language learning week 6 pieter adriaans: [email protected] sophia katrenko:...
TRANSCRIPT


Contents Week 5
Information theory
Learning as Data Compression
Learning regular languages using DFA
Minimum Description Length Principle

The minimum description length (MDL) principle: J.Rissanen
The best theory to explain a set of data is the one which minimizes the sum of- the length, in bits, of the description of the theory and - the length, in bits, of the data when encoded with the help of the theory
Data = d
Theory = t1Encoded data= t1(d)
Theory = t2Encoded data= t2(d)
|t2(d)| + |t2| < |t1(d)| + |t1| < |d| so t2 is the best theory

Local, Incremental (different compression paths)
Data = d
Theory = tEncoded data= t(d)
t1 t1()
t2(,t1()) t2 t1
t3(t2(,t1()),) t2 t1 t3

Learnability
Non-compressible sets
Non-constructivelyCompressible sets
ConstructivelyCompressible sets
Learnable sets =locally, efficiently,
incrementally compressible sets

Regular Languages: Deterministic Finite Automata (DFA)
0
32
1
a
a
a
a
b bb b
DFA = NFA (Non-deterministic) = REG
{w {a,b}* | # aW and # aW both even}
aaabababaaaabbb

Learning DFA’s: 2) MCA(S+)
a
S+ = (c, abc, ababc}
0 1 2 3 4 5
6 7 8
ab b c
9
b c
a
c
Maximal Canonical Automaton

Learning DFA’s: 4) State Merging (Oncina,Vidal 92, Lang 98)
a
S+ = (c, abc, ababc}
0 1 2 3 4 5
8
ab b c
9
c
c
Evidence Driven State merging: 0,2

Learning DFA’s: 4) State Merging (Oncina,Vidal 92, Lang 98)
a
S+ = (c, abc, ababc}
0 1 3 4 5
8
ab c
9
c
c
Evidence Driven State merging: 1,3 and 8,9
b

Learning DFA’s: 4) State Merging (Oncina,Vidal 92, Lang 98)
a
S+ = (c, abc, ababc}
0 1 4 5b c
9
c
Evidence Driven State merging: 0,4
b

Learning DFA’s: 4) State Merging (Oncina,Vidal 92, Lang 98)
a
S+ = (c, abc, ababc}
0 1 5c
9
c
Evidence Driven State merging: 9,5
b
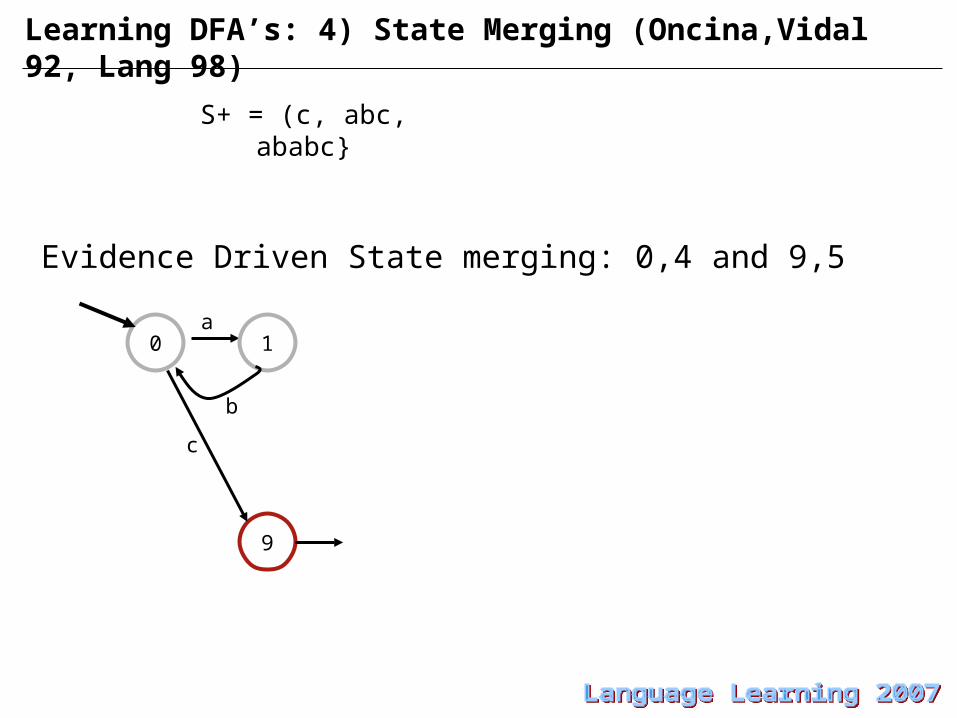
Learning DFA’s: 4) State Merging (Oncina,Vidal 92, Lang 98)
a
S+ = (c, abc, ababc}
0 1
9
c
Evidence Driven State merging: 0,4 and 9,5
b

Learning DFA’s via evidence driven state merging
Input S+, S-
Output: DFA
1) Form MCA(S+)
2) Form PTA(S+)
3) Do until no merging is possible:
- choose merging of two states
- perform cascade of forced mergings to get a deterministic
automaton
- if resulting DFA accepts sentences of S- backtrack and choose
another couple
4) End
Drawback: we need negative examples!!!

Learning DFA using only positive examples with MDL
S+ = (c, cab, cabab, cababab, cababababab }
c0 1 2
b
a
c0
L1 L2
b
a
Coding in bits:|L1| 5 log2 (3+1) 2 log2 (1+1) = 20|L2| 5 log2 (3+1) 2 log2 (1+3) = 40
# ar
row
s
# le
tters
Em
pty
lette
r
# st
ates
Out
side
wor
ld

Learning DFA using only positive examples with MDL
S+ = (c, cab, cabab, cababab, cababababab }
c0 1 2
b
a
c0
L1 L2
b
a
Coding in bits:|L1| 5 log2 (3+1) 2 log2 (1+1) = 20|L2| 5 log2 (3+1) 2 log2 (1+3) = 40
But:L1 has 4 choices in state 0: |L1(S+)|= 26 log2 4 = 52 L2 has 2 choices in state 1: |L2(S+)|= 16 log2 2 = 16
|L2| + |L2(S+)|= 40 + 16 < |L1| + |L1(S+)|= 20 + 52
L2 is the better theory according to MDL

Learning DFA’s using only positive examples with MDL
Input S+
Output: DFA
1) Form MCA(S+)
2) Form DFA = PTA(S+)
3) Do until no merging is possible:
- choose merging of two states
- perform cascade of forced mergings to get a deterministic
automaton DFA’
- if |DFA’|+|DFA’(S+)| |DFA|+|DFA(S+)| backtrack and choose
another couple
4) End
Drawback: Local minima!

Base case: 2-part code optimization
Observed Data
Learned Theory
Input Program
Non-loss compressionLearning
|Theory| < |Data|

Paradigm case: Finite Binary string
Data:
Theory:
Data:
Theory:
|Theory| = |Program| + |input| < |Data|
000110100110011111010101011010100000
010101010101010101010101010101010101
Program
For i = 1 to x print y
Input
x-=18; y= ’01’

Unsupervised Learning
Observed Output
Input Program
Non-loss compressionLearning
|Theory| < |Data|
Non-random (computational)
ProcesInput
Learned Theory
Unknown System

Supervised Learning
Observed Output
Input Program
Non-loss compressionLearning
|Theory| < |Data|
Non-random (computational)
Proces
Observed Input
Learned Theory
Unknown System

Adaptive System
Observed Output
Input Program
Learning
Non-random (computational)
Proces
Observed Input
Learned Theory
Unknown System

Agent System
Non-random (computational)
Proces
Unknown System
Adaptive systems

Scientific Text: Bitterbase (Unilever)
The bitter taste of naringin and limonin was not affected by glutamic acid
[rmflav 160] Exp.Ok;; Naringin, the second of the two bitter principles in citrus,
has been shown to be a depressor of limonin bitterness detection thresholds
[rmflav 1591];; Florisil reduces bitterness and tartness without altering ascorbic
acid and soluble solids (primarily sugars) content [rmflav 584];; nfluence pH on
system was studied. The best substrate for Rhodococcus fascians at pH 7.0 was
limonoate whereas at pH 4.0 to 5.5 it appeared to be limonin. Results suggest
that the citrus juice debittering process start only once the natural precursor of
limonin (limonoate A ring lactone) has been transformed into limonin, the
equilibrium displacement being governed by the citrus juice pH. [rmflav 474]
[rmflav 504];; Limonin D-ring lactone hydrolase, the enzyme catalysing the
reversible lactonization/hydrolysis of D-ring in limonin, has been purified from
citrus seeds and immobilized on Q-Sepharose to produce homogeneous
limonoate A-ring lactone solutions. The immobilized limonin D-ring lactone
hydrolase showed a good operational stability and was stable after sixty-
seventy operations and storing at 4°C for six months.

Bitterbase Frequencies
0
0,5
1
1,5
2
2,5
3
0 1 2 3 4
Log Word Class Size
Lo
g W
ord
Cla
ss
Fre
qu
ency
Bitterbase Frequencies
Study of Benign Distributions

Colloquial Speech: Corpus Spoken Dutch
" omdat ik altijd iets met talen wilde doen."
"dat stond in elk geval uh voorop bij mij."
"en Nederlands leek me leuk."
"da's natuurlijk een erg afgezaagd antwoord maar dat
was 't wel."
"en uhm ik ben d'r maar gewoon aan begonnen aan de en
ik uh heb 't met uh ggg gezondheid."
"ggg."
"ik heb 't met uh met veel plezier gedaan."
"ja prima."
"ja 'k vind 't nog steeds leuk."

CGN Frequencies
-0,50
0,51
1,5
22,5
33,5
4
0 1 2 3 4 5
Log Word Class Size
Lo
g W
ord
Cla
ss
Fre
qu
ency Word Classes
Study of Benign Distributions

Motherese: Sarah-Jaqueline
*JAC: kijk, hier heb je ook puzzeltjes. *SAR: die (i)s van mij. *JAC: die zijn van jouw, ja. *SAR: die (i)s +... *JAC: kijken wat dit is. *SAR: kijken. *JAC: we hoeven natuurlijk niet alle zooi te bewaren. *SAR: en die. *SAR: die (i)s van mij, die. *JAC: die is niet kompleet. *JAC: die legt mamma maar terug. *SAR: die (i)s van mij. *SAR: xxx. *SAR: die ga in de kast, deze. *JAC: die <gaat in de kast> ["], ja. *JAC: molenspel. *SAR: mole(n)spel ["].

Jaqueline-Sarah Motherese Frequencies
-0,5
0
0,5
1
1,5
2
2,5
3
3,5
0 1 2 3 4 5
Log Word Class Size
Lo
g W
ord
Cla
ss F
req
uen
cy
Word Classes
Non Terminal Classes
Study of Benign Distributions

Jaqueline-Sarah Motherese Frequencies
-0,5
0
0,5
1
1,5
2
2,5
3
3,5
0 1 2 3 4 5
Log Word Class Size
Lo
g W
ord
Cla
ss F
req
uen
cy
Word Classes
Non Terminal Classes
Study of Benign Distributions
Structured High FrequencyCore
Heavy Low FrequencyTail

Powerlaws
logc y = -a logc x + b
y = cbx-a
Log x
Log y

Observation
Word Frequencies in human utterances dominated by powerlaws
High Frequency core
Low Frequency heavy tail
Hypothesis: Language is open. Grammar is elastic. Occurence of new
words is natural phenomenon. Syntactic/semantic bootstrapping must play
an important role in language learning.
Bootstrapping might be important for ontology learning as well as child
language acquisition
Better understanding of distributions is necessary
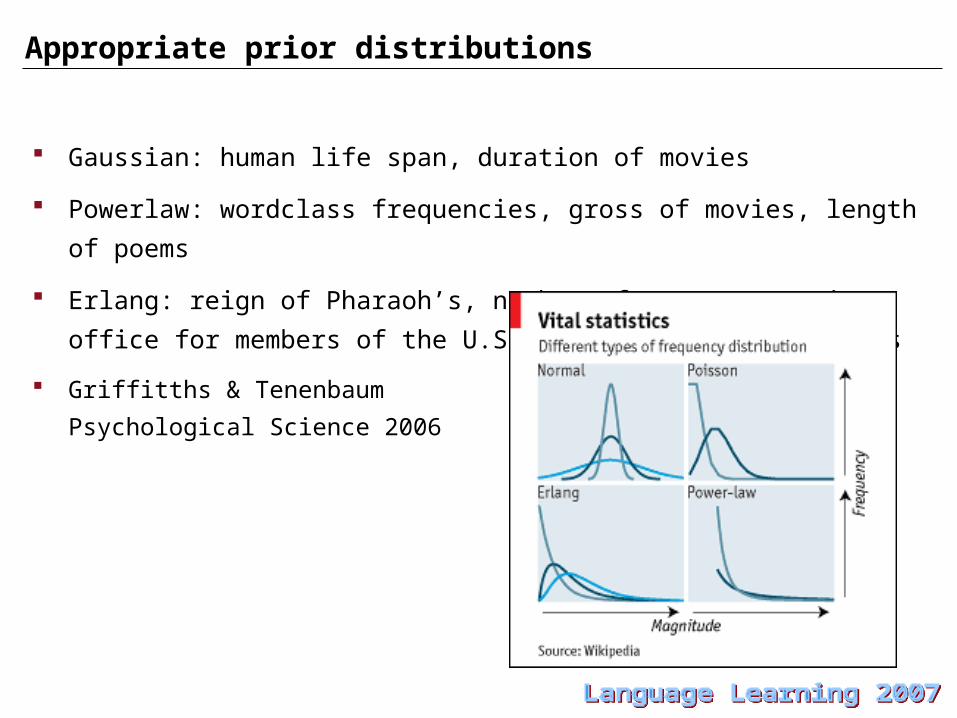
Appropriate prior distributions
Gaussian: human life span, duration of movies
Powerlaw: wordclass frequencies, gross of movies, length of poems
Erlang: reign of Pharaoh’s, number of years spent in office for members of
the U.S. house of representatives
Griffitths & Tenenbaum
Psychological Science 2006

‘Illusions’ caused by inappropriate use of prior distributions
Casino: we see our loss as an investment (cf. survival of the fittest: the harder
you try the bigger is your chance of success.
Monty Hall paradox (aka Marilyn and the goats
A Dutch book (against an agent) is a series of bets, each acceptable to the
agent, but which collectively guarantee her loss, however the world turns
out.
Harvard medical school test: there are no false negatives, 1/1000 is false
positive, 1/1000.000 has the disease.


JPEG File size for equal picture size
0
20
40
60
80
100
120
JPEG File size in Kb
Blauwe heuvelsZonsondergangWaterleliesWinter

25 % noise 50 % noise
75 % noise 100 % noise

JPEG File size with noise added
0
500
1000
1500
2000
JPEG File size in Kb
No noise25 % noise50 % noise75% noise100 % noise

JPEG File Size 7 Kb
JPEG File Size 8 Kb
JPEG File Size 7 Kb

Fact
Standard data compression algorithms do an excellent job when one wants
to study learning as data compression

Contents Week 5
Information theory
Learning as Data Compression
Learning regular languages using DFA
Minimum Description Length Principle