le data mining: méthodologie
DESCRIPTION
Le Data Mining: Méthodologie. Définition et introduction Principales applications Méthodologie du DM Exemples de fonctionnement. 1. Emergence du domaine. Workshops 1991, 1993, 1994 International Conf. on KDD and DM 1995, 1996, 1997, 1998, 1999 - PowerPoint PPT PresentationTRANSCRIPT

1
Le Data Mining: Méthodologie
Définition et introductionPrincipales applicationsMéthodologie du DMExemples de fonctionnement

2
1. Emergence du domaine
Workshops 1991, 1993, 1994
International Conf. on KDD and DM 1995, 1996, 1997, 1998, 1999
Data Mining and Knowledge Discovery Journal (1997)
Special Interest Group Knowledge Discovery in Databases (1999) de l’Association for Computing Machinery (ACM)

3
Métaphore
Par analogie à la recherche des pépites d ’or dans un gisement, la fouille de données vise : à extraire des informations cachées par analyse
globale à découvrir des modèles (“patterns”) difficiles à
percevoir car: le volume de données est très grand le nombre de variables à considérer est importantces “patterns” sont imprévisibles (même à titre
d ’hypothèse à vérifier)

4
Définition
Data mining ensemble de techniques d'exploration de données
afin d'en tirer des connaissances (la signification profonde) sous forme de modèles présentés à l ’utilisateur averti pour examen
Donnéesentrepôt
Datamining Connaissances
Découverte demodèles
CompréhensionPrédiction
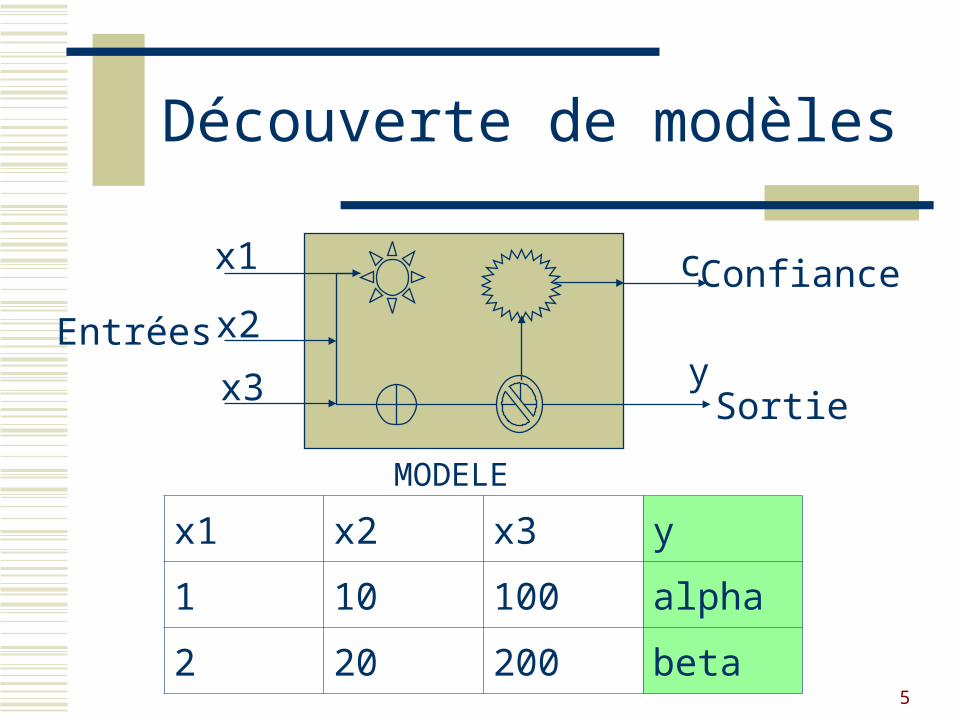
5
Entrées
Sortie
Confiance
Découverte de modèles
x1
x2
x3
c
y
MODELE
x1 x2 x3 y
1 10 100 alpha
2 20 200 beta
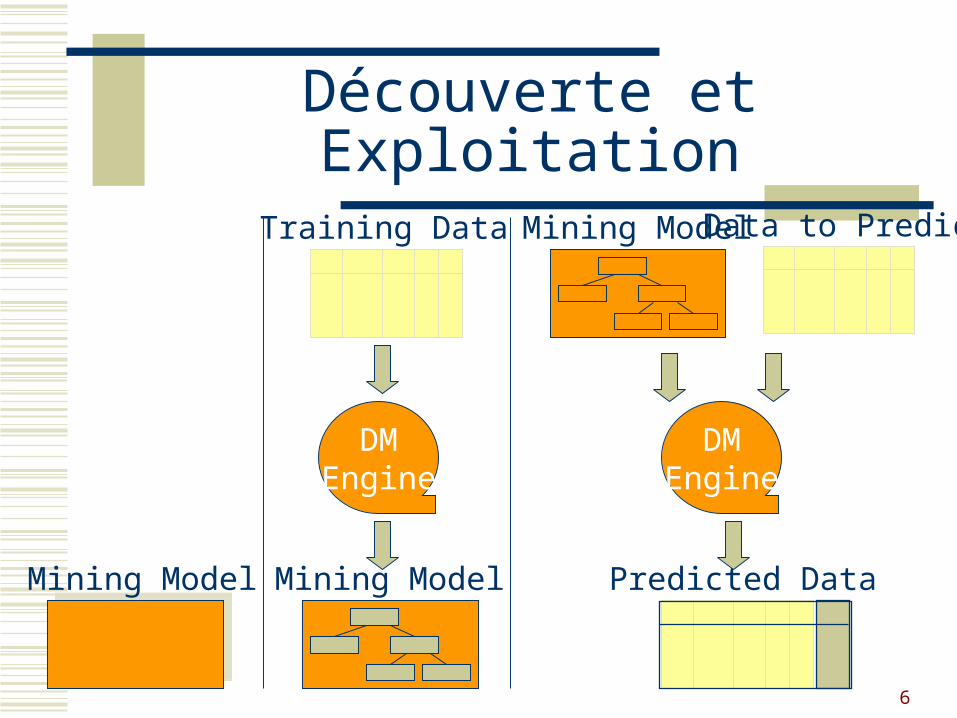
6
Découverte et Exploitation
Mining Model
DMEngine
DMEngine
Predicted Data
Training Data
Mining Model
Mining ModelData to Predict

7
Connaissances
Knowledge Discovery in Databases (KDD) Processus complet d’Extraction de Connaissance des
Données (ECD) Comprend plusieurs phases dont le data mining
Exemples analyses (distribution du trafic en fonction de l ’heure) scores (fidélité d ’un client), classes (mauvais payeurs) règles (si facture > 10000 et mécontent > 0.5 alors
départ à 70%)
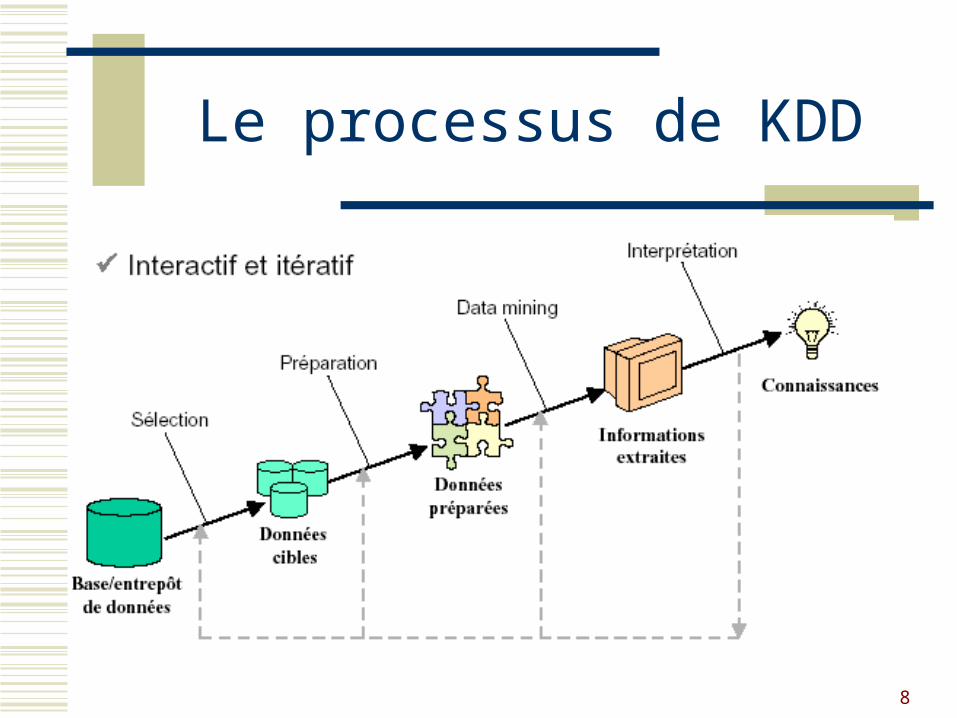
8
Le processus de KDD

9
Etapes du processus
1. Compréhension du domaine d’application 2. Création du fichier cible (target data set) 3. Traitement des données brutes (data cleaning and preprocessing) 4. Réduction des données (data reduction and projection) 5. Définition des tâches de fouille de données 6. Choix des algorithmes appropriés de fouille de données 7. Fouille de données (data mining) 8. Interprétation des formes extraites (mined patterns) 9. Validation des connaissances extraites
(source : Fayyat et al., 1996, p. 1-34)

10
Mécanismes de base
Déduction : base des systèmes experts schéma logique permettant de déduire un théorème à
partir d'axiomes le résultat est sûr, mais la méthode nécessite la
connaissance de règles Induction : base du data mining
méthode permettant de tirer des conclusions à partir d'une série de faits
généralisation un peu abusive indicateurs de confiance permettant la pondération

11
2. Domaines d'application
De plus en plus de domaines explosion des données historisées puissance des machines support nombreux datawarehouses OLAP limité nécessité de mieux comprendre rapports sophistiqués, prédictions aide efficace aux managers

12
Quelques domaines réputés
Analyse de risque (Assurance) Marketing Grande distribution Médecine, Pharmacie Analyse financière Gestion de stocks Maintenance Contrôle de qualité

13
Exemples
Targeted ads “What banner should I display to this visitor?”
Cross sells “What other products is this customer likely to buy?
Fraud detection “Is this insurance claim a fraud?”
Churn analysis “Who are those customers likely to churn?”
Risk Management “Should I approve the loan to this customer?”

14
Churn Analysis
Application de télécom Bases de données des clients et des appels Fichiers des réclamations Qui sont les clients le plus susceptibles de
partir ? Application de techniques de DM Fichiers de 1000 clients les plus risqués 600 ont quittés dans les 3 mois

15
Trading Advisor
Application boursière conseil en achat / vente d'actions
Données de base historique des cours portefeuille client
Analyse du risque Analyse technique du signal Conseils d'achat – vente Mise à disposition sur portail Web

16
3. Méthodologie -1
1. Identifier le problème cerner les objectifs trouver les sources définir les cibles vérifier les besoins
2. Préparer les données préciser les sources collecter les données nettoyer les données transformer les données intégrer les données

17
Méthodologie - 2
3. Explorer des modèles choisir une technique échantillonner sur un groupe valider sur le reste (5% à
1/3) calculer le d ’erreurs
4. Utiliser le modèle observer la réalité recommander des actions
5. Suivre le modèle bâtir des estimateurs corriger et affiner le
modèle

18
Explorer des modèles : SEMMA
Sampling = Échantillonner tirer un échantillon significatif pour extraire les modèles
Exploration = Explorer devenir familier avec les données (patterns)
Manipulation = Manipuler ajouter des informations, coder, grouper des attributs
Modelling = Modéliser construire des modèles (statistiques, réseaux de neuronnes, arbres
de décisions, règles associatives, …) Assessment = Valider
comprendre, valider, expliquer, répondre aux questions

19
Validation d’un modèle
Matrice de confusion comparaison des cas observés par rapport aux prédictions
exemple : prédiction de factures impayées
Validité du modèle nombre exacte (diagonale) / nombre totale = 120/150 = 0.80
Prédit Observé
Payé Retardé Impayé Total
Payé 80 15 5 100
Retardé 1 17 2 20
Impayé 5 2 23 30
Total 86 34 30 150

20
Définition de Mesures
précision Rapport du nombre de documents pertinents trouvés au nombre total
de documents sélectionnés. En anglais precision. rappel
Rapport du nombre de documents pertinents trouvés au nombre total de documents pertinents. En anglais recall.
Soient S l'ensemble des objets qu'un processus considère comme ayant une
propriété recherchée, V l'ensemble des objets qui possèdent effectivement cette propriété, P et R respectivement la précision et le rappel du système :
P = | S ∩ V | / | S | R = | S ∩ V | / | V |

21
Mesures
Précision (Precision) = NbTrouvésCorrects/(1+NbTotal)
Bruit (Noise) = NbTrouvésIncorrects/(1+NbTotal) = 1- Précision
Rappel (Recall) = NbTrouvésCorrects/(1+NbValide)
F-mesure = 2*(précision*rappel)/(précision+rappel)

22
Principales Techniques
Dérivées des statistiques (e.g., réseaux bayésiens) de l'analyse de données (e.g., analyse en composantes) de l'intelligence artificielle (e.g., arbres de décision,
réseaux de neurones) des bases de données (e.g., règles associatives)
Appliquées aux grandes bases de données Difficultés :
passage à l'échelle et performance fonctionnement avec échantillon > qq milliers présentation et validation des résultats

23
4. Quelques produits
Intelligent Miner d'IBM modélisation prédictive
(stat.), groupage, segmentation, analyse d'associations, détection de déviation, analyse de texte libre
SAS de SAS Statistiques, groupage,
arbres de décision, réseaux de neurones, associations, ...
SPSS de SPSS statistiques, classification,
réseaux de neurones
Oracle 10g ODM
SQL Server DM
DB2 V8
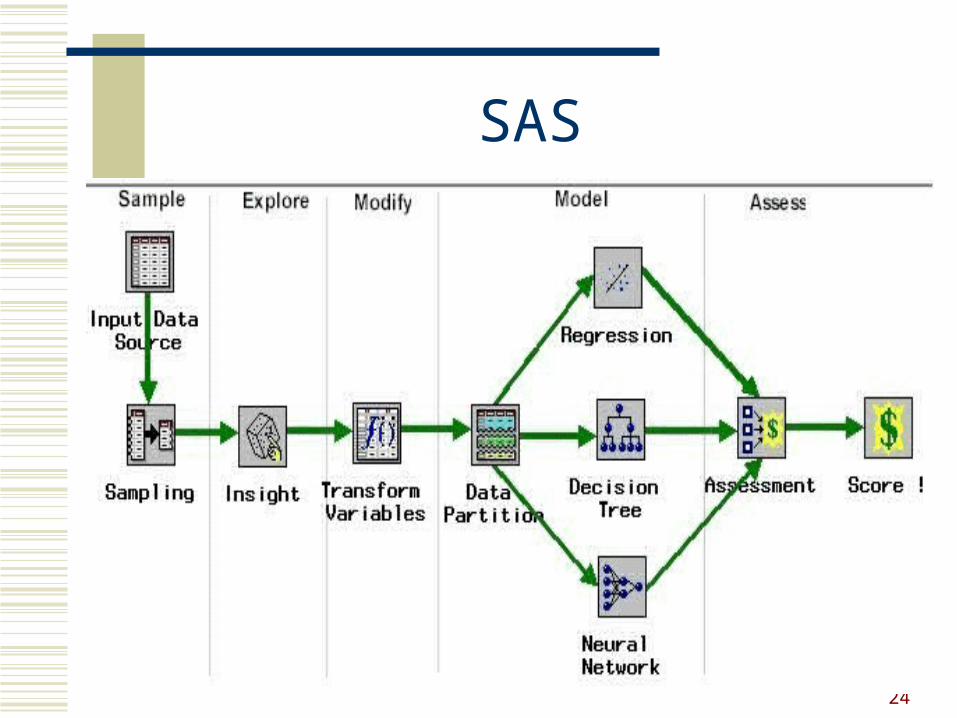
24
SAS

25
INPUT
Choix des variables

26
SAMPLING
Choix du type d'échantillon

27
INSIGHT
Analyse des données en 4D

28
TRANSFORM
Transformation pour préparer

29
PARTITION
Création de partition d'exploration parallèle

30
REGRESSION
Sélection de la méthode de régression

31
DECISION TREE
Construction d'un arbre par 2
32
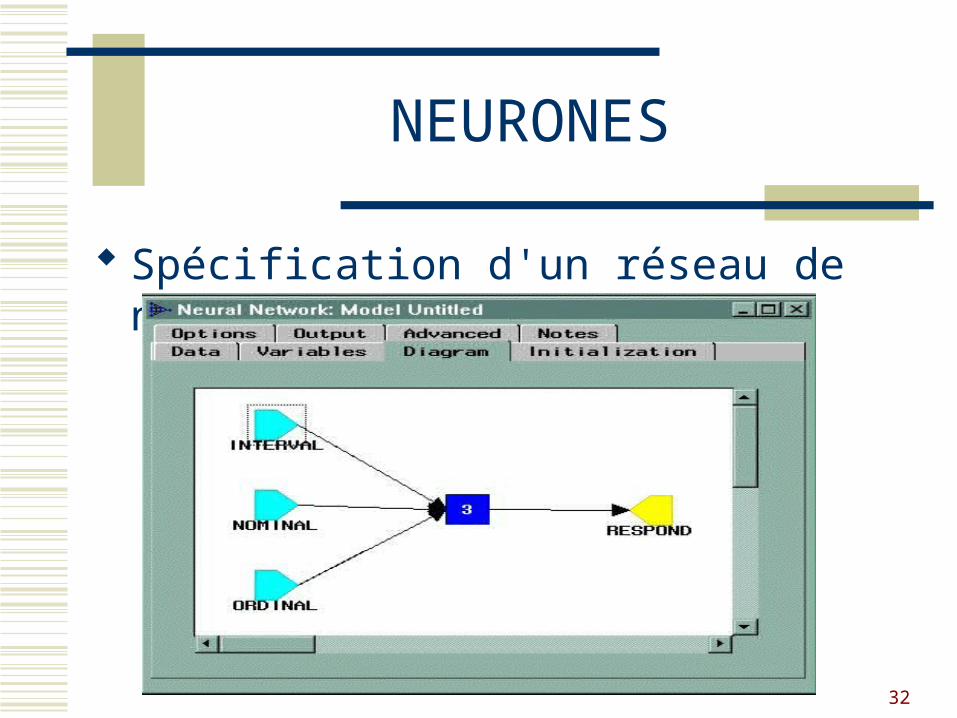
NEURONES
Spécification d'un réseau de neurones

33
ASSESSMENT
Validation des résultats

34
Approches
De multiples approches: Statistiques Classification Clustering Règles associatives …

35
Méthodes d'analyse
1 ... J ... p1..
TableTable = i..n
1 ... J ... p 1 ... J ... p1 1. .. .
Table = i Table = i. .. .n n
Points dans Rp Points dans Rn

36
Familles de méthodes
Nuage de points
Visualisation dansLe meilleur espace réduit
Regroupement dans tout l'espace
METHODES STATISTIQUESET FACTORIELLES
METHODES DE CLASSIFICATION,SUPERVISEE OU NON …

37
5. Méthodes statistiques
Quelques techniques de base
A la limite du DM
Calculs d'information sophistiqués

38
Fonctions Statistiques
Espérance permet de calculer la moyenne pondérée d'une
colonne pi = 1/N par défaut
Variance traduit la dispersion de la distribution de la v.a.
autour de sa valeur moyenne.
Variable centrée réduite Permet d'éliminer le facteur dimension

39
Catégorie d'employé
Catégorie d'employé
ResponsableCadreSecrétariat
Fré
qu
en
ce
400
300
200
100
0
Diagrammes en bâtons
Comptage de fréquence COUNT
Extension aux calculs d'agrégats AVG, MIN, MAX, …
Possibilité d'étendre au 3D
Apporte une vision synthétique
1stQtr
2ndQtr
3rdQtr
4thQtr
EastWest
North
020406080
100
1stQtr
2ndQtr
3rdQtr
4thQtr
EastWest
North
East
West
North
40
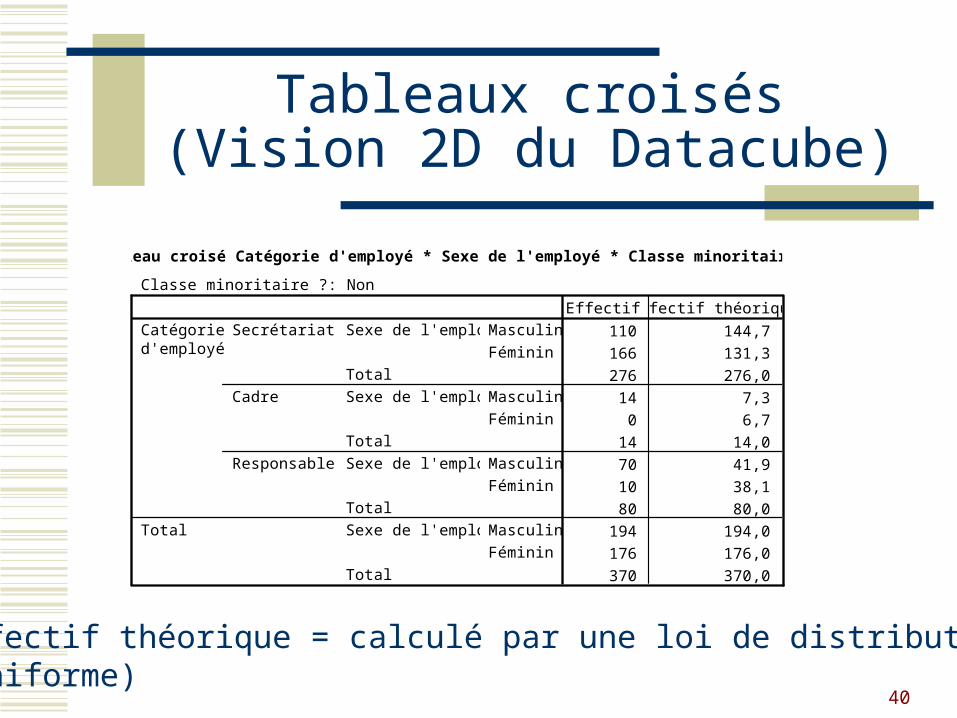
Tableau croisé Catégorie d'employé * Sexe de l'employé * Classe minoritaire ?
Classe minoritaire ?: Non
110 144,7
166 131,3
276 276,0
14 7,3
0 6,7
14 14,0
70 41,9
10 38,1
80 80,0
194 194,0
176 176,0
370 370,0
Masculin
Féminin
Sexe de l'employé
Total
Masculin
Féminin
Sexe de l'employé
Total
Masculin
Féminin
Sexe de l'employé
Total
Masculin
Féminin
Sexe de l'employé
Total
Secrétariat
Cadre
Responsable
Catégoried'employé
Total
Effectif Effectif théorique
Tableaux croisés(Vision 2D du Datacube)
Effectif théorique = calculé par une loi de distribution(uniforme)

41
Corrélation
Covariance La covariance peut être vue comme le moment centré
conjoint d'ordre 1 de deux v.a. Si les deux v.a. sont indépendantes, alors leur covariance
est nulle (mais la réciproque n'est pas vraie en général).
Coefficient de corrélation Elimine le facteur dimension mesure la qualité de la relation linéaire entre deux
variables aléatoires

42
Droite de régression
$20,000 $40,000 $60,000 $80,000
Salaire d'embauche
$40,000
$80,000
$120,000
$160,000
Sal
aire
act
uel
70120
199
Salaire actuel = 1928,21 + 1,91 * saldebR-Deux = 0,77
Régression linéaire
Y = a X + b

43
Test du 2
Détermine l'existence d'une dépendance entre deux variables Exemple : salaire d'embauche, niveau d'étude
Compare la distribution des variables par rapport à une courbe théorique supposant l'indépendance

44
De nombreuses fonctions
Test t sur moyenne ANOVA Analyses de variance sophistiquées Corrélation partielle Régresion logistique Séries chronologiques
Lissage exponentiel, Moyenne mobile, … Comparaison
…

45
Calculs en SQL
Introduction de fonctions d'agrégats AVG = moyenne MAVG = moyenne mobile STDDEV = écart type VARIANCE = variance COVARIANCE = covariance …
Exemple SELECT COVARIANCE(SALAIRE_ACTU,
SALAIRE_EMB) FROM EMPLOYEE WHERE GRADE = "ingénieur" GROUP BY SEXE

46
Statistiques: Conclusion
Calculs statistiques sur variables Mono ou bi-variées Résumé des données Observation de dépendances Peu de modèles prédictifs ...
La plupart sont faisables avec SQL OLAP Extensions cube et rollup Extensions avec fonctions d'agrégats

47
6. Conclusion
Le data mining vise à découvrir des modèles à partir de grandes bases de faits connus (datawarehouse)
Le processus de construction de modèles est complexe
préparer les données modéliser 1/3 de la base valider sur 2/3 expérimenter plusieurs
modèles
Questions ? Quoi de nouveau par
rapport à l'IA et aux statistiques ?

48
DM, Stat., IA
DM Stat. Tableau individu -variable
Calculs numériques
IA Formalisme de la logique
Induction/déduction Recherche de règles de classement
Méthodes de discrimination Réseaux de neuronnes Segmentation
Apprentissage supervisé/ex. -Génèr° de règles -Constr° d'arbre de décision -Raisonnement à base de cas
Régression Méthodes de régression Réseaux de neuronnes _
Classification automatique
Classif° automatique hiérarchique Partitionnement Réseaux de neuronnes
Apprentissage non supervisé -Classif° conceptuelle
Description synthétique
Stat. Élémentaire (histogramme, moy, écart-type) Outils d'interprét° de classes Méthodes factorielles (ACP)
Apprentissage non supervisé -Généralisation
Recherche de dépendances
Corrélations Analyse factorielles des corr. (AFC) Réseaux bayésiens
Apprentissage non supervisé -Généralisation -Recherche d'associations
Détection de déviations
Test stat sur les écarts _