issue 1 competing with intelligence and insight -...
TRANSCRIPT

1
Unlocking the Power of Content by Putting Into Context
Transitioning from Enterprise Content to Cloud-based Context – The Move Is On
Gartner Research: Top Ten Technology Trends Impacting Information Infrastructure, 2011 About MuseGlobal
Virtually Aggregating Federated Content for Competitive Advantage
Executive Summary
Quickly harnessing every relevant element of data in a company and putting it into context to close a new sale, win over a customer for life with excellent service, launch a new product or stay in compliance is making content aggregation a necessity today. Today this need has become a top priority because a lot of the “relevant” data is no longer controlled by the company’s IT team or systems. Current customers, future customers and past customers are using social media platforms to air their views and companies need to listen, aggregate and respond to this externally available content as well.
The competitive dynamics of industries have changed rapidly in the last decade, driven by the consolidation of asset-intensive businesses to ones that are agile, quick to respond to market conditions, and exceptionally strong at rapidly transforming data in its many forms into actionable knowledge quickly. Knowledge-based strategies are more effective than relying on price, especially in industries that have complex, highly process-intensive supply chains such as auto production (Dyer, Nobeoka, 2000). A knowledge-
Issue 1
based network that can quickly interpret data and analyze it, then present the results so decisions can be made will often outperform competitors who rely on dated strategies and techniques (Suh, Shin, 2010).
Consider the following findings from a recent IBM survey of Enterprise Content Management:
• 95% of data outside a business is unstructured and defies categorization by company taxonomies or data structures
Featuring research from
Competing with Intelligence and Insight
2
3 6
20

2
• 85% of information is unstructured and outside a database
• 81% of business is conducted based on unstructured information
• 70% of decisions are made with incomplete or no contextually relevant information
• 60% to 80% of workers can’t find the information they are looking for even when ECM and EKM systems are in place
• 30% of people time is spent any given day searching for information and trying to understand its context and original methodology of how and why it was created
• IBM estimates that data and content is growing at a compound annual growth rate of 64% a year or more
• Even with an ECM or EKM system in place there is still nearly 1TB of data being generated every day in a typical Fortune 500 company that is not leveraged by enterprise applications.
• According to studies by IBM and The MIT Media Lab, 95% of content essential for decision making in a company is unstructured, residing in competitive and industry websites, social networks, blogs, product forums and other sites easily accessible by customers yet defying easy categorization and analysis of data.
The challenge then is to aggregate, normalize and transform this ever increasing content into usable data aligned with roles, needs and devices. Social search is and will increasingly be relied on for defining the context of unstructured content and defining its relevance to a company in the process. A company’s ability to quickly synthesize and use internal and external content in the context of strategies will determine how effectively they compete in the short term, and how well they withstand competitive threats while making the most of opportunities in the long-term.
The strongest companies in any economic downturn are those that have these complex series of processes down to a science. They deliberately set out to transform internal data, often locked in silos of legacy systems and non-integrated databases, into a formidable competitive advantage. Relying
on cloud architectures to integrate and transform unstructured content outside their companies from a myriad of sources and integrate it into workflows provides a greater depth of insight than many of their competitors can match. The many variations of content analytics including trend analysis, sentiment analysis, reputation management, affinity analysis, recommendation analysis, face recognition, speech analytics and visualization analysis are increasingly being used to assign unstructured data into ontological frameworks and taxonomies. This is making it possible to quickly interpret the torrent of unstructured data being generated by social networks, websites, content providers and other sources of unstructured content. The result is greater insight into market dynamics, competitive trends and finding opportunities much faster than competitors who aren’t using data to its fullest extent.
Unlocking the Power of Content by Putting it Into Context
Realizing the full potential of unified content continues to be a high priority in many industries and companies. Conceptually easy to define yet to this point difficult to implement, unifying content and managing it across the enterprise accentuates competitive strengths at the process and strategy level. It has shown to be essential for keeping business agile during turbulent economic times. Transforming content outside a business that is 95% of the time unstructured so it can be used for content analysis, branding and sentiment analysis, reputation monitoring and many other potential uses defies the current capabilities of Enterprise Content Management (ECM) systems. What is needed is a series of aggregation, normalization and transformation Web Services that can quickly interpret, categorize and present the data in a form that is instantly useful and relevant.
Integrating external, unstructured content sources and internally generated and often highly structured systems to create a federated platform that lacks context is still leaving many needs unmet throughout enterprises and organizations. Even with Enterprise Content Management (ECM) and Enterprise Knowledge Management (EKM) systems becoming more adopted in data-intensive industries, there were still large gaps in data, information and knowledge effectiveness, availability. These gaps are widening with the wide adoption of mobile devices. The “Now” economy is here.

3
Getting all the content available to an enterprise - from the highly structured records in relational databases, Enterprise Resource Planning (ERP), Customer Relationship Management (CRM), legacy transaction and Web Content Management systems to the highly unstructured content from customer feedback, service, and support systems - to work together required more than Enterprise Content Management (ECM) platforms. It required the ability to contextualize the content and make it relevant. While many enterprises were realizing their ECM systems would in many cases be as inflexible in this regard as their ERP systems had been in managing new and rapidly changing transaction workflows, the proliferation of content was happening literally overnight on social networks. The added dimension of content analytics, sentiment and trend analysis, and reputation analysis has quickly grown to be considered one of the core components of Social Customer Relationship Management (SCRM) strategies. Content being indexed and created daily through search engines, Internet databases and the decision on the part of hundreds of academic databases including EBSCO Host and others to create Application Programmer Interfaces (APIs) so their content can be accessed from a
contextual standpoint have all accelerated the shift away from federated content management to federated search and virtual content management.
Transitioning from Enterprise Content to Cloud-based Context – The Move Is On
The era of ECM and EKM has passed and the proliferation of unstructured content is setting a pace of innovation that calls for entirely new and innovative processes, strategies, and systems. Cloud-based Web Services architectures are defining data integration bridges that support many different communication protocols including HTTP, LDAP, RSS, SOAP, SRU/SRW, SQL, XML and several others. Taken together, these data integration bridges also enable broader source record support including the many variations of Microsoft Office, Lotus Notes, HTML, XML, fixed length and fixed position records in addition to many others. Content integration across data repositories is proving to be a critical foundation to supporting mission critical business processes as well. Master Data Management (MDM) technologies in the past have attempted to create a single system of record within an organization, scaling to support legacy data, the majority if not all of which are highly structured.
Source: MuseGlobal
FIgUrE 1 A Conceptual Representation of The Content Repositories that a typical customer needs to leverage

4
Source: MuseGlobal
FIgUrE 2 The MUSEGlobal Virtual Content Aggregation Service
The emergence of entirely new types of data repositories, many outside the organization and in unstructured form, will influence and define the future of many businesses orders of magnitude more than their legacy systems. Because of structured legacy data and the plethora of unstructured content being generated in external networks daily, hybrid content architectures will eventually become commonplace.
Session management and stateful Application Programmer Interfaces (APIs) in addition to Cloud-based connectors that include Query, Harvest, Writing and Translation functionality are today being used to extend the integration depth and breadth of virtual content management far beyond the limitations of previous generation ECM and EKM systems. Cloud-based connectors also have the ability to support configurable Web crawling, RSS Feed integration and enable extraction of content for normalization and delivery to any device or interface preferred by system users. All of these technologies combined provide for orders of magnitude greater agility and insight into the proliferating of internal and external context by defining its context and further support hybrid content architectures.
Defining a Model for Cloud-Based Content Aggregation Service
MuseGlobal’s Virtual Content Aggregation Service is purpose-built for an agile business that wants to leverage the extensive content available inside and outside the enterprise. Catering to customer needs across a variety of industries has given MuseGlobal a library of over 6,300 connectors that can access content from enterprise, free or syndicated sources. The service is designed to protect and enhance current investments in ECM, Business Intelligence and Enterprise Search systems by feeding them content that is already aggregated and normalized for their immediate use.
The Virtual Content Aggregation Service is designed for companies that realize that their existing applications need to work with federated content and need an underlying platform that facilitates such an environment. Source Packages (connectors) from MuseGlobal’s Source Factory work in tandem with Muse’s Information Connection Engine (ICE) to serve as main hub in the Muse architecture for accessing and normalizing content and data.

5
Most importantly, the virtual content aggregation model that MUSEGlobal has defined brings greater agility and speed of response to any query, request, analysis, or process workflow relying on this platform. There are numerous benefits of bringing contextual insight into enterprise applications include integrating content analysis, sentiment analysis, fact extraction and reputation analysis into CRM and Social CRM systems.
The enterprise world has moved past the days when email on blackberry was an adequate answer to mobility. We are already seeing the CIOs starting to explore how they can empower their mobile workforce with relevant content for the growing number of iPads and iPhones. The new generations of devices are broadening the horizons of a mobile and productive workforce. Their ability to feed the insatiable need for relevant content will require a dramatically different approach and MuseGlobal is priming their Virtual Content Aggregation Service to fill this critical need.
references
Jeffrey H Dyer & Kentaro Nobeoka. (2000). Creating and managing a high-performance knowledge-sharing network: The Toyota case. Strategic Management Journal: Special Issue: Strategic Networks, 21(3), 345-367.
Suh, A., & Shin, K.. (2010). Exploring the effects of online social ties on knowledge sharing: A comparative analysis of collocated vs dispersed teams. Journal of Information Science, 36(4), 443.
Source: MuseGlobal
Translation and mapping is accomplished using XML-based Document Data Definitions (DTDs) that include semantic translation of mapping. In addition, XSLT style sheets are used for base mapping translations and the definition of taxonomy clouds. Using the combination of XML-based DTDs and XSLT style sheets, the Muse Application creates a Universal Data Model. This normalized data model is pivotal to the defining of taxonomy clouds that provide contextual content to users and the MuseMeter display applets, application and widgets. MuseMeters fulfill the vital role in this architecture of interpreting and displaying in real-time contextual, federated search results through applets, applications or widgets on a variety of end devices.
The contextual value of information is related to the timeliness of its delivery. Legacy ECM and EKM systems often became entrenched in processes and workflows that hindered their effectiveness and gradually slowed response times, rending the data less and less contextual and valuable. Companies are increasingly integrating legacy data behind firewalls through private cloud configurations and relying on cloud platforms for aggregating, normalizing and transforming the immense amount of data generated daily outside their businesses, yet critical to their success. Multiple market segments including law enforcement, healthcare, publishing, education, and professional services are lowering their Total Cost of Ownership (TCO) by embracing the new paradigm of virtually accessing the content that they need from their current repositories.

6
research from gartner
Top 10 Technology Trends Impacting Information Infrastructure, 2011
• Use of some of these technologies requires new skills, as well as dedicated analysts to interpret the results.
recommendations
• Determine, for your current IM projects and those planned in the short term, whether the main emerging trends in technology have been factored into your strategic planning process.
• Compare where these 10 technologies are in Gartner’s 2010 Hype Cycles for content management, data management and enterprise information management. Anticipate their impact and plan adoption accordingly. Some of these technologies are in an early stage of enterprise adoption and come with a risk of failure.
ANALYSIS
1.0 OverviewThis document updates Gartner’s analysis of the top 10 technology trends in IM. Companion documents focus on major innovation forces that will impact on organizations’ ability to leverage information as an asset. These documents identify what is driving IM initiatives inside enterprises and should be used together as a set.
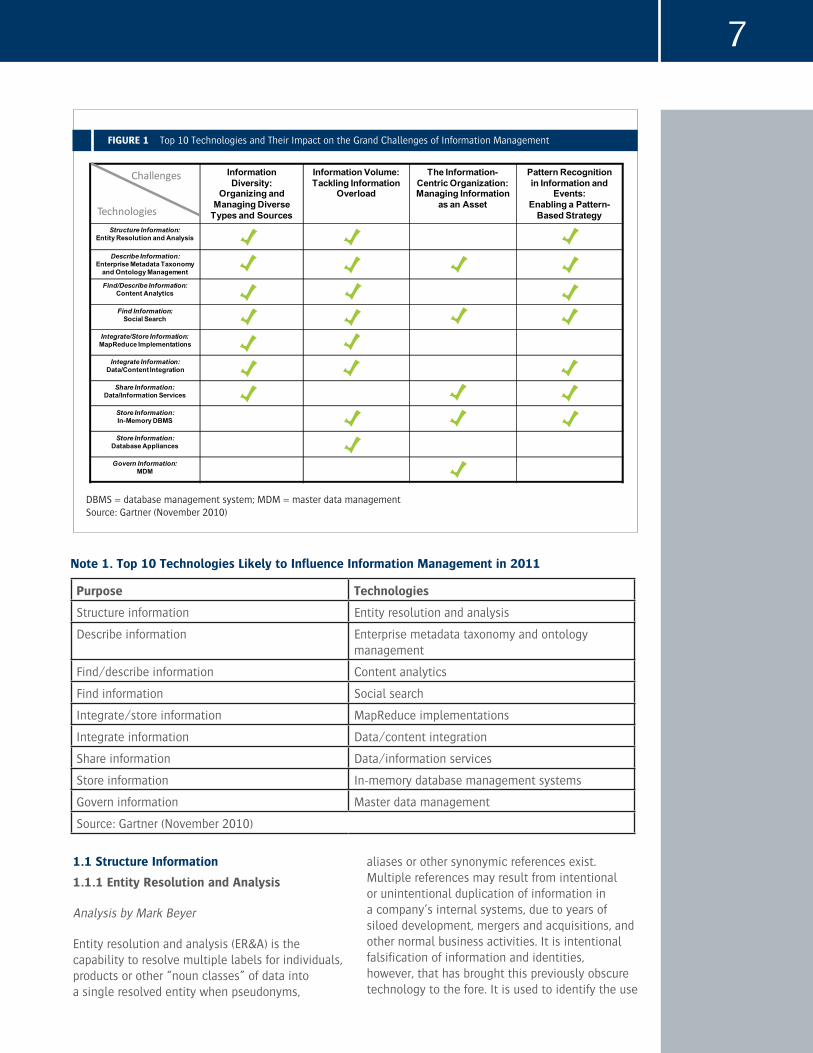
We view these technologies as strategic because they directly address components of the grand challenges of IM as set out in “Gartner’s Information Management Grand Challenges: Opportunities for Resolution.” These challenges represent the most substantial impediments to improvements in organizations’ use and control of data and content assets, and therefore to the value they derive from them. Figure 1 highlights the key relationships between these strategic technologies and the grand challenges they can help to overcome.
This document should be read by CIOs, information architects, information managers, enterprise architects and anyone working in a team evaluating or implementing an enterprise content management system, a business intelligence (BI) application, a master data management (MDM) technology, a document-centric collaboration initiative, an e-discovery effort, an information access project or a data warehouse system.
As evidenced in Gartner’s 2010 Hype Cycles (see Recommended Reading), significant innovation continues in the field of information management (IM) technologies. The key tactical factors driving this innovation are the explosion in the volume and diversity of information and the huge amount of value – and potential liability – locked inside all this ungoverned data.
We have identified four “grand challenges” of IM that enterprises must overcome if they are to make the best use of information as an asset. These are the requirements to:
• Develop a strategic view of information.
• Exploit the diversity of information.
• Tackle “information overload.”
• Detect new patterns within information.
We have also identified four major innovation forces that will influence the future of information infrastructure.
The 10 technologies analyzed in this document influence IM in different ways. As Note 1 shows, some help structure information, some help describe and find information, some integrate and share information across applications and content repositories, some store information, and some govern information.
Key Findings
• Some IM technologies will enable enterprises to reduce risks and avoid certain costs. Others will transform how they use information as an asset.
• The top 10 technologies identified will help enterprises meet the grand challenges of IM in different ways. Some address the diversity of information, some tackle the volume of information, and some help manage information as a strategic asset and improve pattern recognition. However, rising to the grand challenges requires more than just technology – it requires the right IT, people and processes.
7
DBMS = database management system; MDM = master data management Source: Gartner (November 2010)
FIgUrE 1 Top 10 Technologies and Their Impact on the Grand Challenges of Information Management
Information Diversity:
Organizing and Managing Diverse
Types and Sources
Information Volume: Tackling Information
Overload
The Information-Centric Organization: Managing Information
as an Asset
Pattern Recognition in Information and
Events: Enabling a Pattern-
Based StrategyStructure Information:
Entity Resolution and Analysis
Describe Information: Enterprise Metadata Taxonomy
and Ontology Management
Find/Describe Information:Content Analytics
Find Information: Social Search
Integrate/Store Information:MapReduce Implementations
Integrate Information:Data/Content Integration
Share Information: Data/Information Services
Store Information: In-Memory DBMS
Store Information: Database Appliances
Govern Information: MDM
Challenges
Technologies
Purpose Technologies
Structure information Entity resolution and analysis
Describe information Enterprise metadata taxonomy and ontology management
Find/describe information Content analytics
Find information Social search
Integrate/store information MapReduce implementations
Integrate information Data/content integration
Share information Data/information services
Store information In-memory database management systems
Govern information Master data management
Source: Gartner (November 2010)
Note 1. Top 10 Technologies Likely to Influence Information Management in 2011
1.1 Structure Information
1.1.1 Entity resolution and Analysis
Analysis by Mark Beyer
Entity resolution and analysis (ER&A) is the capability to resolve multiple labels for individuals, products or other “noun classes” of data into a single resolved entity when pseudonyms,
aliases or other synonymic references exist. Multiple references may result from intentional or unintentional duplication of information in a company’s internal systems, due to years of siloed development, mergers and acquisitions, and other normal business activities. It is intentional falsification of information and identities, however, that has brought this previously obscure technology to the fore. It is used to identify the use

8
of false identities and networks of individuals who are trying to hide their relationships to each other. The same technologies or analyses are used in the detection of fraud networks, racketeering and money-laundering.
Validation applications – alternative bill-of-materials analysis and consumer reference networks, for example – will see rapid results from using this technology, because market affinities are quickly identified and supplier issues surface rapidly. Although the detection of accidental data entry can reduce confusion, it is the resolution of intentionally misleading references that is of the greatest benefit by detecting perpetrators of illegal activities. In the case of non-criminal use, after resolving individual identities and networks of activity completed by employees, it becomes possible to detect “shadow processes” that may, in practice, replace formal or approved processes in an organization. However, a challenge to ER&A comes from privacy protection laws, in Europe specially.
Mitigation efforts for more malevolent activities will be challenged as criminals exercise creativity in defeating these systems. Linking this technology with voice and speech recognition solutions will help enterprises stay ahead of criminals’ techniques. Additionally, analytics technology that extracts identifying information used in reconciling entities from audio, video, image and other less analyzed data types is needed for the technology to realize its potential.
ER&A draws on many aspects of data integration, MDM and data quality management. It can also contribute to each of these practices. Additionally, all four disciplines – data integration, MDM, data quality management and ER&A – make up a significant portion of the implementation that takes place for enterprise IM.
Through 2011, organizations will fail to differentiate between data integration, MDM, data quality management and ER&A. They will start asking “What else does this give me?” Data management and integration vendors have led the charge toward bringing these different functions together. At its core, ER&A is a discovery and inference model, while MDM and data quality are governance and assurance models. For example, data quality management addresses a “wrong” address for a person or two nonaligned instances of the same person. MDM, for its part, addresses the rule about when a new person record can be created. ER&A addresses the concept that
two very different entries, following the MDM rules to create rows and data quality rules to ensure attributes are populated with valid values, are in fact for the same person, based on their transaction data, known associates and affiliations or some other nascent data point. ER&A has significant benefits but ultimately will merge into data quality technology and MDM practices between 2013 and 2015 and lose much of its functionality – only to return under some new moniker around 2016.
1.1.2 recommendations
Fraud detection and other criminal investigations can use ER&A solutions to enhance their use of available information. Data quality stewards and data governance experts can use them as forensic tools. Through 2014, commercial applications of this technology will be challenged, because data quality problems will diminish the value of resolving data in an active fashion – no good data means no reliable resolution.
In using these evaluation engines, organizations are cautioned to use results only with significant human oversight. Use of this technology should involve data stewards and dedicated analysts to interpret the results. Many vendor solutions offer a more mature solution in entity resolution than in analytics, but it is important to understand that the greatest benefit from this class of technology emerges from both facets and that the use of entity resolution tools only sets the stage for analytics. Review the resolution tool road map for eventual integration with analytics.
1.2 Describe Information
1.2.1 Enterprise Metadata Taxonomy and Ontology Management
Analysis by Mark Beyer
At its core, the ontological method seeks to determine a universal commonality that permits the sharing of concepts across comprehension barriers, so that, although many people can look at something from different viewpoints, they can all realize they are seeing the same thing. Taxonomy design is the process of defining categories and the relationships between them – of determining what features make one thing different from another. In the relational world, these categories and subcategories are expressed as entities and attributes.

9
When analyzing multiple taxonomies in relation to one another, it is important to recognize that multiple metadata descriptions can exist simultaneously for each information asset. In other words, different people and systems attach seemingly different meanings to the same entity. The various metadata sources include business process modeling, federation, extraction, transformation and loading, metadata repository technologies and many others. When rationalizing more than one taxonomy, it is important to remember that taxonomy design and ontological development occur simultaneously and implicitly. An example of daily taxonomy management occurs in data integration projects.
Data integration, at its core, is the process of rationalizing one taxonomy and its incumbent ontology to a second, disparate taxonomy, but with a similar ontology (the ontology of each must have some similarity or else there is little reason to put them together). In other words, it is the reconciliation of meaning – the taxonomies have underlying commonalities which create shared meaning. So to answer the question “Should we reconcile these taxonomies?”, ask whether they are describing more or less the same thing. Reconciling two taxonomies to each either is “point to point” integration.
An alternative to point-to-point data integration can be a process of taking two or more data taxonomies and creating a series of rationalization rules (coded as transformations) that move them to a neutrally designed taxonomy. To do so, there must be some unifying set of principles that brings the datasets together. These are the ontology rules of the new, neutrally-designed taxonomy.
The process of resolving multiple ontologies and their explicit or implicit rules with multiple taxonomy definitions has an extremely high degree of potential for organizations in that this resolution can enable them to leverage data from a much wider array of sources – opening up the possibilities of cloud-based data, enabling rapid integration of new supplier and partner data, and leveraging market data. Gartner sees a growing need for these capabilities, based on the following evidence.
Throughout 2009, business organizations began reporting an increasing need to reconcile multiple pairings of information taxonomies. This was partly because of new awareness resulting from data integration efforts, as well as the growing
realization that even “enterprise” data warehouses were not neutral – approximately 40% of the data warehouse optimization inquiries received by Gartner in 2009 related to this issue.
Approximately 15% of the data integration inquiries concerned accessing nontraditional or unstructured data sources “in place” without transformation and loading – up from less than 5% in 2008. In late 2009 and early 2010, vendors’ products began to address combinations of content with structured sources in analysis. In their inquiries with Gartner, leading-edge clients had to address the fact that any potential data taxonomy derived from content was independent of a document’s structure. In addition, business users began to indicate a need to rationalize multiple ontological sources to a single taxonomy – based on a recognition that a business can reference data by many terms or that a single term can reference different data, depending upon the business unit or business process involved. In other words, there were many differences of meaning in the minds of business users.
A few leading organizations have begun searching for solutions that could use the same logic to resolve multiple taxonomies to each other and provide a basis for interpreting their related ontological relationships – a many-to-many-to-many (M:M:M) rationalization. This particular profile represents a rare case in which the demand has been defined, but the tools generally available in the market are very limited. Existing tools focus on many definitions for a single data or information taxonomy, but that is not what the market demands – the demand is for the ability to resolve discrepancies between two or more ontologies and two or more taxonomies at the same time. It should be noted that many end-user organizations conducting their own research into ontology/taxonomy management have concluded that such a solution may not be possible.
The fundamental issue is that ontologies involve questions of meaning and relationship at what must be described as a metaphysical level. Hence only people can resolve ontological questions. So “may not be possible” is “is not possible.” You can have a methodology for doing it, and then possibly a tool can be used to extract content via rules, but on the whole, this is a knowledge-engineering task.

10
1.2.2 recommendations
Information architects vexed by taxonomy and ontology issues should:
• Identify information-related semantic tools that resolve differing taxonomy and ontology pairs. These include federation tools with advanced modeling capabilities and domain analytics, which populate extensible metadata repositories.
• Acclimatize designated business personnel to their role in creating information assets and to the importance of metadata as a precursor to introducing enterprise metadata taxonomy and ontology management practices. But exercise extreme caution, as end users should not be subjected to the rigor or terminology involved in metadata management.
• Initiate text mining and analytics with a practice to align relational data and content analysis metadata.
1.3 Find/Describe Information
1.3.1 Content Analytics
Analysis by Whit Andrews
Content analytics mine information from different types of content to derive answers to specific questions. Relevant content types include photo captions, blogs, news sites, customer conversations (both audio and text), social network discussions, faces, maps, multimedia and documents. Applications include varieties of text analytics – sentiment analysis, reputation management, trend analysis, affinity analysis, recommendation analysis, face recognition, speech analytics, visualization analysis, and industry-focused analytics such as “voice of the customer” to analyze call center data, fraud detection for insurance companies, crime detection to support law enforcement activities, competitive intelligence and understanding consumer reactions to a new product.
Multicomponent functions are constructed by serializing simpler functions. The output of one analysis is passed as input to the next. As virtually all content analytics applications use proprietary application programming interfaces to integrate functions, there is currently no way to construct
analyses from applications created by different vendors. In the future, the Unstructured Information Management Architecture (UIMA), governed by the Organization for the Advancement of Structured Information Standards (OASIS), may serve this purpose. Such a standard for unstructured data would serve a similar purpose to Structured Query Language (SQL) for structured data.
“Content analytics” is not a household term. But just as “Band-Aid” is widely understood as a category label for adhesive strips, application websites such as Google and Twitter are used as category labels (even verbs) for social content. Content analytics is used to support a broad range of functions. It can identify high-priority clients, product problems, customer sentiment and service problems; analyze competitors’ activities and consumers’ responses to a new product; support security and law enforcement operations by analyzing photographs; and detect fraud by analyzing complex behavioral patterns. Increasingly, it is replacing difficult and time-consuming human analysis with automated analysis, often making previously impossible tasks tractable. Complex results are often represented as visualizations, making them easier for people to understand.
In 2010, interest in content analytics has increased because of the explosion of social networking analysis. Use of both general- and special-purpose content analytics applications continues to grow both as stand-alone applications and as extensions to search and content management applications. But the greatest growth comes from generally available resources.
Websites use different content analytics functions. Examples are:
• Bookmarks to associate related content – http://delicious.com.
• Affinity and recommendations to create community networks – www.facebook.com, www.linkedin.com.
• Recommendations – www.amazon.com.
• Tagging content to enable multimedia content sharing – www.youtube.com.
• Analyzing trends – www.google.com/trends

11
1.3.2 recommendations
Enterprises should employ content analytics to replace or reduce time-consuming and complex human analysis. Firms should identify the analytics most able to simplify and demystify complex business processes. Users should identify vendors with specific products that meet their requirements and review case studies to understand how other users have exploited these technologies. An oversight committee can support application sharing, monitor requirements and understand new content analytics to identify where they can improve key performance indicators. Social networking applications should be used wherever possible to deliver information, gain access to customers, and understand relevant public opinion.
1.4 Find Information
1.4.1 Social Search
Analysis by Whit Andrews
Definition: Social search uses elements of user behavior, both implicit and explicit, to improve the results of searches inside and outside enterprises. Such elements are typically stored as metadata, making social search a sort of metadata mining. Social search also enables users to disambiguate results to queries more effectively. Examples of social search actions include saving searches to shared folders; tagging searches or documents to express what they are about for the benefit of other users; and using implicit indicators of value, such as when saving documents as shared bookmarks or printing documents for later use. Social search is an element of Internet search behavior and provides significant value to Web users. Consumer expectations have driven it into the enterprise, where it augments search capabilities and allows for “people-finding,” instead of “document-finding.” Microsoft’s inclusion of social search elements in the current edition of SharePoint will serve as a major factor in its increased adoption.
1.4.2 recommendations
Include elements of social search in your projects, but do not expect it to improve results dramatically. Disambiguation will benefit from social search use as users scrutinize colleagues’ and fellow searchers’ results to establish meanings and relationships.
1.5 Integrate/Store Information
1.5.1 Mapreduce Implementations
Analysis by Mark Beyer and Donald Feinberg
MapReduce is a programming model for the processing and storage of structured and mixed-type data using parallel programming techniques. Although there are many implementations of MapReduce, Hadoop MapReduce is the most widely used. Hadoop is an Apache open-source software project implementation of MapReduce using the Hadoop Distributed File System (HDFS). The business value of Hadoop MapReduce lies in the performance improvement achieved by enabling the analysis of many complex datasets in a parallel environment composed of inexpensive servers
MapReduce implementations represent a much wider class of processing concepts than this, however. The idea of a centralized repository is becoming unmanageable, given the volume and complexity we have and the available hardware technology. A new architecture is evolving that leverages the much better-performing hardware we have now to create declared and inferred information assets on demand. The processing involved treats search, mashups, metadata, integration and repositories as equal contributors. This requires a new type of processing in which massively parallel capabilities must be leveraged because the volume of data and the widely variant nature of its form/format (which comprises “extreme data”) and content relative to the extremely wide variations in use cases make centralized repositories of “all things informative” unrealistic. Hadoop MapReduce represents the first popular implementation of this new class of combined processing and storage.
Here is an example of how it works. We have four hours of stock ticker data. For two hours, nothing meaningful happens. The Mapper puts two hours of data together and determines, based on a statistical algorithm, there is nothing of value in this period. It then determines that the data for the next 25 minutes is important and groups that data into smaller clusters (each, for example, of 30 seconds). Then, after 25 minutes, the data returns to the same fluctuation pattern as before, but with a much higher average selling price, prompting

12
the creation of a new cluster, different from that for the first two hours. Now reduce works on the clusters, creating one two-hour-long record, multiple 30-second records and a 95-minute record. If the data actually contained billions of records for 400 stocks, the system would distribute portion of the records across a massively parallel processing complex. By the time MapReduce has finished its first run, it has created many different intervals and values. MapReduce then runs again, reconfiguring the clustered data across the system and finding better affinities. It continues to repeat until it finds the answer that best aligns the results with the original statistical algorithm. In other words, the amount of data that can be processed is no longer limited by a database management system (DBMS) running on a dedicated database. Instead, MapReduce can scale across all storage and all available servers, outside the DBMS, and then feed answers in the form of records to the DBMS for final delivery.
1.5.2 recommendations
• Organizations with highly technical developers or skilled statisticians should consider using MapReduce to process large amounts of data, stored in a DBMS, HBase or HDFS, especially for complex mixed data types. The results of MapReduce programs can be then loaded into a data warehouse for further processing or used directly from within the programs.
• Organizations with large amounts of historical data stored outside their data warehouse should consider using MapReduce as an alternative to their current data integration tools as the parallel processing will deliver better performance, especially when coupled with the ability to work with complex, mixed data types. Today, this is one of the primary uses of MapReduce implementations. Note that since the data loaded into a MapReduce process can come from many different sources, there is none of the implied data quality or referential integrity found in some DBMSs; this would have to come from the source systems creating the data.
• Organizations should carefully evaluate the use of MapReduce inside a DBMS, due to the volume of data that would be loaded into the data warehouse. This could result in very large database sizes, especially with complex, mixed data types, which would have a detrimental effect on performance and maintenance and deliver no clear benefit.
1.6 Integrate Information
1.6.1 Data/Content Integration
Analysis by Toby Bell and Ted Friedman
1.6.1.1 Content Integration
Content integration refers to the consolidation of enterprise content into a single view. Content is typically dispersed throughout an enterprise in repositories, Web pages, network drives, file servers and on users’ personal drives. Integration tools may sit above repositories as data integration middleware, or above workflow and business process management systems to provide a unified interface with federated content.
Newly emerging standards may provide consistent repository-to-repository connections, as well as allow direct access by applications and interfaces that relate to federated content stores.
Existing tools have failed to achieve the desired level of integration as the amount of content and dispersion has increased. As an alternative approach, many enterprises are integrating content by migrating it to hybrid content architectures featuring a linked repository of record and a content infrastructure toolset, the latter most often Microsoft SharePoint. As a result, investments in content integration connectors for SharePoint and in migration technologies to move content to SharePoint have increased sharply.
The vast majority of enterprises have multiple repositories. Customized interfaces and commercial connectors/adaptors dominate. Many enterprise content management (ECM) suites use connectors from IBM and Day Software (recently acquired by Adobe), among other vendors. But long-term prospects for custom connectors are limited, due partly to the difficulty of maintaining them and partly to the emergence of Web services and other integration options such as the Java Specification Request (JSR) 170/283 standard and Web-based Distributed Authoring and Versioning (WebDAV). However, none of these match the potential impact of Content Management Interoperability Services (CMIS), an industry-sponsored standard, supported by most of the major ECM vendors and their partners, that is intended to bridge the gap between the Java and Microsoft worlds.

13
Still, many enterprises are also looking to leverage portals and federated search as options for the virtual consolidation of frequently used content at different levels of abstraction. The recent focus on content migration toward Microsoft SharePoint and other ECM alternatives leverages connectors for the one-time, one-way trip for large volumes of content presently stored on file servers or in obsolete repositories. Content integration tools are persistent and bidirectional, whereas migration tools are occasional and one-way bulk-loaders.
Content integration can improve interoperability between a company’s content and its content-centric processes and related data. Thus it can support both governance and cost reduction initiatives by optimizing information assets for availability. Classic use cases often include search tools for legal discovery as well as providing access to content across newly merged or acquired companies. But the biggest potential impact of content integration lies in relating it to the semantic layer over structured data in application databases, as well as linking a horizontal business information supply chain to vertical processes and end-user context.
Content integration technology can facilitate cost control, content availability, providing a single view of the customer, and relating content and data objects via metadata management.
1.6.1.2 recommendations
Enterprises should look beyond JSR 170/283 and WebDAV to integration architectures from vendors including IBM/Venetica, Oracle/Context Media and Day, and to third-party offerings such as those of EntropySoft and MuseGlobal. Most system integration partners also have toolkits to connect products they support with multiple repositories and business applications.
Enterprises should pick content management vendors that have standardized and easily accessible repositories. At present, migration tools that support moving large volumes of content from expensive or poorly managed network drives or end-of-life repositories to newer technology are the biggest story in the market and can add immediate value. Longer term, the focus should be on CMIS version 1.0, the newly-approved OASIS standard. The preliminary concept with CMIS is to provide information-sharing across CMIS-enabled repositories, but the value may ultimately increase
by allowing those repositories to coexist, even as they feed search engines, portals and applications with more information at lower cost and with less complexity. One immediate benefit may also be a single view into content repositories via a CMIS-enabled “content client” richer than what has typically been delivered by ECM vendors. Connecting content to structured data and to end users in a more engaging manner has many implications for commercial applications.
1.6.1.3 Data Integration
The discipline of data integration comprises the practices, architectural techniques and tools for achieving consistent access to, and delivery of, data across the full spectrum of data subject areas and data structure types in the enterprise, in order to meet the data consumption requirements of all applications and business processes. As such, data integration capabilities are at the heart of information-centric infrastructure and will power the frictionless sharing of data across all organizational and system boundaries. Contemporary pressures are leading to increased investment in data integration in all industries and regions. Business drivers, such as the imperative for speed to market and the ability to change business processes and models, are forcing organizations to manage their data assets differently. Simplification of processes and IT infrastructure is necessary to achieve transparency, and transparency requires a consistent and complete view of the data that represents the performance and operation of the business. Data integration is a critical component of an overall enterprise IM (EIM) strategy that can address these data-oriented issues.
From a technology viewpoint, data integration tools were traditionally delivered via a set of related markets, with vendors in each market offering a specific style of data integration tool. Traditionally, tools for extraction, transformation and loading (ETL) used predominantly in data warehouse/data mart implementations held the largest market shares in this space and formed a “center of gravity” for market consolidation.
BI efforts, with their focus on metadata, promoted the infusion of the combined data integration market with metadata management capabilities. However, in the past two years, vendors and leading organizations have been pursuing a

14
strategy of centralizing their capabilities for semantic interpretation and reconciliation as a service within a platform, and reducing, in relative terms, their emphasis on connectivity and specific data delivery styles. A variety of other related markets, such as those for data quality tools, adapters and data modeling tools, overlap with the data integration tools space.
The result of this fragmentation in the markets is the equally fragmented and complex way in which data integration is accomplished in large enterprises – different teams use different tools with little consistency, plenty of overlap and redundancy, and no common management and leverage of metadata. Technology buyers have been forced to acquire a portfolio of tools from multiple vendors to amass the capabilities necessary to address the full range of their data integration requirements. The market has not yet reached a point at which data integration is typically achieved via a single platform or suite, but notable improvements exist, especially in relation to data services delivery and metadata management.
Following the emergence of a data integration tools market, separate and distinct submarkets have continued to converge, at both a vendor and a technology level. This is being driven by buyer demands – for example, organizations realizing they need to think about data integration holistically and have a common set of data integration capabilities they can use across the enterprise, particularly when working on service-oriented architecture initiatives that have many different consumers working in various contexts. It is also being driven by vendors’ actions – for example, vendors in individual data integration submarkets organically expanding their capabilities into neighboring areas, and acquisition activity bringing vendors from multiple submarkets together. The result is a market for complete data integration tools that address a range of different data integration styles and are based on common design tooling, metadata and runtime architecture.
This market has supplanted the former data integration tools submarkets, such as ETL and become the competitive landscape in which Gartner evaluates vendors for placement within its Magic Quadrants. While the traditional ETL vendor submarket was the driver for consolidation, it is important to note that, even after acquiring federation or message-based integration
capabilities, the market is not showing wide implementation of either of these approaches. Vendors that supply all three types of integration technique generally exhibit an overwhelming strength in one – even those vendors that acquired market leaders in a second submarket.
1.6.1.4 recommendations
The data integration tools market is gaining new momentum as organizations recognize the role of these technologies in supporting high-profile initiatives such as MDM, BI and delivery of SOA. Recent focus on cost control has made data integration tools a surprising priority as organizations realize that the “people” commitment for implementing and supporting custom-coded or semi-manual data integration approaches is no longer reasonable. Vendor consolidation continues, driven by the convergence of single-purpose tools into data integration suites or platforms. While most vendors still approach this market with multiple products, metadata-driven architectures supporting a range of data delivery styles continue to emerge. Organizations seeking data integration tools must assess their current and future requirements and map them against product functionality, including support for a range of data integration patterns and latencies. Buyers must recognize that, as an evolving market, disruptions caused by merger and acquisition activity are likely as smaller vendors with valuable technology continue to be subsumed into larger entities to form more complete data integration tool portfolios.
1.7 Share Information
1.7.1 Data/Information Services
Analysis by Mark Beyer
Data/information services are a subcategory of SOA. They consist of processing routines that provide data manipulation for the purposes of data storage, access, delivery, semantic interpretation, stewardship and governance. Unlike point-to-point data integration solutions, data/information services decouple data storage, security and mode of delivery from each other, as well as from individual applications, to deliver them as independently designed and deployed functionalities that can be connected via a registry or composite processing framework.

15
Data/information services, by their nature, call for a style of data access strategy that replaces the data management, access and storage functionality currently deployed in an application-specific or database management manner with an abstracted and invoked style. Data services instantiate a semantic operation that performs metadata-described processing for the purpose of accessing, writing and delivering data external to specific applications. This is an evolutionary architectural style that does not warrant “rip and replace.” It can coexist with current application design techniques or data integration repositories (for example, data warehouses, data marts and operational data stores). Organizations should realize that there is a wide variation in service granularity, ranging from possibly thousands of very fine-grained services performing rudimentary tasks to coarse-grained and composite services.
Organizations have discovered how difficult it is to create varying service granularity with high reuse targets. Data service initiatives for the wider organization have been put on hold or revised in scope to address only master data assets – and these only as request/reply engines of MDM applications.
The deployment difficulty is twofold:
• Legacy applications cannot be easily changed to utilize data services or the semantic layers that could use them.
• The inability to agree on an abstract and neutral data semantic layer is problematic and, out of frustration, organizations sometimes conclude that it is probably insurmountable. Thus, acceptable levels of specificity (such as for data objects or specific domains like “product”) are necessary in data under management and in their commensurate data services. As a result, data services written for well-defined data objects are emerging.
Data services are not an excuse for each organization to write its own unique database management system, as most database management systems store data and provide ready access. Data services can sever the tight links between application interface development and the more infrastructure-style decisions associated with database platforms, operating systems and hardware. This will make applications portable
to lower-cost repository environments when appropriate. It will also create a direct corollary between the cost of IM and the value of the information delivered by delivering semantically consistent data and information to any available presentation format. This is in contrast to the current scenario in which monolithic application design can drive infrastructure costs up because of their dependence on specific platform or database management system capabilities.
1.7.2 recommendations
Organizations should focus on delivering a semantic layer to support the use of granular data services. Data services can begin with data quality tools used to deploy reusable, loosely coupled data stewardship and governance services that run as process calls from within operational application interfaces and data integration efforts.
Integrated and accessible metadata is mandatory for this technology and is the key to interoperability. Shared and common metadata is one approach, but as this technology progresses, services within these tools could pass data between them with accompanying metadata as well. Organizations should avoid vendor solutions and development platforms that do not support interoperability with third-party tools.
A potential issue arises with the need to have significant semantic modeling and logical modeling skills that are intertwined in deploying data services for wide reuse. As a result, organizations are strongly encouraged to begin with a widely used business concept, but in a noncritical operations area – for example, the reallocation of inventory parts, such as screws, from one business purpose to another, or an information access beta test site for nonordering, nonfinancial portals.
1.8 Store Information
1.8.1 In-Memory Database Management Systems
Analysis by Donald Feinberg
An in-memory database management system (IMDBMS) is a DBMS that stores the entire database structure in memory and that accesses the database directly, without the use of input/output (I/O) instructions. This should not be

16
confused with a caching mechanism that stores disk blocks in a memory cache for greater speed. All application transactions take place in memory without the use of traditional disk or disk substitutes, such as solid-state disks (SSDs) or flash memory. Access to the database is through direct memory access and achieved without using a disk controller. Gartner’s definition does allow for logging to disk, as well as for transaction results being written to disk for persistence when required. IMDBMSs are available in both row- and column-based models.
IMDBMSs have been around for many years – examples are Solid and TimesTen, now owned by IBM and Oracle respectively – but most of those currently available have appeared within the past two or three years. Some, such as SAP’s “New DB” and VoltDB, are new in 2010.
IMDBMSs such as Solid, TimesTen and StreamBase were originally developed for high-speed processing of streaming data for applications such as fraud detection, with the data then being written to a standard DBMS for further processing. The newer IMDBMSs are used for OLTP transactions and BI applications and deliver very large increases in performance – they are generally 10 to 20 times faster than traditional disk-based models.
Over the past year, hardware systems have become available at reasonable prices with very large amounts of memory (some have more than 1 terabyte). As these systems become more widely available, larger, more mature and lower in price, the speed of adoption will increase. Some of these IMDBMSs have produced simulated Transaction Processing Performance Council Benchmark C (TPC-C) benchmarks of more than 9 million transaction per second (TPS), compared with figures of around 400,000 TPS for the leaders in traditional disk-based systems.
The primary inhibitor of adoption is the risk of memory failures, combined with a lack of reliable high-availability solutions, disaster recovery and sufficiently fast backup and recovery techniques. As this functionality is added and becomes generally available, this inhibitor will gradually decrease in importance.
Once these IMDBMSs become mature and proven, especially for reliability and fault-tolerance, and the price of memory continues to decrease, their potential for a business is transformational. First,
these systems use hardware systems that require far less power (as little as 1% of the power of an equivalent disk-based system) and cooling, leading to huge cost savings. Also, their high performance means that smaller systems will do the same work as much larger servers, again with major cost savings.
Cost savings are not the only benefit with some of the new models, such as the column-store IMDBMS announced by SAP in May 2010. This model has the potential to support a single database model for both OLTP and data warehousing, using an in-memory column-store DBMS; this would enable an entire set of new applications that were previously impossible due to the latency of data moving from the OLTP system to the data warehouse. This will enable real-time analytics for planning systems, inventory control and many other pattern-based applications requiring real-time access to data from OLTP applications in the data warehouse. This not only reduces the duplication of data between OLTP systems and the data warehouse, saving on data integration, but also reduces maintenance on multiple database models.
IMDBMSs have the potential to change the way we think about and design databases and the infrastructure necessary to support them.
1.8.2 recommendations
• Continue to use an IMDBMS for temporary storage of streaming data where real-time analysis is necessary, followed by persistence in a disk-based DBMS.
• Recognize that:
• For the next few years, IMDBMSs can be used for OLTP with the understanding that extra care must be exercised to ensure a high-availability environment and logging to a persistent store, such as a traditional disk drive or SSD.
• IMDBMSs for analytic acceleration – which are available now – are an effective way to increase performance.
• The single most important advance will come as the IMDBMS matures as a column-store, combined OLTP and OLAP model – it will form the basis for new, previously unavailable applications, taking advantage of real-time data availability for increased performance and reduced maintenance.

17
1.8.3 Database Appliances
Analysis by Donald Feinberg
A database appliance is a prepackaged or preconfigured balanced set of hardware (servers, memory, storage and input/output channels), software (operating system, DBMS and management software), service and support. It is sold as a unit with built-in redundancy for high availability, and positioned as a platform on which a DBMS can be used for online transaction processing (OLTP) and/or data warehousing. Further, to meet Gartner’s definition of a data warehouse appliance, it must be sold on the basis of the amount of source-system-extracted data (“raw data”) to be stored in the data warehouse, not by configuration (for example, the number of servers or storage spindles). There is some flexibility in our performance criteria so that vendors can have several variations to suit customers’ desired service-level agreements for performance and the type of workload.
Database appliances have been around for many years – examples are Teradata offerings for data warehousing and HP NonStop (formerly Tandem NonStop) for OLTP. Since Netezza – which has been acquired by IBM – entered the market about nine years ago, the concept of the database appliance has been gaining in acceptance, and now almost every DBMS vendor offers an appliance, primarily for data warehouses. Given Oracle’s announcement of Exadata V2 as a dual-purpose appliance (for both OLTP and data warehousing), we expect to see additional vendors offering database appliances for OLTP. For this reason, we have broadened our definition of this technology to encompass the broader database appliances used for OLTP, data warehousing or both. Some DBMS vendors offer appliances on multiple hardware platforms: examples are EMC Greenplum (although available as a complete appliance from EMC, this vendor’s appliance is also available on Cisco, Dell and HP platforms), ParAccel and Microsoft, whose PDW is available initially on Bull, Dell, IBM and HP platforms.
The range of technologies used in database appliances includes some that are mature and proven, and some that are new. Some vendors, such as Teradata, have also introduced a line of appliances with different characteristics and sizes (such as an entry-level model and a model
with massive storage for simple workloads but large amounts of data). Adoption of appliances is accelerating because the larger vendors are using the more mature and proven components. We expect rapid growth to continue.
1.8.4 recommendations
Database appliances can simplify DBMS architecture, shorten implementation times and reduce the cost of DBMS implementation. More importantly, they can reduce the risk that a database will perform poorly because of inadequate configuration. For data warehousing, appliances are normally configured according to the estimated size of the data warehouse, with customers having to buy configurations sufficient for the desired functionality and performance. Given the increased use of BI and analytics, it is difficult to estimate the growth in size of a data warehouse over a period of at least three years – but the only risk is in underestimating. For OLTP, a database appliance can be used for application consolidation, greatly reducing the number of required servers and related software licenses, while giving predictable performance. One of the most significant benefits of a database appliance is the single point of service, which simplifies the procedures required for problem identification and resolution.
Enterprises should:
• For data warehousing use, start by defining the specific use, the size of database required (accounting for growth over five years) and the workload.
• Decide how much risk you want to take, bearing in mind that it is generally riskier to buy from one of the newer, smaller vendors (whose future viability may be in question) than from a larger supplier of more mature solutions. You will then be well placed to compile a shortlist of suitable vendors – and a big step closer to identifying an appliance that will perform well and require minimal tuning.
• Always require shortlisted vendors to carry out a proof-of-concept exercise using actual data and queries from your organization.

18
• Be wary of claims that an appliance will solve your performance issues. Appliances are generally more efficient and yield higher performance than equivalent home-grown infrastructure, but as workloads grow, application issues – especially with the data warehousing model – can resurface.
• Look under the “cover” of the appliance’s management software and don’t allow vendors’ claims of “out of the box” operation to stop you determining the actual resources needed to manage the appliance environment.
1.9 govern Information
1.9.1 Master Data Management
Analysis by Andrew White
MDM is a technology-enabled business discipline in which business and IT staff work together to ensure the uniformity, accuracy, stewardship, semantic consistency and accountability of an enterprise’s official shared master data assets. MDM is a critical data-sharing program that enables other business and IT investments and programs, which depend on master data quality and consistency, to yield the expected benefits to the business.
Few organizations sustain a “single version of the truth,” as their IT and business systems are heterogeneous and the necessary business processes to support a “single view” have so far been hard to sustain. This discipline remains a challenge, but the real barriers are ones of organization, process and governance, rather than technology. In 2010, interest in MDM has grown significantly, as measured by spending and the number of inquiries Gartner has received. We expect 2011 to bring a further increase in interest as business and IT departments continue to seek to manage information as a reusable asset.
The MDM market comprises several segments that show signs of convergence. The largest serve the needs of users who seek primarily to master customer data (through MDM of customer data) or product data (through MDM of product data). Despite the names, the differences in the data models of these two segments explain why MDM of customer data is really focused on party-oriented data models (simple object definitions, complex hierarchies and relationships), and why MDM of product data is really focused on things (complex object definitions, simpler hierarchies and relationships). A third segment, very
small and still emerging, is multidomain MDM, which is characterized by users as “a discipline supported by one MDM solution that can master any and all master data.” This is a particularly complex and challenging need that no single vendor has mastered well, across multiple industries, for all use cases and all data domains.
Organizations have multiple and differing MDM requirements, depending on their situation. MDM scenarios vary in terms of:
• Use case: design/construction, operational and analytical.
• Data domain: customer, supplier, partner, person (party), product, item, material, asset (thing), ledger, account (hierarchy) and relationships.
• Vertical market: for example, financial services, government, communications, manufacturing, oil and gas, and retail.
• Organizational structure: the degree to which an organization centralizes its governance and stewardship work.
• Implementation style: consolidation, registry, centralized and coexistent, or hybrids spanning multiple styles.
There are increasing links between MDM and other business and IT programs and initiatives. In 2010 we see – and we expect to see increasingly in 2011 – more work by users to integrate their MDM programs and:
• BI and analytics: Analytical MDM – that is, applying practices and technology related to MDM in a BI environment – continues to grow in importance (judged by distinct inquiries to Gartner), but needs to be more clearly defined. MDM data services, for cleaning data or providing content, are even more industry- and use-case-specific.
• Business process management (BPM): Analyzing and designing process changes requires an understanding of the master data that every business process consumes or uses. As such, BPM models master data at a high level. Some users are beginning to link their BPM and MDM programs, and this will lead to increased integration between the supporting technologies.

19
• Cloud computing: Already MDM programs consume data for enrichment (for example, D&B provides a service whereby users can enrich their customer data with additional information), and some programs are consuming data quality and data integration services for SaaS vendors. We expect to see an increase in the leverage of data sourced from the cloud. An area where we do not expect to see much activity is in the operation of MDM in the cloud. Due to the huge center of gravity in core business processes residing behind an organization’s firewall, it seems impractical for MDM programs to operate outside that firewall.
• Open-source MDM: This remains a long-term opportunity. There is growing interest in open-source software for MDM but it remains more of a curiosity for users or a proof-of-concept tool. Talend, currently the only open-source software provider of MDM technology, is trying to convert OSS users to full enterprise licenses for its MDM product. But adoption of OSS MDM as a kernel for a legitimate MDM implementation remains more something for the future than a present reality.
1.9.2 recommendations
Start creating a holistic, business-driven MDM vision and strategy to meet the MDM needs of your organization. Ensure that you address governance, organizational, process and metrics issues, and that you create a technical reference architecture for MDM. Be aware that for larger firms, and/or those with complex information environments, it is likely that two or more MDM systems will be needed to meet all MDM requirements. Also, ensure that your MDM initiative is aligned with the objectives
of your organization’s EIM program. Without an overarching initiative like EIM, even if MDM is the only initiative adopted, it is very possible that informational and organizational silos will not be broken down completely, because the information infrastructure will be stretched in several, possibly competing, ways.
While keeping the long-term vision in mind, approach individual steps of the MDM journey based on your business priorities and the maturity of MDM technology available. There is experience and proven MDM technology for managing customer and product data in operational use cases, and for developing experience with other data domains, such as supplier, employee and location. There is also experience and proven technology in niche analytical MDM products for managing financial and other types of data.
For the next three years, be prepared to engage multi-MDM vendors, or at least use multiple MDM products from the same vendor, to meet all your MDM requirements. Build an MDM road map, working with your business stakeholders and your enterprise architecture team, to demonstrate how the different facets of MDM will be addressed over time. Align, or leverage, investment in resources associated with a BI or IM competency center.
MDM will require human resources, more to start with, and less once things are properly under way. When assessing your human resources requirements, take account of the need to rationalize multiple MDM initiatives in your organization over the long term.
Gartner RAS Core Research Note G00207405, Regina Casonato, Ted Friedman, Mark A. Beyer, Whit Andrews, Donald Feinberg, Toby Bell, Andrew White, 17 November 2010

20
About MuseGlobal
Competing with Intelligence and Insight is published by MuseGlobal. Editorial supplied by MuseGlobal is independent of Gartner analysis. All Gartner research is © 2010 by Gartner, Inc. and/or its Affiliates. All rights reserved. All Gartner materials are used with Gartner’s permission and in no way does the use or publication of Gartner research indicate Gartner’s endorsement of MuseGlobal’s products and/or strategies. Reproduction and distribution of this publication in any form without prior written permission is forbidden. The information contained herein has been obtained from sources believed to be reliable. Gartner disclaims all warranties as to the accuracy, completeness or adequacy of such information. Gartner shall have no liability for errors, omissions or inadequacies in the information contained herein or for interpretations thereof. The reader assumes sole responsibility for the selection of these materials to achieve its intended results. The opinions expressed herein are subject to change without notice.
MuseGlobal is the world’s leading supplier of content integration, aggregation and transformation solutions for today’s sophisticated publishers, enterprises, government organizations and online and mobile media providers. MuseGlobal’s rapidly deployed and easily maintained content integration technology delivers unified access to more sources of searchable content than anyone else. Through MuseGlobal’s many business partners its content integration technology is deployed in thousands of organizations worldwide.
MuseGlobal was founded by Kate Noerr and Dr. Peter Noerr in the UK in 1998 and established as the commercial entity, MuseGlobal, Inc., in May 2001. The majority of the company’s senior staff has worked with the founders in previous ventures, thus forming a well-functioning group of seasoned executives and technology experts.
The team’s singular focus on content – available in different formats and accessed through different protocols - has led to the development of over 6300 connectors that can combine existing federated content owned by the enterprises
with social media content as well as other externally available content to make the decision makers more effective. Whether it’s structured or unstructured content, Internet, mobile or enterprise networks, startups or Global 2000 corporations, the world’s leading organizations trust MuseGlobal to deliver the most important content from every key source and to facilitate informed decisions.
MuseGlobal works with customers and partners to develop custom content solutions that are tailored to meet their specific strategic goals. The speed and flexibility with which MuseGlobal can access and aggregate content from thousands of sources on a daily basis have proven to be critical success factors for our customer and partners.
Contact MuseGlobal for more information about our company and our services.