lecture @dhbw: data warehouse part ix: big data architecturesbuckenhofer/20182dwh/bucken... ·...
TRANSCRIPT

A company of Daimler AG
LECTURE @DHBW: DATA WAREHOUSE
PART IX: BIG DATA ARCHITECTURESANDREAS BUCKENHOFER, DAIMLER TSS

ABOUT ME
https://de.linkedin.com/in/buckenhofer
https://twitter.com/ABuckenhofer
https://www.doag.org/de/themen/datenbank/in-memory/
http://wwwlehre.dhbw-stuttgart.de/~buckenhofer/
https://www.xing.com/profile/Andreas_Buckenhofer2
Andreas BuckenhoferSenior DB [email protected]
Since 2009 at Daimler TSS Department: Big Data Business Unit: Analytics

ANDREAS BUCKENHOFER, DAIMLER TSS GMBH
Data Warehouse / DHBWDaimler TSS 3
“Forming good abstractions and avoiding complexity is an essential part of a successful data architecture”
Data has always been my main focus during my long-time occupation in the area of data integration. I work for Daimler TSS as Database Professional and Data Architect with over 20 years of experience in Data Warehouse projects. I am working with Hadoop and NoSQL since 2013. I keep my knowledge up-to-date - and I learn new things, experiment, and program every day.
I share my knowledge in internal presentations or as a speaker at international conferences. I'm regularly giving a full lecture on Data Warehousing and a seminar on modern data architectures at Baden-Wuerttemberg Cooperative State University DHBW. I also gained international experience through a two-year project in Greater London and several business trips to Asia.
I’m responsible for In-Memory DB Computing at the independent German Oracle User Group (DOAG) and was honored by Oracle as ACE Associate. I hold current certifications such as "Certified Data Vault 2.0 Practitioner (CDVP2)", "Big Data Architect“, „Oracle Database 12c Administrator Certified Professional“, “IBM InfoSphere Change Data Capture Technical Professional”, etc.
DHBWDOAG
Contact/Connect

As a 100% Daimler subsidiary, we give
100 percent, always and never less.
We love IT and pull out all the stops to
aid Daimler's development with our
expertise on its journey into the future.
Our objective: We make Daimler the
most innovative and digital mobility
company.
NOT JUST AVERAGE: OUTSTANDING.
Daimler TSS
INTERNAL IT PARTNER FOR DAIMLER
+ Holistic solutions according to the Daimler guidelines
+ IT strategy
+ Security
+ Architecture
+ Developing and securing know-how
+ TSS is a partner who can be trusted with sensitive data
As subsidiary: maximum added value for Daimler
+ Market closeness
+ Independence
+ Flexibility (short decision making process,
ability to react quickly)
Daimler TSS 5

Daimler TSS
LOCATIONS
Data Warehouse / DHBW
Daimler TSS ChinaHub Beijing10 employees
Daimler TSS MalaysiaHub Kuala Lumpur42 employees
Daimler TSS IndiaHub Bangalore22 employees
Daimler TSS Germany
7 locations
1000 employees*
Ulm (Headquarters)
Stuttgart
Berlin
Karlsruhe
* as of August 2017
6

• Describe Big Data architectures
• Lambda architecture
• Kappa architecture
DWH LECTURE - LEARNING TARGETS
Data Warehouse / DHBWDaimler TSS 7

• There exist well-known reference architectures for Data Warehouses
• Many tools and schema-on-read came with the Hadoop ecosystem
• Was a “black box” at the beginning
• Gets more and more structure with different layers instead of a “black box”
• Structure, modeling, organization, governance instead of tool-only focus
• The slides provide some architectures with links to more information
BIG DATA / DATA LAKE ARCHITECTURESINTRODUCTION
Data Warehouse / DHBWDaimler TSS 8

• Architecture by Nathan Marz
• Realtime and batch processing
• Batch layer stores and historizes raw data
• Serving layer has to union batch and realtime layer
• Rather complex
• Author recommends graph data model and advises against schema-on-read
LAMBDA ARCHITECTURE
Data Warehouse / DHBWDaimler TSS 9
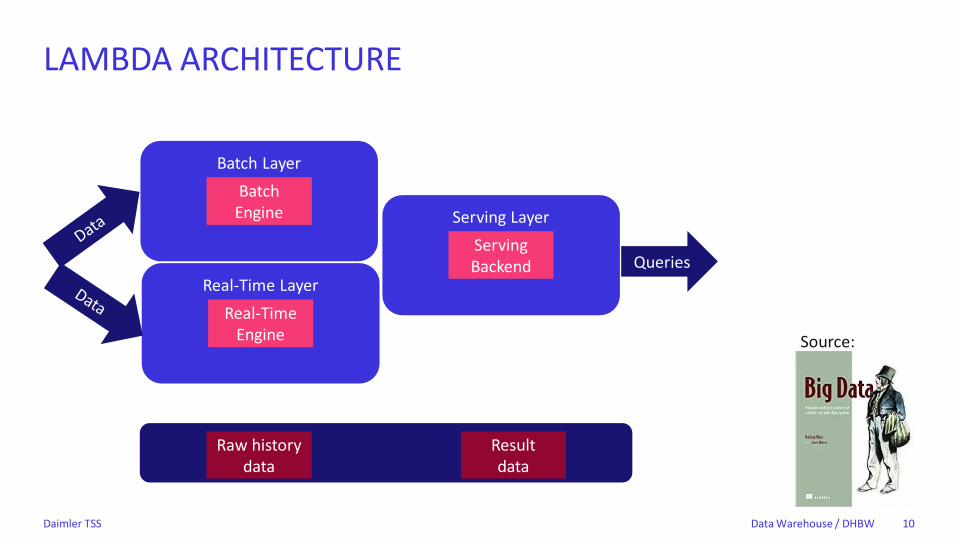
LAMBDA ARCHITECTURE
Data Warehouse / DHBWDaimler TSS 10
Source:
Batch Layer
BatchEngine Serving Layer
ServingBackend Queries
Raw historydata
Resultdata
Real-Time Layer
Real-TimeEngine

• Lack of human fault tolerance
• Bugs will be deployed
• Operational errors will happen, e.g. accidentally delete data
• Data loss / corruption is worst case scenario
• Without data loss / corruption, mistakes can be fixed if original data is still available
• Must design for human error like you’d design for any other fault
WHAT IS THE MAIN INVENITABLE PROBLEM IN DATASYSTEMS?
Data Warehouse and Big Data / DHBWDaimler TSS 11

• Atomic, immutable data
• Ensure that data can not be deleted (accidentally)
• Fundamentally simpler
• Easy to implement on top of a distributed filesystem, eg Hadoop
• CR instead of CRUD• No updates
• No deletes
• Create (insert) and read (select) only
Immutability restricts the range of errors that can cause data loss/corruption
IMMUTABLE DATA
Data Warehouse and Big Data / DHBWDaimler TSS 12

NATHAN MARZ VIEW ON SCHEMA
Data Warehouse / DHBWDaimler TSS 13
• RawnessStore the data as it is. No transformations.
• ImmutabilityDon’t update or delete data, just
add more.
• Graph-like schema recommended
„Many developers go down the path of writing their raw data in a schemaless
format like JSON. This is appealing because of how easy it is to get started, but this
approach quickly leads to problems. Whether due to bugs or misunderstandings
between different developers, data corruption inevitably occurs“
(see page 103, Nathan Marz, „Big Data: Principles and best practices of scalable
realtime data systems", Manning Publications)
Source image: Nathan Marz, James Warren: Big Data: Principles and best practices of scalable realtime data systems, Manning Publications 2015

“My own personal opinion is that data analysis is much less important than data re-analysis. It’s hard for a data team to get things right on the very first try, and the team shouldn’t be faulted for their honest efforts. When everything is available for review, and when more data is added over time, you’ll increase your chances of converging to someplace near the truth.”–Jules J. Berman.
http://www.odbms.org/blog/2014/07/big-data-science-interview-jules-j-berman/
ANALYTICS VS RE-ANALYTICS
Data Warehouse and Big Data / DHBWDaimler TSS 14

NEW APPROACH TO BUILD DATA SYSTEMS
Data Warehouse and Big Data / DHBWDaimler TSS 15
Immutable data(Source of Truth / Single version of
facts)
(Materialized) Views on data
(Materialized) Views on data
(Materialized) Views on data
(Materialized) Views on data
(Materialized) Views on data
Query = Application
HDFS / NoSQLRDBMSNewSQL
(Materialized) Views on data
(Materialized) Views on data
(Materialized) Views on data
(Materialized) Views on data
(Materialized) Views on data
Query = Application

WHAT IS THE LAMBDA ARCHITECTURE?
Data Warehouse and Big Data / DHBWDaimler TSS 16
Batch Layer
All Data
Speed Layer
RealTime Views
Serving Layer
Batch Views
Query(merge)
Data Stream

OVERVIEW LAMBDA ARCHITECTURE
Data Warehouse and Big Data / DHBWDaimler TSS 17
https://de.slideshare.net/gschmutz/big-data-and-fast-data-lambda-architecture-in-action

BATCH VIEWS AND REALTIME VIEWS
Data Warehouse and Big Data / DHBWDaimler TSS 18

DATA ABSOBTION
Data Warehouse and Big Data / DHBWDaimler TSS 19
https://dzone.com/articles/lambda-architecture-with-apache-spark

LAMBDA ARCHITECTURE – DATA EXAMPLECOMPUTE FOLLOWER LIST
Data Warehouse and Big Data / DHBWDaimler TSS 20
Batch Layer
1.1. insert Jim1.1. insert Anne2.1 remove Jim3.1. insert George5.1. insert John (now)
Speed Layer
insert John (now)
ServingLayer
AnneGeorge
Query
Data Stream
AnneGeorgeJohn
Follower: 3

Computing best answer in real time may not always be possible
• Can compute exact answer in batch layer and approximate answer in realtime layer
• Best of both worlds of performance and accuracyFor example, a machine learning application where generation of the batch model requires so much time and resources that the best result achievable in real-time is computing and approximated updates of that model. In such cases, the batch and real-time layers cannot be merged, and the Lambda architecture must be used.
EVENTUAL ACCURACY
Data Warehouse and Big Data / DHBWDaimler TSS 21

WHICH TOOLS COULD BE USED IN THE LAMBDAARCHITECTURE? DB REQUIREMENTS
Data Warehouse and Big Data / DHBWDaimler TSS 22
Easier to implement fordatabase vendors
compared to randomaccess

Batch layer
Write sequential
once
Bulk sequential read many
times
Speed layer
Random write
Random read
Servinglayer
Batch write
Random read
WHICH TOOLS COULD BE USED IN THE LAMBDAARCHITECTURE? DB REQUIREMENTS
Data Warehouse and Big Data / DHBWDaimler TSS 23
More challenging
More challenging More challenging

WHICH TOOLS COULD BE USED IN THE LAMBDAARCHITECTURE?
Data Warehouse and Big Data / DHBWDaimler TSS 24
Batch Layer
All Data
Speed Layer
RealTime Views
Serving Layer
Batch Views
Query(merge)
Data Stream
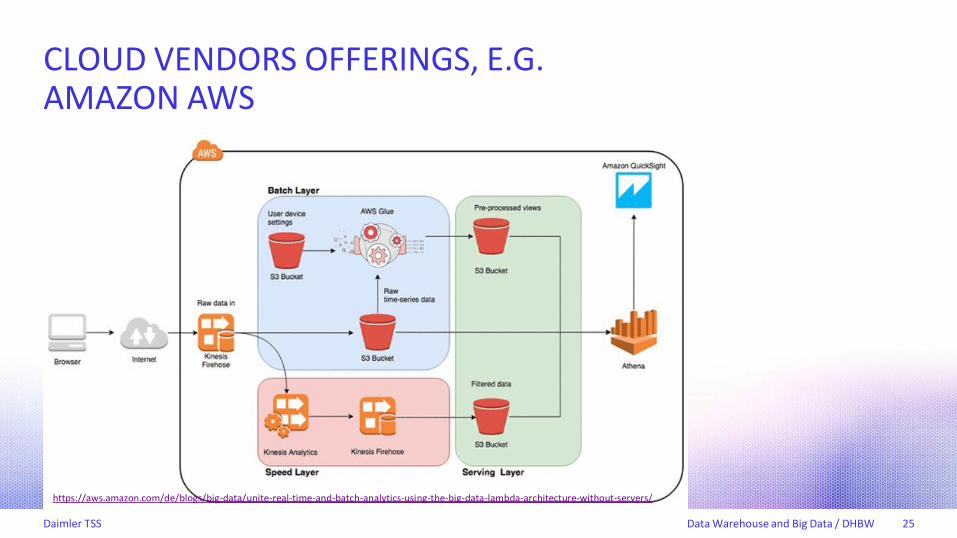
CLOUD VENDORS OFFERINGS, E.G.AMAZON AWS
Data Warehouse and Big Data / DHBWDaimler TSS 25
https://aws.amazon.com/de/blogs/big-data/unite-real-time-and-batch-analytics-using-the-big-data-lambda-architecture-without-servers/

CLOUD VENDORS OFFERINGS, E.G.MICROSOFT AZURE
Data Warehouse and Big Data / DHBWDaimler TSS 26
https://social.technet.microsoft.com/wiki/contents/articles/33626.lambda-architecture-implementation-using-microsoft-azure.aspx

Data Warehouse and Big Data / DHBWDaimler TSS 27
sou
rce:
Mar
kus
Sch
mid
ber
ger
-B
ig D
ata
ist
tot
–Es
leb
eB
usi
nes
s In
telli
gen
z?,
TDW
I 2
01
6

Data Warehouse and Big Data / DHBWDaimler TSS 28
sou
rce:
Mar
kus
Sch
mid
ber
ger
-B
ig D
ata
ist
tot
–Es
leb
eB
usi
nes
s In
telli
gen
z?,
TDW
I 2
01
6
Lambda @glomex• Enrich batch-
driven data processing with real-time requirements
• Adapt Lambda architecture to own requirements
Remark: AWS lambda # lambda architecture

LAMBDA ARCHITECTURE – PROS AND CONS
Data Warehouse and Big Data / DHBWDaimler TSS 29
Pro Con
Architecture emphasizes to keep data immutable. Mistakes can be corrected via recomputation
Maintaining code that needs to produce the same result in two complex distributed systems
Reprocessing is one of the key challenges of stream processing but is very often ignored
Operational burden of running and debugging two systems

• Incoming data is sent to batch and speed layer
• Batch layer constantly (re-) computes batch views
• Master data is stored in the batch layer in raw format: immutable & append-only
• Contains data except most up-to-date data due to high latency
• Replaces data in speed layer as soon as data in newer compared to speed layer
• Speed layer uses incremental algorithms to refresh real-time Views• Receives data stream for real-time processing
• Contains most up-to-date data only
• Serving layer merges results from batch and speed layer
SUMMARY LAMBDA ARCHITECTURE
Data Warehouse and Big Data / DHBWDaimler TSS 30

Jay Kreps wrote an article about „Questioning the Lambda architecture“
• He wrote about his experience with the Lambda architecture
• It works, but not very pleasant or productive
• Keeping code in sync is really hard
• Need to build complex, low-latency processing systems
• Scalable high-latency batch system
• Low-latency stream stream-processing system
• Instead of duct taping batch & speed:
→ Kappa architecture / Log-centric architecture / Stream data platform
QUESTIONING THE LAMBDA ARCHITECTURE
Data Warehouse and Big Data / DHBWDaimler TSS 31
Source: https://www.oreilly.com/ideas/questioning-the-lambda-architecture

• Architecture by Jay Kreps
• Logcentric, write-ahead logging
• Each event is an immutable log entry and is added to the end of the log
• Read and write operations are separated
• Materialized views can be recomputed consistently from data in the log
KAPPA ARCHITECTURE
Data Warehouse / DHBWDaimler TSS 32

WHAT ARE THE THREE PARADIGMS OF PROGRAMMING?
• Request/Response
• Batch
• Stream processing
Data Warehouse and Big Data / DHBWDaimler TSS 33
Source: https://de.slideshare.net/JayKreps1/distributed-stream-processing-with-apache-kafka-71737619

WHAT IS A LOG?
Data Warehouse and Big Data / DHBWDaimler TSS 34
Source: Jay Kreps: I heart logs, O’Reilly 2014

• Database transactions/data
• User, products, etc.
• Events• Tweets, clicks, impressions, pageviews, etc.
• Application metrics
• CPU usage, requests, etc.
• Application logs• Service calls, errors, etc.
TYPES OF DATA
Data Warehouse and Big Data / DHBWDaimler TSS 35

• A bank account’s current balance can be built from a complete list of its debits and credits, but the inverse is not true.
• In this way, the log of transactions is the more “fundamental” data structure than the database records storing the results of those transactions.
A software application’s database is better thought of as a series of time-ordered immutable facts collected since that system was born, instead of as a current snapshot of all data records as of right now.
WHAT IS A LOG?
Data Warehouse and Big Data / DHBWDaimler TSS 36
Source: https://blog.parse.ly/post/1550/kreps-logs/

ENTERPRISE-WIDE ARCHITECTURE TODAYDATA INTEGRATION CHALLENGE
Data Warehouse and Big Data / DHBWDaimler TSS 37
Source: https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea/

ENTERPRISE-WIDE ARCHITECTURE TODAYDATA INTEGRATION CHALLENGE
Data Warehouse and Big Data / DHBWDaimler TSS 38
Source: https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea/

ENTERPRISE-WIDE ARCHITECTURE TODAYDATA INTEGRATION CHALLENGE
Data Warehouse and Big Data / DHBWDaimler TSS 39
Source: https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea/

ENTERPRISE-WIDE ARCHITECTUREUSING LOG-CENTRIC APPROACH
Data Warehouse and Big Data / DHBWDaimler TSS 40
Source: https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea/

ENTERPRISE-WIDE ARCHITECTUREUSING LOG-CENTRIC APPROACH AND CDC
Data Warehouse and Big Data / DHBWDaimler TSS 41
Source: https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea/

LOG CENTRIC ARCHITECTURE / KAPPA ARCHITECTURE / DATA STREAMING PLATFORM
Data Warehouse and Big Data / DHBWDaimler TSS 42
Source: Jay Kreps: I heart logs, O’Reilly 2014

SUMMARY: ENTERPRISE-WIDE ARCHITECTURE
Data Warehouse and Big Data / DHBWDaimler TSS 43
Source: Jay Kreps: I heart logs, O’Reilly 2014

Most common understanding (doing the „T“ in ETL):
• Stream processing is the parallel processing of data in motion = computing on data directly as it is produced or received.
• Not necessarily transient, approximate, lossy (assumptions from Lambda architecture and other event processing systems)
WHAT IS STREAM PROCESSING?
Data Warehouse and Big Data / DHBWDaimler TSS 44

• Active MQ, RabbitMQ
• Problems:• Not distributed
• Throughput
• Persistence
• Ordering
MESSAGING SYSTEMS @LINKEDIN
1st attempt
• Kafka
• Key abstraction: Logs
• build from scratch• Distributed system by design
• Partitioning with local ordering
• Elastic scaling
• Fault tolerance
2nd attempt
Data Warehouse and Big Data / DHBWDaimler TSS 45

• Scalability
• Hundreds of MB/sec/server throughput
• Many TB per node
• Guarantees of a database
• All messages strictly ordered (within a partition)
• All data persistent
• Distributed by default
• Replication
• Partitioning
• Producers + consumers all fault tolerant and horizontally scalable
KAFKA: A MODERN DISTRIBUTED SYSTEM FOR STREAMS
Data Warehouse and Big Data / DHBWDaimler TSS 46

ETL REVISITED WITH KAFKA CONNECT AND KAFKA STREAMS
Data Warehouse and Big Data / DHBWDaimler TSS 47
Source: https://de.slideshare.net/JayKreps1/distributed-stream-processing-with-apache-kafka-71737619
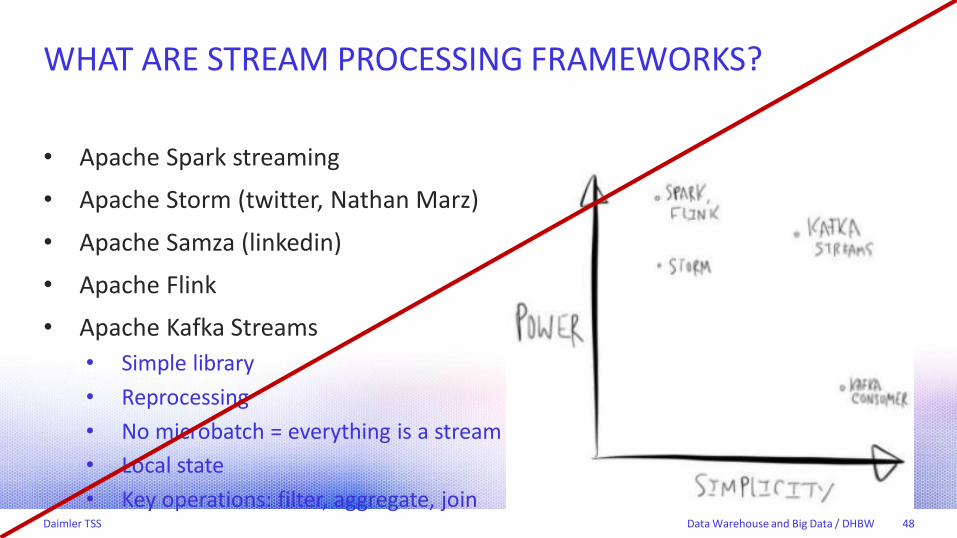
• Apache Spark streaming
• Apache Storm (twitter, Nathan Marz)
• Apache Samza (linkedin)
• Apache Flink
• Apache Kafka Streams
• Simple library
• Reprocessing
• No microbatch = everything is a stream
• Local state
• Key operations: filter, aggregate, join
WHAT ARE STREAM PROCESSING FRAMEWORKS?
Data Warehouse and Big Data / DHBWDaimler TSS 48

Lambda architecture
• Complex
• It works, but not very pleasant or productive
• Keeping code in sync is really hard
• Addresses the challenge of reprocessing
• Bugs
• New requirements
Logs unify• Batch processing
• Stream processing
REPROCESSING
Data Warehouse and Big Data / DHBWDaimler TSS 49

KAFKA @LINKEDIN
Data Warehouse and Big Data / DHBWDaimler TSS 50
Source: https://de.slideshare.net/JayKreps1/i-32858698

SUMMARY: STREAM DATA PLATFORM USING KAFKAUNIFYING BATCH AND STREAM PROCESSING
Data Warehouse and Big Data / DHBWDaimler TSS 51
Source: https://de.slideshare.net/JayKreps1/i-32858698

• A message-oriented implementation requires an efficient messaging backbone that facilitates the exchange of data in a reliable and secure way with the lowest latency possible.
• Creating small, self-contained, data-driven applications that meld streaming data and microservices together is a good practice to break down large problems and projects into approachable chunks, reduce risk, and deliver value faster.
• Think of combinations of data-processing applications with microservices to deliver specific features and insights from a data stream.
KAFKA AND MICROSERVICES
Data Warehouse and Big Data / DHBWDaimler TSS 52

KAPPA ARCHITECTURE
Data Warehouse / DHBWDaimler TSS 53
Source:
Real-Time Layer
Real-TimeEngine
Serving Layer
ServingBackendData Queries
Raw historydata
Resultdata

Daimler TSS GmbHWilhelm-Runge-Straße 11, 89081 Ulm / Telefon +49 731 505-06 / Fax +49 731 505-65 99
[email protected] / Internet: www.daimler-tss.com/ Intranet-Portal-Code: @TSSDomicile and Court of Registry: Ulm / HRB-Nr.: 3844 / Management: Christoph Röger (CEO), Steffen Bäuerle
Data Warehouse / DHBWDaimler TSS 54
THANK YOU
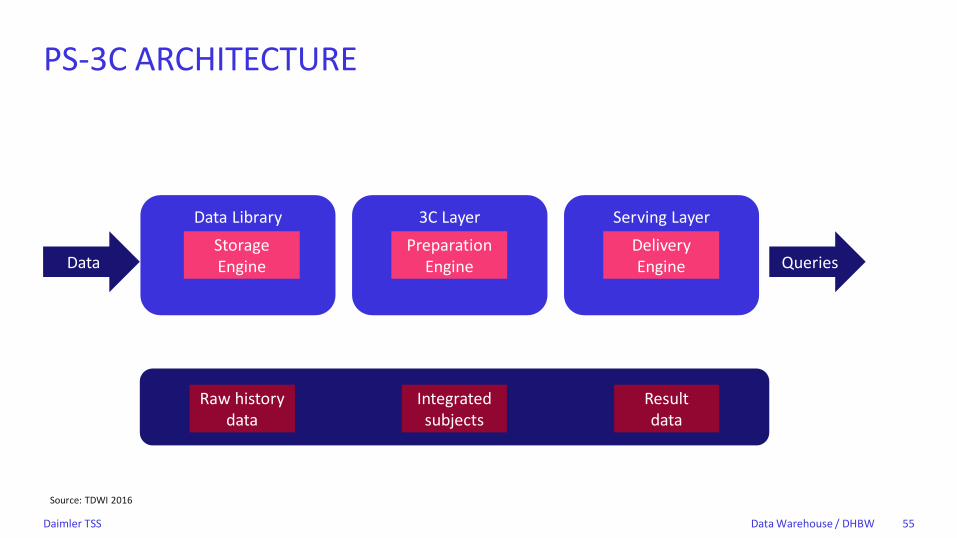
PS-3C ARCHITECTURE
Data Warehouse / DHBWDaimler TSS 55
Source: TDWI 2016
Data Library
StorageEngine
3C Layer
PreparationEngineData Queries
Serving Layer
DeliveryEngine
Raw historydata
Integrated subjects
Resultdata

• Architecture by Rogier Werschkull
• Store incoming data in Data Library Layer (Persistent staging = PS)
• Prepare data in a 3C layer for “Concept – Context – Connector”-model
• Concept + Connector can be virtualized on data in Data Library Layer
PS-3C ARCHITECTURE
Data Warehouse / DHBWDaimler TSS 56

• Architecture by Joe Caserta
• Big Data Warehouse may live in one or more platforms on premise or in the cloud
• Hadoop only
• Hadoop + MPP or RDBMS
• Additionally NoSQL or Search
POLYGLOT WAREHOUSE
Data Warehouse / DHBWDaimler TSS 57

POLYGLOT WAREHOUSE
Data Warehouse / DHBWDaimler TSS 58
Source: https://www.slideshare.net/CasertaConcepts/hadoop-and-your-data-warehouse

• Architecture by Claudia Imhoff
• combine the stability and reliability of the BI architectures while embracing new and innovative technologies and techniques
• 3 components that extend the EDW environment
• Investigative computing platform
• Data refinery
• Real-time (RT) analysis platform
THE EXTENDED DATA WAREHOUSE ARCHITECTURE (XDW)THE ENTERPRISE ANALYTICS ARCHITECTURE
Data Warehouse / DHBWDaimler TSS 59

THE EXTENDED DATA WAREHOUSE ARCHITECTURE (XDW)THE ENTERPRISE ANALYTICS ARCHITECTURE
Data Warehouse / DHBWDaimler TSS 60
Source: https://upside.tdwi.org/articles/2016/03/15/extending-traditional-data-warehouse.aspx

• Inflow Lake: accommodates a collection of data ingested from many different sources that are disconnected outside the lake but can be used together by being colocated within a single place
• Outflow Lake: a landing area for freshly arrived data available for immediate access or via streaming. It employs schema-on-read for the downstream data interpretation and refinement.
• Data Science Lab: most suitable for data discovery and for developing new advanced analytics models
GARTNER DATA LAKE ARCHITECTURE STYLES
Data Warehouse / DHBWDaimler TSS 61
Source: http://blogs.gartner.com/nick-heudecker/data-lake-webinar-recap/

GARTNER DATA LAKE ARCHITECTURE STYLES
Data Warehouse / DHBWDaimler TSS 62
Source: http://blogs.gartner.com/nick-heudecker/data-lake-webinar-recap/

GARTNER – THE LOGICAL DWH
Data Warehouse / DHBWDaimler TSS 63
https://blogs.gartner.com/henry-cook/2018/01/28/the-logical-data-warehouse-and-its-jobs-to-be-done/

SUMMARY
Data Warehouse / DHBWDaimler TSS 64
Landing Area
StorageEngine
Data Lake
IntegrationEngineData Queries
Data Presentation
DeliveryEngine
Raw historydata
Lightly integrated data
Resultdata

• Architecture by Eckerson Group
• DWHs exist together with MDM, ODS, and portions of the data lake as a collection of data that is curated, profiled, and trusted for enterprise reporting and analysis
DATA CORE – DAVE WELLS
Data Warehouse / DHBWDaimler TSS 65
https://www.eckerson.com/articles/the-future-of-the-data-warehouse

DATA CORE – DAVE WELLS
Data Warehouse / DHBWDaimler TSS 66
https://www.eckerson.com/articles/the-future-of-the-data-warehouse

DATA LIFECYCLE – DAVE WELLS
Data Warehouse / DHBWDaimler TSS 67
https://www.eckerson.com/articles/the-future-of-the-data-warehouse

DWH AND DATA LAKE – DAVE WELLSIN PARALLEL VS INSIDE
Data Warehouse / DHBWDaimler TSS 68
https://www.eckerson.com/articles/the-future-of-the-data-warehouse

• Dimensional modeling is not dead.
• The benefits are still valid in the age of Big Data, Hadoop, Spark, etc:
• Eliminate joins
• Data model is understandable for end users
• Well-suited for columnar storage + processing (e.g. SIMD)
• Nesting technique
• E.g. tables with lower granularity can be nested into large fact table
• Usage in SQL: Flatten(kvgen(<json>))
DIMENSIONAL MODELING IN THE AGE OF BIG DATA
Data Warehouse / DHBWDaimler TSS 69

SELF-SERVICE DATA
Data Warehouse / DHBWDaimler TSS 70
https://www.oreilly.com/ideas/how-self-service-data-avoids-the-dangers-of-shadow-analytics
Functional area Why important Self-service approach
Data acceleration
With shadow analytics, users create redundant data copies.
The system must be capable of autonomously identifying the best optimizations and adapting to emerging query patterns over time.
Data catalog Data consumers struggle to find data that is important to their work. Users keep private notes about data sources and data quality, meaning there is no governance.
In the self-service approach, the catalog is automatic—as new data sources are brought online.
Data virtualization
It is virtually impossible for an organization to centralize all data in a single system.
Data consumers need to be able to access all data sets equally well, regardless of the underlying technology or location of the system.

SELF-SERVICE DATA
Data Warehouse / DHBWDaimler TSS 71
https://www.oreilly.com/ideas/how-self-service-data-avoids-the-dangers-of-shadow-analytics
Functional area Why important Self-service approach
Data curation There is no single “shape” of data that works for everyone.
Data consumers need the ability to interact with data sets from the context of the data itself, not exclusively from simple metadata that fails to tell the whole story. Data consumers should be capable of reshaping data to their own needs without writing any code or learning new languages.
Data lineage As data is accessed by data consumers and in different processes, it is important to track the provenance of the data, who accessed the data, how the data was accessed, what tools were used, and what results were obtained.
As users reshape and share data sets with one another through a virtual context, a self-service data platform can seamlessly track these actions and all states of data along the way, providing full audit capabilities as well.

SELF-SERVICE DATA
Data Warehouse / DHBWDaimler TSS 72
https://www.oreilly.com/ideas/how-self-service-data-avoids-the-dangers-of-shadow-analytics
Functional area Why important Self-service approach
Open source Because data is essential to every area of every business, the underlying data formats and technologies used to access and process the data should be open source
Self-service data platforms build on open source standards like Apache Parquet, Apache Arrow, and Apache Calcite to store, query, and analyze data from any source.
Security controls
Organizations safeguard their data assets with security controls that govern authentication (you are who you say you are), authorization (you can perform specific actions), auditing (a record of the actions you take), and encryption (you can only read the data if you have the right key).
Self-service data platforms integrate with existing security controls of the organization, such as LDAP and Kerberos.

Hadoop (and for similar reasons Spark) has its strengths but no as a DWH replacement, e.g.
• Fast query reads only possible in HBase with an inflexible (use case specific) data model
• No sophisticated query optimizer
• Hadoop is very complex with many tools/versions/vendors and no standard
• Security is still at the beginning
IS THE DWH DEAD?
Data Warehouse / DHBWDaimler TSS 73

• The LDW is a multi-server / multi-engine architecture
• The LDW can have multiple engines, the main ones being: The datawarehouse(DW), the operational data store(ODS), data marts and thedata lake
• We should not be trying to choose a single engine for all ourrequirements. Instead, we should be sensibly distributing all ourrequirements across the various components we have to choose from
LOGICAL DWH (GARTNER)
Data Warehouse / DHBWDaimler TSS 74
https://blogs.gartner.com/henry-cook/2018/01/18/logical-data-warehouse-project-plans/