lineage processing over correlated probabilistic databases bhargav kanagal amol deshpande university...
TRANSCRIPT

Lineage Processing over Correlated Probabilistic Databases
Bhargav KanagalAmol Deshpande
University of Maryland
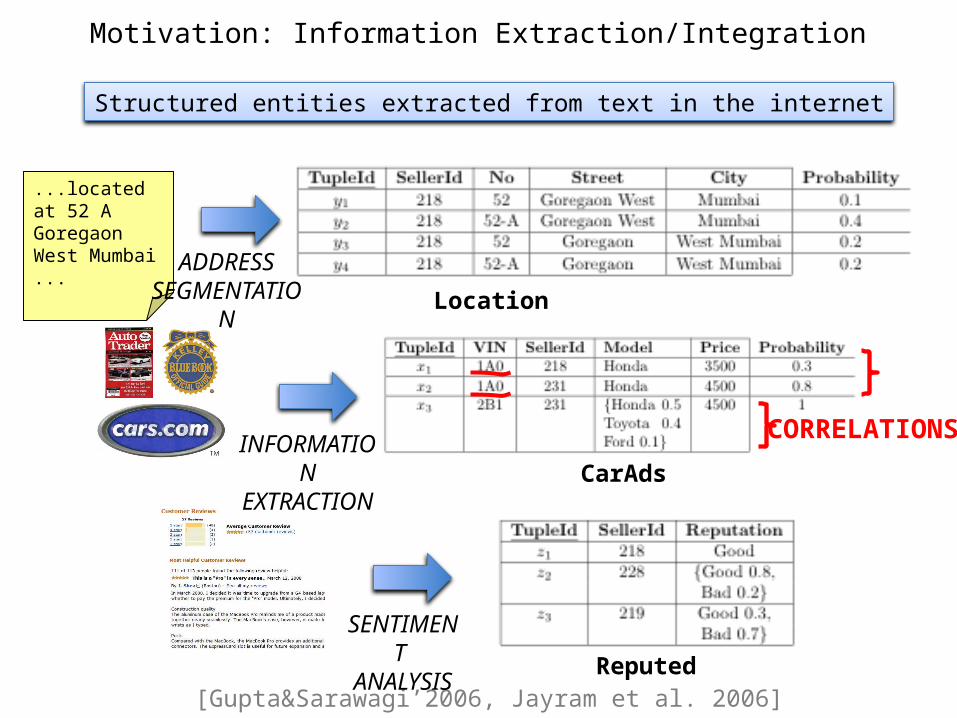
Motivation: Information Extraction/Integration
[Gupta&Sarawagi’2006, Jayram et al. 2006]
Structured entities extracted from text in the internet
Reputed
SENTIMENT ANALYSIS
Location
...located at 52 A Goregaon West Mumbai ...
ADDRESSSEGMENTATION
CarAdsINFORMATIONEXTRACTION
CORRELATIONS

Reputed
SELECT SellerIdFROM Location, CarAds, ReputedWHERE reputation = ‘good’ AND city = `Mumbai’ Location.SellerId = CarAds.SellerId AND CarAds.SellerId = Reputed.SellerId
Why Lineage Processing ?
[Das Sarma et al. 2006]
Location
CarAds
List all “reputed” car sellers in “Mumbai” who offer Honda cars
We need to compute the probabilityof the above boolean formula
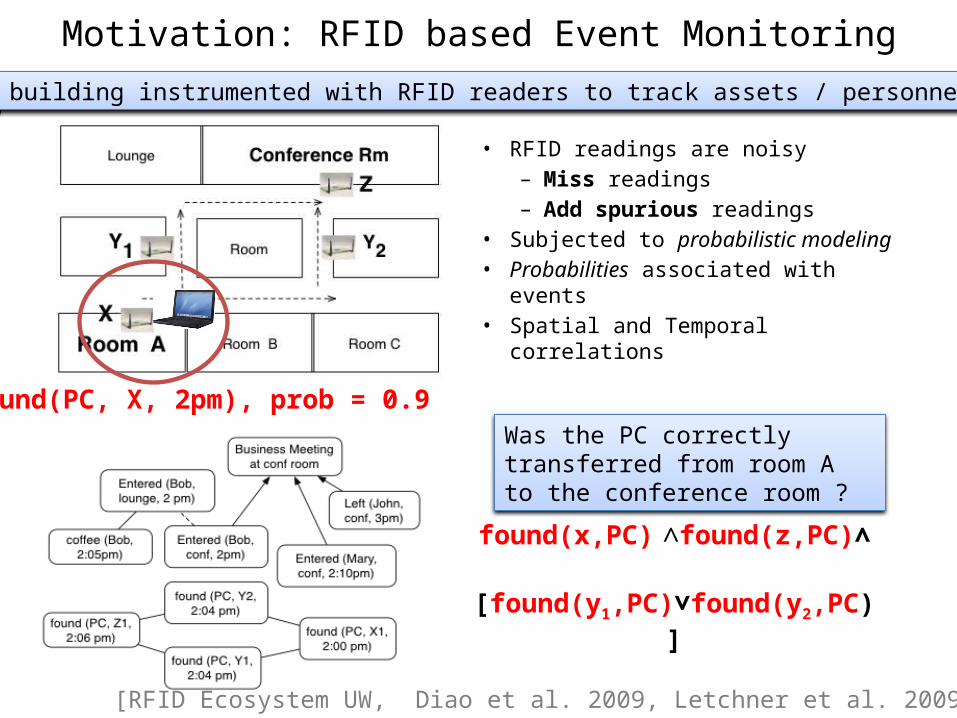
Motivation: RFID based Event Monitoring
[RFID Ecosystem UW, Diao et al. 2009, Letchner et al. 2009, KD 2008]
A building instrumented with RFID readers to track assets / personnel
found(PC, X, 2pm), prob = 0.9
• RFID readings are noisy– Miss readings– Add spurious readings
• Subjected to probabilistic modeling• Probabilities associated with events• Spatial and Temporal correlations
found(x,PC) ∧found(z,PC)∧ [found(y1,PC)∨found(y2,PC)]
Was the PC correctly transferred from room A to the conference room ?
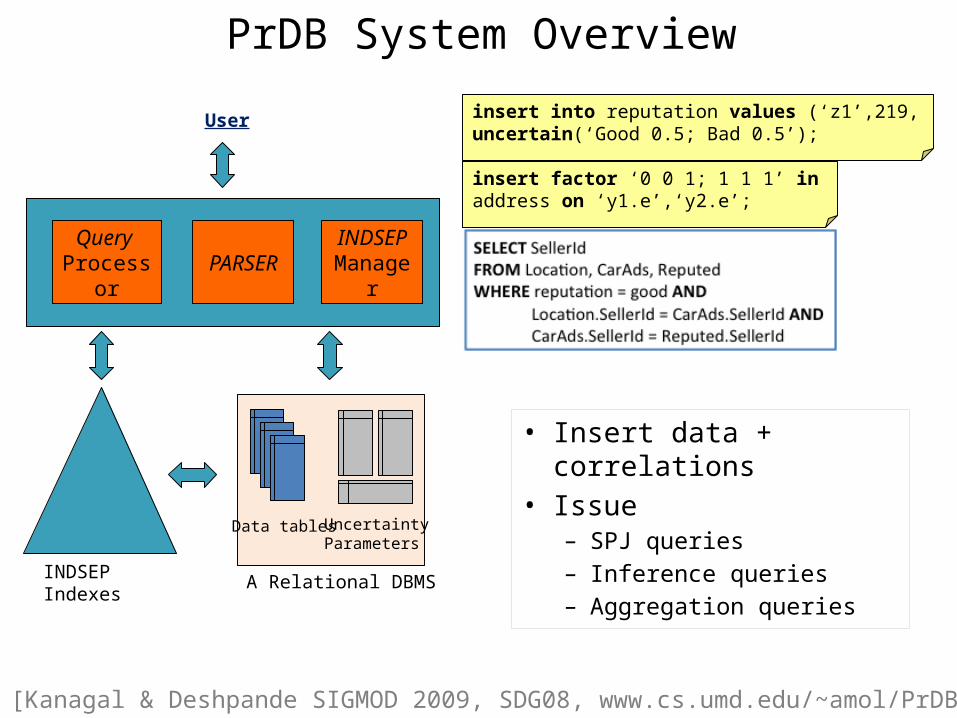
A Relational DBMS
Data tables UncertaintyParameters
INDSEP Indexes
Query Processor PARSER INDSEP
Manager
User insert into reputation values (‘z1’,219, uncertain(‘Good 0.5; Bad 0.5’);
insert factor ‘0 0 1; 1 1 1’ in address on ‘y1.e’,‘y2.e’;
PrDB System Overview
[Kanagal & Deshpande SIGMOD 2009, SDG08, www.cs.umd.edu/~amol/PrDB/]
• Insert data + correlations• Issue
– SPJ queries– Inference queries– Aggregation queries

Outline• Motivation & Problem definition [done]• Background– Probabilistic Databases as Junction trees– Query processing over Junction trees– INDSEP
• Lineage Processing over Junction trees• Lineage Processing using INDSEP• Results

id Y Exists ?1 34 ?
2 33 ?
3 25 ?
.. .. ..
5 11 ?
id Y Exists ?
1 34 a
2 33 b
3 25 c
.. .. ..
5 11 q
Background: ProbDBs as Junction trees
Tuple Uncertainty
Attribute UncertaintyConverted to Tuple Uncertainty
Correlations
Consise encoding of thejoint probability distribution
Query evaluation is performed directly over Junction Trees
Forest of junction trees
Random Variable1 tuple exists0 otherwise
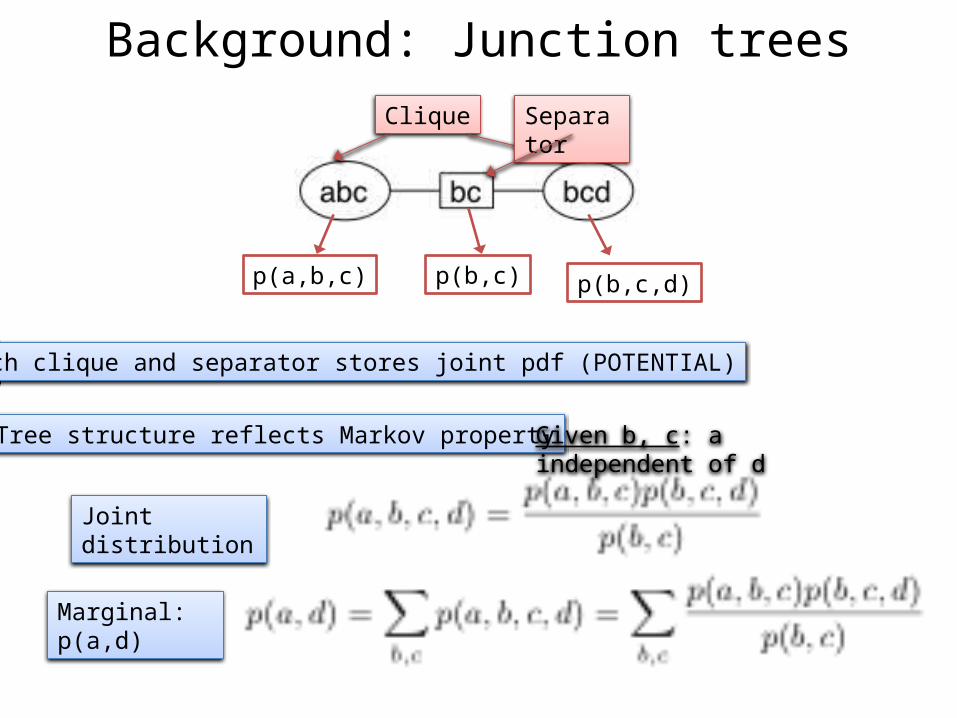
Background: Junction trees
Each clique and separator stores joint pdf (POTENTIAL)
Tree structure reflects Markov property Given b, c: a independent of d
p(a,b,c) p(b,c) p(b,c,d)
Clique Separator
Marginal: p(a,d)
Joint distribution

Marginal Computation
{b, c, n}
Keep query variablesKeep correlationsRemove others
PIVOT
Steiner tree + Send messages toward a given pivot node
For ProbDBs ≈ 1 million tuples, not scalable(1) Span of the query can be very large – almost the
complete database accessed even for a 3 variable query(2) Searching for cliques is expensive: Linear scan over all
the nodes is inefficient
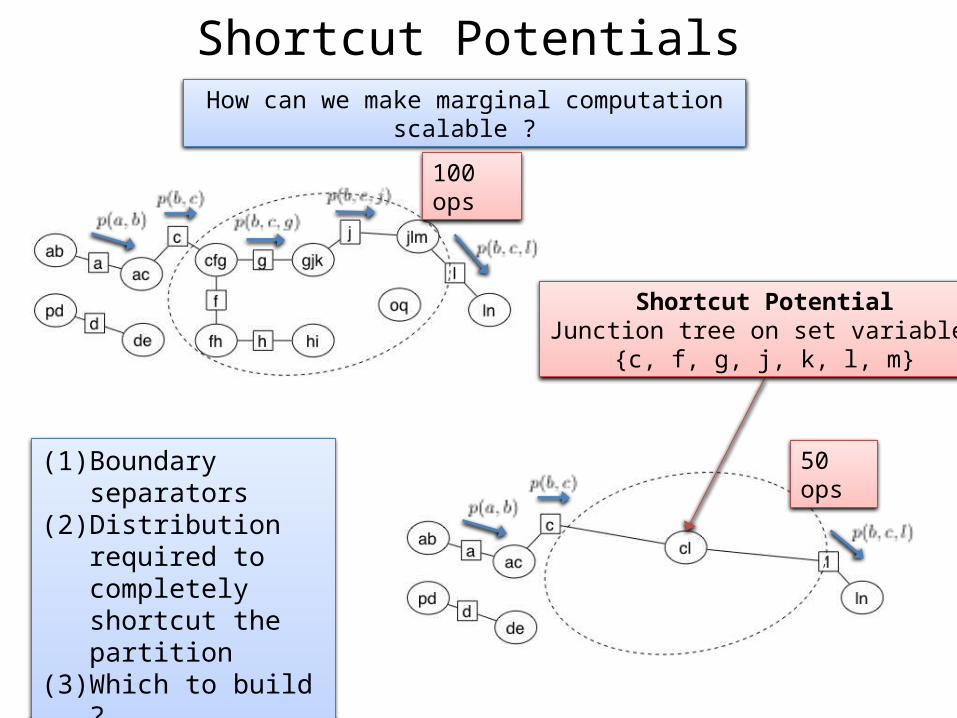
50 ops
Shortcut PotentialsHow can we make marginal computation scalable ?
100 ops
Shortcut PotentialJunction tree on set variables
{c, f, g, j, k, l, m}
(1) Boundary separators(2) Distribution required
to completely shortcut the partition
(3) Which to build ?
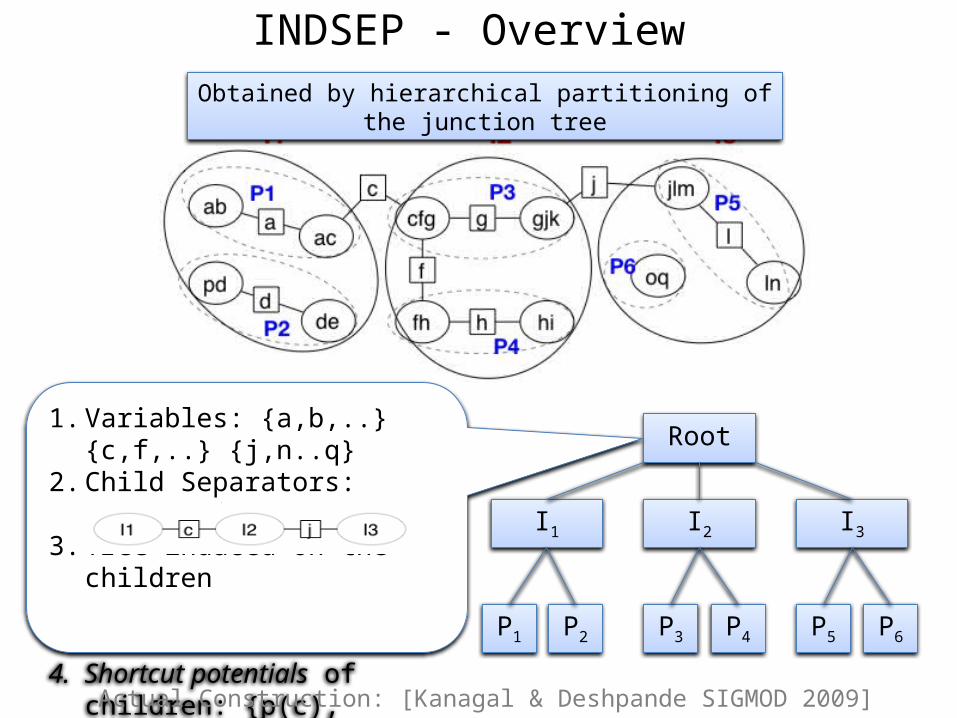
Root
I1 I2 I3
P1 P2 P6P5P4P3
INDSEP - Overview
1. Variables: {a,b,..} {c,f,..} {j,n..q}2. Child Separators: p(c), p(j) 3. Tree induced on the children
4. Shortcut potentials of children: {p(c), p(c,j), p(j)}
Obtained by hierarchical partitioning of the junction tree
Actual Construction: [Kanagal & Deshpande SIGMOD 2009]
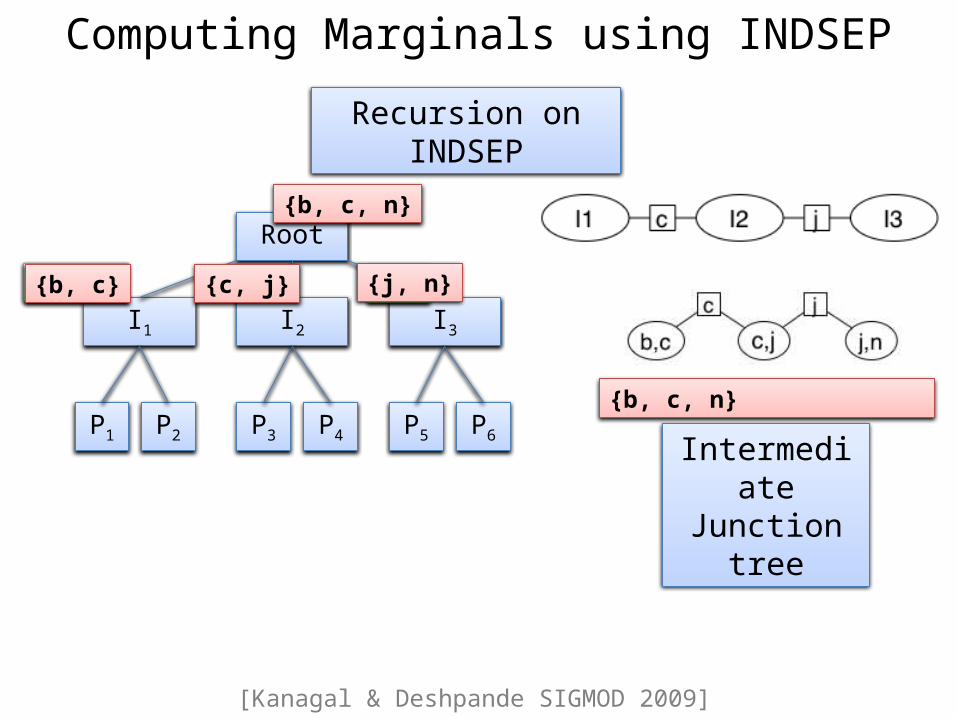
Computing Marginals using INDSEP
Root
I1 I2 I3
P1 P2 P6P5P4P3
{b, c, n}
{b, c} {n}{b, c} {c, j} {j, n}
{b, c, n}
IntermediateJunction tree
[Kanagal & Deshpande SIGMOD 2009]
Recursion on INDSEP

Outline• Motivation & Problem definition [done]• Background [done]– Junction trees & Query processing over junction
trees– INDSEP
• Lineage Processing over Junction trees• Lineage Processing using INDSEP• Results
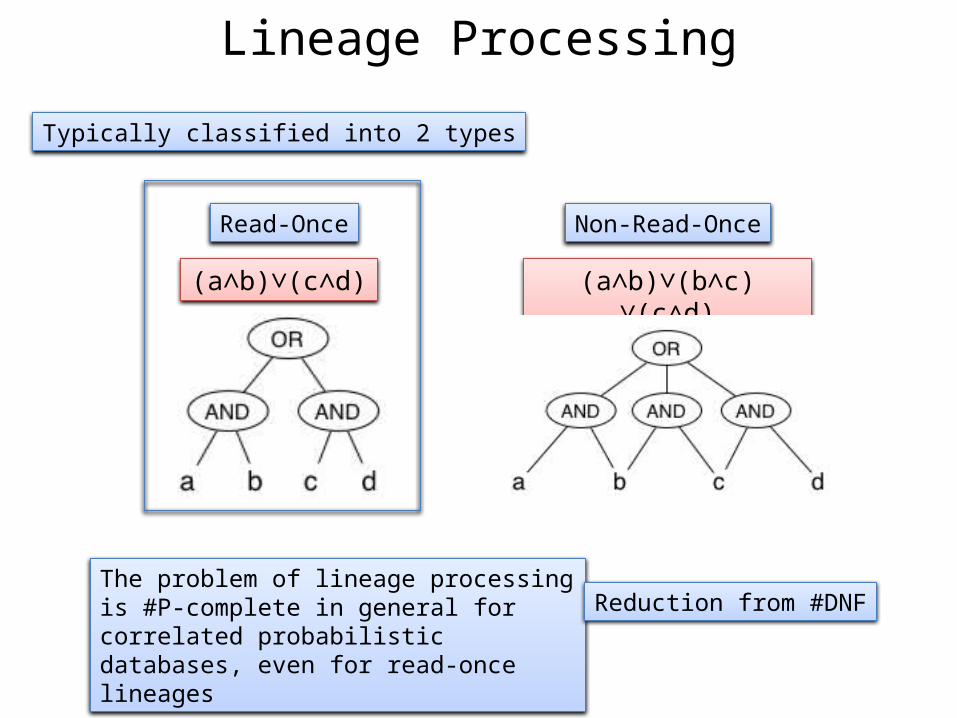
Lineage Processing
Typically classified into 2 types
Read-Once
(a∧b)∨(c∧d)
Non-Read-Once
(a∧b)∨(b∧c) ∨(c∧d)
The problem of lineage processing is #P-complete in general for correlated probabilistic databases, even for read-once lineages
Reduction from #DNF
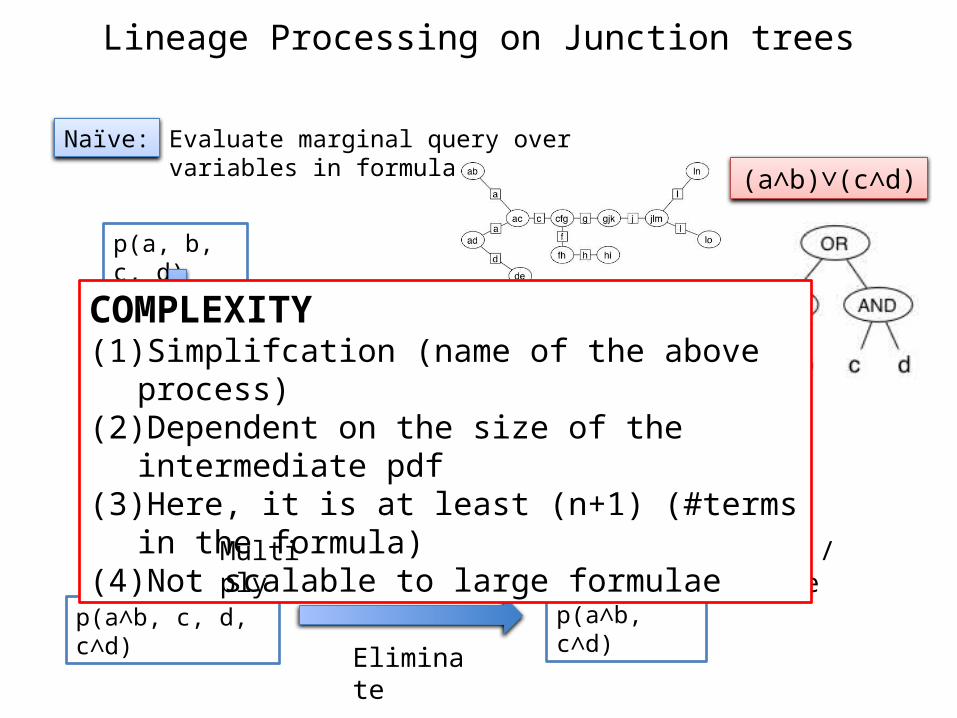
Lineage Processing on Junction trees
Naïve:
(a∧b)∨(c∧d)
p(a, b, c, d)
p(a, b, a∧b, c, d)
p(a∧b, c, d)
p(a∧b, c, d, c∧d) p(a∧b, c∧d)
p((a∧b)∨(c∧d))
Multiply with p(a∧b|a,b)
Eliminate a,b
Multiply / Eliminate
Evaluate marginal query over variables in formula
COMPLEXITY(1) Simplifcation (name of the above process)(2) Dependent on the size of the intermediate pdf(3) Here, it is at least (n+1) (#terms in the formula)(4) Not scalable to large formulae
Multiply
Eliminate
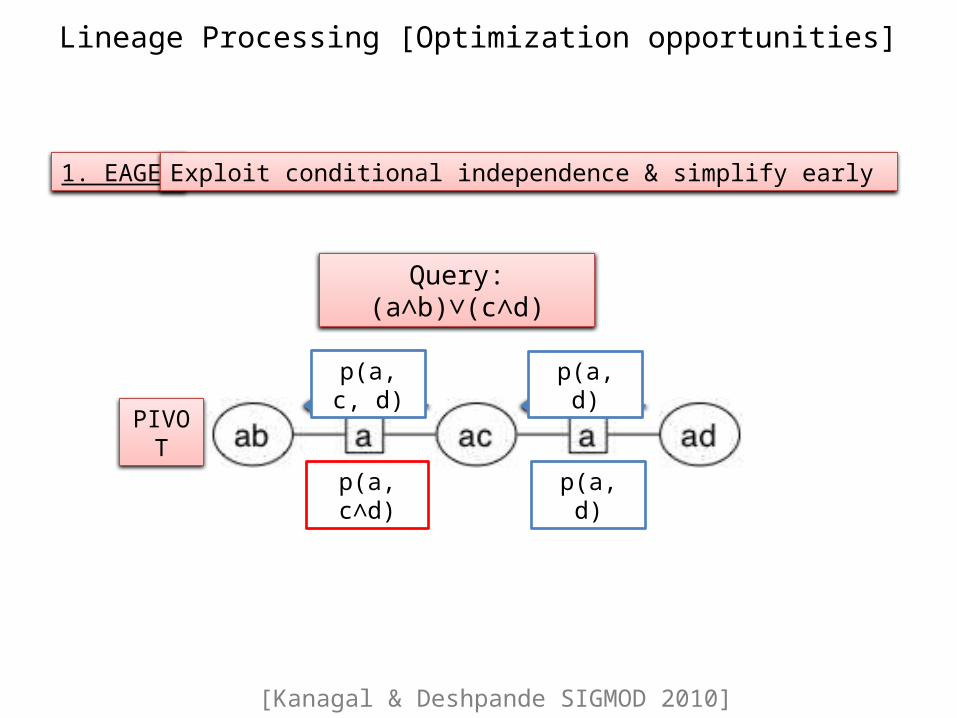
Lineage Processing [Optimization opportunities]
1. EAGER Exploit conditional independence & simplify early
p(a, c, d)
p(a, c∧d)
PIVOT
Query: (a∧b)∨(c∧d)
[Kanagal & Deshpande SIGMOD 2010]
p(a, d)
p(a, d)
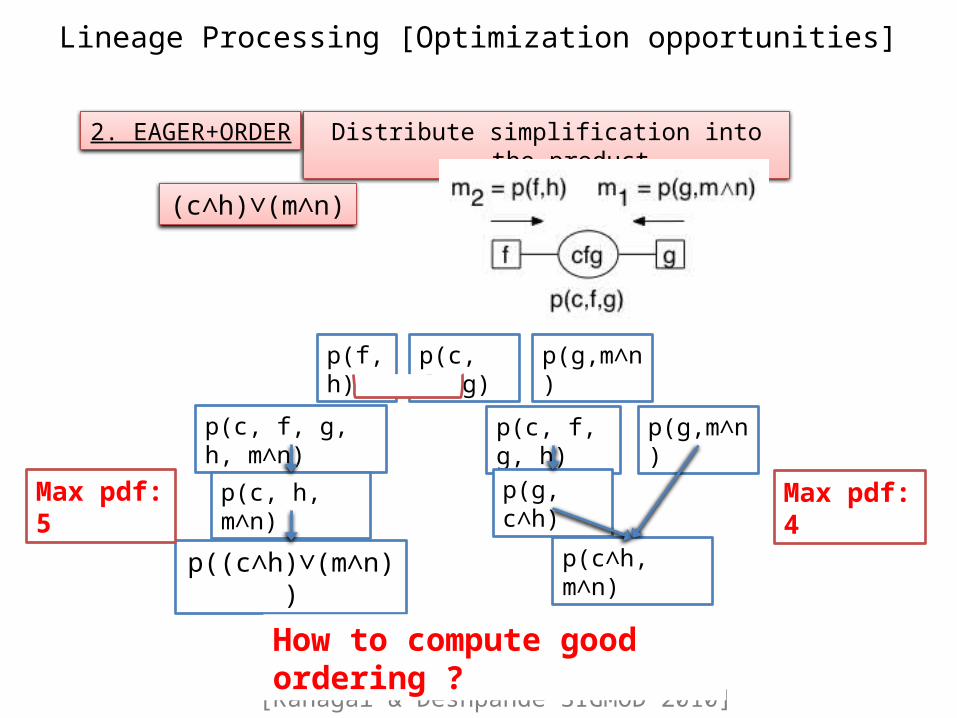
Lineage Processing [Optimization opportunities]
[Kanagal & Deshpande SIGMOD 2010]
p(c, f, g, h, m∧n)
p(c, h, m∧n)
p((c∧h)∨(m∧n))
p(f, h) p(g,m∧n)p(c, f, g)
p(c, f, g, h) p(g,m∧n)
p(g, c∧h)
p(c∧h, m∧n)
Max pdf: 5
Distribute simplification into the product2. EAGER+ORDER
(c∧h)∨(m∧n)
Max pdf: 4
How to compute good ordering ?
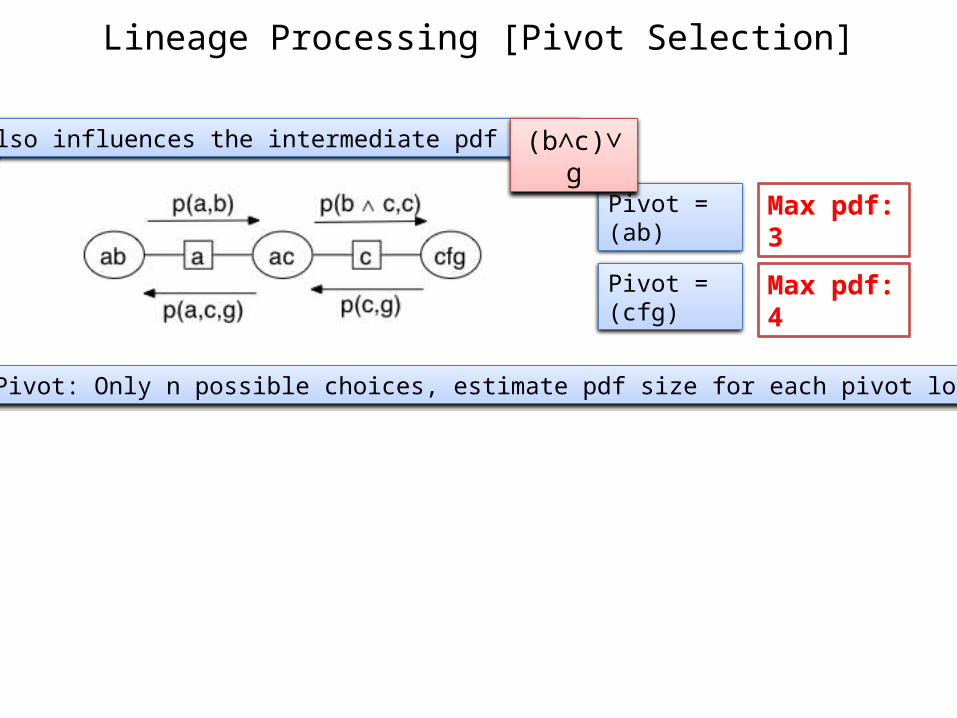
Lineage Processing [Pivot Selection]
Also influences the intermediate pdf size
Optimal Pivot: Only n possible choices, estimate pdf size for each pivot location
Pivot = (ab)
Pivot = (cfg)
(b∧c)∨g
Max pdf: 3
Max pdf: 4

Outline• Motivation & Problem definition [done]• Background [done]– Junction trees & Query processing over junction
trees– INDSEP
• Lineage Processing over Junction trees [done]• Lineage Processing using INDSEP• Results
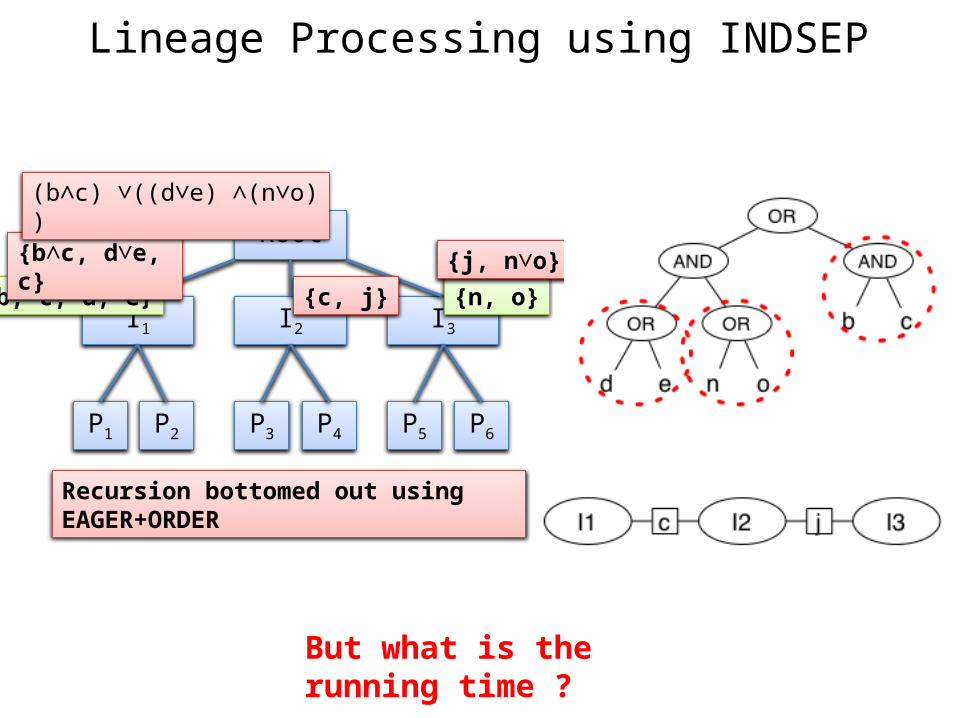
Lineage Processing using INDSEP
Root
I1 I2 I3
P1 P2 P6P5P4P3
{b, c, d, e} {n, o}{j, n∨o}{b∧c, d∨e, c}
{c, j}
Recursion bottomed out using EAGER+ORDER
(b∧c) ∨((d∨e) ∧(n∨o) )
But what is the running time ?
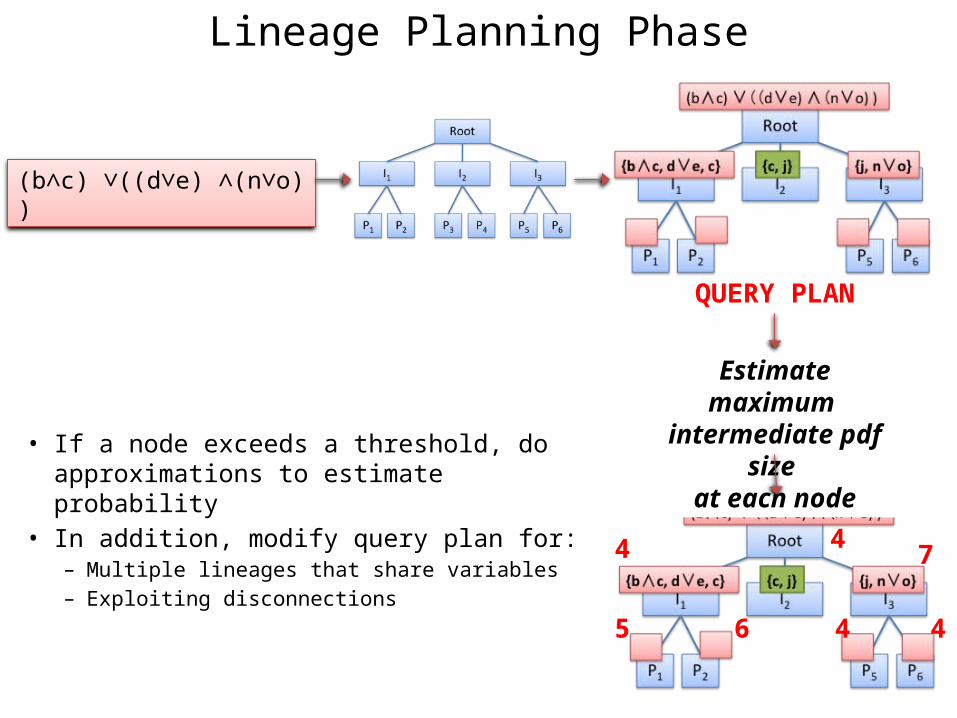
Lineage Planning Phase
(b∧c) ∨((d∨e) ∧(n∨o) )
QUERY PLAN
Estimate maximum intermediate pdf size
at each node
4
5 6 4 4
74
• If a node exceeds a threshold, do approximations to estimate probability
• In addition, modify query plan for:– Multiple lineages that share variables– Exploiting disconnections
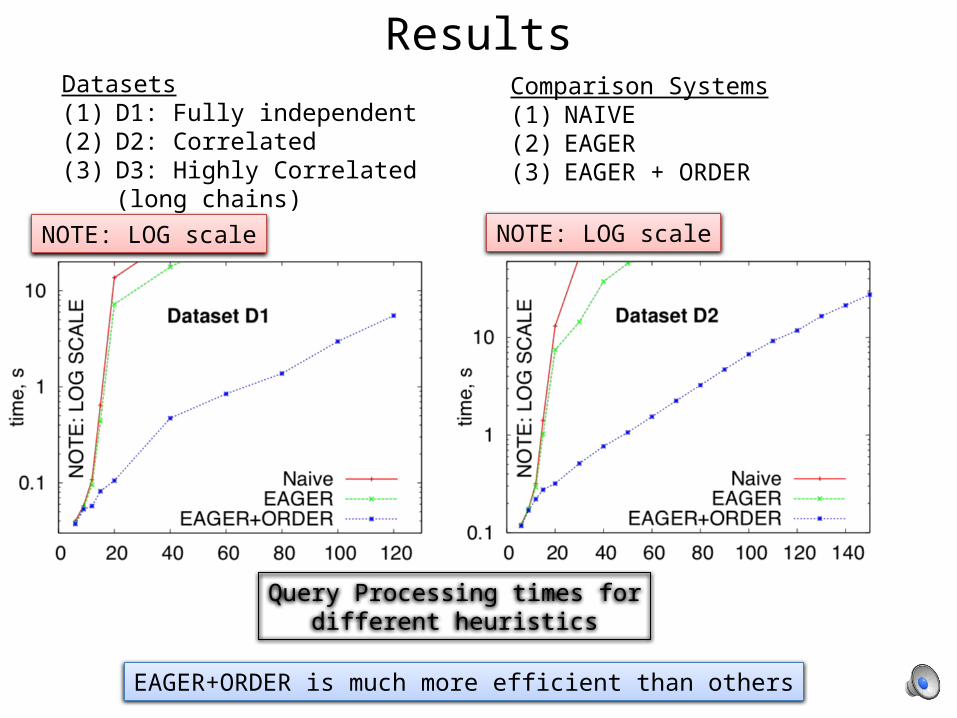
Results
Query Processing times fordifferent heuristics
Datasets(1) D1: Fully independent(2) D2: Correlated(3) D3: Highly Correlated (long chains)
NOTE: LOG scale NOTE: LOG scale
Comparison Systems(1) NAIVE(2) EAGER(3) EAGER + ORDER
EAGER+ORDER is much more efficient than others
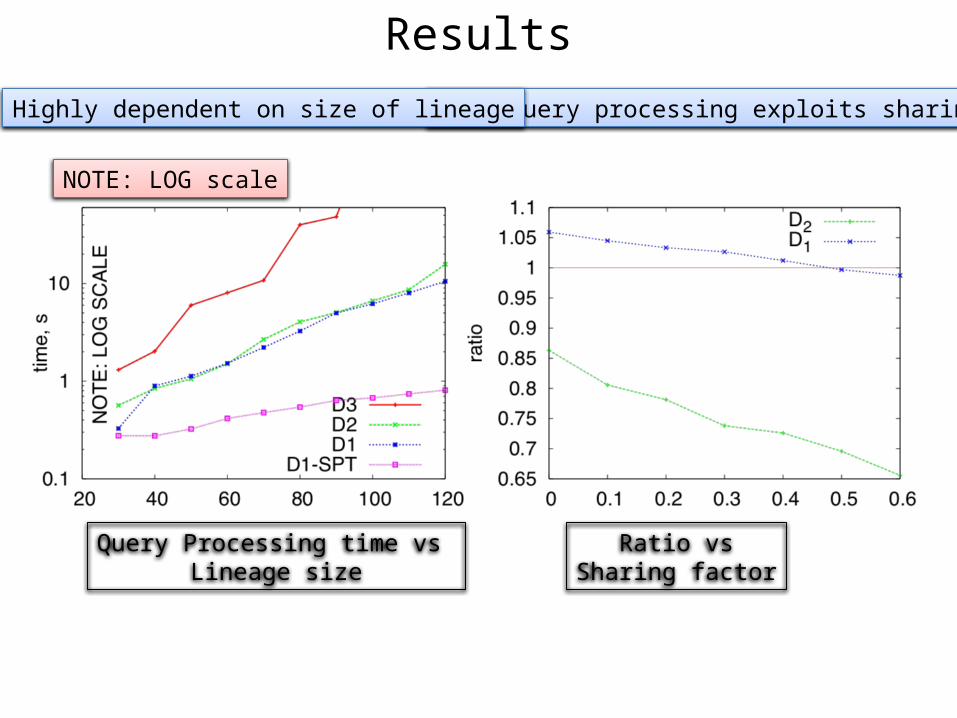
Results
Query Processing time vs Lineage size
NOTE: LOG scale
Ratio vsSharing factor
Multiquery processing exploits sharingHighly dependent on size of lineage

Conclusions
• Proposed a scalable system for evaluating boolean formula queries over correlated probabilistic databases
• Future– Plan to further the approximation approaches– Envelopes of boolean formulas for upper and
lower bounds
Thank you
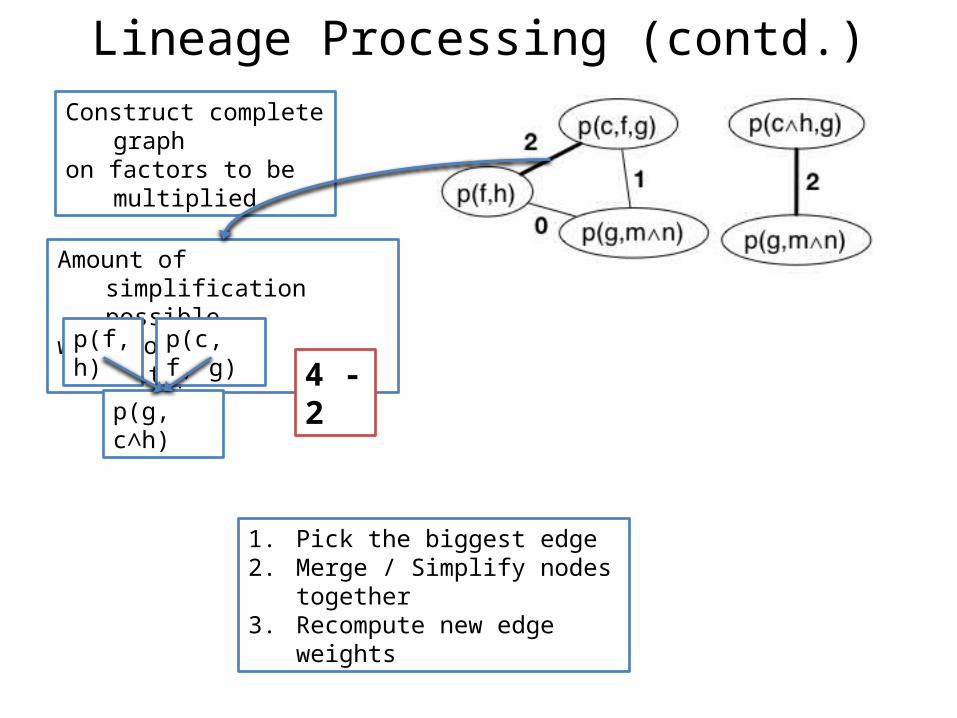
Lineage Processing (contd.)
Amount of simplification possiblewhen nodes are multiplied
Construct complete graphon factors to be multiplied
p(g, c∧h)
p(f, h) p(c, f, g)
4 - 2
1. Pick the biggest edge2. Merge / Simplify nodes together3. Recompute new edge weights
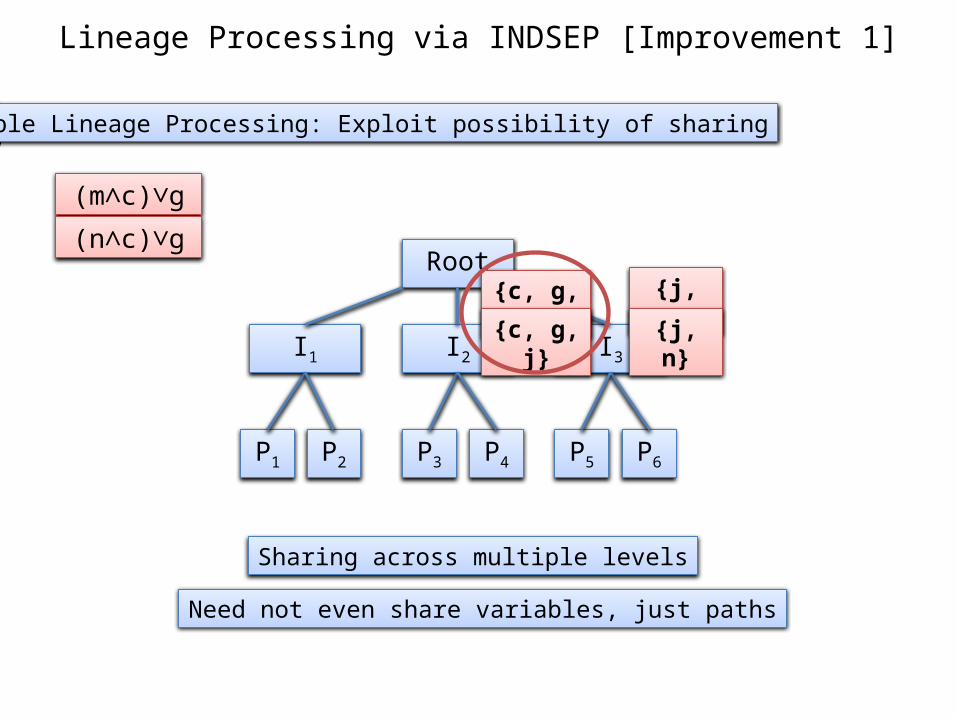
Lineage Processing via INDSEP [Improvement 1]
Multiple Lineage Processing: Exploit possibility of sharing
Root
I1 I2 I3
P1 P2 P6P5P4P3
{c, g, j} {j, m}
{c, g, j} {j, n}
(m∧c)∨g
(n∧c)∨g
Sharing across multiple levels
Need not even share variables, just paths
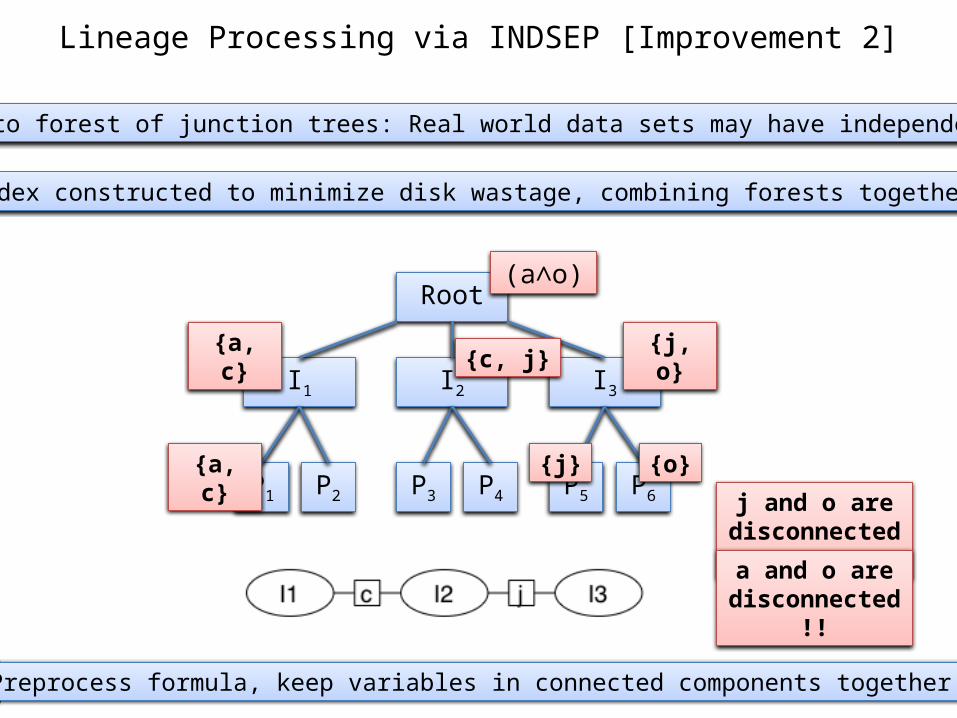
Lineage Processing via INDSEP [Improvement 2]
Extend to forest of junction trees: Real world data sets may have independences
Root
I1 I2 I3
P1 P2 P6P5P4P3
Index constructed to minimize disk wastage, combining forests together
(a∧o)
{a, c} {j, o}
{a, c}
{c, j}
{j} {o}
j and o are disconnected !!
a and o are disconnected !!
Preprocess formula, keep variables in connected components together
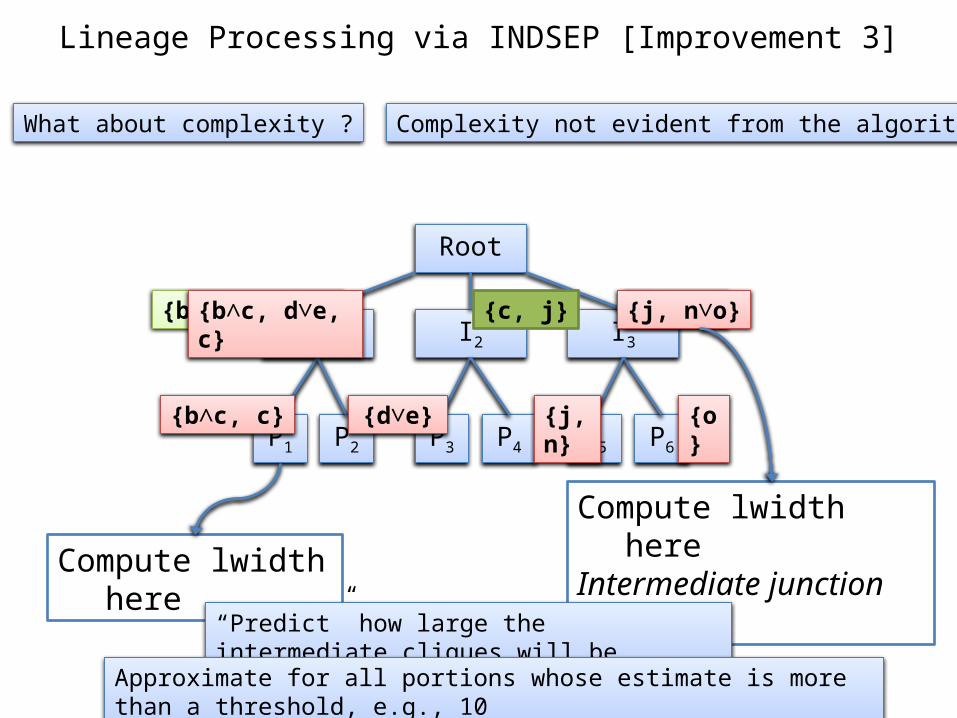
Lineage Processing via INDSEP [Improvement 3]
What about complexity ? Complexity not evident from the algorithm
Root
I1 I2 I3
P1 P2 P6P5P4P3
{b, c, d, e} {n, o}{j, n∨o}{b∧c, d∨e, c} {c, j}
{d∨e}{b∧c, c} {j, n} {o}
Compute lwidth here
Compute lwidth hereIntermediate junction tree
“Predict” how large the intermediate cliques will be
Approximate for all portions whose estimate is more than a threshold, e.g., 10