maria-cristina marinescu martin rinard laboratory for computer science massachusetts institute of...
TRANSCRIPT

Maria-Cristina MarinescuMartin Rinard
Laboratory for Computer ScienceMassachusetts Institute of Technology
A Synthesis Algorithm for Modular Design of Pipelined
Circuits

Overall Goal
Modular,Asynchronous,
SequentialSpecification
Efficient,Synchronous,
ParallelImplementation
in Synthesizable
Verilog

RESET RESET
Instruction Fetch
RegisterOperand
Fetch
Computeand
Writeback
Example: Specification
PC
IM ... ...
RF wen
inc
br
inc

Specification Properties
• Basic Concepts•State
•Registers and Memories•Conceptually Infinite Queues
•Modules (state transformers)• Queues Provide Modularity
•Decouple Modules•Enable Independent Development•Promote Reusable Modular Designs

RESET RESET
Instruction Fetch
RegisterOperand
Fetch
Computeand
Writeback
Example: Implementation
PC
IM
RF wen
inc
br
inc

Implementation Issues
• Synthesizing Efficient Combinational Logic
• Queue Finitization• Synchronous Global Scheduling

Specification Language

Type Declarationstype reg = int(3), val = int(8), loc = int(8);
type ins = <INC reg> | <JZ reg loc>;
type irf = <INC reg val> | <JZ val loc>;
State Declarationsvar PC: loc, IM: ins[N], RF: val[8];
var IQ: queue(ins), RQ: queue(irf);

Modules
• Each module is set of update rules• Each Update Rule Consists of
•Precondition•Action (set of updates)
• Rule is enabled (and can execute) if precondition is true in current state
• When rule executes, atomically applies updates in action to produce new state

Update Rules And Modules
• Instruction Fetch ModuleTRUE
iq = append(iq,im[pc]), pc = pc + 1;
• Register Operand Fetch Module<INC r> = head(iq) and notin(rq, <INC r _>)
iq = tail(iq), rq = append(rq, <INC r rf[r]>);
<JZ r l> = head(iq) and notin(rq, <INC r _>) iq = tail(iq), rq = append(rq, <JZ rf[r]
l>);

Update Rules And Modules
• Compute and Writeback Module<INC r v> = head(rq)
rf = rf[r = v+1], rq = tail(rq);
<JZ v l> = head(rq) and (v == 0) pc = l, iq = nil, rq = nil;
<JZ v l> = head(rq) and (v !=0) rq = tail(rq);

Abstract Model of Execution
• Conceptually, system execution is a sequence of rule executions
• while TRUE choose an enabled rule
execute rule obtain new state
• Concepts in Abstract Execution Model•Rules execute atomically•Rules execute asynchronously•Rules execute sequentially

Synthesis Algorithm

Synthesis Algorithm
• Starting Point•Asynchronous, sequential abstract
execution•Conceptually infinite queues
• Goal: efficient synchronous global schedule•In each clock cycle, multiple rules execute
•Synchronously and Concurrently •(pipeline stages move together)
•Implement each queue with a finite hardware buffer
•Can read and write buffer in same cycle

Basic Idea
• At Each Clock Cycle•Check each rule to see if enabled
•If so, atomically update state to reflect execution
•For each variable, generate expression that specifies new value at end of cycle
• Challenge:sequential, atomic semantics for rules
• Solution: symbolic rule execution

Final Result for PC
if (<JZ v location> = rq and v == 0) new pc = location
else if ((iq == nil) or (<INC r> = iq and <INC r _> != rq)
or (<JZ r l> = iq and <INC r _> != rq))
new pc = pc+1 else
new pc = pc

Algorithm Outline
• Rule Numbering: for symbolic execution• Relaxation: shorten critical path by testing
intial state• Queue Finitization: ensure rules execute
only if will be room for the result in output queues
• Symbolic Execution• Optimizations• Synthesizable Verilog Generation: from
optimized expressions

Rule Numbering
• Goal: •Resolve Conflicts Between Parallel Rule
Executions• Approach:
•For each state variable, number versions according to order
•Feed results of previous rule into next rule

• TRUE iq1 = append(iq0, im[pc0]), pc1 =
pc0+1;
• <INC r> = head(iq1) and notin(rq1, <INC r _>)
iq2 = tail(iq1), rq2 = append(rq1,
<INC r rf1[r]>);
• <JZ r l> = head(iq2) and notin(rq2, <INC r _>)
iq3 = tail(iq2),
rq3 = append(rq2, <JZ rf2[r] l>);
• <INC r v> = head(rq3)
rf4 = rf3[r v+1], rq4 = tail(rq3);
• <JZ v l> = head(rq4) and v != 0
rq5 = tail(rq4);
• <JZ v l> = head(rq5) and v == 0
pc6 = l, rq6 = nil, iq6 = nil;

Relaxation• Issue:
rule numbering may produce long clock cycle
• Solution: for each rule Ri with precondition
Pi for each variable instance vi in precondition Pi
replace vi with its earliest safe version
... Rk-1: Pk-1 -> vk = ... ... Ri : Pi(vi,...) -> ... ...
vk safe for vi if either•Pi[vk/vi] implies Pi
•(Pi,Pk-1) mutually exclusive
0 1 2 3 =>0 1
3
2

Relaxation Result
• Queues separate pipeline stages• Items traverse one stage per clock
cycle• Safety: If a rule executes in new system
•Then it also executes in old system•And it generates same result
• Liveness: After relaxation, all rules test initial state
•If rule enabled in old system but not in new system, then
•Some rule executes in new system

• TRUE iq1 = append(iq0, im[pc0]),
pc1 = pc0+1;
• <INC r> = head(iq0) and notin(rq0, <INC r _>)
iq2 = tail(iq1), rq2 = append(rq1, <INC r rf1[r]>);
• <JZ r l> = head(iq0) and notin(rq0, <INC r _>)
iq3 = tail(iq2), rq3 = append(rq2, <JZ rf2[r] l>);
• <INC r v> = head(rq0)
rf4 = rf3[r v+1], rq4 = tail(rq3);
• <JZ v l> = head(rq0) and v != 0
rq5 = tail(rq4);
• <JZ v l> = head(rq0) and v == 0
pc6 = l, rq6 = nil, iq6 = nil;

Queue Finitization
• Issue:•Conceptually unbounded queues•Finite hardware buffers
• Assumption: queues start within length at beginning of cycle
• Goal: generate circuit that makes queues remain within length at end of cycle
• Basic Approach: •Before enabled rule executes•Be sure will be room for result in output
queues at end of clock cycle

Queue Finitization Algorithm
• Build Producer-Consumer Graph•Nodes are rules•Edge between rules if first inserts into queue and second removes from queue
• In Example:
12
3
4
5
6

Acyclic Graphs• Process Rules in Topological Sort Order
•Augment execution precondition•If rule inserts into a queue, require that either•there is room in queue when rule executes or
•future rules will execute and remove items to make room in queue
• Each queue has counter of number of elements in queue at start of cycle
• Combinational logic tracks queue insertions and deletions

Example
Instruction Fetch Rule After Queue Finitization
Empty(iq0) or
(<JZ v l> = head(rq0) and v == 0) or
<INC r> = head(iq0) and notin(rq0, <INC r _>) or
<JZ r l> = head(iq0) and notin(rq0, <INC r _>)
iq1 = append(iq0, im[pc0]);
pc1 = pc0+1;

Pipeline Implications
• Counter becomes presence bit for single element queues
• Additional preconditions can be viewed as pipeline stall logic
• Design can be written to generate pipeline forwarding/bypassing instead of stall
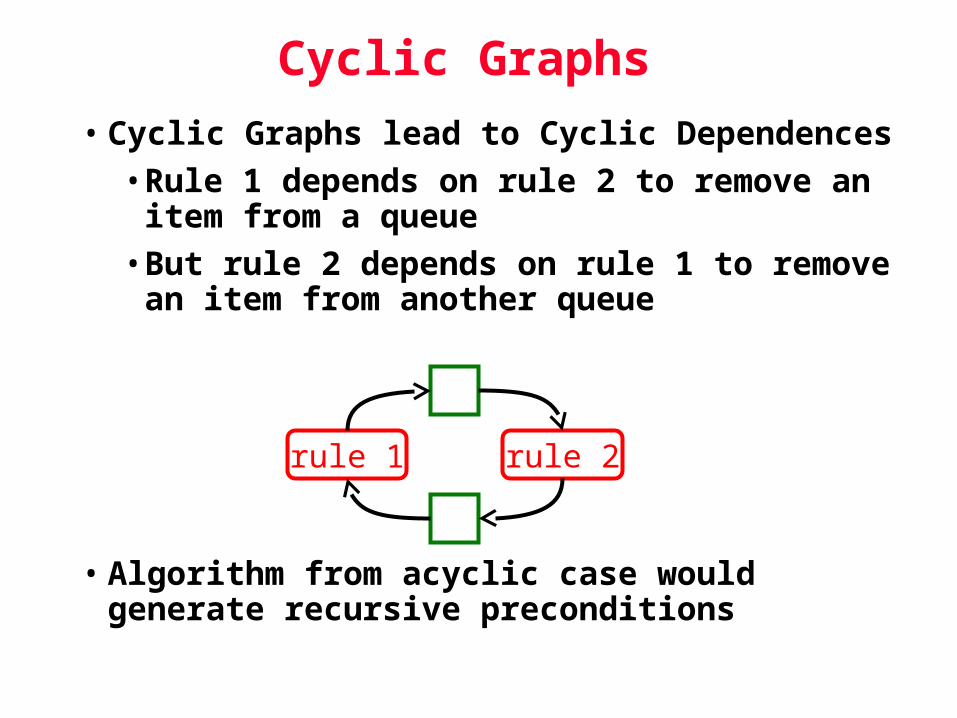
Cyclic Graphs• Cyclic Graphs lead to Cyclic Dependences
•Rule 1 depends on rule 2 to remove an item from a queue
•But rule 2 depends on rule 1 to remove an item from another queue
• Algorithm from acyclic case would generate recursive preconditions
rule 2rule 1

Solution to Cyclic Dependence Problem
• Groups of rules must execute together
• Use depth-first search on producer-consumer graph to find cyclic groups
• Augment preconditions to allow all rules in cycle to execute together
• Extensions include paths into and out of cyclic group

Symbolic Execution
• Substitute out all intermediate versions of variables
• Obtain expression for last version of each variable
• Each expression defines new value of corresponding variable

Optimizations
• Optimize expressions from symbolic execution•CSE: avoid unnecessary replication of
HW•Mutual Exclusion Testing:
•Eliminate computation of values that never occur in practice as result of mutually exclusive preconditions

Symbolic Execution with Optimization
Final result for rq, assuming single item queues
if <JZ v l> = head(rq) and v==0new rq = nil
else if <INC r>=head(iq) and notin(rq,<INC r _>)new rq = <INC r rf[r]>
else if <JZ r l>=head(iq) and notin(rq,<INC r _>)new rq = <JZ rf[r] l>
else new rq = nil

Verilog Generation
• Synthesize HW directly from expressions:•Each queue as one or more registers
•Each memory variable as library block
•Each state variable as one or more registers, depending on type
•Each expression as combinational logic that feeds back into corresponding registers

Experimental Results• We have implemented synthesis
system• Used system to generate synthesizable
Verilog for several specifications
(map effort medium, area effort low, constraints 10ns)
Benchmark Cycle Time Area (cells)Bubblesort 9.34ns ~370Butterfly 9.57ns ~412Processor 11.28ns ~387Filter 9.51ns ~252

Conclusion• Starting Point: (Good for Designer)
Modular, Asynchronous, Sequential Specification with Conceptually Infinite Queues
• Ending Point: (Good for Implementation)
Efficient, Synchronous, Globally Scheduled, Parallel Implementation with Finite Queues in Synthesizable Verilog
• Variety of Techniques:•Symbolic Execution•Queue Finitization