longitudinal latent class models with application to outcomes for bipolar disorder january 24, 2008
TRANSCRIPT

Longitudinal Latent Class Models with Application to
Outcomes for Bipolar Disorder
January 24, 2008

Motivating Case Study: The STEP-BD Study Longitudinal, multi-site study of ~ 3700
patients diagnosed with Type-I and Type-II bipolar disorder
Administered an enhanced, systematic treatment program across sites
Recorded outcomes for up to 3 years on a variety of psychological and functional instruments (MADRS, YMRS, CLINSTAT)
More at www.stepbd.org
“Systematic Treatment Enhancement Program”

Study Aims
1) Identify underlying groups of patients based on their response trajectories
Do some patients improve quickly? Do others stay symptomatic? Do some improve then relapse?
For example, recent work (Perlis, 2006) has shown that 60% of symptomatic patients achieve remission within 2-year period
Yet, only 50% of these stay recovered for a full 2 years
Do patients cluster into groups based on these trajectories? For example, can we identify a “long-term” recovery
group? Can we predict these groups through a regression model?

Study Aims (Cont’d)
2) Given that distinct groups exist, we want to estimate the response trajectories for each class
3) Use patient covariates to predict group membership Can we predict who is likely to belong to a particular
trajectory class?
4) Long-term aim: determine if there are genetic differences among patients in different classes

Latent Class Models for Longitudinal Data A common approach is to fit a parametric regression model
relating Y to covariates X via class-specific parameters θk (k=1,…,K)
The marginal model (1) is a mixture of class specific densities, f, and class membership probabilities, πk Typically assume f belongs to same distributional family for
all components
In particular, πk = Pr(Ci = k), where Ci is a latent class-indicator variable for subject i
Model (1) is called a latent class or finite mixture model Sometimes “latent class” reserved for discrete Y
11
| | , , , (1)K
i i k i i k Kk
f f
y x y x

Latent Class vs. Random Effects Model
Model (1) can be thought of as a discrete counterpart to the usual, continuous random effects model:
In (1) the random effect distribution, g, is discrete rather than continuous
11
| | , , , (1)K
i i k i i k Kk
f f
y x y x
| , | ,i i i i i i i if f g d y x y C c x c c

Aims of Latent Class Modeling in Longitudinal Setting
Estimate class-specific regression parameters, θk
Conditional on data, predict class-membership probabilities for each subject:
These will be determined by subject’s response vector,
Potentially by additional covariates as well
|ik i y
iy

References McLachlan G. and Peel D. (2000). Finite Mixture Models.
(Wiley).
Fruhwirth-Schnatter S. (2006). Finite Mixture and Markov Switching Models. (Springer)
Nagin D. (1999). Analyzing Developmental Trajectories. Psychological Methods, 4(2), 139-157.
Muthén et al. (2002). General Growth Mixture Modeling for Randomized Preventive Interventions. Biostatistics, 3(4), 459-475.
Elliott et al. (2005). Using Bayesian Latent Growth Curve Model to Identify Trajectories of Positive Affect and Negative Events Following Myocardial Infarction. Biostatistics, 6(1), 119-143.
“Growth mixture model” is a finite mixture of random effects models; also called the “heterogeneity model”
(Verbeke and Molenberghs (2000))

Software
Mplus (Muthén and Muthén). http://www.statmodel.com/
SAS Proc Traj http://www.andrew.cmu.edu/user/bjones/index.htm
R: Flexmix and Bayemix packages
WinBUGS
Panel data only (?)

A Simple Simulation
Consider the following two-class model
So, subject i has observed data (yi, ti) and latent variable,
2
1 10 11
22 20 22 23
2
| , ~ , , 1, ,100; 1, ,5; 1,2
0, , 4
|
ij
i
ij ij i k
ij ij
ij
i i n
f y t C k N i j k
t t
t t
V C k I
Y
1
2 1
1 . .
2 . . 1i
w pC
w p
For simplicity, assume conditional independence and homoscedasticity
π1 and π2 may vary across subjects as a function of covariates (e.g., older subject more likely to be in class 1, a priori). See below.
Linear Trend for Class 1
Quadratic Trend for Class 2

Simulation Model
β1=c(2, .5), π1=.43
β2=c(1, 2, -.5), π2=.57
σ2 =1
Simulated Responses (n=100)
Class 1 Class 2
t

Estimation
Aims are to estimate β1, β2 and σ2
Conditional on yi, predict probability that subject i belongs to class k,
If we knew class allocations, Ci’s, then we could estimate parameters via typical regression techniques
In a sense, Ci’s are like missing data
| Pr |ik y iC k y

Complete-Data Estimation
Consider complete-data likelihood,
If we knew this, we could obtain ML estimates of model parameters
For example, is the typical least squares estimate based on subjects from class 1
Likewise,
1
1
111
1i
n
Cin
n n
,f y C
Sample estimate of the true population proportion in class 1

Frequentist Estimation (Cont’d)
Since we don’t know Ci’s, we can use the EM algorithm: E-Step: For each subject, compute expected
complete data log-likelihood using current model estimates
1 1
, | | log |K n
k kD ik i ic i
E l E D f
y D y y Introduce indicator variables, Dik=1 if Ci=k, 0 o.w.
|
1
ˆˆ ;| =
ˆˆ ;
= posterior update via Bayes' Theorem
k kik yik K
j jj
fE D
f
i
i
i
yy
y
MLEs from previous iteration

M-Step
For details on E-Step, see: Fruhwirth-Schnatter (2006) p. 50-51; Also Redner and Walker (1984) and Meng (1997)
M-Step: Obtain parameter estimates, , by maximizing expected complete-data log-likelihood
Note: EM Algorithm used by R Flexmix, Mplus and Proc Traj
,k k

Bayesian Inference
In the Bayesian setting, we place a prior distribution on π, as well as other model parameters
Use MCMC (e.g., Gibbs sampling) to obtain posterior samples for parameters
1) At each iteration, we update class indicators, C i, from their full conditional
2) Conditional on Ci, update other model parameters using standard MCMC techniques
Data augmentation step

Prior Distribution
For our two-class linear model, typical conjugate priors might be:
2
2
1 10 11 2 1 1
2 20 21 22 3 2 2
2
1 ~
~ ,
, ~ ,
, , ~ ,
~ ( , )
i iD C Bern
Be a b
N
N
IG
π2 = probability of class 2 membership. Could be a function of covariates and additional parameters, α. In this case, we would have π2i ; that is, a different prior probability for each covariate profile – SEE BELOW
π2 = probability of class 2 membership. Here assumed same for all subjects.
Di = 0 if class 1, 1 if class 2

Posterior Computation
Gibbs Sampler:
2 2 2 2
2
i
12
2
nm-1 m-1 m-1 m-1m
ii=1
m-1mi 2m 2
i2 i2 k km-1 m-1m mi 2 1 i
nm m
ii=1
k
At iteration m,
1) Draw π from Be a+n ,b+n-n , where n = d
π f y |θ , ′2)Draw d from Bern p , where p = and θ = β ,σπ f y |θ +π f y |θ
3) Set n = d
4) Update β from tyi
m
2
pical normal full conditional restricted to subjects with c =k
5) Update σ from typical full conditional, modified to allow for two classes
Bayes’ Theorem Update

Simulation Example (Cont’d)
In addition, assume that the prior class probabilities are related to subjects’ age ~ N(40, 16) via a probit model:
2 1 2
1
2
40
.5
.5
i iage
Older subjects less likely to be in class 2; more likely in class 1
β1=c(2,.5), π1=.43
β2=c(1,2,-.5), π1=.57
σ2 =1
Class 1 Class 2

Simulation Results
Ran Gibbs Sampler in R and WinBUGS 5,000 iterations, burn-in of 1,500
For R program, used Albert and Chib (1993) data augmentation procedure to estimate α
Compared various initial values In both ML and Bayes estimation, inits do matter!

Results
Parameter True Value Posterior Mean
95% CI
β10 2 1.96 (1.77, 2.16)
β11 0.5 0.51 (0.43, 0.58)
β21 1 1.10 (0.90, 1.33)
β22 2 1.61 (1.35, 1.86)
β23 -0.5 -.41 (-0.46, -0.34)
α1 0.5 0.39 (0.08, 0.73)
α2 -0.5 -0.5 (-0.69, -0.34)
σ 1 1.02 (0.96, 1.07)
Class 1
Class 2

Subject-Specific Class Probabilities
Subject 15: y = (2.01,3.91,2.70,3.46,5.25)age=39.14true class = 1
posterior π1 ≈ 1.0
Subject 9: y = (2.42, 1.99, 3.83, 3.64, 3.39)age=37.9true class=2
posterior π2 = .18
Two subjects out of 100 were “misclassified” prob of being in true class < .5
Average posterior proportion of in Class 2 = .56
Correctly classified
“Misclassified”
Recall: younger class 1

Other Software WinBUGS gives similar results
SAS Proc Traj influenced by choice initial values
Results reasonable if inits chosen carefully
─ Observed
-- Predicted

Proc Traj (Default Inits)
─ Observed
-- Predicted

Non-Identifiability Due to Overfitting
If we fit too many classes to the data, our model may be non-identifiable
Non-Identifiability can arise in two ways:1) Some πk = 0 (empty classes)
No information in the data to estimate πk MLE regularity conditions fail; improper posterior under vague
prior for π
2) θk = θj for some j ≠ k Split a single class into two identical classes, with distinct
membership probabilities Can estimate π but not θk
Need to address the two types separately
See Fruhwirth-Schnatter (2006) section 1.3
11
| | , , , (1)K
i i k i i k Kk
f f
y x y x

Non-Identifiability Due to Label Switching K! different arrangements of components yield same marginal likelihood
For example,
Loosely, it doesn’t matter which classes we label 1 and 2
Not a problem for ML estimation; same MLEs under both labelings
However, in Bayesian setting, can cause problems when trying to sample component specific parameters
For example, we may sample μ1 ≈ 1 at some iterations and μ1 ≈ 3 at others
2 2 21 2
2 21 2
( | , , ) .5 1, 3,
.5 3, 1,
f y N N
N N

Example: f(y)=.5N(μ1 ,1) + .5N(μ2 ,1) Note: vague N(0, 100) prior on μ1 and μ2,, beta(1,1) on π
beta(1,1) prior can yield posterior π1 ≈ 0
Here π1|y ≈ 0 sample from prior for μ1
Posterior Densities and Iteration Plots for μ1 (n=100)
Occasionally, draw μ1’s ≈ 2.5 and μ2’s ≈ 1 and stay there, since it’s a posterior mode
Samples for μ1 never drift
far from 1

Solution: Formal Identifiability Constraints Assume a priori constraints among parameters
Ensure nonempty classes, choose prior that bounds π away from 0 π ~Dir(4,…,4)
For any two classes, make sure there’s at least one parameter θj that differentiates the classes If classes are well-distinguished by data, unconstrained model
probably okay
If classes are not distinct and n is small, the model is not well-identified, and computational problems can arise – need a constraint
In Bayesian context, can implement identifiability constraint via constrained prior distribution on parameters
However, arbitrary constraints do not necessarily avoid label switching (Celeux, 1998; Stephens, 2000)
Ensures no empty classes
Ensures non- identical classes

Constrained Permutation Sampler
Fruhwirth-Shnatter (2006) recommends a constrained permutation sampler
Randomly permute parameters at each iteration, according to assumed constraint
If constraint is valid, then no label switching
If constraint not valid, label switching will arise
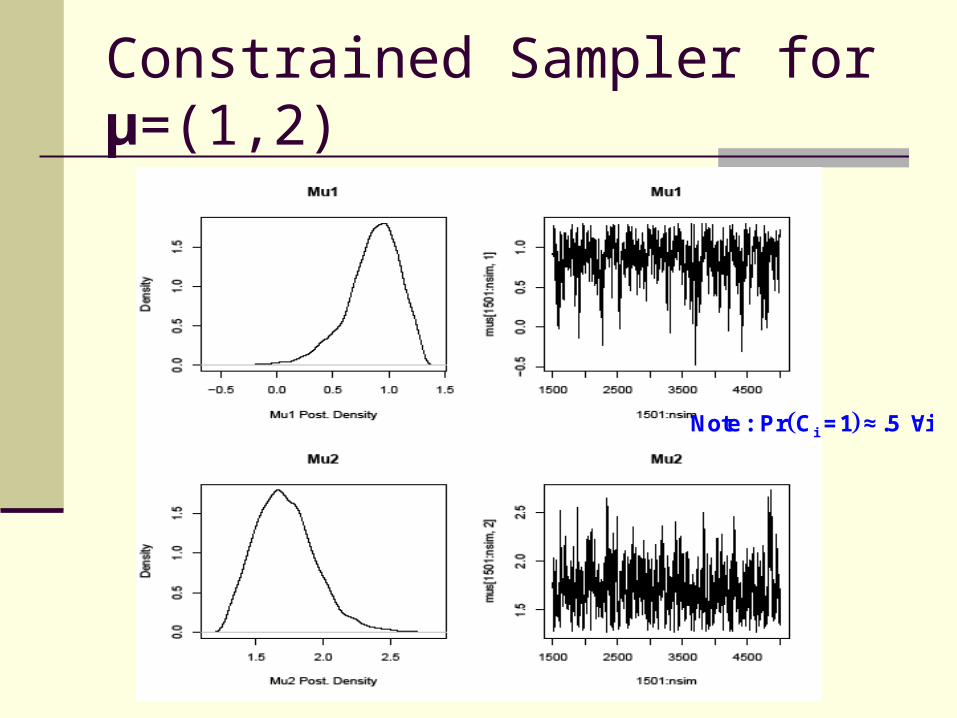
Constrained Sampler for μ=(1,2)
iNote: Pr C =1 ≈.5 ∀i

Determining the Number of Classes (K)
“Mode hunting” plots (Fruhwirth-Schnatter (2006)) Plot posterior draws from unconstrained permutation
sampler for each pair of classes (k,k’)
If K is correct, should get K(K-1) distinct clusters, bounded away from line, μ1 = μ2
Evidence of potential overfitting;recall, n=100

One-Component Model, μ1 = μ2 = 1
What happens if we fit a two-component model to a model simulated under one component, f(y|μ)=N(μ,1)?
Posterior Mode/MLE μ-hat=1 under one-component mixture

Other Strategies for determining K Compare BICK for various choices of K
Choose K that minimizes BIC Reoder and Wasserman (1997) Fraley and Raftery (1998)
Bayes Factors
Posterior Predictive Checks Choose a test statistic, T
At each MCMC iteration, compute T(yf) based on a posterior predictive sample, yf
Plot posterior distribution of T(yf) given y for model MK
If model is underfitting, the observed sample test statistic, T(yobs) , may lie outside, or in tails of posterior distribution, p[T(yf)|y,MK]
Dimension-switching MCMC such as reversible jump (Green, 1995)

Appendix: Related Methods Related methods include:
Cluster analysis: choose partition that minimizes within-cluster variance of response, Y
Model-Based Clustering: Assume that Y arises from a finite-mixture distribution with K components – use model to predict class memberships Banfield and Raftery (1993) Biometrics Fraley and Raftery (1998) The Computer Journal Mclust package in R
Tree-based methods (e.g., CART): sequentially split covariates, X, in a way that “optimizes” the within-cluster homogeneity of Y Nonparametric procedure Segal (1992). Tree-Structured Methods for Longitudinal Data. Journal of the
American Statistical Association, Vol. 87 (418), 407-418 Extends splitting rule to accommodate repeated measures
Rpart and Tree packages in R (may not accommodate repeated measures)
In a sense, latent class regression models combine regression aspect of CART with finite mixture aspect of MBC

Tree Diagram for Simulated Example
CART yields 9 classes, some with small n
Visit 0 Visit > 0
Youngest Patients
Mean Y
Classifies by visits rather than subjects – i.e., ignores repeated measures – may not be meaningful