lab 14: text & corpus processing with nltk - pitt.edunaraehan/ling1330/lab14.pdf · nltk and...
TRANSCRIPT

Lab 14: Text & Corpus
Processing with NLTK
Ling 1330/2330: Computational Linguistics
Na-Rae Han

Getting started with NLTK book
10/18/2018 2
NLTK Book, with navigation panel:
http://www.pitt.edu/~naraehan/ling1330/nltk_book.html
NLTK Book, without:
http://www.nltk.org/book/
Chapter 1. Language Processing and Python
http://www.nltk.org/book/ch01.html
Chapter 2. Accessing Text Corpora and Language Resources
http://www.nltk.org/book/ch02.html

Install NLTK and NLTK data
10/18/2018 3
NLTK (Mac): http://www.pitt.edu/~naraehan/python3/faq.html#Q-install-nltk-mac
NLTK (Win): http://www.pitt.edu/~naraehan/python3/faq.html#Q-install-nltk-win
NLTK data: http://www.pitt.edu/~naraehan/python3/faq.html#Q-nltk-download
Test to confirm everything works:

textstats and pipeline
10/18/2018 4
'Rose is a rose is a rose is a rose.'
getTokens
['rose', 'is', 'a', 'rose', 'is', 'a', 'rose', 'is', 'a', 'rose', '.']
getFreq
{'a': 3, 'is': 3,
'.': 1, 'rose': 4}
getTypes
['.', 'a', 'is', 'rose']
getXFreqWords
['a', 'is', 'rose']
x = 3
getXLengthWords
['is', 'rose']
x = 2
getWord2Grams
[('rose', 'is'), ('is', 'a'),
('a', 'rose'), ('rose', 'is'),
('is', 'a'), … ]

List comprehension can do them all
10/18/2018 5
'Rose is a rose is a rose is a rose.'
getTokens
['rose', 'is', 'a', 'rose', 'is', 'a', 'rose', 'is', 'a', 'rose', '.']
getFreq
{'a': 3, 'is': 3,
'.': 1, 'rose': 4}
getTypes
['.', 'a', 'is', 'rose']
getXFreqWords
['a', 'is', 'rose']
x = 3
getXLengthWords
['is', 'rose']
x = 2
getWord2Grams
[('rose', 'is'), ('is', 'a'),
('a', 'rose'), ('rose', 'is'),
('is', 'a'), … ]
No longer needed.Can be achieved via
list comprehension!
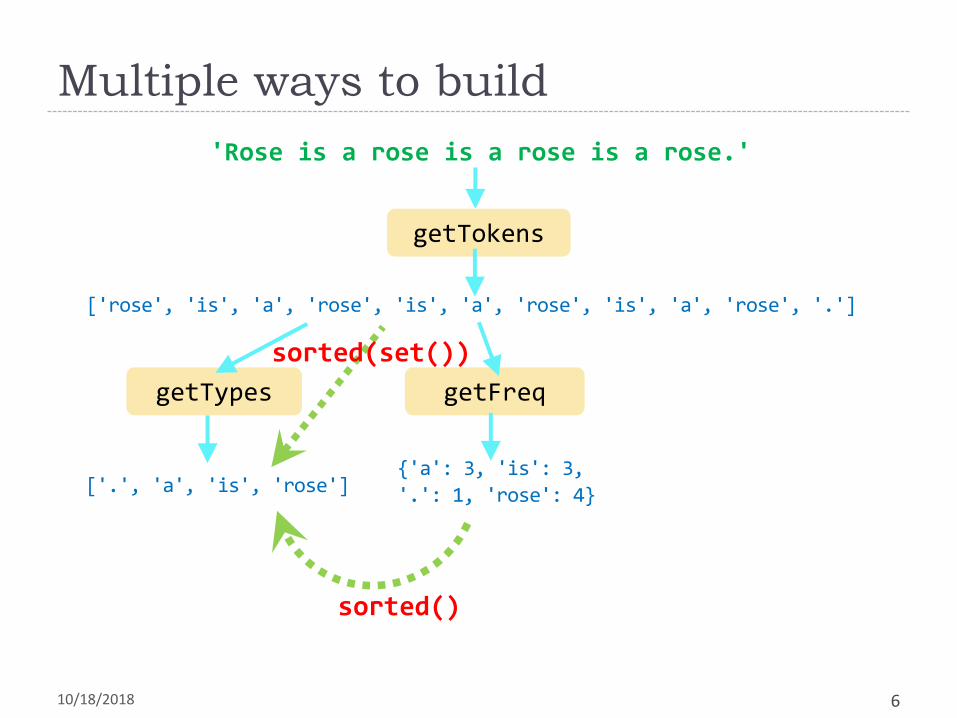
Multiple ways to build
10/18/2018 6
'Rose is a rose is a rose is a rose.'
getTokens
['rose', 'is', 'a', 'rose', 'is', 'a', 'rose', 'is', 'a', 'rose', '.']
getFreq
{'a': 3, 'is': 3,
'.': 1, 'rose': 4}
getTypes
['.', 'a', 'is', 'rose']
sorted()
sorted(set())
Multiple ways to build
10/18/2018 7
'Rose is a rose is a rose is a rose.'
getTokens
['rose', 'is', 'a', 'rose', 'is', 'a', 'rose', 'is', 'a', 'rose', '.']
getFreq
{'a': 3, 'is': 3,
'.': 1, 'rose': 4}
getTypes
['.', 'a', 'is', 'rose']
sorted()
sorted(set())
Goodbye textstats,Hello, NLTK!
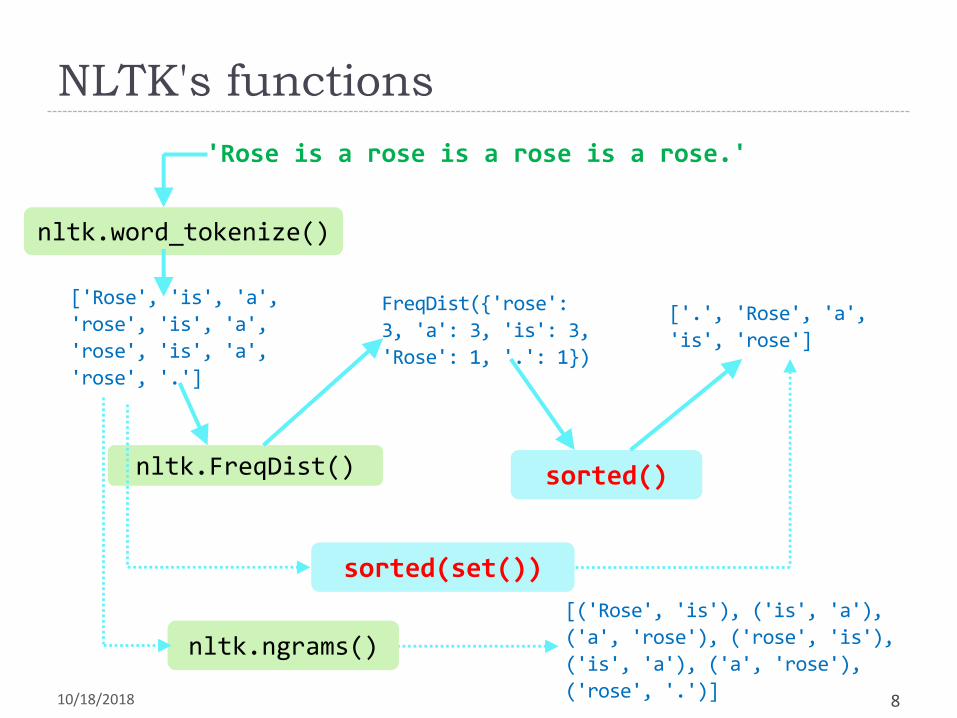
NLTK's functions
10/18/2018 8
'Rose is a rose is a rose is a rose.'
nltk.word_tokenize()
['Rose', 'is', 'a',
'rose', 'is', 'a',
'rose', 'is', 'a',
'rose', '.']
FreqDist({'rose':
3, 'a': 3, 'is': 3,
'Rose': 1, '.': 1})
['.', 'Rose', 'a',
'is', 'rose']
nltk.FreqDist() sorted()
nltk.ngrams()
[('Rose', 'is'), ('is', 'a'),
('a', 'rose'), ('rose', 'is'),
('is', 'a'), ('a', 'rose'),
('rose', '.')]
sorted(set())

NLTK's tokenizer
10/18/2018 9
>>> import nltk>>> nltk.word_tokenize('Hello, world!')['Hello', ',', 'world', '!']>>> nltk.word_tokenize("I haven't seen Star Wars.")['I', 'have', "n't", 'seen', 'Star', 'Wars', '.']>>> nltk.word_tokenize("It's 5 o'clock. Call Ted...!")['It', "'s", '5', "o'clock", '.', 'Call', 'Ted', '...', '!']
>>> rose = 'Rose is a rose is a rose is a rose.'>>> nltk.word_tokenize(rose)['Rose', 'is', 'a', 'rose', 'is', 'a', 'rose', 'is', 'a', 'rose', '.']>>> rtoks = nltk.word_tokenize(rose)>>> rtoks['Rose', 'is', 'a', 'rose', 'is', 'a', 'rose', 'is', 'a', 'rose', '.']>>> type(rtoks)<class 'list'>
Note differences!No lowercasing, n't, o'clock a word
Good-old list type.
nltk.word_tokenize()

NLTK and frequency counts
10/18/2018 10
>>> rfreq = nltk.FreqDist(rtoks)>>> rfreqFreqDist({'rose': 3, 'a': 3, 'is': 3, 'Rose': 1, '.': 1})>>> rfreq['is']3>>> rfreq.keys()dict_keys(['a', 'is', 'Rose', 'rose'])>>> rfreq.values()dict_values([3, 3, 1, 3])>>> rfreq.items()dict_items([('a', 3), ('is', 3), ('Rose', 1), ('rose', 3)])>>> sorted(rfreq)['Rose', 'a', 'is', 'rose']>>> type(rfreq)<class 'nltk.probability.FreqDist'>
FreqDist works very much like our frequency count
dictionary…
nltk.FreqDist()
… but it's NLTK's own custom data type!
word types

FreqDist can do much more
10/18/2018 11
>>> dir(rfreq)['B', 'N', 'Nr', '__add__', '__and__', '__class__', … 'clear', 'copy', 'elements', 'freq', 'fromkeys', 'get', 'hapaxes', 'items', 'keys', 'max', 'most_common', 'pformat', 'plot', 'pop', 'popitem', 'pprint', 'r_Nr', 'setdefault', 'subtract', 'tabulate', 'unicode_repr', 'update', 'values']>>> rfreq.hapaxes()['Rose', '.']>>> rfreq.tabulate()rose a is Rose .
3 3 3 1 1>>> rfreq.most_common(2)[('a', 3), ('is', 3)]>>> rfreq['platypus']0>>> rfreq.plot()>>> rfreq.max()'a'
nltk.FreqDistcomes with
additional handy methods!
No "key not found" error! Defaults to 0.
Graph window pops up

NLTK and n-grams
10/18/2018 12
>>> rtoks['Rose', 'is', 'a', 'rose', 'is', 'a', 'rose', 'is', 'a', 'rose', '.']>>> nltk.ngrams(rtoks, 2)<generator object ngrams at 0x0A18B0C0>>>> for gram in nltk.ngrams(rtoks, 2):
print(gram)
('Rose', 'is')('is', 'a')('a', 'rose')('rose', 'is')('is', 'a')('a', 'rose')('rose', 'is')('is', 'a')('a', 'rose')('rose', '.')
>>> r2grams = nltk.ngrams(rtoks, 2)>>> nltk.FreqDist(r2grams)FreqDist({('is', 'a'): 3, ('a', 'rose'): 3, ('rose', 'is'): 2, ('rose', '.'): 1, ('Rose', 'is'): 1})
nltk.ngrams() returns a generator object.
Cannot see it as a whole, but works in for loop.
Feed to nltk.FreqDist()to obtain bigram frequency
distribution.

New trick: sentence tokenization!
10/18/2018 13
>>> foo = 'Hello, earthlings! I come in peace. Take me to your leader.'>>> nltk.sent_tokenize(foo)['Hello, earthlings!', 'I come in peace.', 'Take me to your leader.']>>> foosents = nltk.sent_tokenize(foo)>>> foosents[0]'Hello, earthlings!'>>> foosents[1]'I come in peace.'>>> foosents[-1]'Take me to your leader.'>>> len(foosents)3 Total number of
sentences
nltk.sent_tokenize()takes a text string,
returns a list of sentences as strings.

Try it out
10/18/2018 14
5 minutes
In IDLE shell, copy and paste the "Moby Dick" opening paragraph from Text samples, as string called motxt.
Then, use NLTK's functions to produce:
word tokens
nltk.word_tokenize(txt)
word frequency distribution
nltk.FreqDist(tokens)
bigram list
nltk.ngrams(tokens, 2)
bigram frequency distribution
nltk.FreqDist(bigrams)
sentence list
nltk.sent_tokenize(txt)
How many words?How many sentences?
"I" occurs how many times?20 most common words?
20 most common bigrams?

NLTK's corpus methods
10/18/2018 15
NLTK provides methods for reading in a corpus as a "corpus object".
http://www.nltk.org/book/ch02.html#loading-your-own-corpus
Many different methods available for different types of corpora (plain text? POS-tagged? XML format?)
PlaintextCorpusReader suits our corpora just fine.
Once a corpus is "loaded" and a corpus object created, we can use pre-defined methods on the corpus.
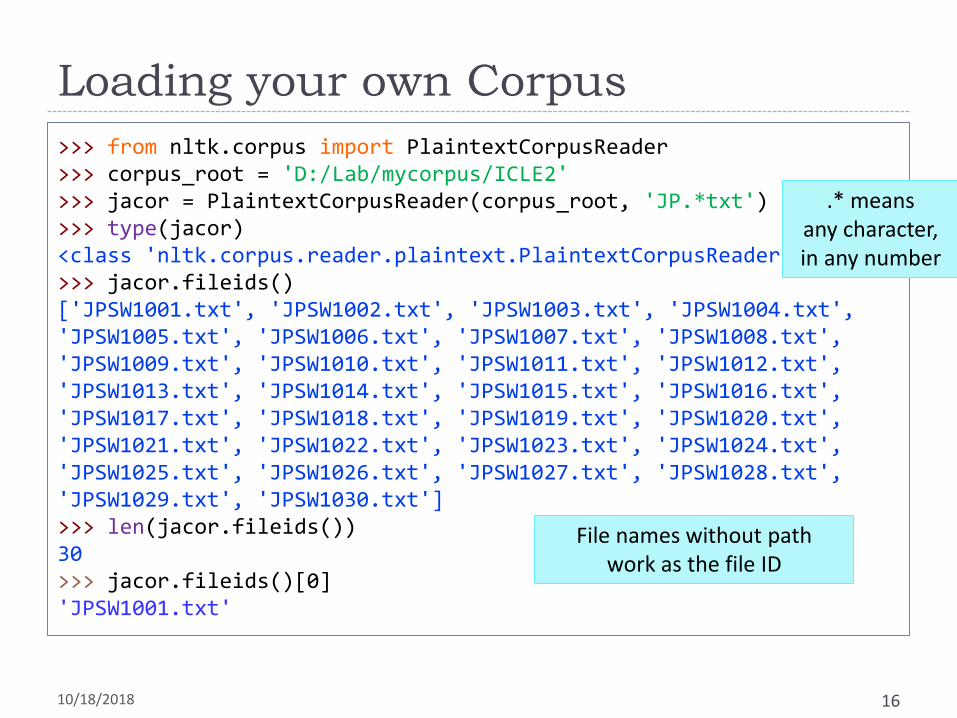
Loading your own Corpus
10/18/2018 16
>>> from nltk.corpus import PlaintextCorpusReader>>> corpus_root = 'D:/Lab/mycorpus/ICLE2'>>> jacor = PlaintextCorpusReader(corpus_root, 'JP.*txt')>>> type(jacor)<class 'nltk.corpus.reader.plaintext.PlaintextCorpusReader'>>>> jacor.fileids()['JPSW1001.txt', 'JPSW1002.txt', 'JPSW1003.txt', 'JPSW1004.txt', 'JPSW1005.txt', 'JPSW1006.txt', 'JPSW1007.txt', 'JPSW1008.txt', 'JPSW1009.txt', 'JPSW1010.txt', 'JPSW1011.txt', 'JPSW1012.txt', 'JPSW1013.txt', 'JPSW1014.txt', 'JPSW1015.txt', 'JPSW1016.txt', 'JPSW1017.txt', 'JPSW1018.txt', 'JPSW1019.txt', 'JPSW1020.txt', 'JPSW1021.txt', 'JPSW1022.txt', 'JPSW1023.txt', 'JPSW1024.txt', 'JPSW1025.txt', 'JPSW1026.txt', 'JPSW1027.txt', 'JPSW1028.txt', 'JPSW1029.txt', 'JPSW1030.txt']>>> len(jacor.fileids())30>>> jacor.fileids()[0]'JPSW1001.txt'
.* means any character, in any number
File names without pathwork as the file ID

.words() is a list of word tokens
10/18/2018 17
>>> jacor.words()['I', 'agree', 'greatly', 'this', 'topic', 'mainly', ...]>>> len(jacor.words())16094>>> jacor.words()[:50]['I', 'agree', 'greatly', 'this', 'topic', 'mainly', 'because', 'I', 'think', 'that', 'English', 'becomes', 'an', 'official', 'language', 'in', 'the', 'not', 'too', 'distant', '.', 'Now', ',', 'many', 'people', 'can', 'speak', 'English', 'or', 'study', 'it', 'all', 'over', 'the', 'world', ',', 'and', 'so', 'more', 'people', 'will', 'be', 'able', 'to', 'speak', 'English', '.', 'Before', 'the', 'Japanese']>>> jacor.words('JPSW1001.txt')['I', 'agree', 'greatly', 'this', 'topic', 'mainly', ...]>>> len(jacor.words('JPSW1001.txt'))475>>> len(jacor.words('JPSW1002.txt'))559
All tokenized words in this corpus
Word tokens in 1st file only
Whoa!Spill-proof!

.sents() is a list of sentence tokens
10/18/2018 18
>>> jacor.sents()[['I', 'agree', 'greatly', 'this', 'topic', 'mainly', 'because', 'I', 'think', 'that', 'English', 'becomes', 'an', 'official', 'language', 'in', 'the', 'not', 'too', 'distant', '.'], ['Now', ',', 'many', 'people', 'can', 'speak', 'English', 'or', 'study', 'it', 'all', 'over', 'the', 'world', ',', 'and', 'so', 'more', 'people', 'will', 'be', 'able', 'to', 'speak', 'English', '.'], ...]>>> jacor.sents()[0]['I', 'agree', 'greatly', 'this', 'topic', 'mainly', 'because', 'I', 'think', 'that', 'English', 'becomes', 'an', 'official', 'language', 'in', 'the', 'not', 'too', 'distant', '.']>>> jacor.sents()[-1]['Let', "'", 's', 'study', 'English', ',', 'and', 'aommunicato', 'with', 'all', 'over', 'the', 'world', '!"']>>> len(jacor.sents())1027
Again, spill-proof.
1st sentence
Last sentence
Unlike nltk.sent_tokenize() output, each sentence is
a list of word tokens! 1027 sentences in this corpus!

.sents() is a list of sentence tokens
10/18/2018 19
>>> jacor.sents('JPSW1001.txt')[['I', 'agree', 'greatly', 'this', 'topic', 'mainly', 'because', 'I', 'think', 'that', 'English', 'becomes', 'an', 'official', 'language', 'in', 'the', 'not', 'too', 'distant', '.'], ['Now', ',', 'many', 'people', 'can', 'speak', 'English', 'or', 'study', 'it', 'all', 'over', 'the', 'world', ',', 'and', 'so', 'more', 'people', 'will', 'be', 'able', 'to', 'speak', 'English', '.'], ...]>>> len(jacor.sents('JPSW1001.txt'))22>>> for f in jacor.fileids():
print(f, 'has', len(jacor.sents(f)), 'sentences')
JPSW1001.txt has 22 sentencesJPSW1002.txt has 43 sentencesJPSW1003.txt has 40 sentencesJPSW1004.txt has 28 sentences…
Sentences in 1st file only
For-loop through file IDs, print out sentence count
of each essay

.raw() is a raw text string
10/18/2018 20
>>> jacor.raw()[:200]'I agree greatly this topic mainly because I think that English becomes an official language in the not too distant. Now, many people can speak English or study it all over the world, and so more peopl'>>> jacor.raw()[-200:]'s. I like to study English than before. English is the common language. If we want to success the work, you need high linguistic ability. Let\'s study English, and aommunicato with all over the world!"'>>> len(jacor.raw())78896>>> jacor.raw('JPSW1001.txt')"I agree greatly this topic mainly because I think that English becomes an official language in the not too distant. Now, many people can speak English or study it all over the world, and so more people will be able to speak English. Before the Japanese fall behind other people, we should be able to speak English, therefore, we must study English not only junior high school students or over
.raw() is not spill-proof,so we must be careful.
Character count of entire corpus Raw text of 1st file only,
small enough to flash in full

Try it out
10/18/2018 21
5 minutes
Download the ICLE2 "Bulgarian vs. Japanese EFL Writing" corpus from CourseWeb (on HW5B).
Then, load the corpus through NLTK:
>>> from nltk.corpus import PlaintextCorpusReader>>> corpus_root = 'D:/Lab/mycorpus/ICLE2'>>> jacor = PlaintextCorpusReader(corpus_root, 'JP.*txt')>>> dir(jacor)['CorpusView', '__class__', '__delattr__', '__dict__', ... 'abspath', 'abspaths', 'citation', 'encoding', 'ensure_loaded', 'fileids', 'license', 'open', 'paras', 'raw', 'readme', 'root', 'sents', 'unicode_repr', 'words']
Try: jacor.fileids() jacor.words() jacor.words('JPSW1001.txt') jacor.sents() jacor.sents('JPSW1001.txt') jacor.raw()[:200] jacor.raw('JPSW1001.txt')

Further corpus processing
10/18/2018 22
A corpus object (PlaintextCorpusReader) already has tokenized words, tokenized sentences, and raw text strings.
Accessible as a whole corpus, or by-file basis
Other data objects should then be built from the tokens:
Word frequency distribution
nltk.FreqDist(tokens)
Word type list
sorted(set(tokens))
sorted(freqdist)
N-gram list
nltk.ngrams(tokens, n)
N-gram frequency distribution
nltk.FreqDist(ngrams)

Word frequency through FreqDist()
10/18/2018 23
>>> jafreq = nltk.FreqDist(jacor.words())>>> jafreq['English']709>>> jafreq['the']352>>> jafreq.most_common(20)[('.', 997), (',', 709), ('English', 709), ('to', 571), ('I', 452), ('is', 413), ('the', 352), ('and', 272), ('we', 240), ('a', 236), ('in', 228), ('of', 197), ('that', 195), ('Japanese', 181), ('language', 180), ('master', 167), ('think', 165), ("'", 163), ('can', 151), ('people', 146)]>>> jafreq.freq('English')0.044053684602957624>>> jafreq.freq('the')0.021871504908661615>>> len(jafreq)1613>>> sorted(jafreq)[-20:]['worth', 'would', 'wouldn', 'write', 'writing', 'written', 'wrong', 'year', 'years', 'yen', 'yes', 'yet', 'yhings', 'you', 'young', 'your', 'yourself', 'youth', '\x81', '\x87']
nltk.FreqDist()builds a frequency distribution object
Word frequency distribution
10/18/2018 24
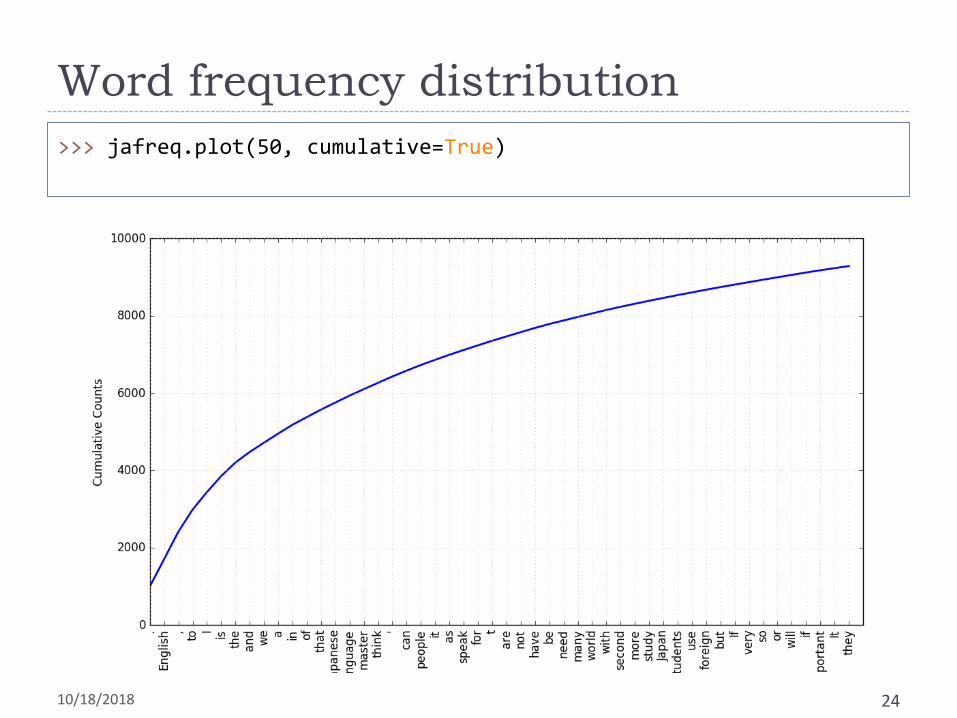
>>> jafreq.plot(50, cumulative=True)

Building n-grams
10/18/2018 25
>>> ja2grams = nltk.ngrams(jacor.words(), 2)>>> ja2grams[:20]Traceback (most recent call last):File "<pyshell#64>", line 1, in <module>
ja2grams[:20]TypeError: 'generator' object is not subscriptable>>> list(ja2grams)[:20][('I', 'agree'), ('agree', 'greatly'), ('greatly', 'this'), ('this', 'topic'), ('topic', 'mainly'), ('mainly', 'because'), ('because', 'I'), ('I', 'think'), ('think', 'that'), ('that', 'English'), ('English', 'becomes'), ('becomes', 'an'), ('an', 'official'), ('official', 'language'), ('language', 'in'), ('in', 'the'), ('the', 'not'), ('not', 'too'), ('too', 'distant'), ('distant', '.')]>>> list(ja2grams)[:20][]
nltk.ngrams()builds an n-gram list
Oops, a generator object --Cannot slice.
list-ify, and then slice.
After a full round of "generating" (list-ifying above,
a for-loop, etc. ), the generator object is now
empty! → next page

n-gram frequency distribution
26
>>> ja2grams = nltk.ngrams(jacor.words(), 2)>>> ja2gramfd = nltk.FreqDist(ja2grams)>>> len(ja2gramfd)7154>>> ja2gramfd.most_common(20)[(('.', 'I'), 152), (('I', 'think'), 137), (('master', 'English'), 127), (('English', 'is'), 125), (('English', '.'), 124), (("'", 't'), 119), (('to', 'master'), 118), ((',', 'I'), 90), (('speak', 'English'), 87), (('English', ','), 82), (('second', 'language'), 80), (('English', 'as'), 78), ((',', 'we'), 78), (('as', 'a'), 76), (('need', 'to'), 74), (('the', 'world'), 73), (('language', '.'), 70), (('a', 'second'), 68), (('it', 'is'), 68), (('in', 'the'), 65)]>>> for (gram, count) in ja2gramfd.most_common(20):
print(gram, count)
('.', 'I') 152('I', 'think') 137('master', 'English') 127('English', 'is') 125('English', '.') 124("'", 't') 119
Whoa.'master English' is #3 most
frequent bigram.
So, in order to use ja2grams again to build a frequency distribution, we should re-build ja2grams.

Try it out
10/18/2018 27
5 minutes
Further process the ICLE2 "Bulgarian vs. Japanese EFL Writing" corpus.
Word frequency distribution
nltk.FreqDist(jacor.words())
Word type list
sorted(set(jacor.words())) # Don't flash to SHELL!
sorted(freqdist)
N-gram list
nltk.ngrams(jacor.words(), n)
N-gram frequency distribution
nltk.FreqDist(ngrams)Most frequent words?
How many times is 'master' mentioned?
How many word types?Most frequent bigrams?
Summary
10/18/2018 28
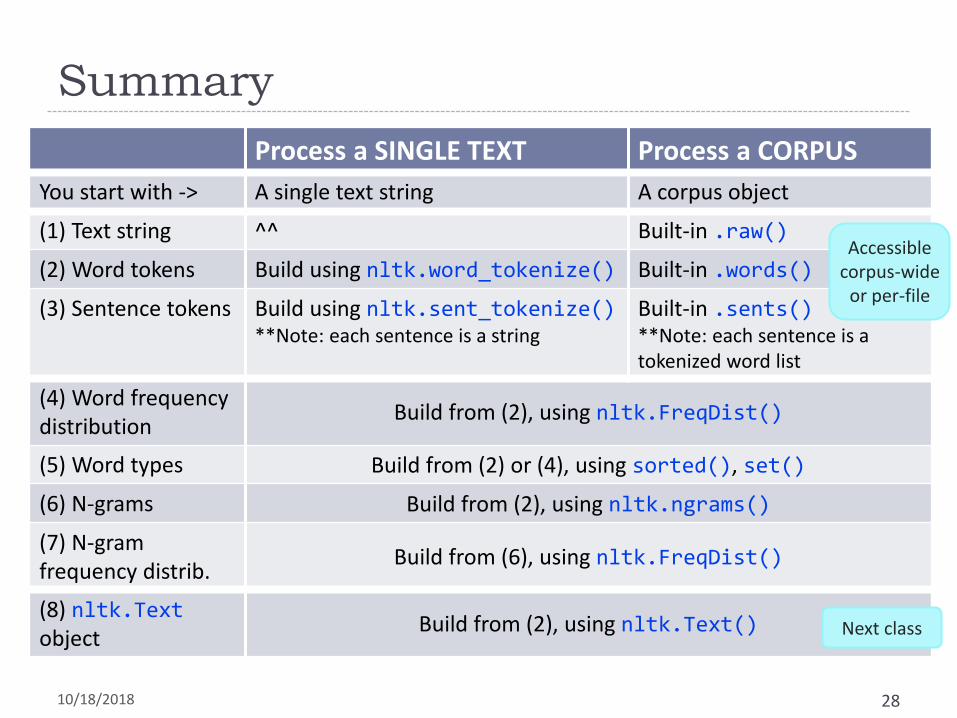
Process a SINGLE TEXT Process a CORPUS
You start with -> A single text string A corpus object
(1) Text string ^^ Built-in .raw()
(2) Word tokens Build using nltk.word_tokenize() Built-in .words()
(3) Sentence tokens Build using nltk.sent_tokenize()**Note: each sentence is a string
Built-in .sents()**Note: each sentence is a tokenized word list
(4) Word frequency distribution
Build from (2), using nltk.FreqDist()
(5) Word types Build from (2) or (4), using sorted(), set()
(6) N-grams Build from (2), using nltk.ngrams()
(7) N-gram frequency distrib.
Build from (6), using nltk.FreqDist()
(8) nltk.Textobject
Build from (2), using nltk.Text()
Accessible corpus-wide
or per-file
Next class
Wrapping up
10/18/2018 29
Homework 6 due next Tuesday
Friday recitation
Final exam:
Monday (Dec 10) 8am – 10am is the assigned time
We decided to have it later at 4pm-6pm, same day, at LMC (G17).