max neunhöffer – joins and aggregations in a distributed nosql db - nosql matters barcelona 2014
TRANSCRIPT

Joins and aggregations in adistributed NoSQL DB
Max Neunhöffer
NoSQLmatters, Barcelona, 22 November 2014
www.arangodb.com

Documents and collections{
"_key": "123456",
"_id": "chars/123456",
"name": "Duck",
"firstname": "Donald",
"dob": "1934-11-13",
"hobbies": ["Golf",
"Singing",
"Running"],
"home":
{"town": "Duck town",
"street": "Lake Road",
"number": 17},
"species": "duck"
}
When I say “document”,Imean “JSON”.A “collection” is a set ofdocuments in a DB.The DB can inspect thevalues, allowing forsecondary indexes.Or one can just treat theDB as a key/value store.Sharding: the data of acollection is distributedbetween multiple servers.
1

Documents and collections{
"_key": "123456",
"_id": "chars/123456",
"name": "Duck",
"firstname": "Donald",
"dob": "1934-11-13",
"hobbies": ["Golf",
"Singing",
"Running"],
"home":
{"town": "Duck town",
"street": "Lake Road",
"number": 17},
"species": "duck"
}
When I say “document”,Imean “JSON”.
A “collection” is a set ofdocuments in a DB.The DB can inspect thevalues, allowing forsecondary indexes.Or one can just treat theDB as a key/value store.Sharding: the data of acollection is distributedbetween multiple servers.
1

Documents and collections{
"_key": "123456",
"_id": "chars/123456",
"name": "Duck",
"firstname": "Donald",
"dob": "1934-11-13",
"hobbies": ["Golf",
"Singing",
"Running"],
"home":
{"town": "Duck town",
"street": "Lake Road",
"number": 17},
"species": "duck"
}
When I say “document”,Imean “JSON”.A “collection” is a set ofdocuments in a DB.
The DB can inspect thevalues, allowing forsecondary indexes.Or one can just treat theDB as a key/value store.Sharding: the data of acollection is distributedbetween multiple servers.
1

Documents and collections{
"_key": "123456",
"_id": "chars/123456",
"name": "Duck",
"firstname": "Donald",
"dob": "1934-11-13",
"hobbies": ["Golf",
"Singing",
"Running"],
"home":
{"town": "Duck town",
"street": "Lake Road",
"number": 17},
"species": "duck"
}
When I say “document”,Imean “JSON”.A “collection” is a set ofdocuments in a DB.The DB can inspect thevalues, allowing forsecondary indexes.
Or one can just treat theDB as a key/value store.Sharding: the data of acollection is distributedbetween multiple servers.
1

Documents and collections{
"_key": "123456",
"_id": "chars/123456",
"name": "Duck",
"firstname": "Donald",
"dob": "1934-11-13",
"hobbies": ["Golf",
"Singing",
"Running"],
"home":
{"town": "Duck town",
"street": "Lake Road",
"number": 17},
"species": "duck"
}
When I say “document”,Imean “JSON”.A “collection” is a set ofdocuments in a DB.The DB can inspect thevalues, allowing forsecondary indexes.Or one can just treat theDB as a key/value store.
Sharding: the data of acollection is distributedbetween multiple servers.
1

Documents and collections{
"_key": "123456",
"_id": "chars/123456",
"name": "Duck",
"firstname": "Donald",
"dob": "1934-11-13",
"hobbies": ["Golf",
"Singing",
"Running"],
"home":
{"town": "Duck town",
"street": "Lake Road",
"number": 17},
"species": "duck"
}
When I say “document”,Imean “JSON”.A “collection” is a set ofdocuments in a DB.The DB can inspect thevalues, allowing forsecondary indexes.Or one can just treat theDB as a key/value store.Sharding: the data of acollection is distributedbetween multiple servers.
1

Graphs
A
B
D
E
F
G
C
"likes"
"hates"
A graph consists of vertices andedges.Graphs model relations, can bedirected or undirected.Vertices and edges aredocuments.Every edge has a _from and a _toattribute.The database offers queries andtransactions dealing with graphs.For example, paths in the graphare interesting.
2

Graphs
A
B
D
E
F
G
C
"likes"
"hates"
A graph consists of vertices andedges.
Graphs model relations, can bedirected or undirected.Vertices and edges aredocuments.Every edge has a _from and a _toattribute.The database offers queries andtransactions dealing with graphs.For example, paths in the graphare interesting.
2

Graphs
A
B
D
E
F
G
C
"likes"
"hates"
A graph consists of vertices andedges.Graphs model relations, can bedirected or undirected.
Vertices and edges aredocuments.Every edge has a _from and a _toattribute.The database offers queries andtransactions dealing with graphs.For example, paths in the graphare interesting.
2

Graphs
A
B
D
E
F
G
C
"likes"
"hates"
A graph consists of vertices andedges.Graphs model relations, can bedirected or undirected.Vertices and edges aredocuments.
Every edge has a _from and a _toattribute.The database offers queries andtransactions dealing with graphs.For example, paths in the graphare interesting.
2

Graphs
A
B
D
E
F
G
C
"likes"
"hates"
A graph consists of vertices andedges.Graphs model relations, can bedirected or undirected.Vertices and edges aredocuments.Every edge has a _from and a _toattribute.
The database offers queries andtransactions dealing with graphs.For example, paths in the graphare interesting.
2

Graphs
A
B
D
E
F
G
C
"likes"
"hates"
A graph consists of vertices andedges.Graphs model relations, can bedirected or undirected.Vertices and edges aredocuments.Every edge has a _from and a _toattribute.The database offers queries andtransactions dealing with graphs.
For example, paths in the graphare interesting.
2

Graphs
A
B
D
E
F
G
C
"likes"
"hates"
A graph consists of vertices andedges.Graphs model relations, can bedirected or undirected.Vertices and edges aredocuments.Every edge has a _from and a _toattribute.The database offers queries andtransactions dealing with graphs.For example, paths in the graphare interesting.
2

Query 1Fetch all documents in a collectionFOR p IN people
RETURN p
[ { "name": "Schmidt", "firstname": "Helmut",
"hobbies": ["Smoking"]},
{ "name": "Neunhöffer", "firstname": "Max",
"hobbies": ["Piano", "Golf"]},
...
]
(Actually, a cursor is returned.)
3

Query 1Fetch all documents in a collectionFOR p IN people
RETURN p
[ { "name": "Schmidt", "firstname": "Helmut",
"hobbies": ["Smoking"]},
{ "name": "Neunhöffer", "firstname": "Max",
"hobbies": ["Piano", "Golf"]},
...
]
(Actually, a cursor is returned.)
3

Query 1Fetch all documents in a collectionFOR p IN people
RETURN p
[ { "name": "Schmidt", "firstname": "Helmut",
"hobbies": ["Smoking"]},
{ "name": "Neunhöffer", "firstname": "Max",
"hobbies": ["Piano", "Golf"]},
...
]
(Actually, a cursor is returned.)3

Query 2Use filtering, sorting and limitFOR p IN people
FILTER p.age >= @minage
SORT p.name, p.firstname
LIMIT @nrlimit
RETURN { name: CONCAT(p.name, ", ", p.firstname),
age : p.age }
[ { "name": "Neunhöffer, Max", "age": 44 },
{ "name": "Schmidt, Helmut", "age": 95 },
...
]
4

Query 2Use filtering, sorting and limitFOR p IN people
FILTER p.age >= @minage
SORT p.name, p.firstname
LIMIT @nrlimit
RETURN { name: CONCAT(p.name, ", ", p.firstname),
age : p.age }
[ { "name": "Neunhöffer, Max", "age": 44 },
{ "name": "Schmidt, Helmut", "age": 95 },
...
]
4

Query 3Aggregation and functionsFOR p IN people
COLLECT a = p.age INTO L
FILTER a >= @minage
RETURN { "age": a, "number": LENGTH(L) }
[ { "age": 18, "number": 10 },
{ "age": 19, "number": 17 },
{ "age": 20, "number": 12 },
...
]
5

Query 3Aggregation and functionsFOR p IN people
COLLECT a = p.age INTO L
FILTER a >= @minage
RETURN { "age": a, "number": LENGTH(L) }
[ { "age": 18, "number": 10 },
{ "age": 19, "number": 17 },
{ "age": 20, "number": 12 },
...
]
5

Query 4JoinsFOR p IN @@peoplecollection
FOR h IN houses
FILTER p._key == h.owner
SORT h.streetname, h.housename
RETURN { housename: h.housename,
streetname: h.streetname,
owner: p.name,
value: h.value }
[ { "housename": "Firlefanz",
"streetname": "Meyer street",
"owner": "Hans Schmidt", "value": 423000
},
...
]
6

Query 4JoinsFOR p IN @@peoplecollection
FOR h IN houses
FILTER p._key == h.owner
SORT h.streetname, h.housename
RETURN { housename: h.housename,
streetname: h.streetname,
owner: p.name,
value: h.value }
[ { "housename": "Firlefanz",
"streetname": "Meyer street",
"owner": "Hans Schmidt", "value": 423000
},
...
]6

Query 5
Modifying dataFOR e IN events
FILTER e.timestamp < "2014-09-01T09:53+0200"
INSERT e IN oldevents
FOR e IN events
FILTER e.timestamp < "2014-09-01T09:53+0200"
REMOVE e._key IN events
7

Query 6Graph queriesFOR x IN GRAPH_SHORTEST_PATH(
"routeplanner", "germanCity/Cologne",
"frenchCity/Paris", {weight: "distance"} )
RETURN { begin : x.startVertex,
end : x.vertex,
distance : x.distance,
nrPaths : LENGTH(x.paths) }
[ { "begin": "germanCity/Cologne",
"end" : {"_id": "frenchCity/Paris", ... },
"distance": 550,
"nrPaths": 10 },
...
]
8

Query 6Graph queriesFOR x IN GRAPH_SHORTEST_PATH(
"routeplanner", "germanCity/Cologne",
"frenchCity/Paris", {weight: "distance"} )
RETURN { begin : x.startVertex,
end : x.vertex,
distance : x.distance,
nrPaths : LENGTH(x.paths) }
[ { "begin": "germanCity/Cologne",
"end" : {"_id": "frenchCity/Paris", ... },
"distance": 550,
"nrPaths": 10 },
...
] 8

Life of a queryText and query parameters come from user
Parse text, produce abstract syntax tree (AST)Substitute query parametersFirst optimisation: constant expressions, etc.Translate AST into an execution plan (EXP)Optimise one EXP, producemany, potentially better EXPsReason about distribution in clusterOptimise distributed EXPsEstimate costs for all EXPs, and sort by ascending costInstanciate “cheapest” plan, i.e. set up execution engineDistribute and link up engines on different serversExecute plan, provide cursor API
9

Life of a queryText and query parameters come from userParse text, produce abstract syntax tree (AST)
Substitute query parametersFirst optimisation: constant expressions, etc.Translate AST into an execution plan (EXP)Optimise one EXP, producemany, potentially better EXPsReason about distribution in clusterOptimise distributed EXPsEstimate costs for all EXPs, and sort by ascending costInstanciate “cheapest” plan, i.e. set up execution engineDistribute and link up engines on different serversExecute plan, provide cursor API
9

Life of a queryText and query parameters come from userParse text, produce abstract syntax tree (AST)Substitute query parameters
First optimisation: constant expressions, etc.Translate AST into an execution plan (EXP)Optimise one EXP, producemany, potentially better EXPsReason about distribution in clusterOptimise distributed EXPsEstimate costs for all EXPs, and sort by ascending costInstanciate “cheapest” plan, i.e. set up execution engineDistribute and link up engines on different serversExecute plan, provide cursor API
9

Life of a queryText and query parameters come from userParse text, produce abstract syntax tree (AST)Substitute query parametersFirst optimisation: constant expressions, etc.
Translate AST into an execution plan (EXP)Optimise one EXP, producemany, potentially better EXPsReason about distribution in clusterOptimise distributed EXPsEstimate costs for all EXPs, and sort by ascending costInstanciate “cheapest” plan, i.e. set up execution engineDistribute and link up engines on different serversExecute plan, provide cursor API
9

Life of a queryText and query parameters come from userParse text, produce abstract syntax tree (AST)Substitute query parametersFirst optimisation: constant expressions, etc.Translate AST into an execution plan (EXP)
Optimise one EXP, producemany, potentially better EXPsReason about distribution in clusterOptimise distributed EXPsEstimate costs for all EXPs, and sort by ascending costInstanciate “cheapest” plan, i.e. set up execution engineDistribute and link up engines on different serversExecute plan, provide cursor API
9

Life of a queryText and query parameters come from userParse text, produce abstract syntax tree (AST)Substitute query parametersFirst optimisation: constant expressions, etc.Translate AST into an execution plan (EXP)Optimise one EXP, producemany, potentially better EXPs
Reason about distribution in clusterOptimise distributed EXPsEstimate costs for all EXPs, and sort by ascending costInstanciate “cheapest” plan, i.e. set up execution engineDistribute and link up engines on different serversExecute plan, provide cursor API
9

Life of a queryText and query parameters come from userParse text, produce abstract syntax tree (AST)Substitute query parametersFirst optimisation: constant expressions, etc.Translate AST into an execution plan (EXP)Optimise one EXP, producemany, potentially better EXPsReason about distribution in cluster
Optimise distributed EXPsEstimate costs for all EXPs, and sort by ascending costInstanciate “cheapest” plan, i.e. set up execution engineDistribute and link up engines on different serversExecute plan, provide cursor API
9

Life of a queryText and query parameters come from userParse text, produce abstract syntax tree (AST)Substitute query parametersFirst optimisation: constant expressions, etc.Translate AST into an execution plan (EXP)Optimise one EXP, producemany, potentially better EXPsReason about distribution in clusterOptimise distributed EXPs
Estimate costs for all EXPs, and sort by ascending costInstanciate “cheapest” plan, i.e. set up execution engineDistribute and link up engines on different serversExecute plan, provide cursor API
9

Life of a queryText and query parameters come from userParse text, produce abstract syntax tree (AST)Substitute query parametersFirst optimisation: constant expressions, etc.Translate AST into an execution plan (EXP)Optimise one EXP, producemany, potentially better EXPsReason about distribution in clusterOptimise distributed EXPsEstimate costs for all EXPs, and sort by ascending cost
Instanciate “cheapest” plan, i.e. set up execution engineDistribute and link up engines on different serversExecute plan, provide cursor API
9

Life of a queryText and query parameters come from userParse text, produce abstract syntax tree (AST)Substitute query parametersFirst optimisation: constant expressions, etc.Translate AST into an execution plan (EXP)Optimise one EXP, producemany, potentially better EXPsReason about distribution in clusterOptimise distributed EXPsEstimate costs for all EXPs, and sort by ascending costInstanciate “cheapest” plan, i.e. set up execution engine
Distribute and link up engines on different serversExecute plan, provide cursor API
9

Life of a queryText and query parameters come from userParse text, produce abstract syntax tree (AST)Substitute query parametersFirst optimisation: constant expressions, etc.Translate AST into an execution plan (EXP)Optimise one EXP, producemany, potentially better EXPsReason about distribution in clusterOptimise distributed EXPsEstimate costs for all EXPs, and sort by ascending costInstanciate “cheapest” plan, i.e. set up execution engineDistribute and link up engines on different servers
Execute plan, provide cursor API
9

Life of a queryText and query parameters come from userParse text, produce abstract syntax tree (AST)Substitute query parametersFirst optimisation: constant expressions, etc.Translate AST into an execution plan (EXP)Optimise one EXP, producemany, potentially better EXPsReason about distribution in clusterOptimise distributed EXPsEstimate costs for all EXPs, and sort by ascending costInstanciate “cheapest” plan, i.e. set up execution engineDistribute and link up engines on different serversExecute plan, provide cursor API
9

Execution plans
FOR a IN collA
RETURN {x: a.x, z: b.z}
EnumerateCollection a
EnumerateCollection b
Calculation xx == b.y
Filter xx == b.y
Singleton
Calculation xx
Return {x: a.x, z: b.z}
Calc {x: a.x, z: b.z}
FILTER xx == b.y
FOR b IN collB
LET xx = a.x
Query→ EXP
Black arrows aredependenciesThink of a pipelineEach node providesa cursor APIBlocks of “Items”travel through thepipelineWhat is an “item”???
10
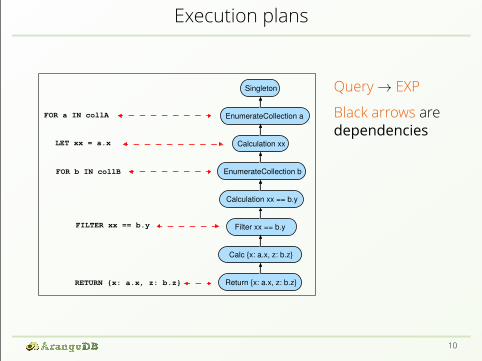
Execution plans
FOR a IN collA
RETURN {x: a.x, z: b.z}
EnumerateCollection a
EnumerateCollection b
Calculation xx == b.y
Filter xx == b.y
Singleton
Calculation xx
Return {x: a.x, z: b.z}
Calc {x: a.x, z: b.z}
FILTER xx == b.y
FOR b IN collB
LET xx = a.x
Query→ EXPBlack arrows aredependencies
Think of a pipelineEach node providesa cursor APIBlocks of “Items”travel through thepipelineWhat is an “item”???
10

Execution plans
FOR a IN collA
RETURN {x: a.x, z: b.z}
EnumerateCollection a
EnumerateCollection b
Calculation xx == b.y
Filter xx == b.y
Singleton
Calculation xx
Return {x: a.x, z: b.z}
Calc {x: a.x, z: b.z}
FILTER xx == b.y
FOR b IN collB
LET xx = a.x
Query→ EXPBlack arrows aredependenciesThink of a pipeline
Each node providesa cursor APIBlocks of “Items”travel through thepipelineWhat is an “item”???
10

Execution plans
FOR a IN collA
RETURN {x: a.x, z: b.z}
EnumerateCollection a
EnumerateCollection b
Calculation xx == b.y
Filter xx == b.y
Singleton
Calculation xx
Return {x: a.x, z: b.z}
Calc {x: a.x, z: b.z}
FILTER xx == b.y
FOR b IN collB
LET xx = a.x
Query→ EXPBlack arrows aredependenciesThink of a pipelineEach node providesa cursor API
Blocks of “Items”travel through thepipelineWhat is an “item”???
10

Execution plans
FOR a IN collA
RETURN {x: a.x, z: b.z}
EnumerateCollection a
EnumerateCollection b
Calculation xx == b.y
Filter xx == b.y
Singleton
Calculation xx
Return {x: a.x, z: b.z}
Calc {x: a.x, z: b.z}
FILTER xx == b.y
FOR b IN collB
LET xx = a.x
Query→ EXPBlack arrows aredependenciesThink of a pipelineEach node providesa cursor APIBlocks of “Items”travel through thepipeline
What is an “item”???
10

Execution plans
FOR a IN collA
RETURN {x: a.x, z: b.z}
EnumerateCollection a
EnumerateCollection b
Calculation xx == b.y
Filter xx == b.y
Singleton
Calculation xx
Return {x: a.x, z: b.z}
Calc {x: a.x, z: b.z}
FILTER xx == b.y
FOR b IN collB
LET xx = a.x
Query→ EXPBlack arrows aredependenciesThink of a pipelineEach node providesa cursor APIBlocks of “Items”travel through thepipelineWhat is an “item”???
10

Pipeline and items
FOR a IN collA EnumerateCollection a
EnumerateCollection b
Singleton
Calculation xx
FOR b IN collB
LET xx = a.x Items have vars a, xx
Items have no vars
Items are the thingies traveling through the pipeline.
An item holds values of those variables in the current frameThus: Items look differently in different parts of the planWe always deal with blocks of items for performance reasons
11

Pipeline and items
FOR a IN collA EnumerateCollection a
EnumerateCollection b
Singleton
Calculation xx
FOR b IN collB
LET xx = a.x Items have vars a, xx
Items have no vars
Items are the thingies traveling through the pipeline.An item holds values of those variables in the current frame
Thus: Items look differently in different parts of the planWe always deal with blocks of items for performance reasons
11

Pipeline and items
FOR a IN collA EnumerateCollection a
EnumerateCollection b
Singleton
Calculation xx
FOR b IN collB
LET xx = a.x Items have vars a, xx
Items have no vars
Items are the thingies traveling through the pipeline.An item holds values of those variables in the current frameThus: Items look differently in different parts of the plan
We always deal with blocks of items for performance reasons
11

Pipeline and items
FOR a IN collA EnumerateCollection a
EnumerateCollection b
Singleton
Calculation xx
FOR b IN collB
LET xx = a.x Items have vars a, xx
Items have no vars
Items are the thingies traveling through the pipeline.An item holds values of those variables in the current frameThus: Items look differently in different parts of the planWe always deal with blocks of items for performance reasons
11

Execution plans
FOR a IN collA
RETURN {x: a.x, z: b.z}
EnumerateCollection a
EnumerateCollection b
Calculation xx == b.y
Filter xx == b.y
Singleton
Calculation xx
Return {x: a.x, z: b.z}
Calc {x: a.x, z: b.z}
FILTER xx == b.y
FOR b IN collB
LET xx = a.x
12

Move filters upFOR a IN collA
FOR b IN collB
FILTER a.x == 10
FILTER a.u == b.v
RETURN {u:a.u,w:b.w}
The result and behaviour does notchange, if the first FILTER is pulledout of the inner FOR.However, the number of items trave-ling in the pipeline is decreased.Note that the two FOR statementscould be interchanged!
Singleton
EnumColl a
EnumColl b
Calc a.x == 10
Return {u:a.u,w:b.w}
Filter a.u == b.v
Calc a.u == b.v
Filter a.x == 10
13
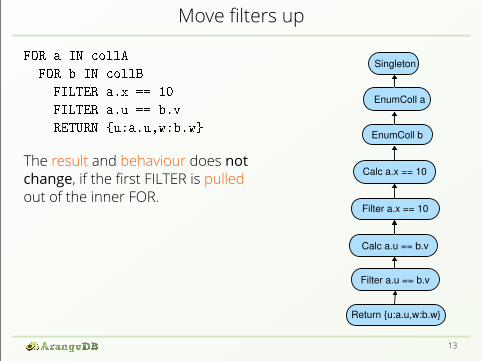
Move filters upFOR a IN collA
FOR b IN collB
FILTER a.x == 10
FILTER a.u == b.v
RETURN {u:a.u,w:b.w}
The result and behaviour does notchange, if the first FILTER is pulledout of the inner FOR.
However, the number of items trave-ling in the pipeline is decreased.Note that the two FOR statementscould be interchanged!
Singleton
EnumColl a
EnumColl b
Calc a.x == 10
Return {u:a.u,w:b.w}
Filter a.u == b.v
Calc a.u == b.v
Filter a.x == 10
13
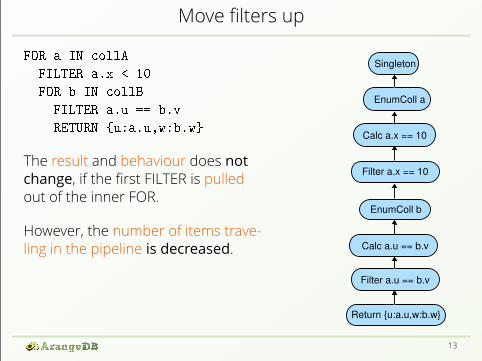
Move filters upFOR a IN collA
FILTER a.x < 10
FOR b IN collB
FILTER a.u == b.v
RETURN {u:a.u,w:b.w}
The result and behaviour does notchange, if the first FILTER is pulledout of the inner FOR.However, the number of items trave-ling in the pipeline is decreased.
Note that the two FOR statementscould be interchanged!
Singleton
EnumColl a
Return {u:a.u,w:b.w}
Filter a.u == b.v
Calc a.u == b.v
Calc a.x == 10
EnumColl b
Filter a.x == 10
13

Move filters upFOR a IN collA
FILTER a.x < 10
FOR b IN collB
FILTER a.u == b.v
RETURN {u:a.u,w:b.w}
The result and behaviour does notchange, if the first FILTER is pulledout of the inner FOR.However, the number of items trave-ling in the pipeline is decreased.Note that the two FOR statementscould be interchanged!
Singleton
EnumColl a
Return {u:a.u,w:b.w}
Filter a.u == b.v
Calc a.u == b.v
Calc a.x == 10
EnumColl b
Filter a.x == 10
13

Remove unnecessary calculationsFOR a IN collA
LET L = LENGTH(a.hobbies)
FOR b IN collB
FILTER a.u == b.v
RETURN {h:a.hobbies,w:b.w}
The Calculation of L is unnecessary!(since it cannot throw an exception).Therefore we can just leave it out.
Singleton
EnumColl a
Calc L = ...
EnumColl b
Calc a.u == b.v
Filter a.u == b.v
Return {...}
14

Remove unnecessary calculationsFOR a IN collA
LET L = LENGTH(a.hobbies)
FOR b IN collB
FILTER a.u == b.v
RETURN {h:a.hobbies,w:b.w}
The Calculation of L is unnecessary!
(since it cannot throw an exception).Therefore we can just leave it out.
Singleton
EnumColl a
Calc L = ...
EnumColl b
Calc a.u == b.v
Filter a.u == b.v
Return {...}
14

Remove unnecessary calculationsFOR a IN collA
FOR b IN collB
FILTER a.u == b.v
RETURN {h:a.hobbies,w:b.w}
The Calculation of L is unnecessary!(since it cannot throw an exception).
Therefore we can just leave it out.
Singleton
EnumColl a
EnumColl b
Calc a.u == b.v
Filter a.u == b.v
Return {...}
14

Remove unnecessary calculationsFOR a IN collA
FOR b IN collB
FILTER a.u == b.v
RETURN {h:a.hobbies,w:b.w}
The Calculation of L is unnecessary!(since it cannot throw an exception).Therefore we can just leave it out.
Singleton
EnumColl a
EnumColl b
Calc a.u == b.v
Filter a.u == b.v
Return {...}
14

Use index for FILTER and SORTFOR a IN collA
FILTER a.x > 17 &&
a.x <= 23 &&
a.y == 10
SORT a.y, a.x
RETURN a
Assume collA has a skiplist index on “y”and “x” (in this order), then we can readoff the half-open interval between{ y: 10, x: 17 } and{ y: 10, x: 23 }from the skiplist index.
The result will automatically be sorted byy and then by x.
Singleton
EnumColl a
Filter ...
Calc ...
Sort a.y, a.x
Return a
15

Use index for FILTER and SORTFOR a IN collA
FILTER a.x > 17 &&
a.x <= 23 &&
a.y == 10
SORT a.y, a.x
RETURN a
Assume collA has a skiplist index on “y”and “x” (in this order),
then we can readoff the half-open interval between{ y: 10, x: 17 } and{ y: 10, x: 23 }from the skiplist index.
The result will automatically be sorted byy and then by x.
Singleton
EnumColl a
Filter ...
Calc ...
Sort a.y, a.x
Return a
15

Use index for FILTER and SORTFOR a IN collA
FILTER a.x > 17 &&
a.x <= 23 &&
a.y == 10
SORT a.y, a.x
RETURN a
Assume collA has a skiplist index on “y”and “x” (in this order), then we can readoff the half-open interval between{ y: 10, x: 17 } and{ y: 10, x: 23 }from the skiplist index.
The result will automatically be sorted byy and then by x.
Singleton
Sort a.y, a.x
Return a
IndexRange a
15

Use index for FILTER and SORTFOR a IN collA
FILTER a.x > 17 &&
a.x <= 23 &&
a.y == 10
SORT a.y, a.x
RETURN a
Assume collA has a skiplist index on “y”and “x” (in this order), then we can readoff the half-open interval between{ y: 10, x: 17 } and{ y: 10, x: 23 }from the skiplist index.
The result will automatically be sorted byy and then by x.
Singleton
Return a
IndexRange a
15

Data distribution in a clusterRequests
DBserver DBserver DBserver
CoordinatorCoordinator
4 2 5 3 11
The shards of a collection are distributed across the DBservers.
The coordinators receive queries and organise theirexecution
16

Data distribution in a clusterRequests
DBserver DBserver DBserver
CoordinatorCoordinator
4 2 5 3 11
The shards of a collection are distributed across the DBservers.The coordinators receive queries and organise theirexecution
16

Scatter/gather
EnumerateCollection
17

Scatter/gather
Remote
EnumShard
Remote Remote
EnumShard
Remote
Concat/Merge
Remote
EnumShard
Remote
Scatter
17

Scatter/gather
Remote
EnumShard
Remote Remote
EnumShard
Remote
Concat/Merge
Remote
EnumShard
Remote
Scatter
17

Modifying queriesFortunately:
There can be at most one modifying node in each query.There can be no modifying nodes in subqueries.
Modifying nodesThe modifying node in a query
is executed on the DBservers,to this end, we either scatter the items to all DBservers,or, if possible, we distribute each item to the shardthat is responsible for the modification.Sometimes, we can even optimise away a gather/scattercombination and parallelise completely.
18

Modifying queriesFortunately:
There can be at most one modifying node in each query.There can be no modifying nodes in subqueries.Modifying nodesThe modifying node in a query
is executed on the DBservers,
to this end, we either scatter the items to all DBservers,or, if possible, we distribute each item to the shardthat is responsible for the modification.Sometimes, we can even optimise away a gather/scattercombination and parallelise completely.
18

Modifying queriesFortunately:
There can be at most one modifying node in each query.There can be no modifying nodes in subqueries.Modifying nodesThe modifying node in a query
is executed on the DBservers,to this end, we either scatter the items to all DBservers,or, if possible, we distribute each item to the shardthat is responsible for the modification.
Sometimes, we can even optimise away a gather/scattercombination and parallelise completely.
18

Modifying queriesFortunately:
There can be at most one modifying node in each query.There can be no modifying nodes in subqueries.Modifying nodesThe modifying node in a query
is executed on the DBservers,to this end, we either scatter the items to all DBservers,or, if possible, we distribute each item to the shardthat is responsible for the modification.Sometimes, we can even optimise away a gather/scattercombination and parallelise completely.
18