manila and sahara integration in openstack report manila and sahara integration in openstack using...
TRANSCRIPT

Technical Report
Manila and Sahara Integration in OpenStack Using NetApp NFS Data in Hadoop and Spark
Jeff Applewhite, NetApp
October 2015 | TR-4464
Abstract
Today’s businesses must store an unprecedented volume of data and must manage the depth
and complexity of the data that they capture. Apache Hadoop has gained in popularity
because of its ability to handle large and diverse data types. Apache Spark has recently
gained in popularity because of its ability to rapidly analyze data through its in-memory
approach to processing and to natively use data stored in a Hadoop Distributed File System
(HDFS). Although some companies are successfully bursting to the cloud for these types of
analytics, the options for ingesting and exporting data to and from these technologies have
been limited in OpenStack until now.
The OpenStack Shared File Systems project (Manila) provides basic provisioning and
management of file shares to users and services in an OpenStack cloud. The OpenStack Data
Processing project (Sahara) provides a framework for exposing big data services, such as
Spark and Hadoop, within an OpenStack cloud. Natural synergy and popular demand led the
two project teams to develop a joint solution that exposes Manila file shares within the Sahara
construct to solve real-world big data challenges. This guide assists end users in the task of
using this important new development in the OpenStack cloud capability. It examines common
workflows for how a Sahara user can access big data that resides in Hadoop, Swift, and
Manila NFS shares.

2 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
TABLE OF CONTENTS
1 Introduction ........................................................................................................................................... 4
1.1 Existing Challenges ........................................................................................................................................4
1.2 New Developments in Manila and Sahara ......................................................................................................4
1.3 Relevant Features in Manila ...........................................................................................................................5
1.4 Ephemeral Storage Versus Cinder Storage in Sahara ....................................................................................6
2 Solution Description............................................................................................................................. 6
2.1 Sahara Architecture ........................................................................................................................................7
2.2 OpenStack Requirements ...............................................................................................................................8
2.3 Manila Configuration .......................................................................................................................................8
2.4 Testbed Workflow for Creating Manila Shares ................................................................................................9
3 Deployment Methodology .................................................................................................................. 11
3.1 Prepare the Manila Data Source ................................................................................................................... 11
3.2 Create the Spark Image ................................................................................................................................ 14
3.3 Create the Spark Binary Data ....................................................................................................................... 15
3.4 Update the Cluster Templates ...................................................................................................................... 16
3.5 Create a Spark Job Template Based on the Spark Binary ............................................................................ 17
3.6 Create a Sahara Data Source That Uses Manila Shares .............................................................................. 17
3.7 Create a Spark Template That Uses Manila Shares ..................................................................................... 18
3.8 Launch the Spark Cluster from Your Template ............................................................................................. 20
4 Use Cases ............................................................................................................................................ 21
4.1 Put a Job Binary on a Manila Share .............................................................................................................. 21
4.2 Put Data from a Manila Share into HDFS ..................................................................................................... 22
4.3 Launch a Job by Using the Manila Share as a Data Source ......................................................................... 23
5 Summary ............................................................................................................................................. 23
6 NFS Shares as a Data Source in Sahara .......................................................................................... 23
Acknowledgments .................................................................................................................................... 23
References ................................................................................................................................................. 24
Version History ......................................................................................................................................... 24
LIST OF TABLES
Table 1) Liberty release updates and proposals related to Manila and Sahara. .............................................................5

3 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
LIST OF FIGURES
Figure 1) Workflow for bringing data from NetApp NFS storage to Sahara. ...................................................................7
Figure 2) Sahara architecture (graphic supplied by OpenStack). ...................................................................................8
Figure 3) Manila workflow for share creation without share servers. ............................................................................ 10

4 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
1 Introduction
One of the significant challenges for enterprises and service providers that deploy big data applications is
that workloads are typically dynamic or “bursty” in nature and yet require dedicated hardware setups.
Dedicated setups sometimes result in wasteful deployment of compute and storage resources.
Another problem is that, until recently, the use of internal cloud resources to serve the needs of big data
processing was not feasible. The core infrastructure was difficult to implement and understand, and the
task of layering the stack of applications and projects that were necessary to gain business value from the
private cloud was daunting.
This landscape is changing, however, with the recent Liberty release of OpenStack. Core integration that
enhances the ease of accessing data from Manila shares has been enabled in the OpenStack Data
Processing service (Sahara). This document highlights and explains these developments.
The OpenStack Data Processing service (and the project under which it is developed, Sahara) builds on
the solid foundation of OpenStack cloud technology by exposing big data workloads to an OpenStack
cloud user. In the past, Sahara was able to ingest data from a limited set of data sources. Now, with the
intersection of the capabilities of Sahara and the OpenStack Shared File Systems project (Manila), these
workloads can access data that resides on NFS shares and other file stores and can write result sets to
them.
This capability can be enabled through a couple of mechanisms. The cross-integration of the Sahara and
Manila projects makes it possible to ingest large data sources from NFS shares either by accessing and
managing existing shares or by provisioning new dedicated shares. In addition, job binaries, libraries, and
configuration files can also reside in a shared Manila file-share location in Sahara to enable easier and
more seamless distribution throughout a Hadoop or Spark cluster.
1.1 Existing Challenges
Before the Liberty release of OpenStack, the data source options in the Sahara big data project were
limited. This limitation made life difficult for operators of Sahara clusters and prevented them from
accessing data that was not in the two supported formats: HDFS and Swift. In addition, no accepted
method for automating the provisioning of a shared file store was available. For data sources, the user
had two options:
HDFS. Data residing in an existing HDFS could be accessed by Hadoop or Spark jobs.
Swift. Data in a Swift object store could be accessed at the swift://<container>/<path> URL.
An additional challenge was that the job binaries, libraries, and configuration files that were required for a
job definition had to be stored in Swift or in the Sahara internal database.
1.2 New Developments in Manila and Sahara
Sahara is a rapidly developing project. Table 1 highlights some recent changes that were implemented in
the project to enable the features that are covered in this guide. With the Liberty release, job binaries,
libraries, and configuration files can be placed on a Manila share for access by all nodes in a Hadoop
cluster through common mount points. This change eliminates the need for distributing files and
configurations throughout multiple nodes.
Table 1 also highlights proposals for adding the new features to the Horizon UI and for using the NetApp®
NFS Connector for Hadoop to support NFS shares as a data source in Sahara. These proposals are in
progress and might or might not land in the Liberty release.
The Horizon UI presented in this guide is based on the changes that are already implemented for the
Liberty release. The release contains full CLI functionality for the described features.

5 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
Table 1) Liberty release updates and proposals related to Manila and Sahara.
Enhancement Status
Manila as a Runtime Data Source Implemented in Liberty release
Addition of Manila as a Binary Store Implemented in Liberty release
API to Mount and Unmount Manila Shares to Sahara Clusters Implemented in Liberty release
Adding Manila Shares as an Option for Data Sources in the Horizon UI In progress
Adding Support for Manila-Based Shares in the Sahara Horizon UI In progress
Using NetApp NFS Driver to Support NFS Shares as a Data Source in Sahara
In progress
1.3 Relevant Features in Manila
The Manila project offers a vendor-agnostic API framework for the provisioning of file shares in an
OpenStack cloud. The file protocol varies depending on the vendor-specific plug-in that is used for
enabling file sharing on various devices.
NetApp has enabled the NFS and CIFS protocols within the NetApp Manila driver. This document
focuses on the NFS protocol as a data source or target for provisioning file shares. For some use cases,
an HDFS plug-in for Manila might hold some advantages over directly accessing HDFS. The primary
advantage that Manila gives the administrator is an API-driven access control framework with which to
secure instance access to the HDFS data nodes.
Manila has specific data management features that are important for big data applications. It supports
capabilities that have long been associated with NetApp storage arrays. In a NetApp storage context,
Manila operates at the level of NetApp FlexVol® volumes such that the following features come into play:
Creation of volume NetApp Snapshot® copies
Creation of shares from Snapshot copies (NetApp FlexClone® technology)
Deduplication
Compression
Thin provisioning or thick provisioning
Creation of a catalog of differentiated storage pools that are based on the underlying disk media (SSD, SAS, or SATA)
These features can be of enormous value for big data applications. Administrators can tailor the
underlying storage to the workload at hand. For large text-based results or datasets, it is possible to
realize substantial storage savings through NetApp deduplication and/or compression with very little to no
performance impact.
When Manila runs with the NetApp clustered Data ONTAP® operating system as the storage back end, it
can run in two distinct modes:
In the first mode, the Manila driver creates an entire NetApp storage virtual machine (SVM) for each share on the target NetApp cluster. This mode provides maximum flexibility in the networking and features that are available to the provisioning process.
In the second mode, Manila creates shared exports from a designated SVM that the storage administrator created. In this case, the driver creates a new FlexVol volume and exports this volume to the desired network segments or users.
The running mode of Manila is largely immaterial for the purposes of this guide. Whether each share
resides within a new SVM or is simply a FlexVol volume within an existing SVM does not matter. What is

6 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
important is that the Spark nodes can access the network from which the NFS server on the SVM serves
data.
1.4 Ephemeral Storage Versus Cinder Storage in Sahara
The Sahara project has mechanisms whereby storage disks can be mounted on an ephemeral disk that
resides on a Nova compute node or remotely on a Cinder volume. It also gives the user the option of
accessing only Cinder volumes that run locally on the node in question. For big data applications, this
option can have significant performance implications because of the volume of data and the design goal
of limiting network round trips to access data. NetApp has reference architectures for Hadoop that
describe how NetApp E-Series arrays can be used to provide both high performance and reduction of the
number of copies of a given object in HDFS. These architectures deliver an easy to manage, high-
performance, and cost-effective solution.
As in every design, administrators have important trade-offs to consider when building a cloud that can
host big data applications effectively. One option is to use high-performance storage and mount it on
ephemeral disks that reside on the Nova compute nodes (for example, on
/var/lib/nova/instances). In this way, the end user can be certain that disks for Hadoop or Spark
instances are local to the compute node on which they are run. Another benefit of this design is that it
adheres to the general maxim that locally accessed disks provide higher throughput for Hadoop
applications. In this scenario, disk interconnects are SATA, SAS, or PCIe.
Note: For more details about mounting a file system and the mount options that are desirable for Hadoop on NetApp E-Series arrays, see TR-3969: NetApp Open Solution for Hadoop Solutions Guide.
It might not be feasible to attach specific disks to Nova compute nodes, though, for reasons of
homogeneity of the cloud deployment. In other cases, the simplicity of having a storage pool that can be
accessed remotely through the Cinder block service project outweighs the loss of data locality that is
gained by using an ephemeral disk or local Cinder storage. Although this document puts forward these
issues for architects to consider, its primary purpose is to highlight the new features in Sahara that enable
shared file systems through Manila shares.
2 Solution Description
Sahara and Manila together offer strong usability for big data administrators. This guide describes a
workflow that enables administrators to bring data into Sahara from enterprise data sources that reside on
NetApp NFS storage. The workflow also enables administrators to save the resultant datasets to the
same shares or to different shares for purposes of distribution, further analysis, and so forth.
This solution is based on new integration work by the Sahara and Manila project teams. The sample
workflow shows an administrator of Sahara how to move data between traditional sources such as HDFS
and the newer NFS Manila-based data source.
Figure 1 illustrates the workflow that Sahara uses to enable Manila shares. Starting at the Sahara
controller, the administrator creates a Spark cluster that results in four Spark instances: a master and
three workers. The Sahara service handles all API calls to the Manila service to add access based on a
Manila data source object. Shares are then mounted within the Spark cluster nodes and are accessible
by them for input or output operations as well as for job binaries, libraries, and so on.

7 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
Figure 1) Workflow for bringing data from NetApp NFS storage to Sahara.
The specific steps for the workflow in Figure 1 are covered in later sections, but at a high level, the
workflow involves the following tasks:
1. The administrator deploys the Spark cluster from a template that includes predefined Manila shares.
2. The administrator boots the Spark nodes. When the boot process finishes, the Sahara code automatically mounts the Manila shares.
3. A Spark binary (for example, word-count) that is stored on one of the shares becomes the source
for the new workload.
4. The Spark workload initializes and uses data on a Manila NFS share that resides on all nodes.
5. The Spark job finishes and writes data to the output Manila file share.
6. End users in the enterprise can consume the resulting datasets natively over familiar protocols.
2.1 Sahara Architecture
The Sahara architecture, which is shown in Figure 2, consists of several components:
Auth component. Responsible for client authentication and authorization; communicates with Keystone, the OpenStack identity service.
Data access layer (DAL). Makes internal models persistent in the database.
Provisioning engine. Responsible for communication with the following OpenStack services: compute (Nova), orchestration (Heat), block storage (Cinder), and image (Glance).

8 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
Vendor plug-ins. Pluggable mechanisms that are responsible for configuring and launching data processing frameworks on the provisioned virtual machines. Existing management solutions, such as Apache Ambari and Cloudera Manager Admin Console, can also be used for that purpose.
Elastic data processing (EDP). Responsible for scheduling and managing data processing jobs on clusters that are provisioned by Sahara.
REST API. Exposes Sahara functionality through a REST HTTP interface.
Python client. Client for the Sahara REST API.
Note: Like other OpenStack components, Sahara has its own Python client.
Sahara pages. GUI for Sahara; located in the OpenStack dashboard (Horizon).
Figure 2) Sahara architecture (graphic supplied by OpenStack).
2.2 OpenStack Requirements
The procedures in this guide were compiled from systems running the Liberty release of OpenStack.
Additional enhancements are planned for Horizon to make some of the configuration steps easier
compared with how they are documented here. All functionality works from the CLI in the Liberty release
and there are no requirements for Horizon beyond the stable Liberty release to achieve the goals that are
outlined in this guide. Future Horizon patches will leverage underlying capabilities in the services and add
a graphical interface to ease administration.
Instructions for the installation of OpenStack are beyond the scope of this guide. For additional
information about OpenStack, see OpenStack Installation Guide for Ubuntu 14.04 (Kilo release).
2.3 Manila Configuration
You configure Manila by changing the contents of the manila.conf file and restarting all of the Manila
processes. Depending on the OpenStack distribution that you use, to restart the processes, you might
need to run commands such as service openstack-manila-api restart or service manila-
api restart.

9 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
manila.conf File
The manila.conf file contains a set of configuration options (one per line) that are specified as
option_name=value. Configuration options are grouped together into stanzas that are denoted by
[stanza_name]. The file must contain at least one stanza named [DEFAULT]. The [DEFAULT] stanza
contains configuration parameters that apply generically to Manila (and not to any particular back end).
You must place options that are associated with a particular Manila back end in a separate stanza.
Note: Although you can specify driver-specific configuration options within the [DEFAULT] stanza, you cannot define multiple Manila back ends within the [DEFAULT] stanza. NetApp strongly recommends that you place driver-specific configuration in separate stanzas. Ensure that you list the back ends that should be enabled as the value for the enabled_share_backends configuration option. For example:
enabled_share_backends=clusterOne,clusterTwo
The enabled_share_backends option must be specified within the [DEFAULT] configuration stanza.
Manila Network Plug-ins
The following network plug-ins are valid as of the Kilo release of OpenStack:
Standalone network. For this plug-in, you define all IP settings (address range, subnet mask, gateway, and version) through configuration options in the driver-specific configuration stanza.
Nova network: simple. This plug-in uses a single Nova network ID for all share servers. You specify the ID of the Nova network to be leveraged through a configuration option in the driver-specific configuration stanza.
Nova network: configurable. This plug-in enables end users of Manila to create share networks that map to different Nova networks. Values for the segmentation protocol (for example, VLAN), IP address, subnet mask, protocol, and gateway are obtained from the Nova network when a new share server is created. You can specify default values for the network ID and for the subnet ID through configuration options in the driver-specific configuration stanza. However, values that are specified by end users when they define share networks take precedence over values that you declare in the configuration file.
Neutron network. This plug-in uses Neutron networks and subnets for defining share networks. Values for the segmentation protocol (for example, VLAN), IP address, subnet mask, protocol, and gateway are obtained from Neutron when a new share server is created. You can specify default values for the network ID and for the subnet ID through configuration options in the driver-specific configuration stanza. However, values that are specified by end users when they define share networks take precedence over values that you declare in the configuration file.
The Manila network plug-ins provide a variety of integration approaches with the network services
available with OpenStack. To choose a network plug-in, set the value of the network_api_class
configuration option within the driver-specific configuration stanza of the manila.conf file. You should
use the plug-ins only with the NetApp clustered Data ONTAP driver with share server management.
2.4 Testbed Workflow for Creating Manila Shares
The setup for the testbed on which this document is based did not require network plug-ins or share
server management. Instead, it used existing Neutron networking and created shares from an existing
SVM (no share server was created).
Note: This guide includes information about the Manila network plug-ins for cases in which more advanced network configurations are required. The mode in which Manila runs is not material to the basic functionality of the new Sahara integrations. For more information about the Manila modes, see the NetApp OpenStack Deployment and Operations Guide.

10 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
Figure 3 shows the steps that take place when a user requests the creation of a share in Manila and the
selected back end does not use share servers.
Figure 3) Manila workflow for share creation without share servers.
The workflow in Figure 3 has the following steps:
1. The client issues a request to create the share by invoking the REST API (the client might use the
python-manilaclient CLI utility). The manila-api process and the manila-scheduler
process perform the following tasks:
a. The manila-api process validates the request and user credentials. After validation, it puts the
message on the AMQP queue for processing.
b. The manila-share process takes the message off the queue and sends the message to
manila-scheduler to determine the pool and the back end into which to provision the share.
c. The manila-scheduler process takes the message off the queue and generates a candidate
list of resource pools. The list is based on the current state and the criteria for the requested share (size, availability zone, and share type, which includes extra specs).
d. The manila-share process reads the response message from manila-scheduler from the
queue; it iterates through the candidate list by invoking back-end driver methods for the corresponding pools until it is successful.
2. If selected by the scheduler, the NetApp Manila driver creates the requested share through interactions with the storage subsystem (depending on configuration and protocol). Without a share server, the NetApp Manila driver exports the shares through the data LIFs in the SVM that is scoped to the Manila back end.
3. The manila-share process creates share metadata and posts a response message to the AMQP
queue. The manila-api process reads the response message from the queue and responds to the
client with share ID information.
4. After a share is created and exported by the back end, the client uses the ID information to request updated share details, and it uses export information from the response to mount the share (through protocol-specific commands). The Sahara code itself then manages the creation of share-access rules that give the instances in OpenStack access to the newly created shares.
For more details about the configuration of Manila, see the NetApp OpenStack Deployment and
Operations Guide.

11 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
3 Deployment Methodology
You can create or manage a Manila share and then use it as a data source or a target in a working Spark
cluster within the Sahara framework. To do so, you must follow the complete workflow that Sahara uses
to enable Manila shares. The workflow is described in the sections that follow.
3.1 Prepare the Manila Data Source
Manila is the starting point for the process. Instructions for the configuration of Manila by using a NetApp
FAS system are covered in detail in the NetApp OpenStack Deployment and Operations Guide.
During the cluster setup, Sahara must access instances through an SSH session. To establish this
connection, it uses either the fixed or the floating IP address of the instance. By default, Sahara is
configured to use floating IP addresses for access. This behavior is controlled by the
use_floating_ips configuration parameter. For this setup, you have two options to enable all
instances to gain a floating IP address:
If you are using the Nova network, you can configure it to assign floating IP addresses automatically
by setting the auto_assign_floating_ips parameter to True in the Nova configuration file
(usually nova.conf). You can specify a floating IP address pool for each node group directly.
Note: When you use floating IP addresses for management (use_floating_ips=True), every instance in the cluster must have a floating IP address, or else Sahara cannot use the cluster.
If you are not using floating IP addresses (use_floating_ips=False), Sahara uses fixed IP
addresses for instance management. If you use Neutron for the networking service, you can choose the fixed IP address network for all instances in the cluster. Whether you use the Nova network or Neutron, verify that all instances running Sahara have access to the fixed IP address networks.
In the test environment, we tested floating IP addresses and fixed IP addresses, and both approaches
worked well. Floating IP addresses are desirable in certain use cases, but they do not generally perform
as well as fixed, unrouted IP connections to the NFS storage. The advantage of using fixed IP addresses
is that network traffic for NFS flows over a native network connection rather than through the additional
overhead of iptables with NAT. For this reason, the performance of a native, unrouted network is
generally better. On the other hand, if complex network requirements are involved for access to the NFS
share, a public network with a shared pool might provide the needed flexibility to access the target.
To begin the workflow, you must have an existing data source that you want to convert and use within
Sahara, or you must create a data source that will contain the analytics result set.
Scenario One: Manage an Existing NFS Share
In some scenarios, you might need existing data in the enterprise for data processing. To bring existing
shares into Manila and thus make them available for later provisioning to Spark or Hadoop clusters,
complete the following steps:
1. Import the NFS share into Manila.
manila manage –os-username admin --name bigData --share-type default fedora@sparkdata#aggr2 nfs
fas01.lab.corp.netapp.com:/vol_14092015_150953
Where:
--name is an identifier for the imported share.
fedora@sparkdata#aggr2 represents the host name output from manila –os-username
admin service-list.
aggr2 represents the Manila pool where the pre-existing share resides.
fas01.lab.corp.netapp.com:/vol_14092015_150953 represents a sample export that
exists within the aggr2 pool (aggregate) on the NetApp driver at instance fedora@sparkdata.

12 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
2. After you run the import operation, verify that the export volume has been renamed on the NetApp
controller to share_<UID> to match the UID string that Manila assigns to the share.
Note: Renaming the volume breaks existing share access outside of Manila.
3. List the share to see its new share path after the import.
stack@fedora:~$ manila list
+--------------------------------------+-------------+------+-------------+-----------+----------
-+------------+-----------------------------------------------------------+----------------------
--+-------------------+
| ID | Name | Size | Share Proto | Status | Is Public
| Share Type | Export location | Host
| Availability Zone |
+--------------------------------------+-------------+------+-------------+-----------+----------
-+------------+-----------------------------------------------------------+----------------------
--+-------------------+
| 12ff384d-789d-46f6-923e-5ece4d590f17 | bigData | 10 | NFS | available | False
| default | fas01.lab.corp.netapp.com:/share_568fec5b_c026_4bea_a7ba_f762a60f3206 |
fedora@sparkdata#aggr2 | nova |
|
+--------------------------------------+-------------+------+-------------+-----------+----------
-+------------+-----------------------------------------------------------+----------------------
--+-------------------+
Scenario Two: Create an NFS Share and a Share Network
You can create a dedicated Manila share to contain the Sahara analytics result set. In this case, you must
also create a Manila share network and give access to the Sahara nodes that will access the shares.
Create a Share
To create the share, complete the following steps:
1. Log in to Horizon as the desired tenant. In this procedure, the tenant is demo.
2. From the Compute tab, click Shares.
3. Click the Create Share button and set the following options:
a. Type a name for the share.
b. Select NFS as the share protocol.
c. Set the share size to 2GB.
d. Select NFS as the share type.
e. Select Nova as the availability zone.

13 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
4. Click Create Share.
5. Repeat step 3 and step 4 to create a second Manila share.
Create a Share Network
To create the share network, complete the following steps:
1. In the Horizon UI, from the Compute tab, click Shares.
2. Click the Share Networks tab.
3. Click the Create Share Network button and set the following options:
a. Name the new network demoShareNet.
b. Select demo for the Neutron network and subnet.
4. Click Create Share Network.
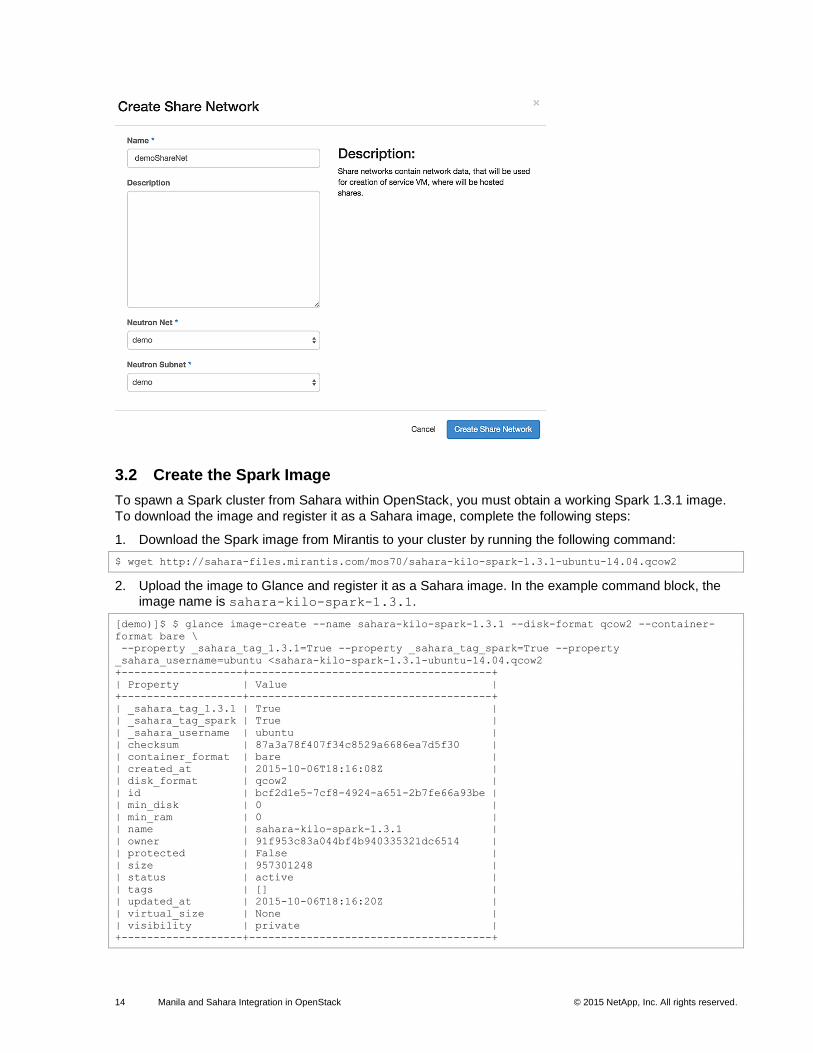
14 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
3.2 Create the Spark Image
To spawn a Spark cluster from Sahara within OpenStack, you must obtain a working Spark 1.3.1 image.
To download the image and register it as a Sahara image, complete the following steps:
1. Download the Spark image from Mirantis to your cluster by running the following command:
$ wget http://sahara-files.mirantis.com/mos70/sahara-kilo-spark-1.3.1-ubuntu-14.04.qcow2
2. Upload the image to Glance and register it as a Sahara image. In the example command block, the
image name is sahara-kilo-spark-1.3.1.
[demo)]$ $ glance image-create --name sahara-kilo-spark-1.3.1 --disk-format qcow2 --container-
format bare \
--property _sahara_tag_1.3.1=True --property _sahara_tag_spark=True --property
_sahara_username=ubuntu <sahara-kilo-spark-1.3.1-ubuntu-14.04.qcow2
+-------------------+--------------------------------------+
| Property | Value |
+-------------------+--------------------------------------+
| _sahara_tag_1.3.1 | True |
| _sahara_tag_spark | True |
| _sahara_username | ubuntu |
| checksum | 87a3a78f407f34c8529a6686ea7d5f30 |
| container_format | bare |
| created_at | 2015-10-06T18:16:08Z |
| disk_format | qcow2 |
| id | bcf2d1e5-7cf8-4924-a651-2b7fe66a93be |
| min_disk | 0 |
| min_ram | 0 |
| name | sahara-kilo-spark-1.3.1 |
| owner | 91f953c83a044bf4b940335321dc6514 |
| protected | False |
| size | 957301248 |
| status | active |
| tags | [] |
| updated_at | 2015-10-06T18:16:20Z |
| virtual_size | None |
| visibility | private |
+-------------------+--------------------------------------+

15 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
3. Verify that your image is a valid Sahara image in the Data Processing tab in Horizon.
Note: If you have specific needs or want to customize your images, consult the following pages for instructions on how to build the images:
Sahara/SparkPlugin
Sahara Image Elements
3.3 Create the Spark Binary Data
You must create a binary within the Sahara database for later use. This binary can be found within the
Sahara source tree. To create the Spark binary, complete the following steps:
1. Clone the Liberty Sahara project to obtain binary samples.
Note: This step is optional if the samples already exist on your cluster.
$ git clone –b stable/liberty https://github.com/openstack/sahara.git
2. Create the spark-wordcount job binary data:
To create it in the internal database, run the following command:
$ sahara job-binary-data-create --file sahara/etc/edp-examples/edp-spark/spark-wordcount.jar
+--------------------------------------+---------------------+
| id | name |
+--------------------------------------+---------------------+
| 43bccfb9-df94-449d-8652-a63a389dedc3 | spark-wordcount.jar |
To create it in the Manila share, run the following command:
$ $ scp sahara/etc/edp-examples/edp-spark/spark-wordcount.jar
[email protected]:/mnt/cb5c3580-5da8-4d16-9071-0251a5e208c1/
spark-wordcount.jar
100% 28KB 28.3KB/s 00:00
Note: In the command block example, 192.168.90.167:/mnt/cb5c3580-5da8-4d16-9071-0251a5e208c1/ represents an actual Sahara node (IP address) with a Manila mount point in your Spark cluster.
3. Create the spark-wordcount binary:
To create it by using the internal database, run the following command:
$ sahara job-binary-create --name spark-wordcount-internal-db --url internal-db://43bccfb9-df94-
449d-8652-a63a389dedc3
+--------------+----------------------------------------------------+

16 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
| Property | Value |
+--------------+----------------------------------------------------+
| name | spark-wordcount |
| url | internal-db://43bccfb9-df94-449d-8652-a63a389dedc3 |
| tenant_id | 91f953c83a044bf4b940335321dc6514 |
| created_at | 2015-09-16T20:50:39 |
| is_protected | False |
| is_public | False |
| id | 91ece0e3-8f9e-4f53-b673-50746d8770d3 |
| description | |
+--------------+----------------------------------------------------+
To create it by using the Manila share, run the following command:
$ sahara job-binary-create --name spark-wordcount --url manila://cb5c3580-5da8-4d16-9071-
0251a5e208c1/spark-wordcount.jar
+--------------+-------------------------------------------------------------------+
| Property | Value |
+--------------+-------------------------------------------------------------------+
| name | spark-wordcount |
| url | manila://cb5c3580-5da8-4d16-9071-0251a5e208c1/spark-wordcount.jar |
| tenant_id | 91f953c83a044bf4b940335321dc6514 |
| created_at | 2015-10-06T20:15:20 |
| is_protected | False |
| is_public | False |
| id | c2e9cc26-6c2c-4c29-92bd-e49a415bed5c |
| description | |
+--------------+-------------------------------------------------------------------+
3.4 Update the Cluster Templates
To update all default templates, complete the following steps:
1. Run the sahara-templates CLI. In this example, 91f953c83a044bf4b940335321dc6514 is the
demo user’s tenant ID.
$ sahara-templates --config-file /etc/sahara/sahara.conf --config-file template.conf update -t
91f953c83a044bf4b940335321dc6514
2. View the new cluster templates in the Horizon UI.

17 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
Note: For more information about how to create and manage Sahara cluster templates, consult the Sahara template readme file.
3.5 Create a Spark Job Template Based on the Spark Binary
To create a Spark job template that is based on the Spark binary, complete the following step:
1. Run the following command:
$ sahara job-template-create --name spark-wordcount --type Spark --main c2e9cc26-6c2c-4c29-92bd-
e49a415bed5c
+--------------+---------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------
----------------------------------------------+
| Property | Value
|
+--------------+---------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------
----------------------------------------------+
| name | spark-wordcount
|
| tenant_id | 91f953c83a044bf4b940335321dc6514
|
| created_at | 2015-09-16T20:53:04
|
| mains | [{u'name': u'spark-wordcount', u'url': u'internal-db://43bccfb9-df94-449d-8652-
a63a389dedc3', u'tenant_id': u'91f953c83a044bf4b940335321dc6514', u'created_at': u'2015-09-
16T20:50:39', u'updated_at': None, u'is_protected': False, u'is_public': False, u'id':
u'91ece0e3-8f9e-4f53-b673-50746d8770d3', u'description': u''}] |
| interface | []
|
| is_protected | False
|
| libs | []
|
| is_public | False
|
| type | Spark
|
| id | fc4b55eb-22b6-4bc7-a6a3-1961fe466ad0
|
| description |
|
+--------------+---------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------
----------------------------------------------+
Where:
c2e9cc26-6c2c-4c29-92bd-e49a415bed5c represents the ID of the Manila job binary that
you created in section 3.3, “Create the Spark Binary Data.”
3.6 Create a Sahara Data Source That Uses Manila Shares
To create the Sahara data source that uses a Manila share, complete the following steps:
1. Create the Manila input data source.
$ sahara data-source-create --name manila-input --type manila --url manila://cb5c3580-5da8-4d16-
9071-0251a5e208c1/input
Where:
manila://cb5c3580-5da8-4d16-9071-0251a5e208c1/ is expanded on execution to an
actual NFS mount path on the Spark cluster nodes (based on the Manila ID in the string).
input is a file name on the NFS mount that will be used as data input for processing.

18 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
2. Create the Manila-based NFS data source that Sahara will use.
$ sahara data-source-create --name manila-output --type manila --url manila://cb5c3580-5da8-4d16-
9071-0251a5e208c1/output-%JOB_EXEC_ID%
+--------------+--------------------------------------------------------------------+
| Property | Value |
+--------------+--------------------------------------------------------------------+
| description | |
| url | manila://cb5c3580-5da8-4d16-9071-0251a5e208c1/output-%JOB_EXEC_ID% |
| tenant_id | 91f953c83a044bf4b940335321dc6514 |
| created_at | 2015-10-01T20:57:29 |
| is_protected | False |
| is_public | False |
| type | manila |
| id | 6d1f53bd-95d6-406d-8697-bd5c521c656f |
| name | manila-output |
+--------------+--------------------------------------------------------------------+
Where:
manila-output is the name of the data source. You will reference this name in the Spark jobs
that you create.
cb5c3580-5da8-4d16-9071-0251a5e208c1 represents the ID of the Manila share that you
created in the “Scenario Two: Create an NFS Share and a Share Network” section. You can repeat the command for the second share, substituting the ID as appropriate.
Note: The %JOB_EXEC_ID% string gives each job a unique output directory to prevent duplicate output errors in Hadoop and Spark.
3.7 Create a Spark Template That Uses Manila Shares
The current method for using Manila shares involves modifying the default cluster template. If you pulled
the source for Sahara by using $ git clone https://github.com/openstack/sahara.git (see
the “Create the Spark Binary Data” section), the source includes the
sahara/plugins/default_templates/spark/v1_3_1/cluster.json file, which defines a valid
Spark cluster. You must copy and edit the file to include a reference to the two Manila shares that you
created in Horizon.
To edit the .json file and create your template, complete the following steps:
1. Copy the .json file and save it as manila-spark-cluster.json.
2. Edit your file to include one or more existing Manila share IDs. The share IDs must correspond to the IDs for the two Manila shares that you created in Horizon.
3. Add the ID for your Neutron management network to the file. The network ID must correspond to one of the following options:
An existing public network (from which a floating ID is obtained by Sahara) if you configured
Sahara with the default setting use_floating_ips=True. Sahara maps the floating IP address
to the VM and uses it for provisioning the shares to Manila through the public network.
An existing private Neutron network if you configured Sahara with the setting
use_floating_ips=False and you can route to or access your NFS storage from this private
network. In this case, your VM instances do not receive a public floating IP address.
Best Practice
Use Manila over nonrouted, private networks that are dedicated to storage.
In the following .json file example, the sample network ID is shown as green text, and the sample share IDs are shown as blue text.

19 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
{
"plugin_name": "spark",
"hadoop_version": "1.3.1",
"node_groups": [
{
"name": "slave",
"count": 3,
"node_group_template_id": "c1f2bf10-10ea-4ba1-8c99-9bd65cad9244"
},
{
"name": "master",
"count": 1,
"node_group_template_id": "67b93ec4-2dd1-407c-bc3d-3c55bb50fb8b"
}
],
"name": "spark-131-manila-cluster",
"neutron_management_network": "84cb58a4-8f82-4ef2-b81f-c413eaff1b06",
"shares": [{"id": "eccccad9-3c3b-473f-827a-28f1469609f1",
"access_level": "rw",
"path": "/mnt/share1"},
{"id": "cb5c3580-5da8-4d16-9071-0251a5e208c1",
"access_level": "ro",
"path": "/mnt/share2"}]
}
4. Run the following command to use your .json file as input for the Spark cluster template.
[fedora@f21-sahara sahara(keystone_demo)]$ sahara cluster-template-create --json manila-spark-
cluster.json
+----------------------------+-------------------------------------------------------------------
-------------------------------------------------------------------------------------------------
------------------------------------+
| Property | Value
|
+----------------------------+-------------------------------------------------------------------
-------------------------------------------------------------------------------------------------
------------------------------------+
| description | None
|
| updated_at | None
|
| plugin_name | spark
|
| is_default | False
|
| use_autoconfig | True
|
| anti_affinity | []
|
| node_groups | slave: 3, master: 1
|
| is_public | False
|
| hadoop_version | 1.3.1
|
| id | c3ca8e75-2559-4c1f-9476-061b1ab01796
|
| neutron_management_network | aa69bfab-978d-4821-aa34-546e01b62d32
|
| name | spark-131-manila-cluster
|
|
| created_at | 2015-09-28T18:27:19
|
| default_image_id | None
|
| shares | [{u'path': u'/mnt/share1', u'id': u'eccccad9-3c3b-473f-827a-
28f1469609f1', u'access_level': u'rw'}, {u'path': u'/mnt/share2', u'id': u'cb5c3580-5da8-4d16-
9071-0251a5e208c1', u'access_level': u'ro'}] |
| is_protected | False
|

20 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
| tenant_id | 91f953c83a044bf4b940335321dc6514
|
+----------------------------+-------------------------------------------------------------------
-------------------------------------------------------------------------------------------------
------------------------------------+
5. Verify that sufficient floating IP addresses to allocate to the new cluster are available in the public Neutron network.
Note: If you are not using floating IP addresses, you do not need to do this precheck.
3.8 Launch the Spark Cluster from Your Template
To launch the Spark cluster in the Horizon UI from your template, complete the following steps:
1. Log in to Horizon as the desired tenant. In this procedure, the tenant is demo.
2. Click the Data Processing tab and then click Clusters.
3. Click the Launch Cluster button.
4. In the dialog box, select Apache Spark and version 1.3.1. Click Next.
5. Specify the cluster information:
a. Type a name for the cluster.
b. Optional: Type a cluster description.
c. Select the spark-131-manila-cluster template that you created in section 3.7, “Create a
Spark Template That Uses Manila Shares,” to give the new cluster access to the necessary shares from the Manila service.
d. Type the number of instances in the cluster.
e. Select your base image.
f. Optional: Select a key pair.
g. Select your tenant’s Neutron management network.

21 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
6. Click Launch.
4 Use Cases
After you launch the Spark cluster from your template, you can put sample data from NFS shares into
HDFS and launch a sample job by using a Manila share.
4.1 Put a Job Binary on a Manila Share
To put a binary on the Manila NFS share that you exposed to the Spark cluster, complete the following
steps:

22 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
1. Browse to the status page of the cluster that you just launched as the demo user and get an IP address for one of your Spark nodes.
2. Get the path of the binary NFS mount on the Sahara master node.
$ ssh [email protected] mount |grep cb5c3580-5da8-4d16-9071-0251a5e208c1
10.254.0.10:/shares/share-cb5c3580-5da8-4d16-9071-0251a5e208c1 on /mnt/cb5c3580-5da8-4d16-9071-
0251a5e208c1 type nfs (rw,vers=4,addr=10.254.0.10,clientaddr=192.168.90.167)
Note: The mount path must be in the /mnt/<manila_share_ID> format.
3. Run scp to copy your job binary to the NFS mount so that it can be accessed by all Spark nodes.
[keystone_demo)]$ scp word-count.jar [email protected]:/mnt/cb5c3580-5da8-4d16-9071-
0251a5e208c1/word-count.jar
100% 7992 7.8KB/s 00:00
4.2 Put Data from a Manila Share into HDFS
To put a file that resides on the Manila NFS share that you exposed to the Spark cluster into HDFS,
complete the following steps:
1. Connect to one of the Spark nodes by using SSH.
$ ssh [email protected]
2. Find a file in your Manila share to put into HDFS.
ubuntu@manila-spark-cluster1-spark-131-master-no-float-0:~$ ls /mnt/cb5c3580-5da8-4d16-9071-
0251a5e208c1/input*
/mnt/cb5c3580-5da8-4d16-9071-0251a5e208c1/input /mnt/cb5c3580-5da8-4d16-9071-0251a5e208c1/input2
/mnt/cb5c3580-5da8-4d16-9071-0251a5e208c1/input3
3. Put the file into HDFS for later processing.
ubuntu@manila-spark-cluster1-spark-131-master-no-float-0:~$ hadoop fs -put /mnt/cb5c3580-5da8-
4d16-9071-0251a5e208c1/input /user/ubuntu/input
4. List your contents to verify that the file is in HDFS.
ubuntu@manila-spark-cluster1-spark-131-master-no-float-0:~$ hadoop fs -ls /user/ubuntu
Found 1 items
-rw-r--r-- 3 ubuntu supergroup 309922 2015-10-01 21:51 /user/ubuntu/input

23 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
4.3 Launch a Job by Using the Manila Share as a Data Source
To launch a job that is based on the Spark template that you created, complete the following steps:
1. Run the spark-wordcount binary that you uploaded against the manila-input data source that
you defined earlier.
$ sahara job-create --job-template fc4b55eb-22b6-4bc7-a6a3-1961fe466ad0 --cluster 82d57678-9372-
4d7c-bddd-5e9dc884a081 --config edp.substitute_data_source_for_name=True --config
edp.java.main_class=sahara.edp.spark.SparkWordCount --arg datasource://manila-input
2. Monitor your job status.
5 Summary
This guide presents examples and use cases that demonstrate the possibilities for integration of NFS-
based data from NetApp storage arrays into Hadoop or Spark clusters. The value of easily moving data
between NFS shares and HDFS and of processing output to and from NFS file shares is rooted in the
flexibility that this capability gives the big data administrator. In addition, job binaries can be stored on
Manila shares and can be referenced by a job directly without the need to copy binaries throughout a
large cluster.
6 NFS Shares as a Data Source in Sahara
In the future, it is expected that the Sahara project will allow integration with the NetApp NFS Connector
for Hadoop directly into Spark or Hadoop clusters without manual configuration. This integration will
represent another path for accessing NFS data such that data residing in NFS files can be mounted and
exposed within HDFS natively (without copying). For more information about this proposal, see Use
NetApp NFS Driver to Support NFS as a Data Source in Sahara.
Acknowledgments
I would like to thank Trevor McKay, Chad Roberts, and Ethan Gafford from Red Hat for their contributions
to the enablement of this integration work and for their technical review of this document. Without them,
this document would not have been possible. I would also like to thank Weiting Chen from Intel for his
work related to the NetApp NFS Connector for Hadoop within the Sahara project. And lastly, I would like
to thank Karthikeyan Nagalingam from NetApp for his assistance with and review of this document.

24 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
References
The following references were used in this document:
Adding Manila Shares as an Option for Data Sources in Horizon UI https://review.openstack.org/#/c/214754/
Adding Support for Manila-Based Shares in Sahara Horizon UI https://review.openstack.org/#/c/207086/
Addition of Manila as a Binary Store http://specs.openstack.org/openstack/sahara-specs/specs/liberty/manila-as-binary-store.html
API to Mount and Unmount Manila Shares to Sahara Clusters http://specs.openstack.org/openstack/sahara-specs/specs/liberty/mount-share-api.html
Manila as a Runtime Data Source http://specs.openstack.org/openstack/sahara-specs/specs/liberty/manila-as-a-data-source.html
NetApp NFS Connector for Hadoop https://github.com/NetApp/NetApp-Hadoop-NFS-Connector
NetApp OpenStack Deployment and Operations Guide http://netapp.github.io/openstack-deploy-ops-guide/
OpenStack Installation Guide for Ubuntu 14.04 (Kilo release) http://docs.openstack.org/kilo/install-guide/install/apt/content/
Readme for the sahara-templates CLI https://github.com/openstack/sahara/blob/stable/liberty/sahara/db/templates/README.rst
Sahara Architecture http://docs.openstack.org/developer/sahara/architecture.html
Sahara Image Elements https://github.com/openstack/sahara-image-elements/tree/stable/liberty
Sahara/SparkPlugin https://wiki.openstack.org/wiki/Sahara/SparkPlugin
TR-3969: NetApp Open Solution for Hadoop Solutions Guide http://www.netapp.com/us/media/tr-3969.pdf
TR-4382: NetApp NFS Connector for Hadoop http://www.netapp.com/us/media/tr-4382.pdf
Using NetApp NFS Driver to Support NFS as a Data Source in Sahara https://blueprints.launchpad.net/sahara/+spec/nfs-as-a-data-source
Version History
Version Date Document Version History
Version 1.0 October 2015 Initial release

25 Manila and Sahara Integration in OpenStack © 2015 NetApp, Inc. All rights reserved.
Refer to the Interoperability Matrix Tool (IMT) on the NetApp Support site to validate that the exact product and feature versions described in this document are supported for your specific environment. The NetApp IMT defines the product components and versions that can be used to construct configurations that are supported by NetApp. Specific results depend on each customer's installation in accordance with published specifications.
Trademark Information
NetApp, the NetApp logo, Go Further, Faster, AltaVault, ASUP, AutoSupport, Campaign Express, Cloud
ONTAP, Clustered Data ONTAP, Customer Fitness, Data ONTAP, DataMotion, Fitness, Flash Accel,
Flash Cache, Flash Pool, FlashRay, FlexArray, FlexCache, FlexClone, FlexPod, FlexScale, FlexShare,
FlexVol, FPolicy, GetSuccessful, LockVault, Manage ONTAP, Mars, MetroCluster, MultiStore, NetApp
Insight, OnCommand, ONTAP, ONTAPI, RAID DP, RAID-TEC, SANtricity, SecureShare, Simplicity,
Simulate ONTAP, SnapCenter, Snap Creator, SnapCopy, SnapDrive, SnapIntegrator, SnapLock,
SnapManager, SnapMirror, SnapMover, SnapProtect, SnapRestore, Snapshot, SnapValidator,
SnapVault, StorageGRID, Tech OnTap, Unbound Cloud, WAFL, and other names are trademarks or
registered trademarks of NetApp Inc., in the United States and/or other countries. All other brands or
products are trademarks or registered trademarks of their respective holders and should be treated as
such. A current list of NetApp trademarks is available on the web at
http://www.netapp.com/us/legal/netapptmlist.aspx. TR-4464-1015
Copyright Information
Copyright © 1994–2015 NetApp, Inc. All rights reserved. Printed in the U.S. No part of this document covered by copyright may be reproduced in any form or by any means—graphic, electronic, or mechanical, including photocopying, recording, taping, or storage in an electronic retrieval system—without prior written permission of the copyright owner.
Software derived from copyrighted NetApp material is subject to the following license and disclaimer:
THIS SOFTWARE IS PROVIDED BY NETAPP "AS IS" AND WITHOUT ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE, WHICH ARE HEREBY DISCLAIMED. IN NO EVENT SHALL NETAPP BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
NetApp reserves the right to change any products described herein at any time, and without notice. NetApp assumes no responsibility or liability arising from the use of products described herein, except as expressly agreed to in writing by NetApp. The use or purchase of this product does not convey a license under any patent rights, trademark rights, or any other intellectual property rights of NetApp.
The product described in this manual may be protected by one or more U.S. patents, foreign patents, or pending applications.
RESTRICTED RIGHTS LEGEND: Use, duplication, or disclosure by the government is subject to restrictions as set forth in subparagraph (c)(1)(ii) of the Rights in Technical Data and Computer Software clause at DFARS 252.277-7103 (October 1988) and FAR 52-227-19 (June 1987).