maximum likelihood linear regression for speaker adaptation of continuous density hidden markov...
TRANSCRIPT

Maximum Likelihood Linear Regression for Speaker Adaptation of
Continuous Density Hidden Markov Models
C. J. Leggetter and P. C. WoodlandDepartment of Engineering, University of Cambridge,
Trumpington Street, Cambridge CB2 1PZ, U.K.
Computer Speech and Language (1995)
Present by Hsu Ting-Wei 2006.03.16

2
Introduction
• Speaker adaptation techniques fall into two main categories:– Speaker normalization
• The input speech is normalized to match the speaker that the system is trained to model
– Model adaptation techniques• The parameters of the model set are adjusted to improve the
modeling of the new speaker• MAP method
– Only update the parameters of models which are observed in the adaptation data
• MLLR method (Maximum Likelihood Linear Regression)
– All model states can be adapted even if no model-specific data is available
Speaker HMM Models
Say: “Hello!”

3
MLLR’s adaptation approach
• This method requires an initial speaker independent continuous density HMM system
• MLLR takes some adaptation data from a new speaker and updates the model mean parameters to maximize the likelihood of the adaptation data
• The other HMM parameters are not adapted since the main differences between speakers are assumed to be characterized by the means

4
MLLR’s adaptation approach (cont.)
• Consider the case of a continuous density HMM system with Gaussian output distributions.
• A particular distribution s ,is characterized by a mean vector , and a covariance matrix
• Given a parameterized speech frame vector , the probability density of that vector being generated by distribution s iswhere n is the dimension of the observation vector
ssC
obs
S
speech frame vector
o
sss oCo
sns e
Cob
1'2/1
2/12/2
1

5
MLLR’s adaptation approach (cont.)
• We use the following equation
• We can simply it
where
• So the probability density function for the adapted system becomes
n*(n+1)
ssss bA ̂
sss W ˆ
'21 ],...,,,[ ns
extended mean vector要調適的分佈的 mean 值 所串起的向量
offset = 1, include an offset in the regressionoffset = 0, ignore offsets若調適語者的錄音環境與初始模型錄音環境不同時,可以加入的一項參數 [ 參考資料 ]
Original ..
(n+1)*1transformation matrices
sssss WoCWo
sns e
Cob
1'2/1
2/12/2
1(1)

6
MLLR’s adaptation approach (cont.)
• The transformation matrices are calculated to maximize the likelihood of the adaptation data
• The transformation matrices can be implemented using the forward–backward algorithm
• A more general approach is adopted in which the same transformations matrix is used for several distributions.
• If some of the distributions are not observed in the adaptation data, a transformation may still be applied (global transformation)
sW

7
Estimation of MLLR regression matrices
|,log|,
,||,log,
)Likelihood-(Maximum
it maximize want to Weand function,auxiliary an Define–
|,|
is sequencen observatio thegenerateset model theof likelihood totalThe–
set by the denoted are Tlength of sequences state possible all And–
as parameters model of
set estimated-re a and by parameters model ofset current theDenote–
...
ns.observatio of series a is , data, adaptation theAssume–
1
OFOF
OOFEQ
OFOF
ooO
TO
V
V
T
• 1.Definition of auxiliary function
objective function
S
speech frame vector
E-step

8
Estimation of MLLR regression matrices (cont.)
• 2.Maximization of auxiliary function
|,|
1
generated is sequencen observatio thegiven that
at time state occupying ofy probabilit posteriori a theas and
system in the onsdistributi state all ofset theas Defines -
log|, constant
log|,
|,log|,
,||,log,
1
21 111
Vts
s
tV
T
t
T
tt
V
V
sOFOF
t
O
tst
S
obOF
obaobOF
OFOF
OOFEQ
t
ttt
only related with mean
(2)
(3)

9
Estimation of MLLR regression matrices (cont.)
• 2.Maximization of auxiliary function (cont.)
log|constant
log|
|,| constant
log|
||,constant
log|, constant ,
|,|
1
1 1
1 1
1 1
1
tj
S
j
T
tj
tj
S
j
T
t
t
tjt
S
j
T
t
tV
T
t
Vts
obtOF
obOF
jOFOF
obOF
OFjOF
obOFQ
sOFOF
t
t
則
已知
(4)expanding this term

10
Estimation of MLLR regression matrices (cont.)
• 2.Maximization of auxiliary function (cont.)
S
j
T
ttjj
S
j
T
tjjtjjjtjj
S
j
T
tjtjjtjj
jtjjtj
S
j
T
tj
S
j
T
tjtjjtj
nj
jtjjtjn
S
j
T
tj
oCo
jn
S
j
T
tj
tj
S
j
T
tj
johCntOF
WoCWoCntOF
oCoCntOF
oCoCntOF
oCoCtOF
oCoCtOF
eC
tOF
obtOFQ
jtjjt
1 1
1 1
1'
1 1
1'
1'
1 1
1 1
1'2/12/
1'2/12/
1 1
2/1
2/12/1 1
1 1
,log2log|2
1constant
log2log|2
1constant
log2log|2
1constant
2
1log
2
12log
2
1|constant
2
1log2log|constant
2
12log|constant
2
1log|constant
log|constant ,
1'

11
T
tssss
T
tstss
T
tsstss
T
tsstss
S
j
T
tjjtjjjtjj
s
S
j
T
tjjtjjjtjj
ss
sWCtoCt
sWoCtOF
sWoCtOF
WoCWoCntWd
dOF
WoCWoCntOFWd
dQ
Wd
d
1
'1
1
'1
1
'1
1
'1
1 1
1'
1 1
1'
hence
0
|
***2*|2
1
log2log|2
1
log2log|2
1constant ,
Estimation of MLLR regression matrices (cont.)
• 2.Maximization of auxiliary function (cont.)M-step
AX2X
AXX T
sW<= 估測 的 general form (5)

12
Estimation of MLLR regression matrices (cont.)
• 3.Re-estimation formula for tied regression matrices
(7)
(6)equation therewrite
(6)
:becomes (5)equation then ...., states Rby shared is If
:form general
)(
1
)(
1 1
'1
1
'
1
1
1 1
'1
21
1
'1
1
'1
rR
r
rT
t
R
rstss
T
tss
R
rss
T
t
R
rstss
R
T
tssss
T
tstss
sDWVoCt
sWCtoCt
ssssW
sWCtoCt
rrr
rrrrrrr
[(n+1)*1][1*(n+1)] =(n+1) *(n+1)
當調適語料不夠多時,可以將調適語料中相關性較大的狀態分為同一類,利用在同一類別中所收集到的語料來估測 Ws 。

13
Estimation of MLLR regression matrices (cont.)
• 3.Re-estimation formula for tied regression matrices (cont.)
(7) 1 1
'1)(
1
)(
T
t
R
rstss
rR
r
r
rrroCtsDWV
so
where 0
where
thensymmetric, is D since and
diagonal, are scovariance all if
1
1 1
)()(
1
)()(
1
)()(
1
1
1 1
)()(
n
q
R
r
rjq
riiiqij
R
r
rjq
rii
R
r
rqj
rip
n
p
n
q
R
r
rqj
rippqij
dvwy
pi
pidvdv
dvwy
(7)is denoted by n*(n+1) matrix Y
basis. row-by-row
aon calculated and methodsion decomposit LU
orn eliminatioGaussian using solves becan equation These
Zand of rows theare and where,
equations ussimultaneo of system thefrom
computed becan hence,parameters model theand
n vectorsobservatio thefrom computed becan both and
on dependent not are and that note
'1)('
1
1
)(1
1 1
)()(
W
W
W
W
S
S
thiii
ii
S
Sijij
n
q
ijqiq
n
q
R
r
rjq
riiiqijij
izwzGw
yz
gwdvwyz
(7)is denoted by n*(n+1) matrix Z
?

14
Special cases of MLLR
• 1.Least squares regression
otherwise ,0
... if ,1
where
(9)
becomes (8)equation the
otherwise ,0
on distributi state toassigned is if ,1
thatso alignment) Viterbiby (e.g.on distributi oneexactly toassigned is framespeech each If
(8)
becomes
(6)
(6)equation thesame, theareation transformsame the to tiedonsdistributi theof scovariance theall If
1t
1
'
1
'
1
'
11 1
'
1
'
1
1
1 1
'1
Rs
T
ts
T
tst
rts
T
tss
R
rs
T
t
R
rsts
T
tss
R
rss
T
t
R
rstss
ss
sWo
sot
sWtot
sWCtoCt
t
ttttt
r
rrrrr
rrrrrrr
1''
21
estimate squaresleast standard theismatrix regression theof estimate the
g,rearrangin and (9)Equation in Y and X ngSubstituti
..., ...
as Y and X matrices theDefining
2121
XXYXW
oooYX
s
sTssTT
(XX’)YX’

15
Special cases of MLLR (cont.)
• 1.Least squares regression (cont.)

16
Special cases of MLLR (cont.)
• 2.Single variable linear regression
sss
nnn
n
s
s
nnn
ns
nnn
s
wD
D
D
W
W
W
W
w
WW
WW
WW
W
ˆˆ
so
0....00....0
00....00..0
::
0..00....00
0..00....0
r mean vecto extended theof elements of up made matrix defining and
:
:
ˆ,
:
0
0
0....
:
..
..0
.regressionlinear variablesingle simpleby calculated becan component
meaneach ofon modificati thet,independen arer mean vecto in the features theall If
2*
1
2
1
1*21,
2,1
1,
1,1
1)*(nn1,1,
3,21,2
2,11,1

17
Special cases of MLLR (cont.)
• 2.Single variable linear regression (cont.))wD(oC)wD(o/
/s
n/sstsste
||Cπ((o)b ˆˆ21
212
1
)2
1
sssss
T
ttsss
T
t
wDCDtoCDt ˆ)()( 1
1
1
1
sssss
T
t
R
rtsss
T
t
R
r
wDCDtoCDtrrrrrˆ)()( 1
11
1
11
0ˆ| ,1
1'
T
tsstcss
s
wDoCDtOFQWd
d
tsss
T
t
R
rssss
T
t
R
rs oCDtDCDtw
rrrrr
1
11
11
11
)()(ˆ
M-step

18
Defining regression classes
• When regression matrices are tied across mixture components, each matrix is associated with many mixture components.
• For the tied approach to be effective it is desirable to put all the mixture components which will use similar transforms into the same class.
• Two approaches for defining regression classes were considered:– Based on broad phonetic classes
• All mixture components in any model representing the same broad phonetic class (e.g. fricatives, nasals, etc.) were placed in the same regression class.
– Based on clustering of mixture components
• The mixture components were compared using a likelihood measure and similar components placed in the same regression class.

19
Experiment: Full regression matrix V.S. Diagonal regression matrix
SD
SI
diagonal
full : a lot of parameters

20
Experiment: Full matrix using global regression class
SD
SI
adapted
21
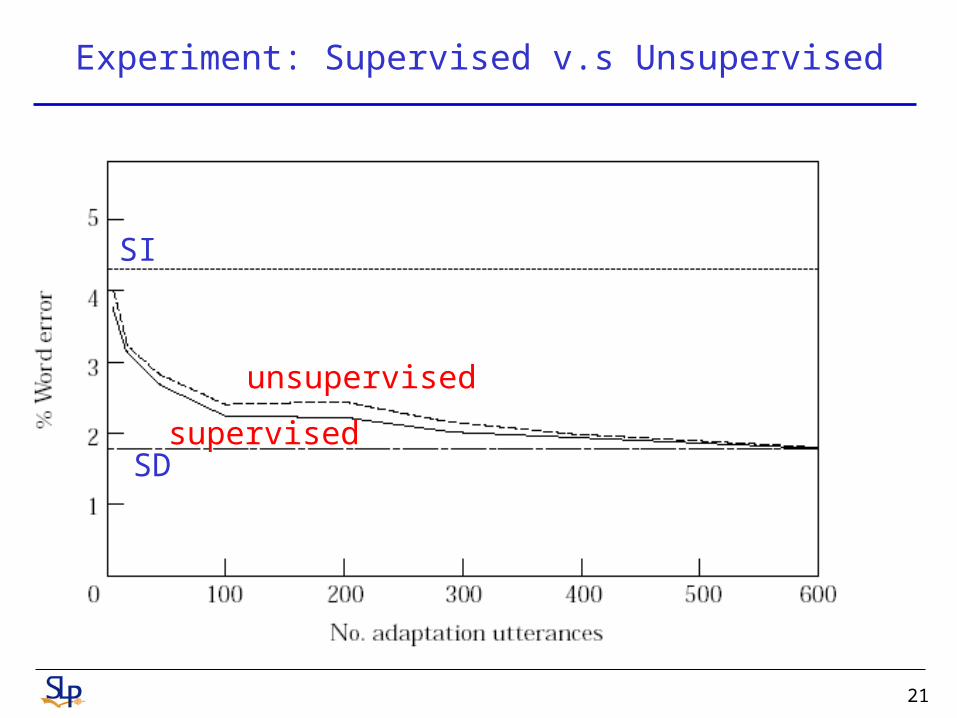
Experiment: Supervised v.s Unsupervised
SD
SI
supervised
unsupervised

22
Conclusion
• MLLR can be applied to continuous density HMMs with a large number of Gaussians and is effective with small amounts of adaptation data.