learning optimal strategies for spoken dialogue systems
DESCRIPTION
Learning Optimal Strategies for Spoken Dialogue Systems. Diane Litman University of Pittsburgh Pittsburgh, PA 15260 USA. Outline. Motivation Markov Decision Processes and Reinforcement Learning NJFun: A Case Study Advanced Topics. Motivation. - PowerPoint PPT PresentationTRANSCRIPT

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 1
Learning Optimal Strategies for Spoken Dialogue Systems
Diane LitmanUniversity of Pittsburgh
Pittsburgh, PA 15260 USA

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 2
Outline
• Motivation• Markov Decision Processes and
Reinforcement Learning• NJFun: A Case Study• Advanced Topics

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 3
Motivation• Builders of real-time spoken dialogue
systems face fundamental design choices that strongly influence system performance – when to confirm/reject/clarify what the user just said?– when to ask a directive versus open prompt?– when to use user, system, or mixed initiative?– when to provide positive/negative/no feedback?– etc.
• Can such decisions be automatically optimized via reinforcement learning?

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 4
Spoken Dialogue Systems (SDS)
• Provide voice access to back-end via telephone or microphone
• Front-end: ASR (automatic speech recognition) and TTS (text to speech)
• Back-end: DB, web, etc.• Middle: dialogue policy (what
action to take at each point in a dialogue)

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 5
Typical SDS ArchitectureLanguage
Understanding
Dialogue Policy
DomainBack-end
LanguageGeneration
SpeechRecognition
Text to Speech

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 6
Reinforcement Learning (RL)
• Learning is associated with a reward• By optimizing reward, algorithm learns
optimal strategy• Application to SDS
– Key assumption: SDS can be represented as a Markov Decision Process
– Key benefit: Formalization (when in a state, what is the reward for taking a particular action, among all action choices?)

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 7
Reinforcement Learning and SDS
LanguageUnderstanding
DialogueManager
DomainBack-end
LanguageGeneration
SpeechRecognition
SpeechSynthesis
noisysemantic input
actions(semantic output)
• debate over design choices• learn choices using
reinforcement learning• agent interacting with an
environment• noisy inputs• temporal / sequential
aspect• task success / failure

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 8
Sample Research Questions
• Which aspects of dialogue management are amenable to learning and what reward functions are needed?
• What representation of the dialogue state best serves this learning?
• What reinforcement learning methods are tractable with large scale dialogue systems?

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 9
Outline
• Motivation• Markov Decision Processes and
Reinforcement Learning• NJFun: A Case Study• Advanced Topics

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 10
Markov Decision Processes (MDP)
• Characterized by:– a set of states S an agent can be in– a set of actions A the agent can take– A reward r(a,s) that the agent
receives for taking an action in a state
– (+ Some other things I’ll come back to (gamma, state transition probabilities))

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 11
Modeling a Spoken Dialogue System as a Probabilistic
Agent• A SDS can be characterized by:
– The current knowledge of the system• A set of states S the agent can be in
– a set of actions A the agent can take– A goal G, which implies
• A success metric that tells us how well the agent achieved its goal
• A way of using this metric to create a strategy or policy for what action to take in any particular state.

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 12
Reinforcement Learning• The agent interacts with its environment to
achieve a goal
• It receives reward (possibly delayed reward) for its actions– it is not told what actions to take– instead, it learns from indirect, potentially delayed
reward, to choose sequences of actions that produce the greatest cumulative reward
• Trial-and-error search– neither exploitation nor exploration can be pursued
exclusively without failing at the task
• Life-long learning– on-going exploration

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 13
ReinforcementLearning
state
action reward
Policy : S A
s0 r0
a0 s1 r1
a1 s2 r2
a2 . . .

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 14
State Value Function, V
s2 s0
s3
s1
r(s0, a1) = 2 p(s0, a1, s2) = 0.3
p(s0, a2, s2) = 0.5
p(s0, a2, s3) = 0.5
p(s0, a1, s1) = 0.7
r(s0, a2) = 5
State, s V(s)
s0 ...
s1 10
s2 15
s3 6
Choosing a1: 2 + 0.7 × 10 + 0.3 × 15 = 13.5Choosing a2: 5 + 0.5 × 15 + 0.5 × 6 = 15.5
V(s) predicts the futuretotal reward we can obtain by entering state s
Ss
sVsaspasr'
)'()',,(),(
can exploit V greedily, i.e. in s, choose action a for which the following is largest:

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 15
Q(s, a) predicts the future total reward we can obtain by executing a in s
Action Value Function, Q
s0
State, s Action, a Q(s, a)
s0 a1 13.5
s0 a2 15.5
s1 a1 ...
s1 a2 ...
can exploit Q greedily, i.e. in s, choose action a for which Q(s, a) is largest

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 16
Q LearningFor each (s, a), initialise Q(s, a) arbitrarily
Observe current state, s
Do until reach goal state
Select action a by exploiting Q ε-greedily, i.e. with probability ε, choose a randomly; else choose the a for which Q(s, a) is largest
Execute a, entering state s’ and receiving immediate reward r
Update the table entry for Q(s, a)
s s’
Exploration versus
exploitation
One-step temporal difference update rule, TD(0)
)),()','(max(),(),('
asQasQrasQasQa
Watkins 1989

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 17
More on Q Learning
s’
s
Q(s, a)
Q(s’, a’)
a’
a
r

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 18
A Brief Tutorial Example
• A Day-and-Month dialogue system• Goal: fill in a two-slot frame:
– Month: November– Day: 12th
• Via the shortest possible interaction with user
• Levin, E., Pieraccini, R. and Eckert, W. A Stochastic Model of Human-Machine Interaction for Learning Dialog Strategies. IEEE Transactions on Speech and Audio Processing. 2000.

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 19
What is a State?
• In principle, MDP state could include any possible information about dialogue– Complete dialogue history so far
• Usually use a much more limited set– Values of slots in current frame– Most recent question asked to user– Users most recent answer– ASR confidence– etc

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 20
State in the Day-and-Month Example
• Values of the two slots day and month.• Total:
– 2 special initial state si and sf.– 365 states with a day and month– 1 state for leap year – 12 states with a month but no day– 31 states with a day but no month– 411 total states

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 21
Actions in MDP Models of Dialogue
• Speech acts!– Ask a question– Explicit confirmation– Rejection– Give the user some database
information– Tell the user their choices
• Do a database query

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 22
Actions in the Day-and-Month Example
• ad: a question asking for the day
• am: a question asking for the month
• adm: a question asking for the day+month
• af: a final action submitting the form and terminating the dialogue

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 23
A Simple Reward Function• For this example, let’s use a cost function for
the entire dialogue• Let
– Ni=number of interactions (duration of dialogue)
– Ne=number of errors in the obtained values (0-2)
– Nf=expected distance from goal• (0 for complete date, 1 if either data or month are missing, 2
if both missing)
• Then (weighted) cost is:
• C = wiNi + weNe + wfNf

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 24
3 Possible Policies
Open prompt
Directive prompt
Dumb
P1=probability of error in open prompt
P2=probability of error in directive prompt

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 25
3 Possible Policies
P1=probability of error in open prompt
P2=probability of error in directive prompt
Strategy 3 is better than strategy 2 when improved error rate justifies longer interaction:
OPEN
DIRECTIVE
p1 p2 wi
2we

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 26
That was an Easy Optimization
• Only two actions, only tiny # of policies
• In general, number of actions, states, policies is quite large
• So finding optimal policy is harder• We need reinforcement learning• Back to MDPs:

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 27
MDP• We can think of a dialogue as a
trajectory in state space
• The best policy is the one with the greatest expected reward over all trajectories
• How to compute a reward for a state sequence?

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 28
Reward for a State Sequence
• One common approach: discounted rewards• Cumulative reward Q of a sequence is
discounted sum of utilities of individual states
• Discount factor between 0 and 1• Makes agent care more about current than
future rewards; the more future a reward, the more discounted its value

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 29
The Markov Assumption
• MDP assumes that state transitions are Markovian
P(st1 | st ,st 1,...,so,at ,at 1,...,ao) PT (st1 | st ,at )

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 30
Expected Reward for an Action
• Expected cumulative reward Q(s,a) for taking a particular action from a particular state can be computed by Bellman equation:
– immediate reward for current state– + expected discounted utility of all possible next states
s’– weighted by probability of moving to that state s’– and assuming once there we take optimal action a’

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 31
Needed for Bellman Equation
• A model of p(s’|s,a) and estimate of R(s,a)– If we had labeled training data
• P(s’|s,a) = C(s,s’,a)/C(s,a)
– If we knew the final reward for whole dialogue R(s1,a1,s2,a2,…,sn)
• Given these parameters, can use value iteration algorithm to learn Q values (pushing back reward values over state sequences) and hence best policy

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 32
How to estimate p(s’|s,a) without labeled data
• Random conversations with real people– Carefully hand-tune small number of states and
policies– Build a dialogue system which explores state space
by generating a few hundred random conversations with real humans
– Set probabilities from this corpus• Random conversations with simulated people
– Have millions of conversations with simulated people– Can have a slightly larger state space

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 33
Final Reward
• What is the final reward for whole dialogue R(s1,a1,s2,a2,…,sn)?
• The general goodness of a whole dialogue!
• Can be automatically computed using PARADISE evaluation framework (more later)

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 34
Outline
• Motivation• Markov Decision Processes and
Reinforcement Learning• NJFun: A Case Study• Advanced Topics

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 35
NJFun: A Case Study
• Idea: use reinforcement learning to make a small set of optimal policy decisions while interacting with real people, and empirically evaluate– Singh, S., D. Litman, M. Kearns, and M.
Walker. Optimizing Dialogue Management with Reinforcement Learning: Experiments with the NJFun System. Journal of AI Research. 2002.

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 36
NJFun (aka RLDS) DialoguesTask Description:"You have lived in Stanhope for many years but have never managed to visit its historic sites.
Today you are feeling virtuous. Use RLDS to find out what you can see this morning.”
TTS: Welcome to RLDS. Please say an activity name or say 'list activities' for a list of activities I know about. USER: I would like to visit a historic site in Stanhope this morning. TTS: Did you say you are interested in going to a zoo? USER: No. TTS: I know about amusement parks, aquariums, cruises, historic sites, museums, parks, theaters, wineries, and zoos. Please say an activity name from this list. USER: I would like to visit a historic site. TTS: Did you say you are interested in going to a historic site? USER: Yes. TTS: Please give me more information. USER: ... TTS: Please tell me the location that you are interested in. You can also tell me the time.…. (8 turns omitted)TTS: Thank you for using the system. Please give me feedback by saying 'good', 'so-so', or 'bad'. USER: Bad. TTS: Goodbye and have a nice day!
TTS: Welcome to RLDS. How may I help you? USER: I would like to um find about Stanhope historic sites. TTS: Did you say you are interested in Stanhope? USER: Yes. TTS: What time of the day do you want to go? USER: Uh...morning. TTS: Did you say you want to go in the morning? USER: Yes. TTS: I found 2 historic sites in Stanhope that are open in the morning. They are the Lenape Indian Village, and the Waterloo Village. Thank you for using the system. Please give me feedback by saying 'good', 'so-so', or 'bad'. USER: Good. TTS: Goodbye and have a nice day!
Unoptimized SystemOptimized
System

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 37
Some Issues in Automatic Speech Recognition (ASR)
• Inputs: audio file; grammar/language model; acoustic model
• Outputs: utterance matched from grammar, or no match; confidence score
• Performance tradeoff:– “small” grammar --> high accuracy on
constrained utterances, lots of no-matches– “large” grammar --> match more
utterances, but with lower confidence

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 38
Some Issues in Dialogue Policy Design
• Initiative policy• Confirmation policy• Criteria to be optimized

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 39
Initiative Policy
• System initiative vs. user initiative:– “Please state your departure city.”– “How can I help you?”
• Influences expectations• ASR grammar must be chosen accordingly• Best choice may differ from state to state• May depend on user population & task

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 40
Confirmation Policy
• High ASR confidence: accept ASR match and move on
• Moderate ASR confidence: confirm• Low ASR confidence: re-ask• How to set confidence thresholds?• Early mistakes can be costly later,
but excessive confirmation is annoying

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 41
Criteria to be Optimized
• Task completion• Sales revenues• User satisfaction• ASR performance• Number of turns

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 42
Typical System Design: Sequential Search
• Choose and implement several “reasonable” dialogue policies
• Field systems, gather dialogue data • Do statistical analyses• Refield system with “best” dialogue
policy• Can only examine a handful of policies

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 43
Why Reinforcement Learning?
• Agents can learn to improve performance by interacting with their environment
• Thousands of possible dialogue policies, and want to automate the choice of the “optimal”
• Can handle many features of spoken dialogue– noisy sensors (ASR output)– stochastic behavior (user population)– delayed rewards, and many possible rewards– multiple plausible actions
• However, many practical challenges remain

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 44
Proposed Approach• Build initial system that is deliberately
exploratory wrt state and action space• Use dialogue data from initial system to
build a Markov decision process (MDP)• Use methods of reinforcement learning
to compute optimal policy (here, dialogue policy) of the MDP
• Refield (improved?) system given by the optimal policy
• Empirically evaluate

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 45
State-Based Design• System state: contains information
relevant for deciding the next action– info attributes perceived so far– individual and average ASR confidences– data on particular user– etc.
• In practice, need a compressed state• Dialogue policy: mapping from each
state in the state space to a system action

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 46
Markov Decision Processes
• System state s (in S)• System action a in (in A)• Transition probabilities P(s’|s,a)• Reward function R(s,a) (stochastic)• Our application: P(s’|s,a) models
the population of users

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 47
SDSs as MDPs
...332211 ususus
Initial systemutterance
Initial userutterance
Actions haveprob. outcomes
estimate transition probabilities... P(next state | current state & action)...and rewards... R(current state, action)...from set of exploratory dialogues (random action choice)Violations of Markov property! Will this work?
a e a e a e ...1 21 2 33
+ system logs

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 48
Computing the Optimal
• Given parameters P(s’|s,a), R(s,a), can efficiently compute policy maximizing expected return
• Typically compute the expected cumulative reward (or Q-value) Q(s,a), using value iteration
• Optimal policy selects the action with the maximum Q-value at each dialogue state

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 49
Potential Benefits• A principled and general framework for
automated dialogue policy synthesis – learn the optimal action to take in each state
• Compares all policies simultaneously– data efficient because actions are evaluated
as a function of state– traditional methods evaluate entire policies
• Potential for “lifelong learning” systems, adapting to changing user populations

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 50
The Application: NJFun• Dialogue system providing telephone
access to a DB of activities in NJ• Want to obtain 3 attributes:
– activity type (e.g., wine tasting)– location (e.g., Lambertville)– time (e.g., morning)
• Failure to bind an attribute: query DB with don’t-care

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 51
NJFun as an MDP
• define state-space• define action-space• define reward structure• collect data for training & learn
policy• evaluate learned policy
a closer look : RL in spoken dialog systems : current challenges : RL for error handling

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 52
The State SpaceFeature Values Explanation Attribute (A) 1,2,3 Which attribute is being worked on
Confi dence/ Confi rmed (C)
0,1,2 3,4
0,1,2 f or low, medium and high ASR confi dence 3.4 f or explicitly confi rmed, disconfi rmed
Value (V) 0,1 Whether value has been obtained f or current attribute
Tries (T) 0,1,2 How many times current attr has been asked
Grammar (G) 0,1 Whether open or closed grammar was used
History (H) 0,1 Whether trouble on any previous attribute
N.B. Non-state variables record attribute values;state does not condition on previous attributes!

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 53
Sample Action Choices
• Initiative (when T = 0)– user (open prompt and grammar)– mixed (constrained prompt, open grammar)– system (constrained prompt and grammar)
• Example– GreetU: “How may I help you?” – GreetS: “Please say an activity name.”

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 54
Sample Confirmation Choices
• Confirmation (when V = 1)– confirm– no confirm
• Example– Conf3: “Did you say want to go in the
<time>?”– NoConf3: “”

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 55
Dialogue Policy Class• Specify “reasonable” actions for each
state– 42 choice states (binary initiative or
confirmation action choices)– no choice for all other states
• Small state space (62), large policy space (2^42)
• Example choice state– initial state: [1,0,0,0,0,0]– action choices: GreetS, GreetU
• Learn optimal action for each choice state

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 56
Some System Details• Uses AT&T’s WATSON ASR and TTS
platform, DMD dialogue manager• Natural language web version used
to build multiple ASR language models
• Initial statistics used to tune bins for confidence values, history bit (informative state encoding)

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 57
The Experiment• Designed 6 specific tasks, each with web survey• Split 75 internal subjects into training and test, controlling
for M/F, native/non-native, experienced/inexperienced• 54 training subjects generated 311 dialogues• Training dialogues used to build MDP• Optimal policy for BINARY TASK COMPLETION computed
and implemented• 21 test subjects (for modified system) generated 124
dialogues• Did statistical analyses of performance changes

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 58
Example of Learning
• Initial state is always– Attribute(1), Confidence/Confirmed(0), Value(0),
Tries(0), Grammar(0), History(0)
• Possible actions in this state– GreetU: How may I help you?– GreetS: Please say an activity name or say “list
activities” for a list of activities I know about
• In this state, system learned that GreetU is the optimal action.

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 59
Reward Function• Binary task completion (objective measure):
– 1 for 3 correct bindings, else -1• Task completion (allows partial credit):
– -1 for an incorrect attribute binding– 0,1,2,3 correct attribute bindings
• Other evaluation measures: ASR performance (objective), and phone feedback, perceived completion, future use, perceived understanding, user understanding, ease of use (all subjective)
• Optimized for binary task completion, but predicted improvements in other measures

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 60
Main Results• Task completion (-1 to 3):
– train mean = 1.72– test mean = 2.18– p-value < 0.03
• Binary task completion:– train mean = 51.5 %– test mean = 63.5 %– p-value < 0.06

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 61
Other Results
• ASR performance (0-3):– train mean = 2.48 – test mean = 2.67 – p-value < 0.04
• Binary task completion for experts (dialogues 3-6):– train mean = 45.6%– test mean = 68.2 %– p-value < 0.01
July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 62
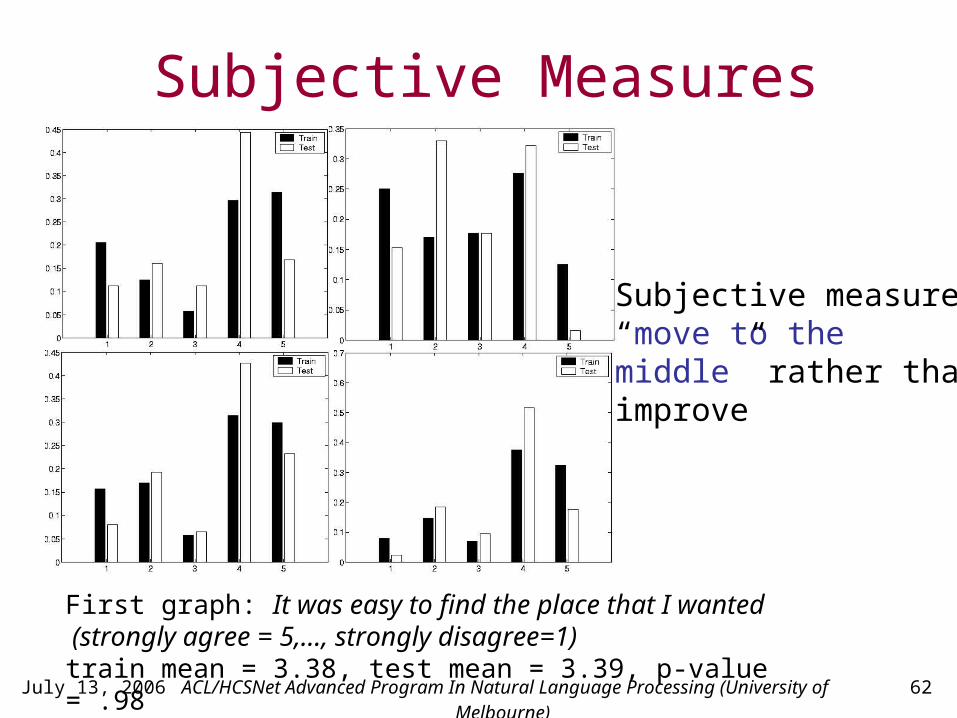
Subjective Measures
Subjective measures“move to the middle” rather thanimprove
First graph: It was easy to find the place that I wanted (strongly agree = 5,…, strongly disagree=1)train mean = 3.38, test mean = 3.39, p-value = .98

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 63
Comparison to Human Design• Fielded comparison infeasible, but
exploratory dialogues provide a Monte Carlo proxy of “consistent trajectories”
• Test policy: Average binary completion reward = 0.67 (based on 12 trajectories)
• Outperforms several standard fixed policies– SysNoConfirm: -0.08 (11)– SysConfirm: -0.6 (5)– UserNoConfirm: -0.2 (15)– Mixed: -0.077 (13)– User Confirm: 0.2727 (11), no difference

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 64
A Sanity Check of the MDP• Generate many random policies • Compare value according to MDP and value based on
consistent exploratory trajectories• MDP evaluation of policy: ideally perfectly accurate
(infinite Monte Carlo sampling), linear fit with slope 1, intercept 0
• Correlation between Monte Carlo and MDP:– 1000 policies, > 0 trajs: cor. 0.31, slope 0.953, int.
0.067, p < 0.001– 868 policies, > 5 trajs: cor. 0.39, slope 1.058, int.
0.087, p < 0.001

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 65
Conclusions from NJFun• MDPs and RL are a promising framework
for automated dialogue policy design• Practical methodology for system-building
– given a relatively small number of exploratory dialogues, learn the optimal policy within a large policy search space
• NJFun: first empirical test of formalism• Resulted in measurable and significant
system improvements, as well as interesting linguistic results

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 66
Caveats
• Must still choose states, actions, reward• Must be exploratory with taste• Data sparsity• Violations of the Markov property• A formal framework and methodology,
hopefully automating one important step in system design

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 67
Outline
• Motivation• Markov Decision Processes and
Reinforcement Learning• NJFun: A Case Study• Advanced Topics

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 68
Some Current Research Topics
• Scale to more complex systems• Automate state representation• POMDPs due to hidden state• Learn terminal (and non-terminal)
reward function• Online rather than batch learning

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 69
Addressing Scalability
• Approach 1: user models / simulations– costly to obtain real data → simulate users
• inexpensive and potentially richer source of large corpora
• but - what’s the quality of the simulated data?
– again, real-world evaluation becomes paramount
• Approach 2: value function approximation– data-driven state abstraction / aggregation

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 70
Some Example Simulation Models
• P (userAction | system Action)• P (yesAnswer | explicitConfirmation)• P (yesAnswer | explicitConfirmation, goal)
• E.g.,– Levin, Pierraccini, Eckert– Georgila, Henderson, Lemon– Pietquin– Scheffler and Young

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 71
Example Simulation Models in Spoken Dialogue Tutoring
• ProbCorrect Model – Answers a question with the same
correctness rate as a real student• Random Model
– Gives random answers
• Hua Ai and Diane Litman. Comparing Real-Real, Simulated-Simulated, and Simulated-Real Spoken Dialogue Corpora. Proceedings of the AAAI Workshop on Statistical and Empirical Approaches for Spoken Dialogue Systems. 2006.

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 72
ProbCorrect Model
• Compute correctness rates from the system logs
• Use real student utterance as candidate answers
• A Bigram Model
Pick an answer
based on the
question
Answers for Question i
Answers for Question j
…

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 73
Random Model
• Randomly pick an answer from the whole utterance set
• A Unigram Model
Pick an answer
from the whole set
Answers for question i
Answers for question j
…

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 74
Simulated Dialogue (ProbCorrect Model)
Tutor said:
To analyze this problem, which law of motion would you use?
You said: The second law.
Tutor said:
The best law is the 3rd law. Do you recall what this law says?
You said: No.
Tutor said:
It says… Is there a gravitational force here?
You said: Yes.
Tutor said:
Good. Now, what’s the relationship between the two force’s magnitudes?
You said: They are equal.
Tutor said:
Yeah. What’s the relationshiop between the two force’s directions?
You said: They’re different.
Tutor said:
To summarize…

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 75
Simulated Dialogue (Random Model)
Tutor said: To analyze this problem, which law of motion would you use?
You said: More.
Tutor said: The best law is the 3rd law. Do you recall what this law says?
You said: After all forces.
Tutor said: It says… Is there a gravitational force here?
You said: Yes.
Tutor said: We just discussed... Now, what’s the relationship between the two force’s magnitudes?
You said: Yes.
Tutor said: Well... What’s the relationshiop between the two force’s directions?
You said: It’s decreasing.
Tutor said: To summarize…

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 76
Evaluating Simulation Models
• Does the model produce human-like behavior– Compare real and simulated user responses– Metrics: precision and recall
• Does the model reproduce the variety of human behavior– Compare real and simulated dialogue corpora– Metrics: statistical characteristics of dialogue
features (see below)

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 77
Evaluating Simulated Corpora
High-level Dialogue Features Dialog Length (Number of turns)Turn Length (Number of actions per turn)Participant Activity (Ratio of system/user actions per dialog)
Dialogue style and cooperativeness Proportion of goal-directed dialogues vs. othersNumber of times a piece of information is re-asked
Dialogue success rate and efficiency Average goal/subgoal achievement rate
– Schatzmann, J., Georgila, K., and Young, S. Quantitative Evaluation of User Simulation Techniques for Spoken Dialogue Systems. In Proceedings 6th SIGdial Workshop on Discourse and Dialogue. 2005.

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 78
Evaluating ProbCorrect vs. Random
• Differences shown by similar metrics are not necessarily related to the reality level – two real corpora can be very different
• Metrics can distinguish to some extent– real from simulated corpora– two simulated corpora generated by different
models trained on the same real corpus – two simulated corpora generated by the same
model trained on two different real corpora

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 79
• Q can be represented by a table only if the number of states & actions is small
• Besides, this makes poor use of experience
• Hence, we use function approximation, e.g.– neural nets– weighted linear functions– case-based/instance-based/memory-based
representations
Scalability Approach 2:Function Approximation

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 80
Current Research Topics
• Scale to more complex systems• Automate state representation• POMDPs due to hidden state• Learn terminal (and non-terminal)
reward function• Online rather than batch learning

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 81
Designing the State Representation
• Incrementally add features to a state and test whether the learned strategy improves
– Frampton, M. and Lemon, O. Learning More Effective Dialogue Strategies Using Limited Dialogue Move Features. Proceedings ACL/Coling. 2006.
• Adding Last System and User Dialogue Acts improves 7.8%
– Tetreault J. and Litman, D. Using Reinforcement Learning to Build a Better Model of Dialogue State. Proceedings EACL. 2006.
• See below

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 82
Example Methodology and Evaluation in SDS Tutoring
• Construct MDP’s to test the inclusion of new state features to a baseline– Develop baseline state and policy– Add a state feature to baseline and compare polices– A feature is deemed important if adding it results in a
change in policy from a baseline policy
– Joel R. Tetreault and Diane J. Litman. Comparing the Utility of State Features in Spoken Dialogue Using Reinforcement Learning. Proceedings HLT/NAACL. 2006.

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 83
Baseline Policy
• Trend: if you only have student correctness as a model of student state, the best policy is to always give simple feedback
# State State Size Policy1 [Correct] 1308 SimpleFeedback
2 [Incorrect] 872 SimpleFeedback

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 84
Adding Certainty Features:Hypothetical Policy Change
Baseline State
Policy B+Certainty State
1 [C] SimFeed [C,Certain] [C,Neutral] [C,Uncertain]
2 [I] SimFeed [I,Certain][I,Neutral][I,Uncertain]
+Cert 1Policy SimFeedSimFeedSimFeed
SimFeedSimFeedSimFeed
+Cert 2Policy MixSimFeedMix
MixComplexFeedbackMix
0 shifts 5 shifts

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 85
Evaluation Results• Incorporating new features into standard
tutorial state representation has an impact on Tutor Feedback policies
• Including Certainty, Student Moves and Concept Repetition into the state effected the most change
• Similar feature utility for choosing Tutor Questions

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 86
Designing the State Representation (continued)
• Other Approaches, e.g.,
• Paek, T. and Chickering, D. The Markov Assumption in Spoken Dialogue Management. Proc. SIGDial. 2005.
• Henderson, J., Lemon, O, and Georgila, K. Hybrid Reinforcement/Supervised Learning for Dialogue Policies from Communicator Data. Proc. IJCAI Workshop on K&R in Practical Dialogue Systems. 2005.

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 87
Current Research Topics
• Scale to more complex systems• Automate state representation• POMDPs due to hidden state• Learn terminal (and non-terminal)
reward function• Online rather than batch learning

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 88
Beyond MDPs
• Partially Observable MDPs (POMDPs)– We don’t REALLY know the user’s state (we only
know what we THOUGHT the user said)– So need to take actions based on our BELIEF , I.e. a
probability distribution over states rather than the “true state”
– e.g., Roy, Pineau and Thrun; Young and Williams
• Decision Theoretic Methods– e.g., Paek and Horvitz

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 89
Why POMDPs?
• Does “state” model uncertainty natively (i.e., is it partially rather than fully observable)?– Yes: POMDP and DT – No: MDP
• Does the system plan (i.e., can cumulative reward force the system to construct a plan for choice of immediate actions)?– Yes: MDP and POMDP– No: DT

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 90
POMDP Intuitions• At each time step t machine in some hidden state sS• Since we don’t observe s, we keep a distribution over states
called a “belief state” b• So the probability of being in state s given belief state b is b(s).• Based on the current belief state b, the machine
– selects an action am Am
– Receives a reward r(s,am)
– Transitions to a new (hidden) state s’, where s’ depends only on s and am
• Machine then receives an observation o’ O, which is dependent on s’ and am
• Belief distribution is then updated based on o’ and am.

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 91
How to Learn Policies?
• State space is now continuous– With smaller discrete state space, MDP
could use dynamic programming; this doesn’t work for POMDB
• Exact solutions only work for small spaces
• Need approximate solutions• And simplifying assumptions

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 92
Current Research Topics
• Scale to more complex systems• Automate state representation• POMDPs due to hidden state• Learn terminal (and non-terminal)
reward function• Online rather than batch learning

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 93
Dialogue System Evaluation
• The normal reason: we need a metric to help us compare different implementations
• A new reason: we need a metric for “how good a dialogue went” to automatically improve SDS performance via reinforcement learning– Marilyn Walker. An Application of Reinforcement Learning to
Dialogue Strategy Selection in a Spoken DIalouge System for Email. JAIR. 2000.

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 94
PARADISE: PARAdigm for DIalogue System Evaluation
• “Performance” of a dialogue system is affected both by what gets accomplished by the user and the dialogue agent and how it gets accomplished
• Walker, M. A., Litman, D. J., Kamm, C. A., and Abella, A. PARADISE: A Framework for Evaluating Spoken Dialogue Agents. Proceedings of ACL/EACL. 1997.

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 95
Performance as User Satisfaction (from
Questionnaire)

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 96
PARADISE Framework
• Measure parameters (interaction costs and benefits) and performance in a corpus
• Train model via multiple linear regression over parameters, predicting performance
System Performance = ∑ wi * pi
• Test model on new corpus
• Predict performance during future system design
n
i=1

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 97
Example Learned Performance Function from Elvis [Walker 2000]
• User Sat.=.27*COMP+.54*MRS- .09*BargeIn%+.15*Reject%– COMP: User perception of task completion (task success)– MRS: Mean (concept) recognition accuracy (quality cost)– BargeIn%: Normalized # of user interruptions (quality cost)– Reject%: Normalized # of ASR rejections (quality cost)
• Amount of variance in User Sat. accounted for by the model– Average Training R2 = .37– Average Testing R2 = .38
• Used as Reward for Reinforcement Learning

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 98
Some Current Research Topics
• Scale to more complex systems• Automate state representation• POMDPs due to hidden state• Learn terminal (and non-terminal)
reward function• Online rather than batch learning

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 99
Offline versus Online Learning
MDP
DialogueSystem
Training dataPolicy
User Simulator
HumanUser
-MDP typically works offline-Would like to learn policy online
-System can improve over time-Policy can change as environment changes
Interactions work online

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 100
Summary• (PO)MDPs and RL are a promising framework
for automated dialogue policy design– Designer states the problem and the desired goal– Solution methods find (or approximate) optimal
plans for any possible state– Disparate sources of uncertainty unified into a
probabilistic framework
• Many interesting problems remain, e.g.,– using this approach as a practical methodology for
system building– making more principled choices (states, rewards,
discount factors, etc.)

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 101
Acknowledgements
• Talks on the web by Dan Bohus, Derek Bridge, Joyce Chai, Dan Jurafsky, Oliver Lemon and James Henderson, Jost Schatzmann and Steve Young, and Jason Williams were used in the development of this presentation
• Slides from ITSPOKE group at University of Pittsburgh

July 13, 2006 ACL/HCSNet Advanced Program In Natural Language Processing (University of Melbourne) 102
Further Information• Reinforcement Learning
– Sutton, R. and Barto G. Reinforcement Learning: An Introduction, MIT Press. 1998 (much available online)
– Artificial Intelligence and Machine Learning Journals and Conferences
• Application to Dialogue– Jurafsky, D. and Martin, J. Dialogue and
Conversational Agents. Chapter 19 of Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. Draft of May 18, 2005 (available online only)
– “ACL” Literature– Spoken Language Community (e.g., IEEE and ISCA
publications)