kalman filtering techniques for parameter estimationjaredb/presentations/biomath... · ·...
TRANSCRIPT

Kalman filtering techniques for parameter estimation
Jared BarberDepartment of Mathematics, University of Pittsburgh
Work with Ivan Yotov and Mark TronzoMarch 17, 2011

Outline
• Motivation for Kalman filter
• Details for Kalman filter
• Practical example with linear Kalman filter
• Discussion of other filters
– Extended Kalman filter
– Stochastic Collocation Kalman filter
– Karhunen-Loeve SC Kalman filter
• Results for simplified NEC model

Necrotizing Enterocolitis (NEC) Model
• Ten nonlinear PDEs
• Four layers
• Time consuming simulations for normal computational refinements
• Approximately fifty free parameters– Diffusion rates
– Growth and death rates
– Interaction rates
0
0.5
1
21
0
2
1
0
00.20.4
Computational Domain-
21
0
2
1
0
00.20.4
Distribution of macrophages

Maximum Likelihood Estimate
• Recall formula (for normal distributions):
• Disadvantages:– Consider all times simultaneously—larger optimization problem
and generally slower– Don’t take into account measurement error and model error
separately– To be more efficient: Want derivative information– Get only one answer…not a distribution (which tells you how
good your answer is)– May be hard to parallelize
n
i i
ii
xMLE
n
i
xMy
i
xMyxexL i
ii
12
2
1
))((
))((minarg;
2
1)(
2
2

Kalman Filter
• Various versions: Linear KF, Extended KF, Ensemble KF, Stochastic Collocation/Unscented KF, Karhunen-Loeve Kalman Filter
• Advantages of some of these methods (to a lesser or greater extent)– Consider each time separately– Keep track of best estimates for your parameters
(means) and your uncertainties (covariances)– Consider data and measurement error separately– Don’t need derivative information– Easy to parallelize

Kalman Filter Picture: Initial State
Measurement
Model Estimate
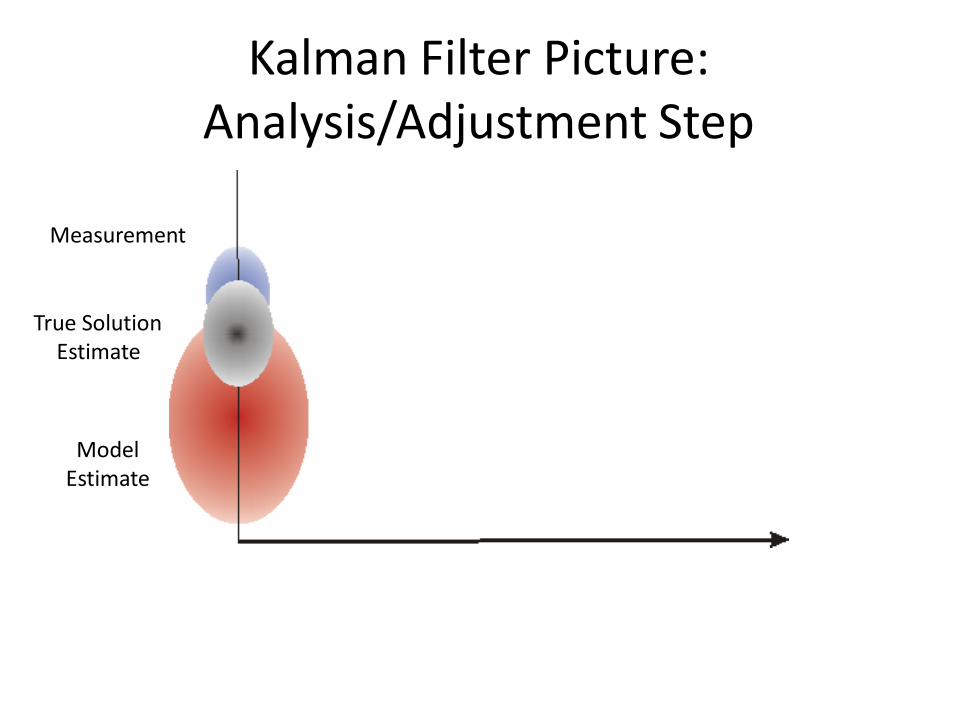
Kalman Filter Picture: Analysis/Adjustment Step
Model Estimate
Measurement
True SolutionEstimate
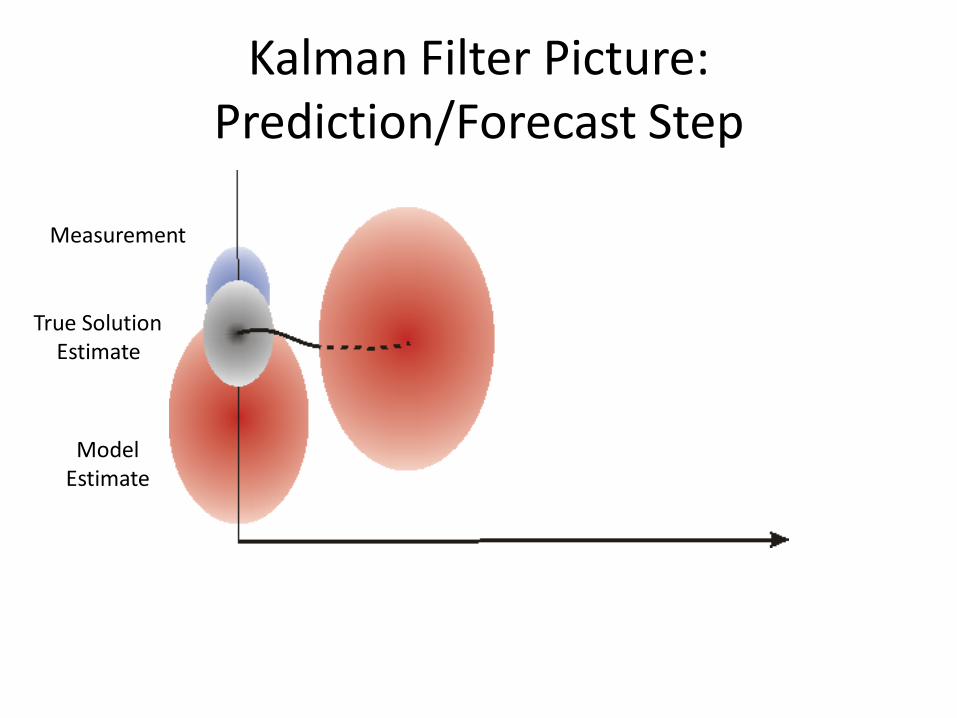
Kalman Filter Picture: Prediction/Forecast Step
Model Estimate
Measurement
True SolutionEstimate

Kalman Filter Picture: Measurement Step
Model Estimate
Measurement
True SolutionEstimate

Kalman Filter: Analysis/Adjustment Step
Model Estimate
Measurement
True SolutionEstimate
Advancing two things: Mean and covariance
Adjusted state vector =Model State Vector + Kk*(Measured Data-Model Data)
Kk = f(Model Covariance, Data Covariance)

Kalman Filter: General Algorithm, Quantities of interest
• Measured data = true data plus measurement noise
• Measurement function
• Optimal “blending factor” Kalman Gain:
• Model/forecast and adjusted state vectors
• Forecast/model function:
• Best/Analyzed model estimate
k
t
k
m
k vdd
a
k
f
k xx ,
t
k
t
k dxh )(
))(( f
k
m
kk
f
k
a
k xhdKxx
)( 1
a
k
f
k xfx
kK

Kalman Filter: General Algorithm, Uncertainties/Covariances of interest
• Prescribed: Measured data and application of model covariance
• Forecast state covariances
• Adjusted state covariances
))((,
T
kk
m
kdd vvEP model
kxxP ,
])][)(][[(
])][)(][[(
])][)(][[(
,
,
,
Tf
k
f
k
f
k
f
k
f
kdd
Tf
k
f
k
f
k
f
k
f
kxd
Tf
k
f
k
f
k
f
k
f
kxx
ddEddEEP
ddExxEEP
xxExxEEP
])][)(][[(,
Ta
k
a
k
a
k
a
k
a
kxx xxExxEEP

Kalman Filter: General Algorithm, Kalman Gain
• Recall to adjust the model’s state vector:
• Minimize the sum of the uncertainties associated with the adjusted state to find the right blending factor
))(( f
k
m
kk
f
k
a
k xhdKxx
1
,,
,
)(
minarg
f
kdd
f
kxdk
a
kxxK
k
PPK
PtraceKk

Linear Kalman Filter
• Special Case:
• Covariances given by:
f
k
f
k
f
k
k
a
kkk
a
k
f
k
Hxxhd
wxAwxfx
)(
)( 1111
Tf
kxdk
f
kxx
a
kxx
meas
kdd
Tf
kxx
f
kdd
Tf
kxx
f
kxd
model
kxx
T
k
a
kxxk
f
kxx
PKPP
PHHPP
HPP
PAPAP
,
,,,
,,,
,,
,,,

Example: Exact system
• Physical system modeled exactly by:
• Exact solution for this physical system is then:
2)0(
1)0(
;24'
;122'
2
1
212
211
y
y
yyy
yyy
.1)2cos(3
;2/)1)2cos(3)2sin(3(
2
1
ty
tty

Example: Model
• Pretend we have a model that we think might work for this system:
• We have three unknown variables, y1, y2, and a.
• We wish to find a that makes the model fit the data.
2)0(
1)0(
;24'
;22'
2
1
212
211
y
y
yyy
ayyy

Example: State vector
• Define the state vector as:
• Note, must make reasonable starting guess for unknown parameter. Here we guessed 1.5 which is close to the actual value of 1.
5.1
2
1
?
2
1
02
1guess
fx
a
y
y
x

Example: Data vector
• Assume we can actually measure y1 and y2 in our system
• Note our measurement function becomes:
995.1
01.1
005.0
01.0
2
1; 000
2
1vdd
y
yd tm
)(010
0012
1
2
1xhxH
a
y
y
y
yd

Example: Model/forecast function
• Assuming that the parameter a is a quantity that should not change with time, we can rewrite the system of equations as:
• Forward euler for our system gives us:
xM
a
y
y
a
y
y
x
2
1
2
1
000
024
122
'
'
'
11111 )( kkkkkk xAxdtMIxdtMxx

Example: Algorithm step through: Initialization
• Start with state vector data:
• Start with data vector data:
1.000
001.00
0001.0
5.1
2
1
,0
model
kxx
f Px
01.00
001.0
995.1
01.1,0
meas
kdd
m Pd

Example: Algorithm step through: Initialization
• Initial forecast model uncertainty as initial uncertainty in model state vector:
1.000
001.00
0001.0
0,
f
xxP

Example: Algorithm step through: Obtaining other covariances
• Use formulas to find other state vector covariances:
00
01.00
001.0
00
10
01
1.000
001.00
0001.0
0,0,
Tf
xx
f
xd HPP

Example: Algorithm step through:Obtaining other covariances
• Use formulas to find other state vector covariances:
02.00
002.0
01.00
001.0
00
10
01
1.000
001.00
0001.0
010
001
0,0,0,
meas
dd
Tf
xx
f
dd PHHPP

Example: Algorithm step through: Obtaining Kalman Gain
• Find Kalman Gain:
00
5.00
05.0
02.00
002.0
00
01.00
001.0
)(
1
1
0,0,0
f
dd
f
xd PPK

Example: Algorithm step through: Obtaining adjusted state vector
• Best estimate, note: halfway in between data and model…this is because the data uncertainties and model uncertainties are the same size
9975.1
005.1
5.1
2
1
010
001
995.1
01.1
00
5.00
05.0
5.1
2
1
)( 00000
fmfa HxdKxx

Example: Algorithm step through: Find adjusted state’s covariance
• Note: Uncertainties are smaller than other covariances…used both data and model to get an estimate with less uncertainty than before
1.000
0005.00
00005.0
001.00
0001.0
00
5.00
05.0
1.000
001.00
0001.0
,
0,00,0,
Tf
xd
f
xx
a
xx PKPP

Example: Algorithm step through
• Predict step, assume dt = 0.1:
5.1
2
6565.0
5.1
9975.1
005.1
100
02.01)4.0(
1.02.0)2.0(1
)( 01
af xdtMIx

Example: Algorithm step through
• New state covariance matrix:
2.0001.0
0014.00016.0
01.00016.00184.0
1.000
001.00
0001.0
001.0
02.12.0
04.02.1
1.000
0005.00
00005.0
000
08.04.0
1.02.02.1
1,11,11,
model
xx
Ta
xx
f
xx PAPAP

Example: Algorithm step through
• “Measure” data
004.2
009.1or
995.1
01.1
002.0
028.0
1))1.0(2cos(3
2/)1))1.0(2cos(3))1.0(2sin(3(
011
measured
simulated
tm vdd

Extended Kalman Filter:Nonlinear equations
• Special Case:
• Covariances given by:)(;)( 11
f
k
f
kk
a
k
f
k xhdwxfx
f
kxxk
a
kxx
meas
kdd
Tf
kxx
f
kdd
xx
Tf
kxx
f
kxd
model
kxx
T
k
a
kxxk
f
kxx
xx
k
PHKIP
PHHPP
x
hH
HPP
PAPAP
x
fA
ak
ak
,,
,,,
,,
,1,,
)(
11

Problems with KF/Ext KF?
• KF only works for linear problems.
• Ext KF
– Works for mildly nonlinear problems
– Must find and store Jacobians
• State vector size >> data vector size
– Reminder: Need to find
– Don’t need any Pxx’s.
– Pxx’s can be big and hard to calculate/keep track of
1
,, )( f
kdd
f
kxdk PPK

Ensemble Kalman Filter: The Ensemble
• Create an ensemble:
.4.2
7.0
3.2
5.4
3.1
4.2
5.4
3.1
2.4
6.3
4.3
2.2
1.4
6.4
9.1
4.4
9.3
9.0
,4.2
7.0
3.2
,5.4
3.1
4.2
,5.4
3.1
2.4
,6.3
4.3
2.2
,1.4
6.4
9.1
,4.4
9.3
9.0
,
etc
etcx f
enk

Ensemble Kalman Filter: Ensemble Properties
• The ensemble carries mean and covariance information
system of statemean
4.4
5.3
3.2
)(
.4.2
1.4
3.2
5.4
3.1
4.2
5.4
3.1
2.4
6.3
4.3
2.2
1.4
6.4
9.1
4.4
9.3
9.0
,
f
k
f
enk
xE
etcx

Ensemble Kalman Filter: New algorithm
Linear KF Ensemble KF
f
kxxk
a
kxx
f
k
m
kk
f
k
a
k
f
kdd
f
kxdk
meas
kdd
Tf
kxx
f
kdd
Tf
kxx
f
kxd
model
kxx
T
k
a
kxxk
f
kxx
f
k
f
k
a
k
f
k
PHKIP
xhdKxx
PPK
PHHPP
HPP
PAPAP
xhdxfx
,,
1
,,
,,,
,,
,1,,
1
)(
))((
)(
);();(
))((
)(
)1/(1
)1/(1
)),(,(
)),(,(
)(
)(
,,,,
1
,,
,
,,,
,
,,,
,,,,,
,,,,,
,,,
,,1,
f
enk
m
enkk
f
enk
a
enk
f
kdd
f
kxdk
Tf
kd
f
kd
f
kdd
Tf
kd
f
kx
f
kxd
f
ienk
f
ienk
f
kd
f
ienk
f
ienk
f
kx
enk
f
enk
f
enk
enk
a
enk
f
enk
xhdKxx
PPK
EEqP
EEqP
dEdE
xExE
vxhd
wxfx

Ensemble KF Advantages
• Handles nonlinearity (better than Ext KF)
• Don’t need Jacobian
• Don’t need Pxx’s

Ensemble KF Disadvantages
• Need many ensemble members to be accurate
– Mean and variances used in algorithm are within O(1/sqrt(q)) of actual (MC integration)
– Accurate representation can affect convergence rate and end error on parameter estimate
• Using many ensemble members requires many model/forecast function evaluations (slow)
Can we use fewer points and obtain more accuracy?
Note: Don’t need a lot of accuracy, just enough to get the job done.

Stochastic Collocation Kalman Filter:Stochastic Collocation
• Consider the expected value of the function g(z) on stochastic space
• ci and zi are collocation weights and locations, respectively
• Collocation exact for linear functions of the components of z and normal pdfs
12
1
2/)()(2/
)(
)det(2
1)()]([
1
n
i
ii
zz
zzPzzn
zgc
dzP
ezgzgE
n
Tzz

Ensemble and Stochastic Collocation Comparison
• En mean (q≈1000 pts) • SC mean (N≈200 pts)
q
i
f
ik
f
k xq
xE1
,1
1][
-10 -8 -6 -4 -2 0 2 4 6 8 10-10
-8
-6
-4
-2
0
2
4
6
8
10
N
i
f
iki
f
k xcxE1
,][

Stochastic Collocation:Kalman Filter Algorithm
ien
a
kxx
a
k
a
ienk
Tf
kxdk
f
kxx
a
kxx
f
k
m
kk
f
k
a
k
f
kdd
f
kxdk
N
i
meas
xx
Tf
k
f
ienk
f
k
f
ienki
f
kdd
N
i
Tf
k
f
ienk
f
k
f
ienki
f
kxd
N
i
model
xx
Tf
k
f
ienk
f
k
f
ienki
f
kxx
N
i
f
ienki
f
k
N
i
f
ienki
f
k
f
enk
f
enk
a
enk
f
enk
zPxx
PKPP
xhdKxx
PPK
PddddcP
ddxxcP
PxxxxcP
dcd
xcx
xhd
xfx
,,,,
,
,,,
1
,,
1
,,,,,
1
,,,,,
1
,,,,,
1
,,
1
,,
,,
,1,
))((
)(
))((
))((
))((
)(
)(

Stochastic Collocation Advantages and Disadvantages
• Faster than En KF for small numbers
• Slower than En KF for large numbers
• Usually more accurate than En KF
• Can handle nonlinearities
• Curse of dimensionality for pdes
– 20x20x20 grid needs 16001 collocation points
• Is there any way to get around this?

Stochastic Collocation Kalman Filter with Karhunen-Loeve Expansion
• On 3-d grids, above methods assume error is independent of location in computational grid
• Instead, assume error is spatially correlated:
• Hope: Most of the error is captured by the most dominant eigenfunctions
• Idea: Keep only the first twenty-five
n
j
jkejkw
n
j
jkejkwk fcyxfcw1
,,,,
1
,,,, ),(

Karhunen-Loeve SC:Kalman Filter Algorithm
ikeike
a
kxx
T
ikeiwen
a
k
a
ienk
Tf
kxdk
f
kxx
a
kxx
f
k
m
kk
f
k
a
k
f
kdd
f
kxdk
N
i
meas
xx
Tf
k
f
ik
f
k
f
iki
f
kdd
N
i
Tf
k
f
ik
f
k
f
iki
f
kxd
N
i
model
xx
Tf
k
f
ik
f
k
f
iki
f
kxx
N
i
f
iki
f
k
N
i
f
iki
f
k
f
enk
f
enk
a
enk
f
enk
ffPfzxx
PKPP
xhdKxx
PPK
PddddcP
ddxxcP
PxxxxcP
dcd
xcx
xhd
xfx
,,,,,,,,,,,
,
,,,
1
,,
1
,,,
1
,,,
1
,,,
1
,
1
,
,,
,1,
)(
))((
)(
))((
))((
))((
)(
)(

Simplified Necrotizing Enterocolitis Model: The experiment
Epithelial Layer
Create woundwith pipette
Epithelial Layer
Wound
≈150 µm

Simplified Necrotizing Enterocolitis Model: The Model and Equation
-500 0 500
-300
0
300
)1()1( 22
2
ccpc
cc
cc eekeee
eD
t
e

Simplified Necrotizing Enterocolitis: Perfect Simulated Data
En KF; SC KF; KL SC KF.
0 1 2 3
1e-10
1e-6
D E
stim
ate
Err
or
Time (hrs)
0.0001
0.1
kp E
stim
ate
Err
or
0 1 2 3
2e-6
3e-6
D E
stim
ate
Time (hrs)
0.6
0.8
1
kp E
stim
ate

Simplified Necrotizing Enterocolitis: Imperfect Simulated Data
En KF; SC KF; KL SC KF.
0 1 2 3
1e-8
1e-6
D E
stim
ate
Err
or
Time (hrs)
0.001
0.1
kp E
stim
ate
Err
or
0 1 2 3
2e-6
3e-6
D E
stim
ate
Time (hrs)
0.6
0.8
1
kp E
stim
ate

Simplified Necrotizing Enterocolitis: Real Data
En KF; SC KF; KL SC KF.
0 1 2 3
0
1e-5
D E
stim
ate
Time (hrs)
1
2
3
kp E
stim
ate

Are parameter estimates good?
• Produce qualitatively correct results t = 0 h t = 0.5 h t = 1 h t = 1.5 h
t = 2 h t = 2.5 h t = 3 h t = 3.5 h
200 m

Comparisons
• With perfect measurements and a pretty good model, SC does best, then KL, then En
• With imperfect measurements, all are comparable
• With real data, KL fails. Why? Guess: Too much error associated with D
• Additional real data info– Gives temporal information about the parameters
– Gives uncertainty estimates
• All run significantly faster than the direct optimization method used