lineage-driven fault injection, sigmod'15
TRANSCRIPT

Lineage-driven Fault Injection
Peter Alvaro Joshua Rosen Joseph M. Hellerstein
UC Berkeley

The future is disorder
• Data-intensive systems are increasingly distributed and heterogeneous
• Distributed systems suffer partial failures • Fault-tolerant code is hard to get right • Composing FT components is hard too!

Motivation: Kafka replication bug
Three correct components: 1. Primary/backup replication 2. Timeout-based failure detectors 3. Zookeeper One nasty bug: Acknowledged writes are lost

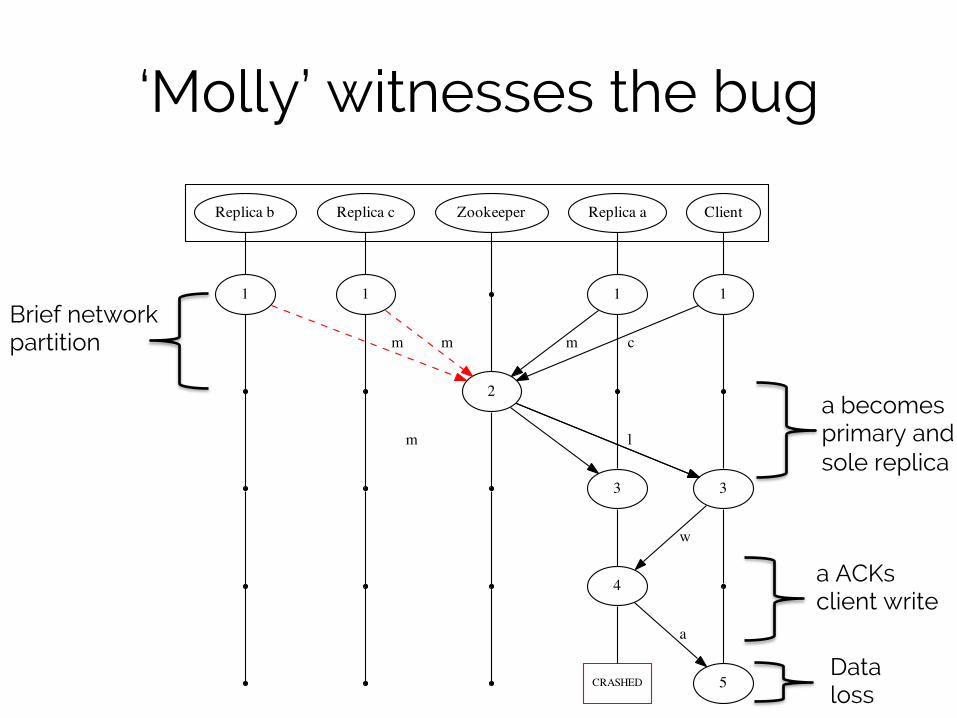
‘Molly’ witnesses the bug
Replica b Replica c Zookeeper Replica a Client
1 1
2
1
3
4
CRASHED
1
3
5
m m
m l
m
a
c
w

‘Molly’ witnesses the bug
Replica b Replica c Zookeeper Replica a Client
1 1
2
1
3
4
CRASHED
1
3
5
m m
m l
m
a
c
w
Brief network partition

‘Molly’ witnesses the bug
Replica b Replica c Zookeeper Replica a Client
1 1
2
1
3
4
CRASHED
1
3
5
m m
m l
m
a
c
w
Brief network partition
a becomes primary and sole replica

‘Molly’ witnesses the bug
Replica b Replica c Zookeeper Replica a Client
1 1
2
1
3
4
CRASHED
1
3
5
m m
m l
m
a
c
w
Brief network partition
a becomes primary and sole replica
a ACKs client write
‘Molly’ witnesses the bug
Replica b Replica c Zookeeper Replica a Client
1 1
2
1
3
4
CRASHED
1
3
5
m m
m l
m
a
c
w
Brief network partition
a becomes primary and sole replica
a ACKs client write
Data loss

Fault-tolerance: the state of the art
1. Bottom-up approaches (e.g. verification) 2. Top-down approaches (e.g. fault injection)
Investment
Returns
Investment
Returns

Fault-tolerance: the state of the art
1. Bottom-up approaches (e.g. verification) 2. Top-down approaches (e.g. fault injection)
Investment
Returns
Investment
Returns

1. Bottom-up approaches (e.g. verification) 2. Top-down approaches (e.g. fault injection)
Fault-tolerance: the state of the art
Investment
Returns

Fault-tolerance: the state of the art
1. Bottom-up approaches (e.g. verification) 2. Top-down approaches (e.g. fault injection)
Investment
Returns

Fault-tolerance: the state of the art
1. Bottom-up approaches (e.g. verification) 2. Top-down approaches (e.g. fault injection)
Investment
Returns

Fault-tolerance: the state of the art
1. Bottom-up approaches (e.g. verification) 2. Top-down approaches (e.g. fault injection)

Lineage-driven fault injection
Goal: whole-system testing that • finds all of the fault-tolerance bugs, or • certifies that none exist Main idea: fault-tolerance is redundancy.

Lineage-driven fault injection
Approach: think backwards from outcomes Use lineage to find evidence of redundancy Original Question: • Could a bad thing ever happen? Reframed question: • Why did a good thing happen? • What could have gone wrong?

A game
Protocol: Reliable broadcast Specification: Pre: A correct process delivers a message m Post: All correct process delivers m Failure Model: (Permanent) crash failures Message loss / partitions
Program'
Output%constraints%

Round 1
The broadcaster makes an attempt to relay the message to the other nodes
“An effort” delivery protocol:

Round 1 in space / time
Process b Process a Process c
2
1
2
log log

Outcomes are data
log(B, “data”)@5
What
Where
When
Some data

Round 1: Lineage
log(B, data)@5

log(B, data)@5
log(B, data)@4
log(Node, Pload)@next :- log(Node, Pload);
log(B, data)@5:- log(B, data)@4;
Round 1: Lineage

Round 1: Lineage
log(B, data)@5
log(B, data)@4
log(B, data)@3

Round 1: Lineage
log(B, data)@5
log(B, data)@4
log(B, data)@3
log(B,data)@2

log(B, data)@5
log(B, data)@4
log(B, data)@3
log(B,data)@2
bcast(A, data)@1
log(Node2, Pload)@async :- bcast(Node1, Pload), node(Node1, Node2);
log(B, data)@2 :- bcast(A, data)@1, node(A, B)@1;
Round 1: Lineage

An execution is a (fragile) “proof” of an outcome
log(A, data)@1 node(A, B)@1
AB1 r2
log(B, data)@2
r1
log(B, data)@3
r1
log(B, data)@4
r1
log(B, data)@5
log(A, data)@1
r1
log(A, data)@2
node(A, B)@1
r3
node(A, B)@2
AB2 r2
log(B, data)@3
r1
log(B, data)@4
r1
log(B, data)@5
log(A, data)@1
r1
log(A, data)@2
r1
log(A, data)@3
node(A, B)@1
r3
node(A, B)@2
r3
node(A, B)@3
AB3 r2
log(B, data)@4
r1
log(B, data)@5
log(A, data)@1
r1
log(A, data)@2
r1
log(A, data)@3
r1
log(A, data)@4
node(A, B)@1
r3
node(A, B)@2
r3
node(A, B)@3
r3
node(A, B)@4
AB4 r2
log(B, data)@5
AB1 ^AB2 ^AB3 ^AB4
1
(which required a message from A to B at time 1)

Round 1: counterexample
The adversary wins!
Process b Process a Process c
1
2
log (LOST) log

Round 2
The broadcaster makes repeated attempts to relay the message to the other nodes
“Sender retries” delivery protocol:

Round 2 in spacetime Process b Process a Process c
2
3
4
5
1
2
3
4
2
3
4
5
log log
log log
log log
log log

Round 2: sender retries
log(B, data)@5

Round 2: sender retries
log(B, data)@5
log(B, data)@4

Round 2: sender retries
log(B, data)@5
log(B, data)@4
log(A, data)@4
log(Node2, Pload)@async :- bcast(Node1, Pload), node(Node1, Node2);
log(B, data)@3 :- bcast(A, data)@2, node(A, B)@2;

Round 2: sender retries
log(B, data)@5
log(B, data)@4
log(A, data)@4
log(B, data)@3
log(A, data)@3

Round 2: sender retries
log(B, data)@5
log(B, data)@4
log(A, data)@4
log(B, data)@3
log(A, data)@3
log(B,data)@2
log(A, data)@2
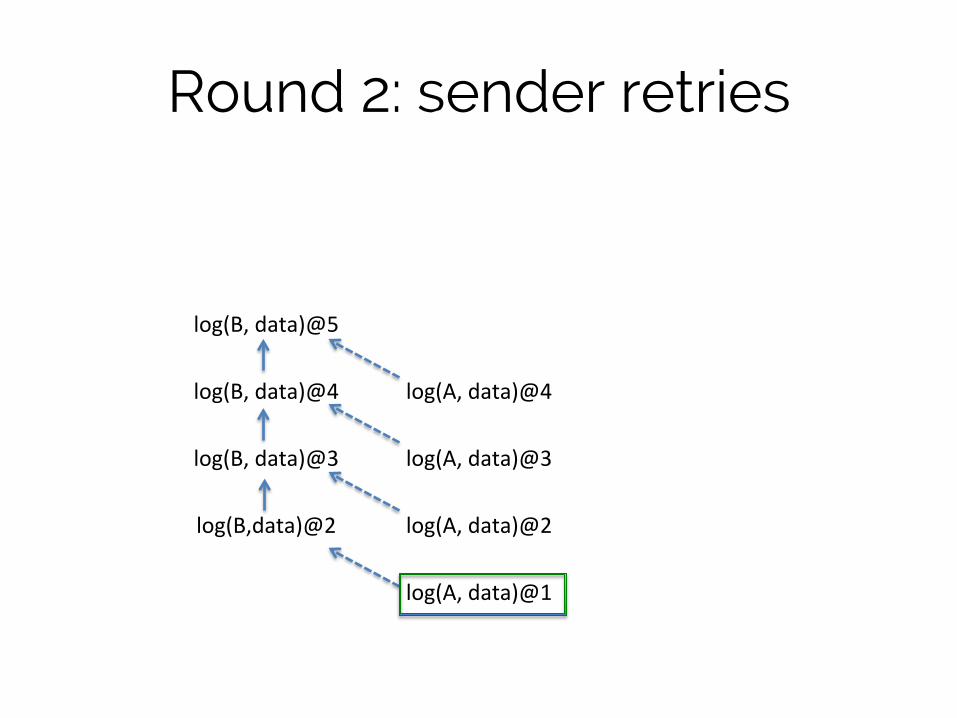
Round 2: sender retries
log(B, data)@5
log(B, data)@4
log(A, data)@4
log(B, data)@3
log(A, data)@3
log(B,data)@2
log(A, data)@2
log(A, data)@1
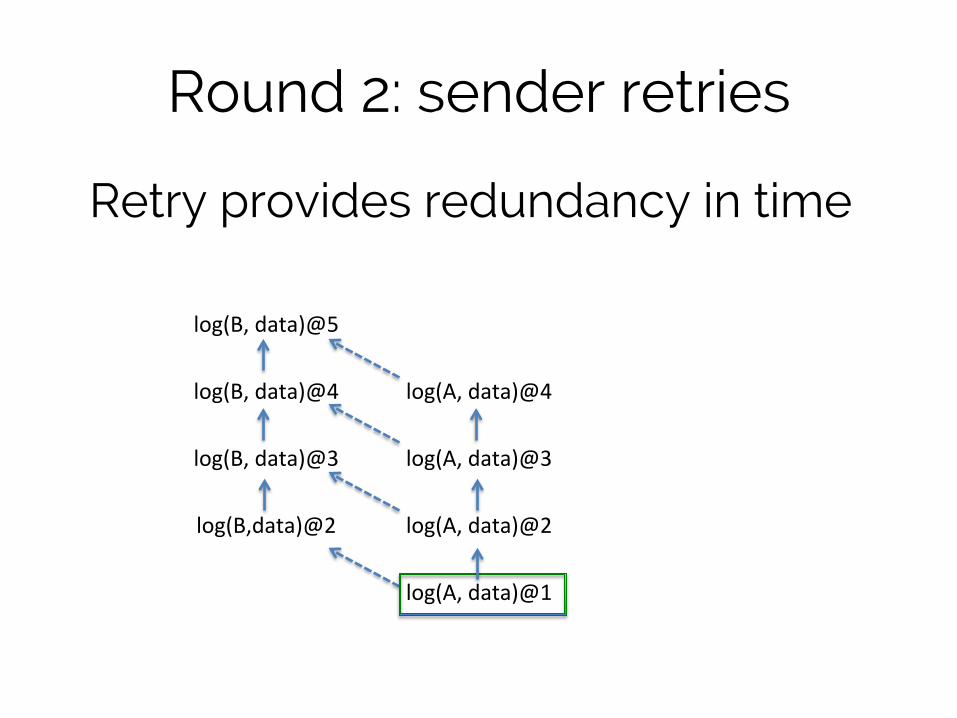
Round 2: sender retries
log(B, data)@5
log(B, data)@4
log(A, data)@4
log(B, data)@3
log(A, data)@3
log(B,data)@2
log(A, data)@2
log(A, data)@1
Retry provides redundancy in time

Traces are forests of proof trees log(A, data)@1 node(A, B)@1
AB1 r2
log(B, data)@2
r1
log(B, data)@3
r1
log(B, data)@4
r1
log(B, data)@5
log(A, data)@1
r1
log(A, data)@2
node(A, B)@1
r3
node(A, B)@2
AB2 r2
log(B, data)@3
r1
log(B, data)@4
r1
log(B, data)@5
log(A, data)@1
r1
log(A, data)@2
r1
log(A, data)@3
node(A, B)@1
r3
node(A, B)@2
r3
node(A, B)@3
AB3 r2
log(B, data)@4
r1
log(B, data)@5
log(A, data)@1
r1
log(A, data)@2
r1
log(A, data)@3
r1
log(A, data)@4
node(A, B)@1
r3
node(A, B)@2
r3
node(A, B)@3
r3
node(A, B)@4
AB4 r2
log(B, data)@5
AB1 ^AB2 ^AB3 ^AB4
1

Traces are forests of proof trees log(A, data)@1 node(A, B)@1
AB1 r2
log(B, data)@2
r1
log(B, data)@3
r1
log(B, data)@4
r1
log(B, data)@5
log(A, data)@1
r1
log(A, data)@2
node(A, B)@1
r3
node(A, B)@2
AB2 r2
log(B, data)@3
r1
log(B, data)@4
r1
log(B, data)@5
log(A, data)@1
r1
log(A, data)@2
r1
log(A, data)@3
node(A, B)@1
r3
node(A, B)@2
r3
node(A, B)@3
AB3 r2
log(B, data)@4
r1
log(B, data)@5
log(A, data)@1
r1
log(A, data)@2
r1
log(A, data)@3
r1
log(A, data)@4
node(A, B)@1
r3
node(A, B)@2
r3
node(A, B)@3
r3
node(A, B)@4
AB4 r2
log(B, data)@5
AB1 ^AB2 ^AB3 ^AB4
1

Traces are forests of proof trees log(A, data)@1 node(A, B)@1
AB1 r2
log(B, data)@2
r1
log(B, data)@3
r1
log(B, data)@4
r1
log(B, data)@5
log(A, data)@1
r1
log(A, data)@2
node(A, B)@1
r3
node(A, B)@2
AB2 r2
log(B, data)@3
r1
log(B, data)@4
r1
log(B, data)@5
log(A, data)@1
r1
log(A, data)@2
r1
log(A, data)@3
node(A, B)@1
r3
node(A, B)@2
r3
node(A, B)@3
AB3 r2
log(B, data)@4
r1
log(B, data)@5
log(A, data)@1
r1
log(A, data)@2
r1
log(A, data)@3
r1
log(A, data)@4
node(A, B)@1
r3
node(A, B)@2
r3
node(A, B)@3
r3
node(A, B)@4
AB4 r2
log(B, data)@5
AB1 ^AB2 ^AB3 ^AB4
1
✖ ✖ ✖

Traces are forests of proof trees log(A, data)@1 node(A, B)@1
AB1 r2
log(B, data)@2
r1
log(B, data)@3
r1
log(B, data)@4
r1
log(B, data)@5
log(A, data)@1
r1
log(A, data)@2
node(A, B)@1
r3
node(A, B)@2
AB2 r2
log(B, data)@3
r1
log(B, data)@4
r1
log(B, data)@5
log(A, data)@1
r1
log(A, data)@2
r1
log(A, data)@3
node(A, B)@1
r3
node(A, B)@2
r3
node(A, B)@3
AB3 r2
log(B, data)@4
r1
log(B, data)@5
log(A, data)@1
r1
log(A, data)@2
r1
log(A, data)@3
r1
log(A, data)@4
node(A, B)@1
r3
node(A, B)@2
r3
node(A, B)@3
r3
node(A, B)@4
AB4 r2
log(B, data)@5
AB1 ^AB2 ^AB3 ^AB4
1
✖ ✖ ✖

Round 2: counterexample
Process b Process a Process c
1
CRASHED 2
log (LOST) log
The adversary wins!

Round 1
All participants make repeated attempts to relay the message to the other nodes
“Symmetric retry” delivery protocol:

Round 3 in space / time Process b Process a Process c
2
3
4
5
1
2
3
4
5
2
3
4
5
log log
log log
log log
log log
log log
log log
log log
log log
log log
log log

Round 3: symmetric retry
log(B, data)@5

Round 3: symmetric retry
log(B, data)@5
log(B, data)@4
log(A, data)@4
log(C, data)@4

Round 3: symmetric retry
log(B, data)@5
log(B, data)@4
log(A, data)@4
log(C, data)@4
Log(B, data)@3
log(A, data)@3
log(C, data)@3

Round 3: symmetric retry
log(B, data)@5
log(B, data)@4
log(A, data)@4
log(C, data)@4
Log(B, data)@3
log(A, data)@3
log(C, data)@3
log(B,data)@2
log(A, data)@2
log(C, data)@2
log(A, data)@1

Round 3: symmetric retry
log(B, data)@5
log(B, data)@4
log(A, data)@4
log(C, data)@4
Log(B, data)@3
log(A, data)@3
log(C, data)@3
log(B,data)@2
log(A, data)@2
log(C, data)@2
log(A, data)@1
Redundancy in space and time

Round 3: symmetric retry
The programmer wins!

Let’s reflect
Intuition: Fault-tolerance is redundancy in space and time.
Strategy: Reason backwards from outcomes using lineageLineage exposes redundancy of outcome support.
Finding bugs: choose failures that “break” all derivations
Fixing bugs: add additional derivations

Automating the role of the adversary
1. Break a proof by dropping any contributing message.
(AB1 ∨ BC2)

Automating the role of the adversary
1. Break a proof by dropping any contributing message.
2. Find a set of failures that breaks all proofs of a good outcome.
Disjunction
Conjunction of disjunctions (AKA CNF)
(AB1 ∨ BC2)
∧ (AC1) ∧ (AC2)

Automating the role of the adversary
1. Break a proof by dropping any contributing message.
2. Find a set of failures that breaks all proofs of a good outcome.
Disjunction
Conjunction of disjunctions (AKA CNF)
(AB1 ∨ BC2)
∧ (AC1) ∧ (AC2)

By injecting only “interesting” faults…
Molly finds bugs quickly

By injecting only “interesting” faults…
Molly finds bugs quickly

By injecting only “interesting” faults…
Molly provides guarantees that outcomes are fault-tolerant
Program Bound Combina/ons Execu/ons
redun-‐deliv 11 8.07 X 1018 11
ack-‐deliv 8 3.08 X 1013 673
paxos-‐synod 7 4.81 X 1011 173
bully-‐leader 10 1.26 X 1017 2
flux 22 6.20 X 1076 187

Molly, the LDFI prototype
Molly finds fault-tolerance violations quickly or guarantees that none exist. Molly uses data lineage to reason about redundancy of support (or lack thereof)
for system outcomes.


Case study: commit protocols Agent a Agent a Coordinator Agent d
2 2
1
3
CRASHED
2
v v
p p p
v
2-Phase commit
Agent a Agent b Coordinator Agent d
2
3
4
5
6
7
2
3
4
5
6
7
1
2
3
CRASHED
2
3
4
5
6
7
vote
decision_req decision_req
vote
decision_req decision_req
prepare prepare prepare
vote
decision_req decision_req
Collaborative termination
Process a Process b Process C Process d
2
4
7
8
2
4
7
8
1
3
5
6
7
8
2
CRASHED
vote_msg
ack
commit
vote_msg
ack
commit
cancommit cancommit cancommit
precommit precommit precommit
abort (LOST) abort (LOST)
abort abort
vote_msg
3-Phase commit
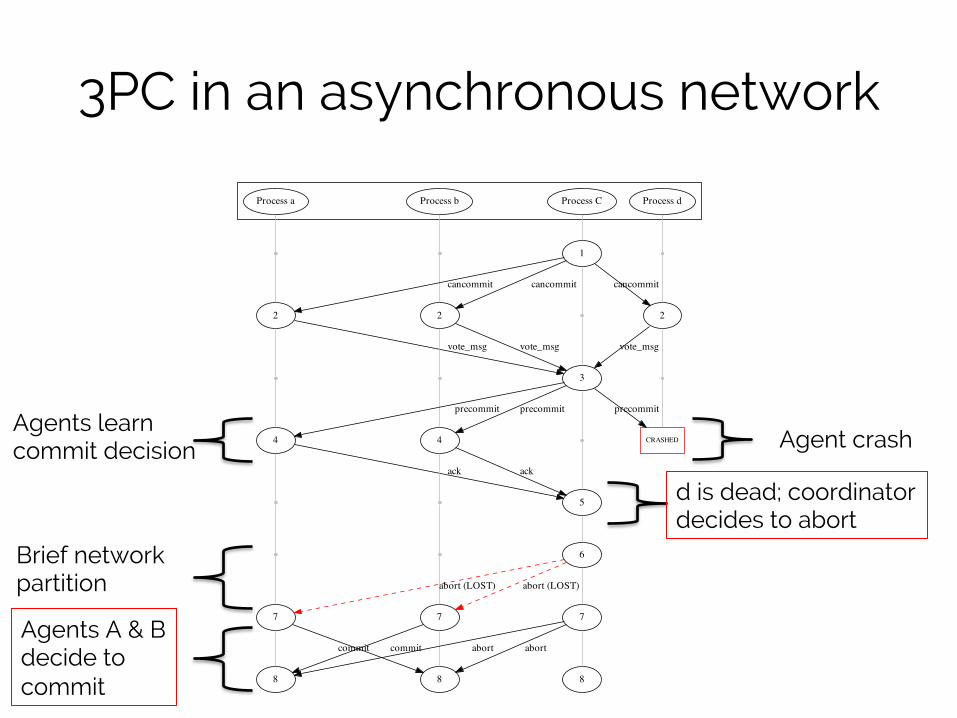
3PC in an asynchronous network
Process a Process b Process C Process d
2
4
7
8
2
4
7
8
1
3
5
6
7
8
2
CRASHED
vote_msg
ack
commit
vote_msg
ack
commit
cancommit cancommit cancommit
precommit precommit precommit
abort (LOST) abort (LOST)
abort abort
vote_msg
Brief network partition
Agent crash Agents learn commit decision
d is dead; coordinator decides to abort
Agents A & B decide to commit