large scale data analytics with spark and cassandra on the dse platform
TRANSCRIPT

© 2014 DataStax, All Rights Reserved
Large Scale Data Analytics with DSE Analytics
Ryan Knight Solutions Engineer @knight_cloud

© 2014 DataStax, All Rights Reserved
Hadoop?

© 2014 DataStax, All Rights Reserved
Hadoop Limitations
• Master / Slave Architecture • Every Processing Step requires Disk IO • Difficult API and Programming Model • Designed for batch-mode jobs • No even-streaming / real-time • Complex Ecosystem

© 2014 DataStax, All Rights Reserved
Introduction to Spark
5
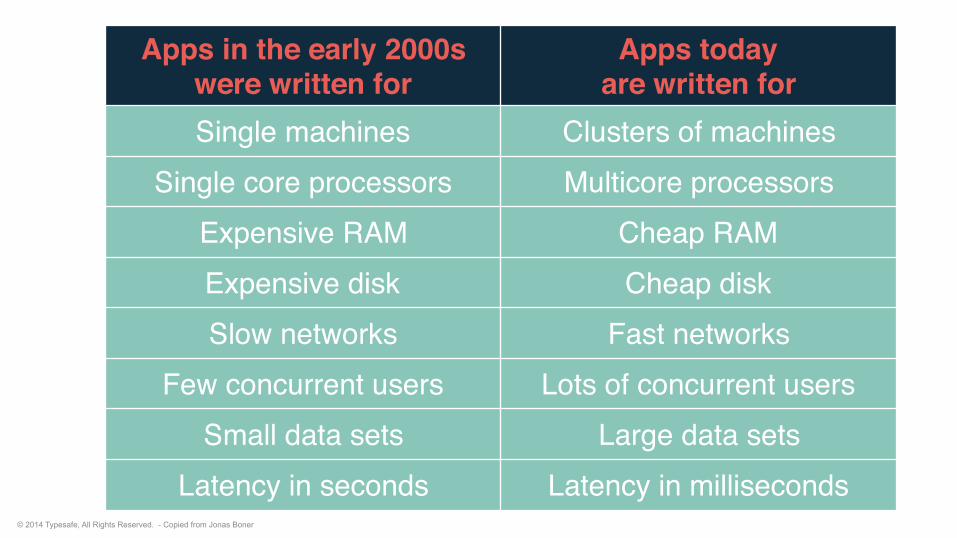
Apps in the early 2000s were written for
Apps today are written for
Single machines Clusters of machinesSingle core processors Multicore processors
Expensive RAM Cheap RAMExpensive disk Cheap diskSlow networks Fast networks
Few concurrent users Lots of concurrent usersSmall data sets Large data sets
Latency in seconds Latency in milliseconds© 2014 Typesafe, All Rights Reserved. - Copied from Jonas Boner

What is Spark?• Fast and general compute engine for large-scale data
processing
• Fault Tolerant Distributed Datasets
• Distributed Transformation on Datasets
• Integrated Batch, Iterative and Streaming Analysis
• In Memory Storage with Spill-over to Disk

© 2014 DataStax, All Rights Reserved
Advantages of Spark• Improves efficiency through:
• In-memory data sharing • General computation graphs - Lazy Evaluates Data • 10x faster on disk, 100x faster in memory than
Hadoop MR
• Improves usability through: • Rich APIs in Java, Scala, Py..?? • 2 to 5x less code • Interactive shell

© 2014 DataStax, All Rights Reserved

Application(Spark Driver)
Spark Master
Worker
Spark Components
You application code which creates the SparkContext
A process which shells out to create a Executor JVM
A Process which Manages the Resources of the Spark Cluster
These processes are all separate and require networking to communicate
Hosting Application UI
:4040
Hosting Spark Master UI
:7080
WorkerWorkerWorkerWorker

© 2014 DataStax, All Rights Reserved
DataStax Analytics

Spark is about Data Analytics
• How do we get data into Spark?
• How can we work with large datasets?
• What do we do with the results of the analytics?

Spark Cassandra Connector

Spark Cassandra Connector • Data locality-aware (speed)
• Read from and Write to Cassandra
• Cassandra Tables Exposed as RDD and DataFrames
• Server-Side filters (where clauses)
• Cross-table operations (JOIN, UNION, etc.)
• Mapping of Java Types to Cassandra Types

© 2014 DataStax, All Rights Reserved ●14
Spark Cassandra Connector uses the DataStax Java Driver to Read from and Write to C*
Spark C*
Full Token Range
Each Executor Maintains a connection to the C* Cluster
Spark Executor
DataStax Java Driver
Tokens 1-1000
Tokens 1001 -2000
Tokens …
RDD’s read into different splits based on sets of tokens
Spark Cassandra Connector

15© 2015. All Rights Reserved.
•Simplified Deployment and Management
•Analytic Nodes configured to run Spark •dse cassandra -k
•HA Spark Master with automatic leader election
•Stores Spark Worker metadata in Cassandra
DSE Analytics with Spark

© 2014 DataStax, All Rights Reserved
DSE Spark Architecture
Cassandra
Executor
ExecutorSpark Worker(JVM)
Cassandra
Executor
ExecutorSpark Worker(JVM)
Node 1
Node 2Node 3
Node 4
Cassandra
Executor
ExecutorSpark Worker(JVM)
Cassandra
Executor
ExecutorSpark Worker(JVM)
Spark Master(JVM)
App Driver

© 2014 DataStax, All Rights Reserved.
Confidential
Mixed Workload In One Cluster
17
Cassandra Mode OLTP Database
Search Mode All Data Searchable
Analytics Mode Streaming and Analytics
C*
C
C
S ADon’t build and maintain these yourself,
especially on top of a distributed data store.
AS

© 2014 DataStax, All Rights Reserved.
Confidential 18
Mixed Workload Cluster

DSE 4.7 Analytics + Search• Allows Analytics Jobs to use Solr Queries
• Allows searching for data across partitions
• Example:
val table = sc.cassandraTable("music","solr")
val result = table.select("id","artist_name").where("solr_query='artist_name:Miles*'").collect

© 2014 DataStax, All Rights Reserved
Spark SQL and DataFrames

© 2014 DataStax, All Rights Reserved
• Creating and Running Spark Programs Faster • Write less code • Read less data • Let the optimizer do the hard work
• Spark SQL Catalyst optimizer
Why Spark SQL?

© 2014 DataStax, All Rights Reserved
• Distributed collection of data • Similar to a Table in a RDBMS • Common API for reading/writing data • API for selecting, filtering, aggregating
and plotting structured data • Similar to a Table in a RDBMS
DataFrame

© 2014 DataStax, All Rights Reserved
• Sources such as Cassandra, structured data files, tables in Hive, external databases, or existing RDDs.
• Optimization and code generation through the Spark SQL Catalyst optimizer
• Decorator around RDD • Previously SchemaRDD
DataFrame Part 2

© 2014 DataStax, All Rights Reserved
• Unified interface to reading/writing data in a variety of formats
• Spark Notebook Example
Write Less Code: Input & Output

Scala for Large Scale Data Analytics
25© 2015. All Rights Reserved.
•Functional Paradigm is ideal for Data Analytics
•Strongly Typed - Enforce Schema at Every Later
•Immutable by Default - Event Logging
•Declarative instead of Imperative - Focus on Transformation not Implementation

Spark Notebook
26© 2015. All Rights Reserved.
C*
C
C A
AANotebook
Notebook
Notebook
Spark Notebook ServerCassandra Cluster with Spark Connector

Apache Spark Notebook
27© 2015. All Rights Reserved.
•Interactive Data Analytics in Browser •Reactive / Dynamic Graphs based on Scala, SQL and DataFrames
•Spark Streaming •Examples notebooks covering visualization, machine learning, streaming, graph analysis, genomics analysis
•Tune and Configure Each Notebook Separately •https://github.com/andypetrella/spark-notebook

© 2014 DataStax, All Rights Reserved
Spark Streaming

© 2014 DataStax, All Rights Reserved
Spark Components

© 2014 DataStax, All Rights Reserved
Spark Versus Spark Streaming

© 2014 DataStax, All Rights Reserved
Spark Streaming General Architecture

© 2014 DataStax, All Rights Reserved
Spark Streaming General Architecture

© 2014 DataStax, All Rights Reserved
DStream Micro Batches

© 2014 DataStax, All Rights Reserved
Windowing

© 2014 DataStax, All Rights Reserved
Windowing

© 2014 DataStax, All Rights Reserved
Streaming Resiliency
• Streaming uses aggressive checkpointing and in-memory data replication to improve resiliency.
• Frequent checkpointing keeps RDD lineages down to a
reasonable size.
• Checkpointing and replication mandatory since streams don’t
have source data files to reconstruct lost RDD partitions (except for the directory ingest case).

© 2014 DataStax, All Rights Reserved
KillrWeather Architecture

© 2014 DataStax, All Rights Reserved
Spark Development

Imperative Code
final List<Integer> numbers = Arrays.asList(1, 2, 3);
final List<Integer> numbersPlusOne = Collections.emptyList();
for (Integer number : numbers) { final Integer numberPlusOne = number + 1; numbersPlusOne.add(numberPlusOne); }

We Want Declarative Code
• Remove temporary lists - List<Integer> numbersPlusOne = Collections.emptyList();
• Remove looping - for (Integer number : numbers)
• Focus on what - x+1

© 2014 DataStax, All Rights Reserved
Functions as Values• Similar to a method - Expression with 0 or more
input arguments• Simple Expressions f(x) = x+1 f(y)=y*y • Avoid side effects and mutable state• Output only depends on input• Functions can be passed similar to other variables

Map, FlatMap and Filter1 2 3 4 5 6 7 8
2 4 6 8 10 12 14 16
map (x*2)
4 6 8 102
filter ( x < 11)
30
reduce( x+nxt)
1,2 8,9 4,1 5,7
2 4 16 18 8 2 10 14
flatMap (x*2)
4 8 22
filter ( x < 10)
16
reduce( x+nxt)

Java 8
final List<Integer> numbers = Arrays.asList(1, 2, 3);
final List<Integer> numbersPlusOne = numbers.stream().map(number -> number + 1). collect(Collectors.toList());
λ

Scalaval numbers = 1 to 20
val incFunc = (x:Int) => x+1 numbers.map(incFunc)
numbers.map(x => x+1)
numbers.map(_+1)
λ

SQL - Declarative or Imperative?
• SQL is Declarative
• What operation to perform and not how to perform it
• Select doesn’t define how just what data we want

Closures vs Functions?
• Closure is a Function which closes over the surrounding context
• Closures can access variables in surrounding context
• Spark Job passes closures to operate on the data

© 2014 DataStax, All Rights Reserved
Spark Development
• Write programs in terms of parallel transformations on distributed datasets
• Programming at a higher level of abstraction

Why Functions with Spark?
• Declarative Programming - Define What and Not How
• Define what operations to perform and Spark figures out how to operate on the data
• Easy to handle Events and Async Results with Functional Callbacks
• Avoid Inner Classes

© 2014 DataStax, All Rights Reserved
Spark RDD

© 2014 DataStax, All Rights Reserved
• The primary abstraction in Spark • Collection of data stored in the Spark Cluster • Fault-tolerant • Enables parallel processing on data sets • In-Memory or On-Disk
Resilient Distributed Datasets (RDD)

© 2014 DataStax, All Rights Reserved
• Parallelized Collections • Take an existing collection and runs functions
on it in parallel • PairRDD • UnionRDD • JsonRDD • ShuffledRDD • CassandraRDD
Examples RDDs
© 2014 DataStax, All Rights Reserved
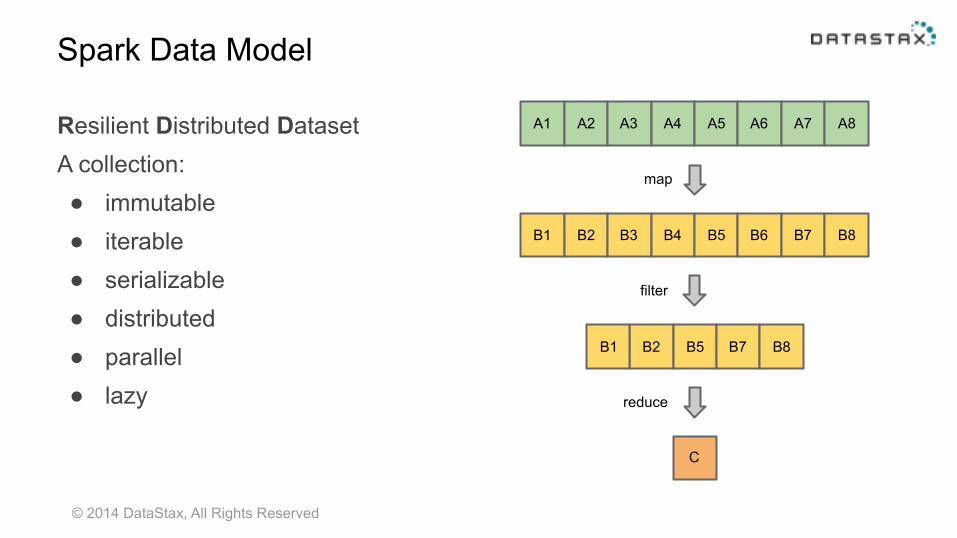
Spark Data Model
A1 A2 A3 A4 A5 A6 A7 A8
B1 B2 B3 B4 B5 B6 B7 B8
map
B2 B5 B7 B8B1
filter
C
reduce
Resilient Distributed Dataset A collection: ● immutable ● iterable ● serializable ● distributed ● parallel ● lazy

© 2014 DataStax, All Rights Reserved
• RDDs are immutable - Each stage of a transformation will create a new RDD.
• RDDs are lazy • A DAG (directed acyclic graph) of computation
is constructed. • The actual data is processed only when
results are requested.
Resilient Distributed Datasets (RDD)

© 2014 DataStax, All Rights Reserved
• RDDs know their “parents” and transitively, all ancestors.
• RDDs are resilient - A lost partition is reconstructed from ancestors.
• Transformation history / Lineage of the Data for Re-computation when needed
Resilient Distributed Datasets (RDD)

© 2014 DataStax, All Rights Reserved
RDD Operations - Not Only Map & Reduce