machine learning in biology and why it doesn't make sense - theo knijnenburg, july 2015
TRANSCRIPT

High-throughput measurement technologies have provided the field of biology with a wealth of molecular and genomic data. Machine learning approaches offer the opportunity to improve our understanding of biology and to directly impact on the quality of life, for example through disease prognosis and personalized drug therapy. In this talk, I will take a critical look at machine learning in biology. How does it differ from machine learning in other domains? What are the specific challenges and how are they addressed? I will describe our work based on The Cancer Genome Atlas (TCGA) and the Genomics of Drug Sensitivity in Cancer (GDSC) projects. Further, I will highlight the importance of interpretable models in biology. Particularly, only if computational models are intuitively understandable can experts overlay their domain knowledge and gain insight that allows them to suggest novel hypotheses and experiments. I will describe approaches that aim to bridge the gap between computational and biological complexity on the one hand and human interpretation on the other.

Machine learning in biology and why it doesn't make sense
Theo Knijnenburg Seattle DAML July meetup

Scientific background
1998-2003 MSc Electrical Engineering
2004-2008 PhD Computational Biology
2009-2010 Postdoc ISB
2011-2012 Postdoc Netherlands Cancer Institute
2013… (Senior) Research Scientist ISB

The Institute for Systems Biology
WE ARE NOT AN ACADEMIC
INSTITUTION
However we do have a deep
and integrated interest in
education both within and
outside of our institution.
WE ARE NOT A BIOTECH
COMPANY
However we do value
impacting society and making
a difference through our
research.
WE ARE A NON-PROFIT SCIENTIFIC
RESEARCH ORGANIZATION
We exist to make profound
breakthroughs in human health and
the environment, leveraging the
revolutionary potential of systems
biology.

The Institute for Systems Biology
An integrative approach towards biology
• Study a biological system as a whole, not just the individual components
• Acknowledge that information exists a multiple scales – Time, space, function
• Bring people from different disciplines together
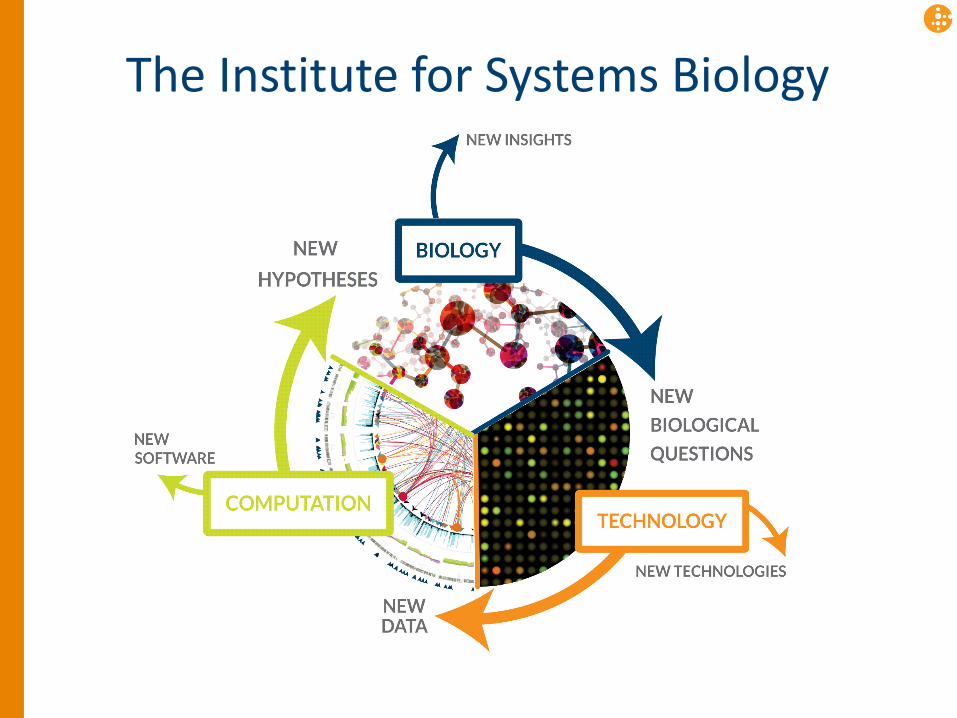
The Institute for Systems Biology
The Institute for Systems Biology

Overview
• Machine learning in high-throughput biology
• Interpretation of supervised machine learning models
• An application: Drug response in cancer modeled as a combination of mutations

Machine learning in high-throughput biology
High-throughput: The use measurement techniques that allow us to rapidly obtain genome-wide molecular and genomic data. For example: - DNA sequence (~3 billion base pairs) - Gene expression (~20,000 genes)

Machine learning in high-throughput biology
• n<<p
• Current challenges in data generation are reflected in the quality of the data
• Lack of formalized knowledge
• Time series data (not so much)

n<<p n: objects/samples/data points/cases
p: observations/predictors/features/attributes
• n is small, because life is expensive • p is big, because life is complex • Consequences
– Proper test or validation sets are often not used – Feature selection/reduction are necessary – Statistical assumptions are often violated – Many specific techniques or modifications have
been proposed
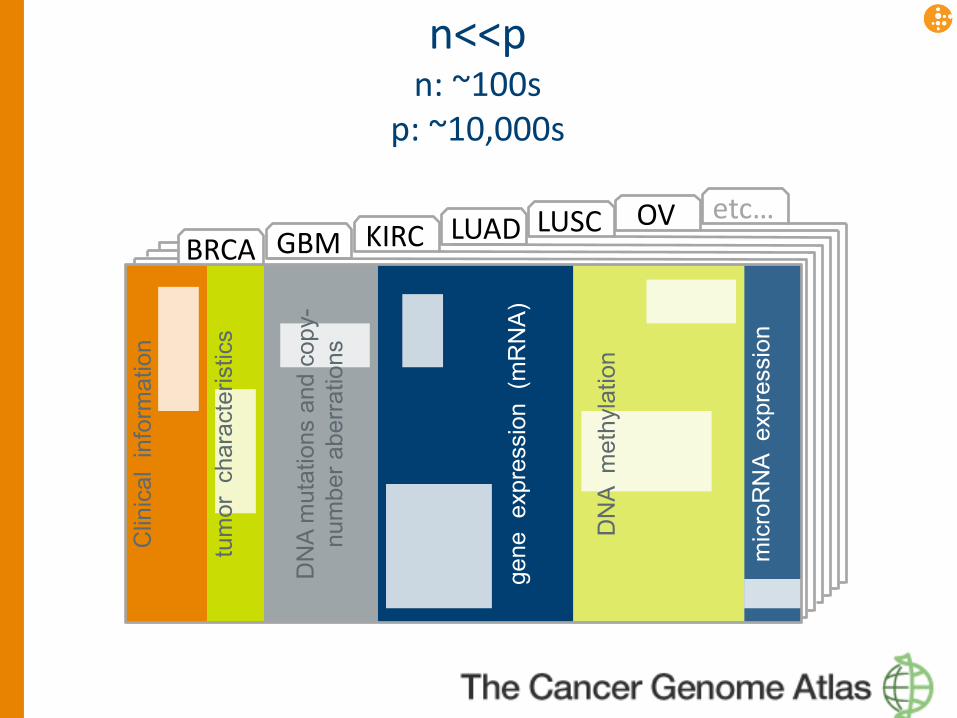
n<<p n: ~100s
p: ~10,000s
Clin
ical
inf
orm
atio
n
tum
or c
hara
cter
istic
s
mic
roR
NA
exp
ress
ion
gene
exp
ress
ion
(mR
NA
)
DN
A m
ethy
latio
n
DN
A m
utat
ions
and
cop
y-nu
mbe
r abe
rrat
ions
BRCA GBM KIRC LUAD LUSC OV etc…

Current challenges in data generation are reflected in the quality of the data
• Technology side – Immature measurement technologies – Batch (or lab) effects
• Biology side – Context specificity of measurements – Many known/unknown covariates affect the data
• Human side – People that do study design are often unaware of power
calculations or statistics in general – Many manual steps involved – Difficulty in digitalizing information and metadata

Lack of formalized knowledge
• We are not really sure what we are measuring as we did not design the system
• Available knowledge is not formalized

Time series data (not so much)
• Measurements are expensive and often not automated
• Exceptions: time lapse MRIs, ECGs
• High-throughput time series data are coming

Quantified self Muse – the brain sensing headband
The guy that bought the headband trying to meditate
Experienced meditator

Interpretation of supervised machine learning models

Application of supervised machine learning
1. Prediction
The value or class of a (new or unseen) case can be predicted.
2. Interpretation
The inferred models inform us about the relationship between the input and the output. They specify how the input variables are (mathematically) interacting with each other to produce the output variable.

A Card Puzzle
A D 4 7 If a card has a vowel on one side, then it has an even number on the other side. Which of the cards would one need to turn over to see if the claim is true or false?

A Card Puzzle
BEER SODA 25 17
If a person is drinking beer, then they are over 21 years of age. Which of the cards would one need to turn over to see if the claim is true or false?

Interpretation
– Variables should make intuitive sense
– Number of variables is small
– Mathematical relation between variables
should be easy to understand

Why interpretable models?
– Allows to add domain knowledge
• A limited amount of knowledge is and can be formalized
– Generate hypotheses and define experiments • Understandable models are actionable models

Machine learning in biology doesn’t make sense, because the inferred models often don’t make sense to the domain experts.

How to generate interpretable models?
– Visualization
• Raw, transformed, reduced, summarized data • Inferred models and associations between features or samples
– Learn complex models
• Postprocessing: interpretation step
– Learn simple small models • Directly interpretable

Drug response in cancer modeled as a combination of
mutations

Background - Cancer

Background - Cancer
Background - Cancer Treatment modes • Surgery
• Radiotherapy
• Chemotherapy

Background - Cancer
Bacterial cell Human cell Cancer cell
ANTI BIOTICS
ANTI CANCER DRUGS

Cell lines, mouse models and patients
Realism, Relevance
Throughput, Controlled environment

Genomics of Drug Sensitivity in Cancer (GDSC) cancer cell line panel
1047 cancer cell lines

Genomics of Drug Sensitivity in Cancer (GDSC) cancer cell line panel
1047 cancer cell lines
532 drugs
Drug response IC50s

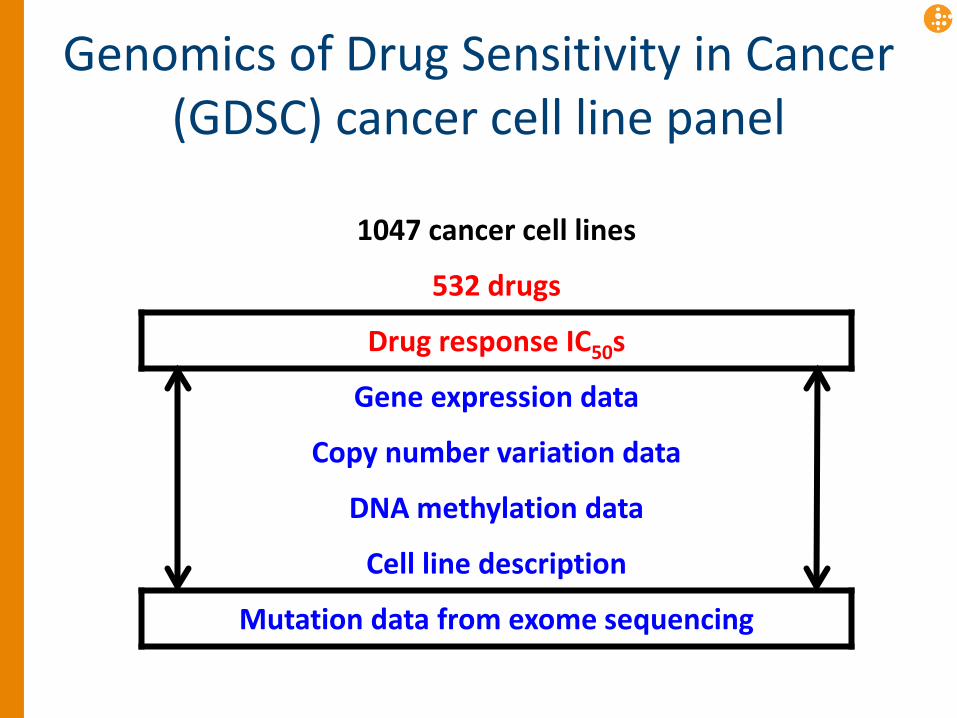
Genomics of Drug Sensitivity in Cancer (GDSC) cancer cell line panel
1047 cancer cell lines
532 drugs
Drug response IC50s
Gene expression data
Copy number variation data
DNA methylation data
Cell line description
Mutation data from exome sequencing
Genomics of Drug Sensitivity in Cancer (GDSC) cancer cell line panel
1047 cancer cell lines
532 drugs
Drug response IC50s
Gene expression data
Copy number variation data
DNA methylation data
Cell line description
Mutation data from exome sequencing
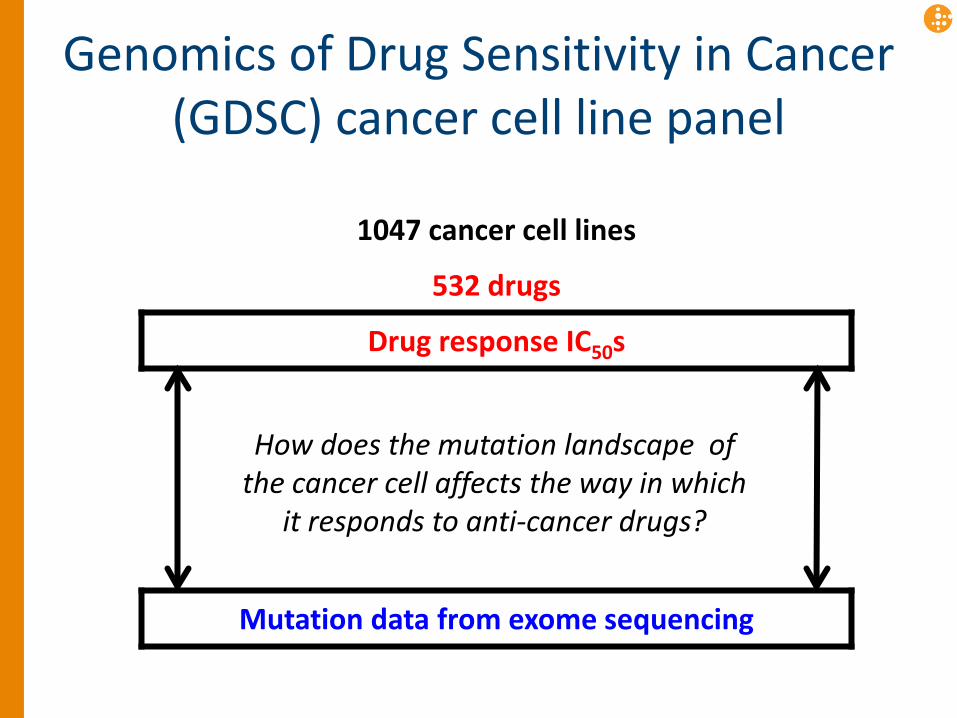
Genomics of Drug Sensitivity in Cancer (GDSC) cancer cell line panel
1047 cancer cell lines
532 drugs
Drug response IC50s
Gene expression data
Copy number variation data
DNA methylation data
Cell line description
Mutation data from exome sequencing
How does the mutation landscape of the cancer cell affects the way in which
it responds to anti-cancer drugs?

Goal - Actionable models
• Models with a small number of variables that make intuitive sense
• Explain drug response as a logic function of mutations
| Sensitivity to AZ628
BRAF KRAS
BCR_ABL
“OR”
& Sensitivity to Metformin
RB1
~PTEN
“AND”
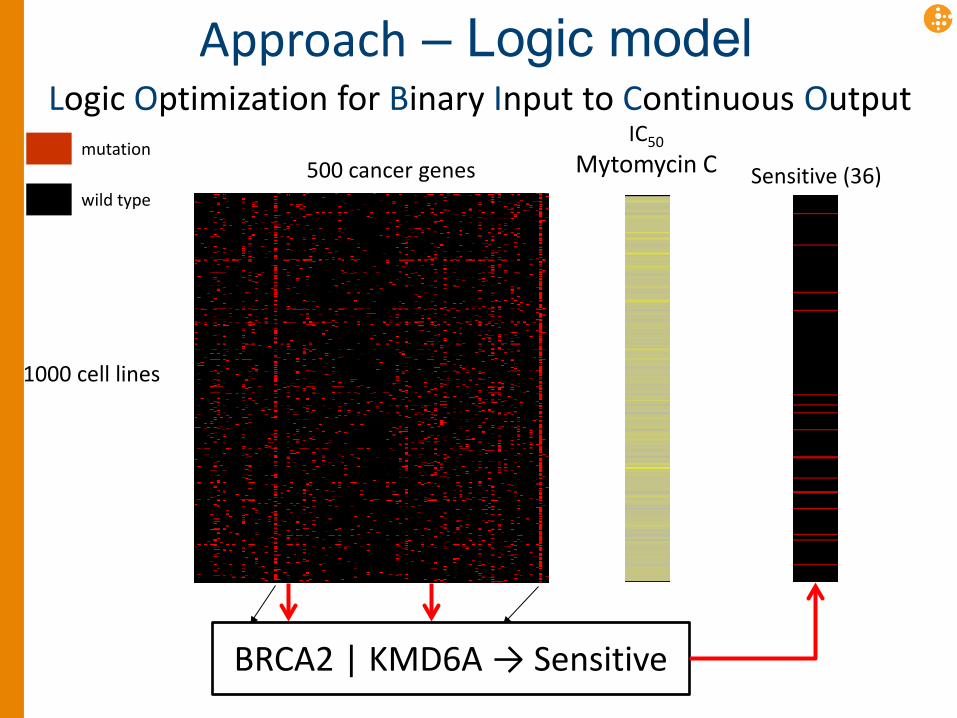
1000 cell lines
500 cancer genes IC50
Mytomycin C mutation
wild type Sensitive (36)
P53 CDKN2A BRCA2 | KMD6A → Sensitive
Approach – Logic model Logic Optimization for Binary Input to Continuous Output

-4 -2 0 2 4 6 8-10
0
10
20
30
40
50
60
70
IC50
Coun
tPLX4720
-4 -2 0 2 4 6 8-10
0
10
20
30
40
50
60
70
IC50
Coun
tPLX4720
Sensitive Resistant
Large error
Small error
BRAF inhibitor PLX4720
Log IC50 (uM)
Approach

1. Output small logic models that are understandable by domain experts (= actionable), while retaining continuous phenotype information • Generate hypotheses • Define experiments • Find biomarkers
2. Find the optimal solution fast by ILP formulation solved
using dedicated and advanced software (CPLEX)
3. Find solutions with predefined constraints on statistical performance criteria, which facilitates clinical application
Contributions

NKI Netherlands
Cancer Institute
TU Delft Delft University of
Technology
Sanger Cancer Genome
Project - Wellcome Trust Sanger Institute
EBI European
Bioinformatics Institute
ISB Institute for
Systems Biology
Lodewyk Wessels Bob Duin Graham Bignell Francesco Iorio Dick Kreisberg
Julian de Ruiter Jeroen de Ridder Howard Lightfoot Michael Menden Vesteinn Thorsson
Mathew Garnett Julio Saez-Rodriguez Sheila Reynolds
Ultan McDermott Brady Bernard
Ilya Shmulevich
Nitin Baliga
Gustavo Glusman
Acknowledgements

Btw: Machine learning in biology does make sense, because the challenges are fundamentally interesting and relevant.