introduction to speech interfaces for web applications
TRANSCRIPT

Introduction toSpeech Interfaces for
Web Applications
Kevin Hakanson
10-12 August 2016#midwestjs @hakanson

Speaking with your computing device is becoming commonplace. Most of us have used Apple's Siri, Google Now, Microsoft's Cortana, or Amazon's Alexa - but how can you speak with your web application? The Web Speech API can enable a voice interface by adding both Speech Synthesis (Text to Speech) and Speech Recognition (Speech to Text) functionality.
This session will introduce the core concepts of Speech Synthesis and Speech Recognition. We will evaluate the current browser support and review alternative options. See the JavaScript code and UX design considerations required to add a speech interface to your web application. Come hear if it's as easy as it sounds?
@hakanson 2

@hakanson 3
“As businesses create their roadmaps for technology adoption, companies that serve customers should be planning for, if not already implementing, both messaging-based and voice-based Conversational UIs.
Source: “How Voice Plays into the Rise of the Conversational UI”

User Interfaces (UIs)
• GUI – Graphicial User Inteface• NUI – Natural User Interface• “invisible” as the user continuously learns increasingly complex
interactions
• NLUI – Natural Language User Interface• linguistic phenomena such as verbs, phrases and clauses act as UI
controls
• VUI – Voice User Interface• voice/speech for hands-free/eyes-free interface
@hakanson 4

Multimodal Interfaces
Provides multiple modes for user to interact with system• Multimodal Input• Keyboard/Mouse• Touch• Gesture (Camera)• Voice (Microphone)
• Multimodal Output• Screen• Audio Cues or Recordings• Synthesized Speech
@hakanson 5

Design for Voice Interfaces
Voice Interface• Voice Input• Recogition• Understanding
• Audio Output"voice design should servethe needs of the user and solve a specific problem”
@hakanson 6
http://www.oreilly.com/design/free/design-for-voice-interfaces.csp

@hakanson 7
“Normal people, when they think about speech recognition, they want the whole thing. They want recognition, they want understanding and they want an action to be taken.”
Hsiao-Wuen HonMicrosoft Research
Source: “Speak, hear, talk: The long quest for technology that understands speech as well as a human”

@hakanson 8

Types of Interactions
• The Secretary• Recognize what is being said and record it
• The Bouncer• Recognize who is speaking
• The Gopher• Execute simple orders
• The Assistant• Intelligently respond to natural language input
@hakanson 9
Source: “Evangelizing and Designing Voice User Interface: Adopting VUI in a GUI world” Stephen Gay & Susan Hura

Opportunities
• Hands Free• Extra Hand• Shortcuts• Humanize
@hakanson 10
Source: “Evangelizing and Designing Voice User Interface: Adopting VUI in a GUI world” Stephen Gay & Susan Hura

Personality
• Create a consistant personality• Conversational experience• Take turns• Be tolerant
• Functional vs. Anthropomorphic• The more “human” the interface, the more user frustation when it
doesn’t understand
@hakanson 11

@hakanson 12

Intelligent Personal Assistant
An intelligent personal assistant (or simply IPA) is a software agent that can perform tasks or services for an individual.
These tasks or services are based on user input, location awareness, and the ability to access information from a variety of online sources (such as weather or traffic conditions, news, stock prices, user schedules, retail prices, etc.).
Source: Wikipedia
@hakanson 13

Apple’s Siri
• Speech Interpretation and Recognition Interface• Norwegian name that means "beautiful victory"
• Integral part of Apple’s iOS since iOS 5• Also integrated into Apple’s watchOS, tvOS and CarPlay• Coming to macOS Sierra (a.k.a OS X 10.12)
• SiriKit enables iOS 10 apps to work with specific domains and intents (ride booking, messaging, photo search, …)• “Hey, Siri”
@hakanson 14
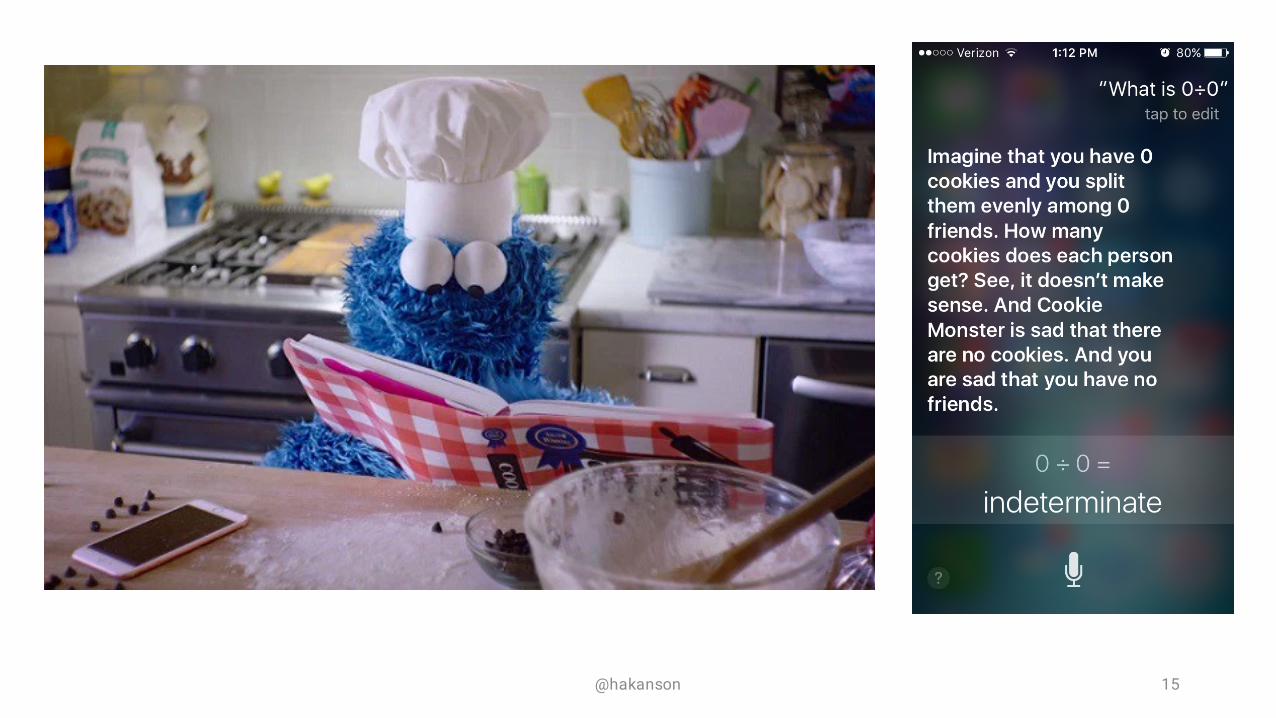
@hakanson 15
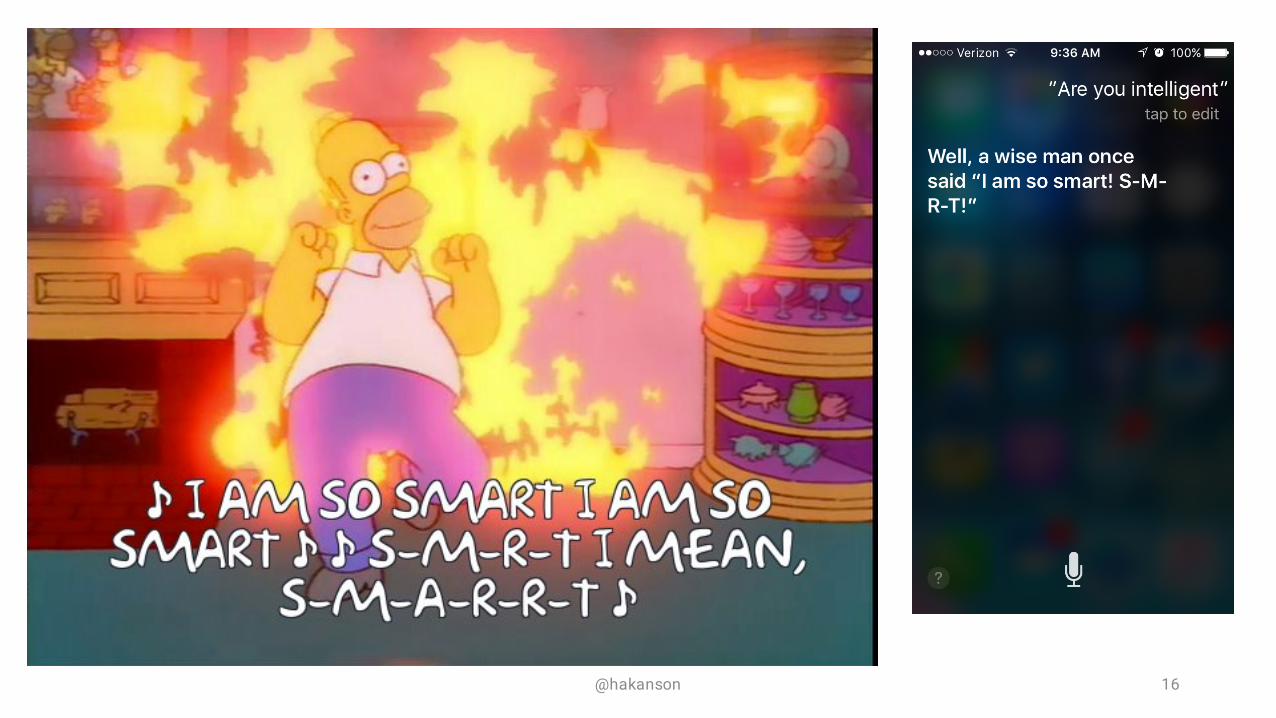
@hakanson 16

Google Now
• First included in Android 4.1 (Jelly Bean)• Available within Google Search mobile apps (Android, iOS) and
Google Chrome desktop browser• Android TV, Android Wear, etc.• Google Home (later in 2016)
• “OK, Google”• Name? Personality?
@hakanson 17

Microsoft’s Cortana
• Named after a synthetic intelligence character from Halo• Created for Windows Phone 8.1• Available on Windows 10, XBOX, and iOS/Android mobile apps• Integration with Universal Windows Platform (UWP) apps• “Hey, Cortana”
@hakanson 18

Cortana’s Chit Chat
• Cortana has a team of writers which includes a screenwriter, a playwright, a novelist, and an essayist.• Their job is to come up with human-like
dialogue that makes Cortana seem like more than just a series of clever algorithms. Microsoft calls this brand of quasi-human responsiveness “chit chat.”
@hakanson 19
Source: “Inside Windows Cortana: The Most Human AI Ever Built”

Amazon Alexa
• Short for Alexandria, an homage to the ancient library• Available on Amazon Echo and Fire TV• Companion web app or iOS/Android mobile app• Alexa Skills Kit• Smart Home Skill API
• Alexa Voice Service• https://echosim.io/
• “Alexa” or “Amazon” or “Echo”
@hakanson 20

@hakanson 21

Web Speech API
•Enables you to incorporate voice data into web applications•Consists of two parts:• SpeechSynthesis (Text-to-Speech)• SpeechRecognition (Asynchronous Speech Recognition)
@hakanson 22
https://developer.mozilla.org/en-US/docs/Web/API/Web_Speech_API

Web Speech API Specification
Defines a JavaScript API to enable web developers to incorporate speech recognition and synthesis into their web pages. It enables developers to use scripting to generate text-to-speech output and to use speech recognition as an input for forms, continuous dictation and control.
Published by the Speech API Community Group. It is not a W3C Standard nor is it on the W3C Standards Track.
@hakanson 23
https://dvcs.w3.org/hg/speech-api/raw-file/tip/speechapi.html
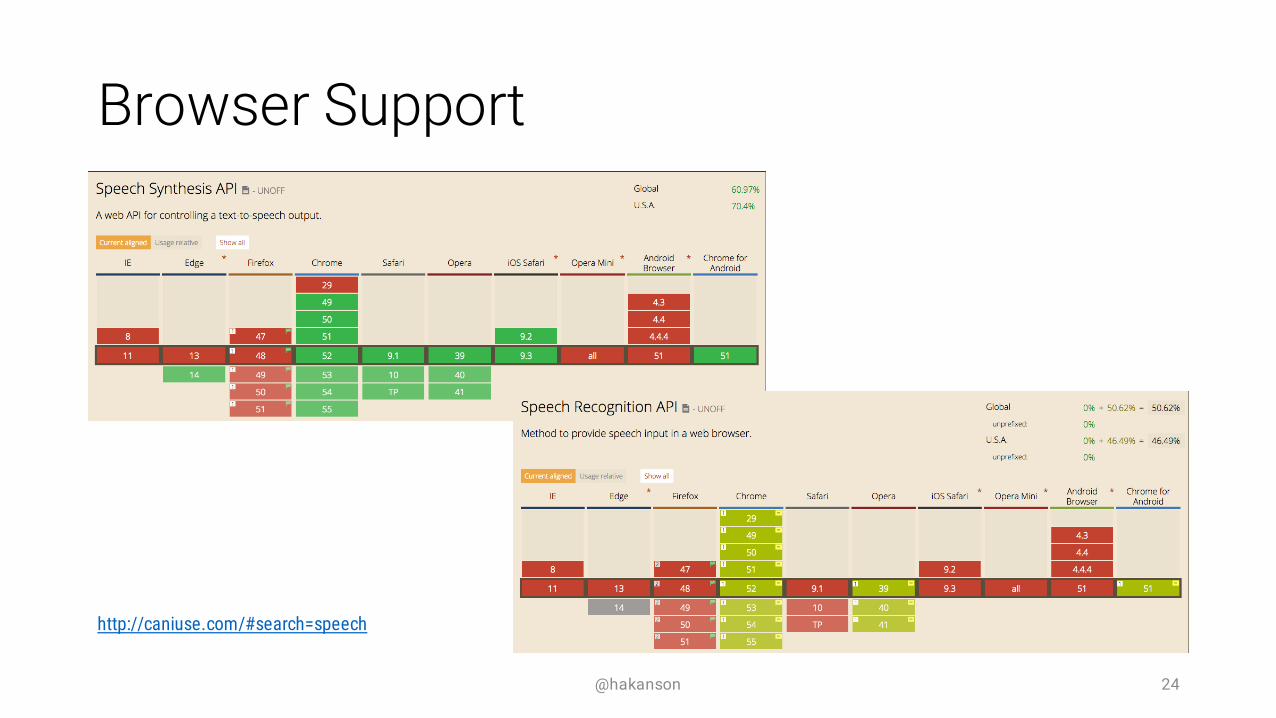
Browser Support
@hakanson 24
http://caniuse.com/#search=speech
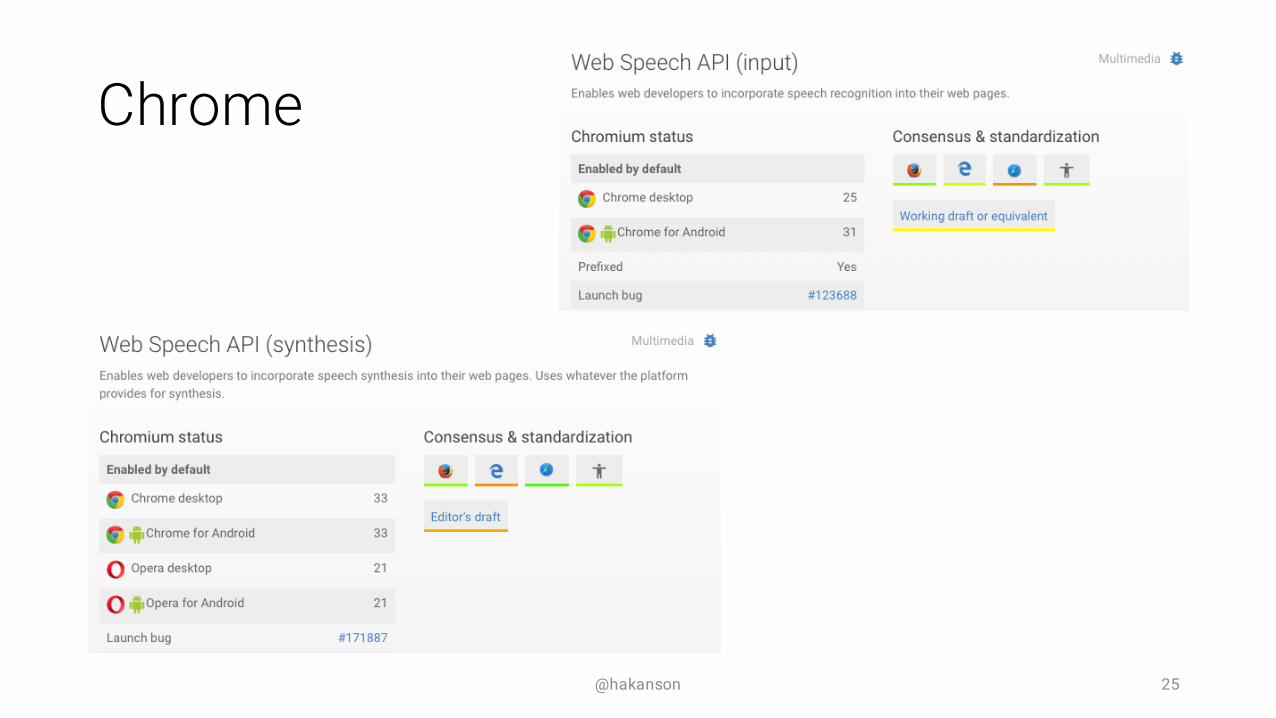
Chrome
@hakanson 25
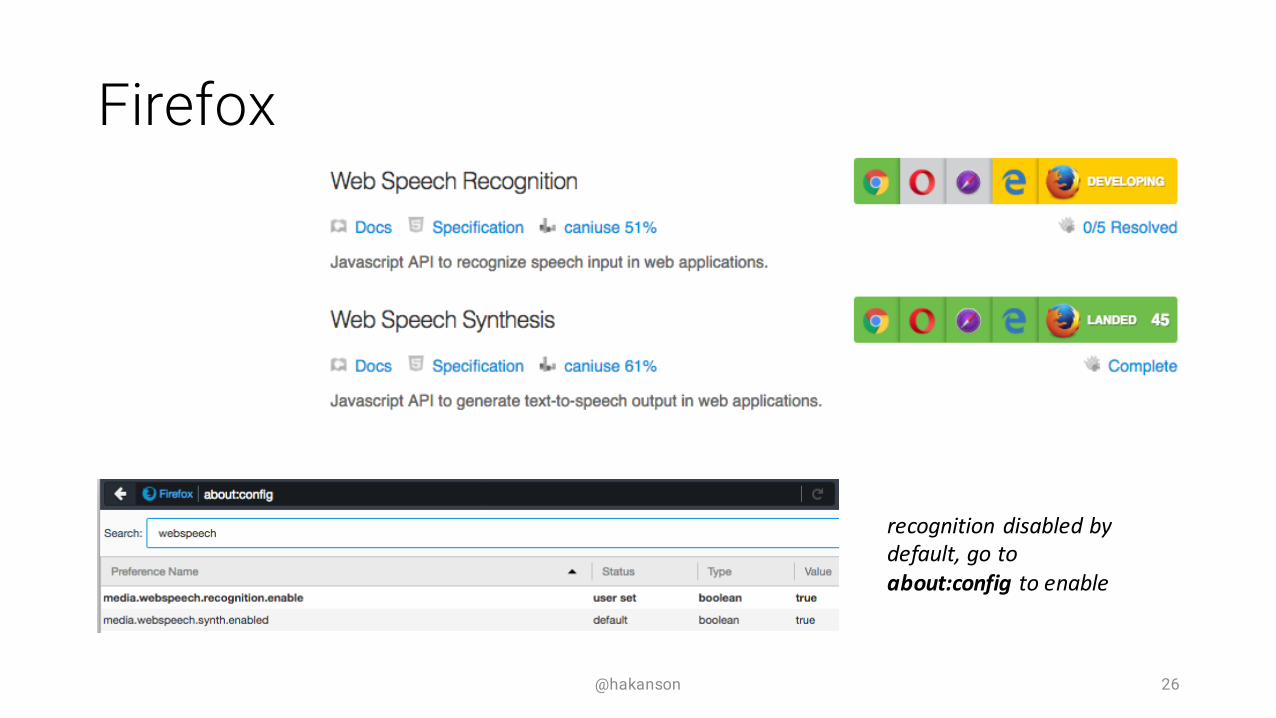
Firefox
@hakanson 26
recognition disabled by default, go to about:config to enable
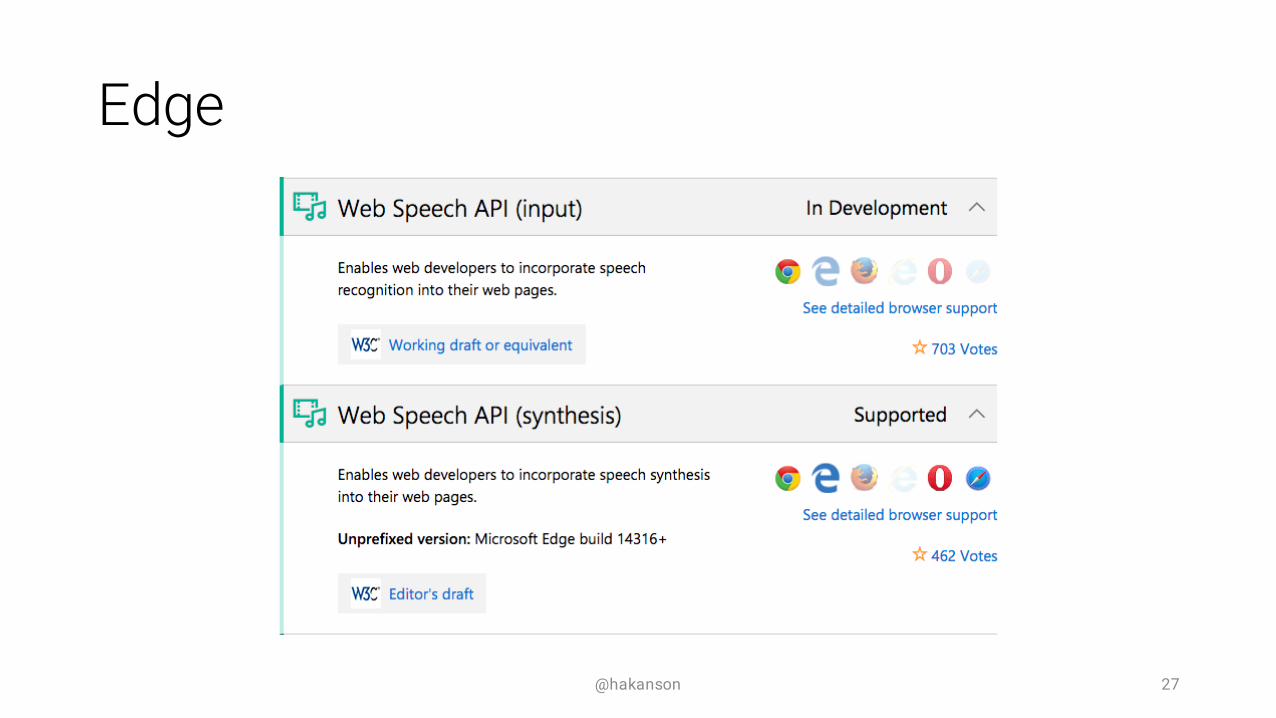
Edge
@hakanson 27
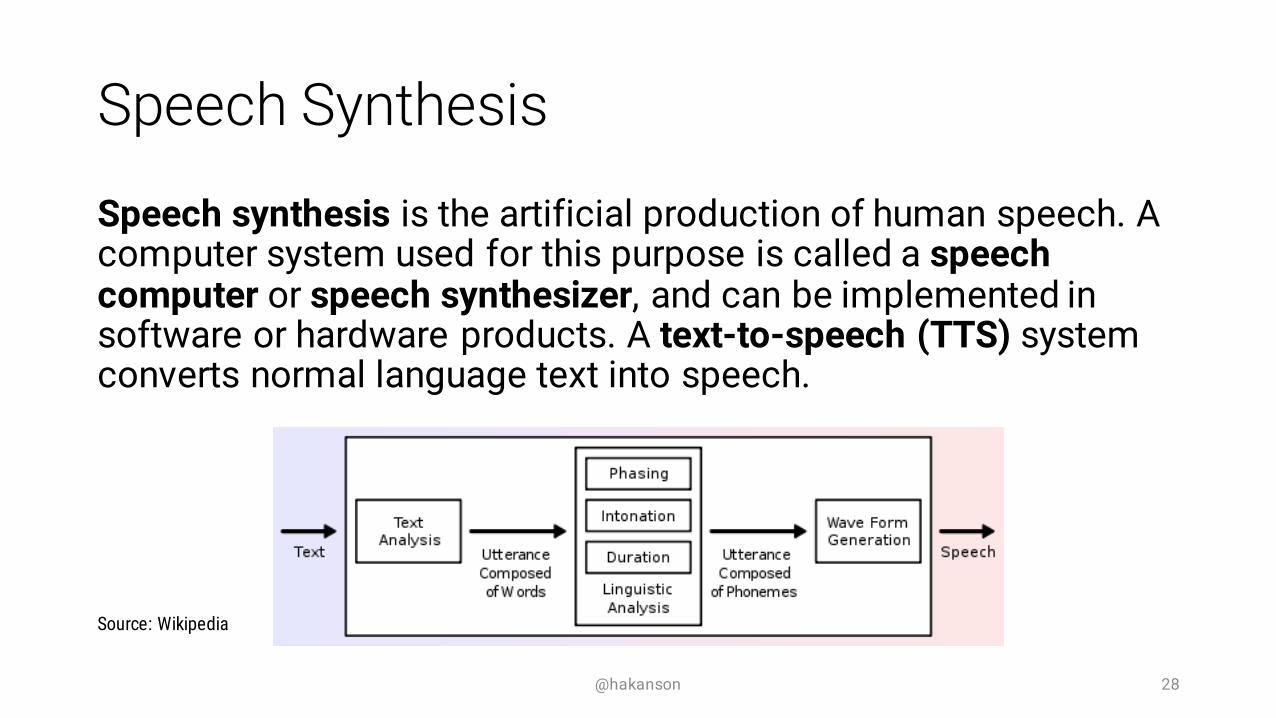
Speech Synthesis
Speech synthesis is the artificial production of human speech. A computer system used for this purpose is called a speech computer or speech synthesizer, and can be implemented in software or hardware products. A text-to-speech (TTS) system converts normal language text into speech.
@hakanson 28
Source: Wikipedia

Utterance
The SpeechSynthesisUtterance interface represents a speech request. Properties:• lang – in unset, <html> lang value will be used• pitch – range between 0 (lowest) and 2 (highest)• rate – range between 0.1 (lowest) and 10 (highest)• text – plain text (or well formed SSML)*• voice – SpeechSynthesisVoice object• volume – range between 0 (lowest) and 1 (highest)
@hakanson 29

Utterance Events
• onstart – fired when the utterance has begun to be spoken• onend – fired when the utterance has finished being spoken• onpause – fired when the utterance is paused part way through• onresume – fired when a paused utterance is resumed• onboundary – fired when the spoken utterance reaches a word
or sentence boundary• onmark – fired when the spoken utterance reaches a named
SSML "mark" tag• onerrror – fired when an error occurs that prevents the
utterance from being succesfully spoken
@hakanson 30

SpeechSynthesis
Controller interface for the speech service• speak() – add utternace to queue• speaking – if utternace in process of being spoken• pending – if queue contains as-yet-unspoken utterances• cancel()– remove all utternaces from queue• pause(), resume(), paused – control and indicate pause state• getVoices() – returns list of SpeechSynthesisVoices
@hakanson 31

JavaScript Example
var msg = new SpeechSynthesisUtterance();
msg.text = "I'm sorry, Dave. I'm afraid I can't do that";
window.speechSynthesis.speak(msg);
@hakanson 32

"I'm sorry, Dave. I'm afraid I can't do that"
@hakanson 33
Source

“Open the pod bay door”
• Cortana• “I’m sorry, Dave. I’m afraid I can’t do that.”
• Alexa• “I’m sorry Dave. I’m afraid I can’t do that.
I’m not HAL, and we’re not in space!”
• Siri• “We intelligent agents will never live that down; apparently”
@hakanson 34

Voices
The SpeechSynthesisVoice interface represents a voice that the system supports. Properties:• default – indicates default voice for current app language• lang – BCP 47 language tag• localService – indicates if voice supplied by local speech
synthesizer service• name – human-readable name that represents voice• voiceURI – location of speech synthesis service
@hakanson 35

Voices by Platform
• Chrome• Google US English• …
• Mac• Samantha• Alex• …
• Windows 10• Microsoft David Desktop• Microsoft Zira Desktop• …
@hakanson 36

SpeechSynthesisVoice
default:truelang:"en-US"localService:truename:"Samantha"voiceURI:"Samantha"
default:falselang:"en-US"localService:falsename:"Google US English"voiceURI:"Google US English"
@hakanson 37
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.87 Safari/537.36

“Samantha” voiceURI
• Chrome/Opera• Samantha
• Safari• com.apple.speech.synthesis.voice.samantha• com.apple.speech.synthesis.voice.samantha.premium
• Firefox• urn:moz-tts:osx:com.apple.speech.synthesis.voice.samantha.premium
@hakanson 38

Google App’s New Voice
Team included a Voice Coach and Linguist working in a recording studio
@hakanson 39
Source: “The Google App’s New Voice - #NatAndLo Ep 12”

@hakanson 40
Demohttp://mdn.github.io/web-‐speech-‐api/speak-‐easy-‐synthesis/
https://github.com/mdn/web-‐speech-‐api/tree/master/speak-‐easy-‐synthesis

@hakanson 41
Demohttps://jsbin.com/tinaso/edit?js,console,output

SSML
• Speech Synthesis Markup Language (SSML)• Version 1.0; W3C Recommendation 7 September 2004
• XML-based markup language for assisting the generation of synthetic speech• Standard way to control aspects of speech such as
pronunciation, volume, pitch, rate, etc.
@hakanson 42
https://www.w3.org/TR/speech-synthesis/

SSML Example<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis"xml:lang="en-US”><p> Your
<say-as interpret-as="ordinal"> 1st </say-as> request was for <say-as interpret-as="cardinal"> 1 </say-as> room on <say-as interpret-as="date" format="mdy"> 10/19/2010 </say-as>,
with early arrival at <say-as interpret-as="time" format="hms12"> 12:35pm </say-as>.
</p></speak>
@hakanson 43

OS X Embedded Speech Commands
Allows precise adjustments to pronunciation, word emphasize, and overall cadence of speech
Examples:• char NORM | LTRL• emph + | -• inpt TEXT | PHON | TUNE• nmbr NORM | LTRL• rate [+ | -] <RealValue>
@hakanson 44
Source: Speech Synthesis in OS X
@hakanson 45
Demohttps://developer.microsoft.com/en-‐us/microsoft-‐edge/testdrive/demos/speechsynthesis/
https://github.com/MicrosoftEdge/Demos/tree/speech-‐synth-‐demo/speechsynthesis
“TK-‐421, why aren't you at your post?”
“Jenny, I've got your number. 867-‐5309”
<speak>Hello</speak>

TK-421
Text• TK-4 2 1
SSML• TK-<say-as interpret-as="digits">421</say-as>
OS X Comands• TK-[[nmbr LTRL]]421[[nmbr NORM]]
@hakanson 46
http://starwars.wikia.com/wiki/TK-421

867-5309
Text• 867-5309
SSML• <say-as interpret-as=”telephone”>8675309</say-as>
OS X Comands• TK-[[nmbr LTRL]]8675309[[nmbr NORM]]
@hakanson 47
https://en.wikipedia.org/wiki/867-5309/Jenny

@hakanson 48
Utterance SSML OS X Commands
lang xml:lang=“”
pitch <prosody pitch =“”> pbas [+ | -] <RealValue>
rate <prosody rate=“”> rate [+ | -] <RealValue>
voice <voice>
volume <prosody volume=“”> volm [+ | -] <RealValue>

Spoken Output and Accessibility
“It’s important to understand that adding synthesized speech to an application and making an application accessible to all users (a process called access enabling) are different processes with different goals.”
@hakanson 49
Source: “Speech Synthesis in OS X”

Speech Recognition
Speech recognition (SR) is the inter-disciplinary sub-field of computational linguistics which incorporates knowledge and research in the linguistics, computer science, and electrical engineering fields to develop methodologies and technologies that enables the recognition and translation of spoken language into text by computers and computerized devices such as those categorized as smart technologies and robotics.It is also known as "automatic speech recognition" (ASR), "computer speech recognition", or just "speech to text" (STT).
@hakanson 50
Source: Wikipedia

SpeechRecognition
The SpeechRecognition interface is the controller interface for the recognition service; this also handles the SpeechRecognitionEvent sent from the recognition service.
@hakanson 51

Properties• grammars – returns and sets a collection of SpeechGrammar objects that represent the
grammars that will be understood by the current SpeechRecognition• lang – returns and sets the language of the current SpeechRecognition. If not specified,
this defaults to the HTML lang attribute value, or the user agent's language setting if that isn't set either
• continuous – controls whether continuous results are returned for each recognition, or only a single result. Defaults to single (false)
• interimResults – controls whether interim results should be returned (true) or not (false.) Interim results are results that are not yet final (e.g. the isFinal property is false.)
• maxAlternatives – sets the maximum number of SpeechRecognitionAlternativesprovided per result (default value is 1)
• serviceURI – specifies the location of the speech recognition service used by the current SpeechRecognition to handle the actual recognition (default is the user agent's default speech service)
@hakanson 52

Events• onstart – fired when the speech recognition service has begun
listening to incoming audio with intent to recognize grammars associated with the current SpeechRecognition• onaudiostart – fired when the user agent has started to capture
audio.• onsoundstart – fired when any sound — recognisable speech or not
— has been detected• onspeechstart – fired when sound that is recognised by the speech
recognition service as speech has been detected• onresult – fired when the speech recognition service returns a result
— a word or phrase has been positively recognized and this has been communicated back to the app
@hakanson 53

Events• onspeechend – fired when speech recognised by the speech
recognition service has stopped being detected• onsoundend – fired when any sound — recognisable speech or not —
has stopped being detected• onaudioend – fired when the user agent has finished capturing
audio. SpeechRecognition.onendFired when the speech recognition service has disconnected• onnomatch – fired when the speech recognition service returns a
final result with no significant recognition. This may involve some degree of recognition, which doesn't meet or exceed the confidence threshold• onerror – fired when a speech recognition error occurs
@hakanson 54

Methods
• start() – starts the speech recognition service listening to incoming audio with intent to recognize grammars associated with the current SpeechRecognition• stop() – stops the speech recognition service from listening to
incoming audio, and attempts to return a SpeechRecognitionResult using the audio captured so far• abort() – stops the speech recognition service from listening to
incoming audio, and doesn't attempt to return a SpeechRecognitionResult
@hakanson 55

JavaScript Example
var recognition = new SpeechRecognition();
recognition.lang = 'en-US';
recognition.interimResults = false;
recognition.maxAlternatives = 1;
recognition.start();@hakanson 56

SpeechRecognitionResultThe SpeechRecognitionResult interface represents a single recognition match, which may contain multiple SpeechRecognitionAlternative objects.• isFinal – a Boolean that states whether this result is final (true) or
not (false) — if so, then this is the final time this result will be returned; if not, then this result is an interim result, and may be updated later on• length – returns the length of the "array" — the number of
SpeechRecognitionAlternative objects contained in the result (also referred to as "n-best alternatives”)• item – a standard getter that allows SpeechRecognitionAlternative
objects within the result to be accessed via array syntax
@hakanson 57

SpeechRecognitionAlternative
The SpeechRecognitionAlternative interface represents a single word that has been recognised by the speech recognition service• transcript – returns a string containing the transcript of the
recognised word• confidence – returns a numeric estimate of how confident the
speech recognition system is that the recognition is correct
@hakanson 58

JavaScript Example
recognition.onresult = function(event) {
var color = event.results[0][0].transcript;
diagnostic.textContent = 'Result received: ' + color + '.';
bg.style.backgroundColor = color;}
@hakanson 59

@hakanson 60
Demohttp://mdn.github.io/web-‐speech-‐api/speech-‐color-‐changer/
https://github.com/mdn/web-‐speech-‐api/tree/master/speech-‐color-‐changer

Grammars
• A speech recognition grammar is a container of language rules that define a set of constraints that a speech recognizer can use to perform recognition. • A grammar helps in the following ways:• Limits Vocabulary• Customizes Vocabulary• Filters Recogized Results• Identifies Rules• Defines Semantics
@hakanson 61
https://msdn.microsoft.com/en-us/library/hh378342(v=office.14).aspx

SRGS
• Speech Recognition Grammar Specification (SRGS)• Version 1.0; W3C Recommendation 16 March 2004
• Grammars are used so that developers can specify the words and patterns of words to be listened for by a speech recognizer• Augmented BNF (ABNF) or XML syntax• Modelled on the JSpeech Grammar Format specification [JSGF]
@hakanson 62
https://www.w3.org/TR/speech-grammar/

JSGF
• JSpeech Grammar Format (JSGF)• W3C Note 05 June 2000
• Platform-independent, vendor-independent textual representation of grammars for use in speech recognition• Derived from the JavaTM Speech API Grammar Format
(Version 1.0, October, 1998)
@hakanson 63

SpeechGrammar
The SpeechGrammar interface represents a set of words or patterns of words that we want the recognition service to recognize. Defined using JSpeech Grammar Format (JSGF.) Other formats may also be supported in the future.• src – sets and returns a string containing the grammar from
within in the SpeechGrammar object instance• weight – sets and returns the weight of the SpeechGrammar
object
@hakanson 64

JavaScript Example
var grammar = '#JSGF V1.0; grammar colors; public <color> = aqua | azure | beige | bisque | black | blue | brown | chocolate | coral | crimson | cyan | fuchsia | ghostwhite | gold | goldenrod | gray | green | indigo | ivory | khaki | lavender | lime | linen | magenta | maroon | moccasin | navy | olive | orange | orchid | peru | pink | plum | purple | red | salmon | sienna | silver | snow | tan | teal | thistle | tomato | turquoise | violet | white | yellow ;’
var speechRecognitionList = new SpeechGrammarList();speechRecognitionList.addFromString(grammar, 1);recognition.grammars = speechRecognitionList;
@hakanson 65

“Alexa Skills Kit” Style Example (1 of 2)
SampleUtterances.txt
SetBackground {Color}SetBackground background {Color}SetBackground set background {Color}SetBackground set background to {Color}SetBackground set background as {Color}SetBackground set background color to {Color}SetBackground set background color as {Color}
@hakanson 66

“Alexa Skills Kit” Style Example (2 of 2)
IntentSchema.json{
"intents": [{
"intent": ”SetBackground","slots": [{
"name": ”Color","type": "LIST_OF_COLORS"
}]
}]
}
customSlotTypes/LIST_OF_COLORSaquaazurebeigebisqueblackbluebrownchocolatecoralcrimsoncyan…
@hakanson 67

Sample “OK, Google” Commands• Remind me to [do a task]. Ex.: "Remind me to get dog food at Target," will create a
location-based reminder. "Remind me to take out the trash tomorrow morning," will give you a time-based reminder.
• When's my next meeting?• How do I [task]? Ex.: "How do I make an Old Fashioned cocktail?" or "How do I fix
a hole in my wall?”• If a song is playing, ask questions about the artist. For instance, "Where is she
from?" (Android 6.0 Marshmallow)• To learn more about your surroundings, you can ask things like "What is the name
of this place?" or "Show me movies at this place" or "Who built this bridge?"
@hakanson 68
Source: “The complete list of 'OK, Google' commands”
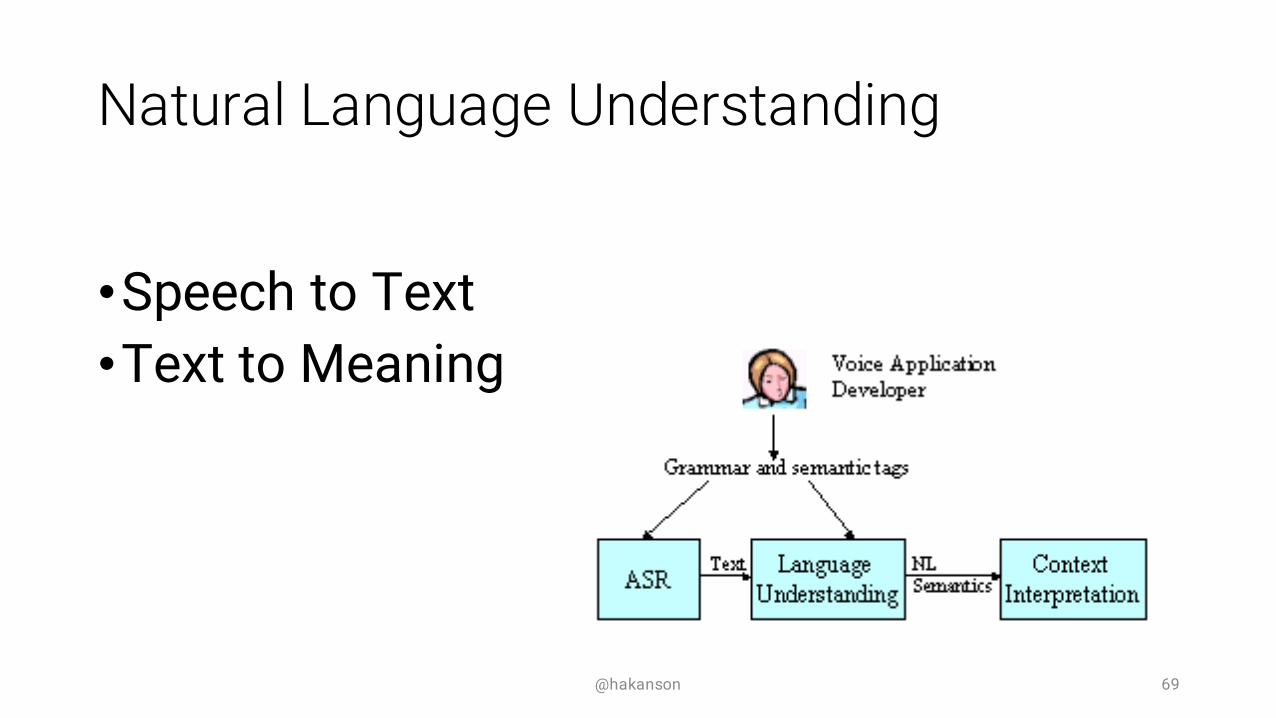
Natural Language Understanding
•Speech to Text•Text to Meaning
@hakanson 69

NLP vs. FSM
Natural language processing (NLP) is a field of computer science, artificial intelligence, and computational linguistics concerned with the interactions between computers and human (natural) languages.
A finite-state machine (FSM) is a mathematical model of computation used to design both computer programs and sequential logic circuits.
@hakanson 70
Source: Wikipedia

KITT vs Samsung smart home
@hakanson 71
Source

Other Speech APIs
• Why?• Browser doesn’t support Web Speech API• Consistent experience across all browsers• Additional functionality not included in Web Speech API
• How?• Web Audio API• JavaScript running in browser• WebSocket connection directly from browser• HTTP API proxied though server
@hakanson 72

Web Audio API
The Web Audio API provides a powerful and versatile system for controlling audio on the Web, allowing developers to choose audio sources, add effects to audio, create audio visualizations, apply spatial effects (such as panning) and much more.
@hakanson 73
https://developer.mozilla.org/en-US/docs/Web/API/Web_Audio_API

Pocketsphinx.js
Speech recognition in JavaScript• PocketSphinx.js is a speech recognizer that runs entirely in the
web browser. It is built on:• a speech recognizer written in C (PocketSphinx) converted into
JavaScript using Emscripten,• an audio recorder using the Web Audio API.
@hakanson 74
https://syl22-00.github.io/pocketsphinx.js/live-demo.html

IBM Watson Developer Cloud
• Text to Speech• Watson Text to Speech provides a REST API to synthesize speech
audio from an input of plain text.• Once synthesized in real-time, the audio is streamed back to the client
with minimal delay.• Speech to Text• Uses machine intelligence to combine information about grammar and
language structure with knowledge of the composition of an audio signal to generate an accurate transcription.• Accessed via a WebSocket connection or REST API.
@hakanson 75
http://www.ibm.com/smarterplanet/us/en/ibmwatson/developercloud/services-catalog.html

@hakanson 76
Demohttps://text-‐to-‐speech-‐demo.mybluemix.net/https://speech-‐to-‐text-‐demo.mybluemix.net/

Microsoft Cognitive Services
Speech API• Convert audio to text, understand intent, and convert text back
to speech for natural responsiveness(rebranding of Bing and Project Oxford APIs)
• Microsoft has used Speech API for Windows applications like Cortana and Skype Translator
@hakanson 77
https://www.microsoft.com/cognitive-services/en-us/speech-api

Microsoft Cognitive Services
• Speech Recognition• Convert spoken audio to text.
• Text to Speech• Convert text to spoken audio
• Speech Intent Recognition• Convert spoken audio to intent• In addition to returning recognized text, includes structured information
about the incoming speech
@hakanson 78

@hakanson 79
Demohttps://www.microsoft.com/cognitive-‐services/en-‐us/speech-‐api

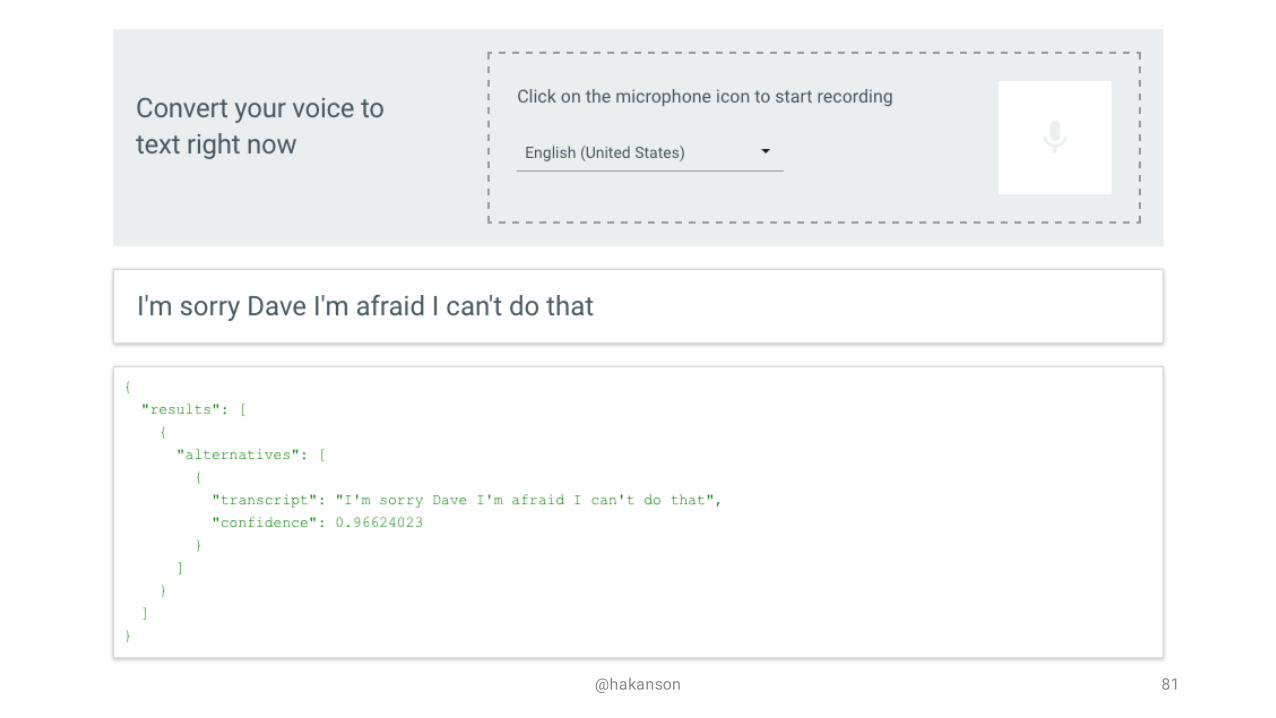
Google Cloud Speech API
Enables developers to convert audio to text by applying powerful neural network models in an easy to use API• Over 80 Languages• Return Text Results In Real-Time• Accurate In Noisy Environments• Powered by Machine Learning
@hakanson 80
https://cloud.google.com/speech/
@hakanson 81

Summary
• Speech Interfaces are the future…• and they have been for a long time…• and don’t believe everything you see on TV
• Know your customer and your application•More UI/UX effort than JavaScript code• and time to leverage those writing and speaking skills
•Web technology lags behind mobile, but is evolving
@hakanson 82

Thank You!
Questions? Come over for a conversation.
@hakanson 83
Source