masvingo state university for... · web viewhe then invented the word association test. wundt...
TRANSCRIPT

MIDLANDS STATE UNIVERSITYDEPARTMENT OF PSYCHOLOGY
BSc. HOUNOURS PSYCHOLOGY
LECTURE NOTES
BY
J. M. KASAYIRA
PSY 410: PSYCHOMETRICS
What is Psychometrics?Psychometrics is the science of psychological assessment. This involves the process of selecting and evaluating human beings (Rust & Golombok 1989, P. 20). The term is further defined by the American Psychological Association (APA) (1985; P.93) as that pertaining to the measurement of the psychological characteristics such as abilities, aptitudes, achievements, personalities, traits, skills, and knowledge. Thus psychometrics is concerned with the design and the analysis of research and the measurement of the human characteristics. One important component of psychometrics is psychological testing that includes intelligence testing, personalities testing and vocational testing. Below we look at psychological testing.
Psychological Testing
Psychological testing is a process of assessing a sample of behaviour through use of objective and standardized instruments. According to Anastasi (1990), psychological testing is rarely concerned with the measurement of the behaviour sample directly covered by the test. Thus, test items need not resemble closely the behaviour the test is to predict. It is not necessary that an empirical correspondence be demonstrated between the psychological test and the behaviour of interest. In the next section we describe some early efforts to develop psychological tests, in particular the intelligence test.
The History of Psychometrics and AssessmentThe two major events that influenced the birth of psychometrics and assessment in the 19th century, developed along relatively independent lines: psychophysics and mental testing. Other influences including some incorporated in the major two are: the

experiment on reaction time, which began with the discovery of the astronomer’s personal equation, the theory of evolution, the development of statistical methods, and the two world wars. Thus, Miller (1964) noted that quantitative psychology has developed from a different number of places where different sponsors pioneered in new directions.
Psychophysics (the forerunner of the first genuinely experimental psychology) developed when human judgements were studied using concepts and tools that had been applied successfully in Physics, Chemistry and Astronomy. Also the urgent need for methods of measuring emotional stability and intelligence in Medicine, Psychiatry, and Social Welfare Research (with the inspiration of Evolutionary Biology) led to the development of the mental- test tradition that centered upon individual differences. The merging of the two influences, with the help of statistical methods, produced the modern methodology of testing.
Curiously, Experimental Psychology and Differential Psychology can be traced to the early experiment in psychological function made by a German astronomer, Friedrich Wilhelm Bessel (1784 – 1846). Bessel had read about the dismissal of Kinnebrook, an assistant to Maskelyne, the royal astronomer at Greenwich Observatory. Kinnebrook had been fired for being persistently, between half a second to one second, slower than his superior in noting the transits of stars used to check the accuracy of clocks.
Contributions of German psychologistsAround 1820, Bessel began experimenting upon himself and other astronomers, and found considerable variation among individuals in speed of response. This finding led to the recognition that people differ in their judgements, and that such individual differences can be accounted for scientifically. The finding also led to the formulation of `personal equation` whereby the characteristic tendency to over or underestimate observations by the certain amount is corrected.
Bessel’s work on ‘reaction time’, also led German philosophers and the early psychologists to begin speculations about the threshold of awareness, the limen. For example, a philosopher, Hebart (1776 – 1841) suggested the concept of an absolute threshold, or lower limit of sensation. And Ernst Weber (1795 – 1878) carried out research on the two point threshold and demonstrated that it varies both in different parts of the body of the same person, and from one person to another for the given region of the body. He then developed the concept of just noticeable difference from which he developed what may be said to be the first truly quantitative law (Schultz, 1981). It states that, the smallest detectable difference between two weights can be expressed by the ratio of the difference between the weights, and the ratio is independent of the absolute values of the weights. This has been termed Weber’s law by Gustav Fechner (1801 – 1887).
Fechner established the science of relation of mental process to physical events (Psychophysics). In 1850, Fechner postulated that the connection between mind and body could be found in the statement of quantitative relation between mental sensation and material stimulus. He reformulated Weber’s law as follows: sensation difference

remains constant when the relative stimulus difference remains constant. Mathematically he expressed it as; a sensation is proportional to the logarithm of its Stimulus (S = k log R).
It was largely because of Fechner’s psychophysical research that Wundt conceived the plan of his Experimental Psychology. According to Tuddenham (1964), Wundt had even attempted to measure the time intervals required by the mind to perceive; to discriminate; and to associate, by noting differences in reaction time for tasks presumably involving different combination of these complex activities. Hence, he developed his mental chronometry. Since the German psychologists have been preoccupied with finding general laws, similar to those found in natural sciences, they had not done much on individual differences. Only a few German researchers, who include Weber, Fechner, and Helmhotz reported individual differences in their experiments. Nevertheless, Wundt and other German workers contributed to the mental test movement and the quantitative psychology as a whole by bringing out the need for vigorous control of the conditions under which observations were made. This led to the standardization of procedures that is very important in psychological assessment today.
Galton’s Contributions
The science of individual differences may be said to have truly began with Sir Francis Galton (1822 – 1911) whose predominant emphasis on heredity as an explanation of difference in intelligence was greatly supported by the zeitgeist up to the mid 1920s. This started with Darwin’s theory of evolution. Spencer, a British philosopher, and Galton were impressed by the emphasis that Darwin put on individual variability as the key to survival and evolution of species. Hence, Herbert Spencer (1820 – 1903) advocated for the application of the theory of evolution to human nature. This led to the development of Social Darwinism. Spencer put forward a theory that humans differ from one another in amount of general intelligence. However, it was Galton who fully elaborated a theory of mental ability and proposed ways of testing it. In both of his major psychological works, ‘Hereditary Genius’ (1869) and ‘Inquiries into Human Faculty and its Development’ (1883), he examined the inheritance of mental abilities with the goal of racial improvement. Thus, in 1883 Galton founded the science of eugenics whose purpose was the betterment of the human race through the control of mating.
Liberal sociologists such as Lester Ward and Charles Cooley vigorously attacked Galton’s theory. Ward and Cooley neither did not reject Galton’s theory completely. They were willing to accept hereditary determinants of behaviour as long as the possibility of environmental determinants was not ruled out. This is when the nature – nurture controversy began. Galton refused to compromise and sought to prove that nature was overwhelmingly more important.
In ‘Hereditary Genius’, Galton had used reputation as his measure of natural ability. Through his critics, however, he came to recognise that he was not measuring natural

abilities. Hence, he devoted much of his later career to finding ways of measuring innate abilities. These later researches gained him the title of, ‘father of mental – testing’.
Following the British empiricist John Locke’s (1632 – 1704) dictum that all knowledge comes through the senses, Galton developed tests that mostly were measures of simple sensory discrimination. To get extensive data on individual differences in wide range of sensory and motor capacities, Galton maintained an Anthropometrical laboratory at South Kensington Museum between 1884 and 1890. More than 9000 people were tested at a cost of three pence per person. To summarise his data, Galton had recourse to statistical methods of Quetelet (1776 – 1874). Quetelet has demonstrated that anthropometrics measurements of unselected samples of persons typically yielded a normal curve. Galton was impressed by Quetelet’s work. Applying Quetelet’s law of deviation from an average and the normal curve, Galton distinguished 14 levels of human ability, ranging from ‘idiocy through mediocrity to genius’. Galton also proposed that the mean and standard deviation could be used to define and summarise the data. He also invented a number of additional statistical tools. Among them, he developed the methods of correlation, and psychological scaling methods, such as the order of merit and the rating scale method. To determine the highest frequency of sound that could be heard, he invented a `supersonic` whistle, with which he tested animals as well as people. In 1833, he introduced the twin-study method to assess the effectiveness of inheritance and environment.
In the area of association, Galton worked on the diversity of association of ideas and the time required to produce association. He then invented the word association test. Wundt adopted the technique, limited the response to a single word, and used it at Leipzig. Galton`s investigation of mental imagery marks the first extensive use of the psychological questionnaire. His student Karl Pearson (1857 – 1936) polished and expanded the statistical techniques Galton had developed. Pearson derived the correlation coefficient, partial correlation, multiple correlations, and factor analysis and laid the foundation for most of the multivariate statistics that are being used in psychology (Nunnally 1959). In America, the most influential psychologist in the development of quantitative psychology is J Mckeen Cattell (1860 – 1944).
Cattell was impressed by Galton`s emphasis on measurement and statistics. He was also influenced by Galton`s idea of eugenics. Back in America Cattell tried to put the science of eugenics into practice and he also carried out extensive research using Galton`s ideas and methods. In 1890, he published an article entitled ‘Mental Tests and Measurements’. Thus while Galton originated mental tests, Cattell coined the term. However, both their tests dealt with elementary bodily or sensory-motor measures. These early tests were not successful measures of psychological phenomena because they were largely of physical qualities such as reaction times, colour recognition and hearing.
Development of Intelligence Scales
The real development of psychometrics as we know it today has been shaped by practical requirements rather than by theoretical developments. In 1904 the French government

assigned Alfred Binet (1857-1911) the task of devising tests that would distinguish educationally bright and mentally retarded children. Together with his colleague Theodore Simon, they developed the Binet-Simon test. Lewis Terman of Stanford University translated and adapted the tests for use in U S A in 1916. The result was what was named the Stanford-Binet Scale that became the model for most subsequent intelligence tests. The pressures for quick and easily applied methods of testing military personnel in the first world wars led to U S A developing the Army Alpha and Army Beta intelligence tests. These served as early model of other group tests of intelligence.
Binet and Simon divided up the children into groups according to age and created norms that reflected the average performance in each age group. The norms were established by recording the percentage of children from a particular age group who could correctly answer each particular item. Those norms enabled them to introduce the concept of mental age (MA). Mental age measures the intelligence ability of a child by comparing it with that of other children of the same age.Instead of calculating mental age, Lewis Terman adopted the concept of intelligence quotient (IQ), invented by the German psychologist William Stern. The intelligence quotient is a score that can be derived for each child, and makes it possible to compare the ability of child of the same and different ages. The formula used by Terman is presented below:
IQ = MA x 100 CA
Children with mental age that are the same as their chronological age will have an IQ of 100. An IQ of 100 is the score of an average child. The normal distribution curve of IQ scores is used as the basis for classifying people into descriptive categories of gifted, average or retarded.
Adults cannot use the IQ formula discussed above because the abilities measured by most IQ tests do not improve much after the age of 16. David Wechsler (1944) introduced the deviation IQ method that is generally used in obtaining IQ scores today. At each chronological age, the distribution of scores is obtained, and those individuals who score at the mean are given an IQ of 100. The IQs of other individuals are obtained by statistically calculating how much they deviated from the mean. Currently this method is used for obtaining IQs for children and adults. Thus an IQ score is no longer an intelligence quotient because there is no longer a division sum with a quotient as a result (Myers, 1995).
Psychometric Theories of Intelligence Psychometric approaches to intelligence study the statistical relationships between different measures, that is, how one set of scores is related to another set. Some influential psychometric theories of intelligence include Spearman’s g factor and Raymond Cattell`s crystallized and fluid intelligence. Spearman’s concept of g and

Cattell`s distinction between fluid and crystallized intelligence, identify statistical relationships among mental abilities.
Spearman’s Two-Factor Theory
Charles Spearman introduced the two-factor theory that proposes intelligence can be seen as the result of two factors or type of abilities: general intelligence (g) and specific intelligence (s). The general intelligence is common to all types of intellectual behaviour.According to Spearman, people with high degree of general intelligence tend to be successful in any activity they perform, whether it is in science or in languages. Spearman also suggested that in addition to the general intelligence, there are various kinds of specific intelligence (s) that are specialised abilities in specific areas. Thus, people’s performance is determined by a combination of:
(1) the amount of general intelligence (g) they possess(2) the amount of their specific aptitude for languages
The relative contribution of the g and s factors varies, depending on the type of task being done. For instance the g factor played an important role in arithmetic reasoning but a less important role in mechanical tasks. Group factor is a common underlying ability shared by specific abilities. Therefore, for Spearman, performance on any intellectual task was determined by a combination of g, s and group factors (Louw 1997:325).
Thurstone’s Theory of Primary Mental Abilities
Louis Thurstone (1938; 1953) proposed that our total intellectual ability depends on the following seven primary mental abilities: Verbal comprehension: The capacity to understand ideas in the form of words Verbal fluency: The capacity to express ourselves fluently in words Spatial visualisation: The capacity to mentally manipulate and rotate objects) in
solving problems Numerical ability: The capacity to work with figures (add, subtract, multiply, and so
on) Memory: The capacity to store and recall information Reasoning: The capacity to plan and solve problems according to rules, principles
and experience Perceptual speed: The capacity to perceive and compare objects rapidlyInitially, Thurstone believed that these abilities were relatively independent of one another. Later, it was discovered that close relationships existed between many of these primary mental abilities (Louw 1997: 326-327).
Fluid intelligence and Crystallised Intelligence
Raymond Cattell`s (1971) suggested that there are two kinds of g: fluid intelligence and crystallised intelligence. Fluid intelligence refers to our ability to reason and solve problems; in other words, it is our ability to create new knowledge.Crystallised intelligence is the ability to apply the knowledge we already have (e.g. vocabulary and multiplication tables) to solve problems. In Cattell`s view, fluid

intelligence is mainly determined by genetic factors while crystallized intelligence is mainly determined by cultural and environmental factors. The psychometrics approaches, some of which have been discussed above, have been criticised on the grounds that researchers have come to widely different conclusions about the number of abilities or factors that make up intelligence. Depending on the methods they used, some researchers have identified as few as 20, while other still describe as many as 150.
Other Theories of Intelligence
Cognitive science approaches define intelligence more broadly; in terms of the tasks and problems they seek to deal with. This view contends that there are several components making up intelligence. In other words, there are several different kinds of intelligence to be demonstrated in human functioning. For instance, Guilford (1959) made important distinction between convergent and divergent thinking. Divergent thinking involves working with information in such a way that a number of solutions flow from it. This type of thinking is characterized by a process of “moving away” in various directions. While convergent thinking is characterized by a bringing together or synthesizing of information and knowledge focused on a solution to a problem (Reber, 1995).
Sternberg’s Triarchic Theory
Sternberg’s (1985; 1988) triarchic theory of intelligence is a good example of the information processing approach. With this approach, intelligence is multi-dimensional and is made up of three different kinds of ability: Componential intelligence, experiential intelligence and contextual intelligence.
Componential intelligence is similar to the traditional concept of intelligence. According to Sternberg, componential intelligence consists of three processes or components.
Meta components, which include abilities such as identifying a problem, and making strategic decisions. They are also called executive processes because they control the other two components.
Performance components carry out the action, which the meta components have planned. They are involved in understanding incoming information from memory, and in making decisions about how to respond.
Knowledge-acquisition components are involved in the learning and storing of new information.
Experiential intelligence refers to the ability to master new tasks and to carry out complex tasks automatically. Contextual intelligence is the ability of people to adjust to the environment around them. In Sternberg’s view, contextual intelligence makes a much more important contribution to achieving success in life than formal education.
Gardner’s Theory of Multiple Intelligence

Gardner identified seven types of intelligence (Louw, 1997:330):
Linguistic intelligence is the ability to communicate by means of language, whether written or spoken. People such as literary critics could be expected to have high linguistics intelligence.
Logical-mathematical intelligence is the ability to solve problems in a logical and analytical way. People such as scientists and philosophers would have an exceptional aptitude in this category.
Spatial intelligence refers to the ability to mentally manipulate and accurately evaluate the position, form, size and orientation of objects. Architects, navigators, artists and carpenters are examples of people who might be expected to have high spatial intelligence.
Musical intelligence is the ability to evaluate, analyze and compose music or to play a musical instrument. Musicians and composers would be expected to have high musical intelligence.
Bodily – kinesthetic intelligence refers to the ability to control body movements – that is, the ability in which sportsmen and dancers excel.
Intrapersonal intelligence is the degree to which you know and understand yourself and your behaviour. Psychologist and psychiatrists would be expected to have high intrapersonal intelligence.
Interpersonal intelligence refers to the degree of understanding and sensitivity people have in their relationships with other people.
The following are claims regarding these factors: There is interaction between the seven though they work independently. The first 3 types are usually measured by traditional intelligence tests. Each type of intelligence is dependent on activity in a specific area of the brain. The culture in which a person is brought up will strongly determine which types
of intelligence will be fully developed.
Below are some criticisms on the factors listed above: Musical intelligence implies there are different professionally defined intelligence
e.g. soccer intelligence, surgeon intelligence etc. Much of the theory is based on speculation and that not enough research has been
done to support it.
The following are advantages of looking at intelligence from different perspectives: Its eclectic tone makes it more comprehensive than traditional theories. It challenges psychologists to avoid focusing narrowly on intelligence as
something fixed and measurable.

Multiple Assessment Approach
This refers to the use of more than one assessment procedure in order to make it possible to evaluate various aspects that affect the client’s current behaviour. This may include evaluation of biological, cognitive, social, and interpersonal variables. The following are the four assessment procedures, which Sattler (1992:3-5) describes as important components of the multiple assessment approach: norm-referenced tests, interviews, observations, and informal assessment.
Norm-Referenced Tests
Norm-referenced tests are standardised on a clearly defined group, termed the norm group, and scaled so that each individual score reflects a rank within the norm group.Norm-referenced tests provide valuables information about a child’s level of functioning in the area covered by the tests.They take relatively little time to administer, permitting a sampling of behaviour within a short time.
“At present, however, norm-referenced tests provide only limited information about the ways children learn, or about ways to ameliorate learning handicaps” (Sattler 1992:4).
Norm-referenced tests provide valuable information about many areas of development, but should be used in conjunction with other sources of data. Glaser ( ) argues that these tests are deliberately constructed to maximize differences between individuals by comparing them. He says they humiliate individuals and this results in diminishing levels of motivation. Popham (1978) says we are interested in whether a person can ride a bicycle or not, the performance of the other people on their bicycles is irrelevant here.
Criterion –Referenced TestsA test is criterion referenced when it has been constructed with particular reference to performance on some objectively define criteria. Concern is on whether a student researched the criterion. The tests are not constructed to maximise differences between people. The tests have been criticized on the grounds that it is difficult to set a good criterion. What is normally referred to as good criteria is really idiosyncratic. One can show a difference unless when compared to other people so they argue.
Interviews
An interview is a face-to-face conversation conducted to gather information about the respondent. It is a very direct approach of obtaining information about a person. Interviews are a more open and less structured way of obtaining information. The interviewees have an opportunity to convey information in their own words.

Observations
Observations of clients in their natural surroundings provide valuable assessment information. Situational behaviour observations refer to first hand study of an individual’s actions and performance in one or more specific settings. For instance a psychologist may study how students behave in school settings, at home and in the neighbourhood.
Informal Assessment
Standardised norm-referenced tests may at times need to be supplemented with informal assessment procedures, such as criterion-referenced tests (which may or may not be standardised and normed) and teacher –made tests. According to Salvia and Ysseldyke(1991:26) informal assessment is an procedure that involves collection of data by anything other than a norm-referenced (standardised) tests. Informal assessment procedures may provide additional information about the child’s learning ability, language style and other areas of functioning. However, because informal assessment procedures have unknown technical adequacy, they must be used cautiously.
Comment On The Four Approaches
Assessment techniques and tests that have been developed fall into the four general procedures discussed above. Major discrepancies among the findings obtained from the various assessment procedures must be resolved before any diagnostic decisions or recommendations are made. In diagnostic assessment of children, it is important to obtain information from parents and other significant individuals in the child’s environment. Guidelines For Assessment
Assessment is meant to evaluate the client’s competencies both quantitatively and quantitatively.Tests are samples of behaviourTests do not directly reveal traits or capacities, but may allow inferences to be made about the examinee.Tests should have adequate reliability and validity. Further, tests scores and other test performances may be adversely affected by temporary states of fatigue, anxiety, or stress; by disturbances in temperament or personality, or by brain damage. Test results should be interpreted in eight of the person’s cultural background, primary language, and any handicapping conditions. Test results are dependent on the client’s cooperation and motivation. Tests claiming to measure the same ability may produce different scores for that ability. Test results should be interpreted in relation to other behavioural data and to case history information, never in isolation.Tests and other assessment procedures are powerful tools, but their effectiveness depend on the practitioner’s knowledge and skill (Sattler 1992:5).

Social And Ethical Considerations In Testing
Use of tests has been criticised on following grounds:
Standardised tests allocate limited educational resources and penalise children whose family, socio-economic status, and cultural experiences were different from those of normative groups.
Intelligence tests and achievement tests are culturally biased and thus harmful to minority groups.
School psychologists and clinical psychologists engage in the following activities, which are not in the best interest of the child:
- Labelling children- Testing children without their permission and without giving them
full knowledge of the possible consequences of testing- Moving children from regular classrooms to potentially damaging
special classes Tests measure only limited and superficial aspects of behaviour. Tests
create anxiety and interfere with learning. Tests represent an invasion of privacy. That is, personal or sensitive information can be obtained without the permission of examinees. Based on Sattler’s (1992:6) defense of the use of tests, the following are some of the responses, which could be made to some of these criticisms.
- Many critics fail to consider that tests have many valid uses- Most persons do not feel threatened by examinations if personal
consequences are minimised.- Tests are a standard for evaluating the extent to which children of
all ethnic groups have learned the basic cognitive and academic skills necessary for survival in a given culture. Few of the critics have proposed reasonable alternatives to present methods.
Sattler (1992:6) observed that the criticisms are not based on research evidence and fail to consider current assessment practices. However, he advises that they be taken into considerations as there are some short-comings in assessment practices.
Labelling a Shona or Ndebele speaking child who does not speak English as mentally retarded, based on the results of an English – language verbal intelligence test, reflects incompetence on the part of the examiner.
To keep poor records of parental permissions authorising evaluations is shoddy practice, and to administer tests without seeking permission is entirely unethical. These and other such practices must not continue.
We are accountable, as professionals, thus we must not ignore the many valid criticisms of tests and test practices simply because we do not like them. We must listen to our critics and make sure that we are following the best scientific and clinical practices.

The following guidelines presented in the July 1989 issue of American Psychologist (pages 1066-1067) must also be taken into consideration and is tabulated here for ease of reference.
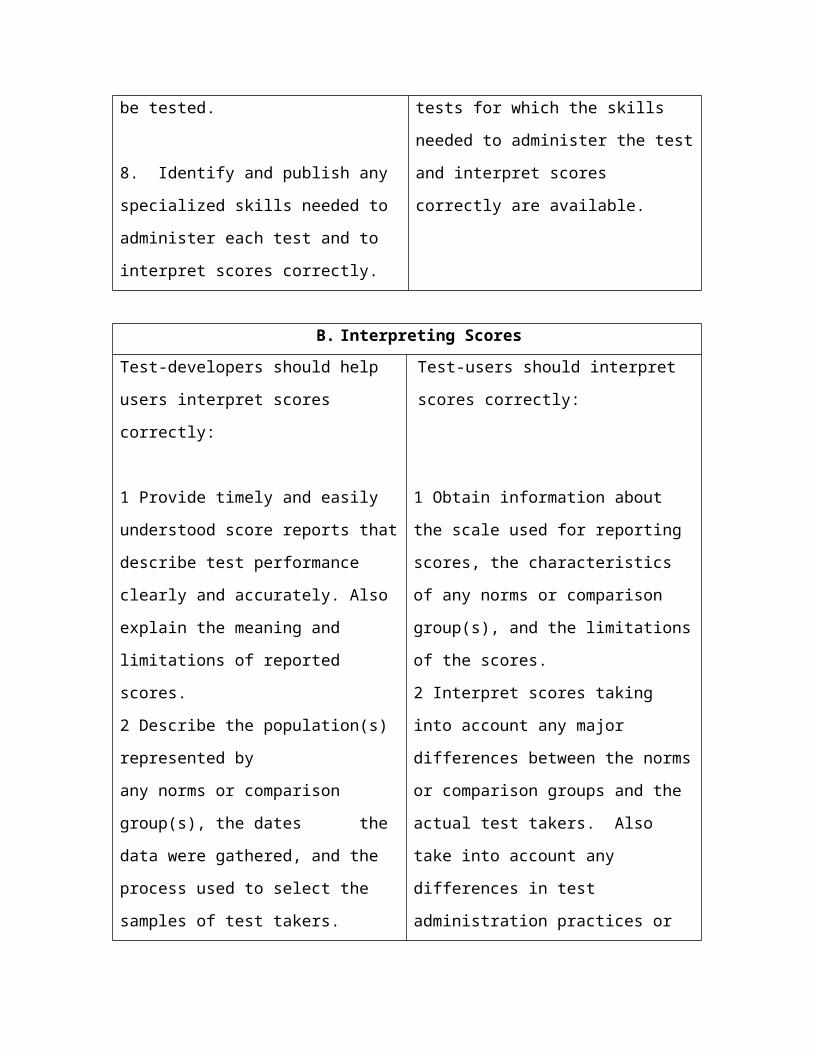
TABLE 1: Guidelines for Use of Tests
A. Developing and Selecting Appropriate Tests
Test developers should provide the
information that test users need to select
appropriate tests.
Test-users should select tests that meet the
purpose for which they are to be used and
that are appropriate for the intended test-
taking populations.
Test developers should:
1. Define what each test measures and what
the test should be used for. Describe the
population(s) for which the test is
appropriate.
2. Accurately represent the characteristics,
usefulness, and limitations of tests for their
intended purposes.
3. Explain relevant measurement concepts
as necessary for clarity at the level of detail
that is appropriate for the intended
audience(s).
4. Describe the process of test
development.
Explain how the content and skills to be
Test-users should:
1. First define the purpose for testing and
the population to be tested. Then, select
a test for that purpose and population
based on a thorough review of the available
information.
2. Investigate potentially useful sources of
information, in addition to scores, to
collaborate the information provided by
tests.
3. Read the materials provided by test
developer and avoid using tests for which
unclear or incomplete information is
provided.
4. Become familiar with how and when
the test was developed and tried out.

tested were selected.
5. Provide evidence that the test meets its
intended purpose(s).
6. Provide either representative samples or
complete copies of test questions,
directions, answer sheets, manuals and
score reports to qualified users.
7. Indicate the nature of the evidence
obtained
concerning the appropriateness of each test
for groups of different racial, ethnic, or
linguistic backgrounds who are likely to be
tested.
8. Identify and publish any specialized
skills needed to administer each test and to
interpret scores correctly.
5. Read independent evaluations of a test
and of possible alternative measures. Look
for evidence required to support the claims
of test developers.
6. Examine specimen sets, disclosed tests
or samples of questions, directions, answer
sheets, manuals, and score reports before
selecting a test.
7. Ascertain whether the test content and
norm group(s) or comparison group(s)are
appropriate for the intended test takers.
8. Select and use only those tests for
which the skills needed to administer the
test and interpret scores correctly are
available.
B. Interpreting Scores
Test-developers should help users interpret
scores correctly:
1 Provide timely and easily understood
score reports that describe test performance
clearly and accurately. Also explain the
Test-users should interpret scores
correctly:
1 Obtain information about the scale used
for reporting scores, the characteristics of

meaning and limitations of reported scores.
2 Describe the population(s) represented by
any norms or comparison group(s), the
dates the data were gathered, and the
process used to select the samples of test
takers.
3 Warn users to avoid specific, reasonably
anticipated misuses of test scores.
4 Provide information that will help users
follow reasonable procedures for setting
passing scores when it is appropriate to use
scores with the test.
5 Provide information that will help users
gather evidence to show that the test is
meeting its intended purposes(s).
any norms or comparison group(s), and the
limitations of the scores.
2 Interpret scores taking into account any
major differences between the norms or
comparison groups and the actual test
takers. Also take into account any
differences in test administration practices
or familiarity with the specific questions in
the test.
3 Avoid using tests for purposes not
specifically recommended by the test
developer unless
evidence is obtained to support the
intended use.
4 Explain how any passing scores were set
and gather evidence to support the
appropriateness of the scores.
5 Obtain evidence to help show that the test
is
meeting its intended purpose(s).
C. Striving for Fairness
1 Test developers should strive to make
tests that are as fair as possible for test
takers of different races, gender, ethnic
backgrounds, or handicapping conditions.
2 Review and revise test questions and
1 Test -users should select tests that have
been developed in ways that attempt to
make them as fair as possible for test-takers
of different races gender, ethnic
backgrounds or handicapping conditions.
2 Evaluate the procedures used by test

related materials to avoid potentially
insensitive content or language.
3 Investigate the performance of test takers
of different races, gender, and ethnic
backgrounds when samples of sufficient
size are available. Enact procedures that
help to ensure that differences in
performance are related primarily to the
skills under assessment rather than to
irrelevant factors.
4 When feasible, make appropriately
modified forms of tests or
administration procedures available for
test takers with handicapping conditions.
Warn test users of potential problems in
using standard norms with modified tests or
administration procedures that result in
noncomparable scores.
developers to avoid potentially insensitive
content or language.
3 Review the performance of test takers of
different races, gender, and ethnic
backgrounds when samples of sufficient
size are available. Evaluate the extent to
which performance differences may have
been caused by inappropriate
characteristics of the test.
4 When necessary and feasible, use
appropriately modified forms of tests or
administration
procedures for test takers
with handicapping conditions. Interpret
standard norms with care in the light of the
modifications that were made.
D. Informing Test-Takers
Under some circumstances, test developers have direct communication with test takers.
Under other circumstances test users communicate directly with test takers. Whichever
group communicates directly with test takers should provide the information described
below.
Test developers or test-users should:
1. When a test is optional, provide test-takers or their parents/guardians with information
to help them judge whether the test should be taken, or if an available alternative to the
test should be used.

2. Provide test takers the information they need to be familiar with the coverage of the
test, the types of question formats, the directions, and appropriate test-taking strategies.
Strive to make such information equally available to all test takers.
Under some circumstances, test-developers have direct control of tests and test scores.
Under other circumstances, test-users have such control. Whichever group has direct
control of tests and test scores should take the steps described below.
Test developers or test-users should:
1. Provide test-takers or their parents/guardians with information about rights test takers
may have to obtain of tests and completed answer sheets, retake tests, have tests re-
scored, and cancel scores.
2. Tell test-takers or their parents/guardians how long scores will be kept on file and
indicate to whom and under what circumstances test scores will or will not be released.
3. Describe the procedures that test-takers or their parents/guardians may use to register
complaints and have problems resolved.
TestA test is defined simply as measuring device or procedure (Cohen, Swerdlik & Phillips, 1996). A test is a sample of behaviour. It tells us something, not everything, about some class of behaviour. Well-designed tests provide representative samples of knowledge or behaviour. The word test is prefaced with a modifier, and this means the measuring device or procedure is designed to measure a variable related to that modifier. For example, psychological test refers to a measuring device or procedure designed to measure variables related to psychology (e.g. intelligence, personality, aptitude, interests, attitudes, and values) as opposed to medical test which refers to measuring device or procedure designed to measure some variables related to the practice of medicines Assessment According to Comer (1999:73) assessment is the process of collecting and interpreting relevant information about an individual or subject. The results of assessment contribute to the understanding of the concerned people or subject so that better – informed decisions are made about current problems or future choices. For Travers, Elliot and

Kratochwill (1993), assessment is the process of gathering information about a student’s abilities or behaviour for the purpose of making decisions about the student. Tests and assessment can be classified in many ways. Note that testing is part of assessment. Testing procedures are concerned with findings, whereas assessment gives meaning to the findings within the context of the person’s life situationMeasurementMeasurement is the act of assigning numbers or symbols of different levels, amounts, or sizes to characteristics of objects (i.e. people, events, or whatever) according to rules. For example, assigning number 1 for each correct answer according to the answer key, and 0 for each incorrect answer. One very important distinction between the measurements of educational and psychological characteristics as opposed to the physical characteristics is that the former do not actually exist. That is they are intangible and can only be inferred from observable characteristics of the individual. Most of these psychological characteristics or hypothetical constructs can at best be assessed on a ‘normative’ scale. That is, it is, only possible to express a student’s performance in art or music as being better than or worse than another student’s performance. The same applies to a student’s performance on an intelligence test. The scores obtained are only relative and usually expressed in relation to the norm of the general populations or some specific sub-population. Thus unlike most physical measures, we cannot use ratio scale of measurement with most educational and psychological characteristics. EvaluationEvaluation refers to the judgement of the quality based on the results of measurement. However, it can also take place without measurement although it tends to become less objective. General principles of evaluation as provided by Gronlund and Linn (1990: 6 –8) are:
- Clearly specifying what is to be evaluated has priority in the evaluation process- An evaluation technique should be selected in terms of its relevance to
characteristics or performance to be measured.- Comprehensive evaluation requires a variety of evaluation techniques- Proper use of evaluation techniques requires an awareness of their limitation- Evaluation is a means to an end, not an end in itself i.e. evaluation is
for a definite purpose.Purpose of AssessmentThe purposes of assessment include screening, diagnosis, counselling and rehabilitation, or progress evaluation.In screening, assessment, a relatively brief examination is done to determine people’s eligibility for special programs or for more comprehensive assessment.In a diagnostic assessment, a detailed evaluation of the person’s strengths and weaknesses in a variety of areas is undertaken.Counselling and rehabilitation assessment are similar to diagnostic assessment except that emphasis is placed on the child’s abilities to adjust to and successfully fulfill daily responsibilities; possible responses to treatment and recovery potential are also considered.In a progress evaluation assessment, the focus is on checking on progress and change in person’s level of functioning in the area covered by the test. They may be on day-to-day or month-to-month progress of the person depending on characteristics being assessed.

Assumptions Underlying AssessmentSalvia and Ysseldyke (1991:17) listed the following assumptions underlying assessment:
- The person giving the test is skilled- No psychological or educational measurement is free from error - The persons to be assessed are like those they will be compared with- The behaviour sampling is adequate- Only present behaviour is observed.
Functions of TestsTests are used in diverse settings such as schools, counselling, industries and so on. Murphy and Davidshofer (1994) showed that tests are used to make important decisions about individuals. Colleges use tests before deciding whether to admit individuals or not. Clinical psychologists used a variety of objective answer projective tests in the process of choosing a course of treatment for individual clients. In industry, tests are used for personnel selection. In schools tests are used to evaluate mastery of the content taught. Below we discuss some four broad categories of the functions of tests namely, instructional, administrative, programme evaluation and guidance proposed by Hopkins, Stanley and Hopkins (1990). Instructional Functions(a) Pre -testing at the beginning of a course helps determine learning readiness hence
facilitates instructional planning.(b) The process of constructing a test encourages the clarification of meaningful course
objectives.(c) A teacher is more likely to stay on course if he/ she is continually reminded of his/
her aim. When teachers have actively participated in defining objectives and in selecting or constructing evaluation instruments, they effectively return to the learning problems and become more committed.
(d) Tests provide feedback to the teacher and the student. This helps the teacher to provide more appropriate instructional methods to the students. Burstein (1983) observed that linking testing and instruction is fundamental in educational practice. Well-designed tests are useful for self-diagnosis by students. It helps them to appreciate their strengths and weaknesses.
(e) Tests can motivate learning. Students generally pursue mastery of objects more diligently if they expect to be evaluated. It has been noted that students study greatly towards examination time.
(f) Tests can facilitate learning. Evaluation strongly influences what students attend to. If students know that they will be tested in content, they tend to pay more attention to that area and retain the information better.
(g) Examinations are a useful means of over-learning. Over-learning is when students revise and practice skills and concepts even after they have been learned.
Administrative Functions(a) Tests provide a mechanism for quality control. Instructional inadequacies can go
unnoticed if there is no measure of evaluation.(b) Tests enable one to make better classification and placement decisions. (c) The test results would make it possible for a teacher to group children according to their

ability levels. Educational psychologists use assessment results to place children in special classes, resource units etc.
(d) Tests can increase the quality of selection decisions. The use of aptitude and achievement tests has been used to identify students who are or are not likely to succeed in various colleges. Certain jobs require certain skills that are best assessed by well-designed tests. Tests are also the main criterion used to identify gifted, learning disabled or retarded children. Programme Evaluation FunctionOutcome measures are necessary to determine whether one programme is better or poorer than the other facilitating the attainment of specific curricular objectives.Teaching is mostly concerned about searching for better ways to help the student learn. Innovations made in the curriculum such as computer assisted instruction, radically different history courses may seem promising to those who propose then but there is need to evaluate the effects of the proposal. Guidance Functions.Tests can be important in diagnosing an individual’s special aptitudes and abilities. Also assessment findings are important aspects in facilitating counselling of students. The uses of tests, including those not listed above, determine how these tests are interpreted
Characteristics of Good AssessmentQualities of good assessment include, objectivity, standardization, reliability, validity and practicality. ReliabilityAccording to Ormrod (2000:642) the reliability of assessment technique is the extent to which it yields consistent information about the knowledge, skills, or other abilities we are trying to measure. Hence, reliability refers to the extent to which measurements are consistent. Thus, with reliable tests one is able to generalize results under one set of conditions to other occasions.Reliability for generalising to different scorers is called inter-rater or inter-scorer reliability.Reliability for generalising to different times is called stability or test-retest reliability.
Reliability for generalising to other test items is called alternate form or internal consistency reliability.The Reliability CoefficientThe symbol used to denote a reliability coefficient is r with two identical subscripts (e.g. rxx or raa).The reliability coefficient is generally defined as the square of the correlation between obtained scores and true scores on a measure (rxt
2 ).This quantity is identical to the ratio of the variance of true scores to the variance of obtained scores for a distribution. Thus, a reliability coefficient indicates the proportion of variability in a set of scores that reflects true differences among individuals.
Where two equivalent forms of a test exist, the Pearson product – moment correlation coefficient between scores from the two forms is equal to the reliability coefficient for

either form. These relationships are summarized in the equation below where X and X1
are parallel measures, and S2 is the variance:
rxx1 = rxt
2 = S 2 true scores S2 obtained scores
An index of 1.00 is perfect reliability.
An index of 0.00 is total unreliability.
The greater the reliability, the less the error of measurement and vice versa.
Below are various methods of estimating reliability depending on what generalization one wishes to make.Test – Retest Reliability: Generalising to Different TimesTest – retest estimate of reliability is an index of stability. This refers to consistency over time. In this procedure, individuals take the same test at two different times with a small time interval between testing. By using a correlation coefficient, the resultant two sets of scores are compared. If the results are stable, persons who score high on the first administration score high on the second administration, and low achievers score low both times. This consistency will be indicated by a high positive correlation. The longer the time interval, the lower test-retest estimates are likely to be. Acceptable reliability is 0.90.Alternative – Forms ReliabilityTo estimate the reliability coefficient using this method, two equivalent forms (A and B) of the same test are administered to a large sample of people. Half the participants receive form A, then B; then other half receive form B, then A. Scores from the two forms are correlated to get the reliability coefficient. The time interval between testing is as short as possible. Acceptable reliability is 0.85.
Estimates of reliability based on alternate forms are subject to one of the same constraints as stability coefficients: the more time between the administration of the two forms, the greater the likelihood of change in the true score. The Product moment correlation coefficient formula is used to estimate test-retest reliability or equivalent form or parallel form reliability.Internal Consistency EstimatesThe internal consistency estimate of reliability is based on the scores obtained during one test administration. Such an estimate should be used only when the test measures a single or unitary concept. One type of internal consistency coefficient is obtained by dividing the test into two equivalent halves (split – half reliability). This division creates two alternate forms of the test. The most common way of dividing the test is to assign odd – numbered items to one form and even – numbered items to the other.
Since the split – half correlations are based on half tests; the obtained correlations underestimate the reliability of the whole test. The Spearman-Brown formula is used to
correct these estimates to what they would be if they were based on the whole test. Acceptable reliability coefficient is 0.95.
Spearman – Brown Formula:
rtt = 2rnn
1+rnn
where rtt = reliability estimaternn = correlation between halvesIf rnn = 0.6
By substituting rtt = 2 x 0.6 1+ 0.6 = 1.2 1.6
= 0.75Thus, the reliability of the whole test was underestimated by 0.15.
Another type of internal consistency reliability coefficient is based on the intercorrelations among all comparable parts of the same test. Special formulas such as Cronbach’s coefficient alpha and the Kuder – Richardson formula 20, measure the uniformity or homogeneity of items throughout the test. Cronbach’s coefficient alpha is a general reliability coefficient that can be used for different scoring systems. It is based on the variance of the test scores and the variance of the item scores. The coefficient reflects the extent to which items measure the same characteristics. Below is the Cronbach’s coefficient alpha formula. rtt = [n/ n-1] [S2
t - ∑ (S2 i )]/ S2
t
Where rtt = coefficient alpha reliability estimate n = number of items in the test S2
t = variance of the total test ∑ S2
i = sum of variances of individual items
S2i = [∑ƒҳ i
2 - (∑ƒ ҳ i) 2 / N] / N
The Kuder – Richardson formula 20 coefficient, a special case of coefficient alpha, is useful for tests that are, scored pass/fail. It is obtained by calculating the proportion of people who pass and fail each item and the variance of the test scores. While the Cronbach’s coefficient alpha formula is used when a test has no right or wrong answers, the KR20 is used for calculating the reliability of a test in which the items are scored 1 or 0 (or right or wrong). However, both coefficients represent the mean of all possible split – half coefficients that could be obtained by various test splittings.

Internal consistency reliability estimates are not appropriate for timed tests and do not take into account changes over time. Generally, the size of the internal consistency coefficient is increased is with greater length.Error Of MeasurementIrrespective of how technically sophisticated a measurement instrument may be (e.g. standardised tests), scores only reflect an approximation of an individual’s ‘true’ score. There is always an error of measurement. Thus, reliability can be considered to consist of two parts: true score and error.
A true score or universe score is a hypothetical value that best represents an individual’s true knowledge or ability. It is the hypothetical mean of an infinite number of tests taken by a participant when practice effects are disregarded (Sax 1989:260). In practice, the best estimate of a person’s true score is the obtained score. Yet chance conditions can sometimes underestimate or overestimate corresponding true scores. An error of measurement or error score is the difference between an obtained score and the true value. The error of measurement has a mean of 0. To understand this concept better, let us first look at the theories of true scores.
The Theory Of True ScoresThe theory of true scores states simply that any score on an item or a test by a participant can be represented by two components parts: the participant’s true score on whatever the item measures, and some error of measurement. This can be stated as:
X = T + EWhere X = observed score T = true score E = the error
The theory of the true scores is based on the following assumptions (Rust and Golombok, 1989: 29 – 30): - All errors are random and normally distributed.- The true scores are uncorrelated with the errors- Different measures of X on the same subject are statistically independent of each other.
Based on the three assumptions, simple equations are made. These equations produce a measurement of error such that when a particular characteristic of a test is known – its reliability – we can determine the error and thus estimate the true score. Two definitions of true score have been put forward: the platonic (Sutcliffe 1965) and the statistical (Carnap 1962).
The Platonic True ScoreThe Platonic concept of a true score is based on Plato’s theory of truth. He believed that if anything can be thought about, then even if it does not physically exist, it must exist somewhere if such thought is to be possible. Non – existence is reserved for objects about which we cannot even think. However, the Platonic idea of the true score is generally held to be a mistake (Thordike 1964).The Statistical True Score

According to Rust and Golombok, (1989:31), the statistical true score is that score which we would obtain if we were to take an infinite number of measures of the observed score on the same person and average them. As the number of observations approaches infinity, then the errors, being random by definition, cancel each other out and leave us with a pure measure of the true score. Since this is not possible to do it practically, the true score can be estimated statistically.
The less reliable the test, the greater the discrepancy between obtained scores and true scores. The estimated true score (X1) equals the test mean plus the product of the reliability coefficient and the difference between the obtained score and the group mean.X1 = X tm
+ ( rxx) (X – X gm )
Salvia and Ysseldyke (1991:135) suggest that one should use the mean of the demographic group that best represents the particular participant. In the absence of means for particular person’s background, one is forced to use the overall mean for the participant’s age. The discrepancy between obtained scores and estimated true scores is a function of both the reliability of the obtained score and the difference between the obtained score and the mean.Standard Error Of MeasurementThe reliability of a test may be expressed in terms of the standard error of measurement. As such, reliability coefficient and standard error of measurement are alternate ways of testing reliability.
Gronlund (1981:19) defines standard error of measurement as “an estimate of the amount of errors that will be expected in a client’s score if he/she were to take the same test over and over again.” The standard error of measurement is directly related to the reliability of a test: the larger the standard error of measurement, the lower the reliability (conversely, the smaller the standard error of measurement, the higher the reliability). Large standard errors of measurement mean less precise measurements and larger confidence intervals or bands.
The standard error of measurement is the standard deviation of the distribution of error scores. It can be computed from the reliability coefficient of the test by multiplying the standard deviation (SD) of the test by the square root of 1 minus the reliability coefficient (rxx ) of the test:SEm = SDx √ 1- rxx
The Bayley scales of Infant Development has SD16 and the Bayley Motor Scale has rxx = 0.84
Therefore, SEm= 16 = 16 = 16 x 0.40 = 6.40
The WISC – R has SD = 15 and rtt = 0.96Therefore, SEm = 15 = 15

= 15 x 0.20 = 3.00
From the above calculation it can be concluded that the WISC – R provides more precise measurements than does the Bayley Motor Scale.Confidence Intervals For Obtained ScoresA confidence interval is a band or range of scores that has a high probability of including the examinee’s true score. The interval may be large or small, depending on the degree of confidence desired. A 95 percent confidence interval can be thought of as the range in which a person’s true score will be found 95 percent of the time. The chances are only 5 in 100 that a person’s true score lies outside this confidence interval.
The following is the confidence interval formula:Confidence interval = obtained score plus or minus Z (SEm )i.e. CI = X Z(SEm )Where: Z = the z score associated with the confidence level chosen
SEm = the standard error of measurement.
The Z score is obtained from a normal curve table that is found in most statistical textbooks. The SEm is found in the test manual or by use of the formula given earlier in this section.
An example is as follows:Construct confidence interval for a child who obtains an IQ of 80 on a test for which SEm
= 5. Use 95 percent level of confidence.
Substituting:Confidence interval = 80 + 1.96 (5) = 80 + 9.8 = 70.2 to 89.8 ≈ 70 to 90 Thus, the chances that the range of scores from 70 to 90 includes the child’s true IQ are about 95 out of 100. When determining an IQ score, it is very important the confidence interval associated with the person’s scores is included. Reporting the confidence intervals enable the reader to recognise that the score obtained reflects a range of possible scores.ObjectivityThe objectivity of a test refers to the degree to which equally competent scorers obtain the same results. Most standardized tests of aptitude and achievement are high in objectivity. The test items are of the objective type (e.g., multiple choice), and the resulting scores are not influenced by the scorer’s judgment or opinion.
In essay testing and various observational procedures, the results depend to a large extent on the person doing the scoring. Different persons get different results, and even the same person may get different results at different times. The solution is not to use only

objective tests and abandon all subjective items, as this would have an adverse effect on validity. Remember, validity is the most important quality of assessment results. A better solution is to select the assessment procedure most appropriate for the behaviour being assessed and then to make the evaluation procedure as objective as possible. In the use of essay tests, for example, objectivity can be increased by careful phrasing of the questions and by a standard set of rules for scoring. Such increased objectivity will contribute to greater reliability without sacrificing validity. Thus the other characteristic of good assessment that is closely related to objectivity is standardization.StandardisationStandardisation refers to the extent to which assessment instruments and procedures involve similar content and format and are administered and scored in the same way for everyone (Ormrod 2000: 6 44). Except in special cases, all students should be given the same instructions, perform identical or similar tasks, have the same time limits, and work under the same constraints. Same criteria should be used for scoring.
Even teacher – developed assessment instruments should be standardized. This would reduce error due to variation in test administration or subjectivity in scoring. The more an assessment is standardized for all students, the higher is its reliability. Equity is an additional consideration: Except in unusual situations, it is only fair to ask all students to be evaluated under similar conditions (Ormrod 2000: 645).Practicality/UsabilityPracticality refers to the extent to which an assessment instrument or procedure is relatively easy to use. Practicality includes concerns such as the following:- How much time will it take to develop the instrument?- How easily can the assessment be administered to a large group of students?- Are expensive materials involved?- How much time will the assessment take away from instructional activities?- How quickly and easily can participants’ performance be evaluated?
There is often a trade – off between practicality and other good characteristics of assessment. Practicality should be considered only when validity, reliability and standardization are not jeopardized. On the other hand, standardization is necessary to the extent that it enhances the reliability of the results.ValidityThe validity of a test is concerned with how well a test measures what it is designed to measure. This also has to do with the appropriateness with which inferences can be made on the basis of the test scores. Thus, tests are valid only for a specific purpose. In the present unit, we will discuss the following types of validity: face validity, content validity, and criterion related validity and construct validity.Face validityFace validity is not validity in the technical sense and it is not always necessary for good validity in this sense. Face validity refers to what the test appears to measure, not what it actually does measure. It is important to test takers in that if the test does not appear to measure what it claims to measure, they may not get motivated. Thus the results may not accurately reflect their abilities.Content validity

According to Oppenheim (1992: 162) content validity is concerned with the extent to which items or questions are a well-balanced sample of the content domain to be measured. In evaluating content validity: - consider the appropriateness of the type of items - the completeness of the item sample- the way in which the items assess the content of the domain involved.
Content validity can be built into a test by including only those items that measure the trait or behaviour of interest. The most convenient way is to use a specification table.Criterion – Related ValidityCriterion – related validity refers to the relationship between test scores and some type of criterion or outcome such as ratings, classifications, or other test scores. The criteria should be readily measurable, free from bias and relevant to the purposes of the test. Criterion validity consists of two types, the concurrent and the predictive validity.Concurrent ValidityConcurrent validity shows how well the test correlates with other, well-validated measures of the same topic, administered at about the same time (Oppeheim, 1992:162). Thus to determine concurrent validity, there is need to the correlate the test scores to some currently available criterion measure.
Concurrent validation is relevant to tests employed for diagnosis of existing status, rather than prediction of future outcomes. Ratings have been employed in the validation of almost every type of test. They are particularly useful in providing criteria for personality tests. However one has to be careful so that the procedure is not affected by criterion contamination, which occurs when the rater has some knowledge of the test scores.Predictive ValidityPredictive validity refers to the extent to which a test can forecast some future criterion such as performance, recovery from illness (prognosis or future examination attainment. Thus with this type of validity, one correlates test scores and performance on a relevant criterion. Where there is a time interval between the test administration and performance on the criterion. The accuracy with which an aptitude or readiness test indicates future learning success in school depends on predictive validity.
Predictive validity is established by giving a test to a group that has yet to perform on the criterion of interest. The group’s performance on the criterion is subsequently measured. The correspondence between the two scores provides between the two scores measure of the predictive validity of the test (Sattler 1992: 30). Correlations used as validity coefficients must he squared in order to determine the amount of variance explained by the predictor (or test).Construct ValidityConstruct validity refers to the extent to which an assessment accurately measures an underlying, unobservable characteristic such as motivation, intelligence and personality. The term construct refers to a hypothesized internal trait that cannot be directly observed but must instead be inferred from the consistencies we see in people’s behaviour. Thus

construct validity can also be seen as an indicator of the logical connection between a test and what it is designed to measure. It answers the question, do these items actually measure the ideas the test is designed to measure?
According to Anastasi (1990:153) construct validation requires the gradual accumulation of information from a variety of sources. Some methods of construct validation include the following:- defining the domain of tasks to be measured - analysing the mental process required by the test items- comparing the scores of known groups - comparing scores before and after some particular treatment - correlating the scores with other measures- factor analysis- internal consistency- convergent and discriminant validationNow let us discuss some of these methods in detail.Correlating With Other MeasuresCorrelations between the scores on a new test and with scores on similar earlier tests are sometimes cited as evidence that the new test measures approximately the same general area or behaviour. Unlike the correlations found in criterion – related validity, these correlations should be moderately high, but not too high.Internal ConsistencyWith the method, the criterion is the total score on the test itself. Sometimes an adaptation of the contrasted group method is used. Here extreme groups are selected on the basis of the total test score. The performance of the upper criterion group on each test item is then compared with that of the lower criterion group. Items that fail to show a significantly greater proportion of keyed responses in the upper than in the lower criterion group are considered invalid, and are either eliminated or revised. Correlational procedures may also be employed for this purpose. For instance, the biserial correlation between pass-fail on each item and total test score can be computed. Only those items yielding significant item-test correlations would be retained. Items selected by this method show internal consistency. Also sub-tests could be correlated with total score. This degree of homogeneity of a test has some relevance to its construct validity.Comparing scores before and after some particular treatmentAnastasi (1990:158) explained that construct validation is also provided by experiments on the effect of selected variables on test scores. One such approach is through a comparison of pre-test and post-test scores. The rationale of such a test can administered before the relevant instruction, and high scores on the post-test.Convergent and Discriminant ValidationWith this method of validation, a test with high construct validity must correlate highly with which it should theoretically correlate (convergent validity) and must not correlate significantly with variables from which it should differ (discriminant validation). Campbell and Fiske (1959) cited by Anastasi (1990:156) proposed a dual approach of convergent and discriminant validation that they called the multi-trait – multi-method matrix. This method requires the assessment of two or more traits by two or more

methods. The scores obtained for the same trait using different methods are correlated; each measure is thus being checked against other, independent measures of the same trait.
“Within the framework of the multi-trait – multi-method matrix, reliability represents agreement between two measures of the same trait obtained through maximally similar methods, such as parallel forms of the same tests: validity represents agreement between two measures of the same trait obtained by maximally different methods, such as test scores and supervisor’s ratings. Since similarity and difference of methods are matters of degree, theoretically reliability and validity can be regarded as falling along a single continuum” (Anastasi 1990:158).Factor AnalysisFactor analysis is a refined statistical technique for analyzing the interrelationships of behaviour data. The analysis will provide a set of results, which give an indication of the underlying relationships between test items or sub-tests. It will tell us which set of items or sub-tests go together, and which stand apart. Factor analysis identifies what are called ‘factors’ in the data. The factors are underlying hypothetical constructs, which often can be used to explain the data. By selecting items, which relate to particular factors, we are able to put together subtests of the construct that the factor represents (Rust and Golombok 1989:114). The extent to which a test correlates with whatever is common to a group of tests is called factorial validity. Ratings and other criterion measures can be utilized, along with other tests to explore the factorial composition of a particular test and to define the common traits it measures. We will again look at factor analysis when we discuss item analysis.Knowledge-Based and Person-Based ItemsItems can be either knowledge based or person based. A knowledge-based item is designed to find out whether a particular person knows a particular piece of information, and such tests measure ability, aptitude, and achievement. Most educational and intelligent tests are of this type as well as some clinical assessment instruments. A person-based test is designed to measure personality, clinical symptoms, mood or attitude. The difference between these two types of tests is that knowledge-based tests are necessarily cumulative. Person-based tests on the other hand carry no such implication. Different personalities and different attitudes are just different. There is no intrinsic implication that to hold one attitude is necessarily better or worse, or more or less advanced, than the holding of another. A consequence of this difference is that the scoring of knowledge-based items tends to be one-dimensional. The person either gets the right or the wrong answer. The scoring of person-based tests on the other hand can go in either direction. Thus someone with a low score on an extraversion scale would have a high score if the scale was reversed and redefined as introversion scale (Rust & Golombok 1989). Objective and Subjective TestsItems can be either entirely be objective, where the scoring criteria can be completely specified beforehand, or open-ended as in essay tests or projective tests. The major type of psychometric item in use is the objective item. Items of this type are called objective because the author decides in advance exactly what defines the correct response, and thereafter responses are marked right or wrong against this standard (Rust & Golombok 1989). In educational setting, objective items of this type can be contrasted with the more

traditional essay- type test, which is relatively open-ended and therefore involves a certain amount of subjective judgment by the examiner in its marking (Rust & Golombok 1989).Correction for GuessingOne common concern with objective knowledge-based tests is guessing. A technique for tackling this problem is to apply a correction for guessing. There are several formulae for this in the literature but the following is the most common (Rust & Golombok 1989):C = (R - W) / (N – 1)Where C is the corrected score, R is the number of correct responses, W is the number of incorrect (wrong) responses, and N is the number of alternatives available.
The formula assumes that a respondent either knows the answer to an item, or guesses. But in practice most guesses are inspired, and a person who guesses is more likely to be right than wrong. The formula therefore underestimates the amount of guessing and therefore under compensates for it. Corrections for guessing are to be avoided in testing as much as is possible (Rust & Golombok 1989).
The greater part of these notes is adapted from Kasayira, J.M. & Gwasira, D. (2005) Psychometrics and Assessment, Module HPSY 408. Z.O.U.: Harare.}
ReferencesAnastasi, A. (1982) Psychological Testing (5th ed.). Macmillan: New York.Anastasi, A. (1990). Psychological Testing (6Th ed). Macmillan: New York.APA (1985) Standards for Educational and Psychological Testing: American Psychological Association: Washington, DC.Drummond, R.J. (2004). Appraisal procedures for counsellors and helping professionals. Pearson Merril Prentice hall: New Jersey.Gronlund, N.E & Linn R.L. (1990) Measurement and Evaluation in Teaching (6th ed).Macmillan: New York.Murphy, K. R & Davidshofer, C.O (1994) Psychological Testing: Principles and Applications. New Jersey: Prentice-Hall, Inc. Englewood Cliffs New Jersey.Oppenheim, A.N. (1996) Questionnaire Design, interviewing and Attitude Measurement (New edition): Printer. London.Ormrod, J, E. (2000) Educational Psychology; Developing Learners.(3rd ed). Merrill: New Jersey.Rust, J. & Golombok, S. (1989) Modern Psychometrics: The science of psychological assessment. Routeledge: London.Sattler, J.M. (1982) Assessment of Children’s Intelligence and Special Abilities (2nd ed.). Allyn & Bacon, Incl.