linguistic annotation framework sc4 wg 1 nancy ide vassar college usa
TRANSCRIPT

Linguistic Annotation FrameworkSC4 WG 1
Nancy Ide • Vassar College • USA

LAF Goal
ISO TC37 SC4 - WG 1
Provide a generic means to represent linguistic data and annotations Based on a formal model Users map their formats into/out of LAF
User formats must conform to underlying model
Pivot or “dump” format for exchange, machine processing

User A’s representation
User B’s representation
DUMP FORMAT
“interlingua”

Principles Separation of data and annotations
Stand-off annotation Separation of user annotation formats and
the exchange (“dump”) format Mappable to one another
Separation of referential structure and annotation content in dump format
Separation of annotation structure (relationships among parts) and content (data categories) in representation of annotations

LAF Development LAF has gone through a slow evolution
Model development (GMT as base) Consideration of processing needs Application to different annotation
types/structures/formats Adjustments to development in other WGs on
specific annotation types and feature structures “Proof of concept” instantiation in the American
National Corpus Transduction of several different annotation types
and formats to LAF format API to merge, transduce to other formats

LAF Status Have now
Reduced FS specification Final XML format / schema
GrAF : Graph Annotation Format Mapping “rules” and examples
Also Coordination with UIMA Header specification including information about
annotation, similar to UIMA type definition

Basic Model Annotation content represented by
feature structures Powerful means to represent any/all
annotations Referential structure represented as a
directed acyclic graph (DAG) Enables exploitation of well-understood
graph traversal and manipulation algorithms

Referential Structure Means by which annotation content is
associated with primary data or other annotations Very simple DAG model No need to consider internal structure of
annotation content (i.e. relations among bits of annotation information)

Primary Data Primary data contains no annotations
“Read-only” Modifications can be regarded as
annotations Insistence on the identification of a
base segmentation of the primary data Identifies contiguous sequences of
indivisible logical units For text, usually a character
“Compatible” annotations (i.e. those that can be merged etc.) use common base segmentation

Primary Segmentation Set of disjoint edges over primary data
Vertices Virtual, located between each logical unit Sequentially numbered
EdgesEach edge (x,y) in the graph delimits a non-
divisible region of primary dataComformance to MAF, SynAF call these edges over primary data a span

Multiple primary segmentations may be defined over a single primary data set Specify segmentations at different levels of
granularity A segmentation is “primary” vis a vis a given
annotation, not the data itself Edges in a primary segmentation can be
defined over any span of contiguous primary data, regardless of its length
No need for spans to be contiguous For text, most common primary
segmentation is the token

Referring to Primary Segmentation Define an edge graph over the edges
(spans) in the primary segmentation Given an edge set, E, create an edge
graph E’ such that for each edge (x,y) in E, there is a vertex xy in E’
Annotations are associated with regions of primary data by referencing the edge graph vertices Annotations never reference the primary
data directly

Edges in E’ are defined when annotations reference vertices in E’ Vertices may or may not be contiguous
An annotation is associated with vertices in E’ as follows:
1. Create a new vertex, v2. Label it with the FS containing the annotation
content3. Create an edge from v to 0 or more vertices in E’
Zero reference is used in the special case where the annotation applies to information not present in the data
References to 2 or more vertices in E’ by by default concatenate the information covered by the referenced vertices (in order)
can be overridden to specify vertices are to be regarded as an ordered list or “bag”
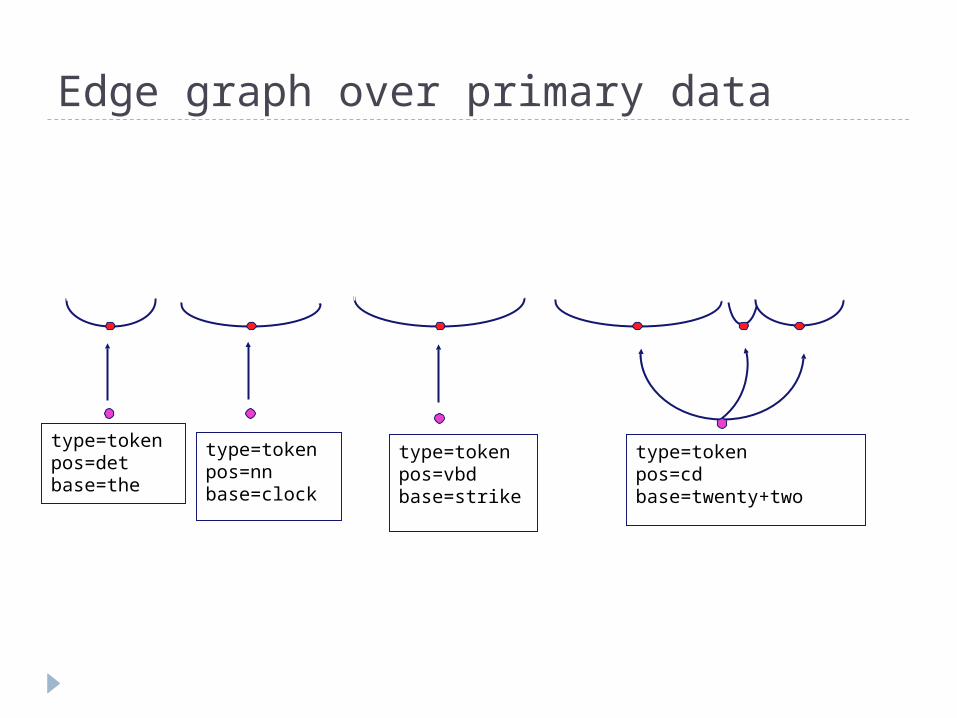
Edge graph over primary data
|T|h|e| |c|l|o|c|k| |s|t|r|u|c|k| |t|w|e|n|t|y|-|t|w|o| |
Annotations associated with vertices
in the primary data edge graph
type=tokenpos=nnbase=clock
type=tokenpos=detbase=the
type=tokenpos=vbdbase=strike
type=tokenpos=cdbase=twenty+two

As many annotations as desired can reference the same segmentation or be layered over lower-level annotations
SEG2
Primary data
MS1
MS2 NP
Syn2
Co-Ref
Syn1SEG1
MS3 Sem

Annotating Annotations Vertices in an annotation may be
referenced from other annotations1. Create a new vertex, v’2. Label it with the FS containing the annotation
content3. Create an edge from v’ to one or more
vertices associated with an annotation The strategy described above may be
applied recursively, thus creating a DAG whose leaves are the vertices in E’
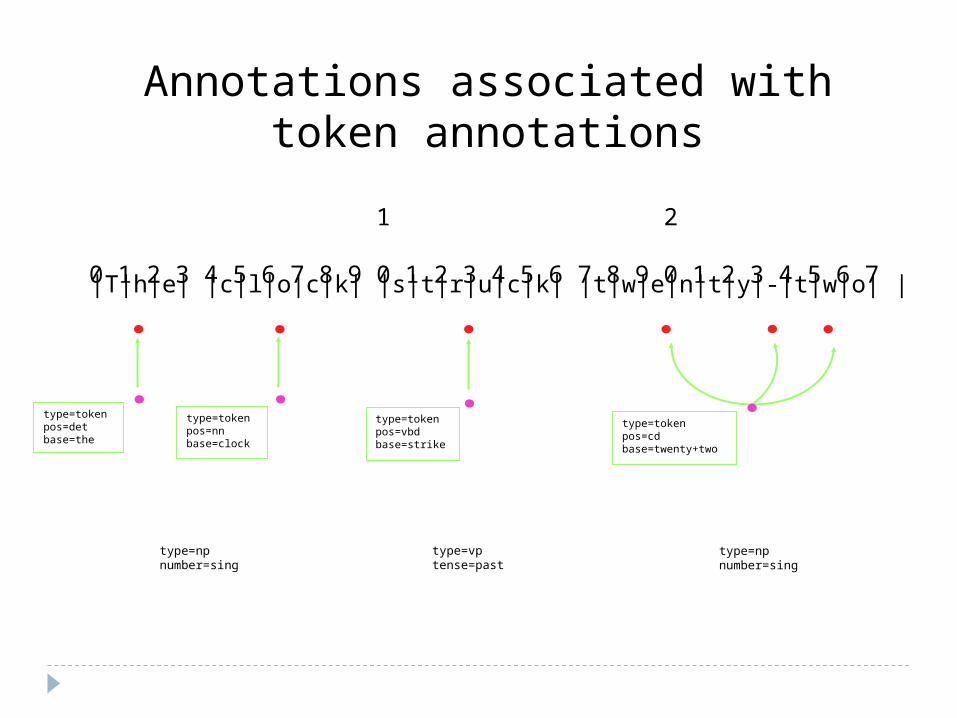
Annotations associated with token annotations
type=npnumber=sing
type=vptense=past
type=npnumber=sing
1 2 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7
type=tokenpos=nnbase=clock
type=tokenpos=detbase=the
type=tokenpos=vbdbase=strike
type=tokenpos=cdbase=twenty+two
|T|h|e| |c|l|o|c|k| |s|t|r|u|c|k| |t|w|e|n|t|y|-|t|w|o| |

XML Instantiation
<!-- edges over primary data --><edge id="e1" from="0" to="3"/><edge id="e2" from="4" to="9"/><edge id="e3" from="10" to="16"/><edge id="e4" from="17" to="23"/><edge id="e5" from="23" to="24"/><edge id="e6" from="14" to="27"/>

Token Annotation
<node id="t2" edgesTo="e2"> <fs type="token"> <f name="base" value="clock"/> <f name="pos" value="NN"/> </fs>
</node>
Creates a new vertex (node) associated with the FS with a single edge to vertex “e2” in the primary segmentation edge graph

NP Annotation
<node id="np1" edgesTo="t1 t2"> <fs type="NP"> <f name="number" sVal="singular"/> </fs></node>
Creates a new vertex (node) associated with the FS with two outgoing edges to vertices “t1” and “t2” in the token annotation

Question
ISO TC37 SC4 - WG 1Beijing 2006
When referring to annotations, edge targets typically represent components E.g. in the example: “the” and “clock” are
components of “NP” But this is not always the case
Could be e.g. a list of co-referents Others?
Possible solution: let the processor deal with it using the FS type

Note
ISO TC37 SC4 - WG 1Beijing 2006
Edges are never labeled, unlike in many linguistic analyses Preserves simplicity of the graph Relations are DatCats
edgesTo attribute can be empty Can create pseudo-nodes Implies a flat (non-nested) structure in the
dump format

ISO TC37 SC4 - WG 1Beijing 2006
<node type="clone" id="E2" ref="t2"/><node id=“c5” edgesTo=“t5”><f name=“role” sVal=“gen”/></node> <node id=“c6” edgesTo=“t2”><f name=“role” sVal=“head”/></node><node id=“c7” edgesTo=“c5 c6”/><node id=“c1” edgesTo=“t1”><f name=“role” sVal=“head”/></node><node id=“c7” edgesTo=“c7”><f name=“role” sVal=“s”/></node><node id=“c3” edgesTo=“t3”><f name=“role” sVal=“obj”/></node><node id=“c4” edgesTo=“E2”><f name=“role” sVal=“subj”/></node><node id=“D1” edgesTo=“c1 c7 c3 c4 E2”/>
objheads
FLEAHAVEheadgen
subj
DOGMY
[DOG]

Advantages of DAG
ISO TC37 SC4 - WG 1Beijing 2006
Can apply graph algorithms to traverse the graph Breadth-first, depth-first traversal, shortest path, minimum spanning
tree Connectedness, articulation vertices Topological sort Graph coloring, graph partitioning Etc.
What can we do with this? What is all info on path to/from node x What is nearest common ancestor of nodes x and y Find matching sub-graphs Identify connected components Which nodes (phenomena) are most connected, form articulation
vertices, etc. …

Feature Structures
ISO TC37 SC4 - WG 1Beijing 2006
Each edge is labeled with a feature value Can be FS, collection (list, bag, set), atom
Alternation and grouping handled by the FS mechanisms
Need to identify “basic” FS mechanisms 90% of annotations use only these Annotations may (optionally) use only this set
Ease of use No need to implement procedures to handle full power
of FS Need to create a FS library for abbreviation

Implications for Other WGs
ISO TC37 SC4 - WG 1Beijing 2006
Should (conceptually at least) separate referential structure from annotation content E.g. “tlink” in TimeML/SemAF: the link itself is the
edge, “tlink” is the annotation content (?) Need for coordination
Inter-project coordination committee? Need examples!

Today’s Work
ISO TC37 SC4 - WG 1Beijing 2006
Discuss the format in terms of specific annotation types Remember that dump format is in principle never
seen by the user Map user format into and out of dump format
Two topics DAG for referential structure FS for representing annotation content