learning to compose domain-specific transformations for data augmentation
TRANSCRIPT

Learning to Compose Domain-Specific Transformations for
Data AugmentationTatsuya Shirakawa [email protected]

ABEJA, Inc. (Researcher) - Deep Learning
- Computer Vision - Natural Language Processing - Graph Convolution / Graph Embedding
- Mathematical Optimization - https://github.com/TatsuyaShiraka
tech blog → http://tech-blog.abeja.asia/
Poincaré Embeddings Graph Convolution
We are hiring! → https://www.abeja.asia/recruit/
→ https://six.abejainc.com/

A. J. Ratner, H. R. Ehrenberg, et al., “Learning to Compose Domain-Specific Transformations for Data Augmentation”, NIPS2017
Today’s Paper
3
Problem to solve • Learning how to compose predefined
data transformations (TFs) to create naturally transformed data (data augmentation)
How to solve • Formulate the problem as a sequence
generation problem • Learned by policy gradient method

1. Introduction
2. Proposed Method
3. Results
4. Summary
Agenda
4

1. Introduction
2. Proposed Method
3. Results
4. Summary
Agenda
5
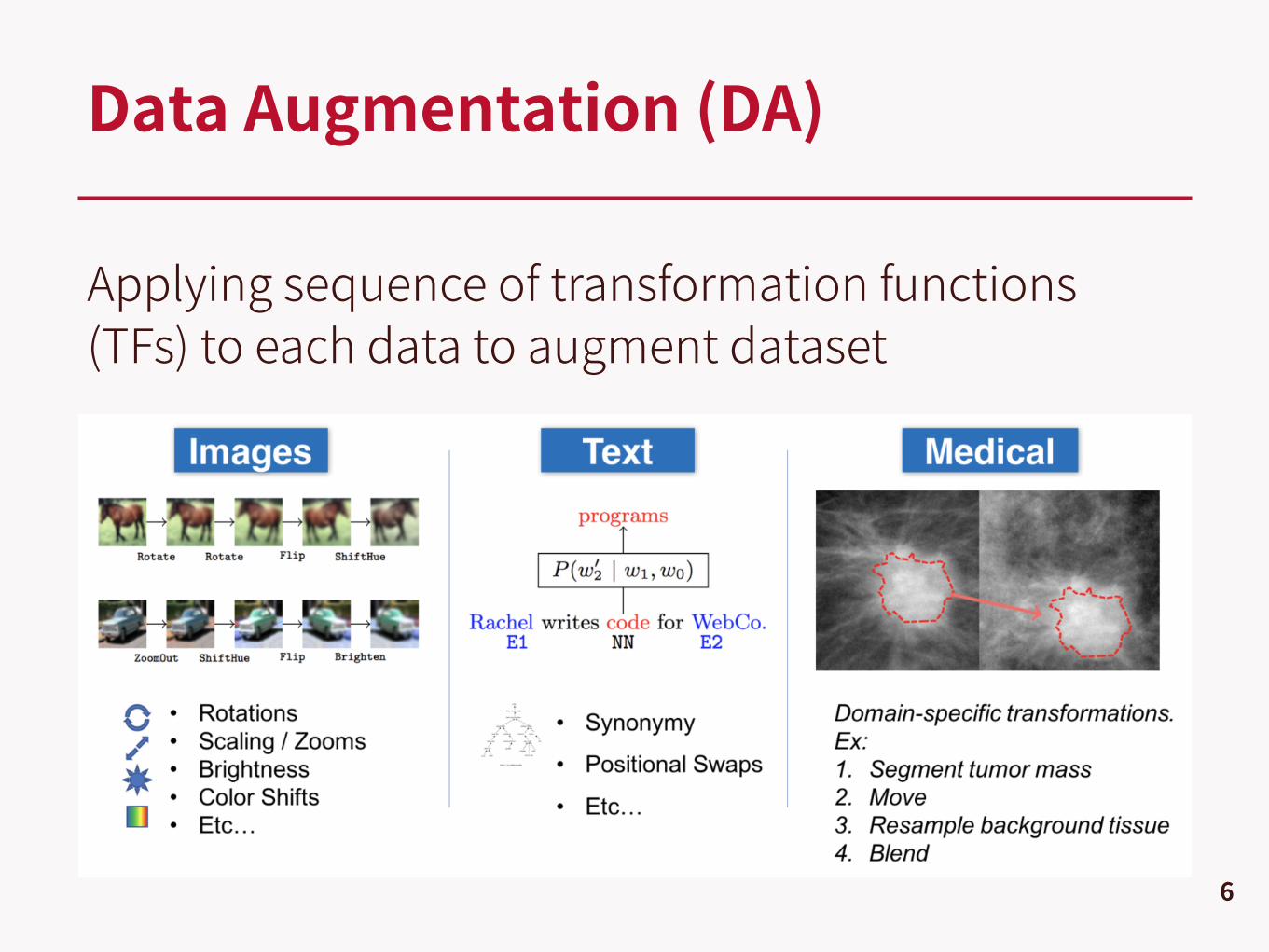
Applying sequence of transformation functions (TFs) to each data to augment dataset
Data Augmentation (DA)
6

Common AssumptionTransformed data are natural and essential informations (e.g. classes) are kept unchanged
… But massive DA can easily break the assumption
DA can break informations
7(CIFAR-10)

• Generator generates sequences of TFs
• Discriminator discriminates transformed data are realistic or not
• End model (learned afterward)
This Paper — Learning to Compose TFs
8
G
D�
Df
Technical Remarks: transformation sequences have same length L

1. Introduction
2. Proposed Method
3. Results
4. Summary
Agenda
9
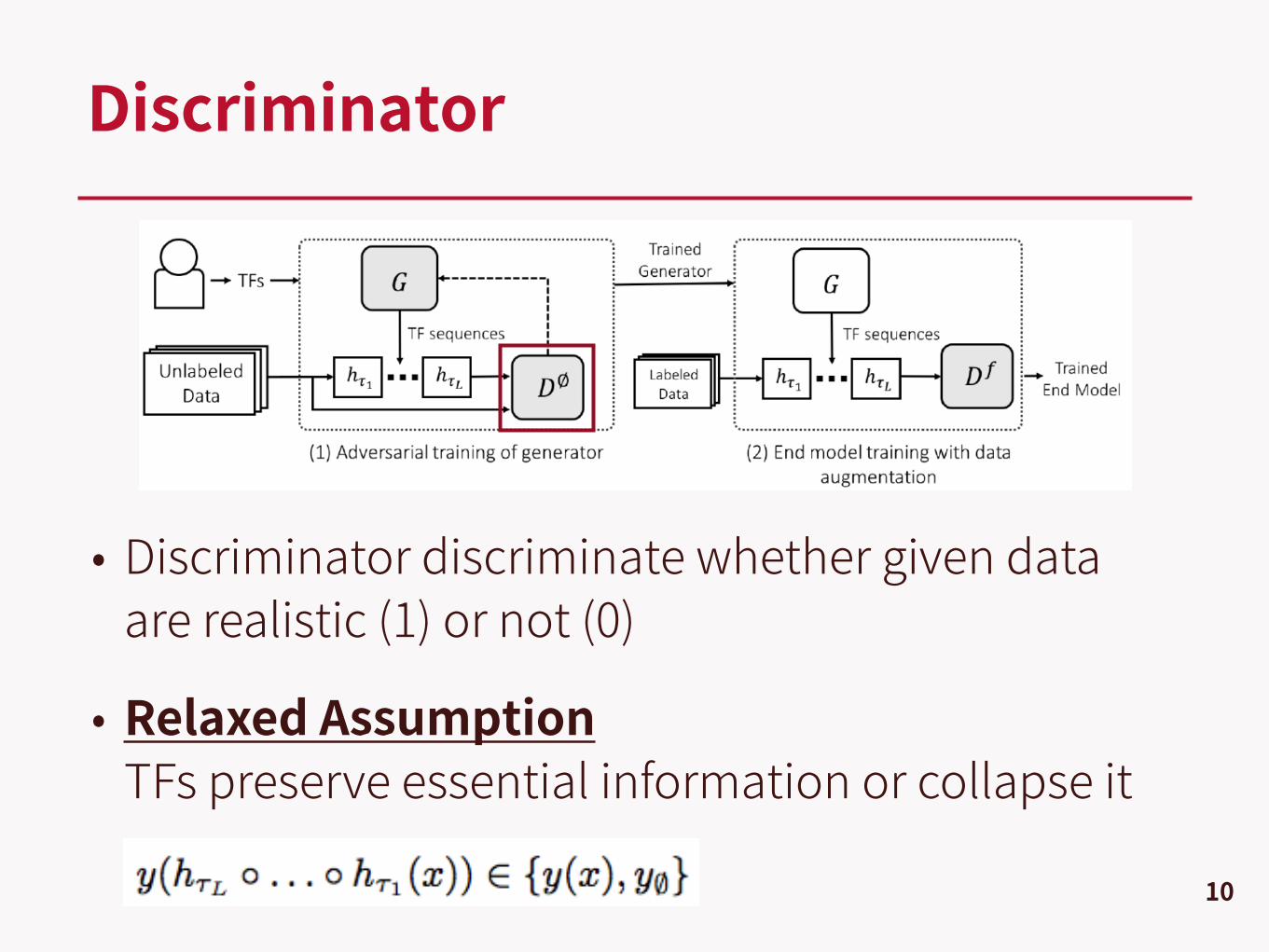
• Discriminator discriminate whether given data are realistic (1) or not (0)
• Relaxed AssumptionTFs preserve essential information or collapse it
Discriminator
10
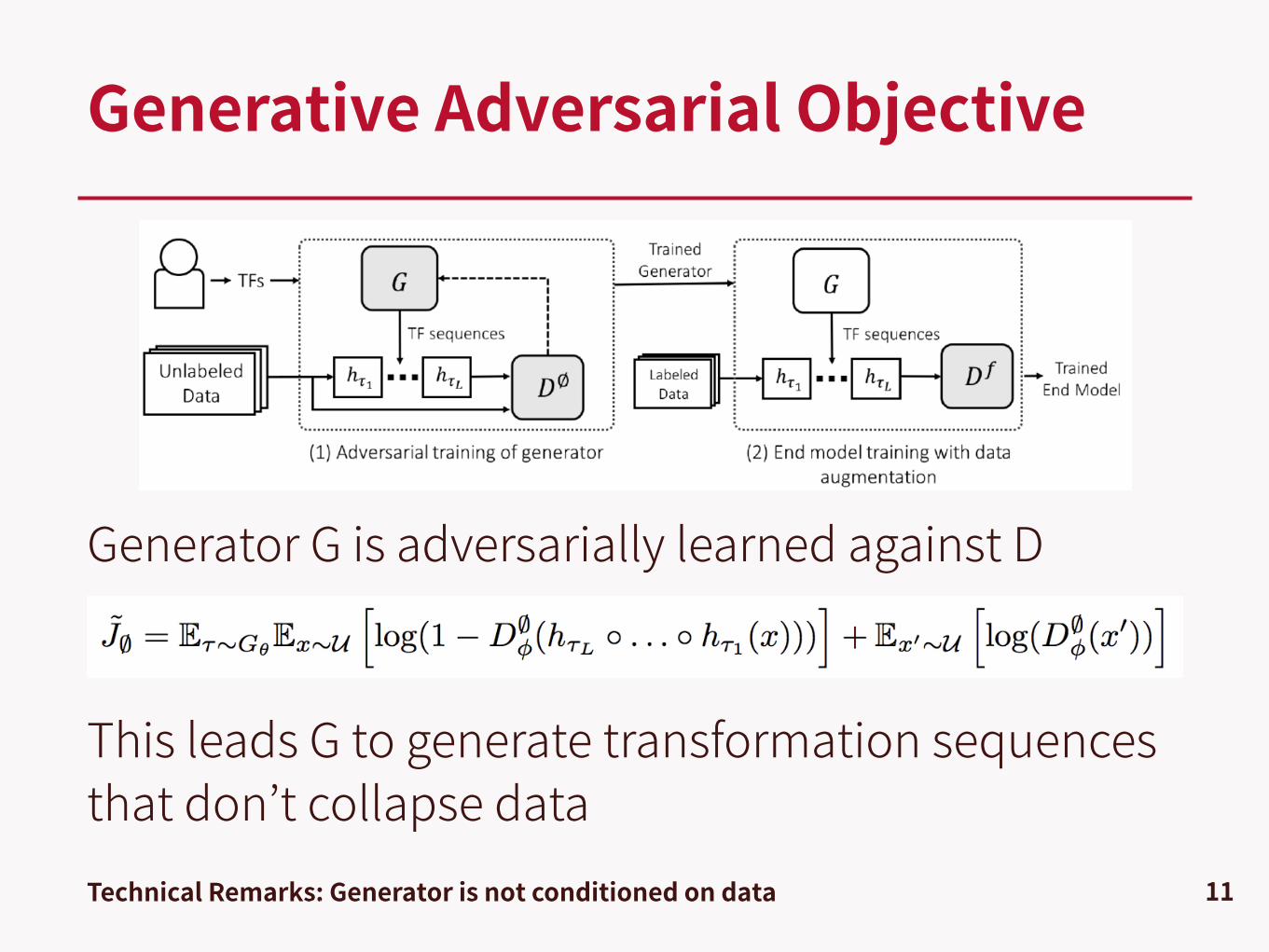
Generator G is adversarially learned against D
This leads G to generate transformation sequences that don’t collapse data
Generative Adversarial Objective
11Technical Remarks: Generator is not conditioned on data

Generator should not learn null transformation sequences, so maximize
Examples of Null transformation sequence
• Horizontal Flip x 2
• Rotate left 5° and rotate right 5°
Diversity Objective
12
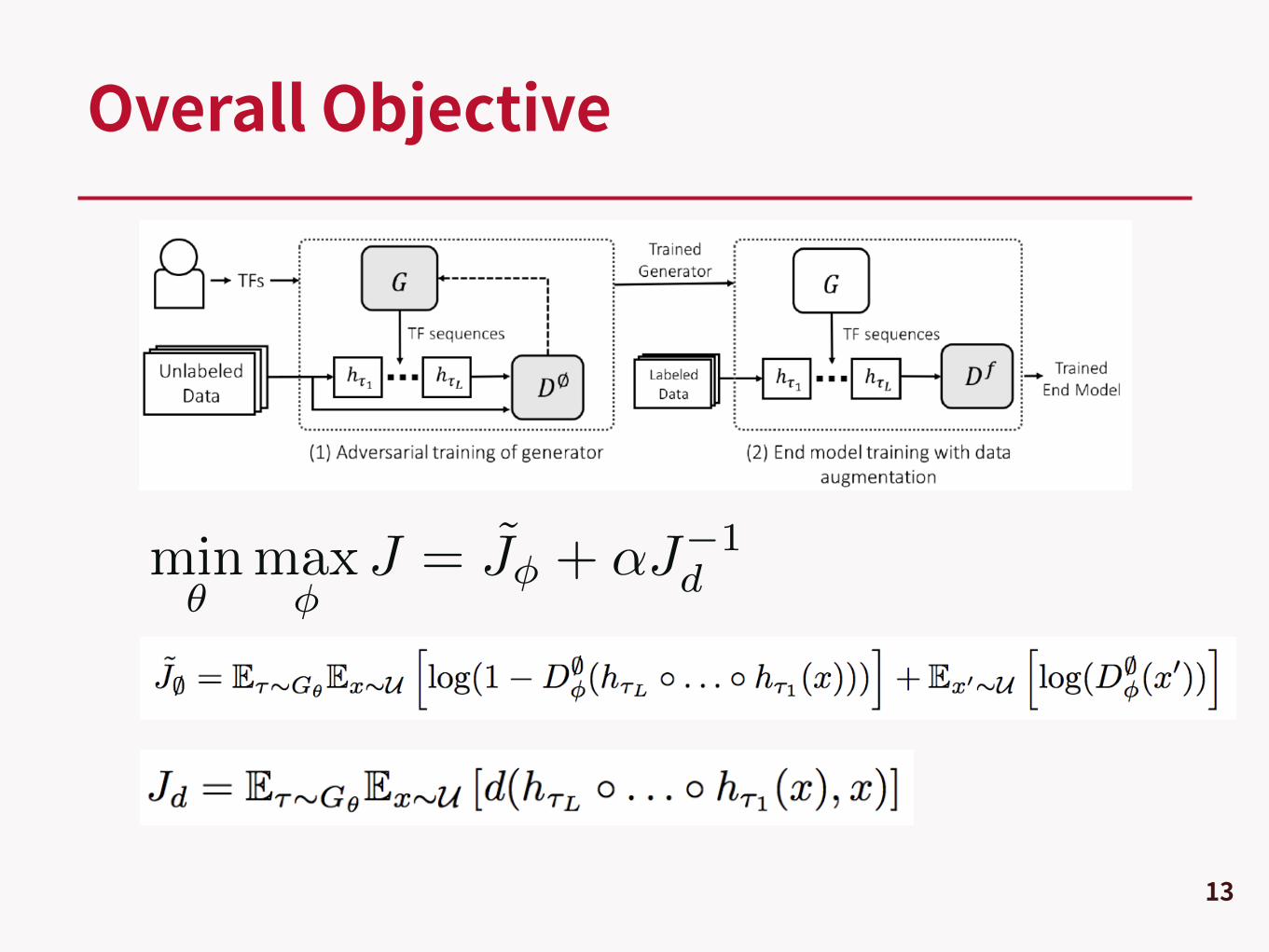
Overall Objective
13
min✓
max�
J = J̃� + ↵J�1d

• We can optimize discriminator and generator alternatively
• Optimization of discriminator can be done by simple gradient ascent method
• Optimization of generator needs optimization of sequence generation process and cannot be applied simple gradient descent method
Optimization
14
G
D�

Reformulate the optimization problem for G as a sequential decision making (RL) problem
Optimization of G — RL problem
15
…
h⌧1 h⌧2 h⌧L
x x̃1 x̃2 x̃L
r1 r2 rL
Technical Remarks: loss is defined as loss(x) = log(1-D(x)) in the paper
rt = loss(x̃t)� loss(x̃t�1),LX
t=1
rt = loss(x̃L)� loss(x)

Final loss can be minimized by policy gradient method
Optimization of G — Policy Gradient
16
π … stochastic transition policy implicitly defined by G
Policy Gradient Method 1.Generate samples (run the policy) 2.Estimate return 3.Improve the policy ✓ ✓ � ⌘r✓U(✓)

Independent Model — Mean Field Modellearning task-specific “accuracy” and “frequency” of each TF e.g.
State-based Model — LSTMsome combination of TFs might be very lossy (e.g. blur -> zoom, brighten -> saturation)
Generator (Policy) Model
17
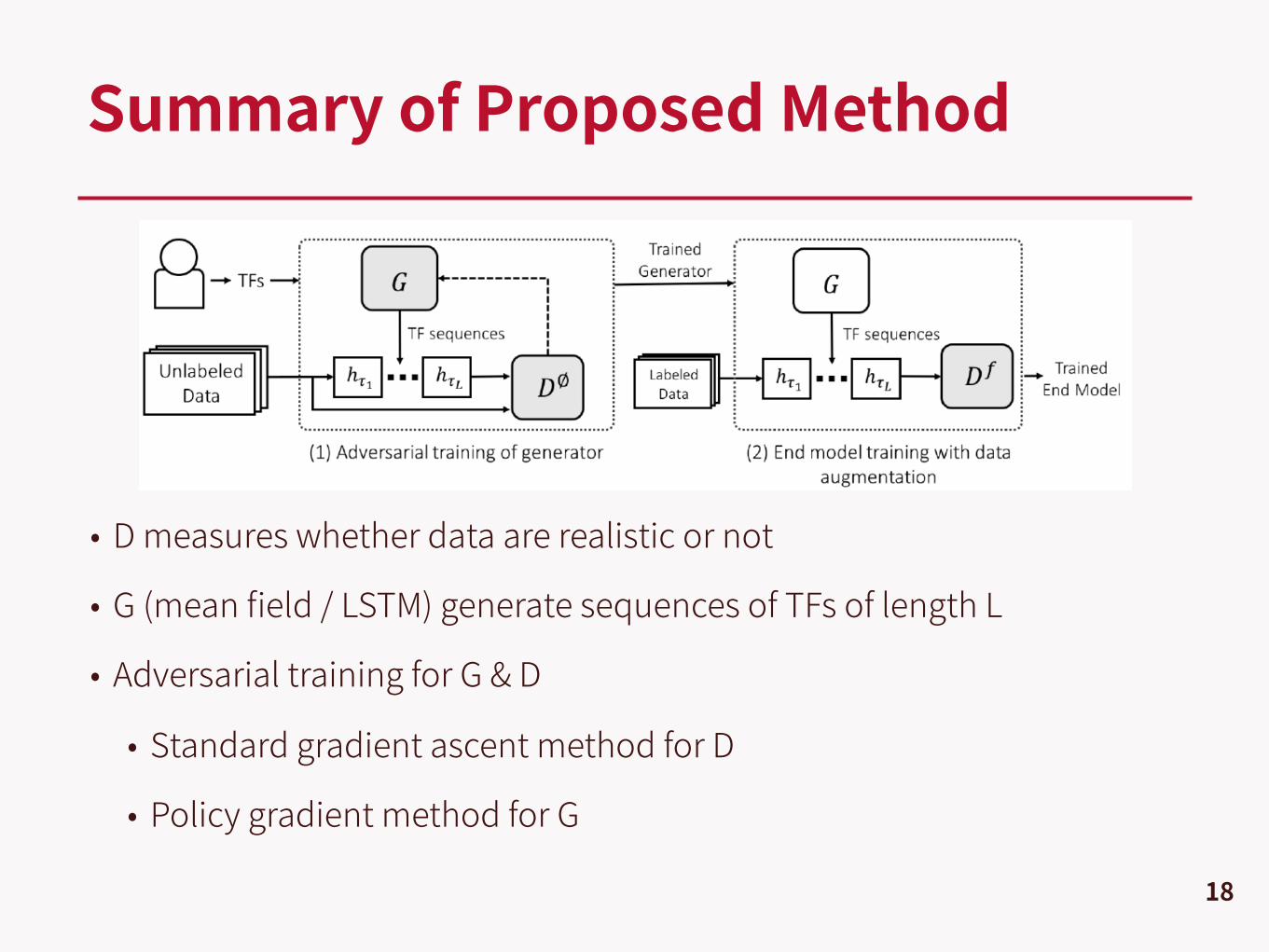
• D measures whether data are realistic or not
• G (mean field / LSTM) generate sequences of TFs of length L
• Adversarial training for G & D
• Standard gradient ascent method for D
• Policy gradient method for G
Summary of Proposed Method
18

1. Introduction
2. Proposed Method
3. Results
4. Summary
Agenda
19

• MNIST
• CIFAR-10
Datasets
20
• ACE corpus • Mammography Tumor-Classification Dataset (DDSM)

• MNIST
• CIFAR-10
Datasets — Image Datasets
21
• ACE corpus • Mammography Tumor-Classification Dataset (DDSM)
MNIST
CIFAR-10
• MNIST
• CIFAR-10
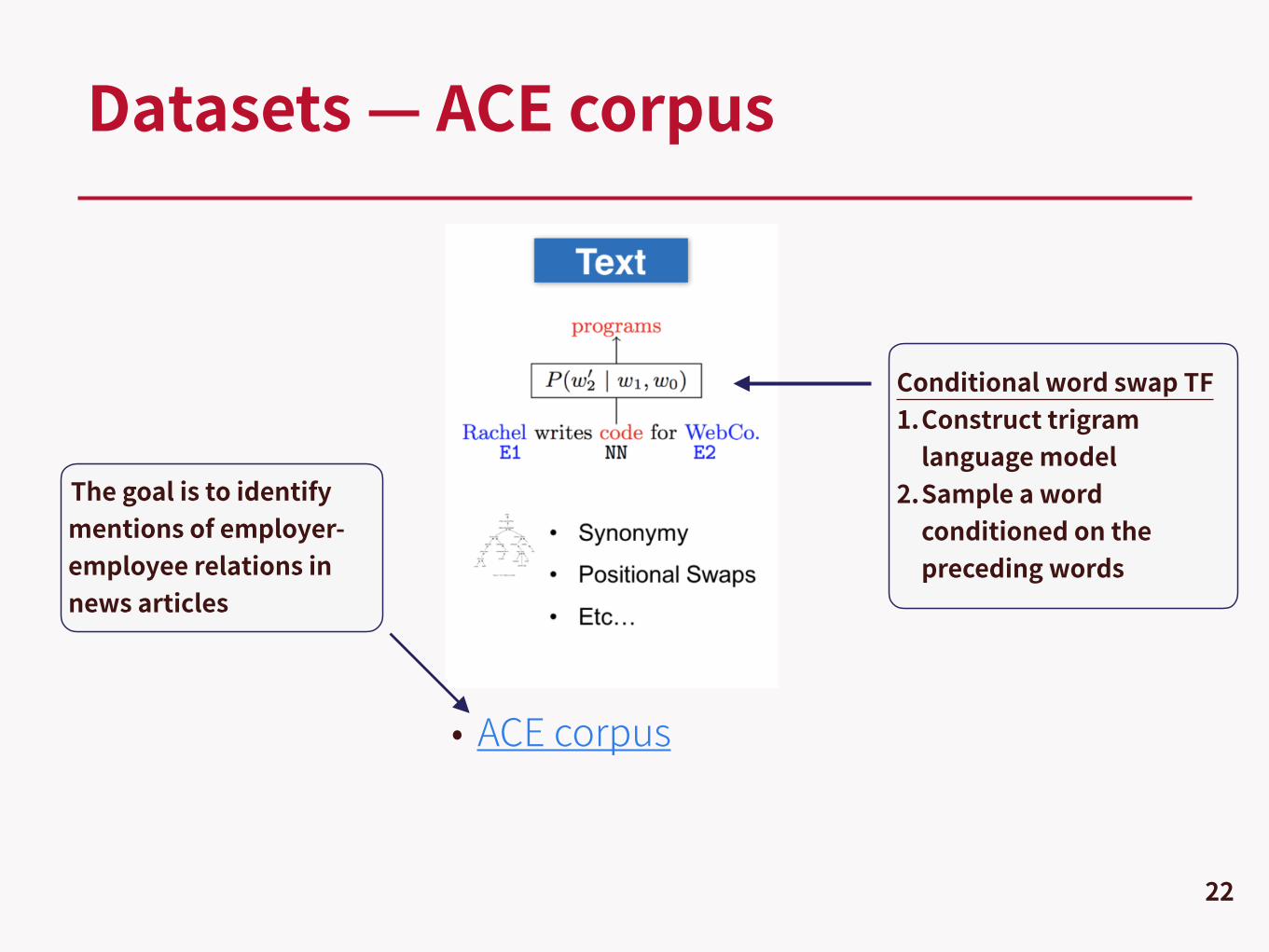
Datasets — ACE corpus
22
• ACE corpus • Mammography Tumor-Classification Dataset (DDSM)
The goal is to identify mentions of employer-employee relations in news articles
Conditional word swap TF 1.Construct trigram
language model 2.Sample a word
conditioned on the preceding words

• MNIST
• CIFAR-10
Datasets — DDSM dataset
23
• ACE corpus • Mammography Tumor-Classification Dataset (DDSM)
Standard image TFs Subselected so as not to break class-invariance
Segmentation-based TFs 1.Segment the tumor mass 2.Perform TFs
(e.g. rotation or shifting) 3.Stitch it into a randomly-
sampled benign tissue image

Results — CIFAR-10 Classification
24
Basic … random crop Heur. … random composition of TFs + DS … allowing domain-specific TFs (semantic-segmentation-based)
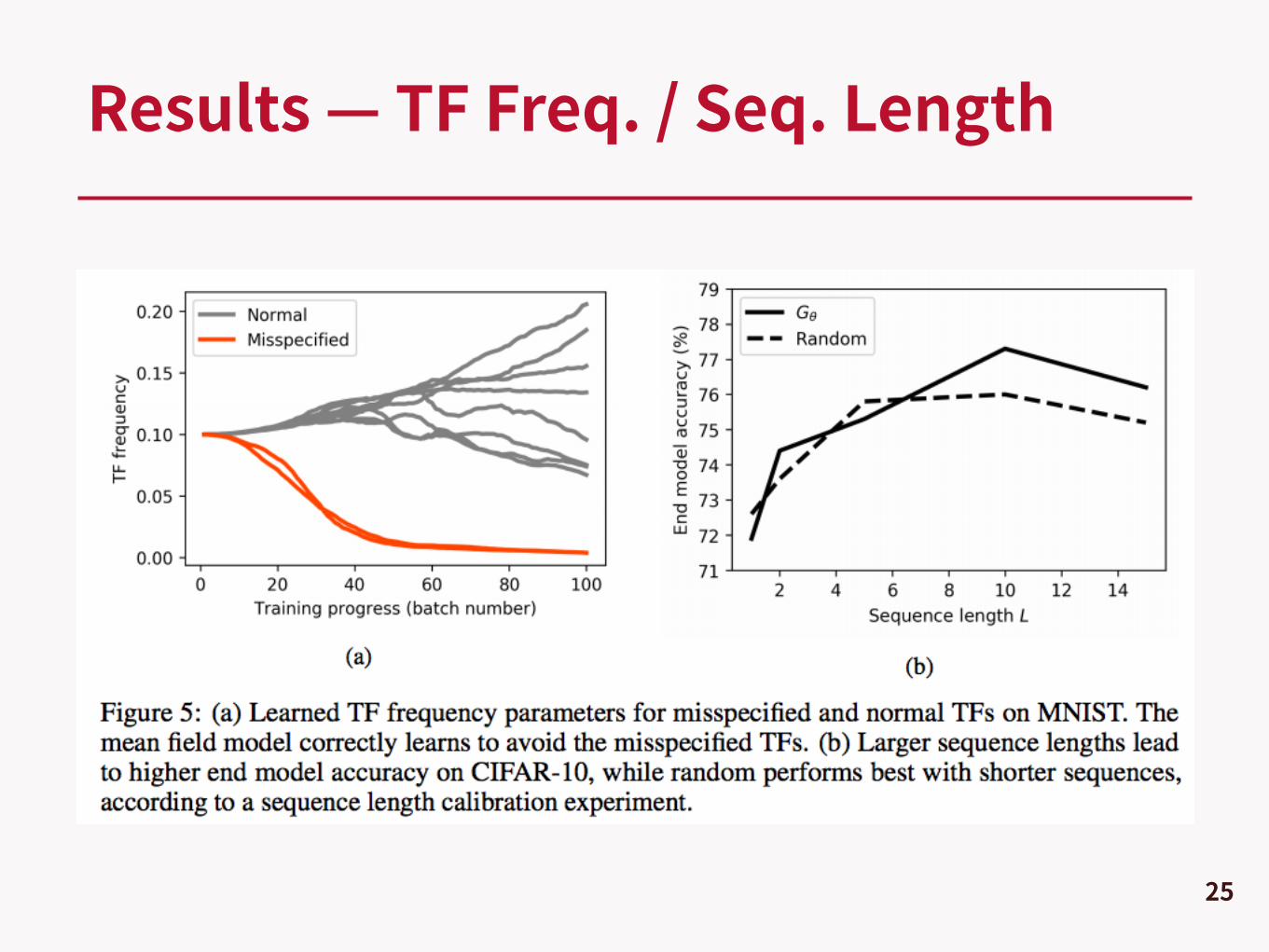
Results — TF Freq. / Seq. Length
25

Results — Training Progress on MNIST
26https://hazyresearch.github.io/snorkel/blog/tanda.html
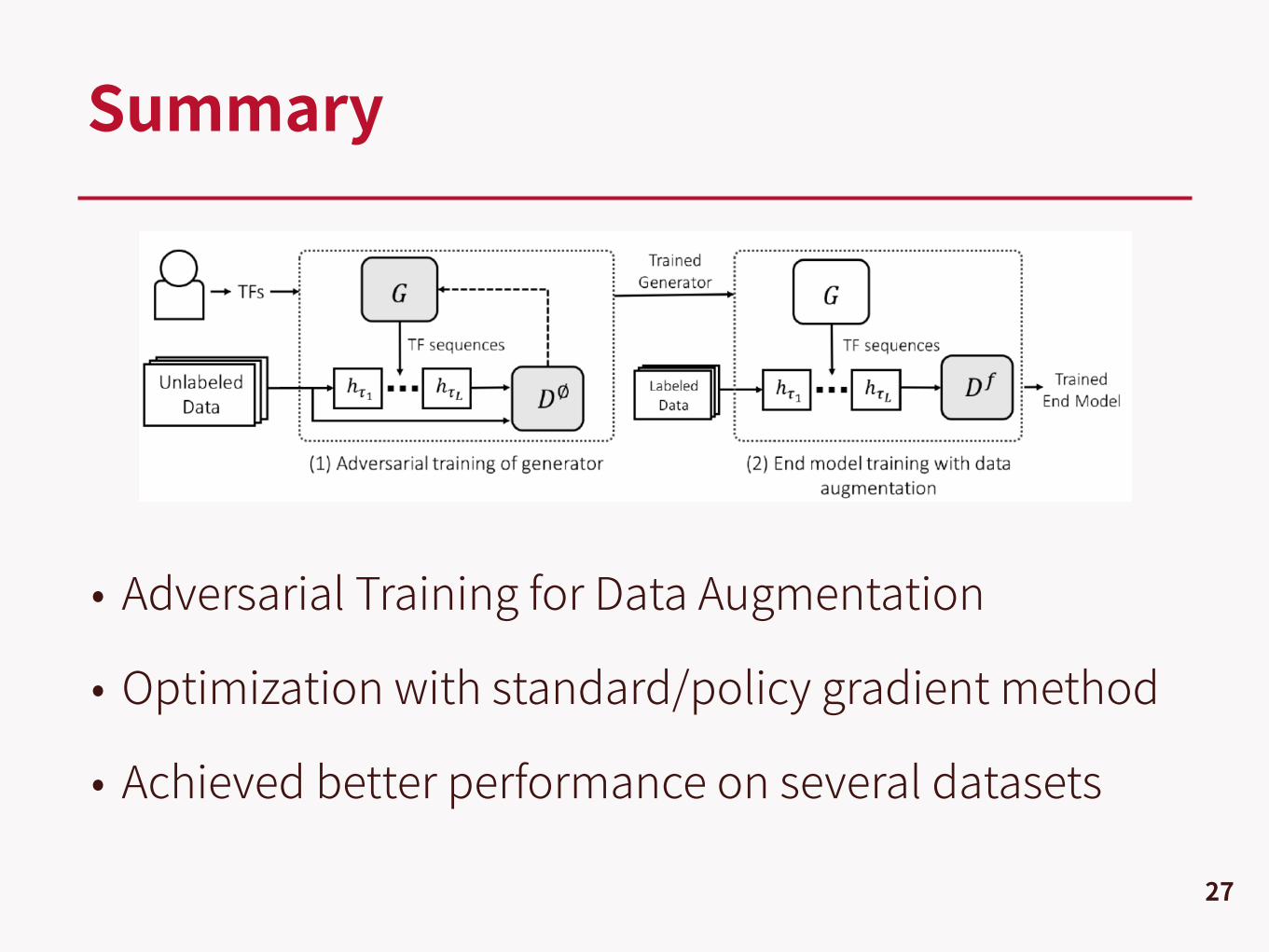
• Adversarial Training for Data Augmentation
• Optimization with standard/policy gradient method
• Achieved better performance on several datasets
Summary
27