mapreduce: acknowledgements: some slides form google university (licensed under the creative commons...
TRANSCRIPT


MapReduce:
Acknowledgements: Some slides form Google University (licensed under the Creative Commons Attribution 2.5 License) others from Jure Leskovik

MapReduce
Concept from functional programming Applied to large number of problems

Java:
int fooA(String[] list) { return bar1(list) + bar2(list); }
int fooB(String[] list) { return bar2(list) + bar1(list); }
Do they give the same result?

Functional Programming:
fun fooA(l: int list) = bar1(l) + bar2(l)
fun fooB(l: int list) = bar2(l) + bar1(l)
They do give the same result!

Functional Programming
Operations do not modify data structures: They always create new ones
Original data still exists in unmodified form

Functional Updates Do Not Modify Structures
fun foo(x, lst) =
let lst' = reverse lst in
reverse ( x :: lst' )
foo: a’ -> a’ list -> a’ list
The foo() function above reverses a list, adds a new element to the front, and returns all of that, reversed, which appends an item.
But it never modifies lst!

Functions Can Be Used As Arguments
fun DoDouble(f, x) = f (f x)
It does not matter what f does to its argument; DoDouble() will do it twice.
What is the type of this function? x: a’ f: a’ -> a’
DoDouble: (a’ -> a’) -> a’ -> a’

map (Functional Programming)
Creates a new list by applying f to each element of the input list; returns output in order.
f f f f f f

map Implementation
This implementation moves left-to-right across the list, mapping elements one at a time
… But does it need to?
fun map f [] = [] | map f (x::xs) = (f x) :: (map f xs)

Implicit Parallelism In map
In a functional setting, elements of a list being computed by map cannot see the effects of the computations on other elements
If order of application of f to elements in list is commutative, we can reorder or parallelize execution

ReduceMoves across a list, applying f to each element
plus an accumulator. f returns the next accumulator value, which is combined with the next element of the list
f f f f f returned
initial
Order of list elements can be significant Fold left moves left-to-right across the list … Again, if operation commutative order not important

MapReduce

Motivation: Large Scale Data Processing
Google: 20+ billion web pages x 20KB = 400+ TB
1 computer reads 30-35 MB/sec from disk~4 months to read the web
~1,000 hard drives to store the web Even more to do something with the data

Web data sets are massive Tens to hundreds of terabytes
Cannot mine on a single server Standard architecture emerging – commodity clusters
Cluster of commodity Linux nodes Gigabit ethernet interconnect How to organize computations on this architecture?
Mask issues such as hardware failure

Traditional ‘big-iron box’ (circa 2003) 8 2GHz Xeons 64GB RAM 8TB disk $758,000 USD
Prototypical Google rack (circa 2003) 176 2GHz Xeons 176GB RAM ~7TB disk 278,000 USD
In Aug 2006 Google had ~450,000 machines
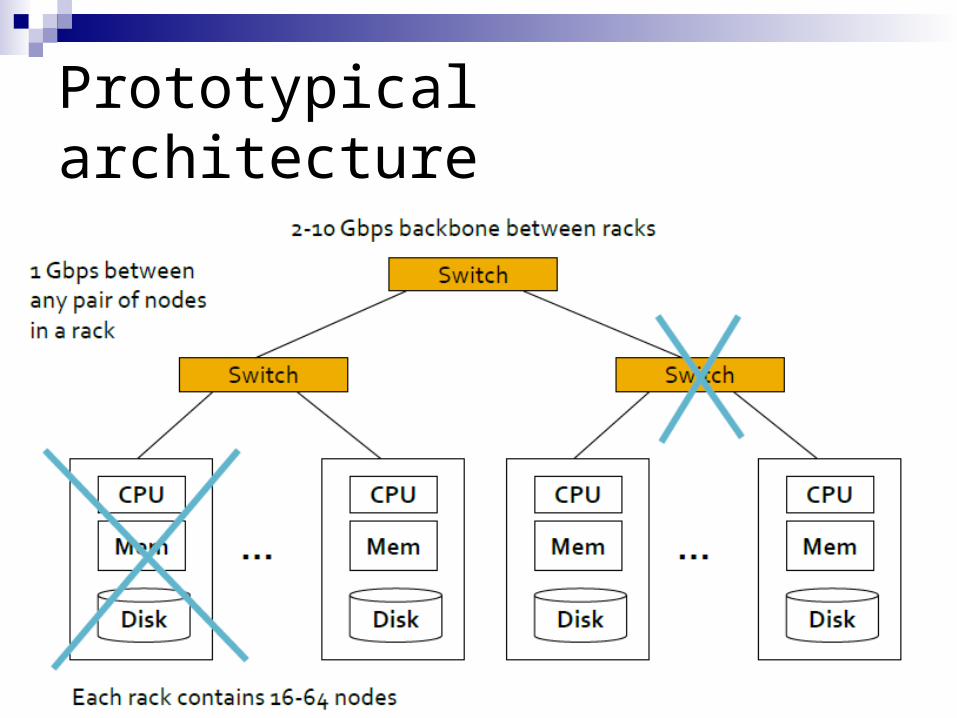
Prototypical architecture

The Challenge: Large-scale data-intensive computing commodity hardware process huge datasets on many computers, e.g., data
mining
Challenges: How do you distribute computation?
Distributed/parallel programming is hard Single machine performance should not matter /
incremental scalability Machines fail
Map-reduce addresses all of the above Elegant way to work with big data

Idea: collocate computation and data (Store files multiple times for reliability)
Need:Programming model
Map-ReduceInfrastructure
File system: Google: GFS, Hadoop: HDFS Runtime engine

MapReduce
Automatic parallelization & distribution Fault-tolerant Provides status and monitoring tools Clean abstraction for programmers

*
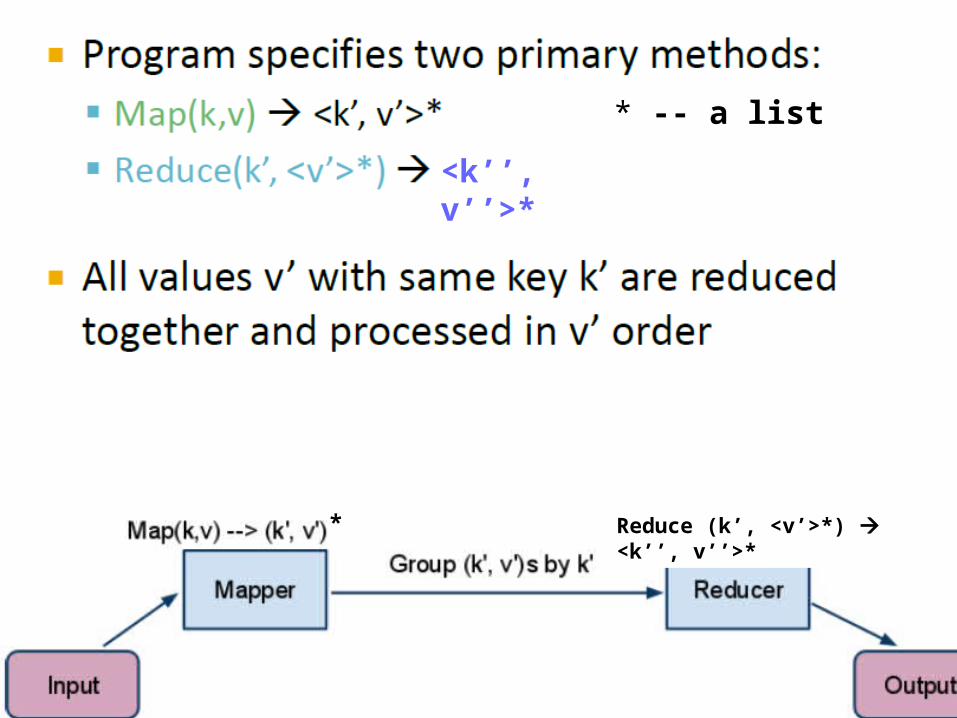
Notation: * -- a list
Reduce (k’, <v’>*) <k’’, v’’>

* -- a list
*
<k’’, v’’>
Reduce (k’, <v’>*) <k’’, v’’>


map(String input_key, String input_value):
// input_key: document name
// input_value: document contents
for each word w in input_value:
EmitIntermediate(w, "1");
reduce(String output_key, intermediate_value_list):
// output_key: a word
// intermediate_value_list: a list of ones
int result = 0;
for each v in intermediate_values:
result += ParseInt(v);
Emit(output_key, AsString(result));


Reversed Web-Link Graph: For a list of web pages produce the set of pages that have links that point to each of these pages.
Email me your solution (pseudocode) by the end of Thursday 27/02

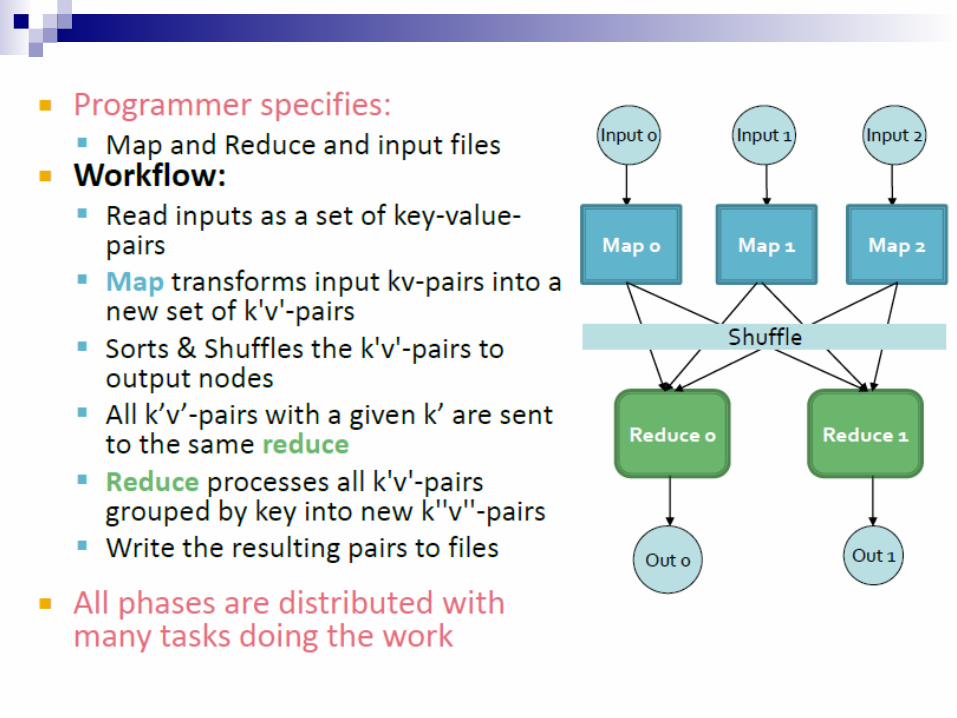
Key ideas behind map-reduce

Key idea 1:Separate the what from the how MapReduce abstracts away the “distributed” part of
the systemdetails are handled by the framework
However, in-depth knowledge of the framework is key for performanceCustom data reader/writerCustom data partitioningMemory utilization
* -- a list
*
<k’’, v’’>*
Reduce (k’, <v’>*) <k’’, v’’>*

Key idea 2:Move processing to the data Drastic departure from high-performance computing model
HPC: distinction between processing nodes and storage nodes. Designed for CPU intensive tasks
Data intensive workloads Generally not processor demanding
The network and I/O are the bottleneck
MapReduce assumes processing and storage nodes to be co-located: (data locality) Distributed filesystems are necessary

Key idea 3:Scale out, not up!
For data-intensive workloads, a large number of commodity servers is preferred over a small
number of high-end servers cost of super-computers is not linear
Some numbers Processing data is quick, I/O is very slow:
1 HDD = 75 MB/sec; 1000 HDDs = 75 GB/sec Data volume processed: 80 PB/day at Google; 60TB/day at Facebook (~2012)

Key idea 4“Shared-nothing” infrastructure(both hard- and soft-ware)
Sharing vs. Shared nothing:Sharing: manage a common/global stateShared nothing: independent entities, no common state
Functional programming as key enabler No side effects Recovery from failures much easier map/reduce – as subset of functional programming







More examples Distributed Grep: The map function emits a line if it
matches a supplied pattern. The reduce function is an identity function that just copies the supplied intermediate data to the output.
Count of URL Access Frequency: The map function processes logs of web page requests and outputs <URL; 1>. The reduce function adds together all values for the same URL and emits a <URL; total count> pair.
ReverseWeb-Link Graph: The map function outputs <target; source> pairs for each link to a target URL found in a page named source. The reduce function concatenates the list of all source URLs associated with a given target URL and emits the pair: <target; list(source)>
Term-Vector per Host: …

More info
MapReduce: Simplified Data Processing on Large ClustersJeffrey Dean and Sanjay Ghemawat,http://labs.google.com/papers/mapreduce.html
The Google File SystemSanjay Ghemawat, Howard Gobioff, and Shun-TakLeung, http://labs.google.com/papers/gfs.html