lean data warehouse via data vault
TRANSCRIPT

DecisionLab.Net
business intelligence is business performance ___________________________________________________________________________________________________________________________________________________________________________________
____________________________________________________________________________________________________________________________________________________________________________________
DecisionLab http://www.decisionlab.net [email protected] Carlsbad, California, USA
Lean Data Warehouse
via
Data Vault

__________________________________________________________________________________________________________________________________________________________________________________
Page 2 of 21
Lean Data Warehouse via Data Vault
Written by Daniel Upton Data Warehouse Architect Certified ScrumMaster
DecisionLab.Net Business Intelligence is Business Performance
[email protected] linkedin.com/in/DanielUpton
Lean Data WarehouseTM is a trademark of Daniel C. Upton. All uses of it throughout this writing are protected by trademark law.
Without my (the writer’s) explicit written permission in advance, the only permissible reproduction or copying of this trademark, or of any
of this written material, is in the form of a review or a brief reference to a specific concept herein, either or which must clearly specify
this writing’s title, author (me), and this web address http://www.slideshare.net/DanielUpton/lean-data-warehouse-via-data-vault . For
permission to reproduce or copy any of this material other than what is specified above, just email me at the above address.
Data Vault is a term, unregistered as far as I know, which I believe was coined by Daniel Linstedt, and is a central term in books by
Daniel Linstedt, Kent Graziano and Hans Hultgren. References to these books can be found at the end of this writing. I am grateful to
these authors for the deeply insightful concepts expressed therein, and I make no attempt to co-opt, or express any authorship for the
term Data Vault. Many of the concepts I learned – from these books or from related social media -- are reflected here, but this material
was not reproduced nor copied from any other material. All aforementioned concepts are expressed exclusively in my own words and
illustrated using my own data and database. I have attempted to give credit to others where it is due.

__________________________________________________________________________________________________________________________________________________________________________________
Page 3 of 21
Lean Data Warehouse via Data Vault
Daniel Upton
Objective: Interpret the principles of a Lean as applied to Data Warehousing, then describes challenges associated with changes in the business, and finally
provides scenarios in which three methods to data warehouse modelling will need to adapt to accommodate those changes, with varying amounts of difficulty.
The three data modelling methods are 3rd Normal Form, Star Schema (Dimensional) and Data Vault (Ensemble Model). For reference materials, see the end of
this article.
Takeaway: This piece demonstrates that data vault, being more easily adaptive to real-world changes, as well as continually imperfect knowledge within a
businesses, is the most Lean methodology of the three. This does not indicate that either of the other two mainstream methods are without value, but rather
only that Data Vault’s strengths validates its place among one of them in the field of data warehousing.
Bottom Line: A data warehouse that does not enjoy these Lean strengths – whether built around a traditional data warehouse design best practice or not – will
suffer from inflexibility and a high cost to support and extend over its lifecycle.
Lean Principles as Applied to Data Warehousing
Focus on the Customer and Eliminate Waste (‘muda’ in Japanese)
o Differentiate efforts based on demand (business requirements) vs. supply (availability and characteristics of source data).
o Data Presentation Layer (downstream): Deliver what is demanded, no less, no more.
o Data Management Layer (upstream): Based on the selection of available source data and its potential for a basic integration (as will soon be
described using Data Vault), model and load that data, no less, no more.
o How Much Source Data is Enough?: Both Lean and Agile principles emphasize the importance of ‘just enough’ thinking. Just enough analysis,
design, development, testing, deployment, training, and support. Having said that, ‘just enough’ can be difficult to determine. A Data Vault model,
due to its modular design and associated loading logic, is easily chunked out into little independent deliverables than are traditional data warehouse
models, so that project managers and leaders have more options in deciding on the scope and frequency of potentially shippable increments (PSI’s).
Having said that, it is also true that choosing to integrate all, or at least all eventually desired, database tables, fields and records from each relevant
source system into a data management layer, such as Data Vault, is a responsible choice, because…
The potential for this basic integration is highest when all relevant source data is integrated.
A basic integration, such as Data Vault, is quicker to accomplish, than an advanced integration attempting a single version of the truth
(SVOT) for all attributes.
Excessive task-switching is a well-known source of waste (muda) needing elimination. As such, allowing engineers to complete the design
and loading of a basic integration in its entirety -- while their mental energy is directed to a specific logical set of data subject areas -- is
sensible.

__________________________________________________________________________________________________________________________________________________________________________________
Page 4 of 21
Historical changes of chosen tables will be tracked as soon as this layer goes into production, and excluding specific tables probably means
leaving holes in the otherwise historically tracked source data.
Multiple simultaneous development tracks are easily established in order to efficiently put more resources onto a focused initiative to
instantiate the data warehouse.
Plan for Change: Design-in…
o Loose Coupling: Little or no dependency between objects, so that change in one entity does not compromise a related entity. Loose coupling is
robust. Tight coupling is fragile. Data Vault establishes loose coupling among entities.
o High Cohesion: To support loose coupling, each entity is focused, self-sufficient, and not overlapping with related entities. Data Vault does this, too.
Optimize the Whole
o Be willing to sub-optimize components a data model if necessary to optimize the scalability and durability of the model as a whole.
How? Add associative tables to break entity dependencies, thereby allowing actual data records, not a fixed data model, to dictate
relative cardinality between related entities.
Automate Processes and Deliver Fast
o Establish and re-use generic patterns to quickly, loosely integrate keys from source tables, without YET performing any data re-interpretation
In this piece, I will provide a simple example of the purely data-related challenges typical in the lifecycle of real-world Data Warehouses, interpreted here as
failures to adhere to Lean principles. As routine as this type of change it, one of the big challenges with traditional data warehousing is that these simple data
changes cause large structural problems in a traditional, rigidly integrated, data warehouse. Although process-related challenges of course, also exist, many of
the toughest ones are actually just challenging accommodations to these same real-world data challenges, large or small.
High-Level Summary of Data Vault Modeling Fundamentals and Resulting Value Proposition
o Note: Business Data Vault, not Raw Data Vault, will be described here. Whereas Raw Vault simply de-constructs each source entity and entity-
relationship into a Hub, Satellite and Link, Business Vault establishes a stronger basic integration by isolating and managing business keys as unique
records, which will be described immediately below.
Generally, in a Business Data Vault, tables from selected source systems end up in the Business Vault de-constructed into Hubs, Satellites and Links, with all
attributes from multiple source entities within and across source systems now aligned around a common unique business key (Hub).
Hub: A Hub table manages a unique business key, which is defined as a key (one or more data elements / fields) which are meaningful not just within a
single system, and not just to a database engineer, but also to the business people familiar with that business process. As an example, in Healthcare, an NPI
(National Provider Identifier) code, CPT (Current Procedural Terminology) code, or Lab Accession Code all have clear meaning to healthcare business people,
whereas a surrogate key or system key typically is only meaningful to the database engineer. Although a Hub includes a standard set of additional fields, as
will be shown below, they are all intended simply to manage the stored business key.
Satellite: A Satellite table, which is always dependent on exactly one Hub, contains the payload of attribute fields which shared a table with the business key
in the source system, but which are now stored separately in order to track attribute changes, essentially with single Type 2 slowly changing dimension
(herein SCD2) function without causing duplication of the Hub’s business key.

__________________________________________________________________________________________________________________________________________________________________________________
Page 5 of 21
Ensemble: In the common situation in which multiple source tables exist all with the granularity of the same Business Key, either within or across source
systems, those tables may end up in Data Vault as multiple Satellites, all as dependents to the same single Hub Table. This set of one Hub and one or more
Satellites is an Ensemble.
Link: Link tables relate two or more Hubs together as an association. In its simplest form, a Link table is an associative table that joins what, in the source
system, was a dependent table and a parent table, whether this relationship was enforced with a foreign key constraint or not. As an associative table, the
Link gracefully handles not only the expected, one might say desirable, one-to-many relationship among actual data records from the two table, but also any
real-world many-to-many conditions in the relationship between actual records in the two source tables. As such, the Link affords a looser, more robust
form of referential integrity between Hubs, but importantly, does so without making either Hub actually dependent on other related Hubs, since Hubs are
never directly dependent on another table, but only by associative Links.
Object Naming: The names of source system tables and fields all remain unchanged, except insofar as tables are usually appended with “_hub, _sat, or
_lnk” suffixes and additional surrogate keys, data stamps and audit fields are added. As such, the name of all business keys and attribute fields remain
unchanged from the source system. This transparency from source to data vault is consistent with the principle that, at the data vault stage, “interpretative”
data transformations, such as calculation, aggregation, filtering, grouping, has not YET occurred. In fact, those processes occur immediately downstream of
data vault.
Pros, Cons and Disclaimers based on Data Vault fundamentals and from multiple in-the-trench implementation experiences
Disclaimers: Data Vault…
o Does not solve unsolvable challenges of data integration, as where two systems lack a set of sufficiently match-able keys in order to achieve a
satisfactory percentage of record matches.
o Does not eliminate the need for data profiling, data quality processing, nor the work of analytics/reporting-driven (conforming) data transformation
of non-key attributes, perhaps achieving a SVOT, but merely defers that phase until immediately after the data is landed, loosely integrated, and
historized.
o Does not eliminate, only defers, the decision-making associated with interpretive data transformations (ie. object renaming, selection of one source
field instead of another, calculation, aggregation, grouping, filtering, and data quality processing.
Cons
o Learning Curve: At first, the Hub, Satellite, Link modeling pattern is unfamiliar and potentially intimidating. As such, it could be a source of
dissatisfaction to a DW team member who rejects the method, whether or not it is well understood.
o Adds tables, thus adds joins required for downstream ETL queries. Those who want to avoid a (non-presentational) data management layer of any
kind between source data and a BI data presentation layer cannot easily see how this one is better than any other one.
Pros
o Establishes a clear distinction between demand-driven (data presentation) design vs. supply-driven (data management layer) design, and an
associated clear opportunity for multiple simultaneous development tracks.

__________________________________________________________________________________________________________________________________________________________________________________
Page 6 of 21
Why? As soon as needed source tables are identified, but perhaps long before reporting / analytics requirements are fully understood (if
they ever really are), thus before Data Presentation Layer modelling is done, data vault design AND loading can be started and even
completed, so that historical source data is quickly manageable with full referential integrity in the data warehouse environment.
As a result, data vault data is easily re-purposable for future requirements for data presentation, reporting, analytics.
o Data Profiling: Data Vault provides a crystal-clear end-point for data profiling. Profiling for data vault is complete when all relevant business keys
have been identified and key-match rates among, and across source systems have been measured.
o Modularization: In deferring interpretive data transformations, as described above, it effectively modularizes those processes and clearly
distinguishes them (downstream) from the process of loosely-coupling, loading and capturing historic changes within relevant source data, and
doing so with transparency.
o Inherently Extensible, Durable and Scalable.
Extensible: Since new data vault features are very easily added onto an existing Vault with little or no refactoring of the existing solution,
multiple simultaneous tracks of data vault development within the same data warehouse solution are also straightforward, because of the
avoidance of entity dependencies within a data vault schema.
Durable: Data Vault is exceptionally easy to re-factor to accommodate changes in source data schema.
Scalable: As data volumes grow, each data vault ensemble is a robust, logically independent structure, each of which can reside on a specific
partitioning or node within a cluster or MPP architecture.
o Simplicity: Since Data Vault is a simple set of patterns, the learning curve is fast for willing learners: For design, inbound ETL, and outbound ETL, the
small set of generic patterns, once learned, quickly become familiar and are easily re-used for new data requirements.
o Transparency: Upstream and Downstream Facing
Upstream Transparency: Views within the Data Vault are easily constructed as a mirror to source data, either as current snapshots or as
time-slices
Downstream Transparency: Using generic data vault patterns, downstream-facing views, special-use tables or user-defined functions, are
also easily constructed to return results identical, with or without object renaming, to downstream structures such as large, complex,
denormalized Type 2 slowly changing dimensions, as well as fact tables ranging from transaction-grained to periodic and accumulating
snapshots. These downstream-facing structures may even be used to standardize on down-stream ETL patterns.
o Data Quality Process Transparency: Data Vault supports the following standardized data quality processing patterns and has an important bonus
feature:
De-duplication: For a base Hub-Satellite ensemble, we can either create a sister ‘Golden Record’ ensemble, with the Satellite containing the
match-able attributes or, for simpler requirements, we might just add a Boolean ‘IsNotGolden’ field to a base Hub table to identify records
which have a duplicate that was chosen over them as being authoritative.
Data Quality Satellites: Records in these tables corresponding to specific data quality issues among source attributes in the corresponding
base-Satellite. These DQ Satellites may contain cleansed values of base Satellite attributes, modified to conform to various standards, but
without altering values in the base Satellite record.
Support for Data Quality Mart: If desired, direct support, using the above structures, for a custom Data Quality Data Mart, providing closed
loop reporting, covering all other data marts, back to data stewards about data quality details issues discovered and resolved (or not

__________________________________________________________________________________________________________________________________________________________________________________
Page 7 of 21
resolved) over time. See Kimball’s ETL Toolkit, Chapter 4, ‘Data Quality Design’, which is easily supplied with data by the aforementioned
structures.
Bonus ‘Data Quality Lifecycle’ Feature: Since data vault stores and historizes largely untransformed source data history, data quality project
work can be performed before, during, or after other project work, and will always have all historic data available. In contrast, performing
data quality work only on temporarily staged data pre-supposes that ALL data quality rules are fully defined, not to mention fully coded,
prior to rolling the data warehouse into production. How likely is that?
-------------------------------------------------------------------------------------------------------------------------------------------------------------

__________________________________________________________________________________________________________________________________________________________________________________
Page 8 of 21
Data Vault* What it is not: A presentation layer, which is optimized, often de-normalized, to both simplify and accelerate analytic queries for a wide-spectrum of users.
What it is:
o An enterprise data management layer, optimized… wherein operational data is loaded, permanently stored, historized, and loosely coupled by keys,
but without yet requiring significant data interpretation (object renaming, selection of certain attributes over others, grouping, filtering, de-
duplication or cleansing. As such the potential for data misinterpretation, loading of wrong data, loss of transparency with source data, data loss, or
inability to re-load historic data are, as project risks, reduced or eliminated.
o Although all of the above not-done yet efforts remain vital, they are all done immediately downstream of a data vault, and hence the complexity and
effort to deliver this layer is a fraction of a classic EDW, and the data vault can serve as the common enterprise data source for building, re-
populating, or refactoring any other data layer, be it a Star Schema, another reporting or analytics presentation layer, a Data Quality processing
layer, or a closed-loop Master Data Management layer.
Note: As the number of tables increases, colors depicting two levels of abstraction become crucial for visualization, communication and sanity with Data
Vault.
o Color by data subject area. Demonstrated in the next set of figures.
o Color by table type (Hub, Satellite, Link). Demonstrated later, when additional tables are shown.
Ultra-Simple High-Level Visual Demo: Student and Major Tables in Student Records System
Assume records in both tables are regularly updated, at which time historical data, while needed for B.I. reporting, is overwritten.
Figure 1: Student and Major Tables in Student Record System (from University OLTP and EDW – Week 1 Day 1.dez)
__________________________________________________________________________________________________________________________________________________________________________________
Page 9 of 21
---------------------------------------------------------------------------------------------------------------------------------------------------------------
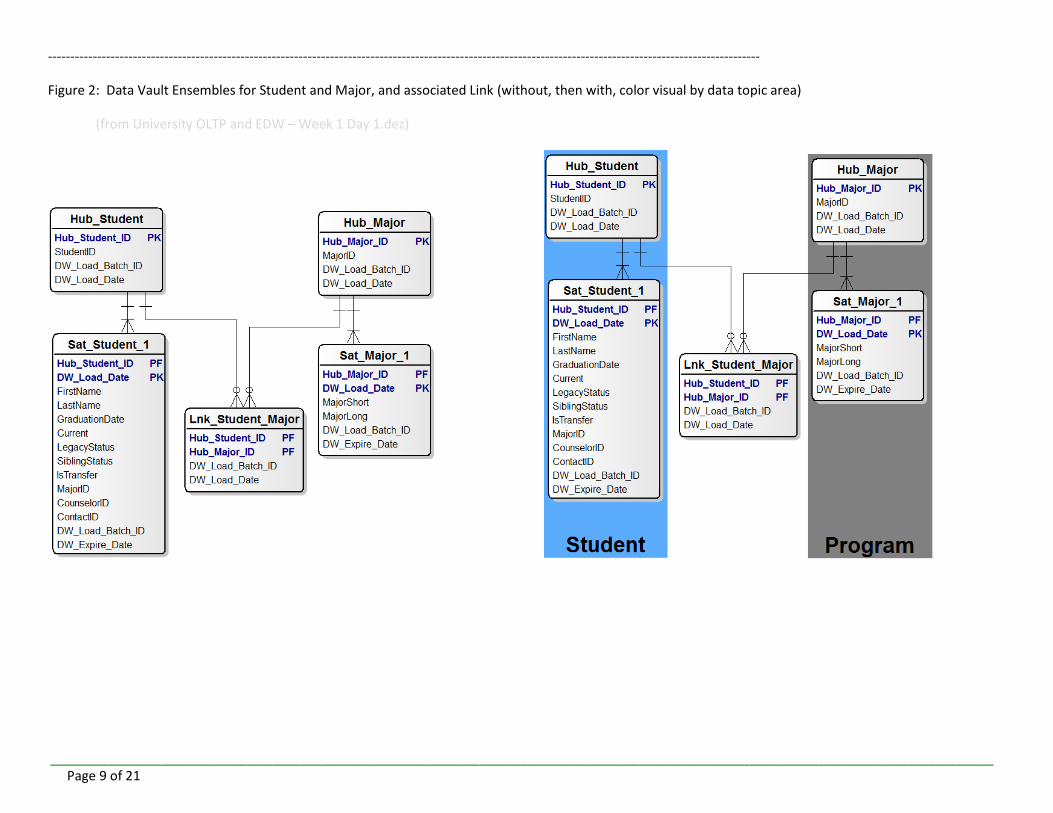
Figure 2: Data Vault Ensembles for Student and Major, and associated Link (without, then with, color visual by data topic area)
(from University OLTP and EDW – Week 1 Day 1.dez)

__________________________________________________________________________________________________________________________________________________________________________________
Page 10 of 21
Scenario: Four related OLTP source entities, existing in two separate systems, become a set of tables in either a third-normal-form EDW model, a
dimensional model, or a data vault.
Step 1: Profile in Source Systems
Four Tables (Entities), from Student Records system and Fundraising system
Three Student Records Tables: Student, Major, Department
One Fundraising Table: Dept_Fundraising_Participation
Notes: The one-to-many relationship between Major and Student is not enforced by a foreign key. Also, the Dept_Fundraiser_Participaton table uses a
different key than the Department table. Lastly, although it’s granularity is ‘one Department’, the subject area of the table is actually more related to
fundraising activity, aggregated at the department level, than it is to the Department itself. As such, these two department-related tables have a weak
context, by themselves, for a tight integration aimed at an SVOT.
Source Table Screenshots (Figures 4a and 4b) correctly capture their associated business processes.
Figure 3a: Three Tables in Student Enrollment System Fig. 3b: Dept_Fundraiser_Participation in Fundraiser System
(both figures are from University OLTP and EDW – Week 1 Day 1.dez)
__________________________________________________________________________________________________________________________________________________________________________________
Page 11 of 21
--------------------------------------------------------------------------------------------------------------------------------------------------------------
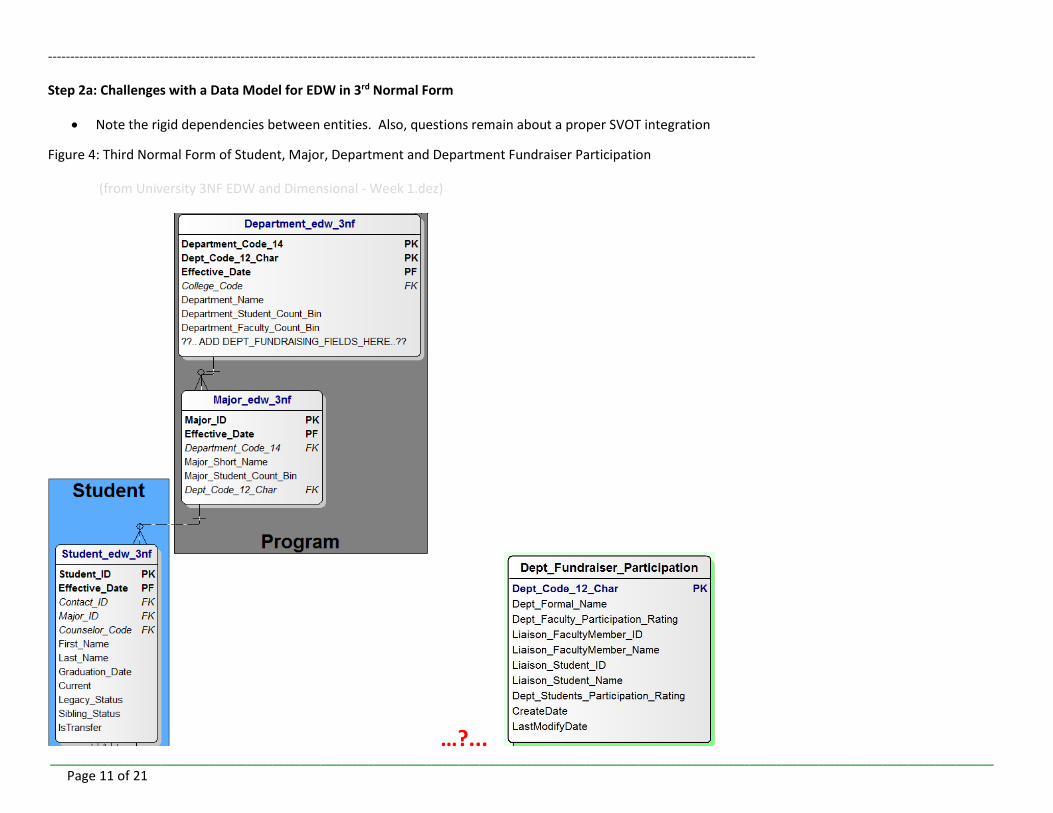
Step 2a: Challenges with a Data Model for EDW in 3rd Normal Form
Note the rigid dependencies between entities. Also, questions remain about a proper SVOT integration
Figure 4: Third Normal Form of Student, Major, Department and Department Fundraiser Participation
(from University 3NF EDW and Dimensional - Week 1.dez)
…?...
__________________________________________________________________________________________________________________________________________________________________________________
Page 12 of 21
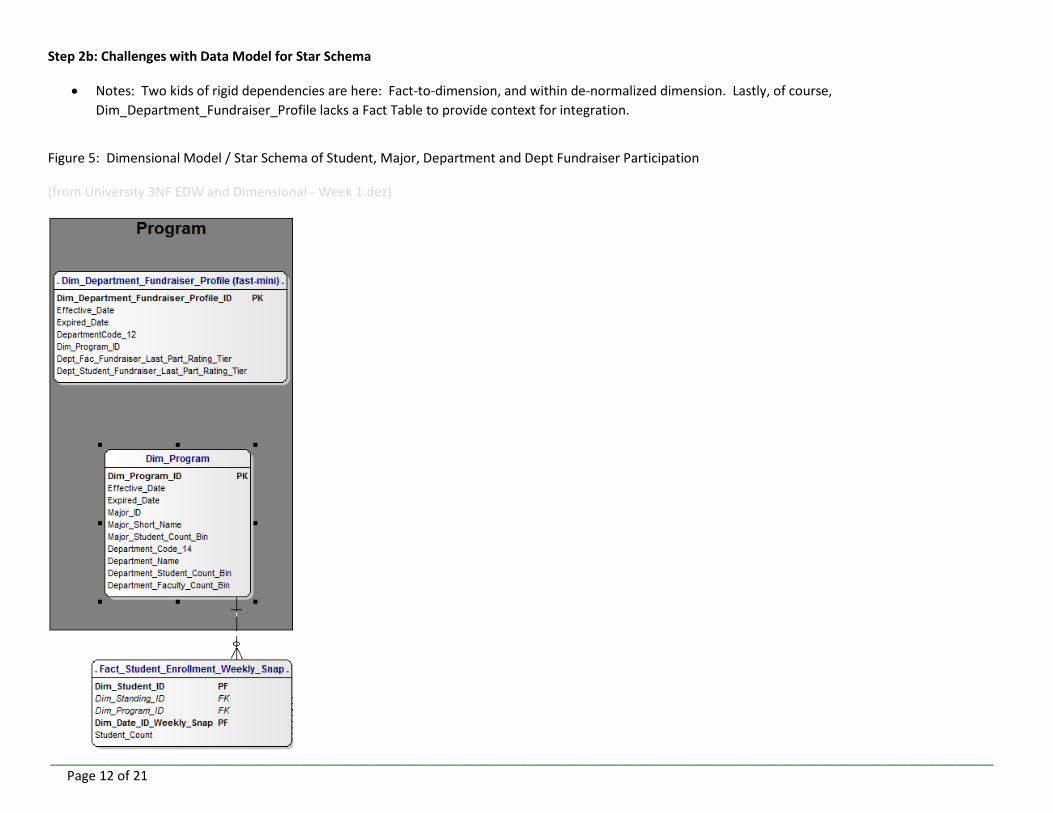
Step 2b: Challenges with Data Model for Star Schema
Notes: Two kids of rigid dependencies are here: Fact-to-dimension, and within de-normalized dimension. Lastly, of course,
Dim_Department_Fundraiser_Profile lacks a Fact Table to provide context for integration.
Figure 5: Dimensional Model / Star Schema of Student, Major, Department and Dept Fundraiser Participation
(from University 3NF EDW and Dimensional - Week 1.dez)

__________________________________________________________________________________________________________________________________________________________________________________
Page 13 of 21
Step 2c: Data Model for Data Vault
Notes:
o Hub Independence: Hubs, with their business keys, are never schema-dependent on another table.
o Link handles the real world data-dependencies, but does so loosely (loose coupling) as an associative table.
o Satellites, with their many attributes, become loosely coupled with related attributes in other tables and systems, with alignment via Business
Keys, and with history-tracking changes captured as versioned rows just like Type 2 slowly-changing dimensions.
Satellites with a single Ensemble may have very different loading frequency.
Colors for table types. In keeping with a general data vault standard, Hubs are depicted in blue in capable modeling tools, Satellites are yellow, and
Links are red. This, in addition to colors by subject area, as also shown in this figure, greatly simplify visual navigation and communication among
involved team members, especially when the number of tables extends to real-world numbers.
Figure 6: Data Vault Model of Student, Major, Department, and Department Fundraiser Participation
(from Univ… OLTP and EDW - Week 2 with MD5 NoSQL Schema.dez)

__________________________________________________________________________________________________________________________________________________________________________________
Page 14 of 21
Step 3: Business process change involves a source system schema change that will compromise the data warehouse if not quickly adapted.
Change: University policy changes so that students may now have double majors or a major and a minor, rather than just one major per student, which
was the old business rule.
The new source schema shown here correctly stores data from this new business process in the Student Records system, in contrast to the original
schema in Figure 4a.
o Note: The retention of the old ‘MajorID’ field was chosen by the OLTP data architect in addition to directing a re-load of all historical foreign key
values into the new “StudentMajorsMinor (v2)’ table. Note: All (v2), etc. characters are for illustration only.
Figure 7: Student Records System Change: Double Majors and Minors
(from University OLTP and EDW - Week 6 with MD5 NoSQL Schema.dez)
__________________________________________________________________________________________________________________________________________________________________________________
Page 15 of 21
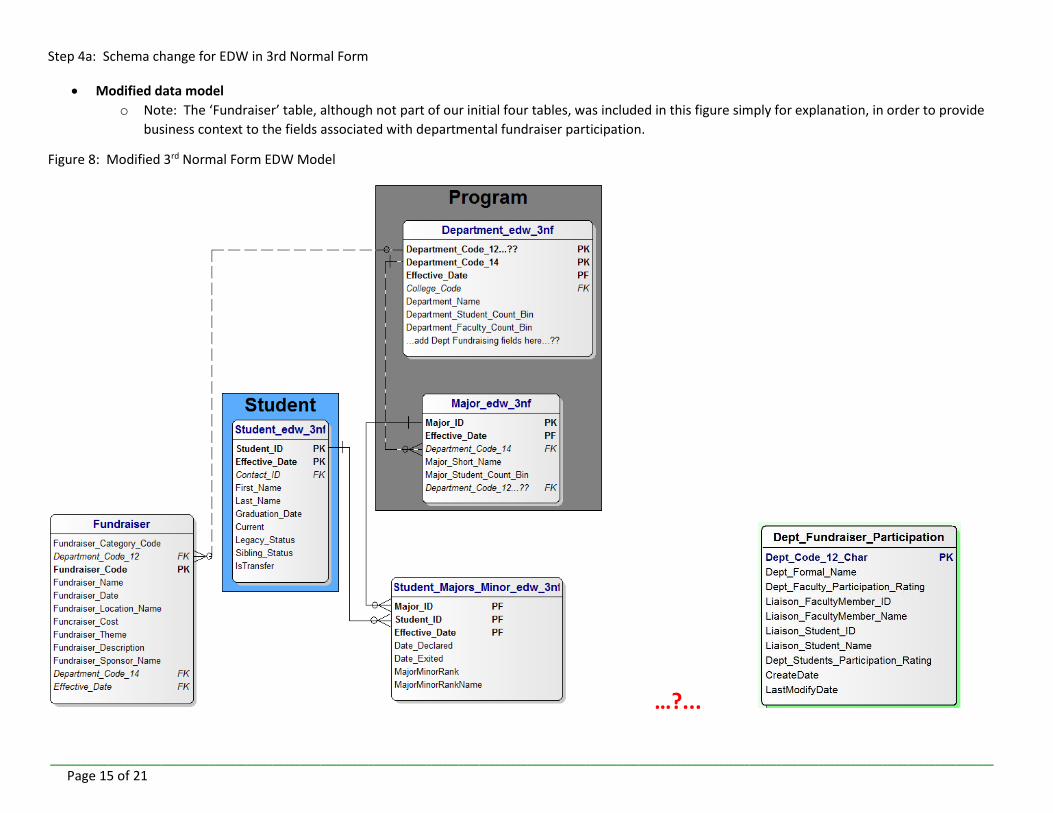
Step 4a: Schema change for EDW in 3rd Normal Form
Modified data model
o Note: The ‘Fundraiser’ table, although not part of our initial four tables, was included in this figure simply for explanation, in order to provide
business context to the fields associated with departmental fundraiser participation.
Figure 8: Modified 3rd Normal Form EDW Model
…?...

__________________________________________________________________________________________________________________________________________________________________________________
Page 16 of 21
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Modified upstream ETL: Is the required effort for this small change acceptable?
o Department_edw_3nf ETL processing now dependent on changes to either Student Records or Fundraising systems. If either source system
delivers records with keys that are not matchable to the other system, the two choices are both complex.
One choice is to either discard the unmatched record and load it in a subsequent increment or hold that record in a control table.
The other choice is to allow for most fields to remain NULL and establish a complex ETL rule that does two things
Initially insert records with fields available from one system, while leaving all fields from the other system as NULLs
Revisiting all such records later with updates from the late-arriving data from the other system.
Modified downstream schema and ETL or queries for downstream reports, dashboards, perhaps Star Schema
o Is this required effort also acceptable for this small source schema change?
o Problem: This set of unfortunate choices has a simple cause, which is the optimistic notion that the EDW schema should not only capture a
given business process correctly when first implemented and loaded, but that this process, as well as related business processes, all now fixed
into a transformed, tightly integrated schema, also will not change much over time. Whether or not that notion of relatively unchanging
business processes was valid back in the 90’s, when third-normal EDW’s were conceived and popularized, the relevant question is really this: Is
it a valid assumption now in 2015?
o Solution: Design Lean data warehouse models that are, along with their associated ETL code, easily adaptive to changing business processes,
even including those business processes that may not reasonably be deeply understood at the time when source data is needed in the data
warehouse, due to a lack of consistent stakeholder participation or authoritative, up to date system documentation.
With data vault, on the other hand, once we understand just the business keys, we are already past the 50 yard line.
__________________________________________________________________________________________________________________________________________________________________________________
Page 17 of 21
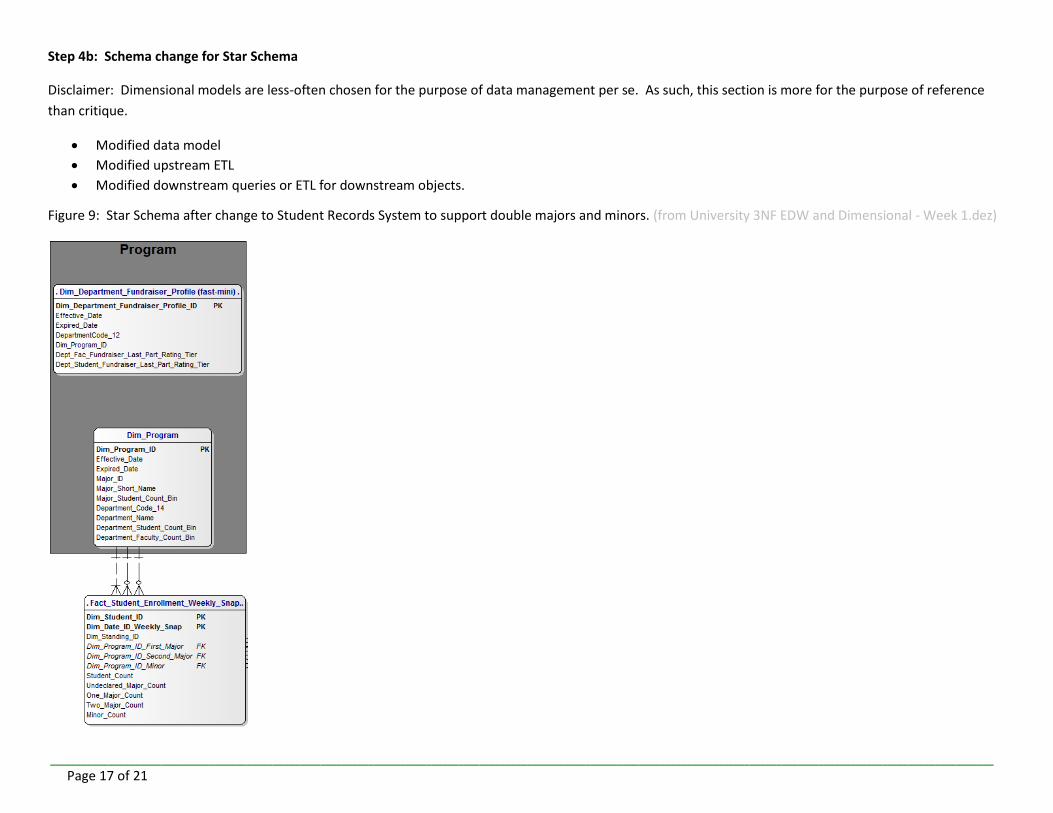
Step 4b: Schema change for Star Schema
Disclaimer: Dimensional models are less-often chosen for the purpose of data management per se. As such, this section is more for the purpose of reference
than critique.
Modified data model
Modified upstream ETL
Modified downstream queries or ETL for downstream objects.
Figure 9: Star Schema after change to Student Records System to support double majors and minors. (from University 3NF EDW and Dimensional - Week 1.dez)

__________________________________________________________________________________________________________________________________________________________________________________
Page 18 of 21
Step 4c: Schema Changes for Data Vault. See Figure 10
No existing schema objects were modified.
Existing ETL is completely untouched, except insofar as the loading of Sat_Student_Progress is discontinued, while the table will remain in use for
historical data prior to the business process change.
Need One New Schema Object and it’s ETL Code: Added a Sat_Lnk_Student_Major as a dependent to Lnk_Student_Major_Department, which, as an
associative table, already had the flexibility to supports the current, or any future combinations of granularity between students, majors and minors.
Figure 10: Data Vault After Source System Mods (from Univ… OLTP and EDW - Week 6 Clean.dez)

__________________________________________________________________________________________________________________________________________________________________________________
Page 19 of 21
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Where do the following related processes fit with Data Vault and a Lean Data Warehouse?
Conforming Dimensions and Facts: Downstream of Data Vault as a stored Dimensional Model, repurpose-able, reloadable at any time from it.
Virtualized dimensional models based on stored data vaults are an interesting, much discussed topic, but I have not (as of early March 2015) seen a
sensible virtual architecture that captures dimensional modelling best practice.
Master Data Management
o Closed-loop MDM, with data vault (as the main MDM data source) handily recording the good, bad, and the ugly exactly as it exists, and as it
is either improved over time, or not improved, in any given source system.
Predictive Analytics: Data Vault’s fidelity to source data, as well as it’s historization of it, should appeal to predictive analysts, who often avoid
highly-transformed data warehouses as data sources. The inclusion in Data Vault of the upstream-facing views, may also assist the predictive analyst
accustomed to source system data.
BigData / NoSQL: Data Vault 2.0 (by D. Linstedt, and not otherwise mentioned in this article), with its MD5 Hash fields as primary keys, offers an
opportunity for massive parallel Data Vault table loading without the typical lookups that to surrogate keys in a target’s parent tables, which
otherwise force sequential table loading.
o Assumption: To do this, BigData records must have granularity loosely defined such that a Business Key does define each record, whether or
not the remainder of attributes are -- from an RDBMS perspective – oddly de-normalized or pivoted. As such, the BigData being referred to
here is more akin to an Apache Cassandra or Hive table than to a Hadoop file.
o One trade-off with an MD5 primary key is, of course, that with the MD5 fields size and datatype (VarBinary in SQL Server), downstream ETL
or queries will be slower-performing than with an Integer primary key used for joins. This, however, may be a worthwhile trade-off in
accommodating the parallel loading of massive BigData.
o If no BigData / NoSQL integration is expected to be required, Data Vault 2.0’s downstream ETL/query performance hit from the required
joins on the lengthy Hash PK’s make little sense.

__________________________________________________________________________________________________________________________________________________________________________________
Page 20 of 21
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Future Topics:
How to Load: Detailed demonstration of data vault loading-transformation logic.
After Load:
o Detailed demonstration of Patterns for data vault views and queries for current or historical snapshots of OLTP data.
o Detailed Demonstration of Patterns for data vault views, queries and point-in-time support tables to support downstream Star-Schema
loading transformations.
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Data Vault* Reference Books:
Super Charge Your Data Warehouse, Daniel Linstedt, 2008-2011, CreateSpace Publishing
The New Business SuperModel: The Business of Data Vault Data Modeling, 2nd Edition, Daniel Linstedt, Kent Graziano, Hans Hultgren, 2008-2009,
Daniel Linstedt
Modeling the Agile Data Warehouse with Data Vault, Hans Hultgren, 2012, Brighton Hamilton

__________________________________________________________________________________________________________________________________________________________________________________
Page 21 of 21
DecisionLab.Net
_____________________________________________________
Thank you. I value your feedback.
___________________________________________________________________________ Daniel Upton DecisionLab http://www.decisionlab.net [email protected] Direct 760.525.3268 Carlsbad, California, USA