iswc dc poster "reconstructing provenance"
TRANSCRIPT

!
"
! "
#$%&'
(
( )*+,-'
! "
#$%&'
./01+#0'*-0+2+0+''
342-/'#$40-40'
5'
6),4+7'8-0-#0$1!'
6),4+7'8-0-#0$1('
5'
6),4+7'9)70-1!'
6),4+7'9)70-1('
5'
#$4:2-4#-';'<=>'
#$4:2-4#-';'<=?'
@1-%1$#-AA)4,' B&%$0C-A-A'D-4-1+E$4' B&%$0C-A-A'@1F4)4,'
(
G,,1-,+E$4'+42'1+4H)4,'
==='
G,,1-,+0$1!'
G,,1-,+0$1('
8$#A'
!
"
! "
!#$%
&& $#"%
'()*+,)%-.)+/+)+%%
01/.(%,21).1)%
013.*%4.-+15,%)67.4%
8.()%49-9:+*9)6%
0-+;.%49-9:+*9)6%
<2-+91=47.,9>,%49-9:+*9)6%
?.)+/+)+%49-9:+*9)6%
@9:).*%).-72*+:%91,2A.*.1,.%
B9-9:+*9)6%)A*.4A2:/4%
<2-+91=47.,9>,%>:).*91;%
C*.7*2,.4491;% D672)A.4.4%E.1.*+521% D672)A.4.4%C*F191;% G;;*.;+521%+1/%*+1H91;%
I.9;A)./%BF-%
<2,4%
Reconstructing ProvenanceAn initial prototype implementationProblem Statement
Research Question
Approach & MethodologyWe propose a multi-signal pipeline approach that reconstructs plausible provenance traces using the contents of the files and metadata as evidence of the relationships between files.
The pipeline consists of four stages, each containing several components that can be executed in parallel:
Sara Magliacane - VU University AmsterdamAdvisors: Paul Groth and Frank van Harmelen
Future work
Initial (encouraging) results
How can one automatically, accurately and efficiently reconstruct a plausible provenance of files in a shared folder, intended as the sequences of operations connecting the files?
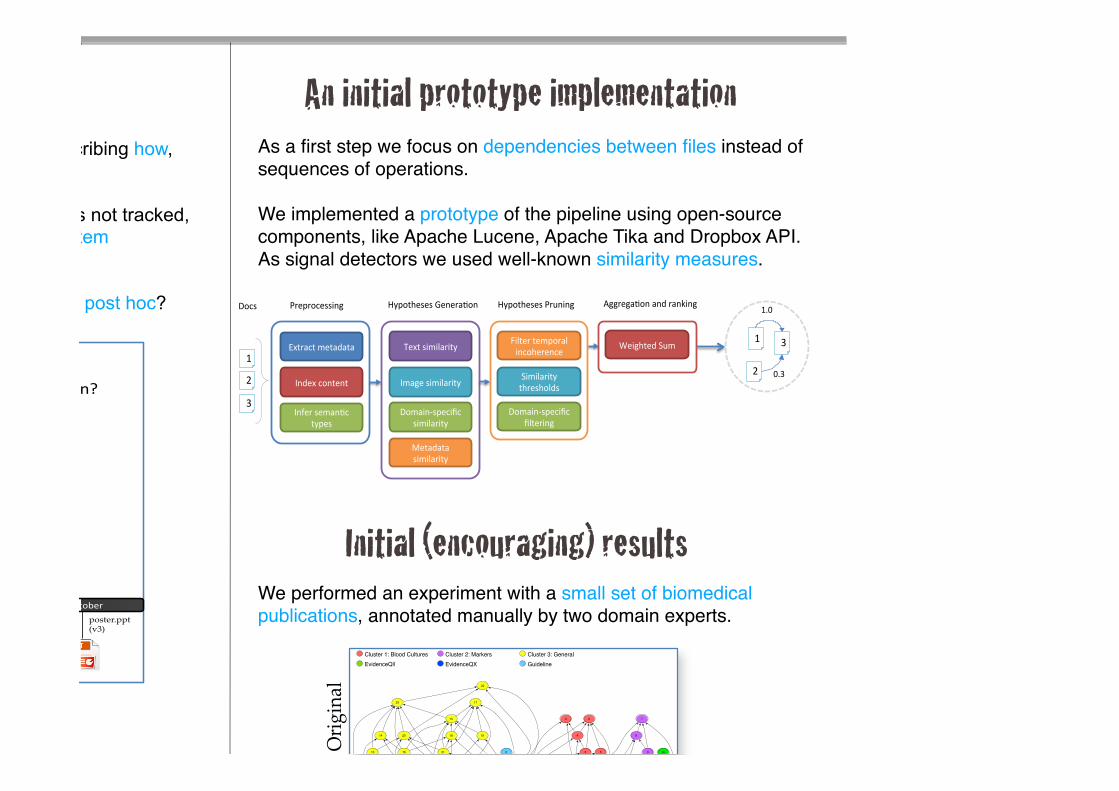
As a first step we focus on dependencies between files instead of sequences of operations.
We implemented a prototype of the pipeline using open-source components, like Apache Lucene, Apache Tika and Dropbox API. As signal detectors we used well-known similarity measures.
F1-score of 0.49 for only text similarityF1-score of 0.70 for the aggregation of various similarities
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#7"#.978,#:5*9#/0,#12,#373,563-:6#################
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#9*-.1,-#7#375785730#4.9.275#/*#373,563-:6#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#;#3757857304#:5*9#/0,#12,#/,<05,3*5/63-:6#
=+",# # # # # # # # # # # # # #></*?,5#
!"!#$%!&'( )#*+$#!,$)%!&'(
!,-)#$%!!)(./01(
!,-)#$%!!)(./21(
!,-)#$%!!)(./31(
4,!5(67"8#(
9"$"!+$"-#:!"$"8$"!+(4,!5(
!"$"8$"!+(
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/6#@*A#<7"#A,#8,/#9*5,#.":*597B*"C#
The provenance of a data item is the metadata describing how, when and by whom the data item was produced.
Provenance is crucial in many settings, but often it is not tracked, resulting in collections of files with only basic filesystem metadata, e.g. timestamps.
In this case, is it possible to reconstruct provenance post hoc?
We performed an experiment with a small set of biomedical publications, annotated manually by two domain experts.
24
13 9
17
8
3
20
6
4
7
5
15
22
23
21
12
16
1
18
100
19
11
14
2
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
17
16
19
18
21
20
23
22
24
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
!"#$
#%&'(
)"*+
#,-*+(
The research methodology is an iterative process, that will incrementally integrate existing approaches in literature and evaluate the performance on benchmark corpora.
Following the planned methodology, we will explore additional components for each of the pipeline phases and consider also computational efficiency.
Bibliography(1) Sara Magliacane: Reconstructing Provenance, ISWC Doctoral Consortium 2012
(2) Paul Groth, Yolanda Gil, Sara Magliacane: Automatic Metadata Annotation through Reconstructing Provenance, Third International Workshop on the role of Semantic Web in Provenance Management, ESWC 2012

!
"
! "
#$%&'
(
( )*+,-'
! "
#$%&'
./01+#0'*-0+2+0+''
342-/'#$40-40'
5'
6),4+7'8-0-#0$1!'
6),4+7'8-0-#0$1('
5'
6),4+7'9)70-1!'
6),4+7'9)70-1('
5'
#$4:2-4#-';'<=>'
#$4:2-4#-';'<=?'
@1-%1$#-AA)4,' B&%$0C-A-A'D-4-1+E$4' B&%$0C-A-A'@1F4)4,'
(
G,,1-,+E$4'+42'1+4H)4,'
==='
G,,1-,+0$1!'
G,,1-,+0$1('
8$#A'
!
"
! "
!#$%
&& $#"%
'()*+,)%-.)+/+)+%%
01/.(%,21).1)%
013.*%4.-+15,%)67.4%
8.()%49-9:+*9)6%
0-+;.%49-9:+*9)6%
<2-+91=47.,9>,%49-9:+*9)6%
?.)+/+)+%49-9:+*9)6%
@9:).*%).-72*+:%91,2A.*.1,.%
B9-9:+*9)6%)A*.4A2:/4%
<2-+91=47.,9>,%>:).*91;%
C*.7*2,.4491;% D672)A.4.4%E.1.*+521% D672)A.4.4%C*F191;% G;;*.;+521%+1/%*+1H91;%
I.9;A)./%BF-%
<2,4%
Reconstructing ProvenanceAn initial prototype implementationProblem Statement
Research Question
Approach & MethodologyWe propose a multi-signal pipeline approach that reconstructs plausible provenance traces using the contents of the files and metadata as evidence of the relationships between files.
The pipeline consists of four stages, each containing several components that can be executed in parallel:
Sara Magliacane - VU University AmsterdamAdvisors: Paul Groth and Frank van Harmelen
Future work
Initial (encouraging) results
How can one automatically, accurately and efficiently reconstruct a plausible provenance of files in a shared folder, intended as the sequences of operations connecting the files?
As a first step we focus on dependencies between files instead of sequences of operations.
We implemented a prototype of the pipeline using open-source components, like Apache Lucene, Apache Tika and Dropbox API. As signal detectors we used well-known similarity measures.
F1-score of 0.49 for only text similarityF1-score of 0.70 for the aggregation of various similarities
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#7"#.978,#:5*9#/0,#12,#373,563-:6#################
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#9*-.1,-#7#375785730#4.9.275#/*#373,563-:6#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#;#3757857304#:5*9#/0,#12,#/,<05,3*5/63-:6#
=+",# # # # # # # # # # # # # #></*?,5#
!"!#$%!&'( )#*+$#!,$)%!&'(
!,-)#$%!!)(./01(
!,-)#$%!!)(./21(
!,-)#$%!!)(./31(
4,!5(67"8#(
9"$"!+$"-#:!"$"8$"!+(4,!5(
!"$"8$"!+(
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/6#@*A#<7"#A,#8,/#9*5,#.":*597B*"C#
The provenance of a data item is the metadata describing how, when and by whom the data item was produced.
Provenance is crucial in many settings, but often it is not tracked, resulting in collections of files with only basic filesystem metadata, e.g. timestamps.
In this case, is it possible to reconstruct provenance post hoc?
We performed an experiment with a small set of biomedical publications, annotated manually by two domain experts.
24
13 9
17
8
3
20
6
4
7
5
15
22
23
21
12
16
1
18
100
19
11
14
2
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
17
16
19
18
21
20
23
22
24
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
!"#$
#%&'(
)"*+
#,-*+(
The research methodology is an iterative process, that will incrementally integrate existing approaches in literature and evaluate the performance on benchmark corpora.
Following the planned methodology, we will explore additional components for each of the pipeline phases and consider also computational efficiency.
Bibliography(1) Sara Magliacane: Reconstructing Provenance, ISWC Doctoral Consortium 2012
(2) Paul Groth, Yolanda Gil, Sara Magliacane: Automatic Metadata Annotation through Reconstructing Provenance, Third International Workshop on the role of Semantic Web in Provenance Management, ESWC 2012

!
"
! "
#$%&'
(
( )*+,-'
! "
#$%&'
./01+#0'*-0+2+0+''
342-/'#$40-40'
5'
6),4+7'8-0-#0$1!'
6),4+7'8-0-#0$1('
5'
6),4+7'9)70-1!'
6),4+7'9)70-1('
5'
#$4:2-4#-';'<=>'
#$4:2-4#-';'<=?'
@1-%1$#-AA)4,' B&%$0C-A-A'D-4-1+E$4' B&%$0C-A-A'@1F4)4,'
(
G,,1-,+E$4'+42'1+4H)4,'
==='
G,,1-,+0$1!'
G,,1-,+0$1('
8$#A'
!
"
! "
!#$%
&& $#"%
'()*+,)%-.)+/+)+%%
01/.(%,21).1)%
013.*%4.-+15,%)67.4%
8.()%49-9:+*9)6%
0-+;.%49-9:+*9)6%
<2-+91=47.,9>,%49-9:+*9)6%
?.)+/+)+%49-9:+*9)6%
@9:).*%).-72*+:%91,2A.*.1,.%
B9-9:+*9)6%)A*.4A2:/4%
<2-+91=47.,9>,%>:).*91;%
C*.7*2,.4491;% D672)A.4.4%E.1.*+521% D672)A.4.4%C*F191;% G;;*.;+521%+1/%*+1H91;%
I.9;A)./%BF-%
<2,4%
Reconstructing ProvenanceAn initial prototype implementationProblem Statement
Research Question
Approach & MethodologyWe propose a multi-signal pipeline approach that reconstructs plausible provenance traces using the contents of the files and metadata as evidence of the relationships between files.
The pipeline consists of four stages, each containing several components that can be executed in parallel:
Sara Magliacane - VU University AmsterdamAdvisors: Paul Groth and Frank van Harmelen
Future work
Initial (encouraging) results
How can one automatically, accurately and efficiently reconstruct a plausible provenance of files in a shared folder, intended as the sequences of operations connecting the files?
As a first step we focus on dependencies between files instead of sequences of operations.
We implemented a prototype of the pipeline using open-source components, like Apache Lucene, Apache Tika and Dropbox API. As signal detectors we used well-known similarity measures.
F1-score of 0.49 for only text similarityF1-score of 0.70 for the aggregation of various similarities
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#7"#.978,#:5*9#/0,#12,#373,563-:6#################
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#9*-.1,-#7#375785730#4.9.275#/*#373,563-:6#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#;#3757857304#:5*9#/0,#12,#/,<05,3*5/63-:6#
=+",# # # # # # # # # # # # # #></*?,5#
!"!#$%!&'( )#*+$#!,$)%!&'(
!,-)#$%!!)(./01(
!,-)#$%!!)(./21(
!,-)#$%!!)(./31(
4,!5(67"8#(
9"$"!+$"-#:!"$"8$"!+(4,!5(
!"$"8$"!+(
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/6#@*A#<7"#A,#8,/#9*5,#.":*597B*"C#
The provenance of a data item is the metadata describing how, when and by whom the data item was produced.
Provenance is crucial in many settings, but often it is not tracked, resulting in collections of files with only basic filesystem metadata, e.g. timestamps.
In this case, is it possible to reconstruct provenance post hoc?
We performed an experiment with a small set of biomedical publications, annotated manually by two domain experts.
24
13 9
17
8
3
20
6
4
7
5
15
22
23
21
12
16
1
18
100
19
11
14
2
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
17
16
19
18
21
20
23
22
24
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
!"#$
#%&'(
)"*+
#,-*+(
The research methodology is an iterative process, that will incrementally integrate existing approaches in literature and evaluate the performance on benchmark corpora.
Following the planned methodology, we will explore additional components for each of the pipeline phases and consider also computational efficiency.
Bibliography(1) Sara Magliacane: Reconstructing Provenance, ISWC Doctoral Consortium 2012
(2) Paul Groth, Yolanda Gil, Sara Magliacane: Automatic Metadata Annotation through Reconstructing Provenance, Third International Workshop on the role of Semantic Web in Provenance Management, ESWC 2012
!
"
! "
#$%&'
(
( )*+,-'
! "
#$%&'
./01+#0'*-0+2+0+''
342-/'#$40-40'
5'
6),4+7'8-0-#0$1!'
6),4+7'8-0-#0$1('
5'
6),4+7'9)70-1!'
6),4+7'9)70-1('
5'
#$4:2-4#-';'<=>'
#$4:2-4#-';'<=?'
@1-%1$#-AA)4,' B&%$0C-A-A'D-4-1+E$4' B&%$0C-A-A'@1F4)4,'
(
G,,1-,+E$4'+42'1+4H)4,'
==='
G,,1-,+0$1!'
G,,1-,+0$1('
8$#A'
!
"
! "
!#$%
&& $#"%
'()*+,)%-.)+/+)+%%
01/.(%,21).1)%
013.*%4.-+15,%)67.4%
8.()%49-9:+*9)6%
0-+;.%49-9:+*9)6%
<2-+91=47.,9>,%49-9:+*9)6%
?.)+/+)+%49-9:+*9)6%
@9:).*%).-72*+:%91,2A.*.1,.%
B9-9:+*9)6%)A*.4A2:/4%
<2-+91=47.,9>,%>:).*91;%
C*.7*2,.4491;% D672)A.4.4%E.1.*+521% D672)A.4.4%C*F191;% G;;*.;+521%+1/%*+1H91;%
I.9;A)./%BF-%
<2,4%
Reconstructing ProvenanceAn initial prototype implementationProblem Statement
Research Question
Approach & MethodologyWe propose a multi-signal pipeline approach that reconstructs plausible provenance traces using the contents of the files and metadata as evidence of the relationships between files.
The pipeline consists of four stages, each containing several components that can be executed in parallel:
Sara Magliacane - VU University AmsterdamAdvisors: Paul Groth and Frank van Harmelen
Future work
Initial (encouraging) results
How can one automatically, accurately and efficiently reconstruct a plausible provenance of files in a shared folder, intended as the sequences of operations connecting the files?
As a first step we focus on dependencies between files instead of sequences of operations.
We implemented a prototype of the pipeline using open-source components, like Apache Lucene, Apache Tika and Dropbox API. As signal detectors we used well-known similarity measures.
F1-score of 0.49 for only text similarityF1-score of 0.70 for the aggregation of various similarities
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#7"#.978,#:5*9#/0,#12,#373,563-:6#################
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#9*-.1,-#7#375785730#4.9.275#/*#373,563-:6#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#;#3757857304#:5*9#/0,#12,#/,<05,3*5/63-:6#
=+",# # # # # # # # # # # # # #></*?,5#
!"!#$%!&'( )#*+$#!,$)%!&'(
!,-)#$%!!)(./01(
!,-)#$%!!)(./21(
!,-)#$%!!)(./31(
4,!5(67"8#(
9"$"!+$"-#:!"$"8$"!+(4,!5(
!"$"8$"!+(
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/6#@*A#<7"#A,#8,/#9*5,#.":*597B*"C#
The provenance of a data item is the metadata describing how, when and by whom the data item was produced.
Provenance is crucial in many settings, but often it is not tracked, resulting in collections of files with only basic filesystem metadata, e.g. timestamps.
In this case, is it possible to reconstruct provenance post hoc?
We performed an experiment with a small set of biomedical publications, annotated manually by two domain experts.
24
13 9
17
8
3
20
6
4
7
5
15
22
23
21
12
16
1
18
100
19
11
14
2
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
17
16
19
18
21
20
23
22
24
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
!"#$
#%&'(
)"*+
#,-*+(
The research methodology is an iterative process, that will incrementally integrate existing approaches in literature and evaluate the performance on benchmark corpora.
Following the planned methodology, we will explore additional components for each of the pipeline phases and consider also computational efficiency.
Bibliography(1) Sara Magliacane: Reconstructing Provenance, ISWC Doctoral Consortium 2012
(2) Paul Groth, Yolanda Gil, Sara Magliacane: Automatic Metadata Annotation through Reconstructing Provenance, Third International Workshop on the role of Semantic Web in Provenance Management, ESWC 2012

!
"
! "
#$%&'
(
( )*+,-'
! "
#$%&'
./01+#0'*-0+2+0+''
342-/'#$40-40'
5'
6),4+7'8-0-#0$1!'
6),4+7'8-0-#0$1('
5'
6),4+7'9)70-1!'
6),4+7'9)70-1('
5'
#$4:2-4#-';'<=>'
#$4:2-4#-';'<=?'
@1-%1$#-AA)4,' B&%$0C-A-A'D-4-1+E$4' B&%$0C-A-A'@1F4)4,'
(
G,,1-,+E$4'+42'1+4H)4,'
==='
G,,1-,+0$1!'
G,,1-,+0$1('
8$#A'
!
"
! "
!#$%
&& $#"%
'()*+,)%-.)+/+)+%%
01/.(%,21).1)%
013.*%4.-+15,%)67.4%
8.()%49-9:+*9)6%
0-+;.%49-9:+*9)6%
<2-+91=47.,9>,%49-9:+*9)6%
?.)+/+)+%49-9:+*9)6%
@9:).*%).-72*+:%91,2A.*.1,.%
B9-9:+*9)6%)A*.4A2:/4%
<2-+91=47.,9>,%>:).*91;%
C*.7*2,.4491;% D672)A.4.4%E.1.*+521% D672)A.4.4%C*F191;% G;;*.;+521%+1/%*+1H91;%
I.9;A)./%BF-%
<2,4%
Reconstructing ProvenanceAn initial prototype implementationProblem Statement
Research Question
Approach & MethodologyWe propose a multi-signal pipeline approach that reconstructs plausible provenance traces using the contents of the files and metadata as evidence of the relationships between files.
The pipeline consists of four stages, each containing several components that can be executed in parallel:
Sara Magliacane - VU University AmsterdamAdvisors: Paul Groth and Frank van Harmelen
Future work
Initial (encouraging) results
How can one automatically, accurately and efficiently reconstruct a plausible provenance of files in a shared folder, intended as the sequences of operations connecting the files?
As a first step we focus on dependencies between files instead of sequences of operations.
We implemented a prototype of the pipeline using open-source components, like Apache Lucene, Apache Tika and Dropbox API. As signal detectors we used well-known similarity measures.
F1-score of 0.49 for only text similarityF1-score of 0.70 for the aggregation of various similarities
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#7"#.978,#:5*9#/0,#12,#373,563-:6#################
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#9*-.1,-#7#375785730#4.9.275#/*#373,563-:6#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#;#3757857304#:5*9#/0,#12,#/,<05,3*5/63-:6#
=+",# # # # # # # # # # # # # #></*?,5#
!"!#$%!&'( )#*+$#!,$)%!&'(
!,-)#$%!!)(./01(
!,-)#$%!!)(./21(
!,-)#$%!!)(./31(
4,!5(67"8#(
9"$"!+$"-#:!"$"8$"!+(4,!5(
!"$"8$"!+(
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/6#@*A#<7"#A,#8,/#9*5,#.":*597B*"C#
The provenance of a data item is the metadata describing how, when and by whom the data item was produced.
Provenance is crucial in many settings, but often it is not tracked, resulting in collections of files with only basic filesystem metadata, e.g. timestamps.
In this case, is it possible to reconstruct provenance post hoc?
We performed an experiment with a small set of biomedical publications, annotated manually by two domain experts.
24
13 9
17
8
3
20
6
4
7
5
15
22
23
21
12
16
1
18
100
19
11
14
2
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
17
16
19
18
21
20
23
22
24
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
!"#$
#%&'(
)"*+
#,-*+(
The research methodology is an iterative process, that will incrementally integrate existing approaches in literature and evaluate the performance on benchmark corpora.
Following the planned methodology, we will explore additional components for each of the pipeline phases and consider also computational efficiency.
Bibliography(1) Sara Magliacane: Reconstructing Provenance, ISWC Doctoral Consortium 2012
(2) Paul Groth, Yolanda Gil, Sara Magliacane: Automatic Metadata Annotation through Reconstructing Provenance, Third International Workshop on the role of Semantic Web in Provenance Management, ESWC 2012
!
"
! "
#$%&'
(
( )*+,-'
! "
#$%&'
./01+#0'*-0+2+0+''
342-/'#$40-40'
5'
6),4+7'8-0-#0$1!'
6),4+7'8-0-#0$1('
5'
6),4+7'9)70-1!'
6),4+7'9)70-1('
5'
#$4:2-4#-';'<=>'
#$4:2-4#-';'<=?'
@1-%1$#-AA)4,' B&%$0C-A-A'D-4-1+E$4' B&%$0C-A-A'@1F4)4,'
(
G,,1-,+E$4'+42'1+4H)4,'
==='
G,,1-,+0$1!'
G,,1-,+0$1('
8$#A'
!
"
! "
!#$%
&& $#"%
'()*+,)%-.)+/+)+%%
01/.(%,21).1)%
013.*%4.-+15,%)67.4%
8.()%49-9:+*9)6%
0-+;.%49-9:+*9)6%
<2-+91=47.,9>,%49-9:+*9)6%
?.)+/+)+%49-9:+*9)6%
@9:).*%).-72*+:%91,2A.*.1,.%
B9-9:+*9)6%)A*.4A2:/4%
<2-+91=47.,9>,%>:).*91;%
C*.7*2,.4491;% D672)A.4.4%E.1.*+521% D672)A.4.4%C*F191;% G;;*.;+521%+1/%*+1H91;%
I.9;A)./%BF-%
<2,4%
Reconstructing ProvenanceAn initial prototype implementationProblem Statement
Research Question
Approach & MethodologyWe propose a multi-signal pipeline approach that reconstructs plausible provenance traces using the contents of the files and metadata as evidence of the relationships between files.
The pipeline consists of four stages, each containing several components that can be executed in parallel:
Sara Magliacane - VU University AmsterdamAdvisors: Paul Groth and Frank van Harmelen
Future work
Initial (encouraging) results
How can one automatically, accurately and efficiently reconstruct a plausible provenance of files in a shared folder, intended as the sequences of operations connecting the files?
As a first step we focus on dependencies between files instead of sequences of operations.
We implemented a prototype of the pipeline using open-source components, like Apache Lucene, Apache Tika and Dropbox API. As signal detectors we used well-known similarity measures.
F1-score of 0.49 for only text similarityF1-score of 0.70 for the aggregation of various similarities
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#7"#.978,#:5*9#/0,#12,#373,563-:6#################
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#9*-.1,-#7#375785730#4.9.275#/*#373,563-:6#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#;#3757857304#:5*9#/0,#12,#/,<05,3*5/63-:6#
=+",# # # # # # # # # # # # # #></*?,5#
!"!#$%!&'( )#*+$#!,$)%!&'(
!,-)#$%!!)(./01(
!,-)#$%!!)(./21(
!,-)#$%!!)(./31(
4,!5(67"8#(
9"$"!+$"-#:!"$"8$"!+(4,!5(
!"$"8$"!+(
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/6#@*A#<7"#A,#8,/#9*5,#.":*597B*"C#
The provenance of a data item is the metadata describing how, when and by whom the data item was produced.
Provenance is crucial in many settings, but often it is not tracked, resulting in collections of files with only basic filesystem metadata, e.g. timestamps.
In this case, is it possible to reconstruct provenance post hoc?
We performed an experiment with a small set of biomedical publications, annotated manually by two domain experts.
24
13 9
17
8
3
20
6
4
7
5
15
22
23
21
12
16
1
18
100
19
11
14
2
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
17
16
19
18
21
20
23
22
24
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
!"#$
#%&'(
)"*+
#,-*+(
The research methodology is an iterative process, that will incrementally integrate existing approaches in literature and evaluate the performance on benchmark corpora.
Following the planned methodology, we will explore additional components for each of the pipeline phases and consider also computational efficiency.
Bibliography(1) Sara Magliacane: Reconstructing Provenance, ISWC Doctoral Consortium 2012
(2) Paul Groth, Yolanda Gil, Sara Magliacane: Automatic Metadata Annotation through Reconstructing Provenance, Third International Workshop on the role of Semantic Web in Provenance Management, ESWC 2012
!
"
! "
#$%&'
(
( )*+,-'
! "
#$%&'
./01+#0'*-0+2+0+''
342-/'#$40-40'
5'
6),4+7'8-0-#0$1!'
6),4+7'8-0-#0$1('
5'
6),4+7'9)70-1!'
6),4+7'9)70-1('
5'
#$4:2-4#-';'<=>'
#$4:2-4#-';'<=?'
@1-%1$#-AA)4,' B&%$0C-A-A'D-4-1+E$4' B&%$0C-A-A'@1F4)4,'
(
G,,1-,+E$4'+42'1+4H)4,'
==='
G,,1-,+0$1!'
G,,1-,+0$1('
8$#A'
!
"
! "
!#$%
&& $#"%
'()*+,)%-.)+/+)+%%
01/.(%,21).1)%
013.*%4.-+15,%)67.4%
8.()%49-9:+*9)6%
0-+;.%49-9:+*9)6%
<2-+91=47.,9>,%49-9:+*9)6%
?.)+/+)+%49-9:+*9)6%
@9:).*%).-72*+:%91,2A.*.1,.%
B9-9:+*9)6%)A*.4A2:/4%
<2-+91=47.,9>,%>:).*91;%
C*.7*2,.4491;% D672)A.4.4%E.1.*+521% D672)A.4.4%C*F191;% G;;*.;+521%+1/%*+1H91;%
I.9;A)./%BF-%
<2,4%
Reconstructing ProvenanceAn initial prototype implementationProblem Statement
Research Question
Approach & MethodologyWe propose a multi-signal pipeline approach that reconstructs plausible provenance traces using the contents of the files and metadata as evidence of the relationships between files.
The pipeline consists of four stages, each containing several components that can be executed in parallel:
Sara Magliacane - VU University AmsterdamAdvisors: Paul Groth and Frank van Harmelen
Future work
Initial (encouraging) results
How can one automatically, accurately and efficiently reconstruct a plausible provenance of files in a shared folder, intended as the sequences of operations connecting the files?
As a first step we focus on dependencies between files instead of sequences of operations.
We implemented a prototype of the pipeline using open-source components, like Apache Lucene, Apache Tika and Dropbox API. As signal detectors we used well-known similarity measures.
F1-score of 0.49 for only text similarityF1-score of 0.70 for the aggregation of various similarities
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#7"#.978,#:5*9#/0,#12,#373,563-:6#################
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#9*-.1,-#7#375785730#4.9.275#/*#373,563-:6#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#;#3757857304#:5*9#/0,#12,#/,<05,3*5/63-:6#
=+",# # # # # # # # # # # # # #></*?,5#
!"!#$%!&'( )#*+$#!,$)%!&'(
!,-)#$%!!)(./01(
!,-)#$%!!)(./21(
!,-)#$%!!)(./31(
4,!5(67"8#(
9"$"!+$"-#:!"$"8$"!+(4,!5(
!"$"8$"!+(
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/6#@*A#<7"#A,#8,/#9*5,#.":*597B*"C#
The provenance of a data item is the metadata describing how, when and by whom the data item was produced.
Provenance is crucial in many settings, but often it is not tracked, resulting in collections of files with only basic filesystem metadata, e.g. timestamps.
In this case, is it possible to reconstruct provenance post hoc?
We performed an experiment with a small set of biomedical publications, annotated manually by two domain experts.
24
13 9
17
8
3
20
6
4
7
5
15
22
23
21
12
16
1
18
100
19
11
14
2
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
17
16
19
18
21
20
23
22
24
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
!"#$
#%&'(
)"*+
#,-*+(
The research methodology is an iterative process, that will incrementally integrate existing approaches in literature and evaluate the performance on benchmark corpora.
Following the planned methodology, we will explore additional components for each of the pipeline phases and consider also computational efficiency.
Bibliography(1) Sara Magliacane: Reconstructing Provenance, ISWC Doctoral Consortium 2012
(2) Paul Groth, Yolanda Gil, Sara Magliacane: Automatic Metadata Annotation through Reconstructing Provenance, Third International Workshop on the role of Semantic Web in Provenance Management, ESWC 2012
!
"
! "
#$%&'
(
( )*+,-'
! "
#$%&'
./01+#0'*-0+2+0+''
342-/'#$40-40'
5'
6),4+7'8-0-#0$1!'
6),4+7'8-0-#0$1('
5'
6),4+7'9)70-1!'
6),4+7'9)70-1('
5'
#$4:2-4#-';'<=>'
#$4:2-4#-';'<=?'
@1-%1$#-AA)4,' B&%$0C-A-A'D-4-1+E$4' B&%$0C-A-A'@1F4)4,'
(
G,,1-,+E$4'+42'1+4H)4,'
==='
G,,1-,+0$1!'
G,,1-,+0$1('
8$#A'
!
"
! "
!#$%
&& $#"%
'()*+,)%-.)+/+)+%%
01/.(%,21).1)%
013.*%4.-+15,%)67.4%
8.()%49-9:+*9)6%
0-+;.%49-9:+*9)6%
<2-+91=47.,9>,%49-9:+*9)6%
?.)+/+)+%49-9:+*9)6%
@9:).*%).-72*+:%91,2A.*.1,.%
B9-9:+*9)6%)A*.4A2:/4%
<2-+91=47.,9>,%>:).*91;%
C*.7*2,.4491;% D672)A.4.4%E.1.*+521% D672)A.4.4%C*F191;% G;;*.;+521%+1/%*+1H91;%
I.9;A)./%BF-%
<2,4%
Reconstructing ProvenanceAn initial prototype implementationProblem Statement
Research Question
Approach & MethodologyWe propose a multi-signal pipeline approach that reconstructs plausible provenance traces using the contents of the files and metadata as evidence of the relationships between files.
The pipeline consists of four stages, each containing several components that can be executed in parallel:
Sara Magliacane - VU University AmsterdamAdvisors: Paul Groth and Frank van Harmelen
Future work
Initial (encouraging) results
How can one automatically, accurately and efficiently reconstruct a plausible provenance of files in a shared folder, intended as the sequences of operations connecting the files?
As a first step we focus on dependencies between files instead of sequences of operations.
We implemented a prototype of the pipeline using open-source components, like Apache Lucene, Apache Tika and Dropbox API. As signal detectors we used well-known similarity measures.
F1-score of 0.49 for only text similarityF1-score of 0.70 for the aggregation of various similarities
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#7"#.978,#:5*9#/0,#12,#373,563-:6#################
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#9*-.1,-#7#375785730#4.9.275#/*#373,563-:6#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#;#3757857304#:5*9#/0,#12,#/,<05,3*5/63-:6#
=+",# # # # # # # # # # # # # #></*?,5#
!"!#$%!&'( )#*+$#!,$)%!&'(
!,-)#$%!!)(./01(
!,-)#$%!!)(./21(
!,-)#$%!!)(./31(
4,!5(67"8#(
9"$"!+$"-#:!"$"8$"!+(4,!5(
!"$"8$"!+(
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/6#@*A#<7"#A,#8,/#9*5,#.":*597B*"C#
The provenance of a data item is the metadata describing how, when and by whom the data item was produced.
Provenance is crucial in many settings, but often it is not tracked, resulting in collections of files with only basic filesystem metadata, e.g. timestamps.
In this case, is it possible to reconstruct provenance post hoc?
We performed an experiment with a small set of biomedical publications, annotated manually by two domain experts.
24
13 9
17
8
3
20
6
4
7
5
15
22
23
21
12
16
1
18
100
19
11
14
2
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
17
16
19
18
21
20
23
22
24
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
!"#$
#%&'(
)"*+
#,-*+(
The research methodology is an iterative process, that will incrementally integrate existing approaches in literature and evaluate the performance on benchmark corpora.
Following the planned methodology, we will explore additional components for each of the pipeline phases and consider also computational efficiency.
Bibliography(1) Sara Magliacane: Reconstructing Provenance, ISWC Doctoral Consortium 2012
(2) Paul Groth, Yolanda Gil, Sara Magliacane: Automatic Metadata Annotation through Reconstructing Provenance, Third International Workshop on the role of Semantic Web in Provenance Management, ESWC 2012

!
"
! "
#$%&'
(
( )*+,-'
! "
#$%&'
./01+#0'*-0+2+0+''
342-/'#$40-40'
5'
6),4+7'8-0-#0$1!'
6),4+7'8-0-#0$1('
5'
6),4+7'9)70-1!'
6),4+7'9)70-1('
5'
#$4:2-4#-';'<=>'
#$4:2-4#-';'<=?'
@1-%1$#-AA)4,' B&%$0C-A-A'D-4-1+E$4' B&%$0C-A-A'@1F4)4,'
(
G,,1-,+E$4'+42'1+4H)4,'
==='
G,,1-,+0$1!'
G,,1-,+0$1('
8$#A'
!
"
! "
!#$%
&& $#"%
'()*+,)%-.)+/+)+%%
01/.(%,21).1)%
013.*%4.-+15,%)67.4%
8.()%49-9:+*9)6%
0-+;.%49-9:+*9)6%
<2-+91=47.,9>,%49-9:+*9)6%
?.)+/+)+%49-9:+*9)6%
@9:).*%).-72*+:%91,2A.*.1,.%
B9-9:+*9)6%)A*.4A2:/4%
<2-+91=47.,9>,%>:).*91;%
C*.7*2,.4491;% D672)A.4.4%E.1.*+521% D672)A.4.4%C*F191;% G;;*.;+521%+1/%*+1H91;%
I.9;A)./%BF-%
<2,4%
Reconstructing ProvenanceAn initial prototype implementationProblem Statement
Research Question
Approach & MethodologyWe propose a multi-signal pipeline approach that reconstructs plausible provenance traces using the contents of the files and metadata as evidence of the relationships between files.
The pipeline consists of four stages, each containing several components that can be executed in parallel:
Sara Magliacane - VU University AmsterdamAdvisors: Paul Groth and Frank van Harmelen
Future work
Initial (encouraging) results
How can one automatically, accurately and efficiently reconstruct a plausible provenance of files in a shared folder, intended as the sequences of operations connecting the files?
As a first step we focus on dependencies between files instead of sequences of operations.
We implemented a prototype of the pipeline using open-source components, like Apache Lucene, Apache Tika and Dropbox API. As signal detectors we used well-known similarity measures.
F1-score of 0.49 for only text similarityF1-score of 0.70 for the aggregation of various similarities
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#7"#.978,#:5*9#/0,#12,#373,563-:6#################
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#9*-.1,-#7#375785730#4.9.275#/*#373,563-:6#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#;#3757857304#:5*9#/0,#12,#/,<05,3*5/63-:6#
=+",# # # # # # # # # # # # # #></*?,5#
!"!#$%!&'( )#*+$#!,$)%!&'(
!,-)#$%!!)(./01(
!,-)#$%!!)(./21(
!,-)#$%!!)(./31(
4,!5(67"8#(
9"$"!+$"-#:!"$"8$"!+(4,!5(
!"$"8$"!+(
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/6#@*A#<7"#A,#8,/#9*5,#.":*597B*"C#
The provenance of a data item is the metadata describing how, when and by whom the data item was produced.
Provenance is crucial in many settings, but often it is not tracked, resulting in collections of files with only basic filesystem metadata, e.g. timestamps.
In this case, is it possible to reconstruct provenance post hoc?
We performed an experiment with a small set of biomedical publications, annotated manually by two domain experts.
24
13 9
17
8
3
20
6
4
7
5
15
22
23
21
12
16
1
18
100
19
11
14
2
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
17
16
19
18
21
20
23
22
24
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
!"#$
#%&'(
)"*+
#,-*+(
The research methodology is an iterative process, that will incrementally integrate existing approaches in literature and evaluate the performance on benchmark corpora.
Following the planned methodology, we will explore additional components for each of the pipeline phases and consider also computational efficiency.
Bibliography(1) Sara Magliacane: Reconstructing Provenance, ISWC Doctoral Consortium 2012
(2) Paul Groth, Yolanda Gil, Sara Magliacane: Automatic Metadata Annotation through Reconstructing Provenance, Third International Workshop on the role of Semantic Web in Provenance Management, ESWC 2012
!
"
! "
#$%&'
(
( )*+,-'
! "
#$%&'
./01+#0'*-0+2+0+''
342-/'#$40-40'
5'
6),4+7'8-0-#0$1!'
6),4+7'8-0-#0$1('
5'
6),4+7'9)70-1!'
6),4+7'9)70-1('
5'
#$4:2-4#-';'<=>'
#$4:2-4#-';'<=?'
@1-%1$#-AA)4,' B&%$0C-A-A'D-4-1+E$4' B&%$0C-A-A'@1F4)4,'
(
G,,1-,+E$4'+42'1+4H)4,'
==='
G,,1-,+0$1!'
G,,1-,+0$1('
8$#A'
!
"
! "
!#$%
&& $#"%
'()*+,)%-.)+/+)+%%
01/.(%,21).1)%
013.*%4.-+15,%)67.4%
8.()%49-9:+*9)6%
0-+;.%49-9:+*9)6%
<2-+91=47.,9>,%49-9:+*9)6%
?.)+/+)+%49-9:+*9)6%
@9:).*%).-72*+:%91,2A.*.1,.%
B9-9:+*9)6%)A*.4A2:/4%
<2-+91=47.,9>,%>:).*91;%
C*.7*2,.4491;% D672)A.4.4%E.1.*+521% D672)A.4.4%C*F191;% G;;*.;+521%+1/%*+1H91;%
I.9;A)./%BF-%
<2,4%
Reconstructing ProvenanceAn initial prototype implementationProblem Statement
Research Question
Approach & MethodologyWe propose a multi-signal pipeline approach that reconstructs plausible provenance traces using the contents of the files and metadata as evidence of the relationships between files.
The pipeline consists of four stages, each containing several components that can be executed in parallel:
Sara Magliacane - VU University AmsterdamAdvisors: Paul Groth and Frank van Harmelen
Future work
Initial (encouraging) results
How can one automatically, accurately and efficiently reconstruct a plausible provenance of files in a shared folder, intended as the sequences of operations connecting the files?
As a first step we focus on dependencies between files instead of sequences of operations.
We implemented a prototype of the pipeline using open-source components, like Apache Lucene, Apache Tika and Dropbox API. As signal detectors we used well-known similarity measures.
F1-score of 0.49 for only text similarityF1-score of 0.70 for the aggregation of various similarities
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#7"#.978,#:5*9#/0,#12,#373,563-:6#################
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#9*-.1,-#7#375785730#4.9.275#/*#373,563-:6#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#;#3757857304#:5*9#/0,#12,#/,<05,3*5/63-:6#
=+",# # # # # # # # # # # # # #></*?,5#
!"!#$%!&'( )#*+$#!,$)%!&'(
!,-)#$%!!)(./01(
!,-)#$%!!)(./21(
!,-)#$%!!)(./31(
4,!5(67"8#(
9"$"!+$"-#:!"$"8$"!+(4,!5(
!"$"8$"!+(
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/6#@*A#<7"#A,#8,/#9*5,#.":*597B*"C#
The provenance of a data item is the metadata describing how, when and by whom the data item was produced.
Provenance is crucial in many settings, but often it is not tracked, resulting in collections of files with only basic filesystem metadata, e.g. timestamps.
In this case, is it possible to reconstruct provenance post hoc?
We performed an experiment with a small set of biomedical publications, annotated manually by two domain experts.
24
13 9
17
8
3
20
6
4
7
5
15
22
23
21
12
16
1
18
100
19
11
14
2
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
17
16
19
18
21
20
23
22
24
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
!"#$
#%&'(
)"*+
#,-*+(
The research methodology is an iterative process, that will incrementally integrate existing approaches in literature and evaluate the performance on benchmark corpora.
Following the planned methodology, we will explore additional components for each of the pipeline phases and consider also computational efficiency.
Bibliography(1) Sara Magliacane: Reconstructing Provenance, ISWC Doctoral Consortium 2012
(2) Paul Groth, Yolanda Gil, Sara Magliacane: Automatic Metadata Annotation through Reconstructing Provenance, Third International Workshop on the role of Semantic Web in Provenance Management, ESWC 2012

!
"
! "
#$%&'
(
( )*+,-'
! "
#$%&'
./01+#0'*-0+2+0+''
342-/'#$40-40'
5'
6),4+7'8-0-#0$1!'
6),4+7'8-0-#0$1('
5'
6),4+7'9)70-1!'
6),4+7'9)70-1('
5'
#$4:2-4#-';'<=>'
#$4:2-4#-';'<=?'
@1-%1$#-AA)4,' B&%$0C-A-A'D-4-1+E$4' B&%$0C-A-A'@1F4)4,'
(
G,,1-,+E$4'+42'1+4H)4,'
==='
G,,1-,+0$1!'
G,,1-,+0$1('
8$#A'
!
"
! "
!#$%
&& $#"%
'()*+,)%-.)+/+)+%%
01/.(%,21).1)%
013.*%4.-+15,%)67.4%
8.()%49-9:+*9)6%
0-+;.%49-9:+*9)6%
<2-+91=47.,9>,%49-9:+*9)6%
?.)+/+)+%49-9:+*9)6%
@9:).*%).-72*+:%91,2A.*.1,.%
B9-9:+*9)6%)A*.4A2:/4%
<2-+91=47.,9>,%>:).*91;%
C*.7*2,.4491;% D672)A.4.4%E.1.*+521% D672)A.4.4%C*F191;% G;;*.;+521%+1/%*+1H91;%
I.9;A)./%BF-%
<2,4%
Reconstructing ProvenanceAn initial prototype implementationProblem Statement
Research Question
Approach & MethodologyWe propose a multi-signal pipeline approach that reconstructs plausible provenance traces using the contents of the files and metadata as evidence of the relationships between files.
The pipeline consists of four stages, each containing several components that can be executed in parallel:
Sara Magliacane - VU University AmsterdamAdvisors: Paul Groth and Frank van Harmelen
Future work
Initial (encouraging) results
How can one automatically, accurately and efficiently reconstruct a plausible provenance of files in a shared folder, intended as the sequences of operations connecting the files?
As a first step we focus on dependencies between files instead of sequences of operations.
We implemented a prototype of the pipeline using open-source components, like Apache Lucene, Apache Tika and Dropbox API. As signal detectors we used well-known similarity measures.
F1-score of 0.49 for only text similarityF1-score of 0.70 for the aggregation of various similarities
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#7"#.978,#:5*9#/0,#12,#373,563-:6#################
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#9*-.1,-#7#375785730#4.9.275#/*#373,563-:6#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#;#3757857304#:5*9#/0,#12,#/,<05,3*5/63-:6#
=+",# # # # # # # # # # # # # #></*?,5#
!"!#$%!&'( )#*+$#!,$)%!&'(
!,-)#$%!!)(./01(
!,-)#$%!!)(./21(
!,-)#$%!!)(./31(
4,!5(67"8#(
9"$"!+$"-#:!"$"8$"!+(4,!5(
!"$"8$"!+(
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/6#@*A#<7"#A,#8,/#9*5,#.":*597B*"C#
The provenance of a data item is the metadata describing how, when and by whom the data item was produced.
Provenance is crucial in many settings, but often it is not tracked, resulting in collections of files with only basic filesystem metadata, e.g. timestamps.
In this case, is it possible to reconstruct provenance post hoc?
We performed an experiment with a small set of biomedical publications, annotated manually by two domain experts.
24
13 9
17
8
3
20
6
4
7
5
15
22
23
21
12
16
1
18
100
19
11
14
2
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
17
16
19
18
21
20
23
22
24
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
!"#$
#%&'(
)"*+
#,-*+(
The research methodology is an iterative process, that will incrementally integrate existing approaches in literature and evaluate the performance on benchmark corpora.
Following the planned methodology, we will explore additional components for each of the pipeline phases and consider also computational efficiency.
Bibliography(1) Sara Magliacane: Reconstructing Provenance, ISWC Doctoral Consortium 2012
(2) Paul Groth, Yolanda Gil, Sara Magliacane: Automatic Metadata Annotation through Reconstructing Provenance, Third International Workshop on the role of Semantic Web in Provenance Management, ESWC 2012
!
"
! "
#$%&'
(
( )*+,-'
! "
#$%&'
./01+#0'*-0+2+0+''
342-/'#$40-40'
5'
6),4+7'8-0-#0$1!'
6),4+7'8-0-#0$1('
5'
6),4+7'9)70-1!'
6),4+7'9)70-1('
5'
#$4:2-4#-';'<=>'
#$4:2-4#-';'<=?'
@1-%1$#-AA)4,' B&%$0C-A-A'D-4-1+E$4' B&%$0C-A-A'@1F4)4,'
(
G,,1-,+E$4'+42'1+4H)4,'
==='
G,,1-,+0$1!'
G,,1-,+0$1('
8$#A'
!
"
! "
!#$%
&& $#"%
'()*+,)%-.)+/+)+%%
01/.(%,21).1)%
013.*%4.-+15,%)67.4%
8.()%49-9:+*9)6%
0-+;.%49-9:+*9)6%
<2-+91=47.,9>,%49-9:+*9)6%
?.)+/+)+%49-9:+*9)6%
@9:).*%).-72*+:%91,2A.*.1,.%
B9-9:+*9)6%)A*.4A2:/4%
<2-+91=47.,9>,%>:).*91;%
C*.7*2,.4491;% D672)A.4.4%E.1.*+521% D672)A.4.4%C*F191;% G;;*.;+521%+1/%*+1H91;%
I.9;A)./%BF-%
<2,4%
Reconstructing ProvenanceAn initial prototype implementationProblem Statement
Research Question
Approach & MethodologyWe propose a multi-signal pipeline approach that reconstructs plausible provenance traces using the contents of the files and metadata as evidence of the relationships between files.
The pipeline consists of four stages, each containing several components that can be executed in parallel:
Sara Magliacane - VU University AmsterdamAdvisors: Paul Groth and Frank van Harmelen
Future work
Initial (encouraging) results
How can one automatically, accurately and efficiently reconstruct a plausible provenance of files in a shared folder, intended as the sequences of operations connecting the files?
As a first step we focus on dependencies between files instead of sequences of operations.
We implemented a prototype of the pipeline using open-source components, like Apache Lucene, Apache Tika and Dropbox API. As signal detectors we used well-known similarity measures.
F1-score of 0.49 for only text similarityF1-score of 0.70 for the aggregation of various similarities
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#7"#.978,#:5*9#/0,#12,#373,563-:6#################
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#9*-.1,-#7#375785730#4.9.275#/*#373,563-:6#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#;#3757857304#:5*9#/0,#12,#/,<05,3*5/63-:6#
=+",# # # # # # # # # # # # # #></*?,5#
!"!#$%!&'( )#*+$#!,$)%!&'(
!,-)#$%!!)(./01(
!,-)#$%!!)(./21(
!,-)#$%!!)(./31(
4,!5(67"8#(
9"$"!+$"-#:!"$"8$"!+(4,!5(
!"$"8$"!+(
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/6#@*A#<7"#A,#8,/#9*5,#.":*597B*"C#
The provenance of a data item is the metadata describing how, when and by whom the data item was produced.
Provenance is crucial in many settings, but often it is not tracked, resulting in collections of files with only basic filesystem metadata, e.g. timestamps.
In this case, is it possible to reconstruct provenance post hoc?
We performed an experiment with a small set of biomedical publications, annotated manually by two domain experts.
24
13 9
17
8
3
20
6
4
7
5
15
22
23
21
12
16
1
18
100
19
11
14
2
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
17
16
19
18
21
20
23
22
24
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
!"#$
#%&'(
)"*+
#,-*+(
The research methodology is an iterative process, that will incrementally integrate existing approaches in literature and evaluate the performance on benchmark corpora.
Following the planned methodology, we will explore additional components for each of the pipeline phases and consider also computational efficiency.
Bibliography(1) Sara Magliacane: Reconstructing Provenance, ISWC Doctoral Consortium 2012
(2) Paul Groth, Yolanda Gil, Sara Magliacane: Automatic Metadata Annotation through Reconstructing Provenance, Third International Workshop on the role of Semantic Web in Provenance Management, ESWC 2012

!
"
! "
#$%&'
(
( )*+,-'
! "
#$%&'
./01+#0'*-0+2+0+''
342-/'#$40-40'
5'
6),4+7'8-0-#0$1!'
6),4+7'8-0-#0$1('
5'
6),4+7'9)70-1!'
6),4+7'9)70-1('
5'
#$4:2-4#-';'<=>'
#$4:2-4#-';'<=?'
@1-%1$#-AA)4,' B&%$0C-A-A'D-4-1+E$4' B&%$0C-A-A'@1F4)4,'
(
G,,1-,+E$4'+42'1+4H)4,'
==='
G,,1-,+0$1!'
G,,1-,+0$1('
8$#A'
!
"
! "
!#$%
&& $#"%
'()*+,)%-.)+/+)+%%
01/.(%,21).1)%
013.*%4.-+15,%)67.4%
8.()%49-9:+*9)6%
0-+;.%49-9:+*9)6%
<2-+91=47.,9>,%49-9:+*9)6%
?.)+/+)+%49-9:+*9)6%
@9:).*%).-72*+:%91,2A.*.1,.%
B9-9:+*9)6%)A*.4A2:/4%
<2-+91=47.,9>,%>:).*91;%
C*.7*2,.4491;% D672)A.4.4%E.1.*+521% D672)A.4.4%C*F191;% G;;*.;+521%+1/%*+1H91;%
I.9;A)./%BF-%
<2,4%
Reconstructing ProvenanceAn initial prototype implementationProblem Statement
Research Question
Approach & MethodologyWe propose a multi-signal pipeline approach that reconstructs plausible provenance traces using the contents of the files and metadata as evidence of the relationships between files.
The pipeline consists of four stages, each containing several components that can be executed in parallel:
Sara Magliacane - VU University AmsterdamAdvisors: Paul Groth and Frank van Harmelen
Future work
Initial (encouraging) results
How can one automatically, accurately and efficiently reconstruct a plausible provenance of files in a shared folder, intended as the sequences of operations connecting the files?
As a first step we focus on dependencies between files instead of sequences of operations.
We implemented a prototype of the pipeline using open-source components, like Apache Lucene, Apache Tika and Dropbox API. As signal detectors we used well-known similarity measures.
F1-score of 0.49 for only text similarityF1-score of 0.70 for the aggregation of various similarities
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#7"#.978,#:5*9#/0,#12,#373,563-:6#################
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#9*-.1,-#7#375785730#4.9.275#/*#373,563-:6#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#7--."8#;#3757857304#:5*9#/0,#12,#/,<05,3*5/63-:6#
=+",# # # # # # # # # # # # # #></*?,5#
!"!#$%!&'( )#*+$#!,$)%!&'(
!,-)#$%!!)(./01(
!,-)#$%!!)(./21(
!,-)#$%!!)(./31(
4,!5(67"8#(
9"$"!+$"-#:!"$"8$"!+(4,!5(
!"$"8$"!+(
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/#
!"#!$%&#'&(#)*+#,-./,-#/0,#12,#3*4/,5633/6#@*A#<7"#A,#8,/#9*5,#.":*597B*"C#
The provenance of a data item is the metadata describing how, when and by whom the data item was produced.
Provenance is crucial in many settings, but often it is not tracked, resulting in collections of files with only basic filesystem metadata, e.g. timestamps.
In this case, is it possible to reconstruct provenance post hoc?
We performed an experiment with a small set of biomedical publications, annotated manually by two domain experts.
24
13 9
17
8
3
20
6
4
7
5
15
22
23
21
12
16
1
18
100
19
11
14
2
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
17
16
19
18
21
20
23
22
24
Cluster 1: Blood Cultures Cluster 3: GeneralEvidenceQ|| GuidelineEvidenceQX
Cluster 2: Markers
!"#$
#%&'(
)"*+
#,-*+(
The research methodology is an iterative process, that will incrementally integrate existing approaches in literature and evaluate the performance on benchmark corpora.
Following the planned methodology, we will explore additional components for each of the pipeline phases and consider also computational efficiency.
Bibliography(1) Sara Magliacane: Reconstructing Provenance, ISWC Doctoral Consortium 2012
(2) Paul Groth, Yolanda Gil, Sara Magliacane: Automatic Metadata Annotation through Reconstructing Provenance, Third International Workshop on the role of Semantic Web in Provenance Management, ESWC 2012