isug ase15 tech insight may
TRANSCRIPT

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 1/58
Jeff Tallman
Staff SW Engineer II/Architect
ITSG Engineering Evangelism Team
Jeff Tallman
Staff SW Engineer II/Architect
ITSG Engineering Evangelism Team
Sybase ASE 15:A Technical Insight

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 2/58
Agenda
• System changes
Roadmap
Catalog, VLSS, scrollable cursors
•Query processing Overall improvements
Optimization goals, criteria, controls
Query plan metrics
Showplan changes
• Computed columns/function indices
Materialized vs. virtual
Deterministic vs. non-deterministic
• Semantic partitions
Partitioning overview
Range, hash, list in-depth discussion

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 3/58
ASE: Past, Present and Future
Q4Q4’’0404 Q1Q1’’0505 Q3Q3’’0505Q2Q2’’0505 Q1Q1’’0606Q4Q4’’0505
ASE 12.5.3ASE 12.5.3
12.5.3.a12.5.3.a
ASE 12.5.4ASE 12.5.4
ASE 15.0ASE 15.0
Q2Q2’’0606 Q3Q3’’0606
15.115.1
beta 2beta 2
• Encrypted columns
• RTDS MQ
• Partitions
• New optimizer
• Function columns/indexes
• Clusters
beta 1beta 1
• Encrypted columns
• RTDS MQ
12.5.2*12.5.2*
Q3Q3’’0404
*ASE 12.5.2 Q2’04; ASE 12.5.0 GA was Q2’2002

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 4/58
Maintaining Performance Lead….
121,065
136,110
150,110
100,000
110,000
120,000
130,000
140,000
150,000
160,000
Transactions/Min
MS SQL 2003 Oracle 10g Sybase 12.5.2
Hardware: HP Integrity Server rx5670, 4 Intel Itanium2 1.5Ghz, 6MB
Memory/OS: Oracle: 96GB/RH 3.0; MS: 64GB/Win Server 2003; ASE: 22GB/RH 3.0
Benchmarks: Oracle & MS SQL from official TPC-C tests
Sybase ASE from unofficial/internal “TPC Style” (TPC Suite)(see white paper “IA64_Benchmark_wp.pdf”)
64
96
220
20
40
60
80
100
Memory (GB)
MS SQL 2003 Oracle 10g ASE 12.5.2
$250K

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 5/58
Row-Locked System Catalogs
• Key catalogs will be row-locked in all databases
Reduced catalog contention for DDL operations
• Higher throughput for applications
Deadlocks due to system catalog contention eliminated
• Improved application availability
• Increases concurrency for maintenance tasks
• Contention in tempdb reduced significantly
Multiple tempdb’s still a good idea• Relieve log/cache contention
• Relieve contention on space allocation pages, etc.
• Blocking due to stored procedure renormalization largely eliminated
Renormalization caused by temp tables created outside proc, etc.

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 6/58
System Changes
• Large identifiers
Remove 30 char limit on object names (255 or 253 with quoted)
• #temp tables – 238 distinct chars (+17 byte hash)
Still limited to 30 chars: login, user, cursor name, etc.
• Sysprocess.hostname, program_name, hostprocess now are varchar(30)
» vs. 10,16, & 8 respectively
• Unsigned and 64-bit integer types
Unsigned int, smallint and tinyint• uint, usmallint, utinyint
64-bit signed and unsigned int
• bigint -9,223,372,036,854,775,808 to +9,223,372,036,854,775,807
• ubigint 0 and 18,446,744,073,709,551,615
• Default packet size = 2048
12.5 and before used 512 due to legacy network protocols

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 7/58
Storage in ASE Pre-15.x
• 256 Device limit per server/32GB per device
Virtual page was a 4 byte mask
• Most significant byte = vdevno = 256 devices
• Last 3 bytes = vpageno = 224*2Kpg = 32GB
» Theoretically, a 16K server *could* have had larger devices, but due to the
default 2K page, a 32GB limit was imposed.
Limit of devices per DB was removed a long time ago
•
DB Limit was 8TB 8TB 256 devices * 32GB
Without device limit, the max would be 32TB w/ 16K pg

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 8/58
VLSS in ASE 15.x
• ASE 15.0 very large storage system
Devices = 231 (2 Billion)
Maximum device size = 4TB
Databases/server = 32,767 (still)• Practical limit is probably still 100
• The maximum storage will be:
Database size:
• 231 pages * 16KB pg = 32 TB
Theoretical server size:
• 231 devices * 4TB size 8,589,934,592 TB
Theoretical DB storage
• 32,767 DB’s * 32TB = 1 EB (exabyte) = 1,048,544 TB
• VLSS does not increase the theoretical maximum size of a database
(32TB)

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 9/58
Automating Update Statistics
• New function to tell how much data has changed
Datachange(object_name, partition_name, column_name)
• The user can define rules at which point update statistics would
need to run In this example update statistics would run only if the data on the object
authors has changed more than 50% since the last update statistics executionselect @datachange = datachange(“authors”, null, null)
if @datachange > 50
begin
update statistics authors
End
• Automated via Job Scheduler

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 10/58
Scrollable Cursors
• Pre-15.x cursors
Unidirectional only – with no positioning
• ASE 15.0 scrollable cursors
Directional scrolling (forwards, backwards) Sensitivity (towards independent changes to table)
• insensitive, semi-sensitive, sensitive
declare C3 insensitive scroll cursor for
select fname from emp_tab
Explicit positioningfetch last [from] <cursor_name>
fetch absolute 500 [from] <cursor_name>
fetch {next | prior | first | last | absolute # |
relative #} [from] <cursor_name>

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 11/58
Agenda
• System changes
Roadmap
Catalog, VLSS, scrollable cursors
•Query processing Overall improvements
Optimization goals, criteria, controls
Query plan metrics
Showplan changes
• Computed columns/function indices
Materialized vs. virtual
Deterministic vs. non-deterministic
• Semantic partitions
Partitioning overview
Range, hash, list in-depth discussion

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 12/58
Mixed Workload Optimizer
• Improved parallelism
Vertical: Bushy join support (especially good for large number of tables)
Horizontal: Parallel optimization for both data and index partitioning
• Pre-ASE 15.x did not support index partitioning – index access was serialized
• More efficient algorithms
Multiple index selection/Index union & intersection
• Supporting both AND & OR clauses
Improved index selection
• especially for joins with OR clauses
• joins and search arguments (SARGs) with mismatched but compatible datatypes
Improved costing, using join histograms for joins with data skews in joiningcolumns
• Improved query plan selection: On-the-fly grouping and ordering using in-memory sorting and hashing
Cost-based pruning and timeout mechanisms that use permutation searchstrategies for large, multi-way joins, and for star and snowflake schema joins

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 13/58
Optimization Goals
• Three new goals:
allrows_mix – the default goal, as well as the most useful goal in a mixed-
query environment. It balances the needs of OLTP and DSS query
environments.
allrows_oltp – the most useful goal for purely OLTP queries.
allrows_dss – the most useful goal for operational DSS queries of
medium-to-high complexity.
•
Syntax/settings Server
• sp_configure "optimization goal", 0, “allrows_oltp"
Session
• set plan optgoal allrows_oltp Query
• select * from A order by A.a plan "(use optgoal allrows_dss)"

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 14/58
Optimization Criteria
• Selective enabling/disabling optimization techniques Joins
• hash_join, merge_join, nl_join
• bushy_search_space – allow bushy-tree-shaped query plans vs. nli
Union/Union All
• append_union_all, merge_union_all,
• hash_union_distinct , merge_union_distinct
Reformatting• store_index , multi_table_store_ind
Distinct() and Group By• opportunistic_distinct_view – flexibility for enforcing distinctness
• distinct_hashing, distinct_sorted, distinct_sorting
• group_hashing, group-sorted
Parallelism• parallel_query, index_intersection
• Syntax set hash_join on
set hash_join on, merge_join off

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 15/58
Controlling Optimization
• Previously done via “set table count”
Good for small joins
Not so good on larger joins (set table count >>4)
•
4!=24; 6!=720; 10!=3.6M; 12!=479M• e.g. “set table count 12” on 12-way on 10’s M rows took 10 min to optimize (but
then 30 sec to run)(11.9.3)
• Now can be controlled
Optimization will ‘timeout’ after a specified percentage of query processingtime – most optimal plan determined by that time will be used.
sp_configure “optimization timeout limit”, 10
• default is 5 – range 1 - 100
JTC N +
I!

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 16/58
Query Plan Metrics
• Allows tracking of query plan metrics
Metrics:• Cpu execution time, elapsed time
• Logical I/O (found in cache, cached by async prefetch)
•
Physical I/O (regular I/O, async prefetch)• Count - # of times query executed
• Tracks min, max and avg (less count)
Formerly “set statistics [io,time] on”• Limited to current session user
• Syntax Server – sp_configure "enable metrics capture", 1
Session – set metrics_capture on/off
• Accessing
QP metrics are captured in default “running” group Move to different group with sp_metrics “groupname”
View with sysquerymetrics view• Each db has it’s own sysquerymetrics
» Built on <db>..sysqueryplans

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 17/58
Sysquerymetrics Columns
Field Definitionuid User ID
gid Group ID
id Unique ID
hashkey The hashkey over the SQL query text
sequence Sequence number for a row when multiple rows arerequired for the SQL text
exec_min Minimum execution time
exec_max Maximum execution time
exec_avg Average execution time
elap_min Minimum elapsed time
elap_max Maximum elapsed time
elap_avg Average elapsed time
lio_min Minimum logical IO
lio_max Maximum logical IO
lio_avg Average logical IO
pio_min Minumum physical IO
pio_max Maximum physical IO
pio_avg Average physical IO
cnt Number of times the query has been executed.
abort_cnt Number of times a query was aborted by Resource
Governor as a resource limit was exceeded.text query text

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 18/58
Show Plan Improvements
• Added more detail
DRI checks (table, index, etc.)
Trigger log scan (inserted/deleted)
Which join, distinct, group by, aggregation method
Store (worktables), Sort (reformatting), etc.
A lot more documentation (see beta docs)
• “Graphical” show plan
Graph tree via show plan text
Available as XML
• set plan for {show_exec_xml, show_execio_xml, show_opt_xml} to
{client|message} [on|off]
• select showplan_in_xml([0-19])

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 19/58
ASE 15 “PlanViewer”
• New ISQL includes GUI based plan viewer
Displays query execution plans in graphical format from SHOWPLANs
Operator drill down capability
Plan for each step in proc/trigger

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 20/58
ASE 15 Query Optimizer
1000
8
703
377
674
1180
250
500
750
1000
Query 1 Query 2 Query 3
I/O Count
Database size – 630 MB
Query 1: Join with expressions and no indexes (infinite improvement)
Query 2: Vector aggregation with Group By (exec time improvement – 186%; I/O savings – 83%)Query 3: Multiple scalar aggregation (exec time improvement – 571%; I/O savings – 93%)
Execution Time
1M 8K
3.6M
621K
1.3M
102K0
1,000,000
2,000,000
3,000,000
4,000,000
Query 1 Query 2 Query 3

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 21/58
ASE 15 QP Performance – Early Results
• Real-world customer mixed workload: One query that takes 31 hours in 12.5.X,
finishes in 8 secs in 15.0
On average this application runs 20% faster
in 15.0
• Real-world customer star-schema and
complex queries:
Star-Schema Query runs 90% faster in 15.0 On average this application runs 50% faster
in 15.0
• TPC-H query execution (untuned): On average runs 40% faster in 15.0
TPC-H Query
ASE 12.5.x
ASE 15
Star Schema Query
ASE 12.5.x
ASE 15
Mixed Workload Application
ASE 12.5.x
ASE 15

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 22/58
Agenda
• System changes
Roadmap
Catalog, VLSS, scrollable cursors
•Query processing Overall improvements
Optimization goals, criteria, controls
Query plan metrics
Showplan changes
• Computed columns/function indices
Materialized vs. virtual
Deterministic vs. non-deterministic
• Semantic partitions
Partitioning overview
Range, hash, list in-depth discussion
C t d C l

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 23/58
Computed Columns
• Some definitions Computed columns
• defined by an expression, whether from regular columns in the same row, or functions, arithmetic operators, path names, and so forth.
Indexes on computed columns, or computed column indexes
• indexes that contain one or more computed columns as index keys.
Function-based indexes• indexes that contain one or more expressions as index keys.
Deterministic property
• a property assuring that an expression always returns the same results from aspecified set of inputs.
• Deterministic and materialization Computed columns can be deterministic or non-deterministic
Computed columns can be materialized (evaluated and stored values) on notmaterialized (aka virtual)
Indexed computed columns must be materialized• but do not need to be deterministic – but care should be taken with queries
Function-based indexes are always materialized and must be deterministic
C t d C l

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 24/58
Computed Columns
• Syntax:create table [database.[owner ].] table_name
(column_name {datatype
| {compute | as} computed_column_expression
[materialized
|not materialized
] }{null | not null}
create table rental
(cust_id int, start_date as getdate()materialized, prod_id int)
create index ind_start_date on rental (start_date)
• Restrictions Column expressions can only ref columns in the same row
• Similar T-SQL datatype rules & column check constraints
•
To bypass, you can invoke a SQLJ function You can’t drop columns referenced by computed columns, etc.
Updating a computed column may have “unexpected” results
• Update base columns in expression instead
D t i i ti Si l E l

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 25/58
Deterministic – Simple Example
create table customer (
first_name varchar(20) not null,
last_name varchar(40) not null,
phone_number varchar(10) not null,
-- an example of a deterministic materialized columncustomer_id as soundex(first_name) + soundex(last_name)
+ convert(varchar(10),phone_number)
materialized not null,
birth_date date not null,
-- two examples of a nondeterministic virtual column
age_yrs as datediff(yy,birth_date,getdate()),
type_person as convert(varchar(8),(case
when datediff(yy,birth_date,getdate())>65 then ‘old’
else ‘young’ end)),
-- example of index on materialized computed column
primary key (customer_id)
)
F ti B d I d

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 26/58
Function Based Indexes
• Syntax:create [unique] [clustered] | nonclustered] index index_name
on [[ database.] owner .] table_name
(column_expression [asc | desc] [, column_expression [asc |
desc]]...
CREATE INDEX generalized_index on parts_table
(general_key(part_no,listPrice, part_no>>version)
• Restrictions
Column_expression must be indexable datatype
• No bit, text, image, java class
Can’t use subqueries, aggregate functions, local variables or another computed column
SQLJ functions are allowed
F ti B d I d

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 27/58
Function Based Indexes
• Functional index is shorthand for an index on a computed column
Computed column + index Function-based index
Allows expressions directly as index keys
CREATE INDEX product_total
ON order (product, unit*price*1.1)
• Provides the same benefits as an index on a computed column, but
no need to change the table schema by adding the column
Indexes on expressions
Index key expressions are pre-evaluated
Don’t need to be evaluated again when being accessed
• Functional index keys considered by optimizer i.e index, joins
Easy way to create indexes on complex data
• XML, Java object, Text and Image
F ti B d I d

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 28/58
Function Based Indexes
• SARGS and Covered Query support
Index expression text is parsed and compared for SARG and column
projections
Index expression value is stored
• So comparison’s in where clause as well as column values returned do not need to
evaluate expression.
CREATE INDEX total ON order (unit*price*1.1)
go
SELECT unit*price*1.1 FROM order WHERE unit*price*1.1 > 200
Covered Query!!!
(Projection & SARG matches index)
XML With Computed Columns

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 29/58
XML With Computed Columns
• XML example
CREATE TABLE Loan_table (
xml_col image,
id as xmlextract(‘//Loan_application/ID/text(),xml_col, returns int) materialized,
ssn as xmlextract(‘//Loan_application/SSN(text(),
xml_col, returns varchar(15)) materialized
)
CREATE INDEX fi_ssn ON Loan_table (id, ssn)
SELECT partial_xml from Loan_table
where id = 168 and ssn = ‘600-60-6000’
• NOTE: Computed columns used to extract relational elements in xml doc
Indexes are created on computed column to improve performance
XML and Function Indexes

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 30/58
XML and Function Indexes
• Indexes on XML data
With the XML support in ASE
CREATE INDEX fi_ssn
ON Loan_table (xmlextract(‘//Loan_application/SSN/text()’,
Xml_Col, returns varchar(15)))
SELECT Xml_Col from Loan_table
WHERE xmlextract(‘//Loan_application/SSN/text()’,Xml_Col, returns varchar(15)) = ‘600-60-6000’
• NOTE:
To find the qualified XML doc, index scan is used without evaluating xmlextract() on
each every row in the table
A big performance improvement
Java and Function Indexes

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 31/58
Java and Function Indexes
• Indexes on Java data type
CREATE TABLE Book_table(book myClass.myBook)
CREATE INDEX fi_author
ON Book_table(book>>getAuthor())
SELECT Book from Book_table
Where book>>getAuthor() = “Peter Pan”
• NOTE:
To find the qualified Java objects, index scan is used without evaluating getAuthor() on
each every row in the table
Agenda

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 32/58
Agenda
• System changes
Roadmap
Catalog, VLSS, scrollable cursors
•
Query processing Overall improvements
Optimization goals, criteria, controls
Query plan metrics
Showplan changes
• Computed columns/function indices
Materialized vs. virtual
Deterministic vs. non-deterministic
• Semantic partitions
Partitioning overview
Range, hash, list in-depth discussion
Pre ASE 15 Partitioning Segment Slices

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 33/58
Pre – ASE 15 Partitioning Segment Slices
• Segment partitioning – aka “slices” Only the table was partitioned
• Primary goals
Decrease last page contention Allow parallel query
Allow parallel dbcc checkstorage
Allow parallel index creation
• Assessment Myth that they are no longer useful due to SAN disk speeds
• Largely used only for parallel dbcc checkstorage
Datarow + partitioned table is fastest for inserts
• IO Contention was within the server – long before pages flushed to disk• Partitioning a table could gain 20-25% over datarow locking alone
Not a great solution
• Parallel query caused excessive cpu & I/O costs
•
No maintenance support
Round-RobinParallel Inserts
Parallel Query/DBCCCreate Index
Worker Threads
Segment Partitions
ASE 15 Semantic Partitioning

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 34/58
Range/Hash
Parallel Inserts
Parallel Query/DBCC
Create Index
Worker Threads
Range/Hash PartitionsA-IA-I J-RJ-R S-ZS-Z
ASE 15 Semantic Partitioning
• Partitioned tables and indexes Partition types in 15.x:
• Range
• Hash
• Round-robin (replaces segment)
• List (enumerated)
Partition maintenance
• Add or Alter one or more partitions
• Global and local indexes on partitions Clustered/non-clustered indexes
• Improved query support
Optimizer and execution support (parallelism & elimination)• Partition-aware maintenance
Update statistics on one or all partitions
Truncate, reorg, dbcc, bcp (out) partition
Using BCP Utility with Partitions

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 35/58
Using BCP Utility with Partitions
• New syntax: Note that old partitions used ‘:slice_num’
New semantic partitions specify ‘partition partn_name’
bcp [[db_name.]owner.]table_name[:slice_num] [partition pname] {in |out} [filename] [-U username] [-P password] [-S server]
[-m maxerrors] [-f formatfile] [-e errfile]
[-F firstrow] [-L lastrow] [-b batchsize]
[-n] [-c] [-t field_terminator] [-r row_terminator]
[-I interfaces_file] [-a display_charset] [-z language] [-v]
[-A packet size] [-J client character set]
[-T text or image size] [-E] [-g id_start_value] [-N] [-X]
[-M LabelName LabelValue] [-labeled]
[-K keytab_file] [-R remote_server_principal][-V [security_options]] [-Z security_mechanism] [-Q] [-Y]
c:\sybase\ocs-15_0\bin\bcp pubs2..hash_partn_test partition partn_1 outhash_partn_test_1.txt -Usa -P -SASE15BETA -c

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 36/58
Clustered (Local) Index – Example

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 37/58
Clustered (Local) Index – Example
• Customer is range-partitioned table on c_custkey columnCreate unique clustered index ci_nkey_ckey on customer
(c_custkey, c_nationkey)
Segment 2 Segment 3Segment 1
Non-clustered Global Index – Example

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 38/58
Non-clustered Global Index – Example
Create unique index ci_nkey_ckey on customer(c_nationkey,
c_custkey)
on segment4
Segment 3Segment 2Segment 1
S e g m e n t 4
Non-clustered Local Index – Example

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 39/58
Non-clustered Local Index Example
Create unique index ci_nkey_ckey on customer(c_nationkey,
c_custkey)
on segment4 local index
Segment 1 Segment 2 Segment 3
S e g m e n t 4
Performance Enhancement Through Partitioned Index

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 40/58
Performance Enhancement Through Partitioned Index
• Increased concurrency through multiple index access points. Reduced root page contention
• Index size adjusted according to the number of rows in eachpartition
•Fewer index pages searched/traversed for smaller partitions
Galaxy Local Index on partitioned tablePre-Galaxy with unpartitioned index
Query A
Query B
Query C
Unpartitioned Table
Unpartitioned Index
Partitioned Table
Query A Query B Query C
Partitioned Index
Shorter Access Path
Partitioning with Multiple Keys

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 41/58
Partitioning with Multiple Keys
• Restrictions/limitations
Up to 31 columns for partition keys
Can use distinct segments or reuse same segment(s)
•
Range partitioning evaluation Keys are lower bounds (<=)
Keys are evaluated in order not in tandem
• This can lead to some really skewed partitions if not careful
• Think of it as:» If < key1 then partition 1
» If = key1 then check key2
» If > key1 then check partition2-n
•
Partitioned indexes support partitioned tables Global index – single unpartitioned index spans partitions
Local index – index is partitioned for same as table
• Inherits partition strategies, partitioning columns, and partition bounds of the base table.
Partitioning with Multiple Keys

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 42/58
Partitioning with Multiple Keys
• Wrong specificationalter table telco_facts_ptn
partition by range (month_key, customer_key)
(p1 values <= (3, 1055000) on part_01,
p2 values <= (3, 1100000) on part_02,
p3 values <= (6, 1055000) on part_03,
p4 values <= (6, 1100000) on part_04,
p5 values <= (9, 1055000) on part_05,
p6 values <= (9, 1100000) on part_06,
p7 values <= (12, 1055000) on part_07,
p8 values <= (12, 1100000) on part_08)
•Result (1.2M row table) Odd partitions contain 250K rows
Even partitions contain 50K rows
Partitioning with Multiple Keys

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 43/58
Partitioning with Multiple Keys
• …The right way…alter table telco_facts_ptn
partition by range (month_key, customer_key)
(p1 values <= (1, 1055000) on part_01,
p2 values <= (1, 1100000) on part_02,
p3 values <= (2, 1055000) on part_03,
p4 values <= (2, 1100000) on part_04,
p5 values <= (3, 1055000) on part_05,
p6 values <= (3, 1100000) on part_06,
p7 values <= (4, 1055000) on part_07,
p8 values <= (4, 1100000) on part_08,
p9 values <= (5, 1055000) on part_01,
p10 values <= (5, 1100000) on part_02,
p11 values <= (6, 1055000) on part_03,
p12 values <= (6, 1100000) on part_04,p13 values <= (7, 1055000) on part_05,
p14 values <= (7, 1100000) on part_06,
p15 values <= (8, 1055000) on part_07,
p16 values <= (8, 1100000) on part_08,
p17 values <= (9, 1055000) on part_01,
p18 values <= (9, 1100000) on part_02,
p19 values <= (10, 1055000) on part_03,p20 values <= (10, 1100000) on part_04,
p21 values <= (11, 1055000) on part_05,
p22 values <= (11, 1100000) on part_06,
p23 values <= (12, 1055000) on part_07,
p24 values <= (12, 1100000) on part_08)
Partitioned Index Example

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 44/58
Partitioned Index Example
create unique nonclustered index primary_key_idx
on telco_facts_ptn (month_key, customer_key,
service_key, status_key)
local index
p1 on part_01, p2 on part_02, p3 on part_03,
p4 on part_04, p5 on part_05, p6 on part_06,
p7 on part_07, p8 on part_08, p9 on part_01,
p10 on part_02, p11 on part_03, p12 on part_04,
p13 on part_05, p14 on part_06, p15 on part_07,
p16 on part_08, p17 on part_01, p18 on part_02,
p19 on part_03, p20 on part_04, p21 on part_05,
p22 on part_06, p23 on part_07, p24 on part_08
Example Showplan

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 45/58
Example Showplan
QUERY PLAN FOR STATEMENT 1 (at line 1).
2 operator(s) under root
The type of query is SELECT.
ROOT:EMIT Operator
|SCALAR AGGREGATE Operator
| Evaluate Ungrouped COUNT AGGREGATE
|
| |SCAN Operator
| | FROM TABLE
| | telco_facts_ptn| | [ Eliminated Partitions : 2 3 4 5 6 7 8 ]
| | Index : primary_key_idx
| | Forward Scan.
| | Positioning by key.
| | Index contains all needed columns. Base table will not be read.
| | Keys are:
| | month_key ASC
| | Using I/O Size 4 Kbytes for index leaf pages.
| | With LRU Buffer Replacement Strategy for index leaf pages.
(1 row affected)
Hash Partitioning

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 46/58
g
• Internal hash function GOAL: even distribution of values
Uses a hash to try to balance a high cardinality of values across the partitions
Hash function assures that partition keys with same values always go to the
same partition
• But you can not *CONTROL* which partition is used
Hash function is determined by storage size
• Altering a partition key datatype (length) could cause rows to move
•
Recommendations: Large numbers of partitions w/ mediumhigh data cardinality
Data with no particular order (i.e. product SKU’s)
Data that is typically accessed using equality (=) vs. range
• Hash key equality would allow partition elimination, however, a range scan mayrequire access many to all partitions.
Hash Partition Syntax

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 47/58
y
• Small number of hash partitionsCreate table tablename (colspec)
partition by hash (column_name[, column_name ] ...)
( partition_name [ on segment_name ]
[, partition_name [ on segment_name ] ] ...)
• Large number of hash partitionsCreate table tablename (colspec)
partition by hash (column_name[, column_name ] ...)number_of_partitions
[ on (segment_name[, segment_name ] ...) ]
Example Hash Partition

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 48/58
p
• Hash partition test table:
create table hash_partn_test (
row_id numeric(10,0) identity not null,
partn_key int not null,
comment_field varchar(255) null,)
lock datarows
partition by hash ( partn_key) (
partn_1 on seg1,
partn_2 on seg1, partn_3 on seg1,
partn_4 on seg1,
partn_5 on seg1,
partn_6 on seg1,
partn_7 on seg1,
partn_8 on seg1,
partn_9 on seg1,
partn_10 on seg1
)
Hash Partition and Data Distribution

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 49/58
• Insert 2,000 rows in random order
insert into hash_partn_test (partn_key, comment_field) values (1, 'This is row 1')
insert into hash_partn_test (partn_key, comment_field) values (2, 'This is row 2')
insert into hash_partn_test (partn_key, comment_field) values (3, 'This is row 3')
insert into hash_partn_test (partn_key, comment_field) values (4, 'This is row 4')
insert into hash_partn_test (partn_key, comment_field) values (5, 'This is row 5')insert into hash_partn_test (partn_key, comment_field) values (6, 'This is row 6')
insert into hash_partn_test (partn_key, comment_field) values (7, 'This is row 7')
insert into hash_partn_test (partn_key, comment_field) values (8, 'This is row 8')
insert into hash_partn_test (partn_key, comment_field) values (9, 'This is row 9')
insert into hash_partn_test (partn_key, comment_field) values (10, 'This is row 10')
insert into hash_partn_test (partn_key, comment_field) values (11, 'This is row 11')insert into hash_partn_test (partn_key, comment_field) values (12, 'This is row 12')
insert into hash_partn_test (partn_key, comment_field) values (13, 'This is row 13')
insert into hash_partn_test (partn_key, comment_field) values (14, 'This is row 14')
insert into hash_partn_test (partn_key, comment_field) values (15, 'This is row 15')
insert into hash_partn_test (partn_key, comment_field) values (16, 'This is row 16')
insert into hash_partn_test (partn_key, comment_field) values (17, 'This is row 17')insert into hash_partn_test (partn_key, comment_field) values (18, 'This is row 18')
insert into hash_partn_test (partn_key, comment_field) values (19, 'This is row 19')
insert into hash_partn_test (partn_key, comment_field) values (20, 'This is row 20')
go 100
Test #1: Distribution of Values

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 50/58
5,12,5,12,5,12,…Partn_10
7,20,7,20,7,20,…Partn_9
4,14,4,14,4,14,…Partn_8
1,6,9,1,6,9,1,6,…Partn_7
16,19,16,19,16,…Partn_6
2,11,18,2,11,18,…Partn_5
17,17,17,17,…Partn_4
{empty}Partn_3
10,13,15,10,13,15,…Partn_2
3,8,3,8,3,8,3,8,…Partn_1
Partn_key ValuesPartition
Hash Partition and Data Distribution

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 51/58
• Insert 2,000 rows in sequential order:
insert into hash_partn_test (partn_key, comment_field) values (1, 'This is row 1')
go 100
insert into hash_partn_test (partn_key, comment_field) values (2, 'This is row 2')
go 100
insert into hash_partn_test (partn_key, comment_field) values (3, 'This is row 3')go 100
insert into hash_partn_test (partn_key, comment_field) values (4, 'This is row 4')
go 100
insert into hash_partn_test (partn_key, comment_field) values (5, 'This is row 5')
go 100
insert into hash_partn_test (partn_key, comment_field) values (6, 'This is row 6')go 100
insert into hash_partn_test (partn_key, comment_field) values (7, 'This is row 7')
go 100
…
insert into hash_partn_test (partn_key, comment_field) values (20, 'This is row 20')
go 100
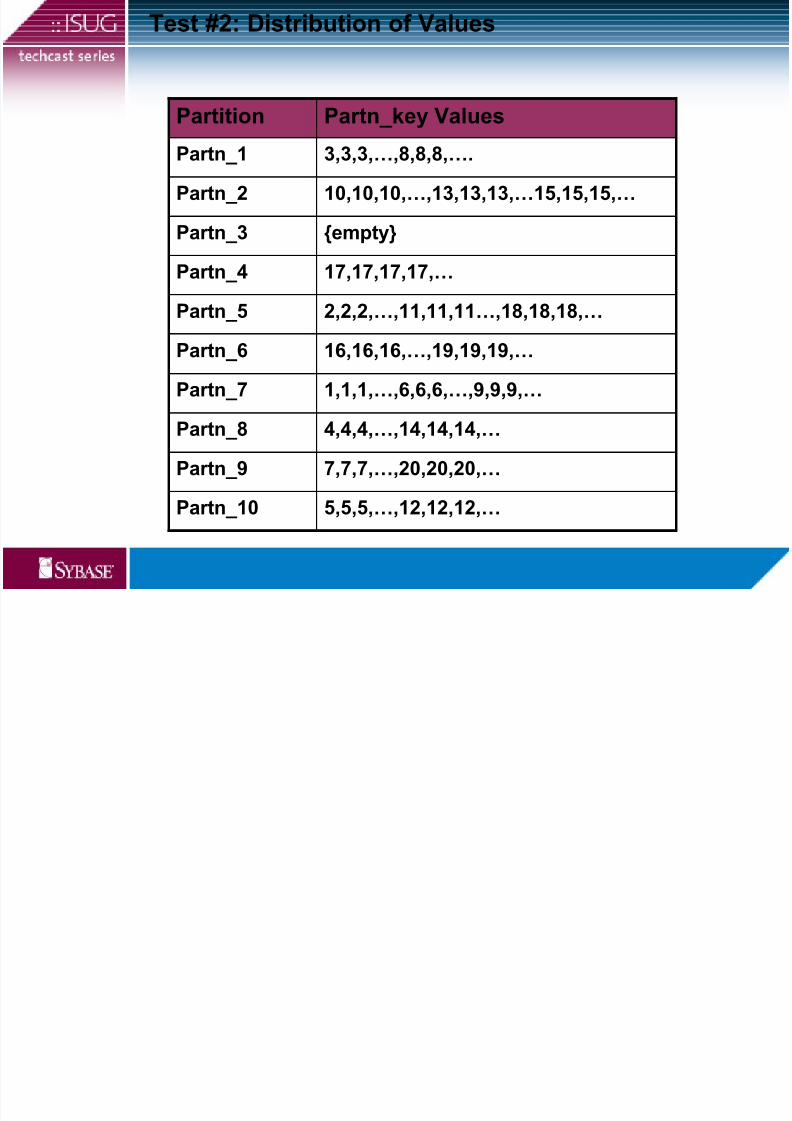
Test #2: Distribution of Values
8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 52/58
5,5,5,…,12,12,12,…Partn_10
7,7,7,…,20,20,20,…Partn_9
4,4,4,…,14,14,14,…Partn_8
1,1,1,…,6,6,6,…,9,9,9,…Partn_7
16,16,16,…,19,19,19,…Partn_6
2,2,2,…,11,11,11…,18,18,18,…Partn_5
17,17,17,17,…Partn_4
{empty}Partn_3
10,10,10,…,13,13,13,…15,15,15,…Partn_2
3,3,3,…,8,8,8,….Partn_1
Partn_key ValuesPartition
Hash Partitioning Observations

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 53/58
• Hash of value is independent of entry order
Hash function does not ‘round-robin’ partitions based on values
Guarantees hash(keyvalue)=value is always the same
•
Partition skew is probable Hash function has no idea of the data distribution
• Impact on sequential keys
If sequential keys are random, values are distributed accordingly
• Not a good option as any maintenance type operations will likely result incontention
If inserted in order, hash columns may be usable
• Consider a date column – object is to purge every 30 days
• Today *may* be in the same partition as 30 days ago, but today’s rows are at theend of the heap, vs. top
• Consequently a delete will not cause conflict, but truncate is not possible in all
circumstances
(Enumerated) List Partitioning

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 54/58
• ‘Value’ designated partitioning
Partition has a list of accepted values for each partition
Allows DBA to explicitly control partitioning
•
Recommendations Small to medium numbers of partitions w/ lowmedium data cardinality
Data that is typically accessed using equality (=) vs. range
• key equality would allow partition elimination, however, a range scan may require
access many to all partitions.• Would work well for range and aggregation when range is within a single partition
or aggregate is grouped by partition key
• Gotcha’s
Partition key values not listed If using for sequential keys, regular maintenance will be required to add
partitions
List Partition Syntax

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 55/58
• SyntaxCreate table tablename (colspec)
partition by list (column_name [, column_name ] ...)
( [ partition_name ] values ( constant[, constant ] ...)
[ on segment_name ][, [ partition_name ] values ( constant[, constant ] ...)
[ on segment_name ] ] ...)
List Partition Example:

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 56/58
create table list_partn_test (row_id numeric(10,0) identity not null,
month varchar(10) not null,
txn_date datetime not null,
txn_amount money not null
)lock datarows
partition by list (month) (
partn_Jan values ("January","Jan") on seg1,
partn_Feb values ("February","Feb") on seg1,
partn_Mar values ("March","Mar") on seg1,
partn_Apr values ("April","Apr") on seg1,
partn_May values ("May") on seg1,
partn_Jun values ("June","Jun") on seg1,
partn_Jul values ("July","Jul") on seg1,
partn_Aug values ("August","Aug") on seg1,
partn_Sep values ("September","Sep") on seg1,
partn_Oct values ("October","Oct") on seg1,
partn_Nov values ("November","Nov") on seg1,
partn_Dec values ("December","Dec") on seg1
)
List Partition and Unlisted Value

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 57/58
• Values not listed in partition clause1> Insert into list_partn_test (month, txn_date, txn_amount)
2> values ("Last Year",getdate(),4.56)
3> go
Msg 9573, Level 16, State 1:Server 'ASE15BETA', Line 1:
The server failed to create or update a row in table 'list_partn_test'
because the values of the row's partition-key columns do not fit into
any of the table's partitions.
Command has been aborted.
(0 rows affected)
• Recommendation
If you don’t want to deal with a ‘new’ error code, add a column constraint/rule
specifying full range of values
• The above may only be possible if list is finite and bounded
If using with unbounded sequential values (dates, etc.), you will need to
maintain partition via alter table in advance of users
Altering Partitions

8/4/2019 ISUG ASE15 Tech Insight May
http://slidepdf.com/reader/full/isug-ase15-tech-insight-may 58/58
• Drop indexes on table first Required if changing partitioning type or partition keys
Recommended if repartitioning
Rationale:
• Local index – inherits partition keys – changing the partition completely changes
the index structure – faster to drop/recreate
• Global index – repartitioning modifies most of the page locations – leaving index
intact slows down repartitioning – faster to drop/recreate
• Adding partitions to range and list
Can’t add partitions to hash or round-robin
You can only add partitions to the high end of a range partition
Rather than trying to modify a list partition to change the values, consider adding a partition on the same segment
• May make maintenance easier as partition can be truncated