making full use of chinese speech corpora thomas fang zheng center of speech technology state key...
Post on 22-Dec-2015
222 views
TRANSCRIPT

Making Full Use of Chinese Speech
CorporaThomas Fang Zheng
Center of Speech TechnologyState Key Laboratory of Intelligent Technology and Systems
Tsinghua Universityhttp://sp.cs.tsinghua.edu.cn/
Beijing d-Ear Technologies Co., Ltd.http://www.d-Ear.com
Oct. 2, 2003
O-COCOSDA, Oct. 1-3, 2003
Sentosa, Singapore

Your Partner in the Century of Speech
2
Outline
Purpose of speech corpora
Factors to be considered in data creation
Data creation
Data transcription
Learning from corpora
Chinese Corpus Consortium (CCC)

Your Partner in the Century of Speech
3
Purpose of Speech Corpora
Item Description Percentage
1. Speech/ speaker recognition
system development, evaluation, sentence comprehension and summarization, speech recognition, speaker recognition
73%
2. Speech synthesis
system development, prosodic analysis 11%
3. Acoustic analysis
acoustic analysis, speech coding 9%
4. Sentence analysis
syntactic and semantic analysis 5%
5. Speech/ language education
speech and language education 2%

Your Partner in the Century of Speech
4
Outline
Purpose of speech corpora
Factors to be considered in data creation
Data creation
Data transcription
Learning from corpora
Chinese Corpus Consortium (CCC)

Your Partner in the Century of Speech
5
Factors to be considered in data creation (1)
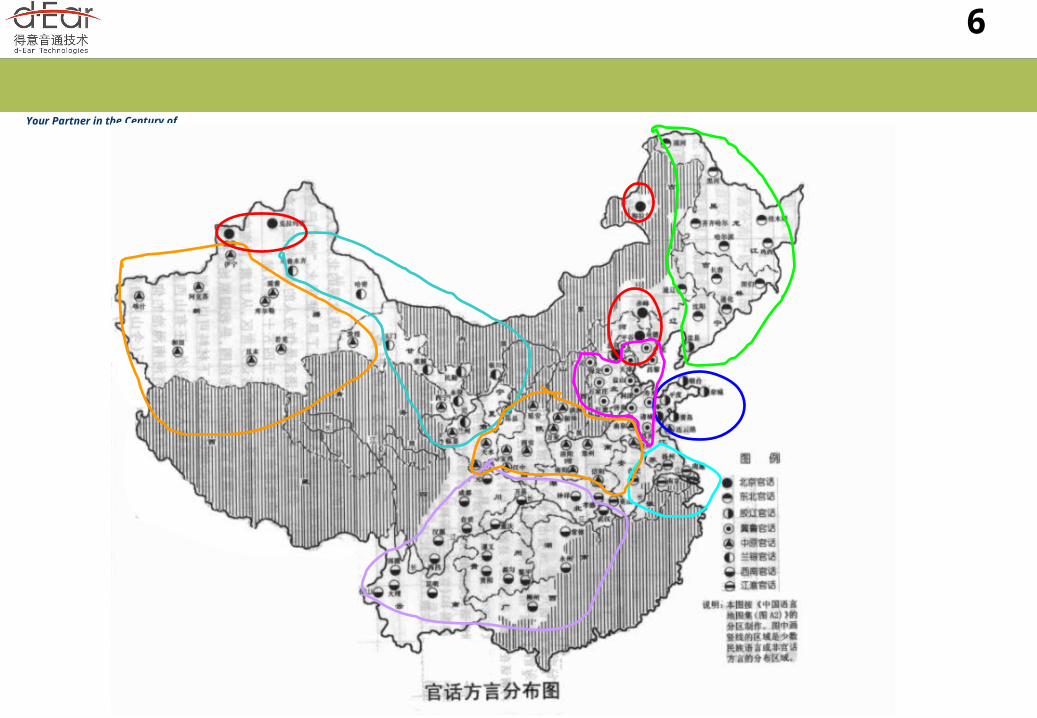
The language. Language: e.g., Chinese or English Dialectal background (e.g., for Chinese) :-
Putonghua or standard Chinese ( 普通话 ); Mandarin ( 官话, Northern China); Wu ( 吴语, Southern Jiangsu, Zhejiang, and Shanghai); Yue ( 粤语, Guangdong, Hong Kong, Nanning Guangxi); Min ( 闽南话, Fujian, Shantou Guangdong, Haikou Hainan, Taipei
Taiwan); Hakka ( 客家话, Meixian Guangdong, Hsin-Chu Taiwan); Xiang ( 湘, Hunan); Gan ( 赣, Jiangxi); Hui ( 徽, Anhui); and Jin ( 晋, Shanxi).
Special for Chinese :- Simplified Chinese Traditional Chinese
Your Partner in the Century of Speech
6

Your Partner in the Century of Speech
7
太湖片
台州片
瓯江片
?
处衢片
苏沪嘉小片江淮官话
徽语
宣州片杭州小片
林绍小片

Your Partner in the Century of Speech
8
Factors to be considered in data creation (2)
Speaking style :- Read: for ASR in earlier research, or for TTS Spontaneous/conversational: for ASR nowadays
Recording channel Depending on goal of task or application, or the
application environment Close-talk microphones: for personal computers (PCs) Telephone, and/or cellular phone: for telephony applications Specific channel: for embedded applications (PDA, digital
recorder, ...), or broadcast news, TV news. Normally mono channel instead of stereo channel. However, microphone array may be used for some
research purpose

Your Partner in the Century of Speech
9
Factors to be considered in data creation (3)
Sampling rate :- 8 kHz: for the telephone/mobile-phone channel where the
bandwidth is about 3.4 kHz 16 kHz: for the close-talk microphone PC channel though the
bandwidth is higher than 8 kHz. Sampling precision :-
16 bits, normally. 8-bit A-law or Miu-law (13-bit wide after decompression).
Signal-to-Noise Ratio (SNR) level: Was/is often collected in a good environment (clean speech
database). For noise-related research, noisy data obtained via :-
Noises (NOISEX 92) mixed with clean speech; Collected in real-world noisy environments.

Your Partner in the Century of Speech
10
Factors to be considered in data creation (4)
Number of speakers and Speaker balance: The more, the better: with a good speaker diversity,
according to :- Gender; Age; Education; Birthplace (or dialectal background); Occupation; and so on.
Corpus size: Measured by either the number of speakers or the
length of valid speech in hour, or both.

Your Partner in the Century of Speech
11
Outline
Purpose of speech corpora
Factors to be considered in data creation
Data creation
Data transcription
Learning from corpora
Chinese Corpus Consortium (CCC)

Your Partner in the Century of Speech
12
Data Creation
Purposes for ASR corpus :- Acoustic training - Training Set Speech recognition evaluation (testing) - Testing Set
Categories of ASR corpus :- Read speech; Spontaneous/conversational speech.
Design of a speech database before creation :- Aspects as mentioned above:
language, speaking style, recording channel, sampling rate and precision, and corpus size: according to the application/task background;
SNR levels, number of speakers and the speaker balance: for diversity consideration.
Speaking content balance - for content diversity consideration, to provide a good training set,
For read speech, the balance could be on a basis of– phone, di-phone, tri-phone, and so on;– IF, di-IF, tri-IF, syllable, di-syllable, tri-syllable for Chinese
For spontaneous speech, topics design.

Your Partner in the Century of Speech
13
Data Creation – Read Speech (1)
Though spontaneous ASR is becoming one of the research focuses, the read speech database collection is still necessary.
A high quality read speech corpus is helpful to train a good initial acoustic model, and then
In spontaneous ASR, pronunciation modelling techniques as well as pronunciation lexicons are adopted to get a practically good acoustic model finally.

Your Partner in the Century of Speech
14
Data Creation – Read Speech (2)
Goal of read speech corpus design is often to balance the speech recognition units (modelling units), so as to cover as many co-articulations as possible using a set of sentences as small as possible.
Such a minimal sentence set can be used for not only the training of acoustic models but also the speaker adaptation.

Your Partner in the Century of Speech
15
Data Creation – Read Speech (3)
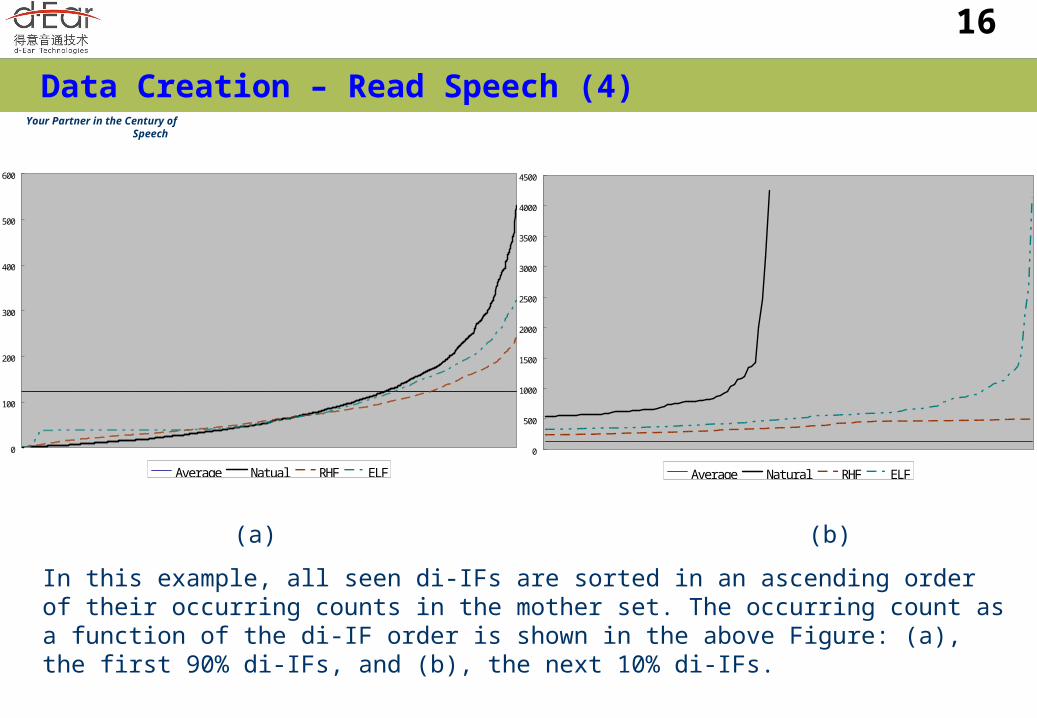
Sentence design example. Goal is to choose 6,000 sentences (about 0.75%)
from 800,000 sentences taken from the People's Daily with a balanced di-IF distribution.
Several criteria: Natural selection - randomly. Almost natural di-IF
distribution. Restraining high-frequency di-IFs (RHF). To restrain
those high-frequency di-IFs from occurring more frequently so that each di-IF occurs almost equally to well train the acoustic model.
Encouraging low-frequency di-IFs (ELF). As an alternative, to encourage those low-frequency di-IFs as frequently as possible. # of occurring times of any di-IF should be greater than a doable pre-defined threshold.
Your Partner in the Century of Speech
16
Data Creation – Read Speech (4)
0
100
200
300
400
500
600
Average Natual RHF ELF
0
500
1000
1500
2000
2500
3000
3500
4000
4500
Average Natural RHF ELF
(a) (b)
In this example, all seen di-IFs are sorted in an ascending order of their occurring counts in the mother set. The occurring count as a function of the di-IF order is shown in the above Figure: (a), the first 90% di-IFs, and (b), the next 10% di-IFs.

Your Partner in the Century of Speech
17
Data Creation – Read Speech (5)
RHF: helpful to make distribution as close to the average curve as
possible It cannot guarantee a minimal occurring count for those less
frequently seen di-IFs. ELF:
Guarantee a minimal occurring count so that data is enough to train the models for those less frequently seen units
Will lead to relatively big occurring counts for those most frequently seen di-IFs though the distribution is close to natural.
It is expected that a good result can be achieved by combining both the RHF and the ELF strategies.

Your Partner in the Century of Speech
18
Data Creation – Read Speech (6)
Quality control is very important, for read speech database, there could be three steps: Self-check Cross-check Final-review

Your Partner in the Century of Speech
19Data Creation – Spontaneous/Conversational Speech (1)
In spontaneous (casual) speech or conversational (dialogue) speech
More spontaneous speech phenomena (phonetically and acoustically)
Richer spoken language phenomena (linguistically)
Man-Man dialogue different from Man-Machine dialogue

Your Partner in the Century of Speech
20Data Creation – Spontaneous/Conversational Speech (2)
Three kinds of scenarios should be considered Spontaneous (Casual):
Giving speech or talking about something Man-Machine conversation:
Leaving a voice message: leaving a voice message is not a true conversation mode, but it is important in telephony speech.
Man-Machine dialogue: given a simulated service provider, the speaker can inquire about whatever he/she wants in the following domains:
– Hotel/ticket reservations– Telephone number inquiries– Stock prices inquiries– Weather inquiries– City route map inquiries– Telephone-based shopping/ordering– ...
Your Partner in the Century of Speech
21Data Creation – Spontaneous/Conversational Speech (3)
Three kinds of scenarios should be considered Spontaneous (Casual): Man-Machine conversation: Man-Man conversation:
Inquiring: given a service provider, the speaker can inquire about whatever he/she wants [recording "by stealth", legal issue very important]
Chatting: chatting could be happening between two recruited speakers given a topic (example topics in the following table)

Your Partner in the Century of Speech
22Data Creation – Spontaneous/Conversational Speech (4)
Topic Sub-topics Topic Sub-Topics
Sports
generalbasketballfootballthe game of gotable tennistennisOlympic games...
Lifestyle
familywork and studyeducationtraffictelecommunicationgoing abroaddrinking and smokinghabits and customslanguage and dialectsfriendship and loveshopping for and buying houses...
Politics&
Economy
generalinternational relationsterrorismeconomic globalization...
Entertainment
generalfilm reviewmovie and teleplaystarsChinese Spring Festival get-togetherscomic dialoguetravel and tourism...
Technologies
computernetworkingcompanycloning...
Your Partner in the Century of Speech
23
Data Creation - Recording
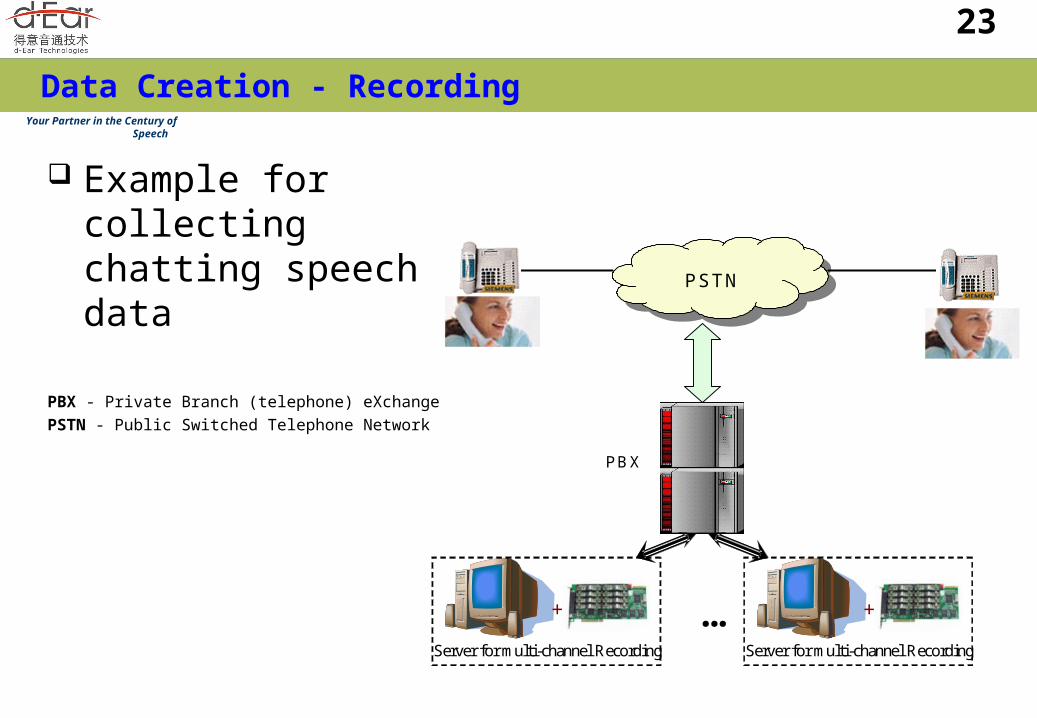
Example for collecting chatting speech data
PBX - Private Branch (telephone) eXchangePSTN - Public Switched Telephone Network
PSTN
PBX
Server for multi-channel Recording
+ ... Server for multi-channel Recording
+

Your Partner in the Century of Speech
24
Outline
Purpose of speech corpora
Factors to be considered in data creation
Data creation
Data transcription
Learning from corpora
Chinese Corpus Consortium (CCC)

Your Partner in the Century of Speech
25
Data Transcription – Symbol (1)
Two major groups of information in need of transcription phonetic information
base form - giving canonical pronunciation; surface form - giving the observed (actual) pronunciation.
linguistic information Symbol Set
International Phonetic Alphabet (IPA) - can be used to accurately represent the actual pronunciation of the utterance, but not machine readable;
Speech Assessment Methods Phonetic Alphabet (SAMPA) – machine readable;
For Chinese, machine-readable IPA symbols adapted for Chinese languages from SAMPA, and named as SAMPA-C.
In SAMPA-C, there are :- 23 phonologic consonants, 9 phonologic vowels, and 10 kinds of sound change marks.

Your Partner in the Century of Speech
26Data Transcription - Symbol (2) - Chinese C/V in SAMPA-C
Consonants Vowels
Pinyin [IPA] SAMPA-C Pinyin [IPA] SAMPA-C Pinyin [IPA] SAMPA-C
b [p] p z [ts] ts a [ ] A
p [pH] p_h c [tsH] ts_h o [o] o
m [m] m s [s] s e [ ] 7
f [f] f zh [t©] ts` i [i] i
d [t] t ch [t©H] ts_h` u [u] u
t [tH] t_h sh [©] s` ü [y] y
n [n] n r [¸] z` ii [¡] i\
(a)n [n] _n j [t»] ts\ iii [Ÿ] i`
l [l] l q [t»H] ts\_h er [Ä] @`
g [k] k x [»]
k [kH] k_h ? ?
h [x] X
ng [Ð] N
§
°

Your Partner in the Century of Speech
27Data Transcription - Symbol (3) - Phonological Vowels in SAMPA-C
PhonemeAllophone
(IPA)SAMPA-C
PhonemeAllophone
(IPA)SAMPA-CPinyin IPA Pinyin IPA
a A a a i I I i
A a_" I I
A J j
Q E ï Ÿ i`
P { ¡ i\
o o O o u u U U
U U u u
U u W w
È @ Ʋ v\
e 7 ü Y Y y
e e á H
E E_r er Ä Ä @`
È @
° °
§ ï

Your Partner in the Century of Speech
28
Data Transcription - Symbol (4) - Sound Changes in SAMPA-C
Classifications SAMPA-CExamples
IPA SAMPA-C Explanation
鼻 化 Nasalized ~ a‹ A~ 'a' is nasalized
央 化 Centralized _" Eƒ e_" 'e' is centeralized
清 化 Voiceless _u n% n_u 'n' is voiceless
浊 化 Voiced _v dŒ d_v 'd' is voiced
圆唇化 More Rounded _O f_O 'f' is more rounded
成音节 Syllabic = M= 'M' is syllabic
喉 化 Pharyngealized _?\ t/ A_?\ 'A' is pharyngealized
送 气 Aspirated/Breathy _h a! a_h 'a' is more breathy
增 音 Inserted (+) (+N) 'N' is inserted
减 音 Deleted (-) (i-) 'i' is deleted.
1m
wf

Your Partner in the Century of Speech
29
Data Transcription – Transcription Layer (1)
Should cover :- the base form and the surface form, as well as some linguistic and non-linguistic information.

Your Partner in the Century of Speech
30
Data Transcription – Transcription Layer (2)
Transcription Layers include :- Chinese character layer: sentences in Chinese
character (without word boundary information), or in Chinese word (with word boundary information). The Chinese character could be either traditional or simplified.
Non-Chinese words should also be labeled, for example, they can be enclosed in {}.
Additionally, paralinguistic and non-linguistic phenomena could also be transcribed (See Table 7 for more details).
Here is an example.– {hi} 你怎么也 LA< 也来了 LA> (w/o word boundary info)or– {hi} 你 / 怎么 / 也 / LA< 也 / 来 / 了 LA> (w word boundary info)

Your Partner in the Century of Speech
31
Data Transcription – Transcription Layer (3)
Transcription Layers include :- Chinese character layer Canonical Chinese Pinyin layer: pronunciation is
given in canonical Chinese Pinyin (or Chinese syllable). Alternatively in Chinese IF. The Pinyin (or Final) here can be either toned or toneless. Similarly, non-Chinese words, paralinguistic phenomena and
non-linguistic phenomena could also be transcribed. The example is as follows:
– {hi} ni3 zen3 me0 ye2 LA< ye2 lai2 la0 LA> (toned Pinyins)or– {hi} n i3 z en3 m e0 ie2 LA< ie2 l ai2 l a0 LA> (toned IFs)

Your Partner in the Century of Speech
32
Data Transcription – Transcription Layer (4)
Transcription Layers include :- Chinese character layer Canonical Chinese Pinyin layer Surface form Chinese IF layer: pronunciation in Chinese IF
roughly. To be more accurate, a super set of the canonical Chinese IF set should be defined, for example the generalized IF (GIF) set. For Chinese, the tones are often changed in spoken language,
known as tone-sandhi. There are some rules for tone-sandhi.– For example, 33 => 23
Depending on tone of following character, tone for character " 一 /yi1/", " 七 /qi1/", " 八 /ba1/", or " 不 /bu4/" will also change, which is different from the ordinary tone change (quasi-canonical tone).– For example " 一个 /yi2 ge4/".
To reflect such tone-sandhi rules, following the Pinyin of such a character is a two-digit tone string where the first digit is the original canonical tone while the second the tone-sandhi.– For example, " 一个 /yi12 ge4/".

Your Partner in the Century of Speech
33
Data Transcription – Transcription Layer (5)
Transcription Layers include :- Chinese character layer Canonical Chinese Pinyin layer Surface form Chinese IF layer Surface form SAMPA-C layer: Alternatively, the
SAMPA-C symbols can be used to provide more accurate surface form transcription (the observed tone is mostly attached to the SAMPA-C sequence of each Final).

Your Partner in the Century of Speech
34
Data Transcription – Transcription Layer (6)
An example on how to transcribe in the Semi-Syllable layer for Wu-Dialect Chinese corpus
The Surface Form Semi-Syllable Tier. The initials and finals are in either the Putonghua IF set or in the Wu Dialect IF set. The observed tone is attached to the Final. Special symbols are:
Prefix “+”: an insertion of the following IF; Prefix “-”: an deletion of the following IF; Prefix “#”: indicating a change of the following IF caused by Wu dialect; Prefix “*”: indicating a change of the following IF caused by
mispronunciation (mistake); Postfix “_v”: indicating a voiced consonant due to the co-articulation,
which is different from Wu Dialect specific voiced consonants. Retroflexed “_r”: indicating the tongue with retroflexed gesture,
which is transcribed as “hua_r1”. Paralinguistic phenomena and non-linguistic phenomena. Tone-sandhi.

Your Partner in the Century of Speech
35
Data Transcription – Transcription Layer (7)
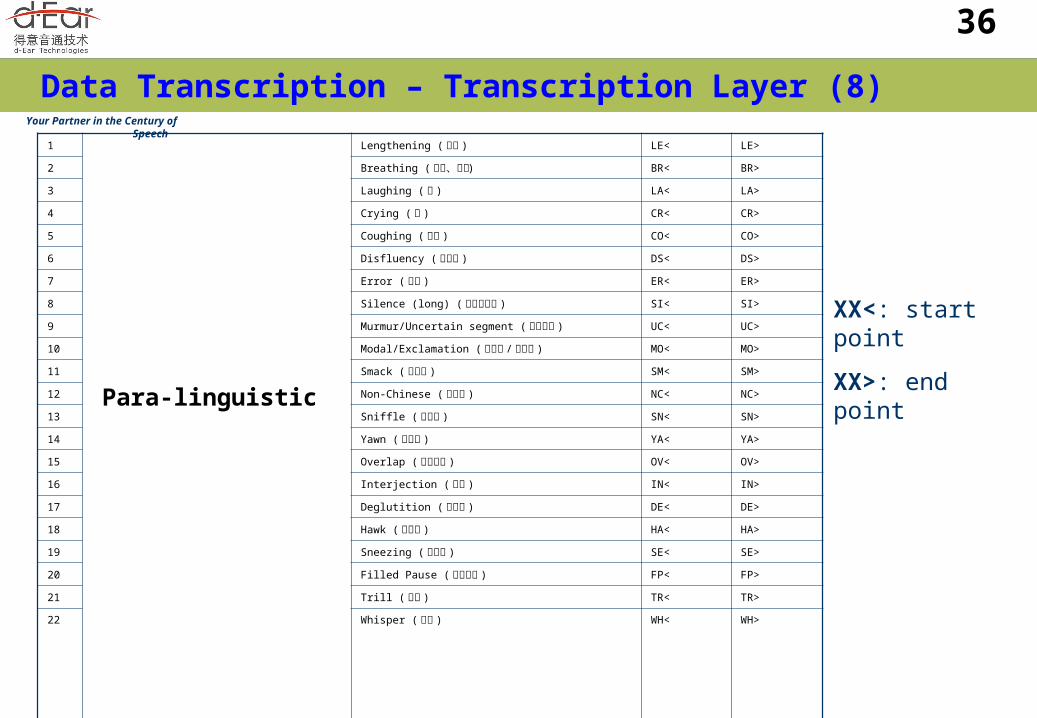
Transcription Layers include :- Chinese character layer Canonical Chinese Pinyin layer Surface form Chinese IF layer Surface form SAMPA-C layer Miscellaneous layer :-
Non-speech information is provided in this layer. Those spontaneous phonetic phenomena and spoken
language phenomena (paralinguistic or non-linguistic) are also given in this layer.
Your Partner in the Century of Speech
36
Data Transcription – Transcription Layer (8)
1
Para-linguistic
Lengthening ( 拉长 ) LE< LE>
2 Breathing ( 吸气、喘气 ) BR< BR>
3 Laughing ( 笑 ) LA< LA>
4 Crying ( 哭 ) CR< CR>
5 Coughing ( 咳嗽 ) CO< CO>
6 Disfluency ( 不联贯 ) DS< DS>
7 Error ( 口误 ) ER< ER>
8 Silence (long) ( 长时间静音 ) SI< SI>
9 Murmur/Uncertain segment ( 不清发音 ) UC< UC>
10 Modal/Exclamation ( 语其次 / 感叹词 ) MO< MO>
11 Smack ( 咂嘴音 ) SM< SM>
12 Non-Chinese ( 非汉语 ) NC< NC>
13 Sniffle ( 吸鼻子 ) SN< SN>
14 Yawn ( 打哈欠 ) YA< YA>
15 Overlap ( 重叠发音 ) OV< OV>
16 Interjection ( 插话 ) IN< IN>
17 Deglutition ( 吞咽音 ) DE< DE>
18 Hawk ( 清嗓子 ) HA< HA>
19 Sneezing ( 打喷嚏 ) SE< SE>
20 Filled Pause ( 填充停顿 ) FP< FP>
21 Trill ( 颤音 ) TR< TR>
22 Whisper ( 耳语 ) WH< WH>
23
Non-linguistics Noise ( 噪音 ) NS< NS>
24 Steady Noise ( 平稳噪音 ) TN< TN>
25 Beep ( 电话忙音 ) BP< BP>
XX<: start point
XX>: end point

Your Partner in the Century of Speech
37
Data Transcription – Transcription Tools (1)
Tool NameItem Praat SFS X-Waves+
URL http://www.fon.hum.uva.nl/praat/
http://www.phon.ucl.ac.uk/resource/sfs/
Platform PC, Mac, WS PC PC, WS
OS Win, MacOS, Unix, Linux Win, Unix, Linux Unix, Linux (X-win)
Price Free Free
Supported file formats
WAV, RIFF, AU, Binary raw, ASCII, etc
WAV, AU, AIFF, ILS, HTK, etc
AU, Binary Raw, ASCII, etc
Analysis Pitch track, Epoch, Pitch modification, Spectrum, Formant, LPC, PSOLA LPC, Wavelet, Cepstrum, Excitation, Cochlea-gram, Vocal track analysis, ...
Re-sampling and speed/pitch changing, Fundamental frequency estimation (from SP or from LX), Spectrographic analysis, Formant frequency estimation & formant synthesis, ...
Pitch track, Epoch, Pitch modification, Spectrum, Format, LPC, etc
Labelling layers Multiple Single Multiple

Your Partner in the Century of Speech
38
Data Transcription – Transcription Tools (2)

Your Partner in the Century of Speech
39
Outline
Purpose of speech corpora
Factors to be considered in data creation
Data creation
Data transcription
Learning from corpora
Chinese Corpus Consortium (CCC)

Your Partner in the Century of Speech
40
Learning from Corpora
Databases exist not only for acoustic model training and system assessment.
Knowledge can be learned from the speech corpus, especially for the spontaneous speech corpus. What can be learned from the corpus includes the
phonetic knowledge that can be used to improve the acoustic model, and
The linguistic knowledge that can be used for the natural language processing and understanding.

Your Partner in the Century of Speech
41
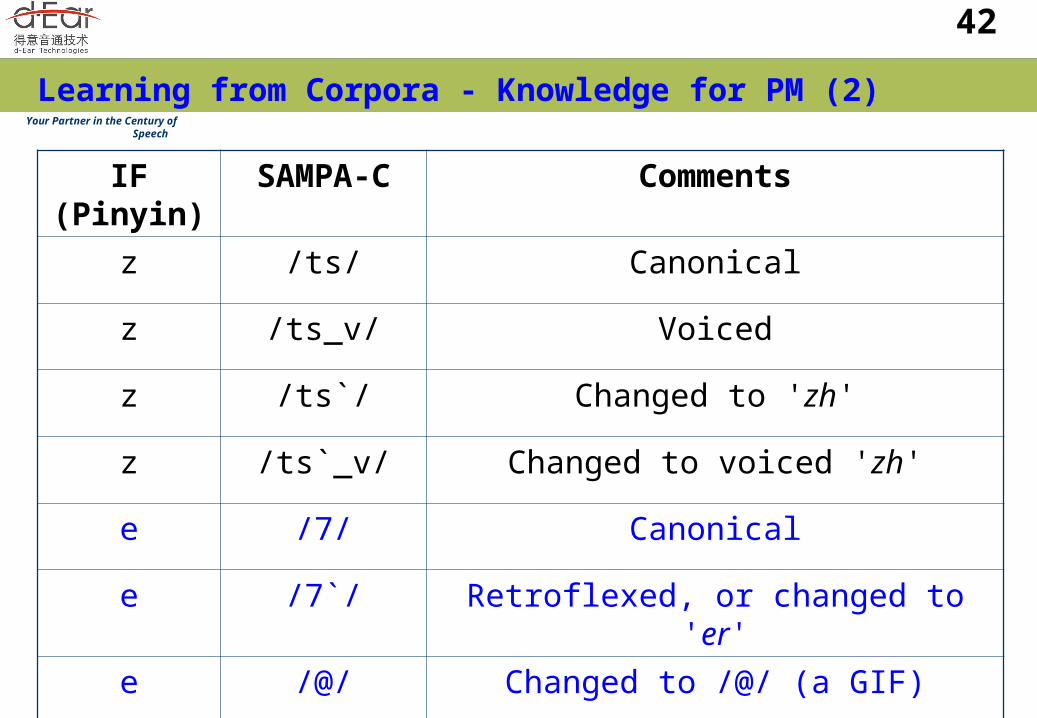
Learning from Corpora - Knowledge for PM (1)
In spontaneous speech, two kinds of differences between canonical IFs and their surface forms if the deletion and insertion are not considered. Sound change from one IF to a SAMPA-C sequence close to its
canonical IF (forming a part of the GIF set); Phone change directly from one IF to another quite different IF
or GIF. Definition of the GIF set: find all possible SAMPA-C
sequences of all IFs in the database. Example:
By searching in the CASS corpus, we initially obtain a GIF set containing over 140 possible SAMPA-C sequences (pronunciations) of IFs;
Some of them are least frequently observed sound variability forms therefore they are merged into the most similar canonical IFs;
Finally we have 86 GIFs.
Your Partner in the Century of Speech
42
Learning from Corpora - Knowledge for PM (2)
IF (Pinyin)
SAMPA-C Comments
z /ts/ Canonical
z /ts_v/ Voiced
z /ts`/ Changed to 'zh'
z /ts`_v/ Changed to voiced 'zh'
e /7/ Canonical
e /7`/ Retroflexed, or changed to 'er'
e /@/ Changed to /@/ (a GIF)

Your Partner in the Century of Speech
43
Learning from Corpora - Knowledge for PM (3)
Probabilistic GIFs output probability given an IF, i.e., P(GIF | IF)
GIF N-Grams, including unigram P(GIF), bigram P(GIF2 | GIF1) and trigram P(GIF3|GIF1,GIF2),
For spontaneous ASR, a multi-pronunciation lexicon is necessary to reflect the pronunciation variation. Can be learned form the database: P(GIF1, GIF2 | Syllable).
Such a lexicon is called a probabilistic multi-entry syllable-to-GIF lexicon.

Your Partner in the Century of Speech
44
Learning from Corpora - Knowledge for PM (4)
Syllable (Pinyin)
Initial (SAMPA-C)
Final (SAMPA-C)
Output Probability
chang ts`_h AN 0.7850
chang ts`_h_v AN 0.1215
chang ts`_v AN 0.0280
chang <del> AN 0.0187
chang z` AN 0.0187
chang <del> iAN 0.0093
chang ts_h AN 0.0093
chang ts`_h UN 0.0093

Your Partner in the Century of Speech
45
Probabilistic Pronunciation Modeling Theory
Recognizer goal K*=argmaxK P(K|A) = argmaxK P(A|K) P(K)
Applying independent assumption P(A|K) = n P(an|kn)
Pronunciation modeling part – via introducing surface s P(a|k) = s P(a|k,s) P(s|k)
Symbols a: Acoustic signal, k: IF, s: GIF A, K, S: corresponding string
AM
LM
Refined AMOutput Prob.
Learning from Corpora - Knowledge for PM (5)

Your Partner in the Century of Speech
46
SER 2.8%
P(a|s) Baseline
P(a|k, s) P(s|b) SER 6.3%
P(a|s) P(s|b) SER 5.1%
SER 3.2%
P(a|b, s) 1 SER 3.6%
+
CDW
S-GIF
B-GIF
PronModeling GIF modeling
Syl N-Gram (from BN/CASS) P(B)
P(A|B) P(B) SER 10.7%
DOP
Learning from Corpora - Knowledge for PM (6)
Experimental results

Your Partner in the Century of Speech
47
Learning from Corpora - Knowledge for NLP (1)
Spoken Language Phenomena :- The courtesy items / sentences inessential for semantic analysis.
C: 喂,你好,请问是中关村航空客运代理处么 ? Hi, hello, could you tell me ...?
Simple repetitions because of the pondering or thinking when speaking.
C: 我问一下那个四月三十呃四月三十号北京到 ... ... 30th April ... 30th April ...
Semantic repetitions for emphasis.C: 请问那个周四就是四月三十号北京到 ... ... Thursday ... 30th April ...
Speech corrections or repairs.C: 呃,那个什么星期三,呃,星期四的去南京的机票还有吗? ... Wednesday ... Thursday ...

Your Partner in the Century of Speech
48
Learning from Corpora - Knowledge for NLP (2)
Spoken Language Phenomena (2) :- Ellipsis in the context.
C: 我问一下那个四月三十呃四月三十号到福州的机票最后一班还有吗 ? (Asking if there are tickets available for the last flight from the departure city to the arrival city, on the departure date.)
O: 只有一班有。 ("Only one flight with ticket available")C: 那个那五月一号的下午三点有么? (How about the flight at a departure
time on another departure date?) Constituents appearing in any order (as long as sufficient
information is given) C: ... 五点二十五国航飞深圳的 ... (Time, airline code, location and some
other items can appear in any order) Constituents appearing in reverse order
C: ... 的机票 多少钱 得 ? How much cost (Normal order: “ 得” “多少钱” )

Your Partner in the Century of Speech
49
Learning from Corpora - Knowledge for NLP (3)
Spoken Language Phenomena (3) :- Parol (verbal idioms) or unnecessary terms.
C: 那,那个八点二十那个是去什么机场的呀? (“ 那” /” 那个” is somewhat similar to “uhm”)
And long sentences with all required information. Or additional explanation following the previous sentence.
C: 哎,您好,这样那个我订一张 (one) 那个明天 (tomorrow) 下午(afternoon) 五点 (5 o’clock) 四十五 (45) 去北京 (from Beijing) 到上海 (to Shanghai) 的那个机票 (ticket) 的。
O: ...C: 您给我看一下有没有 (is there) 北京到湛江 (from Beijing to Zhanjiang)
的 (ticket) ?二十九 (29th) 、三十号 (30th)?

Your Partner in the Century of Speech
50
Learning from Corpora - Knowledge for NLP (4)
Based on the above information, 4 types of parsing rules are proposed for robust spoken language understanding.

Your Partner in the Century of Speech
51
Learning from Corpora - Knowledge for NLP (5)
Robust rule type 0: some crucial information are not allowed to be
mixed/inserted by other terms, e.g. personal ID no. ( 身份证号码 )
up-tying ( 苛刻型 ) rules
sub_id_card_head * ato_0to9_yao ato_0to9_yao ... ato_0to9_yao
(15 identical terms)
id_card_no sub_id_card_head
id_card_no * sub_id_card_head ato_0to9_yao ato_0to9_yao ato_0to9_yao

Your Partner in the Century of Speech
52
Learning from Corpora - Knowledge for NLP (6)
Robust rule type 1: contrarily, some utterances are allowed to be
inserted with recognized garbage/fillers, or some other meaningless parts, e.g. “ 星期啊三嗯星期四”
by-passing ( 跳跃型 ) rules
sub_week_day ato_week ato_1to6
sub_week_day_list sub_week_day
sub_week_day_list sub_week_day sub_week_day_list

Your Partner in the Century of Speech
53
Learning from Corpora - Knowledge for NLP (7)
Robust rule type 2: some information, such as time, city names, plane
types etc., can appear in any order up-messing ( 无序型 ) rules
timeloc_info_cond @ info_date_time_cond info_fromto
plane_info @ mat_airline_code mat_aircraft_type
flight_info_cond @ timeloc_info_cond plane_info

Your Partner in the Century of Speech
54
Learning from Corpora - Knowledge for NLP (8)
Robust rule type 3: some phrases/constituents, such as “是…吗” , may
contain other constituents in between, e.g. “是到北京吗” , “ 是两张吗”
over-crossing ( 交叉型 ) rules
mark_q_is tag_is_or_not
mark_q_is tag_is tag_question_mark
mark_q_is tag_is_q
confirm_request # mark_q_is confirm_c

Your Partner in the Century of Speech
55Learning from Corpora - Knowledge for dialectal ASR (1)
Dialect-related Chinese Syllable Mapping (CSM).Word-independent CSM: e.g. in Southern
Chinese, Initial mappings include zhz, chc, shs, nl, and so on, and Final mappings include engen, ingin, and so on;
Word-dependent CSM: e.g. in dialectal Chuan Chinese, the pinyin 'guo2' is changed into 'gui0' in word ' 中国 (China)' but only the tone is changed in word ' 过去 (past)'.

Your Partner in the Century of Speech
56Learning from Corpora - Knowledge for dialectal ASR (2)
The CSM could be N→1, 1→N, or crossed.
kei kuo kui...
Standard Chinese Syllabe Set
Chuan Dialect
ke
上[课] [克]服
kuo kui
[扩]大 [魁]梧

Your Partner in the Century of Speech
57Learning from Corpora - Knowledge for dialectal ASR (3)
The CSM is not exact. For any mapping AB, it is mostly that the resulted pronunciation is not B exactly, but something quite similar to B, more similar to B than to any other syllable.
A
B
B1
B3
B4
B2
Bi is a variation of B, such as :-
nasalization, centralization, voiced,voiceless, rounding, syllabic, pharyngrealization, aspiration

Your Partner in the Century of Speech
58Learning from Corpora - Knowledge for dialectal ASR (4)
Lexical: a dialect-related lexicon containing two parts :- A common part shared by standard Chinese and most
dialectal Chinese languages (over 50k words), and A dialect-related part (several hundreds).
And in this lexicon: each word has one pinyin string for standard Chinese
pronunciation and a kind of representation for dialectal Chinese pronunciation, and
each of those dialect-related words is corresponding to a word in the common part with the same meaning

Your Partner in the Century of Speech
59Learning from Corpora - Knowledge for dialectal ASR (5)
For each word in the lexicon Word-dependent CSM syllable
– Add a parallel pinyin string, with word-independent CSM pinyin unchanged
• 中国: Putonghua: zhong guo• added: zhong gui
For each pronunciation representation of a word in the lexicon
Word-independent CSM syllable– Add a parallel initial/final arc
• 中国: { (zh | z) (ong) (g) (uo) } | { (zh | z) (ong) (g) (ui) }
• 精神: (j) (ing | in) (sh | s) (en | eng)

Your Partner in the Century of Speech
60Learning from Corpora - Knowledge for dialectal ASR (6)
zh
ong
… x
in
…
中心 忠心
…
zh
ong
… x
in
…
中心 忠心
… z
ing {I*(zh)} {I*(z)}
{*F(in)} {*F(ing)}

Your Partner in the Century of Speech
61Learning from Corpora - Knowledge for dialectal ASR (7)
Dialectal Chinese SpeechRecognition Framework
Standard ChineseSpeech Recognizer
+
Dialectal ChineseSpeech Recognizer
Dialectal Chinese RelatedKnowledge & Resources
Your Partner in the Century of Speech
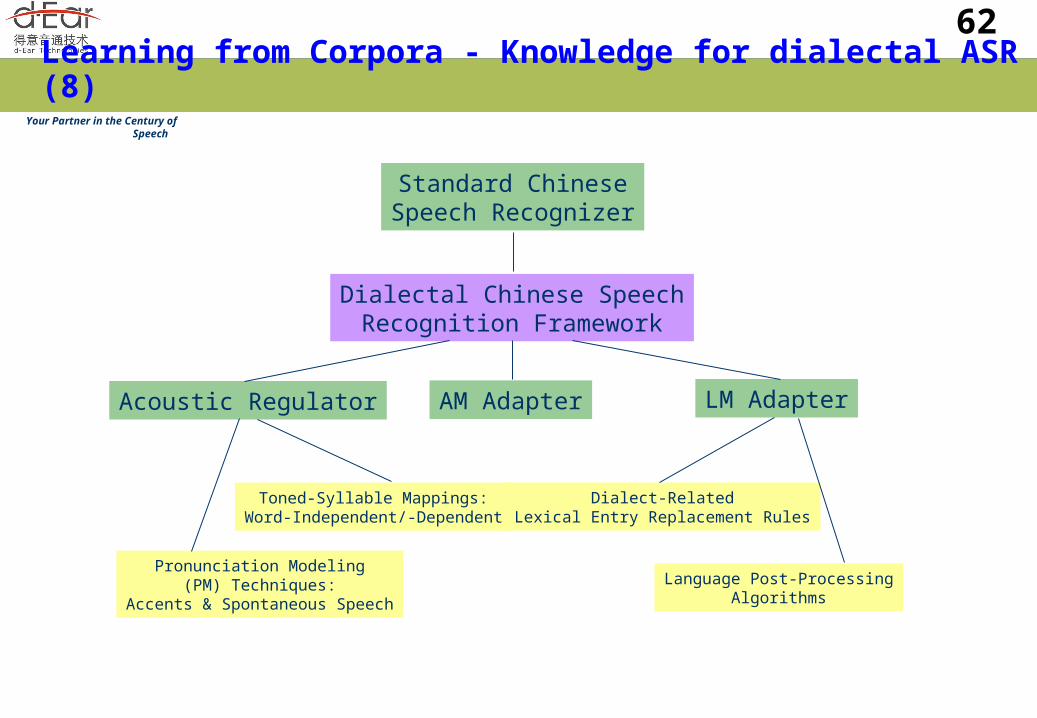
62Learning from Corpora - Knowledge for dialectal ASR (8)
Dialectal Chinese SpeechRecognition Framework
AM AdapterAcoustic Regulator LM Adapter
Pronunciation Modeling(PM) Techniques:
Accents & Spontaneous Speech
Toned-Syllable Mappings:Word-Independent/-Dependent
Dialect-RelatedLexical Entry Replacement Rules
Language Post-ProcessingAlgorithms
Standard ChineseSpeech Recognizer

Your Partner in the Century of Speech
63
Outline
Purpose of speech corpora
Factors to be considered in data creation
Data creation
Data transcription
Learning from corpora
Chinese Corpus Consortium (CCC)

Your Partner in the Century of Speech
64
Chinese Corpus Consortium (CCC) (1)
Speech and text databases are very important to the research and development in the areas of automatic speech recognition, text-to-speech, natural language processing and etc.
And there have been several consortiums or associations devoting themselves in collecting and distributing such data resources, such as the Linguistic Data Consortium (LDC 1992), the European Language Resources Association (ELRA 1995), and The Gengo Shigen Kyouyuukikou Language Resource
Consortium (GSK 1999). We also need such a consortium or association for the
Chinese language.

Your Partner in the Century of Speech
65
Chinese Corpus Consortium (CCC) (2)
After communications and discussions for a long time, now CCC is coming out soon.
CCC will provide corpora for, but not limited to :- Chinese ASR, TTS, NLP, perception analysis, phonetics analysis, linguistic analysis, and so on.
Corpora could be :- speech and text, read and spontaneous, wideband and narrowband, Putonghua, dialectal Chinese and Chinese dialects, clean and with noise, and of any other kinds which are helpful to the foresaid purposes.

Your Partner in the Century of Speech
66
Chinese Corpus Consortium (CCC) (3)
CCC in more international: Mainland China, Hong Kong, Singapore, Japan, USA, [Taiwan], [Europe].
CCC is open to the speech and language research and development society.
More details can be found in the CCC web site (http://www.d-Ear.com/CCC/).

Thomas Fang Zheng
Q/A