lingpipe book 0.2
TRANSCRIPT

Text Analysis
with LingPipe 4.0Volume I


Text Analysiswith LingPipe 4
Volume I
Bob Carpenter
LingPipe PublishingNew York
2010

© LingPipe Publishing
Pending: Library of Congress Cataloging-in-Publication Data
Carpenter, Bob.Text Analysis with LingPipe 4.0 / Bob Carpenter
p. cm.Includes bibliographical references and index.ISBN X-XXX-XXXXX-X (pbk. : alk. paper)
1. Natural Language Processing 2. Java (computer program language) I. Carpenter, Bob II. Title
QAXXX.XXXXXXXX 2010
XXX/.XX’X-xxXX XXXXXXXX
Text printed on demand in the United States of America.
All rights reserved. This book, or parts thereof, may not be reproduced in any form without permis-
sion of the publishers.

Contents
1 Getting Started 11.1 Tools of the Trade . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.1 Unix Shell Tools . . . . . . . . . . . . . . . . . . . . . . . . . 11.1.2 Version Control . . . . . . . . . . . . . . . . . . . . . . . . . 21.1.3 Text Editors . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.1.4 Java Standard Edition 6 . . . . . . . . . . . . . . . . . . . . . 41.1.5 Ant . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.1.6 Integrated Development Environment . . . . . . . . . . . . 61.1.7 Statistical Computing Environment . . . . . . . . . . . . . 71.1.8 Full LingPipe Distribution . . . . . . . . . . . . . . . . . . . 81.1.9 Book Source and Libraries . . . . . . . . . . . . . . . . . . . 8
1.2 Hello World Example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.2.1 Running the Example . . . . . . . . . . . . . . . . . . . . . . 91.2.2 Hello with Arguments . . . . . . . . . . . . . . . . . . . . . 101.2.3 Code Walkthrough . . . . . . . . . . . . . . . . . . . . . . . . 10
1.3 Introduction to Ant . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111.3.1 XML Declaration . . . . . . . . . . . . . . . . . . . . . . . . . 111.3.2 Top-Level Project Element . . . . . . . . . . . . . . . . . . . 121.3.3 Ant Properties . . . . . . . . . . . . . . . . . . . . . . . . . . 121.3.4 Ant Targets . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131.3.5 Property Files . . . . . . . . . . . . . . . . . . . . . . . . . . . 161.3.6 Precedence of Properties . . . . . . . . . . . . . . . . . . . . 17
2 Characters and Strings 192.1 Character Encodings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.1.1 What is a Character? . . . . . . . . . . . . . . . . . . . . . . 192.1.2 Coded Sets and Encoding Schemes . . . . . . . . . . . . . . 202.1.3 Legacy Character Encodings . . . . . . . . . . . . . . . . . . 212.1.4 Unicode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.2 Encoding Java Programs . . . . . . . . . . . . . . . . . . . . . . . . . . . 272.2.1 Unicode Characters in Java Programs . . . . . . . . . . . . 27
2.3 char Primitive Type . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 282.4 Character Class . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.4.1 Static Utilities . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.4.2 Demo: Exploring Unicode Types . . . . . . . . . . . . . . . 31
2.5 CharSequence Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . 332.6 String Class . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
v

2.6.1 Constructing a String . . . . . . . . . . . . . . . . . . . . . . 352.6.2 String Literals . . . . . . . . . . . . . . . . . . . . . . . . . . . 362.6.3 Contents of a String . . . . . . . . . . . . . . . . . . . . . . . 362.6.4 String Equality and Comparison . . . . . . . . . . . . . . . 372.6.5 Hash Codes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 372.6.6 Substrings and Subsequences . . . . . . . . . . . . . . . . . 372.6.7 Simple Pattern Matching . . . . . . . . . . . . . . . . . . . . 382.6.8 Manipulating Strings . . . . . . . . . . . . . . . . . . . . . . 382.6.9 Unicode Code Points . . . . . . . . . . . . . . . . . . . . . . 382.6.10 Testing String Validity . . . . . . . . . . . . . . . . . . . . . 382.6.11 Interning Canonical Representations . . . . . . . . . . . . 392.6.12 Utility Methods . . . . . . . . . . . . . . . . . . . . . . . . . . 392.6.13 Example Conversions . . . . . . . . . . . . . . . . . . . . . . 39
2.7 StringBuilder Class . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 412.7.1 Unicode Support . . . . . . . . . . . . . . . . . . . . . . . . . 422.7.2 Modifying the Contents . . . . . . . . . . . . . . . . . . . . 422.7.3 Reversing Strings . . . . . . . . . . . . . . . . . . . . . . . . 422.7.4 Chaining and String Concatenation . . . . . . . . . . . . . 422.7.5 Equality and Hash Codes . . . . . . . . . . . . . . . . . . . . 432.7.6 String Buffers . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
2.8 CharBuffer Class . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 432.8.1 Basics of Buffer Positions . . . . . . . . . . . . . . . . . . . 432.8.2 Equality and Comparison . . . . . . . . . . . . . . . . . . . 442.8.3 Creating a CharBuffer . . . . . . . . . . . . . . . . . . . . . 442.8.4 Absolute Sets and Gets . . . . . . . . . . . . . . . . . . . . . 442.8.5 Relative Sets and Gets . . . . . . . . . . . . . . . . . . . . . 452.8.6 Thread Safety . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
2.9 Charset Class . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 452.9.1 Creating a Charset . . . . . . . . . . . . . . . . . . . . . . . 462.9.2 Decoding and Encoding with a Charset . . . . . . . . . . 462.9.3 Supported Encodings in Java . . . . . . . . . . . . . . . . . 47
2.10 International Components for Unicode . . . . . . . . . . . . . . . . . . 482.10.1 Unicode Normalization . . . . . . . . . . . . . . . . . . . . . 482.10.2 Encoding Detection . . . . . . . . . . . . . . . . . . . . . . . 492.10.3 General Transliterations . . . . . . . . . . . . . . . . . . . . 51
3 Regular Expressions 553.1 Matching and Finding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.1.1 Matching Entire Strings . . . . . . . . . . . . . . . . . . . . . 553.1.2 Finding Matching Substrings . . . . . . . . . . . . . . . . . 56
3.2 Character Regexes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 573.2.1 Characters as Regexes . . . . . . . . . . . . . . . . . . . . . 573.2.2 Unicode Escapes . . . . . . . . . . . . . . . . . . . . . . . . . 573.2.3 Other Escapes . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3.3 Character Classes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 583.3.1 WildCards . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 593.3.2 Unicode Classes . . . . . . . . . . . . . . . . . . . . . . . . . 59

3.3.3 ASCII Classes . . . . . . . . . . . . . . . . . . . . . . . . . . . 593.3.4 Compound Character Classes . . . . . . . . . . . . . . . . . 60
3.4 Concatenation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 613.4.1 Empty Regex . . . . . . . . . . . . . . . . . . . . . . . . . . . 613.4.2 Concatenation . . . . . . . . . . . . . . . . . . . . . . . . . . 61
3.5 Disjunction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 623.6 Greedy Quantifiers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
3.6.1 Optionality . . . . . . . . . . . . . . . . . . . . . . . . . . . . 633.6.2 Kleene Star . . . . . . . . . . . . . . . . . . . . . . . . . . . . 633.6.3 Kleene Plus . . . . . . . . . . . . . . . . . . . . . . . . . . . . 643.6.4 Match Count Ranges . . . . . . . . . . . . . . . . . . . . . . 65
3.7 Reluctant Quantifiers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 653.8 Possessive Quantifiers . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
3.8.1 Independent Group Possessive Marker . . . . . . . . . . . 663.9 Non-Capturing Regexes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
3.9.1 Boundary Matchers . . . . . . . . . . . . . . . . . . . . . . . 673.9.2 Positive and Negative Lookahead . . . . . . . . . . . . . . . 683.9.3 Positive and Negative Lookbehind . . . . . . . . . . . . . . 683.9.4 Line Terminators and Unix Lines . . . . . . . . . . . . . . . 68
3.10 Parentheses for Grouping . . . . . . . . . . . . . . . . . . . . . . . . . . 693.10.1 Non-Capturing Group . . . . . . . . . . . . . . . . . . . . . . 70
3.11 Back References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 703.12 Pattern Match Flags . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 703.13 Pattern Construction Exceptions . . . . . . . . . . . . . . . . . . . . . . 723.14 Find-and-Replace Operations . . . . . . . . . . . . . . . . . . . . . . . . 723.15 String Regex Utilities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 733.16 Thread Safety, Serialization, and Reuse . . . . . . . . . . . . . . . . . . 73
3.16.1 Thread Safety . . . . . . . . . . . . . . . . . . . . . . . . . . . 733.16.2 Reusing Matchers . . . . . . . . . . . . . . . . . . . . . . . . 733.16.3 Serialization . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
4 Input and Output 754.1 Files . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
4.1.1 Relative vs. Absolute Paths . . . . . . . . . . . . . . . . . . 754.1.2 Windows vs. UNIX File Conventions . . . . . . . . . . . . . 764.1.3 Constructing a File . . . . . . . . . . . . . . . . . . . . . . . 774.1.4 Getting a File’s Canonical Path . . . . . . . . . . . . . . . . 774.1.5 Exploring File Properties . . . . . . . . . . . . . . . . . . . . 774.1.6 Listing the Files in a Directory . . . . . . . . . . . . . . . . 784.1.7 Exploring Partitions . . . . . . . . . . . . . . . . . . . . . . . 794.1.8 Comparison, Equality, and Hash Codes . . . . . . . . . . . 794.1.9 Example Program Listing File Properties . . . . . . . . . . 794.1.10 Creating, Deleting, and Modifying Files and Directories . 804.1.11 Temporary Files . . . . . . . . . . . . . . . . . . . . . . . . . 80
4.2 I/O Exceptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 814.2.1 Catching Subclass Exceptions . . . . . . . . . . . . . . . . . 81
4.3 Security and Security Exceptions . . . . . . . . . . . . . . . . . . . . . . 82

4.4 Input Streams . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 824.4.1 Single Byte Reads . . . . . . . . . . . . . . . . . . . . . . . . 824.4.2 Byte Array Reads . . . . . . . . . . . . . . . . . . . . . . . . . 824.4.3 Available Bytes . . . . . . . . . . . . . . . . . . . . . . . . . . 824.4.4 Mark and Reset . . . . . . . . . . . . . . . . . . . . . . . . . . 834.4.5 Skipping . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
4.5 Output Streams . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 834.5.1 Single Byte Writes . . . . . . . . . . . . . . . . . . . . . . . . 834.5.2 Byte Array Writes . . . . . . . . . . . . . . . . . . . . . . . . 834.5.3 Flushing Writes . . . . . . . . . . . . . . . . . . . . . . . . . . 84
4.6 Closing Streams . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 844.6.1 The Closeable Interface . . . . . . . . . . . . . . . . . . . . 844.6.2 LingPipe Quiet Close Utility . . . . . . . . . . . . . . . . . . 85
4.7 Readers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 854.7.1 The Readable Interface . . . . . . . . . . . . . . . . . . . . 85
4.8 Writers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 864.8.1 The Appendable Interface . . . . . . . . . . . . . . . . . . . 86
4.9 Converting Byte Streams to Characters . . . . . . . . . . . . . . . . . . 864.9.1 The InputStreamReader Class . . . . . . . . . . . . . . . . 864.9.2 The OutputStreamWriter Class . . . . . . . . . . . . . . . 874.9.3 Illegal Sequences . . . . . . . . . . . . . . . . . . . . . . . . . 87
4.10 File Input and Output Streams . . . . . . . . . . . . . . . . . . . . . . . 874.10.1 Constructing File Streams . . . . . . . . . . . . . . . . . . . 874.10.2 Finalizers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 884.10.3 File Descriptors . . . . . . . . . . . . . . . . . . . . . . . . . 884.10.4 Examples of File Streams . . . . . . . . . . . . . . . . . . . . 88
4.11 Buffered Streams . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 904.11.1 Constructing Buffered Streams . . . . . . . . . . . . . . . . 904.11.2 Sizing the Buffer . . . . . . . . . . . . . . . . . . . . . . . . . 914.11.3 Closing a Buffered Stream . . . . . . . . . . . . . . . . . . . 914.11.4 Built-in Buffering . . . . . . . . . . . . . . . . . . . . . . . . . 914.11.5 Line-Based Reads . . . . . . . . . . . . . . . . . . . . . . . . 92
4.12 Array-Backed Input and Output Streams . . . . . . . . . . . . . . . . . 924.12.1 The ByteArrayInputStream Class . . . . . . . . . . . . . 924.12.2 The CharArrayReader Class . . . . . . . . . . . . . . . . . 924.12.3 The ByteArrayOutputStream Class . . . . . . . . . . . . 924.12.4 The CharArrayWriter Class . . . . . . . . . . . . . . . . . 93
4.13 Compressed Streams . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 934.13.1 GZIP Input and Output Streams . . . . . . . . . . . . . . . 934.13.2 ZIP Input and Output Streams . . . . . . . . . . . . . . . . 94
4.14 Tape Archive (Tar) Streams . . . . . . . . . . . . . . . . . . . . . . . . . 974.14.1 Reading Tar Streams . . . . . . . . . . . . . . . . . . . . . . 97
4.15 Accessing Resources from the Classpath . . . . . . . . . . . . . . . . . 994.15.1 Adding Resources to a Jar . . . . . . . . . . . . . . . . . . . 1004.15.2 Resources as Input Streams . . . . . . . . . . . . . . . . . . 100
4.16 Print Streams and Formatted Output . . . . . . . . . . . . . . . . . . . 1014.16.1 Constructing a Print Stream . . . . . . . . . . . . . . . . . . 102

4.16.2 Exception Buffering . . . . . . . . . . . . . . . . . . . . . . . 1024.16.3 Formatted Output . . . . . . . . . . . . . . . . . . . . . . . . 102
4.17 Standard Input, Output, and Error Streams . . . . . . . . . . . . . . . . 1034.17.1 Accessing the Streams . . . . . . . . . . . . . . . . . . . . . 1034.17.2 Redirecting the Streams . . . . . . . . . . . . . . . . . . . . 1034.17.3 UNIX-like Commands . . . . . . . . . . . . . . . . . . . . . . 104
4.18 URIs, URLs and URNs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1044.18.1 Uniform Resource Names . . . . . . . . . . . . . . . . . . . 1044.18.2 Uniform Resource Locators . . . . . . . . . . . . . . . . . . 1054.18.3 URIs and URLs in Java . . . . . . . . . . . . . . . . . . . . . 1054.18.4 Reading from URLs . . . . . . . . . . . . . . . . . . . . . . . 1064.18.5 URL Connections . . . . . . . . . . . . . . . . . . . . . . . . . 107
4.19 The Input Source Abstraction . . . . . . . . . . . . . . . . . . . . . . . . 1074.20 File Channels and Memory Mapped Files . . . . . . . . . . . . . . . . . 1084.21 Object and Data I/O . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
4.21.1 Example of Object and Data I/O . . . . . . . . . . . . . . . 1094.21.2 The Serializable Interface . . . . . . . . . . . . . . . . . 1104.21.3 The Serialization Proxy Pattern . . . . . . . . . . . . . . . . 111
4.22 Lingpipe I/O Utilities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1134.22.1 The FileLineReader Class . . . . . . . . . . . . . . . . . . 1134.22.2 The Files Utility Class . . . . . . . . . . . . . . . . . . . . . 1144.22.3 The Streams Utility Class . . . . . . . . . . . . . . . . . . . 1154.22.4 The Compilable Interface . . . . . . . . . . . . . . . . . . . 1164.22.5 The AbstractExternalizable Class . . . . . . . . . . . . 116
5 Handlers, Parsers, and Corpora 1215.1 Handlers and Object Handlers . . . . . . . . . . . . . . . . . . . . . . . 121
5.1.1 Handlers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1215.1.2 Object Handlers . . . . . . . . . . . . . . . . . . . . . . . . . 1215.1.3 Demo: Character Counting Handler . . . . . . . . . . . . . 122
5.2 Parsers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1225.2.1 The Parser Abstract Base Class . . . . . . . . . . . . . . . 1235.2.2 Abstract Base Helper Parsers . . . . . . . . . . . . . . . . . 1235.2.3 Line-Based Tagging Parser . . . . . . . . . . . . . . . . . . . 1245.2.4 XML Parser . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1245.2.5 Demo: MedPost Part-of-Speech Tagging Parser . . . . . . 124
5.3 Corpora . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1275.3.1 The Corpus Class . . . . . . . . . . . . . . . . . . . . . . . . 1275.3.2 Demo: 20 Newsgroups Corpus . . . . . . . . . . . . . . . . 1275.3.3 The ListCorpus Class . . . . . . . . . . . . . . . . . . . . . 1305.3.4 The DiskCorpus Class . . . . . . . . . . . . . . . . . . . . . 131
5.4 Cross Validation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1315.4.1 Permuting the Corpus . . . . . . . . . . . . . . . . . . . . . 1325.4.2 The CrossValidatingObjectCorpus Class . . . . . . . . 132
6 Classifiers and Evaluation 1356.1 What is a Classifier? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135

6.1.1 Exclusive and Exhaustive Categories . . . . . . . . . . . . . 1356.1.2 First-Best, Ranked and Probabilistic Results . . . . . . . . 1366.1.3 Ordinals, Counts, and Scalars . . . . . . . . . . . . . . . . . 1376.1.4 Reductions to Classification Problems . . . . . . . . . . . 137
6.2 Gold Standards, Annotation, and Reference Data . . . . . . . . . . . . 1386.2.1 Evaluating Annotators . . . . . . . . . . . . . . . . . . . . . 1386.2.2 Majority Rules, Adjudication and Censorship . . . . . . . 139
6.3 Confusion Matrices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1396.3.1 Example: Blind Wine Classification by Grape . . . . . . . 1396.3.2 Classifier Accuracy and Confidence Intervals . . . . . . . 1406.3.3 κ Statistics for Chance-Adjusted Agreement . . . . . . . . 1416.3.4 Information-Theoretic Measures . . . . . . . . . . . . . . . 1426.3.5 χ2 Independence Tests . . . . . . . . . . . . . . . . . . . . . 1436.3.6 The ConfusionMatrix Class . . . . . . . . . . . . . . . . . 1446.3.7 Demo: Confusion Matrices . . . . . . . . . . . . . . . . . . . 1456.3.8 One-Versus-All Evaluations . . . . . . . . . . . . . . . . . . 1476.3.9 Example: Blind Wine Classification (continued) . . . . . . 1476.3.10 Micro-Averaged Evaluations . . . . . . . . . . . . . . . . . . 1486.3.11 The ConfusionMatrix Class (continued) . . . . . . . . . 148
6.4 Precision-Recall Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . 1496.4.1 Example: Blind-Wine One-versus-All . . . . . . . . . . . . . 1496.4.2 Precision, Recall, Etc. . . . . . . . . . . . . . . . . . . . . . . 1496.4.3 Prevalence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1506.4.4 F Measure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1506.4.5 The PrecisionRecallEvaluation Class . . . . . . . . . 151
6.5 Micro- and Macro-Averaged Statistics . . . . . . . . . . . . . . . . . . . 1536.5.1 Macro-Averaged One Versus All . . . . . . . . . . . . . . . 1536.5.2 Micro-Averaged One Versus All . . . . . . . . . . . . . . . . 1546.5.3 Demo: Micro- and Macro-Averaged Precision and Recall 1546.5.4 Generalized Precision-Recall Evaluations for Informa-
tion Extraction . . . . . . . . . . . . . . . . . . . . . . . . . . 1556.6 Scored Precision-Recall Evaluations . . . . . . . . . . . . . . . . . . . . 156
6.6.1 Ranks, Scores and Conditional Probability Estimates . . 1576.6.2 Comparing Scores across Items . . . . . . . . . . . . . . . . 1576.6.3 The ScoredPrecisionRecallEvaluation Class . . . . . 1586.6.4 Demo: Scored Precision-Recall . . . . . . . . . . . . . . . . 159
6.7 Contingency Tables and Derived Statistics . . . . . . . . . . . . . . . . 1646.7.1 χ2 Tests of Independence . . . . . . . . . . . . . . . . . . . 1656.7.2 Further Contingency and Association Statistics . . . . . . 1666.7.3 Information-Theoretic Measures . . . . . . . . . . . . . . . 1676.7.4 Confusion Matrices . . . . . . . . . . . . . . . . . . . . . . . 1686.7.5 κ Statistics for Chance-Adjusted Agreement . . . . . . . . 1686.7.6 Sensitivity-Specificity Matrices . . . . . . . . . . . . . . . . 1696.7.7 Collapsing Confusion Matrices for One-Versus-All . . . . 1726.7.8 Ranked Response Statistics . . . . . . . . . . . . . . . . . . 173
6.8 Bias Correction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1766.9 Post-Stratification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 177

7 Naive Bayes Classifiers 179
8 Tokenization 1818.1 Tokenizers and Tokenizer Factories . . . . . . . . . . . . . . . . . . . . 181
8.1.1 The TokenizerFactory Interface . . . . . . . . . . . . . . 1818.1.2 The Tokenizer Base Class . . . . . . . . . . . . . . . . . . . 1828.1.3 Token Display Demo . . . . . . . . . . . . . . . . . . . . . . 183
8.2 LingPipe’s Base Tokenizer Factories . . . . . . . . . . . . . . . . . . . . 1858.2.1 The IndoEuropeanTokenizerFactory Class . . . . . . . 1858.2.2 The CharacterTokenizerFactory Class . . . . . . . . . 1858.2.3 The RegExTokenizerFactory Class . . . . . . . . . . . . 1868.2.4 The NGramTokenizerFactory Class . . . . . . . . . . . . 1878.2.5 The LineTokenizerFactory Class . . . . . . . . . . . . . 188
8.3 LingPipe’s Filtered Tokenizers . . . . . . . . . . . . . . . . . . . . . . . . 1888.3.1 The ModifiedTokenizerFactory Abstract Class . . . . 1898.3.2 The ModifyTokenTokenizerFactory Abstract Class . . 1898.3.3 The LowerCaseTokenizerFactory Class . . . . . . . . . 1918.3.4 The StopTokenizerFactory Class . . . . . . . . . . . . . 1918.3.5 The RegExFilteredTokenizerFactory Class . . . . . . 1938.3.6 The TokenLengthTokenizerFactory Interface . . . . . 1938.3.7 The WhitespaceNormTokenizerFactory Class . . . . . 194
8.4 Morphology, Stemming, and Lemmatization . . . . . . . . . . . . . . . 1948.4.1 Inflectional Morphology . . . . . . . . . . . . . . . . . . . . 1958.4.2 Derivational Morphology . . . . . . . . . . . . . . . . . . . . 1968.4.3 Compounding . . . . . . . . . . . . . . . . . . . . . . . . . . 1968.4.4 Languages Vary in Amount of Morphology . . . . . . . . . 1968.4.5 Stemming and Lemmatization . . . . . . . . . . . . . . . . 1978.4.6 A Very Simple Stemmer . . . . . . . . . . . . . . . . . . . . 1998.4.7 The PorterStemmerTokenizerFactory Class . . . . . . 199
8.5 Soundex: Pronunciation-Based Tokens . . . . . . . . . . . . . . . . . . 2018.5.1 The American Soundex Algorithm . . . . . . . . . . . . . . 2028.5.2 The SoundexTokenizerFactory Class . . . . . . . . . . . 2038.5.3 Variants of Soundex . . . . . . . . . . . . . . . . . . . . . . . 204
8.6 Character Normalizing Tokenizer Filters . . . . . . . . . . . . . . . . . 2048.6.1 Demo: ICU Transliteration . . . . . . . . . . . . . . . . . . . 204
8.7 Penn Treebank Tokenization . . . . . . . . . . . . . . . . . . . . . . . . 2058.7.1 Pre-Tokenized Datasets . . . . . . . . . . . . . . . . . . . . 2058.7.2 The Treebank Tokenization Scheme . . . . . . . . . . . . . 2068.7.3 Demo: Penn Treebank Tokenizer . . . . . . . . . . . . . . . 207
8.8 Adapting to and From Lucene Analyzers . . . . . . . . . . . . . . . . . 2118.8.1 Adapting Analyzers for Tokenizer Factories . . . . . . . . 2128.8.2 Adapting Tokenizer Factories for Analyzers . . . . . . . . 215
8.9 Tokenizations as Objects . . . . . . . . . . . . . . . . . . . . . . . . . . . 2198.9.1 Tokenizer Results . . . . . . . . . . . . . . . . . . . . . . . . 2208.9.2 The Tokenization Class . . . . . . . . . . . . . . . . . . . 220
9 Symbol Tables 223

9.1 The SymbolTable Interface . . . . . . . . . . . . . . . . . . . . . . . . . 2239.1.1 Querying a Symbol Table . . . . . . . . . . . . . . . . . . . . 223
9.2 The MapSymbolTable Class . . . . . . . . . . . . . . . . . . . . . . . . . 2249.2.1 Demo: Basic Symbol Table Operations . . . . . . . . . . . 2249.2.2 Demo: Removing Symbols . . . . . . . . . . . . . . . . . . . 2259.2.3 Additional MapSymbolTable Methods . . . . . . . . . . . 225
9.3 The SymbolTableCompiler Class . . . . . . . . . . . . . . . . . . . . . 2279.3.1 Adding Symbols . . . . . . . . . . . . . . . . . . . . . . . . . 2279.3.2 Compilation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2289.3.3 Demo: Symbol Table Compiler . . . . . . . . . . . . . . . . 2289.3.4 Static Factory Method . . . . . . . . . . . . . . . . . . . . . . 229
10 Sentence Boundary Detection 231
11 Latent Dirichlet Allocation 23311.1 Corpora, Documents, and Tokens . . . . . . . . . . . . . . . . . . . . . 23311.2 LDA Parameter Estimation . . . . . . . . . . . . . . . . . . . . . . . . . . 234
11.2.1 Synthetic Data Example . . . . . . . . . . . . . . . . . . . . 23411.2.2 LDA Parameters . . . . . . . . . . . . . . . . . . . . . . . . . 236
11.3 Interpreting LDA Output . . . . . . . . . . . . . . . . . . . . . . . . . . . 23811.3.1 Convergence Monitoring . . . . . . . . . . . . . . . . . . . . 23811.3.2 Inferred Topics . . . . . . . . . . . . . . . . . . . . . . . . . . 23911.3.3 Inferred Token and Document Categorizations . . . . . . 240
11.4 LDA’s Gibbs Samples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24111.4.1 Constant, Hyperparameter and Data Access . . . . . . . . 24111.4.2 Word Topic Assignments and Probability Estimates . . . 24111.4.3 Retrieving an LDA Model . . . . . . . . . . . . . . . . . . . . 242
11.5 Handling Gibbs Samples . . . . . . . . . . . . . . . . . . . . . . . . . . . 24211.5.1 Samples are Reused . . . . . . . . . . . . . . . . . . . . . . . 24211.5.2 Reporting Handler Demo . . . . . . . . . . . . . . . . . . . . 24311.5.3 General Handlers . . . . . . . . . . . . . . . . . . . . . . . . 246
11.6 Scalability of LDA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24711.6.1 Wormbase Data . . . . . . . . . . . . . . . . . . . . . . . . . 24711.6.2 Running the Demo . . . . . . . . . . . . . . . . . . . . . . . . 24811.6.3 Code Walkthrough . . . . . . . . . . . . . . . . . . . . . . . . 251
11.7 Understanding the LDA Model Parameters . . . . . . . . . . . . . . . . 25211.7.1 Number of Topics . . . . . . . . . . . . . . . . . . . . . . . . 252
11.8 LDA Instances for Multi-Topic Classification . . . . . . . . . . . . . . . 25311.8.1 Constructing LDA Instances . . . . . . . . . . . . . . . . . . 25311.8.2 Demo: Classifying with LDA . . . . . . . . . . . . . . . . . . 25411.8.3 Bayesian Inference with an LDA Model . . . . . . . . . . . 258
11.9 Comparing Documents with LDA . . . . . . . . . . . . . . . . . . . . . . 25811.10 Stability of Samples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 259
11.10.1 Comparing Topics with Symmetrized KL Divergence . . 25911.10.2 Code Walkthrough . . . . . . . . . . . . . . . . . . . . . . . . 26011.10.3 Running the Demo . . . . . . . . . . . . . . . . . . . . . . . . 262
11.11 The LDA Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 263

11.11.1 Generalized “Documents” . . . . . . . . . . . . . . . . . . . 264
12 Singular Value Decomposition 265
A Mathematics 267A.1 Basic Notation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 267
A.1.1 Summation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 267A.1.2 Multiplication . . . . . . . . . . . . . . . . . . . . . . . . . . . 267
A.2 Useful Functions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 267A.2.1 Exponents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 267A.2.2 Logarithms . . . . . . . . . . . . . . . . . . . . . . . . . . . . 268A.2.3 The Factorial Function . . . . . . . . . . . . . . . . . . . . . 268A.2.4 Binomial Coefficients . . . . . . . . . . . . . . . . . . . . . . 268A.2.5 Multinomial Coefficients . . . . . . . . . . . . . . . . . . . . 269A.2.6 The Γ Function . . . . . . . . . . . . . . . . . . . . . . . . . . 269
B Statistics 271B.1 Discrete Probability Distributions . . . . . . . . . . . . . . . . . . . . . 271
B.1.1 Bernoulli Distribution . . . . . . . . . . . . . . . . . . . . . . 271B.1.2 Binomial Distribution . . . . . . . . . . . . . . . . . . . . . . 271B.1.3 Discrete Distribution . . . . . . . . . . . . . . . . . . . . . . 272B.1.4 Multinomial Distribution . . . . . . . . . . . . . . . . . . . . 272
B.2 Continuous Probability Distributions . . . . . . . . . . . . . . . . . . . 273B.2.1 Normal Distribution . . . . . . . . . . . . . . . . . . . . . . . 273B.2.2 χ2 Distribution . . . . . . . . . . . . . . . . . . . . . . . . . . 273
B.3 Information Theory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273B.3.1 Entropy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273B.3.2 Joint Entropy . . . . . . . . . . . . . . . . . . . . . . . . . . . 274B.3.3 Conditional Entropy . . . . . . . . . . . . . . . . . . . . . . . 275B.3.4 Mutual Information . . . . . . . . . . . . . . . . . . . . . . . 275B.3.5 Cross Entropy . . . . . . . . . . . . . . . . . . . . . . . . . . 276B.3.6 Divergence . . . . . . . . . . . . . . . . . . . . . . . . . . . . 276
C Corpora 279C.1 20 Newsgroups . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 279C.2 MedTag . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 280C.3 WormBase MEDLINE Citations . . . . . . . . . . . . . . . . . . . . . . . . 280
D Java Basics 283D.1 Numbers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283
D.1.1 Digits and Decimal Numbers . . . . . . . . . . . . . . . . . 283D.1.2 Bits and Binary Numbers . . . . . . . . . . . . . . . . . . . . 284D.1.3 Octal Notation . . . . . . . . . . . . . . . . . . . . . . . . . . 284D.1.4 Hexadecimal Notation . . . . . . . . . . . . . . . . . . . . . 284D.1.5 Bytes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284D.1.6 Code Example: Integral Number Bases . . . . . . . . . . . 285D.1.7 Other Primitive Numbers . . . . . . . . . . . . . . . . . . . . 286D.1.8 Floating Point . . . . . . . . . . . . . . . . . . . . . . . . . . . 286

D.2 Objects . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 287D.2.1 Equality . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 287D.2.2 Hash Codes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 287D.2.3 String Representations . . . . . . . . . . . . . . . . . . . . . 287D.2.4 Other Object Methods . . . . . . . . . . . . . . . . . . . . . 288D.2.5 Object Size . . . . . . . . . . . . . . . . . . . . . . . . . . . . 288D.2.6 Number Objects . . . . . . . . . . . . . . . . . . . . . . . . . 289
D.3 Arrays . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 291D.4 Synchronization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 291
D.4.1 Immutable Objects . . . . . . . . . . . . . . . . . . . . . . . 291D.4.2 Read-Write Synchronization . . . . . . . . . . . . . . . . . . 292
D.5 Generating Random Numbers . . . . . . . . . . . . . . . . . . . . . . . . 295D.5.1 Generating Random Numbers . . . . . . . . . . . . . . . . . 295D.5.2 Seeds and Pseudorandomness . . . . . . . . . . . . . . . . 296D.5.3 Alternative Randomization Implementations . . . . . . . 296D.5.4 Synchronization . . . . . . . . . . . . . . . . . . . . . . . . . 296D.5.5 The Math.random() Utility . . . . . . . . . . . . . . . . . . 297
E The Lucene Search Library 299E.1 Fields . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 299
E.1.1 Field Names and Values . . . . . . . . . . . . . . . . . . . . 299E.1.2 Indexing Flags . . . . . . . . . . . . . . . . . . . . . . . . . . 300E.1.3 Constructing Fields . . . . . . . . . . . . . . . . . . . . . . . 301E.1.4 Field Getters . . . . . . . . . . . . . . . . . . . . . . . . . . . 301
E.2 Documents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302E.2.1 Constructing and Populating Documents . . . . . . . . . . 302E.2.2 Accessing Fields in Documents . . . . . . . . . . . . . . . . 302E.2.3 Document Demo . . . . . . . . . . . . . . . . . . . . . . . . . 302
E.3 Analysis and Token Streams . . . . . . . . . . . . . . . . . . . . . . . . . 304E.3.1 Token Streams and Attributes . . . . . . . . . . . . . . . . 304
E.4 Directories . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 306E.4.1 Types of Directory . . . . . . . . . . . . . . . . . . . . . . . . 306E.4.2 Constructing File-System Directories . . . . . . . . . . . . 306
E.5 Indexing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 307E.5.1 Merging and Optimizing . . . . . . . . . . . . . . . . . . . . 307E.5.2 Indexing Demo . . . . . . . . . . . . . . . . . . . . . . . . . . 307E.5.3 Duplicate Documents . . . . . . . . . . . . . . . . . . . . . . 310
E.6 Queries ande Query Parsing . . . . . . . . . . . . . . . . . . . . . . . . . 310E.6.1 Constructing Queries Programatically . . . . . . . . . . . . 310E.6.2 Query Parsing . . . . . . . . . . . . . . . . . . . . . . . . . . . 311E.6.3 Default Fields, Token Queries, and Term Queries . . . . . 312E.6.4 The QueryParser Class . . . . . . . . . . . . . . . . . . . . 312
E.7 Search . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312E.7.1 Index Readers . . . . . . . . . . . . . . . . . . . . . . . . . . 312E.7.2 Index Searchers . . . . . . . . . . . . . . . . . . . . . . . . . 314E.7.3 Search Demo . . . . . . . . . . . . . . . . . . . . . . . . . . . 314E.7.4 Ranking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 316

E.8 Deleting Documents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 317E.8.1 Deleting with an Index Reader . . . . . . . . . . . . . . . . 317E.8.2 Deleting with an Index Writer . . . . . . . . . . . . . . . . . 317E.8.3 Visibility of Deletes . . . . . . . . . . . . . . . . . . . . . . . 317E.8.4 Lucene Deletion Demo . . . . . . . . . . . . . . . . . . . . . 318
E.9 Lucene and Databases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 319E.9.1 Transactional Support . . . . . . . . . . . . . . . . . . . . . 319
F Further Reading 321F.1 Unicode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 321F.2 Java . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 321
F.2.1 Overviews of Java . . . . . . . . . . . . . . . . . . . . . . . . 321F.2.2 Books on Java Libraries and Packages . . . . . . . . . . . . 322F.2.3 General Java Books . . . . . . . . . . . . . . . . . . . . . . . 323F.2.4 Practice Makes Perfect . . . . . . . . . . . . . . . . . . . . . 323
F.3 General Programming . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 323F.4 Algorithms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324F.5 Probability and Statistics . . . . . . . . . . . . . . . . . . . . . . . . . . . 324F.6 Machine Learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 325F.7 Linguistics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 326F.8 Natural Language Processing . . . . . . . . . . . . . . . . . . . . . . . . 326
G Licenses 327G.1 LingPipe License . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 327
G.1.1 Commercial Licensing . . . . . . . . . . . . . . . . . . . . . 327G.1.2 Royalty-Free License . . . . . . . . . . . . . . . . . . . . . . . 327
G.2 Java Licenses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 328G.2.1 Sun Binary License . . . . . . . . . . . . . . . . . . . . . . . . 328G.2.2 Sun Community Source License Version 2.8 . . . . . . . . 331
G.3 Apache License 2.0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335G.4 Common Public License 1.0 . . . . . . . . . . . . . . . . . . . . . . . . . 336G.5 X License . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 338G.6 Creative Commons Attribution-Sharealike 3.0 Unported License . . 338
G.6.1 Creative Commons Deed . . . . . . . . . . . . . . . . . . . . 338G.6.2 License Text . . . . . . . . . . . . . . . . . . . . . . . . . . . . 339


Preface
LingPipe is a software library for natural language processing implemented inJava. This book explains the tools that are available in LingPipe and providesexamples of how they can be used to build natural language processing (NLP) ap-plications for multiple languages and genres, and for many kinds of applications.
LingPipe’s application programming interface (API) is tailored to abstract overlow-level implementation details to enable components such as tokenizers, fea-ture extractors, or classifiers to be swapped in a plug-and-play fashion. LingPipecontains a mixture of heuristic rule-based components and statistical compo-nents, often implementing the same interfaces, such as chunking or tokeniza-tion.
The presentation here will be hands on. You should be comfortable readingshort and relatively simple Java programs. Java programming idioms like loopboundaries being inclusive/exclusive and higher-level design patterns like visi-tors will also be presupposed. More specific aspects of Java coding relating totext processing, such as streaming I/O, character decoding, string representa-tions, and regular expression processing will be discussed in more depth. Wewill also go into some detail on collections, XML/HTML parsing with SAX, andserialization patterns.
We do not presuppose any knowledge of linguistics beyond a simple under-standing of the terms used in dictionaries such as words, syllables, pronuncia-tions, and parts of speech such as noun and preposition. We will spend consid-erable time introducing linguistic concepts, such as word senses or noun phrasechunks, as they relate to natural language processing modules in LingPipe.
We will do our best to introduce LingPipe’s modules and their applicationfrom a hands-on practical API perspective rather than a theoretical one. In mostcases, such as for logistic regression classifiers and conditional random field(CRF) taggers and chunkers, it’s possible learn how to effectively fit complex anduseful models without fully understanding the mathematical basis of LingPipe’sestimation and optimization algorithms. In other cases, such as naive Bayesclassifiers, hierarchical clusterers and hidden Markov models (HMM), the modelsare simpler, estimation is a matter of counting, and there is almost no hand-tuning required.
Deeper understanding of LingPipe’s algorithms and statistical models re-quires familiarity with computational complexity analysis and basic probabilitytheory including information theory. We provide suggested readings in algo-rithms, statistics, machine learning, and linguistics in Appendix F.
xvii

xviii
After introducing LingPipe’s modules and their applications at a program-ming level, we will provide mathematically precise definitions. The goal is acomplete description of the mathematical models underlying LingPipe. To un-derstand these sections will require a stronger background in algorithms andstatistical modeling than the other sections of the book.
We hope you have as much fun with LingPipe as we’ve had. We’d love to hearfrom you, so feel free to drop us a line at [email protected] with any kindof question or comment you might have.
If you’d like to join the LingPipe mailing list, it’s at
http://tech.groups.yahoo.com/group/LingPipe/
We also have a blog at
http://lingpipe-blog.com/
Bob Carpenter
New YorkNovember 2,2010

Text Analysis
with LingPipe 4.0Volume I


Chapter 1
Getting Started
This book is intended to provide two things. First and foremost, it presentsa hands-on introduction to the use of the LingPipe natural language processinglibrary for building natural language processing components and applications.Our main focus is on programming with the LingPipe library. Second, the bookcontains precise mathematical definitions of all of the models and substantial al-gorithms underlying LingPipe. Understanding the finer mathematical points willnot be assumed for the practical sections of the book. Of course, it’s impossibleto fully sidestep mathematics while explaining what is essentially a collection ofalgorithms implementing mathematical models of language.
Before beginning with a “hello world” example that will verify that every-thing’s in place for compiling and executing the code in the book, we’ll takesome time to explain the tools we’ll be using or that you might want to use. Allof these tools are open source and freely available, though under a perplexingarray of licensing terms and conditions. After describing and motivating ourchoice of each tool, we’ll provide downloading and installation instructions.
1.1 Tools of the Trade
In this section, we go over the various tools we use for program development.Most are required at some point for running examples in this book, the ex-ceptions being the full LingPipe download and interactive development environ-ments, neither of which are needed to run the examples.
1.1.1 Unix Shell Tools
We present examples as run from a unix-like command-line shell. One reason touse the shell is that it’s easy to script operations so that they may be repeated.
The main problem with scripts is that they are not portable across operatingsystems or even types of command-line shells. In this book, we use the so-called“Bourne Again Shell” (bash) for Unix-style commands. Bash is the default shell inCygwin on Windows, for Mac OS X, and for Linux, and is also available for Solaris.
1

2 CHAPTER 1. GETTING STARTED
If you’re working in Windows (XP, Vista or 7), we recommend the Cygwin suiteof Unix command-line tools for Windows.
Cygwin is released under version 2 of the GNU Public License (GPLv2), withterms outlined here:
http://cygwin.com/license.html
and also available with a commercial license.Cygwin can be downloaded and installed through Cygwin’s home page,
http://www.cygwin.com/
The setup.exe program is small. When you run it, it goes out over the internet tofind the packages from registered mirrors. It then lists all the packages available.You can install some or all of them. You can just run the setup program againto update or install new packages; it’ll show you what version of what’s alreadyinstalled.
Archive and Compression Tools
In order to unpack data and library distributions, you need to be able to runthe tar archiving tool, as well as the unpacking commands unzip and gunizp.These may be installed as part of Cygwin on Windows.
1.1.2 Version Control
If you don’t live in some kind of version control environment, you should. Notonly can you keep track of your own code across multiple sites and/or users, youcan also keep up to date with projects with version control, such as this book,the LingPipe sandbox, and projects hosted by open source hosting services suchas SourceForge or Google Code.
We are currently using Subversion (SVN) for LingPipe and this book. You caninstall a shell-based version of Subversion, the command-name for which is svn.Subversion itself requires a secure shell (SSH) client over which to run, at leastfor most installations. Both SVN and SSH can be installed through Cygwin forWindows users.
There are graphical interfaces for subversion. Web-SVN, which as its nameimplies, runs as a server and is accessible through a web browser,
WebSVN: http://websvn.tigris.org/
and Tortoise SVN, which integrates with the Windows Explorer,
Tortoise SVN: http://tortoisesvn.net/
Other popular version control systems include the older Concurrent VersionSystem (CVS), as well as the increasingly popular Git system, which is used bythe Linux developers.
The best reference for Subversion of which we are aware is the official guideby the authors, available onlie at
http://svnbook.red-bean.com/

1.1. TOOLS OF THE TRADE 3
1.1.3 Text Editors
In order to generate code, HTML, and reports, you will need to be able to edittext. We like to work in the emacs text editor, because of its configurability. It’sas close as you’ll get to an IDE in a simple text editor.
Spaces, Not Tabs
To make code portable, we highly recommend using spaces instead of tabs. Yes,it takes up a bit more space, but it’s worth it. We follow Sun’s coding standardfor Java, so we use four spaces for a tab. This is a bit easier to read, but wastesmore horizontal space.
(GNU) Emacs
We use the GNU Emacs distribution of emacs, which is available from its homepage,
http://www.gnu.org/software/emacs/
It’s standard on most Unix and Linux distributions; for Windows, there is azipped binary distribution in a subdirectory of the main distribution that onlyneeds to be unpacked in order to be run. We’ve had problems with the Cygwin-based installations in terms of their font integration. And we’ve also not beenable to configure XEmacs for Unicode, which is the main reason for our prefer-ence for GNU Emacs.
We like to work with the Lucida Console font, which is distributed with Win-dows; it’s the font used for code examples in this book. It also supports a widerange of non-Roman fonts. You can change the font by pulling down the Optionsmenu and selecting the Set Default Font... item to pop up a dialog box.Then use the Save Options item in the same menu to save it. It’ll show youwhere it saved a file called .emacs which you will need to edit for the next cus-tomizations.
In order to configure GNU Emacs to run UTF-8, you need to add the followingtext to your .emacs file:1
(prefer-coding-system ’utf-8)(set-default-coding-systems ’utf-8)(set-terminal-coding-system ’utf-8)(set-keyboard-coding-system ’utf-8)(setq default-buffer-file-coding-system ’utf-8)(setq x-select-request-type
’(UTF8_STRING COMPOUND_TEXT TEXT STRING))(set-clipboard-coding-system ’utf-16le-dos)
The requisite commands to force tabs to be replaced with spaces in Java files are:
1The UTF-8 instructions are from the Sacrificial Rabbit blog entry http://blog.jonnay.net/archives/820-Emacs-and-UTF-8-Encoding.html, downloaded 4 August 2010.

4 CHAPTER 1. GETTING STARTED
(defun java-mode-untabify ()(save-excursion
(goto-char (point-min))(if (search-forward "t" nil t)
(untabify (1- (point)) (point-max))))nil)
(add-hook ’java-mode-hook’(lambda ()
(make-local-variable ’write-contents-hooks)(add-hook ’write-contents-hooks ’java-mode-untabify)))
(setq indent-tabs-mode nil)
1.1.4 Java Standard Edition 6
We chose Java as the basis for LingPipe because we felt it provided the besttradeoff among efficiency, usability, portability, and library availability.
The presentation here assumes the reader has a basic working knowledge ofthe Java programming language. We will focus on a few aspects of Java thatare particularly crucial for processing textual language data, such as characterand string representations, input and output streams and character encodings,regular expressions, parsing HTML and XML markup, etc. In explaining LingPipe’sdesign, we will also delve into greater detail on general features of Java such asconcurrency, generics, floating point representations, and the collection package.
This book is based on the latest currently supported standard edition of theJava platform (Java SE), which is version 6. You will need the Java developmentkit (JDK) in order to compile Java programs. A java virtual machine (JVM) isrequired to execute compiled Java programs. A Java runtime environment (JRE)contains platform-specific support and integration for a JVM and often interfacesto web browsers for applet support.
Java is available in 32-bit and 64-bit versions. The 64-bit version is requiredto allocate JVMs with heaps larger than 1.5 or 2 gigabytes (the exact maximumfor 32-bit Java depends on the platform).
Licensing terms for the JRE are at
http://www.java.com/en/download/license.jsp
and for the JDK at
http://java.sun.com/javase/6/jdk-6u20-license.txt
Java is available for the Windows, Linux, and Solaris operating systems inboth 32-bit and 64-bit versions from
http://java.sun.com/javase/downloads/index.jsp
The Java JDK and JRE are included as part of Mac OS X. Updates are availablethrough

1.1. TOOLS OF THE TRADE 5
http://developer.apple.com/java/download/
Java is updated regularly and it’s worth having the latest version. Updates in-clude bug fixes and often include performance enhancements, some of whichcan be quite substantial.
Java must be installed on the operating system so that shell commands willexecute it. We have to manage multiple versions of Java, so typically we willdefine an environment variable JAVA_HOME, and add ${JAVA_HOME}/bin (Unix)or %JAVA_HOME%\bin (Windows) to the PATH environment variable (or its equiv-alent for your operating system). We then set JAVA_HOME to either JAVA_1_5,JAVA_1_6, or JAVA_1_7 depending on use case. Note that JAVA_HOME is onelevel above Java’s bin directory containing the executable Java commands.
You can test whether you can run Java with the following command, whichshould produce similar results.
> java -version
java version "1.6.0_18"Java(TM) SE Runtime Environment (build 1.6.0_18-b07)Java HotSpot(TM) 64-Bit Server VM (build 16.0-b13, mixed mode)
Similarly, you can test for the Java compiler version, using
> javac -version
javac 1.6.0_20
Java Source
You can download the Java source files from the same location as the JDK. Thesource is subject to yet anoher license, available at
http://java.sun.com/javase/6/scsl_6-license.txt
The source provides a fantastic set of examples of how to design, code, and doc-ument Java programs. We especially recommend studying the source for strings,I/O and collections. Further, like all source, it provides a definitive answer to thequestions of what a particular piece of code does and how it does it. This can beuseful for understanding deeper issues like thread safety, equality and hashing,efficiency and memory usage.
1.1.5 Ant
We present examples for compilation and for running programs using theApache Ant build tool. Ant has three key features that make it well suited forexpository purposes. First, it’s portable across all the platforms that supportJava. Second, it provides clear XML representations for core Java concepts suchas classpaths and command-line arguments. Third, invoking a target in Ant di-rectly executes the dependent targets and then all of the commands in the target.Thus we find Ant builds easier to follow than those using the classic Unix build

6 CHAPTER 1. GETTING STARTED
tool Make or its modern incarnation Apache Maven, both of which attempt to re-solve dependencies among targets and determine if targets are up to date beforeexecuting them.
Although we’re not attempting to teach Ant, we’ll walk through a basic Antbuild file later in this chapter to give you at least a reading knowledge of Ant.If you’re using an IDE like Eclipse or NetBeans, you can import Ant build filesdirectly to create a project.
Ant is is an Apache project, and as such, is subject to the Apache license,
http://ant.apache.org/license.html
Ant is available from
http://ant.apache.org/
You only need one of the binary distributions, which will look likeapache-ant-version-bin.tar.gz.
First, you need to unpack the distribution. We like directory structures withrelease names, which is how ant unpacks, using top-level directory names likeapache-ant-1.8.1. Then, you need to put the bin subdirectory of the top-leveldirectory into the PATH environment variable so that Ant may be executed fromthe command line.
Ant requires the JAVA_HOME environment variable to be set to the path abovethe bin directory containing the Java executables. Ant’s installation instructionssuggest setting the ANT_HOME directory in the same way, and then adding but it’snot necessary unless you will be scripting calls to Ant.
Ant build files may be imported directly into either the Eclipse or NetBeansIDEs (see below for a description of these).
You can test whether Ant is installed with
> ant -version
Apache Ant version 1.8.1 compiled on April 30 2010
1.1.6 Integrated Development Environment
Many pepeople prefer to write (and compile and debug) code in an integrated de-velopment environment (IDE). IDEs offer advantages such as automatic method,class and constant completion, easily configurable text formatting, stepwise de-buggers, and automated tools for code generation and refactoring.
LingPipe development may be carried out through an IDE. The two most pop-ular IDEs for Java are Eclipse and NetBeans.
Eclipse IDE
Eclipse provides a full range of code checking, auto-completion and code gen-eration, and debugging facilities. Eclipse is an open-source project with a widerange of additional tools available as plugins. It also has modules for languagesother than Java, such as C++ and PHP.
The full set of Eclipse downloads is listed on the following page,

1.1. TOOLS OF THE TRADE 7
http://download.eclipse.org/eclipse/downloads/
You’ll want to make sure you choose the one compatible with the JDK you areusing. Though originally a Windows-based system, Eclipse has been ported toMac OS X (though Carbon) and Linux.
Eclipse is released under the Eclipse Public License (EPL), a slightly modifiedversion of the Common Public License (CPL) from IBM, the full text of which isavailable from
http://www.eclipse.org/legal/epl-v10.html
NetBeans IDE
Unlike Eclipse, the NetBeans IDE is written entirely in Java. Thus it’s possible torun it under Windows, Linux, Solaris Unix, and Mac OS X. There are also a widerange of plug-ins available for NetBeans.
Netbeans is free, and may be downloaded from its home page,
http://netbeans.org/
Its licensing is rather complex, being released under a dual license consisting ofthe Common Development and Distribution License (CDDL) and version 2 of theGNU Public License version 2 (GPLv2). Full details are at
http://netbeans.org/about/legal/license.html
1.1.7 Statistical Computing Environment
Although not strictly necessary, if you want to draw nice plots of your data orresults, or compute p values for some of the statistics LingPipe reports, it helpsto have a statistical computing language on hand. Such languages are typicallyinterpreted, supported interactive data analysis and plotting.
In some cases, we will provide R code for operations not supported in Ling-Pipe. All of the graphs drawn in the book were rendered as PDFs in R and in-cluded as vector graphics.
R Project for Statistical Computing
The most popular open-source statistical computing language is still the RProject for Statistical Computing (R). R runs under all the major operating sys-tems, though the Windows installers and compatibility with libraries seem to bea bit more advanced than those for Linux or Mac OS X.
R implements a dialect of the S programming language for matrices andstatistics. It has good built-in functionality for standard distributions and ma-trix operations. It also allows linking to C or Fortran back-end implementations.There are also plug ins (of varying quality) for just about everything else you canimagine. The officially sanctioned plug ins are available from the ComprehensiveR Archive Network (CRAN).
R is available from its home page,

8 CHAPTER 1. GETTING STARTED
http://www.r-project.org/
The CRAN mirrors are also linked from the page and usually the first web searchresults for statistics-related queries in R.
R is distributed under the GNU Public License version 2 (GPLv2).
SciPy and NumPy
The Python programming/scripting language is becoming more and more pop-ular for both preprocessing data and analyzing statistics. The library NumPyprovides a matrix library on top of Python and SciPy a scientific library includingstatistics and graphing. The place to get started is the home page,
http://numpy.scipy.org/
NumPy and SciPy and Python itself are distributed under the much more flexibleBSD License.
Like R, Python is interpreted and not very fast at operations like looping.NumPy helps by allowing some operations to be vectorized (as does R). Like R,Python also allows linking C and Fortran back-end packages for efficiency.
1.1.8 Full LingPipe Distribution
LingPipe is distributed under both commercial licenses and under a royalty-freelicense. A copy of the royalty free license is available at:
http://alias-i.com/lingpipe/licenses/lingpipe-license-1.txt
LingPipe may be downloaded with full source from its web site:
http://alias-i.com/lingpipe/
Other than unpacking the gzipped tarball, there is nothing required for installa-tion. Downloading LingPipe is not technically necessary for running the examplesin this book because the LingPipe library jar is included with this book’s sourcedownload.
1.1.9 Book Source and Libraries
The code samples from this book are available via anonymous subversion check-out from the LingPipe sandbox. Specifically, the entire content of the book, in-cluding code and text, may be checked out anonymously using,
> svn co https://aliasi.devguard.com/svn/sandbox/lpbook
The distribution contains all of the code and Ant build files for running it. It alsocontains the LATEX source for the book itself as well as the library we created toextract text from the source for automatic inclusion in the book. This last featureis actually critical to ensure the code in the distribution and in the book match.

1.2. HELLO WORLD EXAMPLE 9
1.2 Hello World Example
In this section, we provide a very simple hello world program. If you can runit, you’ll be all set to jump into the next chapter and get started with the realexamples. We’ll also take this opportunity to walk through a simple Ant buildfile.
1.2.1 Running the Example
To the extent we are able, we’ll start each discussion with an example of howto run examples. This is pretty easy for the hello-world example. As with all ofour examples, we begin by changing directories into the directory containing theexample. We suppose that $BOOK/ is the home page for the book and executethe cd command,
> cd $BOOK/intro
Note that we have italicized the commands issued by the user. We then run thedemo using Ant. In this case, the target is hello, invoked by
> ant hello
which produces the following output
Buildfile: c:\lpb\src\intro\build.xml
jar:[mkdir] Created dir: c:\lpb\src\intro\build\classes[javac] Compiling 1 source file to c:\lpb\src\intro\build\classes
[jar] Building jar: c:\lpb\src\intro\build\lp-book-intro-4.0.jar
hello:[java] Hello World
BUILD SUCCESSFULTotal time: 1 second
First, Ant echoes the name of the build file, here c:\lpb\src\intro\build.xml.When Ant is invoked without specifying a particular build file, it uses thebuild.xml in the directory from which it was called.
Reading down the left side of the output, you see the targets that are invoked.The first target invoked is the jar target, and the second target is the hellotarget. The targets are left aligned and followed by semicolons. A target consistsof an ordered list of dependent targets to invoke before the current target, andan ordered list of tasks to execute after the dependent targets are invoked.
Under the targets, you see the particular tasks that the target executes. Theseare indented, square bracketed, and right aligned. The jar target invokes threetasks, mkdir, javac, and jar. The hello target invokes one task, java. All ofthe output for each task is shown after the task name. If there is more than oneline of output, the name of the task is repeated.

10 CHAPTER 1. GETTING STARTED
In this example, the mkdir task makes a new directory, here thebuild\classes directory. The javac task runs the Java compiler, here compil-ing a single source file into the newly created directory. The jar task builds theJava library into the build subdirectory build in file lp-book-intro-4.0.jar.Moving onto the hello target, the java task runs a command-line Java program,in this case printing the output of the hello world program.
The reason the jar target was invoked was because the hello target was de-fined to depend on the jar target. Ant invokes all dependent targets (recursively)before the invoked target.
Finally, Ant reports that the build was successful and reports the amountof time taken. In the future, we will usually only show the output of the Javaprogram executed and not all of the output from the compilation steps. To savemore space, we also remove the [java] tag on the task. Under this scheme, thehello target invocation would be displayed in this book as
> ant hello
Hello World
1.2.2 Hello with Arguments
Often we need to supply arguments to programs from the command line. Theeasiest way to do this with Ant is by setting the properties on the command line.Our second demo uses this facility to provide a customized greeting.
> ant -Dfirst=Bobby -Dlast=C hello-name
Hello, Bobby C.
Each argument to a program corresponds to a named property, here first andlast. In general, properties are specified -Dkey=val.
1.2.3 Code Walkthrough
The code for the hello world program can be found in$BOOK/src/intro/src/com/lingpipe/book/intro/HelloWorld.java.Throughout the book, the files are organized this way, under the top-levelsrc directory, then the name of the chapter (here intro), followed by src,followed by the path to the actual program. We follow the Java convention ofplacing files in a directory structure that mirrors their package structure, so theremaining part of the path is com/lingpipe/book/intro/HelloWorld.java.The contents of the HelloWorld.java program file is as follows.
package com.lingpipe.book.intro;
public class HelloWorld {
public static void main(String[] args) {System.out.println("Hello World");
}
}

1.3. INTRODUCTION TO ANT 11
As usual for Java programs, the first thing in the file is the package declaration,here com.lingpipe.book.intro; note how it matches the end of the path tothe file, com/lingpipe/book/intro. Next is the class definition, HelloWorld,which matches the name of the file, HelloWorld.java.
When a Java class is invoked from the command line (or equivalently throughAnt), it must implement a static method with a signature like the one shown.Specifically, the method must be named main, must take a single string arrayargument of type String[], must not have a return value (i.e., return type void),and must be declared to be both public and static using the public and staticmodifiers. The method may optionally throw any kind of exception.
The body of the program here just prints Hello World to the system output.As usual, Java provides a handle to the system output through the public staticvariable out of type java.io.PrintStream in the java.lang.System class.
The more complex program HelloName that takes two command-line argu-ments varies in the body of its main() method,
public class HelloName {
public static void main(String[] args) {String first = args[0];String last = args[1];System.out.printf("Hello, %s %s.\n",first,last);
As a convention, we assign the command-line arguments read from the arrayargs to a sequence of named variables. We then use these same names in theAnt properties (see Section 1.3.3).
1.3 Introduction to Ant
Although we will typically skip discussing the Ant build files, as they’re almostall the same, we will go over the one for the hello world program in some detail.
The build file for hello world is located at $BOOK/src/intro/build.xml,where $BOOK/ is the root of the directory in which this book’s files have beenunpacked. In general, the build files will be broken out by chapter and/or sec-tion. The goal is to make each of them relatively self contained so that they maybe used as a minimal basis for further development.
1.3.1 XML Declaration
The first thing in any Ant build file is the XML declaration, here
<?xml version="1.0" encoding="ASCII"?>...
This just tells Ant’s XML parser that what it’s looking at is an XML file and thatthe ASCII character encoding is being used for subsequent data. (See Chapter 2for more information on character encodings). We chose ASCII because we didn’tanticipate using any non-ASCII characters; we could have chosen Latin1 or UTF-8

12 CHAPTER 1. GETTING STARTED
or even Big5 and written the build file in Chinese. Most XML parsers are robustenough to infer the character encoding, but it’s always good practice to make itexplicit.
The ellipses (...) indicate ellided material that will be filled in (or not) incontinuing discussion.
1.3.2 Top-Level Project Element
The top-level element in the XML file is the project declaration, which is just
<project>...</project>
Given our convention for ellipses, the file actually looks as follows,
<?xml version="1.0" encoding="ASCII"?><project>...</project>
with the remaining ellipses to be filled in below.The project element’s tag is project, and there are no required attributes.
The project declaration may optionally be given a name as the value of attributename, a default target to invoke as the value of attribute default, and a basedirectory from which to run as the value of basedir. The base directory defaultsto the directory containing the build file, which is where we set everything up torun from. We will not need a default target as we will specify all targets explicitlyfor clarity. The name doesn’t really have a function.
1.3.3 Ant Properties
We organize Ant build files in the conventional way starting with properties,which are declared first in the project element’s content. The properties defineconstant values for reuse. Here, we have
<property name="version"value="4.0"/>
<property name="jar"value="build/lp-book-intro-${version}.jar"/>
The first property definition defines a property version with value 4.0 (all val-ues are strings). The second property is named jar, with a value, defined interms of the first property, of build/lpb-intro-4.0.jar. note that the valueof the property version has been substituted for the substring ${version}. Ingeneral, properties are accessed by ${...} with the property filled in for theellipses.
Properties may be overridden from the command line by declaring an envi-ronment variable for the command. For example,

1.3. INTRODUCTION TO ANT 13
> ant -Djar=foo.jar jar
calls the build file, setting the value of the jar property to be the string foo.jar(which would create a library archive called foo.jar). The value of a property inAnt is always the first value to which it is set; further attempts to set it (as in thebody of the Ant file) will be ignored.
1.3.4 Ant Targets
Next, we have a sequence of targets, each of which groups together a sequenceof tasks. The order of targets is not important.
Clean Target
The first target we have performs cleanup.
<target name="clean"><delete dir="build"/>
</target>...
This is a conventional clean-up target, given the obvious name of clean. Each tar-get has a sequence of tasks that will be executed whenever the target is invoked.Here, the task is a delete task, which deletes the directory named build.
It is conventional to have a clean task that cleans up all of the automaticallygenerated content in a project. Here, the .class files generated by the compilerand .jar file produced by the archiver will be deleted, as should soon be evident.
Compiliation/Archive Target
The next target is the compilation target, named jar,
<target name="jar"><mkdir dir="build/classes"/><javac debug="yes"
debuglevel="source,lines,vars"destdir="build/classes"includeantruntime="false">
<compilerarg value="-Xlint:all"/><src path="src/"/>
</javac><jar destfile="${jar}">
<fileset dir="build/classes"includes="**/*.class"/>
</jar></target>...

14 CHAPTER 1. GETTING STARTED
Invoking the jar target executes three tasks, a make-directory (mkdir), java com-pilation (javac), and Java archive creation (jar). Note that, as we exploit here,it is allowable to have a target with the same name as a task, because Ant keepsthe namespaces separate.
The first task is the make-directory task, mkdir, takes the path for a di-rectory and creates that directory and all of its necessary parent directories.Here, it builds the directory build/classes. All files are relative to the basedirectory, which is here the directory containing the build.xml file, namely$BOOK/src/intro.
The second task is the Java compilation task, javac, does the actual compi-lation. Here we have supplied the task element with four attributes. The firsttwo, debug and debuglevel are required to insert debugging information intothe compiled code so that we can get stack traces with line numbers when pro-cesses crash. These can be removed to save space, but they can be very help-ful for deployed systems, so we don’t recommend it. The debug element saysto turn debugging on, and the debuglevel says to debug the source down tolines and variable names, which is the maximal amount of debugging informa-tion available. The javac task may specify the character encoding used for theJava program using the attribute encoding.
The destination directory attribute, destdir indicates where the compiledclasses will be stored. Here, the path is build/classes. Note that this is in thedirectory we first created with the make-directory task. Further recall that thebuild directory will be removed by the clean target.
Finally, we have a flag with attribute includeantruntime that says the Antruntime libraries should not be included in the classpath for the compilation. Inour opinion, this should have defaulted to false rather than true and saved usa line in all the build files. If you don’t specify this attribute, Ant gripes and tellsyou what it’s defaulting to.
The java compilation task here has content, startign with a compiler argu-ment. The element compilerarg passes the value of the attribute value to theunderlying call to the javac executable in the JDK. Here, we specified a valueof -Xlint:all. The -X options to javac are documented by running the com-mand javac -X. This -X option specifies lint:all, which says to turn all lintdetection on. This provides extended warnings for form, including deprecation,unchecked casts, lack of serial version IDs, lack or extra override specifications,and so on. These can be turned on and off one by one, but we prefer to leavethem all on and produce lint-free programs. This often involves suppressingwarnings that would otherwise be unavoidable, such as casts after object I/O orinternal uses of deprecated public methods.
When compilation requires external libraries, we may add the classpath spec-ifications either as attributes or elements in the javac task. For instance, we canhave a classpath specification, which is much like a property definition,
<path id="classpath"><pathelement location="${jar}"/><pathelement location="../../lib/icu4j-4_4_1.jar"/>
</path>

1.3. INTRODUCTION TO ANT 15
And then we’d add the element
<classpath refid="classpath"/>
as content in the javac target.The java compilation task’s content continues a source element with tag src.
This says where to find the source code to compile. Here we specify the valueof attribute for the path to the source, path, as src/. As usual, this path isinterpreted relative to the base directory, which is the one holding the build.xmlfile.
The third task is the Java archive task, jar, which packages up the com-piled code into a single compressed file, conventionally suffixed with the string.jar. The file created is specified as the value of the destfile attribute, heregiven as ${jar}, meaning the value of the jar property will be substituted, herebuild/lpb-intro-4.0.jar. As ever, this is interpreted relative to the baseproject directory. Note that the jar is being created in the build directory, whichwill be cleaned by the clean target.
Java Execution Task
The final target is the one that’ll run Java,
<target name="hello"depends="jar">
<java classname="com.lingpipe.book.intro.HelloWorld"classpath="${jar}"fork="true">
</java></target>
Unlike the previous targets, this target has a dependency, as indicated by thedepends attribute on the target element. Here, the value is jar, meaning thatthe jar target is invoked before the tasks in the hello target are executed. Thismeans that the compilation and archive tasks are always executed before thehello target’s task.
It may seem at this point that Ant is using some notion of targets being upto date. In fact, it’s Java’s compiler, javac, and Java’s jar command which aredoing the checking. In particular, if there is a compiled class in the compilationlocation that has a later date than the source file, it is not recompiled.2 Similarly,the jar command will not rebuild the archive if all the files from which it werebuilt are older than the archive itself.
In general, there can be multiple dependencies specified as target names sep-arated by commas, which will be invoked in order before the target declaring thedependencies. Furthermore, if the targets invoked through depends themselveshave dependencies, these will be invoked recursively.
2This leads to a confusing situation for statics. Static constants are compiled by value, rather thanby reference if the value can be computed at compile time. These values are only recomputed when afile containing the static constant is recompiled. If you’re changing the definition of classes on whichstatic constants depend, you need to recompile the file with the constants. Just clean first.

16 CHAPTER 1. GETTING STARTED
The hello target specifies a single task as content. The task is a run-Java task,with element tag java. The attribute classname has a value indicating whichclass is executed. This must be a fully specified class with all of its packagequalifiers separated by periods (.).
To invoke a Java program, we must also have a classpath indicating whereto find the compiled code to run. In Ant, this is specified with the classpathattribute on the java task. The value here is ${jar}, for which the value of theJava archive for the project will be substituted. In general, there can be multiplearchives or directories containing compiled classes on the classpath, and theclasspath may be specifeid with a nested element as well as an attribute. Antcontains an entire syntax for specifying path-like structures.
Finally, there is a flag indicated by attribute fork being set to value true,which tells Ant to fork a new process with a new JVM in which to run the indi-cated class.
The target hello-name that we used for the hello program with two argu-ments consists of the following Java task.
<java classname="com.lingpipe.book.intro.HelloName"classpath="${jar}"fork="true">
<arg value="${first}"/><arg value="${last}"/>
</java>
This time, the element tagged java for the Java task has content, specifically twoargument elements. Each argument element is tagged arg and has a single at-tribute value, the value of which is passed to the named Java programs main()program as arguments. As a convention, our programs will all create string vari-ables of the same name as their first action, just as in our hello program witharguments.
In more elaborate uses of the java task, we can also specify arguments to theJava virtual machine such as the maximum amount of memory to use or to useordinary object pointer compression, set Java system properties, and so on.
1.3.5 Property Files
Properties accessed in an Ant build file may also be specified in an external Javaproperties file. This is particular useful in a setting where many users accessthe same build file in different environments. Typically, the build file itself ischecked into version control. If the build file specifies a properties file, each usermay have their own version of the properties file.
Properties may be loaded directly from the build file, or they may be specifiedon the command line. From within an Ant build file, the file attribute in theproperty element may be used to load properties. For example,
<property file="build.properties"/>
From the command line, a properties file may be specified with

1.3. INTRODUCTION TO ANT 17
> ant -propertyfile build.properties ...
The properties file is interpreted as a Java properties file. For instance, wehave supplied a demo properties file demo.properties in this chapter’s direc-tory we can use with the named greeting program. The contents of this file is
first: Jackylast: R
We invoke the Ant target hello-name to run the demo, specifying that the prop-erties from the file demo.properties be read in.
> ant -propertyfile demo.properties hello-name
Hello, Jacky R.
Any command-line specifications using -D override properties. For example, wecan override the value of first,
> ant -Dfirst=Brooks -propertyfile demo.properties hello-name
Hello, Brooks R.
Parsing Properties Files
The parser for properties file is line oriented, allowing the Unix (\n), Macintosh(\r\n Windows (\r) line-termination sequences. Lines may be continued like onthe shell with a backslash character.
Lines beginning with the hash sign # or exclamation point (!) are taken to becomments and ignored. Blank lines are also ignored.
Each line is interpreted as a key followed by a value. The characters equalsign (=), colon (:) or a whitespace character (there are no line terminators withinlines; line parsing has already been done).
Character escapes, including Unicode escapes, are parsed pretty much as inJava string literals (see Section 2.2.1) with a bit more liberal syntax, a few addi-tional escapes (notably for the colon and equals sign) and some excluded charac-ters (notably backspace).
1.3.6 Precedence of Properties
In Ant, whichever property is read first survives. The command line propertiesprecede any other properties, followed by properties read in from a command-line properties file, followed by the properties read in from Ant build files in theorder they appear.

18 CHAPTER 1. GETTING STARTED

Chapter 2
Characters and Strings
Following Java, LingPipe uses Unicode character representations. In this chap-ter, we describe the Unicode character set, discuss character encodings, and howstrings and other character sequences are created and used in Java.
2.1 Character Encodings
For processing natural language text, we are primarily concerned with the rep-resentation of characters in natural languages. A set of (abstract) characters isknown as a character set. These range from the relatively limited set of 26 char-acters (52 if you count upper and lower case characters) used in English to thetens of thousands of characters used in Chinese.
2.1.1 What is a Character?
Precise definitions of characters in human writing systems is a notoriously trickybusiness.
Types of Character Sets
Characters are used in language to represent sounds at the level of phonemic seg-ments (e.g., Latin), syllables (e.g., Japanese Hirigana and Katakana scripts, LinearB, and Cherokee), or words or morphemes, also known as logograms (e.g., Chi-nese Han characters, Egyptian hieroglyphics).
These distinctions are blurry. For instance, both Chinese characters and Egyp-tian hieroglyphs are typically pronounced as single syllables and words may re-quire multiple characters.
Abstraction over Visualization
One problem with dealing with characters is the issue of visual representationversus the abstraction. Character sets abstract away from the visual representa-tions of characters.
19

20 CHAPTER 2. CHARACTERS AND STRINGS
A sequence of characters is also an abstract concept. When visualizing asequence of characters, different writing systems lay them out differently on thepage. When visualizing a sequence of characters, we must make a choice in howto lay them out on a page. English, for instance, traditionally lays out a sequenceof characters in left to right order horizontally across a page. Arabic, on theother hand, lays out a sequence of characters on a page horizontally from rightto left. In contast, Japanese was traditionally set from top to bottom with thefollowing character being under the preceding characters.
English stacks lines of text from top to bottom, whereas traditional Japaneseorders its columns of text from right to left.
When combining multiple pages, English has pages that “turn” from right toleft, whereas Arabic and traditional Japanese conventionally order their pages inthe opposite direction. Obviously, page order isn’t relevant for digital documentsrendered a page at a time, such as on e-book readers.
Even with conventional layouts, it is not uncommon to see caligraphic writingor signage laid out in different directions. It’s not uncommon to see Englishwritten from top to bottom or diagonally from upper left to lower right.
Compound versus Primitive Characters
Characters may be simple or compound. For instance, the character ö used inGerman is composed of a plain Latin o character with an umlaut diacritic on top.Diacritics are visual representations added to other characters, and there is abroad range of them in European languages.
Hebrew and Arabic are typically written without vowels. In very formal writ-ing, vowels may be indicated in these languages with diacritics on the conso-nants. Devanagari, a script used to write languages including Hindi and Nepali,includes pitch accent marks.
The Hangul script used for Korean is a compound phonemic system ofteninvolving multiple glyphs overlaid to form syllabic units.
2.1.2 Coded Sets and Encoding Schemes
Eventually, we need to represent sequences of characters as sequences of bytes.There are two components to a full character encoding.
The first step is to define a coded character set, which assigns each characterin the set a unique non-negative integer code point. For instance, the Englishcharacter ’A’ (capital A) might be assigned the code point 65 and ’B’ to codepoint 66, and so on. Code points are conventionally written using hexadecimalnotation, so we would typically use the hexadecmial notation 0x41 instead of thedecimal notation 65 for capital A.
The second step is to define a character encoding scheme that maps eachcode point to a sequence of bytes (bytes are often called octets in this context).
Translating a sequence of characters in the character set to a sequence ofbytes thus consists of first translating to the sequence of code points, then en-coding these code points into a sequence of bytes.

2.1. CHARACTER ENCODINGS 21
2.1.3 Legacy Character Encodings
We consider in this section some widely used character encodings, but becausethere are literally hundreds of them in use, we can’t be exhaustive.
The characters in these and many other character sets are part of Unicode.Because LingPipe and Java both work with Unicode, typically the only thing youneed to know about a character encoding in order to convert data in that encod-ing to Unicode is the name of the character encoding.
ASCII
ASCII is a character encoding consisting of a small character set of 128 codepoints. Being designed by computer scientists, the numbering starts at 0, so thecode points are in the range 0–127 (inclusive). Each code point is then encoded asthe corresponding single unsigned byte with the same value. It includes charac-ters for the standard keys of an American typewriter, and also some “characters”representing abstract typesetting notions such as line feeds and carriage returnsas well as terminal controls like ringing the “bell”.
The term “ASCII” is sometimes used informally to refer to character data ingeneral, rather than the specific ASCII character encoding.
Latin1 and the Other Latins
Given that ASCII only uses 7 bits and bytes are 8 bits, the natural extensionis to add another 128 characters to ASCII. Latin1 (officially named ISO-8859-1)did just this, adding common accented European characters to ASCII, as well aspunctuation like upside down exclaimation points and question marks, Frenchquote symbols, section symbols, a copyright symbol, and so on.
There are 256 code points in Latin1, and the encoding just uses the corre-sponding unsigned byte to encode each of the 256 characters numbered 0–255.
The Latin1 character set includes the entire ASCII character set. Conveniently,Latin1 uses the same code points as ASCII for the ASCII characters (code points0–127). This means that every ASCII encoding is also a Latin1 encoding of exactlythe same characters.
Latin1 also introduced ambiguity in coding, containing both an ’a’ character,the ’¨’ umlaut character, and their combination ’ä’. It also includes all of ’a’, ’e’,and the compound ’æ’, as well as ’1’, ’/’, ’2’ and the compound 1
2 .With only 256 characters, Latin1 couldn’t render all of the characters in use
in Indo-European languages, so a slew of similar standards, such as Latin2 (ISO-8859-2) for (some) Eastern European languages, Latin3 (ISO-8859-1) for Turkish,Maltese and Esperanto, up through Latin16 (ISO-8859-16) for other Eastern Euro-pean languages, new styles of Western European languages and Irish Gaelic.
Windows 1252
Microsoft Windows, insisting on doing things its own way, uses a character setknown as Windows-1252, which is almost identical to Latin1, but uses code

22 CHAPTER 2. CHARACTERS AND STRINGS
points 128–159 as graphical characters, such as curly quotes, the euro and yensymbols, and so on.
Big5 and GB(K)
The Big5 character encoding is used for traditional Chinese scripts and the GB(more recently GBK) for simplified Chinese script. Because there are so manycharacters in Chinese, both were designed to use a fixed-width two-byte encodingof each character. Using two bytes allows up to 216 = 65,536 characters, whichis enough for most of the commonly used Chinese characters.
2.1.4 Unicode
Unicode is the de facto standard for character sets of all kinds. The latest versionis Unicode 5.2, and it contains over 1,000,000 distinct characters drawn fromhundreds of languages (technically, it assumes all code points are in the range0x0 to 0x10FFFF (0 to 1,114,111 in decimal notation).
One reason Unicode has been so widely adopted is that it contains almost allof the characters in almost all of the widely used character sets in the world. Italso happens to have done so in a thoughful and well-defined manner.
Conveniently, Unicode’s first 256 code points (0–255) exactly match those ofLatin1, and hence Unicode’s first 128 code points (0–127) exactly match those ofASCII.
Unicode code points are conventionally displayed in text using a hexadecimalrepresentation of their code point padded to at least four digits with initial ze-roes, prefixed by U+. For instance, code point 65 (hex 0x41), which representscapital A in ASCII, Latin1 and Unicode, is conventionally written U+0041 for Uni-code.
The problem with having over a million characters is that it would requirethree bytes to store each character (224 = 16,777,216). This is very wasteful forencoding languages based on Latin characters like Spanish or English.
Unicode Transformation Formats
There are three standard encodings for Unicode code points that are specifiedin the Unicode standard, UTF-8, UTF-16, and UTF-32 (“UTF” stands for “Unicodetransformation format”).1 The numbers represent the coding size; UTF-8 usessingle bytes, UTF-16 pairs of bytes, and UTF-32 quadruples of bytes.
UTF-32
The UTF-32 encoding is fixed-width, meaning each character occupies the samenumber of bytes (in this case, 4). As with ASCII and Latin1, the code points areencoded directly as bits in base 2.
1There are also non-standard encodings of (subsets of) Unicode, like Apache Lucene’s and the onein Java’s DataOutput.writeUTF() method.

2.1. CHARACTER ENCODINGS 23
There are actually two UTF-32 encodings, UTF-32BE and UTF-32LE, dependingon the order of the four bytes making up the 32 bit blocks. In the big-endian(BE) scheme, bytes are ordered from left to right from most significant to leastsignificant digits (like for bits in a byte).
In the little-endian (LE) scheme, they are ordered in the opposite direction. Forinstance, in UTF-32BE, U+0041 (capital A), is encoded as 0x00000041, indicatingthe four byte sequence 0x00, 0x00, 0x00, 0x41. In UTF32-LE, it’s encoded as0x41000000, corresponding to the byte sequence 0x41, 0x00, 0x00, 0x00.
There is also an unmarked encoding scheme, UTF-32, which tries to inferwhich order the bytes come in. Due to restrictions on the coding scheme, this isusually possible. In the simplest case, 0x41000000 is only legal in little endian,because it’d be out of range in big-endian notation.
Different computer processors use different endian-ness internally. For ex-ample, Intel and AMD x86 architecture is little endian, Motorola’s PowerPC is bigendian. Some hardware, such as Sun Sparc, Intel Itanium and the ARM, is calledbi-endian, because endianness may be switched.
UTF-16
The UTF-16 encoding is variable length, meaning that different code points usedifferent numbers of bytes. For UTF-16, each character is represented usingeither two bytes (16 bits) or four bytes (32 bits).
Because there are two bytes involved, their order must be defined. As withUTF-32, UTF-16BE is the big-endian order and UTF-16LE the little-endian order.
In UTF-16, code points below U+10000 are represented using a single byte inthe natural base-2 encodings. For instance, our old friend U+0041 (capital A) isrepresented in big endian as the sequence of bytes 0x00, 0x41.
Code points at or above U+10000 are represented using four bytes arranged intwo pairs. Calculating the two pairs of bytes involves bit-twiddling. For instance,given a code point codepoint, the following code calculates the four bytes. 2
static final int LEAD_OFFSET = 0xD800 - (0x10000 >> 10);static final int SURROGATE_OFFSET = 0x10000 - (0xD800 << 10) - 0xDC00;
int lead = LEAD_OFFSET + (codepoint >> 10);int trail = 0xDC00 + (codepoint & 0x3FF);
int byte1 = lead >>> 8;int byte2 = lead & 0xFF;int byte3 = trail >>> 8;int byte4 = trail & 0xFF;
Going the other way around, given the four bytes, we can calculate the code pointwith the following code.
2This code example and the following one for decoding were adapted from the example codesupplied by the Unicode Consortium in their FAQ at
http://unicode.org/faq/utf_bom.html

24 CHAPTER 2. CHARACTERS AND STRINGS
int lead = byte1 << 8 | byte2;int trail = byte3 << 8 | byte4;
int codepoint = (lead << 10) + trail + SURROGATE_OFFSET;
Another way to view this transformation is through the following table.3
Code Point Bits UTF-16 Bytes
xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx000uuuuuxxxxxxxxxxxxxxxx 110110ww wwxxxxxx 110111xx xxxxxxxx
Here wwww = uuuuu - 1 (interpreted as numbers then recoded as bits). The firstline indicates is that if the value fits in 16 bits, those 16 bits are used as is. Notethat this representation is only possible because not all code points between 0and 216−1 are legal. The second line indicates that if we have a code point aboveU+10000, we strip off the high-order five bits uuuuu and subtract one from it toget four bits wwww; again, this is only possible because of the size restriction onuuuuu. Then, distribute these bits in order across the four bytes shown on theright. The constants 110110 and 110111 are used to indicate what are known assurrogate pairs.
Any 16-bit sequence starting with 110110 is the leading half of a surrogatepair, and any sequence starting with 110111 is the trailing half of a surrogatepair. Any other sequence of initial bits means a 16-bit encoding of the codepoint. Thus it is possible to determine by looking at a pair of bytes whether wehave a whole character, the first half of a character represented as a surrogatepair, or the second half of a character represented as a pair.
UTF-8
UTF-8 works in much the same way as UTF-16 (see the previous section), only us-ing single bytes as the minimum code size. We use the table-based visualizationof the encoding scheme.4
Code Point Bits UTF-8 Bytes
0xxxxxxxx 0xxxxxxx00000yyyyyxxxxxx 110yyyyy 10xxxxxxzzzzyyyyyyxxxxxx 1110zzzz 10yyyyyy 10xxxxxx
000uuuuuzzzzyyyyyyxxxxxx 11110uuu 10uuzzzz 10yyyyyy 10xxxxxx
Thus 7-bit ASCII values, which have values from U+0000 to U+007F, are encodeddirectly in a single byte. Values from U+0080 to U+07FF are represented with twobytes, values between U+0800 and U+FFFF with three bytes, and values betweenU+10000 and U+10FFFF with four bytes.
Non-Overlap Principle
The UTF-8 and UTF-16 encoding schemes obey what the Unicode Consortiumcalls the “non-overlap principle.” Technically, the leading, continuing and trailing
3Adapted from Unicode Standard Version 5.2, Table 3-5.4Adapted from Unicode Standard Version 5.2, Table 3-6.

2.1. CHARACTER ENCODINGS 25
code units (bytes in UTF-8, pairs of bytes in UTF-16) overlap. Take UTF-8 forexample. Bytes starting with 0 are singletons, encoding a single character in therange U+0000 to U+007F. Bytes starting with 110 are the leading byte in a two-byte sequence representing a character in the range U+0080 to U+07FF. Similarly,bytes starting with 1110 represent the leading byte in a three-byte sequence, and11110 the leading byte in a four-byte sequence. Any bytes starting with 10 arecontinuation bytes.
What this means in practice is that it is possible to reconstruct characterslocally, without going back to the beginning of a file. At most, if a byte startswith 10 you have to look back up to three bytes to find the first byte in thesequence.
Furthermore, the corruption of a byte is localized so that the rest of thestream doesn’t get corrupted if one byte is corrupted.
Another advantage is that the sequence of bytes encoding one character isnever a subsequence of the bytes making up another character. This makesapplications like search more robust.
Byte Order Marks
In the encoding schemes which are not explicitly marked as being little or bigendian, namely UTF-32, UTF-16 and UTF-8, it is also legal, according to the Uni-code standard, to prefix the sequence of bytes with a byte-order mark (BOM). Itis not legal to have byte-order marks preceding the explicitly marked encodings,UTF-32BE, UTF-32LE, UTF-16BE, UTF-16LE.
For UTF-32, the byte-order mark is a sequence of four bytes indicatingwhether the following encoding is little endian or big endian. the sequence 0x00,0x00, 0xFE, 0xFF indicates a big-endian encoding and the reverse, 0xFF, 0xFE,0x00, 0x00 indicates little endian.
For UTF-16, two bytes are used, 0xFE, 0xFF for big endian, and the reverse,0xFF, 0xFE for little endian.
Although superfluous in UTF-8, the three byte sequence 0xEF, 0xBB, 0xBF is a“byte order mark”, though there is no byte order to mark. As a result, all threeUTF schemes may be distinguished by inspecting their initial bytes.
Any text processor dealing with Unicode needs to handle the byte ordermarks. Some text editing packages automatically insert byte-order marks forUTF encodings and some don’t.
Character Types and Categories
The Unicode specification defines a number of character types and general cate-gories of character. These are useful in Java applications because characters maybe examined programatically for their class membership and the classes may beused in regular expressions.
For example, category “Me” is the general category for enclosing marks, and“Pf” the general category for final quote punctuation, whereas “Pd” is the generalcategory for dash-like punctuation, and “Sc” the category of currency symbols.

26 CHAPTER 2. CHARACTERS AND STRINGS
Unicode supplies a notion of case, with the category “Lu” used for uppercasecharacters and “Ll” for lowercase.
Unicode marks the directionality in which characters are typically wirtten us-ing character types like “R” for right-to-left and “L” for left-to-right.
We provide a sample program in Section 2.4.2 for exploring the types of prop-erties in Java.
Normalization Forms
In order to aid text processing efforts, such as search, Unicode defines severalnotions of normalization. These are defined in great detail in Unicode StandardAnnex #15, The Unicode Normalization Forms.
First, we consider decomposition of precomposed characters. For example,consider the three Unicode characters: U+00E0, latin small letter a withgrave, rendered à, U+0061, latin small letter a, rendered as a, and U+0300,combining grave accent, which is typically rendered by combining it as anaccent over the previous character. For most purposes, the combination U+00E0means the same thing in text as U+0061 followed by U+0300.
There are four basic normalization forms, reproduced here from Table 1 inthe normalization annex document.
Normalization Form Description
NFD canonical decompositionNFC canonical decomposition, followed by
canonical compositionNFKD compatibility decompositionNFKC compatibility decomposition, followed
by canonical composition
The first two forms, NFD and NFC, first perform a canonical decomposition ofcharacter sequences. This breaks compound characters into a base characterplus accent marks, sorting multiple accent marks into a canonical order. Forinstance, the canonical decomposition of the sequence U+0061, U+0300 (smalla followed by grave accent) is the same as that of the single character U+00E0(small a with grave accent), namely the sequence U+0061, U+0300.
In general, a full canonical decomposition continues to decompose charactersinto their components until a sequence of non-decomposible characters is pro-duced. Furthermore, if there is more than one nonspacing mark (like U+0300),then they are sorted into a canonical order.
NFC differs from NFD in that it further puts the characters back together intotheir canonical composed forms, whereas NFD leaves them as a sequence. Ap-plying NFC normalization to either the sequence U+0061, U+0300 or the precom-posed character U+00E0 results in the canonical composed character U+00E0.
The second two forms, NFKD and NFKC, replace the canonical decompositionwith a compatibility decomposition. This reduces different Unicode code pointsthat are in some sense the same character to a common representation. As anexample, the character U+2075, superscript five, is typically written as a super-scripted version of U+0035, digit five, namely as 5. Both involve the underlying

2.2. ENCODING JAVA PROGRAMS 27
character 5. With canonical decomposition, U+2075 is normalized to U+0035.Similarly, the so-called “full width” forms of ASCII characters, U+FF00 to U+FF5E,are often used in Chinese; each has a corresponding ASCII character in U+0021to U+007E to which it is compatibility normalized.
There are special behaviors for multiple combining marks. When recombin-ing, only one mark may wind up being combined, as the character with multiplemarks may not have its own precomposed code point.
There is also special behavior for composites like the ligature character fi,which in Unicode gets its own precomposed code point, U+FB01, latin smallligature fi. Only the compatibility version decomposes the ligature intoU+0066, latin small f, followed by U+0069, latin small i.
Two strings are said to be canonical equivalent if they have the same canonicaldecomposition, and compatibility equivalent if they have the same compatibilitydecomposition.
The normalizations are nice in that if strings are canonical equivalents, thentheir NFC normalizations are the same. If two strings are canonical equivalents,their NFD normalizations are also the same. The NFD normalization and NFCnormalization of a single string are not necessarily the same. The same prop-erties hold for compatibility equivalents and NFKC and NFKD normalizations.Another nice property is that the transformations are stable in that applying anormalization twice (in the sense of applying it once, then applying it again tothe output), produces the same result as applying it once (i.e., its an idemopotenttransformation).
We show how to convert character sequences to their canonical forms progra-matically using the ICU package in Section 2.10.1.
2.2 Encoding Java Programs
Java has native support for many encodings, as well as the ability to plug in addi-tional encodings as the need arises (see Section 2.9.3). Java programs themselvesmay be written in any supported character encoding.
If you use characters other than ASCII characters in your Java programs, youshould provide the javac command with a specification of which character setyou used. If it’s not specified, the platform default is used, which is typicallyWindows-1252 on Windows systems and Latin1 on other systems, but can bemodified as part of the install.
The command line to write your programs in Chinese using Big5 encoding is
javac -encoding Big5 ...
For Ant, you want to use the encoding attribute on the javac task, as in
<javac encoding="Big5" ...
2.2.1 Unicode Characters in Java Programs
Even if a Java program is encoded in a small character set encoding like ASCII, ithas the ability to express arbitrary Unicode characters by using escapes. In a Java

28 CHAPTER 2. CHARACTERS AND STRINGS
program, the sequence \uxxxx behaves like the character U+xxxx, where xxxx isa hexadecimal encoded value padded to four characters with leading zeroes.
For instance, instead of writing
int n = 1;
we could write
\u0069\u006E\u0074\u0020\u006E\u0020\u003D\u0020\u0031\u003B
and it would behave exactly the same way, because i is U+0069, n is U+006E, t isU+0074, the space character is U+0020, and so on, up through;, which is U+003B.
As popular as Unicode is, it’s not widely enough supported in componentslike text editors and not widely enough understood among engineers. Writingyour programs in any character encoding other than ASCII is thus highly errorprone. Our recommendation, which we follow in LingPipe, is to write your Javaprograms in ASCII, using the full \uxxxx form of non-ASCII characters.
2.3 char Primitive Type
Java’s primitive char data type is essentially a 16-bit (two byte) unsigned integer.Thus a char can hold values between 0 and 216−1 = 65535. Furthermore, arith-metic over char types works like an unsigned 16-bit representation, includingcasting a char to a numerical primitive type (i.e., byte, short, int, or long).
Character Literals
In typical uses, instances of char will be used to model text characters. For thisreason, there is a special syntax for character literals. Any character wrapped insingle quotes is treated as a character in a program. For instance, we can assigna character to a variable with
char c = ’a’;
Given the availability of arbitrary Unicode characters in Java programs using thesyntax \uxxxx, it’s easy to assign arbitrary Unicode characters. For instance, toassign the variable c to the character à, U+00E0, use
char c = ’\u00E0’;
Equivalently, because values of type char act like unsigned short integers, it’spossible to directly assign integer values to them, as in
char c = 0x00E0;
The expression \0x00E0 is an integer literal in hexadecimal notation. In general,the compiler will infer which kind of integer is intended.
Because the Java char data type is only 16 bits, the Unicode escape notationonly goes up to U+FFFF.
Several characters may not be used directly within character (or string) liter-als: new lines, returns, form feeds, backslash, or a single quote character. We

2.3. CHAR PRIMITIVE TYPE 29
can’t just drop in a Unicode escape like \u000A for a newline, because that be-haves just like a newline itself. To get around this problem, Java provides somespecial escape sequences which may be used in character and string literals.
Escape Code Point Description
\n U+000A line feed\t U+0009 character tabulation\b U+0008 backspace\r U+000D carriage return\f U+000C form feed\\ U+005C reverse solidus\’ U+0027 apostrophe\" U+0022 quotation mark
For instance, we’d write
char c = ’\n’;
to assign the newline character to the variable c.
Character Arithmetic
A character expression may be assigned to an integer result, as in
int n = ’a’;
After this statement is executed, the value of the variable n will be 97. This isoften helpful for debugging, because it allows the code points for characters tobe printed or otherwise examined.
It’s also possible, though not recommended, to do arithmetic with Java char-acter types. For instance, the expression ’a’+1 is equal to the expression ’b’.
Character data types behave differently in the context of string concatenationthan integers. The expressions ’a’ + "bc" and \u0061 + "bc" are identicalbecause the compiler treats \u0061 and ’a’ identically, because the Unicodecode point for a is U+0061. Both expressions evaluate to a string equal to "abc".
The expression 0x0061 + "bc" evaluates to "97bc", because 0x0061 is takenas a hexadecimal integer literal, which when concatenated to a string, first getsconverted to its string-based decimal representation, "97". There are staticmethods in java.lang.Integer to convert integers to string-based representa-tions. The method Integer.toString(int) may be used to convert an integerto a string-based decimal notation; Integer.toHexString(int) does the samefor hex.
Characters Interpreted as UTF-16
Java made the questionable decision to use 2-byte representations for charac-ters. This is both too wide and too narrow. It’s wasteful for representing text inWestern European languages, where most characters have single-byte represen-tations. It’s also too narrow, in that any code point above U+FFFF requires two

30 CHAPTER 2. CHARACTERS AND STRINGS
characters to represent in Java; to represent code points would require an integer(primitive int type, which is 4 bytes). 5
When char primitives are used in strings, they are interpreted as UTF-16.For any code point that uses only two bytes in UTF-16, this is just the unsignedinteger representation of that code point. This is why UTF-16 seemed so naturalfor representing characters in the original Java language design. Unfortunately,for code points requiring four bytes in UTF-16, Java requires two characters, sonow we have all the waste of 2-bytes per character and all the disadvantages ofhaving Unicode code points that require multiple characters.
2.4 Character Class
Just like for the numerical types, there is a class, Character, used to box anunderlying primitive of type char with an immutable reference. As for numbers,the preferred way to acquire an instance of Character is with the static factorymethod Character.valueOf(char). Autoboxing and unboxing works the sameway as for numerical values.
Like the numerical classes, the Character class is also serializable and com-parable, with comparison being carried out based on interpreting the underlyingchar as an unsigned integer. There are also utilities in Java to sort sequences ofchar values (such as strings) in a locale-specific way, because not every or dialectof a language uses the same lexicographic sorting.
Equality and hash codes are also defined similarly, so that two character ob-jects are equal if and only if they reference the same underlying character.
2.4.1 Static Utilities
The Character class supports a wide range of Unicode-sensitive static utilityconstants and methods in addition to the factory method valueOf().
For each of the Unicode categories, there is a constant, represented using abyte, because the class predates enums. For instance, the general category “Pe” inthe Unicode specification is represented by the constant END_PUNCTUATION andthe general category of mathematical symbols, “Sm” in Unicode, is representedby the constantMATH_SYMBOL.
For many of these constants, there are corresponding methods. For instance,the method getDirectionality(char) returns the directionality of a characteras a byte value, which can then be tested against the possible values representedas static constants. There are also useful methods for determining the categoryof a characer, such as isLetter(char) and isWhitespace(char).
Because multiple Java char instances might be needed to represent a codepoint, there are also methods operating on code points directly using in-teger (primitive int) arguments. For instance, isLetter(int) is the sameas isLetter(char) but generalized to arbitrary code points. The method
5The designers’ choice is more understandable given that there were no code points that used morethan a single pair of bytes for UTF-16 when Java was designed, though Unicode all along advertisedthat it would continue to add characters and was not imposing a 16-bit upper limit.

2.4. CHARACTER CLASS 31
charCount(int) returns the number of char values required to represent thecode point (so the value will be 1 or 2, reflecting 2 or 4 bytes in UTF-16). Themethods isLowSurrogate(char) and isHighSurrogate(char) determine ifthe char represents the first or second half of the UTF-16 representation of acode point above U+FFFF.
The method charPointAt(char[],int) determines the code point thatstarts at the specified index int he array of char. The methodcharPointCount(char[],int,int) returns the number of code points encodedby the specified char array slice.
2.4.2 Demo: Exploring Unicode Types
The full set of character categories recognized by Java is detailed in the con-stant documentation for java.lang.Character. There’s a missing componentto the implementation, which makes it hard to take a given char value (or codepoint) and find its Unicode properties. To that end, we’ve written a utility classUnicodeProperties that displays properties of Unicode. The code just enu-merates the constants in Character, indexes them by name, writes out a key tothe values produced by Character.getType(char) along with their standardabbreviations (as used in regular expressions) and names.
The code may be run from the Ant target unicode-properties. This targetwill print the key to the types, then the type of each character in a range specifiedby the properites low.hex and high.hex (both inclusive).
> ant -Dlow.hex=0 -Dhigh.hex=FF unicode-properties
ID CD TYPE ID CD TYPE0 Cn UNASSIGNED 15 Cc CONTROL
16 Cf FORMAT1 Lu UPPERCASE_LETTER 18 Co PRIVATE_USE2 Ll LOWERCASE_LETTER 19 Cs SURROGATE3 Lt TITLECASE_LETTER4 Lm MODIFIER_LETTER 20 Pd DASH_PUNCTUATION5 Lo OTHER_LETTER 21 Ps START_PUNCTUATION
22 Pe END_PUNCTUATION6 Mn NON_SPACING_MARK 23 Pc CONNECTOR_PUNCTUATION7 Me ENCLOSING_MARK 24 Po OTHER_PUNCTUATION8 Mc COMBINING_SPACING_MARK 29 Pi INITIAL_QUOTE_PUNCTUATION
30 Pf FINAL_QUOTE_PUNCTUATION9 Nd DECIMAL_DIGIT_NUMBER
10 Nl LETTER_NUMBER 25 Sm MATH_SYMBOL11 No OTHER_NUMBER 26 Sc CURRENCY_SYMBOL
27 Sk MODIFIER_SYMBOL12 Zs SPACE_SEPARATOR 28 So OTHER_SYMBOL13 Zl LINE_SEPARATOR14 Zp PARAGRAPH_SEPARATOR
For display, we have organized the results based on primary type. The initialcharacter of a type, which is capitalized, indicates the main category, and the

32 CHAPTER 2. CHARACTERS AND STRINGS
second character, which is lowercase, indicates the subtype. We’ve added extraspace in the output to pick out the groupings. For instance, there are five lettertypes, all of which begin with L, and three number types, which begin with N.
After displaying all types, the program prints out all of the characters inrange (in hex) followed by their type. We specified the entire Latin1 range in theAnt invocation, but only display the first instance of each type rather all 256characters.
CH CD TYPE CH CD TYPE0 Cc CONTROL 41 Lu UPPERCASE_LETTER
20 Zs SPACE_SEPARATOR 5E Sk MODIFIER_SYMBOL21 Po OTHER_PUNCTUATION 5F Pc CONNECTOR_PUNCTUATION24 Sc CURRENCY_SYMBOL 61 Ll LOWERCASE_LETTER28 Ps START_PUNCTUATION A6 So OTHER_SYMBOL29 Pe END_PUNCTUATION AB Pi INITIAL_QUOTE_PUNCTUATION2B Sm MATH_SYMBOL AD Cf FORMAT2D Pd DASH_PUNCTUATION B2 No OTHER_NUMBER30 Nd DECIMAL_DIGIT_NUMBER BB Pf FINAL_QUOTE_PUNCTUATION
Letter Characters
U+0041, latin capital letter a (A), and U+0061, latin small letter a (a), aretyped as uppercase and lowercase letters (Lu and Ll), respectively. All the otherLatin 1 letters, even the ones with accents, are typed as letters.
Number Characters
U+0030, digit zero (0), is marked as a decimal digit number (Nd), as are theother digits.
U+00B2, superscript two (2), is assigned to the other number type (No).
Separator Characters
U+0020, space, the ordinary (ASCII) space character, is typed as a space separator(Zs). There are also types for line separators (Zl) and paragraph separators (Zp),but there are no characters of these types in Latin1.
Punctuation Characters
U+0021, exclamation mark (!) is classified as other punctuation (Po), as isthe question mark (?) and period (.), as well as the pound sign (#), asterisk (*),percentage sign (%), at-sign (@).
Characters U+0028 and U+0029, left parenthesis (() and right parenthe-sis ()), the round parentheses, are assigned start and end punctuation types (Psand Pe), respectively. Other brackets such as the ASCII curly and square varieties,are also assigned start and end punctuation types.
U+002D, hyphen-minus (-), used for hyphenation and for arithmetical sub-traction, is typed as a dash punctuation (Pd). It can also be used as an arithmetic

2.5. CHARSEQUENCE INTERFACE 33
operation, presenting a problem for a typology based on unique types for char-acters. The problem with whitespace (typed as a separator) and newline (typedas a control character) is similar.
U+005F, low line (_), the ASCII underscore character, is typed as connectorpunctuation (Pc).
U+00AB, left-pointing double angle quotation mark («), and U+00BB,right-pointing double angle quotation mark (»), traditionally known as theleft and right guillemet, and used in French like open and close quotation marksin English, are initial quote and final quote punctuation categories, (Pi and Pf),respectively. The “curly” quotes, U+201C (“), and U+201D (”), are also dividedinto open and initial and final quote punctuation.
In contrast, U+0022, quotation mark ("), and U+0027, apostrophe (’), thestandard ASCII undirected quotation mark and apostrophe, are marked as otherpunctuation (Po). This is problematic because they are also used for quotationsin ASCII-formatted text, which is particularly prevalent on the web.
Symbol Characters
U+0024, dollar sign ($), is marked as a currency symbol (Sc), as are the signsfor the euro, the yen, and other currencies.
U+002B, plus sign (+), the symbol for arithmetic addition, is characterized asa math symbol (Sm).
U+005E, circumflex accent (ˆ), is typed as a modifier symbol (Sm). This is amodifier in the sense that it is typically rendered as a circumflex on the followingcharacter.
U+00A6, the Latin1 broken bar, which is usually displayed as a broken hori-zontal bar, is typed as an other symbol (So).
Control Characters
U+0000, <control> null, is the null control character, and is typed as a controlcharacter (Cc). Backspaces, carriage returns, linefeeds, and other control charac-ters get the same type. This can be confusing for newlines and their ilk, whicharen’t treated as space characters in the Unicode typology, but are in contextslike regular expressions.
Although it is usually rendered visually, U+00AD, soft hyphen, is typed as aformat character (Cf). It’s used in typesetting for continuation hyphens used tosplit words across lines. This allows a word split with a hyphen across lines to beput back together. This character shows up in conversions from PDF documentsgenerated by LATEX, such as the one for this book.
2.5 CharSequence Interface
Java provides an interface for dealing with sequences of characters aptly namedCharSequence. It resides in the package java.lang, so it’s automatically im-ported. Implementations include strings and string builders, which we describein the next sections.

34 CHAPTER 2. CHARACTERS AND STRINGS
The character sequence interface specifies a method length() that returnsthe number of characters in the sequence.
The method charAt(int) may be used to return the character at a specifiedposition in the string. Like arrays, positions are numbered starting from zero.Thus the method must be passed an integer in the range from zero (inclusive) tothe length of the string (exclusive). Passing an index that’s out of range raises anIndexOutOfBoundsException, which is also in the java.lang package.
Indexing from position zero (inclusive) to length (exclusive) supports the con-ventional for loop for iterating over items in a sequence,
CharSeqeunce cs = ...;for (int i = 0; i < cs.length(); ++i) {
char c = cs.charAt(i);...
}
Because lengths are instances of int, are only allowed to be as long as the longestpositive int value, 232−1 − 1, which is approximately 2 billion. Any longer se-quence of characters needs to be streamed (e.g., with a Reader or Writer) orscanned (e.g., with a RandomAccessFile).
Creating Subsequences
Given a character sequence, a subsequence may be generated usingsubSequence(int,int), where the two indexes are start position (inclusive)and end position (exclusive). As for charAt, the indexes must be in range (startgreater than or equal to zero and less than or equal to end, and end less than orequal to the sequence length). One nice feature of this inclusive-start/exclusive-end encoding is that the length of the subsequence is the end minus the start.
The mutable implementations of CharSequence approach subsequencing dif-ferently. The StringBuffer and StringBuilder classes return instances ofString, which are immutable. Thus changes to the buffer or builder won’t af-fect any subsequences generated. The CharBuffer abstract class in java.nioreturns a view into itself rather than an independent copy. Thus when the un-derlying buffer changes, so does the subsequence.
Converting Character Sequences to Strings
The last method in CharSequence is toString(), which is specified to return astring that has the same sequence of characters as the character sequence.
Equality and Hashing
The CharSequence interface does not place any constraints on the behaviorof equality or hash codes. Thus two character sequences may contain thesame sequence of characters while not being equal and having different hashcodes. We’ll discuss equality and hash codes for particular implementations ofCharSequence in the next few sections.

2.6. STRING CLASS 35
2.6 String Class
Strings are so fundamental to Java that they have special literals and opera-tors built into the Java language. Functionally, the class String, in the packagejava.lang, provides an immutable implementation of CharSequence. Sequenceimmutability, along with a careful lazy initialization of the hash code, makesstrings thread safe.
Because String is declared to be final, there can be no subclasses definedthat might potentially override useful invariants such as equality, comparability,and serializability. This is particularly useful because strings are so widely usedas constants and method inputs and outputs.
2.6.1 Constructing a String
Strings may be constructed from arrays of integer Unicode code points, arraysof characters, or arrays of bytes. In all cases, a new array of characters is allo-cated to hold the underlying char values in the string. Thus the string becomesimmutable and subsequent changes to the array from which it was constructedwill not affect it.
From Unicode Code Points
When constructing a string from an array of Unicode code points, the code pointsare encoded using UTF-16 and the resulting sequence converted to a sequenceof char values. Not all integers are valid Unicode code points. This constructorwill throw an IllegalArgumentException if there are illegal code points in thesequence.
From char Values
When constructing a string from an array of characters or another string or char-acter sequence, the characters are just copied into the new array. There is nochecking to ensure that the sequence of char values is a legal UTF-16 sequence.Thus we never know if a string is well-formed Unicode.
A string may also be constructed from another string. In this case, a deepcopy is created with its own fresh underlying array. this may seem useless, butconsider the behavior of substring(), as defined below; in this case, construct-ing a new copy may actually save space. Strings may also be constructed bycopying the current contents of a string builder or string buffer (see the nextsection for more about these classes, which implement the builder pattern forstrings).
From Bytes
When constructing a string from bytes, a character encoding is used to convertthe bytes into char values. Typically character encodings are specified by name.Any supported encoding or one of its aliases may be named; the list of availableencodings may be accessed programatically and listed as shown in Section 2.9.3.

36 CHAPTER 2. CHARACTERS AND STRINGS
If a character encoding is not specified, the platform’s default is used, result-ing in highly non-portable behavior.
A character encoding is represented as an instance of CharSet, which is inthe java.nio.charset package. A CharSet may be provided directly to theconstructor for String, or they may be specified by name. Instances of CharSetmay be retrieved by name using the static method CharSet.forName(String).
If a byte sequence can’t be converted to Unicode code points, its behavioris determined by the underlying CharSetDecoder referenced by the CharSetinstance. This decoder will typically replace illegal sequences of bytes with areplacement string determined by CharSetDecoder.replacement(), typically aquestion mark character.
If you need more control over the behavior in the face of illegal byte se-quences, you may retrieve the CharSet by name and then use its newDecoder()method to get a CharSetDecoder.
2.6.2 String Literals
In Java code, strings may be represented as characters surrounded by doublequotes. For instance,
String name = "Fred";
The characters between the quotes can be any characters in the Java program.Specifically, they can be Unicode escapes, so we could’ve written the above re-placing F and e with Unicode escapes, as in
String name = "\u0046r\u0065d";
In practice, string literals essentially create static constants for the strings.Because strings are immutable, the value of string contstants including literals,will be shared. Thus "abc" == "abc" will evaluate to true because the two liter-als will denote reference identical strings. This is carried out as if intern() hadbeen called on constructed strings, as described in Section 2.6.11.
String literals may contain the same character escape sequences as characterliterals (see Section 2.3).
2.6.3 Contents of a String
Strings are very heavy objects in Java. First, they are full-fledged objects, asopposed to the C-style strings consisting only of a pointer into an array. Second,they contain references to an array of characters, char[], holding the actualcharacters, as well as an integer start index into that array and an integer length.They also store their hash code as an integer. Thus an empty string will be 36bytes in the 32-bit Sun/Oracle JVM and 60 bytes in the 64-bit JVM.6
6The JVM option -XX:+UseCompressedOops will reduce the memory footprint of 64-bit objects tothe same size as 32-bit objects in many cases.

2.6. STRING CLASS 37
2.6.4 String Equality and Comparison
Two strings are equal if they have the same length and the same character ateach position. Strings are not equal to objects of any other runtime class, evenother implementations of CharSequence.
Strings implement Comparable<String> in a way that is consistent withequality. The order they use is lexicographic sort over the underlying char val-ues. This is exactly the way words are sorted in dictionaries. The easiest way todefine lexicographic sort is with code, here comparing strings s and t.
for (int i = 0; i < Math.min(s.length(),t.length()); ++i)if (s.charAt(i) != t.charAt(i))
return s.charAt(i) - t.charAt(i);return s.length() - t.length();
We walk over both strings from the beginning until we find a position wherethe characters are different, at which point we return the difference.7 For in-stance, "abc" is less than "abde" "ae", and "e". If we finish either string, wereturn the difference in lengths. Thus "a" is less than "ab". If we finish one ofthe strings and the strings are the same length, we return zero, because they areequal.
2.6.5 Hash Codes
The hash code for a string s is computed as if by
int hashCode = 0;for (int i = 0; i < s.length(); ++i)
hashCode = 31 * hashCode + s.charAt(i);
This definition is consistent with equals in that two equal strings have the samecharacter sequence, and hence the same hash code.
Because the hash code is expensive to compute, requiring an assignment, addand multiply for each character, it is lazily initialized. What this means is thatwhen hash code is called, if there is not a value already, it will be computed andstored. This operation is thread safe without synchronization because integerassignment is atomic and the sequence of characters is immutable.
2.6.6 Substrings and Subsequences
The substring(int,int) and method return subsequences of a string spec-ified by a start position (inclusive) and an end position (exclusive). ThesubSequence(int,int) method just delegates to the substring method.
When a substring is generated from a string, it shares the same array as thestring from which it was generated. Thus if a large string is created and a sub-string generated, the substring will actually hold a reference to a large array, po-tentially wasting a great deal of memory. Alternatively, if a large string is created
7Conveniently, char values are converted to integers for arithmetic, allowing negative results forthe difference of two values. Also, because string lengths are non-negative, there can’t be underflowor overflow in the difference.

38 CHAPTER 2. CHARACTERS AND STRINGS
and a large number of substrings are created, this implementation potentiallysaves space.
A copy of the character array underlying the string is returned bytoCharArray().
2.6.7 Simple Pattern Matching
Simple text processing may be carried out using methods supplied by String.For instance, endsWith(String) and startsWith(String) return boolean val-ues based on whether the string has the specified exact suffix or prefix. Thesecomparisons are carried out based on the underlying char[] array. There is alsoa multiple argument regionMatches() method that compares a fixed numberthe characters starting at a given position to be matched against the charactersstarting at a different position in a second string.
There is also a method contains(CharSequence), which returns true if thestring contains the characters specified by the character sequence argument asa substring. And there is a method contentEquals(CharSequence) that com-pares the character content of the string with a character sequence.
The indexOf(char,int) method returns the index of the first appearanceof a character after the specified position, and lastIndexOf(char,int) doesthe same thing in reverse, returning the last instance of the character before thespecified position. There are also string-based methods, indexOf(String,int)and lastIndexOf(String,int).
2.6.8 Manipulating Strings
Several useful string manipulation methods are provided, such as trim(), whichreturns a copy of the string with no whitespace at the front or end of the string.The methods toLowerCase(Locale) and toUpperCase(Locale) return a copyof the string in the specified locale.
2.6.9 Unicode Code Points
The string class also defines methods for manipulating Unicode code points,which may be coded by either one or two underlying char values. The methodcodePointAt(int) returns the integer code point starting at the specified index.To find out the length of a string in unicode code points, there is the methodcodePointCount(int,int) which returns the number of Unicode code pointscoded by the specified range of underlying characters. It is up to the user to getthe boundaries correct.
2.6.10 Testing String Validity
LingPipe provides a static utility method isValidUTF16(CharSequence) in theStrings class in the com.aliasi.util package. This method checks that ev-ery high surrogate UTF-16 char value is followed by a low surrogate UTF-16

2.6. STRING CLASS 39
value. Surrogacy is defined as by Java’s Character.isHighSurrogate() andCharacter.isLowSurrogate() methods (see Section 2.4.1).
2.6.11 Interning Canonical Representations
The JVM keeps an underlying pool of string constants. A call to intern() ona string returns a string in the constant pool. The method intern() returns astring that is equal to the string on which it is called, and is furthermore referenceidentical to any other equal string that has also been interned.
For example, suppose we call
String s = new String("abc");String t = new String("abc");
The expression s.equals(t) will be true, but s == t will be false. The construc-tor new always constructs new objects. Next, consider calling
String sIn = s.intern();String tIn = t.inern();
Afterwards, sIn == tIn will return true, as will sIn.equals(tIn). The internedstrings are equal to their originals, so that sIn.equals(s) and tIn.equals(t)also return true.
2.6.12 Utility Methods
There are a number of convenience methods in the string class that reproducebehavior available elsewhere.
Regular Expression Utilities
The string class contains various split() and replaceX() methods based onregular expressions. For instance, split(String) interprets its argument as aregular expression and returns an array of strings containing the sequences oftext between matches of the specified pattern. Matching is defined as in theregular expression method Matcher.find().
String Representations of Primitives
The string class contains a range of static valueOf() methods for convert-ing primitives, objects, and arrays of characters to strings. For instance,valueOf(double) converts a double-precision floating point value to a stringusing the same method as Double.toString(double).
2.6.13 Example Conversions
We wrote a simple program to illustrate encoding and decoding between stringsand byte arrays.

40 CHAPTER 2. CHARACTERS AND STRINGS
public static void main(String[] args)throws UnsupportedEncodingException {
System.setOut(new PrintStream(System.out,true,"UTF-8"));
String s = "D\u00E9j\u00E0 vu";System.out.println(s);
String encode = args[0];String decode = args[1];
byte[] bs = s.getBytes(encode);String t = new String(bs,decode);
First, the string Déjà vu is assigned to variable s. The string literal uses twoUnicode escapes, \u00E9 for é and \u00E0 for à. The name of the characterencoding to use for encoding and decoding are read from the command line.
Then we convert the string s to an array of bytes bs using the character encod-ing encode. Next, we reconstitute a string using the bytes we just created usingthe character encoding decode. Either of these methods may raise an exceptionif the specified encoding is not supported, so the main() method is declared tothrow an UnsupportedEncodingException, imported from java.io. The restof the code just prints the relevant characters and bytes.
There is an Ant target byte-to-string that’s configured to take two argu-ments consisting of the names of the character encodings. The first is used toconvert a string to bytes and the second to convert the bytes back to a string. Forinstance, to use UTF-8 to encode and Latin1 (ISO-8859-1) to decode, the programprints
> ant -Dencode=UTF-8 -Ddecode=Latin1 byte-to-string
char[] from string44 e9 6a e0 20 76 75
byte[] from encoding with UTF-844 c3 a9 6a c3 a0 20 76 75
char[] from decoding with Latin144 c3 a9 6a c3 a0 20 76 75
The characters are printed using hexadecimal notation. The initial line of char-acters is just what we’d expect; for instance the char value 44 is the code pointand UTF-16 representation of U+0044, latin capital letter d, char e9 picksout U+00E9, latin small letter e with acute, and so on.
We have printed out the bytes using unsigned hexadecimal notation (see Ap-pendix D.1.5 for more information about signs and bytes). Note that there aremore bytes than char values. This is because characters above U+0080 requiretwo bytes or more to encode in UTF-8 (see Section 2.1.4). For instance, the se-quence of bytes 0xC3, 0xA9 is the UTF-8 encoding of U+00E9, Latin small let-ter e with acute.
We use Latin1 to decode the bytes back into a sequence of char values.Latin1 simply translates the bytes one-for-one into unsigned characters (see Sec-tion 2.1.3. This is fine for the first byte, 0x44, which corresponds to U+0044, but

2.7. STRINGBUILDER CLASS 41
things go wrong for the second character. Rather than recover the single charvalue U+00E9, we have 0xC3 and 0xA9, which are U+00C3, latin capital lettera with tilde, and U+00A9, copyright sign. Further down, we see 0xA0, whichrepresents U+00A0, no-break space. Thus instead of getting Déjà vu back, weget D©Ãj© vu.
If we use -Dencode=UTF-16 when invoking the Ant target byte-to-string,we get the bytes
byte[] from encoding with UTF-16fe ff 0 44 0 e9 0 6a 0 ...
The first two bytes are the byte-order marks U+00FE and U+00FF; in this order,they indicate big-endian (see Section 2.1.4). The two bytes after the byte-ordermarks are 0x0 and 0x44, which is the UTF-16 big-endian representation of thecharacter U+0044, latin capital letter d. Similarly, 0x0 and 0xE9 are the UTF-16 big-endian representation of U+00E9, latin small letter e with acute. TheUTF-16 encoding is twice as long as the Latin1 encoding, plus an additional twobytes for the byte-order marks.
2.7 StringBuilder Class
The StringBuilder class is essentially a mutable implementation of theCharSequence interface. It contains an underlying array of char values, which itresizes as necessary to support a range of append() methods. It implements astandard builder pattern for strings, where after adding content, toString() isused to construct a string based on the buffered values.
A typical use would be to create a string by concatenating the members of anarray, as in
String[] xs = ...;StringBuilder sb = new StringBuilder();for (String x : xs)
sb.append(x);String s = sb.toString();
First a string builder is created, then values are appended to it, then it is con-verted to a string. When a string builder is converted to a string, a new array isconstructed and the buffered contents of the builder copied into it.
The string builder class lets you append any type of argument, with theeffect being the same as if appending the string resulting from the matchingString.valueOf() method. For instance, non-null objects get converted us-ing their toString() methods and null objects are converted to the string null.Primitive numbers converted to their decimal notation, using scientific notationif necessary, and booleans to either true or false.
The underlying array for buffering characters starts at length 16 by default,though may be set explicitly in the constructor. Resizing adds one to the lengththen doubles it, leading to roughly log (base 2) resizings in the length of thebuffer (e.g., 16, 34, 70, 142, 286, 574, . . . ). Because string builders are rarely used

42 CHAPTER 2. CHARACTERS AND STRINGS
in locations that pose a computational bottleneck, this is usually an acceptablebehavior.
In cases where character sequence arguments suffice, this allows us to bypassthe construction of a string altogether. Thus many of LingPipe’s methods acceptcharacter sequence inputs without first converting to strings.
2.7.1 Unicode Support
The append method appendCodePoint(int) appends the characters represent-ing the UTF-16 encoding of the specified Unicode code point. The builderalso supports a codePointAt(), codePointBefore(), and codePointCount()methods with behavior like those for strings.
2.7.2 Modifying the Contents
String builders are mutable, and hence support operations likesetCharAt(int,char), which replaces a single character, andinsert(int,String) and the longer form replace(int,int,String),which splice the characters of a string into the buffer in place of the specifiedcharacter slice. There is also a setLength(int) method which changes thelength of the charactr sequence, either shrinking or extending the underlyingbuffer as necessary.
2.7.3 Reversing Strings
The method reverse() method in StringBuilder reverses the char values ina string, except valid high-low surrogate pairs, which maintain the same order-ing. Thus if the string builder holds a well-formed UTF-16 sequence representinga sequence of code points, the output will be the well-formed UTF-16 sequencerepresenting the reversed sequence of code points. For instance, the String lit-eral "\uDC00\uD800" constructs a string whose length() returns 2. Because\uDC00 is a high-surrogate UTF-16 char value and \uD800 is a low-surrogate, to-gether they pick out the single code point U+10000, the first code point beyondthe basic multilingual plane. We can verify this by evaluating the expression"\uDC00\uD800".codePointAt(0) and verifying the result is 0x10000.
2.7.4 Chaining and String Concatenation
Like many builder implementations, string builders let you chain arguments.Thus it’s legal to write
int n = 7; String s = "ABC"; boolean b = true;char c = ’C’; Object z = null;String s = new StringBuilder().append(n).append(s).append(b)
.append(c).append(z).toString();
with the reslt that string s has a value equal to the literal "7ABCtrueCnull".

2.8. CHARBUFFER CLASS 43
In fact, this is exactly the behavior underlying Java’s heavily overloaded addi-tion (+) operator. When one of the arguments to addition is a string, the otherargument is converted to a string as if by the appropriate String.valueOf()method. Thus an equivalent way to write the chaining build above is
String s = 7 + " foo";
Multiple additions of strings just get unfolded to multiple appends.
2.7.5 Equality and Hash Codes
The StringBuilder class does not override the definitions of equality or hashcodes in Object. Thus two string builders are equal only if they are referenceequal. In particular, string builders are never equal to strings. There is a utilitymethod on strings, String.contentEquals(CharSequence) method which re-turns true if the char sequence is the same length as the string and contains thesame character as the string at each position.
2.7.6 String Buffers
The class StringBuffer, which predates StringBuilder, is essentially a stringbuilder with synchronization. Because it is rarely desirable to write to a stringbuffer concurrently, StringBuffer has all but disappeared from contemporaryJava programs.
2.8 CharBuffer Class
The CharBuffer class resides in the java.nio package along with correspond-ing classes for other primitive types, such as ByteBuffer and IntBuffer. Thesebuffers all hold sequences of their corresponding primitive types and provideefficient means to bulk load or bulk dump sequences of the primitive values theyhold.
2.8.1 Basics of Buffer Positions
The buffers all extend the Buffer class, also from java.nio. Buffers may becreated backed by an array that holds the appropriate primitive values, thougharray backing is not required.
Every buffer has four important integer values that determine how it behaves,its capacity, position, mark and limit. Buffers may thus only have a capacity ofup to Integer.MAX_VALUE (about 2 billion) primitive values.
The capacity of a buffer is available through the capacity() method. This isthe maximum number of items the buffer can hold.
The position of a buffer is available through the position() method andsettable with setPosition(int). The position is the index of the next valueto be accessed. The position must always be between zero (inclusive) and thebuffer’s capacity (inclusive).

44 CHAPTER 2. CHARACTERS AND STRINGS
Relative read and write operations start at the current position and incrementthe position by the number of primitive values read or written. Underflow oroverflow exceptions will be thrown if there are not enough values to read or writerespectively. There are also absolute read and write operations which require anexplicit index.
The limit for a buffer indicates the first element that should not be read orwritten to. The limit is always between the position (inclusive) and the capacity(inclusive).
Three general methods are used for resetting these values. The clear()method sets the limit to the capacity and the position to zero. The flip()method sets the limit to the current position and the position to zero. Therewind() method just sets the position to zero.
All of the buffers in java.nio also implement the compact() operation,which moves the characters from between the current position and the limit tothe start of the buffer, resetting the position to be just past the moved characters(limit minus original position plus one).
Finally, the mark for a buffer indicates the position the buffer will have aftera call to reset(). It may be set to the current position using mark(). The markmust always be between the zero (inclusive) and the position (inclusive).
2.8.2 Equality and Comparison
Equality and comparison work on the remaining characters, which is thesequence of characters between the current position and the limit. TwoCharBuffer instances are equal if they have the same number of (remaining)elements and all these elements are the same. Thus the value of hashCode()only depends on the remaining characters. Similarly, comparison is done lexico-graphically using the remaining characters.
Because hash codes for buffers may change as their elements change, theyshould not be put into collections based on their hash code (i.e., HashSet orHashMap) or their natural order (i.e., TreeSet or TreeMap).
The length() and charAt(int) methods from CharSequence are also de-fined relative to the remaining characters.
2.8.3 Creating a CharBuffer
A CharBuffer of a given capacity may be created along with a new backing arrayusing CharBuffer.allocate(int); a buffer may also be created from an exist-ing array using CharBuffer.wrap(char[]) or from a slice of an existing array.Wrapped buffers are backed by the specified arrays, so changes to them affectthe buffer and vice-versa.
2.8.4 Absolute Sets and Gets
Values may be added or retrieved as if it were an array, using get(int), whichreturns a char, and set(int,char), which sets the specified index to the speci-fied char value.

2.9. CHARSET CLASS 45
2.8.5 Relative Sets and Gets
There are also relative set and get operations, whose behavior is based on theposition of the buffer. The get() method returns the character at the currentposition and increments the position. The put(char) method sets the characterat the current position to the specified value and increments the position.
In addition to single characters, entire CharSequence or char[] values orslices thereof may be put into the array, with overflow exceptions raised if notall values fit in the buffer. Similarly, get(char[]) fills the specified characterarray starting from the current position and increments the position, throwing anexception if there are not enough characters left in the buffer to fill the specifiedarray. The portion of the array to fill may also be specified by slice.
The idiom for bulk copying between arrays is to fill the first array using rela-tive puts, flip it, then copy to another array using relative gets. For instance, touse a CharBuffer to concatenate the values in an array, we might use8
String[] xs = ...;CharBuffer cb = CharBuffer.allocate(1000);for (String s : ss)
cb.put(s);flip();String s = cb.toString();
After the put() operations in the loop, the position is after the last character.If we were to dump to a string at this point, we would get nothing. So we callflip(), which sets the position back to zero and the limit to the current position.Then when we call toString(), we get the values between zero and the limit,namely all the characters we appended. The call to toString() does not modifythe buffer.
2.8.6 Thread Safety
Buffers maintain state and are not synchronized for thread safety. Read-writesynchronization would be sufficient.
2.9 Charset Class
Conversions between sequences of bytes and sequences of characters are car-ried out by three related classes in the java.nio.charset package. A characterencoding is represented by the confusingly named Charset class. Encoding char-acters as bytes is carried out by an instance of CharsetDecoder and decoding byan instance of CharsetEncoder. All characters are represented as usual in Javawith sequences of char values representing UTF-16 encodings of Unicode.
Encoders read from character buffers and write to byte buffers and de-coders work in the opposite direction. Specifically, they use the java.nio
8Actually, a StringBuilder is better for this job because its size doesn’t need to be set in advancelike a CharBuffer’s.

46 CHAPTER 2. CHARACTERS AND STRINGS
classes CharBuffer and ByteBuffer. The class CharBuffer implementsCharSequence.
2.9.1 Creating a Charset
Typically, instances of Charset and their corresponding encoders and decodersare specified by name and accessed behind the scenes. Examples include con-structing strings from bytes, converting strings to bytes, and constructing charstreams from byte streams.
Java’s built-in implementations of Charset may be accessed by name with thestatic factory method CharSet.forName(String), which returns the characterencoding with a specified name.
It’s also possible to implement subclasses of Charset by implementing theabstract newEncoder() and newDecoder() methods. Decoders and encodersneed to define behavior in the face of malformed input and unmappable charac-ters, possibly defining replacement values. So if you must have Morse code, it’spossible to support it directly.
2.9.2 Decoding and Encoding with a Charset
Once a Charset is obtained, its methods newEncoder() and newDecoder()may be used to get fresh instances of CharsetEncoder and CharsetDecoderas needed. These classes provide methods for encoding char buffers as bytebuffers and decoding byte buffers to char buffers. The Charset class also pro-vides convenience methods for decoding and encoding characters.
The basic encoding method is encode(CharBuffer,ByteBuffer,boolean),which maps the byte values in the ByteBuffer to char values in theCharBuffer. These buffer classes are in java.nio. The third argument is aflag indicating whether or not the bytes are all the bytes that will ever be coded.It’s also possible to use the canEncode(char) or canEncode(CharSequence)methods to test for encodability.
The CharsetEncoder determines the behavior in the face of unmap-pable characters. The options are determined by the values of classCodingErrorAction (also in java.nio.charset).9The three actions al-lowed are to ignore unmappable characters (static constant IGNORE inCodingErrorAction), replace them with a specified sequence of bytes(REPLACE), or to report the error, either by raising an exception or througha return value (REPORT). Whether an exception is raised or an exceptional re-turn value provided depends on the calling method. For the replacement op-tion, the bytes used to replace an unmappable character may be set on theCharsetEncoder using the replaceWith(byte[]) method.
The CharsetDecoder class is similar to the encoder class, only moving froma CharBuffer back to a ByteBuffer. The way the decoder handles malformed
9The error action class is the way type-safe enumerations used to be encoded before enums wereadded diretly to the language, with a private constructor and a set of static constant implementations.

2.9. CHARSET CLASS 47
sequences of bytes is similar to the encoder’s handling of unmappable charac-ters, only allowing a sequence of char as a replacement rather than a sequenceof byte values.
The CharsetEncoder and CharsetDecoder classes maintain buffered state,so are not thread safe. New instances should be created for each encoding anddecoding job, though they may be reused after a call to reset().
2.9.3 Supported Encodings in Java
Each Java installation supports a range of character encodings, with one charac-ter encoding serving as the default encoding. Every compliant Java installationsupports all of the UTF encodings of Unicode. Other encodings, as specifiedby Charset implementations, may be added at the installation level, or imple-mented programatically within a JVM instance.
The supported encodings determine what characters can be used to write Javaprograms, as well as which character encoding objects are available to convertsequences of bytes to sequences of characters.
We provide a class com.lingpipe.book.char.SupportedEncodings to dis-play the default encoding and the complete range of other encodings supported.The first part of the main pulls out the default encoding using a static method ofjava.nio.charset.Charset,
Charset defaultEncoding = Charset.defaultCharset();
The code to pull out the full set of encodings along with their aliases is
Map<String,Charset> encodings = Charset.availableCharsets();for (Charset encoding : encodings.values()) {
Set<String> aliases = encoding.aliases();
The result of running the program is
> ant available-charsets
Default Encoding=windows-1252
Big5csBig5
...x-windows-iso2022jp
windows-iso2022jp
The program first writes out the default encoding. This is windows-1252 onmy Windows install. It’s typically ISO-8859-1 on Linux installs in the UnitedStates. After that, the program writes all of the encodings, with the official namefollowed by a list of aliases that are also recognized. We ellided most of theoutput, because there are dozens of encodings supported.

48 CHAPTER 2. CHARACTERS AND STRINGS
2.10 International Components for Unicode
The International Components for Unicode (ICU) provide a range of useful opensource tools, licensed under the X license (seeSection G.5), for dealing with Uni-code and internationalization (I18N). Mark Davis, the co-developer of Unicodeand president of the Unicode Consortium, designed most of ICU including theJava implementation, and is still active on its project management committee.The original implementation was from IBM, so the class paths still reflect thatfor backward compatibility, though it is now managed independently.
The home page for the package is
http://icu-project.org/
The package has been implemented in both Java and C, with ICU4J being theJava version. There is javadoc, and the user guide section of the site containsextensive tutorial material that goes far beyond what we cover in this section. Itis distributed as a Java archive (jar) file, icu4j-Version.jar, which we includein the $BOOK/lib directory of this book’s distribution. There are additional jarfiles available on the site to deal with even more character encodings and localeimplementations.
We are primarily interested in the Unicode utilities for normalization of char-acter sequences to canonical representations and for auto-detecting characterencodings from sequences of bytes. ICU also contains a range of locale-specificformatting utilities, time calculations and collation (sorting). It also containsdeeper linguistic processing, including boundary detection for words, sentencesand paragraphs as well as transliteration between texts in different languages.
2.10.1 Unicode Normalization
ICU implements all the Unicode normalization schemes (see Section 2.1.4). Thefollowing code shows how to use NFKC, the normalization form that uses com-patibility decomposition, followed by a canonical composition.
Normalizer2 normalizer= Normalizer2.getInstance(null,"nfkc",Mode.COMPOSE);
String s1 = "\u00E0"; // a with graveString s2 = "a\u0300"; // a, grave
String n1 = normalizer.normalize(s1);String n2 = normalizer.normalize(s2);
The ICU class Normalizer2 is defined in the package com.ibm.icu.text. Thereis no public constructor, so we use the rather overloaded and confusing staticfactory method getInstance() to create a normalizer instance. The first argu-ment is null, which causes the normalizer to use ICU’s definitions of normal-ization rather than importing definitions through an input stream. The secondargument, "nfkc" is an unfortunately named string contstant indicating thatwe’ll use NFKC or NFKD normalization. The third argument is the static con-stant COMPOSE, from the static nested class Normalizer2.Mode, which says that

2.10. INTERNATIONAL COMPONENTS FOR UNICODE 49
we want to compose the output, hence producing NFKC. Had we used the con-stant DECOMPOSE for the third argument, we’d get an NFKD normalizer. Finally,it allows case folding after the NFKC normalization by specifying the second ar-gument as "nfkc_cf".
Once we’ve constructed the normalizer, using it is straightforward. We justcall its normalize() method, which takes a CharSequence argument. We firstcreated two sequences of Unicode characters, U+00E0 (small a with grave accent),and U+0061, U+0300 (small a followed by grave accent). After that, we just printout the char values from the strings.
> ant normalize-unicode
s1 char values= e0s2 char values= 61, 300n1 char values= e0n2 char values= e0
Clearly the initial strings s1 and s2 are different. Their normalized forms, n1and n2, are both the same as s1, because we chose the composing normalizationscheme that recomposes compound characters to the extent possible.
2.10.2 Encoding Detection
Unfortunately, we are often faced with texts with unknown character encodings.Even when character encodings are specified, say for an XML document, theycan be wrong. ICU does a good job at detecting the character encoding froma sequence of bytes, although it only supports a limited range of character en-codings, not including the pesky Windows-1252, which is highly confusible withLatin1 and just as confuisble with UTF-8 as Latin1. It’s also problematic for Javause, because the default Java install on Windows machines uses Windows-1252as the default character encoding.
We created a sample class $BOOK/DetectEncoding, which begins its main()method by extracting (and then displaying) the detectable character encodings,
String[] detectableCharsets= CharsetDetector.getAllDetectableCharsets();
These are the only encodings that will ever show up as return values from detec-tion.
The next part of the program does the actual detection
String declared = "ISO-8859-1";String s = "D\u00E9j\u00E0 vu.";String[] encodings = { "UTF-8", "UTF-16", "ISO-8859-1" };for (String encoding : encodings) {
byte[] bs = s.getBytes(encoding);CharsetDetector detector = new CharsetDetector();detector.setDeclaredEncoding(declared);detector.setText(bs);CharsetMatch[] matches = detector.detectAll();

50 CHAPTER 2. CHARACTERS AND STRINGS
First, it sets a variable that we’ll use for the declared encoding, ISO-8859-1, a vari-able for the string we’ll decode, Déjà vu, and an array of encodings we’ll test. Foreach of those encodings, we set the byte array bs to result of getting the bytesusing the current encoding. We then create an instance of CharsetDetector(in com.ibm.icu.text) using the no-arg constructor, set its declared encoding,and set its text to the byte array. We then generate an array of matches us-ing the detecAll() method on the detector. These matches are instances ofCharsetMatch, in the same pacakge.
The rest of our the code just iterates through the matches and prints them.
for (CharsetMatch match : matches) {String name = match.getName();int conf = match.getConfidence();String lang = match.getLanguage();String text = match.getString();
For each match, we grab the name name of the character encoding, the integerconfidence value, which will range from 0 to 100 with higher numbers beingbetter, and the inferred language, which will be a 3-letter ISO code. We also getthe text that is produced by using the specified character encoding to convertthe string. These are then printed, but instead of printing the text, we just printwhether its equal to our original string s.
The result of running the code is
> ant detect-encoding
Detectable Charsets=[UTF-8, UTF-16BE, UTF-16LE, UTF-32BE,UTF-32LE, Shift_JIS, ISO-2022-JP, ISO-2022-CN, ISO-2022-KR,GB18030, EUC-JP, EUC-KR, Big5, ISO-8859-1, ISO-8859-2,ISO-8859-5, ISO-8859-6, ISO-8859-7, ISO-8859-8, windows-1251,windows-1256, KOI8-R, ISO-8859-9, IBM424_rtl, IBM424_ltr,IBM420_rtl, IBM420_ltr]
encoding=UTF-8 # matches=3guess=UTF-8 conf=80 lang=null
chars= 44 e9 6a e0 20 76 75 2eguess=Big5 conf=10 lang=zh
chars= 44 77c7 6a fffd 20 76 75 2e...
encoding=UTF-16 # matches=4guess=UTF-16BE conf=100 lang=null
chars= feff 44 e9 6a e0 20 76 75 2eguess=ISO-8859-2 conf=20 lang=cs
chars= 163 2d9 0 44 0 e9 0 6a 0 155 0 20 0 ......
encoding=ISO-8859-1 # matches=0

2.10. INTERNATIONAL COMPONENTS FOR UNICODE 51
Overall, it doesn’t do such a good job on short strings like this. The only fullycorrect answer is for UTF-8, which retrieves the correct sequence of char values.
The UTF-16BE encoding is the right guess, but it messes up the conversion totext by concatenating the two byte order marks FE and FF indicating big-endianinto a single char with value 0xFEFF. The detector completely misses the Latin1encoding, which seems like it should be easy.
The language detection is very weak, being linked to the character encoding.For instance, if the guessed encoding is Big5, the language is going to be Chinese(ISO code “zh”).
Confidence is fairly low all around other than UTF-16BE, but this is mainlybecause we have a short string. In part, the character set detector is operatingstatistically by weighing how much evidence it has for a decision.
2.10.3 General Transliterations
ICU provides a wide range of transforms over character sequences. For instance,it’s possible to transliterate Latin to Greek, translate unicode to hexadecimal, andto remove accents from outputs. Many of the transforms are reversible. Becausetransforms are mappings from strings to strings, they may be composed. So wecan convert Greek to Latin, then then remove the accents, then convert to hex-adecimal escapes. It’s also possible to implement and load your own transforms.
Using transliteration on strings is as easy as the other interfaces in ICU. Justcreate the transliterator and apply it to a string.
Built-In Transliterations
We first need to know the available transliterations, the identifiers ofwhich are avaialble programatically. We implement a main() method inShowTransliterations as follows
Enumeration<String> idEnum = Transliterator.getAvailableIDs();while (idEnum.hasMoreElements())
System.out.println(idEnum.nextElement());
The ICU Transliterator class is imported from the package.com.ibm.icu.text. We use its static method getAvailableIDs() to pro-duce an enumeration of strings, which we then iterate through and print out.10
An abbreviated list of outputs (converted to two columns) is
> ant show-transliterations10The Enumeration interface in the package java.util from Java 1.0 has been all but deprecated
in favor of the Iterator interface in the same package, which adds a remove method and shortensthe method names, but is otherwise identical.

52 CHAPTER 2. CHARACTERS AND STRINGS
Accents-AnyAmharic-Latin/BGNAny-AccentsAny-PublishingArabic-Latin...Latin-CyrillicLatin-DevanagariLatin-GeorgianLatin-Greek...Han-LatinHangul-LatinHebrew-LatinHebrew-Latin/BGN
Hiragana-KatakanaHiragana-Latin...Persian-Latin/BGNPinyin-NumericPinyin...Any-NullAny-RemoveAny-Hex/UnicodeAny-Hex/Java...Any-NFCAny-NFDAny-NFKC...
The transliterations are indexed by script, not by language. Thus there is noFrench or English, just Latin, because that’s the script. There is only so muchthat can be done at the script level, but the transliterations provided by ICU aresurprisingly good.
In addition to the transliteration among scripts like Arabic and Hiragana,there are also transforms based on Unicode itself. For instance, the Any-Removetransliteration removes combining characters, and thus may be used to con-vert accented characters to their deaccented forms across all the scripts in Uni-code. There areal so conversions to hexadecimal representation; for instanceAny-Hex/Java converts to hexadecimal char escapes suitable for inclusion in aJava program. The normalizations are also avaialble through Any-NFC and so on.
Transliterating
The second demo class is Transliterate, which takes two command line ar-guments, a string to transliterate and a transliteration scheme, and prints theoutput as a string and as a list of char values. The body of the main() methodperforms the transliteration as follows.
String text = args[0];String scheme = args[1];Transliterator trans = Transliterator.getInstance(scheme);String out = trans.transliterate(text);
First we collect the text and transliteration scheme from the two command-linearguments. Then, we create a transliterator with the specified scheme usingthe static factory method getInstance(). Finally, we apply the newly createdtransliterator’s transliterate() method to the input to produce the output.
We use the Ant target transliterate which uses the properties text andscheme for the text to transliterate and coding scheme respectively.
> ant -Dtext="taxi cab" -Dscheme=Latin-Greek transliterate

2.10. INTERNATIONAL COMPONENTS FOR UNICODE 53
Scheme=Latin-GreekInput=taxi cabOutput=???? ???Output char values
3c4 3b1 3be 3b9 20 3ba 3b1 3b2
The reason the output looks like ???? ??? is that it was cut and pasted fromthe Windows DOS shell, which uses the Windows default Java character encod-ing, Windows-1252, which cannot represent the Greek letters (see Section 4.17for information on how to change the encoding for the standard output). Forconvenience, we have thus dumped the hexadecimal representations of the char-acters. For instance, U+03c4, greek small letter tau, is the character τ andU+03b1, greek small letter alpha, is α. The entire string is ταξι καβ, whichif you sound it out, is roughly the same as taxi cab in Latin.
To see how transliteration can be used for dumping out hex character values,consider
> ant -Dtext=abe -Dscheme=Any-Hex/Java transliterate
Input=abeOutput=\u0061\u0062\u0065
The output may be quoted as a string and fed into Java. Translations are alsoreversible, so we can also do it the other way around,
> ant -Dtext=\u0061\u0062\u0065 -Dscheme=Hex/Java-Any transliterate
Input=\u0061\u0062\u0065Output=abe
Filtering and Composing Transliterations
The scope of transforms may be filtered. For instance, if we write [aeiou]Upper, the lower-case ASCII letters are transformed to upper case. For exam-ple, using our demo program, we have
> ant -Dtext="abe" -Dscheme="[aeiou] Upper" transliterate
Scheme=[aeiou] UpperInput=abeOutput=AbE
Transforms may also be composed. For any transforms A and B, the trans-form A; B first applies the transform A, then the transform B. Filters are es-pecially useful when combined with composition. For example, the transformNFD; [:Nonspacing Mark:] Remove; NFC composes three transforms, NFD,[:Nonspacing Mark:] Remove, and NFC. The first transform performs canoni-cal character decomposition (NFD), the second removes the non-spacing marks,such as combining characters, and the third performs a canonical composition(NFC). We can demo this with the string déjà, which we encode using Javaescapes as \u0064\u00E9\u006a\u00E0, by first prefixing the transform withHex/Java-Any to convert the escapes to Unicode. The output is

54 CHAPTER 2. CHARACTERS AND STRINGS
Scheme=Hex/Java-Any; NFD; [:Nonspacing Mark:] Remove; NFCInput=\u0064\u00E9\u006a\u00E0Output=deja

Chapter 3
Regular Expressions
Generalized regular expressions, as implemented in Java and all the scriptinglanguages like Perl and Python, provide a general means for describing spansof Unicode text. Given a regular expression (regex) and some text, basic regexfunctionality allows us to test whether a string matches the regex or find non-overlapping substrings of a string matching the regex.
3.1 Matching and Finding
Despite the rich functionality of regexes, Java’s java.util.regex package con-tains only two classes, Pattern and Matcher. An instance of Pattern providesan immutable representation of a regular expression. An instance of Matcherrepresents the state of the matching of a regular expression against a string.
3.1.1 Matching Entire Strings
It’s easiest to start with an example of using a regular expression for matching,which we wrote as a main() method in the class RegexMatch, the work of whichis done by
String regex = args[0];String text = args[1];
Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(text);boolean matches = matcher.matches();
First, we read the regex from the first command-line argument, then the text fromthe second argument. We then use the regular expression to compile a pattern,using the static factory method pattern.compile(). This pattern is reusable.We next create a matcher instance, using the method matcher() on the patternwe just created. Finally, we assign a boolean variable matches the value of callingthe method matches() on the matcher. And then we print out the result.
Regular expressions may consist of strings, in which case they simply carryout exact string matching. For example, the regex aab does not match the string
55

56 CHAPTER 3. REGULAR EXPRESSIONS
aabb. There is an Ant target regex-match which feeds the command-line argu-ments to our program. For the example at hand, we have
> ant -Dregex="aab" -Dtext="aabb" regex-match
Regex=|aab| Text=|aabb| Matches=false
On the other hand, the regex abc does match the string abc.
> ant -Dregex="abc" -Dtext="abc" regex-match
Regex=|abc| Text=|abc| Matches=true
Note that we have used the vertical bar to mark the boundaries of the regularexpression and text in our output. These vertical bars are not part of the regularexpression or the text. This is a useful trick in situations where space may appearas the prefix or suffix of a string. It may get confusing if there is a vertical barwithin the string, but the outer vertical bars are always the ones dropped.
3.1.2 Finding Matching Substrings
The second main application of regular expressions is to find substrings ofa string that match the regular expression. The main method in our classRegexFind illustrates this. We read in two command-line aguments into stringvariables regex and text as we did for RegexMatch in the previous section.We begin by compling the pattern and creating a matcher for the text just as inRegexFind.
Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(text);while (matcher.find()) {
String found = matcher.group();int start = matcher.start();int end = matcher.end();
The first call of the find() method on a matcher returns true if there is a sub-string of the text that matches the pattern. If find() returned true, then the aremethod group() returns the substring that matched, and the methods start()and end() return the span of the match, which is from the start (inclusive) to theend (exclusive).
Subsequent calls to find() return true if there is a match starting on or afterthe end position of the previous calls. Thus the loop structure in the programabove is the standard idiom for enumerating all the matches.
As an example, we use the Ant target regex-find, which takes the samearguments as regex-match.
> ant -Dregex=aa -Dtext=aaaaab regex-find
Found |aa| at (0,2) Found |aa| at (2,4)

3.2. CHARACTER REGEXES 57
As before, the vertical bars are delimeters, not part of the matching substring.The string aa actually shows up in four distinct locations in aaaaab, at spans(0,2), (1,3), (2,4), and (3,5). Running find only returns two of them. The matcherworks from the start to the end of the string, returning the first match it findsafter the first call to find(). In this case, that’s the substring of aaaaab span-ning (0,2). The second call to find() starts looking for a match at position 2,succeeding with the span (2,4). Next, it starts looking at position 4, but there isno substring starting on or after position 4 that matches aa.
3.2 Character Regexes
The most basic regular expressions describe single characters. Some charactershave special meanings in regexes and thus need to be escaped for use in regularexpresions.
3.2.1 Characters as Regexes
A single character may be used a regular expression. A regular expressionconsisting of a single character only matches that single character. For in-stance, Pattern.compile("a").matcher("a").matches() would evaluate totrue. Using our Ant match target,
> ant -Dregex=b -Dtext=b regex-match
Regex=|b| Text=|b| Matches=true
> ant -Dregex=b -Dtext=c regex-match
Regex=|b| Text=|c| Matches=false
Within a Java program, Java character literals may be used within the string de-noting the regex. For instance, we may write Pattern.compile("\u00E9") tocompile the regular expression that matches the character U+00E9, latin smalle with acute, which would be written as é.
3.2.2 Unicode Escapes
Arbitrary unicode characters may be escaped in the same way as in Java. That is,\uhhhh is a regular expression matching the character with Unicode code pointU+hhhh. For example,
> ant -Dregex=\u0041 -Dtext=A regex-match
Regex=|\u002E| Text=|.| Matches=true
Note that we did not have to escape the backslash for the shell because the fol-lowing character, u, is not an escape. Unicode escapes are useful for for matchingthe period character, U+002E, full stop, which is a reserved character in regexesrepresenting wildcards (see Section 3.3.1).

58 CHAPTER 3. REGULAR EXPRESSIONS
> ant -Dregex="\u002E" -Dtext="." regex-match
Regex=|\u002E| Text=|.| Matches=true
In a Java program, we’d still have to write Pattern.compile("\\u002E").Unicode escapes in regexes are confusing, because they use the same
syntax as Java unicode literals. Further complicating matters, the lit-eral for backslashes in Java programs is itself an escape sequence,\\. There is a world of difference between the patterns produced byPattern.compile("\u002E") and Pattern.compile("\\u002E"). The formeris the same as Patten.compile("."), and matches any character, whereas thelatter uses a regex escape, and only matches the period character.
3.2.3 Other Escapes
There are also other built-in escapes, such as \n for newline and \\ for a back-slash character. Again, we have to be careful about distinguishing Java stringescapes, which are used to create a regex, which itself may contain regex escapes.
To confuse matters, Java itself also uses a backslash for escapes, so that thecharacter for backslash is written ’\\’ and so the regex \n must be written asthe string literal "\\n". To create the regex \\, we need to use two backslashescapes in our string literal, writing Pattern.compile("\\\\").
This is all further confused by the command-line shell, which has its ownescape sequences. Our sample program reads a command from the commandline, which is being supplied by Ant and set as a property on the command-linecall to Ant. For instance, consider this puzzler,
> ant -Dregex="\\\\" -Dtext="\\" regex-match
Regex=|\\| Text=|\| Matches=true
On the command line, backslash is escaped as \\.1 Our Java program gets a valuefor regex consisting of a length-two string made up of two backslashes, andvalue for text consisting of a single backslash. The match succeeds because theregex \\ is the escaped backslash character, which matches a single backslash.
3.3 Character Classes
Regular expressions provide a range of built-in character classes based on ASCIIor Unicode, as well as the ability to define new classes. Each character classmatches a set of characters. The reason to use classes rather than disjunctionsis that they have
1Usually backslash doesn’t need to be escaped because the following character isn’t a valid escape;here, the following character is a quote ("), and \" is a valid escape sequence for the shell.

3.3. CHARACTER CLASSES 59
3.3.1 WildCards
A singe period (.) is a regular expression that matches any single characer. Wemay think of it as the universal character class. For instance, the regex . matchesthe string a, and a.c matches abc.
> ant -Dregex=a.c -Dtext=abc regex-match
Regex=|a.c| Text=|abc| Matches=true
Whether or not a wildcard matches an end-of-line sequence depends onwhether or not the DOTALL flag is set (see Section 3.12); if it is set, the wild-card matches end-of-line sequences. The following two expressions evaluate totrue,
Pattern.compile(".").matcher("A").matches()Pattern.compile(".",DOTALL).matcher("\n").matches()
whereas the following expression evaluates to false,
Pattern.compile(".").matcher("\n").matches()
3.3.2 Unicode Classes
Unicode defines a range of categories for characters, such as the category Lu ofuppercase letters (see Section 2.1.4 for more information). The regular expres-sion p{X} matches any unicode character belonging to the Unicode category X.For example, the class Lu picks out uppercase letters, so we have
> ant -Dregex=\p{Lu} -Dtext=A regex-match
Regex=|\p{Lu}| Text=|A| Matches=true
3.3.3 ASCII Classes
There are character classes built in for ASCII characters. For instance, \d is fordigits, \s for whitespace, and \w for alphanumeric characters. For example,
> ant -Dregex=\d -Dtext=7 regex-match
Regex=|\d| Text=|7| Matches=true
For these three ASCII classes, the capitalized forms match ASCII characters thatdon’t match the lowercase forms. So \D matches non-digits, \S non whitespace,and \W non-alphanumeric characters.
There are a range of built-in ASCII classes from the POSIX standard built in.They use the same syntax as the Unicode classes described in the previous sec-tion. For example, \p{ASCII} matches any ASCII character and \p{Punct} forASCII punctuation characters.
The ASCII characters must be used with care, because they will not have theirdescribed behavior when interpreted over all of Unicode. For example, there arewhitespaces in Unicode that don’t match \s and digits that don’t match \d.

60 CHAPTER 3. REGULAR EXPRESSIONS
3.3.4 Compound Character Classes
Character classes may be built up from single characters and/or other characterclasses using set operations like union, intersection, and negation.
The syntax for compound character classes uses brackets around a characterclass expression. The atomic character class expressions are single characterslike a, and the character class escapes like \p{Lu} for is any uppercase Unicodecharacter. Compound character classes may also be nested. For example,
Character classes may be unioned, which confusingly uses a concatenationsyntax. For instance, [aeiou] is the character class picking out the ASCII vowels.It is composed of the union of character class expressions a, e, . . . , u.
> ant -Dregex="[aeiou]" -Dtext=i regex-match
Regex=|[abc]| Text=|i| Matches=true
Class escapes may be used, so that [\p{Lu}\p{N}] picks out upper case lettersand numbers.
The use of range notation may be used as shorthand for unions. For instance,[0-9] picks out the ASCII digits 0, 1, . . . , 9. For example,
> ant -Dregex="[I-P]" -Dtext=J regex-match
Regex=|[I-P]| Text=|J| Matches=true
Character classes may be complemented. The syntax involves a caret, with[ˆA] picking out the class of characters not in class A. The expression A mustbe either a range or a sequence of character class primitives. For instance, [ˆz]represents the class of every character other than z.
> ant -Dregex="[ˆz]" -Dtext=z regex-match
Regex=|[^z]| Text=|z| Matches=false
> ant -Dregex="[ˆz]" -Dtext=a regex-match
Regex=|[^z]| Text=|a| Matches=true
Unlike the usual rules governing the logical operations disjunction, conjunction,and negation, the character class complementation operator binds more weaklythan union. Thus [ˆaeiou] picks out every character that is not an ASCII vowel.
Character classes may also be intersected. The syntax is the same as forlogical conjunction, with [A&&B] picking out the characters that are in the classesdenoted by both A and B. For instance, we could write [[a-z]&&[ˆaeiou]] topick out all ASCII characters other than the vowels,
> ant -Dregex="[[a-z]&&[ˆaeiou]]" -Dtext=i regex-match
Regex=|[[a-z]&&[^aeiou]]| Text=|i| Matches=false
As described in the Javadoc for Pattern, the order of attachment for charac-ter class operations is

3.4. CONCATENATION 61
Order Expression Example
1 Literal Escape \x2 Grouping [...]3 Range 0-94 Union ab, [0-9][ab],5 Intersection [a-z&&[aeiou]]
Thus the square brackets act like grouping parentheses for character classes.Complementaton must be treated separately. Complementation only applies tocharacter groups or ranges, and must be closed within brackets before beingcombined with union or intersection or the scope may not be what you expect.For instance, [ˆa[b-c]] is not equivalent to [ˆabc], but rather is equivalent to[[ˆa][b-c]].
3.4 Concatenation
As we saw in our early examples, characters may be concatenated together toform a regular expression that matches the string. This is not the same operationas character classes, which confusingly uses the same notation.
With a list of objects being concatenated, the boundary condition is an emptylist, which is why we start this section with a discussion of the empty regex.
3.4.1 Empty Regex
The simplest regular expression is the empty regular expression.It only matches the empty string. For example, the expressionPattern.compile("").matcher("").matches() would evaluate to true.Using our test code from the command-line proves tricky, because we have toescape the quotes if we want to assign environment variables, as in
> ant -Dregex=\"\" -Dtext=\"\" regex-match
Regex=|| Text=|| Matches=true
> ant -Dregex=\"\" -Dtext=a regex-match
Regex=|| Text=|a| Matches=false
3.4.2 Concatenation
Two regular expressions x and y may be concatenated to produce a compoundregular expression xy. The regex xy matches any string that can be decomposedinto a string that matches x followed by a string that matches y. For example, ifwe have a regex [aeiou] that matches vowels and a regex 0-9 that matches dig-its, we can put them together to produce a regex that matches a vowel followedby a digit.
> ant -Dregex=[aeiou][0-9] -Dtext=i7 regex-match
Regex=|[aeiou][0-9]| Text=|i7| Matches=true

62 CHAPTER 3. REGULAR EXPRESSIONS
Concatenation is associative, meaning that if we have three regexes x, y, andz, the regexes (xy)z and x(yz) match exactly the same set of strings. Becauseparentheses may be used for groups (see Section 3.10), the two regexes do notalways behave exactly the same way.
3.5 Disjunction
If X and Y are regular expressions, the regular expression x|y matches any stringthat matches either X or Y (or both). For example,
> ant -Dregex="ab|cd" -Dtext=ab regex-matchRegex=|ab|cd|Text=|ab|Matches=true
> ant -Dregex="ab|cd" -Dtext=cd regex-matchRegex=|ab|cd| Text=|cd| Matches=true
> ant -Dregex="ab|cd" -Dtext=bc regex-matchRegex=|ab|cd| Text=|bc| Matches=false
Concatenation takes precedence over disjunction, so that ab|cd is read as(ab)|(cd), not a(b|c)d.
The order of disjunctions doesn’t matter for matching (other than for effi-ciency), but it matters for the find operation. For finds, disjunctions are evaluatedleft-to-right and the first match returned.
> ant -Dregex="ab|abc" -Dtext=abc regex-findFound |ab| at (0,2)
> ant -Dregex="abc|ab" -Dtext=abc regex-findFound |abc| at (0,3)
Because complex disjunctions are executed through backtracking, disjunc-tions that have to explore many branches can quickly lead to inefficient regularexpressions. Even a regex as short as (a|b)(c|d)(e|f) has 23 = 8 possiblesearch paths to explore. Each disjunction doubles the size of the search space,leading to exponential growth in the search space in the number of interactingdisjunctions. In practice, disjunctions often fail earlier. For instance, if there isno match for a|b, further disjunctions are not explored.
A simple pathological case can be created by concatenating instances of theregex (|a) and then matching a long string of a characters. You can try it outyourself with
> ant -Dregex="(|a)(|a)...(|a)(|a)" -Dtext=aa...aa regex-find
where the elipses are meant to indicate further copies of a. This expression willexplore every branch of every disjunction. Around 25 or 26 copies of (|a) thereare tens of millions of paths to explore, and with 30, there’s over a billion. You’llbe waiting a while for an answer. But if the building block is (a|b), there’s noproblem, because each disjunction has to match a.
> ant -Dregex="(b|a)(b|a)...(b|a)(b|a)" -Dtext=aa...aa regex-find

3.6. GREEDY QUANTIFIERS 63
3.6 Greedy Quantifiers
There are operators for optionality or multiple instances that go under the gen-eral heading of “greedy” because of they match as many times as they can. In thenext section, we consider their “reluctant” counterparts that do the opposite.
3.6.1 Optionality
The simplest greedy quantifier is the optionality marker. The regex A? matchesa string that matches A or the empty string. For example,
> ant -Dregex=a? -Dtext=a regex-match
Regex=|a?| Text=|a| Matches=true
> ant -Dregex=a? -Dtext=\"\" regex-match
Regex=|a?| Text=|| Matches=true
The greediness of the basic optionality marker, which tries to match beforetrying to match the empty string, is illustrated using find(),
> ant -Dregex=a? -Dtext=aa regex-find
Found |a| at (0,1) Found |a| at (1,2) Found || at (2,2)
The first two substrings found match a rather than the empty string. Only whenwe are at position 2, at the end of the string, do we match the empty stringbecause we can no longer match a.
The greediness of optionality means that the A? behaves like the disjunction(A|) of A and the empty string. Because it is the first disjunct, a match against Ais tried first.
3.6.2 Kleene Star
A regular expression x may have the Kleene-star operator2 applied to it to pro-duce the regular expression A*. The regex A* matches a string if the stringis composed of a sequence of zero or more matches of A. For example, [01]*matches any sequence composed only of 0 and 1 characters,
> ant -Dregex="[01]*" -Dtext=00100100 regex-match
Regex=|[01]*| Text=|00100100| Matches=true
It will also match the empty string, but will not match a string with any othercharacter.
Using find, the standard Kleene-star operation is greedy in that it consumesas much as it can during a find() operation. For example, consider
> ant -Dregex="[01]*" -Dtext=001a0100 regex-find2Named after Stephen Kleene, who invented regular expressionsn as a notation for his characteri-
zation of regular languages.

64 CHAPTER 3. REGULAR EXPRESSIONS
Found |001| at (0,3) Found || at (3,3) Found |0100| at (4,8)Found || at (8,8)
The first result of calling find() consumes the expression [01] as many timesas possible, consuming the first three characters, 001. After that, the expres-sion matches the empty string spanning from 3 to 3. It then starts at position4, finding 0100 and then the empty string again after that. Luckily, find() isimplemented cleverly enough that it only returns the empty string once.
Kleene star may also be understood in terms of disjunction, though recursionis required. The greedy Kleene star regex A* behaves like (A(A*))|. Thus it firsttries to match A followed by another match of A*, and only failing that tries tomatch the empty string.
Kleene star interacts with disjunction in the expected way. For example,matching may match an entire string, as with
> ant -Dregex="(ab|abc)*" -Dtext=abcab regex-match
Regex=|(ab|abc)*| Text=|abcab| Matches=true
while finding returns only an initial match,
> ant -Dregex="(ab|abc)*" -Dtext=abcab regex-find
Found |ab| at (0,2) Found || at (2,2) Found |ab| at (3,5)Found || at (5,5)
This is a result of the greediness of the Kleene-star operator and the evaluationorder of disjunctions. If we reorder, we get the whole string,
> ant -Dregex="(abc|ab)*" -Dtext=abcab regex-find
Found |abcab| at (0,5) Found || at (5,5)
because we first match abc against the disjunct, then continue trying to match(abc|ab)*, which matches ab.
3.6.3 Kleene Plus
The Kleene-plus operator is like the Kleene star, but requires at least one match.Thus A+ matches a string if the string is composed of a sequence of one or morematches of A. The Kleene-plus operator may be defined in terms of Kleene starand concatenation, with A+ behaving just like AA*.
Use Kleene plus instead of star to remove those pesky empty string matches.For instance,
> ant -Dregex="(abc|ab)+" -Dtext=abcab regex-find
Found |abcab| at (0,5)

3.7. RELUCTANT QUANTIFIERS 65
3.6.4 Match Count Ranges
We can specify an exact number or a range of possible number of matches. Theregular expression A{m} matches any string that that may be decomposed into asequence of m strings, each of which matches A.
> ant -Dregex="a{3}" -Dtext=aaa regex-match
Regex=|a{3}| Text=|aaa| Matches=true
There is similar notation for spans of counts. The regex A{m,n} matches anystring that may be decomposed into a sequence of between m (inclusive) and n(inclusive) matches of A. The greediness comes in because it prefers to match asmany instances as possible. For example,
> ant -Dregex="a{2,3}" -Dtext=aaaaa regex-find
Found |aaa| at (0,3) Found |aa| at (3,5)
The first result found matches the regex a three times rather than twice.There is also an open-ended variant. The regex A{m,} matches any string that
can be decomposed into m or more strings each of which matches A.
3.7 Reluctant Quantifiers
There are a range of reluctant quantifiers that parallel the more typical greedyquantifiers. For matching, the relunctant quantifiers behave just like their greedycounterparts, whereas for find operations, reluctant quantifiers try to match aslittle as possible.
The reluctant quantifiers are written like the greedy quantifiers followed by aquestion mark. For instance, A*? is the reluctant version of the Kleene star regexA*, A{m,n}? is the reluctant variant of the range egex A{m,n}, and A?? is thereluctant variant of the optionality regex A?.
Reluctant quantifiers may be understood by reversing all the disjuncts in thedefinitions of the greedy quantifier equivalents. For instance, we can think ofA?? as (|A) and A*? as (|AA*?).
Here we repeat some key examples of the previous section using reluctantquantifiers.
> ant -Dregex=a?? -Dtext=aa regex-find
Found || at (0,0) Found || at (1,1) Found || at (2,2)
> ant -Dregex="(abc|ab)+?" -Dtext=abcab regex-find
Found |abc| at (0,3) Found |ab| at (3,5)
> ant -Dregex="a{2,3}?" -Dtext=aaaaa regex-find
Found |aa| at (0,2) Found |aa| at (2,4)

66 CHAPTER 3. REGULAR EXPRESSIONS
3.8 Possessive Quantifiers
The third class of quantified expression is the possessive quantifier. Possessivequantifiers will not match a fewer number of instances of their pattern if theycan match more. Procedurally, they commit to a match once they’ve made it anddo not allow backtracking.
The syntax for a possessive quantifier follows the quantifier symbol with aplus sign (+); for instance, ?+ is possessive optionality and *+ is greedy Kleenestar.
Consider the difference between a greedy Kleene star
> ant "-Dregex=[0-9]*1" -Dtext=1231 regex-match
Regex=|[0-9]*1| Text=|1231| Matches=true
which matches, and a possessive Kleene star,
> ant "-Dregex=[0-9]*+1" -Dtext=1231 regex-match
Regex=|[0-9]*+1| Text=|1231| Matches=false
which does not match. Even though [0-9]* indicates a greedy match, it is ableto back off and only match the first three characters of the input, 123. Thepossessive quantifier, once it has matched 1231, does not let it go, and the overallmatch fails.
3.8.1 Independent Group Possessive Marker
If A is a regex, then (?>A) is a regex that matches the same thing as A, but groupsthe first match possessively. That is, once (?>A) finds a match for A, it does notallow backtracking. We can see this with a pair of examples.
> ant -Dregex="(?>x+)xy" -Dtext=xxy regex-match
Regex=|(?>x+)xy| Text=|xxy| Matches=false
This doesn’t match, because the x+ matches both instances of x in the text beingmatched and doesn’t allow backtracking. Contrast this with
> ant -Dregex="(?>x+)y" -Dtext=xxy regex-match
Regex=|(?>x+)y| Text=|xxy| Matches=true
The parentheses in this construction do not count for grouping (see Sec-tion 3.10). There is a similar construction (?:A) which is not possessive, andalso does not count the parentheses for grouping.
3.9 Non-Capturing Regexes
Some regexes match virtual positions in an input without consuming any textthemselves.

3.9. NON-CAPTURING REGEXES 67
3.9.1 Boundary Matchers
Boundary matchers match specific sequences, but do not consume any inputthemselves.
Begin- and End-of-Line Matchers
The caret (ˆ) is a regular expression that matches the end of a line and the dollarsign ($) a regular expression matching the beginning of a line. For example,
> ant -Dregex="ˆabc$" -Dtext=abc regex-match
Regex=|^abc$| Text=|abc| Matches=true
> ant -Dregex=ab$c -Dtext=abc regex-match
Regex=|ab$c| Text=|abc| Matches=false
The begin- and end-of-line regexes do not themselves consume any characters.These begin-of-line and end-of-line regexes do not match new lines inside of
strings unless the MULTILINE flag is set (see Section 3.12). By default, theseregexes match new-line sequences for any platform (Unix, Macintosh, or Win-dows) and many more (see Section 3.9.4 for the full set of line terminators). Ifthe UNIX_LINES flag is set, they only match Unix newlines (see Section 3.12).
Begin and End of Input
Because begin-of-line and end-of-line have variable behavior, there are regexes \Afor the beginning of the input and \z for the end of the input. These will matchthe begin and end of the input no matter what the match mode is. For instance,
> ant -Dregex=\A(xyz)\z -Dtext=xyz regex-group
regex=|\A(xyz)\z| text=|xyz|Group 0=|xyz| at (0,3) Group 1=|xyz| at (0,3)
Word Boundaries
The regex \b matches a word boundary and \B a non-word boundary, both with-out consuming any input. Word boundaries are the usual punctuation and spacesand the begin and end of input. For example,
> ant -Dregex=\b\w+\b -Dtext="John ran quickly." regex-find
Found |John| at (0,4) Found |ran| at (5,8)Found |quickly| at (9,16)

68 CHAPTER 3. REGULAR EXPRESSIONS
3.9.2 Positive and Negative Lookahead
Often you want to match something only if it occurs in a given context. If A isa regex, then (?=A) is the positive lookahead and (?!A) the negative lookaheadregular expression. These match a context that either matches or doesn’t matchthe specified regular expression. They must be used following other regularexpressions. For instance, to find the instances of numbers preceding periods,we could use
> ant -Dregex="\d+(?=\.)" -Dtext=12.2 regex-find
Found |12| at (0,2)
and to find those not preceding periods,
> ant -Dregex="\d+(?!\.)" -Dtext=12.2 regex-find
Found |1| at (0,1) Found |2| at (3,4)
In a real application, we would probably exclude numbers and periods in thenegative lookahead, with a regex such as \d+(?![\.\d]).
One reason the lookahead is nice is that further finds can match the materialthat the lookahead matched.
3.9.3 Positive and Negative Lookbehind
There are backward-facing variants of the positive and negative lookahead con-structs, (?<=X) and (?<!X). These are more limited in that the regular expres-sion X must expand to a simple sequence, and thus may not contain the Kleene-star or Kleene-plus operations.
For example, the following example finds sequences of digits that do notfollow periods or other digits
> ant -Dregex="(?<![\.\d])\d+" -Dtext=12.32 regex-find
Found |12| at (0,2)
3.9.4 Line Terminators and Unix Lines
Code Point(s) Description Java
U+000A line feed \nU+000D carriage return \rU+000D, U+000A carriage return, line feed \r\nU+0085 next line \u0085U+2028 line separator \u2028U+2029 paragraph separator \u2029

3.10. PARENTHESES FOR GROUPING 69
3.10 Parentheses for Grouping
Parentheses play the usual role of grouping in regular expressions, and may beused to disambiguate what would otherwise be misparsed. For instance, theexpression (a|b)c is very different than a|(bc).
Parentheses also play the role of identifying the subexpressions they wrap.If A is a regular expression, (A) is a regular expression that matches exactly
the same strings as A. Note that parentheses come in matched pairs, and eachpicks out the unique subexpression A it wraps.
The pairs of parentheses in a regular expression are numbered from left toright, beginning with 1. For example, we’ve written a very simple regex with theidentifier of each parentheses group on the next line
a(b(cd)(e))0 1 2 3
There is an implicit pair of parentheses around the entire pattern, with groupnumber 0. Group 1 is b(cd)(e), group 2 is cd, and group 3 is e.
The identities of the groups are useful for pulling out substring matches (thissection), using back references in regexes (see Section 3.11) and replace opera-tions based on regexes (see Section 3.14).
After a match or a find operation, the substring of the match that matchedeach group is available from the matcher with a method group(int), where theargument indicates which group’s match is returned. The start and end positionof a group may also be retrieved, using start(int) and end(int). The totalnumber of groups in the regex is available through the method groupCount().The methods group(), start(), and end() we used earlier to retrieve the matchof the entire string are just shorthand for group(0), start(0), and end(0). Ifthere hasn’t been a match or the last find did not succeed, attempting to retrievegroups or positions raises an illegal state exception.
We provide a simple class RegexGroup to illustrate the workings of groupextraction. The work is done in the main() method by the code
Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(text);if (matcher.matches()) {
for (int i = 0; i <= matcher.groupCount(); ++i) {String group = matcher.group(i);int start = matcher.start(i);int end = matcher.end(i);
Here we call matcher.match(), which requires a match of the entire text.We set up the Ant target regex-group to call it, and test it in the usual way,
using the example whose groups are numbered above.
> ant -Dregex=a(b(cd)(e)) -Dtext=abcde regex-group
regex=|a(b(cd)(e))| text=|abcde|Group 0=|abcde| at (0,5) Group 1=|bcde| at (1,5)Group 2=|cd| at (2,4) Group 3=|e| at (4,5)

70 CHAPTER 3. REGULAR EXPRESSIONS
A more typical linguistic example would be to pull out names after the word Mr,as in
> ant -Dregex=Mr((\s(\p{Lu}\p{L}*))+) -Dtext="Mr J Smith"regex-group
Group 0=|Mr J Smith| at (0,10) Group 1=| J Smith| at (2,10)Group 2=| Smith| at (4,10) Group 3=|Smith| at (5,10)
Group 1 corresponds to the name, but note that we have an extra leading space.We can get rid of that with a more complex regex, and we could also allow op-tional periods after Mr with the appropriate escape, and also deal with periodsin names. Matching complicated patterns with regexes is a tricky business.
3.10.1 Non-Capturing Group
It is possible to use parentheses without capturing. If X is a regex, then (?:X)matches the same things as X, but the parentheses are not treated as capturing.
3.11 Back References
The regex \n is a back reference to the match of the n-th capturing group beforeit. We can use matching references to find pairs of duplicate words in text. Forinstance, consider
> ant -Dregex="(+.).*(\1)" -Dtext="12 over 12" regex-group
Group 0=|12 over 12| at (0,10) Group 1=|12| at (0,2)Group 2=|12| at (8,10)
The regex \1 will match whatever matched group 1. Group 1 is (\d+) and group2 is (\1); both match the expression 12, only at different places. You can seethat the text 12 over 13 would not have matched.
If the match index is out of bound, matching fails without raising an excep-tion.
3.12 Pattern Match Flags
There are a set of flags, all represented as static integer constants inPattern, which may be supplied to the pattern compiler factory methodPattern.compile(String,int) to control the matching behavior of the com-piled pattern.

3.12. PATTERN MATCH FLAGS 71
Constant Value Description
DOTALL 32 Allows the wild card (.) expression to matchany character, including line terminators. Ifthis mode is not set, the wild card does notmatch line terminators.
MULTLINE 8 Allows the begin-of-line (ˆ) and end-of-line($) to match internal line terminators. Ifthis is not set, they only match before thefirst and after the last character. The fullJava notion of newline is used unless the flagUNIX_LINES is also set.
UNIX_LINES 1 Treat newlines as in Unix, with a singleU+000A, line feed, Java string escape \n,representing a new line. This affects the be-havior of wildcard (.) and begin-of-line (ˆ)and end-of-line ($) expressions.
CASE_INSENSITIVE 2 Matching is insensitive to case. Case fold-ing is only for the ASCII charset (U+0000to U+007F) unless the flag UNICODE_CASE isalso set, which uses the Unicode definitionsof case folding.
UNICODE_CASE 64 If this flag and the CASE_INSENSITIVE flagis set, matching ignores case distinctions asdefined by Unicode case folding rules.
CANON_EQ 128 Matches are based on canonical equivalencein Unicode (see Section 2.1.4).
LITERAL 16 Treats the pattern as a literal (i.e., noparsing).
COMMENTS 4 Allows comments in patterns and causespattern-internal whitespace to be ignored.
The flags are defined using a bit-mask pattern whereby multiple flagsare set by taking their bitwise-or value.3 For instance, the expressionDOTALL | MULTILINE allows the wildcard to match anything and the line-terminator expressions to match internal newlines. More than two flagsmay be set this way, so we could further restrict to Unix newlines withDOTALL | MULTILINE | UNIX_LINES.
Even stronger matching than canonical equivalence with unicode case foldingcan be achieved by writinger the regular expression using compatibility normalforms and using the ICU package to perform a compatibility decomposition onthe input (see Section 2.1.4).
3Although bitwise or looks like addition for flags like these with only one bit on, it breaksdown when you try to set flags twice. Thus DOTALL + MULTILINE evaluates to the same thingas DOTALL | MULTINE, DOTALL + DOTALL evaluates to the same thing as UNICODE_CASE, whereasDOTALL | DOTALL evaluates to the same thing as DOTALL.

72 CHAPTER 3. REGULAR EXPRESSIONS
3.13 Pattern Construction Exceptions
Attempting to compile a regular expression with a syntax error raises a runtimeexception, PatternSyntaxException from the java.util.regex package. Theparser tries to provide a helpful warning message. For instance, here’s what wesee if we inadvertently add a right parenthesis to our regex.
> ant -Dregex=aa) -Dtext=aaab regex-find
Exception in thread "main"java.util.regex.PatternSyntaxException:Unmatched closing ’)’ near index 1
3.14 Find-and-Replace Operations
A common usage pattern for regular expressions is to find instances ofone pattern and replace them with another. We provide a sample programRegexReplace, which illustrates replacement in its main() method,
Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(text);String result = matcher.replaceAll(replacement);
The pattern and matcher are created as usual. Then, we create a string by replac-ing all the matches of the pattern in the text provided to the matcher with thespecified replacement. We could also use replaceFirst() to return the resultof only replacing the first match.
With the Ant target regex-replace, we can see this in action.
> ant -Dregex=\d+ -Dreplacement=0 -Dtext="+1 (718) 290-9170"regex-replace
regex=|\d+| replacement=|0|text=|+1 (718) 290-9170| result=|+0 (0) 0-0|
We’ve replaced every sequence of digits with a zero.A nice feature of replace operations is that they may reference pieces of the
match by group number and use them in the replacement. An occurrence of $nin the replacement string represents whatever matched group n in the match.
For instance, we can extract the version number from a jar and redisplay itusing
> ant -Dregex=(\w+)\-([\d\.]+)\.jar -Dreplacement="$1.jar v$2"-Dtext="foo-7.6.jar" regex-replace
regex=|(\w+)\-([\d\.]+)\.jar| replacement=|$1.jar v$2|text=|foo-7.6.jar| result=|foo.jar v7.6|
Note that we had to escape the literal hyphen and period characters in the regex.The class \w is for word characters, which are alphanumerics and the underscore.The example regexes are very fragile, and it is quite difficult to write more robustregexes.

3.15. STRING REGEX UTILITIES 73
3.15 String Regex Utilities
There are many utility methods in the String class that are based on regularexpressions.
The method matches(String) returns true if the string matches the regexspecified by the argument. Given a regex r, matches(r) is just shorthand forPattern.compile(r).matcher(this).matches().
The method replaceAll(String,String), which takes a string repre-senting a regex and a replacement string, returns the result of replacing allthe substrings in the string matching the regex with the replacement string.Given a regex r and replacement s, replaceAll(r,s) is just shorthand forPattern.compile(r).matcher(this).replaceAll(s). As such, the replace-ment may contain references to match groups. There is also a correspondingreplaceFirst() method.
One of the more useful utilities is split(String), which splits a stringaround the matches of a regular expression, returning an array as a result. Forinstance, "foo12bar177baz.split(\d+) splits on digits, returning the string ar-ray { "foo", "bar", "baz" }. Note that the matching numbers are removed.
3.16 Thread Safety, Serialization, and Reuse
3.16.1 Thread Safety
Because instances of Pattern are immutable, it is safe to use them concurrentlyin multiple threads. Because instances of Matcher contain the state of the cur-rent match, it is not thread safe to use matchers concurrently without synchro-nization.
3.16.2 Reusing Matchers
Matchers may be reused. The method reset() may be called on a matcher toreset it to behave as if it had just been constructed with its given pattern andcharacter sequence. The character sequence may be changed. The pattern mayalso be changed on the fly, without changing the current position. This may beuseful if you alternately match first one pattern then another. Although matchersmay be reused, the typical usage pattern is to construct them for a text, use themonce, then discard them.
3.16.3 Serialization
Patterns are serializable. The string representing the pattern and the compilationflags are stored and the version read back in is an instance of Pattern behavingjust like the original. Often patterns do not need to be serialized because they’reeffectively singletons (i.e., constants).

74 CHAPTER 3. REGULAR EXPRESSIONS

Chapter 4
Input and Output
Java provides a rich array of classes for dealing with input and output. At thebasic level, input and output streams provide a means to transfer data consistingof a sequence of bytes. Data may be transferred among memory with memory-backed streams, the file system via file streams or memory mapped files, theterminal via standard input and output streams, and remote servers via sockets.Stream filters may be put in place to compress or decompress data. Streams thatblock awaiting input or output may be dealt with in threads.
Bytes may encode anything, but we are particularly interested in the caseof natural language text data, with or without document structure. To supportstreams of char values, Java provides char streams as byte streams. In orderto crete a character stream from byte stream, the character encoding must beknown.
We are also interested in sequences of bytes that encode Java objects throughserialization. We use serialized objects to represent models and their compo-nents, such as tokenizers.
4.1 Files
Java provides the class File in the java.io package for representing files anddirectories on the local file system. Underlyingly, an instance of File is nothingmore than a string representing a path coupled with a convenient set of utilitymethods, some of which access the underlying file system.
4.1.1 Relative vs. Absolute Paths
Files may be either relative or absolute. An absolute path name provides a fulldescription of where to find a file on the system in question. A relative pathpicks out a file or directory starting from a root directory (the form of which willbe operating system specific). Relative paths may pick out different resources indifferent situations depending on the base directory.
The static method File.listRoots() provides an array of all of the availableroot directories. We wrote a simple demo in the class ListRoots, the heart of
75

76 CHAPTER 4. INPUT AND OUTPUT
which is
File[] roots = File.listRoots();for (File file : roots)
Running it on my Windows machine returns
> ant list-roots
Root DirectoriesC:\E:\
The root directories C:\ and E:\ correspond to my two drives, but they couldalso correspond to partitions of a single drive or a redundant array of indepen-dent disks (RAID), or even a section of memory acting like a disk drive.
Root of Relative Paths
In Java, relative paths are interpreted relative to the directory from which Javawas called. The same goes for Ant, except when a basedir attribute is set on thetop-level project element.
A consequence of this behavior is that the empty string ("") is a path thatpicks out the directory from which Java was called.
4.1.2 Windows vs. UNIX File Conventions
Due to the differing setup of the operating systems, File objects behave differ-ently on different platforms. In all cases, they respect the conventions of the filesystem on which they are run, but it requires some care to create portable codeor Ant tasks that involve files.
On either Windows or UNIX, files are organized hierarchically into directoriesunder one or more root directories. Each file other than one of the root direc-tories has a parent directory. The most prominent difference between the twooperating system flavors is that Windows uses a backslash (\), whereas UNIX usesa forward slash (/) to separate directories and file names in a path.
In Unix, there is a single root directory for the file system, and absolute pathnames will start with a forward slash (/).
In Windows, there may be more than one root directory. Each root directoryis written as a drive letter followed by a colon-backslash (:\), as in C:\ for theroot directory on the drive named C.
Windows also allows Universal Naming Convention (UNC) network paths,which begin with two backslashes (\\) followed by the name of the computer ordevice on the network. For instance, \\MONTAGUE is the root of the shared fileson the network computer named MONTAGUE. Each networked Windows computermakes visible its top-level shared files.
The biggest difference is that in Windows, file names are not case sensitive.Thus FOO, foo, and Foo will all pick out the same file.

4.1. FILES 77
4.1.3 Constructing a File
There are four File constructors. The simplest, File(String), simply takes apath name to construct a file object. The string may be anything, but separatorcharacters will be parsed and normalized.
Conveniently, Java lets you use either forward (Unix) or backward (Windows)slashes interchangeably, as does Ant. Thus in Windows, I can use Unix-styleforward slashes with the same effect as backward slashes. For example, newFile("c:/foo"), constructs the same object as new File("c:\foo").
There are also two-argument constructors taking a parent directory anda file name. The parent may be specified as a string using the con-structor File(String,String) or as a file itself, using the constructorFile(File,String).
URI/URL to File Conversion
There is a fourth File constructor that takes a uniform resource identifier (URI)argument, File(URI) (see Section 4.18 for more information on URIs and URLs).The URI class is in the java.net package, which comes standard with Java.
URIs for files have the form file://host/path, where the (optional) hostpicks out a domain name and path a file path. If the host is not specified, theform devolves to file:///path, and the host is assumed to be the the so-calledlocalhost, the machine on which Java is running.
It is also possible to convert an instance of File to a URI, using the methodtoURI() in File.
It is also possible to get a uniform resource locator (URL) from a file, by firstconverting to a URI and then calling the URI method toURL(), which returns aninstance of URL, also in java.net.
4.1.4 Getting a File’s Canonical Path
The method getCanonicalFile() returns a File based on an absolute pathwith a conventionalized name. For instance, if I happen to be running in directoryc:\lpb (on Windows), then the following two expressions return equivalent files
new File("c:\lpb\Foo").getCanonicalPath()
new File("foo").getCanonicalPath();
Note that this is not truly a unique normal form. The resulting files will havedifferent capitalizations for foo in this case, but will be equivalent running un-der Windows. Further note that the canonical path is not used for equality (seeSection 4.1.8).
4.1.5 Exploring File Properties
There are many methods on File objects which explore the type of a file. Themethod exists() tests whehter it exists, isAbsolute() tests whether it denotes

78 CHAPTER 4. INPUT AND OUTPUT
an absolute path, isDirectory() whether it’s directory, isFile() whether it’san ordinary file, and isHidden() tests whether it’s hidden (starts with a period(.) in Unix or is so marked by the operating system in Windows).
What permissions an application has for a file can be probed withcanExecute(),canRead(), and canWrite(), all of which return boolean values.
The time it was last modified, available through lastModified(), returns thetime as a long denoting milliseconds since the epoch (the standard measure oftime on computers, and the basis of Java’s date and calendar representations).
The number of bytes in a file is returned as a long by length().The name of the file itself (everything but the parent), is returned by
getName(). The methods getParent() and getParentFile() return the parentdirectory as a string or as a file, returning null if no parent was specified.
4.1.6 Listing the Files in a Directory
If a file is a directory, the method listFiles() returns an array of files that thedirectory contains; it returns null if the file’s not a directory. The files may alsobe listed by name using list().
File listings may be filtered with an implementation of FileFilter, an inter-face in java.io specifying a single method accept(File) returning true if thefile is acceptable. An older interface, FilenameFilter, is also available for filename listings.
LingPipe’s FileExtensionFilter
LingPipe provides a convenience class FileExtensionFilter, which imple-ments a FileFilter based on the extension of a file. A file’s extension is heredefined to mean the string after the final period (.) in the file’s name. This ispurely a convention for naming files, which is especially useful in Windows orweb browsers, where each extension may be associated with a program to openor view files with that extesnion.
A file extension filter takes a single or multiple strings specified as an array.A file extension filter is configured with a flag indicating whether it should au-
tomatically accept directories or not, which is convenient for recursive descentsthrough a file system. The default for the unmarked constructors is to acceptdirectories.
File extension filters would implement FilenameFilter directly ifthey could, but it causes a conflict with the polymorphic file methodlistFiles(FilenameFilter) and listFiles(FileFilter). Instead, a file ex-tension filter provides a method fileNameFilter() which returns the corre-sponding file name filter. This is only necessary if you want to test or list files byname rather than as files.
There are two static utility methods in the class Files in com.aliasi.utilthat break file names apart into their suffix and their base name. The methodFiles.extension(File) returns the extesnion of a file, consisting of thetext after the final period (.), or null if there is no period. The methodbaseName(File) returns the base name of a file, which excludes the last period

4.1. FILES 79
and extension. For instance, a file named io.tex has extension tex and basename io, whereas foo.bar.baz has extension baz and base name foo.bar.
4.1.7 Exploring Partitions
Each file in an operating system exists in a partition, which is a top-level rootdirectory. This is of interest because a file can’t be created in a partition that’slarger than the available space in that partition.
There are methods in File for exploring partitions. The methodsgetFreeSpace(), getTotalSpace(), and getUsableSpace() return the respec-tive amounts of space on the partition as a long value.
4.1.8 Comparison, Equality, and Hash Codes
Equality of File objects is based on the underlying platform’s notion of equality.For instance, on Windows, a file created with new File("Foo") creates a file thatis equal to new File("foo"). For better or worse, this comparison is based onthe platform’s convention for file comparison, not by constructing a canonicalpath and comparing that. For instance, if I happen to be running from directoryc:\lpb, then new File("foo") is not equal to c:\lpb\foo, even though theircanonical paths are the same.
4.1.9 Example Program Listing File Properties
We wrote a simple program FileProperties, which given the name of a fileas an argument, lists all of its properties, its canonical path, its URI form, andprovides a listing if it is a directory. The code is just a litany of prints for all ofthe methods described above.
Calling it with the Ant target file-properties, it uses the file.in Antproperty to specify an argument. We can call it on its own source file using arelative path,
> ant -Dfile.in=src/com/lingpipe/book/io/FileProperties.javafile-properties
arg=|src/com/lingpipe/book/io/FileProperties.java|toString()=src\com\lingpipe\book\io\FileProperties.javagetcanonicalFile()=C:\lpb\src\io\src\com\lingpipe\book\
io\FileProperties.javagetName()=FileProperties.javagetParent()=src\com\lingpipe\book\iotoURI()=file:/c:/lpb/src/io/src/com/lingpipe/book/
io/FileProperties.javatoURI().toURL()=file:/c:/lpb/src/io/src/com/lingpipe/
book/io/FileProperties.javaexists()=trueisAbsolute()=falseisDirectory()=false

80 CHAPTER 4. INPUT AND OUTPUT
isFile()=trueisHidden()=falsehashCode()=-72025272lastModified()=1279224002134new Date(lastModified())=Thu Jul 15 16:00:02 EDT 2010length()=2141canRead()=truecanExecute()=truecanWrite()=truegetFreeSpace()=320493494272getTotalSpace()=500105736192getUsableSpace()=320493494272listFiles()={ }
The line breaks plus indents were inserted by hand so it’d fit in the book.
4.1.10 Creating, Deleting, and Modifying Files and Directories
In addition to inspecting files, the File class lets you modify files, too.Calling createNewFile() creates an empty file for the path specified by the
File on which it is called, returning true if a new file was created and false ifit already existed.
The delete() method attempts to delete a file, returning true if it’s suc-cessful. If applied to a directory, delete() will only succeed if the directory isempty. To get around this limitation, LingPipe includes a static utility methodremoveRecursive(File) in the class File in package com.aliasi.util, whichattempts to remove a file and all of its descendants.
The properties of a file may be modified using, for example,setExecutable(boolean, boolean) which attempts to make a file exe-cutable for everyone or just the owner of the file. Similar methods are availablefor readability, writability and last modification date.
Files may be ranemd using renameTo(File), which returns true if it suc-ceeds.
The method mkdir() creates the directory corresponding to the file. Thismethod only creates the directory itself, so the parent must exist. The methodmkdirs() recursively creates the directory and all of its parent directories.
4.1.11 Temporary Files
It is sometimes useful to create a temporary file. One of the properties used tocreate the Java virtual machine is a directory for “temporary” files.
This is typically a platform default directory, like /tmp in UNIX orC:\WINNT\TEMP on Windows, but it may be configured when the JVM starts up.
The static File method createTempFile(String,String) attempts to cre-ate a temporary file in the default temporary file with the specified prefix andsuffix, and it returns the file that’s created. After the file is created, it will exist,but have length zero.

4.2. I/O EXCEPTIONS 81
The temporariness of the file doesn’t mean it’ll be guaranteed to disappear.It is a matter of whether you delete the file yourself or whether the operatingsystem occassionally cleans out the temp directory.
Invoking the method deleteOnExit() on a file tells the operating systemthat the file should be deleted when the JVM exits. Unfortunately, this methodis buggy on Windows, so should not be taken as provided strong cross-platformguarantees. It’s always a good idea to make sure to use a finally block to clearout temporary files.
4.2 I/O Exceptions
Almost all of the I/O operations are declared to throw IOException, a checkedexception in the java.io package. Like all exceptions, I/O exceptions should notbe ignored. In most cases, methods should simply pass on exceptions raised bymethods they call. Thus most methods using I/O operations will themselves bedeclared to throw IOException.
At some point, a method will have to step up and do something with anexception. In a server, this may mean logging an error and continuing on. Ina short-lived command-line program, it may mean terminating the program andprinting an informative error message.
It is important to clean up system resources in a long-running program. Thusit is not uncommon to see code in a try with a finally block to clean up evenif an I/O exception is raised.
4.2.1 Catching Subclass Exceptions
Some methods are declared to throw exceptions that are instances of subclassesof IOException. For instance, the constructor FileInputStream(File) maythrow a FileNotFoundException.
If you are passing on exceptions, don’t fall into the trap of passing just ageneral IOException. Declare your method to throw FileNotFoundExceptionand to throw IOException. This provides more information to clients of themethod, who then have the option to handle the exceptions generically at theIOException level, or more specifically, such as for a FileNotFoundException.It also helps readers of your Javadoc understand what specifically could go wrongwith their method calls.
In general, it’s a good idea to catch subclasses of exceptions separately so thaterror handling and error messages may be as specific as possible. If the methodscalled in the try block are declared to throw the more general IOException,you’ll
To do so, you need to declare the more specific catches first. For example, it’slegal to write
try {in = new FileInputStream(file);
} catch (FileNotFoundException e) {...

82 CHAPTER 4. INPUT AND OUTPUT
} catch (IOException e) {...
}
but if you try to catch the I/O exception first, the compiler will gripe that theFileNotFoundException has already been caught.
4.3 Security and Security Exceptions
Almost all of the I/O operations that attempt to read or modify a file may alsothrow an unchecked SecurityException from the base package java.lang.Typically, such exceptions are thrown when a program attempts to overstep itspermissions.
File security is managed through an instance of SecurityManager, also injava.lang. This is a very flexible interface that is beyond the scope of this book.
4.4 Input Streams
The abstract class InputStream in java.io provides the basic operations avail-able to all byte input streams. Concrete input streams may be constructed inmany ways, but they are all closed through the Closeable interface (see Sec-tion 4.6).
4.4.1 Single Byte Reads
A concrete extension of the InputStream class need only implement the top-level read() method. The read() method uses the C programming languagepattern of returning an integer representing an unsigned byte value between 0(inclusive) and 255 (inclusive) as the value read, or -1 if the end of stream hasbeen reached.
4.4.2 Byte Array Reads
It is usually too inefficient to access data one byte at a time. Instead, it is usuallyaccessed in blocks through an array. The read(byte[]) method reads data intothe specified byte array and returns the number of bytes that have been read. Ifthe return value is -1, the end of the input stream has been reached. There is asimilar method that reads into a slice of an array given an offset and length.
4.4.3 Available Bytes
The method available() returns an integer representing the number of bytesavailable for reading without blocking. This is not the same as the number ofbytes available. For one thing, streams may represent terabytes of data, andavailable() only returns an integer. More importantly, some streams mayblock waiting for more input. For instance, the standard input (see Section 4.17

4.5. OUTPUT STREAMS 83
may block while waiting for user input and show no avaialable bytes, even ifbytes may later become available.
Because no bytes may be available without blocking, it’s possible for the blockread method to return after reading no bytes. This does not mean there won’t bemore bytes to read later. The read() methods will return -1 when there are trulyno more bytes to be read.
4.4.4 Mark and Reset
The method markSupported() returns true for markable input streams. If astream is markable, calling mark() sets the mark at the current position in thestream. A later call to reset() resets the stream back to the marked position.
4.4.5 Skipping
There is also a method skip(long), which attempts to skip past the specifiednumber of bytes, returning the number of bytes it actually skipped. The onlyreason to use this method is that it is often faster than actually reading thebytes and then throwing them away, because it skipping bypasses all the byteassignments that would otherwise be required for a read.
4.5 Output Streams
The OutputStream abstract class in the package java.io provides a generalinterface for writing bytes. It is thus the complement to InputStream. Outputstreams implement the Closeable interface, and should be closed in the sameway as other closeable objects (see Section 4.6).
OutputStream itself implements the array writers in terms of single bytewrites, with the close and flush operations doing nothing. Subclasses overridesome or all of these methods for additional functionality or increased efficiency.
4.5.1 Single Byte Writes
A single abstract method needs to be implemented by concrete subclasses,write(int), which writes a byte in unsigned notation to the output stream. Thelow-order byte in the integer is written and the three high-order bytes are simplyignored (see Appendix D.1.5 for more on the byte organization of integers). Thusthe value should be an unsigned representation of a byte between 0 (inclusive)and 255 (inclusive).
4.5.2 Byte Array Writes
Arrays of bytes may be written using the method write(byte[]), and a slicevariant taking a byte array with a start position and length.
The behavior is slightly different than for reads. When a write method returns,all of the bytes in the array (or specified slice thereof) will have been written.

84 CHAPTER 4. INPUT AND OUTPUT
Thus it is not uncommon for array writes to block if they need to wait for aresource such as a network, file system, or user console input.
4.5.3 Flushing Writes
The method flush() writes any bytes that may be buffered to their final destina-tion. As noted in the documentation, the operating system may provide furtherbuffering, for instance to the network or to disk operations.
The OutputStream class is defined to implement Flushable, the interfacein java.io for flushable objects. Like the general close method from theCloseable interface, it may raise an IOException.
Most streams call the flush() method from their close() method so thatno data is left in the buffer as a result of closing an object.
4.6 Closing Streams
Because most streams impose local or system overhead on open I/O streams, itis good practice to close a stream as soon as you are done with it.
4.6.1 The Closeable Interface
Conveniently, all the streams implement the handy Closeable interface in thepackage java.io. The Closeable interface specifies a single method, close(),which closes a stream and releases any resources it may be maintaining.
Care must be taken in closing streams, as the close() method itself maythrow an IOException. Furthermore, if the stream wasn’t successfully created,the variable to which it was being assigned may be null.
The typical idiom for closing a Closeable may be illustrated with an inputstream
InputStream in = null;try {
in = new FileInputStream(file);...
} finally {if (in != null) {
in.close();}
}
Sometimes, the close method itself is wrapped to suppress warnings, as in
try {in.close();
} catch (IOException e) {/* ignore exception */
}

4.7. READERS 85
Note that even if the close method is wrapped, the operations in the try blockmay throw I/O exceptions. To remove these, I/O exceptions may be caught in ablock parallel to the try and finally.
4.6.2 LingPipe Quiet Close Utility
If a sequence of streams need to be closed, things get ugly quickly.LingPipe provides a utility method Streams.closeQuietly(Closeable) incom.aliasi.util that tests for null and swallows I/O exceptions for close op-erations. Basically, it’s defined as follows.
static void close(Closeable c) {if (c == null) return;try {
c.close();} catch (IOException e) {
/* ignore exception */}
}
If you need to log stream closing exceptions, a similar method may be imple-mented with logging in the catch operation and a message to pass as an argumentin the case of errors.
4.7 Readers
The Reader abstract base class is to char data as InputStream is to byte data.For instance, read() reads a single char coded as an int, with -1 indicating theend of the streamstream. There is a block reading method read(char[]) thatreturns the number of values read, with -1 indicating end of stream, and a simi-lar method taking a slice of an array of char values. There is also a skip(int)method that skips up to the specified number of char values, returning the num-ber of values skipped. The Reader class implements the Closeable interface,and like streams, have a single close() method. All of these methods are de-clared to throw IOException.
Unlike input streams, concrete subclasses must implement the abstract meth-ods close() and the slice-based bulk read method read(char[],int,int).
Some readers are markable, as indicated by the same markSupported()method, with the same mark() method to set the mark at the current positionand reset() method to return to the marked position.
4.7.1 The Readable Interface
The Reader class also implements the Readable interface in java.lang. Thisinterface has a single method read(CharBuffer) that reads char values into aspecified buffer, returning the number of values read or -1 for end of stream (seeSection 2.8 for more on CharBuffer).

86 CHAPTER 4. INPUT AND OUTPUT
4.8 Writers
Writers are to readers as output streams are to input streams. The methodwrite(int) writes a single character using the two low-order bytes of the spec-ified integer as a char.
Arrays of characters may be written using write(char[]) and there is amethod to write only a slice of a character array. Strings and slices of stringsmay also be written.
Like other streams, Writer implements Closeable and is hence closed in theusual way using close(). Like other output streams, it implements Flushable,so calling flush() should try to write any buffered characters.
4.8.1 The Appendable Interface
The Writer class also implements the Appendable interface in java.lang. Thisis the same interface as is implemented by the mutable character sequence im-plementations CharBuffer, StringBuilder, and StringBuffer.
This interface specifies a method for appending a single character,append(char), and for sequences, append(CharSequence), as well as for slicesof character sequences. The result specified in the Appendable interface isAppendable, so calls may be chained. The result specified by Writer is Writer;subclasses may declare more specific return types than their superclasses. Otherimplementations also declare their own types as their return types.
4.9 Converting Byte Streams to Characters
Resources are typically provided as byte streams, but programs manipulatinglanguage data require character streams. Given a character encoding, a bytestream may be converted to a character stream.
4.9.1 The InputStreamReader Class
Given an input stream and a characte encoding, an instance ofInputStreamReader may be constructed to read characters. The usualidiom is
String encoding = ...;InputStream in = ...;Reader reader = new InputStreamReader(in,encoding);...reader.close();
The operations ellided in the middle may then use the reader to retrievecharacter-based data. Instances may also be constructed from an instance ofCharSet or with a CharSetDecoder, both of which are in java.nio.charset;the string-based method is just a shortcut that creates a decoder for a character

4.10. FILE INPUT AND OUTPUT STREAMS 87
set behind the scenes. This decoder is used to convert the sequence of bytesfrom the underlying input stream into the char values returned by the reader.
The question remains as to whether to attempt to close the input streamitself given that the reader was closed. When an InputStreamReader is closed,the input stream it wraps will be closed.1 As long as the reader was constructed,there should be no problem. For more robustness, the stream may be nestedin a try-finally block to ensure it’s closed. The reader should be closed first,and if all goes well, the stream should already be closed when the close in thefinally block is reached. This second call should not cause problems, becausethe Closeable interface specifies that redundant calls to close() should haveno effect on a closed object.
4.9.2 The OutputStreamWriter Class
In the other direction, the class OutputStreamWriter does the conversion.The idiom for construction, use, and closure is the same, only based on aCharSetEncoder to convert sequences of characters to sequences of bytes forwriting.
4.9.3 Illegal Sequences
The documentation for both of these classes indicate that their behavior in theface of illegal byte or char sequences. For instance, an InputStreamReadermay be faced with a sequence of bytes that is not decodeable with the specifiedcharacter encoding. Going the other way, an OutputStreamWriter may receivea sequence char values that is not a legal UTF-16 sequence, or that contains codepoints that are not encodable in the specified character encoding.
In practice, a InputStreamReader’s behavior will be determined by itsCharSetDecoder, and a OutputStreamWriter’s by its CharSetEncoder. Theencoders and decoders may be configured to allow exceptions to be raised forillegal sequences or particular substitutions to be carried out.
4.10 File Input and Output Streams
Streaming access to files is handled by the subclasses FileInputStream andFileOutputStream, which extned the obvious base classes.
4.10.1 Constructing File Streams
A file input stream may be constructed with either a file using theconstructor FileInputStream(File) or the name of a file, usingFileInputStream(String).
1This is not clear from the documentation, but is clear from the source code. Perhaps we’re meantto infer the behavior from the general contract for close() in Closeable, which specifies that itshould release all of the resources it is holding.

88 CHAPTER 4. INPUT AND OUTPUT
Similarly, output streams may be constructed usingFileOuptutStream(File) and FileOuptutStream(String). If constructedthis way, if the file exists, it will be overwritten and resized to the outputproduced by the output stream. To append to a file, construct an output streamusing FileOuptutStream(File,boolean), where the boolean flag specifieswhether or not to append.
The constructors are declared to throw the checked exceptionFileNotFoundException, in package java.io, which is a subcclass ofIOException.
4.10.2 Finalizers
Both the input and output file streams declare finalizer methods which may re-lease any system resources when the related stream is no longer in scope. Theproblem with finalization is that it’s not guaranteed to happen until the JVM onwhich the code was running is terminated. In any case, whether it exits normallyor not, the operating system will recover any process-specific file handles.
4.10.3 File Descriptors
The FileDescriptor class in java.io provides an encapsulation of a file inputor output stream. Every time a file input or output stream is created, it has anassociated file descriptor. The file descriptor may be retrieved from a file inputstream or file output stream using the method getFD(). A new input or outputstream may be constructed based on a file descriptor.
4.10.4 Examples of File Streams
Counting the Bytes in a File
We wrote a demo program FileByteCount that opens a file input stream andthen reads all of its content, counting the number of instances of each byte. Thework is done with
public static void main(String[] args)throws FileNotFoundException, IOException {
File file = new File(args[0]);InputStream in = new FileInputStream(file);long[] counts = new long[256];int b;while ((b = in.read()) != -1)
++counts[b];
Note that the main() method is declared to throw both aFileNotFoundException and its superclass IOException (see Section 4.2for more information on I/O exceptions and their handling).
The body of the method creates an instance of File using the command-lineargument, then an input stream, based on the file. It then allocates an array of

4.10. FILE INPUT AND OUTPUT STREAMS 89
long values the size of the number of bytes, which is used to store the counts(recall that primitive numbers are always initialized to 0 in Java, including inarrays). Then we use the C-style read method to read each bye into the integervariable b. If the value is -1, indicating the end of stream (end of file here), theloop is exited. In the body of the read loop, the count for the byte just read isincremented.
We call the method using the Ant target file-byte-count, specifying thefile.in property for the file to be counted. Here we call it on its own sourcecode,
> ant -Dfile.in=src/com/lingpipe/book/io/FileByteCount.javafile-byte-count
Dec Hex Count10 a 3332 20 18933 21 1
...123 7b 2125 7d 2
Because the file is encoded in ASCII, these bytes can be read as characters. Forinstance, character hexadecimal value 0A is the linefeed, 20 is a newline, 32 isthe digit 2, up through 7D, which is the right curly bracket (}). We can infer thatthe file has 34 lines, because there are 33 line feeds.
Copying from One File to Another
Our next sample program, CopyFile, copies the bytes in one file into anotherfile and illustrates the use of array-based reads and writes.2 After reading in thecommand-line arguments, the work is carried out by
InputStream in = new FileInputStream(fileIn);OutputStream out = new FileOutputStream(fileOut);byte[] buf = new byte[8192];int n;while ((n = in.read(buf)) >= 0)
out.write(buf,0,n);out.close();in.close();
We first create the file input and output streams. We’ve assigned them to vari-ables of type InputStream and OutputStream rather than to their specific sub-classes because we do not need any of the functionality specific to file streams.We then allocate an array buf of bytes to act as a buffer and declare a variable nto hold the count of the number of bytes read. The loop continually reads fromthe input stream into the buffer, assigning the number of bytes read to n, and
2The same functionality is available through the LingPipe static utility methodcopyFile(File,File) from the Files class in com.aliasi.util.

90 CHAPTER 4. INPUT AND OUTPUT
exiting the loop if the number of bytes read is less than zero (signaling end ofstream). In the body of the loop, we write the bytes in the buffer to the outputstream, being careful to specify that we only want to write n bytes. Unlike reads,writes either succeed in writing all their bytes (perhaps having to block), or throwan exception. When we’re done, we close both streams.3
Character Encoding Conversion
As a third example, we’ll show how to wrap our file-based streams in readersand writers in order to carry out character encoding conversion. Here we use acharacter buffer to do the transfer,
InputStream in = new FileInputStream(fileIn);InputStreamReader reader = new InputStreamReader(in,encIn);OutputStream out = new FileOutputStream(fileOut);OutputStreamWriter writer = new OutputStreamWriter(out,encOut);char[] buf = new char[4096];for (int n; (n = reader.read(buf)) >= 0; )
writer.write(buf,0,n);writer.close();reader.close();
The program may be called with the Ant target file-decode-encode with argu-ments given by properties file.in, enc.in, file.out, and enc.out.
4.11 Buffered Streams
Some sources of input, such as an HTTP connection or a file, are most efficientlydealt with in larger chunks than a single byte. In most cases, when using suchstreams, it is more efficient to buffer the input or output. Both byte and char-acter streams may be buffered for both input and output. For byte streams, theclasses are BufferedInputStream and BufferedOutputStream, and for char-acter streams, BufferedReader and BufferedWriter
4.11.1 Constructing Buffered Streams
The buffered byte streams have constructors BufferedInputStream(InputStream,int)and BufferedOutputStream(OutputStream,int) that wrap a specified streamand use a buffer of the specified size to hold bytes. The buffer sizes may bedropped, in which case a default size is used.
For example, we may created a buffered input stream from a file input streamusing
3We don’t need elaborate try-finally logic to close the file streams because they are closed automat-ically when the command-line program exits. We could get into trouble if another program were tocall this main() without exiting the JVM after the call. A more robust version of this program mightcatch I/O exceptions thrown by the write method and delete the output stream rather than leavinga partial copy. We’ve shown what this would look like in the source file for CopyFile in a parallelmethod named main2().

4.11. BUFFERED STREAMS 91
File file = ...;InputStream in = new FileInputStream(file);InputStream bufIn = new BufferedInputStream(in);
The variable bufIn is then used where the unbuffered stream in would’ve beenused. By assigning all these streams of different types to a base InputStream, itmakes it easier to change the code later.
The constructors only save a pointer to the underlying stream and create abuffer, so they don’t throw I/O exceptions, because they’re not doing any I/O.
4.11.2 Sizing the Buffer
There is often a measurable performance improvement from getting the buffersize right for the underlying platform and application, but performance mea-surement is a tricky business (see Section F.2 for recommended reading on per-formance tuning).
4.11.3 Closing a Buffered Stream
When a buffered stream is closed, it closes the contained stream. See the discus-sion in Section 4.9.1 concerning writing robust stream closing idioms. The closewill also flush any bytes or characters currently being buffered.
4.11.4 Built-in Buffering
Many of the streams (or readers and writers) have built-in buffering. For instance,the GZIP input and output streams have built-in buffers. In these cases, there’sno need to buffer twice for efficiency’s sake.
If you are eventually going to wrap a byte stream in a buffered reader orwriter, the byte stream doesn’t itself need to be buffered. The buffering, thoughuse of block reads and writes, carries itself through.
Similarly, if your own code does buffering, as in our example in CopyFile(see Section 4.10.4), there’s no need to buffer the file input or output streams.
By this same line of reasoning, if a byte stream is converted to a characterstream or vice versa, buffering is not required at both places. Usually, the bufferis placed later in the chain, around the reader or writer, as in
InputStream in = new FileInputStream(file);Reader reader = new InputStreamReader(in,"UTF-8");BufferedReader bufReader = new BufferedReader(isReader);
OutputStream out = new FileOutputStream(file);Writer writer = new OutputStreamWriter(out,"UTF-8");BufferedWriter bufWriter = new BufferedWriter(writer);

92 CHAPTER 4. INPUT AND OUTPUT
4.11.5 Line-Based Reads
The BufferedReader class implements a method to read lines. The methodreadLine() returns a String corresponding to the next line of input read, notincluding the end-of-line markers. If the end of stream has been reached, thismethod will return null.
This class recognizes three end-of-line markers, a linefeed (\n), a carriagereturn (\r), or a linefeed followed by a carriage return (\n\r).
4.12 Array-Backed Input and Output Streams
The array-backed input streams and readers read from arrays of data held inmemory. The array-backed output streams and writers buffer the bytes or char-acters written to them and provide access to them as an array at any time.
4.12.1 The ByteArrayInputStream Class
The class ByteArrayInputStream wraps a byte array to produce an in-memoryinput stream. The constructor ByteArrayInputStream(byte[]) creates the in-put stream. The byte array is not copied, so changes to it will affect the inputstream.
Byte array input streams support the mark() and reset() methods.Closing a byte array input stream has no effect whatsoever.
4.12.2 The CharArrayReader Class
The class CharArrayReader performs the same service, creating a Reader froman array of characters. They support the same range of methods with almost allthe same behaviors, only for char data rather than byte data. Inconsistently,close() behaves differently, releasing the reference to the underlying characterarray and causing all subsequent calls to read methods to throw I/O exceptions.
There is also a class StringReader that does the same thing as a characterarray reader for string input.
4.12.3 The ByteArrayOutputStream Class
A ByteArrayOutputStream provides an in-memory output stream that buffersany bytes written to it. Because it uses arrays, the maximum amount of data thatcan be written to an output stream is Integer.MAX_VALUE bytes.
There is a no-argument constructor and one that specifies the initial capacityof the buffer.
The method size() returns the number of bytes that are buffered.All of the bytes written to a byte array output stream are available as a byte
array using the method toByteArray(). The returned array is a copy of thebytes buffered in an underlying array, so changes to it do not affect the outputstream. Calling this method does not remove the returned bytes from the buffer.

4.13. COMPRESSED STREAMS 93
Calling reset() removes all of the currently buffered bytes, allowing a bytearray output stream to be reused.
Closing a byte-array output stream has no effect. In particular, the bytes thathave been buffered will still be available.
4.12.4 The CharArrayWriter Class
A CharArrayWriter does the same thing for characters, implementing methodsof the same name as byte-array output streams.
4.13 Compressed Streams
In many cases, resources are compressed to save storage space or transfer band-width. The standard Java package java.util.zip supports a general pair ofstreams, DeflaterInputStream and InflaterInputStream, for compressingand decompressing sequences of bytes. Although new implementations maybe written, Java builds in support for Gnu Zip (GZIP) compression and for theZIP format for compressing archives consisting of multiple hierarchically namedstreams as an archive. Java’s own Java archive (JAR) files are essentially zippedarchives, and are also implemented.
4.13.1 GZIP Input and Output Streams
The GZIP input and output streams are constructed by wrapping anothr streamand optionally specifying a buffer size. After construction, they behave just likeany other stream.
The sample program FileGZIP wraps a file output stream in a GZIP outputstream in order to implement a simple compression command-line program. Thework in the main() method is done by
InputStream in = new FileInputStream(fileIn);OutputStream out = new FileOutputStream(fileOut);OutputStream zipOut = new GZIPOutputStream(out);
byte[] bs = new byte[8192];for (int n; (n = in.read(bs)) >= 0; )
zipOut.write(bs,0,n);
in.close();zipOut.close();
Aside from the creation of the compressed stream, the rest is just a bufferedstream copy.
The sample program FileUnGZIP uncompresses one file into the other, withall the work being done in the creation of the streams,
InputStream in = new FileInputStream(fileIn);InputStream zipIn = new GZIPInputStream(in);OutputStream out = new FileOutputStream(fileOut);

94 CHAPTER 4. INPUT AND OUTPUT
After the streams are created, the input is copied to the output as before. Bothprograms print the input and output file lengths for convenience.
The Ant target file-gzip calls the program with arguments the value ofproperties file.uncompressed and file.gzipped. It’s conventional to name acompressed file the same thing as the original file with a suffix denoting the typeof compression, which for GZIP is gz. Here we compress the build file build.xml,which being XML, is highly redundant, and hence highly compressible.
> ant -Dfile.uncompressed=build.xml -Dfile.gzipped=build.xml.gzfile-gzip
Original Size=7645 Compressed Size=1333
We can uncompress in the same way, calling the file-ungzip target, whichtakes as command-line arguments the values of properties file.gzipped andfile.ungzipped.
> ant -Dfile.ungzipped=build.xml.copy -Dfile.gzipped=build.xml.gzfile-ungzip
Original Size=1333 Expanded Size=7645
The round trip results in build.xml.copy containing exactly the same bytes asbuild.xml. You may verify the files contain the same content using the diffprogram from the command line,
> diff build.xml build.xml.copy
which prints no output when the files being compared are the same. Listing thedirectory contents shows the sizes,
> ls -l
7645 Aug 5 16:54 build.xml7645 Aug 5 16:58 build.xml.copy1333 Aug 5 16:58 build.xml.gz
Along the same lines, you may verify that command-line versions of GZIP,such as gunzip, can handle the compressed file.45
If you try to compress a stream that isn’t in GZIP format, the input streamwill throw an I/O exception with an explanatory message.
4.13.2 ZIP Input and Output Streams
ZIP streams enable the representation of compressed archives. A ZIP archiveconsists of a sequence of entries. Each entry contains meta information and data.The data is accessed through an input stream for reading and output stream forwriting. The pattern for using the ZIP streams is somewhat unusual, so we willprovide an example.
4We recommend working in a temporary directory so as not to destroy the original build.xml file.The command-line compressors and uncompressors typically work by creating an output file whichadds or removes the compression format’s standard suffix.
5We’ve had trouble getting the compression programs to work from the DOS command line.

4.13. COMPRESSED STREAMS 95
The ZIPEntry Class
The meta-information for an entry is encapsulated in an instance of ZIPEntry inthe java.util.zip package. Information about the entry including compressedsize, CRC-32 checksum, time last modified, comments, and the entry’s name areavailable through methods.
ZIP archives may be arranged hierarchically. Directory structure is describedthrough entry names, with the forward slash (/) acting as the separator. Themethod isDirectory() is available to determine if an entry is a directory, whichis signaled by its ending in a forward slash.
For the purpose of creating archives, the zip entry values may be set withsetter methods corresponding to the get methods. This entails that the ZIPEntryclass is mutable.
Creating a Zip Archive with Ant
To provide a zip file for experimental purposes, we’ve written an Ant targetexample-zip that builds a zipped archive using Ant’s built-in mkdir, echo, andzip tasks. The Ant code is straightforward,
<property name="file.in.zip"value="build/demo-archive.zip"/>
<target name="example-zip"><mkdir dir="build/archive/dir"/><echo message="Hello."
encoding="UTF-8"file="build/archive/hello.txt"/>
...<zip destfile="${file.in.zip}"
basedir="build/archive"encoding="UTF-8"/>
</target>
It uses the property file.in.zip to define the zipped archive’s location. Themkdir task makes a working directory in our build directory, which will becleaned the next time the clean target is invoked. The echo task writes textto a file with a specified encoding. The ellided tasks write two more files. Wethen call the zip target, specifying the target file, the directory which is beingzipped up, and the encoding to use for file names.
The demo file creation target needs to be run before the demo so there’ssomething to unzip.
> ant example-zip
Building zip: c:\lpb\src\io\build\demo-archive.zip

96 CHAPTER 4. INPUT AND OUTPUT
Reading a ZIP Archive
A ZIPInputStream is created, and then the archive is read entry by entry. Themethod getNextEntry() returns the ZIPEntry object for the next entry to beread, or null if there ae no more entries. For each entry, we read its meta-information from the entry object and its data from the input stream.
We provide a sample program FileZipView that reads a ZIP archive from afile and displays its properties and contents. The work in the main() method isdone by
InputStream in = new FileInputStream(fileZipIn);ZipInputStream zipIn = new ZipInputStream(in);byte[] bs = new byte[8192];while (true) {
ZipEntry entry = zipIn.getNextEntry();if (entry == null) break;printEntryProperties(entry);for (int n; (n = zipIn.read(bs)) >= 0; )
System.out.write(bs,0,n);}zipIn.close();
To get going, the file input stream is wrapped in a ZipInputStream. The bufferbs is used for writing. This loop uses the while-true-break idiom to run until acondition discovered in the middle of the body is discovered. Here, we assignthe entry variable to the next entry. If it’s null, we break out of the loop. Oth-erwise, we print the properties of the entry using a subroutine with the obviousimplementation, then read the bytes from the zip input stream and write themto standard output.
We have an Ant target file-zip-view that dumps out the contents of a Ziparchive specified through the file.in.zip property.
> ant -Dfile.in.zip=build/demo-archive.zip file-zip-view
getName()=abc/ isDirectory()=truegetSize()=0 getCompressedSize()=0new Date(getTime())=Tue Jul 20 18:21:36 EDT 2010getCrc()=0 getComment()=null---------------------------getName()=abc/bye.txt isDirectory()=falsegetSize()=7 getCompressedSize()=9new Date(getTime())=Tue Jul 20 18:21:36 EDT 2010getCrc()=3258114536 getComment()=nullGoodbye---------------------------...---------------------------getName()=hello.txt isDirectory()=false...Hello

4.14. TAPE ARCHIVE (TAR) STREAMS 97
We’ve moved lines together to save space and ellided the third entry and part ofthe fourth. Each division is for an entry, and the commands used to access theproperties are printed. For instance, the first entry is a directory named abc/, thesecond entry is an ordinary entry named abc/bye.txt, implying containment inthe first directory by naming. The final entry is another ordinary entry namedhello.txt, which isn’t in any directory. Note that the compressed size is largetthan the uncompressed size, which is not unusual for a short (or random, oralready compressed) sequence of bytes.
After printing out all the properties for each entry, the program prints thecontents by simply writing the bytes read directly to the standard output. Forexample, the entry named abc/bye.txt contains the UTF-8 bytes for Goodbye.
Creating a Zip Archive
Zip archives may be created programmatically using ZipOutputStream by re-versing the process by which they are read. That requires creating ZipEntryobjects for each entry in the archive and setting their properties. The en-try meta-information is then written to the archive using the putNextEntry()method on the Zip output stream, then writing the bytes to the stream. Themethod setMethod(int) may be used with argument constants STORED for un-compressed entries and DEFLATED for compressed entries.
4.14 Tape Archive (Tar) Streams
The archaically named Tape Archive (tar) format is popular, especially amongUnix users, for distributing data with a directory structure. Tar files themselvesare typically compressed using GZIP (see Section 4.13.1). The Ant build librarycontains classes for manipulating tar streams, so we will be importing the Antjar for compiling and running the examples in this section.
4.14.1 Reading Tar Streams
The way in which data may be read out of a tar file is easy to see with an example.
Code Walkthrough
We provide a demo class FileTarView that reads from a tar file that has option-ally been gzipped. The main() method is defined to throw an I/O exception andread a file tarFile and boolean flag gzipped from the first two command-linearguments. The code begins by constructing the tar input stream.
InputStream fileIn = new FileInputStream(tarFile);InputStream in = gzipped
? new GZIPInputStream(fileIn): fileIn;
TarInputStream tarIn = new TarInputStream(in);

98 CHAPTER 4. INPUT AND OUTPUT
We first create a file input stream. Then we wrap it in a GZIP input streamif the gzipped flag has been set. Then, we just wrap the input stream in aTarInputStream, from package org.apache.tools.tar.
We then use a read loop, inside which we access the properties of the entriesand read the entry data.
while (true) {TarEntry entry = tarIn.getNextEntry();if (entry == null) break;
boolean isDirectory = entry.isDirectory();String name = entry.getName();String userName = entry.getUserName();String groupName = entry.getGroupName();int mode = entry.getMode();Date date = entry.getModTime();long size = entry.getSize();
byte[] bs = Streams.toByteArray(tarIn);
We use the getNextEntry() method of the tar input stream to get the nextinstance of TarEntry, also from org.apache.tools.tar. If the entry is null,the stream has ended and we break out of the loop.
If the tar entry exists, we then access some of its more prominent propertiesincluding whether or not it’s a directory, the name of the entry, the name of theuser and group for whom it was created, the mode (usually specified as octal, sowe print it out in octal), the date the entry was last modified, and the entry’s size.
Finally, we use LingPipe’s toByteArray() utility, from class Streams incom.aliasi.util, to read the data in the entry. Note that like for zip inputstreams, this is done by reading to the end of the tar input stream. The tar inputstream is then reset.
After we’re done with the tar input stream, we close it through the closeableinterface.
tarIn.close();
Tar input streams implement Java’s Closeable interface, so we close it throughthe close() method. Although not documented, closing a tar input stream willclose any contained stream other than System.in. Here, this closes the GZIPinput stream, which in turn closes the file input stream.
Running the Demo
The Ant target file-tar-view runs the command, passing the value of prop-erties tar.file and gzipped as command-line arguments. We use the gzipped20 newsgroups distribution as an example (see Section C.1 for a description andlink).
> ant -Dtar.file=c:/carp/data/20news/20news-bydate.tar.gz-Dgzipped=true file-tar-view

4.15. ACCESSING RESOURCES FROM THE CLASSPATH 99
------------------------------------name=20news-bydate-test/ isDirectory=trueuserName=jrennie groupName= mode=755date=Tue Mar 18 07:24:56 EST 2003size=0 #bytes read=0------------------------------------name=20news-bydate-test/alt.atheism/ isDirectory=trueuserName=jrennie groupName= mode=755date=Tue Mar 18 07:23:48 EST 2003size=0 #bytes read=0------------------------------------name=20news-bydate-test/alt.atheism/53265 isDirectory=falseuserName=jrennie groupName= mode=644date=Tue Mar 18 07:23:47 EST 2003size=1994 #bytes read=1994...name=20news-bydate-train/ isDirectory=trueuserName=jrennie groupName= mode=755date=Tue Mar 18 07:24:55 EST 2003size=0 #bytes read=0------------------------------------name=20news-bydate-train/alt.atheism/ isDirectory=true...
Note that we first see the directory 20news-bydate-test. The user name isjrennie, there is no group name, and the mode indicating permissions is 755(octal). The last-modified date is in 2003. The size of the directory is zero,and the number of bytes read is zero. The next directory looks similar, only itsname is test/alt.atheism, indicating that it is nested in the previous entry.In this corpus, it also indicates that the directory contains postings from thealt.atheism newsgroup. The TarEntry object lets you access all the entries forthe files or directories it contains, but that won’t let you read the data.
After the two directories, we see a file, with namebydate-test/alt.atheism/53265 and mode 644 (octal). he reported sizematches the number of bytes read, 1994.
After the files in the alt.atheism directory, there are 19 more test news-group directories. Then, we see the training data, which is organized the sameway.
4.15 Accessing Resources from the Classpath
When distributing an application, it is convenient to package all the necessaryfiles along with the compiled classes in a single Java archive (jar). This is par-ticularly useful in the context of servlets, which are themselves packaged in webarchives (war), a kind of jar with extra meta-information.

100 CHAPTER 4. INPUT AND OUTPUT
4.15.1 Adding Resources to a Jar
Resources that will be accessed programatically are added to an archive file justlike any other file. We provide an Ant target example-resource-jar which maybe used to create a jar at the path picked out by the property resource.jar.
<property name="resource.jar"value="build/demo-text.jar"/>
<target name="example-resource-jar"><mkdir dir="build/resources/com/lingpipe/book/io"/><echo message="Hello from the jar."
encoding="UTF-8"file="build/resources/com/lingpipe/book/io/hello.txt"/>
...<jar destfile="${resource.jar}">
<fileset dir="build/resources"includes="**/*.txt"/>
</jar></target>
We define the default for the property resource.jar to be a file of the samename in the build directory (which is subject to cleaning by the clean target).The target that builds the jar first makes a directory under build/resourcesinto which files will be placed. These are created by echo tasks, for instancecreating a file /com/lingpipe/book/io/hello.txt under build/resources.After the directory structure to be archived is created in build/resources, ajar task creates it, specifying that the archive should include all the files inbuild/resources that match the pattern **/*.txt, which is all files ending in.txt.
This command should be run before the demo in the next section.
> ant -Dresource.jar=build/demo-text.jar example-resource-jar
Building jar: c:\lpb\src\io\build\demo-text.jar
4.15.2 Resources as Input Streams
One of the ways in which an input stream may be accessed is by specifying aresource. The system will then look for the resource on the classpath in a numberof prespecified locations based on its name.
The sample program ResourceInput reads the content of a resource fromthe classpath and writes it to the standard output. The part of the main()method that gets the resource as an input streami is
String resourceName = args[0];InputStream in
= ResourceInput.class.getResourceAsStream(resourceName);

4.16. PRINT STREAMS AND FORMATTED OUTPUT 101
The name of the resource is read in as the first command-line argument. Thenthe method getResourceAsStream(String) is called with the name of the re-source. It is called on the Class instance for the ResourceInput class, specifiedby the static constant ResourceInput.class. The calling class is also importantbecause the rules for locating the resource depend on the particular class loaderused to load the class.
If the name begins with a forward slash (/), it is taken to be an absolute pathname. Otherwise, it is a relative path. Relative paths are interpreted relative tothe package name of the class from which the get method was called. Specifically,the package name of the class using forward slashes as separators is used a prefixfor the name.
The Ant target resource-input look for a resource with the name given byproperty resource.name, adding the archive named by property resource.jarto the classpath. The jar from which we are reading needs to be on the classpath.How it gets there doesn’t matter: you could put it on the command line, set anenvironment variable read by the JVM, use a servlet container’s classpath, etc.Here, we just add the jar named by property resource.jar to the classpath inthe Ant target. Very often, we just bundle resources we want to read from theclass path along with the compiled classes for an application. This is convenientfor everything from document type definitions (DTDs) to compiled statisticalmodels.
We run the program using the resource named hello.txt and the jar wecreated in the last section.
> ant -Dresource.jar=build/demo-text.jar -Dresource.name=hello.txtresource-input
Hello from the jar.
Note that we would get the same result if we specified the resource.name prop-erty to be the absolute path /com/lingpipe/book/io/hello.txt (note the ini-tial forward slash).
Once the stream is retrieved from the resource, it may be manipulated likeany other stream. It may be buffered, converted to a reader or object inputstream, interpreted as an image, etc.
4.16 Print Streams and Formatted Output
A print stream is a very flexible output stream that supports standard streamoutput, conversion of characters to bytes for output, and structured C-style for-matting. This provides most of the functionality of a Writer’s methods, whileextending the base class InputStream.6
6It’s not possible in Java to be both a Writer and a InputStream because these are both abstractbase classes, and a class may only extend one other class. In retrospect, it’d be much more convenientif the streams were all defined as interfaces.

102 CHAPTER 4. INPUT AND OUTPUT
4.16.1 Constructing a Print Stream
A print stream may be constructed by wrapping another input streamor providing a file to which output should be written. The characterencoding and whether auto-flushing should be carried out may also bespecified. We recommend restricting your attention to the constructorsPrintStream(File,String) that writes to a file given a specified encoding, andPrintStream(OutputStream,boolean,String), which prints to the specifiedoutput stream, optionally using auto-flushing, using a specified character en-coding. The othe methods are shorthands that allow some parameters to bedropped.
4.16.2 Exception Buffering
The second unusual feature of print streams is that none of their methods is de-clared to throw an I/O exception. Instead, what it does is implement an exceptionbuffering pattern, only without an actual buffer.7 In cases where other streamswould raise an I/O exception, the print stream methods exit quietly, while atthe same time setting an error flag. The status of this flag is available throughthe method checkError(), which returns true if a method has caught an I/Oexception.
4.16.3 Formatted Output
One of the most convenient aspects of print streams is their implementation ofC-style printf() methods for formatted printing. These methods implicitly usean instance of Formatter in java.util to convert a sequence of objects into astring.
Format syntax is very elaborate, and for the most part, we re-strict our attention to a few operations. The method’s signature isprintf(Locale,String,Object...), where the string is the formatting stringand the variable-length argument Object... is zero or more objects to format.How the objects are formatted depends on the format string and the Locale(from java.util). The locale is optional; if it is not supplied, the default localewill be used. The locale impacts the printing of things like dates and decimalnumbers, which are conventionally printed differently in different places. Al-though we are obsessive about maintaining unadulterated character data andwork in many languages, a discussion of the intricacies f application internation-alization is beyond the scope of this book.
For example, the sample program FileByteCount (see Section 4.10.4) usesstring, decimal and hexadecimal formatting for strings and numbers,
System.out.printf("%4s %4s %10s\n","Dec","Hex","Count");for (int i = 0; i < counts.length; ++i)
if (counts[i] > 0L)System.out.printf("%4d %4h %10d\n",i,i,counts[i]);
7This pattern is sometimes implemented so that the actual exceptions that were raised are acces-sible as a list.

4.17. STANDARD INPUT, OUTPUT, AND ERROR STREAMS 103
The first printf() has the format string "%4s %4s %10s\n", which says to writethe first string using 4 characters, the second string using 4 characters, and thethird string using 10 characters; if they are too short, they align to the right, andif they are too long, they run over their alloted space. The second printf() uses%4d for a four place integer (right aligned), and %4h for a four-digit hexadecimalrepresentation. Note that auto-boxing (see Appendix D.2.6) converts the integersi and counts[i] to instances of Integer to act as inputs to printf(). Format-ted prints do not automatically occupy a line; we have manually added UNIX-styleline boundary with the line feed character escape \n.
Finally, note that the two printf() statements intentionally use the samewidth so the output is formatted like a table with headings aligned above thecolumns.
4.17 Standard Input, Output, and Error Streams
In many contexts, the environment in which a program is executed providesstreams for input, output, and error messages. These streams are known asstandard input, standard output, and standard error. Standard UNIX pipelinesdirect these streams in two ways. They can direct the standard input to be readfrom a file or the standard output or error to be written to a file. Second, they canpipe processes together, so that the standard output from one process is usedfor the standard input of the next process. Shell scripts and scripting languagessuch as Python manage standard input and output from processes in a similarway to shells.8
4.17.1 Accessing the Streams
Java provides access to these streams through three static variables in theclass System in the package java.lang. The variable System.in is of typeInputStream and may be used to read bytes from the shell’s standard input.The standard and error output streams, System.out and System.err, are pro-vided constants of type PrintStream (see Section 4.16 for more information onprint streams). The standard output and error print streams use the platform’sdefault encoding (see below for how to reset this).
4.17.2 Redirecting the Streams
The standard input and output streams may be reset using the meth-ods setIn(InputStream), setOut(PrintStream) and setErr(PrintStream).This is convenient for writing Java programs that act like Python or shell scripts.
8Java provides an implementation of Unix-style pipes through piped streams and readers andwriters. These are based on the classes PipedInputStream, PipedOutputStream, PipedReader,and PipedWriter in the standard java.io package. These classes are multi-threaded so that theymay asynchronously consume the output of one process to provide the input to the next, blocking ifneed be to wait for a read or write.

104 CHAPTER 4. INPUT AND OUTPUT
The mutability of the output and error streams enables a Java program toreset their character encodings. For example, to reset standard output to useUTF-8, insert the following statement before any output is produced,
System.setOut(new PrintStream(System.out,true,"UTF-8"));
The value true enables auto-flushing. The new standard output wraps the oldstandard output in a new print stream with the desired encoding.
The output streams may be similarly redirected to files by using aPrintStream constructed from a file in the same way. For example,
System.setErr(new PrintStream("stdout.utf8.txt","UTF-16BE"));
sends anyting the program writes to the standard error stream to the filestdout.utf8.txt, using the UTF-16BE character encoding to convert charactersto bytes.
The standard input stream may be wrapped in an InputStreamReader orBufferedReader to interpret byte inputs as characters. Standard output anderror may be wrapped in the same way, which is an alternative to resetting thestreams.
4.17.3 UNIX-like Commands
Commands in UNIX are often defined to default to writing to the standard outputif a file is not specified. This idiom is easy to reconstruct for Java commands.Suppose we have a variable file that is initialized to a file or null if the com-mand is to write an output
PrintStream out= (file != null)? new PrintStream(new FileOutputStream(file)): System.out;
If the file is non-null, an output stream for it is wrapepd in a print stream, other-wise the standard output is used. The same can be done for input.
4.18 URIs, URLs and URNs
A uniform resource identifier (URI) picks out something on the web by name.This is a very general notion, but we will only need a few instances in this book.The specifications for these standards are quite complex, and beyond the scopeof this book.
4.18.1 Uniform Resource Names
There are two (overlapping) subtypes of URIs, based on function. A uniformresource name (URN) is a URI that provides a name for something on the web,but may not say how or where to get it. A typical instance of a URN is theDigital Object Identifier (DOI) system, which is becoming more and more widely

4.18. URIS, URLS AND URNS 105
used to identify text resources such as journal articles. For example, the DOIdoi:10.1016/j.jbi.2003.10.001 picks out a paper on which my wife was aco-author. An alternative URN for the same paper is PMID:15016385, which usesthe PubMed identifier (PMID) for the paper.
4.18.2 Uniform Resource Locators
A uniform resource locator (URL) provides a means of locating (a con-crete instance of) an item on the web. A URL indicates how to getsomething by providing a scheme name, such as file:// for files orhttp:// for the hypertext transport protocol (HTTP). For example, theURL http://dx.doi.org/10.1016/j.jbi.2003.10.001 is for the same pa-per as above, but specifies a web protocol, HTTP, and host, dx.doi.orgfrom which to fetch a specific embodiment of the resource. Theremay be many URLs that point to the same object. For instance,http://linkinghub.elsevier.com/retrieve/pii/S1532046403001126 is aURL for the same paper, which links to the publisher’s site.
4.18.3 URIs and URLs in Java
The standard java.net package has a class URI for URIs and a class URL forURLs. Both of them may be constructed using a string representation of theresource. Once constructed, the classes provide a range of structured access tothe fields making up the resource. For instance, both objects have methods suchas getHost() and getPort(), which may return proper values or indicators likenull or -1 that there is no host or port.
The demo program UrlProperties constructs a URL from a command-lineargument and prints out its available properties. The beginning of the main()method is
public static void main(String[] args)throws MalformedURLException {
String url = args[0];URL u = new URL(url);System.out.println("getAuthority()=" + u.getAuthority());
The rest of the program just prints out the rest of the properties. The main()method throws a MalformedURLException, a subclass of IOException, if theURL specified on the command line is not well formed. This ensures that oncea URL is constructed, it is well formed. There are no exceptions to catch for theget methods; they operate only on the string representations and are guaranteedto succeed if the URL was constructed.
The Ant target url-properties calls the command supplying as an argu-ment the value of the property url.in.
> ant -Durl.in="http://google.com/webhp?q=dirichlet"url-properties

106 CHAPTER 4. INPUT AND OUTPUT
getAuthority()=google.comgetDefaultPort()=80getFile()=/webhp?q=dirichletgetHost()=google.comgetPath()=/webhpgetPort()=-1getProtocol()=httpgetQuery()=q=dirichletgetRef()=nullgetUserInfo()=nulltoExternalForm()=http://google.com/webhp?q=dirichlettoString()=http://google.com/webhp?q=dirichlet
Looking over the output shows how the URL is parsed into components suc ashost, path and query.
4.18.4 Reading from URLs
URLs know how to access resources. These resources may reside locally or re-motely. Wherever they arise, and whatever their content, resources are all codedas byte streams. Java provides built-in support for protocols http, https, ftp,file, and jar.
Once a URL is created, the method openStream() returns an InputStreamthat may be used to read the bytes from the URL. Depending on the URL itself,these bytes may be from a local or networked file, a local or remote web server,or elsewhere. Opening the stream may throw an I/O exception, as a connectionis opened to the URL. Once the input stream is opened, it may be used like anyother stream.
The sample program ReadUrl shows how to read the bytes from an URL andrelay them to standard output.
URL u = new URL(url);InputStream in = u.openStream();
byte[] buf = new byte[8096];int n;while ((n = in.read(buf)) >= 0)
System.out.write(buf,0,n);
in.close();
The code between the stream creation and its closing is just a generic bufferedstream copy.
The Ant target read-url is configured to call the sample program using asURL the value of the property url.in.
> ant -Durl.in=http://lingpipe.com url-read
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE html ...

4.19. THE INPUT SOURCE ABSTRACTION 107
<html ...<head><title>LingPipe Home</title><meta http-equiv="Content-type"
content="application/xhtml+xml; charset=utf-8"/>...pageTracker._trackPageview();} catch(err) {}</script></body></html>
As with most pages these days, LingPipe’s home page starts with a title, contenttype, and cascading stylesheet (CSS) declaration, and ends with some Javascript.Whether you can see all of the output of a page depends on your shell; you cansave the output to a file and then view it in a browser.
A file URL may be used as well as an HTTP-based URL. This allows an abstrac-tion over the location of the bytes being read.
4.18.5 URL Connections
The output stream method we used above, getOutputStream(), is just a conve-nience method for calling the openConnection() method to get an instance ofURLConnection and calling its getOutputStream() method. URL connectionsallow various properties of the connection to be inspected and set.
Although the URL method openConnection() is declared to return aURLConenction, if the URL uses the HTTP protocol, the documentation speci-fies that a HttpURLConnection will be returned. Thus the URLConnection maybe cast to HttpURLConnection at run time. The HTTP-based connection pro-vides additional methods for manipulating HTTP headers and responses, such ascontent types, last-modified dates, character encodings, handling redirected webpages, fetching HTTP respose codes, managing timeouts and keep-alive times forthe connection, and other intricacies of HTTP management.
A URL connection may also be used to write to a URL. This makes it possible toattach data for a POST-based request and thus implement general web services.
4.19 The Input Source Abstraction
The class InputSource, in standard Java package org.xml.sax, provides an in-put abstractionforXMLdocuments with a rather awkward mutable implementa-tion. An input source specifies the source of its input as a URL, an input stream,or a reader.
There is a constructor for each mode of input specification.InputSource(String) may be used with a system identifier in the formof a URL, and InputSource(InputStream) and InputSource(Reader) forstream data. We recommend using one of these constructors and not thecorresponding setters. immutable.
There is also a no-argument constructor InputSource() and set-ters for each of the input types. The setters setSystemId(String),

108 CHAPTER 4. INPUT AND OUTPUT
setByteStream(InputStream) and setCharacterStream(Reader) corre-spond to the three contentful constructors.
The system ID may be used to resolve relative paths within an XML document.Thus setting a system ID may be useful even when a byte stream or a characterstream has been specified.
Before using an input source, a character encoding may be specified usingthe setEncoding(String) method. A further awkwardness arises because thismethod only makes sense in conjunction with an input stream or URL; readerssupply already converted char values.
It is up to the consumer of the input source to gather data from whateversource is specified. Typically, consumers will try the reader, then the inputstream, then the URL. Because of the mutability of the class through the setters,an input source may have an input stream and a reader and a URL specified.
4.20 File Channels and Memory Mapped Files
As an alternative to streaming I/O, memory mapping essentially provides a ran-dom access interface for files. The method is by providing an array-like accessabstraction on top of files. It is then up to the operating system’s file manager todeal with actual commits to and reads from disk.
Memory mapped files are great for random access to data on disk. For in-stance, databases and search engines make heavy use of memory mapping.
Both the file input and file output stream classes implement a getChannel()method which returns an instance of FileChannel. File channels are part ofthe “new” I/O, rooted at package name java.nio, specifically in the packagejava.nio.channels.
File channels support reading and writing into ByteBuffer instances. Bytebuffers and other buffers are in the java.nio package. Byte buffers may bewrapped to act as character buffers or other primitive type buffers. See Sec-tion 2.8 for a basic overview of buffers focusing on character buffers.
File channels may also be used to produce a MappedByteBuffer, which cre-ates a memory-mapped file accessible as a ByteBuffer. The other way to cre-ate a file channel which may be used to produce a memory mapped buffer isthrough the RandomAccessFile class in java.io. The random access file classimplements the DataInput and DataOutput interfaces, which provide utilitiesto write arbitrary primitives and strings in addition to bytes.
4.21 Object and Data I/O
Java provides built-in support for writing objects to streams through the classesObjectInputStream and ObjectOutputStream in the package java.io. Ob-ject input and output streams implement the ObjectInput and ObjectOutputinterfaces, which extend the DataInput and DataOutput interfaces. The ob-ject streams deal with writing objects and the data streams with writing prim-itive types and strings. Only objects with a runtime class that implements the

4.21. OBJECT AND DATA I/O 109
Serializable interface in package java.io may be written or read. We firstprovide an example then discuss how to implement the Serializable interface.
4.21.1 Example of Object and Data I/O
The sample program ObjectIo provides an example of using object input andoutput streams to write objects and primitive objects and then reconstitute them.The main() method begins by writing the objects and primitive types,
ByteArrayOutputStream bytesOut = new ByteArrayOutputStream();ObjectOutput out = new ObjectOutputStream(bytesOut);
out.writeObject(new File("foo"));out.writeUTF("bar");out.writeInt(42);
out.close();
Note that a byte array output stream is created and assigned to the appropri-ate variable. We use a byte array for convenience; it could’ve been a file outputstream, a compressed file output stream, or an HTTP write in either direction.The output stream is then wrapped in an object output stream and assigned to avariable of the interface type, ObjectOutput. The object output is then used towrite a file object using the writeObject() method from the ObjectOutput in-terface. Next, a string is written using the writeUTF(String) method from theDataOutput intrface. This does not write the string as an object, but using an ef-ficient UTF-8-like encoding scheme. Lastly, an integer is written; the DataOutputinterface provides write methods for all of the primitive types. Finally, the out-put stream is closed in the usual way through the Closeable interface methodclose().
We then reverse the process to read the object back in,
byte[] bytes = bytesOut.toByteArray();InputStream bytesIn = new ByteArrayInputStream(bytes);ObjectInput in = new ObjectInputStream(bytesIn);
@SuppressWarnings("unchecked")File file = (File) in.readObject();String s = in.readUTF();int n = in.readInt();
in.close();
First, we get the bytes that were written frmo the byte array output streamand use them to create a byte array input stream.9 Then we wrap that in anobject input stream, which we use to read the object, string and primitive in-teger value. Then we close the input stream. The result of the object read
9Note that we assign variables to the most general type possible; the input stream had to beassigned to ByteArrayInputStream because we needed to call the toByteArray() method on it.

110 CHAPTER 4. INPUT AND OUTPUT
must be upcast to File because the readObject() method is declared to re-turn Object.10 Because the class may not be found or the class loader mayfail to load the class for the object, the readObject() method is also declaredto throw a ClassNotFoundException, which we simply declare on the main()method rather than handle. The result of running the program is
> ant object-io
file.getCanonicalPath()=C:\lpb\src\io\foo s=bar n=42
4.21.2 The Serializable Interface
The Serializable interface in package java.io is what’s known as a markerinterface. The marker pattern involves an interface, such as Serializable,which declares no methods. The interface is used to treat classes that imple-ment it differently in some contexts. The object input and output classes use theSerializable marker interface to determine if a class should be serialized ornot.
When a class is serialized, its fully qualified path name is written out as if bythe writeUTF() method. A 64-bit serial version identifier is also written. Thendata representing the state of the class is written.
All that is strictly necessary to make a class serializable is to declare it toimplement the Serializable interface and meet a few additional conditions de-scribed below. If nothing else is specified, the serial version identifier will becomputed from the class’s signature, including the signature of its parents andimplemented interfaces. If nothing else is done, the state of the class is serial-ized by serializing each of its member objects and writing each of its primitivemember variables, including all those inherited from parent classes.
The first condition for default serializability is that all of the class’s membervariables (including those of its superclasses) implement the Serializable in-terface or are declared to be transient. If that is the case, the object outputmethod uses reflection to write out each object and primitive member variablein turn.
The second requirement on a class for default serializabiilty is that it mustimplement a public no-argument constructor. If that is the case, reconstitutingan object will also happen by reflection, first calling the no-argument constructor,then reading and setting all the member variables.
The third requirement is that the same version of the class be used for readingand writing. There are two parts to this requirement. The first version require-ment is that the signature of the class used to read in the serialized instancemust be the same as that used to write the objects. If you change the membervariables, method declarations, subclasses, etc., it will interfere with deserializa-tion. The second version requirement is that the major version of Java beingused to deserialize must be at least as great as that used to deserialize. Thus itis not possible to serialize in Java version 6 and deserialize in version 5.
10The SuppressWarnings annotation is used to suppress the unchecked warning that would oth-erwise be generated by the compiler for the runtime cast. Although the cast can’t fail in this context,because we know what we wrote, it may fail in a runtime context if the expected input format is notreceived.

4.21. OBJECT AND DATA I/O 111
4.21.3 The Serialization Proxy Pattern
Java allows classes to take full control over their serialization and deserializa-tion, which we take advantage of to overcome the limitations of default serial-ization, such as the restrictions on superclass behavior, backward compatibilitywith changing signatures, and the ability to create immutable objects withoutno-arg constructors.
Our recommended approach to serialization is to use the serialization proxypattern, which we describe in this section by example, with an implementationin SerialProxied. The class begins by declaring it implements Serializable,then definining two final member variables in a single two-argument constructor.
public class SerialProxied implements Serializable {
private final String mS;private final int mCount;private final Object mNotSerializable = new Object();
public SerialProxied(String s, int count) {mS = s;mCount = count;
}
The finality of the variables mean that instances of the the class are immutablein the sense that once they are constructed they will never change. We use im-mutable classes wherever possible in LingPipe, checking during construction thatthey are well formed. Immutable classes are easy to reason about, especially inmulti-threaded environments, because they are well formed when constructedand never change behavior.
The writeReplace() Method
Before applying default serialization, the object write methods first check, usingreflection, if a class implements the writeReplace() method. If it does, thereturn result of calling it is serialized instead of the class itself.
The SerialProxied class implements the writeReplace() method by re-turning a new instance of the Serializer class, which we show below
private Object writeReplace() {return new Serializer(this);
}
Note that the method is declared to be private, so it will not appear in the docu-mentation for the class and may not be called by clients. Reflection is still ableto access the method even though it’s private.
Serialization Proxy Implementation
The rest of the work’s done in the class Serializer. We declare the class withinthe SerialProxied class as a static nested class, Serializer.

112 CHAPTER 4. INPUT AND OUTPUT
private static class Serializer implements Externalizable {
SerialProxied mObj;
public Serializer() { }
Serializer(SerialProxied obj) {mObj = obj;
}
The class itself is declared to be private and static. The full name of which wouldbe com.lingpipe.book.io.SerialProxied.Serializer, but given its privacy,we only access it from within SerialProxied anyway.
As we will shortly see, the Externalizable interface it implements extendsSerializable with the ability to take full control over what is written and read.The variables and methods within it are package protected, though they couldalso all be private. There are two constructors, a no-arg constructor which isrequired to be public for deserialization, and a one-argument constructor usedby the writeReplace() method shown above for serialization.
The rest of the methods in the Serializer class are
public void writeExternal(ObjectOutput out)throws IOException {
out.writeUTF(mObj.mS);out.writeInt(mObj.mCount);
}
public void readExternal(ObjectInput in) throws IOException {String s = in.readUTF();int count = in.readInt();mObj = new SerialProxied(s,count);
}
Object readResolve() {return mObj;
}
We describe them in turn below.
The writeExternal() Method
The first method is the writeExternal() method, which writes to the specifiedobject output. In this case, it uses its within-class private access to retrieve andwrite the member variables of the SerialProxied object mObj.
The readExternal() Method
The next method is the readExternal() method. This method and its sistermethod, writeExternal() are specified in the Externalizable interface aspublic, so must be public here.11
11The readExternal() method is also declared to throw a ClassNotFoundException to deal withcases when it fails to deserialize an object using the object input’s readObject() method. We don’t

4.22. LINGPIPE I/O UTILITIES 113
The read method first reads the serialized string and integer from the speci-fied object input. Then it uses these to construct a new SerialProxied instancebased on the strnig and count and assigns it to the object variable mObj.
The readResolve() Method
Finally, the readResolve() method is used to return the object that was readin. This method is the deserialization counterpart to writeReplace(). After thereadExternal() method is called, if readResolve() is defined, its return valueis returned as the result of deserialization. Thus even though the Serializer isthe one being serialized and deserialized, it is not visible at all to external clients.
Serial Version Variable
The final piece of the puzzle to take control over is the computation of the serialversion identifier. This allows serialization to bypass the computation of thisidentifier by inspecting the serialized object’s signature by reflection. This is notonly more efficient, it also allows the signatures to be changed without affectingthe ability to deserialize already serialized instances.
If a class has already been fielded without declaring a serial version ID, thecommand-line program serialver, which is shipped with the Sun/Oracle JDK,may be used to compute the value that would be computed by reflection duringserialization. It only needs the classpath and full name of the class.
> serialver -classpath build/lp-book-io-4.0.jarcom.lingpipe.book.io.SerialProxied
static final long serialVersionUID = -688378786294424932L;
The output is a piece of Java code declaring a constant serialVersionUID withthe current value of the identifier as computed by serialization. We just insertthat into the class SerialProxied class. Technically, we may use whatever num-ber we like here; it’s only checked for consistency during serialization.
We also need to insert the version ID constant into the nested static classSerialProxied.Serializer.
4.22 Lingpipe I/O Utilities
LingPipe provides a number of utilities for input and output, and we discuss thegeneral-purpose ones in this section.
4.22.1 The FileLineReader Class
To deal with line-based file formats, LingPipe provides the classFileLineReader, in the com.aliasi.io package. This class extendsLineNumberReader in java.io, which itself extends BufferedReader, soall the inherited methods are avaiable.
need it here because we are only using the data input methods readUTF() and readInt().

114 CHAPTER 4. INPUT AND OUTPUT
For convenience, the FileLineReader class implements theIterable<String> interface, with iterator() returning anIterator<String> that iterates over the lines produced by the readLine()method inherited from BufferedReader. Being iterable enables for-loop syntax,as in
File file = ...;FileLineReader lines = new FileLineReader(file,"UTF-8");for (String line : lines) {
...}lines.close();
The ellided code block will then perform some operation on each line.There are also static utility methods, readLines() and readLinesArray(),
both taking a file and character encoding name like the constructor, to readall of the lines of a file into either an array of type String[] or a list of typeList<String>.
4.22.2 The Files Utility Class
Some standard file operations are implemented as static methods in the Filesclass from the package com.aliasi.util.
File Name Parsing
The baseName(File) and extension(File) methods split a file’s name into thepart before the last period (.) and the part after the alst period. If there is nolast period, the base name is the entire file name.
File Manipulation
The method removeDescendants(File) removes all the files contained in thespecified directory recursively. The removeRecursive(File) method removesthe descendants of a file and the file itself. The copy(File,File) method copiesthe content of one file into another.
Bulk Reads and Writes
There are methods to read bytes, characters, or a string from a file, and corre-sponding methods to write. The methods all pass on any I/O exceptions theyencounter.
The method readBytesFromFile(File) returns the array of bytes cor-responding to the file’s contents, whereas writeBytesToFile(byte[],File)writes the specified bytes to the specified file.
The methods readCharsFromFile(File,String) andwriteCharsToFile(char[],File,String) do the same thing for

4.22. LINGPIPE I/O UTILITIES 115
char values. These methods both require the character encod-ing to be specified as the final argument. There are corre-sponding methods for strings, readFromFile(File,String) andwriteStringToFile(String,File,String). Together, we can use thesemethods to transcode from one encoding to another,
char[] cs = Files.readCharsFromFile(fileIn,enc1);Files.writeCharsToFile(cs,fileOut,enc2);
4.22.3 The Streams Utility Class
The class Streams in the package com.aliasi.io provides static utility methodsfor dealing with byte and character streams.
Quiet Close Methods
The method closeQuietly(Closeable) closes the specified closeable object,catching and ignoring any I/O exceptions raised by the close operation. If thespecified object is null, the quiet close method returns.
The method closeInputSource(InputSource) closes the byte and charac-ter streams of the specified input source quietly, as if by the closeQuietly()method.
Bulk Reads
There are utility bulk read methods that buffer inputs and return them as anarray. Special utility methods are needed because the amount of data availableor read from a stream is unpredictable. Bulk writing, on teh other hand, is builtinto output streams and writers themselves.
The bulk read method toByteArray(InputStream) reads all of thebytes from the input stream returning them as an array. The methodtoCharArray(Reader) does the same for char values.
The method toCharArray(InputSource) reads from an input source, usingthe reader if available, and if not, the input stream using either the specifiedcharacter encoding or the platfrom default, and barring that, reads from theinput source’s system identifier (URL).
The method toCharArray(InputStream,String) reads an array of charvalues by reading bytes from the specified input stream and converts them tochar values using the specified character encoding.
Copying Streams
The method copy(InputStream,OutputStream) reads bytes from the specifiedinput stream until the end of stream, writing what it finds to the output stream.The copy(Reader,Writer) does the same thing for char value streams.

116 CHAPTER 4. INPUT AND OUTPUT
4.22.4 The Compilable Interface
LingPipe defines the interface Compilable in the package com.aliasi.util forclasses that define a compiled representation.
The interface has a single method, compileTo(ObjectOutput), used forcompiling an object to an object output stream. Like all I/O interface meth-ods, it’s defined to throw an IOException. The method is used just like thewriteExternal(ObjectOutput) method from Java’s Externalizable inter-face. It is assumed that only whatever is written, deserialization will producea single object that is the compiled form of the object that was compiled.
Many of LingPipe’s statistical models, such as language models, classifiersand HMMs have implementations that allow training data to be added incre-mentally. The classes implementing these models are often declared to be bothSerializable and Compilable. If they are serializable, the standard serializa-tion followed by deserialization typically produces an object in the same stateand of the same class as the one serialized. If a model’s compilable, a com-pilation followed by deserialization typically produces an object implementingthe same model more efficiently, but without the ability to be updated with newtraining data.
4.22.5 The AbstractExternalizable Class
LingPipe provides a dual-purpose class AbstractExternalizable in the pack-age com.aliasi.util. This class provides static utility methods for dealing withserializable and compilable objects, as well as supporting the serialization proxypattern.
Base Class for Serialization Proxies
The abstract class AbstractExternalizable in package com.aliasi.util pro-vides a base class for implementing the serializaion proxy pattern, as de-scribed in Section 4.21.3. It is declared to implement Externalizable, and thewriteExternal(ObjectOutput) method from that interface is declared to beabstract and thus must be implemented by a concrete subclass. The methodreadExternal(ObjectInput) is implemented by AbstractExternalizable,as is the serialization method readResolve(). The other abstract method thatmust be implemented is read(ObjectInput), which returns an object. Thismethod is called by readExternal() and the object it returns stored to be usedas the return value for readResolve().
We provide an example class AbstractExternalized that paral-lels our earlier example SerialProxied (see Section 4.21.3, with theAbstractExternalizable interface doing some of the work. The onlything that changes is the declaration of the externalizer,
private static class Serializerextends AbstractExternalizable {
and the read method, which now returns an object rather than assigning it,

4.22. LINGPIPE I/O UTILITIES 117
public Object read(ObjectInput in) throws IOException {String s = in.readUTF();int count = in.readInt();return new AbstractExternalized(s,count);
}
This class makes it particularly easy to implement serialization for a single-ton. We provide an example in SerializedSingleton. Following the usual sin-gleton pattern, we have a private constructor and a public static constant,
public class SerializedSingleton implements Serializable {
private final String mKey;private final int mValue;
private SerializedSingleton(String key, int value) {mKey = key;mValue = value;
}
public static final SerializedSingleton INSTANCE= new SerializedSingleton("foo",42);
We then have the usual definition of writeReplace(), and a particularly simpleimplementation of the serialization proxy itself,
Object writeReplace() {return new Serializer();
}
static class Serializer extends AbstractExternalizable {
public Serializer() { }
@Overridepublic Object read(ObjectInput in) {
return INSTANCE;}
@Overridepublic void writeExternal(ObjectOutput out) { }
static final long serialVersionUID= 8538000269877150506L;
}
If the nested static class had been declared public, we wouldn’t have needed todefine the public no-argument constructor. The version ID is optional, but highlyrecommended for backward compatibility.
To test that it works, we have a simple main() method,
SerializedSingleton s = SerializedSingleton.INSTANCE;Object deser = AbstractExternalizable.serializeDeserialize(s);boolean same = (s == deser);

118 CHAPTER 4. INPUT AND OUTPUT
which serializes and deserializes the instance using the LingPipe utility inAbstractExternalizable, then tests for reference equality.
We can run this code using the Ant target serialized-singleton, whichtakes no arguments,
> ant serialized-singleton
same=true
Serialization Proxy Utilities
The AbstractExternalizable class defines a number of static utility meth-ods supporting serialization of arrays. These methods write the num-ber of members then each member of the array in turn. For instance,writeInts(int[],ObjectOutput) writes an array of integers to an object out-put and readInts(ObjectInput) reads and returns an integer array that was se-rialized using the writeInts() method. There are similar methods for double,float, and String.
The method compileOrSerialize(Object,ObjectOutput) will attemptto compile the specified object if it is compilable, otherwise it willtry to serialize it to the specified object output. It will throw aNotSerializableException if the object is neither serializable nor compil-able. The method serializeOrCompile(Object,ObjectOutput) tries the op-erations in the opposite order, compiling only if the object is nor serializable.
General Serialization Utilities
The AbstractExternalizable class defines a number of general-purpose meth-ods for supporting Java’s serialization and LingPipe’s compilation.
There are in-memory versions of compilation and serialization. The methodcompile(Compilable) returns the result of compiling then deserializing an ob-ject. The method serializeDeserialize(Serializable) serializes and dese-rializes an object in memory. These methods are useful for testing serializationand compilation. These operations are carried out in memory, which requiresenough capacity to store the original object, a byte array holding the serializedor compiled bytes, and the deserialized or compiled object itself. The same op-eration may be performed with a temporary file in much less space because theoriginal object may be garbage collected before deserialization and the bytes re-side out of main memory.
There are also utility methods for serializing or compiling to a file. Themethod serializeTo(Serializable,File) writes a serialized form of the ob-ject to the specified file. The compileTo(Compilable,File) does the samething for compilable objects.
To read serialized or compiled objects back in, the methodreadObject(File) reads a serialized object from a file and returns it.
The method readResourceObject(String) reads an object from a resourcewith the specified absolute path name (see Section 4.15.2 for information onresources including how to create them and put them on the classpath). This

4.22. LINGPIPE I/O UTILITIES 119
method simply creates an input stream from the resource then wraps it in anobject input stream for reading. The readResourceObject(Class<?>,String)method reads a (possibly relative) resource relative to the specified class.

120 CHAPTER 4. INPUT AND OUTPUT

Chapter 5
Handlers, Parsers, and Corpora
LingPipe uses a parser-handler pattern for parsing objects out of files and pro-cessing them. The pattern follows the design of XML’s SAX parser and contenthandlers, which are built into Java in package org.xml.sax.
A parser is created for the format in which the data objects are represented.Then a handler for the data objects is created and attached to the parser. Atthis point, the parser may be used to parse objects from a file or other inputspecification, and all objects found in the file will be passed off to the handlerfor processing.
Many of LingPipe’s modules provide online training through handlers. Forinstance, the dynamic language models implement character sequence handlers.
LingPipe’s batch training modules require an entire corpus for training. Acorpus represents an entire data set with a built-in training and test division. Acorpus has methods that take handlers and deliver to them the training data, thetest data, or both.
5.1 Handlers and Object Handlers
5.1.1 Handlers
The marker interface Handler is included in LingPipe 4 only for backward com-patibility. The original parser/handler design allowed for handlers that imple-mented arbitrary methods, following the design of the SAX content handler in-terface.
5.1.2 Object Handlers
As of Lingpipe 4, all built-in parser/handler usage is through theObjectHandler<E> interface, in package com.aliasi.corpus, which ex-tends Handler. The ObjectHandler<E> interface specifies a single method,handle(E), which processes a single data object of type E. It is like a simpli-fied form of the built-in interface for processing a streaming XML document,ContentHandler, in package org.xml.sax.
121

122 CHAPTER 5. HANDLERS, PARSERS, AND CORPORA
5.1.3 Demo: Character Counting Handler
We define a simple text handler in the demo class CountingTextHandler. It’sso simple that it doesn’t even need a constructor.
public class CountingTextHandlerimplements ObjectHandler<CharSequence> {
long mNumChars = 0L;long mNumSeqs = 0L;
public void handle(CharSequence cs) {mNumChars += cs.length();++mNumSeqs;
}
We declare the class to implement ObjectHandler<CharSequence>. This con-tract is satisfied by our implementation of the handle(CharSequence) method.The method just increments the counters for number of characters and se-quences it’s seen.
The main() method in the same class implements a simple command-linedemo. It creates a conting text handler, then calls is handle method with twostrings (recall that String implements CharSequence).
CountingTextHandler handler = new CountingTextHandler();handler.handle("hello world");handler.handle("goodbye");
The Ant target counting-text-handler calls the main method, which as-sumes no command-line arguments.
> ant counting-text-handler
# seqs=2 # chars=18
The output comes from calling the handler’s toString() method, which is de-fined to print the number of sequences and characters. In most cases, handlerswill either hold references to collections they update or will make summarystatistics or other data accumulated from the calls to the handle() method.We’ll see more examples when we discuss parsers and corpora in the followingsections.
5.2 Parsers
A parser reads character data from an input source or character sequence to pro-duce objects of a specified type. By attaching a handler to a parser, the handlerwill receive a stream of objects produced by the parser.

5.2. PARSERS 123
5.2.1 The Parser Abstract Base Class
The type hierarchy for a parser is more general than usage in LingPipe 4 de-mands. The abstract base class is specified as Parser<H extends Handler>, inpackage com.aliasi.corpus. The generic specification requires the instantia-tion of the type parameter H to extend the Handler interface.
For use in LingPipe 4, all parsers will use object handler insances, so allparsers will actually extend Parser<ObjectHandler<E» for some arbitrary ob-ject type E.
Getting and Setting Handlers
The base parser class implements getters and setters for handlers of the ap-propriate type; getHandler() returns the handler, and setHandler(H) sets thevalue of the handler.
Parsing Methods
There are a range of parsing methods specified for Parser. Two of them are ab-stract, parseString(char[],int,int) and parse(InputSource), which readdata from a character array slice or an input source. The input source abstrac-tion, borrowed from XML’s SAX parsers, generalizes the specification of a char-acter sequence through a reader or an input stream or URL plus a characterencoding specification; input sources also conveniently allow a relative directoryto be specified for finding resources such as DTDs for XML parsing.
There are several helper methods specified on top of these. Themethod parse(CharSequence) reads directly from a character sequence. Theparse(File,String) method reads the characters to parse from a file usingthe specified character encoding.1 The method parse(String,String) readsfrom a resource specified as a system identifier, such as a URL, using the speci-fied character encoding. There are also two parallel methods, parse(File) andparse(String), which do not specify their character encodings.
5.2.2 Abstract Base Helper Parsers
There are two helper subclasses of Parser, both abstract and both in pack-age com.aliasi.corpus. The class StringParser requires a concrete sub-class to implement the abstract method parse(char[],int,int). TheStringParser class implements the parse(InputSource) method by readinga character array from the input source using LingPipe’s static utility methodStreams.toCharArray(InputSource)
The second helper subclass is InputSourceParser, which re-quires subclasses to implement parse(InputSource). It implementsparse(char[],int,int) by converting the character array to an inputsource specified through a reader.
1The encoding is set in an InputSource, which a parser implementation may choose to ignore. Forinstance, an XML parser may choose to read the encoding from the header rather than trusting thespecification. The helper implementations in LingPipe all respect the character encoding declaration.

124 CHAPTER 5. HANDLERS, PARSERS, AND CORPORA
5.2.3 Line-Based Tagging Parser
There are two more specialized classes for parsing. The LineTaggingParser,also in com.aliasi.corpus, parses output for a tagger from a line-oriented for-mat. This format is common due to the simplicity of its parsing and its use inthe Conference on Natural Language Learning (CoNLL).
5.2.4 XML Parser
The XMLParser, in package com.aliasi.corpus, extends InputSourceParserto support parsing of XML-formatted data. The XML parser requires the methodgetXMLHandler() to return an instance of DefaultHandler (built into Java inpackage org.xml.sax.helpers).
The parser works by creating an XML reader using the static methodcreateXMLReader() in XMLReaderFactory, which is in org.xml.sax.helpers.The XML handler returned by the parser method getXMLHandler() is then seton the reader as the content handler, DTD handler, entity resolver, and errorhandler. Thus the XML handler must actually hold a reference to the LingPipehandler or retain a reference to the parser (for instance, by being an inner class)and use the getHandler() method in Parser to pass it data.
5.2.5 Demo: MedPost Part-of-Speech Tagging Parser
As an example, we provide a demo class MedPostPosParser, which provides aparser for taggings represented in the MedPost format. The MedPost corpus isa collection of sentences drawn from biomedical research titles and abstracts inMEDLINE (see Section C.2 for more information and downloading instructions).This parser will extract instances of type Tagging<CharSequence> and sendthem to an arbitrary parser specified at run time.
Corpus Structure
The MedPost corpus is arranged by line. For each sentence fragment, 2 we have aline indicating its source in MEDLINE followed by a line with the tokens and partof speech tags. Here are the first three entries from file tag_cl.ioc.
P01282450A01Pain_NN management_NN ,_, nutritional_JJ support_NN ,_, ...P01350716A05Seven_MC trials_NNS of_II beta-blockers_NNS and_CC 15_MC ...P01421653A15CONCLUSIONS_NNS :_: Although_CS more_RR well-designed_VVNJ ......
We have truncated the part-of-speech tagged lines as indicated by the ellipses(...). The source of the first entry is a MEDLINE citation with PubMed ID
2The sentence fragments were extracted automatically by a system that was not 100% accurateand were left as is for annotation.

5.2. PARSERS 125
01282450, with the rest of the annotation, A01, indicating it was the first frag-ment from the abstract. The first token in the first fragment is Pain, which isassigned a singular noun tag, NN. The second token is management, assigned thesame tag. The third token is a comma, (,), assigned a comma (,) as a tag. Notethat the string beta-blockers is analyzed as a single token, and assigned the pluralnoun tag NNS, as is well-designed, which is assigned a deverbal adjective categoryVVNJ.
Code Walkthrough
We define the MedPost parser to extend StringParser.
public class MedPostPosParserextends StringParser<ObjectHandler<Tagging<String>>> {
The generic parameter for the parser’s handler is specified to be of typeObjectHandler<Tagging<String». LingPipe’s Tagging class, which representstags applied to a sequence of items, is in package com.aliasi.tag; we glossover its details here as we are only using it as an example for parsing.
Because we extended StringParser, we must implement the parseString()method, which is done as follows.
@Overridepublic void parseString(char[] cs, int start, int end) {
String in = new String(cs,start,end-start);for (String sentence : in.split("\n"))
if (sentence.indexOf(’_’) >= 0)process(sentence);
}
We construct a string out of the character array slice passed in, switching fromthe start/end notation of LingPipe and later Java to the start/length notation ofearly Java. We then split it on Unix newlines, looking at each line in the for-eachloop. If the line doesn’t have an underscore character, there are no part-of-speechtags, so we ignore it (we also know there are no underscores in the identifier linesand that there are no comments).
We send each line in the training data with an underscore in it to theprocess() method.
private void process(String sentence) {List<String> tokenList = new ArrayList<String>();List<String> tagList = new ArrayList<String>();
for (String pair : sentence.split(" ")) {String[] tokTag = pair.split("_");tokenList.add(tokTag[0]);tagList.add(tokTag[1]);
}Tagging<String> tagging
= new Tagging<String>(tokenList,tagList);

126 CHAPTER 5. HANDLERS, PARSERS, AND CORPORA
ObjectHandler<Tagging<String>> handler = getHandler();handler.handle(tagging);
}
In order to construct a tagging, we will collect a list of tokens and a list of tags.We split the line on whitespace, and consider the strings representing token/tagpairs in turn. For instance, the first value for pair we see in processing thefragment above is Pain_NN.
We break the token/tag pair down into its token and tag components by split-ting on the underscore character (again, keeping in mind that there are no un-derscores in the tokens). We then just add the first and second elements derivedfrom the split, which are our token and tag pair.
After we add the tokens and tags from all the sentences, we use them to con-struct a tagging. Then, we use the getHandler() method, which is implementedby the superclass Parser, to get the handler itself. The handler then gets calledwith the tagging that’s just been constructed by calling its handle(Tagging)method. In this way, the handler gets all the taggings produced by parsing theinput data.
Even though we’ve implemented our parser over character array slices,through its superclass, we can use it to parse files or input sources. The main()method takes a single command-line argument for the directory containing thetagged data, comprising a set of files ending in the suffix ioc.
The first real work the method does is assign a new tree set of strings to thefinal variable tagSet.
final Set<String> tagSet = new TreeSet<String>();ObjectHandler<Tagging<String>> handler
= new ObjectHandler<Tagging<String>>() {
public void handle(Tagging<String> tagging) {tagSet.addAll(tagging.tags());
}
};
It is final because it’s used in the anonymous inner class defiend to cre-ate an object to assign to variable handler. The anonymous inner classimplements ObjectHandler<Tagging<String», so it must define a methodhandle(Tagging<String>). All the handle method does is add the list of tagsfound in the tagging to the tag set.
Next, we create a parser and set its handler to be the handler we just defined.
Parser<ObjectHandler<Tagging<String>>> parser= new MedPostPosParser();
parser.setHandler(handler);
The last thing the main method does before printing out the tag set is walkover all the files ending in ioc and parse each of them, declaring the characterencoding to be ASCII (see Section 4.1.6 for more information on LingPipe’s fileextension filter class).

5.3. CORPORA 127
Running the Demo
There is an Ant target medpost-parse that passes the value of propertymedpost.dir to the command in MedPostPosParser. We have downloaded thedata and unpacked it into the directory given in the command,
> ant -Dmedpost.dir=c:/lpb/data/medtag/medpost medpost-parse
#Tags=63 Tags= ’’ ( ) , . : CC CC+...VVGJ VVGN VVI VVN VVNJ VVZ ‘‘
We’ve skipped the output for most of the tags, where denoted by ellipses (...).
5.3 Corpora
A corpus, in the linguistic sense, is a body of data. In the context of LingPipe, acorpus of data may be labeled with some kind of conceptual or linguistic anno-tation, or it may consist solely of text data.
5.3.1 The Corpus Class
To represent a corpus, LingPipe uses the abstract base class Corpus, in packagecom.aliasi.corpus. It is parameterized generically the same way as a parser,with Corpus<H extends Handler>. As of LingPipe 4, we only really have needof instances of Corpus<ObjectHandler<E», where E is the type of object beingrepresented by the corpus.
The basic work of a corpus class is done by its visitTrain(H) andvisitTest(H) methods, where H is the handler type. Calling these methodssends all the training or testing events to the specified handler.
The method visitCorpus(H) sends both training and testing events to thespecified handler and visitCorpus(H,H) sends the training events to the firsthandler and the test events to the second.
In all the LingPipe built ins, these methods will bevisitTrain(ObjectHandler<E>) and visitTest(ObjectHandler<E>) forsome object E.
5.3.2 Demo: 20 Newsgroups Corpus
We will use the 20 newsgroups corpus as an example (see Section C.1). Thecorpus contains around 20,000 newsgroup posts to 20 different newsgroups.
The demo class TwentyNewsgroupsCorpus implements a corpus based onthis data. The corpus is implemented so that it doesn’t need to keep all the datain memory; it reads it in from a compressed tar file on each pass. This approachis highly scalable because only one item at a time need reside in memory.

128 CHAPTER 5. HANDLERS, PARSERS, AND CORPORA
Code Walkthrough
The 20 newsgroups corpus class is defined to extend Corpus.
public class TwentyNewsgroupsCorpusextends Corpus<ObjectHandler<Classified<CharSequence>>> {
private final File mCorpusFileTgz;
public TwentyNewsgroupsCorpus(File corpusFileTgz) {mCorpusFileTgz = corpusFileTgz;
}
The handler is an object handler handling objects of typeClassified<CharSequence>, which represent character sequences withfirst-best category assignments from a classification. In the 20 newsgropscorpus, the categories are the newsgroups from which the posts originated andthe objects being classified, of type CharSequence, are the texts of the poststhemselves.
The constructor takes the corpus file, which is presumed to be directory struc-tures that have been tarred and then compressed with GZIP (see Section 4.14 andSection 4.13.1 for more information on tar and GZIP). The corpus file is saved forlater use.
The visitTrain() method sends all the classified character sequences in thetraining data to the specified hander.
@Overridepublic void visitTrain(ObjectHandler<Classified<CharSequence>>
handler)throws IOException {
visitFile("20news-bydate-train",handler);}
The visitTest() method is defined similarly.The visitFile() method which is doing the work, is defined as follows.
private void visitFile(String trainOrTest,ObjectHandler<Classified<CharSequence>> handler)
throws IOException {
InputStream in = new FileInputStream(mCorpusFileTgz);GZIPInputStream gzipIn = new GZIPInputStream(in);TarInputStream tarIn = new TarInputStream(gzipIn);
It takes the string to match against the directories in the tarred directory data,and the handler. It starts by creating an input stream for gzipped tar data.
Next, it walks through the directories and files in he tarred data.
while (true) {TarEntry entry = tarIn.getNextEntry();if (entry == null) break;if (entry.isDirectory()) continue;

5.3. CORPORA 129
String name = entry.getName();int n = name.lastIndexOf(’/’);int m = name.lastIndexOf(’/’,n-1);String trainTest = name.substring(0,m);if (!trainOrTest.equals(trainTest)) continue;String newsgroup = name.substring(m+1,n);byte[] bs = Streams.toByteArray(tarIn);CharSequence text = new String(bs,"ASCII");Classification c = new Classification(newsgroup);Classified<CharSequence> classified
= new Classified<CharSequence>(text,c);handler.handle(classified);
}tarIn.close();
We loop, getting the next tar entry, breaking out of the loop if the entry is null,indicating we have processed every entry. If the entry is a directory, we skip it.Otherwise, we get its name, then parse out the directory structure using the in-dexes of the directory structure slash (/) separators, pulling out the name of thedirectory indicating whether we have training or test data. For example, a file tarentry with name 20news-bydate-test/alt.atheism/53265 uses the top-leveldirectory to indicate the training-testing split, here test, and the subdirectory toindicate the category, here alt.atheism. We are not keeping track of the articlenumber, though it would make sense to set things up to keep track of it for areal application.
If the top-level train-test directory doesn’t match, we continue. If it doesmatch, we pull out the newsgroup name, then read the actual bytes of the entryusing LingPipe’s Streams.toByteArray() utility method. We create a stringusing the ASCII-encoding because the 20 newsgroups corpus is in ASCII. We thencreate a classification with category corresponding to the name of the newsgroup,and use it to create the classified cahracter sequence object. Finally, we give theclassified character sequence to the object handler, which is defined to handleobjects of type Classified<CharSequence>.
When we finish the loop, we close the tar input stream (which closes the otherstreams) and return.
There is a main() method which is called by the demo, converting a singlecommand-line argument into a file tngFileTgz. The code starts by defining afinal set of categories, then an anonymous inner class to define a handler.
final Set<String> catSet = new TreeSet<String>();ObjectHandler<Classified<CharSequence>> handler
= new ObjectHandler<Classified<CharSequence>>() {public void handle(Classified<CharSequence> c) {
catSet.add(c.getClassification().bestCategory());}
};
The handle method extracts the best category from the classification and addsit to the category set. The category set needed to be final so that it could be

130 CHAPTER 5. HANDLERS, PARSERS, AND CORPORA
referenced from within the anonymous inner class’s handle method.Once the handler is defined, we create a corpus from the gzipped tar file, then
send the train and testing events to the handler.
Corpus<ObjectHandler<Classified<CharSequence>>> corpus= new TwentyNewsgroupsCorpus(tngFileTgz);
corpus.visitTrain(handler);corpus.visitTest(handler);
The rest of the code just prints out the categories.
Running the Demo
The Ant target twenty-newsgroups invokes the TwentyNewsgroupsCorpuscommand, sending the value of property tng.tgz as the command-line argu-ment.
> ant -Dtng.tgz=c:/lpb/data/20news-bydate.tar.gztwenty-newsgroups
Cats= alt.atheism comp.graphics comp.os.ms-windows.misc...talk.politics.mideast talk.politics.misc talk.religion.misc
We have left out some in the middle, but the result is indeed the twenty expectedcategories, which correspond to the newsgroups.
5.3.3 The ListCorpus Class
LingPipe provides a dynamic, in-memory corpus implementation in the classListCorpus, in package com.aliasi.corpus. The class has a generic param-eter, ListCorpus<E>, where E is the type of objects handled. It is defined toextend Corpus<ObjectHandler<E», so the handler will be an object handler fortype E objects.
There is a zero-argument constructor ListCorpus() that constructs an ini-tially empty corpus. The two methods addTrain(E) and addTest(E) allow train-ing or test items to be added to the corpus.
The methods trainCases() and testCases() return lists of the trainingand test items in the corpus. These lists are unmodifiable views of the underly-ing lists. Although they cannot be changed, they will track changes to the listsunderlying the corpus.
There is an additional method permuteCorpus(Random), that uses the spec-ified random number generator to permute the order of the test and trainingitems.
Serialization
A list-based corpus may be serialized if the underlying objects it stores may beserialized. Upon being reconstituted, the result will be a ListCorpus that maybe cast to the appropriate generic type.

5.4. CROSS VALIDATION 131
Thread Safety
A list corpus must be read-write synchronized, where the add and permute meth-ods are writers, and the visit methods are readers.
5.3.4 The DiskCorpus Class
The DiskCorpus class provides an implementation of the Corpus interface basedon one directory of files containing training cases and one containing test cases.A parser is used to extract data from the files in the training and test directories.
Like our example in the previous section, a disk corpus reads its data in dy-namically rather than loading it into memory. Thus, if the data changes on disk,the next run through the corpus may produce different data.
The directories are expored recursively, and files with GZIP or Zip compres-sion indicated by suffix .gz or .zip are automatically unpacked. For zip files,each entry is visited.
At the lowest level, every ordinary file, eithe in the directory structure or in aZip archive is visited and processed.
Constructing a Disk Corpus
An instance of DiskCorpus<H>, where H extends or implements the marker inter-face Handler, is constructed using DiskCoropus(Parser<H>,File,File), withthe two files specifying the training and test directories respectively.
Once a disk corpus is constructed, the methods setSystemId(String) andsetCharEncoding(String) may be used to configure it. These settings will bepassed to the input sources constructed and sent to the parser.
Thread Safety
As long as there are no sets and the file system doesn’t change, it’ll be safe touse a single insance of a disk corpus from multiple threads.
5.4 Cross Validation
Cross validation is a process for evaluating a learning system in such a way as toextract as many evaluation points as possible from a fixed collection of data.
Cross validation works by dividing a corpus up into a set of non-overlappingslices, called folds. Then, each fold is used for evaluation in turn, using the otherfolds as training data. For instance, if we have 1000 data items, we may dividethem into 3 folds of 333, 333, and 334 items respectively. We then evaluatefold 1 using fold 2 and 3 for training, evaluate on fold 2 using folds 1 and 3 fortraining, and evaluate on fold 3 using folds 1 and 2 for training. This way, everyitem in the corpus is used as a test case.

132 CHAPTER 5. HANDLERS, PARSERS, AND CORPORA
Leave-One-Out Evaluation
At the limit where the number of folds equals the number of data items, we havewhat is called leave-one-out (LOO) evaluation. For instance, with 1000 data items,we have 1000 folds. This uses as much data as possible in the training set. Thisis usually too slow to implement directly by retraining learning systems for eachfold of leave-one-out evaluation.
Bias in Cross Validation
In some sitautions, cross-validation may be very biased. For instance, supposewe have 100 items, 50 of which are “positive” and 50 of which are “negative”and we consider leave-one-out evaluation. Even though our full training data isbalanced, with equal numbers of positive and negative items, each fold of leave-one-out evaluation has 50 examples of the other category, and 49 examples ofthe category being evaluated. For learners that use this ratio in the training datato help with predictions, such as naive Bayes classifiers, there will be a noticeablebias against the category being evaluated in a leave-one-out evaluation.
5.4.1 Permuting the Corpus
Cross-validation only makes sense theoretically when the items are all drawnat random from some large population (or potential population) of items. Veryrarely does natural language data satisfy this requirement. Instead, we gatherdata by document and by date. If you have the choice, by all means take a trulyrandom sample of data.
It is sometimes reasonable to permute the items in a cross-validating corpus.Often, this is because examples of the same item may be stored together andshould be broken up for evaluation.
Permuting may make some problems too easy. For instance, if the items arechunkings of sentences for named entities, and more than one sentence is drawnfrom a given document, it makes sense to keep these together (or at least notintentionally split them apart). Otherwise, we are much more likely to have beentrained no the rare words appearing in sentences.
5.4.2 The CrossValidatingObjectCorpus Class
LingPipe provides a corpus implementation tailored to implementing cross val-idation. The class CrossValidatingObjectCorpus<E> has a generic parame-ter E defining the objects that are handled in the corpus. The class extendsCorpus<ObjectHandler<E», so the handlers for a cross-validating object cor-pus will have a handle(E) method.
Construction
The cross-validating corpus has a constructorCrossValidatingObjectCorpus(int), where the number of folds mustbe specified. These may be changed later using the setNumFolds(int) method.

5.4. CROSS VALIDATION 133
Populating the Corpus
Items are added to the corpus using the method handle(E). These are all storedin lists in memory.
For convenience, the cross-validating corpus class is defined to implementObjectHandler<E> itself, which only requires the handle(E) method. Thus anentire cross-validating corpus may be sent to a parser for population.
The size() method indicates the total number of objects in the corpus.
Using the Corpus
The particular fold to use to divide up the data is set using the methodsetFold(int). The current fold is available through the method fold(). Thefolds are numbered starting at 0 and ending at the number of folds minusone. The number of folds may also be reset at any time using the methodsetFold(int). The corpus may be permuted using a specified pseudorandomnumber generator with the method permuteCorpus(Random).
Serialization
A cross-validating corpus will be serializable if the objects it contains are serial-izable.
Thread Safety and Concurrent Cross-Validation
Cross-validating corpus instances must be read-write synchronized (see Sec-tion D.4.2). The read operations are in the handle, permute and set methods.
The obstacle to using a cross-validating corpus across threads is that the foldis set on the class itself. To get around this limitation, the method itemView()returns a “view” of the corpus that allows the fold number or number of foldsto be changed, but not the items. Thus to cross-validate across folds, just createand populate and permute a corpus. Then use itemView() to produce as manyvirtual copies as you need, setting the folds on each one.
Note that this does not help with the problem of evaluators being used to ag-gregate scores across folds not being thread safe. Given that it is usually trainingthat is the bottleneck in cross validation, explicit synchronization of the evalua-tors should not cause too much of a synchronization bottleneck.

134 CHAPTER 5. HANDLERS, PARSERS, AND CORPORA

Chapter 6
Classifiers and Evaluation
We are going to introduce the classifier interface, discuss what classifiers do, andthen show how to evaluate them. In subsequent chapters, we consider a selectionof the classifier implementations offered in LingPipe.
6.1 What is a Classifier?
A classifier takes inputs, which could be just about anything, and return a clas-sification of the input over a finite number of discrete categories. For example,a classifier might take a biomedical research paper’s abstract and determine ifit is about genomics or not. The outputs are “about genomics” and “not aboutgenomics.”
Classifiers can have more than two outputs. For instance, a classifier mighttake a newswire article and classify whether it is politics, sports, entertainment,science and technology, or world or local news; this is what Google and Bing’snews services do.1 Other applications of text classifiers, either alone or in concertwith other components, range from classifying documents by topic, identifyingthe language of a snippet of text, analyzing whether a movie review is postiveor negative, linking a mention of a gene name in a text to a database entry forthat gene, or resolving the sense of an ambiguous word like bank as meaning asavings institution or a flowing body of water. In each of these cases, we have aknown finite set of outcomes and some evidence in the form of text.
6.1.1 Exclusive and Exhaustive Categories
In the standard formulation of classification, which LingPipe follows, the cate-gories are taken to be both exhaustive and mutually exclusive. Thus every itembeing classified has exactly one category.
One way to get around the exhaustiveness problem is to include an “other”category that matches any input that doesn’t match one of the other categories.The other category is sometimes called a “sink” or “trash” category, and may behandled differently than the other categories during training.
1At http://news.google.com and http://news.bing.com.
135

136 CHAPTER 6. CLASSIFIERS AND EVALUATION
Exclusivity is more difficult to engineer. While it is possible to allow categoriesthat represent more than one outcome, if we have n base categories, we’ll have(n2
)unique pairs of categories. The combinatorics quickly gets out of hand.
If an item needs to be classified for two cross-cutting categorizations, we canuse two classifiers, one for each categorization. For instance, we might classifyMEDLINE citations as being about genomics or not, and about being about clin-ical trials or not. The two binary classifiers produce four possible outcomes.Another example of this would be to use two binary classifiers for sentiment,one indicating if a text had positive sentiment or not, and another indicating if ithad negative sentiment or not. The result is a four-way classification, with a neu-tral article having neither positive nor negative sentiment, a mixed review havingboth positive and negative sentiment, and a positive or negative review havingone or the other.
The latent Dirichlet allocation (LDA) model we consider in Chapter 11 assignsmore than one category to each document, under the assumption that everydocument is a mixture of topics blended according to some document-specificratio that the model infers.
6.1.2 First-Best, Ranked and Probabilistic Results
A simple first-best classifier need only return its best guess for the category ofeach input item. Some applications only allow a single best guess, and thus someevaluations are geared toward evaluating only a classifiers’ first-best guess for aninput.
A ranking classifier returns the possible categories in rank order of theirmatch to the input. The top ranked answer is the first-best result. We still as-sume exhaustive and exclusive categories, but the classfier supplies its second-best guess, third-best guess and so on. In cases where there are large numbers ofcategories, an application might return more than one possible answer to a user.
A scoring classifier goes one step further and assigns a (floating point) scoreto each categories. These may then be sorted to provide a ranking and a first-bestresult, with higher scores taken to be better matches. For example, LingPipe’simplementations of averaged perceptrons returns scored results.
Scores for categories given an input are often normalized so that they repre-sent an estimate of the conditional probability of a category given the input. Thisis the case for LingPipe’s logistic regression classifiers and k-nearest neighborsclassifiers. For instance, a classifier might see a MEDLINE citation about testingfor a disease with a known genetic component and estimate a 40% probabilityit is about genomics and 60% probability that it is not about genomics. Becausethe outcomes are exhaustive and exclusive, the probabilities assigned to the cat-egories must sum to 1.
In the case of generative statistical models, such as naive Bayes classifiers orhidden Markov models, the score represents the joint probabilty of the outputcategory and the input being classified. Given the joint probabilities, we can usethe rule of total probability to compute conditional probabilities of categoriesgiven inputs.

6.1. WHAT IS A CLASSIFIER? 137
6.1.3 Ordinals, Counts, and Scalars
A classifier is an instance of what statisticians call categorical models. The out-come of a classification is a category, not a number.
Classifiers deal with categorical outcomes. Ordinal outcomes are like cate-gorical outcomes, only they come with an order. Examples of ordinal outcomesinclude rating movies on a {1,2,3,4,5} scale, answering a survey question withstrongly-disagree, disagree, neutral, agree, or strongly agree, and rating a politi-cal attitude as left, center, or right.
In many cases, we will be dealing with counts, which are non-negative natu-ral numbers. Examples of count variables include the number of times a wordappears in a document, the length of a document’s title in characters, and thenumber of home runs a baseball player gets in a season. Classifiers like naiveBayes convert word count data into categorical outcomes based on a probabilitymodel for documents (see Chapter 7).
Scalar outcomes are typically continuous. Examples of continuous scalar vari-ables include a person’s height, the length of the vowel sequence in millisecondsin the pronunciation of the word lion, or the number of miles between two cities.Wes
Rating movies on an ordinal 1-5 scale doesn’t allow ratings like 1.793823.Half-star ratings could be accomodated by including additional discrete out-comes like 1.5, 2.5, 3.5 and 4.5, leaving a total of 9 possible ratings. When thereare 100 possible ratings, it makes less sense to treat the outcome as ordinal.Often, it is approximated by a continuous scalar variable.
Models that predict or estimate the values of ordinal, count and scalar valuesall have different evaluation metrics than categorical outcomes. In this section,we focus exclusively on categorical outcomes.
6.1.4 Reductions to Classification Problems
Many problems that don’t at first blush appear to be classification problemsmay be reduced to classification problems. For instance, the standard documentsearch problem (see Chapter E) may be recast as a classification problem. Givena user query, such as [be-bim-bop recipe], documents may be classified asrelevant or not-relevant to the search.
Another popular reduction is that for ranking. If we want to rank a set ofitems, we can build a binary classifier for assessing whether one item is greaterthan another in the ordering. In this case, it is then a challenge to piece backtogether all these binary decisions to get a final rank ordering.
Ordinal classification problems may also be reduced to classifications. Sup-pose we have a three-outcome ordered result, say N ∈ {1,2,3}. We can develop apair of binary classifiers and use them as an ordinal three-way classifier. The firstclassifier will test if N < 2 and the second if N < 3. If the first classifier returnstrue, the response is 1, else if the second classifier returns true the response is 2,else the response is 3. Note that if the first classifier returns true and the secondfalse, we have an inconsistent situation, which we have resolved by returning 1.
Just about any problem that may be cast in a hypothesize-and-test algorithm

138 CHAPTER 6. CLASSIFIERS AND EVALUATION
may use a classifier to do the testing, with a simple binary outcome of accept orreject. For instance, we can generate possible named-entity mention chunkingsof a text and then use a binary classifier to evaluate if they are correct or not.
Such reductions are often not interpetable probabilistically in the sense ofassigning probabilities to possible outcomes.
6.2 Gold Standards, Annotation, and Reference Data
For classification and other natural language tasks, the categories assigned totexts are designed and applied by humans, who are notoriously noisy in thesemantic judgments for natural language.
For instance, we made up the classification of genomics/non-genomics forMEDLINE citations. In order to gather evaluation data for a classifier, we wouldtypically select a bunch of MEDLINE citations at random (or maybe look at asubset of interest), and label them as to whether they are about genomics or not.
At this point, we have a problem. If one annotator goes about his or hermerry way and annotates all the data, everything may seem fine. But as soonas you have a second annotator try to annotate the same data, you will see aremarkable number of disagreements over what seem like reasonably simple no-tions, like being “about” genomics. For instance, what’s the status of a citation inwhich DNA is only mentioned in passing? What about articles that only mentionproteins and their interactions? What about an article on the sociology of thehuman genome project? These boundary cases may seem outlandish, but try tolabel some data and see what happens.
In the Message Understanding Conference evaluations, there were a largenumber of test instances involving the word Mars used to refer to the planet.The contestants’ systems varied in whether they treated this as a location or not.The reference data did, but there weren’t any planets mentioned in the trainingdata.
6.2.1 Evaluating Annotators
The simplest way to compare a pair of annotations is to look at percentage ofagreement between the annotators.
Given more than two annotators, pairwise statistics may be calculated. Thesemay then be aggregated, most commonly by averaging, to get an overall agree-ment statistic. It is also worth inspecting the counts assigned to categories tosee if any annotators are biased toward too many or too few assignments to aparticular category.
In general, pairs of annotators may be evaluated as if they were themselvesclassifiers. One is treated as the reference (gold standard) and one as the re-sponse (system guess), and the response is evaluated against the reference.
It is common to see Cohen’s κ statistic used to evaluate annotators; see Sec-tion 6.3.3 for more information.

6.3. CONFUSION MATRICES 139
6.2.2 Majority Rules, Adjudication and Censorship
Data sets are sometimes created by taking a majority vote on the category foritems in a corpus. If there is no majority (for instance, if there are two annota-tors and they disagree), there are two options. First, the data can be censored,meaning that it’s removed from consideration. This has the adverse side effect ofmaking the actual test cases in the corpus easier than a random selection mightbe because the borderline cases are removed. Perhaps one could argue this is anadvantage, because we’re not even sure what the categories are for those border-line cases, so who cares what the system does with them.
The second approach to disagreements during annotation is adjudication.This can be as simple as having a third judge look at the data. This will break atie for a binary classification problem, but may not make the task any clearer. Itmay also introduce noise as borderline cases are resolved inconsistently.
A more labor intensive approach is to consider the cases of uncertainty andattempt to update the notion of what is being annotated. It helps to do this withbatches of examples rather than one example at a time.
The ideal is to have a standalone written coding standard explaining how thedata was annotated that is so clear that a third party could read it and label thedata consistently with the reference data.
6.3 Confusion Matrices
One of the fundamental tools for evaluating first-best classifiers is the confusionmatrix. A confusion matrix reports on the number of agreements between a clas-sifier and the reference (or “true”) categories. This can be done for classificationproblems with any number of categories.
6.3.1 Example: Blind Wine Classification by Grape
Confusion matrices are perhaps most easily understood with an example. Con-sider blind wine tasting, which may be viewed as an attempt by a taster to classifya wine, whose label is hidden, as to whether it is made primarily from the syrah,pinot (noir), or cabernet (sauvignon) grape. We have to assume that each wineis made primarily from one of these three grapes so the categories are exclu-sive and exhaustive. An alternative, binary classification problem would be todetermine if a wine had syrah in it or not.
Suppose our taster works their way through 27 wines, assigning a single grapeas a guess for each wine. For each of the 27 wines, we have assumed there is atrue answer among the three grapes syrah, pinot and cabernet. The resultingconfusion matrix might look as in Figure 6.1. Each row represents results for aspecific reference category. In the example, the first row represents the resultsfor all wines that were truly cabernets. Of the 12 cabernets presented, the tasterguessed that 9 were cabernets, 3 were syrah, and none were guessed to be apinot. The total number of items in a row is represented at the end in italices,here 12. The second row represents the taster’s resuls for the 9 syrahs in the

140 CHAPTER 6. CLASSIFIERS AND EVALUATION
Responsecabernet syrah pinot
Referencecabernet 9 3 0 12
syrah 3 5 1 9pinot 1 1 4 6
13 9 5 27
Figure 6.1: Confusion matrix for responses of a taster guessing the grape of 27 differentwines. The actual grapes in the wines make up the reference against which the taster’sresponses are judged. Values within the table indicate the number of times a referencegrape was guessed as each of the three possibilities. Italicized values outside the box aretotals, and the bold italic 27 in the lower right corner is the total number of test cases.
evaluation. Of these, 5 were correctly classified as syrahs, whereas 3 were mis-classified as cabernets and one as a pinot. The last row is the pinots, with 4correctly identified and 1 misclassified as cabernet and 1 as syrah. Note that thetable is not symmetric. One pinot was guessed to be a cabernet, but no cabernetswere guessed to be pinots.
The totals along the right are total number of reference items, of which therewere 12 cabernets, 9 syrahs, and 6 pinots. The totals along the bottom are forresponses. The taster guessed 13 wines were cabernets, 9 were syrahs, and 5were pinots. The overall total in the lower right is 27, which is sum of the valuesin all the cells, and equal to the total number of wines evaluated.
Contingency matrices are particular kinds of contingency tables which hap-pen to be square and have the same outcome labels on the rows and columns.In Section 6.7, we suvey the most popular techniques culled from a vast litertureconcerning the statistical analysis of contingency tables in general and confusionmatrices in particular.
6.3.2 Classifier Accuracy and Confidence Intervals
The overall accuracy is just the number of correct responses divided by the totalnumbe of responses. A correct response for an item occurs when the responsecategory matches the reference category. The count of correct responses arethus on the diagonal of the confusion matrix. There were 9 correct responsesfor reference cabernets, 5 for syrahs, and 4 for pinots, for a total of 18 correctresponses. The total accuracy of the classifier is thus 18/27 ≈ 0.67.
Assuming that the reference items occur in the same distribution as they willin further test cases, the overall accuracy is an estimate of the probability that aclassifier will make the correct categorization of the next item it faces. If furthertest data are distributed differently than our evaluation data, we can apply post-stratification, as described in Section 6.9.
We will also measure accuracy on a category-by-category basis, as we explainbelow when we discuss one-versus-all evaluations in Section 6.3.8.
Because overall accuracy is a simple binomial statistic, we can compute a nor-mal approximation to a 95% confidence interval directly (see Section B.1.2 for an

6.3. CONFUSION MATRICES 141
explanation of the formula). For our example, the 95% interval is approximatelyplus or minus 0.18 and the 99% interval approximately plus or minus 0.23.2 Asusual, with so few evaluation cases, we don’t get a tight estimate of our system’saccuracy.
In the case of classifier evaluations (and in many other situations in statistics),the width of confidence intervals, assuming the same distribution of results, isinversely proportional to the square root of the number of cases. For instance,to cut the size of confidence intervals in half, we need four times as much data.Concretely, if we had four times as much data in the same proportions as in ourexample, our 95% confidence intervals would be plus or minus 0.09.
6.3.3 κ Statistics for Chance-Adjusted Agreement
There is a family of statistics called κ statistics that are used to provide an adjust-ment to accuracy or agreement statistics based on how likely agreement wouldbe “by chance”. All of the κ statistics are defined in the same way, using theformula:
κ = a− e1− e (6.1)
where a is a response’s total accuracy, and e is accuracy achievable by guessingrandomly. For example, if we have a system that has accuracy a = 0.8, if thechance accuracy is e = 0.2, then κ = (0.8− 0.2)/(1− 0.2) = 0.75.
In general, κ statistics are smaller than accuracy, κ ≤ a, with equality only inthe limit of zero random accuracy, e = 0.
The minimum possible value for κ is when the system is completely inaccu-rate, with a = 0, producing κ = −e/(1−e), which works out to the negative oddsfor a randomly chosen item to be guessed correctly at random.
There are three forms of κ statistic in popular use, varying by the way inwhich e is defined. Accuracy a is always as we computed it in the previoussection.
Cohen’s κ
Cohen’s κ assumes that the response is chosen at random based on the respon-dent’s proportion of answers. For instance, in our runing example, we can readthis off the bottom row, with the response being cabernet in 13/27 cases, syrahin 9/27 cases, and pinot 5/27 cases. If we assume that the reference values arechosen at random the same way, this time reading 12/27 cabernet, 9/27 syrahand 6/27 pinot from the right-most totals column. Thus our expected chance ofagreement is (
1327× 12
27
)+(
927× 9
27
)+(
527× 6
27
)≈ 0.3663. (6.2)
(We use so many decimal places here to compare two different versions of κbelow.)
2Because we’re using a normal approximation, we might get restuls like 95% plus or minus 10%,leading to confidence intervals like [85%,105%], which extend beyond the possible values of a param-eter like accuracy.

142 CHAPTER 6. CLASSIFIERS AND EVALUATION
For Cohen’s κ, the highest random accuracy e arises when the proportion ofanswers of each category match in the reference and response.
Siegel and Castellan’s κ
A popular alternative to Cohen’s version is Siegel and Castellan’s κ, which usesthe average of the reference and response proportions in place of the individualproportions to compute the chance accuracy.
In the Siegel and Castellan version of κ, we average the reference and re-sponse proportions. For instance, with a reference proportion of 12/27 and re-sponse proportion of 13/27 for cabernet, the average is 12.5/27. The calculationthen becomes (
12.527
)2
+(
927
)2
+(
5.527
)2
≈ 0.3669. (6.3)
In general, Siegel and Castellan’s expected agreement will be higher than withCohen’s calculation.
Byrt, Bishop and Carlin’s κ
If we assume our chance accuracy is a coin flip, with e = 0.5, we get Byrt et al.’sκ statistic, which works out to
κ = 2a− 1 (6.4)
where a is the accuracy. The minimum value, for 0% accuracy, is -1, the maximumvalue, for 100% accuracy is 1, and the breakeven poin is 50% accuracy, yielding aκ value of 0.
6.3.4 Information-Theoretic Measures
We can use the empirical counts in a confusion matrix to estimate both the indi-vidual distributions of responses and references, as we used in the κ statistics, aswell as their joint distribution, as represented by the entire confusion matrix. Thebasic definitions for information-theoretic concepts are defined in Section B.3.
With these estimates in hand, we can use any of the information-theoreticmeasures to consider the individual distributions or joint distributions. Specifi-cally, we can compute the entropy of the reference or response distribution, orthe conditional entropy of one given the other, or the cross entropy. We can alsocompute divergence statistics between the distributions.
Conditional Entropy
Of all the information-theoretic measures, we will focus on conditional entropy(see Section B.3.3), as it is the most informative for classification. It tells us howmuch information knowing the reference value gives us about the response.
In evaluating a classifier, we are really interested in how much the classifierreduces the undertainty in the outcome. Without the classfier, the uncertainty ismeasured by the entropy of the reference distribution, as calculated above. With

6.3. CONFUSION MATRICES 143
the classifier in place, we need to measure the entropy of the outcome given theresponse of the classifier.
Let’s focus on the response in the case of wines whose reference category ispinot. In those cases, of which there were 6, the classifier classified 1 as cabernet,1 as syrah, and 4 as pinot. This corresponds to a discrete distribution withprobabilities 1/6, 1/6 and 4/6. Calculating the entropy for this outcome, we get(
16× log2
16
)+(
16× log2
16
)+(
46× log2
46
)≈ 1.25. (6.5)
We will refer to this value as the conditional entropy of the outcome given thereference category is pinot and observing the classifer’s response. The valueis 0.81 for cabernet and 1.35 for syrah. We then weight these values by thereference counts of each of these categories, and divide by the total number ofcounts, to produce
127((12× 0.81)+ (9× 1.35)+ (6× 1.25)) = 1.09 (6.6)
The units are bits, and as usual, they’re on a log scale. A value of 1.09 bits meansthat we’ve reduced the three-way decision to a 21.09, or 2.1-way decision.
We can read the reference entropy the same way. Its value is 1.53, meaningthat the base classification problem is effectively a 21.53 or 2.9-way decision. Thevalue would work out to a 3-way decision if the probabilty of seeing a cabernettest case was the same as for seeing a pinot or syrah test case. The value lowerthan 3 arises because of the 12/9/6 distribution of the data. If it were moreskewed, entropy would be lower.
Mutual Information
A related measure to conditional entropy is mutual information (see Sec-tion B.3.4). It measures the difference in entropy in the entire table betweenguessing the response category randomly and guessing it based on the condi-tional distribution.
6.3.5 χ2 Independence Tests
Pearson’s χ2 independence test is for the hypothesis that the the reference andresponse categories for an item were assigned independently (see Section B.2.2).In the blind-wine tasting case, this would correspond guessing the wine beforetasting it by simply generating a random category based on the taster’s distribu-tion of answers. This is the same kind of independent reference and responsegeneration that underlies the expected correct answers by chance used in thedefinition of Cohen’s κ statistic (see Section 6.3.3) and mutual information (seeSection 6.3.4).
Pearson’s X2 statistic (see Section B.2.2) is used for the χ2 test, with highervalues of X2 being less likely to have arisen from random guessing. In our run-ning example, the value of the statistic is 15.5, which is quite high.
To compute p values, we need to determine where X2 falls in the cumula-tive distribution of χ2
ν , where ν is the degrees of freedom (here (K − 1)2 for K

144 CHAPTER 6. CLASSIFIERS AND EVALUATION
categories). For our example, the chi square statistic X2 is 15.5. The R functionfunction phchisq() for the cumulative density of χ2 may be used to computep-values by:
> 1 - pchisq(15.5,df=4)
[1] 0.003768997
The way to interpret a p value is as the probability under the null hypothesis(here independence) of seeing as extreme a value as was seen (here 15.5) in thedistribution at hand (here the χ2 distribution with 4 degrees of freedom). In otherwords, our p value of 0.0038 means that there is less than a 0.4% chance thattwo independent distributions were in as good agreement as what we observedin our table. This is usually considered a low enough p value to reject the nullhypothesis that the two results were independent.3
LingPipe is also able to report Pearson’s mean-square contingency statisticϕ2, Cramér’s V statistic of association, and Goodman and Kruskal’s index ofpredictive association, all of which are defined in Section 6.7.2
6.3.6 The ConfusionMatrix Class
A confusion matrix is represented in LingPipe as an instance of the classConfusionMatrix, which is in package com.aliasi.classify.
Constructing a Confusion Matrix
A confusion matrix minimally requires an array of categories for construction,with constructor ConfusionMatrix(String[]). It may optionally take a matrixof counts, with constructor ConfusionMatrix(String[],int[][]).
Getters and Increments
We can retrieve (a copy of) the categories as an array using categories(). Theevaluation keeps a symbol table under the hood (see Chapter 9) to support map-pings from categories to their indices. This is available indirectly through themethod getIndex(String), which returns the index for a category in the arrayof category names or -1 if there is no such category.
It’s also possible to retrieve (a copy of) the entire matrix, using matrix(),which returns an int[][].
We can get the count in a particular cell using count(int,int), where thefirst index is for the reference category. If we want to get the count by category,we can use the getIndex() method first.
We can increment the values in the confusion matrix by reference and re-sponse category, or by index. The method increment(int,int) takes a refer-ence and response category index and increments the counts by one. The methodincrement(String,String) takes the names of the categories. There is also a
3We never accept the null hypothesis. With a high p value we simply fail to reject it.

6.3. CONFUSION MATRICES 145
method incrementByN(int,int,int), which takes two category indices and anamount by which to increment.
Often classifiers do not perform equally well for all categories. To help assessperformance on a per-category basis, we can look at the category’s row or columnof the confusion matrix. The confusion matrix class also supports one-versus-allevaluations, as discussed in Section 6.3.8.
xo
6.3.7 Demo: Confusion Matrices
In the rest of this section, we will illustrate the use of confusion matrices tocompute the statistics defined earlier in this section. The demo is in classConfusionMatrixDemo.
Code Walkthrough
The work is all in the main() method, which starts by allocating the contents ofthe confusion matrix and then the matrix itself, with data corresponding to ourrunning blind-wine classication example.
String[] cats = new String[] {"cabernet", "syrah", "pinot"
};
int[][] cells = new int[][] {{ 9, 3, 0 },{ 3, 5, 1 },{ 1, 1, 4 }
};
ConfusionMatrix cm = new ConfusionMatrix(cats, cells);
After that, it’s just a bunch of getters and assigns, which we will print at the encof the code. First, the categories, total count, total correct and accuracies, withconfidence intervals,
String[] categories = cm.categories();
int totalCount = cm.totalCount();int totalCorrect= cm.totalCorrect();double totalAccuracy = cm.totalAccuracy();double confidence95 = cm.confidence95();double confidence99 = cm.confidence99();
Next, the three versions of the κ statistic,
double randomAccuracy = cm.randomAccuracy();double randomAccuracyUnbiased = cm.randomAccuracyUnbiased();double kappa = cm.kappa();double kappaUnbiased = cm.kappaUnbiased();double kappaNoPrevalence = cm.kappaNoPrevalence();

146 CHAPTER 6. CLASSIFIERS AND EVALUATION
Then the information theoretic measures,
double referenceEntropy = cm.referenceEntropy();double responseEntropy = cm.responseEntropy();double crossEntropy = cm.crossEntropy();double jointEntropy = cm.jointEntropy();double conditionalEntropy = cm.conditionalEntropy();double mutualInformation = cm.mutualInformation();double klDivergence = cm.klDivergence();
double conditionalEntropyCab = cm.conditionalEntropy(0);double conditionalEntropySyr = cm.conditionalEntropy(1);double conditionalEntropyPin = cm.conditionalEntropy(2);
Finally, we have the χ2 and related statistics and the λ statistics,
double chiSquared = cm.chiSquared();double chiSquaredDegreesOfFreedom
= cm.chiSquaredDegreesOfFreedom();double phiSquared = cm.phiSquared();double cramersV = cm.cramersV();
double lambdaA = cm.lambdaA();double lambdaB = cm.lambdaB();
All of these statistics are explained in Section 6.7.
Running the Demo
The Ant target confusion-matrix runs the demo. There are no command-linearguments, so there’s nothing else to provide.
> ant confusion-matrix
categories[0]=cabernetcategories[1]=syrahcategories[2]=pinot
totalCount=27totalCorrect=18totalAccuracy=0.6666666666666666confidence95=0.17781481095759366confidence99=0.23406235319928148
randomAccuracy=0.36625514403292175randomAccuracyUnbiased=0.3669410150891632kappa=0.4740259740259741kappaUnbiased=0.4734561213434452kappaNoPrevalence=0.33333333333333326
referenceEntropy=1.5304930567574824

6.3. CONFUSION MATRICES 147
RespRef cab notcab 9 3not 4 11
RespRef syrah not
syrah 5 4not 4 14
RespRef pinot not
pinot 4 2not 1 20
Figure 6.2: The one-versus-all confusion matrices defined by joining categories of the 3× 3confusion matrix shown in Figure 6.1.
responseEntropy=1.486565953154142crossEntropy=1.5376219392005763jointEntropy=2.619748965432189conditionalEntropy=1.089255908674706mutualInformation=0.39731004447943596klDivergence=0.007128882443093773conditionalEntropyCab=0.8112781244591328conditionalEntropySyr=1.3516441151533922conditionalEntropyPin=1.2516291673878228
chiSquared=15.525641025641026chiSquaredDegreesOfFreedom=4.0phiSquared=0.5750237416904084cramersV=0.5362013342441477
lambdaA=0.4lambdaB=0.35714285714285715
6.3.8 One-Versus-All Evaluations
We often want to evaluate the performance of a classifier on a single refer-ence category. LingPipe’s confusion matrix classes support this kind of single-category evaluation by projecting a confusion matrix down to a 2 × 2 confusionmatrix comparing a single category to all other categories. Because our categoriesare exhaustive and exclusive, the reduced matrix compares a single category toits complement.
6.3.9 Example: Blind Wine Classification (continued)
Going back to our sample confusion matrix in Figure 6.1, we can render theresults for the three different wines into the following three 2× 2 confusion ma-trices, which we show in Figure 6.2. The one number that stays the same is thenumber of correct identifications of the category. For instance, for syrah, thetaster had 9 correct identifications. Thus there is a 9 in the cabernet-cabernetcell of the cabernet-versus-all matrix. The count for cabernet reference and non-cabernet response sums the two original cells for cabernet reference/syrah re-sponse and cabernet reference/pinot response, which were 3 and 0, yielding atotal of 3 times that a cabernet was misclassified as something other than caber-net. Similarly, the cell for non-cabernet reference and cabernet response, repre-

148 CHAPTER 6. CLASSIFIERS AND EVALUATION
RespRef positive negative
positive 18 9negative 9 45
Figure 6.3: The micro-averaged confusion matrix resulting from summing the one-versus-all matrices in Figure 6.2.
senting non-cabernets classified as cabernets, is 4, for the 3 syrahs 1 pinot andthe taster classified as cabernets. All other values go in the remaining cell ofnot-cabernet reference and not-cabernet response. The total is 11, being the sumof the syrah reference/syrah response, syrah reference/pinot response, pinotreference/syrah response, and pinot reference/pinot response. Note that this in-cludes both correct and incorrect classifications for the original three-way catego-rization scheme. Here, the 11 classifications of non-cabernets as non-cabernetsare treated as correct. The other two tables, for syrah-versus-all and pinot-versus-all are calculated in the same way.
6.3.10 Micro-Averaged Evaluations
Now that we have a 2 × 2 one-versus-all matrix for each category, we may sumthem into a single matrix, which will be used for what are known as micro-averaged evaluations. The 2×2 micro-averaged confusion matrix for our runningblind-wine tasting example is given in Figure 6.3. The micro-average confusionmatrix is closely related to our original matrix (here Figure 6.1). The total countwill be the number of categories (here 3) times the number of test cases (here27, for a total count of 81). The number of true positives is just the numberof correct classifications in the original matrix (here 18, for the three diagonalelements 9 + 5 + 4). The number of false positives and false negatives will bethe same, and each will be equal to the sum of the off-diagonal elements, here3+1+1+3+0+1). The true negative slot gets the rest of the total, which is justtriple the original count (here 3× 27 = 81) minus the number of correct answersin the original matrix (here 18) minus twice the number of errors in the originalmatrix (here 2× 9 = 18, for a total of 45).
6.3.11 The ConfusionMatrix Class (continued)
The method oneVsAll(int) in ConfusionMatrix returns the one-versus-allstatistics for the category with the specified index (recall that getIndex(String)converts a category name to its index). The method microAverage() returnsthe micro-averaged confusion matrix. For our example, these are the three one-versus-all confusion matrices shown Figure 6.2 and the micro-averaged matrixshown in Figure 6.3.
These statistics are returned as an instance of PrecisionRecallEvaluation,which is also in the package com.aliasi.classify. A precision-recall matriximplements many of the same statistics as are found in a general confusion ma-

6.4. PRECISION-RECALL EVALUATION 149
ResponseReference positive negative
positive 9 (TP) 3 (FN)negative 4 (FP) 11 (TN)
Figure 6.4: A 2× 2 confusion matrix for precision-recall analysis. In general, the rows aremarked as references and the columns as reponses. The two categories are “positive” and“negative”, with “positive” conventionally listed first.
trix, as well as a number of methods specific to 2×2 matrices with a distinguishedpositive and negative category. We turn to these in the next section.
6.4 Precision-Recall Evaluation
Precision-recall evaluations are based on a 2 × 2 confusion matrix with onecategory distinguished as “positive” and the other “negative” (equivalently “ac-cept”/”reject”, “true”/”false”, etc.). As with confusion matrices, we distinguishthe rows as the reference and the columns as the response.
For instance, in a search problem, the relevant documents are consideredpositive and the irrelevant ones negative. In a named entity chunking problem,spans of text that mention person names are positive and spans that don’t men-tion person names are negative. In a blood test for a disease, having the diseaseis positive and not having the disease negative.
6.4.1 Example: Blind-Wine One-versus-All
An example of a confusion matrix suitable for precision-recall evaluations isshown in Figure 6.4. This is exactly the same matrix as shown in the cabernet-versus-all classifier in Figure 6.2. We have also added in names for the fourdistinguished slots. In the case the response is positive and the reference ispositive, we have a true positive (TP). If the response is positive but the referencenegative, we have a false positive (FP). Similarly, a negative response and negativereference is a true negative (TN) case, whereas a negative response with positivereference is a false negative (FN). So the second letter is “N” or “P” dependingon whether the response is negative or positive. There are 13 positive responsesand 14 negative responses, whereas there are 12 items that are actually positivein the reference and 15 that are actually negative.
6.4.2 Precision, Recall, Etc.
We call these special 2 × 2 confusion matrices precision-recall matrices becauseprecision and recall are the most commonly reported statistics for natural lan-guage processing tasks.
The recall (or sensitivity) of a classifier is the percentage of positive cases forwhich the response is positive. The positive cases are either true positives (TP) if

150 CHAPTER 6. CLASSIFIERS AND EVALUATION
the response is positive or false negatives (FN) if the response is negative. Thusrecall is given by
rec = sens = TP/(TP + FN). (6.7)
In the example in Figure 6.4, TP=9 and FN=3, so recall is 9/(9+ 3) = 0.75. Thus75% of the positive cases received a positive response.
The specificity of a classifier is like sensitivity, only for negative cases. That is,specificity is the percentage of negative cases for which the response is negative.the negative cases are either true negatives (TN) if the response is negative orfalse positives (FP) if the response is positive. Specificity is thus defined to be
spec = TN/(TN + FP). (6.8)
In Figure 6.4, TN=11 and FP=4, so specificity is 11/(11+ 4) ≈ 0.73.Precision is not based on accuracy as a percentage of true cases, but accuracy
as a percentage of positive responses. It measures how likely a positive responseis to be correct, and in thus also known as (positive) predictive accuracy. Preci-sion is defined by
prec = TP/(TP + FP). (6.9)
In our example, TP=9, FP=4, so precision is 9/(9 + 4) ≈ 0.69. What counts foran error for precision is a false positive, whereas an error for recall is a falsenegative. Both treat true positives as positives.
The final member of this quartet of statistics is known as selectivity or nega-tive predictive accuracy. Selectivity is like precision, only for negative cases. Thatis, it is the percentage of the false responses that are correct. The definition is
selec = TN/(TN + FN). (6.10)
6.4.3 Prevalence
Another commonly reported statistic for precision-recall matrices is prevalence,which is just the percentage of positive cases among all cases. This is defined by
prev = (TP + FN)/(TP + FP + TN + FN) (6.11)
If we know the prevalence of true cases as well as a classifier’s sensitivity andspecificity, we can reconstruct the entire confusion matrix,
TP = prev× sens, FN = prev× (1− sens), (6.12)
FP = (1− prev)× (1− spec), and TN = (1− prev)× spec. (6.13)
6.4.4 F Measure
It is common to combine precision and recall into a single number. The tradi-tional way to do this is using the (balanced) harmonic mean, which in the case ofprecision and recall, is known as F measure. The definition is
F = 2× prec× recrec+ prec
. (6.14)

6.4. PRECISION-RECALL EVALUATION 151
recall
prec
isio
n 0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Figure 6.5: Contour plot of F measure as a function of recall and precision. Each contourline indicates a particular F measure value as marked. For any given precision and recall,we can see roughly the result F measure by which contour lines they’re between. Forinstance, tracing a line up from 0.4 recall to 0.6 precision leaves us roughly equidistantbetween the F = 0.4 and F = 0.5 contour lines.
In Figure 6.5, we show a contour plot of F measure as a function of recall andprecision.
Although precision and recall are the most commonly reported pair of statis-tics for natural language classification tasks, neither of them involve the truenegative count. That is, they are only based on the TP, FP and FN counts, whichinvolve either a positive reference category or positive response.
6.4.5 The PrecisionRecallEvaluation Class
The LignPipe class PrecisionRecallEvaluation, from the packagecom.aliasi.classify, encapsulates a precision-recall matrix and providesmethods for the common statistics described in this section as well as theconfusion matrix methods detailed the previous section.
Construction and Population
There are two constructors for a precision-recall evaluation instance. The first,PrecisionRecallEvaluation(), starts with zero counts in all cells, whereasPrecisionRecallEvaluation(long,long,long,long) starts with the speci-fied number of TP, FN, FP, and TN counts respectively.
Once a precision-recall evaluation instance is constructed, the methodaddCase(boolean,boolean) adds another test case, where the first boolean ar-gument represents the reference category and the second the response category.Positive responses are coded as boolean true and negatives as false. Thus call-ing addCase(true,true) adds a true positive, addcase(true,false) a falsenegative, addcase(false,false) a true negative, and addcase(false,true) afalse positive.

152 CHAPTER 6. CLASSIFIERS AND EVALUATION
Counts and Statistics
As for the confusion matrix implementation, the raw counts in the cells as wellas row- and column-wise sums are available directly. The cell coutns are avail-able through methods truePositive(), falsePositive(), trueNegative()and falseNegative().
The basic statistics are also named in the obvious way, with the threemain methods being precision(), recall(), and fMeasure(). The precision-recall evaluation class ues the terms rejectionRecall() for specificity andrejectionPrecision() for selectivity, pointing out their duality with precisionand recall by swapping positive/negative category naming.
The row totals are availabe as positiveReference() andnegativeReference(), indicating the balance of positive and negativecases in the reference (often the test) set. Column totals for responses arepositiveResponse() and negativeResponse(). The total number of items,that is the sum of all cells, is available through total().
The proportion of positive cases in the reference set is given byreferenceLikelihood(), and the corresponding statistic for responses, namelythe proportion of positive responses, as responseLikelihood().
All of the other statistics are defined in exactly the same way as for consuionmatrices.
Demo: Precision-Recall Evaluations
We provide a demo of precision-recall evaluations in the classPrecisionRecallDemo. We’ll use the one-versus-all classification matrixas we provided as a demo in Figure 6.2, which is the same as the result of run-ning the confusion matrix demo in Section 6.3.7 and retrieving the one-versus-allevaluation for cabernet.
All of the work’s done in the main() method, which accepts four arguments,representing the TP, FN, FP and TN counts respectively. These are parsed as longvalues and assigned to variables tp, fn, fp, and tn respectively. At this point, wecan construct our evaluation and inspect the counts assigned.
PrecisionRecallEvaluation eval= new PrecisionRecallEvaluation(tp,fn,fp,tn);
long tpOut = eval.truePositive();long fnOut = eval.falseNegative();long fpOut = eval.falsePositive();long tnOut = eval.trueNegative();
long positiveRef = eval.positiveReference();long positiveResp = eval.positiveResponse();
long total = eval.total();
We may then retrieve the various precision- and recall-like statistics from theevaluation, including F measure (and prevalence).

6.5. MICRO- AND MACRO-AVERAGED STATISTICS 153
double precision = eval.precision();double recall = eval.recall();double specificity = eval.rejectionRecall();double selectivity = eval.rejectionPrecision();
double fMeasure = eval.fMeasure();
double prevalence = eval.referenceLikelihood();
Finally, we pull out some of the statistics that are available; the rest are definedin the Javadoc and explained in the confusion matrix demo.
double accuracy = eval.accuracy();double accuracyStdDev = eval.accuracyDeviation();
double kappa = eval.kappa();
double chiSq = eval.chiSquared();double df = 1;
We can run the demo using the Ant target precision-recall. It provides thevalues of properties tp, fn, fp, and tn as the first four arguments. For instance,we can call it with the values from the syrah-versus-all evaluation.
> ant -Dtp=9 -Dfn=3 -Dfp=4 -Dtn=11 precision-recall
tpOut=9 fnOut=3 fpOut=4 tnOut=11positiveRef=12 positiveResp=13 total=27precision=0.692 recall=0.75 fMeasure=0.719specificity=0.733 selectivity=0.785 prevalence=0.444accuracy=0.740 accuracyStdDev=0.084kappa=0.479 chisq=6.23
We’ve reduced the number of digits by truncation and removed some line breaksto save space in the book.
6.5 Micro- and Macro-Averaged Statistics
So far, in considering confusion matrices, we only considered overall evaluationmeasures, such as accuracy, κ statistics, and χ2 independence tests. In thissection, we consider two ways of evaluating general classification results on amore category-by-category basis.
6.5.1 Macro-Averaged One Versus All
In our treatment of confusion matrices, we showed how the 3 × 3 confusionmatrix in Figure 6.1 could be reduced the three 2× 2 confusion matrices, shownin Figure 6.2.
Suppose take each of these 2 × 2 confusion matrices and consider its pre-cision, recall and F measure. For instance, precision for the cabernet matrix isapproximately 0.69, for syrah approximately 0.56, and for pinot noir 0.67. The

154 CHAPTER 6. CLASSIFIERS AND EVALUATION
macro-averaged precision is then given by averaging these values, the result ofwhich is 0.64. We can similarly macro average any of the precision-recall eval-uation statistics. Most commonly, we see macro-averaged values for precision,recall, and F measure.
Macro averaging has the property of emphasizing instances in low-count cat-egories more than in high-count categories. For instance, even though there areonly 6 actual pinots versus 12 actual cabernets, recall on the 6 pinots is weightedthe same as recall on the 12 cabernets. Thus the pinot recall is weighted twice asheavily on a per-item basis.
Macro averaging is often used for evaluations of classifiers, with the intent ofweighting the categories equally so that systems can’t spend all their effort onhigh-frequency categories.
6.5.2 Micro-Averaged One Versus All
Micro-averaging is like macro-averaging, only instead of weighting each categoryequally, we weight each item equally. In practice, we can compute micro-averagedresults over the 2×2 precision-recall matrix produced by summing the three one-versus-all precision-recall matrices. We showed an example of this in Figure 6.3,which is the result of simply adding up the three one-versus-all evaluations inFigure 6.2.
When we sum one-versus-all matrices, we wind up with a matrix with a num-ber of true positives equal to the number of elements on the original matrix’sdiagonal. That is, the true positives in the micro-averaged matrix are just thecorrect answers in the original matrix, each of which shows up as a true positivein exactly one of the one-versus-all matrices (the one with its category).
In the micro-averaged confusion example in Figure 6.3, we have 18 true pos-itives and 9 false positives, for a precision of exactly 2/3. Recall is also exactly2/3. And so is F measure.
Micro-averaged results are often reported along with macro-averaged resultsfor classifier evaluations. If the evaluators care about ranking classifiers, thisprovides more than one way to do it, and different evaluatiosn focus on differentmeasures.
6.5.3 Demo: Micro- and Macro-Averaged Precision and Recall
A demo for micro- and macro-averaged results is in the class MicroMacroAvg.The code is all in the main() method, which expects no arguments. It startsby setting up a confusion matrix exactly as in our confusion matrix demo, sowe don’t show that. The calculation of micro- and macro-averaged results is asfollows.
ConfusionMatrix cm = new ConfusionMatrix(cats, cells);
double macroPrec = cm.macroAvgPrecision();double macroRec = cm.macroAvgRecall();double macroF = cm.macroAvgFMeasure();
PrecisionRecallEvaluation prMicro = cm.microAverage();

6.5. MICRO- AND MACRO-AVERAGED STATISTICS 155
double microPrec = prMicro.precision();double microRec = prMicro.recall();double microF = prMicro.fMeasure();
The macro-averaged results are computed directly by the confusion matrix class.The micro-averaged results are derived by first extracting a precision-recall ma-trix for micro-averaged results, then calling its methods.
For convenience, we also extract all the precision-recall evaluations on whichthe macro-averaged results were based and extract their precision, recall and Fmeasures.
for (int i = 0; i < cats.length; ++i) {PrecisionRecallEvaluation pr = cm.oneVsAll(i);double prec = pr.precision();double rec = pr.recall();double f = pr.fMeasure();
We do not show the print statements.The demo may be run from Ant using the target micro-macro-avg.
> ant micro-macro-avg
cat=cabernet prec=0.692 rec=0.750 F=0.720cat= syrah prec=0.556 rec=0.556 F=0.556cat= pinot prec=0.800 rec=0.667 F=0.727Macro prec=0.683 rec=0.657 F=0.668Micro prec=0.667 rec=0.667 F=0.667
From these results, it’s also clear that we can recover the micro-averaged resultsby taking a weighted average of the one-versus-all results. For instance, lookingat recall, we have one-versus-all values of 0.750 for cabernet, 0.556 for syrah, and0.667 for pinot. If we average these results weighted by the number of instances(12 for cabernet, 9 for syrah, 6 for pinot), we get the same result,
0.667 = (12× 0.750)+ (9× 0.556)+ (6× 0.667)12+ 9+ 6
. (6.15)
In most evaluations, micro-averaged results tend to be better, because perfor-mance is usually better on high-count categories than low-count ones. Macro-averaged results will be higher than micro-averaged ones if low count categoriesperform relatively better than high count categories.
6.5.4 Generalized Precision-Recall Evaluations for InformationExtraction
Precision-recall evaluations are applicable to broader classes of problems thansimple classifiers. In fact, the most popular applications of precision-recall eval-uations are to information-finding problems. A typical example of this is namedentity mention recognition. A named-entity mention is a sequence of text that

156 CHAPTER 6. CLASSIFIERS AND EVALUATION
refers to some object in the real world by name. For example, Detroit might re-fer to a city, Denny McClain to a person, and Tigers to an organization in thesentence Denny McClain played for the Tigers in Detroit.
Suppose we have a reference corpus of named entity mentions. We evaluate anamed-entity mention chunking system by running it over the text and returningall the entity mentions found by the system. Given the reference answers, it’seasy to classify each mention returned by the system as a true positive if theresponse matches a mention in the reference or a false positive if the responsedoesn’t match a mention in the reference. Then, each mention in the referencethat’s not in the response is marked as a false negative. With the TP, FP, and FNstatistics, it’s straightforward to compute precision and recall.
We have so far said nothing about true negatives. The problem with truenegatives for a named entity mention finding task is that any span of text maypotentially refer to any type of entity, so there are vast numbers of true nega-tives. For instance, played, McClain played, played for, McClain played for, andso on, are all true negatives in our example for any type of entity to which they’reassigned.
This explains why precision is a more popular measure of information ex-traction systems than specificity. For specificity, we need to know about the truenegatives, whereas precision and recall are based only on the combined set ofpositive reference items and positive response items.
Similar precision-recall evaluations are applied to information retrieval (IR)systems. In the standard Cranfield evaluation model4 for evaluating IR systems,a test (or reference) corpus consists of a sequence of queries and for each query,the set of relevant documents from a collection. A system then returns a numberof documents for a query. Each of these returned document will be either a truepositive (if it’s marked as relevant in the reference corpus) or a false positive(if it’s not marked as relevant). The relevant documents not returned are falsenegatives and the rest are true negatives. These evaluations are often extendedto systems that provide ranked and scored results, as we discuss in the nextsection.
6.6 Scored Precision-Recall Evaluations
So far, we have assumed that the system’s response to a classification problem isa single first-best guess at a category. Many different kinds of classifiers supportreturning more than one guess, typically with a score for each result determininga rank order. In many cases, the results are associated with conditional proba-bility estimates of the response category given the item being classified; in othercases, scores have a geometric interpretation, such as the margin from the clas-sification hyperplane for a perceptron or the cosine for TF/IDF rankings.
4Developed around the Cranfield test collection of 1400 documents in aeronautics in the 1960s.

6.6. SCORED PRECISION-RECALL EVALUATIONS 157
6.6.1 Ranks, Scores and Conditional Probability Estimates
For instance, given our blind-wine grape-guessing task, a taster may be presentedwith a wine, and respond that their first guess is cabernet, their second guesssyrah, and their third guess pinot noir. That’s a ranked response. In addition,they might further specify that cabernet has a score of −1.2, syrah a score of−1.3, and pinot a score of −2.0 (yes, scores may be negative; they still get sortedfrom largest, here −1.2, to smallest, −2.0, for purposes of ranking). That’s whatwe call a scored response.
An even more refined response contains a conditional probability estimate ofthe output category given the input, such as 55% cabernet, 35% syrah, and 10%pinot noir. That’s a conditional probability response.5
6.6.2 Comparing Scores across Items
Ranked results support ranking categories within the response to a single itembeing classified, such as a single wine. For instance, I may be guessing the grapesin two wines, and rank the first one syrah, cabernet, and pinot, and the secondone pinot, syrah, and cabernet. Without scores, there’s no way to tell if the tasteris more confident about the guess of syrah for the first wine or pinot for thesecond wine.
With scores, we are sometimes able to compare a classifier’s response acrossitems. Usually we can’t, though, because the scores will only be calibrated amongthe category responses for a single item. For instance, it doesn’t usually makesense to compare scores for different documents across different searches inan information retrieval system like Lucene (see Chapter E), because of all thedocument- and query-specific effects built into scoring.
Conditional probabilities, on the other hand, are naturally calibrated to becomparable across runs. If I have two wines, and for the first one respond 55%cabernet, 35% syrah and 10% pinot, and for the second, 90% cabernet, 8% syrah,and 2% pinot, I can rank my choices. My best guess is that wine 2 is a cabernet,because I’ve estimated a 90% chance of being right. My second best guess is thatwine 1 is a cabernet (55%), my third-best guess that wine 1 is a syrah (35%), myfourth-best guess that wine 1 is pinot (10%), my fifth-best that wine 2 is syrah(8%), and my least likely guess is that wine 2 is a pinot (2%).
In this section, we will assume that we’re evaluating system responses in asituation where the scores (or conditional probabilities) are calibrated across dif-ferent items. This lets us arrange all of our guesses for all of our items in order.It is this ordering, an example of which we saw in the last paragraph, that formsthe basis for scored precision recall evaluations.
5There are also joint probability responses, from which conditional probabilities can be derived.The joint probabilities are less useful for evaluation, so we put off considering them until we see aclassifier that uses them.

158 CHAPTER 6. CLASSIFIERS AND EVALUATION
6.6.3 The ScoredPrecisionRecallEvaluation Class
The LingPipe class ScoredPrecisionRecallEvaluation, in packagecom.aliasi.classify, implements precision-recall type statistics basedon scored results.
Construction and Population
Most often, like precision-recall evaluations, scored precision-recall evaluationswill be constructed automatically by encapsulated testing classes for each kindof system. LingPipe generates scored precision-recall evaluations when givenappropriately probabilistic taggers, chunkers, spelling correctors, or classifiers.For now, we consider direct construction and manipulation to get a feeling forthe evaluation class itself.
There is a single no-arg constructor, ScoredPrecisionRecallEvaluation().The evaluation initially starts out with no data.
Responses are added to the evaluation using the methodaddCase(boolean,double), which takes two arguments, the first beingwhether the result was correct, and second what the score was. Note that we arenot keeping track of the individual categories, just their scores and whether theyare correct or not.
Going back to our example, of the previous section, suppose the first winewas a syrah, and the second a cabernet. Here we repeat the responses along withan indication of whether the response was true or not. For the first wine, wehave 55% cabernet (false), 35% syrah (true), and 10% pinot noir (false), and forthe second wine, 90% cabernet (true), 8% syrah (false), and 2% pinot noir (false).To populate the evaluation with these results requires six calls to addCase(),addCase(false,0.55), addCase(true,0.35), and addCase(false,0.10) forthe three responses for the first wine, and similarly for the three results from thesecond wine.
If the responses are exhaustive for each item, this is all we have to do. The keyobservation is that the correct answers will show up in every set of responses.Unfortunately, this is often not the case. For instance, consider a named-entitychunker that returns the 100-best potential entity mentions for each sentence. Ifwe know the true entity mentions, we can rank each of these results as true orfalse, based on whether the entity mention is in the reference standard or not.But there’s no guarantee that the system will find all the entities in a sentence,even if it returns its 100-best guesses.
In the case where not every positive reference item is included in the systemresponse, the method addMisses(int) lets you add in the number of positivereference items that were missed by the system’s responses. For instance, sup-pose we have the following sentence, marked for named entities.
Johan van der Dorp took the train to den Haag.012345678901234567890123456789012345678901234560 1 2 3 4(0,18):PER (37,45):LOC

6.6. SCORED PRECISION-RECALL EVALUATIONS 159
The entities are marked by character offsets, with (0,18):PER indicating thatthe text spanning from character 0 (inclusive) to character 18 (exclusive), namelyJohan van der Dorp, mentions a person. Simiarly, the other entity indicates thatden Haag refers to a location. This is a tricky sentence for a system trained onEnglish data without an extensive list of names or locations, because both namescontain tokens that are not capitalized.
Given the input text, a named-entity mention chunker might return all foundchunks with estimated probability above 0.01, which might lead to the followingsix chunks, for example.
( 4, 8):LOC 0.89 (41,45):ORG 0.43 (41,45):LOC 0.09( 0, 5):PER 0.46 (41,45):PER 0.21 ( 0,18):PER 0.02
In this case, only the guess (0,18):PER is correct, with the other five beingwrong. We call addScore() for each response, including the probability estimateand correctness, the latter of which is false for the first five responses and truefor the last one. After adding the scores, we must call addMisses(1), indicatingthat one of the reference entities, namely (37,45):LOC, was not included amongthe system responses.6
To evaluate information retrieval results, the system is used in the sameway, with the method addScore() being called for each system response andaddMisses() for the results that the system didn’t return.
6.6.4 Demo: Scored Precision-Recall
We provide a demo of the scored precision-recall evaluation class inScoredPrecisionRecallDemo. All of the work is in the main() method, whichhas no command-line arguments.
Construction and Population of Results
The main() method starts by constructing an evaluation and populating it.
ScoredPrecisionRecallEvaluation eval= new ScoredPrecisionRecallEvaluation();
eval.addCase(false,-1.21); eval.addCase(false,-1.80);eval.addCase(true,-1.60); eval.addCase(false,-1.65);eval.addCase(false,-1.39); eval.addCase(true,-1.47);eval.addCase(true,-2.01); eval.addCase(false,-3.70);eval.addCase(true,-1.27); eval.addCase(false,-1.79);
eval.addMisses(1);
After construction, we add ten scored results, four of which are true positivesand six of which are false positivies. We then add a single miss representing areference positive that was not returned by the system.
6These low-level adds, for both found chunks and misses, is automated in the chunker evaluationclasses. We’re just using named entity spotting as an example here.

160 CHAPTER 6. CLASSIFIERS AND EVALUATION
Rank Score Correct TP TN FP FN Rec Prec Spec
0 −1.21 no 0 5 1 5 0.00 1.00 0.831 −1.27 yes 1 5 1 4 0.20 0.50 0.832 −1.39 no 1 4 2 4 0.20 0.33 0.673 −1.47 yes 2 4 2 3 0.40 0.50 0.674 −1.60 yes 3 4 2 2 0.60 0.60 0.675 −1.65 no 3 3 3 2 0.60 0.50 0.506 −1.79 no 3 2 4 2 0.60 0.43 0.337 −1.80 no 3 1 5 2 0.60 0.38 0.178 −2.01 yes 4 1 5 1 0.80 0.44 0.179 −3.70 no 4 0 6 1 0.80 0.40 0.00
10 miss yes 5 0 6 0 1.00 0.00 0.00
Figure 6.6: Example of a scored precision-recall evaluation. The responses are shown withtheir correctness, sorted by score. There is a single missed positive item for which there wasno response, so we include it at the bottom of the table without a score. In total, the numberof positive cases is 5 and the total number of negative cases is 5. The ranks, numbered from0, are determined by score. The counts of TP, TN, FP and FN and the corresponding recall(TP/(TP+FN)), precision (TP/(TP+FP)), and specificity (TN/(TN+FP)) values are shown.
Statistics at Ranks
The evaluation is most easily understood by considering the sorted table of eval-uated responses, which may be found in Figure 6.6. The first column of the tableindicates the rank of the response (numbering from zero), the second the scoreof the response, and the third whether it was a correct (true) response or not. Forexample, the top-ranked response has a score of −1.21 and is incorrect, whereasthe second-best response has a score of −1.27 and is correct.
We use this table to generate confusion matrices for precision/recall for allof the results up to that rank. The next four columns represent the counts in thecells of the confusion matrix, TP, TN, FP, and FN, for each rank. These are thebasis for the computation of the next three columns, which are recall, precision,and specificity, at rank N .7 For recall, this is the fraction of all reference positiveitems that have been retrieved at the specified rank or before. The highest recallachieved for non-zero precision is only 0.80 because we added a missed item, fora total of five reference positive items. Every time we hit a correct answer, therecall (sensitivity) and precision go up and specificity stays the same.
Precision is calculated slightly differently, being the fraction of results re-turned so far that are correct. Thus the first value is zero, because we haveTP = 0 and FP = 1 at this point, for a precision of TP/(TP+FP) = 0. At rank 1, wehave TP = 1 and FP = 1, for a precision of 0.5. By the time we get down to rank9, we have TP = 4 and FP = 6, for a precision of 0.4. We pin the precision andspecificity of results corresponding to calls to addMisses() to 0, because thereis no indication of the number of false positives that may show up ahead of the
7LingPipe numbers ranks from zero for the purpose of precision-recall and ROC curves, but num-bers them from one for the purposes of computing the conventional precision-at-rank and reciprocalrank statistics.

6.6. SCORED PRECISION-RECALL EVALUATIONS 161
misses.Specificity (or rejection recall) is calculated more like recall than precision.
Specifically, we assume that at each rank, we have correctly rejected all the itemswe haven’t mentioned. So at rank 0, we have TN = 6 and FP = 1.
Inspecting Precision-Recall Curves
After constructing and populating the evaluation, the code in the main() methodgoes on to print out the precision-recall curve implied by the data and repre-sented in the instance eval of a scored precision-recall evaluation.
boolean interpolate = false;double[][] prCurve = eval.prCurve(interpolate);for (double[] pr : prCurve) {
double recall = pr[0];double precision = pr[1];
We have set the interpolation flag to false, and then walked over the resultingcurve pulling out recall/precision operating points (and then printing them incode not shown).
The Ant target scored-precision-recall runs the demo, which takes nocommand-line arguments. If we run it, the following shows the results for un-interpolated and interpolated precision-recall curves (the repeated code to printout the interpolated results is not shown here; it only differs in setting the inter-polation flag to true).
> ant scored-precision-recall
Uninterpolated P/R Interpolated P/Rprec=1.00 rec=0.00 prec=1.00 rec=0.00prec=0.50 rec=0.20 prec=0.60 rec=0.20prec=0.33 rec=0.20 prec=0.60 rec=0.40prec=0.50 rec=0.40 prec=0.60 rec=0.60prec=0.60 rec=0.60 prec=0.44 rec=0.80prec=0.50 rec=0.60 prec=0.00 rec=1.00prec=0.43 rec=0.60prec=0.38 rec=0.60prec=0.44 rec=0.80prec=0.40 rec=0.80prec=0.00 rec=1.00
The uninterpolated results are just the precision and recall values from our table.Interpolation has the effect of setting the precision at a given recall point r tobe the maximum precision at any operating point of the same or higher recall.For instance, the precision at recall point 0.4 is interpolated to 0.6, becaus etheprecision at recall point 0.6 is 0.6.
A graph of the uninterpolated and interpolated precision-recall curves areshown in Figure 6.7.

162 CHAPTER 6. CLASSIFIERS AND EVALUATION
●
●
●
●
●
●
●
●
●
●
●
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Uninterpolated
recall
prec
isio
n●
● ● ●
●
●
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Interpolated
recall
prec
isio
n
Figure 6.7: Uninterpolated and interpolated precision-recall curves for the data in Fig-ure 6.6. In both graphs, the filled circles are the points on the curve. In the interpolatedgraphs, the diamonds correspond to points on the original, uninterpolated, curve.
Inspecting ROC Curves
The code for retrieving receiver operating characteristic (ROC) curves is identicalto that for precision/recall curves, only it uses the method rocCurve(boolean)rather than prCurve(boolean) and returns 1 − specificity/sensitivity pairs in-stead of recall/precision pairs.
interpolate = false;double[][] rocCurve = eval.rocCurve(interpolate);for (double[] ss : rocCurve) {
double oneMinusSpecificity = ss[0];double sensitivity = ss[1];
The output from this block of code, and from the next block, which is identicalother than setting the interpolation flag, is as follows.
Uninterpolated ROC Interpolated ROC1-spec=0.00 sens=0.00 1-spec=0.00 sens=0.001-spec=0.17 sens=0.00 1-spec=0.17 sens=0.201-spec=0.17 sens=0.20 1-spec=0.33 sens=0.601-spec=0.33 sens=0.20 1-spec=0.50 sens=0.601-spec=0.33 sens=0.40 1-spec=0.67 sens=0.601-spec=0.33 sens=0.60 1-spec=0.83 sens=0.801-spec=0.50 sens=0.60 1-spec=1.00 sens=1.001-spec=0.67 sens=0.601-spec=0.83 sens=0.601-spec=0.83 sens=0.801-spec=1.00 sens=0.801-spec=1.00 sens=1.00
Interpolation works the same way as for precision-recall curves, removing domi-nated points with the same x-axis value. Graphs of the uninterpolated and inter-
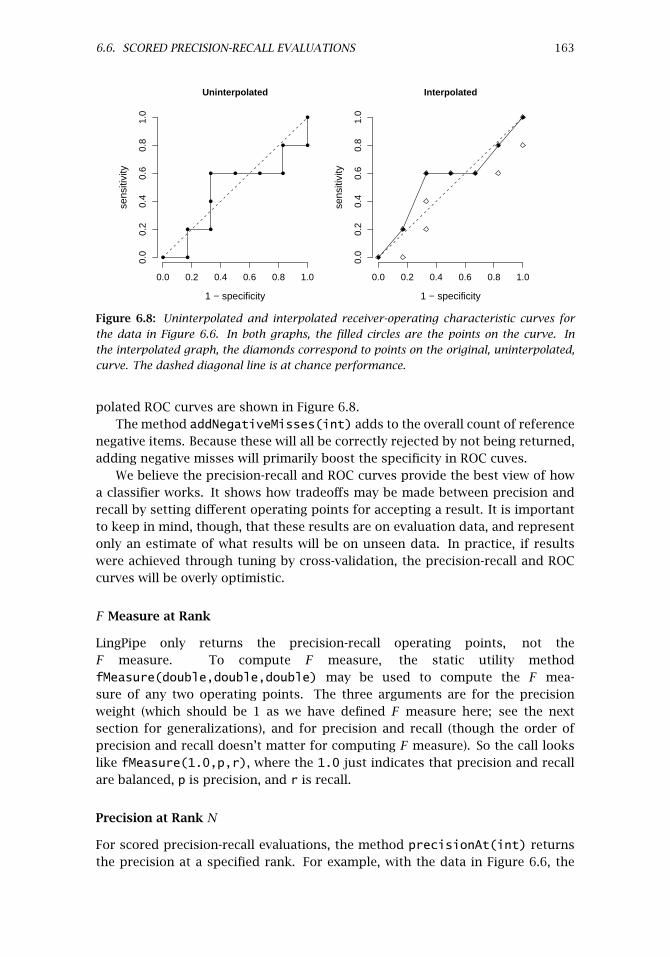
6.6. SCORED PRECISION-RECALL EVALUATIONS 163
● ●
● ●
●
● ● ● ●
● ●
●
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Uninterpolated
1 − specificity
sens
itivi
ty
●
●
● ● ●
●
●
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
Interpolated
1 − specificity
sens
itivi
ty
Figure 6.8: Uninterpolated and interpolated receiver-operating characteristic curves forthe data in Figure 6.6. In both graphs, the filled circles are the points on the curve. Inthe interpolated graph, the diamonds correspond to points on the original, uninterpolated,curve. The dashed diagonal line is at chance performance.
polated ROC curves are shown in Figure 6.8.The method addNegativeMisses(int) adds to the overall count of reference
negative items. Because these will all be correctly rejected by not being returned,adding negative misses will primarily boost the specificity in ROC cuves.
We believe the precision-recall and ROC curves provide the best view of howa classifier works. It shows how tradeoffs may be made between precision andrecall by setting different operating points for accepting a result. It is importantto keep in mind, though, that these results are on evaluation data, and representonly an estimate of what results will be on unseen data. In practice, if resultswere achieved through tuning by cross-validation, the precision-recall and ROCcurves will be overly optimistic.
F Measure at Rank
LingPipe only returns the precision-recall operating points, not theF measure. To compute F measure, the static utility methodfMeasure(double,double,double) may be used to compute the F mea-sure of any two operating points. The three arguments are for the precisionweight (which should be 1 as we have defined F measure here; see the nextsection for generalizations), and for precision and recall (though the order ofprecision and recall doesn’t matter for computing F measure). So the call lookslike fMeasure(1.0,p,r), where the 1.0 just indicates that precision and recallare balanced, p is precision, and r is recall.
Precision at Rank N
For scored precision-recall evaluations, the method precisionAt(int) returnsthe precision at a specified rank. For example, with the data in Figure 6.6, the

164 CHAPTER 6. CLASSIFIERS AND EVALUATION
precision at rank N is determined by looking up the precision for that rank.Ranks are conventionally counted from 1, so that is how we count for theprecisionAt() method.
The precision at every rank is calculated with the following code.
for (int n = 1; n <= eval.numCases(); ++n) {double precisionAtN = eval.precisionAt(n);
Note that our loop starts from 1 and uses a less-than-or-equal bound test toadjust for the fact that precision-at ranks start at 1. The output corresponds tothe precisions in Figure 6.6.
Prec at 1=0.00 Prec at 5=0.60 Prec at 9=0.44Prec at 2=0.50 Prec at 6=0.50 Prec at 10=0.40Prec at 3=0.33 Prec at 7=0.43 Prec at 11=0.36Prec at 4=0.50 Prec at 8=0.38
Maximum F Measure and BEP
Two other commonly reported operating points derived from the precision-recallcurve are the maximum F measure and precision-recall breakeven point (BEP).Continuing our example, these are extracted as follows.
double maximumFMeasure = eval.maximumFMeasure();double bep = eval.prBreakevenPoint();
Their values are output (code not shown) as
Maximum F =0.60 Prec/Rec BEP=0.44
These values are both computed from the uninterpolated curves and corre-spond to real points on the operating curve.
Break-even point is also known as R-precision, because it is equivalent tothe precision at R, where R is the number of reference positive results. That’sbecause if we have n true positives after R results, the the precision and recallare both n/R.
6.7 Contingency Tables and Derived Statistics
In this section, we provide a precise definition of contingency tables and discussthe computation and interpretation of statistics on contingency tables.
A contingency table is an M ×N matrix C of counts (i.e., Cm,n ∈ N). A genericcontingency table is shown in Figure 6.9. We use the notation Cm,+ for the sumof the values in rowm, C+,n for the sum of the values in column n, and and C+,+for the sum of the entire table. These values are defined by
Cm,+ =N∑n=1
Cm,n, C+,n =M∑m=1
Cm,n, and C+,+ =M∑m=1
N∑n=1
Cm,n. (6.16)

6.7. CONTINGENCY TABLES AND DERIVED STATISTICS 165
1 2 · · · N Total
1 C1,1 C1,2 · · · C1,N C1,+2 C2,1 C2,2 · · · C2,N C2,+...
......
. . ....
...M CM,1 CM,2 · · · CM,N CM,+
Total C+,1 C+,2 · · · C+,N C+,+
Figure 6.9: A generic M ×N contingency table C . Each entry Cm,n represents a cell count.The values along the bottom and on the right side are totals of their respective columns androws. The value in the lower right corner is the total count in the table.
6.7.1 χ2 Tests of Independence
The χ2 distribution may be used to test the null hypothesis that that a pair ofcategorical random variables are generated independently.
Suppose we have K independent and identically distributed (i.i.d.) pairs Ak, Bkof categorical random variables taking values Ak ∈ 1:M and Bk ∈ 1:N . Beingidentically distributed means the pairs share distributions, so that
pAi,Bi = pAj ,Bj for i, j ∈ 1:K. (6.17)
Independence requires that the value of the pair Ai, Bi is independent of thevalue of the pair Aj , Bj if i ≠ j.
So far, we have allowed for the possibility that A and B are not independentof each other. If Ak and Bk are independent, then
pAk,Bk(x,y) = pAk(x)× pBk(y). (6.18)
Because we’ve assumed the Ak, Bk pairs are i.i.d., they share distributions andhence are either all independent or all non-independent.
We define an M ×N contingency table C by setting
Cm,n =K∑k=1
I(Ak =m,Bk = n). (6.19)
That is, Cm,n is the number of times Ai was m and Bi was n. Note that C is amatrix random variable defined as a function of the random variables A and B.
Given a contingency table C , we can estimate the marginal distributionspA(m) and pB(n) by maximum likelihood using the observed counts in C . Be-cause pA and pB are multinomials, we assume pA = Bern(θ) and pB = Bern(φ).The maximum likelihood estimates θ∗,φ∗ of θ,φ given C are
θ∗m =Cm,+C+,+
and φ∗n =C+,nC+,+
. (6.20)
Pearson’s independence test involves the statistic X2, which is defined interms of C by
X2 =M∑m=1
N∑n=1
(Cm,n − Em,n)2Em,n
(6.21)

166 CHAPTER 6. CLASSIFIERS AND EVALUATION
where Em,n is the expected value of Cm,n (given our estimates θ∗ and φ∗) if Aand B are independent,
Em,n = C+,+ × θ∗m × φ∗n. (6.22)
If Ak and Bk are independent, the distribution of the statistic X2 is approxi-mately χ2 with (M − 1) × (N − 1) degrees of freedom (see Section B.2.2).8 Theusual rule of thumb is that the approximation is reliable if each of the expectedcounts Em,n is at least 5.
As usual, the classical hypothesis test rejects the null hypothesis with p-valueα if the value of the test statistic X2 is outside of the central and columns areindependent if the X2 statistic is outside of the central probabiilty interval of1− p.
6.7.2 Further Contingency and Association Statistics
Pearson’s Mean Square Contingency
Dividing Pearson’s χ2 statistic X2 by the number of cases yields Pearson’s ϕ2
statistic.
ϕ2 = X2
C+,+(6.23)
The ϕ2 statistic is known as the mean square contingency for the table C . Aswith X2, larger values indicate more contingency.
Cramér’s Degree of Association
Cramér’s V statistic9 is designed to measure the degree of association betweenthe rows and columns in a general contingency table. The square of V is definedby dividing ϕ2 by the minimum of the number of rows and columns minus 1,
V 2 = ϕ2
min(M,N)− 1. (6.24)
Obviously, the definition only makes sense if M,N ≥ 2, and if M = 2 or N = 2,V 2 reduces to ϕ2. As with ϕ2 and X2, larger values of V 2 indicate strongerassociations.
8The proof is too complex, but we provide some hints as to its form. We have MN cells, so haveMN −1 degrees of freedom, of which we lose M −1 and N −1 because we are estimating θ∗ and φ∗,which have one less than their dimensionality degrees of freedom, M − 1 and N − 1, for a total ofMN −1− (M +N −2) = (M −1)(N −1) degrees of freedom (again, asymptotically). Because the Cm,nare binomially distributed with success probability θ∗m×φ∗n and C+,+ trials, the central limit theoremensures asymptotic normality of Cm,n as C+,+ grows. The mean or expected value of the binomial isEm,n, and a binomial’s variance is equal to its mean. Rewriting the term inside the summation in thedefinition of the X2 statistic as ((Cm,n − Em,n)/
√Em,n)2 reveals that its just a squared z-score.
9H. Cramér. 1999. Mathematical Methods of Statistics. Princeton University Press.

6.7. CONTINGENCY TABLES AND DERIVED STATISTICS 167
Goodman And Kruskal’s Index of Predictive Association
Goodman and Kruskal defined an asymmetric measure of predictive associationwhich they called λB .10 The value of λB is (an estimate of) the reduction in errorlikelihood from knowing the response category and using it to predict the ref-erence category. It takes on values between 0 and 1, with higher values beingbetter, 0 indicating independence and 1 perfect assocaition.
Given our M × N confusion matrix C , Goodman and Kruskal’s index of pre-dictive association λB is defined by
λA =(∑
n Rn)− S
C+,+ − S(6.25)
where S and Rn are defined by
S =maxnC+,n and Rn =max
mCn,m. (6.26)
These statistics are unusual in using the maximum rather than matching. Di-viding through by C+,+ reveals a structure very much like the κ statistic (seeSection 6.7.5), with e replaced by S/C+,+ and with a replaced by
∑n Rn/C+,+.
The λB statistic is not symmetric between the rows and columns. If we trans-pose the matrix and compute the same statistic, we get λAp.
6.7.3 Information-Theoretic Measures
If we use the counts in C to estimate probability distributions using maximumlikelihood, we may use any of the information-theoretic measures available tocompare distributions (see Section B.3 for definitions).
For example, suppose we define random variables X and Y for the rows andcolumns, with joint distribution given by the maximum likelihood estimate giventhe contingency table C , which entails
pX,Y (m,n) =Cm,nC+,+
. (6.27)
Given this defintion, the marginal distributions for X and Y are
pX(m) =Cm,+C+,+
and pY (n) =C+,nC+,+
. (6.28)
The conditional distributions for X given Y and vice-versa are
pX|Y (m|n) =Cm,nCm,+
and pY |X(m|n) =Cm,nC+,n
. (6.29)
With all of these definitions in hand, we can easily compute the various infor-mation theoretic measures, which are defined in Section B.3.
10Goodman and Kruskal wrote three papers analyzing cross-classified data such as is found incontingency matrices, starting with Goodman, L. A. and W. H. Kruskal, 1954, Measures of associationfor cross classifications, Part I, Journal of the American Statistical Association 49:732—764. With thesame journal and title, Part II was published in 1959 in volume 53, pages 123–163, and Part III in1963 in volumne 58, pages 310–364.

168 CHAPTER 6. CLASSIFIERS AND EVALUATION
For instance, we can compute the entropy corresponding to the rows of thecontingency table as H[X] and to the columns as H[Y]. We can also compute theKL-divergences, symmetrized divergences and Jensen-Shannon divergence basedon the marginal distributions pX and pY implied by the contingency table.
With the joint and conditional estimates, we can tabulate the joint entropyH[X, Y], conditional entropies H[X|Y] and H[Y |X], as well as and mutual infor-mation I[X;Y].
6.7.4 Confusion Matrices
A confusion matrix is just a square (N ×N) contingency table where the variablerepresented by the rows and columns has the same set of categorical outcomes.Confusion matrices are often used to evaluate classifiers, taking the rows to rep-resent reference categories and columns to represent system responses.
There is a wide range of statistics that have been applied to evaluating theperformance of classifiers using confusion matrices.
6.7.5 κ Statistics for Chance-Adjusted Agreement
Suppose we have an N ×N confusion matrix C .Cohen’s κ statistic11 is defined by
κ = a− e1− e , (6.30)
where
a =∑Nn=1 Cn,nC+,+
and e =N∑n=1
θ∗n × φ∗n =En,nC+,+
. (6.31)
In words, a is the percentage of cases in which there was agreement, in otherwords the total accuracy, and e is the expected accuracy if the reference andresponse are independent.
Siegel and Castellan’s κ statistic12 has the same definitional form as Cohen’s,but the calculation of the expectation is based on averaging the reference andresponse to define
e =N∑n=1
(θ∗n +φ∗n2
)2
. (6.32)
Byrt et al.’s κ statistic13 completely ignores the adjustment for category preva-lence found in e, taking an arbitrary 50% chance of agreement, corresponding toe = 1/2, and resulting in a definition of κ = 2a− 1.
11Cohen, Jacob. 1960. A coefficient of agreement for nominal scales. Educational And PsychologicalMeasurement 20:37-46.
12Siegel, Sidney and N. John Castellan, Jr. 1988. Nonparametric Statistics for the Behavioral Sciences.McGraw Hill.
13Byrt, Ted, Janet Bishop and John B. Carlin. 1993. Bias, prevalence, and kappa. Journal of ClinicalEpidemiology 46(5):423–429.

6.7. CONTINGENCY TABLES AND DERIVED STATISTICS 169
ResponsePositive Negative
ReferencePositive TP FN
Negative FP TN
Figure 6.10: A generic sensitivity-specificity matrix is a 2×2 confusion matrix with columnsand rows labeled with “positive” and “negative.”. The code P (positive) is assigned to ref-erence positives and N (negative) to reference negatives, with T (true) assigned to correctresponses and F (false) to incorrect responses.
6.7.6 Sensitivity-Specificity Matrices
A sensitivity-specificity matrix is a 2× 2 confusion matrix where the binary cate-gories are distinguished as “positive” and “negative” (or “true” and “false” or “ac-cept” and “reject”). The cells have conventional names in a sensitivity-specificymatrix, which we show in Figure 6.10. The true positives (TP), false positives (FP)are for correct and incorrect responses when the reference category is positive,and true negative (TN) and false negative (FN) for correct and incorrect responseswhen the reference category is negative. False positives are also known as type-Ierrors or false alarms, and false negatives as misses or type-II errors.
Precision and Recall
For search and many classification evaluations, precision and recall are the mostcommonly reported metrics. Given a sensitivity-specificity matrix, precision andrecall are calculated as
precision = TPTP + FP and recall = TP
TP + FN . (6.33)
Precision is the percentage of positive responses (TP + FN) that are correct,whereas and recall the percentage of positive reference items (TP+ FP) that wereassigned a positive response. Looking at the matrix, we see that recall is basedon the top row and precision on the left column. In the next sections, we’ll fill inthe dual statistics.
Precision is sometimes called positive predictive accuracy, because it’s theaccuracy for items that get a positive prediction.
Sensitivity and Specificity
Sensitivity and specificity are more commonly used to evaluate sensitivity-specificity matrices (hence the name we gave them). These are defined by
sensitivity = TPTP + FN and specificity = TN
TN + FP (6.34)
Sensitivity is the same statistic as recall, being based on the top row of the matrix.One minus specificity is sometimes called fallout.
The easiest way to think of sensitivity and specificity is as accuracies on ref-erence positives (TP+ FN) and reference negatives (TN+ FP), respectively.

170 CHAPTER 6. CLASSIFIERS AND EVALUATION
Recall
Pos NegPos + –
Neg
Precision
Pos NegPos +
Neg –
Rej. Recall
Pos NegPos
Neg – +
Rej. Precicision
Pos NegPos –
Neg +
Figure 6.11: A graphical illustration of the transposition dualities involved in the defini-tions of recall (sensitivity) and precision (positive predictive accuracy) and in the definitionsof rejection recall (specificity) and rejection precision (negative predictive accuracy). Thesymbol + indicates successfull attempts and – failed attempts. The statistic labeing the tableis calculated as the percentage of attempts that were successful based on the value of thecells (see Figure 6.10).
Sensitivity and specificity are based on all four cells of the matrix, whereasprecision and recall do not use the true negative count.
Transpose Duals and Rejection Precision
If we transpose the roles of the reference and response, we swap FN and FPcounts, but TP and TN remain the same. Precision becomes recall and vice versain the transposed matrix. Specificity, on the other hand, does not have a dualdefined yet. To complete the picture, we introduce a statistic we call rejectionprecision, which is defined by
rejection-precision = TNTN + FP . (6.35)
This is the percentage of negative responses that are truly negative, and couldalso be called negative predictive accuracy.
To use terminology to match rejection precision, we could call specificity re-jection recall. Rejection precision and rejection recall swap when the matrix istransposed in the same way as precision and recall. The dualities are clearestwhen viewed in table form, as laid out in Figure 6.11.
F Measure
A common measure used in information retrieval research is F measure, whichis defined as the harmonic mean of precision and recall,
F =(precision−1 + recall−1
)−1= 2× precision× recall
precision+ recall. (6.36)
Sometimes, this measure is generalized with a weighting β to be
Fβ =(1+ β2)× precision× recall
recall+ (β2 × precision). (6.37)
With this generalization, the original F measure in Equation 6.36 corresonds tothe generalized F measure with β = 1.F measure has the property, because it is based on a harmonic mean, of
always being less than the simple average of precision and recall.

6.7. CONTINGENCY TABLES AND DERIVED STATISTICS 171
For some reason, F measure is the only commonly applied statistic basedon the harmonic mean. You don’t see people compute the harmonic mean ofsensitivity and specificity or of rejection recall and rejection precision.
Jaccard Similarity Coefficient
The Jaccard similarity coefficient14 provides a single measure of the quality ofmatch between a response and a reference. Teh similarity coefficient J is definedby
J = TPTP+ FP+ FN
. (6.38)
It turns out to be very closely related to F measure, which may be rewritten byunfolding the defintion of precision and recall to
F = 2× precision× recalprecision+ recall
= (2× TP)(2× TP)+ FP+ FN
. (6.39)
This formulation reveals the relation of F measure to the Jaccard similarity coeffi-cient; the difference is a factor of 2 boost to the true positives for F measure. TheJaccard similarity coefficient is less than F for non-degenerate matrices. Specifi-cally, we will have F > J if both TP > 0 and FP+ FN > 0.
Fowlkes-Mallows Similarity Measure
Fowlkes and Mallows presented a measure of similarity for clusterings that maybe adapted to sensitivity-specific matrices.15. 16 With a sensitivity-specificitymatrix in hand, Fowlkes and Mallows used the geometric mean of precision andrecall as their statistic,
B =√
precision× recall = TP√(TP+ FN)× (TP+ FP)
. (6.40)
Yule’s Q
Yule’s Q statistic of association is based on the odds ratio
ρ = sens/(1− sens)(1− spec)/spec
=
(TP
TP+FN
)/(FN
TP+FN
)(
FPFP+TN
)/(TN
FP+TN
) = TP/FNFP/TN
= TP× TNFN× FP
. (6.41)
The numerator is the odds of a positive item being correctly classified (sens)versus being incorrectly classified (1 − sens), and the denominator is the odds
14Jaccard, Paul. 1901. Étude comparative de la distribution florale dans une portion des Alpes etdes Jura. Bulletin de la Société Vaudoise des Sciences Naturelles 37:547–579.
15Fowlkes E. B. and C. L. Mallows. 1983. A method for comparing two hierarchical clusterings.Journal of the American Statistical Association 78(384):553–584. doi:10.2307/2288117
16They first reduce hierarchical clusterings to flat clusterings (by setting a threshold on dendrogramheight) then these flat clusterings to a sensitivity-specificity matrix. The set of cases is all pairs ofobjects being clustered. One clustering is set as the reference and one as the response. Referencepositives are then defined as pairs of objects in the same cluster in the reference clustering andsimilarly for responses.

172 CHAPTER 6. CLASSIFIERS AND EVALUATION
of a negative item being incorrectly classified (1 − spec) versus being correctlyclassified (spec). The numerator is the odds of the response being positive giventhat the reference is positive. The denominator is the odds of the response beingpositive given that the reference is negative. The ratio gives the increase in theodds of the response being negative given that the reference is negative.
Yule’s Q statistic transforms the odds ratio ρ to the [−1,1] scale by
Q = ρ − 1ρ + 1
= (TP× TN)− (FN× FP)(TP× TN)+ (FN× FP)
. (6.42)
Yule’s Y statistic dampens all these effects with square roots,
Y =√(TP× TN)−
√(FN× FP)√
(TP× TN)+√(FN× FP)
. (6.43)
6.7.7 Collapsing Confusion Matrices for One-Versus-All
In evaluating classifiers and related systems, we often want to focus our analysison a single category. We can do that by looking at that category in a confusionmatrix. The alternative presented in this section instead reduces the confusionmatrix to a sensitivity-specificity matrix for a single category. This is done bycollapsing all the other categories by treating them as if they were the same.
Supose we have an N × N confusion matrix C , where Cn,m is the count ofthe number of items with reference category n and response category m. Wecan pick a category n ∈ 1:N and collapse the confusion matrix to a sensitivity-specificity matrix by making the following definitions. True positives and falsepositives are
TP = Cn,n and FP = C+,n − Cn,n. (6.44)
In words, the true positives correspond to reference instances of category n cat-egorized as being category n. The false positives are items with response n andreference category other than n.
On the negative side, we have
FN = Cn,+ − Cn,n and TN = C+,+ − Cn,+ − C+,n + Cn,n. (6.45)
Here, the false negatives correspond to items which are of category n in thereference, but not in the response. The true negatives include all other cases,and works out to TN = C+,+ − TP− FP− FN.
Macro-Averaged Results
Statistics like overall accuracy computed on confusion matrices constitute whatare known as micro-averaged results. The defining characteristic of micro-averaged statistics is that they are weighted by item, so that each item beingevaluated contributes equally to the final statistics.
Macro averaging attempts to weight results so that each category has thesame weight instead of every instance. The way this is usually carried out is toaverage one-versus-all results.

6.7. CONTINGENCY TABLES AND DERIVED STATISTICS 173
Suppose we have the following confusion matrix,
C =
85 5 103 20 21 1 3
, (6.46)
where as usual the rows are the reference and the columsn the response. Thiscollapses into the three one-versus-all matrices.
D1 =[
85 154 26
], D2 =
[20 56 99
], and D3 =
[3 2
12 113
]. (6.47)
To compute the micro-averaged values, we just sum the three one-versus-all ma-trices position-wise to get
D+ =[
108 2222 238
]. (6.48)
The combined matrix always has the property that the false positive value is thesame as the false negative count (here 22).
Micro-averaged statistics are calcluated directly from D+. Macro-averagedstatistics are calculated by first calculating the statistic on each Dn then aver-aging the results.
We can now compare micro- and macro-averaged statistics. For example,micro-averaged precision is 108/130 and micro-averaged recall is also 108/130,yielding a micro-averaged F measure of 108/130, or about 83%. Macro-averagedprecision is the average of 85/100 (85%), 20/25 (80%) and 3/5 (60category 3brings down the averages from the high count cases. This can work out the otherway around, with macro-averaged values being higher than their micro-averagedcounterparts.
6.7.8 Ranked Response Statistics
In natural language processing applications, especially ones related to search,system responses often take the form of ranked N-best lists.
For instance, a traditional web search engine might return the top N results,ranked in order of estimated relevance to the user’s query.17 Another exampleis a named-entity system that takes a biomedical journal article and returns aranked list of identifiers for genes that were mentioned in the article. Yet anotherexample would be automatically assigning keywords or tags to a blog entry orassigning MeSH terms to untagged MEDLINE citations.
Mathematical Formulation
In order to carry out ranked evaluations, we only need a ranked list of N re-sponses along with an indication of whether they are correct or not. Mathemati-cally, this is just a boolean vector y ∈ {0,1}N . Very often the ordering is definedfrom an underlying score, which we might also have available as a parallel vectorx ∈ RN .
17In practice for search, there is some benefit to balancing relevance and diversity in results.

174 CHAPTER 6. CLASSIFIERS AND EVALUATION
Exhaustiveness for Evaluating Sensitivity
If we want to evaluate ranked sensitivity or recall, it’s critical that we know howmany positive answers there are in total. If we want to evaluate speicificity, wealso need to know how many negative answers there are in total.
For example, suppose there is a set T of 10 tags that might apply to a doc-ument. Now suppose we have a document and we know the relevant tags are{T2, T3, T8} of the total set of tags. Now suppose an automatic tagging systemreturns a ranked list of responses 〈T3, T4, T7, T8〉. Because the first and fourthranked responses T3 and T8 are actually relevant, we take our boolean vectorrepresentation to be y = 〈1,0,0,1〉.
By knowing that there is one additional reference tag not in the response,namely T2, we are able to tell what percentage of all tags are found at each rankin the list of results.
We could complete the response pessimistically (as far as evaluation goes) to〈1,0,0,1,0,0,0,1〉, by placing the correct response at the last possible rank. Itmight be better to average a bunch of random samples, but it’s a lot of work.Instead, we will just truncate our evaluations at the extent of the user input.
Statistics at Rank n
Suppose we have an evaluated rank vector y = {0,1}J and we know that thereare a total of T possible correct responses and F possible incorrect responsesaltogether.
The statistics at rank n ∈ N, defined for n < N , are calcluated by convertingthe first n responses into a sensitivity-specificity matrix. The response positivecases have the obvious definitions
TPn =n∑i=1
yi and FPn =n∑i=1
(1−yi). (6.49)
To fill in the rest of the matrix, we know that everything we missed is a falsenegative and the rest are true negatives, giving us
FNn = T − TPn and TNn = F − FPn (6.50)
As expected, we have T + F = TP+ FP+ FN+ TN.
ROC and PR Curves
We now have a way to calculate a sensitivity-specificity matrix for each rank.The recieved operating characteristic (ROC) curve is defined to be the plot ofsensitivity (on the vertical axis) versus one minus specificity (on the horizontalaxis).
In addition to the ROC curves, it is common to see precision versus recallplotted in the same way, though there is less of a convention as to which valuegoes on which axis. We will call such plots PR curves.

6.7. CONTINGENCY TABLES AND DERIVED STATISTICS 175
Interpolated ROC and PR Curves
It is common in the information retrieval literature to see PR curves calculated byinterpolation. Interpolation for both kinds of curves means adjusting the valuefor a given point on the x axis to be the maximum value for any point at thatposition or higher.18
By the same reasoning, we typically include operating points for 0% recall and100% precision and for 100% recall and 0% precision. Interpolation may modifythese operating points, so they may not appear as is in interpolated results.
Area under PR and ROC Curves
In order to reduce performance to a single statistic, it is common to see the areaunder the curve (AUC) reported.
The conventional approach to calculating these areas differs between PR andROC curves. For PR curves, the usual approach is to use step-functions basedon interpolation rather than connecting the operating points. In this case, areaunder the PR curve corresponds exactly to the average of the precision values atoperating points corresponding to true positives. These will be evenly spaced inthe interval between 0 and 1, and hence their average will correspond to the areaunder the curve.
For ROC curves, the usual approach is to report the area under the curve de-fined by connecting the points in the uninterpolated ROC curve.19 The area-undermethods in LingPipe compute actual area by using the resulting parallelograms.Areas may be computed under interpolated and uninterpolated curves.
The area under the ROC curve has a probabilistic interpretation as the es-timate of the probability that a classifier will rank a random positive intstanceahead of a randomly chosen negative instance. This is because the area under thecurve will be the average specificity at true positive points, which is the averagespecificity at each true positive, and hence an estimate of the probability that arandom negative item is ranked below a random positive item. In the continuouscurve setting, this average becomes an integral, but the idea remains the same.
Averages on ROC and P-R Curves
The average value of precision is often reported for PR curves. This is conven-tionally done over all operating points, not just the ones on the convex hull,though it may be calculated either way.
18As can be seen in the examples earlier, this does not quite correspond to computing the convexhull, because the results may still not be convex. The convex hull is an even more agressive interpo-lation that makes sense in some conditions where a system may probabilistically interpolate betweenresults.
19The following article contains an excellent introduction to ROC curves and estimating the areaunder them:
Lasko, Thomas A., Jui G. Bhagwat, Kelly H. Zou, and Lucila Ohno-Machado. 2005. Theuse of receiver operating characteristic curves in biomedical informatics. Journal ofBiomedical Informatics 38:404—415.

176 CHAPTER 6. CLASSIFIERS AND EVALUATION
When we have a whole set of evaluations, resulting in multiple PR curves, it’scommon to see mean average precision (MAP) reported, which simply averagesthe average precision precision values across the different PR curves.
Special Points on the P-R and ROC Curves
Several points on these curves are often called out for special attention. ForPR curves, the precision-recall breakeven point (BEP) is the point on the curve forwhich precision equals recall. As we noted above, this value is equal to precision-at-R, where R is the number of reference positive results.
The second point that is often reported is the point on the PR curve withmaximum F measure. In fact, we can compute any of the statistics applicable tosensitivity-specificity matrices and find the operating point that maximizes (orminimizes) it.
For information retrieval applications, it is common to see precision-at-Nnumbers reported, where we see what the precision is for the top N results.This statistic is relevant because we often present only N results to users.
Reciprocal Rank of First True Positive
The reciprocal rank statistic for ranked results is just the inverse 1/n of the rankn at which the first true positive appears int he list. Because we start countingfrom 1, 1/n will always fall between 0 and 1, with 1 being best.
As for average precision, it is common to report the average value of recipro-cal rank across a number of evaluations.
6.8 Bias Correction
Suppose that when we evaluate a classifier on held-out data, it has a bias towardone category or the other. For instance, suppose we have a binary classifier witha sensitivity (accuracy on reference positive cases) of θ1 = 0.8 and a specificity(accuracy on negative reference cases) of θ0 = 0.9. If there are I = 200 positivereference cases and J = 100 negative cases, the classifier is expected to returnan estimate of the number M of positive cases of
M = θ1I + (1− θ0)J = 0.8× 200+ (1− 0.9)× 100 = 170, (6.51)
and an estimate of the number N of negative cases of
N = (1− θ1)I + θ0J = (1− 0.8)× 200+ 0.9× 100 = 130. (6.52)
We will assume that we’ve evaluated our classifier so that we have an estimateof its sensitivity θ1 and specificity θ0.20 In practice, we don’t know the values of
20In practice, there is uncertainty associated with these estimates which translates into downstreamuncertainty in our adjusted estimates, but we’ll take our Bayesian hats off for the time being andpretend our point estimates are correct.

6.9. POST-STRATIFICATION 177
I or J, but we will know M and N . So we get a pair of equations:
θ1I + (1− θ0)J = M, and (6.53)
(1− θ1)I + θ0J = N, (6.54)
which allows us to solve for I and J in terms of M,N,θ0, and θ1. This allows usto estimate the prevalence of positive responses, even though we have a biasedclassifier.
6.9 Post-Stratification
If the data are not in the same proportion in held out data as in test data, butwe know the test data proportions, we could use post-stratification to predictoverall accuracy on new test data.
This situation most commonly arises when we have artificially “balanced”training data. For instance, suppose we have 1000 positive and 1000 negativetraining examples for a binary classifier. Suppose we know our system has asensitivity (accuracy on reference positive items) of 0.8 and a specificity (accuracyon reference negative items) of 0.9. On the test data, the overall accuracyw willbe (0.8× 1000+ 0.9× 1000)/2000, which is 0.85.
But what if we know our test set is balanced completely differently, with 50positive test items and 500 negative test items. If we don’t know the proportionof each item in the test set, we could sample and annotate until we do. Forinstance, we know that about 15% of the 5000 or so articles released each day inMEDLINE are about genomics. But we might have training data with 1000 articleson genomics and 1000 items not on genomics.
Knowing the sensitivity θ1, specificity θ0, and prevalence π , which is the per-centage of positive test items, we can predict our system’s accuracy on the testdata as πθ1 + (1−π)θ0.

178 CHAPTER 6. CLASSIFIERS AND EVALUATION

Chapter 7
Naive Bayes Classifiers
So-called naive Bayes classifiers are neither naive nor, in their usual application,Bayesian. LingPipe has two naive Bayes implementations, and in this section wefocus on the traditional implementation in TradNaiveBayes.
179

180 CHAPTER 7. NAIVE BAYES CLASSIFIERS

Chapter 8
Tokenization
Many natural-language processing algorithms operate at the word level, such asmost part-of-speech taggers and named-entity chunkers, some classifiers, someparameterizations of spelling correction, etc.
A token is a generalized kind of word that is derived from segmenting an in-put character sequence and potentially transforming the segments. For instance,a search engine query like [London restaurants] might be converted into aboolean search for the (case normalized) token london and the (plurality normal-ized) token restaurant.
8.1 Tokenizers and Tokenizer Factories
LingPipe provides a package com.aliasi.tokenizer for handling tokenization.
8.1.1 The TokenizerFactory Interface
The TokenizerFactory factory interface defines a single method,tokenizer(char[],int,int), which takes a slice of a character array asan argument and returns an instance of Tokenizer.
LingPipe’s tokenizer factory implementations come in two flavors Basic tok-enizer factories are constructed from simple parameters. For the basic tokeniz-ers with no parameters, a singleton instance is supplied as a static constant inthe class.
Tokenizer filters are constructed from other tokenizer factories and modifytheir outputs in some way, such as by case normalization, stemming, or stop-word filtering.
In order to bundle a tokenizer factory with a model, it must be serializable.All of LingPipe’s tokenizer factories are serializable, including ones made up bycomposing a sequence of filters.
181

182 CHAPTER 8. TOKENIZATION
8.1.2 The Tokenizer Base Class
All tokenizers extend the abstract base class Tokenizer. Tokenizers provide astream of tokens. An instance of Tokenizer represents the state of tokenizing aparticular string.
Constructing a Tokenizer
There is no state represented in the Tokenizer abstract class, so there is a singleno-argument constructor Tokenizer().
Because tokenizers are usually created through the TokenizerFactory inter-face, most. classes extending Tokenizer are not delcared to be public. Instead,only the factory is visible, and the documentation for a tokenizer’s behavior willbe in the factory’s class documentation.
Streaming Tokens
The only method that is required to be implemented is nextToken(), which re-turns the next token in the token stream as a string, or null if there are no moretokens. There is no reference in a tokenizer itself to the underlying sequence ofcharacters.
Token Positions
We often wish to maintain the position of a token in the underlying text.Given that tokens may be modified or even dropped altogether, the po-sition of a token is not necessarily going to be recoverable from the se-quence of tokens and whitespaces. So the Tokenizer class supplies methodslastTokenStartPosition() and lastTokenEndPosition(), which return theindex of the first character and of one past the last character. If no tokens haveyet been returned, these methods both return -1. These positions are relative tothe slice being tokenized, not to the underlying character array.
The token position methods are implemented in the Tokenizer base class tothrow an UnsupportedOperationException. Subclasses that want token posi-tions should override these methods. Tokenizer filters should almost always justpass the positions of the tokens being modified.
Iteration
The method iterator() returns an iterator over strings representing tokens. Inthe Tokenzer base class, the iterator is defined by delegation to the nextToken()method. Thus subclasses do not usually need to redefine this method.
This iterator() method allows the Tokenizer class to implement theIterable<String> interface. Thus the tokens can be read from a tokenizerwith a for loop. Given a tokenizer factory tokFac and the character slice forinput, the usual idiom is
Tokenizer tokenizer = tokFac.tokenizer(cs,start,length);for (String token : tokenizer) { ... }

8.1. TOKENIZERS AND TOKENIZER FACTORIES 183
Bulk Tokenization
The method tokenize() returns an array of the remaining tokens andtokenize(List,List) writes the remaining tokens and whitespaces to the spec-ified list.
Serializability and Thread Safety
Because they involve dynamic state, tokenizers are almost never serializable andalmost never thread safe.
Streaming Whitespaces
Over time, LingPipe has moved from the use of whitespace returned from to-kenizers to token start and end positions. Unless otherwise noted, tokenizersneed not concern themselves with whitespace. LingPipe’s built-in tokenizers al-most all define the whitespace to be the string between the last token and thenext token, or the empty string if that is not well defined.
The method nextWhitespace() returns the next whitespace from the to-kenizer. “White space” is the general term for the material between tokens,because in most cases, all non-whitespace is part of some token. LingPipe’sTokenizer class generalizes the notion of whitespace to arbitrary strings.
Each token is preceded by a whitespace and the sequence ends with a whites-pace. That is, the sequence goes whitespace, token, whitespace, token, . . . ,whitespace, token, whitespace. So the number of whitespaces is one greaterthan the number of tokens, and the minimum output of a tokenizer is a singlewhitespace.
If the nextWhitespace() method is not implemented by a subclass, the im-plementation inherited from the Tokenizer base class simply returns a stringconsisting of a single space character, U+0020, space.
If the nextWhitespace() method is implemented to return the text betweentokens, tokens do not overlap, and the string for a token is not modified in anyway, then concatenating the sequence of whitespaces and tokens will producethe underlying characters that were tokenized.
8.1.3 Token Display Demo
We provide a demo program DisplayTokens, which runs a tokenizer over thecommand-line argument. The main() method of the command calls a utilitymethod on a string variable text supplied on the command line, using a built-intokenizer
TokenizerFactory tokFact= IndoEuropeanTokenizerFactory.INSTANCE;
displayTextPositions(text);displayTokens(text,tokFact);
The IndoEuropeanTokenizerFactory class is in com.aliasi.tokenizer, andprovides a reusable instance through the static constant INSTANCE.

184 CHAPTER 8. TOKENIZATION
The displayTextPositions() method just prints out the string on a sin-gle line followed by lines providing indexes into the string. This method won’tdisplay properly if there are newlines in the string itself.
The work is actually done in the subroutine, the body of which is
char[] cs = Strings.toCharArray(in);Tokenizer tokenizer = tokFact.tokenizer(cs,0,cs.length);
for (String token : tokenizer) {int start = tokenizer.lastTokenStartPosition();int end = tokenizer.lastTokenEndPosition();
We first convert the character sequence in to a character array using the utilitymethod toCharArray(CharSequence) from the class Strings in the packagecom.aliasi.util. then, we create the tokenizer from the tokenizer factory.Next, we just iterate over the tokens, extract their start and end positions, andprint the results.
We provide a corresponding Ant target display-tokens, which is given asingle command-line argument consisting of the value of the property text.
> ant -Dtext="The note says, ’Mr. Sutton-Smith owes $15.20.’"display-tokens
The note says, ’Mr. Sutton-Smith owes $15.20.’01234567890123456789012345678901234567890123450 1 2 3 4
START END TOKEN START END TOKEN0 3 |The| 26 27 |-|4 8 |note| 27 32 |Smith|9 13 |says| 33 37 |owes|
13 14 |,| 38 39 |$|15 16 |’| 39 44 |15.20|16 18 |Mr| 44 45 |.|18 19 |.| 45 46 |’|20 26 |Sutton|
In writing the string, we put the ones-place indexes below it, then the tens-placeindexes, and so on. Because we count from zero, the very first T has index 0,whereas the M in Mr has index 16 and the final apostrophe index 45. The stringis 46 characters long; the last index is always one less than the length.
We then show the tokens along with their start and end positions. As always,the start is the index of the first character and the end is one past the index of thelast character. Thus the name Smith starts at character 27 and ends on character31. This also means that the end position of one token may be the start positionof the next when there is no space between them. For example, says has an endposition of 13 (which is exclusive) and the following comma a start position of13 (which is inclusive).

8.2. LINGPIPE’S BASE TOKENIZER FACTORIES 185
8.2 LingPipe’s Base Tokenizer Factories
LingPipe provides several base tokenizer factories. These may be combined withfilters, which we describe in the next section, to create compound tokenizers.
8.2.1 The IndoEuropeanTokenizerFactory Class
LingPipe’s IndoEuropeanTokenizer is a fairly fine-grained tokenizer in thesense that it splits most things apart. The notable exception in this instanceis the number 15.20, which is kept as a whole token. Basically, it consumes aslarge a token as possible according to the following classes.
Kinds of Tokens
An alphanumeric token is a sequence of one or more digits or letters as de-fined by the utility methods isDigit() and isCharacter() methods in Java’sCharacter class. Thus aaa, A1, and 1234 are all considered single tokens.
A token may consist of a combination of digits with any number of token-internal periods or commas. Thus 1.4.2 is considered a token, as is 12,493.27,but a2.1 is three tokens, a2, . (a period), and 1.
A token may be an arbitrarily long sequence of hyphens (-) or an arbitrar-ily long sequence of equal signs (=). The former are often used as en-dashesand em-dashes in ASCII-formatted text, and longer sequences are often used fordocument structure.
Double grave accents (“) and double apostrophes (”) are treated as singletokens, as they are often used to indicate quotations.
All other non-space characters, such as question marks or ampersands, areconsidered tokens themselves.
Construction
The static constant INSTANCE refers to an instance ofIndoEuropeanTokenizerFactory that may be reused. The no-argumentconstructor may also be used.
Thread Safety and Serializability
The IndoEuropeanTokenizerFactory class is both thread safe and serializable.The deserialized object will be reference identical to the factory picked out bythe INSTANCE constant.
8.2.2 The CharacterTokenizerFactory Class
The CharacterTokenizerFactory treats each non-whitespace char valuein the input as a token. The definition of whitespace is from Java’sCharacter.isWhitespace() method. The whitespaces returned will consist ofall of the whitespace found between the non-whitespace characters.

186 CHAPTER 8. TOKENIZATION
For instance, for the string a dog, there are four tokens, a, d, o, and g. Thewhitespaces are all length zero other than for the single space between the a andd characters.
This tokenizer factory is particularly useful for Chinese, where there is nowhitespace separating words, but words are typically only one or two characters(with a long tail of longer words).
This class produces a token for each char value. This means that a surrogatepair consisting of a high surrogate UTF-16 value and low surrogate UTF-16 value,which represent a single Unicode code point, will produce two tokens. Specifi-cally, unicode code points outside of the basic multilingual plane (BMP), that iswith values at or above U+10000, will produce two tokens (see Section 2.1.4 formore information).
The class is thread safe and serializable. There is no constructor, only a staticconstant INSTANCE. The instance is also the result of deserialization.
8.2.3 The RegExTokenizerFactory Class
For parsing programming languages, the lexical analysis stage typically breaks aprogram down into a sequence of tokens. Traditional C packages like Lex andJava packages like JavaCC specify regular expressions for tokens (and context-free grammars with side effects for parse trees). Regular expression-based tok-enization is also popular for natural language processing.
LingPipe’s RegExTokenizerFactory implements tokenizers where the to-kens are defined by running regular expression matchers in find mode (see Sec-tion 3.1.2). An instance may be constructed from a Pattern, or from a Stringrepresenting a regular expression with optional integer flags (see Section 3.12 forinformation on how to use the flags and their numerical values).
The demo class RegexTokens implements a simple regular expression to-kenizer factory based on three command line arguments, one for the regularexpression, one for the flags, and one for the text being tokenized.
int flagInt = Integer.valueOf(flags);TokenizerFactory tokFact
= new RegExTokenizerFactory(regex,flagInt);
DisplayTokens.displayTokens(text,tokFact);
The Ant target regex-tokens runs the command, setting three command linearguments for three properties, regex for the string representation of the regularexpression, flags for the integer flags, and text for the text to be tokenized.
> ant -Dregex="\p{L}+" -Dflags=32 -Dtext="John likes 123-Jello."regex-tokens
regex=|\p{L}+|flags=32 (binary 100000)
John likes 123-Jello.012345678901234567890

8.2. LINGPIPE’S BASE TOKENIZER FACTORIES 187
0 1 2
START END TOKEN0 4 |John|5 10 |likes|
15 20 |Jello|
First we print the regex and the flags (in both decimal and binary forms), thenthe string with indexes, and finally the tokens. Because we used the pattern\p{L}+, our tokens consist of maximally long sequences of letter characters.Other characters such as spaces, numbers, punctuation, etc., are simply skippedso that they become part of the whitespace.
Instances of RegExTokenizerFactory are serializable. They are also threadsafe.
8.2.4 The NGramTokenizerFactory Class
An NGramTokenizerFactory produces tokens from an input string consisting ofall of the substrings of the input within specified size bounds. Substrings of aninput string of length n are typically called n-grams (and sometimes q-grams).
Thus such a factory is constructed using a minimum and maximum sequencesize, with NGramTokenizerFactory(int,int). The sequences produced in-clude the whitespaces between what we typically think of as tokens. Tokenizerssuch as these are especially useful for extracting features for classifiers.
We provide an example implementation in the demo class NGramTokens. Theonly thing novel is the construction of the tokenizer factory itself,
NGramTokenizerFactory tokFact= new NGramTokenizerFactory(minNGramInt,maxNGramInt);
DisplayTokens.displayTokens(text,tokFact);
It takes three command-line arguments, the minimum and maximum se-quence lengths and the text to analyze. These are supplied to Ant targetngram-tokens as properties minNGram, maxNGram, and text.
> ant -DminNGram=1 -DmaxNGram=3 -Dtext="I ran." ngram-tokens
minNGram=1maxNGram=3
I ran.012345
START END TOKEN START END TOKEN0 1 |I| 2 4 |ra|1 2 | | 3 5 |an|2 3 |r| 4 6 |n.|3 4 |a| 0 3 |I r|4 5 |n| 1 4 | ra|

188 CHAPTER 8. TOKENIZATION
5 6 |.| 2 5 |ran|0 2 |I | 3 6 |an.|1 3 | r|
You can see from the output that the tokenizer first outputs the 1-grams , thenthe 2-grams, then the 3-grams. These are typically referred to as “unigrams,”“bigrams,” and “trigrams.”1 Note that the spaces and punctuation are treatedlike any other characters. For instance, the unigram token spanning positions1 to 2 is the string consisting of a single space character and the one spanningfrom 5 to 6 is the string consisting of a single period character. The first bigramtoken, spanning from positions 0 to 2, is the two-character string consisting ofan uppercase I followed by a space. By the time we get to trigrams, we beginto get cross-word tokens, like the trigram token spanning from position 0 to 3,consistinf of an uppercase I, space, and lowercase r.
In terms of the information conveyed, the spaces before and after words helpdefine word boundaries. Without the bigram token spanning 1 to 3 or the trigramspanning 1 to 4, we wouldn’t know that the lowercase r started a word. The cross-word ngram tokens help define the transitions between words. With long enoughngrams, we can even get three-word effects,
8.2.5 The LineTokenizerFactory Class
A LineTokenizerFactory treats each line of input as a single token. It is just aconvenience class extending RegExTokenizerFactory supplying the regex .+.
Line termination is thus defined as for regular expression patterns (see Sec-tion 3.9.4 for the full set of line-end sequences recognized). Final empty lines arenot included in the sequence of tokens.
There is a static constant INSTANCE which may be used. This is also the valueof deserialization. Line tokenizer factories are thread safe.
8.3 LingPipe’s Filtered Tokenizers
Following the same filter-based pattern as we saw for Java’s I/O, LingPipe pro-vides a number of classes whose job is to filter the tokens from an embeddedtokenizer. In all cases, there will be a base tokenizer producing a tokenizerwhich is then modified by a filter to produce a different tokenizer.
The reason the tokenizer is modified rather than, say, the characters being to-kenized, is that we usually want to be able to link the tokens back to the originaltext. If we allow an arbitrary transformation of the text, that’s no longer possi-ble. Thus if the text itself needs to be modified, that should be done externallyto tokenization.
1Curiously, we get a transition in common usage from Latin to Greek at 4-grams (tetragrams), and5-grams (pentagrams), 6-grams (hexagrams) etc. Some authors stick to all Greek prefixes, preferringthe terms “monogram” and “digram” to “unigram” and “bigram.”

8.3. LINGPIPE’S FILTERED TOKENIZERS 189
8.3.1 The ModifiedTokenizerFactory Abstract Class
The abstract class ModifiedTokenizerFactory in the packagecom.aliasi.tokenizer provides a basis for filtered tokenizers implementedin the usual way. Like many LingPipe filter classes, a modified tokenizerfactory is immutable. Thus the base tokenizer factory it contains mustbe provided at construction time. This is done through the single con-structor ModifiedTokenizerFactory(TokenizerFactory). The specifiedtokenizer factory will be stored, and is made available through the methodbaseTokenizerFactory() (it is common to see protected member variableshere, but we prefer methods).
It then implements the tokenizer(char[],int,int) method in the tok-enizer factory interface using the base tokenizer factory to produce a tokenizerwhich is then passed through the method modify(Tokenizer), which returns aTokenizer that may then be returned. This is perhaps easier to see in code,
protected abstract Tokenizer modify(Tokenizer tokenizer);
public Tokenizer tokenizer(char[] cs, int start, int length) {TokenizerFactory tokFact = baseTokenizerFactory();Tokenizer tok = tokFact.tokenizer(cs,start,length);return modify(tok);
}
Serialization
A modified tokenizer factory will be serializable if its base tokenizer factory isserializable. But unless the subclass defines a public no-argument constructor,trying to deserialize it will throw an exception. If a subclass fixes a base tokenizerfactory, there may be a public no-argument constructor. A subclass intended tobe used as a general filter will not have a public no-argument constructor becauseit would lead to instances without base tokenizers defined.
As elsewhere, subclasses should take control of their serialization. We rec-ommend using the serialization proxy, and show an example in the next section.
Thread Safety
A modified tokenizer factory is thread safe if its modify() method is thread safe.
8.3.2 The ModifyTokenTokenizerFactory Abstract Class
In the previous section, we saw how the ModifyTokenizerFactory baseclass could be used to define tokenizer filters. That class had a modifymethod that consumed a tokenizer and returned a tokenizer. The classModifyTokenTokenizerFactory is a subclass of ModifiedTokenizerFactorythat works at the token level. Almost all of LingPipe’s tokenizer filters are in-stances of this subclass.

190 CHAPTER 8. TOKENIZATION
The method modifyToken(String) operates a token at a time, returning ei-ther a modified token or null to remove the token from the stream. The imple-mentation in the base class just returns its input.
There is a similar method modifyWhitespace(String), though whitespacesmay not be removed. If tokens are removed, whitespaces around them are accu-mulated. For instance, if we had w1, t1,w2, t2,w3 as the stream of whitespacesand tokens, then removed token t2, the stream would be w1, t1,w2 ·w3, with thelast two whitespaces being concatenated and the token being removed.
The start and end points for modified tokens will be the same as for theunderlying tokenizer. This allows classes that operate on modified tokens tolink their results back to the string from which they arose.
This subclass behaves exactly the same way as its superclass with respect toserialization and thread safety. For thread safety, both the modify methods mustboth be thread safe.
Example: Reversing Tokens
As an example, we provide a demo class ReverseTokenTokenizerFactory. Thisfilter simply reverses the text of each token. Basically, the implementation in-volves a declaration, constructor and definition of the modify operation,
public class ReverseTokenTokenizerFactoryextends ModifyTokenTokenizerFactory {
public ReverseTokenTokenizerFactory(TokenizerFactory f) {super(f);
}
public String modifyToken(String tok) {return new StringBuilder(tok).reverse().toString();
}
In addition, the class implements a serialization proxy (see Section 4.21.3).The main() method for the demo reads a command line argument into the
variable text, then constructs a token-reversing tokenizer factory based on anIndo-European tokenizer factory, then displays the output,
TokenizerFactory baseTokFact= IndoEuropeanTokenizerFactory.INSTANCE;
ReverseTokenTokenizerFactory tokFact= new ReverseTokenTokenizerFactory(baseTokFact);
DisplayTokens.displayTextPositions(text);DisplayTokens.displayTokens(text,tokFact);
It also serializes and deserializes the factory and displays the output for that,but we’ve not shown the code here.
The Ant target reverse-tokens calls the class’s main() method, supplyingthe value of property text as the command-line argument.
> ant reverse-tokens

8.3. LINGPIPE’S FILTERED TOKENIZERS 191
The note says, ’Mr. Sutton-Smith owes $15.20.’01234567890123456789012345678901234567890123450 1 2 3 4
START END TOKEN0 3 |ehT|4 8 |eton|9 13 |syas|
...39 44 |02.51|44 45 |.|45 46 |’|
The results are the same positions as for the Indo-European tokenizer, only withthe content of each token reversed. We have not shown the serialized and thendeserialized output; it’s the same.
8.3.3 The LowerCaseTokenizerFactory Class
The LowerCaseTokenizerFactory class modifies tokens by converting them tolower case. This could’ve just as easily been upper case – it just needs to benormalized.
Case normalization is often applied in contexts where the case of wordsdoesn’t matter, or provides more noise than information. For instance, searchengines typically store case-normalized tokens in their reverse index. And clas-sifiers often normalize words for case (and other properties).
Instances are constructed by wrapping a base tokenizer factory. Optionally,an instance of Locale to define the specific lowercasing operations. If no localeis specified, Locale.ENGLISH is used. (This ensures consistent behavior acrossplatforms, unlike using the platform’s default locale.)
Whitespace and start and end positions of tokens are defined as by the baseclassifier.
The class is used like other filters. For instance, to create a tokenizer fac-tory that returns lowercase tokens produced the Indo-European tokenizer usingGerman lowercasing, just use
TokenizerFactory f = IndoEuropeanTokenizerFactory.INSTANCE;Locale loc = Locale.GERMAN;TokenizerFactory fact = new LowerCaseTokenizerFactory(f,loc);
Instances will be serializable if the base tokenizer factory is serializable. Se-rialization stores the locale using its built-in serialization, as well as the basetokenizer factory. Instances will be thread safe if the base tokenizer factory isthread safe.
8.3.4 The StopTokenizerFactory Class
The StopTokenizerFactory provides a tokenizer factory filter that removes to-kens that appear in a specified set of tokens. The set of tokens removed is typi-

192 CHAPTER 8. TOKENIZATION
cally called a stop list. The stop list is case sensitive for this class, but stoplistingis often applied after case normalization.
It is common in token-based classifiers and search engines to further normal-ize input by removing very common words. For instance, the words the or bein English documents typically convey very little information themselves (theycan convey more information in context). Sometimes this is done for efficiencyreasons, in order to store fewer tokens in an index or in statistical model param-eter vectors. It may also help with accuracy, especially in situations with limitedamounts of training data. In small data sets, the danger is that these stop wordswill become associated with some categories more than others at random andthus randomly bias the resulting system.
Stop lists themselves are represented as sets of tokens. Stoplisting tokenizersare constructed by wrapping a base tokenizer and providing a stop list. Forinstance, to remove the words the and be, we could use
Set<String> stopSet = CollectionUtils.asSet("the","be");TokenizerFactory f1 = IndoEuropeanTokenizerFactory.INSTANCE;TokenizerFactory f2 = new LowerCaseTokenizerFactory(f1);TokenizerFactory f3 = new StopTokenizerFactory(f2,stopSet);
The first line uses the static utility method asSet() in the LingPipe utility classCollectionUtils. This method is defined with signature
static <E> HashSet<E> asSet(E... es);
so that it takes a variable-length number of E objects and returns a hash set ofthat type. Because Java performs type inference on method types (like the <E>generic in asSet()), we don’t need to specify a type on the method call.
We then wrap an Indo-European tokenizer factory in a lowercasing and thena stoplisting filter. Operationally, what will happen is that the Indo-Europeantokenizer will tokenize, the resulting tokens will be converted to lower case, andthen stop words will be removed. The calls start out in reverse, though, with f3called to tokenize, which then calls f2 and filters the resulting tokens, where f2itself calls f1 and then filters its results.
What’s a Good Stop List?
The utility of any given stop list will depend heavily on the application. It oftenmakes sense in an application to run several different stop lists to see which oneworks best.
Usually words on the stop list will be of relatively high frequency. One strat-egy is to print out the top few hundred or thousand words in a corpus sorted byfrequency and inspect them by hand to see which ones are “uninformative” orpotentially misleading.
Built-in For English
LingPipe provides a built-in stop list for English. TheEnglishStopTokenizerFactory class extends the StopTokenizerFactoryclass, plugging in the following stoplist for English:

8.3. LINGPIPE’S FILTERED TOKENIZERS 193
a, be, had, it, only, she, was, about, because, has, its, of, some, we,after, been, have, last, on, such, were, all, but, he, more, one, than,when, also, by, her, most, or, that, which, an, can, his, mr, other, the,who, any, co, if, mrs, out, their, will, and, corp, in, ms, over, there,with, are, could, inc, mz, s, they, would, as, for, into, no, so, this, up,at, from, is, not, says, to
Note that the entries are all lowercase. It thus makes sense to run this filter to atokenizer factory that produces only lowercase tokens.
This is a fairly large stop list. It’s mostly function words, but also includessome content words like mr, corp, and last. Also note that some words are am-biguous, which is problematic for stoplisting. For instance, the word can actsas both a modal auxiliary verb (presently possible) and a noun (meaning amongother things, a kind of container).
8.3.5 The RegExFilteredTokenizerFactory Class
The RegExFilteredTokenizerFactory class provides a general filter that re-moves all tokens that do not match a specified regular expression. For a tokento be retained, it must match the specified regular expression (in the sense ofmatch() from Matcher).
An instance of RegExFilteredTokenizerFactory may be constructed froma base tokenizer factory and a Pattern (from java.util.regex). For instance,we could retain only tokens that started with capital letters (as defined by Uni-code) using
TokenizerFactory f = ...;Pattern p = Pattern.compile("\p{Lu}.*");TokenizerFactory f2 = new RegExFilteredTokenizerFactory(f,p);
We could just as easily retain only tokens that didn’t start with an uppercaseletter by using the regex [ˆ\p{Lu}].* instead of the one supplied.
Although stop lists could be implemented this way, it would not be efficient.For one thing, regex matching is not very efficient for large disjunctions; setlookup is much faster. Also, at the present time, the class creates a new Matcherfor each token, generating a large number of short-lived objects for garbage col-lection.2
Like the other filter tokenizers, a regex filtered tokenizer is thread safe andserializable if its base tokenizer factory is.
8.3.6 The TokenLengthTokenizerFactory Interface
The class TokenLengthTokenizerFactory implements a tokenizer filter thatremoves tokens that do not fall in a prespecified length range. In real text, tokens
2A more efficient implementation would reuse a matcher for each token in a given to-kenization. The only problem is that it can’t be done naturally and thread-safely by ex-tending ModifyTokenTokenizerFactory. It would be possible to do this by extendingModifiedTokenizerFactory.

194 CHAPTER 8. TOKENIZATION
can get very long. Fror instance, mistakes in document formatting can producea document where all the words are concatenated without space. If you lookat large amounts of text (in the gigabytes range), especially if you’re looking atunedited sources like the web, you will find longer and longer tokens used onpurpose. It’s not unusual to see no, noo, and nooooooo!. Look at enough text,and someone will add 250 lowercase O characters after the n.
The length range is supplied in the constructor, which takes a tokenizer fac-tory, minimum token length, and maximum token length. Like the other filters,a length filtering tokenizer will be serializable and thread safe if the base tok-enizer factory is. And like some of the other filters, this could be implementedvery easily, but not as efficiently, with regular expressions (in this case the regex.{m,n} would do the trick).
8.3.7 The WhitespaceNormTokenizerFactory Class
When interpreting HTML documents on the web, whitespace (outside of <pre>environments) comes in two flavors, no space and some space. Any number ofspaces beyond will be treated the same way for rendering documents as a singlespace.
This is such a reasonable normalization scheme that we often normalize ourinput texts in exactly the same way. This is easy to do with a regex, replacinga string text with text.replaceAll("\\s+"," "), which says to replace anynon-empty sequence of spaces with a single space.
It’s not always possible to normalize inputs. You may need to link resultsback to some original text that’s not under your control. In these cases, it’spossible to modify the whitespaces produced by the tokenizer. This will nothave any effect on the underlying text or the spans of the tokens themselves.Unfortunately, very few of LingPipe’s classes pay attention to the whitespace,and for some that do, it’s the token bounds that matter, not the values returnedby nextWhitespace().
A WhitespaceNormTokenizerFactory is constructed from a base tokenizerfactory. Like the other filter tokenizer factories, it will be serializable if the basetokenizer factory is serializable and will be thread safe if the base tokenizerfactory is thread safe.
8.4 Morphology, Stemming, and Lemmatization
In linguistics, morphology is the study of how words are formed. AMorphology crosses the study of several other phenomena, including syn-
tax (parts of speech and how words combine), phonology (how words are pro-nounced), orthography (how a language is written, including how words arespelled), and semantics (what a word means).
LingPipe does not contain a general morphological analyzer, but it imple-ments many parts of word syntax, semantics and orthography.
A morpheme is the minimal meaningful unit of language. A morphemedoesn’t need to be a word itself. As we will see shortly, it can be a word, a suffix,

8.4. MORPHOLOGY, STEMMING, AND LEMMATIZATION 195
a vowel-change rule, or a template instantiation. Often the term is extended toinclude syntactic markers, though these almost always have some semantic orsemantic-like effect, such as marking gender.
We consider these different aspects of word forms in different sections. Ling-Pipe has part-of-speech taggers to determine the syntactic form a word, syllabi-fiers to break a word down into phonemic or orthographic syllables, word-sensedisambiguators which figure out which meaning of an ambiguous word is in-tended, and many forms of word clustering and comparison that can be basedon frequency, context similarity and orthographic similarity. LingPipe also hasspelling correctors to fix misspelled words, which is often handled in the samepart of a processing pipeline as morphological analysis.
In this section, we provide a brief overview of natural language morphology,then consider the processes of stemming and lemmatization and how they relateto tokenization.
8.4.1 Inflectional Morphology
Inflectional morphology is concerned with how the basic paradigmatic variantsof a word are realized. For instance, in English, the two nouns computer andcomputers differ in number, the first being singular, the second plural. Theseshow up in different syntactic contexts — we say one computer and two comput-ers, but not one computers and two computer.3 This is an instance of agreement— the grammatical number of the noun must agree with the number of the de-terminer. In English, there are only two numbers, singular and plural, but otherlanguages, like Icelandic and Sanskrit, have duals (for two things), and some lan-guages go even further, defining numbers for three objects, or distinguishingmany from a few.
In English, the verbs code, codes, coded, and coding are all inflectional vari-ants of the same underlying word, differing in person, number, tense, and aspect.We get agreement between verbs and subject nouns in English for these features.For instance, a person might say I code in referring to themselves, but she codeswhen referring to another woman coding. Other languages, such as French orRussian, also have agreement for gender, which can be natural (male personversus female person versus versus non-person) or grammatical (as in French).Natural gender is based on what is being talked about. That’s the distinctionwe get in English between the relative pronouns who, which is used for peopleand other animate objects, and what, which is used for inanimate objects. Forinstance, we say who did you see? if we expect the answer to be a person, andwhat did you see? if we want a thing.
Most languages have fairly straightforward inflectional morphology, defininga few variants of the basic nouns and verbs. The actual morphological operationsmay be as simple as adding an affix, but even this is complicated by boundaryeffects. For instance, in English present participle verbs, we have race/racing,eat/eating, and run/running. In the first case, we delete the final e before addingthe suffix -ing, in the second case, we just append the suffix, and in the third
3These ungrammatical forms like one computers will appear in text. You’ll find just about every-thing in free text and even in fairly tightly edited text like newswire if you look at enough of it.

196 CHAPTER 8. TOKENIZATION
case, we insert an extra n before adding the suffix. The same thing happens withnumber for nouns, as with boy/boys versus box/boxes, in which the first caseappends the suffix s whereas the second adds an e before the suffix (the result ofwhich, boxes, is two syllables).
It is also common to see internal vowel changes, as in the English alternationrun/ran. Languages like Arabic and Hebrew take this to the extreme with theirtemplatic morphology systems in which a base form consists of a sequence ofconsonants and an inflected form mixes in vowles.
8.4.2 Derivational Morphology
Derivational morphology, in contrast to inflectional morphology, involves mod-ifying a word to create a new word, typically with a different function. For in-stance, from the verb run we can derive the noun runner and from the adjectivequick we can derive the adverb quickly. After we’ve derived a new form, we caninflect it, with singular form runner and plural form runners.
Inflectional morphology is almost always bounded to a finite set of possibleinflected forms for each base word and category. Derivational morphology, onthe other hand, is unbounded. We can take the noun fortune, derive the adjectivefortunate, the adjective unfortunate, and then the adverb unfortunately.
Sometimes there’s zero derivational morphology, meaning not that there’sno derivational morphology, but that it has no surface effect. For instance, wecan turn most nouns in English into verbs, especially in the business world, andmost verbs into nouns (where they are called gerunds). For instance, I can say therunning of the race where the verb running is used as a noun, or Bill will leveragethat deal, where the noun leverage (itself an inflected form of lever) may be usedas a verb. In American English, we’re also losing the adjective/adverb distinction,with many speakers not even bothering to use an adverbial form of an adjective,saying things like John runs fast.
8.4.3 Compounding
Some languages, like German, allow two nouns to be combined into a singleword, written with no spaces, as in combining schnell (fast) and Zug (train) intothe compound schnellzug. This is a relatively short example involving two nouns.
Comnpounds may themselves be inflected. For instance, in English, we maycombine foot and ball to produce the compound noun football, which may then beinflected in the plural to get footballs. They may also be modified derivationally,to get footballer, and then inflected, to get footballers.
8.4.4 Languages Vary in Amount of Morphology
Languages are not all the same. Some code up lots of information in their mor-phological systems (e.g., Russian), and some not much at all (e.g., Chinese). Somelanguages allow very long words consisting of lots of independent morphemes(e.g., Turkish, Finnish), whereas most only allow inflection and derivation.

8.4. MORPHOLOGY, STEMMING, AND LEMMATIZATION 197
8.4.5 Stemming and Lemmatization
In some applications, the differences between different morphological variantsof the same base word are not particularly informative. For instance, shouldthe query [new car] provide a different search result than [new cars]? Thedifference is that one query uses the singular form car and the other the pluralcars.
Lemmatization is the process of mapping a word to its root form(s). It mayalso involve determining which affixes, vowel changes, wrappers or infixes ortemplates are involved, but typically not for most applications.
Stemming is the process of mapping a word to a canonical representation.The main difference from a linguistic point of view is that the output of a stem-mer isn’t necessarily a word (or morpheme) itself.
Example: Lemma author
It is very hard to know where to draw the line in stemming. Some systems takea strictly inflectional point of view, only stripping off inflectional affixes or tem-platic fillers. Others allow full derivational morphology. Even so, the line isunclear.
Consider the stem author. In the English Gigaword corpus,4 which consistsof a bit over a billion words of English newswire text, which is relatively wellbehaved, the following variants are observed
antiauthoritarian, antiauthoritarianism, antiauthority, author, au-thoratative, authoratatively, authordom, authored, authoress, au-thoresses, authorhood, authorial, authoring, authorisation, autho-rised, authorises, authoritarian, authoritarianism, authoritarians, au-thoritative, authoritatively, authoritativeness, authorities, authori-tory, authority, authorization, authorizations, authorize, authorized,authorizer, authorizers, authorizes, authorizing, authorless, authorly,authors, authorship, authorships, coauthor, coauthored, coauthor-ing, coauthors, cyberauthor, deauthorized, multiauthored, nonau-thor, nonauthoritarian, nonauthorized, preauthorization, preautho-rizations, preauthorized, quasiauthoritarian, reauthorization, reau-thorizations, reauthorize, reauthorized, reauthorizes, reauthoriz-ing, semiauthoritarian, semiauthorized, superauthoritarian, unautho-rised, unauthoritative, unauthorized
We’re not just looking for the substring author. Because of the complexity ofmorphological affixing in English, this is neither necessary or sufficient. To seethat it’s not sufficient, note that urn and turn are not related, nor are knot andnot. To see that it’s not necessary, consider pace and pacing or take and took.
Each of the words in the list above is etymologically derived from the wordauthor. The problem is that over time, meanings drift. This makes it very hard todraw a line for which words to consider equivalent for a given task. The shared
4Graff, David and Christopher Cieri. 2003. English Gigaword. Linguistic Data Consortium (LDC).University of Pennsylvania. Catalog number LDC2003T05.

198 CHAPTER 8. TOKENIZATION
root of author and authorize is not only lost to most native speakers, the wordsare only weakly semeantically related, despite the latter form being derived fromthe former using the regular suffix -ize. The meaning has drifted.
In contrast, the relation between notary and notarize is regular and the mean-ing of the latter is fairly predictable from the meaning of the former. Mov-ing down a derivational level, the relation between note and notary feels moreopaque.
Suppose we search for [authoritarian], perhaps researching organiza-tional behavior. We probably don’t want to see documents about coauthoringpapers. We probably don’t want to see documents containing unauthoritative,because that’s usually used in a different context, but we might want to see doc-uments containing the word antiauthority, and would probably want to see doc-uments containing antiauthoritarianism. As you can see, it’s rather difficult todraw a line here.
David A. Hull provides a range of interesting examples of the performance ofa range of stemmers from the very simple (see Section 8.4.6) through the main-stream medium complex systems (see Section 8.4.7) to the very complex (Xerox’sfinite-state-transducer based stemmer).5 For example, one of Hull’s queries con-tained the word superconductivity, but matching documents contained only theword superconductor. This clearly requiring derivational morphology to find theright documents. A similar problem occurs for the terms surrogate mother ver-sus surrogate motherhood and genetic engineering versus genetically engineeredin another. Another example where stemming helped was failure versus fail inthe context of bank failures.
An example where stemming hurt was in the compound term client servermatching documents containing the words serve and client, leading to numerousfalse positive matches. This is really a frequency argument, as servers in thecomputer sense do serve data, but so many other people and organizations servethings to clients that it provides more noise than utility. Another example thatcaused problems was was reducing fishing to fish; even though this looks like asimple inflectional change, the nominal use of fish is so prevalent that documentsabout cooking and eating show up rather than documents about catching fish.Similar problems arise in lemmatizing privatization to private; the latter termjust shows up in too many contexts not related to privatization.
These uncertainties in derivational stem equivalence are why many peoplewant to restrict stemming to inflectional morphology. The problem with restrict-ing to inflectional morphology is that it’s not the right cut at the problem. Some-times derivational stemming helps and sometimes inflectional stemming hurts.
Context Sensitivity of Morphology
Words are ambiguous in many different ways, including morphologically. De-pending on the context, the same token may be interpreted differently. For in-stance, the plural noun runs is the same word as the present tense verb runs. Fornouns, only run and runs are appropriate, both of which are also verbal forms.
5Hull, David A. 1996. Stemming algorithms: a case study for detailed evaluation. Journal of theAmerican Society for Information Science 47(1).

8.4. MORPHOLOGY, STEMMING, AND LEMMATIZATION 199
Additional verbal forms include running and ran. A word like hyper might beused as the short-form adjective meaning the same thing as hyperactive, or itcould be a noun derived from the the verb hype, meaning someone who hypessomething (in the publicicity sense).
8.4.6 A Very Simple Stemmer
One approach to stemming that is surprisingly effective for English (and othermostly suffixing languages) given its simplicity is to just map every word downto its first k characters. Typical values for k would be 5 or 6. This clearly missesprefixes like un- and anti-, it’ll lump together all the other forms of author dis-cussed in the previous section. It is also too agressive at lumping things together,merging words like regent and regeneration.
We provide an implementation of this simple stemmer inthe class PrefixStemmer. The class is defined to extendModifyTokenTokenizerFactory, the constructor passes the base tokenizerfactory to the superclass, and the work is all done in the modifyToken()method,
public String modifyToken(String token) {return token.length() <= mPrefixLength
? token: token.substring(0,mPrefixLength);
There is also a main() method that wraps an Indo-European tokenizer factory ina prefix stemmer and displays the tokenizer’s output.
The Ant target prefix-stem-tokens runs the program, with first argumentgiven by property prefixLen and the second by property text.
> ant -DprefixLen=4 -Dtext="Joe smiled" prefix-stem-tokens
START END TOKEN START END TOKEN0 3 |Joe| 4 10 |smil|
As you can see, the token smiled is reduced to smil, but Joe is unaltered.In an application, the non-text tokens would probably also be normalized in
some way, for instance by mapping all non-decimal numbers to 0 and all deci-mal numbers to 0.0, or simply by replacing all digits with 0. Punctuation mightalso get normalized into bins such as end-of-sentence, quotes, etc. The Unicodeclasses are helpful for this.
8.4.7 The PorterStemmerTokenizerFactory Class
The most widely used approach to stemming in English is that developed byMartin Porter in what has come to be known generically as the Porter stemmer.6
One of the reasons for its popularity is that Porter and others have made it freelyavailable and ported it to a number of programming languages such as Java.
6Porter, Martin. 1980. An algorithm for suffix stripping. Program. 14:3.

200 CHAPTER 8. TOKENIZATION
The stemmer has a very simple input/output behavior, taking a string argu-ment and returning a string. LingPipe incorporates Porter’s implementation ofhis algorithm in the PorterStemmerTokenizerFactory. Porter’s stemming op-eration is encapsulated in the static method stem(String), which returns thestemmed form of a string.
The tokenizer factory implementation simply dele-gates the modifyToken(String) method in the superclassModifyTokenTokenizerFactory to the stem(String) method.
Demo Code
We provide an example use of the stemmer in the demo classPorterStemTokens. The main() method does nothing more than create aPorter stemmer tokenizer,
TokenizerFactory f1 = IndoEuropeanTokenizerFactory.INSTANCE;TokenizerFactory f2 = new PorterStemmerTokenizerFactory(f1);
and then display the results.The Ant target porter-stemmer-tokens runs the program with a command
line argument given by the value of the property text,
> ant -Dtext="Smith was bravely charging the front lines"porter-stemmer-tokens
Smith was Bravely charging the front lines.01234567890123456789012345678901234567890120 1 2 3 4
START END TOKEN START END TOKEN0 5 |Smith| 27 30 |the|6 9 |wa| 31 36 |front|
10 17 |Brave| 37 42 |line|18 26 |charg| 42 43 |.|
Note that the token spans are for the token before stemming, so that the tokenbreavely starts at position 10 (inclusive) and ends at 17 (exclusive), spanning thesubstring of the input text bravley.
You can see that the resulting tokens are not necessarily words, with wasstemmed to wa and charging stemmed to charge. The token charge also stemsto charg. In many cases, the Porter stemmer strips off final e and s characters. Itperforms other word-final normalizations, such as stemming cleanly and cleanli-ness to cleanli.
You can also see from the reduction of Bravely to Brave that the stemmer isnot case sensitive, but also does not case normalization. Typically the input oroutput would be case normalized. You can also see that punctuation, like thefinal period, is passed through unchanged.
The Porter stemmer does not build in knowledge of common words of En-glish. It thus misses many non-regular relations. For instance, consider

8.5. SOUNDEX: PRONUNCIATION-BASED TOKENS 201
> ant -Dtext="eat eats ate eaten eating" porter-stemmer-tokens
START END TOKEN START END TOKEN0 3 |eat| 13 18 |eaten|4 8 |eat| 19 25 |eat|9 12 |at|
It fails to equate ate and eaten to the other forms. And it unfortunately reducesat to the same stem as would be found for the preposition of the same spelling.
The Porter stemmer continues to apply until no more reductions are pos-sible. This provides the nice property that for any string s, the expressionstem(stem(s)) produces a string that’s equal to stem(s).
> ant -Dtext="fortune fortunate fortunately"porter-stemmer-tokens
START END TOKEN START END TOKEN0 7 |fortun| 18 29 |fortun|8 17 |fortun|
The Porter stemmer does not attempt to remove prefixes.
> ant -Dtext="antiwar unhappy noncompliant inflammabletripartite" porter-stemmer-tokens
START END TOKEN START END TOKEN0 7 |antiwar| 29 40 |inflamm|8 15 |unhappi| 41 51 |tripartit|
16 28 |noncompli|
Thread Safety and Serialization
A Porter stemmer tokenizer factory is thread safe if its base tokenizer factory isthread safe. It is serializable if the base factory is serializable.
8.5 Soundex: Pronunciation-Based Tokens
For some applications involving unedited or transliterated text, it’s useful to re-duce tokens to punctuation. Although LingPipe does not contain a general pro-nunciation module, it does provide a combination of lightweight pronunciationand stemming through an implementation of the Soundex System. Soundex wasdefined in the early 20th century and patented by Robert C. Russell. 7 Themain application was for indexing card catalogs of names. The LingPipe versionis based on the a modified version of Soundex known as “American Soundex,”which was used by the United States Census Bureau in the 1930s. You can stillaccess census records by Soundex today.
7United States Patents 1,261,167 and 1,435,663.

202 CHAPTER 8. TOKENIZATION
8.5.1 The American Soundex Algorithm
Soundex produces a four-character long representation of arbitrary words thatattempts to model something like a pronunciation class.
The Algorithm
The basic procedure, as implemented in LingPipe, is described in the followingpseudocode, which references the character code table in the next section. Thealgorithm itself, as well as the examples, are based on pseudocode by DonaldKnuth.8
1. Normalize input by removing all characters that are not Latin1 letters, andconverting all other characters to uppercase ASCII after first removing anydiacritics.
2. If the input is empty, return 0000
3. Set the first letter of the output to the first letter of the input.
4. While there are less than four letters of output do:
(a) If the next letter is a vowel, unset the last letter’s code.
(b) If the next letter is A, E, I, O, U, H, W, Y, continue.
(c) If the next letter’s code is equal to the previous letter’s code, continue.
(d) Set the next letter of output to the current letter’s code.
5. If there are fewer than four characters of output, pad the output with zeros(0)
6. Return the output string.
Character Codes
Soundex’s character coding attempts to group together letters with similarsounds. While this is a reasonable goal, it can’t be perfect (or even reasonablyaccurate) because pronunciation in English is so context dependent.
The table of individual character codes is as follows.
Characters Code
B, F, P, V 1C, G, J, K, Q, S, X, Z 2D, T 3L 4M, N 5R 6
8Knuth, Donald E. 1973. The Art of Computer Programming, Volume 3: Sorting and Searching.2nd Edition. Addison-Wesley. Pages 394-395.

8.5. SOUNDEX: PRONUNCIATION-BASED TOKENS 203
Examples
Here are some examples of Soundex codes, drawn from Knuth’s presentation.
Tokens Encoding
Gutierrez G362Pfister P236Jackson J250Tymczak T522Ashcraft A261Robert, Rupert R163Euler, Ellery E460
Tokens Encoding
Gauss, Ghosh G200Hilbert, Heilbronn H416Knuth, Kant K530Lloyd, Liddy L300Lukasiewicz, Lissajous L222Wachs, Waugh W200
8.5.2 The SoundexTokenizerFactory Class
LingPipe provides a tokenizer factory filter based on the American Soundexdefined above in the class SoundexTokenizerFactory in the packagecom.aliasi.tokenizer.
Like the Porter stemmer tokenizer filter, there is a static utility method, herenamed soundexEncoding(String), for carrying out the basic encoding. Providea token, get its American Soundex encoding back. Also like the Porter stemmer,the rest of the implementation just uses this static method to transform tokensas they stream by.
Demo
We provide a demo of the Soundex encodings in the class SoundexTokens. Likethe Porter stemmer demo,9 it just wraps an Indo-European tokenizer factory in aSoundex tokenizer factory.
TokenizerFactory f1 = IndoEuropeanTokenizerFactory.INSTANCE;TokenizerFactory f2 = new SoundexTokenizerFactory(f1);
Also like the Porter stemmer demo, the main() method consumes a singlecommand-line argument and displays the text with indexes and then the result-ing tokens.
We provide an Ant target soundex-tokens, which feeds the value of propertytext to the program.
> ant -Dtext="Mr. Roberts knows Don Knuth." soundex-tokens
Mr. Roberts knows Don Knuth.01234567890123456789012345670 1 2
START END TOKEN START END TOKEN0 2 |M600| 18 21 |D500|2 3 |0000| 22 27 |K530|
9While we could’ve encapsulated the text and display functionality, we’re trying to keep our demosrelatively independent from one another so that they are easier to follow.

204 CHAPTER 8. TOKENIZATION
4 11 |R163| 27 28 |0000|12 17 |K520|
For instance, the first token spans from 0 to 2, covering the text Mr and produc-ing the Soundex encoding M600. The following period, spanning from position 2to 3, gets code 0000, because it is not all Latin1 characters. The token spanning12 to 17, covering text Roberts, gets code R163, the same as Robert in the tableof examples. Similarly, we see that Knuth gets its proper code from positions 22to 27.
From this example, we see that it might make sense to follow the Soundex to-kenizer with a stop list tokenizer that removes the token 0000, which is unlikelyto be very informative in most contexts.
8.5.3 Variants of Soundex
Over the years, Soundex-like algorithms have been developed for many lan-guages. Other pronunciation-based stemmers have also been developed, perhapsthe most popular being Metaphone and its variant, Double Metaphone.
8.6 Character Normalizing Tokenizer Filters
We demonstrated how to use the International Components for Unicide (ICU)package for normalizing sequences of Unicode characters in Section 2.10.1. Inthis section, we’ll show how to plug that together with tokenization to providetokenizers that produce output with normalized text.
The alternative to normalizing with a token filter would be to normalize thetext before input. As a general rule, we prefer not to modify the original under-lying text if it can be avoided. A case where it makes sense to parse or modifytext before processing would be an XML and HTML document.
8.6.1 Demo: ICU Transliteration
We wrote a demo class, UnicodeNormTokenizerFactory, which uses the theTransliterate class from ICU to do the work (see Section 2.10.3 for an intro-duction to the class and more examples). A transliterator is configured with atransliteration scheme, so we configure our factory the same way,
public class UnicodeNormTokenizerFactoryextends ModifyTokenTokenizerFactory {
private final String mScheme;private final Transliterator mTransliterator;
public UnicodeNormTokenizerFactory(String scheme,TokenizerFactory f) {
super(f);mScheme = scheme;mTransliterator = Transliterator.getInstance(scheme);

8.7. PENN TREEBANK TOKENIZATION 205
}
public String modifyToken(String in) {return mTransliterator.transliterate(in);
}
As with our other filters, we extend ModifyTokenTokenizerFactory, and thendo the actualy work in the modifyToken(String) method. Here, the construc-tor stores the scheme and creates the transliterator using the static factorymethod getInstance(String) from Transliterator. Transliteration opera-tions in ICU are thread safe as long as the transliterator is not modified duringthe transliteration.
The class also includes a definition of a serialization proxy, which only needsto store the scheme and base tokenizer in order to reconstruct the transliteratingtokenizer.
The Ant target unicode-norm-tokens runs the program, using the propertytranslit.scheme to define the transliteration scheme (see Section 2.10.3 for adescription of the available schemes and the language for composing them) andproperty text for the text to modify.
> ant "-Dtext=Déjà vu" "-DtranslitScheme=NFD; [:Nonspacing Mark:]Remove; NFC" unicode-norm-tokens
translitScheme=NFD; [:Nonspacing Mark:] Remove; NFC
Déjà vu0123456
START END TOKEN0 4 |Deja|5 7 |vu|
To get the output encoded correctly, we had to reset System.out to use UTF-8(see Section 4.17.2).
8.7 Penn Treebank Tokenization
One of the more widely used resources for natural language processing is thePenn Treebank.10
8.7.1 Pre-Tokenized Datasets
Like many older data sets, the Penn Treebank is presented only in terms of itstokens, each separated by a space. So there’s no way to get back to the underlyingtext. This is convenient because it allows very simple scripts to be used to parsedata. Thus it is easy to train and evaluate models. You don’t even have to write a
10Marcus, Mitchell P., Beatrice Santorini, Mary Ann Marcinkiewicz, and Ann Taylor. 1999. Treebank-3. Linguistic Data Consortium. University of Pennsylvania. Catalog number LDC99T42.

206 CHAPTER 8. TOKENIZATION
tokenizer, and there can’t be any tokenization errors. More modern datasets tendto use either XML infix annotation or offset annotation, allowing the boundariesof tokens in the original text to be recovered.
The major drawback is that there is no access to the underlying text. Asa consequence, there is no way to train whitespace-sensitive models using thePenn Treebank as is (it might be possible to reconstitute the token alignmentsgiven the original texts and the parser).
Although it is easy to train and evaluate in a pre-tokenized data set, usingit on new data from the wild requires an implementation of the tokenizationscheme used to create the corpus.
8.7.2 The Treebank Tokenization Scheme
In this section, we provide an overview of the Penn Treebank’s tokenizationscheme.11 The major distinguishing feature of the Treebank’s tokenizer is thatthey analyze punctuation based on context. For instance, a period at the end ofthe sentence is treated as a standalone token, whereas an abbreviation followedby a period, such as Mr., is treated as a single token. Thus the input needs toalready be segmented into sentences, a process we consider in Chapter 10.
The Treebank tokenizer was designed for the ASCII chaacters (U+0000–U+007F), which means it is not defined for characters such as Unicode punc-tuation. Following the convention of LATEXrather than Unicode, the Treebank to-kenizer analyzes a quote character (") as two grave accents (“) if it’s an openingqoe and two apostrophes (”) if it’s a closing quote. Like periods, determining thestatus of the quotes requires context.
The Treebank tokenizer is also English specific. In its context-sensitive treat-ment of apostrophes (’), it attempts to distinguish the underlying words makingup contractions together, so that a word like I’m is split into two tokens, I and ’m,the second of which is the contracted form of am. To handle negative contrac-tions, it keeps the negation together, splitting don’t into do and n’t. The reasonfor this is that the Treebank labels syntactic categories, and they wanted to as-sign I to a pronoun category and ’m to an auxiliary verb category just like am;similarly, do is an auxiliary verb and n’t a negative particle.
Ellipses, which appear in ASCII text as a sequence of periods (...), are handledas single tokens. Pairs of hyphens (--), which are found as an ASCII replacementfor an en-dash (–).
Other than the treatment of periods, quotation marks and apostrophes in theaforementioned contexts, the Treebank tokenizer splits out other punctuationcharacters into their own tokens.
The ASCII bracket characters, left and right, round and square and curly,are replaced with acronyms and hyphens. For instance, U+005B, left squarebracket ([) produces the token -LSB-. The acronym LSB stands for left squarebracket; other brackets are coded similarly alternating R for right in the firstposition, and R for round and C for curly in the second position.
11We draw from the online description http://www.cis.upenn.edu/~treebank/tokenization.html (downloaded 30 July 2010) and Robert MacIntyre’s implementation as a SED script, releasedunder the Gnu Public License, in http://www.cis.upenn.edu/~treebank/tokenizer.sed.

8.7. PENN TREEBANK TOKENIZATION 207
8.7.3 Demo: Penn Treebank Tokenizer
We provide a port and generalization of the Penn Treebank tokenizer based onRobert MacIntyre’s SED script in the class PennTreebankTokenizerFactory. Wehave also generalized it to Unicode character codes where possible.
The original SED script worked by transforming the input string by addingor deleting spaces and transforming characters. If we transformed the input,the positions of the tokens would all be off unless we somehow kept track ofthem. Luckily, an easier solution presents itself with Java regular expressionsand LingPipe’s built-in regex tokenizer factories and token filter.
Our implementation works in three parts. First, the original string is trans-formed, but in a position-preserving way. This mainly takes care of issues indetecting opening versus closing quotes. Second, a regular expression tokenizeris used to break the input into tokens. Third, the tokens are transformed on atoken-by-token basis into the Penn Treebank’s representation.
Construction
Before any of these steps, we declare the tokenizer factory to extend the token-modifying token factory and to be serailizable,
public class PennTreebankTokenizerFactoryextends ModifyTokenTokenizerFactoryimplements Serializable {
public static final TokenizerFactory INSTANCE= new PennTreebankTokenizerFactory();
private PennTreebankTokenizerFactory() {super(new RegExTokenizerFactory(BASE_REGEX,
Pattern.CASE_INSENSITIVE));
}
We had to supply the base tokenizer factory as an argument to super() in orderto supply the superclass with its base tokenizer. This is a regex-based tokenizerfactory which we describe below. There’s also a serialization proxy implementa-tion we don’t show.
We chose to implement the Penn Treebank tokenizer as a singleton, with aprivate constructor and static constant instance. The constructor could’ve justas easily been made public, but we only need a single instance.
Input String Munging
In the first processing step, we override the tokenization method itself totrasnform the input text using a sequence of regex replace operations (see Sec-tion 3.14),
@Overridepublic Tokenizer tokenizer(char[] cs, int start, int len) {

208 CHAPTER 8. TOKENIZATION
String s = new String(cs,start,len).replaceAll("(ˆ\")","\u201C").replaceAll("(?<=[ \\p{Z}\\p{Ps}])\"","\u201C").replaceAll("\"","\u201D").replaceAll("\\{Pi}","\u201C").replaceAll("\\{Pf}","\u201D");
return super.tokenizer(s.toCharArray(),0,len);}
The replaceAll() methods chain, starting with a string produced from thecharacter slice input. The first replacement replaces an instance of U+0022, quo-tation mark, ("), the ordinary typewriter non-directional quotation mark sym-bol, with U+201C, left double quotation mark (“). The second replacementreplaces a quotation mark after characters of class Z (separators such as spaces,line or paragraph separators) or class Ps, the start-punctuation class, which in-cludes all the open brackets specified in the original SED script. The contextcharacters are specified as a non-capturing lookbehind (see Section 3.9.3), Thethird replacement converts remaining quote characters U+201D, right doublequotation mark ((”)). The fourth replacement converts any character typed asinitial quote punctuation (Pi) and replaces it with a left double quotation mark,and similarly for final quote punctuation (Pf).
We take the final string and convert it to a character array to send the su-perclass’s implementation of tokenizer(). We have been careful to only usereplacements that do not modify the length of the input, so that all of our offsetsfor tokens will remain correct.
Base Tokenizer Regex
The implementation of tokenize() in the superclassModifyTokenTokenizerFactory invokes the base tokenizer, which wassupplied to the constructor, then feeds the results through the modifyToken()method, which we describe below.
The base tokenizer factory is constructed from a constant representing theregular expression and the specification that matching is to be case insensitive.The regex used is
static final String BASE_REGEX= "("+ "\\.\\.\\." + "|" + "-"+ "|" + "can(?=not\\b)" + "|" + "d’(?=ye\\b)"+ "|" + "gim(?=me\\b)" + "|" + "lem(?=me\\b)"+ "|" + "gon(?=na\\b)" + "|" + "wan(?=na\\b)"+ "|" + "more(?=’n\\b)" + "|" + "’t(?=is\\b)"+ "|" + "’t(?=was\\b)" + "|" + "ha(?=ddya\\b)"+ "|" + "dd(?=ya\\b)" + "|" + "ha(?=tcha\\b)"+ "|" + "t(?=cha\\b)"+ "|" + "’(ll|re|ve|s|d|m|n)" + "|" + "n’t"+ "|" + "[\\p{L}\\p{N}]+(?=(\\.$|\\.([\\{Pf}\"’])+|n’t))"

8.7. PENN TREEBANK TOKENIZATION 209
+ "|" + "[\\p{L}\\p{N}\\.]+"+ "|" + "[ˆ\\p{Z}]"+ ")";
We have broken it out into pieces and used string concatenation to put it backtogether so it’s more readable.
The first disjunct allows three period characters to be a token, the second apair of dashes.
The next thirteen disjuncts are spread over several lines. Each of these simplybreaks a compound apart. For instance, cannot will be split into two tokens, canand not. This is achieved in each case by matching the first half of a compoundwhen followed by the second half. The following context is a positive lookahead,requiring the rest of the compound and then a word boundary (regex \b is theword boundary matcher).
The next two disjuncts pull out the contracted part of contractions, such as’s, ’ve and n’t.
Next, we match tokens consisting of sequences of letters and/or numbers(Unicode types L and N). The first disjunct pulls off tokens that directly precedethe final period or the sequence n’t. The disjunct uses positive lookahead tomatch the following context. Because regexes are greedy, the disjunct just de-scribed will match if possible. If not, periods are included alongw ith letters andnumbers (but no other punctuation).
The final disjunct treats any other non-separator character as a token.
Modified Token Output
To conform to the Penn Treebank’s output format for characters, we do a finalreplace on the tokens, using
@Overridepublic String modifyToken(String token) {
return token.replaceAll("\\(","-LRB-").replaceAll("\\)","-RRB-").replaceAll("\\[","-LSB-").replaceAll("\\]","-RSB-").replaceAll("\\{","-LCB-").replaceAll("\\}","-RCB-").replaceAll("\u201C","“").replaceAll("\u201D","”");
}
Each of the ASCII brackets is replaced with a five-letter sequence. Any initialquote characters are replaced with two grave accents (‘‘) and then final quotecharacters are replaced with two apostrophes (’’).
Running It
The Ant target treebank-tokens runs the Penn Treebank tokenizer, supplyingthe value of the Ant property text as the first argument, which is the string totokenize.
> ant -Dtext="Ms. Smith’s papers’ - weren’t (gonna) miss."treebank-tokens

210 CHAPTER 8. TOKENIZATION
Ms. Smith’s papers’ -- weren’t (gonna) miss.012345678901234567890123456789012345678901230 1 2 3 4
START END TOKEN START END TOKEN0 3 |Ms.| 27 30 |n’t|4 9 |Smith| 31 32 |-LRB-|9 11 |’s| 32 35 |gon|
12 18 |papers| 35 37 |na|18 19 |’| 37 38 |-RRB-|20 22 |--| 39 43 |miss|23 27 |were| 43 44 |.|
This short example illustrates the different handling of periods sentence-internally and finally, the treatment of contractions, distinguished tokens likethe double-dash, and compounds like gonna. It also shows how the brackets getsubstituted, for instance the left with token -LRB-; note that these have their orig-inal spans, so that the token -RRB- spans from 37 (inclusive) to 38 (exclusive), theposition of the right round bracket in the original text.
The first disjunct after all the special cases allows a sequence of letters andnumbers to form a token subject to the negative lookahead constraint. The neg-ative lookahead makes sure that periods are not picked up as part of tokens ifthey are followed by the end of input or a non-empty sequence of punctuationcharacters including final punctuation like right brackets (Unicode class Pf), thedouble quote character or the apostrophe.
> ant -Dtext="(John ran.)" treebank-tokens
(john ran.)01234567890
START END TOKEN START END TOKEN0 1 |-LRB-| 9 10 |.|1 5 |John| 10 11 |-RRB-|6 9 |ran|
The period is not tokenized along with ran, because it is followed by a rightround bracket character ()), an instance of final punctuation matching Pf. With-out the negative lookahead disjunct appearing before the general disjunct, theperiod would’ve been included.
The final disjunct in the negative lookahead constraint ensures the suffix n’tis kept together as we saw in the first example; without lookahead, the n wouldbe part of the previous token.
Given how difficult it is to get a standard quote character into a propertydefinition,12 we’ve used a properties file in config/text2.properties. Thecontent of the properties file is
12Although the double quote character itself can be escaped in any halfway decent shell, they alldo it differently. The real problem is that Ant’s scripts can’t handle -D property specifications withembedded quotes.

8.8. ADAPTING TO AND FROM LUCENE ANALYZERS 211
text=I say, \\"John runs\\".
Recall that in Java properties files, strings are parsed in the same way as stringliterals in Java programs. In particular, we can use Unicode and Java backslashescapes,13 We run the Ant target by specifying the properties file on the com-mand line,
> ant -propertyfile=config/text2.properties treebank-tokens
I say, "John runs".01234567890123456780 1
START END TOKEN START END TOKEN0 1 |I| 8 12 |John|2 5 |say| 13 17 |runs|5 6 |,| 17 18 |’’|7 8 |‘‘| 18 19 |.|
The output demonstrates how open double quotes are treated differently thanclose double quotes. Like the bracket token substitutions, the two characterssubstituted for quotes still span only a single token of the input.
Discussion
There are several problems with the Penn Treebank tokenizer as presented. Theproblems are typical of systems developed on limited sets of data with the goalof parsing the data at hand rather than generalizing. We fixed one such problem,only recognizing ASCII quotes and only recognizing ASCII brackets, by general-izing to Unicode classes in our regular expressions.
Another problem, which is fairly obvious from looking at the code, is thatwe’ve only handled a small set of contractions. We haven’t handled y’all or c’mon,which are in everyday use in English. I happen to be a fan of nautical fiction, butthe tokenizer will stumble on fo’c’s’le, the conventional contraction of forecastle.Things get even worse when we move into technical domains like chemistry ormathematics, where apostrophes are used as primes or have other meanings.
We’ve also only handled a small set of word-like punctuation. What about thee-mail smiley punctuation, :-)? It’s a unit, but will be broken into three tokens bythe current tokenizer.
8.8 Adapting to and From Lucene Analyzers
In Section E.3, we discuss the role of Lucene’s analyzers in the indexing process.A Lucene document maps field names to text values. A Lucene analyzer mapsa field name and text to a stream of tokens. In this section, we show how toconvert a Lucene analyzer to a LingPipe tokenizer factory and vice-versa.
13Unicode escapes for the quote character will be interpreted rather than literal, so you need to usethe backslash. And the backslash needs to be escaped, just as in Java source.

212 CHAPTER 8. TOKENIZATION
8.8.1 Adapting Analyzers for Tokenizer Factories
Because of the wide range of basic analyzers and filters employed by Lucene, it’suseful to be able to wrap a Lucene analyzer for use in LingPipe. For instance, wecould analyze Arabic with stemming this way, or even Chinese.
The demo class AnalyzerTokenizerFactory implements LingPipe’sTokenizerFactory interface based on a Lucene Analyzer and field name. Ingeneral design terms, the class adapts an analyzer to do the work of a tokenizerfactory.
The class is declared to implement the tokenizer factory interface to be seri-alizable,
public class AnalyzerTokenizerFactoryimplements TokenizerFactory, Serializable {
private final Analyzer mAnalyzer;private final String mFieldName;
public AnalyzerTokenizerFactory(Analyzer analyzer,String fieldName) {
mAnalyzer = analyzer;mFieldName = fieldName;
}
The constructor simply stores an analyzer and field name in private final membervariables.
The only method we need to implement is tokenizer(),
public Tokenizer tokenizer(char[] cs, int start, int len) {Reader reader = new CharArrayReader(cs,start,len);TokenStream tokenStream
= mAnalyzer.tokenStream(mFieldName,reader);return new TokenStreamTokenizer(tokenStream);
}
It creates a reader from the character array slice and then uses the storedanalyzer to convert it to a Lucene TokenStream. A new instance ofTokenStreamTokenizer is constructed based on the token stream and returned.
The TokenStreamTokenizer class is a nested static class. It is defined toextend LingPipe’s Tokenizer base class and implement Java’s Closeable inter-face.
static class TokenStreamTokenizer extends Tokenizer {
private final TokenStream mTokenStream;private final TermAttribute mTermAttribute;private final OffsetAttribute mOffsetAttribute;
private int mLastTokenStartPosition = -1;private int mLastTokenEndPosition = -1;
public TokenStreamTokenizer(TokenStream tokenStream) {mTokenStream = tokenStream;

8.8. ADAPTING TO AND FROM LUCENE ANALYZERS 213
mTermAttribute= mTokenStream.addAttribute(TermAttribute.class);
mOffsetAttribute= mTokenStream.addAttribute(OffsetAttribute.class);
}
The constructor stores the token stream in a member variable, along with theterm and offset attributes it adds to the token stream. The token start positionsare initialized to -1, which is the proper return value before any tokens have beenfound.
The nextToken() method is implemented by delegating to the contained to-ken stream’s incrementToken() method, which advances the underlying tokenstream.
@Overridepublic String nextToken() {
try {if (mTokenStream.incrementToken()) {
mLastTokenStartPosition= mOffsetAttribute.startOffset();
mLastTokenEndPosition= mOffsetAttribute.endOffset();
return mTermAttribute.term();} else {
closeQuietly();return null;
}} catch (IOException e) {
closeQuietly();return null;
}}
After the increment, the start and end positions are stored befre returning theterm as the next token. If the token stream is finished or the increment methodthrows an I/O exception, the stream is ended and closed quietly (see below).
public void closeQuietly() {try {
mTokenStream.end();} catch (IOException e) {
/* ignore */} finally {
Streams.closeQuietly(mTokenStream);}
}
The methods for start and end just return the stored values. For example,

214 CHAPTER 8. TOKENIZATION
@Overridepublic int lastTokenStartPosition() {
return mLastTokenStartPosition;}
The main() method for the demo takes a command-line argument for thetext. It sets up a standard Lucene analyzer, then constructs a tokenizer factoryfrom it using the field text (the field doesn’t matter to the standard analyzer,but may matter for other analyzers).
String text = args[0];
StandardAnalyzer analyzer= new StandardAnalyzer(Version.LUCENE_30);
AnalyzerTokenizerFactory tokFact= new AnalyzerTokenizerFactory(analyzer,"foo");
DisplayTokens.displayTextPositions(text);DisplayTokens.displayTokens(text,tokFact);
We then just display the text and tokens as we have in previous demos.The Ant target lucene-lp-tokens runs the example, with property text
passed in as the command-line argument.
> ant -Dtext="Mr. Smith is happy!" lucene-lp-tokens
Mr. Smith is happy!01234567890123456780 1
START END TOKEN START END TOKEN0 2 |mr| 13 18 |happy|4 9 |smith|
As before, we see the stoplisting and case normalization of the standard Luceneanalyzer.
An Arabic Analyzer with Stemming and Stoplisting
The contributed Lucene class ArabicAnalyzer implements Larkey, Ballesterosand Connell’s tokenizer and stemmer.14 This class performs basic word seg-mentation, character normalization, “light” stemming, and stop listing, with aconfiguarable stop list. Because it’s a contributed class, it’s found in a separatejar, lucene-analyzers-3.0.2.jar, which we’ve included with the distributionand inserted into the classpath for this chapter’s Ant build file.
We provide a demo class ArabicTokenizerFactory, which provides a staticsingleton implementation of a tokenizer factory wrapping Lucene’s Arabic an-alyzer. We don’t need anything other than the Lucene Analyzer and LingPipeTokenizerFactory,
14Larkey, Leah, Lisa Ballesteros and Margaret Connell. 2007. Light Stemming for Arabic InformationRetrieval. In A. Soudi, A. van den Bosch, and G. Neumann, (eds.) Arabic Computational Morphology.221–243. Springer.

8.8. ADAPTING TO AND FROM LUCENE ANALYZERS 215
public static final Analyzer ANALYZER= new ArabicAnalyzer(Version.LUCENE_30);
public static final TokenizerFactory INSTANCE= new AnalyzerTokenizerFactory(ANALYZER,"foo");
In the file src/tok/config/arabic-sample.utf8.txt, we have placed someArabic text15 encoded with UTF-8; the first few lines of the file are as follows.
, ú
¯PAKñËð
@
�èQ�m
�'. ñë è
ñ
��
�Ó . @Y
JÊ
J®K. ñËð
@
�骣A
�®Ó ú
¯ Qî
E (Oulujoki) ú
»ñKñËð
@
�é¢m× 12 H.
Qêm.× Qî
DË @ .
��J¢ÊJ. Ë @ Qm�'
. ú
¯ I. ��ð ñ
JKA¿ Õæ
Ê�¯@
áÓ @Q�J.»�@Z Qk. ù
¢
ªK
. . . . @ðAªJÓ 541
©ÊJ.
�K
�éJk. A
�JK @
�èPY
�®K.
�éJ
KAÓQêºË@
�é�¯A¢Ë@ YJËñ
�JË
There is a main() class that reads a file name from the command line, readsthe file in and tokenizes it for display. The Ant target arabic-tokens runs thetokenizer over a file specified by name as the first command specified file,
> ant "-Dfile=config\arabic-sample.utf8.txt" arabic-tokens
file=config\arabic-sample.utf8.txt-----text-----
ú»ñKñËð
@ (Oulujoki) ...
...from: http://ar.wikipedia.org/wiki/ú
»ñKñËð
@_Qî
E
-----end text-----START END TOKEN
0 8 |¼ñKñËð@|
10 18 |oulujoki|20 23 |Qî
E|
27 33 |©£A�®Ó|
...292 295 |org|296 300 |wiki|301 309 |¼ñKñËð@|
310 313 |QîE|
Note that the text mixes Roman characters and Arabic characters. The sourceURL is part of the text. The Roman characters are separated out as their owntokens and retained, but all punctuation is ignored. The very first token, whichis also part of the URL, is stemmed.
8.8.2 Adapting Tokenizer Factories for Analyzers
Recall that a Lucene analyzer maps fields and readers to token streams. We canimplement an analyzer given a mapping from fields to tokenizer factories. We
15Downloaded from http://ar.wikipedia.org/wiki/%D9%86%D9%87%D8%B1_%D8%A3%D9%88%D9%84%D9%88%D9%8A%D9%88%D9%83%D9%8A on 9 July 2010.

216 CHAPTER 8. TOKENIZATION
will also use a default tokenizer factory to apply to fields that are not defined inthe map.
The demo class TokenizerFactoryAnalyzer provides such an implementa-tion. The class definition and constructor are
public class TokenizerFactoryAnalyzer extends Analyzer {
private final Map<String,TokenizerFactory> mTfMap;
private final TokenizerFactory mDefaultTf;
publicTokenizerFactoryAnalyzer(Map<String,
TokenizerFactory> tfMap,TokenizerFactory defaultTf) {
mTfMap = new HashMap<String,TokenizerFactory>(tfMap);mDefaultTf = defaultTf;
}
The mapping and default factory are stored as final member variables.Version 3.0 of Lucene has been defined to allow greater efficiency through
object pooling, such as reuse of token streams. This makes the implementationof tokenStream() more complex than may at first seem necessary.
@Overridepublic TokenStream tokenStream(String fieldName,
Reader reader) {TokenizerTokenStream tokenizer
= new TokenizerTokenStream();tokenizer.setField(fieldName);try {
tokenizer.reset(reader);return tokenizer;
} catch (IOException e) {return new EmptyTokenStream();
}}
The method creates a new instance of TokenizerTokenStream, the definition ofwhich we show below. It then sets the field name using the method setField()and the reader using the method reset(). If the setting a field throws an excep-tion, the tokenStream() method returns an instance EmptyTokenStream.16
We also define the reusableTokenStream() method for efficiency, whichreuses the previous token stream if there is one or uses tokenStream() to createone.
The class TokenizerTokenStream is defined as a (non-static) inner class.
class TokenizerTokenStreamextends org.apache.lucene.analysis.Tokenizer {
16From the package org.apache.lucene.analysis.miscellaneous, in the contributed analyzerslibrary, lucene-analyzers-3.0.2.jar.

8.8. ADAPTING TO AND FROM LUCENE ANALYZERS 217
private TermAttribute mTermAttribute;private OffsetAttribute mOffsetAttribute;private PositionIncrementAttribute mPositionAttribute;
private String mFieldName;private TokenizerFactory mTokenizerFactory;private char[] mCs;private Tokenizer mTokenizer;
TokenizerTokenStream() {mOffsetAttribute = addAttribute(OffsetAttribute.class);mTermAttribute = addAttribute(TermAttribute.class);mPositionAttribute
= addAttribute(PositionIncrementAttribute.class);}
It is defined to extend Lucene’s Tokenizer interface, whose full package,org.apache.lucene.analysis, is included to avoid conflict with LingPipe’sTokenizer class. Lucene’s Tokenizer class is a subclass of TokenStream de-fined to support basic tokenizers (the other abstract base class supports tokenstream filters). As with our use of token streams in the previous section to adaptanalyzers to tokenizer factories, we again add and store the term, offset andposition increment attributes.
The field and reader are set and reset as follows.
public void setField(String fieldName) {mFieldName = fieldName;
}
@Overridepublic void reset(Reader reader) throws IOException {
mCs = Streams.toCharArray(reader);mTokenizerFactory
= mTfMap.containsKey(mFieldName)? mTfMap.get(mFieldName): mDefaultTf;
reset();}
@Overridepublic void reset() throws IOException {
if (mCs == null) {String msg = "Cannot reset after close()"
+ " or before a reader has been set.";throw new IOException(msg);
}mTokenizer = mTokenizerFactory.tokenizer(mCs,0,mCs.length);
}
The setField() method simply stores the field name. The reset(Reader)

218 CHAPTER 8. TOKENIZATION
method extracts and stores the characters from the reader using LingPipe’s util-ity method toCharArray(). The tokenizer factory is retrieved from the mapusing the field name as a key, returning the default tokenizer factory if the fieldname is not in the map. After setting the characters and tokenizer, it calls thereset() method. The reset() method sets the tokenizer based on the currenttokenizer factory and stored strings, throwing an exception if reset(Reader)has not yet been called or the close() method has been called.
Once a token stream is set up, its incrementToken() method sets up tehproperties for the next token if there is one.
@Overridepublic boolean incrementToken() {
String token = mTokenizer.nextToken();if (token == null)
return false;char[] cs = mTermAttribute.termBuffer();token.getChars(0,token.length(),cs,0);mTermAttribute.setTermLength(token.length());mOffsetAttribute
.setOffset(mTokenizer.lastTokenStartPosition(),mTokenizer.lastTokenEndPosition());
return true;
}
It gathers the token itself from the LingPipe tokenizer stored in member variablemTokenizer. If the token’s null, we’ve reached the end of the token stream, andreturn false from the incrementToken() method to signal the end of stream.Otherwise, we grab the character buffer from the term attribute and fill it withthe characters from the token using the String method getChars(). We alsoset the Lucene tokenizr’s offset attribute based on the LingPipe tokenizer’s startand end position.
Lucene’s Tokenizer class specifies a method end that advances the tokenposition past the final token; we set the offset to indicate there is no more ofteh input string left. The close() method, which is intended to be called aftera client is finished with the token stream, frees up the character array used tostore the characters being tokenized.
Tokenizer Factory Analzyer Demo
There’s a main() method in the TokenizerFactoryAnalzyer class that we willuse as a demo. It mirrors the Lucene analysis demo.
String text = args[0];
Map<String,TokenizerFactory> fieldToTokenizerFactory= new HashMap<String,TokenizerFactory>();
fieldToTokenizerFactory.put("foo",IndoEuropeanTokenizerFactory.INSTANCE);
fieldToTokenizerFactory

8.9. TOKENIZATIONS AS OBJECTS 219
.put("bar",new NGramTokenizerFactory(3,3));
TokenizerFactory defaultFactory= new RegExTokenizerFactory("\\S+");
TokenizerFactoryAnalyzer analyzer= new TokenizerFactoryAnalyzer(fieldToTokenizerFactory,
defaultFactory);
First, we grab the text from the first command-line argument. Then we set upthe mapping from field names to tokenizer factories, using an Indo-Europeantokenizer factory for field foo and a trigram tokenizer factory for field bar. Thedefault tokenizer factory is based on a regex matching sequences of non-spacecharacters. Finally, the analyzer is constructed from the map and default factory.The rest just prints the tokens and the results of the analysis.
The Ant target lp-lucene-tokens runs the command with the value of prop-erty text passed in as an argument.
> ant -Dtext="Jim ran." lp-lucene-tokens
Jim ran.01234567
Field=foo Field=jibPos Start End Pos Start End
1 0 3 Jim 1 0 3 Jim1 4 7 ran 1 4 8 ran.1 7 8 .
Field=barPos Start End
1 0 3 Jim1 1 4 im
...1 5 8 an.
We see the tokens produced in each field are derived in the case of foo from theIndo-European tokenzier factory, in the case of bar from the trigram tokenizerfactory, and in the case of the feature jar, the default tokenizer factory. In allcases, the position increment is 1; LingPipe’s tokenization framework is not setup to account for position offsets for phrasal search.
8.9 Tokenizations as Objects
In our examples so far, we have used the iterator-like streaming interface totokens.

220 CHAPTER 8. TOKENIZATION
8.9.1 Tokenizer Results
The Tokenizer base class itself provides two ways to get at the entire sequenceof tokens (and whitespaces) produced by a tokenizer.
The method tokenize() returns a string array containing the sequence oftokens produced by the tokenizer.
Tokenizer tokenizer = tokFactory.tokenizer(cs,0,cs.length);String[] tokens = tokenizer.tokenize();
The method tokenize(List<String>,List<String>) adds the lists of tokensto the first list specified and the list of tokens to the second list. The usagepattern is
Tokenizer tokenizer = tokFactory.tokenizer(cs,0,cs.length);List<String> tokens = new ArrayList<String>();List<String> whitespaces = new ArrayList<String>();tokenizer.tokenize(tokens,whitespaces);
In both cases, the results are only sequences of tokens and whitespaces. Theunderlying string being tokenized nor the positions of the tokens are part of theresult.
8.9.2 The Tokenization Class
The class Tokenization in com.aliasi.tokenizer represents all of the infor-mation in a complete tokenization of an input character sequence. This includesthe sequence of tokens, the sequence of whitespaces, the character sequence thatwas tokenized, and the start and end positions of each token.
Constructing a Tokenization
There are three constructors for the Tokenization class. Twoof them, Tokenization(char[],int,int,TokenizerFactory) andTokenization(CharSequence,TokenizerFactory), take a tokenizerfactory and a sequence of characters as input, and store the re-sults of the tokenizer produced by the tokenizer factory. Thethird constructor takes all of the components of a tokenizationas arguments, the text, tokens, whitespaces, and token positions,Tokenization(String,List<String>,List<String>,int[],int[]).
The constructors all store copies of their arguments so that they are notlinked to the constructor arguments.
Getters for Tokenization
Once constructed, a tokenization is immutable. There are getters for all of theinformation in a tokenization. The method text() returns the underlying textthat was tokenized. The method numTokens() returns the total number of to-kens (there will be one more whitespace than tokens). The methods token(int)

8.9. TOKENIZATIONS AS OBJECTS 221
and whitespace(int) return the token and whitespace at the specified position.The methods tokenStart(int) and tokenEnd(int) return the starting offset(inclusive) of the token and the ending position (exclusive0 for the token at thespecified index.
There are also methods to retrieve sequences of values. The methodtokenList() returns an unmodifiable view of the underlying tokens andtokens() returns a copy of an array of the tokens. The methodswhitespaceList() and whitespaces() are similar.
Equality and Hash Codes
Two tokenization objects are equal if their character sequences poroduce thesame strings, they have equivalent token and whitespace lists, and the arraysof start and end positions for tokens are the same. Hash codes are definedconsistently with equality.
Serialization
A tokenization may be serialized. The deserialized object is a Tokenizationthat is equal to the first.
Thread Safety
Tokenizations are immutable and completely thread safe once constructed.
Demo of Tokenization
The demo class DisplayTokenization provides an example of how theTokenization class may be used. The work is in the main() method, whichbegins as follows.
TokenizerFactory tokFact= new RegExTokenizerFactory("\\p{L}+");
Tokenization tokenization = new Tokenization(text,tokFact);
List<String> tokenList = tokenization.tokenList();List<String> whitespaceList = tokenization.whitespaceList();String textTok = tokenization.text();
It begins by creatig a tokenizer factory from a regex that matches arbitrary se-quences of letters as tokens. Then it creates the Tokenization object using thetext from the command-line argument and the tokenizer factory. Then we col-lect up the list of tokens, list of whitespaces and underlying text. The commandcontinues by looping over the tokens.
for (int n = 0; n < tokenization.numTokens(); ++n) {int start = tokenization.tokenStart(n);int end = tokenization.tokenEnd(n);String whsp = tokenization.whitespace(n);String token = tokenization.token(n);

222 CHAPTER 8. TOKENIZATION
For each token, it extracts the start position (inclusive), end position (exclusive),whitespace before the token, and the token itself. These are printed. After theloop, it prints out the final whitespace.
String lastWhitespace= tokenization.whitespace(tokenization.numTokens());
The Ant target tokenization runs the demo command with the value ofproperty text as the command-line argument.
> ant -Dtext="John didn’t run. " tokenization
tokenList=[John, didn, t, run]whitespaceList=[, , ’, , . ]textTok=|John didn’t run. |
John didn’t run.012345678901234560 1
n start end whsp token0 0 4 || |John|1 5 9 | | |didn|2 10 11 |’| |t|3 12 15 | | |run|
lastWhitespace=|. |
We have added vertical bars around the text, tokens and whitespaces to highlightthe final space. The spans here are only for the tokens. The whitespaces spanthe interstitial spaces between tokens, so their span can be computed as the endof the previous token to the start of the next token. The last whitespace ends atthe underlying text length.
Because tokens are only defined to be contiguous sequences of letters, theapostrophe in didn’t and the final period appear in the whitespace. The periodonly appears in the final whitespace.

Chapter 9
Symbol Tables
Strings are unwieldy objects — they consume substantial memory and are slow tocompare, making them slow for sorting and use as hash keys. In many contexts,we don’t care about the string itself per se, but only its identity. For instance,document search indexes like Lucene consider only the identity of a term. NaiveBayes classifiers, token-based language models and clusterers like K-means orlatent Dirichlet allocation do not care about the identity of tokens either. Evencompilers for languages like Java do not care about the names of variables, justtheir identity.
In applications where the identity of tokens is not important, the traditionalapproach is to use a symbol table. A symbol table provides integer-based rep-resentations of strings, supporting mappings from integer identifiers to stringsand from strings to identifiers. The usage pattern is to add symbols to a sym-bol table, then reason with their integer representations. So many of LingPipe’sclasses operate either explicitly or implicitly with symbol tables, that we’re break-ing them out into their own chapter.
9.1 The SymbolTable Interface
The interface SymbolTable in com.aliasi.symbol provides a bidirectionalmapping between string-based symbols and numerical identifiers.
9.1.1 Querying a Symbol Table
The two key methods are symbolToID(String), which returns the integer iden-tifier for a string, or -1 if the symbol is not in the symbol table. The inversemethod idToSymbol(int) returns the string symbol for an identifier; it throwsan IndexOutOfBoundsException if the identifier is not valid.
The method numSymbols() returns the total number of symbols stored inthe table as an integer (hence the upper bound on the size of a symbol table isInteger.MAX_VALUE).
223

224 CHAPTER 9. SYMBOL TABLES
Modifying a Symbol Table
Like the Collection interface in java.util, LingPipe’s symbol table interfacespecifies optional methods for modifying the symbol table. In concrete imple-mentations of SymbolTable, these methods either modify the symbol table orthrow an UnsupportedOperationException.
The method clear() removes all the entires in the symbol table. The methodremoveSymbol(String) removes the specified symbol from the symbol table,returning its former identifier or -1 if it was not in the table.
The method getOrAddSymbol(String) returns the identifier for the speci-fied string, adding it to the symbol table if necessary.
9.2 The MapSymbolTable Class
Of the two concrete implementations of SymbolTable provided in LingPipe, themap-based table is the most flexible.
9.2.1 Demo: Basic Symbol Table Operations
The class SymbolTableDemo contains a demo of the basic symbol table oper-ations using a MapSymbolTable. The main() method contains the followingstatements (followed by prints).
MapSymbolTable st = new MapSymbolTable();
int id1 = st.getOrAddSymbol("foo");int id2 = st.getOrAddSymbol("bar");int id3 = st.getOrAddSymbol("foo");
int id4 = st.symbolToID("foo");int id5 = st.symbolToID("bazz");
String s1 = st.idToSymbol(0);String s2 = st.idToSymbol(1);
int n = st.numSymbols();
The first statement constructs a new map symbol table. Then three symbolsare added to it using the getOrAddSymbol() method, with the resulting symbolbeing assigned to local variables. Note that "foo" is added to the table twice.This method adds the symbol if it doesn’t exist, so the results returned are alwaysnon-negative.
Next, we use the symbolToID() methods to get identifiers and also assignthem to local variables. This method does not add the symbol if it doesn’t alreadyexist. Finally, we retrieve the number of symbols.
The Ant target symbol-table-demo runs the command.
> ant symbol-table-demo
id1=0 s1=fooid2=1 s2=bar

9.2. THE MAPSYMBOLTABLE CLASS 225
id3=0 n=2id4=0id5=-1
Note that id1 and id3 are the same, getting the identifier 0 for string"foo". This is also the value returned by the symboltoID() method, asshown by the value of id4. Becase we used symbolToID("bazz") rather thangetOrAddSymbol("bazz"), the value assigned to id5 is -1, the special value forsymbols not in the symbol table.
The idToSymbol() method invert the mappings as shown by their results.Finally, note there are 2 symbols in the symbol table when we are done, "foo"and "bar".
9.2.2 Demo: Removing Symbols
The class RemoveSymbolsDemo shows how the map symbol table can be used tomodify a symbol table. Its main() method is
st.getOrAddSymbol("foo");st.getOrAddSymbol("bar");int n1 = st.numSymbols();
st.removeSymbol("foo");int n2 = st.numSymbols();
st.clear();int n3 = st.numSymbols();
We first add the symbols "foo" and "bar", then query the number of symbols.Then we remove "foo" using the method removeSymbol() and query the numbeof symbols again. Finally, we clear the symbol table of all symbols using themethod clear(), and query a final time.
We can run the demo with the Ant target remove-symbol-demo,
> ant remove-symbol-demo
n1=2 n2=1 n3=0
By removing symbols, we may create holes in the run of identifiers. For in-stance, the identifier 17 may have a symbol but identifier 16 may not. This needsto be kept in mind for printing or enumerating the symbols, which is why thereare symbol and identifier set views in a map symbol table (see below).
9.2.3 Additional MapSymbolTable Methods
The implementation MapSymbolTable provides several methods not found in theSymbolTable interface.

226 CHAPTER 9. SYMBOL TABLES
Boxed Methods
The map symbol table duplicates the primitive-based SymbolTable methodswith methods accepting and returning Integer objects. This avoids round tripautomatic unboxing and boxing when integrating symbol tables with collectionsin java.util.
The methods getOrAddSymbolInteger(String),symbolToIDInteger(String) return integer objects rather than primitives.The method idToSymbol(Integer) returns the symbol corresponding to theinteger object identifier.
Symbol and Identifier Set Views
The method symbolSet() returns the set of symbols stored in the table as a setof strings, Set<String>. The method idSet() returns the set of IDs stored inthe table as a set of integer objects, Set<Integer>.
These sets are views of the underlying data and as such track the data in thesymbol table from which they originated. As the symbol table changes, so do thesets of symbols and sets of identifiers.
These sets are immutable. All of the collection methods that might modifytheir contents will throw unsupported operation exceptions.
Providing immutable views of underlying objects is a common interface id-iom. It allows the object to maintain the consistency of the two sets while lettingthe sets reflect changes in the underlying symbol table.
We provide a demo in SymbolTableViewsDemo. The main() method uses thefollowing code.
MapSymbolTable st = new MapSymbolTable();Set<String> symbolSet = st.symbolSet();Set<Integer> idSet = st.idSet();System.out.println("symbolSet=" + symbolSet
+ " idSet=" + idSet);
st.getOrAddSymbol("foo");st.getOrAddSymbol("bar");System.out.println("symbolSet=" + symbolSet
+ " idSet=" + idSet);
st.removeSymbol("foo");System.out.println("symbolSet=" + symbolSet
+ " idSet=" + idSet);
The two sets are assigned as soon as the symbol table is constructed. We thenprint out the set of symbols and identifiers. After that, we add the symbols "foo"and "bar" and print again. Finally, we remove "foo" and print for the last time.
The Ant target symbol-table-views runs the demo,
> ant symbol-table-views-demo
// don’t know why I need this here – variable spacing, I think

9.3. THE SYMBOLTABLECOMPILER CLASS 227
symbolSet=[] idSet=[]symbolSet=[foo, bar] idSet=[0, 1]symbolSet=[bar] idSet=[1]
As advertised, the values track the underlying symbol table’s values.
Unmodifiable Symbol Table Views
In many cases in LingPipe, models will guard their symbol tables closely. Ratherthan returning their actual symbol table, they return an unmodifiable view of theentire table. The method unmodifiableView(SymbolTable) returns a symboltable that tracks the specified symbol table, but does not support any of themodification methods.
This method employs the same pattern as the generic static utility method<T>unmodifiableSet(Set<? extends T>) in the utility class Collectionsfrom the built-in package java.util; it returns a value of type Set<T> whichtracks the specified set, but may not be modified. This collection utility is usedunder the hood to implement the symbol and identifier set views discussed inthe previous section.
Thread Safety
Map symbol tables are not thread safe. They require read-write synchroniza-tion, where all the methods that may modify the underlying table are consideredwriters.
Serialization
Map symbol tables are serializable. They deserialize to a MapSymbolTable withthe same behavior as the one serialized. Specifically, the identifiers do no change.
9.3 The SymbolTableCompiler Class
The SymbolTableCompiler implementation of SymbolTable is a legacy classused in some of the earlier LingPipe models. We could have gotten away with-out the entire com.aliasi.symbol package and just dropped MapSymbolTableinto com.aliasi.util. Instead, we abstracted an interface and added a parallelimplementation in order to maintain backward compatibility at the model level.
Once a symbol is added, it can’t be removed. Symbol table compilers do notsupport the remove() or clear() methods; these methods throw unsupportedoperation exceptions.
9.3.1 Adding Symbols
The symbol table compiler implements a very unwieldy usage pattern. It beginswith a no-argument constructor. The usual getOrAddSymbol(String) methodfrom the SymbolTable interface will throw an unsupported operation exception.

228 CHAPTER 9. SYMBOL TABLES
Instead, the method addSymbol(String) is used to add symbols to the table,returning true if the symbol hasn’t previously been added.
The really broken part about this class is that it doesn’t actually implementSymbolTable properly until after its been compiled.
9.3.2 Compilation
A symbol table compiler implements LingPipe’s Compilable interface (see Sec-tion 4.22.4).
9.3.3 Demo: Symbol Table Compiler
The demo class SymbolTableCompilerDemo implements a main() methoddemonstrating the usage of a symbol table compiler. The method begins bysetting up the compiler and adding some symbols
SymbolTableCompiler stc = new SymbolTableCompiler();stc.addSymbol("foo");stc.addSymbol("bar");
int n1 = stc.symbolToID("foo");int n2 = stc.symbolToID("bar");int n3 = stc.symbolToID("bazz");
It sets some variables that result from attempting to get the symbols again atthis point.
Next, we compile the symbol table using the static utility method compile()from LingPipe’s AbstractExternalizable class. We use the original symboltable then the compiled version to convert symbols to identifiers.
The Ant target symbol-table-compiler-demo runs the command.
> ant symbol-table-compiler-demo
n1=-1 n2=-1 n3=-1n4=1 n5=0 n6=-1n7=1 n8=0 n9=-1
st.getClass()=class com.aliasi.symbol.CompiledSymbolTable
The symbols are all unknown before compilation, returning -1 as their identifier.After compilation, both the compiler and the compiled version agree on symbolidentifiers. We also print the class for the result, which is the package-protectedclass CompiledSymbolTable. This class does implement SymbolTable, but theget-or-add method is not supported.
One nice property of the class is that we are guaranteed to have identifiersnumbered from 0 to the number of symbols minus 1. We are also guaranteed toget symbols stored in alphabetical order. Note that the symbol "bar" is assignedidentifier 0 even though it was added after the symbol "foo".
Be careful with this class. If more symbols are added, then the table is com-piled again, identifiers will change. This is because it relies on an underlyingsorted array of symbols to store the symbols and look up their identifiers.

9.3. THE SYMBOLTABLECOMPILER CLASS 229
9.3.4 Static Factory Method
The static utility method asSymbolTable(String[]) constructs a symbol tablefrom an array of symbols. It will throw an illegal argument exception if thereare duplicates in the symbol table. Perhaps a SortedSet would’ve been a betterinterface here.

230 CHAPTER 9. SYMBOL TABLES

Chapter 10
Sentence Boundary Detection
231

232 CHAPTER 10. SENTENCE BOUNDARY DETECTION

Chapter 11
Latent Dirichlet Allocation
Latent Dirichlet allocation (LDA) provides a statistical approach to documentclustering based on the words (or tokens) that appear in a document. Given aset of documents, a tokenization scheme to convert them to bags of words, anda number of topics, LDA is able to infer the set of topics making up the collec-tion of documents and the mixture of topics found in each document. Theseassignments are soft in that they are expressed as probability distributions, notabsolute decisions.
At the basis of the LDA model is the notion that each document is gener-ated from its own mixture of topics. For instance, a blog post about a dinnerparty might 70% about cooking, 20% about sustainable farming, and 10% aboutentertaining.
Applications of LDA include document similarity measurement, documentclustering, topic discovery, word association for search, feature extraction fordiscriminative models such as logistic regression or conditional random fields,classification of new documents, language modeling, and many more.
11.1 Corpora, Documents, and Tokens
For LDA, a corpus is nothing more than a collection of documents. Each docu-ment is modeled as a sequence of tokens, which are often words or normalizedforms of words.
Applications of LDA typically start with a real document collection consist-ing of character data. LingPipe uses tokenizer factories to convert charactersequences to sequences of tokens (see Chapter 8). Utilities in the LDA implemen-tation class help convert these to appropriate representations with the help ofsymbol tables (see Chapter 9).
For LDA, and many other models such as traditional naive Bayes classificationand k-means clustering, only the count of the words is significant, not their order.A bag is a data structure like a set, only with (non-negative) counts for eachmember. Mathematically, we may model a bag as a mapping from its membersto their counts. Like other models that don’t distinguish word order, LDA iscalled a bag-of-words model.
233

234 CHAPTER 11. LATENT DIRICHLET ALLOCATION
11.2 LDA Parameter Estimation
In this section, we will cover the steps necessary to set up the constant parame-ters for an LDA model and then estimate the unknown parameters from a corpusof text data.
11.2.1 Synthetic Data Example
We begin with a synthetic example due to Steyvers and Griffiths.1 Synthetic or“fake data” models play an important role in statistics, where they are used likeunit tests for statistical inference mechanisms.
In this section, we will create an LDA model by fixing all of its parameters,then use it to generate synthetic data according to the model. Then, we willprovide the generated data to our LDA inference algorithm and make sure that itcan recover the known structure of the data.
The implementation of our synthetic example, which illustrates the basic in-ference mechanism for LDA, is in the demo class SyntheticLdaExample.
Tokens
Steyvers and Griffiths’ synthetic example involved only two topics and five words.The words are river, stream, bank, money, and loan. The first two words typicallyoccur in articles about rivers, and the last two words in articles about money.The word bank, the canonical example of an ambiguous word in English, occursin both types of articles.
What’s a Topic?
A topic in LDA is nothing more than a discrete probability distribution overwords. That is, given a topic, each word has a probability of occurring, andthe sum of all word probabilities in a topic must be one.
Steyvers and Griffiths’ example involves two topics, one about banking andone about rivers, with the following word probabilities.
river stream bank money loan
Topic 1 1/3 1/3 1/3 0 0Topic 2 0 0 1/3 1/3 1/3
Topic 1 is about water and topic 2 about money. If a word is drawn from topic 1,there is a 1/3 chance it is river, a 1/3 chance it is stream and a 1/3 chance it isbank.
What’s a Document?
For the purposes of LDA, a document is modeled as a sequence of tokens. Weuse a tokenizer factory to convert the documents into counts. The identity of
1From Steyvers, Mark and Tom Griffiths. 2007. Probabilistic topic models. In Thomas K. Landauer,Danielle S. McNamara, Simon Dennis and Walter Kintsch (eds.), Handbook of Latent Semantic Analysis.Laurence Erlbaum.

11.2. LDA PARAMETER ESTIMATION 235
the tokens doesn’t matter. It turns out the order of the tokens doesn’t matterfor fitting the model, though we preserve order and identity so that we can labeltokens with topics in our final output.
The code in SyntheticLdaExample starts out defining an array of sixteencharacter sequences making up the document collection that will be clustered.These documents were generated randomly from an LDA model by Steyvers andGriffiths. The texts making up the documents are defined starting with
static final CharSequence[] TEXTS = new String[] {"bank loan money loan loan money bank loan bank loan"+ " loan money bank money money money",
"loan money money loan bank bank money bank money loan"+ " money money bank loan bank money",
and ending with
"river stream stream stream river stream stream bank"+ " bank bank bank river river stream bank stream",
"stream river river bank stream stream stream stream"+ " bank river river stream bank river stream bank"
};
The only reason we used concatenation is so that the lines would fit on the pagesof the book. The complete set of documents is most easily described in a table.
Doc ID river stream bank money loan
0 0 0 4 6 61 0 0 5 7 42 0 0 7 5 43 0 0 7 6 34 0 0 7 2 75 0 0 9 3 46 1 0 4 6 57 1 2 6 4 38 1 3 6 4 29 2 3 6 1 4
10 2 3 7 3 111 3 6 6 1 012 6 3 6 0 113 2 8 6 0 014 4 7 5 0 015 5 7 4 0 0
The first document (identifier/position 0) has four instances of bank, six ofmoney and six of loan. Each document has sixteen tokens, but equal sized docu-ments is just an artifact of Steyvers and Griffiths’ example. In general, documentsizes will differ.

236 CHAPTER 11. LATENT DIRICHLET ALLOCATION
Tokenizing Documents
LDA deals with token identifiers in the form of a matrix, not with string tokens.But there’s a handy utility method to produce such a matrix from a corpus oftexts and a tokenizer factory. The first few lines of the main() method in theSyntheticLdaExample class provide the conversion given our static array TEXTSof character sequences:
TokenizerFactory tokFact= new RegExTokenizerFactory("\\p{L}+");
SymbolTable symTab = new MapSymbolTable();int minCount = 1;int[][] docWords
= tokenizeDocuments(TEXTS,tokFact,symTab,minCount);
The regex-based tokenizer factory is used with a regex defining tokens as max-imal sequences of characters in the Unicode letter class (see Section 8.2.3 forregex tokenizer factories and Section 3.3.2 for Unicode regex classes). This willpull out each of the words in our documents.
Next, we create a symbol table (see Section 9.2) which we will use to provideinteger indexes to each of the tokens.
The variable minCount will specify how many instances of a token must beseen in the entire set of documents for it to be used in the model. Here we setthe threshold to 1, so no tokens will be pruned out. For most applications, itmakes sense to use a slightly larger value.
Then, we create a two-dimensional array of document-word identifiers. Thevalue of docWords[n] is an array of the symbol identifiers from the symbol tablefor the words in document n (which will range from 0 (inclusive) to 15 (inclusive)for our 16-document corpus).
The program prints the symbol table and document-word array so you maysee what is actually produced,
symbTab={0=stream, 1=money, 2=bank, 3=loan, 4=river}
docWords[ 0] = { 2, 3, 1, 3, 3, 1, 2, 3, 2, 3, 3, 1, 2, 1, 1, 1 }docWords[ 1] = { 3, 1, 1, 3, 2, 2, 1, 2, 1, 3, 1, 1, 2, 3, 2, 1 }...docWords[14] = { 4, 0, 0, 0, 4, 0, 0, 2, 2, 2, 2, 4, 4, 0, 2, 0 }docWords[15] = { 0, 4, 4, 2, 0, 0, 0, 0, 2, 4, 4, 0, 2, 4, 0, 2 }
Given the symbol table, the first document (index 0) has tokens 2 (bank), 3 (loan),1 (money), and so on, matching the input.
It is this document-word matrix that is input to LDA.
11.2.2 LDA Parameters
Before running LDA, we need to set up a number of parameters, which we willexplain after seeing the example run. The first of these are the model parameters,

11.2. LDA PARAMETER ESTIMATION 237
short numTopics = 2;double docTopicPrior = 0.1;double topicWordPrior = 0.01;
First, we set up the number of topics, which must be fixed in advance. Here wecheat and set it to 2, which we happen to know in this case is the actual numberof topics used to generate the documents. In general, we won’t know the bestvalue for the number of topics for a particular application.
Sampler Parameters
Next, we set up the variables that control the sampler underlying the LDA infer-ence mechanism.
int burnin = 0;int sampleLag = 1;int numSamples = 256;Random random = new Random(43L);
These are the number of samples we take, the number of samples thrown awayduring the burnin phase, and the period between samples after burnin (we ex-plain these parameters in full detail below).
The sampler also requires a pseudo-random number generator. We use Java’sbuilt-in pseudo-random number generator in the class Random in java.util (seeAppendix D.5 for more information bout Random and using it in experimentalsettings). By providing the constructor an explicit seed, 43L, the program willhave the same behavior each time it is run. Remove the argument or provide adifferent seed to get different behavior.
Reporting Callback Handler Parameters
After that, we set up a handler that’ll be used for reporting on the progress of thesampler. Specifically, we define a callback class ReportingLdaSampleHandler(the code of which we describe below), which will be passed to the inferencemethod.
int reportPeriod = 4;ReportingLdaSampleHandler handler
= new ReportingLdaSampleHandler(symTab,reportPeriod);
The callback handler will receive information about each sample produced andprovides the flexibility to perform online Bayesian inference (which we explainbelow). It’s constructed with the symbol table and takes an argument specifyingthe period between reports (measured in samples).
Invoking the Sampler
At last, we are in a position to actually call the LDA inference method, which isnamed after the algorithmic approach, Gibbs sampling, which we’ll also definebelow,

238 CHAPTER 11. LATENT DIRICHLET ALLOCATION
GibbsSample sample= gibbsSampler(docWords,
numTopics, docTopicPrior, topicWordPrior,burnin, sampleLag, numSamples,random, handler);
Basically, we pass it all of our parameters, including the document-token matrix.After the method returns, we have a sample in hand. We use the reporting
methods in the handler to print out information about the final sample. It re-quires the final sample and parameters controlling verbosity (printing at most5 words per topic and 2 topics per document, which here, are not actually con-straints).
int wordsPerTopic = 5;int topicsPerDoc = 2;boolean reportTokens = true;handler.reportParameters(sample);handler.reportTopics(sample,wordsPerTopic);handler.reportDocs(sample,topicsPerDoc,reportTokens);
11.3 Interpreting LDA Output
We run the example using the Ant target synthetic-lda to run the main()method in SyntheticLdaExample. a
> ant synthetic-lda
We’ve already seen the output of the symbol table and the document-token ma-trix above.
11.3.1 Convergence Monitoring
The next thing that’s output is monitoring information from the sampler.
n= 0 t= :00 x-entropy-rate= 2.1553n= 4 t= :00 x-entropy-rate= 2.1528...n= 20 t= :00 x-entropy-rate= 1.7837n= 24 t= :00 x-entropy-rate= 1.7787...n= 248 t= :00 x-entropy-rate= 1.7811n= 252 t= :00 x-entropy-rate= 1.7946
The results here are typical. The report for the sample number. Note that weonly get a report for every four samples because of how we parameterized thehandler. We can report every epoch, but it’s relatively expensive. The secondcolumn is the elapsed time. This example is so slow, it takes less than a secondtotal. The third column is the cross-entropy rate. This is roughly a measureof the expected number of bits required to code a word if we were to use the

11.3. INTERPRETING LDA OUTPUT 239
LDA model for compression.2 Note that the cross-entropy starts high, at 2.1 bits,but quickly drops to 1.8 bits. Further note that at the converged state, LDA isproviding a better model than randomly generating words, which would have across-entropy of − log2 1/5 ≈ 2.3 bits.
The goal in running Gibbs samplers is to reach convergence, where numberslike cross-entropy rates stabilize. Note that Gibbs sampling is not an optimiza-tion algorithm, so while the cross-entropy rates start high and get lower, oncethey’ve reached about 1.78 in this example, they start bouncing around.
The number of samples used for burnin should be large enough that it getsyou to the bouncing around stage. After that, results should be relatively stable(see below for more discussion of LDA stability).
11.3.2 Inferred Topics
Next, we get a report of the parameters we’ve fit for the topic models themselves.
TOPIC 0 (total count=104)SYMBOL WORD COUNT PROB Z--------------------------------------------------
0 stream 42 0.404 4.22 bank 35 0.336 -0.54 river 27 0.260 3.3
TOPIC 1 (total count=152)SYMBOL WORD COUNT PROB Z--------------------------------------------------
2 bank 60 0.395 0.51 money 48 0.316 3.13 loan 44 0.289 3.0
We fixed the number of topics at 2. LDA operates by assigning each token to atopic (as we will see in a second). These reports show the most frequent wordsassociated with each topic along with the symbol table ID and the number oftimes each word was assigned to a topic. At the top of the report is the totalnumber of words assigned to that topic (just a sum of the word counts).
The probability column displays the estimated probabiltiy of a word in atopic. Thus if we sample a word from topic 0, it is 40.4% likely to be stream,33.6% likely to be bank and 26.6% likely to be river. Note that these probabilitiesadd up to 1. Also note that these are not probabilities of topics given words. Theprobability of bank in topic 1 is only 39.5% and thus it should be evident thatthese can’t be probabilities of topics given words, becuase they don’t add up to1 (33.6% + 39.5% = 78.1% < 1).
These probabilities estimated from the small set of randomly generated dataare as close as could be expected to the actual probability distributions. Withlarger data sets, results will be tighter.
2This figure ignores the generation of the multinomial for the document. For use in compression,we would also need to encode a discrete approximation of the draw of the document’s multinomialfrom the Dirichlet prior.

240 CHAPTER 11. LATENT DIRICHLET ALLOCATION
The order of the topics is not determined. With a different random seed orstopping after different numbers of samples, we will get slightly different results.One difference may be that the identifiers on the topics will be switched. Thislack of identifiability of the topic identifier is typical of clustering models. Wereturn to its effect on Bayesian inference below.
The final column provides a z score for the word in the topic. This valuemeasures how much more prevalent a word is in a topic than it is in the corpus asa whole. The units are standard deviations. For instance, the word bank appears95 times in the corpus of 256 words, accounting for 95/256, or approximately37% of all tokens. In topic 0, it appears 35 times in 104 tokens, accountingfor approximately 34% of all tokens; in topic 1, it appears 60 times in 152 words,accounting for roughly 39% of the total number of words. Because the prevalenceof bank in topic 0 is less than in the corpus (34% versus 37%), its z score isnegative; because it’s higher in topic 1 than in the corpus (39% versus 37%), thez score is positive.
11.3.3 Inferred Token and Document Categorizations
The final form of output is on a per-document basis (controlled by a flag to thefinal output method). This provides a report on a document-by-document basisof how each word is assigned.
DOC 0TOPIC COUNT PROB----------------------
1 16 0.994
bank(1) loan(1) money(1) loan(1) loan(1) money(1) bank(1)loan(1) bank(1) loan(1) loan(1) money(1) bank(1) money(1)money(1) money(1)...DOC 8TOPIC COUNT PROB----------------------
1 11 0.6850 5 0.315
money(1) bank(1) money(1) loan(1) stream(0) bank(1) loan(1)bank(1) bank(1) stream(0) money(1) bank(0) bank(1) stream(0)river(0) money(1)...DOC 15TOPIC COUNT PROB----------------------
0 16 0.994
stream(0) river(0) river(0) bank(0) stream(0) stream(0)

11.4. LDA’S GIBBS SAMPLES 241
stream(0) stream(0) bank(0) river(0) river(0) stream(0) bank(0)river(0) stream(0) bank(0)
We’ve only shown the output from three representative documents. For eachdocument, we show the topic assignment to each token in parens after the token.All the words in document 0 are assigned to topic 1 whereas all the word indocument 15 are assigned to topic 0. In document 8, we see that 11 words areassigned topic 1 and 5 words topic 0. The word bank is assigned to both topic 0and topic 1 in the document. This shows how LDA accounts for documents thatare about more than one topic.
The aggregate counts show how many words are assigned to each topic, andthe probability that a word from a document is chosen from the probability.
Even though all words were assigned to topic 1 in document 0, the probabilityis still only 0.994. This is because of the priors, which induce smoothing, settingaside a small count for unseen topics in each document. This kind of smoothingis immensely helpful for robustness in the face of noisy data, and almost allnatural language data is immensely noisy.
11.4 LDA’s Gibbs Samples
The return value of the LDA estimation method is a Gibbs sample.
11.4.1 Constant, Hyperparameter and Data Access
The samples store all the argments supplied to the LDA method other than num-ber of samples information. These values will be constant for the chain of sam-ples produced by the iterator.
The method numTopics() returns the constant number of topics spec-ified in the original invocation. The methods topicWordPrior() anddocumentTopicPrior() return the two hyperparameters (i.e., constant prior pa-rameters).
The sample object also provides access to the underlying document-word ma-trix matrix through the methods numDocuments(), documentLength(int), andword(int,int).
11.4.2 Word Topic Assignments and Probability Estimates
What we’re really after is the actual content of the sample. Each step of samplingcontains an assignment of each token in each document to one of the topics.The method topicSample(int,int) returns the short-valued topic identifierfor the specified document and token position.
These assignments of topics to words, combined with the priors’ hyperparam-eters, determine the probability estimates for topics and documents we showedin the output in the previous section. The method topicWordProb(int,int)returns the double-valued probability estimate of a word in a topic. These prob-ability distributions fix the behavior of the topics themselves.

242 CHAPTER 11. LATENT DIRICHLET ALLOCATION
The method documentTopicProb(int,int) returns the double-valued proa-bility estimate for a topic in a document. These probabilities summarize thetopics assigned to the document.
These probability estimates, coupled with the underlying document-worddata matrix, allows us to compute corpusLog2Probability(), which is theprobability of the topics and words given the models. Note that it does notinclude the probabilities of the document multinomials or the topic multinomi-als given their Dirichlet priors. The main reason they’re excluded is that themultinomials are not sampled in the collapsed sampler.
The static utility method dirichletLog2Prob(double[],double[]) in theclass Statistics in LingPipe’s stats package may be used to computeDirichlet probabilities. We may plug the maximum a posteriori (MAP) esti-mates provided by the methods topicWordProb() and documentTopicProb()into the dirichletLog2Prob() method along with the relevant prior,topicWordPrior() and documentTopicPrior(), respectively.
11.4.3 Retrieving an LDA Model
Each Gibbs sample contains a factory method lda() to construct an instance ofLatentDirichletAllocation based on the topic-word distributions implied bythe sample and the prior hyperparameters.
Although the Gibbs samples themselves are not serializable, the LDA mod-els they return are. We turn to the use of an LDA instance in the nextsection. The method we used in the last section to invoke the sampler re-turned a single Gibbs sample. There is a related static estimation method inLatentDirichletAllocation that returns an iterator over all of the Gibbs sam-ples. The iterator and one-shot sampler return instances of GibbsSample, whichis a static class nested in LatentDirichletAllocation.
Samples are produced in order by the sampler. The poorly named methodepoch() returns the sample number, with numbering beginning from 0.
11.5 Handling Gibbs Samples
In our running synthetic data example, we provided an instance of the demo classReporingLdaSampleHandler to the LDA estimation method gibbsSampler().The use of the handler class follows LingPipe’s generic callback handler pattern.For every Gibbs sample produced by the sampler, the handler object receives areference to it through a callback.
11.5.1 Samples are Reused
Unlike many of our other callbacks, the Gibbs sampler callbacks were imple-mented for efficiency. Rather than getting a new Gibbs sample object for eachsample, the same instance of GibbsSample is reused. Thus it does not make anysense to create a collection of the Gibbs samples for later use. All statistics must

11.5. HANDLING GIBBS SAMPLES 243
be computed online or accumulated outside the Gibbs sample object for lateruse.
11.5.2 Reporting Handler Demo
The reporting handler demo is overloaded to serve two purposes. First, it handlesGibbs samples as they arrive as required by its interface. Second, it provides afinal report in a class-specific method.
Online Sample Handler
The class declaration, member variables and constructor for the handler are asfollows.
public class ReportingLdaSampleHandlerimplements ObjectHandler<GibbsSample> {
private final SymbolTable mSymbolTable;private final long mStartTime;private final int mReportPeriod;
public ReportingLdaSampleHandler(SymbolTable symbolTable,int reportPeriod) {
mSymbolTable = symbolTable;mStartTime = System.currentTimeMillis();mReportPeriod = reportPeriod;
}
We maintain a reference to the symbol table so that our reports can reassociatethe integer identifiers with which LDA works with the tokens from which theyarose. We see how the report period is used in the implementation of the handlermethod.
The class was defined to implement the interfaceObjectHandler<GibbsSample>. It thus requires an implementation of thevoid return method handle(GibbsSample). Up to the print statement, thismethod is implemented as follows.
public void handle(GibbsSample sample) {int epoch = sample.epoch();if ((epoch % mReportPeriod) != 0) return;long t = System.currentTimeMillis() - mStartTime;double xEntropyRate
= -sample.corpusLog2Probability() / sample.numTokens();
This is the callback method that will be called for every sample. It first grabs theepoch, or sample number. If this is not an even multiple of the report period, themethod returns without performing any action. Otherwise, we fall through andcalcualte the elapsed time and cross-entropy rate. Note that the cross-entropyrate as reported here is the negative log (base 2) probability of the entire corpusof documents divided by the number of tokens in the entire corpus. This cross-entropy rate is what we saw printed and what we monitor for convergence.

244 CHAPTER 11. LATENT DIRICHLET ALLOCATION
General Reporting
There are additional reporting methods in the handler above the required onethat provide more detailed reporting for a sample. They produce the outputshown in the previous section after the online reporting of cross-entropy ratesfinishes and the final sample is produced by LDA’s gibbsSampler() method.
The general parameter reporting method, reportParameters(), just printsgeneral corpus and estimator parameters from the sample. There are two moreinteresting reporters, one for topics and one for documents. The topic reportingmethod, reportTopics(), begins as follows.
public void reportTopics(GibbsSample sample, int maxWords) {for (int topic = 0; topic < sample.numTopics(); ++topic) {
int topicCount = sample.topicCount(topic);ObjectToCounterMap<Integer> counter
= new ObjectToCounterMap<Integer>();for (int word = 0; word < sample.numWords(); ++word)
counter.set(word,sample.topicWordCount(topic,word));
List<Integer> topWords= counter.keysOrderedByCountList();
The loop is over the topic identifiers. Within the loop, the method begins byassigning the number of words assigned to a topic. It then allocates a generalLingPipe object counter to use for the word counts. Each word identifier is con-sidered int he inner loop, and the counter’s value for that word is set to thenumber of times the word was assigned to the current topic. After collecting thecounts in our map, we create a list of the keys, here word indexes, ordered indescending order of their counts.
We continue by looping over the words by rank.
for (int rank = 0;rank < maxWords && rank < topWords.size();++rank) {
int wordId = topWords.get(rank);String word = mSymbolTable.idToSymbol(wordId);int wordCount = sample.wordCount(wordId);int topicWordCount
= sample.topicWordCount(topic,wordId);double topicWordProb
= sample.topicWordProb(topic,wordId);double z = binomialZ(topicWordCount,
topicCount,wordCount,sample.numTokens());
We bound the number of words by the maximum given and make sure not tooverflow the model’s size bounds. Inside the loop, we just pull out identifiersand counts, and calculate the z-score. This is where we need the symbol table in

11.5. HANDLING GIBBS SAMPLES 245
order to print out the actual words rather than just their numbers. The rest ofthe method is just printing.
The method used to calculate the z-score is
static double binomialZ(double wordCountInDoc,double wordsInDoc,double wordCountinCorpus,double wordsInCorpus) {
double pCorpus = wordCountinCorpus / wordsInCorpus;double var = wordsInCorpus * pCorpus * (1 - pCorpus);double dev = Math.sqrt(var);double expected = wordsInDoc * pCorpus;return (wordCountInDoc - expected) / dev;
}
It first calculates the maximum likelihood estimate of the word’s probabilty inthe corpus, which is just the overall count of the word divided by the number ofwords in the corpus. The maximum likelihood variance estimate is calculated asusual for a binomial outcome over n samples (here wordsInCorpus) with knownprobabiltiy θ (here pCorpus), namely n × θ × (1 − θ). The expected number ofoccurrences if it had the corpus distribution is given by the number of words inthe document times the probability in the corpus. The z-score is then the actualvalue minus the expected value scaled by the expected deviation.
Returning to the general reporting, we have a method reportDocs(), whichprovides a report on the documents, optionally including a word-by-word reportof topic assignments.
public void reportDocs(GibbsSample sample, int maxTopics,boolean reportTokens) {
for (int doc = 0; doc < sample.numDocuments(); ++doc) {ObjectToCounterMap<Integer> counter
= new ObjectToCounterMap<Integer>();for (int topic = 0;
topic < sample.numTopics();++topic)
counter.set(topic,sample.documentTopicCount(doc,topic));
List<Integer> topTopics= counter.keysOrderedByCountList();
This method enumerates all the documents in the corpus, reporting on each onein turn. For each topic, we follow the same pattern as we did for the topics beofre,establishing a LingPipe object counter mapping topic identifiers to the numberof times a word in the current document was assigned to that topic. We then sortas before, then loop over the ranks up to the maximum number of topics or totalnumber of topics in the model.
for (int rank = 0;rank < topTopics.size() && rank < maxTopics;

246 CHAPTER 11. LATENT DIRICHLET ALLOCATION
++rank) {
int topic = topTopics.get(rank);int docTopicCount
= sample.documentTopicCount(doc,topic);double docTopicProb
= sample.documentTopicProb(doc,topic);
For each rank, we calculate the counts and probabilities and display them.Finally, we report on a token-by-token basis if the flag is set.
if (!reportTokens) continue;int numDocTokens = sample.documentLength(doc);for (int tok = 0; tok < numDocTokens; ++tok) {
int symbol = sample.word(doc,tok);short topic = sample.topicSample(doc,tok);String word = mSymbolTable.idToSymbol(symbol);
Here we just enumerate over the tokens in a document printing the topic to whichthey were assigned.
11.5.3 General Handlers
In general, handlers can do anything. For instance, they can be used to accu-mulate results such as running averages, thus supporting full Bayesian inferencewith a small memory footprint (only the current sample need stay in memory).
For instance, the following handler would calculate average corpus log 2 prob-ability over all samples.
public class CorpusLog2ProbAvgHandlerimplements ObjectHandler<GibbsSample> {
OnlineNormalEstimator mAvg = new OnlineNormalEstimator();
public void handle(GibbsSample sample) {mAvg.handle(sample.corpusLog2Probability());
}
public OnlineNormalEstimator avg() {return mAvg;
}}
We use an instance of LingPipe’s OnlineNormalEstimator for the calculation. Itcalculates averages and sample variances and standard deviations online withoutaccumulating the data points. The method mAvg.mean() returns the samplemean and mAvg.varianceUnbiased() the unbiased sample variance.
Along these sample lines, more complex statistics such as word or documentsimilarities or held out data entropy estimates may be computed online.

11.6. SCALABILITY OF LDA 247
11.6 Scalability of LDA
LDA is a highly scalable model. It takes an amount of time per token that isproportional to the number of topics. Thus with a fixed number of topics, itscales linearly in topic size. Tens of thousands of documents are no problem ondesktop machines.
11.6.1 Wormbase Data
In this section, we consider a larger scale LDA estimation problem, in analyzing acollection of biomedical research paper citations related to the model organismCaenorhabditis elegans (C. elegans), the nematode worm. The data was down-loaded from the WormBase site (see Section C.3 for mroe information). Similardata from a slightly different source on a smaller scale was analyzed by Blei etal. in an attempt to relate the topics inferred using LDA with those added forgenetics by the database curators.3 An example of a citation in raw form is
%0 Journal Article%T Determination of life-span in Caenorhabditis elegans
by four clock genes.%A Lakowski, B%A Hekimi, S%D 1996%V 272%P 1010-1013%J Science%M WBPaper00002456%X The nematode worm Caenorhabditis elegans is a model system
for the study of the genetic basis of aging. Maternal-effectmutations in four genes--clk-1, clk-2, clk-3, and gro-1--interact genetically to determine both the duration ofdevelopment and life-span. Analysis of the phenotypes ofphysiological clock in the worm. Mutations in certain genesinvolved in dauer formation (an alternative larval stageinduced by adverse conditions in which development isarrested) can also extend life-span, but the life extensionof Clock mutants appears to be independent of these genes.The daf-2(e1370) clk-1(e2519) worms, which carry life-span-extending mutations from two different pathways, live nearlyfive times as long as wild-type worms.
There are not actually line breaks in the %T and %X elements.
3Blei et al. analyzed a smaller set of worm citations from the Caenorhabditis Genetic Center (CGC)bibliography. This data is available from the WormBook site at http://www.wormbook.org/wli/cgcbib.
Blei, D. M., K. Franks, M. I. Jordan and I. S. Mian. 2006. Statistical modeling of biomedicalcorpora: mining the Caenorhabditis Genetic Center Bibliography for genes related tolife span. BMC Bioinformatics 7:250.
Blei et al. considered 50 topics generated from 5225 documents using a total of 28,971 distinct words.

248 CHAPTER 11. LATENT DIRICHLET ALLOCATION
11.6.2 Running the Demo
First, you’ll need to download the gzipped data from wormbase; see Section C.3.It doesn’t matter where you put it; the program takes the location as a parameter.
We created an Ant target lda-worm to run the demo. It is configured to pro-vide seven command-line arguments as properties, wormbase.corpus.gz for thelocation of the gzipped corpus, min.token.count for the minimum token countin the corpus to preserve the word in the model, num.topics for the number oftopics to generate, topic.prior and word.prior for the priors, random.seedfor the random seed, and num.samples for the total number of samples to draw.
> ant -Dwormbase.corpus.gz="../../data-dist/2007-12-01-wormbase-literature.endnote.gz"-Dmin.token.count=5 -Dnum.topics=50 -Dtopic.prior=0.1-Dword.prior=0.001 -Drandom.seed=43 -Dnum.samples=500-Dmodel.file=wormbase.LatentDirichletAllocation-Dsymbol.table.file=wormbase.SymbolTable lda-worm > temp.txt
It takes about half an hour to generate the 500 samples on my workstation, andquite a bit more time to generate the roughly 50MB of output reporting on thetopics and the assignment of tokens in documents. Because there’s so muchoutput, we redirect the results to a file; you can use the command tail -f tofollow along in real time.
The output begins by reporting on the parameters and the corpus itself, theinteresting part of which reports corpus statistics rather than what we entered.
...#articles=26888 #chars=43343525Number of unique words above count threshold=28499Tokenized. #Tokens After Pruning=3731693
We see that there are 26,888 total citations, made up of around 43 million charac-ters. After tokenization, there are roughly 28 thousand distinct tokens that eachappeared at least 5 times (the minimum token count), and a total token count ofaround 3.7 million instances. That means each Gibbs sampling step is going toreassign all 3.7 million tokens.
After the corpus statistics, it reports on the iterator’s progress, as before.
n= 0 t= :03 x-entropy-rate= 11.6898n= 5 t= :21 x-entropy-rate= 11.3218n= 10 t= :39 x-entropy-rate= 10.9798n= 15 t= :57 x-entropy-rate= 10.8136n= 20 t= 1:15 x-entropy-rate= 10.7245...n= 485 t= 28:50 x-entropy-rate= 10.3250n= 490 t= 29:08 x-entropy-rate= 10.3246n= 495 t= 29:26 x-entropy-rate= 10.3237...
We only ran for 500 samples, and at that point, we still haven’t converged to thelowest cross-entropy rate. We ran the sampler overnight, and it hadn’t converged

11.6. SCALABILITY OF LDA 249
even after 10,000 samples. Because LDA’s an approximate statistical processanyway, stopping before convergence to retrieve a single sample isn’t going tomake much of a difference in terms of the clustering output.4
The program then reports the topic distributions and document distributionsand token topic assignments, all based on the 500th sample. These look differentthan the ones we saw in the synthetic example, because there are many morelonger documents (though stil short, being based on abstracts) and many moretokens.
The first few words in the first few topics are.
[java] TOPIC 0 (total count=70201)[java] SYMBOL WORD COUNT PROB Z[java] --------------------------------------------------[java] 18616 disease 1136 0.016 30.6[java] 10640 infection 686 0.010 25.7[java] 26059 pathogen 658 0.009 25.2[java] 4513 fatty 576 0.008 23.6[java] 1863 toxicity 638 0.009 23.4[java] 20474 drug 732 0.010 21.2[java] 26758 immune 394 0.006 19.0
...[java] 23394 alzheimer 163 0.002 10.6[java] 5756 agent 216 0.003 10.6[java] 20684 clinical 128 0.002 10.4
[java] TOPIC 1 (total count=88370)[java] SYMBOL WORD COUNT PROB Z[java] --------------------------------------------------[java] 17182 transcription 3813 0.043 51.3[java] 6619 factor 4383 0.050 49.7[java] 717 binding 1913 0.022 25.0[java] 21676 transcriptional 1215 0.014 24.6[java] 17200 regulatory 1347 0.015 24.6[java] 22813 element 1433 0.016 22.7[java] 12394 zinc 594 0.007 20.6[java] 13680 target 1423 0.016 19.7[java] 11864 finger 597 0.007 19.2
...[java] 11043 tissue-specific 188 0.002 8.2[java] 9171 hypoxia 111 0.001 7.9[java] 22550 dna 829 0.009 7.6
Overall, the topics seem coherenent and well separated.Blei et al.’s paper analyzing the same data was concerned with seeing that
topics about genes grouped genes that participate in the same pathways to showup in the same topic. This is easy to see in the data, with genes that operate
4On the other hand, if we wanted to estimate posterior variance, or get a very tight estimate onthe posterior means, we would have to run to convergence.
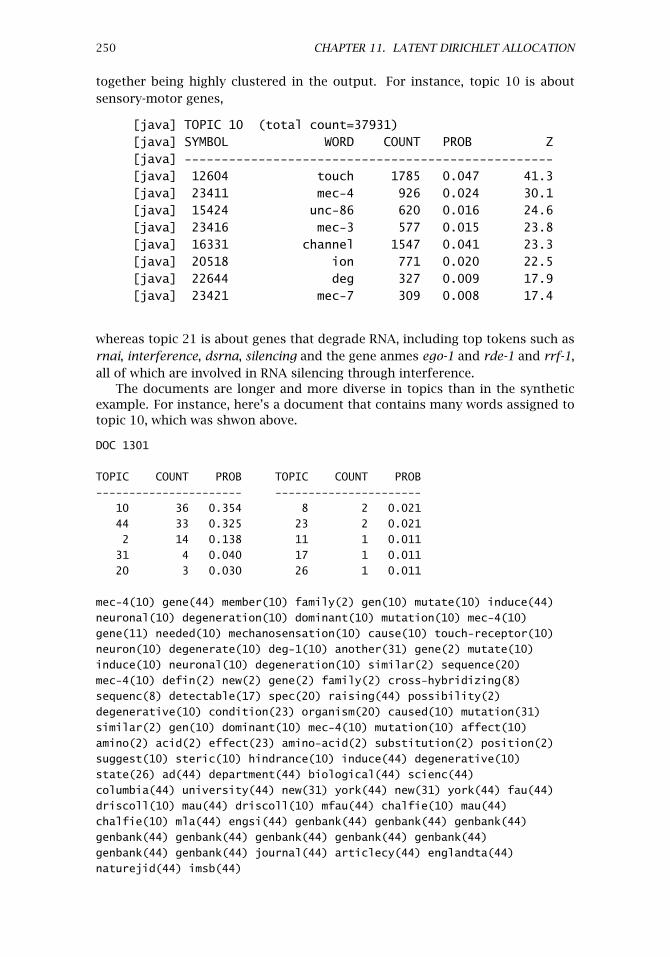
250 CHAPTER 11. LATENT DIRICHLET ALLOCATION
together being highly clustered in the output. For instance, topic 10 is aboutsensory-motor genes,
[java] TOPIC 10 (total count=37931)[java] SYMBOL WORD COUNT PROB Z[java] --------------------------------------------------[java] 12604 touch 1785 0.047 41.3[java] 23411 mec-4 926 0.024 30.1[java] 15424 unc-86 620 0.016 24.6[java] 23416 mec-3 577 0.015 23.8[java] 16331 channel 1547 0.041 23.3[java] 20518 ion 771 0.020 22.5[java] 22644 deg 327 0.009 17.9[java] 23421 mec-7 309 0.008 17.4
whereas topic 21 is about genes that degrade RNA, including top tokens such asrnai, interference, dsrna, silencing and the gene anmes ego-1 and rde-1 and rrf-1,all of which are involved in RNA silencing through interference.
The documents are longer and more diverse in topics than in the syntheticexample. For instance, here’s a document that contains many words assigned totopic 10, which was shwon above.
DOC 1301
TOPIC COUNT PROB TOPIC COUNT PROB
---------------------- ----------------------
10 36 0.354 8 2 0.021
44 33 0.325 23 2 0.021
2 14 0.138 11 1 0.011
31 4 0.040 17 1 0.011
20 3 0.030 26 1 0.011
mec-4(10) gene(44) member(10) family(2) gen(10) mutate(10) induce(44)
neuronal(10) degeneration(10) dominant(10) mutation(10) mec-4(10)
gene(11) needed(10) mechanosensation(10) cause(10) touch-receptor(10)
neuron(10) degenerate(10) deg-1(10) another(31) gene(2) mutate(10)
induce(10) neuronal(10) degeneration(10) similar(2) sequence(20)
mec-4(10) defin(2) new(2) gene(2) family(2) cross-hybridizing(8)
sequenc(8) detectable(17) spec(20) raising(44) possibility(2)
degenerative(10) condition(23) organism(20) caused(10) mutation(31)
similar(2) gen(10) dominant(10) mec-4(10) mutation(10) affect(10)
amino(2) acid(2) effect(23) amino-acid(2) substitution(2) position(2)
suggest(10) steric(10) hindrance(10) induce(44) degenerative(10)
state(26) ad(44) department(44) biological(44) scienc(44)
columbia(44) university(44) new(31) york(44) new(31) york(44) fau(44)
driscoll(10) mau(44) driscoll(10) mfau(44) chalfie(10) mau(44)
chalfie(10) mla(44) engsi(44) genbank(44) genbank(44) genbank(44)
genbank(44) genbank(44) genbank(44) genbank(44) genbank(44)
genbank(44) genbank(44) journal(44) articlecy(44) englandta(44)
naturejid(44) imsb(44)

11.6. SCALABILITY OF LDA 251
11.6.3 Code Walkthrough
The code is all in the class LdaWorm. The main differences from the syntheticdemo include the parser for the compressed data and a custom tokenizer for theWormbase data.
The method to read the corpus into an array of character sequences is basedon LingPipe’s FileLineReader utility (see Section 4.22.1). It just scans the linesand accumulates texts and adds them to an accumulating list.
The tokenization scheme is more interesting. We create it with the followingmethod.
static final TokenizerFactory wormbaseTokenizerFactory() {String regex = "[\\x2D\\p{L}\\p{N}]{2,}";TokenizerFactory factory
= new RegExTokenizerFactory(regex);Pattern alpha = Pattern.compile(".*\\p{L}.*");factory = new RegExFilteredTokenizerFactory(factory,alpha);factory = new LowerCaseTokenizerFactory(factory);factory = new EnglishStopTokenizerFactory(factory);factory = new StopTokenizerFactory(factory,STOPWORD_SET);factory = new StemTokenizerFactory(factory);factory = new StopTokenizerFactory(factory,STOPWORD_SET); /.
./ stop before and after stemmingreturn factory;
}
It creates a regex-based tokenizer that includes hyphens, letters and numbers asparts of tokens. We include hyphens and allow alphanumeric mixtures to includetokens for gene or protein names such as p53 and daf-19, which would otherwisebe separated. It also requires at least two characters.
It then immediately filters out tokens that are not at least two characters longand don’t contain at least one letter. This filter could’ve been rolled into thebase regex, but these kinds of exclusions quickly get clunky when mixed withalternations like in our base tokenizer factory.
We then convert the tokens to lower case and remove standard English stopwords. We also remove custom stop words we discovered from looking at thedistribution of tokens in the corpus. This list contains domain-specific wordslike elegan (remember the “plural” stripping) and non-topical words from thebiomedical research domain such as however and although. We also remove thenames of numbers, such as eleven and Roman numerals, such as viii, which areprevalent in this data. Note that we have already lowercased before stoplisting,so the stop list consists only of lowercase entries.
The last filter is our own custom stemmer, which was designed to followthe approach to removing English plural markers outlined in Blei et al.’s paper.Here’s the code.
static class StemTokenizerFactoryextends ModifyTokenTokenizerFactory {

252 CHAPTER 11. LATENT DIRICHLET ALLOCATION
public StemTokenizerFactory(TokenizerFactory factory) {super(factory);
}
public String modifyToken(String token) {Matcher matcher = SUFFIX_PATTERN.matcher(token);return matcher.matches() ? matcher.group(1) : token;
}
static final Pattern SUFFIX_PATTERN= Pattern.compile("(.+?[aeiouy].*?|.*?[aeiouy].+?)"
+ "(ss|ies|es|s)");
This filter fairly crudely strips off suffixes consisting of simple English pluralmarkers, ensuring that what’s left behind is at least two characters long. It usesrelucatant quantifiers on the contexts ensuring the match of the plural suffix isas long as possible. Thus we map fixes to fix not fixe, and map theories to theori,not theorie. In contrast, we reduce lies to lie, because we can’t match the firstgroup with a vowel if we pull of -ies, but we map entries to entr.
This crude stemmer will overstrip in the situation where a word ends withone of these suffixes but is not plural. It just checks for suffixes and stripsthem off. If the result is too short or no longer contains a vowel, we return theoriginal stem. (The restriction to ASCII is OK here because the documents wereall normalized to ASCII by the bibliography curators.)
11.7 Understanding the LDA Model Parameters
Given a tokenizer and corpus, there are three key parameters that control thebehavior the LDA model: the number of topics and the two priors.
11.7.1 Number of Topics
The number of topics parameter controls the number of topics into which themodel factors the data. The main effect of increasing the number of topics isthat the topics may become more fine grained. If there are only 10 topics tocategorize all the worlds’ news, we will not discover small topics like Americanbaseball or Australian politics.
As the number of topics increases, the amount of data available to estimateeach topic goes down. If the corpus is very large, it may be possible to fit a largenumber of topics effectively.
Which number of topics works best will depend on the application and thesize and the shape of data. In the end, like any clustering or other exploratorydata analysis technique, the best solution is to use trial and error. Explore arange of different topic sizes, such as 10, 50, 100, and 500.
The time to process each token is proportional to the total number of topics.It takes ten times as long to generate a sample for a 500-topic model than a50-topic model.

11.8. LDA INSTANCES FOR MULTI-TOPIC CLASSIFICATION 253
Document-Topic and Topic-Word Priors
The two priors control how diffuse the models are. Technically, as we explain inSection 11.11, the priors are additive smoothing terms for the model of topics ina document and the model of words in a topic.
In LDA, each document is modeled as a mixture of different topics. Whenthe document-topic prior is low, the model is encouraged to model a documentusing fewer topics than when the document-topic prior is high. What is going onprobabilistically is that the prior adds to the probability of all topics, bringingthe distribution over topics in a document closer to uniform (where all topicshave equal probability).
Similarly, each topic is modeled as a distribution over words. When the topic-word prior is high, each topic is encouraged to be more balanced in the proba-bilities it assigns to each word. As with the document-topic prior, it moves thedistribution of words in topics closer to the uniform distribution.
As with the number of topics, it will likely take some experimentation to findreasonable priors for a problem. A reasonable starting point for both priors isthe inverse number of outcomes. For instance, with 50 topics, 1/50 is a goodstarting prior for the document-topic prior, and with 30,000 words, 1/30,000is a reasonable starting point for the topic-word prior. It’s unlikely you’ll wantmuch smaller priors than these, but raising the priors above these levels will leadto smoother topic and document models, and may be more reasonable for someapplications.
11.8 LDA Instances for Multi-Topic Classification
We can use instances of the LatentDirichletAllocation class to perform clas-sification on documents that were not in the training corpus. These new docu-ments are classified with multiple topics and each word is assigned to a topicjust as when LDA is applied to a corpus of documents.
11.8.1 Constructing LDA Instances
An instance of LDA represents a particular parameterization of LDA’s multi-topicdocument model. Specifically, it stores the document-topic prior (the “Dirichlet”part of LDA) and a set of topic models in the form of distributions over words.
Direct Construction
The LDA class has a single constructor, LatentDirichletAllocation(double,double[]),which takes a document-topic prior and array of topic-word distributions. You’llnotice that this does not include a symbol table or tokenizer. LDA runs purelyas a multinomial model, and all symbol processing and tokenization happenexternally.
With an external means of generating distributions over words (say, with atraditional naive Bayes classifier or K-means clusterer), we can create an LDAinstance from the word distributions (and document-topic prior).

254 CHAPTER 11. LATENT DIRICHLET ALLOCATION
Construction from a Sample
More commonly, we will construct an LDA instance using a Gibbs sample gener-ated from a corpus using the static method gibbsSample(). We saw an exampleof this in the stability evaluate example in Section 11.10.
At the end of the Wormbase example in Section 11.6.3, after we’d generatedthe Gibbs sample and assigned it to variable sample, we snuck the following linesof code.
static final TokenizerFactory wormbaseTokenizerFactory() {String regex = "[\\x2D\\p{L}\\p{N}]{2,}";TokenizerFactory factory
= new RegExTokenizerFactory(regex);Pattern alpha = Pattern.compile(".*\\p{L}.*");factory = new RegExFilteredTokenizerFactory(factory,alpha);factory = new LowerCaseTokenizerFactory(factory);factory = new EnglishStopTokenizerFactory(factory);factory = new StopTokenizerFactory(factory,STOPWORD_SET);factory = new StemTokenizerFactory(factory);factory = new StopTokenizerFactory(factory,STOPWORD_SET); /.
./ stop before and after stemmingreturn factory;
}
This shows the production of an LDA instance from a sample using the lda()method on the sample. Then we use LingPipe’s abstract extenalizable utility (seeSection 4.22.5) to write its serialized form to a file. We also serialize the mapsymbol table to file.
We will be able to deserialize this model from disk and use it to classify newdocuments that were not in the corpus used to generate the chain of samples.
11.8.2 Demo: Classifying with LDA
In the sample class LdaClassifier, we show how a serialized LDA model andsymbol table We provide a sample program that illustrates the procedure forusing an LDA model and symbol table for classification.
Code Walkthrough
The code is all in the main() method, and starts by assigning a model filemodelFile, symbol table file symbolTableFile, text text, and random seedrandomSeed from the command-line parameters. We then deserialize the twomodels and recreate the tokenizer factory.
@SuppressWarnings("unchecked")LatentDirichletAllocation lda
= (LatentDirichletAllocation)AbstractExternalizable.readObject(modelFile);

11.8. LDA INSTANCES FOR MULTI-TOPIC CLASSIFICATION 255
@SuppressWarnings("unchecked")SymbolTable symbolTable
= (SymbolTable)AbstractExternalizable.readObject(symbolTableFile);
TokenizerFactory tokFact = LdaWorm.wormbaseTokenizerFactory();
We have to cast the deserialized object and suppress the warnings theunchecked cast would otherwise generate. Deserialize also throws aClassNotFoundException, which the main() method is also declared to throwin addition to an IOException.
We next marshal the parameters needed for classification and run the clasis-fier.
int[] tokenIds= LatentDirichletAllocation.tokenizeDocument(text,tokFact,symbolTable);
int numSamples = 100;int burnin = numSamples / 2;int sampleLag = 1;Random random = new Random(randomSeed);
double[] topicDist= lda.bayesTopicEstimate(tokenIds,numSamples,burnin,
sampleLag,random);
We use the tokenizer factory and symbol table to convert the text to a se-quence of token identifiers in the symbol table, using the static utility methodtokenizeDocument() built into LDA. We then set parameters of the topic estima-tion method, including the number of samples, burnin, sample lag and randomnumber generator, all of which have the same interpretation as for the main LDAGibbs sampling method. Finally, we call LDA’s bayesTopicEstimate() methodwith the tokens and Gibbs sampling parameters.
What happens under the hood is that we run a chain of Gibbs samples justlike we did for LDA itself. But rather than returning an iterator over the samplesor a single sample, we return an average over all the samples. Because the topicsare fixed by the LDA model, this produces (an approximation of) the Bayesian es-timate of the topic distribution for the text. Usually we don’t need many samplesbecause we don’t need multiple decimal places of accuracy.
What we get back is an array of doubles topicDist, indexed by topic. Topick has probability topicDist[k]. The rest of the code just prints out the top 10of these in order of probability.
Running the Demo
The Ant target lda-classify runs the classification demo, using propertiesmodel.file, symbol.table.file, text, and random.seed as command-line ar-guments.

256 CHAPTER 11. LATENT DIRICHLET ALLOCATION
For an example, we chose a MEDLINE citation about C. elegans that was morerecent than the corpus used to estimate the LDA model.5
Evolution of early embryogenesis in rhabditid nematodes. The cell-biologicalevents that guide early-embryonic development occur with great precisionwithin species but can be quite diverse across species. How these cellu-lar processes evolve and which molecular components underlie evolutionarychanges is poorly understood. To begin to address these questions, we sys-tematically investigated early embryogenesis, from the one- to the four-cellembryo, in 34 nematode species related to C. elegans. We found 40 cell-biological characters that captured the phenotypic differences between thesespecies. By tracing the evolutionary changes on a molecular phylogeny, wefound that these characters evolved multiple times and independently of oneanother. Strikingly, all these phenotypes are mimicked by single-gene RNAiexperiments in C. elegans. We use these comparisons to hypothesize themolecular mechanisms underlying the evolutionary changes. For example,we predict that a cell polarity module was altered during the evolution of theProtorhabditis group and show that PAR-1, a kinase localized asymmetricallyin C. elegans early embryos, is symmetrically localized in the one-cell stageof Protorhabditis group species. Our genome-wide approach identifies candi-date molecules—and thereby modules—associated with evolutionary changesin cell-biological phenotypes.
We set the property text to this value in the Ant file, but do not show it onthe command line. We run the command as follows.
> ant -Dmodel.file=wormbase.LatentDirichletAllocation-Dsymbol.table.file=wormbase.SymbolTable -Drandom.seed=42lda-classify
Topic Pr Topic Pr------ ----- ------ -----
20 0.310 3 0.0176 0.254 38 0.015
25 0.229 35 0.01421 0.077 7 0.00526 0.024 32 0.004
Like LDA as a whole (see Section 11.10), we get similar results for the biggertopics with different random seeds. Even with the small number of samples, 100,we used here. For instance, using seed 195334, we get very similar values for thetop 8 topics.
> ant lda-classify -Drandom.seed=195334 ...
Topic Pr Topic Pr------ ----- ------ -----
20 0.308 26 0.0256 0.252 38 0.015
5Brauchle M., K. Kiontke, P. MacMenamin, D. H. Fitch, and F. Piano. 2009. Evolution of earlyembryogenesis in rhabditid nematodes. Dev Biol. 335(1). doi:10.1016/j.ydbio.2009.07.033.
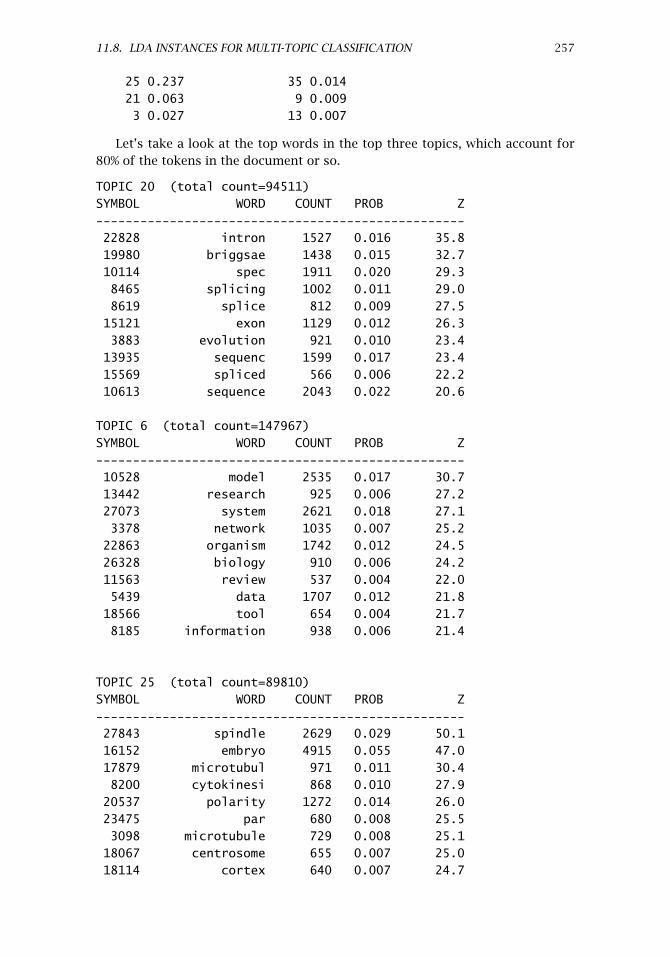
11.8. LDA INSTANCES FOR MULTI-TOPIC CLASSIFICATION 257
25 0.237 35 0.01421 0.063 9 0.0093 0.027 13 0.007
Let’s take a look at the top words in the top three topics, which account for80% of the tokens in the document or so.
TOPIC 20 (total count=94511)SYMBOL WORD COUNT PROB Z--------------------------------------------------22828 intron 1527 0.016 35.819980 briggsae 1438 0.015 32.710114 spec 1911 0.020 29.38465 splicing 1002 0.011 29.08619 splice 812 0.009 27.515121 exon 1129 0.012 26.33883 evolution 921 0.010 23.413935 sequenc 1599 0.017 23.415569 spliced 566 0.006 22.210613 sequence 2043 0.022 20.6
TOPIC 6 (total count=147967)SYMBOL WORD COUNT PROB Z--------------------------------------------------10528 model 2535 0.017 30.713442 research 925 0.006 27.227073 system 2621 0.018 27.13378 network 1035 0.007 25.222863 organism 1742 0.012 24.526328 biology 910 0.006 24.211563 review 537 0.004 22.05439 data 1707 0.012 21.818566 tool 654 0.004 21.78185 information 938 0.006 21.4
TOPIC 25 (total count=89810)SYMBOL WORD COUNT PROB Z--------------------------------------------------27843 spindle 2629 0.029 50.116152 embryo 4915 0.055 47.017879 microtubul 971 0.011 30.48200 cytokinesi 868 0.010 27.920537 polarity 1272 0.014 26.023475 par 680 0.008 25.53098 microtubule 729 0.008 25.118067 centrosome 655 0.007 25.018114 cortex 640 0.007 24.7

258 CHAPTER 11. LATENT DIRICHLET ALLOCATION
7615 cortical 592 0.007 23.3
These topics are reasonable. Topic 20 is largely about evolution as it relatesto splicing and introns, topic 6 is about systems biology and this is definitelya systems biology paper, and topic 25 is about embryos and the family of pargenes that control them (including the gene par-1 mentioned in the article atrank 20 or so.
With different random seeds, the LDA models produced from a corpus willvary. This will also affect document similarlity. It’s possible to use full Bayesiananalysis to average over all this uncertainty (see Section 11.8.3).
11.8.3 Bayesian Inference with an LDA Model
In the last section, we showed how to provide the Bayesian point estimate forthe topic distributions. This is a reasonable estimate in that it minimizes the ex-pected difference between the estimates and the “true” values (given the model).We could then plug these estimates in to reason about the document.
The basic problem with point estimates is that they do not encode the vari-ance of the estimate. Some of the numbers may be more or less certain thanothers, and this can affect downstream inference.
The LDA class also provides support for full Bayesian inference in classifica-tion.6 For Bayesian inference, we collect a group of samples, reason about eachsample, then average the results. This may seem like what we did in the last sec-tion, but there we averaged over the Gibbs samples before performing inference.With full Bayesian inference, we do the averaging of the result of reasoning withover each Gibbs sample.
To retrieve a set of Gibbs samples, the LDA method sampleTopics(), takingexactly the same arguments in the same sequence as bayestopicEstimat(),produces an array of samples, each assigning each token to a single topic. Eachmember of the two-dimensional array assigns each token in the document to atopic.
The point estimation method we described in the last section for classificationcould be reconstructed by averaging the result of sampling (with the priors usedfor estimation). Roughly, we just count up all the words assigned to a given topicand divide by the total number of words; in reality, we also apply the prior.
11.9 Comparing Documents with LDA
After running LDA on a corpus, or on fresh documents using the classifier, it’spossible to use the output of LDA to compare documents to each other. Eachdocument gets a distribution over topics. These may be compared to each otherusing KL-divergence in exactly the same way as we compared topics to each other(see Section 11.10).
6What we discuss uses a point estimate of the LDA model. If we used more than one LDA model,we could start producing Bayesian estimaes one level back. The problem with doing that is that thetopics are not identified in LDA, so we couldn’t use multiple Gibbs samples of LDA parameters forclassification directly.

11.10. STABILITY OF SAMPLES 259
The benefit of comparing documents this way is that two documents thatshare few or even no words may be considered similar by being about the sametopic. For instance, a document mentioning p53 (a tumor suppressor gene) willbe related to a document mentioning tumor and suppressor, even if the docu-ments have no other words in common. This is because p53 often mentionedin the same documents as tumor and suppressor, so they will belong to similartopics.
Comparing documents is a situation in which we can usefully apply fullBayesian inference (see Section 11.8.3), because it doesn’t depend on the iden-tity of topics across samples when comparing documents.
11.10 Stability of Samples
Because LDA uses a random initialization, the results will not be the same eachtime it is run with a different random seed. For instance, a roughly similar topicin two runs may be topic number 17 in one run and topic 25 in another run. Thetopics may even drift over time in very, very long chains of samples.
The issue is then one of whether the topics are stable independent of theirnumbering. It turns out that across runs, many topics tend to be relatively stable,but other topics will vary. This idea could even be used to decide how manytopics to select, restricting the number to those that are stable.
Steyvers and Griffiths tested the stability of topics by running LDA over thesame corpus from two different seeds, then comparing the set of topics that areproduced. Their basic approach is to line up the topics in the two samples basedon the similarity of their probability distributions. In this section, we replicatetheir approach with a demo. The code is in demo class LdaTopicSimilarity.
11.10.1 Comparing Topics with Symmetrized KL Divergence
Because topics are nothing more than probability distributions over tokens, tocompare topics, we need a way to compare probabiilty distributions. Here, wefollow Steyvers and Griffiths in using symmetrized Kullback-Leibler (KL) diver-gence (see Section B.3.6 for definitions and examples).
Steyvers and Griffiths produced two chains of Gibbs samples, both of whichthey ran for a large nubmer of iterations. They then compared the last samplesfrom each chain to each other. Specifically, they compared every every topic inthe final sample from chain 1 against every topic in the final sample from chain2.
The basis of their comparison was a greedy alignment. Conceptually, if we putthe pairwise scores in order from lowest divergence to highest, we walk down thelist of pairs, retaining every pair for which neither topic has been consumed. Thatway, every topic only shows up once on each side of the pairing. The choices aregreedy in that we always select the least divergent pair of topics to add next fromamong the topics that haven’t yet been assigned.

260 CHAPTER 11. LATENT DIRICHLET ALLOCATION
11.10.2 Code Walkthrough
The code to run the example is in LdaTopicSimilarity. Most of the work isdone in the main() method of the command. It’s declared to throw not only anI/O exception, but also an interrupted exception, because we are going to runeach chain in its own thread.
public static void main(String[] args)throws IOException, InterruptedException {
After that, the method parses the text, creates the tokenizer factory, and extractsthe tokens the same way as in our earlier Wormbase demo, using the utilitymethods introduced in the demo class LdaWorm.
We run two chains concurrently in their own threads. We basically just createthe runnable from the doc-token matrix and random seed, create threads for tehrunnable, start the threads, join them so our main() method’s thread waits forthe newly spawned threads to complete. We then extract the LDA model from theresult, where they are stored in the member variable mLda. Finally, we computethe scores, then print them out.
long seed1 = 42L;long seed2 = 43L;LdaRunnable runnable1 = new LdaRunnable(docTokens,seed1);LdaRunnable runnable2 = new LdaRunnable(docTokens,seed2);Thread thread1 = new Thread(runnable1);Thread thread2 = new Thread(runnable2);thread1.start();thread2.start();thread1.join();thread2.join();LatentDirichletAllocation lda0 = runnable1.mLda;LatentDirichletAllocation lda1 = runnable2.mLda;
double[] scores = similarity(lda0,lda1);
The real work’s in the runnable and in the similarity method.The runnable that executes in each thread is defined to simply generate 199
Gibbs samples, then set the 200th as the value of the member variable mLda.
static class LdaRunnable implements Runnable {
LatentDirichletAllocation mLda;final int[][] mDocTokens;final Random mRandom;
LdaRunnable(int[][] docTokens, long seed) {mDocTokens = docTokens;mRandom = new Random(seed);
}
public void run() {short numTopics = 50;

11.10. STABILITY OF SAMPLES 261
double topicPrior = 0.1;double wordPrior = 0.001;int numSamples = 200;Iterator<GibbsSample> it
= LatentDirichletAllocation.gibbsSample(mDocTokens,numTopics,topicPrior,
wordPrior,mRandom);for (int i = 1; i < numSamples; ++i)
it.next();mLda = it.next().lda();
}}
We save the doc-token matrix and the random generated from the seed. Therun() method uses the other Gibbs sampling method in LDA, which returns aniterator over samples. It’s simpler to configure because there’s nothing aboutnumber of epochs or reporting with callbacks. We then generate number of sam-ples minus one samples in a for loop, then take another sample and assign it tomLda for later use.
The similarity method which computes the greedy alignment between topicsin the two LDA instances is as follows.
static double[] similarity(LatentDirichletAllocation lda0,LatentDirichletAllocation lda1) {
int numTopics = lda0.numTopics();List<TopicSim> pairs = new ArrayList<TopicSim>();for (int i = 0; i < numTopics; ++i) {
double[] pi = lda0.wordProbabilities(i);for (int j = 0; j < numTopics; ++j) {
double[] pj = lda1.wordProbabilities(j);double divergence
= Statistics.symmetrizedKlDivergence(pi,pj);TopicSim ts = new TopicSim(i,j,divergence);pairs.add(ts);
}}Collections.sort(pairs,ScoredObject.comparator());boolean[] taken0 = new boolean[numTopics];boolean[] taken1 = new boolean[numTopics];double[] scores = new double[numTopics];int scorePos = 0;for (TopicSim ts : pairs) {
if (!taken0[ts.mI] && !taken1[ts.mJ]) {taken0[ts.mI] = taken1[ts.mJ] = true;scores[scorePos++] = ts.score();
}}return scores;

262 CHAPTER 11. LATENT DIRICHLET ALLOCATION
}
It starts by walking over the pairs of topics, extracting the distribution for a spec-ified topic using the method wordProbabilities(int), which is defined on theLDA object. We compute the divergence using the symmetrized KL divergence inLingPipe’s Statistics utility class.
We keep track of the pairs of topics and their scores using a nested staticclass, TopicSim, defined in the same file.
static class TopicSim implements Scored {
final int mI, mJ;final double mScore;
public TopicSim(int i, int j, double score) {mI = i;mJ = j;mScore = score;
}
public double score() {return mScore;
}}
The constructor stores the indices of the topics and the divergence between theirtopics. The class is defined to implement LingPipe’s Scored interface to alloweasy sorting.
Once we have the set of pairs, we sort it using Java’s static sort() utilitymethod in the utility class Collections. This ensures the pairs are sorted inorder of increasing divergence.
Next, we create boolean arrays to keep track of which topics have already beenassigned. All values start with default false values, then they are set to truewhen the topic with the index is used. This makes sure we don’t double-assigntopics in our alignment across samples. We then just walk over the pairs inincreasing order of divergence, and if both their topics are not already assigned,we assign the topics to each other, set the score, and set the fact that we’veassigned. Then, we just return the result.
11.10.3 Running the Demo
The demo is hard coded for everything but the path to the compressed data,which is specified as in the simple LDA example. The Ant target lda-topic-siminvokes the demo, specifying the path to the compressed corpus as the value ofthe property wormbase.corpus.gz.
> ant -Dwormbase.corpus.gz="../../data-dist/2007-12-01-wormbase-literature.endnote.gz"lda-topic-sim
0 3.0 14 5.1 29 7.2 44 11.91 3.2 15 5.2 31 7.3 45 12.0

11.11. THE LDA MODEL 263
2 3.5 16 5.3 32 7.5 46 12.63 3.8 17 5.6 33 7.6 47 13.14 4.0 18 5.7 34 7.9 48 14.55 4.2 19 6.1 35 8.0 49 15.76 4.4 20 6.2 36 8.17 4.4 21 6.3 37 8.38 4.5 22 6.4 38 8.99 4.7 23 6.5 39 9.4
10 4.8 24 6.8 40 9.911 5.0 25 6.9 41 9.912 5.0 26 7.0 42 10.313 5.0 27 7.1 43 11.6
The most closely related topics from the two samples drawn from differentchains have a KL-divergence of roughly 3 bits, down to almost 16 bits for thelast pair of topics. You can also try running for more epochs or with differentrandom seeds, though these are hard-coded into the demo. As the estimates con-verge to their stationary states, you’ll see the top topics coming closer togetherand the bottom topics moving further apart in this greedy alignment.
If you really care about comparing topics, this program is easily modified toprint out the identifiers of the topics linked this way. By printing the topics aswe did before, you can compare them by eye.
11.11 The LDA Model
LDA is a kind of probabilistic model known as a generative model. Generativemodels provide step-by-step characterizations of how to generate a corpus ofdocuments.7 This setup seems strange to many people at first because we are inpractice presenting LDA with a collection of documents and asking it to infer thetopic model, not the other way around. Nevertheless, the probabilistic model isgenerative.
LDA generates each document independently based on the model parame-ters. To generate a document, LDA first generates a topic distribution for thatdocument.8 This happens before any of the words in a document are generated.At this stage, we might only know that a document is 70% about politics and 30%about the economy, not what words it contains.
After generating the topic distribution for a document, we generate the wordsfor the document.
In the case of LDA, we suppose that the number of documents and the numberof tokens in each document is given. This means they’re not part of
That means we don’t try to predict how long each document is or usedocument-length information for relating documents. Furthermore, LDA does
7LDA does not model the number of documents in a corpus or the number of tokens in eachdocument. These values must be provided as constants. This is usually not a problem because thecorpus is given as data.
8The topic distribution for a document is generated from a Dirichlet distribution, which is wherethe model gets its name.

264 CHAPTER 11. LATENT DIRICHLET ALLOCATION
not We also do not attempt to model the size of the corpus.
11.11.1 Generalized “Documents”
Although LDA is framed in terms of documents and words, it turns out it onlyuses the identities of the tokens. As such, it may be applied to collections of“documents” consisting of any kind of count data, not just bags of words. Forinstance, LDA may be applied to RNA expression data.

Chapter 12
Singular Value Decomposition
265

266 CHAPTER 12. SINGULAR VALUE DECOMPOSITION

Appendix A
Mathematics
This appendix provides a refresher in some of the mathematics underlying ma-chine learning and natural language processing.
A.1 Basic Notation
A.1.1 Summation
We use summation notation throughout, writing∑n∈N xn for the sum of the xn
values for all n ∈ N . For instance, if N = {1,5,7}, then∑n∈N xn = x1 + x5 + x7.
We also write∑bn=a xn for the sum xa + xa+1, . . . , xb−1, xb. If a = −∞ or
b = ∞, the sums are open ended. For instance, we write∑∞n=a xn for the infinite
sum xa + xa+1 + xa+2 + · · · .The boundary condition of
∑n∈N xn when N is the empty set is 0, because 0
is the additive unit (i.e., 0+n = n+ 0 = n).
A.1.2 Multiplication
We use product notation just like summation notation, swapping the productsymbol
∏for the summation symbol
∑. For instance, we write
∏n∈N xn for the
product of all the xn values for n ∈ N . We use bounded and infinite products inexactly the same way as for summation.
The boundary condition for∏n∈N xn in the case where N is empty is 1, be-
cause 1 is the multiplicative unit (i.e., 1×n = n× 1 = n).
A.2 Useful Functions
A.2.1 Exponents
The exponential function exp(x) is defined as the unique non-zero solution tothe differential equation f ′ = f . Thus we have
ddx
exp(x) = exp(x) and∫
exp(x) dx = exp(x). (A.1)
267

268 APPENDIX A. MATHEMATICS
It turns out the solution is exp(x) = ex , where e, known as Euler’s number, isapproximately 2.718.
The exponential function may be applied to any real number, but its value isalways positive. The exponential function has some convenient properties, suchas
exp(a+ b) = exp(a)× exp(b), and (A.2)
exp(a× b) = exp(a)b. (A.3)
A.2.2 Logarithms
The natural logarithm, logx is defined as the inverse of exp(x). That is, logxis defined to be the y such that exp(y) = x. Thus for all x ∈ (−∞,∞) and ally ∈ (0,∞) we have
log exp(x) = x and exp(logy) = y. (A.4)
Logarithms convert multiplication into addition and exponentiation into mul-tiplication, with
log(x ×y) = logx + logy, and (A.5)
logxy = y logx. (A.6)
We can define logarithms in different bases, where logb x is defined to be they such that by = x. In terms of natural logs, we have
logb x = logx/ logb. (A.7)
A.2.3 The Factorial Function
The factorial function computes the number of different ordered permutationsthere are of a list of a given (non-negative) number of distinct objects. The facto-rial function is written n! and defined for n ∈ N by
n! = 1× 2× · · · ×n =n∏m=1
m. (A.8)
The convention is to set 0! = 1 so that the boundary conditions of definitions likethe one we provided for the binomial coefficient work out properly.
A.2.4 Binomial Coefficients
The binomial coefficient has many uses. We’re mainly interested in combina-torics, so we think of it as providing the number of ways to select a subset ofa given size from a superset of a given size. The binomial coefficient is writtenmchoosen, prounced “m choose n,” and defined for m,n ∈ N with n ≥m by(
nm
)= n!m! (n−m)! . (A.9)

A.2. USEFUL FUNCTIONS 269
A.2.5 Multinomial Coefficients
The multinomial coefficient generalizes the binomial coefficient to choosing morethan one item. It tells us how many ways there are to partition a set into subsetsof fixed sizes. For a set of size n, the number of ways partition it into subsets ofsizes m1, . . . ,mK , where mk ∈ N and n =
∑Kk=1mk, is(
nm1, . . . ,mK
)= n!∏K
k=1mk!. (A.10)
A.2.6 The Γ Function
The Γ function is the complex generalization of the factorial function (see Sec-tion A.2.3). It is written Γ(x), and we’re only concerned with real x ∈ [0,∞),where its value is defined by
Γ(x) =∫∞
0tx−1 exp(−t) dt. (A.11)
In general, we haveΓ(x + 1) = x Γ(x). (A.12)
Because we have Γ(1) = 1, we also have for all n ∈ N, n > 0,
Γ(n) = (n− 1)!. (A.13)

270 APPENDIX A. MATHEMATICS

Appendix B
Statistics
This appendix provides a refresher in some of the statistics underlying machinelearning and natural language processing.
B.1 Discrete Probability Distributions
B.1.1 Bernoulli Distribution
The Bernoulli distribution has binary outcomes 0 and 1, with outcome 1 con-ventionally referred to as “success.” The distribution has a single parameterθ ∈ [0,1] for the chance of success. If a random variable X has a Bernoullidistribution with parameter θ we write X ∼ Bern(θ). The resulting probablitydistribution for x ∼ Bern(θ) is defined for x ∈ {0,1} by
pX(x) = θx × (1− θ)1−x. (B.1)
Working out the cases, if x = 1, we have pX(x) = θ and if x = 0, we havepX(x) = 1− θ.
The variance and standard deviation for X ∼ Bern(θ) are given by
var[X] = θ(1− θ) and sd[X] =√θ(1− θ). (B.2)
B.1.2 Binomial Distribution
The binomial distribution is parameterized by a chance-of-success parameter θ ∈[0,1] and a number-of-trials parameter N ∈ N. If a random variable X has abinomial distribution with parameters θ and N , we write X ∼ Binom(θ,N). Theresulting probability distribution is defined for n ∈ 0:N by
pX(n) =(Nn
)θn (1− θ)N−n. (B.3)
The variance and standard deviation of a binomially-distributed random vari-able X ∼ Binom(θ,N) are given by
var[X] = θ(1− θ)N
and sd[X] =√θ(1− θ)N
. (B.4)
271

272 APPENDIX B. STATISTICS
We are often more interested in the percentage of the N trials that resultedin success, which is given by the random variable X/N (note that N is a constanthere). The variable X/N is scaled to be between 0 and 1. With large N , X/N , willbe approximately equal to θ for almost every trial. The variance and standarddeviation of X/N are derived in the usual way, by dividing by the constant N ,
var[X/N] = θ(1− θ) and sd[X/N] =√θ(1− θ). (B.5)
B.1.3 Discrete Distribution
The discrete distribution generalizes the Bernoulli distribution to K outcomes. Adiscrete distribution is parameterized by a vector θ ∈ [0,1]K such that
K∑k=1
θk = 1. (B.6)
If the variable X has a discrete distribution with parameter θ, we write X ∼Discr(θ). The resulting probabilty distribution for X ∼ Discr(θ) is defined forx ∈ 1:K by
pX(x) = θx. (B.7)
If K = 2, a discrete distribution has the same distribution over outcomes 1and 2 as a Bernoulli has over outcomes 0 and 1. In symbols, for x ∈ {0,1}, wehave
Bern(x|θ) = Discr(x + 1|〈1− θ,θ〉) (B.8)
Note that if we collapse categories together so that we are left with two out-comes (either one versus all, or one subset versus another subset), we are leftwith a Bernoulli distribution.
B.1.4 Multinomial Distribution
Multinomials generalize discrete distributions to counts in the same way thatbinomials generalize Bernoulli distributions. Given a K-dimensional discrete pa-rameter θ and a number of trials N , the multinomial distribution assigns proba-bilities to K-dimesnional vectors of counts (non-negative integers in N) that sumto N . If a vector random variable X is distributed as a multinomial with discreteparameter θ and number of trials N , we write X ∼ Multinom(θ,N,). For a vari-able X ∼ Multinom(θ,N,), the probability assigned to outcome x ∈ NK where∑Kk=1 xk = N , is
pX(x) =(
Nx1, . . . , xK
) K∏k=1
θxkk . (B.9)
where we the normalizing term is a multinomial coefficient as defined in Sec-tion A.2.5.

B.2. CONTINUOUS PROBABILITY DISTRIBUTIONS 273
B.2 Continuous Probability Distributions
B.2.1 Normal Distribution
B.2.2 χ2 Distribution
The χ2 distribution with n degrees of freedom arises as the sum of the squaresof n independent unit normal distributions (see Section B.2.1). In symbols, ifXn ∼ Norm((,0),1) for n ∈ 1:N , then
Y =N∑n=1
X2n (B.10)
has a χ2 distribution with N degrees of freedom.If a variable X has a χ2 distribution with N degrees of freedom, we write
X ∼ ChiSq(N). The probability distribution for X is defined for x ∈ [0,∞) by
pX(x) =1
2N/2 Γ(n/2)xN/2−1 exp(−x/2). (B.11)
If X ∼ ChiSq(N), then the mean, variance and standard deviation of X are
E[X] = N, var[X] = 2n, and sd[X] =√
2n. (B.12)
B.3 Information Theory
Information theory was originally developed by Claude Shannon to model thetransmission of messages over noisy channels such as telephones or telegraphs.1
B.3.1 Entropy
Entropy is an information-theoretic measure of the randomness of a distribution.The entropy of a random variable X is most easily expressed as the expecta-
tion of the negative log probability of the variable,
H[X] = E[− log2 pX(X)]. (B.13)
Because we use base 2, the results are in units of binary digits, otherwise knownas bits.
For a discrete random variable X, unfolding the expectation notation yields
H[X] = −∑n∈N
pX(n) log2 pX(n). (B.14)
For a continous random variable X, we replace the summations over naturalnumbers with integration over the real numbers,
H[X] = −∫∞−∞pX(x) log2 pX(x) dx (B.15)
1Claude Shannon. 1948. A mathematical theory of communication. Bell System Technical Journal27:379–423 and 27:623–656.

274 APPENDIX B. STATISTICS
theta
H[B
ern(
thet
a)]
0.0 0.5 1.0
0.0
0.5
1.0
Figure B.1: Entropy of a random variable distributed as Bern(θ).
For example, if we have a Bernoulli-distributed random variable Y ∼ Bern(θ),its entropy is
H[Y] = −pY (1) log2 pY (1)− pY (0) log2 pY (0) (B.16)
= −θ log2 θ − (1− θ) log2(1− θ). (B.17)
A plot of H[Y] for Y ∼ Bern(θ) is provided in Figure B.1. The graph makes itclear that when θ = 0 or θ = 1, the outcome is certain, and therefore the entropyis 0. The maximum entropy possible for a Bernoulli distribution is 1 bit, achievedat θ = 0.5.
Entropy and Compression
Entropy has a natural interpretation in terms of compression. Suppose we wantto send the a message X which might take on values in N.2 If the sender andreceiver both know the distribution pX of outcomes, the expected cost to sendthe message is H[X] bits. For instance, if we need to send a bit with value 0 or 1,and each outcome is equally likely, it will require 1 bit to send the message. Onthe other hand, if one outcome is more likely than the other, we can save space(if we have repeated messages to send; otherwise, we must round up).
B.3.2 Joint Entropy
We can measure the entropy of two variables X and Y by measuring the entropyof their joint distribution pX,Y , generalizing our definition to
H[X, Y] = E[log2 pX,Y (x,y)]. (B.18)
For instance, with discrete X and Y , this works out to
H[X, Y] = −∑x
∑ypX,Y (x,y) log2 pX,Y (x,y). (B.19)
Joint entropy is symmetric, so that
H[X, Y] = H[Y ,X]. (B.20)2We can always code sequences of characters as numbers, as originally noted by Kurt Gödel, and
as explained in any introductory computer science theory text. Just think of a string as representinga number in the base of the number characters.

B.3. INFORMATION THEORY 275
B.3.3 Conditional Entropy
We can measure the entropy of a variable X conditional on knowing the value ofanother variable Y . The expectation-based definition is thus
H[X|Y] = E[− log2 pX|Y (X|Y)]. (B.21)
In the case of discrete X and Y , this works out to
H[X|Y] = −∑y
∑xpX,Y (x,y) log2 pX|Y (x|y) (B.22)
= −∑ypY (y)
∑xpX|Y (x|y) log2 pX|Y (x|y). (B.23)
Conditional entropy, joint entropy and entropy are related as for probabiltydistributions, with
H[X, Y] = H[X|Y]+H[Y]. (B.24)
B.3.4 Mutual Information
The mutual information between a pair of variables X and Y measures how muchmore information there is in knowing their joint distribution than their individualdistributions for prediction. Using expectations, mutual information betweenvariables X and Y is defined to be
I[X;Y] = E[− log2pX,Y (x,y)pX(x) pY (y)
] (B.25)
= E[− log2 pX,Y (x,y)]+ E[log2 pX(x)]+ E[log2 pY (y)] (B.26)
Another way of looking at mutual information is in terms of the ratio of a con-ditional and marginal distribution. If we unfold the joint distribution pX,Y (x,y)into the product of the marginal pX(x) and conditional pY (y|x), we get
I[X;Y] = E[− log2pX|Y (x|y)pX(x)
] = E[− log2pY |X(y|x))pY (y)
]. (B.27)
In the discrete case, this unfolds to
I[X;Y] = −∑x,ypX,Y (x,y) log2
pX,Y (x,y)pX(x) pY (y)
. (B.28)
Mutual information is symmetric, so that
I[X;Y] = I[X;Y]. (B.29)
It’s related to conditional and joint entropies by the unfolding in the second stepof the definition through
I[X;Y] = H[X]+H[Y]−H[X, Y] (B.30)
= H[X]−H[X|Y]. (B.31)

276 APPENDIX B. STATISTICS
B.3.5 Cross Entropy
Cross-entropy measures the number of bits required, on average, to transmit avalue of X using the distribution of Y for coding. Using expectation notation, thedefinition reduces to
CH[X ‖ Y] = E[− log2 pY (X)]. (B.32)
In the case of discrete random variables X and Y , this works out to
CH[X ‖ Y] = −∑npX(n) log2 pY (n). (B.33)
B.3.6 Divergence
Kullback-Leibler (KL) divergence is the standard method to compare two distri-butions. Pairs of distributions that have similar probabilities will have low diver-gence from each other. Because KL divergence is not symmetric, we also considertwo standard symmetric variants.
Following the standard convention, our previous infomration definitions wereall in terms of random variables X and Y , even though the definitions only de-pendeded on their corresponding probability distributions pX and pY . Diver-gence is conventionally defined directly on distributions, mainly to avoid the caseof comparing two different random variables X and Y with the same distributionpX = pY .
KL Divergence
Given two discrete distributions pX and pY , the KL divergence of pY from pX isgiven by
DKL(pX‖pY ) =N∑n=1
pX(n) log2pX(n)pY (n)
. (B.34)
If there is an outcome n where pY (n) = 0 and pX(n) > 0, the divergence isinfinite. We may allow pX(n) = 0 by interpreting 0 log2
0pY (n) = 0 by convention
(even if pY (n) > 0).If we assume pX and pY arose from random variables X and Y , KL divergence
may expressed using expectations as
DKL(pX‖pY ) = E[log2pX(X)pY (X)
] (B.35)
= E[log2 pX(X)]− E[log2 pY (X)] (B.36)
= E[− log2 pY (X)]− E[− log2 pX(X)] (B.37)
= CH[X ‖ Y]−H[X]. (B.38)
This definition makes clear that KL divergence may be viewed as as the expectedpenalty in bits for using pY to transmit values drawn from X rather than pXitself. In other words, KL divergence is just the cross-entropy minus the entropy.
Although we do not provide a proof, we note that DKL(pX‖pY ) ≥ 0 for alldistributions pX and pY . We further note without proof that DKL(pX‖pY ) = 0 ifand only if pX = pY .

B.3. INFORMATION THEORY 277
Symmetrized KL Divergence
KL divergence is not symmetric in the sense that there exist pairs of randomvariables X and Y such that DKL(pX‖pY ) ≠ DKL(pY‖pX).
There are several divergence measures derived from KL divergence that aresymmetric. The simplest approach is just to introduce symmetry by brute force.The symmetrized KL-divergence DSKL(pX‖pY ) between distributions pX and pYis defined by averaging the divergence of pX from pY and the divergence of pYfrom pX , yielding gives us
DSKL(pX‖pY ) =12(DKL(pX‖pY )+DKL(pY‖pX)). (B.39)
Obviously, DSKL(pX‖pY ) = DSKL(pY‖pX) by definition, so the measure is sym-metric. As with KL divergence, symmetrized KL divergence so that, in general,DSKL(pX‖pY ) ≥ 0 with DSKL(pX‖pY ) = 0 if and only if pX = pY .
Jensen-Shannon Divergence
Another widely used symmetric divergence measure derived from KL divergenceis the Jensen-Shannon divergence. To compare X and Y using Jensen-Shannondivergence, we first define a new distribution pZ by averaging the distributionspX and pY , by
pZ(n) =12(pX(n)+ pY (n)). (B.40)
If X and Y are random variables and Z is defined to be (X + Y)/2, then pX , pYand pZ satisfy the above definition.
Given the average distribution pZ , we can define Jensen-Shannon divergenceby taking average divergence of pX and pY from pZ as defined in Equation B.40,setting
DJS(pX‖pY ) =12(DKL(pX‖pZ)+DKL(pY‖pZ)). (B.41)
As with the symmetrized KL divergence, Jensen-Shannon divergence is symmet-ric by definition.
LingPipe KL-Divergence Utilities
KL-divergence is implemented as a static utility method in the Statistics util-ity class in package com.aliasi.stats. The method takes two double arraysrepresenting probability distributions and measures how much the first is likethe second.
In order to give you a sense of KL-divergence, we implement a simple utility inthe demo class KlDivergence to let you try various values. The code just parsesout double arrays from teh command line and sends them to the KL function.
public static void main(String[] args) {double[] pX = parseDoubles(args[0],"pX");double[] pY = parseDoubles(args[1],"pY");double kld = Statistics.klDivergence(pX,pY);double skld = Statistics.symmetrizedKlDivergence(pX,pY);double jsd = Statistics.jsDivergence(pX,pY);

278 APPENDIX B. STATISTICS
The ant target kl runs the command with the first two arguments given byproperties p.x and p.y. To calculate the example from above, we have
> ant -Dp.x="0.2 0.8" -Dp.y="0.4 0.6" kl
pX=(0.2, 0.8) pY=(0.4, 0.6)kld=0.13202999942307514skld=0.1415037499278844jsd=0.03485155455967723
The Jensen-Shannon divergence is less than the symmetrized KL divergence be-cause the interpolated distribution pZ is closer to both of the original distribu-tions pX and pY than they are to each other.

Appendix C
Corpora
In this appendix, we list the corpora that we use for examples in the text.
C.1 20 Newsgroups
Contents
The corpus contains roughly 20,000 posts to 20 different newsgroups. These are
comp.graphics rec.autos sci.cryptcomp.os.ms-windows.misc rec.motorcycles sci.electronicscomp.sys.ibm.pc.hardware rec.sport.baseball sci.medcomp.sys.mac.hardware rec.sport.hockey sci.spacecomp.windows.x
misc.forsale talk.politics.misc talk.religion.misctalk.politics.guns alt.atheismtalk.politics.mideast soc.religion.christian
Authors
It is currently being maintained by Jason Rennie, who speculates that Ken Langmay be the original curator.
Licensing
There are no licensing terms listed and the data may be downloaded directly.
Download
http://people.csail.mit.edu/jrennie/20Newsgroups/
279

280 APPENDIX C. CORPORA
C.2 MedTag
Contents
The MedTag corpus has two components, MedPost, a part-of-speech-tagged cor-pus, and GENETAG, a gene/protein mention tagged corpus. The data annotatedconsists of sentences, and sentence fragments from MEDLINE citation titles andabstracts.
Authors
The MedPost corpus was developed at the U. S. National Center for BiotechnologyInformation (NCBI), a part of the National Library of Medicine (NLM), which isitself one of the National Institutes of Health (NIH). Its contents are described in
Smith, L. H., L. Tanabe, T. Rindflesch, and W. J. Wilbur. 2005. MedTag:a collection of biomedical annotations. In Proceedings of the ACL-ISMBWorkshop on Linking Biological Literature, Ontologies and Databases:Mining Biological Semantics. 32–37.
Licensing
The MedPost corpus is a public domain corpus released as a “United States Gov-ernment Work.”
Download
ftp://ftp.ncbi.nlm.nih.gov/pub/lsmith/MedTag/medtag.tar.gz
C.3 WormBase MEDLINE Citations
The WormBase web site, http://wormbase.org, curates and distributes re-sources related to the model organism Caenorhabditis elegans, the nematodeworm. Part of that distribution is a set of citation to published research on C. el-egans. These literature distributions consist of MEDLINE citations in a simpleline-oriented format.
Authors
Wormbase is a collaboration among many cites with many supporters. It is de-scribed in
Harris, T. W. et al. 2010. WormBase: A comprehensiveresource for nematode research. Nucleic Acids Research 38.doi:10.1093/nar/gkp952

C.3. WORMBASE MEDLINE CITATIONS 281
Download
ftp://ftp.wormbase.org/pub/wormbase/misc/literature/2007-12-01-wormbase-literature.endnote.gz (15MB)

282 APPENDIX C. CORPORA

Appendix D
Java Basics
In this appendix, we go over some of the basics of Java that are particularlyrelevant for text and numerical processing.
D.1 Numbers
In this section, we explain different numerical bases, including decimal, octal,hexadecimal and binary.
D.1.1 Digits and Decimal Numbers
Typically we write numbers in the Arabic form (as opposed to, say, the Romanform), using decimal notation. That is, we employ sequences of the ten digits 0,1, 2, 3, 4, 5, 6, 7, 8, 9.
A number such as 23 may be decomposed into a 2 in the “tens place” and a3 in the “ones place”. What that means is that 23 = (2× 10)+ (3× 1); similarly4700 = (4×1000)+ (7×100). We can write these equivalently as 23 = 2×101+3 × 100 and 4700 = (4 × 103) + (7 × 102). Because of the base of the exponent,decimal notation is also called “base 10”.
The number 0 is special. It’s the additive identity, meaning that for any num-ber x, 0+ x = x + 0 = x.
We also conventionally use negative numbers and negation. For instance, -22is read as “negative 22”. We have to add 22 to it to get back to zero. That is,negation is the additive inverse, so that x + (−x) = (−x)+ x = 0.
The number 1 is also special. 1 is the multiplicative identity, so that 1× x =x×1 = x. Division is multiplicative inverse, so that for all numbers x other than0, xx = 1.
We also use fractions, written after the decimal place. Fractions are definedusing negative exponents. For instance .2 = 2× 10−1 = 2
101 , and .85 = .8× 10−1+.5× 10−2.
For really large or really small numbers, we use scientific notation, whichdecomposes a value into a number times an exponent of 10. For instance, wewrite 4700 as 4.7 × 103 and 0.0047 as 4.7 × 10−3. In computer languages, 4700
283

284 APPENDIX D. JAVA BASICS
and 0.0047 are typically written as 4.7E+3 and 4.7E-3. Java’s floating pointnumbers may be input and output in scientific notation.
D.1.2 Bits and Binary Numbers
Rather than the decimal system, computers work in the binary system, wherethere are only two values. In binary arithmetic, bits play the role that digits playin the decimal system. A bit can have the value 0 or 1.
A number in binary notation consists of a sequence of bits (0s and 1s). Bitsin binary binary numbers play the same role as digits in decimal numbers; theonly difference is that the base is 2 rather than 10. For instance, in binary, 101 =(1 × 23) + (0 × 22) + (1 × 20), which is 7 in decimal notation. Fractions can behandled the same way as in decimal numbers. Scientific notation is not generallyused for binary numbers.
D.1.3 Octal Notation
Two other schemes for representing numbers are common in computer lan-guages, octal and hexadecimal. As may be gathered from its name, octaloctalis base 8, conventionally written using the digits 0–7. Numbers are read in theusual way, so that octal 43 is expanded as (4 × 81) + (3 × 80), or 35 in decimalnotation.
In Java (and many other computer languages), octal notation is very confus-ing. Prefixing a numeric literal with a 0 (that’s a zero, not a capital o) leads to itbeing interpreted as octal. For instance, the Java literal 043 is interpreted as thedecimal 35.
D.1.4 Hexadecimal Notation
Hexadecimal is base 16, and thus we need some additional symbols. The first 16numbers in hex are conventionally written
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F.
In hexadecimal, the value of A is what we’d write as 10 in decimal notation.Similarly, C has the value 12 and F the value 15. We read off compound numbersin the usual way, so that in hex, 93 = (9 × 161) + (3 × 160), or 138 in decimalnotation. Similarly, in hex, the number B2F = (11× 162)+ (2× 161)+ (15× 160),or 2863 in decimal notation.
In Java (and other languages), hexadecimal numbers are distinguished by pre-fixing them with 0x. For example, 0xB2F is the hexadecimal equivalent of thedecimal 2863.
D.1.5 Bytes
The basic unit of organization in contemporary computing systems is the byte.By this we mean it’s the smallest chunk of data that may be accessed programat-ically, though in point of fact, hardware often groups bytes together into larger

D.1. NUMBERS 285
groups that it operates on all at once. For instance, 32-bit architectures oftenoperate on a sequence of 4 bytes at once and 64-bit architectures on 8 bytesat once. The term “word” is ambiguously applied to a sequence of two bytes,or to the size of the sequence of bytes at which a particular piece of hardwareoperates.
A bytebyte is a sequence of 8 bits, and is sometimes called an octet for thatreason. Thus there are 256 distinct bytes, ranging from 00000000 to 11111111.The bits are read from the high (left) end to the low (right end).
In Java, the byte primitive type is signed. Any number between 00000000and 01111111 is interpreted as a binary number with decimal value between 0and 127 (inclusive). If the high order bit is 1, the value is interpreted as negative.The negative value is value of the least significant 7 bits minus 128. For instance,10000011 is interpreted as 3 − 128 = −125, because 00000011 (the result ofsetting the high bit to 0) is interpreted as 3.
The unsigned value of a byte b is returned by (b < 0 ? (b + 256) : b).The primitive data type for computers is a sequence of bytes. For instance,
the contents of a file is a sequence of bytes, and so is the response from a webserver to an HTTP request for a web page. Most importantly for using LingPipe,sequences of characters are represented by sequences of bytes.
D.1.6 Code Example: Integral Number Bases
There is a simple program in the code directory for this appendix
src/java/src/com/lingpipe/book/appjava/ByteTable.java
for displaying bytes, their corresponding unsigned value, and the conversion ofthe unsigned value to octal, hexadecimal and binary notations. The work is doneby the loop
for (int i = 0; i < 256; ++i) {byte b = (byte) i; // overflows if i > 127int k = b < 0 ? (b + 256) : b;System.out.printf("%3d %5d %3s %2s %8s\n",
k, b, Integer.toOctalString(k),Integer.toHexString(k),Integer.toBinaryString(k));
}
This code may be run from Ant by first changing into this chapter’s directoryand then invoking the byte-table target,
> cd $BOOK/src/java
> ant byte-table
The output, after trimming the filler generated by Ant, looks like
BASES10 -10 8 16 2

286 APPENDIX D. JAVA BASICS
0 0 0 0 01 1 1 1 12 2 2 2 10
...9 9 11 9 100110 10 12 a 101011 11 13 b 1011
...127 127 177 7f 1111111128 -128 200 80 10000000129 -127 201 81 10000001...254 -2 376 fe 11111110255 -1 377 ff 11111111
D.1.7 Other Primitive Numbers
In addition to bytes, Java provides three other primitive integer types. Each has afixed width in bytes. Values of type short occupy 2 bytes, int 4 bytes, and long8 bytes. All of them use the same signed notation as byte, only with more bits.
D.1.8 Floating Point
Java has two floating point types, float and double. A float is representedwith 4 bytes and said to be single precision, whereas a double is representedwith 8 bytes and said to be double precision.
In addition to finite values, Java follows the IEEE 754 floating point standardin providing three additional values. There is positive infinity, conventionally ∞in mathematical notation, and referenced for floating point values by the staticconstant Float.POSITIVE_INFINITY in Java. There is also negative infinity, −∞,referenced by the constant Float.NEGATIVE_INFINITY. There is also an “unde-fined” value, picked out by the constant Float.NaN. There are correspondingconstants in Double with the same names.
If any value in an expression is NaN, the result is NaN. A NaN result is alsoreturned if you try to divide 0 by 0, subtract an infinite number from itself(or equivalently add a positive and negative infinite number), divide one infinitenumber by another, or multiple an infinite number by 0.
Both n/Double.POSITIVE_INFINITY and n/Double.NEGATIVE_INFINITYevaluate to 0 if n is finite and non-negative. Conversely, n/0 evaluates to ∞if n is positive and −∞ if n is negative. The result of multiplying two infinitenumber is ∞ if they are both positive or both negative, and −∞ otherwise. IfDouble.POSITIVE_INFINITY is added to itself, the result is itself, and the samefor Double.NEGATIVE_INFINITY. If one is added to the other, the result is NaN.The negation of an infinite number is the infinite number of opposite sign.
Monotonic transcendental operations like exponentiation and logarithms alsoplay nicely with infinite numbers. In particular, the log of a negative number is

D.2. OBJECTS 287
NaN, the log of 0 is negative infinity, and the log of positive infinity is positiveinfinity. The exponent of positive infinity is positive infinity and the exponent ofnegative infinity is zero.
D.2 Objects
Every object in Java inherits from the base class Object. There are several kindsof methods defined for Object, which are thus defined on every Java object.
D.2.1 Equality
Java distinguishes reference equality, written ==, from object equality. Referenceequality requires that the two variables refer to the exact same object. Someobjects may be equal, even if they are not identical. To handle this possibility,the Object class defines a method equals(Object) returning a boolean result.
In the Object class itself, the equality method delegates to reference equality.Thus subclasses that do not override Object’s implementation of equality willhave their equality conditions defined by reference equality.
Subclasses that define their own notion of equality, such as String, should doso consistently. Specifically, equality should form an equivalence relation. First,equality should be reflexive, so that every object is equal to itself; x.equals(x)is always true for non-null x. Second, equality should be symmetric, so if x isequal to y, y is equal to x; x.equals(y) is true if and only if y.equals(x) istrue. Third, equality should be transitive, so that if x is equal to y and y is equalto z, then x is equal to z; x.equals(y) and y.equals(z) both being true implyx.equals(z) is true.
D.2.2 Hash Codes
The Object class also defines a hashCode() method, returning an int value.This value is typically used in collections as a first approximation to equality.Thus the specification requires consistency with equality in that if two objectsare equal as defined by equals(), they must have the same hash code.
In order for collections and other hash-code dependent objects to functionproperly, hash codes should be defined
Although the implementation of hashCode() is not determined for Objectby the language specification, it is required to be consistent with equality. Thusany two objects that are reference equal must have the same hash code.
D.2.3 String Representations
The Object class defines a toString() method returning a String. The defaultbehavior is to return the name of the class followed by a hexadecimal representa-tion of its hash code. This method should be overridden in subclasses primarilyto help with debugging. Some subclasses use toString() for real work, too, aswe will see with StringBuilder.

288 APPENDIX D. JAVA BASICS
D.2.4 Other Object Methods
Determining an Object’s Class
The runtime class of an object is returned by the getClass() method. This isparticularly useful for deserialized objects and other objects passed in whoseclass might not be known. It is neither very clear nor very efficient to exploitgetClass() for branching logic. Note that because generics are erased at run-time, there is no generic information in the return.
Finalization
At some point after there are no more references to an object left alive in aprogram, it will be finalized by a call to finalize() by the garbage collector.Using finalization is tricky and we will not have cause to do so in this book. Forsome reason, it was defined to throw arbitrary throwables (the superinterface ofexceptions).
Threading
Java supports multithreaded applications as part of its language specification.The primitives for synchronization are built on top of the Object class. Eachobject may be used as a lock to synchronize arbitrary blocks of code usingthe synchronized keyword. Methods may also be marked with synchornized,which is equivalent to explicitly marking their code block as synchronized.
In addition, there are three wait() methods that cause the current thread topause and wait for a notification, and two notify() methods that wake up (oneor all) threads waiting for this object.
Rather than dealing with Java concurrency directly, we strongly recommendthe java.util.concurrent library for handling threading of any complexitybeyond exclusive synchronization.
D.2.5 Object Size
There’s no getting around it – Java objects are heavy. The lack of a C-like structtype presents a serious obstacle to even medium-performance computing. To getaround this problem, in places where you might declare an array of struct typein C, LingPipe employs parallel arrays rather than arrays of objects.
The language specification does not describe how objects are represented ondisk, and different JVMs may handle things differently. We’ll discuss how the32-bit and 64-bit Sun/Oracle JVMs work.
Header
Objects consist of a header and the values of their member variables. The headeritself consists of two references. The first establishes the object’s identity. Thisidentity reference is used for reference equality (==) and thus for locking, andalso as a return value for the hashCode() implementation in Object. Even if an

D.2. OBJECTS 289
object is relocated in memory, its reference identity and locking properties re-main fixed. The second piece of information is a reference to the class definition.
A reference-sized chunk of memory is used for each piece of information. Ina a 32-bit architecture, references are four bytes. In 64-bit architectures, they are8 bytes by default.
As of build 14 of Java SE 6, the -XX:+UseCompressedOops option may beused as an argument to java on 64-bit JVMs to instruct them to compress theirordinary object pointers (OOP) to 32-bit representations. This saves an enormousamount of space, cutting the size of a simple Object in half. It does limit theheap size to around four billion objects, which should be sufficient for mostapplications.
Member Values
Additional storage is required for member variables. Each primitive membervariable requires at least the amount of storage required for the primitive (e.g., 1byte for byte, 2 bytes for short, and 8 bytes for double). References will be 4bytes in a 32-bit JVM and a 64-bit JVM using compressed pointers, and 8 bytes inthe default 64-bit JVM.
To help with word alignment, values are ordered in decreasing order of size,with doubles and longs coming first, then references, then ints and floats, downto bytes.
Finally, the object size is rounded up so that its overall size is a multiple of8 bytes. This is so all the internal 8-byte objects inside of an object line up on8-byte word boundaries.
Static variables are stored at the class level, not at the individual object level.
Subclasses
Subclasses reference their own class definition, which will in turn reference thesuperclass definition. They lay their superclass member variables out the sameway as their superclass. They then lay out their own member variables. If thesuperclass needed to be padded, some space is recoverable by reordering thesubclass member variables slightly.
D.2.6 Number Objects
For each of the primitive number types, there is a corrsponding class for repre-senting the object. Specifically, the number classes for integers are Byte, Short,Integer, and Long. For floating point, there is Float and Double. These objectsare all in the base package java.lang, so they do not need to be explicitly im-ported before they are used. Objects are useful because many of the underlyingJava libraries, particular the collection framework in java.util, operate overobjects, rather than over primitives.1
1Open source libraries are available for primitive collections. The Jakarta Commons Primitives andCarrot Search’s High Performance Primitive Collections are released under the Apache license, andGNU Trove under the Lessger GNU Public License (LGPL).

290 APPENDIX D. JAVA BASICS
Each of these wrapper classes holds an immutable reference to an object ofthe underlying type. Thus the class is said to “box” the underlying primitive(as in “put in a box”). Each object has a corresponding method to return theunderlying object. For instance, to get the underlying byte from a Byte object,use byteValue().
Two numerical objects are equal if and only if they are of the same type andrefer to the same primitive value. Each of the numerical object classes is bothserializable and comparable, with comparison being defined numerically.
Constructing Numerical Objects
Number objects may be created using one-argument constructors. For instance,we can construct an object for the integer 42 using new Integer(42).
The problem with construction is that a fresh object is allocated for each callto new. Because the underlying references are immutable, we only need a singleinstance of each object for each underlying primitive value. The current JVMimplementations are smart enough to save and reuse numerical objects ratherthan creating new ones. The preferred way to acquire a reference to a numericalobject is to use the valueOf() static factory method from the approrpiate class.For example, Integer.valueOf(42) returns an object that is equal to the resultof new Integer(42), but is not guaranteed to be a fresh instance, and thus maybe reference equal (==) to other Integer objects.
Autoboxing
Autoboxing automatically provides an object wrapper for a primitive type whena primitive expression is used where an object is expected. For instance, it islegal to write
Integer i = 7;
Here we require an Integer object to assign, but the expression 7 returns an intprimitive. The compiler automatically boxes the primitive, rendering the abovecode equivalent to
Integer i = Integer.valueOf(7);
Autoboxing also applies in other contexts, such as loops, where we may write
int[] ns = new int[] { 1, 2, 3 };for (Integer n : ns) { ... }
Each member of the array visited in the loop body is autoboxed. Boxing is rela-tively expensive in time and memory, and should be avoided where possible.
The Java compiler also carries out auto-unboxing, which allows things like
int n = Integer.valueOf(15);
This is equivalent to using the intValue() method,
Integer nI = Integer.valueOf(15);int n = nI.intValue();

D.3. ARRAYS 291
Number Base Class
Conveniently, all of the numerical classes extend the abstract class Number.The class Number simply defines all of the get-value methods, byteValue(),shortValue(), ..., doubleValue(), returning the corresponding primitive type.Thus we can call doubleValue() on an Integer object; the return value is equiv-alent to casting the int returned by intValue() to a double.
D.3 Arrays
Arrays in Java are objects. They have a fixed size that is determined whenthey are constructed. Attempts to set or get objects out of range raises anIndexOutOfBoundsException. This is much better behaved than C, where outof bounds indexes may point into some other part of memory that may then beinadvertently read or corrupted.
In addition to the usual object header, arrays also store an integer length in4 bytes. After that, they store the elements one after the other. If the valuesare double or long values or uncompressed references, there is an additional 4bytes of padding after the length so that they start on 8-byte boundaries.
D.4 Synchronization
LingPipe follows to fairly simple approaches to synchronization, which we de-scribe in the next two sections. For more information on synchronization, seeGoetz et al.’s definitive book Java Concurrency in Practice (see Appendix F.2.2for a full reference).
D.4.1 Immutable Objects
Wherever possible, instances of LingPipe classes are immutable. After they areconstructed, immutable objects are completely thread safe in the sense of allow-ing arbitrary concurrent calls to its methods.
(Effectively) Final Member Variables
In LingPipe’s immutable objects, almost all member variabls are declared to befinal or implemented to behave as if they are declared to be final.
Final objects can never change. Once they are set in the constructor, theyalways have the same value.
LingPipe’s effectively final variables never change value. In this way, they dis-play the same behavior as the hash code variable in the implementation of Java’sString. In the source code for java.lang.String in Java Standard Edition ver-sion 1.6.18, authored by Lee Boynton and Arthur van Hoff, we have the followingfour member variables:
private final char value[];

292 APPENDIX D. JAVA BASICS
private final int offset;private final int count;private int hash;
The final member variables value, offset, and count represent the characteslice on which the string is based. This is not enough to guarantee true im-mutability, because the values in the value array may change. The design of theString class guarantees that they don’t. Whenever a string is constructed, itsvalue array is derived from another string, or is copied. Thus no references tovalue ever escape to client code.
The hash variable is not final. It is initialized lazily when the hashCode()method is called if it is has not already been set.
public int hashCode() {int h = hash;if (h == 0) {
int off = offset;char val[] = value;int len = count;for (int i = 0; i < len; i++) {
h = 31*h + val[off++];}hash = h;
}return h;
}
Note that there is no synchronization. The lack of synchronization and publicnature of hashCode() exposes a race condition. Specifically, two threads mayconcurrently call hashCode() and each see the hash code variable hash withvalue 0. They would then both enter the loop to compute and set the variable.This is safe because the value computed for hash only depends on the truly finalvariables offset, value, and count.
Safe Construction
The immutable objects follow the safe-construction practice of not releasing ref-erences to the object being constructed to escape during construction. Specifi-cally, we do not supply the this variable to other objects within constructors.Not only must we avoid sending a direct reference through this, but we canalso not let inner classes or other data structures containing implicit or explicitreferences to this to escape.
D.4.2 Read-Write Synchronization
Objects which are not immutable in LingPipe require read-write synchronization.A read method is one that does not change the underlying state of an object. Inan immutable object, all methods are read methods. A write method may changethe state of an object.

D.4. SYNCHRONIZATION 293
Read-write synchronization allows concurrent read operations, but ensuresthat writes do not execute concurrently with reads or other writes.
Java’s Concurrency Utilities
Java’s built-in synchronized keyword and block declarations use objects forsimple mutex-like locks. Non-static methods declared to be synchronized usetheir object instance for synchronization, whereas static methods use the objectfor the class.
In the built-in java.util.concurrent library, there are a number of lockinterfaces and implementations in the subpackage locks.
The util.concurrent base interface Lock generalizes Java’s built-insynchronized blocks to support more fine-grained forms of lock acquisitionand relaese, allowing operations like acquisitions that time out.
The subinterface ReentrantLock adds reentrancy to the basic lock mecha-nism, allowing the same thread to acquire the same lock more than once withoutblocking.
The util.concurrent library also supplies an interface ReadWriteLock forread-write locks. It contains two methods, readLock() and writeLock(), whichreturn instances of the interface Lock.
There is only a single implementation of ReadWriteLock, in the classReentrantReadWriteLock. Both of the locks in the implementation are de-clared to be reentrant (recall that a subclass may declare more specific returntypes than its superclass or the interfaces it implements). More specifically, theyare declared to return instances of the static classes ReadLock and WriteLock,which are nested in ReentrantReadWriteLock.
The basic usage of a read-write lock is straightforward, though configuringand tuning its behavior is more involved. We illustrate the basic usage with thesimplest possible case, the implementation of a paired integer data structure.The class has two methods, a paired set and a paired get, that deal with twovalues at once.
Construction simply stores a new read write lock, which itself never changes,so may be declared final.
private final ReadWriteLock mRwLock;private int mX, mY;
public SynchedPair(boolean isFair) {mRwLock = new ReentrantReadWriteLock(isFair);
}
The set method acquires the write lock before setting both values.
public void set(int x, int y) {try {
mRwLock.writeLock().lock();mX = x;mY = y;
} finally {

294 APPENDIX D. JAVA BASICS
mRwLock.writeLock().unlock();}
}
Note that it releases the lock in a finally block. This is the only way to guar-antee, in general, that locks are released even if the work done by the methodraises an exception.
The get method is implemented with the same idiom, but using the read lock.
public int[] xy() {try {
mRwLock.readLock().lock();return new int[] { mX, mY };
} finally {mRwLock.readLock().unlock();
}}
Note that it, too, does all of its work after the lock is acquired, returning anarray consisting of both values. If we’d tried to have two separate methods, onereturning the first integer and one returning the second, there would be no wayto actually get both values at once in a synchronized way without exposing theread-write lock itself. If we’d had two set and two get methods, one for eachcomponent, we’d have to use the read-write lock on the outside to guarantee thetwo operations always happened together.
We can test the method with the following command-line program.
public static void main(String[] args) throwsInterruptedException {final SynchedPair pair = new SynchedPair(true);Thread[] threads = new Thread[32];for (int i = 0; i < threads.length; ++i)
threads[i] = new Thread(new Runnable() {public void run() {
for (int i = 0; i < 2000; ++i) {int[] xy = pair.xy();if (xy[0] != xy[1])
System.out.println("error");pair.set(i,i);Thread.yield();
}}
});for (int i = 0; i < threads.length; ++i)
threads[i].start();for (int i = 0; i < threads.length; ++i)
threads[i].join();System.out.println("OK");
}

D.5. GENERATING RANDOM NUMBERS 295
It constructs a SynchedPair and assigns it to the variable pair, which is del-cared to be final so as to allow its usage in the anonymous inner class runnable.It then creates an array of threads, setting each one’s runnable to do a sequenceof paired sets where the two values are the same. It tests first that the values itreads are coherent and writes out an error message if they are not. The runnablesall yield after their operations to allow more interleaving of the threads in thetest. After constructing the threads with anonymous inner class Runnable im-plementations, we start each of the threads and join them so the message won’tprint and JVM won’t exit until they’re ll done.
The Ant target synched-pair runs the demo.
> ant synched-pair
OK
The program takes about 5 seconds to run on our four-core notebook.
D.5 Generating Random Numbers
Java has a built-in pseudorandom number generator. It is implemented in theclass Random in package java.util.
D.5.1 Generating Random Numbers
Given an instance of Random (see the next section for construction details), weare able to use it to generate random outcomes of several primitive types.
Discrete Random Numbers
The method nextBoolean() returns a random booleann value, nextInt() arandom int, and nextLong() a random long. The algorithms generating thesevalues are designed to assign equal probabilities to all outcomes.
The method nextInt(int) is particularly useful in that it generates a valuebetween 0 (inclusive) and its argument (exclusive).
Byte are generated using the C-like method nextBytes(byte[]), which fillsthe specified byte array with random bytes.
Floating Point Numbers
As with all things floating point, random number generation is tricky. Themethod nextFloat() and nextDouble() return values beteween 0.0 (inclusive)and 1.0 (exclusive). This is, in part, to compensate for the uneven distributionof values across the bit-level representations. When values are large, there arelarger gaps between possible floating point representations. The algorithms usedare not quite generating random bit-level representations; they are documentedin the class’s Javadoc.
There is also a method nextGaussian() that generates a draw from a unitnormal, Norm(0,1), distribution.

296 APPENDIX D. JAVA BASICS
D.5.2 Seeds and Pseudorandomness
A random number generator is constructed using a base costructorRandom(long). The argument is called the seed of the random number gen-erator.
The behavior of Random is fully determined by the seed. A generator with de-terministic behavior like this is said to be pseudorandom. By setting the seed, weare able to generate the same “random” results whenever we run the algorithm.This is immensely helpful for debugging purposes.
If you want true randomization, just use the zero-argument construc-tor Random(). This constructor combines the time obtained from Java’sSystem.nanoTime()) and a changing internal key in an attempt to generateunique seeds each time it is called.
We sometimes use the following pattern to enable us a fresh random seed foreach run, but still enable reproducible results.
Random seeder = new Random();long seed = seeder.nextLong();System.out.printf("Using seed=" + seed);Random random = new Random(seed);
By printing out the seed, we can reproduce any results from a run. This is es-pecially useful for random algorithms (that is, algorithms that makes choicesprobabilistically, such as Gibbs samplers or K-means clusterers).
LingPipe is set up so that randomized algorithms take an explicit Randomargument, so that results may be reproduced.
D.5.3 Alternative Randomization Implementations
Because the Random class is not final, it is possible to plug in different implemen-tations. In fact, Random was designed for extension by implementing most of itswork through the protected next(int) method. This method is used to definethe other random number generators, sometimes being called more than once ina method.
D.5.4 Synchronization
Although not externally documented, there is a great deal of careful synchro-nization underlying the methods in Random. As of Java 1.6, the various nextX()methods (other than nextGaussian()) use a scalable compare-and-set (CAS)strategy through Java’s built-in AtomicLong class. The nextGaussian() methoduses its own synchronization.
This synchronization happens in the next(int) method, so classes that ex-tend Random need to be designed with thread safety in mind.
Even with its design for liveness, the Javadoc itself recommends using a sep-arate random number generator in each thread if possible to reduce even theminimal lock contention imposed by the atomic long’s compare-and-set opera-tion.

D.5. GENERATING RANDOM NUMBERS 297
D.5.5 The Math.random() Utility
The Math utility class in the built-in java.lang package provides a simple meansof generating double values. The utility method Math.random() that returns theresult of calling nextDouble() on a random number generator, thus returning avalue between 0.0 (inclusive) and 1.0 (exclusive). The random number generatoris lazily initialized thread safely so that calls to the method are thread safe.

298 APPENDIX D. JAVA BASICS

Appendix E
The Lucene Search Library
Apache Lucene is a search library written in Java. Due to its performance, con-figurability and generous licensing terms, it has become very popular in bothacademic and commercial settings. In this section, we’ll provide an overview ofLucene’s components and how to use them, based on a single simple hello-worldtype example.
Lucene provides search over documents. A document is essentially a collec-tion of fields, where a field supplies a field name and value. Lucene can storenumerical and binary data, but we will concentrate on text values.
Lucene manages a dynamic document index, which supports adding docu-ments to the index and retrieving documents from the index using a highly ex-pressive search API.
What actually gets indexed is a set of terms. A term combines a field namewith a token that may be used for search. For instance, a title field like MolecularBiology, 2nd Edition might yield the tokens molecul, biolog, 2, and edition aftercase normalization, stemming and stoplisting. The index structure provides thereverse mapping from terms, consisting of field names and tokens, back to doc-uments.
E.1 Fields
All fields in Lucene are instances of the Fieldable interface in the packageorg.apache.lucene.document. Numeric fields are still marked as experimen-tal, and we are mainly interested in text, so we concentrate on the other built-in concrete implementation of Fieldable, the final class Field, also in thedocument package. This implementation can store both binary and characterdata, but we only consider text.
E.1.1 Field Names and Values
Each constructor for a field requires a name for the field. At search time, usersearches are directed at particular fields. For instance, a MEDLINE citation mightstore the name of the article, the journal in which it was published, the authors
299

300 APPENDIX E. THE LUCENE SEARCH LIBRARY
of the article, the date of publication, the text of the article’s abstract, and a listof topic keywords drawn from Medical Subject Headings (MeSH). Each of thesefields would get a different name, and at search time, the client could specifythat it was searching for authors or titles or both, potentially restricting to a daterange and set of journals.
We will focus on text fields. The value for a text field may be supplied as aJava String or Reader.1 The value for a binary (blob) field is supplied as a bytearray slice.
E.1.2 Indexing Flags
Documents are overloaded for use during indexing and search. For use in index-ing, fields include information about how they are indexed and/or stored. Thisinformation is provided to a field during construction in the form of a number offlags. These flags are implemented as nested enum instances in the Field class,all in the document package.
The Field.Store Enum
All fields are marked as to whether their raw value is stored in the index or not.Storing raw values allows you to retrieve them at search time, but may consumesubstantial space.
The enum Field.Store is used to mark whether or not to store the value ofa field. Its two instances, Store.YES and Store.NO, have the obvious interpre-tations.
The Field.Index Enum
All fields are also marked as to whether they are indexed or not. A field must beindexed in order for it to be searchable. While it’s possible to have a field that isindexed but not stored, or stored but not indexed, it’s pointless to have a fieldthat is neither stored nor indexed.
Whether a field is indexed is controlled by an instance of the Field.Indexenum. The value Index.NO turns off indexing for a field. The other values allturn on indexing for a field. Where they vary is how the terms that are indexedare pulled out of the field value. The value Index.ANALYZED indexes a field withtokenization turned on (see Section E.3). The value Index.NOT_ANALYZED causesthe field value to be treated like a single token; it’s primarily used for identifierfields that are not decomposed into searchable terms.
1We recommend not using a Reader, because the policy on closing such readers is confusing. It’sup to the client to close, but the close can only be done after the document has been added to anindex. Making fields stateful in this way introduces a lifecycle management problem that’s easilyavoided. Very rarely will documents be such that a file or network-based reader may be used as isin a field; usually such streams are parsed into fields before indexing, eliminating any performanceadvantage readers might have.

E.1. FIELDS 301
The Field.TermVector Enum
The final specification on a field is whether to store term vectors or not, and ifthey are stored, what specifically to store. Term vectors are an advanced datastructure encapsulating the geometric search structure of a document’s terms(the pieces extracted from a field by an analyzer). They may be useful for down-stream processing like results clustering or finding documents that are similarto a known document.
Whether to use term vectors is controlled by an instance of the enumField.TermVector. The default is not to store term vectors, correspondingto value TermVector.NO. Because we do not need term vectors for our simpledemo, we restrict attention to constructors for Field which implicitly set theterm vector flag to TermVector.NO.
E.1.3 Constructing Fields
A field requires all of its components to be specified in the constructor. Evenso, fields are defined to be mutable so that their values, but not their fieldnames, may be reset after construction. The explicit constructor for textfields is Field(String,String,Field.Store,Field.Index), where the firsttwo strings are field and value, and the remaining three are the enum flags disc-sussed in the previous section.2 There are also several utility constructors thatprovide default values for the flags in addition to those taking the text valueas a Reader. There is also a public constructor that takes a TokenStream (seeSection E.3) rather than a string.3
E.1.4 Field Getters
Once we have a field, we can access the components of it such as its name, value,whether its indexed, stored, or tokenized, and whether term vectors are stored.These methods are all specified in the Fieldable interface. For instance, name()returns a field’s name, and stringValue() its value.4
There are convenience getters derived from the flag settings. For instance,isIndexed() indicates if the field is indexed, and isTokenized() indicateswhether the indexing involved analysis of some sort. The method isStored()indicates if the value is stored in the index, and isTermVectorStored() whetherthe term vector is stored in the index.
2The full constructor has two additional arguments. The first is a boolean flag controlling whetherthe field’s name is interned or not (see Section 2.6.11), with the default setting being true. The secondis a TermVector enum indicating how to store term vectors, with the default being TermVector.NO.
3It’s not clear what the use case is for this constructor. Users must be careful to make sure thetoken stream provided is consistent with whatever analysis will happen at query time.
4For fields constructed with a Reader for a value, the method stringValue() returns null. In-stead, the method readerValue() must be used. Similarly, the methods tokenStreamValue() andbinaryValue() are used to retrieve values of fields constructed with token streams or byte arrayvalues. The problem with classes like this that that allow disjoint setters (or constructors) is that itcomplicates usage for clients, who now have to check where they can get their data. Another exampleof this anti-pattern is Java’s built-in XML InputSource in package org.xml.sax.

302 APPENDIX E. THE LUCENE SEARCH LIBRARY
E.2 Documents
In Lucene, documents are represented as instances of the final class Document,in package org.apache.lucene.document.
E.2.1 Constructing and Populating Documents
Documents are constructed using a zero-arg constructor Document(). Once adocument is constructed, the method add(Fieldable) is used to add fields tothe document.
Lucene does not in any way constrain document structures. An index maystore a heterogeneous set of documents, with any number of different fieldswhich may vary by document in arbitrary ways. It is up to the user to enforceconsistency at the document collection level.
A document may have more than one field with the same name added to it.All of the fields with a given name will be searchable under that name (if thefield is indexed, of course). The behavior is conceptually similar to what you’dget from concatenating all the field values; the main difference is that phrasesearches don’t work across fields.
E.2.2 Accessing Fields in Documents
The Document class provides a means of getting fields by name. The methodgetFieldable(String) returns the field for a specified name. If there’s no fieldwith the specified name, it returns null rather than raising an exception.
The return type is Fieldable, but this interface provides nearly the same listof methods as Field itself, so there is rarely a need to cast a fieldable to a field.
If there is more than one field in a document with the same name, the simplemethod getFieldable(String) only returns the first one added. The methodgetFieldables(String) returns an array of all fields in a document with thegiven name. It’s costly to construct arrays at run time (in both space and time forallocation and garbage collection), so if there is only a single value, the simplermethod is preferable.
E.2.3 Document Demo
We provide a simple demo class, DocDemo, which illustrates the construction,setting and accessing of fields and documents.
Code Walkthrough
The main() method starts by constructing a document and populating it.
Document doc = new Document();doc.add(new Field("title", "Fast and Accurate Read Alignment",
Store.YES,Index.ANALYZED, TermVector.NO));doc.add(new Field("author", "Heng Li",
Store.YES,Index.ANALYZED));

E.2. DOCUMENTS 303
doc.add(new Field("author", "Richard Durbin",Store.YES,Index.ANALYZED));
doc.add(new Field("journal","Bioinformatics",Store.YES,Index.ANALYZED));
doc.add(new Field("mesh","algorithms",Store.YES,Index.ANALYZED));
doc.add(new Field("mesh","genomics/methods",Store.YES,Index.ANALYZED));
doc.add(new Field("mesh","sequence alignment/methods",Store.YES,Index.ANALYZED));
doc.add(new Field("pmid","20080505",Store.YES,Index.NOT_ANALYZED));
After constructing the document, we add a sequence of fields, including a titlefield, two author fields, a field for the name of the journal, several fields storingmesh terms, and a field storing the document’s PubMed identifier. These termsare all stored and analyzed other than the identifier, which is not analyzed.
After constructing the document, we loop over the fields and inspect them.
for (Fieldable f : doc.getFields()) {String name = f.name();String value = f.stringValue();boolean isIndexed = f.isIndexed();boolean isStored = f.isStored();boolean isTokenized = f.isTokenized();boolean isTermVectorStored = f.isTermVectorStored();
Note that the access is through the Fieldable interface.
Running the Demo
The Ant target doc-demo runs the demo.
> ant doc-demo
name=title value=Fast and Accurate Read Alignmentindexed=true store=true tok=true termVecs=false
name=author value=Heng Liindexed=true store=true tok=true termVecs=false
...name=mesh value=genomics/methods
indexed=true store=true tok=true termVecs=falsename=mesh value=sequence alignment/methods
indexed=true store=true tok=true termVecs=falsename=pmid value=20080505
indexed=true store=true tok=false termVecs=false
We’ve elided three fields, marked by ellipses.

304 APPENDIX E. THE LUCENE SEARCH LIBRARY
E.3 Analysis and Token Streams
At indexing time, Lucene employs analyzers to convert the text value of a fieldsmarked as analyzed to a stream of tokens. At indexing time, Lucene is sup-plied with an implementation of the abstract base class Analyzer in packageorg.apache.lucene.analysis. An analyzer maps a field name and text valueto a TokenStream, also in the analysis package, from which the terms to beindexed may be retrieved using an iterator-like pattern.
E.3.1 Token Streams and Attributes
Before version 3.0 of Lucene, token streams had a string-position oriented tok-enization API, much like LingPipe’s tokenizers. Version 3.0 generalized the in-terface for token streams and other basic objects using a very general designpattern based on attributes of other objects. 5
Code Walkthrough
We provide a sample class LuceneAnalysis that applies an analyzer to a fieldname and text input and prints out the resulting tokens. The work is done ina simple main() with two arguments, the field name, set as the string variablefieldName, and the text to be analyzed, set as the string variable text.
The first step is to create the analyzer.
StandardAnalyzer analyzer= new StandardAnalyzer(Version.LUCENE_30);
Here we’ve used Lucene’s StandardAnalyzer, in packageorg.apache.lucene.analysis.standard, which applies case normaliza-tion and English stoplisting to the simple tokenizer, which pays attention toissues like periods and e-mail addresses (see Chapter 8 for an overview ofnatural language tokenization in LingPipe, as well as adapters between Luceneanalyzers and LingPipe tokenizer factories). Note that it’s constructed with aconstant for the Lucene version, as the behavior has changed over time.
The standard analyzer, like almost all of Lucene’s built-in analyzers, ignoresthe name of the field that is passed in. Such analyzers essentially implementsimple token stream factories, like LingPipe’s tokenizer factories.6
The next step of the main() method constructs the token stream given thestring values of the command-line arguments fieldName and text.
5The benefit of this pattern is not in its use, which is less convenient than a direct implementation.The advantage of Lucene’s attribute pattern is that it leaves enormous flexibility for the developersto add new features without breaking backward compatibility.
6It is unfortunate that Lucene does not present a token stream factory interface to produce tokenstreams from text inputs. Then it would be natural to construct an analyzer by associating tokenstream factories with field names. We follow this pattern in adapting LingPipe’s tokenizer factoriesto analyzers in Section 8.8. Lucene’s sister package, Solr, which embeds Lucene in a client-serverarchitecture, includes a token stream factory interface TokenizerFactory, which is very much likeLingPipe’s other than operating over readers rather than character sequences and providing Solr-specific initialization and configuration management.

E.3. ANALYSIS AND TOKEN STREAMS 305
Reader textReader = new StringReader(text);
TokenStream tokenStream= analyzer.tokenStream(fieldName,textReader);
TermAttribute terms= tokenStream.addAttribute(TermAttribute.class);
OffsetAttribute offsets= tokenStream.addAttribute(OffsetAttribute.class);
PositionIncrementAttribute positions= tokenStream.addAttribute(PositionIncrementAttribute.class);
We first have to create a Reader, which we do by wrapping the input text stringin a StringReader (from java.io).7 Then we use the analyzer to create a to-ken stream from the field name and text reader. The next three statements at-tach attributes to the token stream, specifically a term attribute, offset attributeand position increment attribute. These are used to retrieve the text of a term,the span of the term in the original text, and the ordinal position of the termin the sequence of terms in the document. The position is given by an incre-ment from the previous position, and Lucene uses these values for phrase-basedsearch (i.e., searching for a fixed sequence of tokens in the given order withoutintervening material).
The last block of code in the main() method iterates through the tokenstream, printing the attributes of each token it finds.
while (tokenStream.incrementToken()) {int increment = positions.getPositionIncrement();int start = offsets.startOffset();int end = offsets.endOffset();String term = terms.term();
The while loop continually calls incrementToken() on the token stream, whichadvances to the next token, returning true if there are more tokens. The bodyof the loop just pulls out the increment, start and end positions, and term forthe token. The rest of the code, which isn’t shown, just prints these values. thispattern of increment-then-get is particularly popular for tokenizers; LingPipe’stokenizers use a similar model.
Running the Demo
It may be run from the Ant target lucene-analysis, with the arguments pro-vided by properties field.name and text respectively.
> ant -Dfield.name=foo -Dtext="Mr. Sutton-Smith will pay $1.20for the book." lucene-analysis
7Unlike the case for documents, there is no alternative to using readers for analysis. It is commonto use string readers because they do not maintain handles on resources other than their stringreference.

306 APPENDIX E. THE LUCENE SEARCH LIBRARY
Mr. Sutton-Smith will pay $1.20 for the book.0123456789012345678901234567890123456789012340 1 2 3 4
INCR (START, END) TERM INCR (START, END) TERM1 ( 0, 2) mr 2 ( 22, 25) pay1 ( 4, 10) sutton 1 ( 27, 31) 1.201 ( 11, 16) smith 3 ( 40, 44) book
The terms are all lowercased, and non-word-internal punctuation has been re-moved. The stop words will, for and the are also removed from the output.Unlike punctuation, when a stop word is removed, it causes the increment be-tween terms to be larger. For instance, the increment between smith and pay is2, because the stopword will was removed between them. The start (inclusive)and end (exclusive) positions of the extracted terms is also shown.
E.4 Directories
Lucene provides a storage abstraction on top of Java in the abstract base classDirectory in the org.apache.lucene.store package. Directories provide aninterface that’s similar to an operating system’s file system.
E.4.1 Types of Directory
The FSDirectory abstract base class, also in package store, extends Directoryto support implementations based on a file system. This is the most common wayto create a directory in Lucene.8
The implementation RAMDirectory, also in store supports in-memory direc-tories, which are efficient, but less scalable than file-system directories.
The DbDirectory class, in the contributed packageorg.apache.lucene.store.db, uses Java Database Connectivity (JDBC) tosupport a transactional and persistent directory on top of a database. There arealso more specialized implementations.
E.4.2 Constructing File-System Directories
An instance of a file-system directory may be created using the factory methodFSDirectory.open(File), which returns an implementation of FSDirectory.The finer-grained factory method open(File,LockFactory) allows a specifica-tion of how the files on the file system will be locked. Also, one of the threesubclasses of FSDirectory may be used for even more control over how thebytes in the file are managed.9
8The class FileSwitchDirectory, also in package store, uses two different on-disk files to storedifferent kinds of files. This may allow for more efficient merges when multiple physical disk orsolid-state drives are available. The class is still marked as “new and experimental,” with a warningthat its behavior may change in the future.
9NIOFSDirectory uses the java.nio package, but suffers from a JRE bug that makes it un-suitable for use on Windows. The SimpleFSDirectory uses a standard RandomAccessFile from

E.5. INDEXING 307
E.5 Indexing
Lucene uses the IndexWriter class in org.apache.lucene.index to add doc-uments to an index and optimize existing indexes. Documents do not all needto be added at once — documents may be added to or removed from an existingindex. We consider deleting documents in Section E.8.
E.5.1 Merging and Optimizing
Indexing maintains a small buffer of documents in memory, occassionally writingthe data in that batch of documents out to disk. After enough such batches havebeen written to disk, Lucene automatically merges the individual batches intobigger batches. Then, after a number of larger chunks of index accumulate, theseare merged. You can observe this behavior in your file browser f you’re using adisk directory for indexing a large batch of documents. As more documents areadded, small index segments are continually added. Then, at various points,these smaller indexes are merged into larger indexes.
It’s possible to control the size of the in-memory buffer and the frequency ofmerges.
It’s even possible to programatically merge two indexes from different direc-tories. Lucene’s IndexWriter class provides a handy variable-argument-lengthmethod addIndexes(IndexReader...) which adds indexes maintained by thespecified readers to the index writer. Then, when the writer is optimized, theindexes will all be merged into the writer’s index directory.
Being able to merge indexes makes it easy to split the indexing job into multi-ple independent jobs and then either merge the results or use all of the indexestogether withour merging them (using a MultiReader).
E.5.2 Indexing Demo
We provide a demo class LuceneIndexing that shows how basic text indexingworks.
Code Walkthrough
The work is all done in the main() method, whcih starts by constructing theindex writer.
public static void main(String[] args)throws CorruptIndexException, LockObtainFailedException,
IOException {
File docDir = new File(args[0]);File indexDir = new File(args[1]);
Directory fsDir = FSDirectory.open(indexDir);
java.io and is safe for Windows, but is unfortunately over-synchronized for concurrent usage. TheMMapDirectory uses memory-mapped I/O and works in either Windows or Unix, though see theextensive qualifications about resource locking in the Javadoc.

308 APPENDIX E. THE LUCENE SEARCH LIBRARY
Analyzer an = new StandardAnalyzer(Version.LUCENE_30);IndexWriter indexWriter
= new IndexWriter(fsDir,an,MaxFieldLength.UNLIMITED);
The two arguments correspond to the directory from which documents to beindexed are read and the directory to which the Lucene index is written. Wecreate a file-system-based directory using the index directory (see Section E.4).We then create a standard analyzer (see Section E.3). Finally, we create an indexwriter from the directory and analyzer.
The enum MaxFieldLength, which is nested in the class IndexWriter,specifies whether to truncate text fields to a length (controlled by a staticconstant) or whether to index all of their content. We use the valueMaxFieldLength.UNLIMITED to index all of the text in a field.
The index constructor creates an index if one does not exist, or opens anexisting index if an index already exists in the specified directory. An alternativeconstructor lets you specify that even if an index exists, it should be overwrittenwith a fresh index.
Constructing the index may throw all three exceptions listed on the main()method. The first two exceptions are Lucene’s, and both extend IOException.You may wish to catch them separately in some cases, as they clearly indicatewhat went wrong. A CorruptIndexException will be thrown if we attempt toopen an index that is not well formed. A LockObtainFailedException will bethrown if the index writer could not obtain a file lock on the index directory. Aplain-old Java IOException will be thrown if there is an underlying I/O errorreading or writing from the files in the directory.
The second half of the main() method loops over the files in the specifieddocument directory, converting them to documents and adding them to the in-dex.
long numChars = 0L;for (File f : docDir.listFiles()) {
String fileName = f.getName();String text = Files.readFromFile(f,"ASCII");numChars += text.length();Document d = new Document();d.add(new Field("file",fileName,
Store.YES,Index.NOT_ANALYZED));d.add(new Field("text",text,
Store.YES,Index.ANALYZED));indexWriter.addDocument(d);
}
indexWriter.optimize();indexWriter.close();int numDocs = indexWriter.numDocs();
We keep a count of the number of characters processed in the variable numChars.We then loop is over all the files in the specified document directory. For each

E.5. INDEXING 309
file, we get its name and its text (using LingPipe’s static readFromFile() util-ity method, which converts the bytes in the file to a string using the specifiedcharacter encoding, here ASCII).
We then create a document and add the file name as an unanalyzed fieldand the text as an analyzed field. After creating the document, we call theaddDocument(Document) method of the index writer to add it to the index.
After we’ve finished indexing all the files, we call the index writer’soptimize() method, which tamps the index down into a minimal file rep-resentation that’s not only optimized for search speed, but also compactedfor minimal size. We then close the index writer using the close()method, which may throw an IOException; the IndexWriter class is de-clared to implement Java’s Closeable interface, so we could’ve used LingPipe’sStreams.closeSilently() utility method to close it and swallow any I/O ex-ceptions raised.
Finally, we get the number of documents that are in the current index usingthe method numDocs(); if documents were in the index when it was opened,these are included in the count. We also print out other counts, such as thenumber of characters.
Running the Demo
The Ant target lucene-index runs the indexing demo. It supplies the values ofproperties doc.dir and index.dir to the program as the first two command-line arguments. We created a directory containing the 85 Federalist Papers, anduse them as an example document collection.
> ant -Ddoc.dir=../../data/federalist-papers/texts-Dindex.dir=temp.idx lucene-index
Index Directory=C:\lpb\src\applucene\temp.idxDoc Directory=C:\lpb\data\federalist-papers\textsnum docs=85num chars=1154664
Lucene’s very fast. On my workstation, it takes less than a second to run thedemo, including forking a new JVM. The run indexed 85 documents consisting ofapproximately 1.1 million words total.
After indexing, we can look at the contents of the index directory.
> ls -l temp.idx
-rwxrwxrwx 1 Admin None 355803 Aug 24 17:48 _0.cfs-rwxrwxrwx 1 Admin None 1157101 Aug 24 17:48 _0.cfx-rwxrwxrwx 1 Admin None 20 Aug 24 17:48 segments.gen-rwxrwxrwx 1 Admin None 235 Aug 24 17:48 segments_2
These files contain binary representations of the index. The .cfs file contains theindex (including the position of each token in each file). The .cfx file containsthe stored fields. The two segments files contain indexes into these files. The

310 APPENDIX E. THE LUCENE SEARCH LIBRARY
indexes will be stored in memory to allow fast random access to the appropiratefile contents.
With the standard analyzer, the index file is only a quarter the size of the textfile, whereas the stored field file is slightly larger than the set of texts indexed.
E.5.3 Duplicate Documents
If we were to run the demo program again, each of the documents would beadded to the index a second time, and the number of documents reported willbe 170 (twice the initial 85). Although a Lucene index provides identifiers fordocuments that are unique (though not necessarily stable over optimizations),nothing in the index enforces uniqueness of document contents. Lucene willhappily create another document with the same fields and values as anotherdocument. It keeps them separate internally using its own identifiers.
E.6 Queries ande Query Parsing
Lucene provides a highly configurable hybrid form of search that combines ex-act boolean searches with softer, more relevance-ranking-oriented vector-spacesearch methods. All searches are field-specific. 10
E.6.1 Constructing Queries Programatically
Queries may be constructed programatically using the dozen or so built-in implementations of the the Query abstract base class from the packageorg.apache.lucene.search.
The most basic query is over a single term in a single field. This form ofquery is implemented in Lucene’s TermQuery class, also in the search pack-age. A term query is constructed from a Term, which is found in packageorg.apache.lucene.index. A term is constructed from a field name and textfor the term, both specified as strings.
The BooleanQuery class is very misleadingly named; it supports both hardboolean queries and relevance-ranked vector-space queries, as well as allowingthem to be mixed.
A boolean query may be constructed with the no-argument constructorBooleanQuery() (there is also a constructor that provides extra control oversimilarity scoring by turning off the coordination component of scoring).
Other queries may then be added to the boolean query using the methodadd(Query,BooleanClause.Occur). The second argument, an instance of thenested enum BooleanClause.Occur in package search, indicates whether theadded query is to be treated as a hard boolean constraint or contribute to therelevance ranking of vector queries. Possible values are BooleanClause.MUST,BooleanClause.MUST_NOT, and BooleanClause.SHOULD. The first two are used
10Unfortunately, there’s no way to easily have a query search over all fields. Instead, field-specificqueries must be disjoined to achieve this effect. Another approach is to denormalize the documentsby creating synthetic fields that concatenate the value of other fields.

E.6. QUERIES ANDE QUERY PARSING 311
for hard boolean queries, requiring the term to appear or not appear in any result.The last value, SHOULD, is used for vector-space queries. With this occurrencevalue, Lucene will prefer results that match the query, but may return resultsthat do not match the query.
The recursive nature of the API and the overloading of queries to act as bothhard boolean and vector-type relevance queries, leads to the situation wherequeries may mix hard and soft constraints. It appears that clauses constrainedby hard boolean occurrence constraints, MUST or MUST_NOT, do not contribute toscoring. It’s less clear what happens when one of these hybrid queries is nestedinside another boolean query with its own occurrence specification. For instance,it’s not clear what happens when we nest a query with must-occur and should-occur clauses as a must-occur clause in a larger query.
BooleanQuery bq1 = new BooleanQuery();bq1.add(new TermQuery(new Term("text","biology")), Occur.MUST);bq1.add(new TermQuery(new Term("text","cell")), Occur.SHOULD);
BooleanQuery bq2 = new BooleanQuery();bq2.add(new TermQuery(new Term("text","micro")), Occur.SHOULD);bq2.add(bq1,Occur.MUST);
E.6.2 Query Parsing
Lucene specifies a language in which queries may be expressed.For instance, [computer NOT java]11 produces a query that specifies the
term computer must appear in the default field and the term java must not ap-pear. Queries may specify fields, as in text:java, which requires the term java toappear in the text field of a document.
The full syntax specification is available from http://lucene.apache.org/java/3_0_2/queryparsersyntax.html. The syntax includes basic term andfield specifications, modifiers for wildcard, fuzzy, proximity or range searches,and boolean operators for requiring a term to be present, absent, or for com-bining queries with logical operators. Finally, sub-queries may be boosted byproviding numeric values to raise or lower their prominence relative to otherparts of the query.
A query parser is constructed using an analyzer, default field, and Luceneversion. The default field is used for queries that do not otherwise specify thefield they search over. It may then be used to convert string-based queries intoquery objects for searching.
The query language in Lucene suffers from a confusion between queries overtokens and queries over terms. Complete queries, must of course, be over terms.But parts of queries are naturally constrained to be over tokens in the sense ofnot mentioning any field values. For instance, if Q is a well-formed query, thenso is foo:Q. In proper usage, the query Q should be constrained to not mentionany fields. In other words, Q should be a query over tokens, not a general query.
11We display queries Q as [Q] to indicate the scope of the search without using quotes, which areoften part of the search itself.

312 APPENDIX E. THE LUCENE SEARCH LIBRARY
Query Language Syntax
In Figure E.1, we provide an overview of the full syntax available through Lucene’squery parser. The following characters must be escaped by preceding them witha backslash:
+ - & | ! ( ) { } [ ] ^ " ~ * ? : \
For example, [foo:a\(c] searches for the three-character token a(c in the fieldfoo. Of course, if the queries are specified as Java string literals, further escapingis required (see Section 2.3).
E.6.3 Default Fields, Token Queries, and Term Queries
When we set up a query parser, we will be supplying a default field. Unmarkedtoken queries will then be interrpeted as if constrained to that field. For instance,if title is the default query field, then query [cell] is the same as the query[title:cell].
Like the programmatic queries, Lucene’s query language does not clearly sep-arate the role of token-level queries, which match tokens or sequences of tokens,and term-level queries, which match tokens within a field. Thus it’s possibleto write out queries with rather unclear structure, such as [text:(money ANDfile:12.ascii.txt)]; this query will actually match (as you can try with thecdemo in the next section) because the embedded field file takes precedenceover the top-level field text.
E.6.4 The QueryParser Class
Lucene’s QueryParser class, in package org.apache.lucene.queryparser,converts string-based using Lucene’s query syntax into Query objects.
The constructor QueryParser(Version,String,Analyzer) requires aLucene version, a string picking out a default field for unmarked tokens, andan analyzer with which to break phrasal queries down into token sequences.
Query parsing is accomplished through the method parse(String), whichreturns a Query. The parse method will throw a Lucene ParseException, alsoin package queryparser, if the query is not well formed.
E.7 Search
E.7.1 Index Readers
Lucene uses instances of the aptly named IndexReader to read data from anindex.
Distributed Readers
A convenient feature of the reader design in Lucene is that we may constructan index reader from multiple indexes, which will then combine their contents
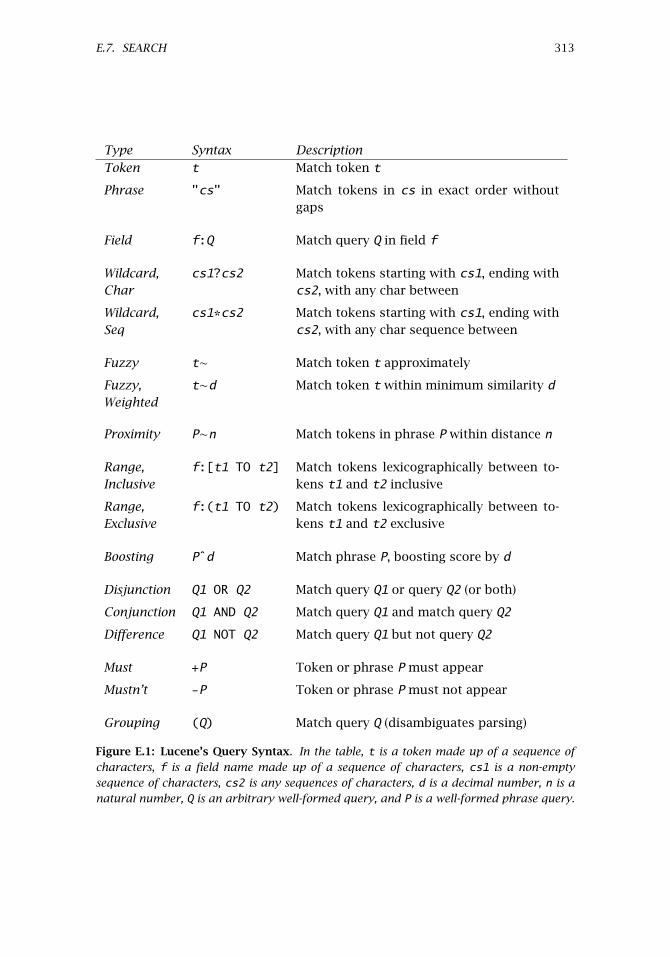
E.7. SEARCH 313
Type Syntax Description
Token t Match token t
Phrase "cs" Match tokens in cs in exact order withoutgaps
Field f:Q Match query Q in field f
Wildcard,Char
cs1?cs2 Match tokens starting with cs1, ending withcs2, with any char between
Wildcard,Seq
cs1*cs2 Match tokens starting with cs1, ending withcs2, with any char sequence between
Fuzzy t∼ Match token t approximately
Fuzzy,Weighted
t∼d Match token t within minimum similarity d
Proximity P∼n Match tokens in phrase P within distance n
Range,Inclusive
f:[t1 TO t2] Match tokens lexicographically between to-kens t1 and t2 inclusive
Range,Exclusive
f:(t1 TO t2) Match tokens lexicographically between to-kens t1 and t2 exclusive
Boosting Pˆd Match phrase P, boosting score by d
Disjunction Q1 OR Q2 Match query Q1 or query Q2 (or both)
Conjunction Q1 AND Q2 Match query Q1 and match query Q2
Difference Q1 NOT Q2 Match query Q1 but not query Q2
Must +P Token or phrase P must appear
Mustn’t -P Token or phrase P must not appear
Grouping (Q) Match query Q (disambiguates parsing)
Figure E.1: Lucene’s Query Syntax. In the table, t is a token made up of a sequence ofcharacters, f is a field name made up of a sequence of characters, cs1 is a non-emptysequence of characters, cs2 is any sequences of characters, d is a decimal number, n is anatural number, Q is an arbitrary well-formed query, and P is a well-formed phrase query.

314 APPENDIX E. THE LUCENE SEARCH LIBRARY
at search time. From the reader’s client’s perspective, the behavior is indistin-guishable (other than in terms of speed) from a combined and optimized index.We can even distribute these indexes over multiple machines on a network usingJava’s Remote Method Invocation (RMI).
E.7.2 Index Searchers
Lucene supplies an IndexSearcher class that performs the actual search. Everyindex searcher wraps an index reader to get a handle on the indexed data. Oncewe have an index searcher, we can supply queries to it and enumerate results inorder of their score.
There is really nothing to configure in an index searcher other than its reader,so we’ll jump straight to the demo code.
E.7.3 Search Demo
We provide a simple implementation of Lucene search based on the index wecreated in the last section.
Code Walkthrough
The code is in the main() method of the demo class LuceneSearch. The methodstarts off by reading in command-line arguments.
public static void main(String[] args)throws ParseException, CorruptIndexException,
IOException {
File indexDir = new File(args[0]);String query = args[1];int maxHits = Integer.parseInt(args[2]);
We need the directory for the index, a string representing the query in Lucene’squery language, and a specification of the maximum number of hits to return.The method is declared to throw a Lucene corrupt index exception if the indexisn’t well formed, a Lucene parse exception if the query isn’t well formed, and ageneral Java I/O exception if there is a problem reading from or writing to theindex directory.
After setting the command-line arguments, the next step is to create a Lucenedirectory, index reader, index searcher and query parser.
Directory dir = FSDirectory.open(indexDir);IndexReader reader = IndexReader.open(dir);IndexSearcher searcher = new IndexSearcher(reader);
Version v = Version.LUCENE_30;String defaultField = "text";Analyzer analyzer = new StandardAnalyzer(v);QueryParser parser
= new QueryParser(v,defaultField,analyzer);

E.7. SEARCH 315
It is important to use the same analyzer in the query parser as is used in thecreation of the index. If they don’t match, queries that should succeed will failbecause the tokens won’t match. For instance, if we apply stemming in the in-dexing to reduce codes to code, then we better do the same thing for the query,because we won’t find codes in the index, only its stemmed form code.
The last bit of code in the search demo uses the query parser to parse thequery, then searches the index and reports the results.
Query q = parser.parse(query);
TopDocs hits = searcher.search(q,maxHits);ScoreDoc[] scoreDocs = hits.scoreDocs;
for (int n = 0; n < scoreDocs.length; ++n) {ScoreDoc sd = scoreDocs[n];float score = sd.score;int docId = sd.doc;Document d = searcher.doc(docId);String fileName = d.get("file");
The Query object is created by using the parser to parse the text query. We thenuse the searcher instance to search given the query and an upper bound on thenumber of hits to return. This returns an instance of the Lucene class TopDocs,from package search, which encapsulates the results of a search (through refer-ences back into the index).
The TopDocs result provides access to an array of search results. Each resultis an instance of the Lucene class ScoreDoc, also in the search package, whichencapsulates a document reference with a floating point score.
The array of search results is sorted in decreasing order of score, with higherscores representing better matches. We then enumerate over the array, and foreach ScoreDoc object, we pull its score out using the public member variablescore. We then pull its document reference number (Lucene’s internal identifierfor the doc) out with the member variable doc. With the Lucene document identi-fer, we are able to retrieve the document from the searcher (which just delegatesthis operation to its index reader internally). Finally, with the document in hand,we retrieve its file name using the get() method on the document; we use get()here rather than getValues(), which returns an array, because we know thereis only one file name for each document in the index. We could’ve also retrievedthe text of the document, because we stored it in the index.
Running the Demo
The Ant target lucene-search invokes the demo with command-line argumentsprovided by the value of properties index.dir, query, and max.hits.
> ant -Dindex.dir=luceneIndex -Dquery="money power united"-Dmax.hits=15 lucene-search
Index Dir=C:\lpb\src\applucene\luceneIndexquery=money power united

316 APPENDIX E. THE LUCENE SEARCH LIBRARY
max hits=15Hits (rank,score,file name)
0 0.16 44.ascii.txt1 0.13 32.ascii.txt2 0.13 80.ascii.txt
...13 0.10 23.ascii.txt14 0.10 26.ascii.txt
Lucene returns 15 results numbered 0 to 14. We see that paper 44 is the closestmatch to our query money power united. This document contains 4 instancesof the term money, over 40 instances of the term power, and 8 instances ofunited. This seems like a low score on a 0–1 scale for a document which matchesall the tokens in the query; the reason is because the documents are long, so thepercentage of tokens in the doucment matching the query tokens is relativelylow.
The token food does not show up in any documents, so the query [food]returns no hits. If we consider the query [money food], it returns exactly thesame hits as the query [money], in exactly the same order, but with lower scores.If we use the query [money +food], we are insisting that the token food appearin any matching document. Because it doesn’t appear in the corpus at all, thequery money +food has zero hits. On the other hand, the must-not query [money-food] has the same hits with the same scores as the query money.
E.7.4 Ranking
For scoring documents against queries, Lucene uses the complex andhighly configurable abstract base class Similarity in the package inorg.apache.lucene.search. If nothing else is specified, as in our simple de-mos, the concrete subclass DefaultSimilarity will be used.
Similarity deals with scoring queries with SHOULD-occur terms. In the searchlanguage, all tokens are treated as SHOULD unless prefixed with the must-occurmarking plus-sign (+) or must-not occur negation (-).
The basic idea is that the more instances of query terms in a document thebetter. Terms are not weighted equally. A term is weighted based on its inversedocument frequency (IDF), so that terms that occur in fewer documents receivehigher weights. Weights may also be boosted or lowered in the query syntax orprogramatically with a query object.
All else being equal, shorter documents are preferred. The idea here is thatif there are the same number of instances of query terms in two documents, theshorter one has a higher density of query terms, and is thus likely to be a bettermatch.
There is also a component of scoring based on the percentage of the queryterms that appear in the document. All else being equal, we prefer documentsthat cover more terms in the query.

E.8. DELETING DOCUMENTS 317
E.8 Deleting Documents
Documents may be deleted through an IndexReader or an IndexWriter, but themethods available and their behavior is slightly different.
E.8.1 Deleting with an Index Reader
Given an index reader, the method deleteDocument(int) deletes a documentspecified by its Lucene index. The reason this method is in the reader is that thestandard way to access document identifiers is through search, which returnsa TopDocs object consisting of an ordered array of ScoreDoc objects, each ofwhich contains a document identifier (see Section E.7.3 for an example).
Index reader also implements a method deleteDocuments(Term) whichdeletes all documents containing the specified term; recall that a term consistsof a field name and token.
In many cases, the documents being indexed have unique identifiers. Forinstance, in our file-based index, the file names are meant to be unique.12
We can then create a term containing the application’s document identifierfield and delete by term. For instance, we could call deleteDocuments(newTerm("file","12.ascii.txt")) to delete the document with file identifier12.ascii.txt.
E.8.2 Deleting with an Index Writer
Like the index reader, the IndexWriter class supports the samedeleteDocuments(Term) method as an index reader. It also deletes alldocuments containing the specified term. Index writers also implement themore general method deleteDocuments(Query), which removes all documentsmatching the specified query. There is also a deleteAll() method to completelyclear the index.
E.8.3 Visibility of Deletes
When a delete method is called on a reader or writer based on a term or documentidentifier, the documents are not immediately physically deleted from the index.Instead, their identifiers are buffered and they are treated as if virtually deleted.
This approach to document deletion was made for the same efficiency rea-sons and faces many of the same issues as concurrent sets of variables in Java’smemory model. Even when deletes are called on one index, not every reader orwriter with a handle on that index will be able to see the delete.
With an index reader, any deletions are visibile immediately on that reader,but not on other readers attached to the same index. With an index writer, anynew reader opened on the index after the delete will see the deletion.
12Unlike a database, which lets you declare identifiers as keys, Lucene requires the programmer totreat fields as keys by convention.

318 APPENDIX E. THE LUCENE SEARCH LIBRARY
The storage space for a deleted document in the index directory is only re-claimed during a merge step or an optimization, which implicitly merges all out-standing small indexes into a single index.
E.8.4 Lucene Deletion Demo
We have implemented an example of deleting documents in the demo classLuceneDelete.
Code Walkthrough
The code is entirely straightforward, with the main() method taking threecommand-line arguments, the index directory path, along with the field nameand token used to construct the term to delete.
Directory dir = FSDirectory.open(indexDir);boolean readOnly = false;IndexReader reader = IndexReader.open(dir,readOnly);
int numDocsBefore = reader.numDocs();
Term term = new Term(fieldName,token);reader.deleteDocuments(term);
int numDocsAfter = reader.numDocs();int numDeletedDocs = reader.numDeletedDocs();
reader.close();
We create an index reader slightly differently than we did for search. Here weprovide a boolean flag set to false to allow us to delete documents; if the flag istrue, as in the default, the reader gets read-only access to the index.
We then construct a term out of the field and token and pass them to thereader’s delete method. After the deletion, we close the reader using its close()method. One side effect of the close method is that the deletions are committedto the index.
If we had an index searcher wrapping the index reader, we could see how thedeletes affect search.
Running the Demo
The Ant target lucene-delete invokes the class, supplying the value of proper-ties index.dir, field.name, and token as command-line arguments.
Make sure that before you run this demo, you’ve run the indexing demo ex-actly once. You can always delete the index directory and rebuild it if it getsmessed up.
> ant -Dindex.dir=luceneIndex -Dfield.name=file-Dtoken=12.ascii.txt lucene-deleteindex.dir=C:\lpb\src\applucene\luceneIndexfield.name=file token=12.ascii.txtNum docs < delete=85 Num docs > delete=84 Num deleted docs=1

E.9. LUCENE AND DATABASES 319
After the demo is run, we can look at the index directory again.
> ls -l luceneIndex
-rwxrwxrwx 1 Admin None 355803 Aug 26 14:13 _0.cfs-rwxrwxrwx 1 Admin None 1157101 Aug 26 14:13 _0.cfx-rwxrwxrwx 1 Admin None 19 Aug 26 16:40 _0_1.del-rwxrwxrwx 1 Admin None 20 Aug 26 16:40 segments.gen-rwxrwxrwx 1 Admin None 235 Aug 26 16:40 segments_3
There is now an extra file with suffix .del that holds information about whichitems have been deleted. These deletes will now be visible to other index readersthat open (or re-open) their indices. The file containing the deletions will beremoved, and the actual content deleted, when the index is merged or optimizedby an index writer.
E.9 Lucene and Databases
Lucene is like a database in its storage and indexing of data in a disk-like ab-straction. The main difference between Lucene and a database is in the type ofobjects they store. Databases store multiple type-able tables consisting of smalldata objects in the rows. The Structured Query Language (SQL) is then usedto retrieve results from a database, often calling on multiple tables to performcomplex joins and filters.
Lucene, on the other hand, provides a configurable, but more homogeneousinterface. It mainly operates through text search (with some lightweight numeri-cal and date-based embellishments), and returns entire documents.13
E.9.1 Transactional Support
In enterprise settings, we are usually very concerned with maintaining the in-tegrity of our data. In addition to backups, we want to ensure that our indexesdon’t get corrupted as they are being processed.
A transaction in the database sense, as encapsulated in the Java 2 EnterpriseEdition (J2EE), is a way of grouping a sequence of complex operations, such ascommitting changes to an index, such that they all happen or none of themhappen. That is, it’s about making complex operations behave as if they wereatomic in the concurrency sense.
Earlier versions of Lucene were not like databases in not having any kind oftransactional support. More recently, Lucene introduced configurable commitoperations for indexes. These commit operations are transactional in the sensethat if they fail, they roll back any changes they were in the middle of. Thisallows standard database-type two-phase commits to be implemented directlywith fine-grained control over preparing and rolling back.
13Nothing prevents us from treating paragraphs or even sentences in a “real” document as a docu-ment for Lucene’s purposes.

320 APPENDIX E. THE LUCENE SEARCH LIBRARY

Appendix F
Further Reading
In order to fully appreciate contemporary approaches to natural language pro-cessing requires three fairly broad areas of expertise: linguistics, statistics, andalgorithms. We don’t pretend to introduce these areas in any depth in this book.Instead, we recommend the following textbooks, sorted by area, from among themany that are currently available.
F.1 Unicode
Given that we’re dealing with text data, and that Java uses Unicode internally, ithelps to be familiar with the specification. Or at least know where to find moreinformation. The actual specification reference book is quite readable. The latestavailable in print is for version 5.0,
• Unicode Consortium, The. The Unicode Standard 5.0. Addison-Wesley.
This is the final word on the unicode standard, and quite readable.
You can also find the latest version (currently 5.2) online at
http://unicode.org
This includes all of the code tables for the latest version, which are available inPDF files or through search, at
http://unicode.org/charts/
F.2 Java
F.2.1 Overviews of Java
For learning Java, we recommend the following three books pitched at beginnersand intermediate Java programmers,
• Arnold, Ken, James Gosling and David Holmes. 2005. The Java Program-ming Language, 4th Edition. Prentice-Hall.
321

322 APPENDIX F. FURTHER READING
Gosling invented Java, and this is the “official” introduction to the lan-
guage. It’s also very good.
• Bloch, Joshua. 2008. Effective Java, 2nd Edition. Prentice-Hall.
Bloch was one of the main architects of Java from version 1.1 forward.
This book is about taking Java program design to the next level.
• Fowler, Martin, Kent Beck, John Brant, William Opdyke, and Don Roberts.1999. Refactoring: Improving the Design of Existing Code. Addison-Wesley.
Great book on making code better, both existing code and code yet to be
created.
F.2.2 Books on Java Libraries and Packages
There is a substantial collection of widely used libraries for Java. Here are refer-ence books for the Java libraries we use in this book.
• Loughran, Steve and Erik Hatcher. 2007 Ant in Action. Manning.
This is technically the second edition of their 2002 book, Java Development
with Ant. Both authors are committers for the Apache Ant project.
• Tahchiev, Peter, Felipe Leme, Vincent Massol, and Gary Gregory. 2010. JUnitin Action, Second Edition. Manning.
A good overview for JUnit. Should be up-to-date with the latest attribute-
driven versions, unlike either Kent Beck’s book (he’s the author of Ant). As
much as we liked The Pragmatic Programmer, Hunt and Thomas’s book
on JUnit is not particularly useful.
• McCandless, Michael, Erik Hatcher and Otis Gospodnetic. 2010. Lucene inAction, Second Edition. Manning.
A fairly definitive overview of the Apaceh Lucene search engine by three
project committers.
• Hunter, Jason and William Crawford. 2001. Java Servlet Programming,Second Edition. O’Reilly.
It only covers version 2.2, so it’s a bit out of date relative to recent stan-
dards, but the basics haven’t changed, and although there are more el-
ementary introductions, this book is a very good introduction to what
servlets can do. It also explains HTTP itself quite clearly. The first au-
thor is an Apache Tomcat developer and was involved in developing the
original servlet standard.
• Goetz, Brian, Tim Peierls, Joshua Bloch, Joseph Bowbeer, David Holmes, andDoug Lea. 2006. Java Concurrency in Practice. Addison-Wesley.
This fantastic book covers threading and concurrency patterns
and their application, along with implementations in Java’s
java.util.concurrent package. Doug Lea was the original au-
thor of util.concurrent before it was brought into Java itself, and his
previous book, Concurrent Programming in Java, Second Edition (1999;

F.3. GENERAL PROGRAMMING 323
Prentice Hall), is wroth reading for a deeper theoretical understanding of
concurrency in Java.
• Hitchens, Ron. 2002. Java NIO. O’Reilly.
A concise and readable introduction to the “new” I/O package, java.nio
and the concepts behind it, like buffers and multicast reads.
• McLaughlin, Brett and Justin Edelson. 2006. Java and XML, Third Edition.O’Reilly.
A good introduction to the set of tools available in Java for parsing and
generating XML with SAX and DOM, specifying structure with DTDs and
XML Schema, transforming XML with XSLT, as well as the general high-
level libraries JAXP and JAXB.
F.2.3 General Java Books
There are also general-purpose books about Java that do not focus on particularclasses or applications.
• Shirazi, Jack. 2003. Java Performance Tuning, 2nd Edition. O’Reilly
Although already dated, it provides a good introduction to profiling and
thinking about performance tuning. The author and friends also run the
web site javaperformancetuning.com, which is a monthly digest of Java
performance tuning tips (and advertising). If you know C, start with Jon
Bentley’s classic, Programming Pearls (Addison-Wesley).
F.2.4 Practice Makes Perfect
Really, the only way to learn how to code is to practice. Being a good coder meanstwo things: being fast and efficient (assuming accuracy). By accurate, we meanwriting code that does what it’s supposed to do. By fast, we mean the codinggoes quickly. By efficient, we mean the resulting code is efficient.
For practice, we highly recommend the algorithm section of the TopCodercontests. TopCoder provides a complete online Java environment, well thoughtout problems at varying specified levels of difficulty, unit tests that check yoursubmissions, and examples of what others did to provide code-reading practice.
http://www.topcoder.com/tc
F.3 General Programming
We would also recommend a book about programming in general, especially forthose who have not worked collaboratively with a good group of professionalprogrammers.
• Hunt, Andrew and David Thomas. 1999. The Pragmatic Programmer.Addison-Wesley.

324 APPENDIX F. FURTHER READING
Read this book and follow its advice, which is just as relevant now as when
it was written. The best book on how to program we know. A competitor
to books like Steve McConnell’s Code Complete (2004) and books on “agile”
or “extreme” programming.
• Collins-Susman, Ben, Brian W. Fitzpatrick, and C. Michael Pilato. 2010.Collins-Sussman et al.’s Version Control with Subversion. Subversion 1.6.CreateSpace.
This is the official guide to Subversion from the authors. It’s also availableonline at
http://svnbook.red-bean.com/
F.4 Algorithms
Because natural language processing requires comptuational implementationsof its models, a good knowledge of algorithm analysis goes a long way in under-standing the approaches found in a tool kit like LingPipe.
• Cormen, Thomas H., Charles E. Leiserson, Ronald L. Rivest, and CliffordStein. 2009. Introduciton to Algorithms, Third Edition. MIT Press.
A thorough yet readable introduction to algorithms.
• Durbin, Richard, Sean R. Eddy, Anders Krogh, Grame Mitchison. BiologicalSequence Analysis: Probabilistic Models of Proteins and Nucleic Acids. Cam-bridge University Press.
Even though it focuses on biology, it has great descriptions of several key
natural language processing algorithms such as hidden Markov models
and probabilistic context-free grammars.
• Gusfield, Dan. 1997. Algorithms on Strings, Trees and Sequences. Cam-bridge University Press.
Incredibly detailed and thorough introduction to string algorithms, mainly
aimed at computational biology, but useful for all string and tree process-
ing.
F.5 Probability and Statistics
Most of the tools in LingPipe are statistical in nature. To fully understand modernnatural language processing it’s necessary to understand the statistical modelswhich make up their foundation. To do this requires an understanding of thebasics of statistics. Much of the work in natural language processing is Bayesian,so understanding Bayesian statistics is now a must for understanding the field.Much of it also relies on information theory, which is also introduced in themachine learning textbooks.
• Bulmer, M. G. 1979. Principles of Statistics. Dover.

F.6. MACHINE LEARNING 325
Packs an amazing amount of information into a readable little volume,
though it assumes some mathematical sophistication.
• Cover, Thomas M. and Joy A. Thomas. 2006. Elements of Information The-ory, Second Edition. Wiley.
This is the classic textbook for information theory.
• DeGroot, Morris H. and Mark J. Schervish. 2002. Probability and Statistics,Third Edition. Addison-Wesley.
Another introduction to classical frequentist statistical hypothesis testing
and estimation but with some Bayesian concepts thrown into the mix.
• Gelman, Andrew and Jennifer Hill. 2006. Data Analysis Using Regressionand Multilevel/Hierarchical Models. Cambridge University Press.
A great practical introduction to regression from a Bayesian perspective
with an emphasis on multilevel models. Much less mathematically de-
manding than the other introductions, but still very rigorous.
• Gelman, Andrew, John B. Carlin, Hal S. Stern, and Donald B. Rubin. 2003.Bayesian Data Analysis, Second Edition. Chapman and Hall.
The bible for Bayesian methods. Presupposes high mathematical sophisti-
cation and a background in classical probability and statistics to the level
of DeGroot and Schervish or Larsen and Marx’s books.
• Larsen, Richard J. and Morris L. Marx. 2005. Introduction to MathematicalStatistics and Its Applications, Fourth Edition. Prentice-Hall.
A nice intro to classical frequentist statistics.
• Agresti, A. 2002. Categorical Data Analysis, Second Edition. Wiley.
A thorough survey of classical approaches to analyzing categorical data,
focusing on contingency tables.
F.6 Machine Learning
Machine learning, in contrast to statistics, focuses on implementation detailsand tends to concentrate on predictive inference for larger scale applications. Assuch, understanding machine learning requires a background in both statisticsand algorithms.
• Bishop, Christopher M. 2007. Pattern Recognition and Machine Learning.Springer.
Introduction to general machine learning techniques that is self contained,
but assumes more mathematical sophistication than this book.
• Hastie, Trevor, Robert Tibshirani and Jerome Friedman. 2009. The Elementsof Statistical Learning, Second Edition. Springer.
Presupposes a great deal of mathematics, providing fairly rigorous intro-
ductions to a wide range of algorithms and statistical models.

326 APPENDIX F. FURTHER READING
• MacKay, David J. C. 2002. Information Theory, Inference, and LearningAlgorithms. Cambridge University Press.
More of a set of insightful case studies than a coherent textbook. Presup-
poses a high degree of mathematical sophistication.
• Witten, Ian H. and Eibe Frank. 2005. Data Mining: Practical Machine Learn-ing Tools and Techniques (Second Edition). Elsevier.
The most similar to this book, explaining general machine learning tech-
niques at a high level and linking to the Java implementations (from their
widely used Weka toolkit).
F.7 Linguistics
Natural language processing is about language. To fully appreciate the models inLingPipe, it is necessary to have some background in linguistics. Unfortunately,most of the textbooks out there are based on traditional Chomskyan theoreticallinguistics which divorces language from its processing, and from which naturallanguage processing diverged several decades ago.
• Bergmann, Anouschka, Kathleen Currie Hall, and Sharon Miriam Ross (edi-tors). 2007. Language Files, Tenth Edition. Ohio State University Press.
Easy to follow and engaging overview of just about every aspect of human
language and linguistics. Books on specific areas of linguistics tend to be
more theory specific.
F.8 Natural Language Processing
Natural language processing is largely about designing and coding computer pro-grams that operate over natural language data. Because most NLP is statisticalthese days, this requires not only a knowledge of linguistics, but also of algo-rithms and statistics.
• Jurafsky, Daniel, James H. Martin. 2008. Speech and Language Processing,Second Edition. Prentice-Hall.
High-level overview of both speech and language processing.
• Manning, Christopher D., Raghavan Prabhakar, and Hinrich Schütze. 2008.Introduction to Information Retrieval. Cambridge University Press.
Good intro to IR and better intro to some NLP than Manning and Schütze’s
previous book, which is starting to feel dated.
• Manning, Christopher D. and Hinrich Schütze. 1999. Foundations of Statis-tical Natural Language Processing. MIT Press.
Needs a rewrite to bring it up to date, but still worth reading given the
lack of alternatives.

Appendix G
Licenses
This chapter includes the text of the licenses for all of the software used fordemonstration purposes.
G.1 LingPipe License
G.1.1 Commercial Licensing
Customized commercial licenses for LingPipe or components of LingPipe are ava-ialble through LingPipe, Inc.
G.1.2 Royalty-Free License
Both LingPipe and the code in this book are distributed under the Alias-i RoyaltyFree License Version 1.
Alias-i ROYALTY FREE LICENSE VERSION 1
Copyright (c) 2003-2010 Alias-i, Inc All Rights Reserved
1. This Alias-i Royalty Free License Version 1 ("License") governs the copying, modifying, and distributing of the computerprogram or work containing a notice stating that it is subject to the terms of this License and any derivative works of thatcomputer program or work. The computer program or work and any derivative works thereof are the "Software." Your copying,modifying, or distributing of the Software constitutes acceptance of this License. Although you are not required to acceptthis License, since you have not signed it, nothing else grants you permission to copy, modify, or distribute the Software. Ifyou wish to receive a license from Alias-i under different terms than those contained in this License, please contact Alias-i.Otherwise, if you do not accept this License, any copying, modifying, or distributing of the Software is strictly prohibited bylaw.
2. You may copy or modify the Software or use any output of the Software (i) for internal non-production trial, testing andevaluation of the Software, or (ii) in connection with any product or service you provide to third parties for free. Copying ormodifying the Software includes the acts of "installing", "running", "using", "accessing" or "deploying" the Software as thoseterms are understood in the software industry. Therefore, those activities are only permitted under this License in the waysthat copying or modifying are permitted.
3. You may distribute the Software, provided that you: (i) distribute the Software only under the terms of this License, nomore, no less; (ii) include a copy of this License along with any such distribution; (iii) include the complete correspondingmachine-readable source code of the Software you are distributing; (iv) do not remove any copyright or other notices from theSoftware; and, (v) cause any files of the Software that you modified to carry prominent notices stating that you changed theSoftware and the date of any change so that recipients know that they are not receiving the original Software.
4. Whether you distribute the Software or not, if you distribute any computer program that is not the Software, but that (a)is distributed in connection with the Software or contains any part of the Software, (b) causes the Software to be copied ormodified (i.e., ran, used, or executed), such as through an API call, or (c) uses any output of the Software, then you mustdistribute that other computer program under a license defined as a Free Software License by the Free Software Foundation or anApproved Open Source License by the Open Source Initiative.
5. You may not copy, modify, or distribute the Software except as expressly provided under this License, unless you receive adifferent written license from Alias-i to do so. Any attempt otherwise to copy, modify, or distribute the Software is without
327

328 APPENDIX G. LICENSES
Alias-i’s permission, is void, and will automatically terminate your rights under this License. Your rights under this Licensemay only be reinstated by a signed writing from Alias-i.
THE SOFTWARE IS PROVIDED "AS IS." TO THE MAXIMUM EXTENT PERMITTED BY APPLICABLE LAW, ALIAS-i DOES NOT MAKE, AND HEREBY EXPRESSLYDISCLAIMS, ANY WARRANTIES, EXPRESS, IMPLIED, STATUTORY OR OTHERWISE, CONCERNING THE SOFTWARE OR ANY SUBJECT MATTER OF THISLICENSE. SPECIFICALLY, BUT WITHOUT LIMITING THE FOREGOING, LICENSOR MAKES NO EXPRESS OR IMPLIED WARRANTY OF MERCHANTABILITY,FITNESS (FOR A PARTICULAR PURPOSE OR OTHERWISE), QUALITY, USEFULNESS, TITLE, OR NON-INFRINGEMENT. TO THE MAXIMUM EXTENT PERMITTEDBY APPLICABLE LAW, IN NO EVENT SHALL LICENSOR BE LIABLE TO YOU OR ANY THIRD PARTY FOR ANY DAMAGES OR IN RESPECT OF ANY CLAIMUNDER ANY TORT, CONTRACT, STRICT LIABILITY, NEGLIGENCE OR OTHER THEORY FOR ANY DIRECT, INDIRECT, INCIDENTAL, CONSEQUENTIAL,PUNITIVE, SPECIAL OR EXEMPLARY DAMAGES, EVEN IF IT HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES, OR FOR ANY AMOUNTS INEXCESS OF THE AMOUNT YOU PAID ALIAS-i FOR THIS LICENSE. YOU MUST PASS THIS ENTIRE LICENSE, INCLUDING SPECIFICALLY THIS DISCLAIMERAND LIMITATION OF LIABILITY, ON WHENEVER YOU DISTRIBUTE THE SOFTWARE.
G.2 Java Licenses
The Java executables comes with two licenses, one for the Java runtime envi-ronment (JRE), which is required to execute Java programs, and one for the Javadevelopment kit (JDK), required to compile programs. There is a third license forthe Java source code.
G.2.1 Sun Binary License
Both the JRE and JDK are subject to Sun’s Binary Code License Agreement.
Sun Microsystems, IncBinary Code License Agreementfor the JAVA SE RUNTIME ENVIRONMENT (JRE) VERSION 6 and JAVAFX RUNTIME VERSION 1
SUN MICROSYSTEMS, INC. ("SUN") IS WILLING TO LICENSE THE SOFTWARE IDENTIFIED BELOW TO YOU ONLY UPON THE CONDITION THAT YOU ACCEPTALL OF THE TERMS CONTAINED IN THIS BINARY CODE LICENSE AGREEMENT AND SUPPLEMENTAL LICENSE TERMS (COLLECTIVELY "AGREEMENT").PLEASE READ THE AGREEMENT CAREFULLY. BY USING THE SOFTWARE YOU ACKNOWLEDGE THAT YOU HAVE READ THE TERMS AND AGREE TO THEM. IF YOUARE AGREEING TO THESE TERMS ON BEHALF OF A COMPANY OR OTHER LEGAL ENTITY, YOU REPRESENT THAT YOU HAVE THE LEGAL AUTHORITY TO BINDTHE LEGAL ENTITY TO THESE TERMS. IF YOU DO NOT HAVE SUCH AUTHORITY, OR IF YOU DO NOT WISH TO BE BOUND BY THE TERMS, THEN YOU MUSTNOT USE THE SOFTWARE ON THIS SITE OR ANY OTHER MEDIA ON WHICH THE SOFTWARE IS CONTAINED.
1. DEFINITIONS. "Software" means the identified above in binary form, any other machine readable materials (including, but notlimited to, libraries, source files, header files, and data files), any updates or error corrections provided by Sun, and anyuser manuals, programming guides and other documentation provided to you by Sun under this Agreement. "General Purpose DesktopComputers and Servers" means computers, including desktop and laptop computers, or servers, used for general computing functionsunder end user control (such as but not specifically limited to email, general purpose Internet browsing, and office suiteproductivity tools). The use of Software in systems and solutions that provide dedicated functionality (other than as mentionedabove) or designed for use in embedded or function-specific software applications, for example but not limited to: Softwareembedded in or bundled with industrial control systems, wireless mobile telephones, wireless handheld devices, netbooks, kiosks,TV/STB, Blu-ray Disc devices, telematics and network control switching equipment, printers and storage management systems,and other related systems are excluded from this definition and not licensed under this Agreement. "Programs" means (a) Javatechnology applets and applications intended to run on the Java Platform Standard Edition (Java SE) platform on Java-enabledGeneral Purpose Desktop Computers and Servers, and (b) JavaFX technology applications intended to run on the JavaFX Runtime onJavaFX-enabled General Purpose Desktop Computers and Servers.
2. LICENSE TO USE. Subject to the terms and conditions of this Agreement, including, but not limited to the Java TechnologyRestrictions of the Supplemental License Terms, Sun grants you a non-exclusive, non-transferable, limited license without licensefees to reproduce and use internally Software complete and unmodified for the sole purpose of running Programs. Additionallicenses for developers and/or publishers are granted in the Supplemental License Terms.
3. RESTRICTIONS. Software is confidential and copyrighted. Title to Software and all associated intellectual property rightsis retained by Sun and/or its licensors. Unless enforcement is prohibited by applicable law, you may not modify, decompile,or reverse engineer Software. You acknowledge that Licensed Software is not designed or intended for use in the design,construction, operation or maintenance of any nuclear facility. Sun Microsystems, Inc. disclaims any express or impliedwarranty of fitness for such uses. No right, title or interest in or to any trademark, service mark, logo or trade name of Sunor its licensors is granted under this Agreement. Additional restrictions for developers and/or publishers licenses are setforth in the Supplemental License Terms.
4. LIMITED WARRANTY. Sun warrants to you that for a period of ninety (90) days from the date of purchase, as evidenced by acopy of the receipt, the media on which Software is furnished (if any) will be free of defects in materials and workmanship undernormal use. Except for the foregoing, Software is provided "AS IS". Your exclusive remedy and Sun’s entire liability under thislimited warranty will be at Sun’s option to replace Software media or refund the fee paid for Software. Any implied warrantieson the Software are limited to 90 days. Some states do not allow limitations on duration of an implied warranty, so the abovemay not apply to you. This limited warranty gives you specific legal rights. You may have others, which vary from state tostate.
5. DISCLAIMER OF WARRANTY. UNLESS SPECIFIED IN THIS AGREEMENT, ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS ANDWARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT AREDISCLAIMED, EXCEPT TO THE EXTENT THAT THESE DISCLAIMERS ARE HELD TO BE LEGALLY INVALID.
6. LIMITATION OF LIABILITY. TO THE EXTENT NOT PROHIBITED BY LAW, IN NO EVENT WILL SUN OR ITS LICENSORS BE LIABLE FOR ANY LOSTREVENUE, PROFIT OR DATA, OR FOR SPECIAL, INDIRECT, CONSEQUENTIAL, INCIDENTAL OR PUNITIVE DAMAGES, HOWEVER CAUSED REGARDLESS OFTHE THEORY OF LIABILITY, ARISING OUT OF OR RELATED TO THE USE OF OR INABILITY TO USE SOFTWARE, EVEN IF SUN HAS BEEN ADVISED OFTHE POSSIBILITY OF SUCH DAMAGES. In no event will Sun’s liability to you, whether in contract, tort (including negligence), orotherwise, exceed the amount paid by you for Software under this Agreement. The foregoing limitations will apply even if theabove stated warranty fails of its essential purpose. Some states do not allow the exclusion of incidental or consequentialdamages, so some of the terms above may not be applicable to you.

G.2. JAVA LICENSES 329
7. TERMINATION. This Agreement is effective until terminated. You may terminate this Agreement at any time by destroying allcopies of Software. This Agreement will terminate immediately without notice from Sun if you fail to comply with any provisionof this Agreement. Either party may terminate this Agreement immediately should any Software become, or in either party’sopinion be likely to become, the subject of a claim of infringement of any intellectual property right. Upon Termination, youmust destroy all copies of Software.
8. EXPORT REGULATIONS. All Software and technical data delivered under this Agreement are subject to US export control lawsand may be subject to export or import regulations in other countries. You agree to comply strictly with all such laws andregulations and acknowledge that you have the responsibility to obtain such licenses to export, re-export, or import as may berequired after delivery to you.
9. TRADEMARKS AND LOGOS. You acknowledge and agree as between you and Sun that Sun owns the SUN, SOLARIS, JAVA, JINI, FORTE,and iPLANET trademarks and all SUN, SOLARIS, JAVA, JINI, FORTE, and iPLANET-related trademarks, service marks, logos and otherbrand designations ("Sun Marks"), and you agree to comply with the Sun Trademark and Logo Usage Requirements currently located athttp://www.sun.com/policies/trademarks. Any use you make of the Sun Marks inures to Sun’s benefit.
10. U.S. GOVERNMENT RESTRICTED RIGHTS. If Software is being acquired by or on behalf of the U.S. Government or by a U.S.Government prime contractor or subcontractor (at any tier), then the Government’s rights in Software and accompanyingdocumentation will be only as set forth in this Agreement; this is in accordance with 48 CFR 227.7201 through 227.7202-4 (forDepartment of Defense (DOD) acquisitions) and with 48 CFR 2.101 and 12.212 (for non-DOD acquisitions).
11. GOVERNING LAW. Any action related to this Agreement will be governed by California law and controlling U.S. federal law. Nochoice of law rules of any jurisdiction will apply.
12. SEVERABILITY. If any provision of this Agreement is held to be unenforceable, this Agreement will remain in effect withthe provision omitted, unless omission would frustrate the intent of the parties, in which case this Agreement will immediatelyterminate.
13. INTEGRATION. This Agreement is the entire agreement between you and Sun relating to its subject matter. It supersedesall prior or contemporaneous oral or written communications, proposals, representations and warranties and prevails over anyconflicting or additional terms of any quote, order, acknowledgment, or other communication between the parties relating toits subject matter during the term of this Agreement. No modification of this Agreement will be binding, unless in writing andsigned by an authorized representative of each party.
JRE Supplemental Terms
In addition to the binary license, the JRE is additionally subject to the followingsupplemental license terms.
SUPPLEMENTAL LICENSE TERMS
These Supplemental License Terms add to or modify the terms of the Binary Code License Agreement. Capitalized terms notdefined in these Supplemental Terms shall have the same meanings ascribed to them in the Binary Code License Agreement. TheseSupplemental Terms shall supersede any inconsistent or conflicting terms in the Binary Code License Agreement, or in any licensecontained within the Software.
1. Software Internal Use and Development License Grant. Subject to the terms and conditions of this Agreement and restrictionsand exceptions set forth in the Software "README" file incorporated herein by reference, including, but not limited to the JavaTechnology Restrictions of these Supplemental Terms, Sun grants you a non-exclusive, non-transferable, limited license withoutfees to reproduce internally and use internally the Software complete and unmodified for the purpose of designing, developing,and testing your Programs.
2. License to Distribute Software. Subject to the terms and conditions of this Agreement and restrictions and exceptions setforth in the Software README file, including, but not limited to the Java Technology Restrictions of these Supplemental Terms,Sun grants you a non-exclusive, non-transferable, limited license without fees to reproduce and distribute the Software (exceptfor the JavaFX Runtime), provided that (i) you distribute the Software complete and unmodified and only bundled as part of, andfor the sole purpose of running, your Programs, (ii) the Programs add significant and primary functionality to the Software,(iii) you do not distribute additional software intended to replace any component(s) of the Software, (iv) you do not remove oralter any proprietary legends or notices contained in the Software, (v) you only distribute the Software subject to a licenseagreement that protects Sun’s interests consistent with the terms contained in this Agreement, and (vi) you agree to defend andindemnify Sun and its licensors from and against any damages, costs, liabilities, settlement amounts and/or expenses (includingattorneys’ fees) incurred in connection with any claim, lawsuit or action by any third party that arises or results from the useor distribution of any and all Programs and/or Software.
3. Java Technology Restrictions. You may not create, modify, or change the behavior of, or authorize your licensees to create,modify, or change the behavior of, classes, interfaces, or subpackages that are in any way identified as "java", "javax", "sun"or similar convention as specified by Sun in any naming convention designation.
4. Source Code. Software may contain source code that, unless expressly licensed for other purposes, is provided solely forreference purposes pursuant to the terms of this Agreement. Source code may not be redistributed unless expressly provided forin this Agreement.
5. Third Party Code. Additional copyright notices and license terms applicable to portions of the Software are set forth inthe THIRDPARTYLICENSEREADME.txt file. In addition to any terms and conditions of any third party opensource/freeware licenseidentified in the THIRDPARTYLICENSEREADME.txt file, the disclaimer of warranty and limitation of liability provisions inparagraphs 5 and 6 of the Binary Code License Agreement shall apply to all Software in this distribution.
6. Termination for Infringement. Either party may terminate this Agreement immediately should any Software become, or in eitherparty’s opinion be likely to become, the subject of a claim of infringement of any intellectual property right.
7. Installation and Auto-Update. The Software’s installation and auto-update processes transmit a limited amount of datato Sun (or its service provider) about those specific processes to help Sun understand and optimize them. Sun does notassociate the data with personally identifiable information. You can find more information about the data Sun collects athttp://java.com/data/.
For inquiries please contact: Sun Microsystems, Inc., 4150 Network Circle, Santa Clara, California 95054, U.S.A.

330 APPENDIX G. LICENSES
JDK Supplemental License Terms
The JDK is additionally subject to the following supplemental license terms.
SUPPLEMENTAL LICENSE TERMS
These Supplemental License Terms add to or modify the terms of the Binary Code License Agreement. Capitalized terms notdefined in these Supplemental Terms shall have the same meanings ascribed to them in the Binary Code License Agreement . TheseSupplemental Terms shall supersede any inconsistent or conflicting terms in the Binary Code License Agreement, or in any licensecontained within the Software.
A. Software Internal Use and Development License Grant. Subject to the terms and conditions of this Agreement and restrictionsand exceptions set forth in the Software "README" file incorporated herein by reference, including, but not limited to the JavaTechnology Restrictions of these Supplemental Terms, Sun grants you a non-exclusive, non-transferable, limited license withoutfees to reproduce internally and use internally the Software complete and unmodified for the purpose of designing, developing,and testing your Programs.
B. License to Distribute Software. Subject to the terms and conditions of this Agreement and restrictions and exceptionsset forth in the Software README file, including, but not limited to the Java Technology Restrictions of these SupplementalTerms, Sun grants you a non-exclusive, non-transferable, limited license without fees to reproduce and distribute the Software,provided that (i) you distribute the Software complete and unmodified and only bundled as part of, and for the sole purpose ofrunning, your Programs, (ii) the Programs add significant and primary functionality to the Software, (iii) you do not distributeadditional software intended to replace any component(s) of the Software, (iv) you do not remove or alter any proprietary legendsor notices contained in the Software, (v) you only distribute the Software subject to a license agreement that protects Sun’sinterests consistent with the terms contained in this Agreement, and (vi) you agree to defend and indemnify Sun and its licensorsfrom and against any damages, costs, liabilities, settlement amounts and/or expenses (including attorneys’ fees) incurred inconnection with any claim, lawsuit or action by any third party that arises or results from the use or distribution of any andall Programs and/or Software.
C. License to Distribute Redistributables. Subject to the terms and conditions of this Agreement and restrictions and exceptionsset forth in the Software README file, including but not limited to the Java Technology Restrictions of these SupplementalTerms, Sun grants you a non-exclusive, non-transferable, limited license without fees to reproduce and distribute those filesspecifically identified as redistributable in the Software "README" file ("Redistributables") provided that: (i) you distributethe Redistributables complete and unmodified, and only bundled as part of Programs, (ii) the Programs add significant and primaryfunctionality to the Redistributables, (iii) you do not distribute additional software intended to supersede any component(s) ofthe Redistributables (unless otherwise specified in the applicable README file), (iv) you do not remove or alter any proprietarylegends or notices contained in or on the Redistributables, (v) you only distribute the Redistributables pursuant to a licenseagreement that protects Sun’s interests consistent with the terms contained in the Agreement, (vi) you agree to defend andindemnify Sun and its licensors from and against any damages, costs, liabilities, settlement amounts and/or expenses (includingattorneys’ fees) incurred in connection with any claim, lawsuit or action by any third party that arises or results from the useor distribution of any and all Programs and/or Software.
D. Java Technology Restrictions. You may not create, modify, or change the behavior of, or authorize your licensees to create,modify, or change the behavior of, classes, interfaces, or subpackages that are in any way identified as "java", "javax", "sun"or similar convention as specified by Sun in any naming convention designation.
E. Distribution by Publishers. This section pertains to your distribution of the Software with your printed book or magazine(as those terms are commonly used in the industry) relating to Java technology ("Publication"). Subject to and conditioned uponyour compliance with the restrictions and obligations contained in the Agreement, in addition to the license granted in Paragraph1 above, Sun hereby grants to you a non-exclusive, nontransferable limited right to reproduce complete and unmodified copiesof the Software on electronic media (the "Media") for the sole purpose of inclusion and distribution with your Publication(s),subject to the following terms: (i) You may not distribute the Software on a stand-alone basis; it must be distributed with yourPublication(s); (ii) You are responsible for downloading the Software from the applicable Sun web site; (iii) You must refer tothe Software as JavaTM SE Development Kit 6; (iv) The Software must be reproduced in its entirety and without any modificationwhatsoever (including, without limitation, the Binary Code License and Supplemental License Terms accompanying the Software andproprietary rights notices contained in the Software); (v) The Media label shall include the following information: Copyright2006, Sun Microsystems, Inc. All rights reserved. Use is subject to license terms. Sun, Sun Microsystems, the Sun logo,Solaris, Java, the Java Coffee Cup logo, J2SE, and all trademarks and logos based on Java are trademarks or registered trademarksof Sun Microsystems, Inc. in the U.S. and other countries. This information must be placed on the Media label in such a manneras to only apply to the Sun Software; (vi) You must clearly identify the Software as Sun’s product on the Media holder or Medialabel, and you may not state or imply that Sun is responsible for any third-party software contained on the Media; (vii) Youmay not include any third party software on the Media which is intended to be a replacement or substitute for the Software;(viii) You shall indemnify Sun for all damages arising from your failure to comply with the requirements of this Agreement. Inaddition, you shall defend, at your expense, any and all claims brought against Sun by third parties, and shall pay all damagesawarded by a court of competent jurisdiction, or such settlement amount negotiated by you, arising out of or in connection withyour use, reproduction or distribution of the Software and/or the Publication. Your obligation to provide indemnification underthis section shall arise provided that Sun: (a) provides you prompt notice of the claim; (b) gives you sole control of thedefense and settlement of the claim; (c) provides you, at your expense, with all available information, assistance and authorityto defend; and (d) has not compromised or settled such claim without your prior written consent; and (ix) You shall provide Sunwith a written notice for each Publication; such notice shall include the following information: (1) title of Publication, (2)author(s), (3) date of Publication, and (4) ISBN or ISSN numbers. Such notice shall be sent to Sun Microsystems, Inc., 4150Network Circle, M/S USCA12-110, Santa Clara, California 95054, U.S.A , Attention: Contracts Administration.
F. Source Code. Software may contain source code that, unless expressly licensed for other purposes, is provided solely forreference purposes pursuant to the terms of this Agreement. Source code may not be redistributed unless expressly provided forin this Agreement.
G. Third Party Code. Additional copyright notices and license terms applicable to portions of the Software are set forth inthe THIRDPARTYLICENSEREADME.txt file. In addition to any terms and conditions of any third party opensource/freeware licenseidentified in the THIRDPARTYLICENSEREADME.txt file, the disclaimer of warranty and limitation of liability provisions inparagraphs 5 and 6 of the Binary Code License Agreement shall apply to all Software in this distribution.
H. Termination for Infringement. Either party may terminate this Agreement immediately should any Software become, or in eitherparty’s opinion be likely to become, the subject of a claim of infringement of any intellectual property right.
I. Installation and Auto-Update. The Software’s installation and auto-update processes transmit a limited amount of datato Sun (or its service provider) about those specific processes to help Sun understand and optimize them. Sun does notassociate the data with personally identifiable information. You can find more information about the data Sun collects athttp://java.com/data/.
For inquiries please contact: Sun Microsystems, Inc., 4150 Network Circle, Santa Clara, California 95054, U.S.A.

G.2. JAVA LICENSES 331
G.2.2 Sun Community Source License Version 2.8
The license for the Java source code isSUN COMMUNITY SOURCE LICENSE Version 2.8 (Rev. Date January 17, 2001)
RECITALSOriginal Contributor has developed Specifications and Source Code implementations of certain Technology; andOriginal Contributor desires to license the Technology to a large community to facilitate research, innovation andproduct
development while maintaining compatibility of such products with the Technology as delivered by Original Contributor; andOriginal Contributor desires to license certain Sun Trademarks for the purpose of branding products that are compatible with
the relevant Technology delivered by Original Contributor; andYou desire to license the Technology and possibly certain Sun Trademarks from Original Contributor on the terms and
conditions specified in this License.In consideration for the mutual covenants contained herein, You and Original Contributor agree as follows:AGREEMENT1. Introduction. The Sun Community Source License and effective attachments ("License") may include five distinct
licenses: Research Use, TCK, Internal Deployment Use, Commercial Use and Trademark License. The Research Use license iseffective when You execute this License. The TCK and Internal Deployment Use licenses are effective when You execute thisLicense, unless otherwise specified in the TCK and Internal Deployment Use attachments. The Commercial Use and Trademarklicenses must be signed by You and Original Contributor in order to become effective. Once effective, these licenses and theassociated requirements and responsibilities are cumulative. Capitalized terms used in this License are defined in the Glossary.
2. License Grants.2.1. Original Contributor Grant. Subject to Your compliance with Sections 3, 8.10 and Attachment A of this License,
Original Contributor grants to You a worldwide, royalty-free, non-exclusive license, to the extent of Original Contributor’sIntellectual Property Rights covering the Original Code, Upgraded Code and Specifications, to do the following:
a) Research Use License: (i) use, reproduce and modify the Original Code, Upgraded Code and Specifications to createModifications and Reformatted Specifications for Research Use by You, (ii) publish and display Original Code, Upgraded Code andSpecifications with, or as part of Modifications, as permitted under Section 3.1 b) below, (iii) reproduce and distribute copiesof Original Code and Upgraded Code to Licensees and students for Research Use by You, (iv) compile, reproduce and distributeOriginal Code and Upgraded Code in Executable form, and Reformatted Specifications to anyone for Research Use by You.
b) Other than the licenses expressly granted in this License, Original Contributor retains all right, title, and interest inOriginal Code and Upgraded Code and Specifications. 2.2. Your Grants.
a) To Other Licensees. You hereby grant to each Licensee a license to Your Error Corrections and Shared Modifications, ofthe same scope and extent as Original Contributor’s licenses under Section 2.1 a) above relative to Research Use, Attachment Crelative to Internal Deployment Use, and Attachment D relative to Commercial Use.
b) To Original Contributor. You hereby grant to Original Contributor a worldwide, royalty-free, non-exclusive,perpetual and irrevocable license, to the extent of Your Intellectual Property Rights covering Your Error Corrections, SharedModifications and Reformatted Specifications, to use, reproduce, modify, display and distribute Your Error Corrections, SharedModifications and Reformatted Specifications, in any form, including the right to sublicense such rights through multiple tiersof distribution.
c) Other than the licenses expressly granted in Sections 2.2 a) and b) above, and the restriction set forth in Section3.1 d)(iv) below, You retain all right, title, and interest in Your Error Corrections, Shared Modifications and ReformattedSpecifications.
2.3. Contributor Modifications. You may use, reproduce, modify, display and distribute Contributor Error Corrections,Shared Modifications and Reformatted Specifications, obtained by You under this License, to the same scope and extent as withOriginal Code, Upgraded Code and Specifications.
2.4. Subcontracting. You may deliver the Source Code of Covered Code to other Licensees having at least a Research Uselicense, for the sole purpose of furnishing development services to You in connection with Your rights granted in this License.All such Licensees must execute appropriate documents with respect to such work consistent with the terms of this License,and acknowledging their work-made-for-hire status or assigning exclusive right to the work product and associated IntellectualProperty Rights to You.
3. Requirements and Responsibilities.3.1. Research Use License. As a condition of exercising the rights granted under Section 2.1 a) above, You agree to comply
with the following:a) Your Contribution to the Community. All Error Corrections and Shared Modifications which You create or contribute to
are automatically subject to the licenses granted under Section 2.2 above. You are encouraged to license all of Your otherModifications under Section 2.2 as Shared Modifications, but are not required to do so. You agree to notify Original Contributorof any errors in the Specification.
b) Source Code Availability. You agree to provide all Your Error Corrections to Original Contributor as soon as reasonablypracticable and, in any event, prior to Internal Deployment Use or Commercial Use, if applicable. Original Contributor may,at its discretion, post Source Code for Your Error Corrections and Shared Modifications on the Community Webserver. You mayalso post Error Corrections and Shared Modifications on a web-server of Your choice; provided, that You must take reasonableprecautions to ensure that only Licensees have access to such Error Corrections and Shared Modifications. Such precautionsshall include, without limitation, a password protection scheme limited to Licensees and a click-on, download certification ofLicensee status required of those attempting to download from the server. An example of an acceptable certification is attachedas Attachment A-2.
c) Notices. All Error Corrections and Shared Modifications You create or contribute to must include a file documentingthe additions and changes You made and the date of such additions and changes. You must also include the notice set forthin Attachment A-1 in the file header. If it is not possible to put the notice in a particular Source Code file due to itsstructure, then You must include the notice in a location (such as a relevant directory file), where a recipient would be mostlikely to look for such a notice.
d) Redistribution.(i) Source. Covered Code may be distributed in Source Code form only to another Licensee (except for students as provided
below). You may not offer or impose any terms on any Covered Code that alter the rights, requirements, or responsibilities ofsuch Licensee. You may distribute Covered Code to students for use in connection with their course work and research projectsundertaken at accredited educational institutions. Such students need not be Licensees, but must be given a copy of the noticeset forth in Attachment A-3 and such notice must also be included in a file header or prominent location in the Source Code madeavailable to such students.
(ii) Executable. You may distribute Executable version(s) of Covered Code to Licensees and other third parties only for thepurpose of evaluation and comment in connection with Research Use by You and under a license of Your choice, but which limits useof such Executable version(s) of Covered Code only to that purpose.
(iii) Modified Class, Interface and Package Naming. In connection with Research Use by You only, You may use OriginalContributor’s class, interface and package names only to accurately reference or invoke the Source Code files You modify.Original Contributor grants to You a limited license to the extent necessary for such purposes.
(iv) Modifications. You expressly agree that any distribution, in whole or in part, of Modifications developed by You shallonly be done pursuant to the term and conditions of this License.
e) Extensions.(i) Covered Code. You may not include any Source Code of Community Code in any Extensions;(ii) Publication. No later than the date on which You first distribute such Extension for Commercial Use, You must publish
to the industry, on a non-confidential basis and free of all copyright restrictions with respect to reproduction and use, anaccurate and current specification for any Extension. In addition, You must make available an appropriate test suite, pursuantto the same rights as the specification, sufficiently detailed to allow any third party reasonably skilled in the technology toproduce implementations of the Extension compatible with the specification. Such test suites must be made available as soon as

332 APPENDIX G. LICENSES
reasonably practicable but, in no event, later than ninety (90) days after Your first Commercial Use of the Extension. You mustuse reasonable efforts to promptly clarify and correct the specification and the test suite upon written request by OriginalContributor.
(iii) Open. You agree to refrain from enforcing any Intellectual Property Rights You may have covering any interface(s)of Your Extension, which would prevent the implementation of such interface(s) by Original Contributor or any Licensee. Thisobligation does not prevent You from enforcing any Intellectual Property Right You have that would otherwise be infringed by animplementation of Your Extension.
(iv) Class, Interface and Package Naming. You may not add any packages, or any public or protected classes or interfaceswith names that originate or might appear to originate from Original Contributor including, without limitation, package orclass names which begin with "sun", "java", "javax", "jini", "net.jini", "com.sun" or their equivalents in any subsequent class,interface and/or package naming convention adopted by Original Contributor. It is specifically suggested that You name any newpackages using the "Unique Package Naming Convention" as described in "The Java Language Specification" by James Gosling, BillJoy, and Guy Steele, ISBN 0-201-63451-1, August 1996. Section 7.7 "Unique Package Names", on page 125 of this specificationwhich states, in part:
"You form a unique package name by first having (or belonging to an organization that has) an Internet domain name, such as"sun.com". You then reverse the name, component by component, to obtain, in this example, "Com.sun", and use this as a prefixfor Your package names, using a convention developed within Your organization to further administer package names."
3.2. Additional Requirements and Responsibilities. Any additional requirements and responsibilities relating to theTechnology are listed in Attachment F (Additional Requirements and Responsibilities), if applicable, and are hereby incorporatedinto this Section 3.
4. Versions of the License.4.1. License Versions. Original Contributor may publish revised versions of the License from time to time. Each version
will be given a distinguishing version number.4.2. Effect. Once a particular version of Covered Code has been provided under a version of the License, You may always
continue to use such Covered Code under the terms of that version of the License. You may also choose to use such Covered Codeunder the terms of any subsequent version of the License. No one other than Original Contributor has the right to promulgateLicense versions.
5. Disclaimer of Warranty.5.1. COVERED CODE IS PROVIDED UNDER THIS LICENSE "AS IS," WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED,
INCLUDING, WITHOUT LIMITATION, WARRANTIES THAT THE COVERED CODE IS FREE OF DEFECTS, MERCHANTABLE, FIT FOR A PARTICULAR PURPOSEOR NON-INFRINGING. YOU AGREE TO BEAR THE ENTIRE RISK IN CONNECTION WITH YOUR USE AND DISTRIBUTION OF COVERED CODE UNDER THISLICENSE. THIS DISCLAIMER OF WARRANTY CONSTITUTES AN ESSENTIAL PART OF THIS LICENSE. NO USE OF ANY COVERED CODE IS AUTHORIZEDHEREUNDER EXCEPT SUBJECT TO THIS DISCLAIMER.
5.2. You acknowledge that Original Code, Upgraded Code and Specifications are not designed or intended for use in (i)on-line control of aircraft, air traffic, aircraft navigation or aircraft communications; or (ii) in the design, construction,operation or maintenance of any nuclear facility. Original Contributor disclaims any express or implied warranty of fitness forsuch uses.
6. Termination.6.1. By You. You may terminate this Research Use license at anytime by providing written notice to Original Contributor.6.2. By Original Contributor. This License and the rights granted hereunder will terminate: (i) automatically if You fail
to comply with the terms of this License and fail to cure such breach within 30 days of receipt of written notice of the breach;(ii) immediately in the event of circumstances specified in Sections 7.1 and 8.4; or (iii) at Original Contributor’s discretionupon any action initiated in the first instance by You alleging that use or distribution by Original Contributor or any Licensee,of Original Code, Upgraded Code, Error Corrections or Shared Modifications contributed by You, or Specifications, infringe apatent owned or controlled by You.
6.3. Effect of Termination. Upon termination, You agree to discontinue use and return or destroy all copies of CoveredCode in your possession. All sublicenses to the Covered Code which you have properly granted shall survive any termination ofthis License. Provisions which, by their nature, should remain in effect beyond the termination of this License shall surviveincluding, without limitation, Sections 2.2, 3, 5, 7 and 8.
6.4. Each party waives and releases the other from any claim to compensation or indemnity for permitted or lawfultermination of the business relationship established by this License.
7. Liability.7.1. Infringement. Should any of the Original Code, Upgraded Code, TCK or Specifications ("Materials") become the subject
of a claim of infringement, Original Contributor may, at its sole option, (i) attempt to procure the rights necessary for You tocontinue using the Materials, (ii) modify the Materials so that they are no longer infringing, or (iii) terminate Your right touse the Materials, immediately upon written notice, and refund to You the amount, if any, having then actually been paid by Youto Original Contributor for the Original Code, Upgraded Code and TCK, depreciated on a straight line, five year basis.
7.2. LIMITATION OF LIABILITY. TO THE FULL EXTENT ALLOWED BY APPLICABLE LAW, ORIGINAL CONTRIBUTOR’S LIABILITY TO YOU FORCLAIMS RELATING TO THIS LICENSE, WHETHER FOR BREACH OR IN TORT, SHALL BE LIMITED TO ONE HUNDRED PERCENT (100%) OF THE AMOUNTHAVING THEN ACTUALLY BEEN PAID BY YOU TO ORIGINAL CONTRIBUTOR FOR ALL COPIES LICENSED HEREUNDER OF THE PARTICULAR ITEMS GIVINGRISE TO SUCH CLAIM, IF ANY. IN NO EVENT WILL YOU (RELATIVE TO YOUR SHARED MODIFICATIONS OR ERROR CORRECTIONS) OR ORIGINALCONTRIBUTOR BE LIABLE FOR ANY INDIRECT, PUNITIVE, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES IN CONNECTION WITH OR ARISINGOUT OF THIS LICENSE (INCLUDING, WITHOUT LIMITATION, LOSS OF PROFITS, USE, DATA, OR OTHER ECONOMIC ADVANTAGE), HOWEVER IT ARISESAND ON ANY THEORY OF LIABILITY, WHETHER IN AN ACTION FOR CONTRACT, STRICT LIABILITY OR TORT (INCLUDING NEGLIGENCE) OR OTHERWISE,WHETHER OR NOT YOU OR ORIGINAL CONTRIBUTOR HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGE AND NOTWITHSTANDING THE FAILURE OFESSENTIAL PURPOSE OF ANY REMEDY.
8. Miscellaneous.8.1. Trademark. You agree to comply with the then current Sun Trademark & Logo Usage Requirements accessible through
the SCSL Webpage. Except as expressly provided in the License, You are granted no right, title or license to, or interest in,any Sun Trademarks. You agree not to (i) challenge Original Contributor’s ownership or use of Sun Trademarks; (ii) attempt toregister any Sun Trademarks, or any mark or logo substantially similar thereto; or (iii) incorporate any Sun Trademarks into yourown trademarks, product names, service marks, company names, or domain names.
8.2. Integration. This License represents the complete agreement concerning the subject matter hereof.8.3. Assignment. Original Contributor may assign this License, and its rights and obligations hereunder, in its sole
discretion. You may assign the Research Use portions of this License to a third party upon prior written notice to OriginalContributor (which may be provided via the Community Web-Server). You may not assign the Commercial Use license or TCK license,including by way of merger (regardless of whether You are the surviving entity) or acquisition, without Original Contributor’sprior written consent.
8.4. Severability. If any provision of this License is held to be unenforceable, such provision shall be reformed onlyto the extent necessary to make it enforceable. Notwithstanding the foregoing, if You are prohibited by law from fully andspecifically complying with Sections 2.2 or 3, this License will immediately terminate and You must immediately discontinue anyuse of Covered Code.
8.5. Governing Law. This License shall be governed by the laws of the United States and the State of California, asapplied to contracts entered into and to be performed in California between California residents. The application of the UnitedNations Convention on Contracts for the International Sale of Goods is expressly excluded.
8.6. Dispute Resolution.a) Any dispute arising out of or relating to this License shall be finally settled by arbitration as set out herein, except
that either party may bring any action, in a court of competent jurisdiction (which jurisdiction shall be exclusive), withrespect to any dispute relating to such party’s Intellectual Property Rights or with respect to Your compliance with the TCKlicense. Arbitration shall be administered: (i) by the American Arbitration Association (AAA), (ii) in accordance with therules of the United Nations Commission on International Trade Law (UNCITRAL) (the "Rules") in effect at the time of arbitrationas modified herein; and (iii) the arbitrator will apply the substantive laws of California and United States. Judgment upon theaward rendered by the arbitrator may be entered in any court having jurisdiction to enforce such award.

G.2. JAVA LICENSES 333
b) All arbitration proceedings shall be conducted in English by a single arbitrator selected in accordance with the Rules,who must be fluent in English and be either a retired judge or practicing attorney having at least ten (10) years litigationexperience and be reasonably familiar with the technology matters relative to the dispute. Unless otherwise agreed, arbitrationvenue shall be in London, Tokyo, or San Francisco, whichever is closest to defendant’s principal business office. The arbitratormay award monetary damages only and nothing shall preclude either party from seeking provisional or emergency relief from a courtof competent jurisdiction. The arbitrator shall have no authority to award damages in excess of those permitted in this Licenseand any such award in excess is void. All awards will be payable in U.S. dollars and may include, for the prevailing party (i)pre-judgment award interest, (ii) reasonable attorneys’ fees incurred in connection with the arbitration, and (iii) reasonablecosts and expenses incurred in enforcing the award. The arbitrator will order each party to produce identified documents andrespond to no more than twenty-five single question interrogatories.
8.7. Construction. Any law or regulation which provides that the language of a contract shall be construed against thedrafter shall not apply to this License.
8.8. U.S. Government End Users. The Covered Code is a "commercial item," as that term is defined in 48 C.F.R. 2.101 (Oct.1995), consisting of "commercial computer software" and "commercial computer software documentation," as such terms are used in48 C.F.R. 12.212 (Sept. 1995). Consistent with 48 C.F.R. 12.212 and 48 C.F.R. 227.7202-1 through 227.7202-4 (June 1995), allU.S. Government End Users acquire Covered Code with only those rights set forth herein. You agree to pass this notice to Yourlicensees.
8.9. Press Announcements. All press announcements relative to the execution of this License must be reviewed and approvedby Original Contributor and You prior to release.
8.10. International Use.a) Export/Import Laws. Covered Code is subject to U.S. export control laws and may be subject to export or import
regulations in other countries. Each party agrees to comply strictly with all such laws and regulations and acknowledges theirresponsibility to obtain such licenses to export, re-export, or import as may be required. You agree to pass these obligationsto Your licensees.
b) Intellectual Property Protection. Due to limited intellectual property protection and enforcement in certain countries,You agree not to redistribute the Original Code, Upgraded Code, TCK and Specifications to any country other than the list ofrestricted countries on the SCSL Webpage.
8.11. Language. This License is in the English language only, which language shall be controlling in all respects, andall versions of this License in any other language shall be for accommodation only and shall not be binding on the parties tothis License. All communications and notices made or given pursuant to this License, and all documentation and support to beprovided, unless otherwise noted, shall be in the English language.
PLEASE READ THE TERMS OF THIS LICENSE CAREFULLY. BY CLICKING ON THE "ACCEPT" BUTTON BELOW YOU ARE ACCEPTING AND AGREEING TOTHE TERMS AND CONDITIONS OF THIS LICENSE WITH SUN MICROSYSTEMS, INC. IF YOU ARE AGREEING TO THIS LICENSE ON BEHALF OF A COMPANY,YOU REPRESENT THAT YOU ARE AUTHORIZED TO BIND THE COMPANY TO SUCH A LICENSE. WHETHER YOU ARE ACTING ON YOUR OWN BEHALF, ORREPRESENTING A COMPANY, YOU MUST BE OF MAJORITY AGE AND BE OTHERWISE COMPETENT TO ENTER INTO CONTRACTS. IF YOU DO NOT MEET THISCRITERIA OR YOU DO NOT AGREE TO ANY OF THE TERMS AND CONDITIONS OF THIS LICENSE, CLICK ON THE REJECT BUTTON TO EXIT.
ACCEPT REJECTGLOSSARY1. "Commercial Use" means any use (excluding Internal Deployment Use) or distribution, directly or indirectly of Compliant
Covered Code by You to any third party, alone or bundled with any other software or hardware, for direct or indirect commercialor strategic gain or advantage, subject to execution of Attachment D by You and Original Contributor.
2. "Community Code" means the Original Code, Upgraded Code, Error Corrections, Shared Modifications, or any combinationthereof.
3. "Community Webserver(s)" means the webservers designated by Original Contributor for posting Error Corrections andShared Modifications.
4. "Compliant Covered Code" means Covered Code that complies with the requirements of the TCK.5. "Contributor" means each Licensee that creates or contributes to the creation of any Error Correction or Shared
Modification.6. "Covered Code" means the Original Code, Upgraded Code, Modifications, or any combination thereof.7. "Error Correction" means any change made to Community Code which conforms to the Specification and corrects the adverse
effect of a failure of Community Code to perform any function set forth in or required by the Specifications.8. "Executable" means Covered Code that has been converted to a form other than Source Code.9. "Extension(s)" means any additional classes or other programming code and/or interfaces developed by or for You which:
(i) are designed for use with the Technology; (ii) constitute an API for a library of computing functions or services; and (iii)are disclosed to third party software developers for the purpose of developing software which invokes such additional classes orother programming code and/or interfaces. The foregoing shall not apply to software development by Your subcontractors to beexclusively used by You.
10. "Intellectual Property Rights" means worldwide statutory and common law rights associated solely with (i) patents andpatent applications; (ii) works of authorship including copyrights, copyright applications, copyright registrations and "moralrights"; (iii) the protection of trade and industrial secrets and confidential information; and (iv) divisions, continuations,renewals, and re-issuances of the foregoing now existing or acquired in the future.
11. "Internal Deployment Use" means use of Compliant Covered Code (excluding Research Use) within Your business ororganization only by Your employees and/or agents, subject to execution of Attachment C by You and Original Contributor, ifrequired.
12. "Licensee" means any party that has entered into and has in effect a version of this License with Original Contributor.13. "Modification(s)" means (i) any change to Covered Code; (ii) any new file or other representation of computer
program statements that contains any portion of Covered Code; and/or (iii) any new Source Code implementing any portion ofthe Specifications.
14. "Original Code" means the initial Source Code for the Technology as described on the Technology Download Site.15. "Original Contributor" means Sun Microsystems, Inc., its affiliates and its successors and assigns.16. "Reformatted Specifications" means any revision to the Specifications which translates or reformats the Specifications
(as for example in connection with Your documentation) but which does not alter, subset or superset the functional or operationalaspects of the Specifications.
17. "Research Use" means use and distribution of Covered Code only for Your research, development, educational or personaland individual use, and expressly excludes Internal Deployment Use and Commercial Use.
18. "SCSL Webpage" means the Sun Community Source license webpage located at http://sun.com/software/communitysource, orsuch other url that Original Contributor may designate from time to time.
19. "Shared Modifications" means Modifications provided by You, at Your option, pursuant to Section 2.2, or received by Youfrom a Contributor pursuant to Section 2.3.
20. "Source Code" means computer program statements written in any high-level, readable form suitable for modification anddevelopment.
21. "Specifications" means the specifications for the Technology and other documentation, as designated on the TechnologyDownload Site, as may be revised by Original Contributor from time to time.
22. "Sun Trademarks" means Original Contributor’s SUN, JAVA, and JINI trademarks and logos, whether now used or adopted inthe future.
23. "Technology" means the technology described in Attachment B, and Upgrades.24. "Technology Compatibility Kit" or "TCK" means the test programs, procedures and/or other requirements, designated by
Original Contributor for use in verifying compliance of Covered Code with the Specifications, in conjunction with the OriginalCode and Upgraded Code. Original Contributor may, in its sole discretion and from time to time, revise a TCK to correct errorsand/or omissions and in connection with Upgrades.
25. "Technology Download Site" means the site(s) designated by Original Contributor for access to the Original Code,Upgraded Code, TCK and Specifications.

334 APPENDIX G. LICENSES
26. "Upgrade(s)" means new versions of Technology designated exclusively by Original Contributor as an Upgrade and releasedby Original Contributor from time to time.
27. "Upgraded Code" means the Source Code for Upgrades, possibly including Modifications made by Contributors.28. "You(r)" means an individual, or a legal entity acting by and through an individual or individuals, exercising rights
either under this License or under a future version of this License issued pursuant to Section 4.1. For legal entities, "You(r)"includes any entity that by majority voting interest controls, is controlled by, or is under common control with You.
ATTACHMENT A REQUIRED NOTICESATTACHMENT A-1 REQUIRED IN ALL CASES"The contents of this file, or the files included with this file, are subject to the current version of Sun Community Source
License for [fill in name of applicable Technology] (the "License"); You may not use this file except in compliance with theLicense. You may obtain a copy of the License at http:// sun.com/software/communitysource. See the License for the rights,obligations and limitations governing use of the contents of the file.
The Original and Upgraded Code is [fill in name of applicable Technology]. The developer of the Original and Upgraded Codeis Sun Microsystems, Inc. Sun Microsystems, Inc. owns the copyrights in the portions it created. All Rights Reserved.
Contributor(s): --Associated Test Suite(s) Location: --"ATTACHMENT A-2 SAMPLE LICENSEE CERTIFICATION"By clicking the ’Agree’ button below, You certify that You are a Licensee in good standing under the Sun Community Source
License, [fill in name of applicable Technology] ("License") and that Your access, use and distribution of code and informationYou may obtain at this site is subject to the License."
ATTACHMENT A-3 REQUIRED STUDENT NOTIFICATION"This software and related documentation has been obtained by your educational institution subject to the Sun Community
Source License, [fill in name of applicable Technology]. You have been provided access to the software and related documentationfor use only in connection with your course work and research activities as a matriculated student of your educationalinstitution. Any other use is expressly prohibited.
THIS SOFTWARE AND RELATED DOCUMENTATION CONTAINS PROPRIETARY MATERIAL OF SUN MICROSYSTEMS, INC, WHICH ARE PROTECTED BYVARIOUS INTELLECTUAL PROPERTY RIGHTS.
You may not use this file except in compliance with the License. You may obtain a copy of the License on the web athttp://sun.com/software/ communitysource."
ATTACHMENT BJava (tm) Platform, Standard Edition, JDK 6 Source TechnologyDescription of "Technology"Java (tm) Platform, Standard Edition, JDK 6 Source Technology as described on the Technology Download Site.ATTACHMENT C INTERNAL DEPLOYMENT USEThis Attachment C is only effective for the Technology specified in Attachment B, upon execution of Attachment D (Commercial
Use License) including the requirement to pay royalties. In the event of a conflict between the terms of this Attachment C andAttachment D, the terms of Attachment D shall govern.
1. Internal Deployment License Grant. Subject to Your compliance with Section 2 below, and Section 8.10 of the ResearchUse license; in addition to the Research Use license and the TCK license, Original Contributor grants to You a worldwide,non-exclusive license, to the extent of Original Contributor’s Intellectual Property Rights covering the Original Code, UpgradedCode and Specifications, to do the following:
a) reproduce and distribute internally, Original Code and Upgraded Code as part of Compliant Covered Code, andSpecifications, for Internal Deployment Use,
b) compile such Original Code and Upgraded Code, as part of Compliant Covered Code, and reproduce and distribute internallythe same in Executable form for Internal Deployment Use, and
c) reproduce and distribute internally, Reformatted Specifications for use in connection with Internal Deployment Use.2. Additional Requirements and Responsibilities. In addition to the requirements and responsibilities described under
Section 3.1 of the Research Use license, and as a condition to exercising the rights granted under Section 3 above, You agree tothe following additional requirements and responsibilities:
2.1. Compatibility. All Covered Code must be Compliant Covered Code prior to any Internal Deployment Use or CommercialUse, whether originating with You or acquired from a third party. Successful compatibility testing must be completed inaccordance with the TCK License. If You make any further Modifications to any Covered Code previously determined to be CompliantCovered Code, you must ensure that it continues to be Compliant Covered Code.
ATTACHMENT D COMMERCIAL USE LICENSE[Contact Sun Microsystems For Commercial Use Terms and Conditions]ATTACHMENT E TECHNOLOGY COMPATIBILITY KITThe following license is effective for the Java (tm) Platform, Standard Edition, JDK 6 Technology Compatibility Kit only
upon execution of a separate support agreement between You and Original Contributor (subject to an annual fee) as described onthe SCSL Webpage. The applicable Technology Compatibility Kit for the Technology specified in Attachment B may be accessed atthe Technology Download Site only upon execution of the support agreement.
1. TCK License.a) Subject to the restrictions set forth in Section 1.b below and Section 8.10 of the Research Use license, in addition to
the Research Use license, Original Contributor grants to You a worldwide, non-exclusive, non-transferable license, to the extentof Original Contributor’s Intellectual Property Rights in the TCK (without the right to sublicense), to use the TCK to developand test Covered Code.
b) TCK Use Restrictions. You are not authorized to create derivative works of the TCK or use the TCK to test anyimplementation of the Specification that is not Covered Code. You may not publish your test results or make claims ofcomparative compatibility with respect to other implementations of the Specification. In consideration for the license grant inSection 1.a above you agree not to develop your own tests which are intended to validate conformation with the Specification.
2. Requirements for Determining Compliance.2.1. Definitions.a) "Added Value" means code which:(i) has a principal purpose which is substantially different from that of the stand-alone Technology;(ii) represents a significant functional and value enhancement to the Technology;(iii) operates in conjunction with the Technology; and(iv) is not marketed as a technology which replaces or substitutes for the Technology.b) "Java Classes" means the specific class libraries associated with each Technology defined in Attachment B.c) "Java Runtime Interpreter" means the program(s) which implement the Java virtual machine for the Technology as defined in
the Specification.d) "Platform Dependent Part" means those Original Code and Upgraded Code files of the Technology which are not in a share
directory or subdirectory thereof.e) "Shared Part" means those Original Code and Upgraded Code files of the Technology which are identified as "shared"
(or words of similar meaning) or which are in any "share" directory or subdirectory thereof, except those files specificallydesignated by Original Contributor as modifiable.
f) "User’s Guide" means the users guide for the TCK which Original Contributor makes available to You to provide directionin how to run the TCK and properly interpret the results, as may be revised by Original Contributor from time to time.
2.2. Development Restrictions. Compliant Covered Code:a) must include Added Value;b) must fully comply with the Specifications for the Technology specified in Attachment B;c) must include the Shared Part, complete and unmodified;d) may not modify the functional behavior of the Java Runtime Interpreter or the Java Classes;e) may not modify, subset or superset the interfaces of the Java Runtime Interpreter or the Java Classes;f) may not subset or superset the Java Classes;

G.3. APACHE LICENSE 2.0 335
g) may not modify or extend the required public class or public interface declarations whose names begin with "java","javax", "jini", "net.jini", "sun.hotjava", "COM.sun" or their equivalents in any subsequent naming convention;
h) Profiles. The following provisions apply if You are licensing a Java Platform, Micro Edition Connected DeviceConfiguration, Java Platform, Micro Edition Connected Limited Device Configuration and/or a Profile:
(i) Profiles may not include an implementation of any part of a Profile or use any of the APIs within a Profile, unlessYou implement the Profile in its entirety in conformance with the applicable compatibility requirements and test suites asdeveloped and licensed by Original Contributor or other authorized party. "Profile" means: (A) for Java Platform, MicroEdition Connected Device Configuration, Foundation Profile, Personal Profile or such other profile as may be developed underor in connection with the Java Community Process or as otherwise authorized by Original Contributor; (B) for Java Platform,Micro Edition Connected Limited Device Configuration, Java Platform, Micro Edition, Mobile Information Device Profile or suchother profile as may be developed under or in connection with the Java Community Process or as otherwise authorized by OriginalContributor. Notwithstanding the foregoing, nothing herein shall be construed as eliminating or modifying Your obligation toinclude Added Value as set forth in Section 2.2(a), above; and
(ii) Profile(s) must be tightly integrated with, and must be configured to run in conjunction with, an implementationof a Configuration from Original Contributor (or an authorized third party) which meets Original Contributor’s compatibilityrequirements. "Configuration" means, as defined in Original Contributor’s compatibility requirements, either (A) Java Platform,Micro Edition Connected Device Configuration; or (B) Java Platform, Micro Edition Connected Limited Device Configuration.
(iii) A Profile as integrated with a Configuration must pass the applicable TCK for the Technology.2.3. Compatibility Testing. Successful compatibility testing must be completed by You, or at Original Contributor’s
option, a third party designated by Original Contributor to conduct such tests, in accordance with the User’s Guide. ATechnology must pass the applicable TCK for the Technology. You must use the most current version of the applicable TCKavailable from Original Contributor one hundred twenty (120) days (two hundred forty [240] days in the case of siliconimplementations) prior to: (i) Your Internal Deployment Use; and (ii) each release of Compliant Covered Code by You forCommercial Use. In the event that You elect to use a version of Upgraded Code that is newer than that which is required underthis Section 2.3, then You agree to pass the version of the TCK that corresponds to such newer version of Upgraded Code.
2.4. Test Results. You agree to provide to Original Contributor or the third party test facility if applicable, Yourtest results that demonstrate that Covered Code is Compliant Covered Code and that Original Contributor may publish or otherwisedistribute such test results.
G.3 Apache License 2.0
NekoHTML is licensed under version 2 of the Apache License.
Apache License Version 2.0, January 2004http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of thisdocument.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are undercommon control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, tocause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) ormore of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code,documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but notlimited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by acopyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and forwhich the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work ofauthorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merelylink (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additionsto that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by thecopyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposesof this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or itsrepresentatives, including but not limited to communication on electronic mailing lists, source code control systems, andissue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work,but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not aContribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received byLicensor and subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You aperpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare DerivativeWorks of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Objectform.
3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You aperpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license tomake, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to thosepatent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination oftheir Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against anyentity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within theWork constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for thatWork shall terminate as of the date such litigation is filed.

336 APPENDIX G. LICENSES
4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with orwithout modifications, and in Source or Object form, provided that You meet the following conditions:
1. You must give any other recipients of the Work or Derivative Works a copy of this License; and
2. You must cause any modified files to carry prominent notices stating that You changed the files; and
3. You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, andattribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the DerivativeWorks; and
4. If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute mustinclude a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertainto any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part ofthe Derivative Works; within the Source form or documentation, if provided long with the Derivative Works; or, within a displaygenerated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file arefor informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Worksthat You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attributionnotices cannot be construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms andconditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, providedYour use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusionin the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms orconditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement youmay have executed with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product namesof the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing thecontent of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and eachContributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express orimplied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESSFOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work andassume any risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, orotherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shallany Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages ofany character arising as a result of this License or out of the use or inability to use the Work (including but not limited todamages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses),even if such Contributor has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose tooffer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistentwith this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility,not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for anyliability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additionalliability.
END OF TERMS AND CONDITIONS
G.4 Common Public License 1.0
JUnit is distributed under the Common Public License, version 1.0
Common Public License - v 1.0
THE ACCOMPANYING PROGRAM IS PROVIDED UNDER THE TERMS OF THIS COMMON PUBLIC LICENSE ("AGREEMENT"). ANY USE, REPRODUCTION ORDISTRIBUTION OF THE PROGRAM CONSTITUTES RECIPIENT’S ACCEPTANCE OF THIS AGREEMENT.
1. DEFINITIONS
"Contribution" means:
a) in the case of the initial Contributor, the initial code and documentation distributed under this Agreement, and
b) in the case of each subsequent Contributor:
i) changes to the Program, and
ii) additions to the Program;
where such changes and/or additions to the Program originate from and are distributed by that particular Contributor. AContribution ’originates’ from a Contributor if it was added to the Program by such Contributor itself or anyone acting onsuch Contributor’s behalf. Contributions do not include additions to the Program which: (i) are separate modules of softwaredistributed in conjunction with the Program under their own license agreement, and (ii) are not derivative works of the Program.
"Contributor" means any person or entity that distributes the Program.
"Licensed Patents " mean patent claims licensable by a Contributor which are necessarily infringed by the use or sale of itsContribution alone or when combined with the Program.
"Program" means the Contributions distributed in accordance with this Agreement.
"Recipient" means anyone who receives the Program under this Agreement, including all Contributors.
2. GRANT OF RIGHTS
a) Subject to the terms of this Agreement, each Contributor hereby grants Recipient a non-exclusive, worldwide, royalty-freecopyright license to reproduce, prepare derivative works of, publicly display, publicly perform, distribute and sublicense theContribution of such Contributor, if any, and such derivative works, in source code and object code form.

G.4. COMMON PUBLIC LICENSE 1.0 337
b) Subject to the terms of this Agreement, each Contributor hereby grants Recipient a non-exclusive, worldwide, royalty-freepatent license under Licensed Patents to make, use, sell, offer to sell, import and otherwise transfer the Contribution of suchContributor, if any, in source code and object code form. This patent license shall apply to the combination of the Contributionand the Program if, at the time the Contribution is added by the Contributor, such addition of the Contribution causes suchcombination to be covered by the Licensed Patents. The patent license shall not apply to any other combinations which includethe Contribution. No hardware per se is licensed hereunder.
c) Recipient understands that although each Contributor grants the licenses to its Contributions set forth herein, no assurancesare provided by any Contributor that the Program does not infringe the patent or other intellectual property rights of any otherentity. Each Contributor disclaims any liability to Recipient for claims brought by any other entity based on infringementof intellectual property rights or otherwise. As a condition to exercising the rights and licenses granted hereunder, eachRecipient hereby assumes sole responsibility to secure any other intellectual property rights needed, if any. For example, if athird party patent license is required to allow Recipient to distribute the Program, it is Recipient’s responsibility to acquirethat license before distributing the Program.
d) Each Contributor represents that to its knowledge it has sufficient copyright rights in its Contribution, if any, to grant thecopyright license set forth in this Agreement.
3. REQUIREMENTS
A Contributor may choose to distribute the Program in object code form under its own license agreement, provided that:
a) it complies with the terms and conditions of this Agreement; and
b) its license agreement:
i) effectively disclaims on behalf of all Contributors all warranties and conditions, express and implied, including warrantiesor conditions of title and non-infringement, and implied warranties or conditions of merchantability and fitness for a particularpurpose;
ii) effectively excludes on behalf of all Contributors all liability for damages, including direct, indirect, special, incidentaland consequential damages, such as lost profits;
iii) states that any provisions which differ from this Agreement are offered by that Contributor alone and not by any otherparty; and
iv) states that source code for the Program is available from such Contributor, and informs licensees how to obtain it in areasonable manner on or through a medium customarily used for software exchange.
When the Program is made available in source code form:
a) it must be made available under this Agreement; and
b) a copy of this Agreement must be included with each copy of the Program.
Contributors may not remove or alter any copyright notices contained within the Program.
Each Contributor must identify itself as the originator of its Contribution, if any, in a manner that reasonably allowssubsequent Recipients to identify the originator of the Contribution.
4. COMMERCIAL DISTRIBUTION
Commercial distributors of software may accept certain responsibilities with respect to end users, business partners and thelike. While this license is intended to facilitate the commercial use of the Program, the Contributor who includes the Programin a commercial product offering should do so in a manner which does not create potential liability for other Contributors.Therefore, if a Contributor includes the Program in a commercial product offering, such Contributor ("Commercial Contributor")hereby agrees to defend and indemnify every other Contributor ("Indemnified Contributor") against any losses, damages and costs(collectively "Losses") arising from claims, lawsuits and other legal actions brought by a third party against the IndemnifiedContributor to the extent caused by the acts or omissions of such Commercial Contributor in connection with its distribution ofthe Program in a commercial product offering. The obligations in this section do not apply to any claims or Losses relating toany actual or alleged intellectual property infringement. In order to qualify, an Indemnified Contributor must: a) promptlynotify the Commercial Contributor in writing of such claim, and b) allow the Commercial Contributor to control, and cooperatewith the Commercial Contributor in, the defense and any related settlement negotiations. The Indemnified Contributor mayparticipate in any such claim at its own expense.
For example, a Contributor might include the Program in a commercial product offering, Product X. That Contributor is then aCommercial Contributor. If that Commercial Contributor then makes performance claims, or offers warranties related to ProductX, those performance claims and warranties are such Commercial Contributor’s responsibility alone. Under this section, theCommercial Contributor would have to defend claims against the other Contributors related to those performance claims andwarranties, and if a court requires any other Contributor to pay any damages as a result, the Commercial Contributor must paythose damages.
5. NO WARRANTY
EXCEPT AS EXPRESSLY SET FORTH IN THIS AGREEMENT, THE PROGRAM IS PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONSOF ANY KIND, EITHER EXPRESS OR IMPLIED INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OR CONDITIONS OF TITLE, NON-INFRINGEMENT,MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. Each Recipient is solely responsible for determining the appropriateness ofusing and distributing the Program and assumes all risks associated with its exercise of rights under this Agreement, includingbut not limited to the risks and costs of program errors, compliance with applicable laws, damage to or loss of data, programs orequipment, and unavailability or interruption of operations.
6. DISCLAIMER OF LIABILITY
EXCEPT AS EXPRESSLY SET FORTH IN THIS AGREEMENT, NEITHER RECIPIENT NOR ANY CONTRIBUTORS SHALL HAVE ANY LIABILITY FOR ANY DIRECT,INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING WITHOUT LIMITATION LOST PROFITS), HOWEVER CAUSEDAND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING INANY WAY OUT OF THE USE OR DISTRIBUTION OF THE PROGRAM OR THE EXERCISE OF ANY RIGHTS GRANTED HEREUNDER, EVEN IF ADVISED OF THEPOSSIBILITY OF SUCH DAMAGES.
7. GENERAL
If any provision of this Agreement is invalid or unenforceable under applicable law, it shall not affect the validity orenforceability of the remainder of the terms of this Agreement, and without further action by the parties hereto, such provisionshall be reformed to the minimum extent necessary to make such provision valid and enforceable.
If Recipient institutes patent litigation against a Contributor with respect to a patent applicable to software (including across-claim or counterclaim in a lawsuit), then any patent licenses granted by that Contributor to such Recipient under thisAgreement shall terminate as of the date such litigation is filed. In addition, if Recipient institutes patent litigationagainst any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Program itself (excludingcombinations of the Program with other software or hardware) infringes such Recipient’s patent(s), then such Recipient’s rightsgranted under Section 2(b) shall terminate as of the date such litigation is filed.
All Recipient’s rights under this Agreement shall terminate if it fails to comply with any of the material terms or conditions

338 APPENDIX G. LICENSES
of this Agreement and does not cure such failure in a reasonable period of time after becoming aware of such noncompliance. Ifall Recipient’s rights under this Agreement terminate, Recipient agrees to cease use and distribution of the Program as soon asreasonably practicable. However, Recipient’s obligations under this Agreement and any licenses granted by Recipient relating tothe Program shall continue and survive.
Everyone is permitted to copy and distribute copies of this Agreement, but in order to avoid inconsistency the Agreement iscopyrighted and may only be modified in the following manner. The Agreement Steward reserves the right to publish new versions(including revisions) of this Agreement from time to time. No one other than the Agreement Steward has the right to modifythis Agreement. IBM is the initial Agreement Steward. IBM may assign the responsibility to serve as the Agreement Stewardto a suitable separate entity. Each new version of the Agreement will be given a distinguishing version number. The Program(including Contributions) may always be distributed subject to the version of the Agreement under which it was received. Inaddition, after a new version of the Agreement is published, Contributor may elect to distribute the Program (including itsContributions) under the new version. Except as expressly stated in Sections 2(a) and 2(b) above, Recipient receives no rightsor licenses to the intellectual property of any Contributor under this Agreement, whether expressly, by implication, estoppel orotherwise. All rights in the Program not expressly granted under this Agreement are reserved.
This Agreement is governed by the laws of the State of New York and the intellectual property laws of the United States ofAmerica. No party to this Agreement will bring a legal action under this Agreement more than one year after the cause of actionarose. Each party waives its rights to a jury trial in any resulting litigation.
G.5 X License
ICU is distributed under the X License, also known as the MIT License.
COPYRIGHT AND PERMISSION NOTICE
Copyright (c) 1995-2010 International Business Machines Corporation and others
All rights reserved.
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files(the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify,merge, publish, distribute, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so,provided that the above copyright notice(s) and this permission notice appear in all copies of the Software and that both theabove copyright notice(s) and this permission notice appear in supporting documentation.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIESOF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT OF THIRD PARTY RIGHTS. IN NO EVENT SHALL THE COPYRIGHTHOLDER OR HOLDERS INCLUDED IN THIS NOTICE BE LIABLE FOR ANY CLAIM, OR ANY SPECIAL INDIRECT OR CONSEQUENTIAL DAMAGES, OR ANYDAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUSACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
Except as contained in this notice, the name of a copyright holder shall not be used in advertising or otherwise to promote thesale, use or other dealings in this Software without prior written authorization of the copyright holder.
G.6 Creative Commons Attribution-Sharealike 3.0
Unported License
Text drawn from the Wikipedia is licensed under the Creative CommonsAttribution-Sharealike (CC-BY-SA) 3.0 Unported License, which we reproduce be-low. The creative commons website is http://creativecommons.org/.
G.6.1 Creative Commons DeedCreative Commons Deed
This is a human-readable summary of the full license below.
You are free:
* to Share--to copy, distribute and transmit the work, and * to Remix--to adapt the work
Under the following conditions:
* Attribution--You must attribute the work in the manner specified by the author or licensor (but not in any way that suggeststhat they endorse you or your use of the work.)
* Share Alike--If you alter, transform, or build upon this work, you may distribute the resulting work only under the same,similar or a compatible license.
With the understanding that:
* Waiver--Any of the above conditions can be waived if you get permission from the copyright holder.
* Other Rights--In no way are any of the following rights affected by the license:
o your fair dealing or fair use rights;
o the author’s moral rights; and
o rights other persons may have either in the work itself or in how the work is used, such as publicity or privacy rights.

G.6. CREATIVE COMMONS ATTRIBUTION-SHAREALIKE 3.0 UNPORTED LICENSE 339
* Notice--For any reuse or distribution, you must make clear to others the license terms of this work. The best way to do thatis with a link to http://creativecommons.org/licenses/by-sa/3.0/
G.6.2 License TextTHE WORK (AS DEFINED BELOW) IS PROVIDED UNDER THE TERMS OF THIS CREATIVE COMMONS PUBLIC LICENSE ("CCPL" OR "LICENSE"). THEWORK IS PROTECTED BY COPYRIGHT AND/OR OTHER APPLICABLE LAW. ANY USE OF THE WORK OTHER THAN AS AUTHORIZED UNDER THIS LICENSE ORCOPYRIGHT LAW IS PROHIBITED.
BY EXERCISING ANY RIGHTS TO THE WORK PROVIDED HERE, YOU ACCEPT AND AGREE TO BE BOUND BY THE TERMS OF THIS LICENSE. TO THE EXTENTTHIS LICENSE MAY BE CONSIDERED TO BE A CONTRACT, THE LICENSOR GRANTS YOU THE RIGHTS CONTAINED HERE IN CONSIDERATION OF YOURACCEPTANCE OF SUCH TERMS AND CONDITIONS.
1. Definitions
1. "Adaptation" means a work based upon the Work, or upon the Work and other pre-existing works, such as a translation,adaptation, derivative work, arrangement of music or other alterations of a literary or artistic work, or phonogram orperformance and includes cinematographic adaptations or any other form in which the Work may be recast, transformed, oradapted including in any form recognizably derived from the original, except that a work that constitutes a Collection willnot be considered an Adaptation for the purpose of this License. For the avoidance of doubt, where the Work is a musical work,performance or phonogram, the synchronization of the Work in timed-relation with a moving image ("synching") will be consideredan Adaptation for the purpose of this License.
2. "Collection" means a collection of literary or artistic works, such as encyclopedias and anthologies, or performances,phonograms or broadcasts, or other works or subject matter other than works listed in Section 1(f) below, which, by reason of theselection and arrangement of their contents, constitute intellectual creations, in which the Work is included in its entirety inunmodified form along with one or more other contributions, each constituting separate and independent works in themselves, whichtogether are assembled into a collective whole. A work that constitutes a Collection will not be considered an Adaptation (asdefined below) for the purposes of this License.
3. "Creative Commons Compatible License" means a license that is listed at http://creativecommons.org/compatiblelicenses thathas been approved by Creative Commons as being essentially equivalent to this License, including, at a minimum, because thatlicense: (i) contains terms that have the same purpose, meaning and effect as the License Elements of this License; and, (ii)explicitly permits the relicensing of adaptations of works made available under that license under this License or a CreativeCommons jurisdiction license with the same License Elements as this License.
4. "Distribute" means to make available to the public the original and copies of the Work or Adaptation, as appropriate, throughsale or other transfer of ownership.
5. "License Elements" means the following high-level license attributes as selected by Licensor and indicated in the title ofthis License: Attribution, ShareAlike.
6. "Licensor" means the individual, individuals, entity or entities that offer(s) the Work under the terms of this License.
7. "Original Author" means, in the case of a literary or artistic work, the individual, individuals, entity or entities whocreated the Work or if no individual or entity can be identified, the publisher; and in addition (i) in the case of a performancethe actors, singers, musicians, dancers, and other persons who act, sing, deliver, declaim, play in, interpret or otherwiseperform literary or artistic works or expressions of folklore; (ii) in the case of a phonogram the producer being the person orlegal entity who first fixes the sounds of a performance or other sounds; and, (iii) in the case of broadcasts, the organizationthat transmits the broadcast.
8. "Work" means the literary and/or artistic work offered under the terms of this License including without limitation anyproduction in the literary, scientific and artistic domain, whatever may be the mode or form of its expression including digitalform, such as a book, pamphlet and other writing; a lecture, address, sermon or other work of the same nature; a dramatic ordramatico-musical work; a choreographic work or entertainment in dumb show; a musical composition with or without words; acinematographic work to which are assimilated works expressed by a process analogous to cinematography; a work of drawing,painting, architecture, sculpture, engraving or lithography; a photographic work to which are assimilated works expressed by aprocess analogous to photography; a work of applied art; an illustration, map, plan, sketch or three-dimensional work relativeto geography, topography, architecture or science; a performance; a broadcast; a phonogram; a compilation of data to the extentit is protected as a copyrightable work; or a work performed by a variety or circus performer to the extent it is not otherwiseconsidered a literary or artistic work.
9. "You" means an individual or entity exercising rights under this License who has not previously violated the terms of thisLicense with respect to the Work, or who has received express permission from the Licensor to exercise rights under this Licensedespite a previous violation.
10. "Publicly Perform" means to perform public recitations of the Work and to communicate to the public those publicrecitations, by any means or process, including by wire or wireless means or public digital performances; to make availableto the public Works in such a way that members of the public may access these Works from a place and at a place individuallychosen by them; to perform the Work to the public by any means or process and the communication to the public of the performancesof the Work, including by public digital performance; to broadcast and rebroadcast the Work by any means including signs, soundsor images.
11. "Reproduce" means to make copies of the Work by any means including without limitation by sound or visual recordings and theright of fixation and reproducing fixations of the Work, including storage of a protected performance or phonogram in digitalform or other electronic medium.
2. Fair Dealing Rights
Nothing in this License is intended to reduce, limit, or restrict any uses free from copyright or rights arising from limitationsor exceptions that are provided for in connection with the copyright protection under copyright law or other applicable laws.
3. License Grant
Subject to the terms and conditions of this License, Licensor hereby grants You a worldwide, royalty-free, non-exclusive,perpetual (for the duration of the applicable copyright) license to exercise the rights in the Work as stated below:
1. to Reproduce the Work, to incorporate the Work into one or more Collections, and to Reproduce the Work as incorporated in theCollections;
2. to create and Reproduce Adaptations provided that any such Adaptation, including any translation in any medium, takesreasonable steps to clearly label, demarcate or otherwise identify that changes were made to the original Work. For example, atranslation could be marked "The original work was translated from English to Spanish," or a modification could indicate "Theoriginal work has been modified.";
3. to Distribute and Publicly Perform the Work including as incorporated in Collections; and,
4. to Distribute and Publicly Perform Adaptations.

340 APPENDIX G. LICENSES
5. For the avoidance of doubt:
1. (intentionally blank)
2. Non-waivable Compulsory License Schemes. In those jurisdictions in which the right to collect royalties through anystatutory or compulsory licensing scheme cannot be waived, the Licensor reserves the exclusive right to collect such royaltiesfor any exercise by You of the rights granted under this License;
3. Waivable Compulsory License Schemes. In those jurisdictions in which the right to collect royalties through any statutory orcompulsory licensing scheme can be waived, the Licensor waives the exclusive right to collect such royalties for any exercise byYou of the rights granted under this License; and,
4. Voluntary License Schemes. The Licensor waives the right to collect royalties, whether individually or, in the eventthat the Licensor is a member of a collecting society that administers voluntary licensing schemes, via that society, from anyexercise by You of the rights granted under this License.
The above rights may be exercised in all media and formats whether now known or hereafter devised. The above rights includethe right to make such modifications as are technically necessary to exercise the rights in other media and formats. Subject toSection 8(f), all rights not expressly granted by Licensor are hereby reserved.
4. Restrictions
The license granted in Section 3 above is expressly made subject to and limited by the following restrictions:
1. You may Distribute or Publicly Perform the Work only under the terms of this License. You must include a copy of, or theUniform Resource Identifier (URI) for, this License with every copy of the Work You Distribute or Publicly Perform. You maynot offer or impose any terms on the Work that restrict the terms of this License or the ability of the recipient of the Work toexercise the rights granted to that recipient under the terms of the License. You may not sublicense the Work. You must keepintact all notices that refer to this License and to the disclaimer of warranties with every copy of the Work You Distribute orPublicly Perform. When You Distribute or Publicly Perform the Work, You may not impose any effective technological measures onthe Work that restrict the ability of a recipient of the Work from You to exercise the rights granted to that recipient underthe terms of the License. This Section 4(a) applies to the Work as incorporated in a Collection, but this does not require theCollection apart from the Work itself to be made subject to the terms of this License. If You create a Collection, upon noticefrom any Licensor You must, to the extent practicable, remove from the Collection any credit as required by Section 4(c), asrequested. If You create an Adaptation, upon notice from any Licensor You must, to the extent practicable, remove from theAdaptation any credit as required by Section 4(c), as requested.
2. You may Distribute or Publicly Perform an Adaptation only under the terms of: (i) this License; (ii) a later version of thisLicense with the same License Elements as this License; (iii) a Creative Commons jurisdiction license (either this or a laterlicense version) that contains the same License Elements as this License (e.g., Attribution-ShareAlike 3.0 US)); (iv) a CreativeCommons Compatible License. If you license the Adaptation under one of the licenses mentioned in (iv), you must comply withthe terms of that license. If you license the Adaptation under the terms of any of the licenses mentioned in (i), (ii) or (iii)(the "Applicable License"), you must comply with the terms of the Applicable License generally and the following provisions: (I)You must include a copy of, or the URI for, the Applicable License with every copy of each Adaptation You Distribute or PubliclyPerform; (II) You may not offer or impose any terms on the Adaptation that restrict the terms of the Applicable License or theability of the recipient of the Adaptation to exercise the rights granted to that recipient under the terms of the ApplicableLicense; (III) You must keep intact all notices that refer to the Applicable License and to the disclaimer of warranties withevery copy of the Work as included in the Adaptation You Distribute or Publicly Perform; (IV) when You Distribute or PubliclyPerform the Adaptation, You may not impose any effective technological measures on the Adaptation that restrict the ability of arecipient of the Adaptation from You to exercise the rights granted to that recipient under the terms of the Applicable License.This Section 4(b) applies to the Adaptation as incorporated in a Collection, but this does not require the Collection apart fromthe Adaptation itself to be made subject to the terms of the Applicable License.
3. If You Distribute, or Publicly Perform the Work or any Adaptations or Collections, You must, unless a request has been madepursuant to Section 4(a), keep intact all copyright notices for the Work and provide, reasonable to the medium or means You areutilizing: (i) the name of the Original Author (or pseudonym, if applicable) if supplied, and/or if the Original Author and/orLicensor designate another party or parties (e.g., a sponsor institute, publishing entity, journal) for attribution ("AttributionParties") in Licensor’s copyright notice, terms of service or by other reasonable means, the name of such party or parties; (ii)the title of the Work if supplied; (iii) to the extent reasonably practicable, the URI, if any, that Licensor specifies to beassociated with the Work, unless such URI does not refer to the copyright notice or licensing information for the Work; and (iv), consistent with Ssection 3(b), in the case of an Adaptation, a credit identifying the use of the Work in the Adaptation (e.g.,"French translation of the Work by Original Author," or "Screenplay based on original Work by Original Author"). The creditrequired by this Section 4(c) may be implemented in any reasonable manner; provided, however, that in the case of a Adaptationor Collection, at a minimum such credit will appear, if a credit for all contributing authors of the Adaptation or Collectionappears, then as part of these credits and in a manner at least as prominent as the credits for the other contributing authors.For the avoidance of doubt, You may only use the credit required by this Section for the purpose of attribution in the manner setout above and, by exercising Your rights under this License, You may not implicitly or explicitly assert or imply any connectionwith, sponsorship or endorsement by the Original Author, Licensor and/or Attribution Parties, as appropriate, of You or Your useof the Work, without the separate, express prior written permission of the Original Author, Licensor and/or Attribution Parties.
4. Except as otherwise agreed in writing by the Licensor or as may be otherwise permitted by applicable law, if You Reproduce,Distribute or Publicly Perform the Work either by itself or as part of any Adaptations or Collections, You must not distort,mutilate, modify or take other derogatory action in relation to the Work which would be prejudicial to the Original Author’shonor or reputation. Licensor agrees that in those jurisdictions (e.g. Japan), in which any exercise of the right granted inSection 3(b) of this License (the right to make Adaptations) would be deemed to be a distortion, mutilation, modification orother derogatory action prejudicial to the Original Author’s honor and reputation, the Licensor will waive or not assert, asappropriate, this Section, to the fullest extent permitted by the applicable national law, to enable You to reasonably exerciseYour right under Section 3(b) of this License (right to make Adaptations) but not otherwise.
5. Representations, Warranties and Disclaimer
UNLESS OTHERWISE MUTUALLY AGREED TO BY THE PARTIES IN WRITING, LICENSOR OFFERS THE WORK AS-IS AND MAKES NO REPRESENTATIONS ORWARRANTIES OF ANY KIND CONCERNING THE WORK, EXPRESS, IMPLIED, STATUTORY OR OTHERWISE, INCLUDING, WITHOUT LIMITATION, WARRANTIESOF TITLE, MERCHANTIBILITY, FITNESS FOR A PARTICULAR PURPOSE, NONINFRINGEMENT, OR THE ABSENCE OF LATENT OR OTHER DEFECTS,ACCURACY, OR THE PRESENCE OF ABSENCE OF ERRORS, WHETHER OR NOT DISCOVERABLE. SOME JURISDICTIONS DO NOT ALLOW THE EXCLUSION OFIMPLIED WARRANTIES, SO SUCH EXCLUSION MAY NOT APPLY TO YOU.
6. Limitation on Liability
EXCEPT TO THE EXTENT REQUIRED BY APPLICABLE LAW, IN NO EVENT WILL LICENSOR BE LIABLE TO YOU ON ANY LEGAL THEORY FOR ANY SPECIAL,INCIDENTAL, CONSEQUENTIAL, PUNITIVE OR EXEMPLARY DAMAGES ARISING OUT OF THIS LICENSE OR THE USE OF THE WORK, EVEN IF LICENSOR HASBEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
7. Termination
1. This License and the rights granted hereunder will terminate automatically upon any breach by You of the terms of thisLicense. Individuals or entities who have received Adaptations or Collections from You under this License, however, will nothave their licenses terminated provided such individuals or entities remain in full compliance with those licenses. Sections 1,2, 5, 6, 7, and 8 will survive any termination of this License.

G.6. CREATIVE COMMONS ATTRIBUTION-SHAREALIKE 3.0 UNPORTED LICENSE 341
2. Subject to the above terms and conditions, the license granted here is perpetual (for the duration of the applicablecopyright in the Work). Notwithstanding the above, Licensor reserves the right to release the Work under different licenseterms or to stop distributing the Work at any time; provided, however that any such election will not serve to withdraw thisLicense (or any other license that has been, or is required to be, granted under the terms of this License), and this Licensewill continue in full force and effect unless terminated as stated above.
8. Miscellaneous
1. Each time You Distribute or Publicly Perform the Work or a Collection, the Licensor offers to the recipient a license to theWork on the same terms and conditions as the license granted to You under this License.
2. Each time You Distribute or Publicly Perform an Adaptation, Licensor offers to the recipient a license to the original Workon the same terms and conditions as the license granted to You under this License.
3. If any provision of this License is invalid or unenforceable under applicable law, it shall not affect the validity orenforceability of the remainder of the terms of this License, and without further action by the parties to this agreement, suchprovision shall be reformed to the minimum extent necessary to make such provision valid and enforceable.
4. No term or provision of this License shall be deemed waived and no breach consented to unless such waiver or consent shall bein writing and signed by the party to be charged with such waiver or consent.
5. This License constitutes the entire agreement between the parties with respect to the Work licensed here. There are nounderstandings, agreements or representations with respect to the Work not specified here. Licensor shall not be bound by anyadditional provisions that may appear in any communication from You. This License may not be modified without the mutual writtenagreement of the Licensor and You.
6. The rights granted under, and the subject matter referenced, in this License were drafted utilizing the terminology ofthe Berne Convention for the Protection of Literary and Artistic Works (as amended on September 28, 1979), the Rome Conventionof 1961, the WIPO Copyright Treaty of 1996, the WIPO Performances and Phonograms Treaty of 1996 and the Universal CopyrightConvention (as revised on July 24, 1971). These rights and subject matter take effect in the relevant jurisdiction in whichthe License terms are sought to be enforced according to the corresponding provisions of the implementation of those treatyprovisions in the applicable national law. If the standard suite of rights granted under applicable copyright law includesadditional rights not granted under this License, such additional rights are deemed to be included in the License; this Licenseis not intended to restrict the license of any rights under applicable law.

342 APPENDIX G. LICENSES

Index
Aarithmetic
floating point, 286
Bbinary, 284bit, 284byte, 285
Hhexadecimal, 284
notation, 284
JJava
primitivebyte, 285
Ooctal, 284
notation, 284
343