learning and vision for multimodal conversational interfaces trevor darrell vision interface group...
TRANSCRIPT

Learning and Vision for Multimodal Conversational Interfaces
Trevor DarrellVision Interface GroupMIT CSAIL Lab

Natural Interfaces
• Conversation would improve many interactions.
• Currently, conversational interfaces are useless in most situations with more than one user, or with real-world references.
• Visual Context is missing…

Visual Context for Conversation
• Who is there? (presence, identity)• Which person said that? (audiovisual grouping)• Where are they? (location)• What are they looking / pointing at? (pose, gaze)• What are they doing? (activity)

Learning
• Visual conversational context cues are hard to model analytically.
• Learning methods are appropriate• Different techniques for different cues, levels of
representation, input modes, ...
(At least for now…)

Today
• Speaker segregation using audio-visual mutual information- discard background sounds- separate multiple conversational streams
• Head pose detection and tracking with multi-view appearance models- attention- agreement
• Articulated pose tracking by learning model constraints, or example-based inference…- gesture- “body language”

Today
• Speaker segregation using audio-visual mutual information- discard background sounds- separate multiple conversational streams
• Head pose detection and tracking with multi-view appearance models- attention- agreement
• Articulated pose tracking by learning model constraints, or example-based inference…- gesture- “body language”

blah blah blahblah blah blah
blah blah blahblah blah blah
blah blah blahblah blah blah
blah blah blah blah
computer, show me the NIPS presentation
Is that you talking?
blah blah blahblah blah blah
blah blah blahblah blah blah
blah blah blahblah blah blah
blah blah blah blah
computer, show me the NIPS presentation

Audio-visual synchrony
Can we find a relationship between audio and visual events (e.g., speech)?
?

Audio-visual synchrony
Can we find a relationship between audio and visual events (e.g., speech)?
Model-free?
?

Audio-visual synchrony
Yes, by learning a model of audio-visual synchrony. Three approaches:
• Pixel-wise corellation with video [Hershey and Movellan]
• Correlation of optimal projection [Slaney and Covell]
• Non-parametric Mutual Information analysis on optimal projection [Fisher et al.]

Audio-based Image localization
E.g., locate visual sources given audio information:
Original Sequence

Audio-based Image localization
Image variance (ignoring audio) will find all motion in the sequence:
Image Variance

Audio-based Image localization
Estimate mutual information between audio and video:
Pixels which have high mutual information w.r.t
audio track

A(t)
V(x,y,t)
time
I(x,y)
EvaluateStatistic
),,(),,,(~),,(),(
),,(),,,(~),,(
)(),(~)(
,, kVAkVAmnkk
kVkVmk
kAkAnk
tyxtyxtyxVtA
tyxtyxtyxV
tttA
• Assumes jointly Gaussian audio and video
• Recursively estimate statistics over a window of time (~.5 sec)
• Calculates pixelwise mutual information / correlation (m=n=1)
),,(
),,()(log
2
1),,(),(
, kVA
kVkAkk
tyx
tyxttyxVtAI
• Determine speaker by finding “centroid” of
AudioVision: Hershey and Movellan (NIPS 1999) video obtained from http://mplab.ucsd.edu/~jhershey/
),,(),( kk tyxVtAI
A threshold and Gaussian influence function reduce the contribution of spuriously high MI values away from the centroid (shown as a + in the video).
Pixel-wise correlation

EvaluateStatistic
“Learned” Subspace
I
• Uses canonical correlation to find the best projection of audio and video.
i.e. Define: projection of audio projection of video
and find
AAa T '
]''[]''[
]''[maxarg, vvEaaE
vaEcca
VVv T '
• Uses a face detector to locate and align faces in video.
• Training step finds and . • Testing evaluates correlation between and for new audio and video data.'a 'v
FaceSync: Slaney and Covell (NIPS 2001)
Cannonical correlation projection

Non-parametric Mutual Information
• Match audio to video using adaptive feature basis • Exploit joint statistics of image and audio signal• Efficient non-parametric density estimation

Maximally Informative Subspace
i
Tv v if h V
i
Ta a if h A
• Treat each image/audio frame in the sequence as a sample of a random variable.• Projections optimize the joint audio/video. statistics in the lower dimensional feature space.• Approximate joint density with Parzen window nonparametric model.• Gradient of approximate entropy can be computed efficiently [Fisher 97]• Current work uses single projection; extending to multidimensional projection…

Audio-visual synchrony detection
MI: 0.68 0.61 0.19 0.20
Compute similarity matrix for 8 subjects: No errors!
No training!
Also can use for audio/visual temporal alignment
[Fisher and Darrell ECCV 2002]

Today
• Speaker segregation using audio-visual mutual information- discard background sounds- separate multiple conversational streams
• Head pose detection and tracking with multi-view appearance models- attention- agreement
• Articulated pose tracking by learning model constraints, or example-based inference…- gesture- “body language”

Head pose tracking

Lots of Work on Face Pose Tracking…
• Cylindrical approx. [LaCascia & Sclaroff]• 3D Mesh approx. [Essa]
• 3D Morphable model [Blanz & Vetter]• Multi-view keyframes from 3D model [Vachetti et al.]• View-based eigenspaces [Srinivasan & Boyer]
[Pentland et al.]• …
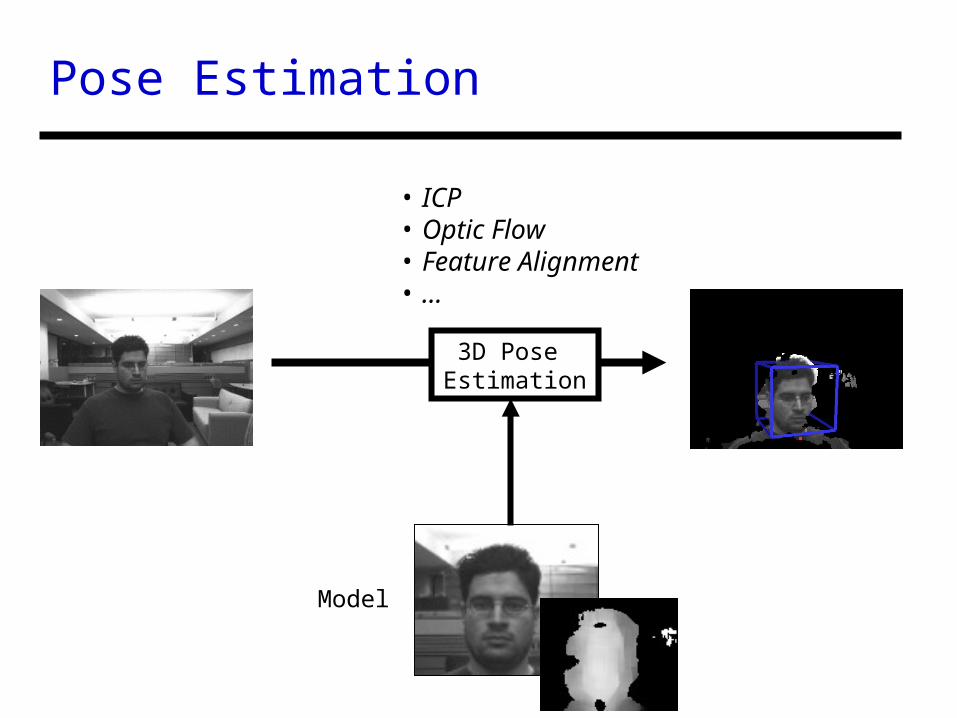
Pose Estimation
3D Pose Estimation
Model
• ICP• Optic Flow• Feature Alignment• …

User Dependent Keyframes
?
3D Pose Estimation
3D Pose Estimation

User-Independent Prior Model
3D Pose Estimation
3D Pose Estimation
PriorModel
Multi-viewReconstruction

3D View-based Eigenspaces
3D View-basedEigenspaces
3D Pose Estimation
3D Pose Estimation
Multi-viewReconstruction

View-based Eigenspaces
PCA
1 PCA
PCA
PCA
PCA
2
3
4
5
ΙIV
1I 2I

3D View-based Eigenspaces?
?
?
?
?
ZΙ , ZI VV ,1I 2I1Z 2Z
1
2
3
4
5

3D View-based Eigenspaces
ZUDV IIT
Z11
Transfer weights to depth images:
TIIIII )()( 21
TZZZZZ )()( 21
1
1I 2I1Z 2Z
TIII VDUI
SVD Decomposition of intensity image:
weights

Reconstruction1Ι 1I
V
2Ι 2IVtIsubwindow
tZ
2iIiiti VwIIE
Minimize the reconstruction error
iwLeast-square Optimal
Eigenvectorweights
ii IiiR VwII
ii ZiiR VwZZ
1. For each subwindow {It , Zt } and view i:

Reconstruction
tI
1Ι 1IV
2Ι 2IV
… and compute the normalized cross-correlation
),(),(ii RtRti ZZcorrIIcorrc
2. Select the view i and the subwindow {It , Zt } that optimize ci
subwindow
tZ
1. For each subwindow {It , Zt } and view i:

Reconstruction
Input subwindow
Ground truth
tI
1Ι 1IV
2Ι 2IVsubwindow
tZ
3. Reconstruct all views:
Reconstruction
ii IiR VwII
ii ZiR VwZZ

Pose Estimation
t
View registration[ICPR 2002]
1. Search new frame for best subwindow using correlation
2. Select k best keyframes
3. Compute rigid motion using ICP + Normal Flow

Pose Estimation
t
• Observation Model:
Kalman filter framework
},,,{21PPtX
},,{21t
PtPY
[CVPR 2003]
ii Pt
tPiY

Experiments
• Image sequences from stereo cameras• Prior model: 14 subjects in 28 orientations• Ground truth with Inertia Cube sensor• Compare with OSU pose estimator [Srinivasan & Boyer
’02]- Use same training set for eigenspaces

Results
1,331,555
2,02
3,23
3,735
0
0,5
1
1,5
2
2,5
3
3,5
4
Rotation X Rotation Y Rotation Z
Ave
rage
RM
S Er
ror
Multi-view
OSU

Exploiting cascades for speed
• But, correlation search step is very slow!• Using a cascade detection paradigm [Viola, Jones], many patterns
can be quickly rejected.- Set false negative rate to be very low (e.g. 1%) per stage
- each stage may have low hit rate (30-40%) but overall architecture is efficient and accurate
• Multi-view cascade detection to obtain coarse initial pose estimate

Pose aware interfaces
• Interface Agent responds to gaze of user- agent should know when it’s being attended to- turn-taking pragmatics- eventually, anaphora + object reference
• Prototype- Smart-room interface “sam”- Early experiments with face tracker on meeting room table…

Subject not looking at SAMASR turned off
SAM
Pose tracker

Subject looking at SAMASR turned on
SAM
Pose tracker

Head nod detection
• Track 6DOF motion of head nod and shake gestures• Experiment with simple motion energy ratio test.• Initial results promising

Today
• Speaker segregation using audio-visual mutual information- discard background sounds- separate multiple conversational streams
• Head pose detection and tracking with multi-view appearance models- attention- agreement
• Articulated pose tracking by learning model constraints, or example-based inference…- gesture- “body language”

Articulated pose sensing

Learning Articulated Tracking
• Model-based approach works for 3-D data and pure articulation constraints…
• Need to learn joint limits and other behavioral constraints (with a classic model-based tracker)
• Without direct 3-D data, example-based techniques are most promising…

Model-based Approach
depth image

Model-based Approach
depth image
ICP with articulation constraint
model

Model-based Approach
depth image
ICP with articulation constraint
model
1. Find closest points2. Update poses3. Constrain…

ICP with articulated motion constraint
• Minimize distance between 3D-data and 3-D articulated model
- Apply ICP to each object in the articulated model to find motion (twist) kt) with covariancek for each limb.
- Enforce joint constraints: find a set of motions k’ close to original motions that satisfy joint constraints
• Pure articulation can be expressed as a linear projection on stacked rigid motion

Non-linear constraints
• Limitations of Pure Articulation Constraints- Can not capture the limits on the range of motion of human joints- Can not capture behavioral limits of body pose
• Learning approach: learn a discriminative model of valid / invalid pose
• Train SVM for use as a Lagrangian constraint- Valid body poses extracted from mocap data (150,000 poses)- Invalid body poses generated randomly- Cross-validation classification error rates at around .061%
Support Vectors

Video

Multimodal gestures

Learning pose without 3-D observations
• Model based approach difficult with more impoverished observations…e.g., contour or edge features
• Example based learning approach- Generate corpus of training data with model (Poser)- Find nearest neighbors using fast hashing techniques (LSH)- Optionally use local regression on NN
• With segmented contours - shape context features- bipartite graph matching via Earth Movers’ Distance
• With unsegmented edge features- feature selection using paired classification problem- extend LSH to use “Parameter sensitive Hashing”

Parameter sensitive hashing
• When explicit feature (shape context) is not available, feature selection is needed
• Features for an optimal distance can be found by training a classifier on an equivalence task
• LSH+classifier-based feature selection=PSH
e.g., hashing functions sensitive to distance in a parameter space, not feature space.
“Parameter Sensitive Hashing” [Shakhnarovich et al.]

Parameter sensitive hashing
(Details tomorrow…!)

Saturday Workshop

Schedule
5:30pm-5:50pm: TalkFast Example-based Estimation with Parameter-Sensitive HashingGreg Shakhnarovich
10:30am: PosterContour Matching Using Approximate Earth Mover's DistanceKristen Grauman

Today
Learning methods are critical for robust estimation of synchrony, pose and other conversational context cues:
• Speaker segregation using audiovisual mutual information
• Head pose estimation using multi-view manifolds and detection cascade trees
• Real-time articulated tracking from stereo data with SVM-based joint constraints
• Monocular tracking using example-based inference with fast nearest neighbor methods

Acknowledgements
• Greg Shakhnarovich• Kristen Grauman• Neal Checka• David Demirdjian• Theresa Ko• John Fisher• Louis-Philippe Morency• Mike Siracusa• …