lexical association measures
TRANSCRIPT

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Lexical Association MeasuresCollocation Extraction
Pavel Pecina
[email protected] [email protected]
Dublin City University, Dublin Charles University, PragueCentre for Next Generation Localisation Institute of Formal and Applied Linguistics
Seminar strojoveho ucenı a modelovanı14/04/2011

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Talk outline
1. Introduction
2. Collocation extraction
3. Lexical association measures
4. Reference data
5. Empirical evaluation
6. Combining association measures
7. Conclusions

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Lexical association 1/30
Semantic associationI reflects semantic relationship between wordsI synonymy, antonymy, hyponymy, meronymy, etc. Ô stored in a thesaurus
sick – ill, baby – infant, dog – cat
Cross-language associationI corresponds to potential translations of words between languagesI translation equivalents Ô stored in a dictionary
maison(FR) – house(EN) , baum(GE) – tree(EN) , kvetina(CZ) – flower(EN)
Collocational associationI restricts combination of words into phrases (beyond grammar!)I collocations / multiword expressions Ô stored in a lexicon
crystal clear, cosmetic surgery, cold war

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Lexical association 1/30
Semantic associationI reflects semantic relationship between wordsI synonymy, antonymy, hyponymy, meronymy, etc. Ô stored in a thesaurus
sick – ill, baby – infant, dog – cat
Cross-language associationI corresponds to potential translations of words between languagesI translation equivalents Ô stored in a dictionary
maison(FR) – house(EN) , baum(GE) – tree(EN) , kvetina(CZ) – flower(EN)
Collocational associationI restricts combination of words into phrases (beyond grammar!)I collocations / multiword expressions Ô stored in a lexicon
crystal clear, cosmetic surgery, cold war

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Lexical association 1/30
Semantic associationI reflects semantic relationship between wordsI synonymy, antonymy, hyponymy, meronymy, etc. Ô stored in a thesaurus
sick – ill, baby – infant, dog – cat
Cross-language associationI corresponds to potential translations of words between languagesI translation equivalents Ô stored in a dictionary
maison(FR) – house(EN) , baum(GE) – tree(EN) , kvetina(CZ) – flower(EN)
Collocational associationI restricts combination of words into phrases (beyond grammar!)I collocations / multiword expressions Ô stored in a lexicon
crystal clear, cosmetic surgery, cold war

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Measuring lexical association 2/30
MotivationI automatic acquisition of associated words (into a lexicon/thesarus/dictionary)
Tool: Lexical association measuresI mathematical formulas determining strength of association between two
(or more) words based on their occurrences and cooccurrences in a corpus
ApplicationsI lexicography, natural language generation, word sense disambiguationI bilingual word alignment, identification of translation equivalentsI information retrieval, cross-lingual information retrievalI keyword extraction, named entity recognitionI syntactic constituent boundary detectionI collocation extraction
Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Measuring lexical association 2/30
MotivationI automatic acquisition of associated words (into a lexicon/thesarus/dictionary)
Tool: Lexical association measuresI mathematical formulas determining strength of association between two
(or more) words based on their occurrences and cooccurrences in a corpus
ApplicationsI lexicography, natural language generation, word sense disambiguationI bilingual word alignment, identification of translation equivalentsI information retrieval, cross-lingual information retrievalI keyword extraction, named entity recognitionI syntactic constituent boundary detectionI collocation extraction

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Measuring lexical association 2/30
MotivationI automatic acquisition of associated words (into a lexicon/thesarus/dictionary)
Tool: Lexical association measuresI mathematical formulas determining strength of association between two
(or more) words based on their occurrences and cooccurrences in a corpus
ApplicationsI lexicography, natural language generation, word sense disambiguationI bilingual word alignment, identification of translation equivalentsI information retrieval, cross-lingual information retrievalI keyword extraction, named entity recognitionI syntactic constituent boundary detectionI collocation extraction

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Goals, objectives, and limitations 3/30
GoalI application of lexical association measures to collocation extraction
Objectives
1. to compile a comprehensive inventory of lexical association measures
2. to build reference data sets for collocation extraction
3. to evaluate the lexical association measures on these data sets
4. to explore the possibility of combining these measures into more complexmodels and advance the state of the art in collocation extraction
Limitations
3 focus on bigram (two-word) collocations(limited scalability to higher-order n-grams; limited corpus size)
3 binary (two-class) discrimination only (collocation/non-collocation)

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Goals, objectives, and limitations 3/30
GoalI application of lexical association measures to collocation extraction
Objectives
1. to compile a comprehensive inventory of lexical association measures
2. to build reference data sets for collocation extraction
3. to evaluate the lexical association measures on these data sets
4. to explore the possibility of combining these measures into more complexmodels and advance the state of the art in collocation extraction
Limitations
3 focus on bigram (two-word) collocations(limited scalability to higher-order n-grams; limited corpus size)
3 binary (two-class) discrimination only (collocation/non-collocation)

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Goals, objectives, and limitations 3/30
GoalI application of lexical association measures to collocation extraction
Objectives
1. to compile a comprehensive inventory of lexical association measures
2. to build reference data sets for collocation extraction
3. to evaluate the lexical association measures on these data sets
4. to explore the possibility of combining these measures into more complexmodels and advance the state of the art in collocation extraction
Limitations
3 focus on bigram (two-word) collocations(limited scalability to higher-order n-grams; limited corpus size)
3 binary (two-class) discrimination only (collocation/non-collocation)

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Collocational association 4/30
CollocabilityI the ability of words to combine with other words in textI governed by a system of rules and constraints: syntactic, semantic, pragmaticI must be adhered to in order to produce correct, meaningful, fluent utterancesI ranges from free word combinations to idiomsI specified intensionally (general rules) or extensionally (particular constraints)
CollocationsI word combinations with extensionally restricted collocabilityI should be listed in a lexicon and learned in the same way as single words
Types of collocations1. idioms (to kick the bucket, to hear st. through the grapevine)2. proper names (New York, Old Town), Vaclav Havel3. technical terms (car oil, stock owl, hard disk)4. phrasal verbs (to switch off, to look after)5. light verb compounds (to take a nap, to do homework)6. lexically restricted expressions (strong tea, broad daylight)

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Collocational association 4/30
CollocabilityI the ability of words to combine with other words in textI governed by a system of rules and constraints: syntactic, semantic, pragmaticI must be adhered to in order to produce correct, meaningful, fluent utterancesI ranges from free word combinations to idiomsI specified intensionally (general rules) or extensionally (particular constraints)
CollocationsI word combinations with extensionally restricted collocabilityI should be listed in a lexicon and learned in the same way as single words
Types of collocations1. idioms (to kick the bucket, to hear st. through the grapevine)2. proper names (New York, Old Town), Vaclav Havel3. technical terms (car oil, stock owl, hard disk)4. phrasal verbs (to switch off, to look after)5. light verb compounds (to take a nap, to do homework)6. lexically restricted expressions (strong tea, broad daylight)

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Collocational association 4/30
CollocabilityI the ability of words to combine with other words in textI governed by a system of rules and constraints: syntactic, semantic, pragmaticI must be adhered to in order to produce correct, meaningful, fluent utterancesI ranges from free word combinations to idiomsI specified intensionally (general rules) or extensionally (particular constraints)
CollocationsI word combinations with extensionally restricted collocabilityI should be listed in a lexicon and learned in the same way as single words
Types of collocations1. idioms (to kick the bucket, to hear st. through the grapevine)2. proper names (New York, Old Town), Vaclav Havel3. technical terms (car oil, stock owl, hard disk)4. phrasal verbs (to switch off, to look after)5. light verb compounds (to take a nap, to do homework)6. lexically restricted expressions (strong tea, broad daylight)

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Collocation properties 5/30
Semantic non-compositionalityI exact meaning cannot be (fully) inferred from the meaning of components
to kick the bucket
Syntactic non-modifiabilityI syntactic structure cannot be freely modified (word order, word insertions etc.)
poor as a church mouse vs. poor as a *big church mouse
Lexical non-substitutabilityI components cannot be substituted by synonyms or other words
stiff breeze vs. *stiff wind
Translatability into other languagesI translation cannot generally be performed blindly, word by word
ice cream – zmrzlina
Domain dependencyI collocational character only in specific domains
carriage return

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Collocation properties 5/30
Semantic non-compositionalityI exact meaning cannot be (fully) inferred from the meaning of components
to kick the bucket
Syntactic non-modifiabilityI syntactic structure cannot be freely modified (word order, word insertions etc.)
poor as a church mouse vs. poor as a *big church mouse
Lexical non-substitutabilityI components cannot be substituted by synonyms or other words
stiff breeze vs. *stiff wind
Translatability into other languagesI translation cannot generally be performed blindly, word by word
ice cream – zmrzlina
Domain dependencyI collocational character only in specific domains
carriage return
Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Collocation properties 5/30
Semantic non-compositionalityI exact meaning cannot be (fully) inferred from the meaning of components
to kick the bucket
Syntactic non-modifiabilityI syntactic structure cannot be freely modified (word order, word insertions etc.)
poor as a church mouse vs. poor as a *big church mouse
Lexical non-substitutabilityI components cannot be substituted by synonyms or other words
stiff breeze vs. *stiff wind
Translatability into other languagesI translation cannot generally be performed blindly, word by word
ice cream – zmrzlina
Domain dependencyI collocational character only in specific domains
carriage return

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Collocation properties 5/30
Semantic non-compositionalityI exact meaning cannot be (fully) inferred from the meaning of components
to kick the bucket
Syntactic non-modifiabilityI syntactic structure cannot be freely modified (word order, word insertions etc.)
poor as a church mouse vs. poor as a *big church mouse
Lexical non-substitutabilityI components cannot be substituted by synonyms or other words
stiff breeze vs. *stiff wind
Translatability into other languagesI translation cannot generally be performed blindly, word by word
ice cream – zmrzlina
Domain dependencyI collocational character only in specific domains
carriage return

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Collocation properties 5/30
Semantic non-compositionalityI exact meaning cannot be (fully) inferred from the meaning of components
to kick the bucket
Syntactic non-modifiabilityI syntactic structure cannot be freely modified (word order, word insertions etc.)
poor as a church mouse vs. poor as a *big church mouse
Lexical non-substitutabilityI components cannot be substituted by synonyms or other words
stiff breeze vs. *stiff wind
Translatability into other languagesI translation cannot generally be performed blindly, word by word
ice cream – zmrzlina
Domain dependencyI collocational character only in specific domains
carriage return

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Collocation extraction 6/30
TaskI to extract a list of collocations (types) from a text corpusI no need to identify particular occurrences (instances) of collocations
MethodsI based on extraction principles verifying characteristic collocation propertiesI i.e. hypotheses about word occurences and cooccurrences in the corpusI formulated as lexical association measuresI compute association score for each collocation candidate from the corpusI the scores indicate a chance of a candidate to be a collocation
Extraction principles
1. “Collocation components occur together more often than by chance”
2. “Collocations occur as units in information-theoretically noisy environment”
3. “Collocations occur in different contexts to their components”

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Collocation extraction 6/30
TaskI to extract a list of collocations (types) from a text corpusI no need to identify particular occurrences (instances) of collocations
MethodsI based on extraction principles verifying characteristic collocation propertiesI i.e. hypotheses about word occurences and cooccurrences in the corpusI formulated as lexical association measuresI compute association score for each collocation candidate from the corpusI the scores indicate a chance of a candidate to be a collocation
Extraction principles
1. “Collocation components occur together more often than by chance”
2. “Collocations occur as units in information-theoretically noisy environment”
3. “Collocations occur in different contexts to their components”

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Collocation extraction 6/30
TaskI to extract a list of collocations (types) from a text corpusI no need to identify particular occurrences (instances) of collocations
MethodsI based on extraction principles verifying characteristic collocation propertiesI i.e. hypotheses about word occurences and cooccurrences in the corpusI formulated as lexical association measuresI compute association score for each collocation candidate from the corpusI the scores indicate a chance of a candidate to be a collocation
Extraction principles
1. “Collocation components occur together more often than by chance”
2. “Collocations occur as units in information-theoretically noisy environment”
3. “Collocations occur in different contexts to their components”

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Extraction principle I 7/30
“Collocation components occur together more often than by chance”
I the corpus is interepreted as a sequence of randomly generated wordsI word (marginal) probability ML estimations: p(x) = f(x)
N
I bigram (joint) probability ML estimations: p(xy) =f(xy)N
I the chance ∼ the null hypothesis of independence: H0: p(xy) = p(x) · p(y)
AM: Log-likelihood ratio, χ2test, Odds ratio, Jaccard, Pointwise mutual information
Example: Pointwise Mutual Information
Data: f(iron curtain) = 11 MLE: p(iron curtain) = 0.000007
f(iron) = 30 p(iron) = 0.000020
f(curtain) = 15 p(curtain) = 0.000010
H0: p(iron curtain) = p(iron) · p(curtain) = 0.000000000020
f(iron curtain) = 0.000030
AM: PMI(iron curtain) = logp(xy)
p(xy)= log
0.000007
0.000000000020= 18.417

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Extraction principle I 7/30
“Collocation components occur together more often than by chance”
I the corpus is interepreted as a sequence of randomly generated wordsI word (marginal) probability ML estimations: p(x) = f(x)
N
I bigram (joint) probability ML estimations: p(xy) =f(xy)N
I the chance ∼ the null hypothesis of independence: H0: p(xy) = p(x) · p(y)
AM: Log-likelihood ratio, χ2test, Odds ratio, Jaccard, Pointwise mutual information
Example: Pointwise Mutual Information
Data: f(iron curtain) = 11 MLE: p(iron curtain) = 0.000007
f(iron) = 30 p(iron) = 0.000020
f(curtain) = 15 p(curtain) = 0.000010
H0: p(iron curtain) = p(iron) · p(curtain) = 0.000000000020
f(iron curtain) = 0.000030
AM: PMI(iron curtain) = logp(xy)
p(xy)= log
0.000007
0.000000000020= 18.417

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Extraction principle II 8/30
“Collocations occur as units in information-theoretically noisy environment”
I the corpus again interpreted as a sequence of randomly generated wordsI at each point of the sequence we estimate:
1. probability distribution of words occurring after/before: p(w|Crxy), p(w|Cl
xy)
2. uncertainty (entropy) what the next/previous word is: H(p(w|Crxy)),H(p(w|Cl
xy))
I points with high uncertainty are likely to be collocation boundariesI points with low uncertainty are likely to be located within a collocation
AM: Left context entropy, Right context entropy
Example: H(p(w|Crxy))
Cesky kapitalovy trh dnes ovlivnil pokles cen vsech cennych papıru a zejmena akciı.

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Extraction principle II 8/30
“Collocations occur as units in information-theoretically noisy environment”
I the corpus again interpreted as a sequence of randomly generated wordsI at each point of the sequence we estimate:
1. probability distribution of words occurring after/before: p(w|Crxy), p(w|Cl
xy)
2. uncertainty (entropy) what the next/previous word is: H(p(w|Crxy)),H(p(w|Cl
xy))
I points with high uncertainty are likely to be collocation boundariesI points with low uncertainty are likely to be located within a collocation
AM: Left context entropy, Right context entropy
Example: H(p(w|Crxy))
Cesky kapitalovy trh dnes ovlivnil pokles cen vsech cennych papıru a zejmena akciı.

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Extraction principle III 9/30
“Collocations occur in different contexts to their components”
I non-compositionality: meaning of a collocation must differ from the union ofthe meaning of its components
I modeling meanings by empirical contexts: a bag of words occurring withina specified context window of a word or an expression
I the more different the contexts of an expression to its components are, thehigher the chance is that the expression is a collocation
AM: J-S divergence, K-L divergence, Skew divergence, Cosine similarity in vector space
Example: Cxy , Cx
. . . nenı. Maltske liry lze nakoupit pouze ve smenarnach, cerny trh s valutami neexistuje. Na Malte je v porovnanı s . . .. . . prestal. V patach za krizı vstoupil do Belehradu cerny trh , pasovanı a zvysena kriminalita. Prekupnıci provazejı . . .
. . . nebyli z toho obvineni. Rıdı gangy, ktere kontrolujı cerny trh a okradajı cizince. Oba byli zbaveni funkcı a byl . . .. . . antidrogove hysterii. Nasledkem toho neexistoval ani cerny trh , protoze nebylo na cem vydelavat. V roce 1957 bylo . . .
. . . doruceny k rychlemu zpracovanı. Naplno se jiz rozjızdı cerny trh se vstupenkami. Na zavod na 5000 m v rychlobruslaru . . .. . . na celnem mıste obchodu se zbranemi. Zatımco cerny trh se zbranemi se pro cely svet stava cım dal tım vetsı. . . .
. . . ctenım v parlamentu. Verım, ze brzy bude regulovat cerny trh s ohrozenymi druhy zvırat, mını. Promoravske strany . . .
. . . jako malı ctyrletı a petiletı kluci. Byl to dobytcı trh jako z minuleho stoletı. Se vsım vsudy prodavali . . .. . . pranı nez realnych moznostı. Na rozdıl od dolaru se trh americkych statnıch dluhopisu nezmenil. A novymi . . .
. . . opetnemu narustu. Podle Plan Econu si cesky kapitalovy trh bude v nejblizsım roce pocınat o neco lepe. Vetsina . . .. . . To by mohlo vzhledem k propojenı pres mezibankovnı trh depozit vest k retezovym reakcım. Prıliv kapitalu . . .
. . . PVT, na cene ztratil take indexovy Tabak. Volny trh ma vsak nastestı i svetle stranky. K nim patrı naprıklad . . .. . . spoluzakladatel. Take v Madarsku se uvolnı medialnı trh jiz letos. Madarsko jako prvnı z postkomunistickych . . .
. . . . Mezi ne patrı i OfficePorte Voice, ktery byl na trh uveden pod heslem ”vıce nez modem”. Obsahuje totiz . . .

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Extraction principle III 9/30
“Collocations occur in different contexts to their components”
I non-compositionality: meaning of a collocation must differ from the union ofthe meaning of its components
I modeling meanings by empirical contexts: a bag of words occurring withina specified context window of a word or an expression
I the more different the contexts of an expression to its components are, thehigher the chance is that the expression is a collocation
AM: J-S divergence, K-L divergence, Skew divergence, Cosine similarity in vector space
Example: Cxy , Cx
. . . nenı. Maltske liry lze nakoupit pouze ve smenarnach, cerny trh s valutami neexistuje. Na Malte je v porovnanı s . . .. . . prestal. V patach za krizı vstoupil do Belehradu cerny trh , pasovanı a zvysena kriminalita. Prekupnıci provazejı . . .
. . . nebyli z toho obvineni. Rıdı gangy, ktere kontrolujı cerny trh a okradajı cizince. Oba byli zbaveni funkcı a byl . . .. . . antidrogove hysterii. Nasledkem toho neexistoval ani cerny trh , protoze nebylo na cem vydelavat. V roce 1957 bylo . . .
. . . doruceny k rychlemu zpracovanı. Naplno se jiz rozjızdı cerny trh se vstupenkami. Na zavod na 5000 m v rychlobruslaru . . .. . . na celnem mıste obchodu se zbranemi. Zatımco cerny trh se zbranemi se pro cely svet stava cım dal tım vetsı. . . .
. . . ctenım v parlamentu. Verım, ze brzy bude regulovat cerny trh s ohrozenymi druhy zvırat, mını. Promoravske strany . . .
. . . jako malı ctyrletı a petiletı kluci. Byl to dobytcı trh jako z minuleho stoletı. Se vsım vsudy prodavali . . .. . . pranı nez realnych moznostı. Na rozdıl od dolaru se trh americkych statnıch dluhopisu nezmenil. A novymi . . .
. . . opetnemu narustu. Podle Plan Econu si cesky kapitalovy trh bude v nejblizsım roce pocınat o neco lepe. Vetsina . . .. . . To by mohlo vzhledem k propojenı pres mezibankovnı trh depozit vest k retezovym reakcım. Prıliv kapitalu . . .
. . . PVT, na cene ztratil take indexovy Tabak. Volny trh ma vsak nastestı i svetle stranky. K nim patrı naprıklad . . .. . . spoluzakladatel. Take v Madarsku se uvolnı medialnı trh jiz letos. Madarsko jako prvnı z postkomunistickych . . .
. . . . Mezi ne patrı i OfficePorte Voice, ktery byl na trh uveden pod heslem ”vıce nez modem”. Obsahuje totiz . . .

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Inventory of lexical association measures 10/30
� ���� ������
�� ����� ��������� � ������ ��� ����� ��������� � ������� ������� ��� ����� ��������� � �����
�� ��������� ���� ���������� ��� � ����� ����� ����
�� ���� ���� ���� ���� ��� � �����
� ����� ����
�� ��� ��������� ���� �� ��� � �����
� ����� ����� ��� � ����
� ������� � �������� �����������������
� ���� � �������� �����������������
� � ����
�� !����� ��� � �����
� ����� ����� ��� �����
��� ������"� �� �����
���
�����������
����
��� #��$��"� � �� ���� ��������������������������� �����������������������������
��� � ���� ������ ������������������������
��� � ����� ������ ����������������� ���������
��� ������ �����%���� ������������������ � �������� ������
� �
��� ��� �&��$�� ���� ���
��� ��� ��� ���� ����
��� !���� �� �&��$�� ���� ���
��� ��� ����� ����
�� �����'�� �����
�� !�&'���$���� � �����
��� ������'(������ � �������
��� )��� �� ������������
��� ($�� !�&'!���$ ����
��� ���� ����
��� #���� *������&� ���
��� !���� !�&'!���$ �������
��� !���� *������&� ���
���
���
��� #����$ !�&'!���$ ���
���
���
���
���
�� + � ���� ��
�� ,��"� ��
��
��� �
���
��� ,��"� � ��� ���
��� -�����'*������ ���������
��� #���$ !�&'!���$ ���������� ���� ���
��� ������ ������������� ���� ���
��� .����'/���� ��
������
��� .���'.����� ���������
��� !������ ���������
��� ���$� �� ����
�� ���������
�� �������� ��������
�� #��� ���������
� ��
���� ��
��� /����� �������� ��� ��
� �� �
�
� ��
� ��
� �
��� � ���� ����� � �������� ��������
�
��� � ���� ����� � ���������
���
�
��� � ���� ����� � ��
� � ����� � ��
�
��� � ������� �����
� � � �
��� �$� � ������ ����� ������ ����� �������� ��������� �����
��� *�� � ������ �������� ����� ������ ������ �������� ����� ������ ������ �����
� ���� ������
��� � ������� ����� ���� �� � ������ ����
� ����� �� � ������� �����
�
� ���� �� � ������ ����
� ����� �� � ������� �����
�
��� ��� ��� ����� ������ ������ � �������� � � �����
� � ������ ������� � ��������� � � �������� ������ ������ � �������� � � �����
� ������� ������� � ��������� � � ���������� � ���� ����� ������ � ������
��� ������� ������ �������� ������
��� �������� ������
�
�� � ����� ����� ����� ����� �����
�� ������ ����
� ������
�� ���������������� � ���� � � ����� ����
��� ��������� ���� � ����� ������� ������� ����
�� ������� ����
��� �����
��� �� ����� ���� ����� ����� � � ����� � ����� � � �������� � �������� ������� � ������ ������
� ����� ����� ������ ����� ��� ����� ������ ������ ����
��� ������ ������
��� � ����
� ���� � ��
��� � ���� ��� �� ��
�� ������� �� � �������
��� ���� � ���� ��� �� ��
�� �����
��� �� � ��������
��� !���� � ���� ��� �� ��
�� �����
��� �� � ��������
��� ���� � ���� �������� � ���� �� � ���� � �
�� �����
��� �� � ��������
�� !���� � ���� �������� � ���� �� � ���� � �
�� �����
��� �� � ��������
�� �� �� ��� �� ��
�� ������ �� � ������
��� !������ �� �� ��� �� ��
�� ������ �� � ������
��� "�������� ���������������
�������� �
��� #������ ���
�
��� ������ � � ��������
��� � ��� ���
� � ������� �������
� � ���������
� � �������
��� �� ���
��� ������ � � �������
��� � ���� �� $�$������
�
� ������� ������� ���� ����
��� !������ � ���� �� $�$������
�
� ������� ������� ���� ����
��� %������� �������� ������������ �
�������� ��������
��������� ��������� ���������
�� � ��� � � ��&������
� ������������
� ��������
�
� ������
�� � ���������
�� ������ �� � ������
� ������
��� !������ � ���������
�� ������ ��
� ������
� ������
��� ���& �������� ���������������� � � ������������ !������ ���& �������� ���������������� � � ���������
��� ������ & � � ������� ���
��������
�����
��������
������
��� ' � ��� ����� ���
�������������
����� �������������
������
� ��� � ���� ����������( ���������� ���� ������� �����
� ������ ������� �����
������
�����
�
���
��� � $ ��� ���� � ����� �� � ������� ����� � �� ���� � ����� �� ������� ���� � �� � ��� ���� � ����� �� ������� �� �
������� ������� ��� ��������
)��� � ���� ����������( ����������� ���� �������� �����
� ������ �������� ���� ��
�����
����
�
���
�� � $ ��� ���� � ����� �� � ������� ���� � �� ���� � ����� �� ������� ���� � �� � ��� ���� � ����� �� ������� �� �
������� ������� ��� ��������
*�$�� +( �������� �� ������� ����������� �������� ��� ����������� �����������

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Extraction pipeline 11/30
1. linguistic preprocessing (morphological and syntactic level)
2. identification of collocation candidates (dependency/surface/distance bigrams)
3. extraction of occurrence and cooccurrence statistics (frequency, contexts)
4. filtering the candidates to improve precision (POS patterns)
5. application of a choosen lexical association measure
6. ranking/classification of collocation candidates according to their scores
Ranking
red cross 15.66decimal point 14.01arithmetic operation 10.52paper feeder 10.17system type 3.54and others 0.54program in 0.35level is 0.25
Classification
red cross 1decimal point 1arithmetic operation 1paper feeder 1system type 0and others 0program in 0level is 0

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Extraction pipeline 11/30
1. linguistic preprocessing (morphological and syntactic level)
2. identification of collocation candidates (dependency/surface/distance bigrams)
3. extraction of occurrence and cooccurrence statistics (frequency, contexts)
4. filtering the candidates to improve precision (POS patterns)
5. application of a choosen lexical association measure
6. ranking/classification of collocation candidates according to their scores
Ranking
red cross 15.66decimal point 14.01arithmetic operation 10.52paper feeder 10.17system type 3.54and others 0.54program in 0.35level is 0.25
Classification
red cross 1decimal point 1arithmetic operation 1paper feeder 1system type 0and others 0program in 0level is 0

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Extraction pipeline 11/30
1. linguistic preprocessing (morphological and syntactic level)
2. identification of collocation candidates (dependency/surface/distance bigrams)
3. extraction of occurrence and cooccurrence statistics (frequency, contexts)
4. filtering the candidates to improve precision (POS patterns)
5. application of a choosen lexical association measure
6. ranking/classification of collocation candidates according to their scores
Ranking
red cross 15.66decimal point 14.01arithmetic operation 10.52paper feeder 10.17system type 3.54and others 0.54program in 0.35level is 0.25
Classification
red cross 1decimal point 1arithmetic operation 1paper feeder 1system type 0and others 0program in 0level is 0

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Reference data set 12/30
Source corpusI Prague Dependency Treebank 2.0, 1.5 mil. tokensI manually annotated on morphological and analytical level
Collocation candidatesI dependency bigrams: direct dependency relation between componentsI morphological normalization (lemma proper + pos + gender + degree + negation)I part-of-speech filter (A:N, N:N, V:N, R:N, C:N, N:V, N:C, D:A, N:A, D:V, N:T, N:D, D:D)I frequency filter (minimal frequency required, f >5)
AnnotationI three independent parallel annotations (no context; full agreement required)I 6 categories, merged into two: collocations (1-5), non-collocations (0):
5. idiomatic expressions4. technical terms3. support verb constructions2. proper names1. frequent unpredictable usages0. non-collocations
I 12 232 candidates = 2 557 true collocations + 9 675 true non-collocations

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Reference data set 12/30
Source corpusI Prague Dependency Treebank 2.0, 1.5 mil. tokensI manually annotated on morphological and analytical level
Collocation candidatesI dependency bigrams: direct dependency relation between componentsI morphological normalization (lemma proper + pos + gender + degree + negation)I part-of-speech filter (A:N, N:N, V:N, R:N, C:N, N:V, N:C, D:A, N:A, D:V, N:T, N:D, D:D)I frequency filter (minimal frequency required, f >5)
AnnotationI three independent parallel annotations (no context; full agreement required)I 6 categories, merged into two: collocations (1-5), non-collocations (0):
5. idiomatic expressions4. technical terms3. support verb constructions2. proper names1. frequent unpredictable usages0. non-collocations
I 12 232 candidates = 2 557 true collocations + 9 675 true non-collocations

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Reference data set 12/30
Source corpusI Prague Dependency Treebank 2.0, 1.5 mil. tokensI manually annotated on morphological and analytical level
Collocation candidatesI dependency bigrams: direct dependency relation between componentsI morphological normalization (lemma proper + pos + gender + degree + negation)I part-of-speech filter (A:N, N:N, V:N, R:N, C:N, N:V, N:C, D:A, N:A, D:V, N:T, N:D, D:D)I frequency filter (minimal frequency required, f >5)
AnnotationI three independent parallel annotations (no context; full agreement required)I 6 categories, merged into two: collocations (1-5), non-collocations (0):
5. idiomatic expressions4. technical terms3. support verb constructions2. proper names1. frequent unpredictable usages0. non-collocations
0 1 2 3 4 5
020
0040
0060
0080
00
I 12 232 candidates = 2 557 true collocations + 9 675 true non-collocations

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Experimental design 13/30
Reference dataI split into 7 stratified folds of the same size (the same ratio of true collocations)I 1 fold put aside as held-out dataI 6 folds used for evaluation of AMs
eval1 eval2 eval3 eval4 eval5 eval6 held-out
EvaluationI based on quality of ranking (ranking performance)I evaluation measures estimated on each eval fold separately and averaged
Significance testingI methods compared by paired Wilcoxon signed-ranked test on the 6 eval foldsI significance level α = 0.05

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Experimental design 13/30
Reference dataI split into 7 stratified folds of the same size (the same ratio of true collocations)I 1 fold put aside as held-out dataI 6 folds used for evaluation of AMs
eval1 eval2 eval3 eval4 eval5 eval6 held-out
EvaluationI based on quality of ranking (ranking performance)I evaluation measures estimated on each eval fold separately and averaged
Significance testingI methods compared by paired Wilcoxon signed-ranked test on the 6 eval foldsI significance level α = 0.05

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Experimental design 13/30
Reference dataI split into 7 stratified folds of the same size (the same ratio of true collocations)I 1 fold put aside as held-out dataI 6 folds used for evaluation of AMs
eval1 eval2 eval3 eval4 eval5 eval6 held-out
EvaluationI based on quality of ranking (ranking performance)I evaluation measures estimated on each eval fold separately and averaged
Significance testingI methods compared by paired Wilcoxon signed-ranked test on the 6 eval foldsI significance level α = 0.05

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Evaluation measures: Precision – Recall 14/30
1) Precision =|correctly classified collocations||total classified as collocations|
Recall =|correctly classified collocations|
|total collocations|

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Evaluation measures: Precision – Recall 14/30
1) Precision =|correctly classified collocations||total classified as collocations|
Recall =|correctly classified collocations|
|total collocations|
Rankingred cross 15.66iron curtain 15.23decimal point 14.01coupon book 13.83book author 11.05arithmetic operation 10.52paper feeder 10.17new book 10.09round table 7.03new wave 6.59gas station 6.04system type 3.54central part 1.54and others 0.54program in 0.35level is 0.25

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Evaluation measures: Precision – Recall 14/30
1) Precision =|correctly classified collocations||total classified as collocations|
Recall =|correctly classified collocations|
|total collocations|
Rankingred cross 15.66iron curtain 15.23decimal point 14.01coupon book 13.83book author 11.05arithmetic operation 10.52paper feeder 10.17new book 10.09round table 7.03new wave 6.59gas station 6.04system type 3.54central part 1.54and others 0.54program in 0.35level is 0.25

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Evaluation measures: Precision – Recall 14/30
1) Precision =|correctly classified collocations||total classified as collocations|
Recall =|correctly classified collocations|
|total collocations|
Rankingred cross 15.66iron curtain 15.23decimal point 14.01coupon book 13.83book author 11.05arithmetic operation 10.52paper feeder 10.17new book 10.09round table 7.03new wave 6.59gas station 6.04system type 3.54central part 1.54and others 0.54program in 0.35level is 0.25
Classificationred cross 1iron curtain 1decimal point 1coupon book 1book author 0arithmetic operation 0paper feeder 0new book 0round table 0new wave 0gas station 0system type 0central part 0and others 0program in 0level is 0

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Evaluation measures: Precision – Recall 14/30
1) Precision =|correctly classified collocations||total classified as collocations|
Recall =|correctly classified collocations|
|total collocations|
Rankingred cross 15.66iron curtain 15.23decimal point 14.01coupon book 13.83book author 11.05arithmetic operation 10.52paper feeder 10.17new book 10.09round table 7.03new wave 6.59gas station 6.04system type 3.54central part 1.54and others 0.54program in 0.35level is 0.25
Classificationred cross 1iron curtain 1decimal point 1coupon book 1book author 0arithmetic operation 0paper feeder 0new book 0round table 0new wave 0gas station 0system type 0central part 0and others 0program in 0level is 0

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Evaluation measures: Precision – Recall 14/30
1) Precision =|correctly classified collocations||total classified as collocations|
Recall =|correctly classified collocations|
|total collocations|
Rankingred cross 15.66iron curtain 15.23decimal point 14.01coupon book 13.83book author 11.05arithmetic operation 10.52paper feeder 10.17new book 10.09round table 7.03new wave 6.59gas station 6.04system type 3.54central part 1.54and others 0.54program in 0.35level is 0.25
Classificationred cross 1iron curtain 1decimal point 1coupon book 1book author 0arithmetic operation 0paper feeder 0new book 0round table 0new wave 0gas station 0system type 0central part 0and others 0program in 0level is 0
Precision Recall
100 % 50 %

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Evaluation measures: Precision – Recall 14/30
1) Precision =|correctly classified collocations||total classified as collocations|
Recall =|correctly classified collocations|
|total collocations|
Rankingred cross 15.66iron curtain 15.23decimal point 14.01coupon book 13.83book author 11.05arithmetic operation 10.52paper feeder 10.17new book 10.09round table 7.03new wave 6.59gas station 6.04system type 3.54central part 1.54and others 0.54program in 0.35level is 0.25
Classificationred cross 1iron curtain 1decimal point 1coupon book 1book author 1arithmetic operation 0paper feeder 0new book 0round table 0new wave 0gas station 0system type 0central part 0and others 0program in 0level is 0
Precision Recall
100 % 50 %80 % 50 %

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Evaluation measures: Precision – Recall 14/30
1) Precision =|correctly classified collocations||total classified as collocations|
Recall =|correctly classified collocations|
|total collocations|
Rankingred cross 15.66iron curtain 15.23decimal point 14.01coupon book 13.83book author 11.05arithmetic operation 10.52paper feeder 10.17new book 10.09round table 7.03new wave 6.59gas station 6.04system type 3.54central part 1.54and others 0.54program in 0.35level is 0.25
Classificationred cross 1iron curtain 1decimal point 1coupon book 1book author 1arithmetic operation 1paper feeder 1new book 1round table 1new wave 1gas station 1system type 1central part 1and others 1program in 1level is 1
Precision Recall100 % 12 %100 % 25 %100 % 37 %100 % 50 %
80 % 50 %83 % 62 %85 % 75 %75 % 75 %77 % 87 %70 % 87 %72 % 100 %66 % 100 %61 % 100 %57 % 100 %53 % 100 %50 % 100 %
I measured within the entire interval of possible threshold values

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Visual evaluation: Precision-Recall curves 15/30
I graphical plots of recall vs. precisionI the closer to the top and right, the better ranking performanceI estimated for each eval fold and vertically averaging
Precision-Recall curve averaging
Recall
Pre
cisi
on
0.0 0.2 0.4 0.6 0.8 1.0
0.2
0.4
0.6
0.8
1.0
Unaveraged curves

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Visual evaluation: Precision-Recall curves 15/30
I graphical plots of recall vs. precisionI the closer to the top and right, the better ranking performanceI estimated for each eval fold and vertically averaging
Precision-Recall curve averaging
Recall
Pre
cisi
on
0.0 0.2 0.4 0.6 0.8 1.0
0.2
0.4
0.6
0.8
1.0
Averaged curveUnaveraged curves

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Evaluation results: Precision-Recall curves 16/30
The best-performing association measures
Recall
Ave
rage
d pr
ecis
ion
0.0 0.2 0.4 0.6 0.8 1.0
0.2
0.4
0.6
0.8
1.0
Pointwise mutual information (4)Pearson’s test (10)z score (13)Unigram subtuple measure (39)Cosine context similarity in boolean vector space (77)

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Evaluation measure: Average Precision 17/30
2) Average Precision: E[P (R)], R ∼U(0, 1) AP =1
r
r∑i=1
pi
Rankingred cross 15.66iron curtain 15.23decimal point 14.01coupon book 13.83book author 11.05arithmetic operation 10.52paper feeder 10.17new book 10.09round table 7.03new wave 6.59gas station 6.04system type 3.54central part 1.54and others 0.54program in 0.35level is 0.25
Classificationred cross 1iron curtain 1decimal point 1coupon book 1book author 1arithmetic operation 1paper feeder 1new book 1round table 1new wave 1gas station 1system type 1central part 1and others 1program in 1level is 1
Precision Recall100 % 12 %100 % 25 %100 % 37 %100 % 50 %
80 % 50 %83 % 62 %85 % 75 %75 % 75 %77 % 87 %70 % 87 %72 % 100 %66 % 100 %61 % 100 %57 % 100 %53 % 100 %50 % 100 %

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Evaluation measure: Average Precision 17/30
2) Average Precision: E[P (R)], R ∼U(0, 1) AP =1
r
r∑i=1
pi
Rankingred cross 15.66iron curtain 15.23decimal point 14.01coupon book 13.83book author 11.05arithmetic operation 10.52paper feeder 10.17new book 10.09round table 7.03new wave 6.59gas station 6.04system type 3.54central part 1.54and others 0.54program in 0.35level is 0.25
Classificationred cross 1iron curtain 1decimal point 1coupon book 1book author 1arithmetic operation 1paper feeder 1new book 1round table 1new wave 1gas station 1system type 1central part 1and others 1program in 1level is 1
Precision Recall100 % 12 %100 % 25 %100 % 37 %100 % 50 %
80 % 50 %83 % 62 %85 % 75 %75 % 75 %77 % 87 %70 % 87 %72 % 100 %66 % 100 %61 % 100 %57 % 100 %53 % 100 %50 % 100 %

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Evaluation measure: Average Precision 17/30
2) Average Precision: E[P (R)], R ∼U(0, 1) AP =1
r
r∑i=1
pi
Rankingred cross 15.66iron curtain 15.23decimal point 14.01coupon book 13.83book author 11.05arithmetic operation 10.52paper feeder 10.17new book 10.09round table 7.03new wave 6.59gas station 6.04system type 3.54central part 1.54and others 0.54program in 0.35level is 0.25
Classificationred cross 1iron curtain 1decimal point 1coupon book 1book author 1arithmetic operation 1paper feeder 1new book 1round table 1new wave 1gas station 1system type 1central part 1and others 1program in 1level is 1
Precision Recall100 % 12 %100 % 25 %100 % 37 %100 % 50 %
80 % 50 %83 % 62 %85 % 75 %75 % 75 %77 % 87 %70 % 87 %72 % 100 %66 % 100 %61 % 100 %57 % 100 %53 % 100 %50 % 100 %
89.6 % = AP

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Evaluation measure: Average Precision 17/30
2) Average Precision: E[P (R)], R ∼U(0, 1) AP =1
r
r∑i=1
pi
Rankingred cross 15.66iron curtain 15.23decimal point 14.01coupon book 13.83book author 11.05arithmetic operation 10.52paper feeder 10.17new book 10.09round table 7.03new wave 6.59gas station 6.04system type 3.54central part 1.54and others 0.54program in 0.35level is 0.25
Classificationred cross 1iron curtain 1decimal point 1coupon book 1book author 1arithmetic operation 1paper feeder 1new book 1round table 1new wave 1gas station 1system type 1central part 1and others 1program in 1level is 1
Precision Recall100 % 12 %100 % 25 %100 % 37 %100 % 50 %
80 % 50 %83 % 62 %85 % 75 %75 % 75 %77 % 87 %70 % 87 %72 % 100 %66 % 100 %61 % 100 %57 % 100 %53 % 100 %50 % 100 %
3) Mean Average Precision: E[AP ] MAP =1
6
6∑i=1
APi 89.6 % = AP

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Overall results: Mean Average Precision 18/30
MAP of all lexical association measures in descending order77 39 80 38 32 13 10 31 30 37 5 42 27 28 29 4 63 16 23 22 24 45 33 7 21 18 19 20 43 34 6 54 9 76 50 82 48 3 8 59 44 66 61 73 71 26 70 25 15 14 72 74 11 69 53 52 49 35 41 68 55 64 40 47 65 81 75 46 56 12 78 2 60 79 51 36 58 62 57 1 17 67
Mea
n A
vera
ge P
reci
sion
0.0
0.2
0.4
0.6
0.8
I Baseline (ratio of true collocations): 21.02 %I Best context-based measure (n): Cosine similarity in vector space: 66.79 %I Best statistical association measure (n): Unigram subtuple measure: 66.72 %I Best 16 measures – statistically indistinguishable MAP ∼ current state of the art

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Overall results: Mean Average Precision 18/30
MAP of all lexical association measures in descending order77 39 80 38 32 13 10 31 30 37 5 42 27 28 29 4 63 16 23 22 24 45 33 7 21 18 19 20 43 34 6 54 9 76 50 82 48 3 8 59 44 66 61 73 71 26 70 25 15 14 72 74 11 69 53 52 49 35 41 68 55 64 40 47 65 81 75 46 56 12 78 2 60 79 51 36 58 62 57 1 17 67
Mea
n A
vera
ge P
reci
sion
0.0
0.2
0.4
0.6
0.8
I Baseline (ratio of true collocations): 21.02 %I Best context-based measure (n): Cosine similarity in vector space: 66.79 %I Best statistical association measure (n): Unigram subtuple measure: 66.72 %I Best 16 measures – statistically indistinguishable MAP ∼ current state of the art

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Overall results: Mean Average Precision 18/30
MAP of all lexical association measures in descending order77 39 80 38 32 13 10 31 30 37 5 42 27 28 29 4 63 16 23 22 24 45 33 7 21 18 19 20 43 34 6 54 9 76 50 82 48 3 8 59 44 66 61 73 71 26 70 25 15 14 72 74 11 69 53 52 49 35 41 68 55 64 40 47 65 81 75 46 56 12 78 2 60 79 51 36 58 62 57 1 17 67
Mea
n A
vera
ge P
reci
sion
0.0
0.2
0.4
0.6
0.8
I Baseline (ratio of true collocations): 21.02 %I Best context-based measure (n): Cosine similarity in vector space: 66.79 %I Best statistical association measure (n): Unigram subtuple measure: 66.72 %I Best 16 measures – statistically indistinguishable MAP ∼ current state of the art

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Overall results: Mean Average Precision 18/30
MAP of all lexical association measures in descending order77 39 80 38 32 13 10 31 30 37 5 42 27 28 29 4 63 16 23 22 24 45 33 7 21 18 19 20 43 34 6 54 9 76 50 82 48 3 8 59 44 66 61 73 71 26 70 25 15 14 72 74 11 69 53 52 49 35 41 68 55 64 40 47 65 81 75 46 56 12 78 2 60 79 51 36 58 62 57 1 17 67
Mea
n A
vera
ge P
reci
sion
0.0
0.2
0.4
0.6
0.8
I Baseline (ratio of true collocations): 21.02 %I Best context-based measure (n): Cosine similarity in vector space: 66.79 %I Best statistical association measure (n): Unigram subtuple measure: 66.72 %I Best 16 measures – statistically indistinguishable MAP ∼ current state of the art

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Overall results: Mean Average Precision 18/30
MAP of all lexical association measures in descending order77 39 80 38 32 13 10 31 30 37 5 42 27 28 29 4 63 16 23 22 24 45 33 7 21 18 19 20 43 34 6 54 9 76 50 82 48 3 8 59 44 66 61 73 71 26 70 25 15 14 72 74 11 69 53 52 49 35 41 68 55 64 40 47 65 81 75 46 56 12 78 2 60 79 51 36 58 62 57 1 17 67
Mea
n A
vera
ge P
reci
sion
0.0
0.2
0.4
0.6
0.8
I Baseline (ratio of true collocations): 21.02 %I Best context-based measure (n): Cosine similarity in vector space: 66.79 %I Best statistical association measure (n): Unigram subtuple measure: 66.72 %I Best 16 measures – statistically indistinguishable MAP ∼ current state of the art

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
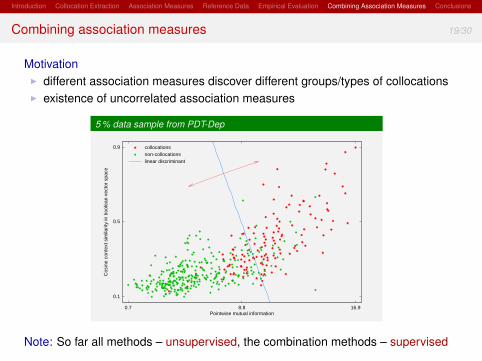
Combining association measures 19/30
MotivationI different association measures discover different groups/types of collocationsI existence of uncorrelated association measures

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Combining association measures 19/30
MotivationI different association measures discover different groups/types of collocationsI existence of uncorrelated association measures
5 % data sample from PDT-Dep
0.9
0.5
0.1
16.98.80.7
Cos
ine
cont
ext s
imila
rity
in b
oole
an v
ecto
r sp
ace
Pointwise mutual information
collocationsnon-collocationslinear discriminant
Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Combining association measures 19/30
MotivationI different association measures discover different groups/types of collocationsI existence of uncorrelated association measures
5 % data sample from PDT-Dep
0.9
0.5
0.1
16.98.80.7
Cos
ine
cont
ext s
imila
rity
in b
oole
an v
ecto
r sp
ace
Pointwise mutual information
collocationsnon-collocationslinear discriminant
Note: So far all methods – unsupervised, the combination methods – supervised

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Combination models 20/30
FrameworkI each collocation candidate xi is described by the feature vector
xi=(xi1, . . . , xi82)
T consisting of scores of all association measuresI and assigned a label yi ∈ {0, 1} indicating whether the bigram is considered
to be a true collocation (y = 1) or not (y = 0)I we look for a ranker function f(xi) determining the strength of lexical
association between components of a candidate xi
I e.g. linear combination of association scores: f(xi) = w0 +w1xi1 + . . .+w82x
i82
Methods1. Linear logistic regression2. Linear discriminant analysis3. Support vector machines4. Neural networks
I in the training phase used as regular classifiers on two-class dataI in the application phase no classification threshold applies

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Combination models 20/30
FrameworkI each collocation candidate xi is described by the feature vector
xi=(xi1, . . . , xi82)
T consisting of scores of all association measuresI and assigned a label yi ∈ {0, 1} indicating whether the bigram is considered
to be a true collocation (y = 1) or not (y = 0)I we look for a ranker function f(xi) determining the strength of lexical
association between components of a candidate xi
I e.g. linear combination of association scores: f(xi) = w0 +w1xi1 + . . .+w82x
i82
Methods1. Linear logistic regression2. Linear discriminant analysis3. Support vector machines4. Neural networks
I in the training phase used as regular classifiers on two-class dataI in the application phase no classification threshold applies

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Combination models 20/30
FrameworkI each collocation candidate xi is described by the feature vector
xi=(xi1, . . . , xi82)
T consisting of scores of all association measuresI and assigned a label yi ∈ {0, 1} indicating whether the bigram is considered
to be a true collocation (y = 1) or not (y = 0)I we look for a ranker function f(xi) determining the strength of lexical
association between components of a candidate xi
I e.g. linear combination of association scores: f(xi) = w0 +w1xi1 + . . .+w82x
i82
Methods1. Linear logistic regression2. Linear discriminant analysis3. Support vector machines4. Neural networks
I in the training phase used as regular classifiers on two-class dataI in the application phase no classification threshold applies

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Combination models: Evaluation 21/30
Evaluation schemeI 6-fold crossvalidation on the 6 evaluation foldsI 5 folds for training (fitting parameters), 1 fold for testing (ranking performance)I PR curve and AP score estimated on each test fold and averaged
train1 train2 train3 train4 train5 test6 held-out
Results: Mean Average Precision
method MAP +%Unigram subtuple measure 66.72 –Cosine similarity in vector space 66.79 0.00Support Vector Machine 73.03 9.35Neural Network (1 unit) 74.88 12.11Linear Discriminant Analysis 75.16 12.54Linear Logistic Regression 77.36 15.82Neural Network (5 units) 80.87 21.08

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Combination models: Evaluation 21/30
Evaluation schemeI 6-fold crossvalidation on the 6 evaluation foldsI 5 folds for training (fitting parameters), 1 fold for testing (ranking performance)I PR curve and AP score estimated on each test fold and averaged
train1 train2 train3 train4 train5 test6 held-out
Results: Mean Average Precision
method MAP +%Unigram subtuple measure 66.72 –Cosine similarity in vector space 66.79 0.00Support Vector Machine 73.03 9.35Neural Network (1 unit) 74.88 12.11Linear Discriminant Analysis 75.16 12.54Linear Logistic Regression 77.36 15.82Neural Network (5 units) 80.87 21.08

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Results: Precision-Recall curves 22/30
Combination methods compared with the best association measures
Recall
Ave
rage
pre
cisi
on
0.0 0.2 0.4 0.6 0.8 1.0
0.2
0.4
0.6
0.8
1.0
Neural network (5 units)Linear logistic regressionSupport vector machine (linear)Linear discriminant analysisNeural network (1 unit)
Cosine context similarity in boolean vector space (77)Unigram subtuple measure (39)

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Learning curve analysis 23/30
Neural network (5 units) learning curve
Training data size (%)
Mea
n av
erag
e pr
ecis
ion
0 20 40 60 80 100
0.50
0.55
0.60
0.65
0.70
0.75
0.80
I 100% of training data = 5 training folds (8 737 annotated collocation candidates)I 95% of the final MAP achieved with 15% of training dataI 99% of the final MAP achieved with 50% of training data

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Adding linguistic features 24/30
IdeaI improving the combination models by adding linguistic featuresI categorical features can be transformed to binary dummy features
New featuresI Part-of-Speech pattern: combination of component POS (A:N, N:N, . . . )I Syntactic relation: dependency type (attribute, object, . . . )
Results: Mean Average Precision
method MAP +%
Unigram subtuple measure 66.72 –Cosine similarity in vector space 66.79 0.00
NNet/5 (AM) 80.87 21.08NNet/5 (AM+POS) 82.79 24.09NNet/5 (AM+POS+DEP) 84.53 26.69

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Adding linguistic features 24/30
IdeaI improving the combination models by adding linguistic featuresI categorical features can be transformed to binary dummy features
New featuresI Part-of-Speech pattern: combination of component POS (A:N, N:N, . . . )I Syntactic relation: dependency type (attribute, object, . . . )
Results: Mean Average Precision
method MAP +%
Unigram subtuple measure 66.72 –Cosine similarity in vector space 66.79 0.00
NNet/5 (AM) 80.87 21.08NNet/5 (AM+POS) 82.79 24.09NNet/5 (AM+POS+DEP) 84.53 26.69

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Adding linguistic features 24/30
IdeaI improving the combination models by adding linguistic featuresI categorical features can be transformed to binary dummy features
New featuresI Part-of-Speech pattern: combination of component POS (A:N, N:N, . . . )I Syntactic relation: dependency type (attribute, object, . . . )
Results: Mean Average Precision
method MAP +%
Unigram subtuple measure 66.72 –Cosine similarity in vector space 66.79 0.00
NNet/5 (AM) 80.87 21.08NNet/5 (AM+POS) 82.79 24.09NNet/5 (AM+POS+DEP) 84.53 26.69
Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Model reduction 25/30
MotivationI “Ocama’s razor”I combination of all 82 association measures is too complexI models should be reduced: redundant variables removed
Two issues
1. groups of highly correlated measures
2. measures with no or minimal contribution to the model
Two-step solution
1. correlation based clustering; one representative selected from each cluster
2. step-wise procedure removing variables one by one

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Model reduction 25/30
MotivationI “Ocama’s razor”I combination of all 82 association measures is too complexI models should be reduced: redundant variables removed
Two issues
1. groups of highly correlated measures
2. measures with no or minimal contribution to the model
Two-step solution
1. correlation based clustering; one representative selected from each cluster
2. step-wise procedure removing variables one by one

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Model reduction 25/30
MotivationI “Ocama’s razor”I combination of all 82 association measures is too complexI models should be reduced: redundant variables removed
Two issues
1. groups of highly correlated measures
2. measures with no or minimal contribution to the model
Two-step solution
1. correlation based clustering; one representative selected from each cluster
2. step-wise procedure removing variables one by one

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Model reduction: 1) Clustering 26/30
Agglomerative hierarchical clusteringI groups the measures with the same/similar contribution to the modelI begins with each measure as a separate cluster and merge them into
successively larger clustersI distance metrics = 1- |Pearson’s correlation| (estimated on the held-out fold)

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Model reduction: 1) Clustering 26/30
Agglomerative hierarchical clusteringI groups the measures with the same/similar contribution to the modelI begins with each measure as a separate cluster and merge them into
successively larger clustersI distance metrics = 1- |Pearson’s correlation| (estimated on the held-out fold)
6978 79
57 56 58 12 1 17 51 36 55 478
15 14 23 37 2716
24 42 10 43 34 22 45 7 63 13 38 32 31 30 68 59 44 33 19 18 20 21 54 29 28 6 9 539 4
5061 73 71 48 3 77 80 26 25 49 35 53 52
4146 2
60 6776 11
70 40 7562 74 72 82 81 66 64 65

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Model reduction: 1) Clustering 26/30
Agglomerative hierarchical clusteringI groups the measures with the same/similar contribution to the modelI begins with each measure as a separate cluster and merge them into
successively larger clustersI distance metrics = 1- |Pearson’s correlation| (estimated on the held-out fold)
6978 79
57 56 58 12 1 17 51 36 55 478
15 14 23 37 2716
24 42 10 43 34 22 45 7 63 13 38 32 31 30 68 59 44 33 19 18 20 21 54 29 28 6 9 539 4
5061 73 71 48 3 77 80 26 25 49 35 53 52
4146 2
60 6776 11
70 40 7562 74 72 82 81 66 64 65
I number of the final clusters empirically set to 60I the best performing measure (by MAP on the held-out fold) selected as the
representative from each cluster

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Model reduction: 2) Stepwise variable removal 27/30
Iterative procedureI initiated with the 60 variables/measuresI in each iteration we remove the variable causing minimal performance
degradation when not used in the model (by MAP on the held-out fold)I stops before the degradation becomes statistically significant

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Model reduction: 2) Stepwise variable removal 27/30
Iterative procedureI initiated with the 60 variables/measuresI in each iteration we remove the variable causing minimal performance
degradation when not used in the model (by MAP on the held-out fold)I stops before the degradation becomes statistically significant
Number of variables
Mea
n av
erag
e pr
ecis
ion
60 50 40 30 20 10 1
0.60
0.65
0.70
0.75
0.80
0.85
held−out MAPtest MAP

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Model reduction: 2) Stepwise variable removal 27/30
Iterative procedureI initiated with the 60 variables/measuresI in each iteration we remove the variable causing minimal performance
degradation when not used in the model (by MAP on the held-out fold)I stops before the degradation becomes statistically significant
Number of variables
Mea
n av
erag
e pr
ecis
ion
60 50 40 30 20 10 1
0.60
0.65
0.70
0.75
0.80
0.85
held−out MAPtest MAP
I the final model contains 13 variables/lexical association measures

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Model reduction: Process overview 28/30
MAP of individual lexical association measures77 39 80 38 32 13 10 31 30 37 5 42 27 28 29 4 63 16 23 22 24 45 33 7 21 18 19 20 43 34 6 54 9 76 50 82 48 3 8 59 44 66 61 73 71 26 70 25 15 14 72 74 11 69 53 52 49 35 41 68 55 64 40 47 65 81 75 46 56 12 78 2 60 79 51 36 58 62 57 1 17 67
Mea
n A
vera
ge P
reci
sion
0.0
0.2
0.4
0.6
0.8
I procedure initiated with all 82 association measuresI highly correlated measures removed in the first phase (clustering)I 13 measures left after the second phase (stepwise removal)
= 4 statistical association mesaures (n) + 9 context-based measures (n)

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Model reduction: Process overview 28/30
MAP of individual lexical association measures77 39 80 38 32 13 10 31 30 37 5 42 27 28 29 4 63 16 23 22 24 45 33 7 21 18 19 20 43 34 6 54 9 76 50 82 48 3 8 59 44 66 61 73 71 26 70 25 15 14 72 74 11 69 53 52 49 35 41 68 55 64 40 47 65 81 75 46 56 12 78 2 60 79 51 36 58 62 57 1 17 67
Mea
n A
vera
ge P
reci
sion
0.0
0.2
0.4
0.6
0.8
I procedure initiated with all 82 association measuresI highly correlated measures removed in the first phase (clustering)I 13 measures left after the second phase (stepwise removal)
= 4 statistical association mesaures (n) + 9 context-based measures (n)

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Model reduction: Process overview 28/30
MAP of individual lexical association measures77 39 80 38 32 13 10 31 30 37 5 42 27 28 29 4 63 16 23 22 24 45 33 7 21 18 19 20 43 34 6 54 9 76 50 82 48 3 8 59 44 66 61 73 71 26 70 25 15 14 72 74 11 69 53 52 49 35 41 68 55 64 40 47 65 81 75 46 56 12 78 2 60 79 51 36 58 62 57 1 17 67
Mea
n A
vera
ge P
reci
sion
0.0
0.2
0.4
0.6
0.8
I procedure initiated with all 82 association measuresI highly correlated measures removed in the first phase (clustering)I 13 measures left after the second phase (stepwise removal)
= 4 statistical association mesaures (n) + 9 context-based measures (n)

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Model reduction results: Precision-Recall curves 29/30
Reduced combination models compared with the best association measures
Recall
Ave
rage
d pr
ecis
ion
0.0 0.2 0.4 0.6 0.8 1.0
0.2
0.4
0.6
0.8
1.0
NNet (5 units) with 82 variablesNNet (5 units) with 47 variablesNNet (5 units) with 13 variablesNNet (5 units) with 7 variables
Cosine context similarity in boolean vector space (77)Unigram subtuple measure (39)

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Conslusions 30/30
Main results
1. inventory of 82 lexical association measures
2. 4 reference data sets
3. all lexical association measures evaluated on these data sets
4. combining association measures improved state of the art in collocation extraction
5. combination models reduced to 13 measures without performance degradation
Other contribution of the thesis
I overview of different notions of collocation (definitions, typology, classification)
I evaluation scheme (average precision, crossvalidation, significance tests)
I reference data sets used in MWE 2008 Shared Task

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Conslusions 30/30
Main results
1. inventory of 82 lexical association measures
2. 4 reference data sets
3. all lexical association measures evaluated on these data sets
4. combining association measures improved state of the art in collocation extraction
5. combination models reduced to 13 measures without performance degradation
Other contribution of the thesis
I overview of different notions of collocation (definitions, typology, classification)
I evaluation scheme (average precision, crossvalidation, significance tests)
I reference data sets used in MWE 2008 Shared Task

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
List of relevant publications
Pavel Pecina: Lexical Association Measures and Collocation Extraction, Multiword expressions: Hard going orplain sailing? Special issue of the International Journal of Language Resources and Evaluation, Springer, 2009(accepted).
Pavel Pecina: Lexical Association Measures: Collocation Extraction, PhD Thesis, Charles University, Prague,Czech Republic, 2008.
Pavel Pecina: Machine Learning Approach to Multiword Expression Extraction, In Proceedings of the sixthInternational Conference on Language Resources and Evaluation (LREC) Workshop: Towards a Shared Task forMultiword Expressions, Marrakech, Morocco, 2008.
Pavel Pecina: Reference Data for Czech Collocation Extraction, In Proceedings of the sixth InternationalConference on Language Resources and Evaluation (LREC) Workshop: Towards a Shared Task for MultiwordExpressions, Marrakech, Morocco, 2008.
Pavel Pecina, Pavel Schlesinger: Combining Association Measures for Collocation Extraction, In Proceedings ofthe 21th International Conference on Computational Linguistics and 44th Annual Meeting of the Association forComputational Linguistics (COLING/ACL), Sydney, Australia, 2006.
Silvie Cinkova, Petr Podvesky, Pavel Pecina, Pavel Schlesinger: Semi-automatic Building of Swedish CollocationLexicon, In Proceedings of the 5th International Conference on Language Resources and Evaluation (LREC),Genova, Italy, 2006.
Pavel Pecina: An Extensive Empirical Study of Collocation Extraction Methods, In Proceedings of theAssociation for Computational Linguistics Student Research Workshop (ACL), Ann Arbor, Michigan, USA, 2005.
Pavel Pecina, Martin Holub: Semantically Significant Collocations, UFAL/CKL Technical Report TR-2002-13,Faculty of Mathematics and Physics, Charles University, Prague, Czech Rep., 2002.

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Additional data sets
PDT-SurfI analogous to PDT-Dep (corpus, filtering, annotation)I collocation candidates extracted as surface bigrams: pairs of adjacent wordsI assumption: collocations cannot be modified by insertion of another wordI annotation consistent with PDT-Dep
CNC-SurfI collocation candidates – instances of PDT-Surf in the Czech National CorpusI SYN 2000 and 2005, 240 mil. tokens, morphologicaly tagged and lemmatizedI annotation consistent with PDT-Surf
PAR-DistI source corpus: Swedish Parole, 22 mil. tokensI automatic morphological tagging and lemmatizationI distance bigrams: word pairs occurring within a distance of 1–3 wordsI annotation: non-exhaustive manual extraction of support verb constructionsI no frequency filter applied

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Reference data summary
reference data set PDT-Dep PDT-Surf CNC-Surf PAR-Dist
source corpus PDT PDT CNC PAROLE
language Czech Czech Czech Swedish
morphology manual manual auto auto
syntax manual none none none
bigram types dependency surface surface distance
tokens 1 504 847 1 504 847 242 272 798 22 883 361
bigram types 635 952 638 030 30 608 916 13 370 375
after frequency filtering 26 450 29 035 2 941 414 13 370 375
after part-of-speech filtering 12 232 10 021 1 503 072 898 324
collocation candidates 12 232 10 021 9 868 17 027
data sample size 100 % 100 % 0.66 % 1.90 %
true collocations 2 557 2 293 2 263 1 292
baseline precision (%) 21.02 22.88 22.66 7.59

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Context-based vs. statistical association measures
PDT-Dep
77 39 80 38 32 13 10 31 30 37 5 42 27 28 29 4 63 16 23 22 24 45 33 7 21 18 19 20 43 34 6 54 9 76 50 82 48 3 8 59 44 66 61 73 71 26 70 25 15 14 72 74 11 69 53 52 49 35 41 68 55 64 40 47 65 81 75 46 56 12 78 2 60 79 51 36 58 62 57 1 17 67
Mea
n A
vera
ge P
reci
sion
0.0
0.2
0.4
0.6
0.8
PDT-Surf
39 38 32 27 28 29 31 30 37 13 10 5 42 4 16 24 22 23 33 45 7 77 80 18 21 20 19 9 63 6 43 50 34 54 48 3 26 25 59 44 8 53 52 76 35 49 41 82 55 15 14 47 70 11 66 61 73 71 72 74 69 46 2 60 64 65 68 40 12 75 81 51 36 56 78 79 58 62 57 17 1 67
Mea
n A
vera
ge P
reci
sion
0.0
0.2
0.4
0.6
0.8
CNC-Surf
39 4 27 28 29 38 37 32 31 30 42 9 13 10 5 33 16 22 23 24 63 50 45 43 18 19 21 20 34 7 54 3 48 77 59 44 26 25 82 80 41 35 53 52 6 49 66 69 73 71 8 61 55 72 74 62 70 15 14 47 64 79 46 60 65 78 40 2 81 1 17 11 12 56 75 36 51 76 68 67 57 58
Mea
n A
vera
ge P
reci
sion
0.0
0.2
0.4
0.6
0.8
PAR-Dist
36 51 12 47 56 69 1 17 57 15 14 78 11 9 6 65 55 8 61 62 44 68 54 18 19 21 20 59 58 66 33 64 73 71 37 27 28 29 34 43 23 24 22 2 40 63 38 5 32 30 42 31 82 13 77 80 3 48 52 53 7 45 4 70 50 81 26 79 25 46 67 35 41 39 76 74 49 60 75 10 16 72
Mea
n A
vera
ge P
reci
sion
0.0
0.1
0.2
0.3
0.4

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Results / Mean average precision: PDT-Dep vs. PDT-Surf
Dependency bigrams vs. surface bigrams
77 39 80 38 32 13 10 31 30 37 5 42 27 28 29 4 63 16 23 22 24 45 33 7 21 18 19 20 43 34 6 54 9 76 50 82 48 3 8 59 44 66 61 73 71 26 70 25 15 14 72 74 11 69 53 52 49 35 41 68 55 64 40 47 65 81 75 46 56 12 78 2 60 79 51 36 58 62 57 1 17 67
Mea
n A
vera
ge P
reci
sion
0.0
0.2
0.4
0.6
0.8

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Results / Mean average precision: PDT-Surf vs. CNC-Surf
Small source corpus vs. large source corpus
39 38 32 27 28 29 31 30 37 13 10 5 42 4 16 24 22 23 33 45 7 77 80 18 21 20 19 9 6 43 50 34 63 54 48 3 26 25 59 44 8 53 52 35 49 41 55 82 15 70 14 47 66 11 73 61 71 74 72 69 76 46 2 60 64 65 40 81 12 68 56 51 36 78 79 58 62 57 75 17 1 67
Mea
n A
vera
ge P
reci
sion
0.0
0.2
0.4
0.6
0.8

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Results / Mean average precision: PAR-Dist vs. PDT-Dep
Different corpus, different language, different task
36 51 12 47 56 69 1 17 57 15 14 78 11 9 6 65 55 8 61 62 44 68 54 18 19 21 20 59 58 66 33 64 73 71 37 27 28 29 34 43 23 24 22 2 40 63 38 5 32 30 42 31 82 13 77 80 3 48 52 53 7 45 4 70 50 81 26 79 25 46 67 35 41 39 76 74 49 60 75 10 16 72
Mea
n A
vera
ge P
reci
sion
0.0
0.2
0.4
0.6
0.8

Introduction Collocation Extraction Association Measures Reference Data Empirical Evaluation Combining Association Measures Conclusions
Comparison of AM evaluation results on different data sets
PDT−Dep
0.2 0.4 0.6 0.08 0.12 0.16
0.2
0.3
0.4
0.5
0.6
0.2
0.4
0.6
PDT−Surf
CNC−Surf
0.0
0.2
0.4
0.6
0.2 0.3 0.4 0.5 0.6
0.08
0.12
0.16
0.0 0.2 0.4 0.6
PAR−Dist