linking named entities to a structured knowledge...
TRANSCRIPT

LINKING NAMED ENTITIES TO A
STRUCTURED KNOWLEDGE BASE
By
Kranthi Reddy. B
200502008
A THESIS SUBMITTED IN PARTIAL FULFILLMENT OF THEREQUIREMENTS FOR THE DEGREE OF
Master of Science (by Research)in
Computer Science & Engineering
Search and Information Extraction Lab
Language Technologies Research Centre
International Institute of Information Technology
Hyderabad, India
June 2010

Copyright c© 2010 Kranthi Reddy. B
All Rights Reserved

To all my dearer ones

INTERNATIONAL INSTITUTE OF INFORMATION TECHNOLOGY
Hyderabad, India
CERTIFICATE
It is certified that the work contained in this thesis, titled “ Linking Named Entities
to a Structured Knowledge Base ” by Kranthi Reddy.B (200502008) submitted
in partial fulfillment for the award of the degree of Master of Science (by Research)
in Computer Science & Engineering, has been carried out under my supervision
and it is not submitted elsewhere for a degree.
Date Advisor :
Dr. Vasudeva VarmaAssociate Professor
IIIT, Hyderabad

Acknowledgements
I am grateful to my advisor, Dr Vasudeva Varma for his advice and for believing
in me throughout the duration of my thesis work. His regular suggestions have been
of great value. I would also like to thank Dr Prasad Pingali for his valuable insights
on research. I have had great pleasure and joy to work with him for the whole
duration of my MS by Research studies. I have been fortunate to get timely advice
and quick feedback from Dr Prasad Pingali and Dr Vasudeva Varma inspite of their
hectic schedules. I would like to thank Mr Babji who worked tirelessly to keep the
IE lab servers running 24/7.
I would also like to acknowledge the time, help and guidance provided by Pra-
neeth and Sai Krishna. Both have been monumental in giving shape to my thesis
draft, without whom it would have an herculean task. Along with Kiran they not
only helped me through the difficult times and but also helped me to coup with the
pressure. Their confidence in me gave a lot of moral support. I have the pleasure of
working and publishing work with all three of them. Thanks to them, who showed
that research can be done with interest and fun.
I thank all my colleagues in Setu Software Systems Pvt. Ltd where I have been
working as an intern during the entire period of my thesis. I have had great time
and fun working in their companionship.
A person can be defined by the social circle he is associated with. I think I had
one of the best friend circle during my stay in IIIT. I thank Abhilash and Ambati
for their inputs and discussions on my Thesis work. A special thanks to Phani
Chaitanya, Ganesh, Girish, Gopal, Vijay, Harsha and Samrat who have been my
close knit of friends. Their frequent visits to campus during my research had lifted

my spirits many a time. Special thanks to charan. He always gave philosophical
and motivating talks whenever he saw me in dull mood.
Last, but not the least, I would like to thank my parents and sister for having the
trust in my abilities. They gave freedom and space to grow more as an individual. I
thank them for being my invisible sources of moral and mental support.
vi

Abstract
The World Wide Web (WWW) is a huge, widely distributed global source of in-
formation to web users. Web documents are broadly classified into: unstructured
and structured documents. Users prefer structured documents when looking for a
piece of information. Hence, in the past decade research community focused on
mining structured information from unstructured documents and attempted to pre-
serve them in the form of attribute-value pairs, tables, flow charts etc. But, the focus
has been only on extracting information at document level or on particular domains
like disaster, finance, medicine etc. The techniques never attempted to integrate the
extracted information to common knowledge repositories like Wikipedia, DBPedia
etc.
Structured databases like Wikipedia, DBPedia etc are created through collabo-
rative contributions from volunteers and organizations. Since they rely heavily on
manual effort, the process of updating these databases is not only tedious and time
consuming but is also fraught with many drawbacks. Hence, automatic updation of
structured databases has become one of the hot topics of research in the past few
years. Automatic updation of structured databases can be broken down into two sub
problems: Entity Linking and Slot Filling. In this thesis, we address Entity Link-
ing. Entity Linking is the task of linking named entities occurring in a document
to entries in a Knowledge Base. This is a challenging task because entities can not
only occur in various forms, viz: acronyms, nick names, spelling variations etc but
can also occur in various contexts.

Once named entities from documents are linked to entries in a knowledge base,
information can be integrated across them. Current IE techniques can be used to ex-
tract information from documents. Person named disambiguation and Co-reference
Resolution are two tasks that share a lot of similarities with Entity Linking. These
tasks have attempted to link entities across documents but never attempted to inte-
grate them into a common Knowledge Base.
Our approach to Entity Linking begins with building of an Entity Repository
(ER). ER contains information about different forms of named entities and is built
using Wikipedia structural information like redirect pages, disambiguation pages
and bold text from first paragraph. Our core algorithm for Entity Linking can be
broken down into two steps : Candidate List Generation (CLG) and Ranking.
In the CLG phase, we use the ER, Web search results and a named entity rec-
ognizer to identify all possible variations of a given named entity. Using these
variations we obtain an unordered list of candidate nodes from the KB which can
be linked to the given named entity in a document. In the ranking phase, we rank
the unordered list of candidate nodes using various similarity techniques. We cal-
culate the similarity between the text of the candidate nodes and the document in
which the named entity occurrs. We experiment ranking using various similarity
functions like cosine similarity, Naı̈ve Bayes, maximum entropy, Tf-idf ranking
and re-ranking using pseudo relevance feedback. Our experiments show that cosine
similarity and Naı̈ve Bayes perform close to state of the art and the Tf-idf ranking
function performs better in some cases.
Our approach was tested on a standard Entity Linking dataset provided as part
of Text Analysis Conference (TAC) for Knowledge Base Population (KBP) shared
task. We evaluated our approach using Micro-Average Score which is the standard
evaluation metrics. We achieved very impressive MAS of 83% and 85% on TAC-
KBP, Entity Linking 2009 and 2010 data sets, which secured top spot in these shared
tasks respectively.

Publications
• Kranthi Reddy, Karun Kumar, Sai Krishna, Prasad Pingali, Vasudeva Varma ,“Linking Named Entities to a Structured Knowledge Base”, in Cicling 2010.Published in “International Journal of Computational Linguistics and Appli-cations, ISSN 0976-0962 ”.
• Vasudeva Varma, Vijay Bharath Reddy, Sudheer K, Praveen Bysani, GSKSantosh, kiran kumar, kranthi Reddy, karuna Kumar, nithin M, “IIIT Hy-derabad at TAC 2009”, In the Working Notes of Text Analysis Conference(TAC), National Institute of Standards and Technology Gaithersburg, Mary-land USA, November, 2009.
• Praveen Bysani, Kranthi Reddy, Vijay Bharath Reddy, Sudheer Kovelamudi,Prasad Pingali, Vasudeva Varma, “IIIT Hyderabad in Guided Summarizationand Knowledge Base Population”, In the Working Notes of Text AnalysisConference (TAC), National Institute of Standards and Technology Gaithers-burg, Maryland USA, November, 2010.

Contents
Table of Contents x
List of Tables xiii
List of Figures xiv
1 Introduction 11.1 Structured Information Database : Knowledge Base . . . . . . . . . . . . . 21.2 Challenges in Manual Maintenance of Knowledge Bases . . . . . . . . . . 41.3 Problem Description . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.3.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.3.2 Problem Statement . . . . . . . . . . . . . . . . . . . . . . . . . . 71.3.3 Challenges . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.4 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.4.1 Co-reference Resolution . . . . . . . . . . . . . . . . . . . . . . . 101.4.2 Difference Between Entity Linking and Co-reference Resolution . . 12
1.5 Overview of the Proposed Methodology . . . . . . . . . . . . . . . . . . . 131.5.1 Building Entity Repository . . . . . . . . . . . . . . . . . . . . . . 131.5.2 Candidate List Generation and Ranking . . . . . . . . . . . . . . . 14
1.6 Thesis Organization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2 Related Work 162.1 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.1.1 Unsupervised Person Name Disambiguation . . . . . . . . . . . . . 172.1.2 Vector Space Model for Co-reference Resolution . . . . . . . . . . 17
2.2 Using Wikipedia Taxonomy for Entity Linking . . . . . . . . . . . . . . . 192.2.1 Support Vector Machines for Entity Linking . . . . . . . . . . . . . 192.2.2 A Heuristic Based approach for Entity Linking . . . . . . . . . . . 21
2.3 Approaches to Entity Linking . . . . . . . . . . . . . . . . . . . . . . . . . 222.3.1 Entity Linking as Cross-document Co-reference Resolution . . . . 232.3.2 Two stage methodology for Entity Linking . . . . . . . . . . . . . 262.3.3 Supervised Machine Learning for Entity Linking . . . . . . . . . . 29
2.4 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
x

CONTENTS
3 Candidate List Generation 313.1 Building Entity Repository . . . . . . . . . . . . . . . . . . . . . . . . . . 323.2 Identifying Query Entity Variations . . . . . . . . . . . . . . . . . . . . . . 37
3.2.1 Using Query Document in Context . . . . . . . . . . . . . . . . . 373.2.2 Using Entity Repository . . . . . . . . . . . . . . . . . . . . . . . 393.2.3 Using Web Search Results . . . . . . . . . . . . . . . . . . . . . . 39
3.3 Candidate Nodes Identification . . . . . . . . . . . . . . . . . . . . . . . . 403.4 Adding Wikipedia Article to the Candidate List . . . . . . . . . . . . . . . 413.5 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4 Entity Linking as Ranking 434.1 Entity Linking as Ranking . . . . . . . . . . . . . . . . . . . . . . . . . . 444.2 Vector Representation of Documents . . . . . . . . . . . . . . . . . . . . . 444.3 Cosine Similarity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 454.4 Classification Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.4.1 Naı̈ve Bayes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 474.4.2 Maximum Entropy . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.5 Tf-idf Ranking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 504.5.1 Term frequency and weighting . . . . . . . . . . . . . . . . . . . . 504.5.2 Inverse document frequency . . . . . . . . . . . . . . . . . . . . . 514.5.3 Tf-idf Weighting . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.6 Pseudo Relevance Feedback for Re-ranking . . . . . . . . . . . . . . . . . 524.6.1 Pseudo Relevance Feedback . . . . . . . . . . . . . . . . . . . . . 524.6.2 Hyperspace to Analogue Language(HAL) Model . . . . . . . . . . 534.6.3 Re-ranked Candidate Nodes : . . . . . . . . . . . . . . . . . . . . 54
4.7 Mapping Node Identification . . . . . . . . . . . . . . . . . . . . . . . . . 554.8 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
5 Data Set 565.1 Text Analysis Conference . . . . . . . . . . . . . . . . . . . . . . . . . . . 565.2 Data set and Evaluation Metrics . . . . . . . . . . . . . . . . . . . . . . . 58
5.2.1 Structure of nodes in Knowledge Base . . . . . . . . . . . . . . . . 585.2.2 Structure of documents in Document Collection . . . . . . . . . . . 595.2.3 Structure of an Entity Linking Query . . . . . . . . . . . . . . . . 61
5.3 Evaluation Metrics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
6 Evaluation 636.1 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 636.2 TAC-KBP 2009 and 2010 Query Set Analysis . . . . . . . . . . . . . . . . 636.3 Candidate List Size Analysis . . . . . . . . . . . . . . . . . . . . . . . . . 666.4 Candidate List Generation Phase Analysis . . . . . . . . . . . . . . . . . . 686.5 Entity Linking System Performance . . . . . . . . . . . . . . . . . . . . . 696.6 Precision Vs Top “N” results . . . . . . . . . . . . . . . . . . . . . . . . . 71
xi

CONTENTS
6.7 NIL Prediction Accuracy . . . . . . . . . . . . . . . . . . . . . . . . . . . 736.8 Comparison with Top 5 systems at TAC-KBP . . . . . . . . . . . . . . . . 746.9 Error Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 756.10 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
7 Conclusion 777.1 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 797.2 Future Directions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 817.3 Application of Entity Linking . . . . . . . . . . . . . . . . . . . . . . . . . 82
Bibliography 85
xii

List of Tables
5.1 Percentage break down of entity types in the Knowledge Base. . . . . . . . 595.2 No:Of documents from various sources in Document Collection. . . . . . . 605.3 System output for a set of query strings . . . . . . . . . . . . . . . . . . . 62
6.1 Statistics on 2009 and 2010 query sets. . . . . . . . . . . . . . . . . . . . . 646.2 Distribution of Non-Nil queries. . . . . . . . . . . . . . . . . . . . . . . . 646.3 Sample Queries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 656.4 The above table indicates the number of queries(2010 query set) having a
particular candidate list size. . . . . . . . . . . . . . . . . . . . . . . . . . 666.5 The above table indicates the number of queries(2009 query set) having a
particular candidate list size. . . . . . . . . . . . . . . . . . . . . . . . . . 676.6 The above table indicates the failure to list the correct candidate node in
the Candidate List even though the mapping node exist in the KnowledgeBase. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
6.7 Average Micro-Average Score and Base line scores obtained by variousparticipating universities/teams for TAC-KBP Entity Linking task on 2009and 2010 query sets. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
6.8 Micro-Average Score for individual heuristics for 2010 Query set. GoogleSearch includes both Google spell suggestion and Google directive search. . 70
6.9 Micro-average score for individual heuristics for 2009 Query set. GoogleSearch includes both Google spell suggestion and Google directive search. . 71
6.10 Statistics of NIL predictions and its accuracy for 2010 Query Set. . . . . . . 736.11 Statistics of NIL predictions and its accuracy for 2009 Query Set. . . . . . . 746.12 Performance Comparison with Top 5 systems at TAC-KBP 2010 Entity
Linking sub task. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 756.13 Performance Comparison with Top 5 systems at TAC-KBP 2009 Entity
Linking sub task. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
xiii

List of Figures
3.1 A sample article/document in Wikipedia. . . . . . . . . . . . . . . . . . . . 333.2 A sample redirect document in Wikipedia. . . . . . . . . . . . . . . . . . . 353.3 A sample disambiguation document in Wikipedia. . . . . . . . . . . . . . . 363.4 Flow Chart of Candidate List Generation Phase . . . . . . . . . . . . . . . 42
4.1 Cosine Similarity. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.1 Knowledge Base Node . . . . . . . . . . . . . . . . . . . . . . . . . . . . 595.2 Document Collection Document . . . . . . . . . . . . . . . . . . . . . . . 605.3 Sample Query from the Query Set. . . . . . . . . . . . . . . . . . . . . . . 61
6.1 Precision Vs Top “N” results for Non-Nil Queries from 2010 TAC-KBPEntity Linking Query Set. . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
6.2 Precision Vs Top “N” results for Non-Nil Queries from 2009 TAC-KBPEntity Linking Query Set. . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
7.1 An application of Entity Linking flow chart. . . . . . . . . . . . . . . . . . 837.2 Possible application of Entity Linking. . . . . . . . . . . . . . . . . . . . . 83
xiv

Chapter 1
Introduction
The World Wide Web (WWW) is a huge, widely distributed global source of information
to web users. Web documents are broadly classified into: unstructured and structured
documents. Users read unstructured documents thoroughly in order to mine the information
they are looking for. To ease this task, research community focused on mining structured
information from unstructured documents and attempted to preserve them in the form of
attribute-value pairs, tables, flow charts etc. In this process many Information Extraction
(IE) techniques [16, 8, 14, 46, 23] have been proposed to extract structured information
from unstructured documents. But, they have focused only on extracting information at
document level or on particular domains like disaster, finance [66], medicine [20] etc. The
techniques never attempted to integrate the extracted information to common knowledge
repositories like Wikipedia 1, DBPedia 2 etc.
Recently, there have been attempts to build and maintain global knowledge reposito-
ries (structured documents) like Wikipedia, DBPedia, Freebase 3, Uniprot 4, Medline 5 etc.
These databases are created through collaborative contributions from volunteers and or-
1http://en.wikipedia.org/2http://dbpedia.org/3http://www.freebase.com/4http://www.uniprot.org/5http://www.nlm.nih.gov/databases/databases medline.html
1

CHAPTER 1. INTRODUCTION
ganizations [47]. Since they rely heavily on manual effort, the process of updating these
databases is not only tedious and time consuming but is also fraught with many drawbacks.
The research community has identified this problem and has started working towards au-
tomating the process of maintaining these databases. Hence, automatic updation of struc-
tured databases has become one of the hot topics of research in the past few years.
In this chapter, we give a brief overview of the problem we address in this thesis. In the
next section, we give an overview of a structured database a.k.a Knowledge Base (KB).
1.1 Structured Information Database : Knowledge Base
A Knowledge Base (KB) is a special kind of database for knowledge management, provid-
ing the means for the computerized collection, organization and retrieval of knowledge. In
layman terms, a KB is a semi-structured/structured database containing information about
a named entity or an event. Since a definite structure is followed while building a KB, they
are not only human readable, but also machine readable and hence can be used for a wide
range of applications.
Knowledge Bases (KBs) like Wikipedia reduce the time and effort spent by a user in
finding a key piece of information about an event or named entity on the web, as users can
find answers to most of their questions here quickly. Since a standard structure is followed
in these KBs, it is easy to build applications that can exploit these structures. KBs have been
used in a wide range of applications in the fields of Natural Language Processing (NLP)
[19, 39] , Information Extraction (IE) [70] , establishing Entity Relationships [46, 23] ,
Search [43], Named Entity Recognition (NER) [25, 57] , Named Entity Disambiguation
[13], Text Mining etc.
Such highly useful resources like KBs can be created and maintained in two ways :
• Manual : Current KBs are created and maintained through collaborative contribu-
tions from volunteers and organizations [47]. Such practices have been followed
2

CHAPTER 1. INTRODUCTION
since biblical times, with scribes transcribed and at the same time often edited, up-
dated, interpreted or reinterpreted using original texts[35]. But open access large
scale public collaborative content creation projects are relatively recent phenomena
on the Web. This phenomena of knowledge creation and sharing has been fueled by
the content management technologies such as wiki6.
• Automatic : Unlike the process followed for current KBs, the process of creating
and updating KBs with up to date information can be automated. Automating this
task overcomes many problems faced by current day KBs. The process of automating
this task can be broken down into two sub problems.
– Entity Linking (EL) : Entity Linking addresses the problem of mapping named
entities occurring in a textual document to entries/nodes 7 in the KB. The prob-
lem is complicated by the fact that entities can be referred to using multiple
name variants (e.g., aliases, acronyms, misspellings) and because many entities
share the same name (e.g., Washington might refer to a person, city, state, or
football team).
– Slot Filling (SF) : Slot Filling addresses the problem of mining structured infor-
mation about entities from unstructured documents. The structured information
can be in the form of attribute value pairs, tables etc. In addition to requir-
ing that extracted information be correct, exact and supported by a document,
the information must also be previously unrecorded in the KB. Complexity in
natural language is another major problem confronted by SF.
In this thesis, we address the problem of Entity Linking. We now discuss about the
problems that arise from maintaining a KB manually.
6http://en.wikipedia.org/wiki/Wiki7A node is an entry in the KB which contains information and attribute value pairs about a named entity
or event
3

CHAPTER 1. INTRODUCTION
1.2 Challenges in Manual Maintenance of Knowledge Bases
Since KBs are built manually, they face quite a few complex problems. Some of the major
problems faced by KBs like Wikipedia are :
• Inconsistency in information : Since current KBs are collaborativately maintained
by volunteers, integration of knowledge from multiple sources is an important aspect.
Under these circumstances KBs are confronted with the prospect of inconsistency.
• Incomplete information : Another key problem faced by current day KBs is that
they might not have all the pertinent information about an entity or event. This leads
to the problem of incomplete information being found about an entity/event.
• Accuracy of facts : The information provided by volunteers is not only verified by
themselves, but it is also scrutinized by the KB moderators before it is updated. Even
after taking several measures like verifying the information by multiple volunteers to
ensure the correctness of the information, sometimes the information might still be
inaccurate and error prone.
• Outdated information : Since the current set of KBs are being edited and updated
manually by volunteers, there is very high chance that some pieces of information
about an entity/event might become outdated during the course of time.
• Manual effort is slow and time consuming : The process of knowledge acquisition
from different volunteers is a slow and time consuming process.
• Scalability : Manually scaling KBs to different domains and large number of entries
is very time consuming and tedious. Wikipedia has taken nearly 10 years to develop
into a rich knowledge repository.
• Adaptations to new domains : Creating a KB for a new domain manually will
require large amount of human effort and time.
4

CHAPTER 1. INTRODUCTION
Automatically updating KBs from news articles is a possible solution, because it can
overcome the above mentioned problems to a major extent. Upon automating the process of
knowledge acquisition to KBs, the major problem addressed will be scalability, adaptations
to new domains, reproducibility in labs etc and will certainly reduce the effort put in by
humans today in maintaining the KBs. In view of this solution, a need arises to address
the task of linking named entities found in news articles to nodes/entities in the KB. This
task is referred to as Entity Linking (EL). This thesis addresses the problem of EL, its
challenges, our methodology and results.
1.3 Problem Description
Most of the research community till date have focused on extracting structured information
from unstructured documents. But none of them have focused on integrating this extracted
information to global KBs. Until relatively recently, there has been very little focus to-
wards this direction as there were no publicly available KBs. But with the emergence of
Wikipedia, DBPedia, Freebase etc. as an important repository of information, community
efforts are focused towards integrating the information extracted from web documents like
news articles to these KBs automatically. The success and rapid growth of these KBs show
that the very useful to web users. Wikipedia alone has around 14 million registered users
8. These KBs provide rich source of information to the users in the form of text, tables and
flowcharts etc.
But, current day KBs face a lot of problems because of manual maintenance. We
showed that this process of knowledge acquisition and updating information into a KB
can be automated. We further discussed how EL is an important prerequisite for automatic
updation of KBs. In this thesis, we address various problems of EL, our methodology and
results. In this section, we explain our motivation behind attempting this problem. Then,
we state the problem in formal terms and finally conclude with a discussion on major chal-
8http://en.wikipedia.org/wiki/Special:Statistics
5

CHAPTER 1. INTRODUCTION
lenges in EL.
1.3.1 Motivation
The rise of Web 2.0 technology has provided a platform for user generated content on the
web through blogs, forums etc. This has led to the growth of information on web at a
staggering rate and hence the problem of information overload [27]. Information overload
refers to the difficulty a person can have in understanding an issue and making decisions
that can be caused by the presence of too much information. Some of the general causes of
information overload on the web are
• Rapidly increasing rate of novel information.
• Ease of duplication and transmission of data across the Internet.
• An increase in the available channels of incoming information.
• Large amounts of historical information to dig through.
• Contradictions and inaccuracies in available information.
Information overload is a growing problem for users in the web era. The overabundance
of information on the web has resulted in time consuming and difficult challenge for users
searching for a key piece of information in an increasingly competitive world. Information
overload is more than an inconvenience to a user and the rate at which it is growing will only
create bigger challenges and problems in the near future. Current day KBs like Wikipedia
try to overcome this problem by providing information about named entities/events under
a single roof. With a staggering rate of information growth on the web, it is imperative to
provide users with tools for efficient and effective access to knowledge repositories. An EL
system is an important component to maintain KBs automatically.
6

CHAPTER 1. INTRODUCTION
1.3.2 Problem Statement
Given a Knowledge Base and a textual document, the task of Entity Linking is to determine
for each named entity (NE) and the document in which it appears, which KB node is being
referred to, or if the entity is a new entity and not present in the KB. This is a challenging
task because entities can not only occur in various forms, viz: acronyms, nick names,
spelling variations etc but can also occur in various contexts.
Throughout this thesis, we refer the entity to be linked as Query Entity and the document
in which it appears as Query Document. For entities that do not have an entry in the
Knowledge Base, we return NIL and call this as NIL detection problem.
There has been a shared task; Knowledge Base Population (KBP) in Text Analysis
Conference 9 (TAC), 2009 and 2010. Entity Linking was sub task of the KBP track. Hence,
we evaluated our algorithm on this data set. The data set consisted of
• Query Entity : This refers to a named entity occurring in a document which is to be
linked to a node in the KB, if any.
• Query Document : It provides context for disambiguating the query entity.
• Knowledge Base : KB consists of a set of nodes, to which the query entity should
be linked.
We explain the complete data set and evaluation metrics in chapter 5. Though EL solves
many problems, it is not an easy task. In the next section we explain in detail the various
challenges of EL.
1.3.3 Challenges
Some of the major challenges involved in EL are :
9http://www.nist.gov/tac/
7

CHAPTER 1. INTRODUCTION
• Mention Ambiguity : An instance of a named entity can refer to different real world
entities based on the context in which it occurs. This ambiguity is called as mention
ambiguity and is one of the commonly faced problems on the web [13].
For example, the entity mention “Texas” refers to more than twenty different named
entities in Wikipedia. In the context “former Texas quarterback James Street”, Texas
refers to the University of Texas at Austin; in the context “in 2000, Texas released a
greatest hits album”, Texas refers to Bishop pop band; in the context “Texas borders
Oklahoma on the north”, Texas refers to the United States state; and in the context
“the characters in Texas include both real and fictional explorers”, Texas refers to the
novel written by James A.Michener.
• Named Entity Variations : An instance of the named entity can be referred using
various forms like
– Acronyms : Acronyms are abbreviations that are formed using the initial com-
ponents of a phrase or name. A named entity can always be referred using its
acronym and the same acronym can refer to different named entities based on
the context it appears.
For example, the acronym “SRT” refers to “Sachin Ramesh Tendulkar” in the
context “SRT is an Indian cricketer widely regarded as one of the greatest bats-
men in the history of cricket” whereas, it refers to “Street and Racing Tech-
nology” in the context “SRT is a high-performance automobile group within
Chrysler LLC.”
– Nick Names : Some times named entities are referred using either nick names,
alias names etc. The main difficulty here is that the nick name need not be a
named entity by itself.
For example, “Sachin Tendulkar” a batsmen of the Indian cricket team is re-
ferred using seven different nick names. They are “The God of Cricket, Little
8

CHAPTER 1. INTRODUCTION
Master, Tendlya, Master Blaster, The Master, The Little Champion, The Great
Man”. None of these seven names is a named entity by itself.
– Spelling Variations : Finally, a named entity can also be referred using multi-
ple spelling variations based on an pronunciation.
For example, “Angela Dorothea Merkel” the vice chancellor of Germany is
referred using different spellings like “Angie Merkel, Angelika Merkel, Angela
Merkel, Angela Markel, Angel Merkel” etc.
• NIL Detection : When trying to link named entities from a large, generic collection
of documents, there is highly likelihood that large number of entities have no map-
ping node in the KB. In such cases, the system is expected to predict NIL. We call
this NIL Detection problem.
The combination of all these issues make EL a challenging task. Sometimes a mention
of an entity can involve more than one of the above challenges. Consider the occurrence
of the entity “Dorothea”. An Italian might be reminded of “Dorotea Bucca” an Italian
physician, where as for an Irish person “Dorothea” might strike as “Dorothea Jordan”, an
Irish actress. However, the mention of “Dorothea” in the textual document might refer to
the entity “Angela Dorothea Kasner”, which in turn is a name variation of “Angela Merkel”,
chancellor of Germany. Thus, an EL system must determine if either of the two “Dorothea”
is correct, even though neither are exact matches. If the system determines neither, should
it return NIL or the variant “Angela Merkel”?.
1.4 Background
Named entities are the fundamental constituents in the texts present on the web. The ability
to identify named entities like persons, organizations and locations; extracting knowledge
about them and identifying entity relationships has many applications. The task of identi-
fying the named entities like persons, organizations and locations occurring in a piece of9

CHAPTER 1. INTRODUCTION
text is referred as Named Entity Recognition(NER). For example, an NER would recog-
nize the mention of Sachin Tendulkar and 24 April 1973 as Person and Date respectively.
NER is a sub task of information extraction problem and is one of the widely explored
[65, 40, 17, 11, 71] problems in this field. A relation extraction system [3, 68, 6, 8] would
establish the relation between named entities occurring in a document. This ability to dis-
cover entity relationships embedded in the documents would be very useful not only for
information retrieval but also for question answering [54, 67, 44, 30, 50, 63] and summa-
rization [33, 4, 5, 22, 32, 29] tasks. Though information extraction algorithms are capable
of extracting such valuable information automatically, they never addressed the problem
of integrating the extracted information to KBs like Wikipedia or DBpedia. This task of
inserting the extracted knowledge into a KB has many challenges that arise from natural
language ambiguity, inconsistencies in text and lack of world knowledge. The focus of this
thesis is to establish the mapping between an entity occurring in a document to an entity
in a KB, if any. The ability to disambiguate various named entities is an important prereq-
uisite for updating an entity’s record (Node) in the KB. This task has been referred to as
Entity Linking or Named Entity Disambiguation. When performed without a KB, EL is
called as Co-reference Resolution (CR).
CR shares a lot of similarities with EL. In the next section, we first explain in detail
the problem of CR and then give a brief introduction of the various tasks held in this area.
Finally, we compare how EL differs from CR.
1.4.1 Co-reference Resolution
The task of Co-reference Resolution [2] aims to determine whether two occurrences in a
document correspond to the same entity or not. Entity mentions that map to the same real
world entity are grouped into the same cluster. This task becomes more complex when we
try to determine whether the instances of two entities across different documents co-refer or
not. When CR is performed across documents it is called as Cross-document Co-reference
10

CHAPTER 1. INTRODUCTION
Resolution (CDCR).
Cross-document co-reference occurs when the same person, place, event or concept
is discussed in more than one text source. Computer recognition of this phenomenon is
important because it helps break the document boundary by allowing a user to examine in-
formation about a particular entity from multiple text sources at the same time. Resolving
cross-document co-reference allows a user to identify trends and dependencies across the
documents. Once the document barrier is broken, CR becomes a central tool for informa-
tion fusion and for generating summaries from multiple documents.
CDCR differs substantially from within document CR. There is certain level of consis-
tency within a document which makes CR an easier task when compared to CDCR. CDCR
is a challenging problem because the documents can come from different sources and they
might also have different conventions and styles. In addition, the problems encountered
during within document co-reference are compounded when looking for co-references
across documents because the underlying principles of linguistics and discourse context
no longer apply across documents and the underlying assumptions in CDCR are distinct.
CR also differs from NER. In the task of NER, we try to identify phrases which might
refer to a person, location or organization. While identifying the named entities, each
entity mention is treated to be unique and distinct. Whereas, in the task of CR we attempt
to determine whether entity mentions in a document are actually referring to the same real
world entity or not. Various community efforts have taken place in the form of shared tasks
viz: Message Understanding Conference 10, Tipster 11 and Web People Search 12 to address
the challenges of CR and CDCR.
10http://www-nlpir.nist.gov/related projects/muc/11http://www-nlpir.nist.gov/related projects/tipster/12http://nlp.uned.es/weps/
11

CHAPTER 1. INTRODUCTION
1.4.2 Difference Between Entity Linking and Co-reference Resolution
Though the task of EL and CR share similarities i.e. both these tasks aim at disambiguating
named entities, there exists a slight difference between them in the aspect of what the final
goal of each task is. In CR, we have a set of documents/document all of which mention the
same entity name. The difficulty lies in clustering these documents into sets which refer to
the same real world named entity. Whereas, in EL, the same entity name could be referred
to in different contexts and also using various forms like acronyms, nick names etc. Our
problem is to link this named entity to an entry in the KB, if present.
For example, consider the following five different contexts. We show the expected
output of EL and CR.
Context 1 : A spokeswoman for Abbott said it does not expect the guidelines to affect
approval of its Xience stent, which is expected in the second quarter.
Context 2 : Aside from items offered by the 67-year-old Fonda, the auction included
memorabilia related to Peter Frampton, Elvis Presley and Abbot and Costello.
Context 3 : Abbott, which spun off HPD in 2004, rejected the charges, insisting it has
“consistently complied with all laws and regulations.”
Context 4 : Most of his screenplays, which included several Abbott and Costello come-
dies, as well as scripts for television shows, were written between the 1930s and 1960s.
Context 5 : Abbott was appointed to a three year position as chairman of the California
Board of Forestry.
In context 1 and context 3, the mention of “Abbott” refers to “Abbott Laboratories” (A
pharmaceuticals and health care company), whereas in context 2 and context 4 the same
mention of “Abbott” refers to “Bud Abbott” (An American film actor) and in context 5 it
refers to “Abbott Kinney” (An American conservationist).
In the task of CR we would form a cluster for mention of “Abbott” in context 1 and
context 3 and another cluster for the mention of “Abbott” in context 2 and context 4 is
formed and a separate cluster for context 5 is formed. Each cluster corresponds to a unique
12

CHAPTER 1. INTRODUCTION
real world named entity. However successful CR is insufficient for correct EL, as the co-
reference chain must still be correctly mapped to it’s corresponding KB node. CR does not
identify to which real world entity do the mention of named entity in the cluster belong.
In the task of EL, we link the entity mention of “Abbott” in context 2 and context
4 to “Bud Abbott” node in the KB, entity mention in context 5 to “Abbot Kinney” and
entity mention in context 1 and context 3 are linked to “Abbott Laboratories” node in the
KB. Since the KB is a structured database containing information about entities, with the
linking of these new documents, new information about the corresponding named entity
can be extracted and updated into the KB node automatically. In the next section, we give
a brief over of our proposed methodology.
1.5 Overview of the Proposed Methodology
Our approach consists of building an Entity Repository (ER). ER contains information
about different forms of named entities and is built using various features from Wikipedia.
Using ER, Web search results and an NER system, a set of candidate nodes are obtained
from the KB (Candidate List Generation, CLG). These candidate nodes are ranked to iden-
tify the mapping node, if any. In the CLG phase, query entity 13 is expanded to obtain
its variations. These variations are used to generate candidate nodes from the KB. These
candidate nodes are ranked using various similarity techniques. The top ranked node is
returned as the mapping node for the input query entity.
1.5.1 Building Entity Repository
We build an Entity Repository (ER) which contains various forms in which a named entity
could be referred, viz: alias names, nick names, acronyms etc. We use Wikipedia which
is the largest semi-structured KB available to the public. Wikipedia structural information
13Query Entity refers to a named entity occurring in a document which is to be linked to a node in the
Knowledge Base, if any.
13

CHAPTER 1. INTRODUCTION
(Redirection, Disambiguation, Bold Text) comes handy in extracting few of the variations
of a named entity. Snap shot of XML dump of the Wikipedia is used to build ER.
1.5.2 Candidate List Generation and Ranking
• Candidate List Generation (CLG) : In this phase, we obtain possible variations of
the query entity using various heuristics. We use the ER, an NER and Web search
engine results to obtain all the possible variations of the query entity. Using the
identified variations of the query entity, we obtain an unordered list of candidate
nodes from the KB which might be linked to the query entity.
• Entity Linking as Ranking : We rank the unordered list of candidate nodes using
various similarity techniques. We calculate the similarity between the text of the can-
didate nodes and the query document. We experiment ranking using various similar-
ity functions like cosine similarity, Naı̈ve Bayes, maximum entropy, Tf-idf ranking
and re-ranking using pseudo relevance feedback. We show that cosine similarity and
Naı̈ve Bayes perform close to state of the art and the Tf-idf ranking function performs
better in some cases.
Our proposed approach was tested on a standard data set provided as part of Text
Analysis Conference (TAC), Knowledge Base Population (KBP), Entity Linking
shared task. We participated in the TAC-KBP, EL 2009 and 2010 shared tasks. We
used the standard evaluation metric i.e. Micro-Average Score (MAS) for evaluating
our algorithms performance. We achieved very impressive MAS of 83% and 85% on
TAC-KBP, EL 2009 and 2010 data sets. Also, our proposed approaches performed
very well in the TAC-KBP, EL shared tasks.
1.6 Thesis Organization
The rest of the thesis is organized as follows
14

CHAPTER 1. INTRODUCTION
In chapter 2, we discuss literature work and current state-of-the-art algorithms on EL.
We also discuss algorithms developed as part of TAC-KBP, EL shared task, so that we
have a platform to compare our system. We also discuss seminal work on named entity
disambiguation and CR, as they are closely related to EL.
In chapter 3, we describe the task of building Entity Repository (ER) and the Candidate
List Generation (CLG) phase of our EL algorithm. We discuss in detail the various features
used in building ER. We also discuss how an unordered list of candidate nodes are obtained
from the KB.
Chapter 4 describes EL as a ranking problem. We rank the set of unordered list of
candidate nodes obtained in chapter 3 using various similarity techniques, viz: cosine sim-
ilarity, Naı̈ve Bayes, maximum entropy, Tf-idf ranking and pseudo relevance feedback for
re-ranking. We also discuss how the mapping node is arrived upon from the initial un-
ordered list of candidate nodes.
In chapter 5, we describe the data set used and further explain the evaluation metric
used to evaluate the performance of an EL algorithm.
In chapter 6, we describe the experiments conducted on 2009 and 2010 TAC-KBP,
EL query sets to validate our methodology. We report the results using our methodology
and evaluate in detail the impact of various features we used in developing our algorithm.
We also compare the performance of our algorithm with the existing state-of-the-art ap-
proaches. We discuss the results and present our observations in detail.
Finally, we conclude the thesis by outlining our contributions, providing some insights
on how to extend this work in future in chapter 7.
15

Chapter 2
Related Work
2.1 Related Work
In this chapter, we discuss the literature related to Entity Linking (EL). First, we discuss
seminal work on person name disambiguation and co-reference resolution (CR) as they
share a lot of similarities with EL. In what follows, we focus on the first works on EL and
finally, conclude with discussions on recent literature in EL.
Until relatively recently, there has been very little focus on EL because there was no
general purpose publicly available collection of information about named entities. How-
ever, with the emergence of Wikipedia, DBpedia and Freebase as an important repository
of semi-structured database about named entities, EL has received a lot of attention from
various research communities. Accordingly these databases have been exploited for a num-
ber of tasks ranging from named entity recognition to relation extraction, but with passage
of time it has been observed that the maintenance of these databases is time consuming
and a costly affair. Hence, EL has received a lot of attention recently because it addresses
the problem of information integration and helps in automating the task of maintaining
the databases with up-to-date information. EL has been addressed using various heuristic
based approaches and machine learning techniques. All these approaches rely heavily on
the document context as features to link the entities.
16

CHAPTER 2. RELATED WORK
2.1.1 Unsupervised Person Name Disambiguation
Person name disambiguation is closely related to EL in the sense that it also tries to disam-
biguate and identify named entities. This task is also called as proper noun disambiguation.
The goal of this task is to cluster mentions of person entities in documents to unique en-
tities. Simple word senses and translation ambiguity may typically have 1-10 alternative
meanings that must be resolved based on the context they occur. Whereas, a personal name
like “Jim Clark” might potentially refer to hundreds or even thousands of distinct individ-
uals. Each unique referent typically has it’s own distinct contextual characteristics. These
characteristics can help distinguish and resolve the referent when they occur in documents.
First significant contribution was done by Mann and Yarowsky in 2003 [34].
Their approach utilizes an unsupervised clustering technique over a rich feature space
of biographic facts, which are automatically extracted via a language-independent boot-
strapping process. The induced clustering of named entities are then partitioned and linked
to their real referents via the automatically extracted biographic data. The biographic facts
extracted can be birth year, occupation and affiliation etc. They are extracted using manu-
ally written regular expressions.
2.1.2 Vector Space Model for Co-reference Resolution
Co-reference resolution (CR) is another problem which is very closely related to EL. Co-
reference [2] occurs when the same person, place, event or concept is discussed at various
points in a text. When it occurs in multiple text sources it is called as Cross-document Co-
reference Resolution (CDCR). Computer recognition of this phenomenon helps in breaking
the document barrier and helps in mining or examining information about an entity from
multiple sources simultaneously. In particular, resolving cross-document co-references al-
lows a user to analyze different trends and dependencies across multiple documents. It
can be used as a central tool in generating multi document summaries and in information
fusion.
17

CHAPTER 2. RELATED WORK
The task of CR is to determine if two occurrences of an entity in a document correspond
to the same unique real world entity. This task becomes more complex when performed
across documents, as the documents could come from different sources and might also
follow different styles and conventions. In CDCR, we have a set of documents all of which
mention the same entity name. The difficulty lies in clustering these documents into sets
which mention the same entity. Additionally, most of CR data sets have never been modeled
to address named entity synonym problem. Seminal work on CDCR was done by Bagga
and Baldwin [2].
Bagga and Baldwin used a Vector Space Model (VSM) [60] to form clusters on enti-
ties. In their approach, the documents are passed through a sentence extraction module.
For each document this module extracts all the sentences relevant to a particular entity
of interest. In other words, the sentence extractor module produces a “summary” of the
article with respect to the entity of interest. Then for each article, VSM disambiguate mod-
ule uses the summary extracted by the sentence extractor and computes its similarity with
the summaries extracted from each of the other articles. If the similarity computed between
summaries is above a pre-defined threshold, then the entity of interest in the two summaries
are considered to be co-referent.
Their algorithm was tested on a highly ambiguous test set which consisted of 197 ar-
ticles from 1996 and 1997 editions of the New York Times. All the articles whose text
contained the expression John.*?Smith, i.e. contained some variation of John Smith were
included. There were a total of 35 different John Smiths in these articles out of which 24 of
them had only a single article. The remaining 11 John Smiths had 173 articles. These doc-
uments were manually grouped based on the mention of John Smith. None of the articles
had multiple occurrences and hence the annotations were done at the document level only.
The experimental results showed that the system had very high performance. The problem
with this data set is that none of the documents have synonym mention of John Smith, that
is John Smith could have been referred using “Mr. John, Mr. Smith, Jo Smith” etc. Most
CDCR data sets are collected in a way that they don’t address the problem of synonym
18

CHAPTER 2. RELATED WORK
resolution. Although CR integrates the information about an entity from multiple sources,
it does not address the problem of integrating this information to a KB.
2.2 Using Wikipedia Taxonomy for Entity Linking
Seminal work on EL was done by Bunesca and Pasca [7] and Cucerzan [13]. Cucerzan uses
a heuristic based approach and exploits Wikipedia structure to derive mappings between
surface forms of entities and their Wikipedia entries. Context vectors are derived as a
prototype for each entity in Wikipedia and these vectors are compared against the context
vectors of unknown entity mentions from documents for disambiguation. In the work by
Bunescu and Pasca [7], a supervised Support Vector Machines ranking model is used for
disambiguation. Both the approaches rely heavily on Wikipedia structural information,
such as category hierarchies and disambiguation links.
2.2.1 Support Vector Machines for Entity Linking
Bunescu and Pasca [7] use a supervised Support Vector Machines (SVM) kernel ranking
model for disambiguation. The SVM kernel is trained so as to exploit the high coverage
and rich structure of information encoded in an online encyclopedia. Since there was no
manually labeled data available for evaluation, they trained and evaluated the algorithm
developed on Wikipedia’s link anchor text. A subset of inter article links were obtained
from Wikipedia for evaluation. These articles were obtained using two heuristics.
• To ensure that the article was talking about a named entity, a set of heuristics were
framed. The heuristics used were
– If the article title is multiword, all the content words were checked for capital-
ization, i.e. words other than prepositions, determiners, conjunctions, relative
pronouns or negations. If all the content words are capitalized it was considered
as a named entity.19

CHAPTER 2. RELATED WORK
– If the article title is a one word title that contains at least two capital letters, then
also it is considered as a named entity. Otherwise, next step is done.
– A count of how many times the article title occurs in the text of the article, in
positions other than at the beginning of a sentence is calculated. If at least 75%
of these occurrences are capitalized, then it is considered as a named entity.
• A setC2 was obtained, which includes only child categories of People by Occupation,
that are assigned to at least 200 articles. Then, if one of the categories assigned to the
article belongs to C2, the article was considered to be talking about a named entity.
The positive examples constituted the articles that matched the above heuristics and
had link mentions. Articles that did not match the above heuristics constituted the set of
negative examples.
The mention of an entity in the text was used to generate a set of candidates. An exact
match was done on Wikipedia article titles, redirect titles and disambiguation titles. The
articles that had the exact match of the entity were considered as candidates.
For disambiguating the candidates obtained above, Bunescu and Pasca used a SVM
ranking model implemented in SVM light toolkit1. They used two classes of features to
train the model. The first feature used was the cosine similarity between the context in
which the named entity occurred and the text present in the Wikipedia candidate article.
The second feature was created using a 2 tuple for each combination of the candidate
categories and context words. They learned to predict NIL for queries by including NIL
candidates. This helped the system in learning a linking threshold. The experimental results
showed that the system had very high performance.
However, the drawback with this approach is that the system is heavily dependent on
Wikipedia structural information like redirect and disambiguation pages.
1http://www.cs.cornell.edu/people/tj/svm light/svm rank.html
20

CHAPTER 2. RELATED WORK
2.2.2 A Heuristic Based approach for Entity Linking
Cucerzan [13] uses a heuristics based approach to link named entities occurring in docu-
ments to entities in Wikipedia. His work assumes that all the mentions of unknown entities
have a corresponding entry in the Wikipedia. However, the assumption fails for a significant
percentage of entities present in news articles as they do not have an entry in Wikipedia.
Context vectors are derived as a prototype for each entity in Wikipedia and these vectors
are compared against the context vectors of the unknown entity mentions in a document for
disambiguation.
In the first phase, entity mentions are identified that need to be linked to Wikipedia
articles. For this, the system splits a document into sentences and true cases the beginning
of each sentence, hypothesizing whether the first word is part of an entity or is it capitalized
because of orthographic conventions. It also identifies all the titles and hypothesizes correct
case for all the words in the titles. This is done based on statistics obtained from a one-
billion-word corpus, with back-off to web statistics. In the second stage, a hybrid NER
based on capitalization rules, web statistics, and statistics extracted from the CoNLL 2003
shared task data [65] are used to identify the boundaries of the entity mentions in the text.
It also assigns to each set of entity mentions sharing the same surface form a probability
distribution over four labels: Person, Location, Organization, and Miscellaneous 2. Then,
in document co-reference was performed to obtain longer surface forms for entities. It is
fairly common for one of the mentions of an entity in a document to be a long, typical
surface form of that entity (e.g., George W. Bush), while the other mentions are shorter
surface forms (e.g., Bush). Therefore, before attempting to solve the semantic ambiguity,
the system hypothesizes in document co-references and maps short surface forms to longer
surface forms with the same dominant label (for example, Brown/PERSON can be mapped
to Michael Brown/PERSON). Similar approach is also employed to acronyms to identify
2While the named entity labels are used only to solve in document coreferences by the current system, as
described further in this section, preliminary experiments of probabilistically labeling the Wikipedia pages
show that the these labels could also be used successfully in the disambiguation process.
21

CHAPTER 2. RELATED WORK
their expanded forms.
In the candidate generation phase, Cucerzan relied on an extensive pre-processing step
and used a rich set of features for aliases identification. For identifying various aliases of
a named entity, Cucerzan used Wikipedia redirect titles, disambiguation titles, link anchor
titles and truncated article titles. Longer mentions from co-reference chains were used to
replace the entities identified by the NER.
Cucerzan disambiguated the mention of the query entity with respect to document level
vectors obtained from all mentions of the entities in the document. Wikipedia contexts that
occur in the document and their category tags are aggregated into a document vector, which
is subsequently compared with the Wikipedia entity vector (of categories and contexts) of
each possible entity for disambiguation. The entities are assigned to surface forms that
maximize the similarity between the document vector and the Wikipedia entity vectors.
The main drawback with Cucerzan approach is that his approach does not handle NIL
entities, that is entities not having an entry in the Wikipedia, are not handled. His work
assumes that all mentions of entities in a document will surely have a mapping entry in
Wikipedia. This assumption fails when news articles are considered as they have many
entity mentions that might not have an entry in the Wikipedia. The query set for evaluating
this algorithm was also developed in such a way that entity mentions having no appropriate
article in Wikipedia were set aside from the evaluation set.
2.3 Approaches to Entity Linking
In this section, we discuss recent state-of-the-art work on EL. These algorithms have been
developed as part of the TAC-KBP, EL shared task. We discuss two heuristic based ap-
proaches and a machine learning approach and explain their short comings. All these ap-
proaches follow more or less a similar strategy. Their approach can be broken down into
two steps: First, they obtain a small set of possible candidate nodes from the KB using
various heuristics. Second, these possible candidate nodes are ranked using various simi-
22

CHAPTER 2. RELATED WORK
larity techniques to identify the mapping node. We now discuss each of these algorithms
in detail.
2.3.1 Entity Linking as Cross-document Co-reference Resolution
Si Li et.al [62] model the task of EL as a CDCR problem. Their approach can be broken
down into four basic steps:
• Entity Retrieval : Since a KB generally contains millions of entities, it will be a
time consuming task to traverse the entire collection for linking an entity occurring
in a document (We refer to this entity occurring in a document which needs to linked
to a node in the KB, as query entity 3). Hence, Si Li et al. try to obtain a small set of
possible candidate nodes from the KB that can be linked to the query entity. In order
to arrive at this possible candidate set of nodes, they use Indri Retrieval Toolkit4,
which is based on language model and inference network. The system carries out a
basic topic relevance retrieval to get the top 10 possible mapping nodes from the KB
for each query entity.
• Named Entity Type Recognition : The entity types may be Person, Organization
or a Geo-Political entity. If the type of a target query entity is uncertain, then it is
regarded to be Unknown (UKN). In order to improve the accuracy of the resolution,
query entity (present in a document) type is identified by Stanford NER 5.
• Summarization : Since the test documents can be from various news articles and
transcripts, Si Li et.al believe that these documents might contain a lot of irrelevant
content for the query entity. Hence, they generate query specific summary instead of
using the original text for similarity measure between two documents; also different
3Query Entity refers to a named entity occurring in a document which is to be linked to a node in the
Knowledge Base, if any.4http://www.lemurproject.org/indri/5http://nlp.stanford.edu/software/CRF-NER.shtml
23

CHAPTER 2. RELATED WORK
queries may produce different summaries of the same original text. Intra document
CR is performed before extracting the summary. The heuristics used to generate the
summary were
– A sentence is considered part of the summary if it contains at least one word of
the query entity.
– If the pronoun in a sentence refers to an antecedent of the previous sentence
and if it is already present in the summary sentences, the current sentence is
also added to the summary sentences. The simplified Hobbs Naive algorithm
[12] is used for pronoun resolution.
– A sentence is not a summary sentence if it does not meet the above two require-
ments.
– Sometimes, no summary might be extracted by using their algorithm if there is
no query term in the document. In such cases, the original text is used instead
of the summary.
• Similarity Metrics : Si Li et.al calculate the similarity between the candidate nodes
obtained in entity retrieval phase and the given text document using two different
methods: Vector Space Model and KL divergence method.
– Vector Space Model : Let the summary vector of a document D be ~V (S). The
cosine similarity between two document D1 and D2 is computed as
Sim(D1, D2) =~V (D1) · ~V (D2)
|~V (D1)||~V (D2)|=
∑commonterms:tj
W1j ∗W2j (2.1)
Where tj is a term present in both D1 and D2, W1j is the weight of the term tj
in D1 and W2j is the weight of tj in D2. The weight of a term tj in the vector
~V (S) is given by:
24

CHAPTER 2. RELATED WORK
Wj =tfj√∑Mi=1 tf
2i
(2.2)
Where tfi is the frequency of the term ti in the summary.
– The KL divergence Model : In probability theory and information theory,
the Kullback-Leibler divergence is a non-symmetric measure of the difference
between two probability distributions P and Q. Here they use improved KL di-
vergence model to measure the similarity between two documents. It is defined
to be
DKL(P ||Q) =∑i
(P (i)−Q(i))logP (i)
Q(i)(2.3)
where P stands for the distribution of terms in the summary of documentD1, Q
stands for the distribution of terms in the summary documentD2, word i occurs
in D1 or D2.
Different from the KL divergence, the improved KL divergence formula is sym-
metrical and non-negative. The more close to zero the value is, more similar
are the two documents.
The final similarity score between the document associated with the query entity and
candidate nodes is calculated using
F = 0.4 ∗ Sim(S1, S2) + 0.4 ∗ T + 0.2 ∗ S (2.4)
Where Sim(S1, S2) is the score obtained from Vector Space Model or KL divergence
method. T is a Boolean value and it is set to 1 if query entity and KB entity are the
exact match strings, else 0. S is the similarity between query entity and candidate
nodes, and the similarity score is obtained from Indri.
Finally, the output of the system is based on a co-reference decision which is made
by combining the entity type recognition and similarity measure. Two entity mentions are25

CHAPTER 2. RELATED WORK
co-referent to the same entity only in the case when they have high similarity measure and
matched entity type.
The drawback with the approach of Si Li et.al is that their entity retrieval module is
naive and random. It results in the retrieval of many irrelevant candidate nodes from the
KB. Also, the technique of using the summary generated to calculate the similarity score
is not good because there is loss of valuable contextual information for the query entity.
We show through our experiments that a good entity retrieval module is highly important
for obtaining a high performing EL system. Also, using the complete document text for
calculating similarity increases the performance.
2.3.2 Two stage methodology for Entity Linking
Xianpei Han et.al [21] employed a two stage EL method, where the two stages corresponds
to the two main components of their system: The first component is a multi-way entity
candidate detector, which identifies all the possible nodes in the KB for a query entity
based on a variety of knowledge sources, such as the Wikipedia anchor dictionary, the web
etc. The second component is an entity linker, which links an entity mention with the real
world entity(KB node), it refers to by measuring the similarity between them, based on
the Wikipedia semantic knowledge and bag of words (BOW) model. We now explain the
complete system in detail.
The multi-way entity candidate detector phase uses three features to obtain possible
candidate nodes from the KB that can mapped to the query entity. The features used are
• Candidate detection using contextual information : In general, the context sur-
rounding a named entity is rich in information about the entity, especially for iden-
tifying abbreviations. Xianpei Han et.al use this intuition to obtain the variations of
the given query entity, if any. They manually framed a few patterns to identify these
variations. For example, a pattern (Cap∗?)(Abbr) would extract text phrases like
“the newly-formed All Basotho Convention (ABC) is far from certain”. Expanded
26

CHAPTER 2. RELATED WORK
form of an abbreviated word is obtained in this way.
• Candidate detection using Wikipedia anchor dictionary : Entity candidates are
identified using the anchor dictionary of Wikipedia, which encodes rich information
about entities. A count of the anchor text phrase and the directed Wikipedia article
title is calculated. These counts are then used to identify the candidate nodes from
the KB for the given query entity.
• Candidate detection using web : The query entity along with the surrounding con-
textual words are submitted to the Google search engine 6. From the top K ranked
results they consider only the articles that belong to Wikipedia. These article titles
are also used to identify the candidate nodes.
Once the set of candidate nodes are obtained from the KB using the above heuristics,
they are ranked using a linear combination of two similarity metrics. Let the set of candi-
date nodes be E = {e1, e2, ..., en} for the query entity m and let the vector representations
be ei = {w1, w2, ..., wn} and m = {w′1, w
′2, ..., w
′n} respectively.
• BOW based similarity : Using the bag of words (BOW) model, both the query entity
mention m and the candidate nodes E are represented as a vector of word features,
and each word is weighted using the standard Tf-idf measure. The BOW based
similarity captures the word co-occurrence information. The similarity between e
and m is calculated using
SIMBOW (e,m) =
∑i
wiw′
i√∑i
(wi)2√∑
i
(w′
i)2
(2.5)
• Wikipedia Semantic Knowledge Based (WSKB) Similarity : Wikipedia seman-
tic similarity is computed between the candidate nodes E and query entity mention
document m. This is done in three steps6http://www.google.com/
27

CHAPTER 2. RELATED WORK
– Wikipedia concept detection : The appearances of Wikipedia concepts are
detected using the method describe in Milne and Witten [42]. Then, the query
entity mention document and the candidate nodes are represented as a vector of
Wikipedia concepts {c1, c2, ..., cm}.
– Wikipedia concept weighting : Since all the concepts in representation are not
equally helpful, each concept is assigned a weight indicating its relatedness to
the query entity mention or the candidate node. In detail, for each concept c in
representation, we assign it a weight by averaging the semantic relatedness of c
to all other Wikipedia concept vectors i.e.
w(c, e) = |e|−1(∑
ci∈e,ci 6=c
sr(c, ci)) (2.6)
where sr(c, ci) is the semantic relatedness measure between two concepts c and
ci, which is computed using the method described in Milne and Witten [42].
– Finally, Wikipedia semantic similarity is calculated using
SIMwiki(e,m) =
∑ci∈m
∑cj∈ew(ci,m) ∗ w(cj, e) ∗ sr(ci, cj)∑
ci∈m∑
cj∈ew(ci,m) ∗ w(cj, e)(2.7)
The final similarity score for each candidate node is a linear combination of BOW and
WSKB similarities.
SIMHybrid(e,m) = λ ∗ SIMBOW (e,m) + (1− λ) ∗ SIMwiki(e,m) (2.8)
If the best ranked candidate node similarity score is greater than 0.4 it returned as the
mapping node, else NIL is predicted.
The system developed by us and Xianpei Han et.al bears a lot of similarities. Both
systems create candidate sets and then rank the sets using BOW as a feature. The difference
between the systems is that we use a more fine tuned module for generating the candidate
sets and for handling acronyms. Another key difference is in the approach to NIL detection.
28

CHAPTER 2. RELATED WORK
We augment the KB with Wikipedia in order to predict NIL for entities that don’t have a
mapping node in the KB, where as Xianpei Han et.al predict a mapping node or NIL based
on a fixed threshold.
The main draw back with this approach is that the manually written heuristics for can-
didate detection will cover limited patterns. Another draw back is with respect to NIL
prediction methodology proposed by Xianpei Han et.al. Fixing the same threshold for
query entities occurring across various contexts is never a good strategy.
2.3.3 Supervised Machine Learning for Entity Linking
Fangtao Li et al. [28] use a “Learning to Rank” strategy to find the mapping node in the
KB for a query entity. They employ a list wise learning to rank model and augment it
with Naı̈ve Bayes binary classifier to find a mapping node. Their algorithm can be broken
down into multiple steps, but the main components remain the same i.e. candidate nodes
generation and ranking. We now explain the algorithm in detail.
• Preprocessing : Since, the KB can be in the order of millions, Fangtao Li et.al index
them for faster access of the documents. Also, sometimes query entities might be
misspelled, they use query correction function from Google, altavista 7 etc.
• Query Expansion : Fangtao Li et.al argue that using only the given query entity
is not sufficient to find the correct mapping node from the KB. Hence, they use
various strategies like using the document associated with the query entity to find the
expanded form for abbreviations, use Wikipedia redirect, disambiguation and link
information to obtain various possible variations of an entity.
• Candidate Generation : Using the obtained variations, they retrieve top 20 doc-
uments from the KB by forming an “OR” query from the entity variations. The
obtained set of candidate nodes are then ranked to identify the mapping node.
7http://www.altavista.com/
29

CHAPTER 2. RELATED WORK
• List wise learning to Rank : Using a small training data of 285 queries they adopt
a ListNet, an algorithm of learning to rank proposed by Zhe Cao [9]. The candidate
nodes obtained are ranked using the model built. Then, they use a Naı̈ve Bayes
binary classifier to decide whether the top ranked node is correct or if NIL should be
predicted.
The drawback with the approach of Fangtao Li et al. is that it requires large corpus
of human annotated data to train the model. Creating a training data for three categories
mainly person, location and organization covering various contexts is a difficult and time
consuming task. McNamee et.al [37] also propose a supervised machine learning similar
to Fangtao Li et.al. The only difference is that McName considers absence as another entry
to rank and selects the top ranked node directly, unlike Fangtao Li et.al who use a Naı̈ve
Bayes binary classifier. We show that our approach scales to large scale KBs easily and
performs better than all the above algorithms without any training data.
2.4 Conclusions
In this chapter, we did elaborate discussions on the literature related to EL. We discussed
seminal work on Person Name Disambiguation and Co-reference Resolution as they share
a lot of similarities with EL. Then, we discussed seminal work on EL by Curezan, Bunescu
and Pasca. Later, we explained in detail the three systems developed as part of the TAC-
KBP, EL shared task and explained their shortcomings. We also discussed how our ap-
proach overcomes their shortcomings. In the next chapter, we explain the first phase of our
algorithm, Candidate List Generation (CLG).
30

Chapter 3
Candidate List Generation
Given a KB, the task of EL is to determine for each named entity occurring in a document,
which KB node is being referred to, or if it is a new entity and not present in the KB.
As discussed in Section 1.5, we break EL into two steps. In the first step, we build an
entity repository (ER), which contains different forms of various named entities. ER is
built using various features from Wikipedia. ER is a prerequisite for identifying candidate
nodes because it contains information about various forms in which a named entity can
occur.
In the next step, query entity1 is expanded to obtain its variations. In addition to using
ER for identifying query entity variations, we use web search results and Stanford NER.
These variations are used to generate candidate nodes from the KB, referred as Candidate
List (CL). This phase of generating the CL is referred as Candidate List Generation (CLG)
phase. These candidate nodes are finally ranked using various similarity techniques. In this
chapter, we explain in detail about the CLG phase.
1Query Entity refers to a named entity occurring in a document which is to be linked to a node in the
Knowledge Base, if any.
31

CHAPTER 3. CANDIDATE LIST GENERATION
3.1 Building Entity Repository
In real world, a named entity can be referred using various forms like nick names, alias
names, acronyms and spelling variations. We introduced how a named entity could be
referred using these various forms with examples in Chapter 1. In order to handle these
variations, we build an ER which contains various forms in which an entity could be re-
ferred. Though web contains various forms of named entities, it is not an ideal place for us
to extract entity variations because of the following reasons.
• Web is voluminous and continuous to grow at an astounding rate in both the sheer
volume of traffic and size. Valuable information about entities is sparsely distributed
across the web. The process of mining entity variations from such voluminous data
is tedious and time consuming.
• Large percentage of web documents are unstructured. Inferencing information from
such wide range of documents is extremely difficult and not an ideal solution.
• Most of the information available on the web is never moderated. Hence, extracting
information from the web can result in false and unauthenticated data being extracted.
Hence, we use Wikipedia which is the largest semi-structured database [55] available
to mine various forms of named entities. The advantages of using Wikipedia are
• It has better coverage of named entities [69]. Since the KB provided by TAC-KBP
shared task covers only named entities, Wikipedia acts as a perfect platform for build-
ing our ER.
• Articles in Wikipedia are heavily linked and structured. We use the information
encoded in redirect and disambiguation pages for extracting named entity variations.
• With over 3.5 million articles Wikipedia is rightly sized and big enough to provide
information about name variants.
32

CHAPTER 3. CANDIDATE LIST GENERATION
• Since data on Wikipedia is moderated, we can be assured to a certain level of authen-
tication on the information present in it.
The existing literature [18, 41, 45] confirms the fact that valuable information can be
mined from Wikipedia. A sample Wikipedia article/document encoded in XML is shown
in the figure 3.1.
Figure 3.1 A sample article/document in Wikipedia.
A Wikipedia article contains a unique title, an ID, text carrying information about an
entity/event and some meta information. We use the title and text of an article for identify-
ing name variants.
The features we use in extracting name variants from Wikipedia are33

CHAPTER 3. CANDIDATE LIST GENERATION
• Redirect Pages : A redirect page in Wikipedia is an aid to navigation, it contains
no content but only a link to another article (target page) and strongly relates to
the concept of target page. In lay man terms, a redirect is a page which has no
content itself, but sends the reader to another article or a section of an article, or page,
usually from an alternative title. Redirect pages help in identifying the following
name variants.
– Alternative names (for example, “Edison Arantes do Nascimento” redirects to
“Pel”).
– Plurals (for example, “Greenhouse gases” redirects to “Greenhouse gas”).
– Closely related words (for example, “Symbiont” redirects to “Symbiosis”).
– Less specific forms of names, for which the article subject is still the primary
topic. For example, “Hitler” redirects to “Adolf Hitler”.
– More specific forms of names (for example, “Articles of Confederation and
Perpetual Union” redirects to “Articles of Confederation”).
– Abbreviations (for example, “DSM-IV” redirects to “Diagnostic and Statistical
Manual of Mental Disorders”).
– Alternative spellings or punctuation. For example, “Colour” redirects to “Color,
and Al-Jazeera” redirects to “Al Jazeera”.
– Likely misspellings (for example, “Condoleeza Rice” redirects to “Condoleezza
Rice”).
– Likely alternative capitalizations (for example, “Natural Selection” redirects to
“Natural selection”).
A sample redirect page encoded in XML is shown in the figure 3.2. A redirect page
contains a unique title and redirect information to the original article. For example,
from figure 3.2, we obtain “Tendulkar” as a name variant of “Sachin Tendulkar”.
34

CHAPTER 3. CANDIDATE LIST GENERATION
Figure 3.2 A sample redirect document in Wikipedia.
• Disambiguation Pages : Disambiguation pages are specifically created for ambigu-
ous entities, and consist of links to articles defining the different meanings of the
entity. They are used as a process of resolving conflicts in article titles that occur
when a single term can be associated with more than one topic, making that term
likely to be the natural title for more than one article. In other words, disambigua-
tions are paths leading to different articles which could, in principle, have the same
title. For example, the word “Mercury” can refer to an element, a planet, a Roman
god, and many other things. This feature helps in homonym resolution.
A sample disambiguation page encoded in XML is shown in the figure 3.3. From fig-
ure 3.3, we can conclude that “Sachin” is a name variant for “Sachin Tendulkar”,“Sachin
Pilgaonkar” etc.
• Bold Text From First Paragraph : On randomly analyzing few pages in Wikipedia
we found that bold text from the first paragraph of a Wikipedia article in general
refers to the full/nick name of a named entity. This feature helps in identifying
full/nick names of an entity.
From figure 3.1, we can conclude that “Sachin Ramesh Tendulkar” (text in black
color) is a name variant of “Sachin Tendulkar”.
35

CHAPTER 3. CANDIDATE LIST GENERATION
Figure 3.3 A sample disambiguation document in Wikipedia.
Using the above features from Wikipedia we obtain different variations of a named
entity. For example, variations obtained for “Sachin Tendulkar” are
• “Sachin Ramesh Tendulkar” from bold text of first paragraph, which is in fact the
full name of “Sachin Tendulkar”.
• “Tendulkar” from redirect page, which is the less specific form of “Sachin Ten-
dulkar”.
• “Sachin” from disambiguation page.
All these variations are indexed using Lucene 2 a high-performance, full-featured text
search engine to enable fast retrieval of documents.
ER is important because we have information about various forms of named entities at
one place. These variations are used in our CLG phase to identify candidate nodes from
the KB.2http://lucene.apache.org
36

CHAPTER 3. CANDIDATE LIST GENERATION
3.2 Identifying Query Entity Variations
In this phase, we identify all possible variations of the query entity. We use query document
in context, web search results and ER to identify query entity variations. The entity vari-
ants obtained are then used during the candidate list 3 (CL) identification phase to identify
mapping nodes from the KB. We now describe the various steps in identifying query entity
variations in detail.
3.2.1 Using Query Document in Context
We use the given query document for two purposes. First, We use it identify expanded
form of the query entity, if it is an acronym. Secondly, we use it to identify full name, nick
name, alias name etc if any. We use Stanford NER for the establishing the second task. We
now describe each in detail.
Acronym Expansion : Here the goal is to find the expanded form of the query entity, if
it is an acronym. For this we check if the query entity is an acronym i.e. contains all upper
case characters. If the given query entity is an acronym, we try to find the expanded form
from the corresponding query document, if any. We use an N-Gram based approach to find
the expanded form of the query entity. For this we remove stop words from the document
and check if “N” continuous sequence of tokens have the same initials as our query entity.
If an expanded form is found we use it along with the query entity (acronym) to search in
ER. The intuition behind this is that, it is common for entities to be introduced in text as
full forms and subsequently referred to by shorter forms or pronouns. Resolving these in
document co-reference links to retrieve the full form can thus have a substantial impact on
candidate ambiguity.
For example, given the following sentences :
• ...the newly-formed All Basotho Convention (ABC) is far from certain...3The unordered list of candidate nodes obtained using query entity variations is referred as Candidate List
(CL).
37

CHAPTER 3. CANDIDATE LIST GENERATION
• ...Abbott Laboratories (ABT:NYSE) ...
• ...the Anti-Corruption Unit (ACU) of the International Cricket Council (ICC) ...
• ...member countries of Asian Clearing Union (ACU) recorded...
We can easily identify the expanded forms of all the above acronyms using our simple
N-Gram based technique. For example, ABC refers to All Basotho Convention, the first
ACU refers to Anti-Corruption Unit and the second ACU refers to Asian Clearing Union.
Stanford Named Entity Recognizer 4 : Stanford NER provides a general implemen-
tation of linear chain Conditional Random Field (CRF) sequence models, coupled with
well-engineered feature extractors for NER. It can identify Person, Location and Organiza-
tion.
We run the Stanford NER on the query document. It would tokenize and extract named
entity mentions from the text and tag them as either “PERSON/LOCATION/ ORGANI-
ZATION”. Phrases belonging to either of the three categories and having our query entity
as a sub-string are identified as possible variations of the query entity. This feature would
help us in identifying full name, nick name, alias name etc of the query entity, if any. The
purpose of this heuristic is to use the least ambiguous mentions in the document as the basis
for CL identification. It is common for entities to be introduced in discourse as full forms
and subsequently referred to by shorter forms or pronouns. Resolving these in document
co-reference links to retrieve the full form can thus have a substantial impact on candidate
ambiguity, and subsequently on an EL system.
For example, the mention of “Columbus” will be co-referred to the full form “Colum-
bus, Ohio” if it is extracted as a mention from the query document.
4http://nlp.stanford.edu/software/CRF-NER.shtml
38

CHAPTER 3. CANDIDATE LIST GENERATION
3.2.2 Using Entity Repository
Using the ER built, we obtain all possible name variants for the given query entity. In
simple terms the variations obtained are nothing but name variants of the query entity from
Wikipedia. The given query entity is searched upon the Lucene index built for the ER. The
results obtained are name variants of the query entity.
For example, “George W. Bush, George H. W. Bush, George P. Bush” etc are name
variants of “George Bush” found from ER.
3.2.3 Using Web Search Results
We use Google search engine to identify query entity variations. We use Google’s spell
suggestion and Google’s site specific search feature. We now describe each in detail.
Google Spell Suggestion : Essentially Google spell checking compares words entered
against a constantly changing list of the most common searches and isolates when a user
may have intended to enter a different word or words. Because it does not depend on a rigid
dictionary, it is more effective in isolating words and phrases that may be commonly used
but are often not included in formal dictionaries i.e. named entities. Google’s checker is
particularly good at recognizing frequently made typos, misspellings, and misconceptions.
For our purpose, although most of the query entity strings are well formed, there are still
some spelling errors, so we try to correct the spelling errors using spell suggestion feature
supplied by the Google search engine. We input the query entity string to the search engine,
and then the search engine will return a corrected spelling of the string if the original one
was wrong. Since our query entities are about named entities this would return the best
possible spelling.
Google Site Specific Search : Google allows a user to specify a single website from
which a user might want to get the results from. For example, the query [ Iraq site:nytimes.com
] will return pages about Iraq but only from nytimes.com . This feature of Google will per-
39

CHAPTER 3. CANDIDATE LIST GENERATION
form a site specific search on that particular website and return a ranked set of documents
from the mentioned website. We use this feature to obtain ranked set of documents for
our query entities from Wikipedia. This feature helps us in identifying name variant of the
query entity when Wikipedia documents are ranked using Google search engine.
“site:en.wikipedia.org” is used to obtain a ranked set of documents from the Wikipedia
domain for a query entity. From the ranked set of web search results we consider the top
most ranked result title as a variation of our query entity.
For Example, HDFC Bank is obtained as a variation of the query entity HDFC.
3.3 Candidate Nodes Identification
Once the set of name variants of the query entity are obtained, we need to identify the set
of possible mapping nodes from the KB. We search the name variants of the query entity in
the titles of the KB. This searching of the name variants to identify mapping nodes from the
KB is an important step because if the correct mapping node isn’t picked into the Candidate
List 5 (CL), the system will fail irrespective of how good the ranking algorithm might be.
We believe that as long as the correct mapping node is picked into the CL, the likelihood of
it being returned as a mapping node after ranking is very high. This search of name variants
on the KB titles is done in the following way.
• Token Search : The name variants of the query entity are searched on the titles of
KB nodes. Boolean “AND” search of all the tokens of each query entity variation is
done on the KB node title. If all the tokens are present, we add the KB node to CL.
For example, If the given query entity is “CCP” and we find its name variant to
be “Chinese Communist Party”; We would retrieve nodes with the title “Chinese
Communist party” or “Communist Party of China”.
5The unordered list of candidate nodes obtained during candidate node identification is referred as Can-
didate List.
40

CHAPTER 3. CANDIDATE LIST GENERATION
3.4 Adding Wikipedia Article to the Candidate List
As we need to predict NIL for query entities that don’t have a mapping node in the KB, we
add Wikipedia nodes also to the CL. We search the Wikipedia using the same name variants
obtained for a query entity. Token search used for searching the KB is used for searching
Wikipedia also. We only add Wikipedia nodes which aren’t present in the KB to the CL.
Adding Wikipedia articles to the CL allows us to consider strong matches against query
entities that do not have any corresponding node in the KB and hence we can return NIL.
That is, for a given query entity if the ranking function maps to the Wikipedia article from
the CL, we can confirm the non-presence of a node in the KB about the query entity. This
method of appending a given KB is far better strategy when compared to fixing a threshold
value for predicting NIL.
The result of the CLG phase is an unordered list of candidate nodes. We need to rank
this unordered list in order to find the correct mapping node. We have experimented with
various similarity functions for ranking which are explained in the next chapter.
A flow chart of our CLG phase is shown in the figure 3.4
3.5 Conclusions
In this chapter, we described various features used to build ER from Wikipedia. We used
Wikipedia specific syntax i.e redirect pages, disambiguation pages and bold text from first
paragraph of an article to build ER. Later, we used ER, web search results and Stanford
NER to identify query entity variations. Using these variations, we search the given KB
and Wikipedia to identify an unordered list of candidate nodes, referred as CL. In the next
chapter, we use various similarity techniques to rank the nodes in CL to obtain the mapping
node.
41

CHAPTER 3. CANDIDATE LIST GENERATION
Figure 3.4 Flow Chart of Candidate List Generation Phase
42

Chapter 4
Entity Linking as Ranking
In this chapter, we describe the core part of our approach i.e. predicting the mapping node
from the generated list of candidate nodes, CL. We rank the candidate nodes based on its
similarity to the query document. Predicting the mapping node can be broken down into
three steps :
1. The list of candidate nodes and the query document are tokenized and represented as
token vectors.
2. We use a wide variety of similarity techniques in IR to compute the similarity be-
tween candidate node vectors and query document vector. The candidate node with
highest similarity score is referred as Best Ranked Node (BRN).
3. Mapping node or NIL is predicted based on BRN ∈ KB or BRN ∈Wikipedia.
To calculate the similarity between candidate nodes and the query document, we have
experimented with cosine similarity, Naı̈ve Bayes, maximum entropy, Tf-idf ranking and
pseudo relevance feedback ranking.
43

CHAPTER 4. ENTITY LINKING AS RANKING
4.1 Entity Linking as Ranking
The result of CLG phase in Chapter 4 is an unordered list of candidate nodes. If |CL|=0
1, we return NIL, otherwise we rank the candidate nodes to predict the mapping node.
For |CL|=0 is a case where no name variant of the query entity is present in the KB or
Wikipedia titles. We predict NIL for such cases as no candidate node could be obtained.
When |CL| 6= 0, similarity is calculated between the candidate nodes and the query doc-
ument using various techniques. For this, we represent the query document Dq and the
candidate nodes C = {C1, C2, ..., Cn}, where Ci ∈ C, as vectors. Similarity is calculated
between the vector representations of the query document (Dq) and candidate nodes (Ci).
4.2 Vector Representation of Documents
In this section, we describe briefly the process of obtaining the vector representation of a
document. First, query document (Dq) and candidate nodes (Ci) are tokenized using space
as a delimiter. Tokens belonging to the stop words list 2 are removed and the remaining
tokens are stemmed to obtain vectors for each document. The representation of a set of
documents as vectors in a common vector space is known as the Vector Space Model [60]
and is fundamental to a host of information retrieval operations ranging from scoring doc-
uments on a query, document classification and document clustering.
Let S denote the set of all stop words. Consider the document associated with the
query entity as Dq, where Dq={q1, q2, ..., qn} with qi /∈ S and qi is the stemmed word. Let
~V (Dq)=(q1, q2, ..., qn) be the vector representation of the query document.
Similarly, let the set of candidate nodes be C, where C={C1, C2, ..., Cn}. Ci is a can-
didate node and Ci ∈ C, Ci={w1, w2, ..., wm} with wi /∈ S and wi is the stem word. Let
~C={~V (D1), ..., ~V (Dn)}, with ~V (Di)=(wi1, wi2, ..., wim), be the vector representation of
candidate nodes.1|CL| refers to the size of the candidate list (CL).2we used a list of 200 frequently occurring stop words from the web.
44

CHAPTER 4. ENTITY LINKING AS RANKING
We now discuss various techniques we experimented to calculate similarity between
candidate nodes and the query document.
4.3 Cosine Similarity
In this section, we describe in detail how we identify the BRN from the CL using cosine
similarity. The model is based on the intuition that documents with higher number of
common terms are more similar. In this model, we view the set of candidate nodes as a
set of vectors in a vector space, in which there is one axis for each token. We compute the
similarity between the query document and candidate nodes as the magnitude of the vector
difference between the vectors ~V (Dq) and candidate node vectors ~C .
Figure 4.1 Cosine Similarity.
The cosine similarity between the query document Dq and a candidate node Ci is com-
puted as
sim(Dq, Ci) =~V (Dq) · ~V (Ci)
|~V (Dq)||~V (Ci)|(4.1)
where the numerator represents the dot product (also known as the inner product) of the
vectors ~V (Dq) and ~V (Ci), while the denominator is the product of their euclidean lengths.
45

CHAPTER 4. ENTITY LINKING AS RANKING
The dot product ~V (Dq) · ~V (Ci) of two vectors is defined asM∑j=1
DqCi, with M representing
union of tokens representing the documents Dq and Ci. The Euclidean length of Dq is
defined to be
√√√√ M∑j=1
~V (Dq). Similarly euclidean length for Ci is calculated.
The effect of the denominator of equation (4.1) is to length-normalize the vectors
~V (Dq) and ~V (Ci) to unit vectors ~v(Dq) = ~V (Dq)/|~V (Dq)| and ~v(Ci) = ~V (Ci)/|~V (Ci)|.
We can then rewrite (4.1) as
sim(Dq, Ci) = ~v(Dq) · ~v(Ci) (4.2)
Thus, (4.2) can be viewed as the dot product of the normalized versions of the two
vectors. This measure is the cosine of the angle θ between the two vectors, shown in Figure
4.1.
The candidate node Ci with highest cosine similarity score to query document Dq is
returned as the BRN.
4.4 Classification Model
In the field of IR, document classification is the task of assigning a document to one or
more classes, based on its features. This task is also referred as text classification, text
categorization, topic classification or topic spotting. The notion of classification is very
general and has many applications within and beyond IR. In our scenario, we assume each
candidate node Ci to represent a unique class label (Li). We need to determine which class
(Li) is the closest mapping class for our query document Dq. We have experimented with
two classification techniques
• Naı̈ve Bayes.
• Maximum Entropy.
46

CHAPTER 4. ENTITY LINKING AS RANKING
We use the implementation of Naı̈ve Bayes and maximum entropy available in Rainbow
Text Classifier3.
Supervised classification models like Naı̈ve Bayes and maximum entropy require la-
beled training data. The labeled training data is obtained using a set of features to represent
a document. Selecting a set of features to represent a document is called as feature selec-
tion. We now explain the importance of feature selection process and later describe how
we use features to represent the training documents (Ci).
Feature Selection : Feature selection is the process of selecting a subset of the terms
occurring in the training set (C) and using only this subset as features in text classification.
Feature selection serves two main purposes.
• First, it makes training and applying a classifier more efficient by decreasing the size
of the effective vocabulary.
• Second, feature selection often increases classification accuracy by eliminating noise
features 4.
Our representation of the candidate nodes (C) obtained in section 4.2 serves this pur-
pose. By using the stop word removal and tokenization feature we have obtained subset of
effective vocabulary terms which represent the candidate nodes (Ci) better.
4.4.1 Naı̈ve Bayes
In this section, we explain how Naı̈ve Bayes is used for identifying BRN. Naı̈ve Bayes is a
simple probabilistic classifier based on applying Bayes theorem with strong independence
assumptions. It has been used for a wide range of applications like text classification [26,
56, 1, 61] , word sense disambiguation [49, 15] , sentiment classification [48, 64, 38] etc.
3http://www.cs.cmu.edu/∼mccallum/bow/rainbow/4A noise feature is one that, when added to the document representation, increases the classification error
on new data.
47

CHAPTER 4. ENTITY LINKING AS RANKING
We now describe how Naı̈ve Bayes is used for identifying BRN. The probability of the
query document Dq being in class Li (candidate node, Ci) is computed as
P (Li|Dq) ∝ P (Li)∏
1≤k≤n
P (qk|Li) (4.3)
where P (qk|Li) is the conditional probability of term qk occurring in a candidate node
of class Li. We interpret P (qk|Li) as a measure of how much evidence qk contributes that
Li is the correct class. P (Li) is the prior probability of a candidate node occurring in class
Li. If a candidate node’s terms do not provide clear evidence for one class versus another,
we choose the one that has a higher prior probability. < q1, q2, ..., qn > are the tokens in
query document Dq that are part of the vocabulary we use for classification and n is the
number of such tokens in Dq.
Our goal is to find the best mapping class (Li) for the query document (Dq). The best
class in Naı̈ve Bayes classification is the most likely or maximum a posterior (MAP) class
cmap :
cmap = argmaxLiεC
P̂ (Li|Dq) = argmaxLiεC
P̂ (Li)∏
1≤k≤n
P̂ (qk|Li) (4.4)
We write P̂ for P because we do not know the true values of the parameters P (Li) and
P (qk|Li), but estimate them from the training set.
We obtain the likelihood for each candidate node (Li) and rank them accordingly. The
candidate node (Ci) with best likelihood score is returned as the BRN.
4.4.2 Maximum Entropy
In this section, we describe maximum entropy technique for identifying BRN from the
candidate nodes set (C). Maximum entropy has been widely used for variety of natural
language tasks like, language modeling [10, 58], part-of-speech tagging [52] and preposi-
tional phrase attachment [53]. The over-riding principle in maximum entropy is that when
48

CHAPTER 4. ENTITY LINKING AS RANKING
nothing is known, the distribution should be as uniform as possible, that is, have maximal
entropy.
Our case being more similar to text classification, maximum entropy estimates the con-
ditional distribution of the class label (Li) given a candidate node Ci. We use the represen-
tation of the candidate nodes (C) obtained in section 4.2 and bag of words as a feature. The
labeled training data is used to estimate the expected value of the tokens on a class-by-class
basis. First, we introduce how to select a feature set for setting the constraints and building
the training model. Then, we move on to explain how it is used for identifying BRN.
Constraints and Features : In maximum entropy, we use the training data (Ci belong-
ing to class Li) to set constraints on the conditional distribution. We let any real-valued
function of the candidate node Ci and the class Li be a feature, fi(Ci, Li). Maximum en-
tropy allows us to restrict the model distribution to have the same expected value for this
feature as seen in the training data, candidate node setC. Thus, we stipulate that the learned
conditional distribution P (Li|Ci) must have the property:
1
|C|∑Ci∈C
fi(Ci, c(Ci)) =∑Ci
P (Ci)∑Li
P (Li|Ci)fi(Ci, Li) (4.5)
Thus, when using maximum entropy, the first step is to identify a set of feature functions
that will be useful for classification. Then, for each feature, measure its expected value
over the training data and take this to be a constraint for the model distribution. More
specifically, for each word-class combination we instantiate a feature as:
fw,L′i(Ci, Li) =
0, if Li 6= L
′i
N(Ci, w)
N(Ci)Otherwise,
(4.6)
where N(Ci, w) is the number of times word w occurs in document Ci, and N(Ci) is
the number of words in Ci. With this representation, if a word occurs often in one class,
we would expect the weight for that word-class pair to be higher than for the word paired
with other classes.
49

CHAPTER 4. ENTITY LINKING AS RANKING
We use the representation of the documents obtained in section 4.2 to train a maximum
entropy probability distribution model and use it to classify the query document Dq. The
candidate node (Ci) which receives the highest probability estimate is returned as BRN.
4.5 Tf-idf Ranking
The Tf-idf weight (term frequency-inverse document frequency) [59] is often used for vari-
ous tasks in information retrieval and text mining. This weight is a statistical measure used
to evaluate how important a word is to a document in a collection or corpus. The impor-
tance increases proportionally to the number of times a word appears in the document but
is offset by the frequency of the word in the corpus. The intuition behind this model is that
a document that mentions a term more often has more to do with that term and therefore
should receive a higher score. Variations of the tf-idf weighting scheme are often used by
search engines as a central tool in scoring and ranking a document’s relevance given a user
query. We now explain how Tf-idf ranking is used in identifying the BRN.
4.5.1 Term frequency and weighting
Term frequency (TF) refers to how often a term appears in a specific document. Each
term in candidate node Ci is assigned a weight depending on the number of occurrences
of the term in the Ci. ∀qi, qi ∈ Dq, we compute a score between the query term qi and
candidate node Ci, based on the weight of qi in Dq. We assign the weight to be equal to the
number of occurrences of term qi in document Ci. This weighting scheme is referred to as
term frequency and is denoted tfqi,Ci, with the subscripts denoting the query term and the
candidate node in order. The ordering of the terms in the Ci is ignored but the number of
occurrences of each qi is all that is considered. We only retain information on the number
of occurrences of each qi.
50

CHAPTER 4. ENTITY LINKING AS RANKING
4.5.2 Inverse document frequency
Inverse Document Frequency (IDF) is a measure of the general importance of a term.
Above mentioned raw term frequency suffers from a critical problem: all terms are con-
sidered equally important when it comes to assessing relevancy on a qi. In fact certain qi
have little or no discriminating power in determining relevance. To this end, we introduce
a mechanism for attenuating the effect of qi that occur too often in candidate nodes C to
be meaningful for relevance determination. An immediate idea is to scale down the term
weights of qi with high collection frequency, defined to be the total number of occurrences
of qi in the C. The idea would be to reduce the tf weight of qi by a factor that grows with
its frequency in candidate nodes C. By using this document-level statistic (the number of
documents containing qi) we discriminate between Ci for the purpose of scoring. IDF is
given by
idfqi = log|C|
1 + |qi ∈ Ci|(4.7)
where |C| is the total number of candidate nodes. |qi ∈ Ci| is the number of candidate
nodes where qi appears. If qi is not in the candidate nodes C, this will lead to a division-
by-zero. Hence, we use 1 + |qi ∈ Ci|.
4.5.3 Tf-idf Weighting
Combining the definitions of TF and IDF, we produce a composite weight for each qi in
each Ci. The tf-idf weighting scheme assigns to each qi a weight in document Ci and is
given by
tf − idfqi,Ci= tfqi,Ci
× idfqi (4.8)
In other words, tf − idfqi,Ciassigns to qi a weight in Ci that is
• highest when qi occurs many times within a small number of candidate nodesC (thus
51

CHAPTER 4. ENTITY LINKING AS RANKING
lending high discriminating power to those candidate nodes);
• lower when the qi occurs fewer times in Ci, or occurs in many candidate nodes C
(thus offering a less pronounced relevance signal);
• lowest when the qi occurs in virtually all candidate nodes C.
Finally, the similarity between the query documentDq and a candidate nodeCi, Ci ∈ C
is given by
Similarity(Ci, Dq) =∑qiinDq
tf(qi, Ci) ∗ idf(qi) (4.9)
The candidate nodes Ci are ranked in descending order and the candidate node with
highest tf-idf score is returned as the Best Ranked Node (BRN).
4.6 Pseudo Relevance Feedback for Re-ranking
In this section we give a brief overview of Hyperspace to Analogue Language (HAL)
model. Later, we show how HAL is used to re-rank the ranked set of candidate nodes
obtained by Tf-idf ranking to identify BRN.
4.6.1 Pseudo Relevance Feedback
Pseudo relevance feedback, also known as blind relevance feedback, provides a method for
automatic local analysis. It automates the manual part of relevance feedback, so that the
user gets improved retrieval performance without an extended interaction. The method is to
do normal retrieval to find an initial set of most relevant documents, to then assume that the
top k ranked documents are relevant, and finally to do relevance feedback as before under
this assumption. Following this intuition top k documents are used to generate a language
model using HAL model, which is used to re-rank the candidate nodes.
52

CHAPTER 4. ENTITY LINKING AS RANKING
4.6.2 Hyperspace to Analogue Language(HAL) Model
Hyperspace Analogue to Language [31] model constructs the dependencies of a word w on
other words based on their occurrence in the context of w in a sufficiently large corpus. The
intuition underlying HAL spaces is that when humans encounter a new concept, they derive
its meaning from accumulated experience of the context in which the concept appears. Thus
the meaning of the new concept can be learn’t from its usage with other concepts within
the same context. Lund and Burgess [31] discusses the use of lexical co-occurrence to
construct high dimensional semantic spaces in which a word can be represented as a point.
The representational model of this space can be constructed automatically from a corpus of
text.
The construction of HAL space can be seen as a vector representation of each word w,
occurring in the vocabulary T, in a high dimensional space spanned by different words in
the vocabulary. This process results in a |T |X|T | HAL matrix, where |T | is the number
of different words in the vocabulary. The HAL matrix is constructed by taking a window
of length K words and moving it across the corpus at one term increments. All words in
the window are said to co-occur with the first word, with strengths inversely proportional
to the distance between them. In our approach we have considered the co-occurrence to be
bidirectional, because in general it is agreed that preserving the word order is not useful for
IR. The weights assigned to each co-occurrence of terms are accumulated over the entire
corpus. That is, if n(w, k, w′) denote the number of times word w′ occurs k ≤ K distance
away from w when considered a window of length K, and W (k) = K − k + 1 denotes the
strength of this co-occurrence between the two words, then
HAL(w′/w) =
K∑k=0
W (k)n(w, k, w′) (4.10)
The length of the window size will invariably influence the quality of the associations
between a pair of terms. For instance, as the size of the window increases, the higher the
chance of representing spurious associations between terms. Various window sizes have
53

CHAPTER 4. ENTITY LINKING AS RANKING
been used from 2 to 10. However, it is unclear what the best size of window is, experi-
ments [31] suggest a window of 4 or 8 for the purposes of IR. The original HAL Space
is direction sensitive because it records the co-occurrence information for terms preceding
every term. In general, it was found that preserving this term order was not useful for IR
and the combination of the row and column vectors for a term (thus a bidirectional win-
dow) was more effective. For instance with the sentences “The black cat ...” and “The cat
is black.”, while the ordering is different the notion that the cat is a particular color, black,
is preserved when taking both directions into account.
4.6.3 Re-ranked Candidate Nodes :
Using the popular tf-idf weighting for ranking results in the most important candidate nodes
being ranked on the top. Though the most important candidate nodes might appear in the
top-k results, we are still left with the problem of choosing a single node as the BRN. For
this we re-rank the candidate nodes using pseudo relevance feedback approach.
We build an HAL matrix over the top-k ranked candidate nodes. From the HAL matrix,
we use all the co-occurring words around our query entity within a window of size four and
expand the query. Experiments for various window sizes for HAL showed that fixing it at
four captures sufficient context. We re-rank the candidate nodes using the expanded query
and obtain re-ranked score for each candidate node. From experimental results we choose
to consider the top-5 ranked candidate nodes for building HAL matrix.
The final score of each candidate node is a weighted linear combination of its rank score
and re-rank score. The final score is given by
Final Score = λ ∗RankingScore+ (1− λ) ∗Re− rankedScore (4.11)
λ is the weight for each of the scores. Experimental results show that setting λ to 0.7
gave the best results.
We illustrate how pseudo relevance feedback works with an example. For a query
entity “Laguna Beach” from the query set the correct mapping node is “Laguna Beach,54

CHAPTER 4. ENTITY LINKING AS RANKING
California”. The query document contains terms like “show, MTV, Jessica, Jason” etc and
this results in the tf-idf ranking function to assign a higher rank to “Laguna Beach: The
Real Orange County”, an MTV reality show.
After query expansion using HAL the words: “lifeguards, coastal, land, geography” etc
are added to the query. This actually results in a higher re-ranked score for the candidate
node “Laguna Beach, California”. The final score(a linear combination of ranking and
re-ranking score) results in “Laguna Beach, California” as the BRN.
4.7 Mapping Node Identification
Using the above five techniques we obtain a ranked set of candidate nodes, from the initially
unordered set of candidate nodes. From the above ranked list, candidate node with highest
similarity score to the query document is returned as BRN. BRN could be either from the
KB or Wikipedia. If BRN∈KB, we return it as a map for the query entity or NIL otherwise.
The output of our system for a query entity is summarized in equation 4.12
Mapping Node =
NIL, if CL=0
NIL, if CL ≥ 1 and BRN ∈Wikipedia
Node Id if CL ≥ 1 and BRN ∈ KB
(4.12)
4.8 Conclusions
In this chapter, we discussed various similarity techniques to rank the unordered list of
candidate nodes. We experimented with cosine similarity, Naı̈ve Bayes, maximum entropy,
TF-IDF ranking and pseudo relevance feedback ranking. The node with highest similarity
to the query document was returned as BRN. Mapping node or NIL was predicted based
on BRN ∈ KB or BRN ∈ Wikipedia. In the next chapter, we discuss the structure of the
data set used to evaluate our algorithm. We also describe the evaluation metric.
55

Chapter 5
Data Set
In this chapter, we give background of Text Analysis Conference (TAC). We then give a
brief overview of the data set that is required for evaluating an EL algorithm. We explain
in detail about the general structure of a Knowledge Base, Document Collection 1 and
Query Entities when encoded in XML. We conclude the chapter with an overview of the
evaluation metric.
5.1 Text Analysis Conference
Recently there has been wide spread interest in community wide evaluations for research
in information technologies. The Text Analysis Conference (TAC) is a series of evaluation
workshops organized to encourage research in Natural Language Processing (NLP) and
related applications, by providing a large test collection, common evaluation procedures,
and a forum for organizations to share their results. TAC comprises sets of tasks known
as “tracks”, each of which focuses on a particular sub problem of NLP. TAC tracks focus
on end-user tasks, but also include component evaluations situated within the context of
end-user tasks.
Question answering and information Extraction have been studied over the past decade;
1Set of query documents is referred as Document Collection.
56

CHAPTER 5. DATA SET
however evaluation has generally been limited to isolated targets or small scopes (i.e., sin-
gle documents). The Knowledge Base Population (KBP) Track at TAC was proposed to
explore extraction of information about entities with reference to an external knowledge
source. Using basic schema for persons, organizations, and locations, nodes in an ontology
must be created and populated using unstructured information found in text. This task has
been broken down into two sub problems: Entity Linking, where names must be aligned to
entities in the KB and Slot Filling, which involves mining information about entities from
text. The EL sub task was present in both TAC-KBP 20092 and 20103.
Compared to previous information extraction evaluations such as the Message Under-
standing Conference (MUC) and Automatic Content Extraction (ACE), KBP is different in
the following perspectives
• Extraction at large scale (e.g. 1 million documents).
• Using a representative collection (not selected for relevance).
• Cross-document entity resolution (extending the limited effort in ACE).
• Linking the facts in text to KB.
• Rapid adaptation to new relations.
We have evaluated the performance of our algorithm against the TAC-KBP 2009 and
2010 EL data sets. In the next section, we explain in detail the data set provided for TAC-
KBP track. We then give a brief overview of the evaluation metrics used to evaluate an EL
system.
2http://www.nist.gov/tac/2009/3http://www.nist.gov/tac/2010/
57

CHAPTER 5. DATA SET
5.2 Data set and Evaluation Metrics
For evaluating an EL system, we require a KB which contains nodes/entries having in-
formation about named entities and a set of documents which contain instances of and
information about named entities. We would also require a query which contains a named
entity and the document in which it occurs. We are required to link the named entity in
the query, present in a document, to a node in the KB. The data set provided by TAC-KBP
consists of a KB, document collection and a query set. Firstly, we give a brief overview of
the structure of the KB nodes.
5.2.1 Structure of nodes in Knowledge Base
KB is a structured database containing nodes describing a named entity. The KB provided
for the TAC-KBP track is derived from Wikipedia. Each KB entry (also referred to as a
node) contains
• A unique identifier (ID, like “E101”).
• A name string and a title.
• An assigned entity type of Person (PER), Organization (ORG), Geo-political Entity
(GPE) or Unknown (UKN).
• An automatically parsed version of the data from the infobox in the entity’s Wikipedia
article i.e. a set of slot names and values.
• A stripped version of the text from the Wikipedia article.
The title and name are canonical forms derived from Wikipedia. A sample KB node
encoded in XML is shown in the Fig.5.1.
There are a total of 818,741 nodes in the KB. The KB was same for both 2009 and 2010
data sets. Table 5.1 shows the breakdown of the number of nodes for each entity type.
58

CHAPTER 5. DATA SET
Figure 5.1 Knowledge Base Node
Type Count Percentage
Person (PER) 114,523 14.0%
Organization (ORG) 55,813 6.8%
Geo Political Entity (GPE) 116,499 14.2%
Unknown (UKN) 531,907 65%
All 818,741 100%
Table 5.1 Percentage break down of entity types in the Knowledge Base.
5.2.2 Structure of documents in Document Collection
The document collection contains a set of documents obtained from various sources like
news wire, newsgroup, conversational telephone speech transcripts etc. These articles con-
tain mentions of, and information about target query entities. They provide context for
disambiguating the query entity. A document in the document collection consists
• A unique document id.
• Source from where the document was obtained.
• A headline.
• And a disambiguation text which contains an instance of or information about an
entity or event.
59

CHAPTER 5. DATA SET
The document collection consists of a total of 1,287,292 documents. This collection of
documents formed the document collection for the 2009 TAC-KBP data set. An additional
490,596 blog articles were added to the 2009 document collection to form the 2010 TAC-
KBP document collection. A sample document collection document encoded in XML is
shown in the figure.5.2.
Figure 5.2 Document Collection Document
Number of documents from various sources in the document collection is shown in the
table 5.2.
Genre # documents
Broadcast Conversation 17
Broadcast News 665
Conversational Telephone Speech 1
News wire 1,286,609
Blog Articles 490,596
Table 5.2 No:Of documents from various sources in Document Collection.
60

CHAPTER 5. DATA SET
5.2.3 Structure of an Entity Linking Query
The query set contains a set of queries, where each query consists of a query entity and an
associated document-id from the document collection. This document provides the context
for the query entity. Query entities can occur as multiple queries using different name
variants or in multiple documents. Each query must be processed independently. Since the
documents can come from different sources, various name variations like acronyms and
nick names etc could refer to the same query entity. They might also occur in different
contexts. A sample query encoded in XML is shown in the figure 5.3.
Figure 5.3 Sample Query from the Query Set.
5.3 Evaluation Metrics
In this section, we give an overview of the standard evaluation metric used to evaluate
an EL algorithm. Micro-Average Score (MAS) is the standard evaluation metric used
for evaluating an EL system. In short, MAS is the precision over all the queries and is
calculated using
Micro Average Score =No.of correct responses
No.of Queries(5.1)
For example, Table 5.3 shows the query entity occurring in a query, correct mapping
node from the KB and the output of a system. The system was able to predict the correct
mapping node for 3 out of the 6 queries. Hence the MAS is 3/6=0.5 .
Another metric that can be used to evaluate an EL system is the Macro-Average Score.
In this metric, precision is calculated for each entity (nil and non-nil) and an average is
61

CHAPTER 5. DATA SET
Query string KB-id system output
Abbott 1 1
Abbott 1 101
Abbott 1 1
Abbott Labs 2 101
Abbott Laboratories 2 nil
Abbott Labs 2 2
Table 5.3 System output for a set of query strings
taken across the entities. The main problem with such a metric is that it might be biased
towards the system’s output. It would be unstable with respect to low-mention-count query
entities. The example below explains the calculation of Macro-Average Score.
From Table 5.3, the entity corresponding to the KB node with ID=1 was linked correctly
2 of 3 times for a precision of 0.67. The entity with ID=2 was linked correctly 1 of 3 times
for a precision of 0.33.The macro-averaged precision is 0.5. (0.67+0.33)/2.
In the next chapter, we explain in detail the experiments we have conducted and evaluate
the performance of our system on TAC-KBP 2009 and 2010 data sets. Discussions on error
analysis is also done.
62

Chapter 6
Evaluation
6.1 Evaluation
Thus far, we have discussed the algorithm developed by us for linking named entities oc-
curring in a text document to nodes in a KB. We evaluate our algorithm on two standard
data sets viz: 2009 and 2010 TAC-KBP, EL track data. The structure of the data set was
described in chapter 5. First, we give a brief overview of the two query sets and analyze
them. Later, we analyze the impact of each feature we have used in building our system
and do an error analysis. Finally, we conclude this chapter with a comparison of our sys-
tems performance with the performance of top five systems submitted at 2009 and 2010
TAC-KBP, EL shared task.
6.2 TAC-KBP 2009 and 2010 Query Set Analysis
In this section, we introduce a few statistics about the 2009 and 2010 TAC-KBP, EL track
query set. We compare how the queries are distributed over three different categories i.e.
Person, Location and Organization. Table 6.1 shows the total number of query entities
present in 2009 and 2010 query sets respectively and distribution of query types. The 2010
query set contains 2250 query entity mentions for 403 unique entities. The 2009 query
63

CHAPTER 6. EVALUATION
set contains 3904 entity mentions for 560 unique entities. It is evident from Table 6.1
that 2010 query set has an even distribution of query entity types. Whereas, in the 2009
query set most of the queries are of the type organization. We feel that the 2010 query set
provides a better base for conducting our evaluations and experiments. However, we have
also conducted experiments on 2009 query set so as to test the robustness of the system.
Year No:of Queries Unique Person Location Organization NIL
2009 3904 560 627 567 2710 57%
2010 2250 403 751 749 750 54.6%
Table 6.1 Statistics on 2009 and 2010 query sets.
There are almost same percentage of queries in both the query sets for which NIL
should be predicted. In 2009 query set, 57% of queries had no entry in the KB whereas,
2010 query set had 54.6%.
Year No:of Queries # 1 # 2 # 3 # 4 # 5
2009 3904 43 17 8 14 6
2010 2250 208 80 32 22 12
Table 6.2 Distribution of Non-Nil queries.
Query entities can occur as multiple queries using different name variants or in multiple
documents (providing different contexts). An example of how a query entity can occur in
multiple queries using different name variants and in multiple documents was shown in
section 5.2.3. A single KB node can be the output(mapping node) for multiple queries.
Table 6.2 shows the number of unique KB nodes mapped from 2009 and 2010 query
sets (query entities). An input query entity finally gets mapped to one node in the KB.
As mentioned in section 5.2.3 an input query entity can take multiple forms(nicknames,
aliases, acronyms etc) and could also occur in various contexts. In spite of these variations
the entities would ideally be linked to the same KB node. From Table 6.2, it can be seen64

CHAPTER 6. EVALUATION
that the 2010 query set has 80 of such KB nodes which were referred to by two query
variations.
To understand the complexity of the task consider the following table 6.3, with sample
queries taken from the TAC-KBP 2009 Query Set. It shows that there are 15 queries with
“Abbott/Abbot” as the query entity, but they refer to different KB nodes and belong to
different entity types. The same query entity is associated with 15 different documents
showing how varied the context is.
Query
string
KB-id KB title No:of
Queries
Unique query
documents
Entity Type
Abbot E0064214 Bud Abbott 1 1 Person
Abbott E0064214 Bud Abbott 4 4 Person
Abbott E0272065 Abbott Laboratories 9 9 Unknown
Abbott E0003813 Abbot, Texas 1 1 Geo-political
entity
Table 6.3 Sample Queries
The following two examples show how varied the context can be.
Context 1: A spokeswoman for Abbott said it does not expect the guidelines to affect
approval of its Xience stent, which is expected in the second quarter.
Context 2: Aside from items offered by the 67-year-old Fonda, the auction included
memorabilia related to Peter Frampton, Elvis Presley and Abbott and Costello.
In context 1 “Abbott” refers to “Abbott Laboratories” whereas in context 2 it refers to
“Bud Abbott”.
65

CHAPTER 6. EVALUATION
6.3 Candidate List Size Analysis
As our EL system can be broken down into two phases, we analyze each phase and its im-
pact on the overall performance of the system. We have used various heuristics to identify
named entity variations. Using the obtained name variants we identify the candidate nodes
from the KB and Wikipedia to form our CL.
Table 6.4 shows the mapping between number of query entities with a specific CL size
for various experiments(Runs) for 2010 query set. For example, we obtained only one
candidate node in the CLG phase for 908 queries in Run No.6 . Queries with least or
no disambiguation generally resulted in a CL of size less than 5. For highly ambiguous
queries, the CLG phase returns large number of variations of the query entity resulting in a
very sharp increase in the CL size. Average CL size per query is highest (8.01) when all the
heuristics(Run No.6) are used in CLG phase and it reduces drastically to 0.63 when only
using redirect pages from Wikipedia (Run No.3). This is because redirect pages result in
either a single name variant or none.
Run
No.
Heuristics Used |CL|=0 |CL|=1 |CL|=2 |CL|=3 |CL|=4 |CL|=5 Average
|CL|
1 Disambiguation pages* 1203 538 19 22 35 28 5.99
2 Bold text** 921 740 99 82 55 27 3.49
3 Redirect pages* 972 1256 16 1 0 1 0.63
4 Run No.s 1+2+3 630 935 84 61 22 30 7.91
5 Run No. 4 + Stanford
NER
626 924 99 61 22 30 7.93
6 Run No. 5 + Google
Search
535 908 161 90 38 30 8.01
Table 6.4 The above table indicates the number of queries(2010 query set) havinga particular candidate list size.
66

CHAPTER 6. EVALUATION
Run
No.
Heuristics Used |CL|=0 |CL|=1 |CL|=2 |CL|=3 |CL|=4 |CL|=5 Average
|CL|
1 Disambiguation pages* 1468 1525 69 81 82 30 5.38
2 Bold text** 1016 1886 246 182 93 122 2.72
3 Redirect pages* 1234 2516 70 54 0 0 0.95
4 Run No.s 1+2+3 679 1872 242 135 101 145 6.68
5 Run No. 4 + Stanford
NER
679 1872 242 135 101 145 6.69
6 Run No. 5 + Google
Search
602 1898 267 157 102 121 6.75
Table 6.5 The above table indicates the number of queries(2009 query set) havinga particular candidate list size.
Similarly Table 6.5 shows the mapping between number of query entities with a specific
CL size for various experiments (Runs) for 2009 query set. Clearly we can see the same
trend of average CL size increasing with the increase in number of heuristics used for iden-
tifying the name variants. Also it can be seen that when only redirect page from Wikipedia
is used the average CL size is 0.95. The major difference between the two data sets is the
percentage of queries for which the CL size is one for each heuristic. A large percentage
(48.6%) of queries in 2009 query set had resulted in a CL of size one compared to 40.3% in
2010 query set for Run No. 6. Using the redirect pages feature from Wikipedia will result
in either a single name variant or none. This redirect feature has very high impact on the
performance of our EL system which is shown in section 6.5.
Another key difference is the impact of Stanford NER and Google search for identify-
ing the name variants. Both the data sets show that by using Stanford NER and Google
0* indicates from Wikipedia and ** indicates from first paragraph of Wikipedia article. Google Search
includes both Google spell suggestion and Google directive search. Same notation is followed for rest of this
chapter.
67
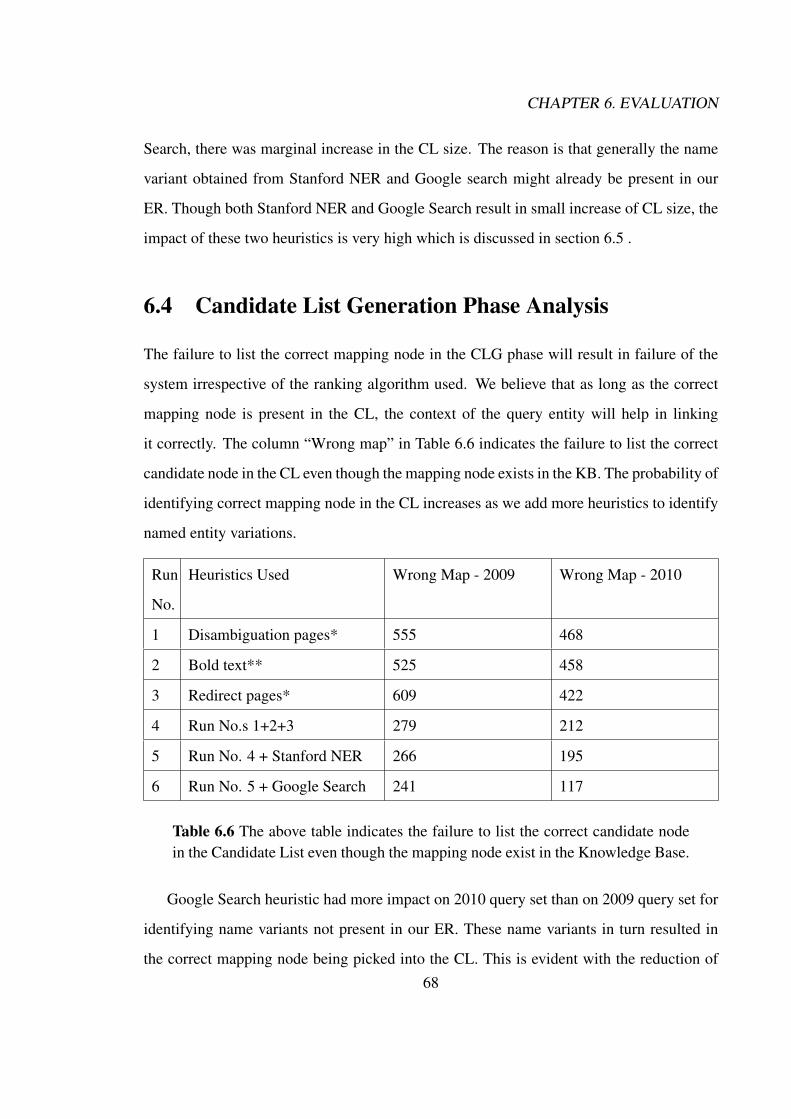
CHAPTER 6. EVALUATION
Search, there was marginal increase in the CL size. The reason is that generally the name
variant obtained from Stanford NER and Google search might already be present in our
ER. Though both Stanford NER and Google Search result in small increase of CL size, the
impact of these two heuristics is very high which is discussed in section 6.5 .
6.4 Candidate List Generation Phase Analysis
The failure to list the correct mapping node in the CLG phase will result in failure of the
system irrespective of the ranking algorithm used. We believe that as long as the correct
mapping node is present in the CL, the context of the query entity will help in linking
it correctly. The column “Wrong map” in Table 6.6 indicates the failure to list the correct
candidate node in the CL even though the mapping node exists in the KB. The probability of
identifying correct mapping node in the CL increases as we add more heuristics to identify
named entity variations.
Run
No.
Heuristics Used Wrong Map - 2009 Wrong Map - 2010
1 Disambiguation pages* 555 468
2 Bold text** 525 458
3 Redirect pages* 609 422
4 Run No.s 1+2+3 279 212
5 Run No. 4 + Stanford NER 266 195
6 Run No. 5 + Google Search 241 117
Table 6.6 The above table indicates the failure to list the correct candidate nodein the Candidate List even though the mapping node exist in the Knowledge Base.
Google Search heuristic had more impact on 2010 query set than on 2009 query set for
identifying name variants not present in our ER. These name variants in turn resulted in
the correct mapping node being picked into the CL. This is evident with the reduction of68
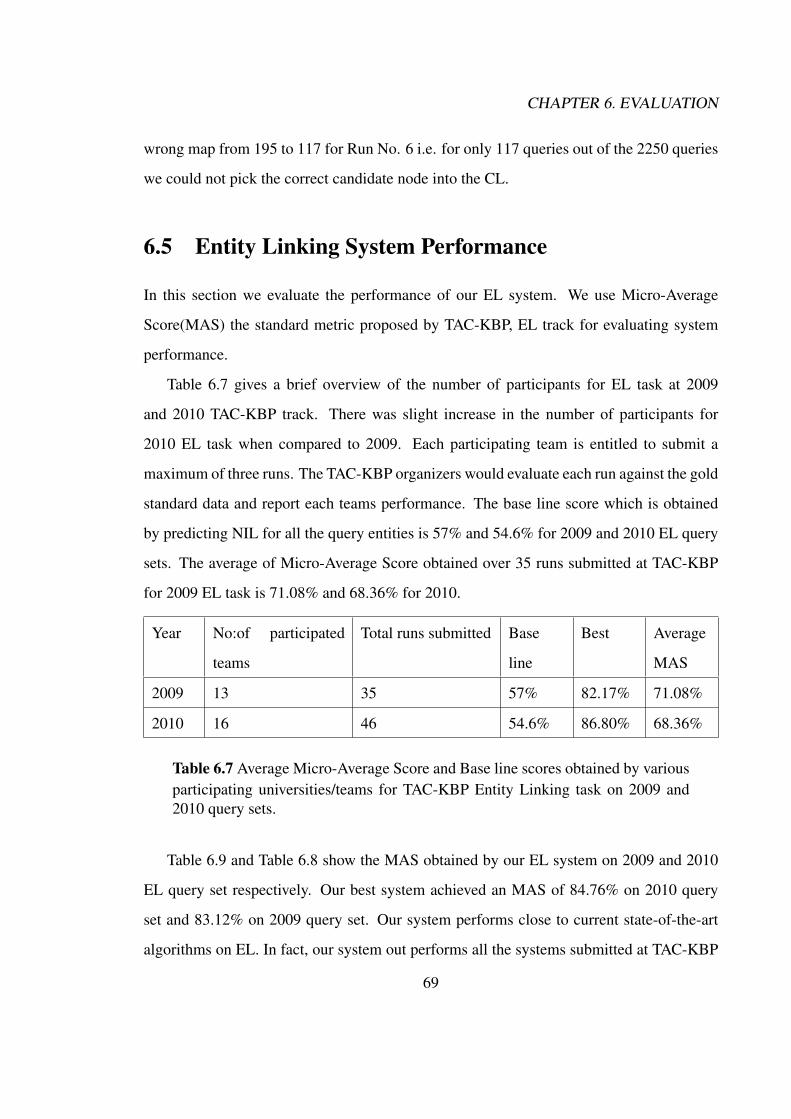
CHAPTER 6. EVALUATION
wrong map from 195 to 117 for Run No. 6 i.e. for only 117 queries out of the 2250 queries
we could not pick the correct candidate node into the CL.
6.5 Entity Linking System Performance
In this section we evaluate the performance of our EL system. We use Micro-Average
Score(MAS) the standard metric proposed by TAC-KBP, EL track for evaluating system
performance.
Table 6.7 gives a brief overview of the number of participants for EL task at 2009
and 2010 TAC-KBP track. There was slight increase in the number of participants for
2010 EL task when compared to 2009. Each participating team is entitled to submit a
maximum of three runs. The TAC-KBP organizers would evaluate each run against the gold
standard data and report each teams performance. The base line score which is obtained
by predicting NIL for all the query entities is 57% and 54.6% for 2009 and 2010 EL query
sets. The average of Micro-Average Score obtained over 35 runs submitted at TAC-KBP
for 2009 EL task is 71.08% and 68.36% for 2010.
Year No:of participated
teams
Total runs submitted Base
line
Best Average
MAS
2009 13 35 57% 82.17% 71.08%
2010 16 46 54.6% 86.80% 68.36%
Table 6.7 Average Micro-Average Score and Base line scores obtained by variousparticipating universities/teams for TAC-KBP Entity Linking task on 2009 and2010 query sets.
Table 6.9 and Table 6.8 show the MAS obtained by our EL system on 2009 and 2010
EL query set respectively. Our best system achieved an MAS of 84.76% on 2010 query
set and 83.12% on 2009 query set. Our system performs close to current state-of-the-art
algorithms on EL. In fact, our system out performs all the systems submitted at TAC-KBP
69

CHAPTER 6. EVALUATION
2009 EL task and is only marginally behind the best system submitted at TAC-KBP 2010.
This shows the robustness of our algorithm and also the performance is very high when
compared to base line score or average MAS for all the runs submitted at 2009 and 2010
TAC-KBP EL task.
It is evident from Table 6.9 and Table 6.8 that pseudo relevance feedback for re-ranking
has performed very well. This shows that using co-occurrence statistics of a named entity
with other words helps in disambiguation and efficient ranking of candidate nodes. Re-
ranking has worked significantly well with all the CLG heuristics except in case of redirects
where the increase in performance is comparatively low. Cosine similarity and Naı̈ve Bayes
performed almost equally using bag of words as feature. This shows that using a simple bag
of words approach is sufficient to build a fairly well performing EL system. This simple
approach outperforms the baseline (54.6%) and the median(68.36%) across all the 46 runs
submitted for EL task at 2010 TAC-KBP, as well as for 2009. Maximum Entropy didnt fare
well as the data available for training the model was not sufficient i.e. certain candidate
nodes had sufficient text to describe an entity where as others didn’t. Hence, maximum
entropy couldn’t perform well.
Run
No.
Heuristics Used Maxent Cosine
Sim
Naı̈ve
Bayes
tf-idf
Ranking
Re-
ranking
1 Disambiguation pages* 67.96 71.02 71.29 71.96 72.49
2 Bold text** 69.96 73.07 73.87 74.71 75.16
3 Redirect pages* 74.36 78.4 78.53 78.44 78.53
4 Run No.s 1+2+3 75.69 79.73 79.82 81.02 81.38
5 Run No. 4 + Stanford NER 76.27 80.40 80.53 81.56 82.00
6 Run No. 5 + Google Search 77.11 81.51 81.59 82.89 84.76
Table 6.8 Micro-Average Score for individual heuristics for 2010 Query set.Google Search includes both Google spell suggestion and Google directive search.
70

CHAPTER 6. EVALUATION
Run
No.
Heuristics Used Maxent Cosine
Sim
Naı̈ve
Bayes
tf-idf
Ranking
Re-
ranking
1 Disambiguation pages* 74.03 76.36 76.54 76.95 77.09
2 Bold text** 74.85 77.36 77.48 78.41 78.76
3 Redirect pages* 77.66 80.43 80.56 80.58 80.78
4 Run No.s 1+2+3 78.64 81.25 81.32 81.92 82.02
5 Run No. 4 + Stanford NER 78.76 81.58 81.66 82.12 82.79
6 Run No. 5 + Google Search 79.02 81.81 81.86 82.69 83.12
Table 6.9 Micro-average score for individual heuristics for 2009 Query set.Google Search includes both Google spell suggestion and Google directive search.
6.6 Precision Vs Top “N” results
In this section, we plot the Precision Vs Top “N” results for Non-Nil queries for the five
techniques. Figure 6.1 and Figure 6.2 shows the plot for 2010 and 2009 TAC-KBP EL
query set respectively. It can be seen clearly that as we consider a higher number of hits,
the probability of finding the correct map for the query entity in the hits list increases.
From the both the figures it is evident that Tf-idf technique results in ranking the map-
ping node higher (in the ranked list) when compared to others. Further simple techniques
like cosine similarity and Naı̈ve Bayes perform consistently better than maximum entropy,
which shows that word occurrence statistics are sufficient for building a decently perform-
ing EL System. This is also reflected in the results presented in the Section 6.5.
Pseudo relevance feedback re-ranking strategy results in picking the mapping node as
the BRN. Re-ranking will work only as long as the mapping node is present in the top 5
ranked nodes, because we consider only top 5 ranked nodes for query expansion. If the
mapping node is present in the top 5 ranked nodes, there is very good probability that
it might be the BRN after re-ranking. There can be only one mapping node at the best in
71

CHAPTER 6. EVALUATION
Figure 6.1 Precision Vs Top “N” results for Non-Nil Queries from 2010 TAC-KBP Entity Linking Query Set.
Figure 6.2 Precision Vs Top “N” results for Non-Nil Queries from 2009 TAC-KBP Entity Linking Query Set.
these top 5 ranked nodes. If the mapping node isn’t present in the top 5 ranked nodes, query
expansion using pseudo relevance feedback will result in addition of irrelevant tokens and
72

CHAPTER 6. EVALUATION
hence will result in performance degradation which is evident from the figures 6.1 and 6.2.
6.7 NIL Prediction Accuracy
In total there are 1230 (54.6%) queries in the 2010 TAC-KBP EL query set and 2229 (57%)
queries in 2009 TAC-KBP EL query set for which there is no mapping node in the KB.
Table 6.10 and Table 6.11 demonstrates the number of queries for which NIL was predicted
when |CL| = 0, and |CL| ≥ 1 for various approaches. The tables also show correct NIL
prediction count and accuracy. Since a query entity can occur in any of the variations, it is
very important to search the KB with all possible variations. Therefore the approach which
extracts major variations is likely to have better NIL accuracy. Experimental results for
Run No.6 on 2009 and 2010 EL query sets support this intuition.
Run
No.
|CL|=0 |CL| ≥ 1 and BRN ∈Wikipedia
- Predicted Correct
predictions
Accuracy Predicted Correct
predictions
Accuracy
1 417 304 72.9% 1203 859 71.4%
2 638 499 78.2% 921 665 72.2%
3 577 424 73.4% 972 747 76.8%
4 704 575 81.7% 630 553 87.7%
5 694 574 82.7% 626 553 88.3%
6 654 565 86.4% 535 513 95.8%
Table 6.10 Statistics of NIL predictions and its accuracy for 2010 Query Set.
73

CHAPTER 6. EVALUATION
Run
No.
|CL|=0 |CL| ≥ 1 and BRN ∈Wikipedia
- Predicted Correct
predictions
Accuracy Predicted Correct
predictions
Accuracy
1 1005 855 85.07% 1468 1112 75.74%
2 1388 1203 86.67% 1016 759 74.70%
3 1403 1135 80.89% 1234 959 77.7%
4 1468 1338 91.14% 679 572 84.24%
5 1468 1338 91.14% 679 572 84.24%
6 1410 1282 90.92% 602 532 88.37%
Table 6.11 Statistics of NIL predictions and its accuracy for 2009 Query Set.
6.8 Comparison with Top 5 systems at TAC-KBP
We compare the MAS of our best system with the top 5 runs submitted at 2009 and 2010
TAC-KBP, EL task [36] [24]. Siel is the team name with which we had participated. Our
system performed the best at 2009 TAC-KBP, EL task and was runner up at 2010 TAC-KBP.
Table 6.12 and Table 6.13 compare the performance of our system against the best ranked
systems developed by other teams. Some of the participating teams are IBM research labs
1, John Hopkins University 2, Stanford University 3 etc.
Our system got an MAS of 83.73% and 82.17% on TAC-KBP, 2010 and 2009 EL shared
task. After post analysis and improving the algorithm we obtained an MAS of 84.76% and
83.12% for 2010 and 2009, EL data sets respectively.
1http://www.watson.ibm.com/index.shtml2http://www.jhu.edu/3http://www.stanford.edu/
74

CHAPTER 6. EVALUATION
Team Micro-Average Score
LCC 86.80%
Siel 83.73%
CMCRC 81.9%
hltcoe 81.47%
Stanford UBC 80.00%
Table 6.12 Performance Comparison with Top 5 systems at TAC-KBP 2010 EntityLinking sub task.
Team Micro-Average Score
Siel 82.17%
QUANTA1 80.33%
hltcoe1 79.84%
Stanford UBC2 78.84%
NLPR KBP1 76.72%
Table 6.13 Performance Comparison with Top 5 systems at TAC-KBP 2009 EntityLinking sub task.
6.9 Error Analysis
In this section, we give a few example queries for which our EL System has failed. Our
system can fail either in the CLG phase or the ranking phase. In the CLG phase, our system
failed for queries like “Air Group Inc., Marufu, LULAC” etc. The correct mapping nodes
are “Midwest-airlines, Grace Mugabe, Texas’s 21st Congressional District” respectively.
This is because our heuristics in CLG phase couldn’t identify the latter as variations for
query entities. As these variations could not be identified, we could not pick those nodes
from the KB into the CL.
In the ranking phase, query entity might be wrongly mapped to KB node as the docu-
75

CHAPTER 6. EVALUATION
ment context in which the query entity occurs might not be sufficient for disambiguating it.
For the four techniques i.e. cosine similarity, maximum entropy, Naı̈ve Bayes and Tf-idf
ranking once the wrong node is mapped we can’t correct it. But in the case of pseudo
relevance feedback re-ranking strategy, we make use of the ranked results to expand the
query for re-ranking. Here we found that for certain generic and ambiguous query enti-
ties which were wrongly mapped during the ranking phase were correctly mapped after
re-ranking. For example, generic and ambiguous queries like “Cleveland, George Bush,
UC” were correctly mapped to “Cleveland, Ohio, George W. Bush, University of Cincin-
nati” respectively, when the contextual information from HAL was used for re-ranking.
(They were wrongly mapped to “Grover Cleveland, George H. W. Bush, Xavier University
(Cincinnati)” respectively when only ranking was done to predict the mapping node).
Our manual examination of 2010 TAC-KBP, EL gold standard data showed that 5
queries had been wrongly mapped. We have raised these issues with the TAC organiz-
ing committee and our suggestions were deemed correct. For example, for the query entity
“Jeff Fiser” the gold standard result was “2006 Tennessee Titans season”, whereas the cor-
rect answer is “NIL”. Jeff Fisher was the head coach of “2006 Tennessee Titans season”,
but linking them is wrong. The other errors were on similar lines. On incorporating these
changes to the gold standard data our best system i.e. 84.76% would become 84.98%.
6.10 Conclusions
In this chapter, we did a detail comparison of TAC-KBP, EL query sets for the year 2009
and 2010. Later, we discussed in detail the impact of each feature we used during the CLG
phase. Further, we described the performance of our algorithm on the TAC-KBP, EL data
set. We also compared the performance of our algorithm against the top 5 participants at
TAC-KBP, EL shared task. In the next chapter, we state the contributions of this thesis and
conclude with a real world application of an EL system.
76

Chapter 7
Conclusion
Structured KBs are a rich source of data for various NLP, IE and IR tasks. Recently, with
the emergence of publicly available databases, they have been exploited for a number of IE
tasks ranging from NER to relation extraction systems. But, KBs face quite a few problems
like : inconsistency in the information present, incompleteness, inaccuracy of the facts and
outdated information being present. These problems arise from the fact that the KBs are
maintained manually. In this thesis, we addressed the problem of linking named entities
from a document to nodes in a KB, a key component for automatic updation of KBs. In
the last decade, many techniques were proposed to extract structured information from un-
structured documents, but they never focused on integrating this extracted information to
globally available KBs. This motivated us to work on methodologies that can be used to
link entities in textual documents to KB nodes. We believe that research on EL will help
reduce the manual effort put in by contributors across the world in keeping the information
up to date in public KBs. This new area of research moves beyond the problems of NER,
CR and CDCR. EL breaks the document barrier and helps in automating the task of updat-
ing KBs. It opens up a range of applications from information aggregation to automated
reasoning over extracted information.
We showed that the process of creating and updating KBs can be automated. The
process of automating this task can be broken down into two sub problems.
77

CHAPTER 7. CONCLUSION
• Entity Linking
• Slot Filling
In this thesis, we addressed the problem of EL. We discussed in detail current ap-
proaches to EL and their short comings. Most of the current approaches are either too
rigid, cannot scale to large KBs or require huge training data. We discussed various chal-
lenges involved in EL like mention ambiguity, variations in named entities viz: acronyms,
nick names, spelling variations and NIL detection. We proposed a robust solution which
addresses the above issues and scales to large KBs with millions of entries.
Our proposed technique uses Wikipedia syntax to find variants of various named en-
tities. Wikipedia specific features like redirect pages, disambiguation pages and bold text
from first paragraph were used to identify synonyms, homonyms etc. Google spell sugges-
tion and Google site specific search was also used to obtain name variants from the web.
Additionally, an NER was used to find name variants of the query entity from the given
query document context. Using the variations obtained, a Boolean “AND” search was
done on the KB node titles. A subset of nodes, referred as candidate nodes (Candidate List,
CL), were obtained from the KB that can be linked to the query entity. Similarly, nodes
from Wikipedia were also added to the CL. Adding Wikipedia articles to the CL allows us
to consider strong matches against query entities that do not have any corresponding node
in the KB and hence we can return NIL. That is, for a given query entity if the ranking
function maps to the Wikipedia article from the CL, we can confirm the non-presence of a
node in the KB about the query entity. The identification of these candidate nodes from the
KB and Wikipedia was referred to as Candidate List Generation (CLG) phase.
Once the list of candidate nodes were obtained, the candidate nodes and query docu-
ment were tokenized and represented as token vectors. Using these vectors, similarity score
was calculated between the query document and candidate nodes. The similarity score be-
tween query document and the candidate nodes was calculated using five techniques. The
techniques used were cosine similarity, Naı̈ve Bayes, maximum entropy, Tf-idf and pseudo
78

CHAPTER 7. CONCLUSION
relevance feedback for re-ranking. The candidate node with highest similarity score was
returned as the Best Ranked Node (BRN). If BRN ∈ KB, we return it as a map for the
query entity or NIL otherwise.
Our algorithm was evaluated on a standard data set obtained from TAC-KBP, EL shared
task. Evaluation was done against TAC-KBP, 2009 and 2010 EL data set. Micro Average
Score (MAS) was used to evaluate our algorithms performance. We obtained very impres-
sive MAS of 83% and 85% on 2009 and 2010, EL data sets. Our results in chapter 6 show
that simple techniques like cosine similarity, Naı̈ve Bayes etc perform close to state of the
art. Pseudo relevance feedback performed close to state of the art algorithms and performed
the best on 2009 EL data set.
In this chapter, we discuss the contributions of this thesis and possible future directions.
We conclude with discussion on real world possible applications of an EL system.
7.1 Contributions
Most of the research community has focused on extracting structured information from
unstructured documents. But, using this extracted information to update KBs has received
very little focus. In this thesis, we attempted to fill this gap by trying to link entities occur-
ring in textual documents to nodes in a large KB. Once entities are linked to nodes in a KB,
document barrier is broken and information can be integrated across documents. We ap-
proached the problem of EL as a two stage problem. The basis for this technique is that we
focused on developing algorithms which can scale to large KBs and are robust. We experi-
mented with various similarity techniques and showed that simple approaches can perform
close to state-of-art algorithms and sometimes better. This was the major contribution of
the thesis. Some of the other contributions are :
• Identifying Named Entity Variations : We proposed three different methodologies
to identify named entity variations. We used Wikipedia specific syntax i.e. redi-
rect pages, disambiguation pages and bold text from first paragraph for identifying79

CHAPTER 7. CONCLUSION
synonyms, homonyms, nick names, alias names etc. Additionally, web search re-
sults and an NER were also used to identify various forms in which a named entity
could occur. Web search results and NER feature generate very few variations of an
entity, but their prediction accuracy is very high, which shows that they are highly
important features. We used Google spell suggestion feature and Google site specific
search for identifying spelling errors and to identify entity variations as well. We
used the obtained variations to identify candidate nodes from the KB.
• Robust Candidate Nodes Generation : Our system is flexible enough to find name
variants but sufficiently restrictive to produce manageable candidate list despite a
large-scale KB. We used Boolean “AND” search to identify candidate nodes from the
KB and Wikipedia. Table 6.6 shows that our system was able to identify mapping
node in the CL for high percentage of queries. We firmly believe that as long the
correct mapping node is present in the CL, the likelihood of it being returned as the
mapping node is very high, which is reflected in our results. Furthermore, our system
can scale to large KBs with millions of entries.
• Features for Entity Disambiguation and Ranking : We developed a rich and ex-
tensible set of features based on the query entity mention, the query document, and
KB nodes. We used tokenization, stop word removal and stemming to represent the
documents as vectors. This basic feature set had high impact on the final performance
of the system because of cleaner representation of the documents. Also, we experi-
mented with various similarity techniques to rank the candidate nodes. To the best of
our knowledge we found no work that experimented with so many different similarity
techniques. This is one of the major contributions of this thesis. We showed simple
techniques like cosine similarity, Naı̈ve Bayes, Tf-idf ranking etc perform close to
state of the art approaches, without any training data.
• NIL Detection : We proposed a technique of appending a given KB with Wikipedia
documents in order to identify NIL mapping entities, which obviates hand tuning.80

CHAPTER 7. CONCLUSION
From Table 6.10 and Table 6.11, it is clearly evident that this is a very useful feature.
This technique unlike other current approaches obviates the technique of fixing a
threshold for predicting NIL.
Our experiments were conducted on standard data sets for EL, provided by the TAC-
KBP. We evaluated our approach on both TAC-KBP, 2009 and 2010 EL data set. The
data set consisted of a KB, DC and query set. The DC consisted of news and blog arti-
cles providing real world documents and contexts to test our approach. Evaluation of our
methodology was confirming to the standard evaluation metrics for EL task. MAS was
used to evaluate our approach, which is the standard evaluation metric for EL.
Results of our experiments were reported in Chapter 6. Our algorithm achieved good
accuracy values while linking named entities to nodes in a large KB. Our results were on
par or better to the state-of-the-art approaches and systems developed as part of TAC-KBP
shared task. Our system was ranked first and second in TAC-KBP, EL shared tasks in 2009
and 2010 respectively.
7.2 Future Directions
Our approach can be considered as the building block for future research on EL. In this the-
sis, we have explored simple techniques like cosine similarity, Naı̈ve Bayes, Tf-idf ranking
etc and showed that they perform close to state-of-the-art and sometimes better. We feel
that now with training data available from TAC-KBP, machine learning techniques can be
explored. Another area that can be looked into is, refining the document context to cap-
ture only terms that describe the query entity. This would result in better ranking of the
candidate nodes and hence higher accuracy.
We firmly believe that as long as the candidate node is present in the CL, there is very
high likelihood of it being identified as the mapping node. The current research community
has been focusing more on the ranking algorithms as it is an interesting field. The perfor-
mance of an EL system is highly dependent on the CL identification phase. The higher81

CHAPTER 7. CONCLUSION
accuracy with which candidate nodes are identified, the higher the probability of identi-
fying it as a mapping node. It is worthwhile to consider candidate generation strategies
carefully.
Also, in our current approach we have exploited Wikipedia, an NER and Web search
results for identifying name variants. This is another area of research where we need to
separate this module and make it independent of any resource.
Nil node clustering is an area where focus of the research community is needed. Current
EL systems either predict a mapping node or NIL, if no mapping node is present in the KB.
If Nil node clustering is done, the data for a single named entity could be integrated into
one and hence can be used to creating new nodes in the KB.
A cross lingual EL system would be very promising area of research, because research
in this area will help in building KBs for local languages. With the growth of new websites
and blogs in the local languages of different regions this would certainly give the opportu-
nity for the less resourced languages to have a KB of their own which in due time will help
in the growth of users using local languages.
7.3 Application of Entity Linking
We discuss some real world applications of EL.
Metadata Integration : A possible application could be importing of metadata from
KBs by linking the named entities in a document. On successful linkage, metadata from the
KBs could be imported to the document, which otherwise might not be explicitly present
in the document. The metadata when imported can also contain property value pairs like
Age:35, Name:Sachin etc and complex queries like that of SPARQL [51] can be fired. In
figure 7.1, information flow of such a system is shown. From figure 7.2, we can see how a
document would look like when information about entities “Assange, WikiLeaks, Elmers”
is imported from a KB. With this integration of information into a document, search space
for a user is increased, because this document is retrieved even for keyword searches like
82

CHAPTER 7. CONCLUSION
“whistle blowers, swiss people, online archives” etc as this metadata is imported from the
KB.
Figure 7.1 An application of Entity Linking flow chart.
Figure 7.2 Possible application of Entity Linking.
Financial Domain : In the finance domain, EL can be used to identify company names
in a textual document and link them to a KB of tradable company names listed on the
stock markets. This can be used to aggregate company information into the document with
respect to stock market codes, analysis of relationship between news and share prices etc.
Search Feature Enhancement : Current day search engines return documents relevant
to the query posted by a user. The search engine results in general are a list of ranked
documents, where each result generally contains a title, a url, a snippet etc. We can use an
EL system to link the named entities present in the snippet/titles to a publicly available KB.
By doing this we can import information from the KB to the search results enhancing the83

CHAPTER 7. CONCLUSION
user experience and can also provide him with structured information.
84

Bibliography
[1] I. Androutsopoulos, G. Paliouras, V. Karkaletsis, G. Sakkis, C.D. Spyropoulos, andP. Stamatopoulos. Learning to filter spam e-mail: A comparison of a naive bayesianand a memory-based approach. Arxiv preprint cs/0009009, 2000.
[2] A. Bagga and B. Baldwin. Entity-based cross-document coreferencing using the vec-tor space model. In Proceedings of the 17th international conference on Computa-tional linguistics-Volume 1, pages 79–85. Association for Computational Linguistics,1998.
[3] M. Banko, O. Etzioni, and T. Center. The tradeoffs between open and traditionalrelation extraction. Proceedings of ACL-08: HLT, pages 28–36, 2008.
[4] R. Barzilay and M. Elhadad. Using lexical chains for text summarization. In Proceed-ings of the ACL Workshop on Intelligent Scalable Text Summarization, volume 17.Madrid, spain, 1997.
[5] R. Barzilay, K.R. McKeown, and M. Elhadad. Information fusion in the context ofmulti-document summarization. In Proceedings of the 37th annual meeting of theAssociation for Computational Linguistics on Computational Linguistics, pages 550–557. Association for Computational Linguistics, 1999.
[6] R. Bunescu and R. Mooney. Subsequence kernels for relation extraction. Advancesin Neural Information Processing Systems, 18:171, 2006.
[7] R. Bunescu and M. Pasca. Using encyclopedic knowledge for named entity disam-biguation. In Proceedings of EACL, volume 6, 2006.
[8] R.C. Bunescu and R.J. Mooney. A shortest path dependency kernel for relation ex-traction. In Proceedings of the conference on Human Language Technology and Em-pirical Methods in Natural Language Processing, pages 724–731. Association forComputational Linguistics, 2005.
[9] Z. Cao, T. Qin, T.Y. Liu, M.F. Tsai, and H. Li. Learning to rank: from pairwiseapproach to listwise approach. In Proceedings of the 24th international conferenceon Machine learning, pages 129–136. ACM, 2007.
85

BIBLIOGRAPHY
[10] S.F. Chen, R. Rosenfeld, and CARNEGIE-MELLON UNIV PITTSBURGH PASCHOOL OF COMPUTER SCIENCE. A Gaussian prior for smoothing maximumentropy models, 1999.
[11] H.L. Chieu and H.T. Ng. Named entity recognition: a maximum entropy approachusing global information. In Proceedings of the 19th international conference onComputational linguistics-Volume 1, pages 1–7. Association for Computational Lin-guistics, 2002.
[12] S.P. Converse. Resolving pronominal references in Chinese with the Hobbs algorithm.In Proceedings of the 4th SIGHAN workshop on Chinese language processing, pages116–122, 2005.
[13] S. Cucerzan. Large-scale named entity disambiguation based on Wikipedia data. InProceedings of EMNLP-CoNLL, volume 2007, pages 708–716, 2007.
[14] A. Culotta and J. Sorensen. Dependency tree kernels for relation extraction. In Pro-ceedings of the 42nd Annual Meeting on Association for Computational Linguistics,pages 423–es. Association for Computational Linguistics, 2004.
[15] G. Escudero, L. Marquez, and G. Rigau. Naive Bayes and exemplar-based approachesto word sense disambiguation revisited. Arxiv preprint cs/0007011, 2000.
[16] O. Etzioni, M. Cafarella, D. Downey, A.M. Popescu, T. Shaked, S. Soderland, D.S.Weld, and A. Yates. Unsupervised named-entity extraction from the web: An experi-mental study. Artificial Intelligence, 165(1):91–134, 2005.
[17] R. Florian, A. Ittycheriah, H. Jing, and T. Zhang. Named entity recognition throughclassifier combination. In Proceedings of the seventh conference on Natural languagelearning at HLT-NAACL 2003-Volume 4, pages 168–171. Association for Computa-tional Linguistics, 2003.
[18] E. Gabrilovich and S. Markovitch. Computing semantic relatedness using wikipedia-based explicit semantic analysis. In Proceedings of the 20th International Joint Con-ference on Artificial Intelligence, pages 6–12, 2007.
[19] E. Gabrilovich and S. Markovitch. Wikipedia-based semantic interpretation for natu-ral language processing. Journal of Artificial Intelligence Research, 34(1):443–498,2009.
[20] C. Giuliano, A. Lavelli, and L. Romano. Exploiting shallow linguistic informationfor relation extraction from biomedical literature. In Proceedings of the EleventhConference of the European Chapter of the Association for Computational Linguistics(EACL-2006), pages 5–7, 2006.
[21] X. Han and J. Zhao. NLPR KBP in TAC 2009 KBP Track: A Two-Stage Method toEntity Linking. In Proceedings of Test Analysis Conference 2009 (TAC 09).
86

BIBLIOGRAPHY
[22] E. Hovy and C.Y. Lin. Automated text summarization in SUMMARIST. Advancesin Automatic Text Summarization, 94, 1999.
[23] A. Iftene and A. Balahur-Dobrescu. Named entity relation mining usingwikipedia. Proceedings of the Sixth International Language Resources and Evalu-ation (LREC’08), pages 2–9517408, 2008.
[24] H. Ji, R. Grishman, H.T. Dang, and K. Griffitt. Overview of the TAC 2010 KnowledgeBase Population Track [DRAFT].
[25] K.T. JunichiKazama. Exploiting Wikipedia as external knowledge for named entityrecognition. In Proc. EMNLP-CoNLL, pages 698–707, 2007.
[26] S.B. Kim, K.S. Han, H.C. Rim, and S.H. Myaeng. Some effective techniques for naivebayes text classification. IEEE Transactions on Knowledge and Data Engineering,pages 1457–1466, 2006.
[27] M. Knights. Web 2.0. Communications Engineer, 5(1):30–35, 2007.
[28] F. Li, Z. Zhang, F. Bu, Y. Tang, X. Zhu, and M. Huang. THU QUANTA at TAC 2009KBP and RTE Track. In Text Analysis Conference (TAC), 2009.
[29] C.Y. Lin and E. Hovy. From single to multi-document summarization: A prototypesystem and its evaluation. In Proceedings of the 40th Annual Meeting on Associa-tion for Computational Linguistics, pages 457–464. Association for ComputationalLinguistics, 2002.
[30] V. Lopez, M. Pasin, and E. Motta. Aqualog: An ontology-portable question answeringsystem for the semantic web. The Semantic Web: Research and Applications, pages546–562, 2005.
[31] K. Lund and C. Burgess. Producing high-dimensional semantic spaces from lexicalco-occurrence. Behavior Research Methods Instruments and Computers, 28(2):203–208, 1996.
[32] I. Mani and E. Bloedorn. Multi-document summarization by graph search and match-ing. Arxiv preprint cmp-lg/9712004, 1997.
[33] I. Mani and M.T. Maybury. Advances in automatic text summarization. the MITPress, 1999.
[34] G.S. Mann and D. Yarowsky. Unsupervised personal name disambiguation. In Pro-ceedings of the seventh conference on Natural language learning at HLT-NAACL2003-Volume 4, pages 33–40. Association for Computational Linguistics, 2003.
[35] T. McArthur. Worlds of reference: lexicography, learning and language from the claytablet to the computer. 1986.
87

BIBLIOGRAPHY
[36] P. McNamee and H.T. Dang. Overview of the TAC 2009 knowledge base populationtrack. In Text Analysis Conference (TAC), 2009.
[37] P. McNamee, M. Dredze, A. Gerber, N. Garera, T. Finin, J. Mayfield, C. Piatko,D. Rao, D. Yarowsky, and M. Dreyer. HLTCOE approaches to knowledge base pop-ulation at TAC 2009. In Text Analysis Conference (TAC), 2009.
[38] P. Melville, W. Gryc, and R.D. Lawrence. Sentiment analysis of blogs by combininglexical knowledge with text classification. In Proceedings of the 15th ACM SIGKDDinternational conference on Knowledge discovery and data mining, pages 1275–1284.ACM, 2009.
[39] R. Mihalcea. Using wikipedia for automatic word sense disambiguation. In Proceed-ings of NAACL HLT, volume 2007, 2007.
[40] A. Mikheev, M. Moens, and C. Grover. Named entity recognition without gazetteers.In Proceedings of the ninth conference on European chapter of the Association forComputational Linguistics, pages 1–8. Association for Computational Linguistics,1999.
[41] D. Milne, O. Medelyan, and I.H. Witten. Mining domain-specific thesauri fromwikipedia: A case study. In Proceedings of the 2006 IEEE/WIC/ACM InternationalConference on Web Intelligence, pages 442–448. IEEE Computer Society, 2006.
[42] D. Milne and I.H. Witten. Learning to link with wikipedia. In Proceeding of the 17thACM conference on Information and knowledge management, pages 509–518. ACM,2008.
[43] D.N. Milne, I.H. Witten, and D.M. Nichols. A knowledge-based search engine pow-ered by wikipedia. In Proceedings of the sixteenth ACM conference on Conferenceon information and knowledge management, pages 445–454. ACM, 2007.
[44] D. Moldovan, S. Harabagiu, M. Pasca, R. Mihalcea, R. Girju, R. Goodrum, andV. Rus. The structure and performance of an open-domain question answering sys-tem. In Proceedings of the 38th Annual Meeting on Association for ComputationalLinguistics, pages 563–570. Association for Computational Linguistics, 2000.
[45] K. Nakayama, T. Hara, and S. Nishio. Wikipedia mining for an association webthesaurus construction. Web Information Systems Engineering–WISE 2007, pages322–334, 2007.
[46] D.P.T. Nguyen, Y. Matsuo, and M. Ishizuka. Relation extraction from wikipedia usingsubtree mining. In Proceedings of the National Conference on Artificial Intelligence,volume 22, page 1414. Menlo Park, CA; Cambridge, MA; London; AAAI Press; MITPress; 1999, 2007.
88

BIBLIOGRAPHY
[47] F. Ortega, J.M. Gonzalez-Barahona, and G. Robles. On the inequality of contributionsto Wikipedia. In Hawaii International Conference on System Sciences, Proceedingsof the 41st Annual, page 304. IEEE, 2008.
[48] B. Pang, L. Lee, and S. Vaithyanathan. Thumbs up?: sentiment classification usingmachine learning techniques. In Proceedings of the ACL-02 conference on Empiricalmethods in natural language processing-Volume 10, pages 79–86. Association forComputational Linguistics, 2002.
[49] T. Pedersen. A simple approach to building ensembles of Naive Bayesian classifiersfor word sense disambiguation. In Proceedings of the 1st North American chapterof the Association for Computational Linguistics conference, pages 63–69. MorganKaufmann Publishers Inc., 2000.
[50] W.J. Plath. REQUEST: a natural language question-answering system. IBM Journalof Research and Development, 20(4):326–335, 1976.
[51] E. PrudHommeaux, A. Seaborne, et al. SPARQL query language for RDF. W3Cworking draft, 4, 2006.
[52] A. Ratnaparkhi et al. A maximum entropy model for part-of-speech tagging. InProceedings of the conference on empirical methods in natural language processing,volume 1, pages 133–142, 1996.
[53] A. Ratnaparkhi, J. Reynar, and S. Roukos. A maximum entropy model for prepo-sitional phrase attachment. In Proceedings of the workshop on Human LanguageTechnology, pages 250–255. Association for Computational Linguistics, 1994.
[54] D. Ravichandran and E. Hovy. Learning surface text patterns for a question answeringsystem. In Proceedings of the 40th Annual Meeting on Association for ComputationalLinguistics, pages 41–47. Association for Computational Linguistics, 2002.
[55] M. Remy. Wikipedia: The free encyclopedia. Reference Reviews, 16(6):5, 2002.
[56] J.D.M. Rennie. Improving multi-class text classification with naive Bayes. PhD thesis,Citeseer, 2001.
[57] A.E. Richman and P. Schone. Mining wiki resources for multilingual named entityrecognition. In Proceedings of the 46th Annual Meeting of the Association for Com-putational Linguistics: Human Language Technologies, pages 1–9. Citeseer, 2008.
[58] R. Rosenfeld. Adaptive statistical language modeling: a maximum entropy approach.PhD thesis, Citeseer, 2005.
[59] G. Salton and C. Buckley. Term-weighting approaches in automatic text retrieval* 1.Information processing & management, 24(5):513–523, 1988.
89

BIBLIOGRAPHY
[60] G. Salton, A. Wong, and C.S. Yang. A vector space model for information retrieval.Journal of the American Society for information Science, 18(11):613–620, 1975.
[61] K.M. Schneider. A comparison of event models for Naive Bayes anti-spam e-mail fil-tering. In Proceedings of the tenth conference on European chapter of the Associationfor Computational Linguistics-Volume 1, pages 307–314. Association for Computa-tional Linguistics, 2003.
[62] Zongyu Zhang Xinsheng Li Jingyi Guan Weiran Xu Jun Guo Si Li, Sanyuan Gao.PRIS at TAC 2009: Experiments in KBP Track. In Proceedings of Test AnalysisConference 2009 (TAC 09).
[63] R. Srihari and W. Li. A question answering system supported by information extrac-tion. In Proceedings of the sixth conference on Applied natural language processing,pages 166–172. Association for Computational Linguistics, 2000.
[64] S. Tan, X. Cheng, Y. Wang, and H. Xu. Adapting naive bayes to domain adaptationfor sentiment analysis. Advances in Information Retrieval, pages 337–349, 2009.
[65] E.F. Tjong Kim Sang and F. De Meulder. Introduction to the CoNLL-2003 sharedtask: Language-independent named entity recognition. In Proceedings of the seventhconference on Natural language learning at HLT-NAACL 2003-Volume 4, pages 142–147. Association for Computational Linguistics, 2003.
[66] M. Vela and T. Declerck. Concept and relation extraction in the finance domain.In Proceedings of the Eighth International Conference on Computational Semantics,pages 346–350. Association for Computational Linguistics, 2009.
[67] D.L. Waltz. An English language question answering system for a large relationaldatabase. Communications of the ACM, 21(7):526–539, 1978.
[68] D. Zelenko, C. Aone, and A. Richardella. Kernel methods for relation extraction. TheJournal of Machine Learning Research, 3:1083–1106, 2003.
[69] T. Zesch, I. Gurevych, and M. M”uhlh”auser. Analyzing and accessing Wikipedia as a lexical semantic resource. DataStructures for Linguistic Resources and Applications, pages 197–205, 2007.
[70] T. Zesch, C. Muller, and I. Gurevych. Extracting lexical semantic knowledge fromwikipedia and wiktionary. In Proceedings of the Conference on Language Resourcesand Evaluation (LREC), pages 1646–1652. Citeseer, 2008.
[71] G.D. Zhou and J. Su. Named entity recognition using an HMM-based chunk tag-ger. In Proceedings of the 40th Annual Meeting on Association for ComputationalLinguistics, pages 473–480. Association for Computational Linguistics, 2002.
90