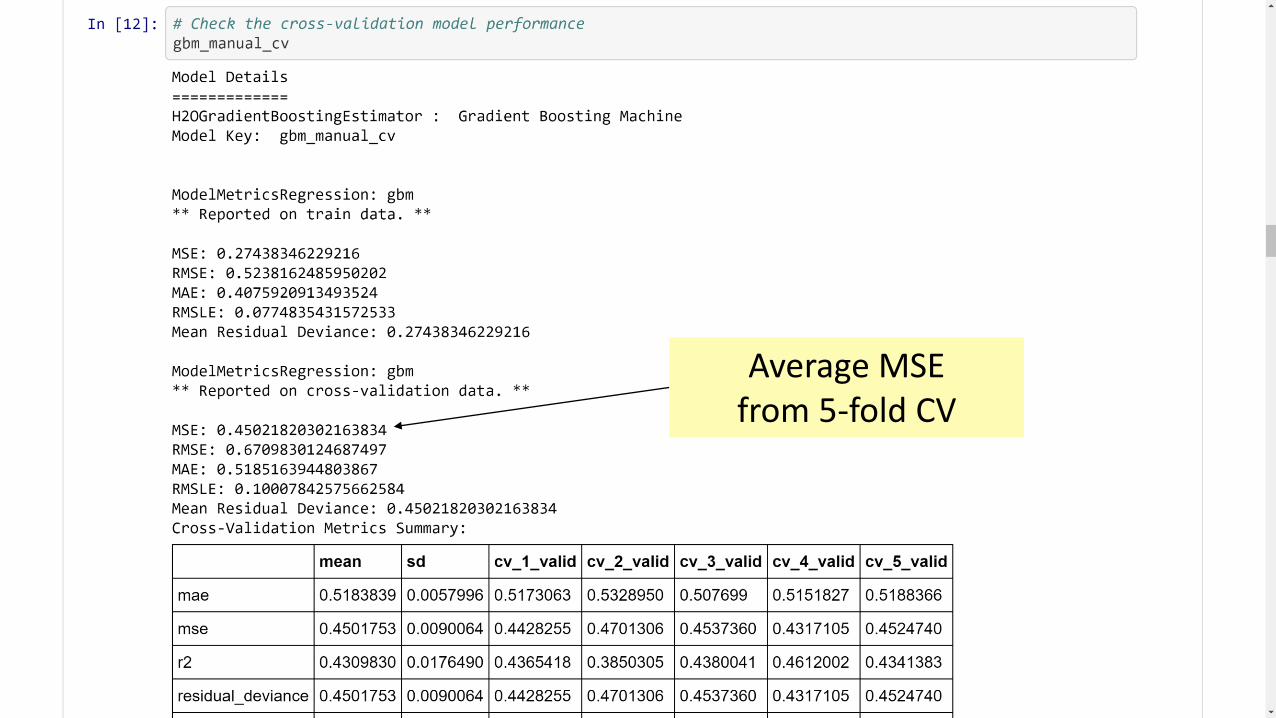
91
Average MSE from 5-fold CV

Improving Model Performance (Step-by-Step)
92
Model Settings MSE (CV) MSE (Test)
GBM with default settings N/A 0.4551
GBM with manual settings N/A 0.4433
Manual settings + cross-validation 0.4502 0.4433
Manual + CV + early stopping 0.4429 0.4287
CV + early stopping + full grid search 0.4378 0.4196
CV + early stopping + random grid search 0.4227 0.4047
Stacking models from random grid search N/A 0.3969

Early Stopping
93

94
Search for lowest MSE
from 5-fold CV

Improving Model Performance (Step-by-Step)
95
Model Settings MSE (CV) MSE (Test)
GBM with default settings N/A 0.4551
GBM with manual settings N/A 0.4433
Manual settings + cross-validation 0.4502 0.4433
Manual + CV + early stopping 0.4429 0.4287
CV + early stopping + full grid search 0.4378 0.4196
CV + early stopping + random grid search 0.4227 0.4047
Stacking models from random grid search N/A 0.3969

Grid Search
96
Combination Parameter 1 Parameter 2
1 0.7 0.7
2 0.7 0.8
3 0.7 0.9
4 0.8 0.7
5 0.8 0.8
6 0.8 0.9
7 0.9 0.7
8 0.9 0.8
9 0.9 0.9

97

98
Sort Results by MSEBest Model on Top
Lowest MSE
99
Stopped at 187 trees(automatic)

Improving Model Performance (Step-by-Step)
100
Model Settings MSE (CV) MSE (Test)
GBM with default settings N/A 0.4551
GBM with manual settings N/A 0.4433
Manual settings + cross-validation 0.4502 0.4433
Manual + CV + early stopping 0.4429 0.4287
CV + early stopping + full grid search 0.4378 0.4196
CV + early stopping + random grid search 0.4227 0.4047
Stacking models from random grid search N/A 0.3969

101
Expand Search Space
Only search for 9 combinations

102
Sort Results by MSEBest Model on Top
Lowest MSE

Improving Model Performance (Step-by-Step)
103
Model Settings MSE (CV) MSE (Test)
GBM with default settings N/A 0.4551
GBM with manual settings N/A 0.4433
Manual settings + cross-validation 0.4502 0.4433
Manual + CV + early stopping 0.4429 0.4287
CV + early stopping + full grid search 0.4378 0.4196
CV + early stopping + random grid search 0.4227 0.4047
Stacking models from random grid search N/A 0.3969

Regression Models (Ensembles)py_03c_regression_ensembles.ipynb
104

105
https://github.com/h2oai/h2o-meetups/blob/master/2017_02_23_Metis_SF_Sacked_Ensembles_Deep_Water/stacked_ensembles_in_h2o_feb2017.pdf

106
Keep the Best Model after Random Grid Search

107
Keep the Best Model after Random Grid Search

108
Keep the Best Model after Random Grid Search

109
Lowest MSE = Best Performance
API for Stacked Ensembles
Use the three models from previous steps

Improving Model Performance (Step-by-Step)
110
Model Settings MSE (CV) MSE (Test)
GBM with default settings N/A 0.4551
GBM with manual settings N/A 0.4433
Manual settings + cross-validation 0.4502 0.4433
Manual + CV + early stopping 0.4429 0.4287
CV + early stopping + full grid search 0.4378 0.4196
CV + early stopping + random grid search 0.4227 0.4047
Stacking models from random grid search N/A 0.3969
Lowest MSE = Best Performance

Classification Models (Ensembles)py_04_classification_ensembles.ipynb
111

112
Highest AUC = Best Performance

H2O in the Cloudpy_05_h2o_in_the_cloud.ipynb
113

114

115

Recap
116

Learning Objectives
• Start and connect to a local H2O cluster from Python.
• Import data from Python data frames, local files or web.
• Perform basic data transformation and exploration.
• Train regression and classification models using various H2O machine learning algorithms.
• Evaluate models and make predictions.
• Improve performance by tuning and stacking.
• Connect to H2O cluster in the cloud.
117

Improving Model Performance (Step-by-Step)
118
Model Settings MSE (CV) MSE (Test)
GBM with default settings N/A 0.4551
GBM with manual settings N/A 0.4433
Manual settings + cross-validation 0.4502 0.4433
Manual + CV + early stopping 0.4429 0.4287
CV + early stopping + full grid search 0.4378 0.4196
CV + early stopping + random grid search 0.4227 0.4047
Stacking models from random grid search N/A 0.3969
Lowest MSE = Best Performance

119

• Our Friends at
• Find us at Poznan R Meetup• Today at 6:15 pm• Uniwersytet Ekonomiczny w Poznaniu
Centrum Edukacyjne Usług Elektronicznych
120
Thanks!
• Code, Slides & Documents• bit.ly/h2o_meetups• docs.h2o.ai
• Contact• [email protected]• @matlabulous• github.com/woobe
• Please search/ask questions on Stack Overflow• Use the tag `h2o` (not H2 zero)