lecture 2 part 3
TRANSCRIPT


What is Hadoop?, What Hadoop is not?, and Hadoop Assumptions.
What is Rack, Cluster, Nodes and Commodity Hardware?
HDFS - Hadoop Distributed File System
Using HDFS commands
MapReduce
Higher-level languages over Hadoop: Pig and Hive
HBase – Overview
HCatalog

What is Hadoop and its components?
What is the commodity server/Hardware?
Why HDFS ?
What is the responsibility of NameNode in HDFS?
What is Fault Tolerance?
What is the default replication factor in HDFS?
What is the heartbeat in HDFS?
What are JobTracker and TaskTracker?
Why MapReduce programming model?
Where do we have Data Locality in MapReduce?
Why we need to use Pig and Hive?
What is the difference between Hbase and HCatalog

• At Google:• Index building for Google Search
• Article clustering for Google News
• Statistical machine translation
• At Yahoo!:• Index building for Yahoo! Search
• Spam detection for Yahoo! Mail
• At Facebook:• Data mining
• Ad optimization
• Spam detection

The MapReduce algorithm contains two important tasks (Map and Reduce tasks)
• The Map task:
• The Reduce task
Map Output (key-value pairs)
The quickBrown foxThe fox ate
Map input (set of data )
converts
The 1quick 1Brown 1Fox 1The 1Fox 1Ate 1
Ate 1Brown 1Fox 1Fox 1quick 1The 1The 1
combines
Reduce input (key-value pairs)
Ate 1Brown 1Fox 2quick 1The 2
Reduce Output
I’m a
leading task
MapReduce
By the way,
I always
start first

• Data type: key-value records
• Map function:
• Reduce function:

def mapper(line):
foreach word in line.split():
output(word, 1)
def reducer(key, values):
output(key, sum(values))
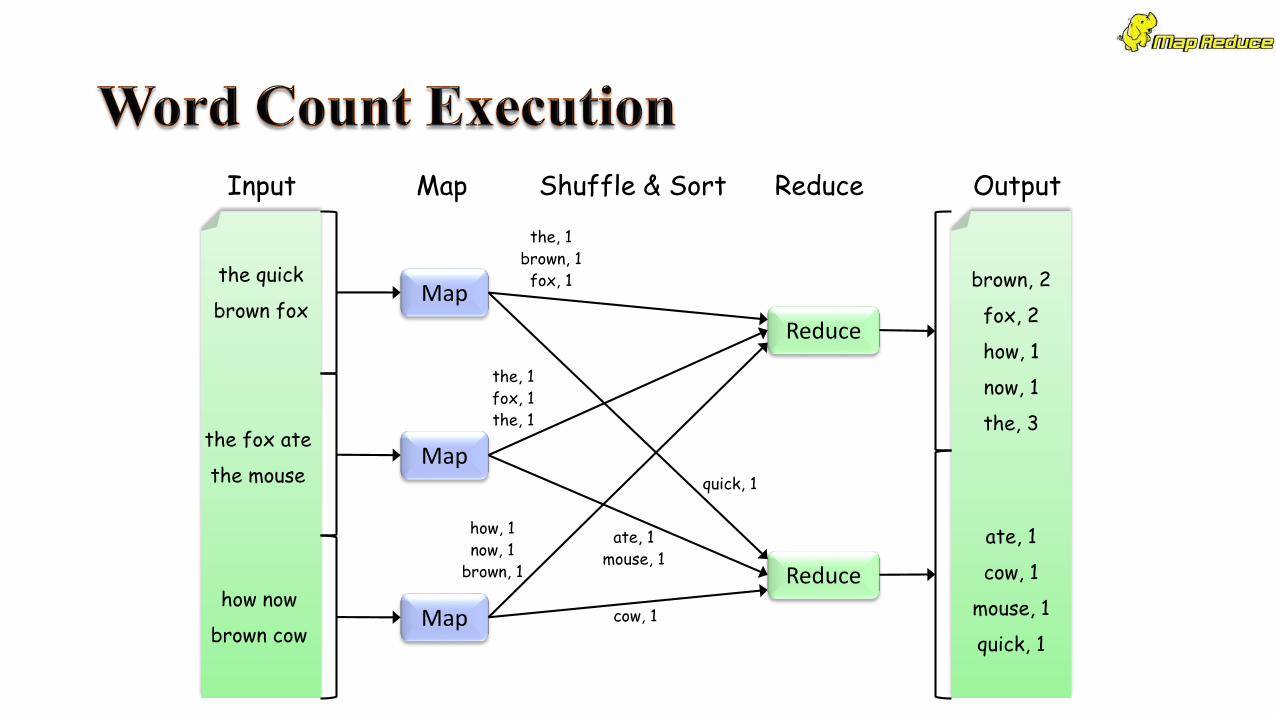
the quick
brown fox
the fox ate
the mouse
how now
brown cow
Map
Map
Map
Reduce
Reduce
brown, 2
fox, 2
how, 1
now, 1
the, 3
ate, 1
cow, 1
mouse, 1
quick, 1
the, 1
brown, 1fox, 1
quick, 1
the, 1
fox, 1the, 1
how, 1
now, 1brown, 1
ate, 1
mouse, 1
cow, 1
Input Map Shuffle & Sort Reduce Output

• Single master controls job execution on multiple slaves
• Mappers preferentially placed on same node or same rack as their input block
• Minimizes network usage
• Mappers save outputs to local disk before serving them to reducers
• Allows recovery if a reducer crashes
• Allows having more reducers than nodes

• A combiner is a local aggregation function for repeated keys
produced by same map
• Works for associative functions like sum, count, max
• Decreases size of intermediate data
• Example: map-side aggregation for Word Count:
def combiner(key, values):
output(key, sum(values))
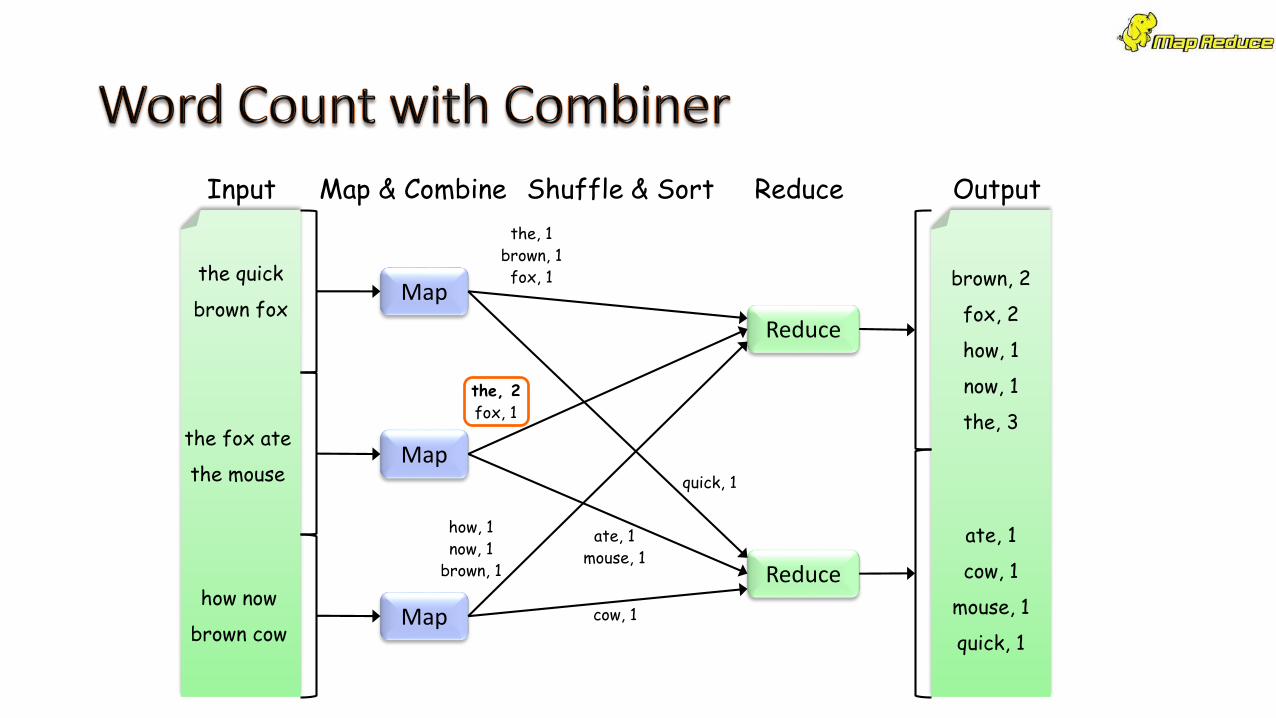
Input Map & Combine Shuffle & Sort Reduce Output
the quick
brown fox
the fox ate
the mouse
how now
brown cow
Map
Map
Map
Reduce
Reduce
brown, 2
fox, 2
how, 1
now, 1
the, 3
ate, 1
cow, 1
mouse, 1
quick, 1
the, 1
brown, 1fox, 1
quick, 1
the, 2
fox, 1
how, 1
now, 1brown, 1
ate, 1
mouse, 1
cow, 1

Input Phase − Here we have a Record Reader that
translates each record in an input file and sends the
parsed data to the mapper in the form of key-value pairs.
Map Phase − Map is a user-defined function, which takes
a series of key-value pairs and processes each one of them
to generate zero or more key-value pairs.
Intermediate Keys − They key-value pairs generated by
the mapper are known as intermediate keys.

Combiner − A combiner is a type of local Reducer thatgroups similar data from the map phase into identifiablesets. It takes the intermediate keys from the mapper asinput and applies a user-defined code to aggregate thevalues in a small scope of one mapper. It is not a part ofthe main MapReduce algorithm; it is optional.
Shuffle and Sort − The Reducer task starts with theShuffle and Sort step. It downloads the grouped key-valuepairs onto the local machine, where the Reducer isrunning. The individual key-value pairs are sorted by keyinto a larger data list. The data list groups the equivalentkeys together so that their values can be iterated easily inthe Reducer task.

Reducer − The Reducer takes the grouped key-valuepaired data as input and runs a Reducer function on eachone of them. Here, the data can be aggregated, filtered,and combined in a number of ways, and it requires a widerange of processing. Once the execution is over, it giveszero or more key-value pairs to the final step.
Output Phase − In the output phase, we have an outputformatter that translates the final key-value pairs fromthe Reducer function and writes them onto a file using arecord writer.

Word Count in Java
public class MapClass extends MapReduceBaseimplements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable ONE = new IntWritable(1);
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> out, Reporter reporter) throws IOException {
String line = value.toString();StringTokenizer itr = new StringTokenizer(line);while (itr.hasMoreTokens()) {
out.collect(new text(itr.nextToken()), ONE);}
}}

public class ReduceClass extends MapReduceBase
implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> out,
Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
out.collect(key, new IntWritable(sum));
}
}
Word Count in Java

public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setMapperClass(MapClass.class);
conf.setCombinerClass(ReduceClass.class);
conf.setReducerClass(ReduceClass.class);
FileInputFormat.setInputPaths(conf, args[0]);
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
conf.setOutputKeyClass(Text.class); // out keys are words
(strings)
conf.setOutputValueClass(IntWritable.class); // values are counts
JobClient.runJob(conf);
}

import sys
for line in sys.stdin:
for word in line.split():
print(word.lower() + "\t" + 1)
import sys
counts = {}
for line in sys.stdin:
word, count = line.split("\t”)
dict[word] = dict.get(word, 0) +
int(count)
for word, count in counts:
print(word.lower() + "\t" + 1)

A real-world example to comprehend the power of MapReduce. Twitter receives around 500 million tweets per day, which is nearly 3000 tweets per second. The following illustration shows how Tweeter manages its tweets with the help of MapReduce.

Many parallel algorithms can be expressed by a series of MapReduce jobs
But MapReduce is fairly low-level: must think about keys, values, partitioning, etc
Can we capture common “job building blocks”?

Started at Yahoo! Research
Runs about 30% of Yahoo!’s jobs
Features:• Expresses sequences of MapReduce jobs
• Data model: nested “bags” of items
• Provides relational (SQL) operators (JOIN, GROUP BY, etc)
• Easy to plug in Java functions
• Pig Pen development environment for Eclipse

• Suppose you have user data in
one file, page view data in
another, and you need to find
the top 5 most visited pages by
users aged 18 - 25.
Load Users Load Pages
Filter by age
Join on name
Group on url
Count clicks
Order by clicks
Take top 5

In MapReduce
Example from http://wiki.apache.org/pig-data/attachments/PigTalksPapers/attachments/ApacheConEurope09.ppt

Users = load ‘users’ as (name, age);
Filtered = filter Users by
age >= 18 and age <= 25;
Pages = load ‘pages’ as (user, url);
Joined = join Filtered by name, Pages by user;
Grouped = group Joined by url;
Summed = foreach Grouped generate group,
count(Joined) as clicks;
Sorted = order Summed by clicks desc;
Top5 = limit Sorted 5;
store Top5 into ‘top5sites’;
Example from http://wiki.apache.org/pig-data/attachments/PigTalksPapers/attachments/ApacheConEurope09.ppt

Notice how naturally the components of the job translate into Pig Latin.
Job 1
Job 3
Load Users Load Pages
Filter by age
Join on name
Group on url
Count clicks
Order by clicks
Take top 5
Users = load …
Filtered = filter …
Pages = load …
Joined = join …
Grouped = group …
Summed = … count()…
Sorted = order …
Top5 = limit …

Developed at Facebook
Used for majority of Facebook jobs
“Relational database” built on Hadoop
Maintains list of table schemas
SQL-like query language (HQL)
Can call Hadoop Streaming scripts from HQL
Supports table partitioning, clustering, complexdata types, some optimizations

•Find top 5 pages visited by users aged 18-25:
•Filter page views through Python script:

Limitations of Hadoop
Hadoop can perform only batch processing, and data will be accessed only in a sequential manner. That means one has to search the entire dataset even for the simplest of jobs. A new solution is needed to access any point of data in a single unit of time (random access).
What is HBase?
HBase is a distributed column-oriented database built on top of the Hadoop file system. It is designed to provide quick random access to huge amounts of structured data. It leverages the fault tolerance provided by the Hadoop File System (HDFS).

Rowid Column Family Column Family Column Family Column Family
col1 col2 col3 col1 col2 col3 col1 col2 col3 col1 col2 col3
1
2
3

Features of HBase
• HBase is linearly scalable.
• It has automatic failure
support.
• It provides consistent read
and writes.
• It integrates with Hadoop,
both as a source and a
destination.
• It has easy java API for client.
• It provides data replication
across clusters.
Where to Use HBase
• Apache HBase is used to have
random, real-time read/write
access to Big Data.
• It hosts very large tables on top of
clusters of commodity hardware.
• Apache HBase is a non-relational
database modeled after Google's
Bigtable. Bigtable acts up on
Google File System, likewise
Apache HBase works on top of
Hadoop and HDFS.
Applications of HBase
• It is used whenever
there is a need to write
heavy applications.
• HBase is used whenever
we need to provide fast
random access to
available data.
• Companies such as
Facebook, Twitter,
Yahoo, and Adobe use
HBase internally.

HDFS HBase

HBase RDBMS
HBase is schema-less, it doesn't have the concept
of fixed columns schema; defines only column
families.
An RDBMS is governed by its schema, which
describes the whole structure of tables.
It is built for wide tables. HBase is horizontally
scalable.
It is thin and built for small tables. Hard to scale.
No transactions are there in HBase. RDBMS is transactional.
It has de-normalized data. It will have normalized data.
It is good for semi-structured as well as structured
data.
It is good for structured data.
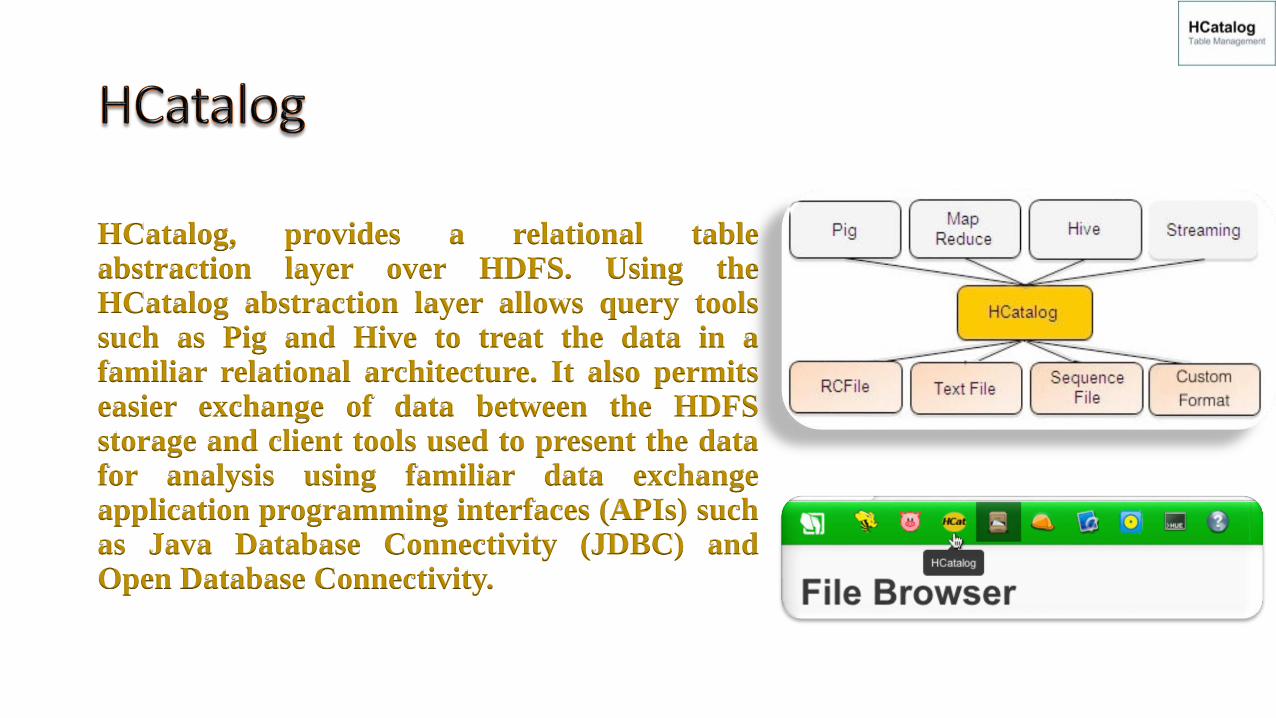
HCatalog, provides a relational table abstraction layer over HDFS. Using the HCatalog abstraction layer allows query tools such as Pig and Hive to treat the data in a familiar relational architecture. It also permits easier exchange of data between the HDFS storage and client tools used to present the data for analysis using familiar data exchange application programming interfaces (APIs) such as Java Database Connectivity (JDBC) and Open Database Connectivity.

