large volume data analysis on the typesafe reactive platform - big data scala by the bay 2015
TRANSCRIPT

Martin Zapletal @zapletal_martinCake Solutions @cakesolutions

● Increasing importance of data analytics, data mining and machine learning
● Current state○ Destructive updates○ Analytics tools with poor scalability and integration○ Manual processes○ Slow iterations○ Not suitable for large amounts and fast data

● Shared memory, disk, shared nothing, threads, mutexes, transactional memory, message passing, CSP, actors, futures, coroutines, evented, dataflow, ...
We can think of two reasons for using distributed machine learning: because you have to (so much data), or because you want to (hoping it will be faster). Only the first reason is good.
Elapsed times for 20 PageRank iterations
[1, 2]Zygmunt Z
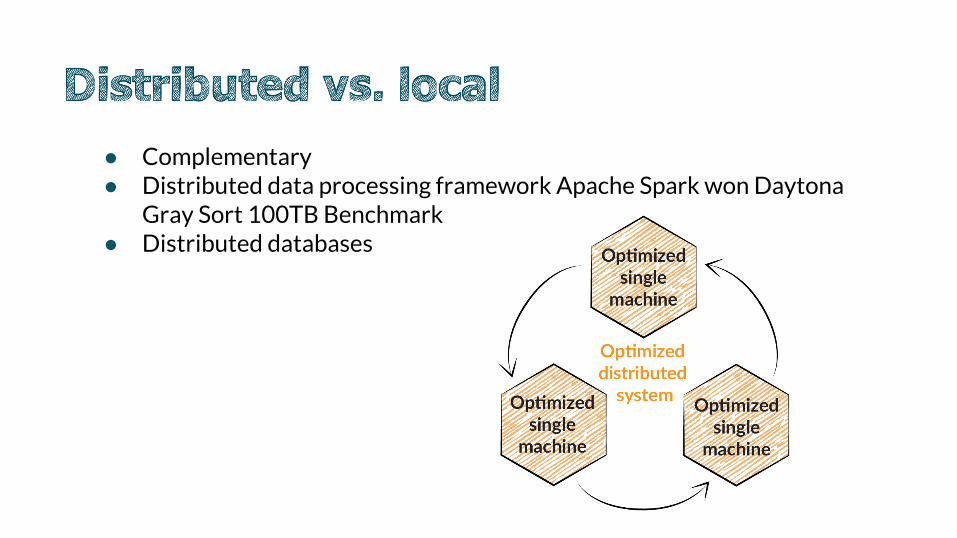
● Complementary● Distributed data processing framework Apache Spark won Daytona
Gray Sort 100TB Benchmark● Distributed databases

● Whole lifecycle of data
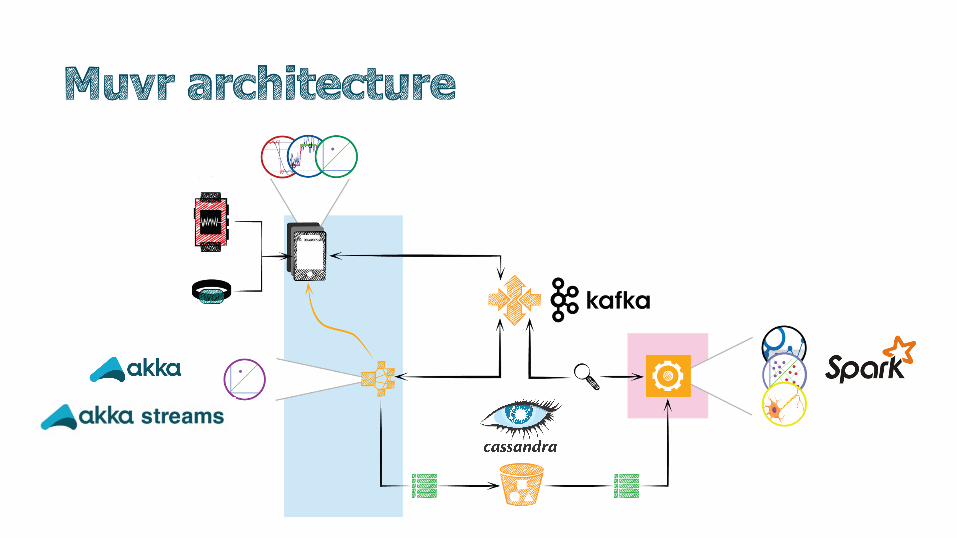
● Data processing - Futures, Akka, Akka Cluster, Reactive Streams, Spark, …
● Data stores● Integration and messaging● Distributed computing primitives● Cluster managers and task schedulers● Deployment, configuration management and DevOps● Data analytics and machine learning
ACID Mutable State

CQRS
Kappa architecture
Batch-Pipeline
Kafka
All
you
r d
ata
NoSQL
SQL
Spark
Client
Client
Client Views
Streamprocessor
Client
QueryCommand
DBDB
Denormalise/Precompute
Flume
ScoopHive
Impala
Serving DB
Oozie
HDFS
Lambda Architecture
Batch Layer Serving Layer
Stream layer (fast)
Query
Query
All
you
r d
ata
[3]
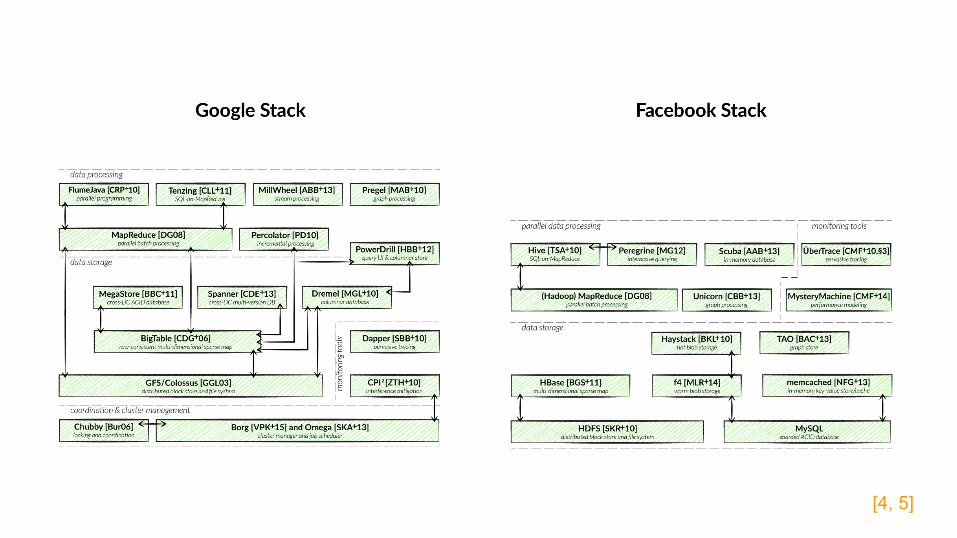
[4, 5]

Output 0 with result 0.6615020337700888 in 12:15:53.564Output 0 with result 0.6622847063345205 in 12:15:53.564
● Pure scala● Functional programming● Synchronization and memory management

● Actor framework for truly concurrent and distributed systems● Thread safe mutable state - consistency boundary● Domain modelling● Distributed state, work, communication patterns● Simple programming model - send messages, create new actors,
change behaviour

class UserActor extends PersistentActor {
override def persistenceId: String = UserPersistenceId(self.path.name).persistenceId
private[this] val userAccountKey = GSetKey[Account]("userAccountKey")
override def receiveCommand: Receive = notRegistered(DistributedData(context.system).replicator)
def notRegistered(distributedData: ActorRef): Receive = { case cmd: AccountCommand => persist(AccountEvent(cmd.account)){ acc => distributedData ! Update(userAccountKey, GSet.empty[Account], WriteLocal)(_ + acc.account) context.become(registered(acc)) } }
def registered(account: Account): Receive = { case eres @ EntireResistanceExerciseSession(id, session, sets, examples, deviations) => persist(eres)(data => sender() ! \/-(id)) }
override def receiveRecover: Receive = { ... }}

class SensorDataProcessor[P, S] extends ActorPublisher[SensorData] with DataSink[P] with DataProcessingFlow[S] {
implicit val materializer = ActorMaterializer()
override def preStart() = {
FlowGraph.closed(sink) { implicit builder: FlowGraph.Builder[Future[Unit]] => s =>
Source(ActorPublisher(self)) ~> flow ~> s
}.run()
super.preStart()
}
def source(buffer: Seq[SensorData]): Receive = {
case data: SensorData if totalDemand > 0 && buffer.isEmpty => onNext(data)
case data: SensorData => context.become(source(buffer :+ data))
case Request(_) if buffer.nonEmpty =>
onNext(buffer.head)
context.become(source(buffer.tail))
}
override def receive: Receive = source(Seq())
}

Persistence
Sharding Replication
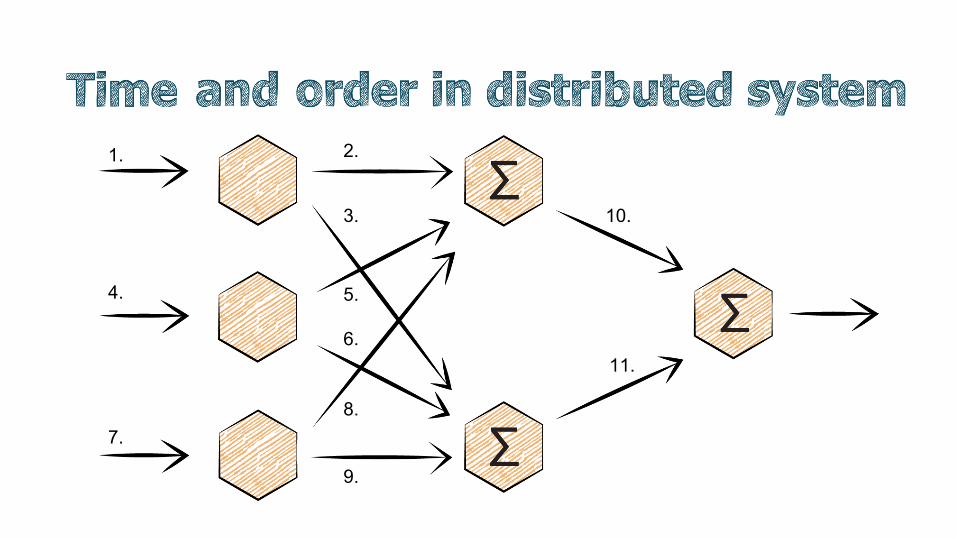
1.
4.
7.
2.
3.
5.
6.
8.
9.
10.
11.

?
?
?
? + 1
? + 1
? + 1
? + 1
? + 1
? + 1
? + 2
? + 2
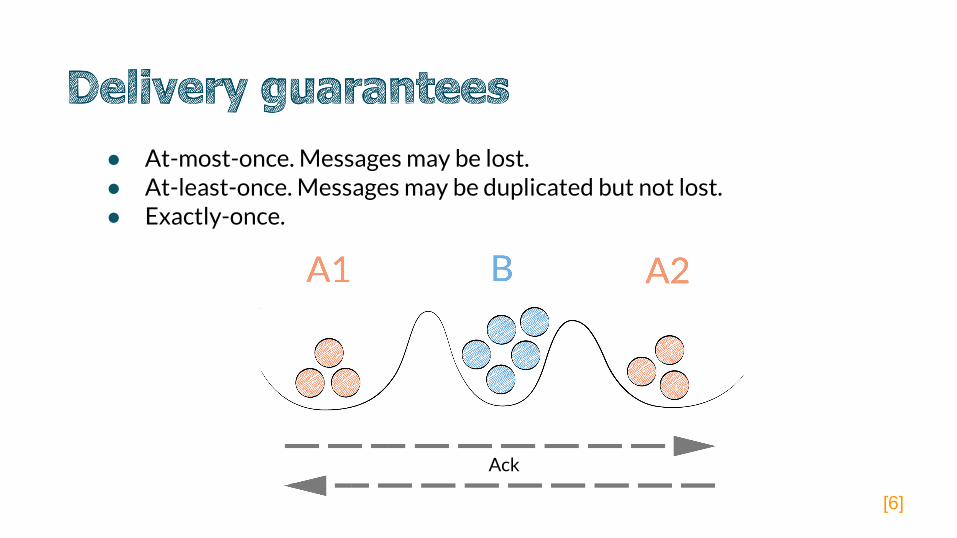
● At-most-once. Messages may be lost.● At-least-once. Messages may be duplicated but not lost.● Exactly-once.
Ack
[6]

Output 18853 with result 0.6445355972059068 in 17:33:12.248Output 18854 with result 0.6392081778097862 in 17:33:12.248Output 18855 with result 0.6476549338361918 in 17:33:12.248
[17:33:12.353] [ClusterSystem-akka.actor.default-dispatcher-21] [Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://[email protected]:2551] - Leader is removing unreachable node [akka.tcp://[email protected]:54495][17:33:12.388] [ClusterSystem-akka.actor.default-dispatcher-22] [akka.tcp://[email protected]:2551/user/sharding/PerceptronCoordinator] Member removed [akka.tcp://[email protected]:54495][17:33:12.388] [ClusterSystem-akka.actor.default-dispatcher-35] [17:33:12.415] [ClusterSystem-akka.actor.default-dispatcher-18] [akka://ClusterSystem/user/sharding/Edge/e-2-1-3-1] null java.lang.NullPointerException

● Microsoft's data centers average failure rate is 5.2 devices per day and 40.8 links per day,
with a median time to repair of approximately five minutes (and a maximum of one week).
● Google new cluster over one year. Five times rack issues 40-80 machines seeing 50 percent
packet loss. Eight network maintenance events (four of which might cause ~30-minute
random connectivity losses). Three router failures (resulting in the need to pull traffic
immediately for an hour).
● CENIC 500 isolating network partitions with median 2.7 and 32 minutes; 95th percentile of
19.9 minutes and 3.7 days, respectively for software and hardware problems[7]

● MongoDB separated primary from its 2 secondaries. 2 hours later the old primary rejoined and rolled back everything on the new primary
● A network partition isolated the Redis primary from all secondaries. Every API call caused the billing system to recharge customer credit cards automatically, resulting in 1.1 percent of customers being overbilled over a period of 40 minutes.
● The partition caused inconsistency in the MySQL database. Because foreign key relationships were not consistent, Github showed private repositories to the wrong users' dashboards and incorrectly routed some newly created repositories.
● For several seconds, Elasticsearch is happy to believe two nodes in the same cluster are both primaries, will accept writes on both of those nodes, and later discard the writes to one side.
● RabbitMQ lost ~35% of acknowledged writes under those conditions.● Redis threw away 56% of the writes it told us succeeded.● In Riak, last-write-wins resulted in dropping 30-70% of writes, even with the strongest consistency
settings● MongoDB “strictly consistent” reads see stale versions of documents, but they can also return garbage
data from writes that never should have occurred.
[8]
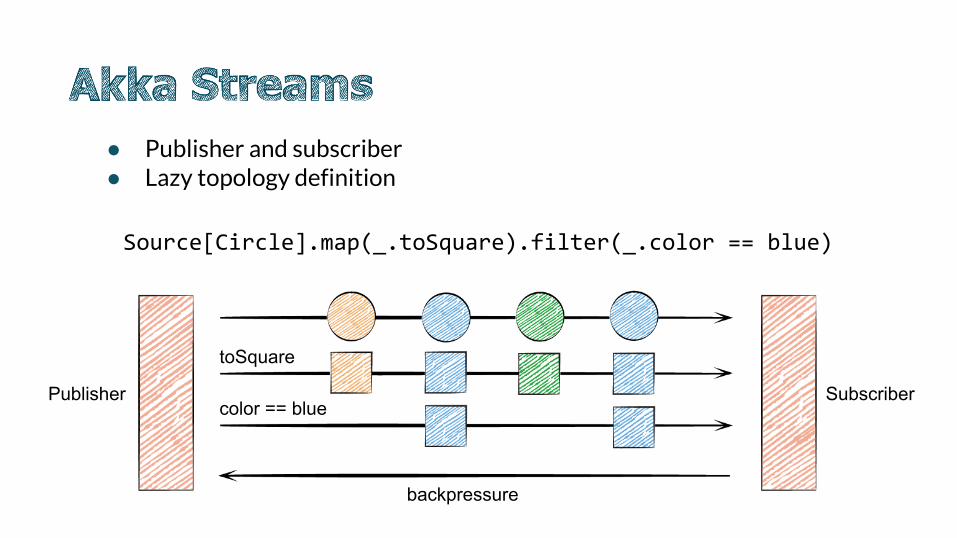
● Publisher and subscriber● Lazy topology definition
Source[Circle].map(_.toSquare).filter(_.color == blue)
Publisher Subscriber
toSquare
color == blue
backpressure
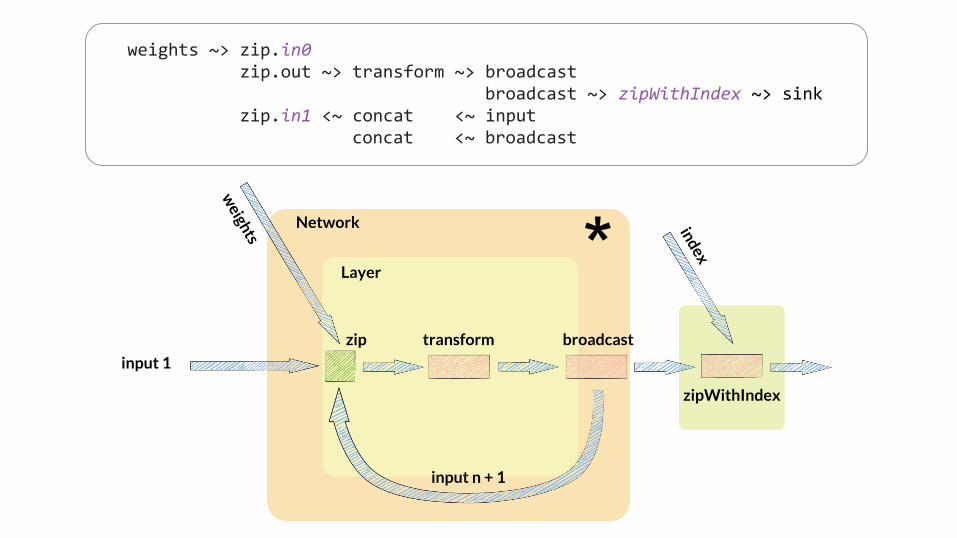
weights ~> zip.in0 zip.out ~> transform ~> broadcast broadcast ~> zipWithIndex ~> sink zip.in1 <~ concat <~ input concat <~ broadcast
Network
zip transform
*zipWithIndex
Layer
input n + 1
input 1
broadcast
index
weights
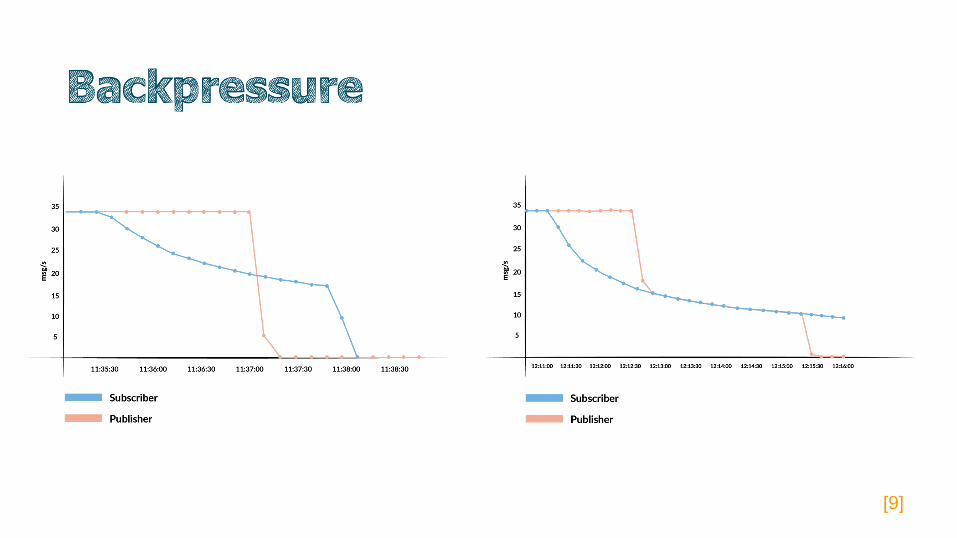
[9]



7 * Dumbbell Alternating Curl

● In memory dataflow distributed data processing framework, streaming and batch
● Distributes computation using a higher level API● Load balancing● Moves computation to data ● Fault tolerant

● Resilient Distributed Datasets● Fault tolerance● Caching● Serialization● Transformations
○ Lazy, form the DAG○ map, filter, flatMap, union, group, reduce, sort, join, repartition, cartesian, glom, ...
● Actions○ Execute DAG, retrieve result○ reduce, collect, count, first, take, foreach, saveAs…, min, max, ...
● Accumulators● Broadcast Variables● Integration● Streaming● Machine Learning● Graph Processing
Data
transform
transform
transform
collect
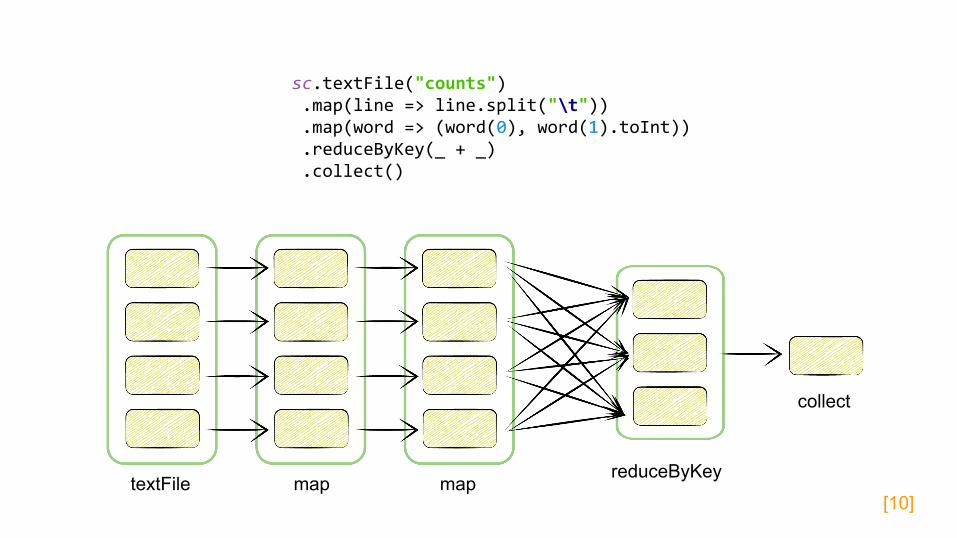
textFile mapmapreduceByKey
collect
sc.textFile("counts") .map(line => line.split("\t")) .map(word => (word(0), word(1).toInt)) .reduceByKey(_ + _) .collect()
[10]

● Catalyst● Multiple phases● DataFrame
[11]
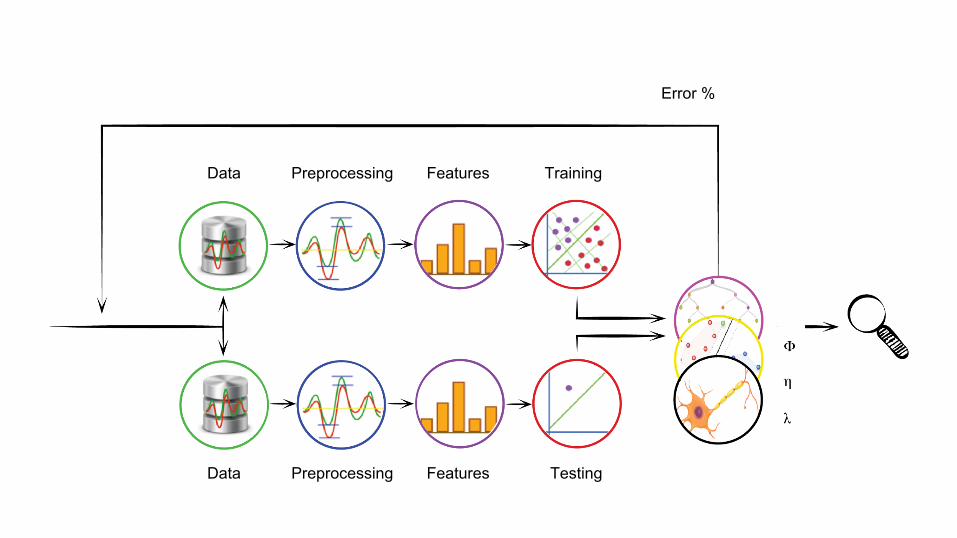
Data
Data
Preprocessing
Preprocessing
Features
Features
Training
Testing
Error %

val events = sc.eventTable().cache().toDF()
val pipeline = new Pipeline().setStages(Array(
new UserFilter(),
new ZScoreNormalizer(),
new IntensityFeatureExtractor(),
new LinearRegression()
))
getEligibleUsers(events, sessionEndedBefore)
.map { user =>
val model = pipeline.fit(
events,
ParamMap(ParamPair(userIdParam, user)))
val testData = // Prepare test data.
val predictions = model.transform(testData)
submitResult(userId, predictions, config)
}

Choose the best combination of tools for given use case.
Understand the internals of selected tools.
The environment often fully asynchronous and distributed.
1)
2)
3)


● Jobs at www.cakesolutions.net/careers● Code at https://github.com/muvr ● Twitter @zapletal_martin

[1] http://www.csie.ntu.edu.tw/~cjlin/talks/twdatasci_cjlin.pdf
[2] http://blog.acolyer.org/2015/06/05/scalability-but-at-what-cost/
[3] http://www.benstopford.com/2015/04/28/elements-of-scale-composing-and-scaling-data-platforms/
[4] http://malteschwarzkopf.de/research/assets/google-stack.pdf
[5] http://malteschwarzkopf.de/research/assets/facebook-stack.pdf
[6] http://en.wikipedia.org/wiki/Two_Generals%27_Problem
[7] https://queue.acm.org/detail.cfm?id=2655736
[8] https://aphyr.com/
[9] http://www.smartjava.org/content/visualizing-back-pressure-and-reactive-streams-akka-streams-statsd-grafana-and-influxdb
[10] http://www.slideshare.net/LisaHua/spark-overview-37479609
[11] https://ogirardot.wordpress.com/2015/05/29/rdds-are-the-new-bytecode-of-apache-spark/