inverse problems and data errors conference in honor of douglas o. gough on the occasion of his 60...
Post on 21-Dec-2015
214 views
TRANSCRIPT

Inverse Problems and Data ErrorsConference in Honor ofDouglas O. Gough
On the Occasion of his 60th Birthday
Chateau de Mons, Caussens, FranceP.B. StarkDepartment of StatisticsUniversity of CaliforniaBerkeley CA www.stat.berkeley.edu/~stark

Acknowledgements
• Media pirated from websites of – Global Oscillations Network Group
(GONG)
– Solar and Heliospheric Observer (SOHO) Solar Oscillations Investigation
• Much joint work, incl. S. Evans (UCB), I.K. Fodor (LLNL), C.R. Genovese (CMU), D.O.Gough (Cambridge), Y. Gu (GONG), R. Komm (GONG), T. Sekii (Natl. Astron. Obs.of Japan), M.J. Thompson (QMW)Source: sohowww.nascom.nasa.gov
Source: www.gong.noao.edu

The Difference between Theory and Practice
• In Theory, there is no difference between Theory and Practice.
• In Practice, there is.

Part I: Theory

Forward Problems in Statistics: Ingredients• Measurable space X of possible data.
• Set of possible descriptions of the world--models.
• Family P = {P : } of probability distributions on X , indexed by models .
•Forward operator P maps model into a probability measure on X .
Data X are a sample from P.
P is whole story: stochastic variability in the “truth,” contamination by measurement error, systematic error, censoring, etc.

ModelsIndex set that usually has special structure. For example, could be a convex subset of a separable Banach space T.
The forward mapping P maps the index of the model to a probability distribution for the data.
The physical significance of generally gives P reasonable analytic properties, e.g., continuity.

Forward Problems in Physics and Applied MathComposition of steps:
– transform correct description of the world into ideal, noise-free, infinite-dimensional data (“physics”)
– censor ideal data to retain only a finite list of numbers, because can only measure, record, and compute with such lists
– possibly corrupt the list with deterministic measurement error.
Equivalent to single-step procedure with corruption on par with physics, and mapping incorporating the censoring.

Physical v. Statistical Forward Problems
Statistical framework for forward problems is more general:
Forward problems of Applied Math and Physics are instances of statistical forward problems.

Parameters
A parameter of a model θ is the value g(θ) at θ of a continuous G-valued function g defined on
(g can be the identity.)

Inverse ProblemsObserve data X drawn from distribution Pθ for some unknown . (Assume contains at least two points; otherwise, data superfluous.)
Use X and the knowledge that to learn about ; for example, to estimate a parameter g().

Applied Math and Statistical Perspectives• Applied Math: recover a parameter of a pde or the solution of
an integral equation from infinitely many data, noise-free or with deterministic error.
– Common issues: existence, uniqueness, construction, stability for deterministic noise.
• Statistics: estimate or draw inference about parameter from finitely many noisy data
– Common issues: identifiability, consistency, bias, variance, efficiency, MSE, etc.

Many ConnectionsIdentifiability--distinct parameter values yield distinct probability distributions for the observables--similar to uniqueness--forward operator maps at most one model into the observed data.Consistency--parameter can be estimated with arbitrary accuracy as the number of data grows--related to stability of a recovery algorithm--small changes in the data produce small changes in the recovered model. quantitative connections too.

Physical Inverse Problems
• Inverse problems in applied Physics often are tackled using applied math methods for “Ill-posed problems” (e.g., Tichonov regularization, analytic inversions)
• Those methods are designed to answer different questions; can behave poorly with data (bad bias & variance)
• Inference construction: statistical viewpoint more appropriate for data

Elements of the Statistical View
Distinguish between characteristics of the problem, and characteristics of methods used to draw inferencesFundamental property of a parameter:g is identifiable if for all η, υ Θ,
{g(η) g(υ)} {Pη Pυ}.In most inverse problems, g(θ) = θ not identifiable, and few linear functionals of θ are identifiable

Decision RulesA (randomized) decision rule
δ: X M1(A)
x δx(.),is a measurable mapping from the space X of possible data to the collection M1(A) of probability distributions on a separable metric space A of actions. A non-randomized decision rule is a randomized decision rule that, to each x X, assigns a unit point mass at some value
a = a(x) A.

EstimatorsAn estimator of a parameter g(θ) is a decision rule for which the space A of possible actions is the space G of possible parameter values.
ĝ is common notation for an estimator of g(θ).
Usually write non-randomized estimator as a G-valued function of x instead of a M1(G)-valued function.

Comparing Estimators
Infinitely many estimators.
Which one to use?The best one!
But what does best mean?

Loss and Risk• Formulate as 2-player game: Nature v. Statistician.• Nature picks θ from Θ. θ is secret.• Statistician picks δ from a set D of decision rules. δ is secret.• Generate data X from Pθ, apply δ. • Statistician pays loss l (θ, δ(X)). l should be dictated by
scientific context, but…• Risk is expected loss: r(θ, δ) = Eθl (θ, δ(X))• Good estimator has small risk, but what does small mean?

StrategyRare that a single estimator has smallest risk for every
• Estimator is admissible if not dominated by another.• Minimax estimator minimizes supr (θ, δ) over D• Bayes estimator minimizes over D
for a given prior probability distribution on • Duality: minimax is Bayes for least favorable prior
θ)( πδ)θ,( dr

Common Risk: Mean Distance Error (MDE)
Let dG denote the metric on G. MDE at θ of estimator ĝ of g is
MDEθ(ĝ, g) = Eθ [d(ĝ, g(θ))].When metric derives from norm, MDE is called mean norm error (MNE).When the norm is Hilbertian, (MNE)2 is called mean squared error (MSE).

BiasWhen G is a Banach space, can define bias at θ of ĝ:
biasθ(ĝ, g) = Eθ [ĝ - g(θ)]
(when the expectation is well-defined).
• If biasθ(ĝ, g) = 0, say ĝ is unbiased at θ (for g).
• If ĝ is unbiased at θ for g for every θ, say ĝ is unbiased for g. If such ĝ exists, g is unbiasedly estimable.
• If g is unbiasedly estimable then g is identifiable.

More Notation
Let T be a separable Banach space, T * its normed dual.
Write the pairing between T and T *
<•, •>: T * x T R.

Linear Forward ProblemsA forward problem is linear if• Θ is a subset of a separable Banach space T• For some fixed sequence (κj)j=1
n of elements of T*,
X = (Xj) j=1n, where
Xj = <κj, θ> + εj, θΘ, and
ε = (εj)j=1n
is a vector of stochastic errors whose distribution does not depend on θ (so X = Rn).

Linear Forward Problems, contd.• The functionals {κj} are the “representers” or “data kernels”• The distribution Pθ is the probability distribution of X.
Typically, dim(Θ) = ; at the very least, n < dim(Θ), so estimating θ is an underdetermined problem.
DefineK : T Rn
Θ (<κj, θ>)j=1n .
Abbreviate forward problem by X = Kθ + ε, θ Θ.

Linear Inverse Problems
Use X = Kθ + ε, and the knowledge θ Θ to estimate or draw inferences about g(θ).Probability distribution of X depends on θ only through Kθ, so if there are two points
θ1, θ2 Θ such that Kθ1 = Kθ2 but
g(θ1)g(θ2), then g(θ) is not identifiable.

Backus-Gilbert++: Necessary conditionsLet g be an identifiable real-valued parameter. Suppose θ0Θ, a symmetric convex set Ť T, cR, and ğ: Ť R such that:
1. θ0 + Ť Θ
2. For t Ť, g(θ0 + t) = c + ğ(t), and ğ(-t) = -ğ(t)
3. ğ(a1t1 + a2t2) = a1ğ(t1) + a2ğ(t2), t1, t2 Ť, a1, a2 0, a1+a2 = 1, and
4. supt Ť | ğ(t)| <.
Then 1×n matrix Λ s.t. the restriction of ğ to Ť is the restriction of Λ.K to Ť.

Backus-Gilbert++: Sufficient ConditionsSuppose g = (gi)i=1
m is an Rm-valued parameter that can be written as the restriction to Θ of Λ.K for some m×n matrix Λ.
Then
1. g is identifiable.
2. If E[ε] = 0, Λ.X is an unbiased estimator of g.
3. If, in addition, ε has covariance matrix Σ = E[εεT], the covariance matrix of Λ.X is Λ.Σ.ΛT whatever be Pθ.

Corollary: Backus-GilbertLet T be a Hilbert space; let Θ = T ; let g T = T * be a linear parameter; and let {κj}j=1
n T *.The parameter g(θ) is identifiable iff g = Λ.K for some 1×n matrix Λ.In that case, if E[ε] = 0, then ĝ = Λ.X is unbiased for g.If, in addition, ε has covariance matrix Σ = E[εεT], then the MSE of ĝ is Λ.Σ.ΛT.

Consistency in Linear Inverse Problems
• Xi = i + i, i=1, 2, 3, … subset of separable Banach{i} * linear, bounded on {i} iid
consistently estimable w.r.t. weak topology iff {Tk}, Tk Borel function of X1, . . . , Xk s.t. , >0, *, limk P{|Tk - |>} = 0

• µ a prob. measure on ; µa(B) = µ(B-a), a
• Hellinger distance
• Pseudo-metric on **:
• If restriction to converges to metric compatible with weak topology, can estimate consistently in weak topology.
• For given sequence of functionals {i}, µ rougher consistent estimation easier.
Importance of the Error Distribution
2/121
1
221 }{ )κ,κ(δ
1),( ii
k
ik tt
kttD
2/12ba2
1 }{ )( dμdμ b)δ(a,

Example: Linear Combinations of Splitting Kernels
Cuts through kernels for rotation:A: l=15, m=8. B: l=28, m=14. C: l=28, m=24.D: two targeted combinations: 0.7R, 60o; 0.82R, 30o
Thompson et al., 1996. Science 272, 1300-1305.
Estimated rotation rate as a function of depthat three latitudes.Source: SOHO-SOI/MDI website

Part II: Practice

Linear Forward Problem for Rotation
dθdθ),(κν rrrlmnlmn
Note language change: θ is now latitude, Ώ is the model. Relationship assumes eigenfunctions and radial structure known. Observational errors usually are assumed to be zero-mean independent normal random variables with known variances.

Data Reduction
Harvey et al., 1996. Science 272, 1284-1286

GONG Data Pipeline1. Read tapes from sites.
2. Correct for CCD characteristics
3. Transform intensities to Doppler velocities
4. Calibrate velocities using daily calibration images
5. Find image geometry and modulation transfer function (atmospheric effects, lens dirt, instrument characteristics, ...)
6. High-pass filter to remove steady flows
7. Remap images to heliographic coordinates, interpolate, resample, correct for line-of-sight
8. Transform to spherical harmonics: window, Legendre stack in latitude, FFT in longitude
9. Adjust spherical harmonic coefficients for estimated modulation transfer function
10. Merge time series of spherical harmonic coefficients from different stations; weight for relative uncertainties
11. Fill data gaps of up to 30 minutes by ARMA modeling
12. Take periodogram of time series of spherical harmonic coefficients
13. Fit parametric model to power spectrum by iterative approximate maximum likelihood
14. Identify quantum numbers; report frequencies, linewidths, background power, and uncertainties
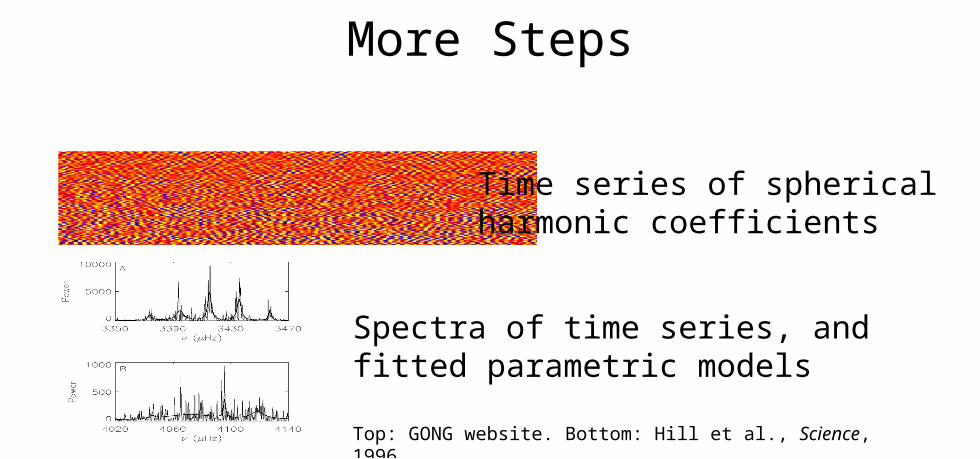
More Steps
Time series of spherical harmonic coefficients
Spectra of time series, and fitted parametric models
Top: GONG website. Bottom: Hill et al., Science, 1996.

Effect of Gaps
• Don’t observe process of interest.• Observe process × window• Fourier transform of data is FT of
process, convolved with FT of window.
• FT of window has many large sidelobes
• Convolution causes energy to “leak” from distant frequencies into any particular band of interest.
Power spectrum of window
95% duty cycle window

Tapering
• Want simplicity of periodogram, but less leakage
• Traditional approach—multiply data by a smooth “taper” that vanishes where there are no data
• Smoother tapersmaller sidelobes, but more local smearing (loss of resolution)
• Pose choosing taper as optimization problem

• What taper minimizes “leakage” while maximizing resolution?
• Leakage is a bias; optimality depends on definition
• Broad-band & asymptotic yield eigenvalue problems:
Optimal Tapering
2
2
maxargsupp:
w
Aw
wnw
taperoptimal

Prolate Spheroidal Tapers
• Maximize the fraction of energy in a band [-w, w] around zero
• Analytic solution when no gaps:– 2wT tapers nearly perfect
– others very poor
• Must choose w
• Character different with gapsT = 1024, w = 0.004. Fodor&Stark, 2000. IEEE Trans. Sig. Proc., 48, 3472-3483

Minimum Asymptotic Bias Tapers• Minimize integral of
spectrum against frequency squared
• Leading term in asymptotic bias
T = 1024 Fodor&Stark, 2000. IEEE Trans. Sig. Proc., 48, 3472-3483

Sine Tapers
• Without gaps, approximate minimum asymptotic bias tapers
• With gaps, reorthogonalize
T = 1024.Fodor&Stark, 2000. IEEE Trans. Sig. Proc. 48, 3472-3483.

Optimization Problems
• Prolate and minimum asymptotic bias tapers are top eigenfunctions of large eigenvalue problems
• The problems have special structure; can be solved efficiently (top 6 tapers for T=103,680 in < 1day)
• Sine tapers very cheap to compute

Sample Concentration of TapersT=1024, w = 0.004
Order Prolate Prolate w/ gaps Projected prolate
0 0.9999 0.9980 0.8126
1 0.9999 0.9977 0.9704
2 0.9999 0.9785 0.9317
3 0.9999 0.9753 0.9722
4 0.9999 0.9609 0.9550
Fodor & Stark, 2000. IEEE Trans. Sig. Proc., 48, 3472-3483

Sample Asymptotic Bias of Tapers, T = 1024
Order Minimum Asympt Bias Min Bias w/ gaps Projected Min Bias
0 0.00021 0.00437 0.73516
1 0.00090 0.02265 0.43173
2 0.00212 0.13854 0.63884
3 0.00382 0.23002 0.55921
4 0.00594 0.27385 0.45409
Fodor & Stark, 2000. IEEE Trans. Sig. Proc., 48, 3472-3483

Multitaper Estimation• Top several eigenfunctions have eigenvalues close to 1.• Eigenvalues drop to zero, abruptly for no-gap• Estimates using orthogonal tapers are asymptotically
independent (mild conditions)• Averaging spectrum estimates from several “good” tapers can
decrease variance without increasing bias much.• Get rank K quadratic estimator.

Multitaper Procedure
• Compute K orthogonal tapers, each with good concentration
• Multiply data by each taper in turn
• Compute periodogram of each product
• Average the periodograms
Special case: break data into segments

Cheapest is Fine
For simulated and real helioseismic time series of length T=103,680, no discernable systematic difference among 12-taper multitaper estimates using the three families of tapers.
Use re-orthogonalized sine tapers because they are much cheaper to compute, for each gap pattern in each time series.

Multitaper Simulation
• Can combine with segmenting to decrease dependence
• Prettier than periodogram; less leakage.
• Better, too?T=103,680. Truth in grey. Left panels: periodogram. Right panels: 3-segment 4-taper gapped sine taper estimate. Fodor&Stark, 2000.

Multitaper: SOHO Data
• Easier to identify mode parameters from multitaper spectrum
• Maximum likelihood more stable; can identify 20% to 60% more modes (Komm et al., 1999. Ap.J., 519, 407-421) SOHO l=85, m=0. T = 103, 680.
Periodogram (left) and 3-segment 4 sine taper estimateFodor&Stark, 2000. IEEE Trans. Sig. Proc., 48, 3472-3483

Error bars: Confidence Level in SimulationMethod % Coverage Method % Coverage
Parametric chi-square 72 Blockwise bootstrap 56
Simulation from Estimate 82 Bootstrap pivot percentile 71
Jackknife 75 Pre-pivot bootstrap 78
Bootstrap normal 77 Iterated pre-pivot bootstrap 91
Bootstrap-t 78 Bootstrap percentile of percentiles 90
Bootstrap percentile 69 Bootstrap pivot percentile of percentiles 96
1,000 realizations of simulated normal mode data. 95% target confidence level. Fodor&Stark, 2000. IEEE Trans. Sig. Proc., 48, 3472-3483