leveraging the power of solr with spark
TRANSCRIPT

Leveraging the Power of Solr with SparkInteraktive Datenanalyse mit Solr Cloud und Spark
Mainz, 21.04.2016 | Johannes Weigend | QAware GmbH

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Stellen Sie Ihre Fragen direkt oderper Twitter mit dem Hashtag #cloudnativenerd
JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
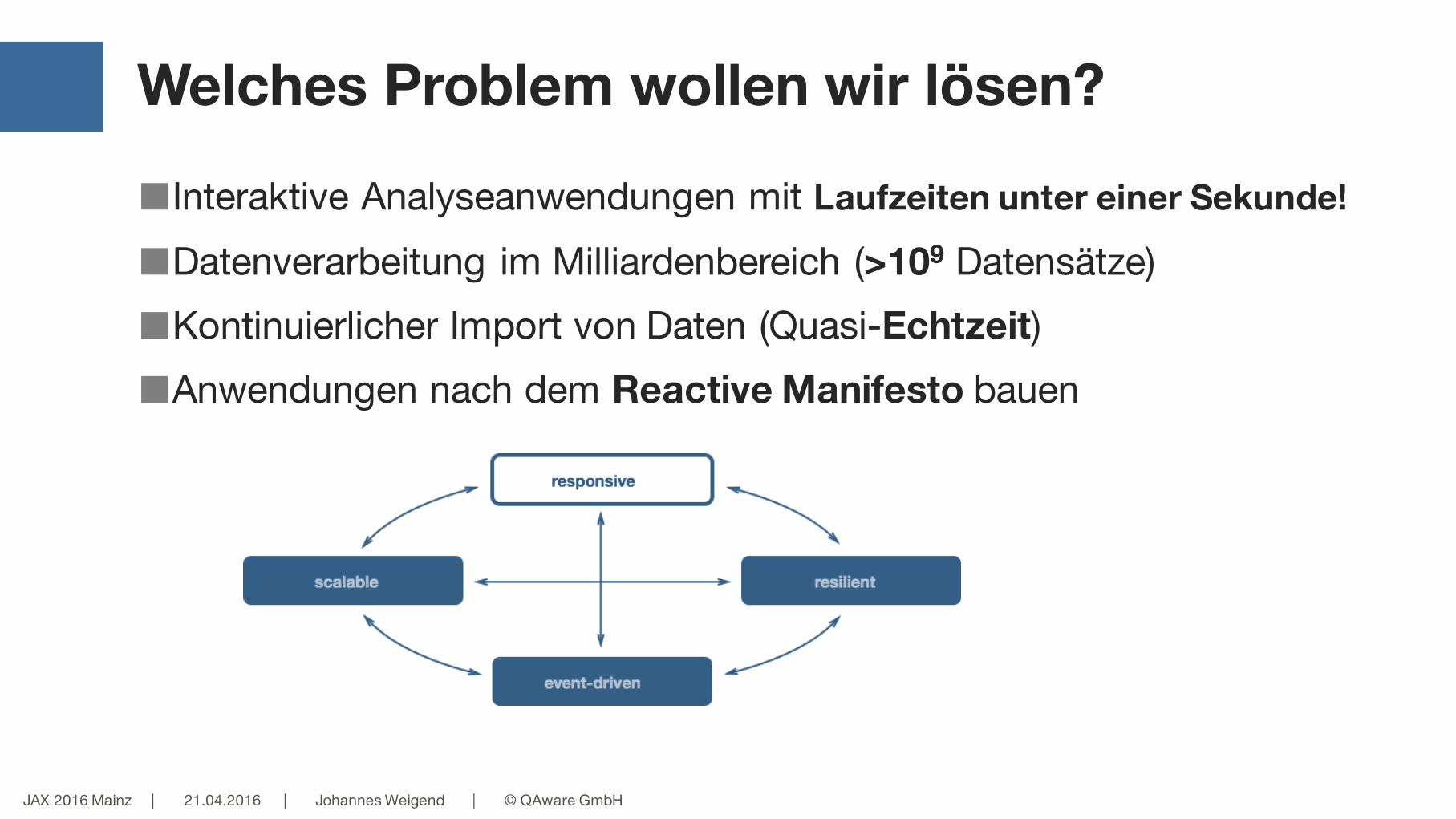
Welches Problem wollen wir lösen?
■Interaktive Analyseanwendungen mit Laufzeiten unter einer Sekunde!
■Datenverarbeitung im Milliardenbereich (>109 Datensätze)■Kontinuierlicher Import von Daten (Quasi-Echtzeit)■Anwendungen nach dem Reactive Manifesto bauen

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Horizontal skalieren ist schwierig!
■Horizontale Skalierung von Funktionalität ■ Trivial ■ Loadbalancing von (zustandslosen) Services (Makro- / Microservices) ■Mehr Benutzer à Mehr Maschinen
■Nicht trivial■Mehr Maschinen à Geringer Antwortzeit
■Horizontale Skalierung von Daten■ Trivial■ Lineare Aufteilung von Daten auf Maschinen■Mehr Maschinen à Mehr Daten
■Nicht trivial■Konstante Laufzeit bei steigendem Datenvolumen
JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
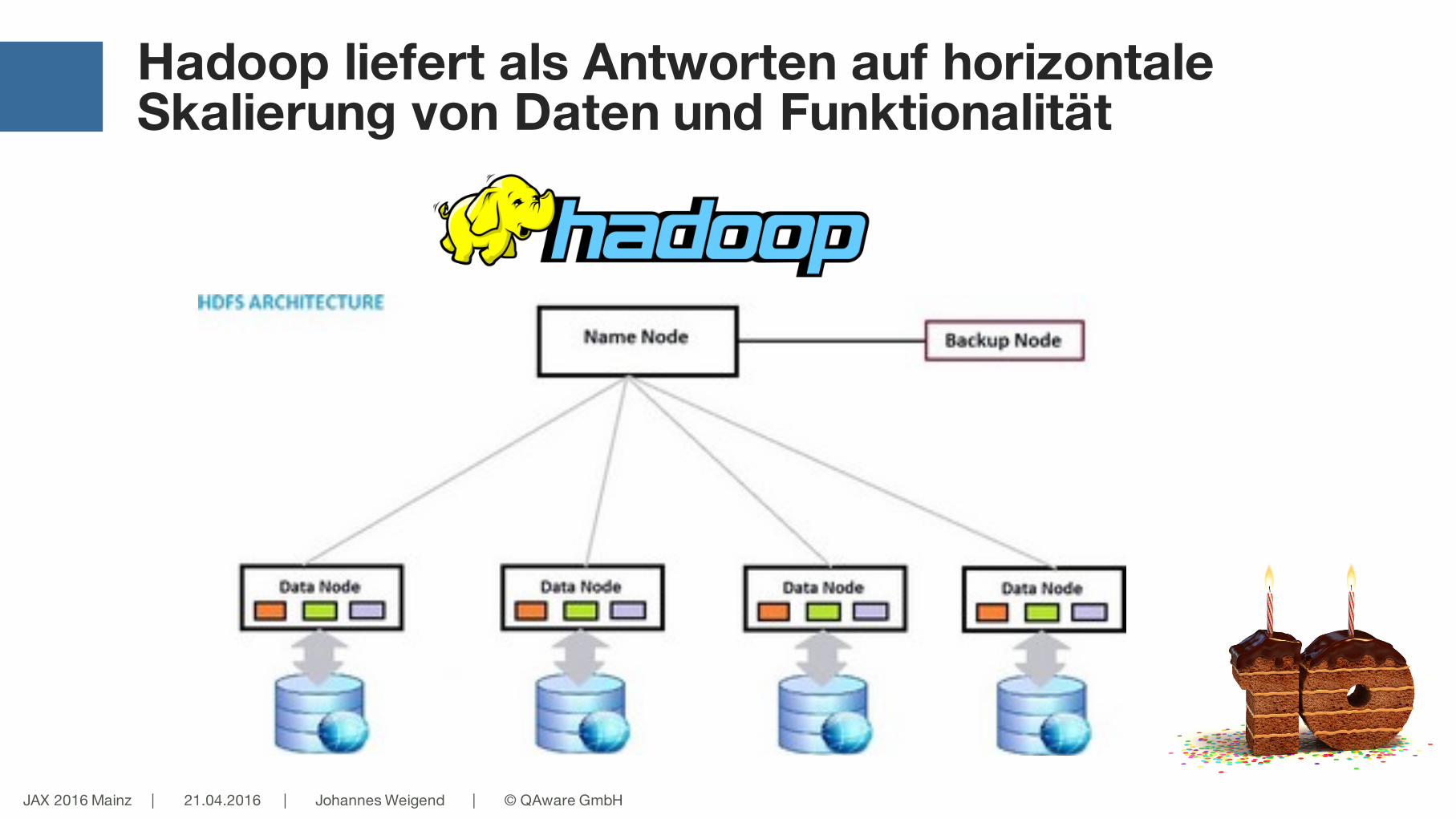
Hadoop liefert als Antworten auf horizontale Skalierung von Daten und Funktionalität

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Die Verarbeitung von verteilten Daten kann langsam sein
9
Datenfluss
Read Read Read
Filter Filter Filter
Map Map Map
Reduce
foreach() -> Minutes / Hours
HDFS/NFS/NoSQL

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Durch Indizieren und intelligente Suche entfällt das vollständige Lesen der Ausgangsdaten
10
Filter
Search Search Search
Map Map Map
Reduce
DatenflussFilter Filterforeach()->Seconds/Minutes
Search/NoSQL

SparkSearch Search Search
Map Map Map
Reduce
Distributed Data
ClusterProcessing
Business Layer
Frontend

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
DEMO
Spark
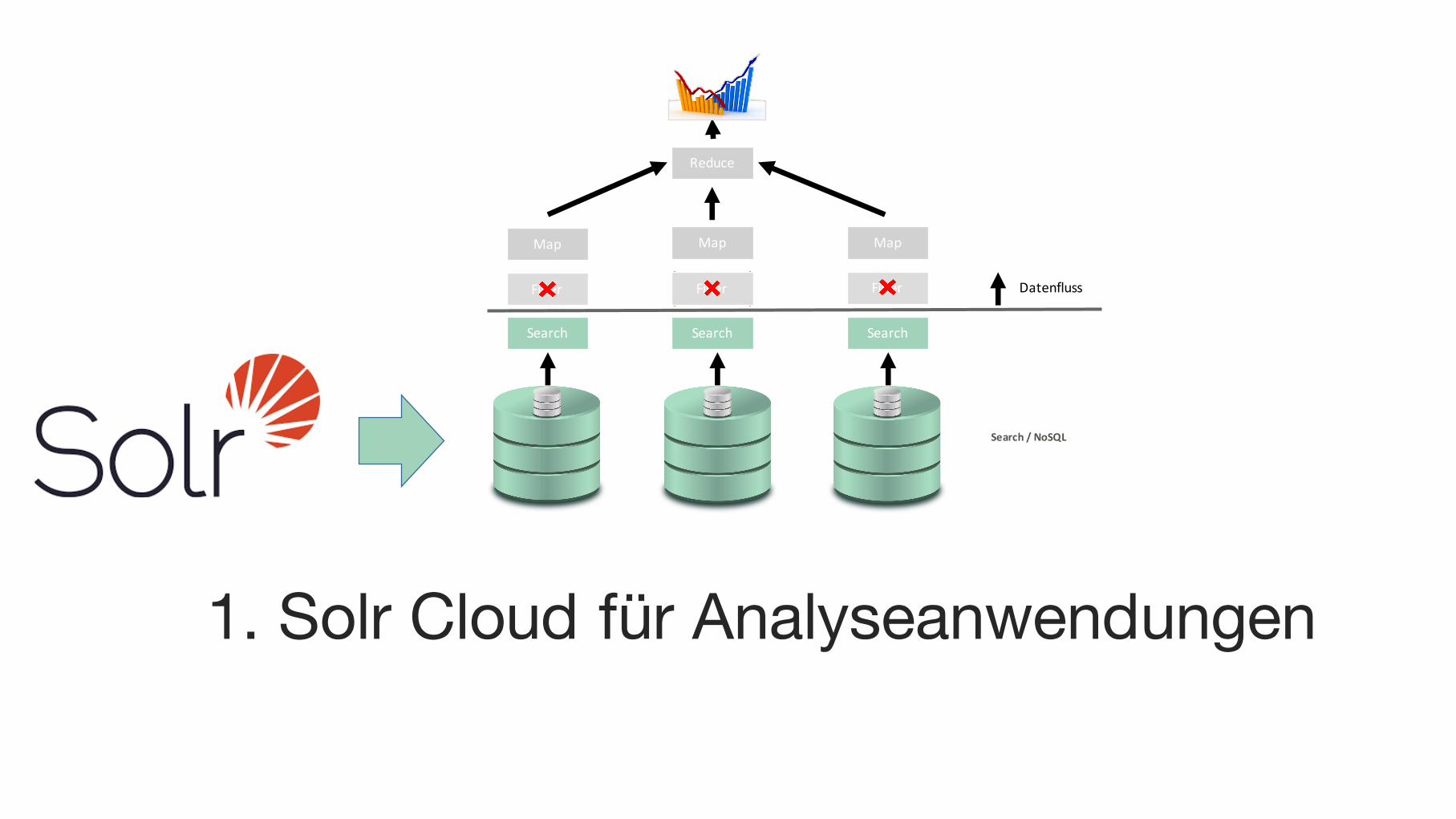
1. Solr Cloud für Analyseanwendungen
Filter
Search Search Search
Map Map Map
Reduce
DatenflussFilter Filter
Search/NoSQL

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
■Suchoptimierte, Dokumentenoritentierte NoSQL Datenbank■Ein Dokument ist eine Sammlung von Feldern (string, number, date, …)■Einfache und Multiple Felder (Felder können Arrays sein)■Geschachtelte Dokumente (Nested)■Statisches und dynamisches Schema■Mächtige Query-Sprache (Lucene)
■Horizontal Skalierbar (Solr Cloud)■Verteilte Daten in Shards■Resilent durch Replikation
■Mächtige Aggregationsfunktionen (Facets)■Stabil—> V 6.0
14
Cloud

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Shard2
Die (T) Architektur von Solr Cloud
Solr Server
Zookeeper
Solr ServerSolr Server
Shard1
Zookeeper Zookeeper Zookeeper Cluster
Solr Cloud
Leader
Scale Out
Shard3
Replika8 Replika9
Shard5Shard4 Shard6 Shard8Shard7 Shard9
Replika2 Replika3 Replika5
Shards
Replicas
Collection
Replica4 Replica7 Replika1 Shard6
JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
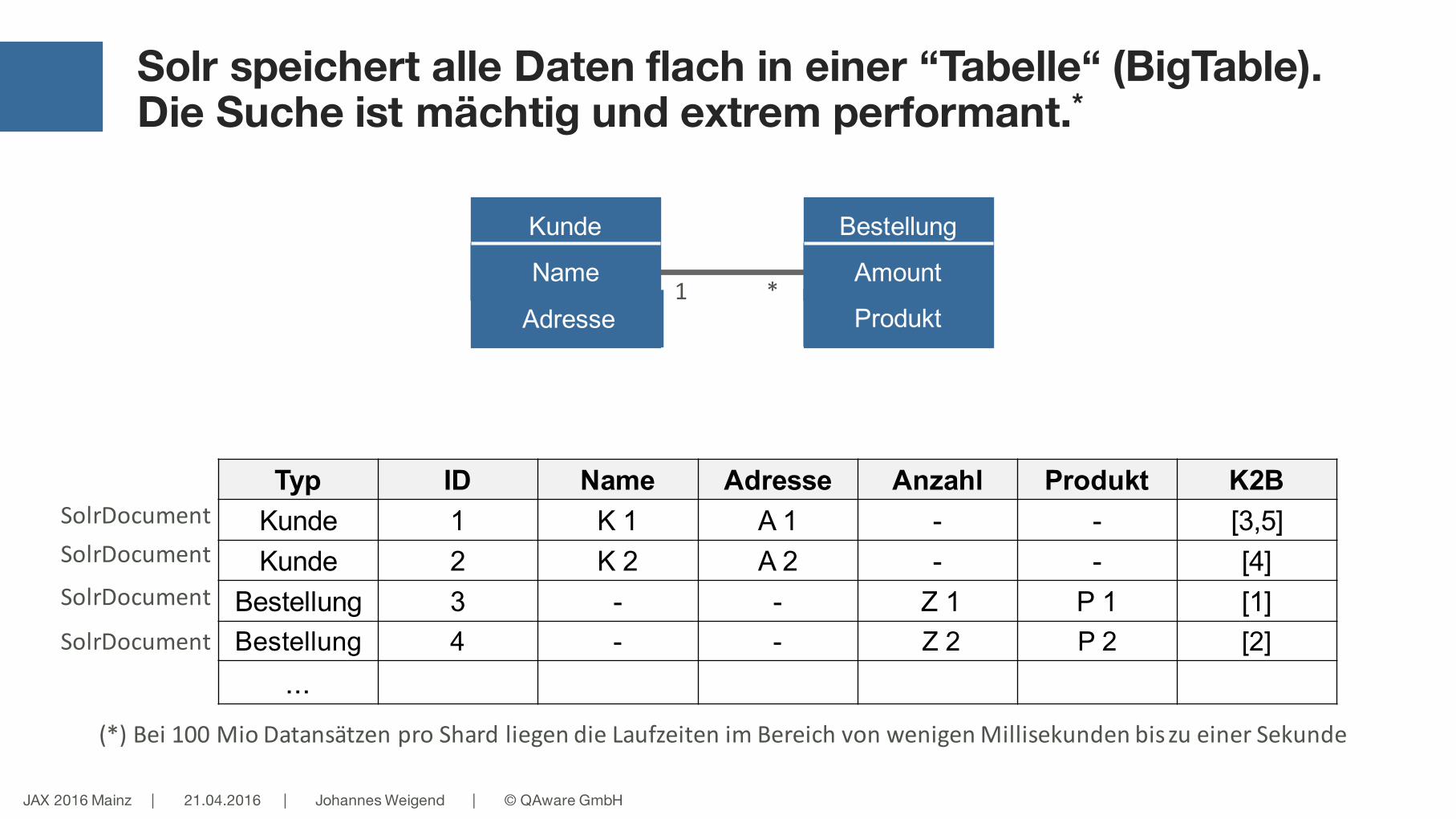
Solr speichert alle Daten flach in einer “Tabelle“ (BigTable). Die Suche ist mächtig und extrem performant.*
Kunde Bestellung
*1Name Amount
Adresse Produkt
Typ ID Name Adresse Anzahl Produkt K2BKunde 1 K 1 A 1 - - [3,5]Kunde 2 K 2 A 2 - - [4]
Bestellung 3 - - Z 1 P 1 [1]Bestellung 4 - - Z 2 P 2 [2]
...
SolrDocumentSolrDocument
SolrDocument
SolrDocument
(*)Bei100Mio Datansätzen proShard liegendieLaufzeitenimBereichvonwenigenMillisekundenbiszueinerSekunde

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Eine lokale Solr Cloud kann einfach gestartet werden
■ Schema anlegen und anpassen■ Im Verzeichnis $SOLR_HOME/server/solr/configsets liegen Beispiel-Konfigurationen die kopiert
und angepasst werden koennen
■ Solr starten
■ Testen
cp $SOLR_HOME/server/solr/configset/basic_configs$SOLR_HOME/server/solr/configsets/jax2016
$SOLR_HOME/bin/solr start –e cloud
curl localhost:8983/solr/jax2016/query?q=*:*

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Über die Solr Cloud Collection REST API können Shardsangelegt, verändert oder gelöscht werden.
■ Collection anlegen
■ Collection löschen <<SOLRURL>>/solr/admin/collections?action=DELETE&name=ekgdata
<<SOLRURL>>/solr/admin/collections?action=CREATE&name=ekgdata&numShards=16&replicationFactor=2&maxShardsPerNode=8&collection.configName=ekgdata
https://cwiki.apache.org/confluence/display/solr/Collections+API

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Bei einer verteilten Solr Cloud muss Zookeeper gestartet werden und die Solr Konfigurationen geladen werden.
1.Starte Zookeeper auf 2n+1-Knoten (ungerade Anzahl)
2.Lade die Solr Konfiguration in den Zookeeper Cluster
3.Starte Solr Server im Cloud Modus auf n-Knoten mit Zookeeper Cluster
4.Erzeuge eine Collection mit Shards und Replicas unter Angabe des Konfigurationsnamens in Zookeeper
$SOLR_HOME/bin/solr start –c -z 192.168.1.100:2181,192.168.1.101:2181,192.168.1.102
$SOLR_HOME/server/scripts/cloud-scripts$ ./zkcli.sh -cmd upconfig -zkhost192.168.1.100:2181,192.168.1.101:2181,192.168.1.102 -confname ekgdata -solrhome/opt/solr/server/solr -confdir /opt/solr/server/solr/configsets/ekgdata_configs/conf
$ZOO_HOME/bin/zkServer.sh start
JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
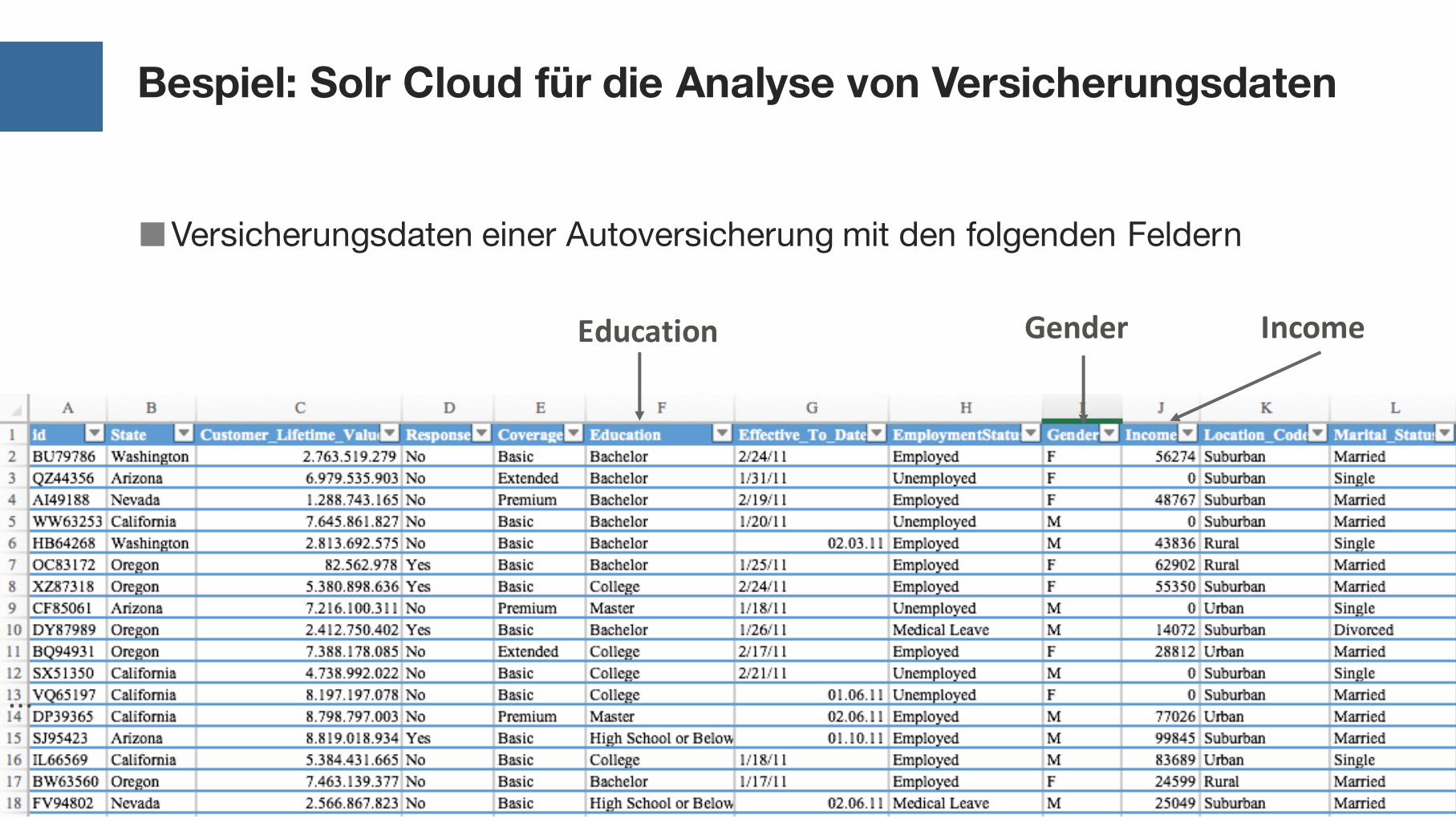
Bespiel: Solr Cloud für die Analyse von Versicherungsdaten
■Versicherungsdaten einer Autoversicherung mit den folgenden Feldern
Education IncomeGender
...

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
DEMO

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Solr unterstützt JSON Queries im HTTP-Post Header

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Mit Term Facets können Felder gruppiert und gezählt werden.
23

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Function Facets sind Aggregationsfunktonen
24http://yonik.com/solr-facet-functions/

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Facets können hierarchisch zu Pivot Facets geschachtelt werden.
25
JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
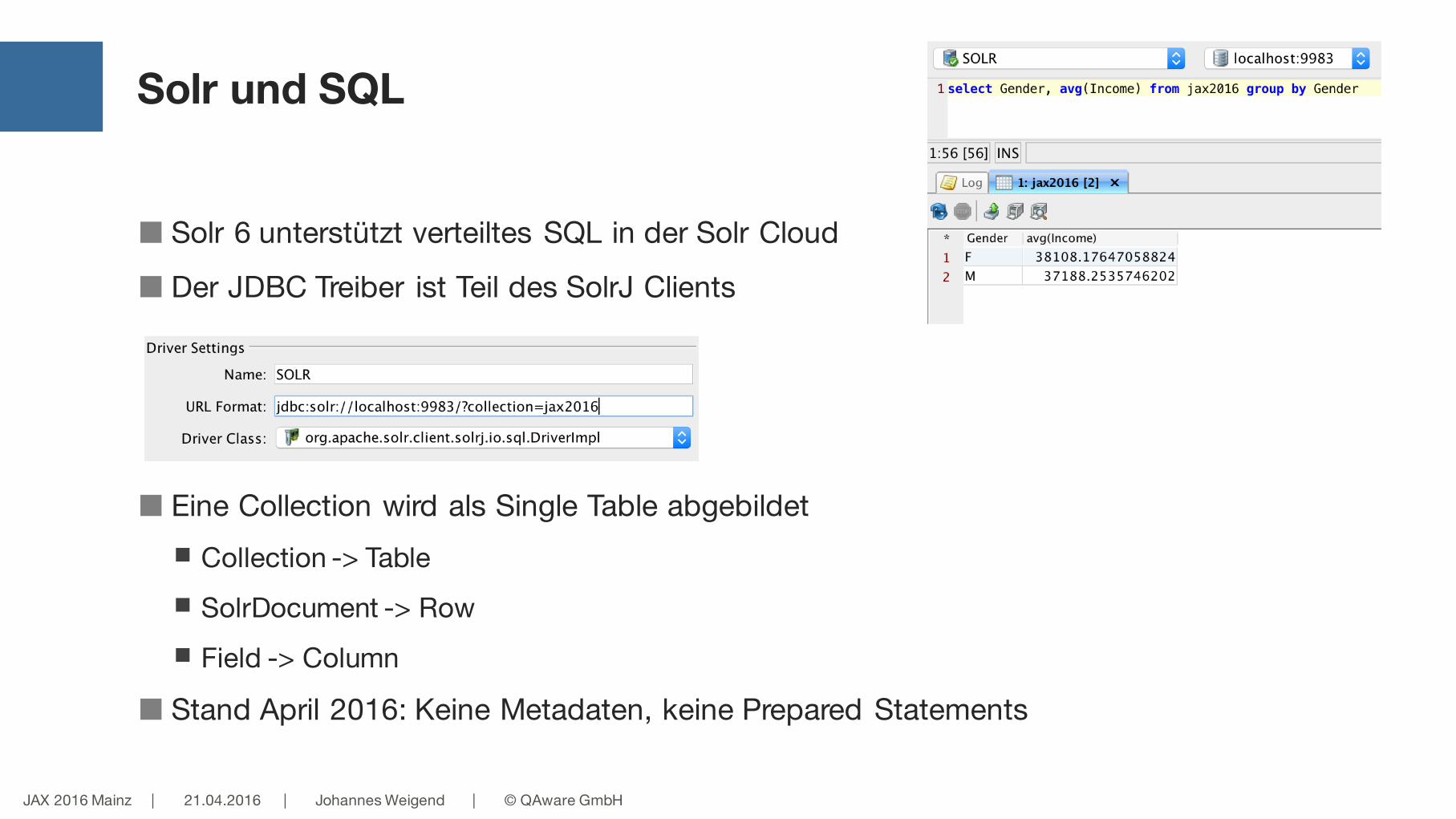
Solr und SQL
■ Solr 6 unterstützt verteiltes SQL in der Solr Cloud
■ Der JDBC Treiber ist Teil des SolrJ Clients
■ Eine Collection wird als Single Table abgebildet■ Collection -> Table
■ SolrDocument -> Row
■ Field -> Column
■ Stand April 2016: Keine Metadaten, keine Prepared Statements

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Resilience
■Die Anzahl der Replikas pro Shard kann beliebig hoch konfiguriert werden (replication factor)
■Diese Anzahl korrespondiert mit der Anzahl der Server die im Betrieb ausfallen können
■Zookeeper kann in mehreren Instanzen betrieben werden. Einer Instanz wird automatisch der Status “Leader“ zugewiesen.
■Die Solr Cloud kennt per Konfiguration alle Zookeeper Instanzen. Minimal muss ein Zookeeper erreichbar bleiben

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Alles super! – Oder?

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Alles Super! – Oder?
■Clientseitiges Weiterverarbeiten von Solr Dokumenten skaliert nicht
■Keine Möglichkeit eigene Businesslogik parallel in Solr auszuführen
■Die Ablage von großen Daten macht in Solr keinen Sinn
■Bilder■Videos
■Binaries / large text documents
■Keine Schnittstellen zu Machine Learing, Statistik (R) ...
29
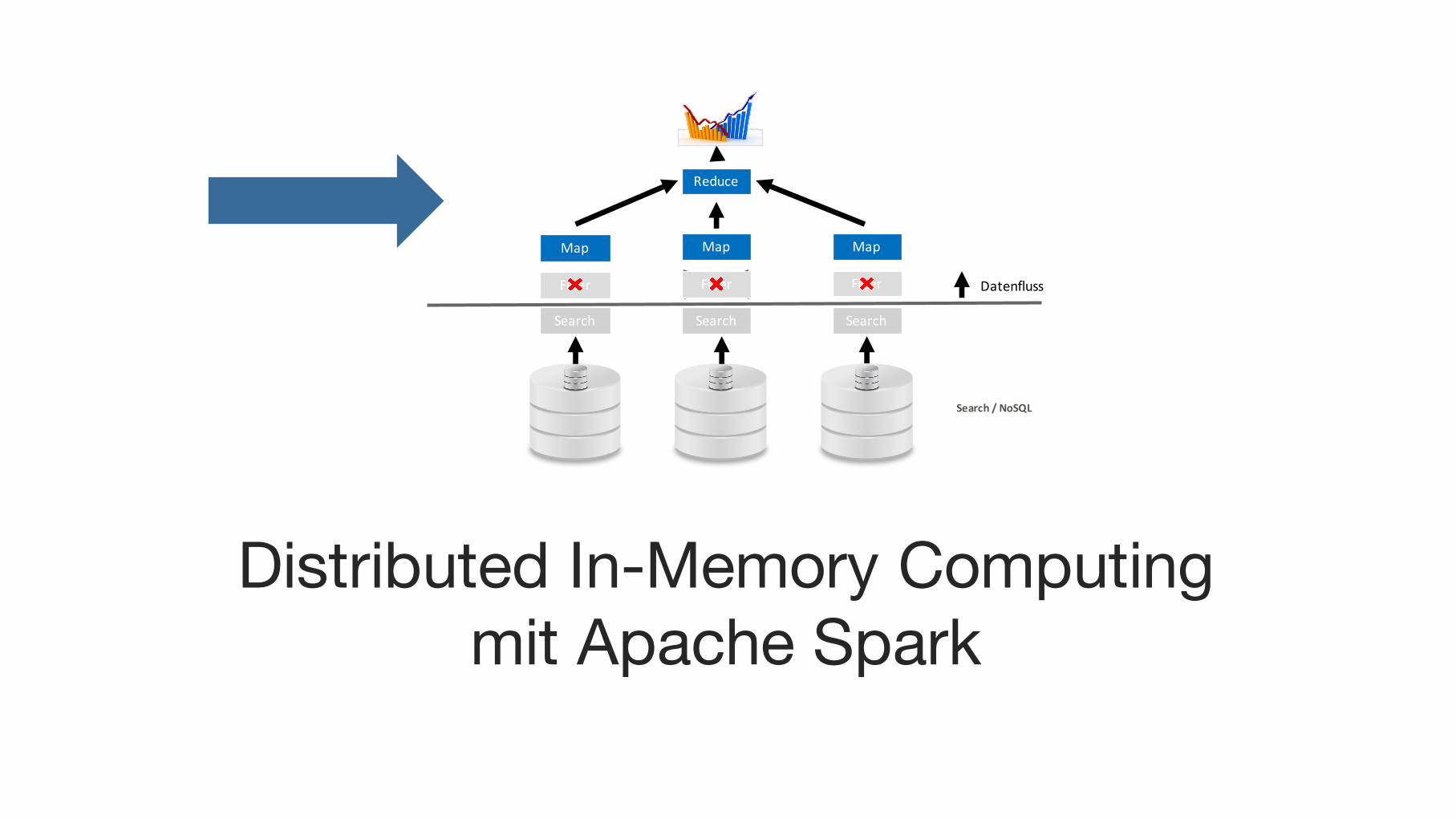
Spark
Distributed In-Memory Computing mit Apache Spark
Filter
Search Search Search
Map Map Map
Reduce
DatenflussFilter Filter
Search/NoSQL

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
■Distributed Computing (100x schneller als Hadoop (M/R)■Verteiltes Map/Reduce auf verteilten In-Memory Daten■Programmiert in Scala (JVM)■Java/Scala/Python APIs■Verarbeitet Daten aus verteilten und nicht-verteilten Datenquellen■ Textfiles (accessible from all nodes)
■Hadoop File System (HDFS)
■Databases (JDBC)
■Solr per Lucidworks API
■ ...31
READTHIS:https://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Cluster
JVM
Slave
Slave
JVM
JVM
JVM
Slave
Master / Yarn / MesosJVM
Executor
Executor
JVM
JVM
JVM
Executor
start
start
start
TaskTask(s)
Worker Host
Worker Host
Worker Host
Master Host
Spark Context
MasterURL
Resilient Distributed
Dataset RDD
Driver Node
erzeugt
Driver Anwendung
Anwendungscode
nutzt
Partition
Task(s)
Partition
Task(s)
Partition
Die Spark Architektur im Überblick

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Ein erstes Spark Programm
JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
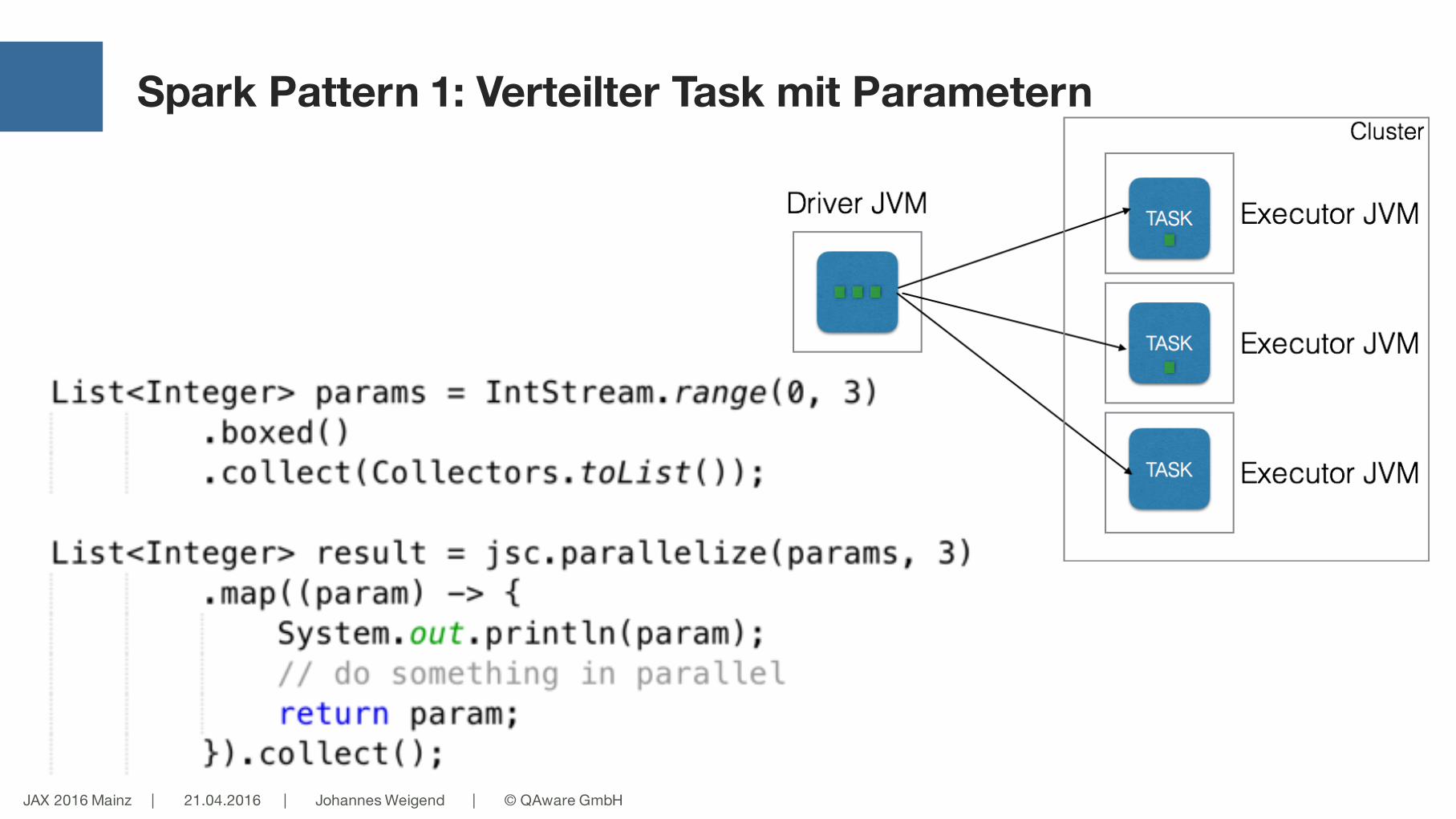
Spark Pattern 1: Verteilter Task mit Parametern
JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
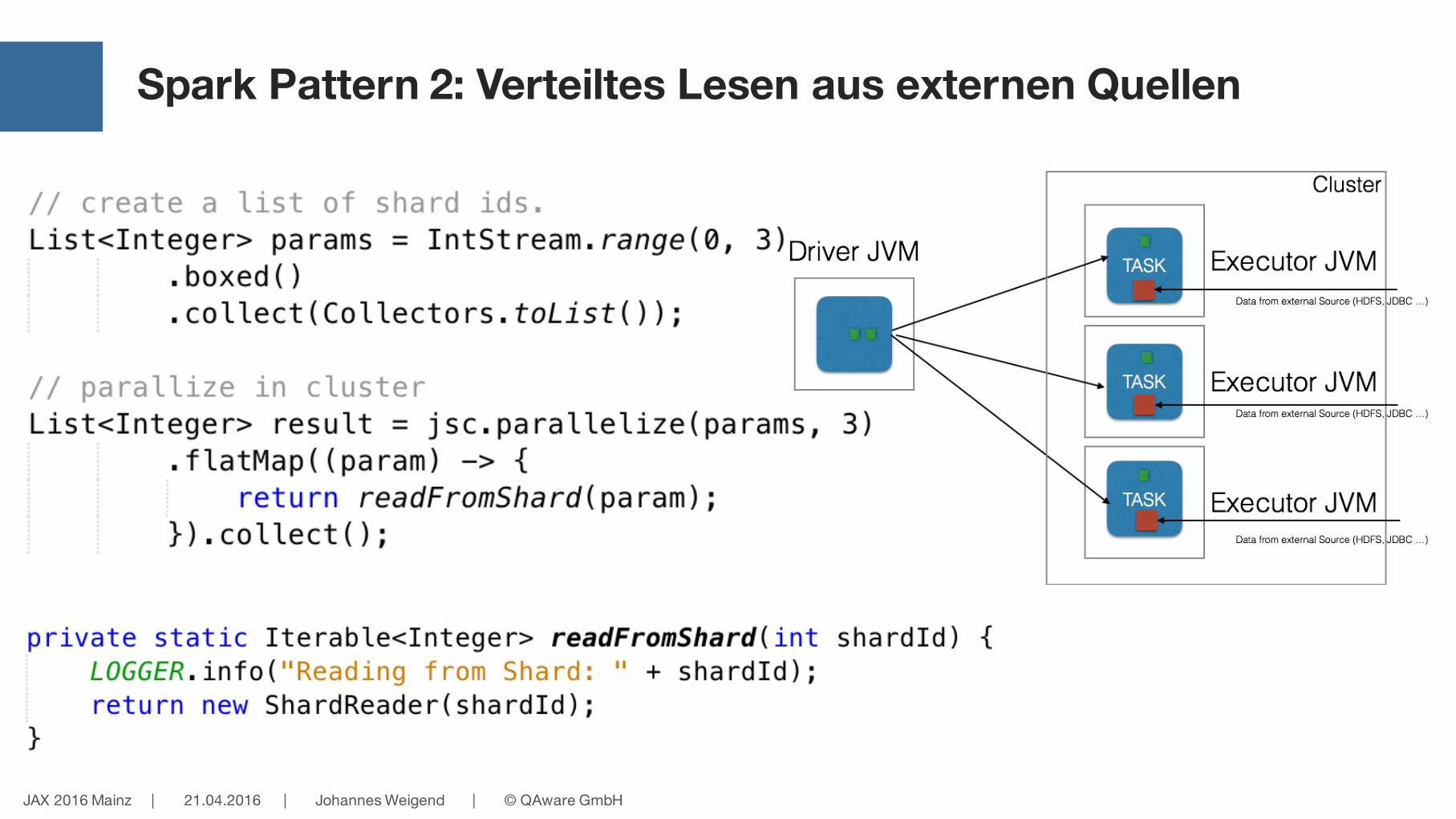
Spark Pattern 2: Verteiltes Lesen aus externen Quellen

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Spark Pattern 3: Caching und Weiterverarbeitung als RDD

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
DEMO
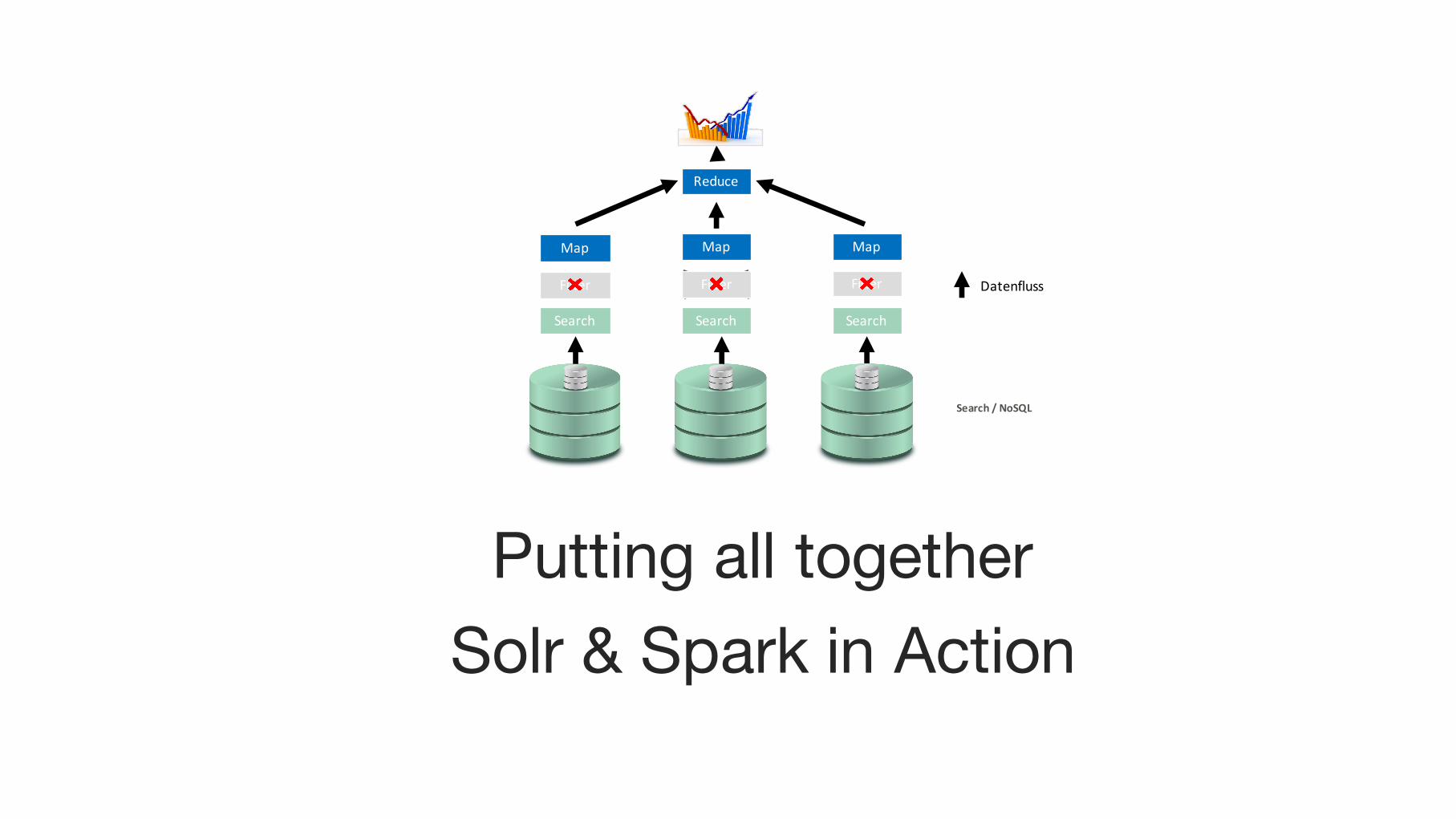
Spark
Putting all togetherSolr & Spark in Action
Filter
Search Search Search
Map Map Map
Reduce
DatenflussFilter Filter
Search/NoSQL

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Wie implementiert man readFromShard() mit Solr
■ SolrJ: SolrStream■ /export Handler kann Massendaten aus SOLR streamen
■ Unterstützt nur JSON Export (Kein Binary Format !)
■ Oder: SolrJ Cursor Marks verwenden
■ Oder: Eigenen Export Handler bauen (Nach dem obigen Vorbild)
http://localhost:8983/solr/jax2016/export?q=*:*&sort=id%20asc&fl=id&wt=xml
Filter
Search
Map
JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
LucidWorks hat bereits eine fertige RDD Implementierung.https://github.com/lucidworks/spark-solr

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
1
2
3
4
Lucidworks Solr-SparkAdapterV2.1

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Beispiele für Logfile Analyse mit Solr und Spark
■Histogramm aller Ausnahmen der Server A,B,C im Zeitraum D■Schritt 1: Suche ■Solr Query (q=*Exception AND (server: A OR server:B OR server:C) AND timestamp
between [1.1.2015, 31.12.2015]
■Schritt 2: Erzeuge eine Map mit Key = << Name der Ausname >>, Value = Anzahl mit Spark■Spark Grouping
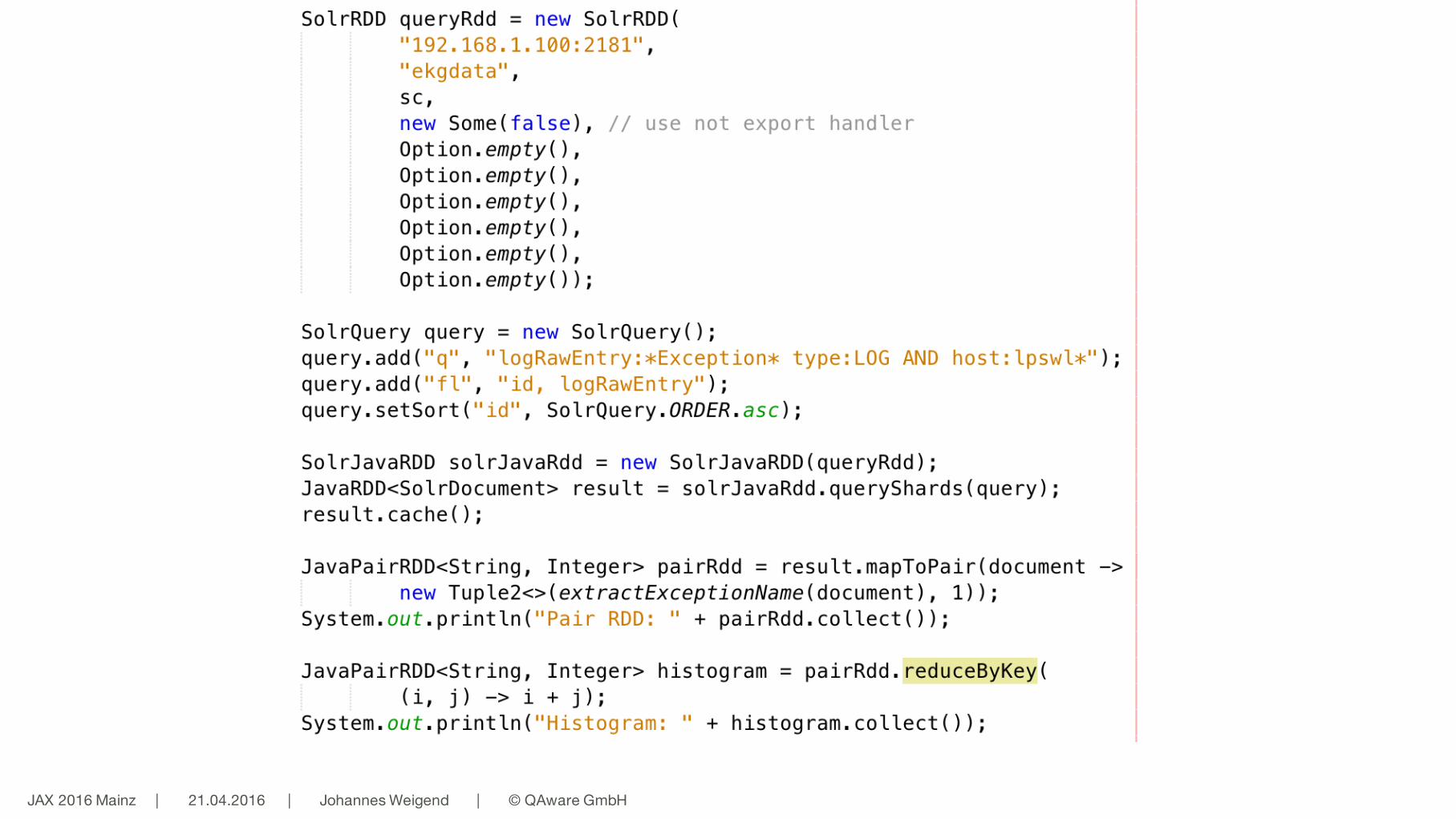
JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH 44

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
DEMO
+

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Technische Daten – Intel NUC6i5SYK
46
6thgeneration Intel®Core™i5-6260Uprocessor with Intel®Iris™graphics(1.9GHzup to 2.8GHzTurbo,DualCore,4MBCache,15WTDP)
CPU
32GBDual-channel DDR4SODIMMs1.2V,2133MHz
RAM
256GBSamsungM.2internalSSDDISK
à DerKofferistsoleistungsfähigwie4Laptops
8Cores,16HTUnits,128GBRAM,1TBDiskTotal

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH47
Technische Cluster Architektur
NFS
Ubuntu Linux
Solr Cloud
Zookeeper#1
Spark
Zeppelin
Master JVM Slave JVM
Executor JVM #1
Ubuntu Linux
Solr Cloud
Zookeeper#2
Spark
Zeppelin
Master JVM #2 Slave JVM #2
Executor JVM #2
Ubuntu Linux
Solr Cloud
SparkMaster JVM #4 Slave JVM #4
Executor JVM #4
Ubuntu Linux
Solr Cloud
Zookeeper#3
Spark
Master JVM #3 Slave JVM #3
Executor JVM #3
s1 s2 s3 s4
s5 s6 s7 s8
s13 s14 s15 s16
s9 s10 s11 s12
1
23
4

SPARK WorkerSOLR 5.3
48
Odroid XU42 GB RAM64 GB eMMC DiskUbuntu Linux70$
SPARK WorkerSOLR 5.3
SPARK WorkerSOLR 5.3
SPARK WorkerSOLR 5.3
SPARK Master
SOLR 5.3SPARK Worker
ZOOKEEPER
40 Cores10 GB RAM320 GB eMMC Disk

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Zusammenfassung
■SOLR Cloud und Spark sind eine mächtige Kombination für interaktive, Analyse- und Recherche-Anwendungen
■Die Herausforderungen für Entwickler sind hoch. Es gilt nach wie vor das erste Gesetz der verteilten Verarbeitung: „Verteile nur wenn Du es wirklich musst“
■100% Open Source■Beide Bausteine lassen relativ einfach miteinander integrieren■Falls ein Kaufprodukt auf der technischen Basis verwendet werden
soll, bietet sich Lucidworks Fusion an. Fusion integriert Solr und Spark zu einer offenen Plattform und liefert professionellen Produktsupport

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
@JohannesWeigend@qaware
slideshare.net/qaware
blog.qaware.de

JAX 2016 Mainz | 21.04.2016 | Johannes Weigend | © QAware GmbH
Alle Demos & Technologien kann man heute Abend im Meetuplive anfassen. Herzliche Einladung!
Unter anderem mit Jake Mannix, Twitter/Lucidworks, Apache Mahout Commiter, Solr und Spark ExperteJörg Schad, Mesosphere, Experte für DCOS und verteilte Betriebssysteme und dem Cloudcase ®