machine learning - doctoral class - edic epfl - lasa @ 2006 a.. billard machine learning...
Post on 20-Dec-2015
225 views
TRANSCRIPT

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
MACHINE LEARNING
Information Theory and The Neuron - II
Aude Billard

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Overview
LECTURE I: • Neuron – Biological Inspiration• Information Theory and the Neuron • Weight Decay + Anti-Hebbian Learning PCA• Anti-Hebbian Learning ICA
LECTURE II: • Capacity of the single Neuron• Capacity of Associative Memories (Willshaw Net, Extended Hopfield Network)
LECTURE III: • Continuous Time-Delay NN• Limit-Cycles, Stability and Convergence

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
CellBody
Dendrites
Synapse
E Electrical Potential
time
dtxE1
t
E
Integration Decay-depolarization
Neural Processing - The Brain
A neuron receives and integrate input from other neurons. Once the input exceeds a critical level, the neuron discharges a spike. This spiking event is also called depolarization, and is followed by a refractory period, during which the neuron is unable to fire.
Refractory
1x
2x E

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
You can view the neuron as a memory.• What can you store in this memory? • What is the maximal capacity?• How can you find a learning rule that maximizes the capacity?
W1
W2
W3
W4
Output: y
X
iii xwfy
Information Theory and The Neuron
EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Information Theory and The Neuron
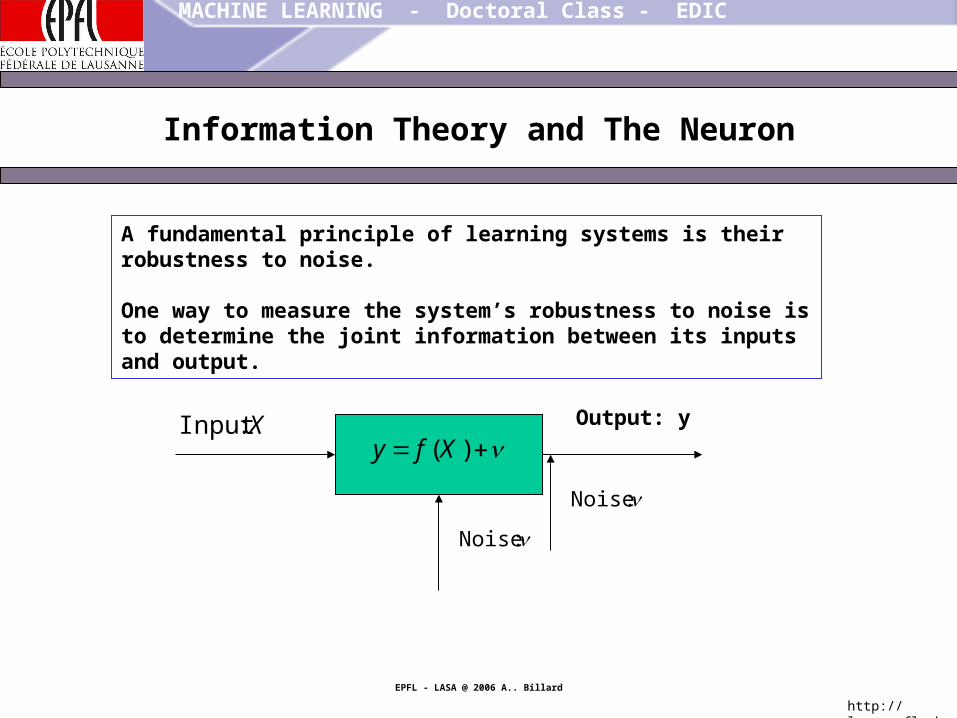
A fundamental principle of learning systems is their robustness to noise.
One way to measure the system’s robustness to noise is to determine the joint information between its inputs and output.
Output: yX
:Input)(Xfy
:Noise
),( Xfy
:Noise
)(Xfy

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Consider the neuron as a sender-receiver system, with X being the message sent and y the received message.
Information theory can give you a measure of the information conveyed by y about X.
If the transmission system is imperfect (noisy), you must find a way to ensure minimal disturbance in the transmission.
W1
W2
W3
W4
Output: y
X
iii xwfy
Information Theory and The Neuron

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
W1
W2
W3
W4
Output: y
X
2
2
log2
1,
yyxI
The mutual information between the neuron output y and itsInputs x is given by:
where is the signal-to-noise ratio.2
2
y
In order to maximize the ratio, one can increase the magnitude of the weights.
Information Theory and The Neuron

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
The mutual information between the neuron output y and itsInputs X is given by:
This time, one cannot simply increase the magnitude of the weights, as this affects the value of as well.
W1
W2
W3
W4
Output: y
X
i i ii
y w x
1
2
3
4
2y
Information Theory and The Neuron
j
iv
y
wyxI
22
2
2log
2
1,

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
x
1y
2y
1
2
j ij i ji
y w x
Information Theory and The Neuron
2
4 2 2 2 2 2 21 2 1 2 12
det( ), log
det( ) 2 1
RI x y
R

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
How to define a learning rule to optimize the mutual information?

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Hebbian Learning
OutputInput
j
iijj xwy
ijwix jy
jiij yxw
If x I and y I fire simultaneously, the weight of the connection between them will be strengthened in proportion to their strength of firing.
rate Learning :

Hebbian Learning – Limit Cycle
tCWtWdt
d
Stability? 0 0dW t W t
dt
* * such that 0i iw E w
* 0i i j j i ij jj j
E w E yx E w x x C w
: correlation matrixC
This is true for all i, thus, w_j is an eigenvector of C, with associated Eigenvalue 0
* * 0E w C w C Under a small disturbance The weights tend to grow in the direction of the largest eigenvalue of C.
C is a positive, symmetric and semi-definite matrix all eigenvalues are >=0.

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Hebbian Learning – Weight Decay
The only advantage of substractive rules over simply clipping the weights lies in that it allows to eliminates weights that have little importance.
The simple weight decay rule belong to a class of decay rule calledSubstractive Rule
Another important type of decay rules is the Multiplicative Rule
: function of the weight
ij i j ij ij
ij
w x y w w
w
The advantage of multiplicative rules is that, in addition to giving small weights, they also give useful weights.
ijjiij wyxw

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
W1
W2
W3
W4
Output: y
X
i i ii
y w x
1
2
3
4
2y
Information Theory and The Neuron
j
iv
y
iTi
iTi
i wyxI
ww
CwwwJ
22
2
2log
2
1, ~
Oja’s one neuron model 2 i i iw x y y w
The weights converge toward the first eigenvector of the input covariance matrix and are normalized.

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Hebbian Learning – Weight Decay
2
**
detlog, ~
v
iTi
nji
iTi
jTi
ij
RyxI
Iww
nyny
ww
CwwwJ
Oja’s subspace algorithm
k
kkjiijijywyyxw
Equivalent to minimizing the generalized form of J:

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Hebbian Learning – Weight Decay
Why PCA, LDA, ICA with ANN?
• Explain the way the brain could derive important properties of the sensory and motor space.
• Allows to discover new mode of computation with simple iterative and local learning rules.

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Recurrence in Neural Networks
Sofar, we have considered only feed-forward neural networks
Most biological network have recurrent connections.
This change of direction in the flow of information is interesting, as it can allow:
• To keep a memory of the activation of the neuron• To propagate the information across output neurons

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Anti-Hebbian Learning
x
1y
2y
How to maximize information transmission in a network, I.e. maximize: I(x;y)
Anti-Hebbian Learning

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Anti-Hebbian Learning
x
1y
2y
Anti-Hebbian Learning
ij i jw y y
Anti-Hebbian learning is also known as lateral inhibition
Average of values taken over all training patterns

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Anti-Hebbian Learning
ij i jw y y
If the two outputs are highly correlated, then, the weights between them will grow to a large negative value and each will tend to turn the other off.
No need for weight decay or renormalizing on anti-Hebbian weights, as they are automatically self-limiting!
0 0 jiij yyw

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Anti-Hebbian Learning
Foldiak’s first Model
1
n
i i ij jj
y x w y
for ij i jw y y i j
1y T x I W x
1
y x W y
y I W x
In Matrix Terms

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Anti-Hebbian Learning
Foldiak’s first Model
21 1fw
One can further show that there is a stable point in the weight space.

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Anti-Hebbian Learning
Foldiak’s 2ND Model
Allows all neurons to receive their own outputs with weight 1
1ii i iw y y
TW I YY
This network will converge when:1) the outputs are decorrelated 2) the expected variance of the outputs is equal to 1.

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
PCA versus ICA
PCA looks at the covariance matrix only. What if the data is not well described by the covariance matrix?
The only distribution which is uniquely specified by its covariance (with the subtracted mean) is the Gaussian distribution. Distributions which deviate from the Gaussian are poorly described by their covariances.

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
PCA versus ICA
Even with non-Gaussian data, variance maximization leads to themost faithful representation in a reconstruction error sense.
The mean-square error measure implicitly assumes Gaussianity, sinceit penalizes datapoints close to the mean less that those that arefar away.
But it does not in general lead to the most meaningful representation.
We need to perform gradient descent in some function other thanthe reconstruction error.

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Uncorrelated and Statistical Independent
IndependentUncorrelated
True for any non-linear transformation f
Statistical Independence is a stronger constraint than decorrelation.
1, 2 1 2( ) ( ) ( )E y y E y E y 1 2 1 2( ) ( ) ( )E f y f y E f y E f y

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Objective Function of ICA
We want to ensure that the outputs yi are maximally independent.
This is identical to requiring that the mutual information be small.
Or alternately that the joint entropy be large.
H(x,y)
H(x) H(y)
H(x|y) I(x,y) H(y|x)

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Anti-Hebbian Learning and ICA
Anti-Hebbian Learning can also lead to a decomposition in Statistically Independent Component, and, as such allow to do a decomposition of the type of ICA.
1 2 1 2( ) ( ) ( )E f y f y E f y E f y
To ensure independence, the network must converge to a solution that satisfies the condition:
For any given function f.

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
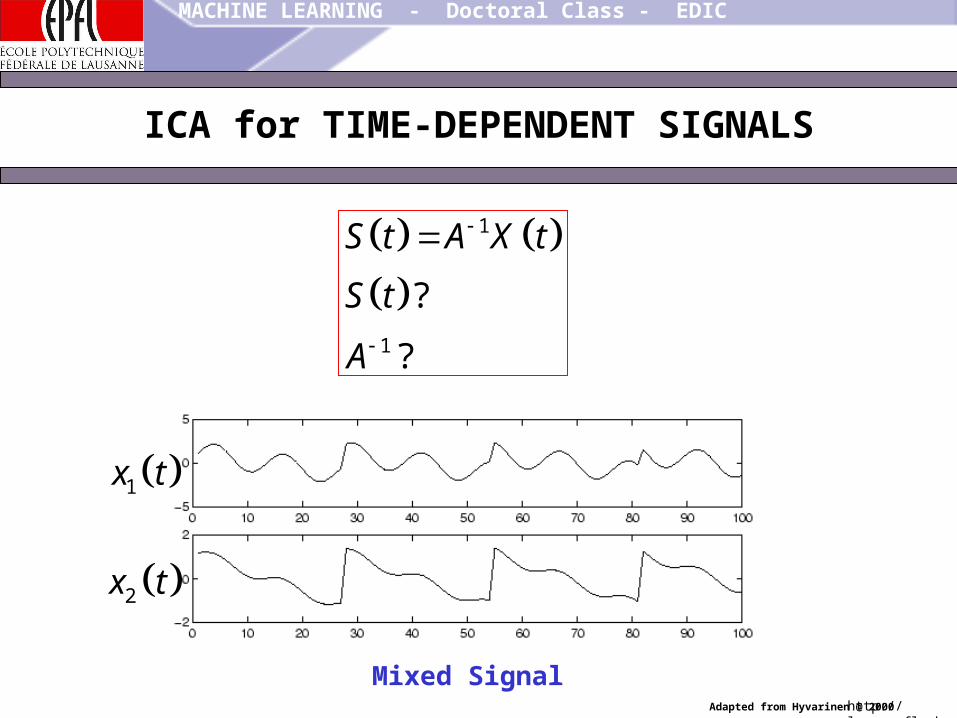
ICA for TIME-DEPENDENT SIGNALS
Original Signal
1s t
2s t
Mixed Signal
1x t
2x t
X t AS t
EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.chAdapted from Hyvarinen @ 2000
Mixed Signal
1x t
2x t
1
1
?
?
S t A X t
S t
A
ICA for TIME-DEPENDENT SIGNALS

Anti-Hebbian Learning and ICA
Jutten and Herault Model
1
n
i i ij jj
y x w y
y x Wy
Non-linear Learning Rule
for ij i jw f y g y i j
1y I W x
If f and g are the identity, we find again the Hebbian Rule, which ensures convergence to uncorrelated outputs: 1 2, 0E y y
1 2 1 2( ) ( ) ( )E f y f y E f y E f y
To ensure independence, the network must converge to a solution that satisfies the condition:
For any given function f.

Anti-Hebbian Learning and ICA
HINT: Use two odd functions for f and g (f(-x)=-f(x)), then their taylor series expansion consists solely of the odd terms
0
12
12j
j
jxaxf
0
12
12j
j
jxbxg
0
12
2
12
10
21
j
kj
kk
j
ij
yyba
ygyfw
00 12
2
12
1 kj
ijyyEw
12
2
12
1
12
2
12
1
kjkj yEyEyyE
Since most (audio) signals have an even distribution, at convergence, one has:

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
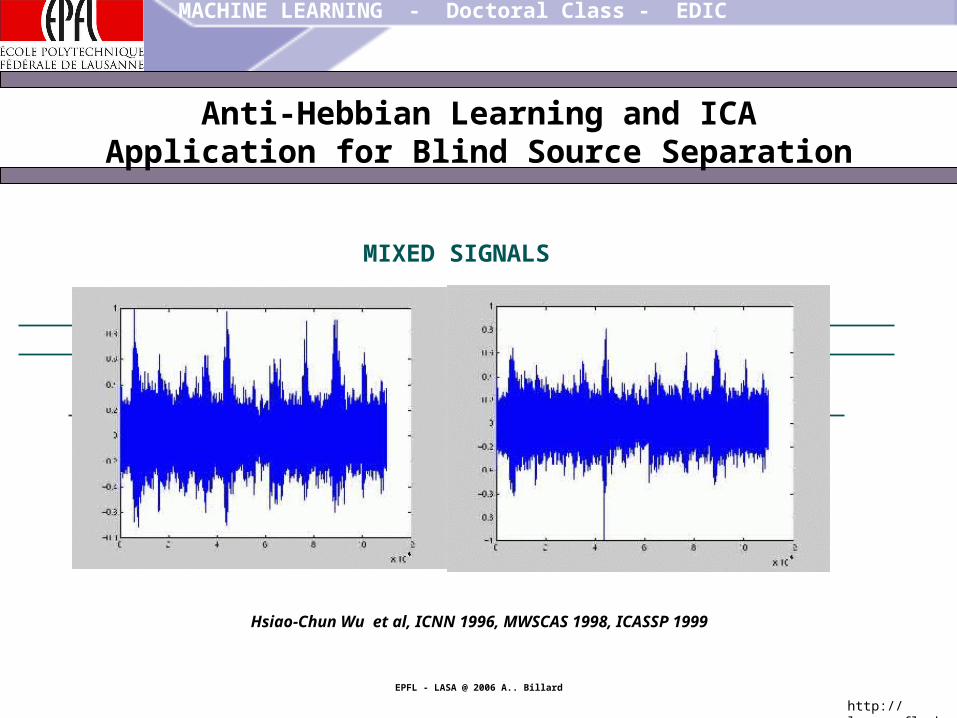
Anti-Hebbian Learning and ICAApplication for Blind Source Separation
MIXED SIGNALS
Hsiao-Chun Wu et al, ICNN 1996, MWSCAS 1998, ICASSP 1999

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Anti-Hebbian Learning and ICAApplication for Blind Source Separation
UNMIXED SIGNALS THROUGH GENERALIZED ANTI-HEBBIAN LEARNING
Hsiao-Chun Wu et al, ICNN 1996, MWSCAS 1998, ICASSP 1999
EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Anti-Hebbian Learning and ICAApplication for Blind Source Separation
MIXED SIGNALS
Hsiao-Chun Wu et al, ICNN 1996, MWSCAS 1998, ICASSP 1999

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Anti-Hebbian Learning and ICAApplication for Blind Source Separation
UNMIXED SIGNALS THROUGH GENERALIZED ANTI HEBBIAN LEARNING
Hsiao-Chun Wu et al, ICNN 1996, MWSCAS 1998, ICASSP 1999

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Information Maximization
Bell & Sejnowsky proposed a network to maximize the mutual information between the output and the input when those are not subjected to noise (or rather when the input and the noise can no longer be distinguished, then H(Y|X) tend to negative infinity).
Bell A.J. and Sejnowski T.J. 1995. An information maximisation approach to blind separation and blind deconvolution, Neural Computation, 7, 6, 1129-1159
W1
W2
W3
W4
Output: y
X
1
2
3
4 W0
01
1wWXe
y

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Information Maximization
Bell & Sejnowsky proposed a network to maximize the mutual information between the output and the input when those are not subjected to noise (or rather when the input and the noise can no longer be distinguished, then H(Y|X) tend to negative infinity).
xyHyHyxI |,
Bell A.J. and Sejnowski T.J. 1995. An information maximisation approach to blind separation and blind deconvolution, Neural Computation, 7, 6, 1129-1159
H(Y|X) is independent of the weights W and so

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Information Maximization
Bell A.J. and Sejnowski T.J. 1995. An information maximisation approach to blind separation and blind deconvolution, Neural Computation, 7, 6, 1129-1159
The entropy of a distribution is maximized when all outcomes are equally likely.
We must choose an activation function at the output neurons which equalizes each neuron’s chances of firing and so maximizes their collective entropy.
EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
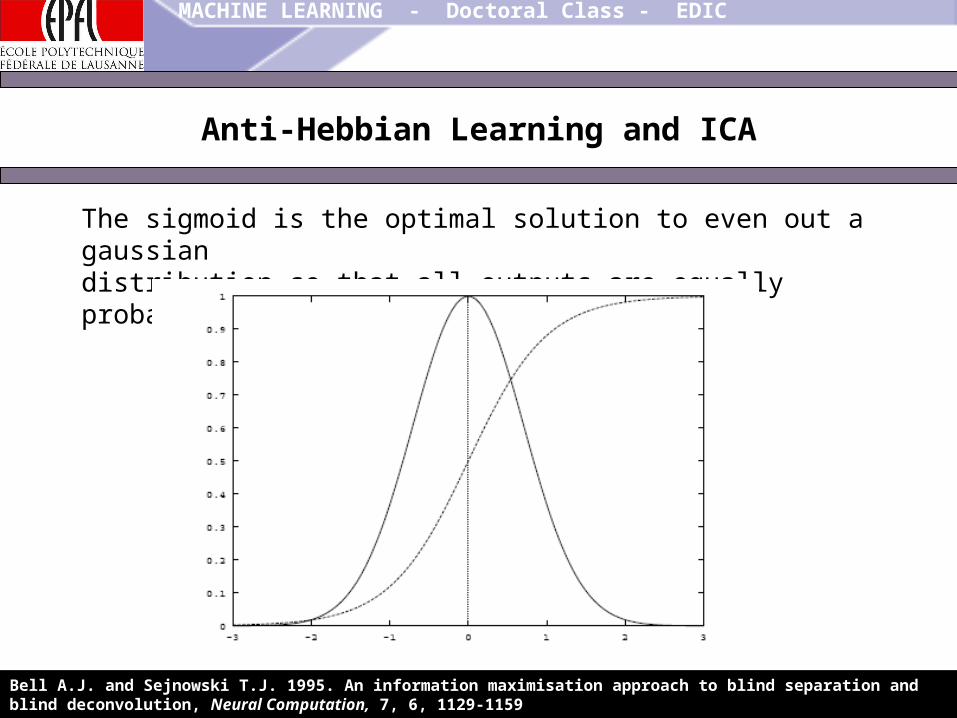
Anti-Hebbian Learning and ICA
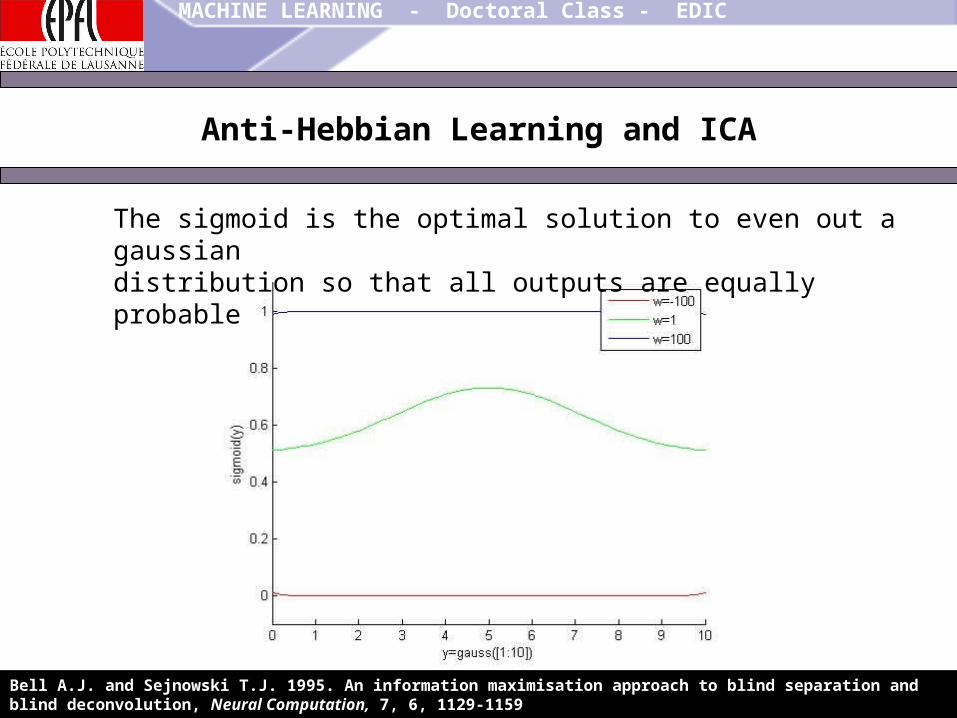
The sigmoid is the optimal solution to even out a gaussiandistribution so that all outputs are equally probable
Bell A.J. and Sejnowski T.J. 1995. An information maximisation approach to blind separation and blind deconvolution, Neural Computation, 7, 6, 1129-1159
EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Anti-Hebbian Learning and ICA
The sigmoid is the optimal solution to even out a gaussiandistribution so that all outputs are equally probable
Bell A.J. and Sejnowski T.J. 1995. An information maximisation approach to blind separation and blind deconvolution, Neural Computation, 7, 6, 1129-1159

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Anti-Hebbian Learning and ICA
The sigmoid is the optimal solution to even out a gaussiandistribution so that all outputs are equally probable
Bell A.J. and Sejnowski T.J. 1995. An information maximisation approach to blind separation and blind deconvolution, Neural Computation, 7, 6, 1129-1159
W1
W2
W3
W4
Output: y
X
1
2
3
4 W0
01
1wWXe
y

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Anti-Hebbian Learning and ICA
The pdf of the output can be written as:
Bell A.J. and Sejnowski T.J. 1995. An information maximisation approach to blind separation and blind deconvolution, Neural Computation, 7, 6, 1129-1159
The entropy of the output is then given by:
The learning rules that optimize this entropy are given by:

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Anti-Hebbian Learning and ICA
Bell A.J. and Sejnowski T.J. 1995. An information maximization approach to blind separation and blind deconvolution, Neural Computation, 7, 6, 1129-1159
Anti-weight decay(moves away from simple solution w=0)
Anti-Hebbian(avoids solution y=1)

EPFL - LASA @ 2006 A.. Billard
MACHINE LEARNING - Doctoral Class - EDIC
http://lasa.epfl.ch
Anti-Hebbian Learning and ICA
This can be generalized to a many inputs - many outputs network with sigmoid function for the output. The learning rules that optimizes the mutual information between input and output are then given by:
Bell A.J. and Sejnowski T.J. 1995. An information maximisation approach to blind separation and blind deconvolution, Neural Computation, 7, 6, 1129-1159
Such a network can linearly decompose up to 10 sources.