keeping things lean & mean: crawl optimisation - search marketing summit au
TRANSCRIPT

Keeping Things Lean & Mean Crawl Optimisation
JASON MUN
CO-FOUNDER, BESPOKE bespokeagency.com.au

About Me
Jason Mun Co-founder of Bespoke Specialise in eCommerce SEO Bespokeagency.com.au @jasonmun au.linkedin.com/in/jason-mun-8698a13

What I’ll Be Covering Today
• What is Crawl Optimisation? The importance of it
• Crawl Budget – What is it?
• Case Study
• Identify crawl wastage & how to fix it
• Summary

Crawl Optimisation

Crawl Optimisation is about…
1. Controlling what spiders can and can’t crawl AND…
2. What spiders should and shouldn’t index
3. Minimise crawl budget waste – getting deeper and more frequent crawls from search engines
4. Achieving a complete crawl of your website in a reasonable time
5. Faster discovery of changes/updates on your website

Bigger Isn’t Always Better
When you only have 5,000 active SKU’s at any given time, this is an
ISSUE!

Crawl Budget

What is Crawl Budget?
“The best way to think about it is that the number of pages that we crawl is roughly proportional to your PageRank. So if you have a lot of incoming links on your root page, we’ll definitely crawl that. Then your root page may link to other pages, and those will get PageRank and we’ll crawl those as well. As you get deeper and deeper in your site, however, PageRank tends to decline.”
https://www.stonetemple.com/matt-cutts-interviewed-by-eric-enge-2/

Looks Something Like This
PageRank
# Pa
ges
Craw
led

Crawl Budget = Traffic (Maybe)
http://searchengineland.com/how-i-think-crawl-budget-works-sort-of-59768
That might imply a correlation between crawl budget and organic traffic. But it also might just mean sites with higher authority get more organic traffic. Which hints at a relationship between crawl budget and traffic, but hardly confirms it.
Ian Lurie, Portent

Crawl Budget, Scheduling, Host Load
https://www.seroundtable.com/googles-gary-illyes-crawl-budget-scheduling-host-load-22097.html
Q: Historically, people have talked about Google having a crawl budget. Is that a correct notion, like Google comes in they're going to take 327 pages from your site today. A: I think what you are talking about is actually scheduling. Basically how many pages do we ask from indexing side to be crawled by Googlebot. That is driven mainly by the importance of the pages on the site but not by the number of URLS or how many URLS you want to crawl….For example high PageRank URLs probably should be crawled more often and we have a bunch of other signals that we use.
WATCH THE VIDEO!

Crawl Budget, Scheduling, Host Load
https://www.seroundtable.com/googles-gary-illyes-crawl-budget-scheduling-host-load-22097.html
Q: Is it true that if I have pages that are duplicates or that are not allowed in the index. If Google spends time crawling those pages then they are spending less time crawling pages that are indexed and making us money. A: Yes, definitely.
WATCH THE VIDEO – SE Rountable did not transcribe the above!

Confused Yet?
The BOTTOM LINE is this:
• Higher PageRank = High Importance = Higher Crawl Frequency
• Host Load = Server Performance = Crawl Efficiency
• Help Google spend more time crawling pages that you want indexed and your money pages!

Case Study Ecommerce Website

Identifying Crawl Issues
Google Search Console started showing irregularities in number
of pages crawled
OK
OK
OK
WTF
WTF
X2

Caused Indexed Pages to Spike
From a lean website averaging about 2,500 pages in the index, it
has spiked to 23,000 pages

Impact on Organic Visibility
AWR reported a slight decline in visibility score. Minimal movement in rankings.

Organic Performance Declined
In the same period, organic traffic declined
by 16%
Severely impacted conversions and
revenue

What Was Happening
• Google was wasting time and resources crawling USELESS pages/URLs
• Increase in crawled pages resulted in an increase in indexed pages (index bloat)
• Decline in organic visibility = Decline in traffic & revenue
• Ecommerce websites heavily rely on call-to-actions to improve SERP click-through - Meta-data were not refreshed quick enough to reflect promo

Investigating the Issue #1
Robots.txt file dropped out when devs pushed changes from
staging to production. Robots.txt file had 56 lines of exclusions!
Disappeared

Investigating the Issue #2
This created MANY url combinations. Multiply those combinations with the number of category and sub-category pages, generated thousands and thousands of INDEXABLE urls.
Comparing Screaming Frog crawls a week prior, discovered 15k+
more urls. All these URLs were set to INDEX,FOLLOW!

Let the Clean Up Begin
Google Search Console > URL parameters > No URLs
Applied NOINDEX,FOLLOW to new faceted nav URLs
Google Search Console > Fetch as Google
Reinstated robots.txt
Added more exclusions in robots.txt for new faceted nav options
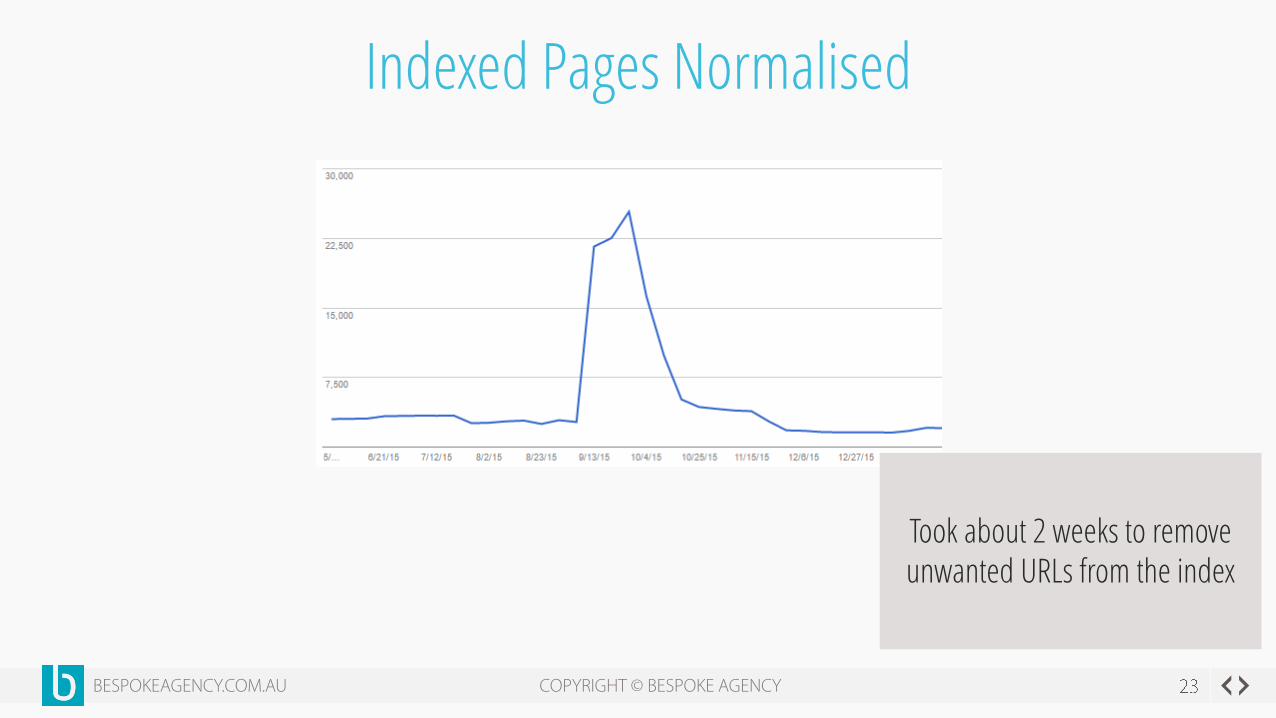
Indexed Pages Normalised
Took about 2 weeks to remove unwanted URLs from the index

Organic Performance Improved
Organic traffic recovered to what it
was before
Revenue & conversions improved. Promos were
getting refreshed quicker in SERPs

Identifying Crawl Wastage

1 – Discrepancy w/ Crawled & Indexed Pages

2 – Internal Search Result Pages
Internal SERPS are “thin” and generate duplicate content. Block them via robots.txt and
apply NOINDEX, FOLLOW meta robots. This is future proof against index bloat in case
robots.txt goes missing

3 – XML Sitemap Submit-Index
Check that your XML sitemap does not contain unwanted URLs. It shouldn’t contain any URLs that
you do not want crawled or indexed
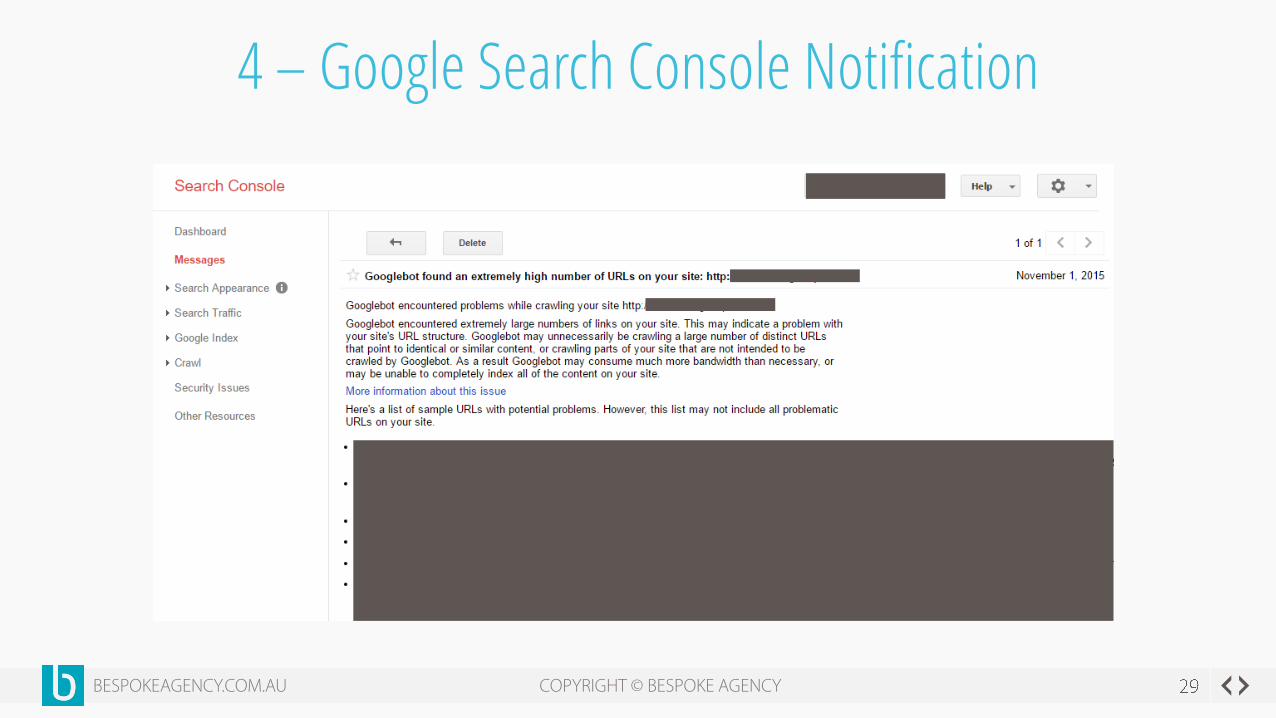
4 – Google Search Console Notification
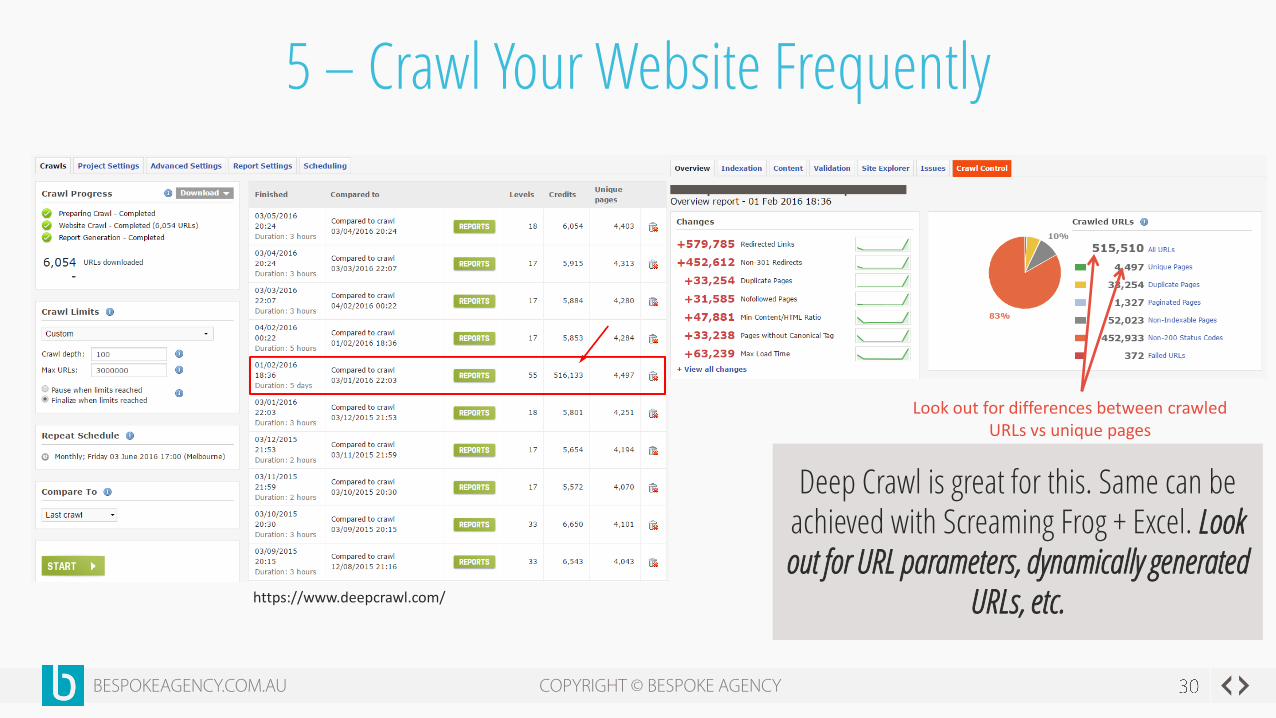
5 – Crawl Your Website Frequently
Look out for differences between crawled URLs vs unique pages
https://www.deepcrawl.com/
Deep Crawl is great for this. Same can be achieved with Screaming Frog + Excel. Look out for URL parameters, dynamically generated
URLs, etc.

6 – Keep an Eye on URL Parameters
Tell Google what they are and how to
handle them
Lookout for any new URL parameters detected via Google
Search Console. Make use of robots.txt – Disallow: /*?order=*
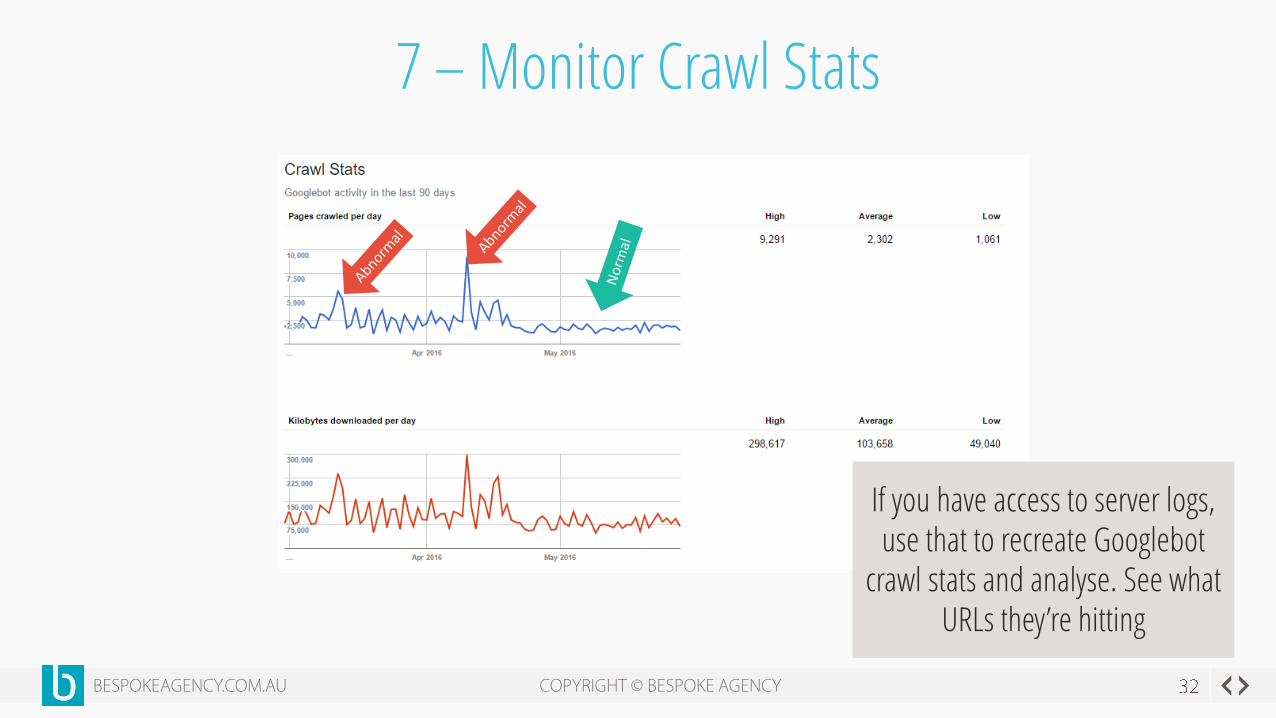
7 – Monitor Crawl Stats
If you have access to server logs, use that to recreate Googlebot
crawl stats and analyse. See what URLs they’re hitting

7 – Monitor Crawl Stats
Server access logs should match GSC crawl stats.
Analyse urls hits before/during/after
irregulaties. Use Screaming Frog or Excel.

8 – Faceted Navigation
Faceted navigation creates LOTS of url
combinations Filter & sort adds to the
URL combinations
https://www.toysparadise.com.au/toysgender/boys?price=2%2C100&toysplayersnavigation=40
https://www.toysparadise.com.au/toysgender/boys?dir=asc&order=name&price=2%2C100&toysplayersnavigation=40
Faceted navigation is great for usability but not handled correctly can send search
engines in to an “infinite loop”. Block URL parameters in robots.txt and use NOINDEX,
FOLLOW

8 – Faceted Navigation
Faceted navigation creates LOTS of url
combinations
http://www.takingshape.com/uk/dresses/filter/size/14.html
http://www.takingshape.com/uk/dresses/filter/parentcolor/black/size/14.html
Beware of some faceted navigation creating combinations of search engine friendly
URLs. Use robots.txt to restrict crawl and apply NOINDEX, FOLLOW

8 – Faceted Navigation
Add rel=“nofollow” to faceted nav links
http://www.cichic.com/midi-dresses/shopby/cloth_type-a_type/color-black.html
Sometimes it is difficult to identify a pattern to block via robots.txt. Adding every possible
URL combination + wildcards may not be feasible. Use rel=“nofollow” attribute.
http://www.cichic.com/maxi-dresses/shopby/fabric-cotton_blend/style-vintage.html
http://www.cichic.com/t-shirts/shopby/cloth_type-fitted/sleeve_length_style-long_sleeve.html

Crawl Optimisation Summary
Herding the Sheeps Bots

Guide Search Engines, Tell Them What To Do
Homepage Category Sub-Category Faceted / Filtering Internal Search Result Pages

In Summary
• Don’t let search engines figure it out, tell them what to do
• Anything that you do not want indexed shouldn’t be crawled
• Monitor your website periodically: o Crawl stats in Google Search Console
oMonthly/Weekly crawl of website using SF or DeepCrawl
o Log file analysis
• Master the use of robots directive tools: o Robots.txt
oNOINDEX,FOLLOW meta robots tag

KEEP THINGS LEAN & MEAN

THANK YOU