meant: semi-automatic metric for evaluating for mt evaluation via semantic frames an asembling of...
TRANSCRIPT

MEANT: semi-automatic metric for evaluatingfor MT evaluation via semantic frames
an asembling of ACL11,IJCAI11,SSST11 Chi-kiu Lo & Dekai Wu
Presented by SUN Jun

MT’s often bad• MT3:
So far , the sale in the mainland of China for nearly two months of SK – II line of products
• MT1:So far , nearly two months sk –ii the sale of products in the mainland of China to resume sales.
• MT2: So far, in the mainland of China to stop selling nearly two months of SK – 2 products sales resumed.
• Ref:Until after their sales had ceased in mainland China for almost tow months, sales of the complete range of SK – II products have now been resumed.
BLEU: 0.124
BLEU: 0.012
BLEU: 0.013

Metrics besides BLEU have problems
• Lexical similarity based metrics (eg. NIST, METEOR)– Good at capturing fluency– Correlate poorly with human judgment on adequacy
• Syntax based (eg. STM, Liu and Gildea, 2005)– Much better at capturing grammaticality– Still more fluency oriented than adequacy-oriented
• Non-automatic metrics (eg. HTER)– Use human annotators to solve non-trivial problem of
finding min edit distance to evaluate adequacy– Human-training & Labor intensive

MEANT: SRL for MT evaluation
• Intuition behind the idea:– Useful translation help users accurately understand
the basic event structure of source utterances—“ who did what to whom, when, where and why” .
• Hypothesis of the work:– MT utility can best be evaluated via SRL– Better than:• N-gram based metrics like BLEU (adequacy)• Human training intensive metrics like HTER (time cost)• Complex aggregate metrics like ULC (representation
transparency)

Q. Do PRED & ARGj correlate to human adequacy judgments?
N-gram Matching # Syntax-subtree
Matching # SRL Matching #
1-gram 15 1-level 34 Predicate 0
2-gram 4 2-level 8
3-gram 3 3-level 2
4-gram 1 4-level 0

Q. Do PRED & ARGj correlate to human adequacy judgments?
N-gram Matching # Syntax-subtree
Matching # SRL Matching #
1-gram 15 15 1-level 35 34 Predicate 2 0
2-gram 4 4 2-level 6 8 Argument 1 0
3-gram 1 3 3-level 1 2
4-gram 0 1 4-level 0 0

Experimental settings
• Exp settings 1 -- Corpus– ACL11: draw 40 sentences from Newswire
datasets in GALE P2.5 (with SRL in ref/src, 3-output)
– IJCAI11: draw 40, draw 35 from previous data set and draw 39 from broadcast news WMT2010-MetricsMaTr

Experimental settings
• Exp settings 2 – Annotation of SRL on MT reference and output– SRL: Propbank style

Experimental settings
• Exp settings 3 –SRL evaluation as MT evaluation– Correct, incorrect, partial (predicate & argument)• Partial: part of the meaning is correctly translated• Extra meaning in a role filler is not penalized unless it
belongs in another role• Incorrectly translated predicate means the entire frame is
wrong (no count of arguments)

Experimental settings
• Exp settings 3 –SRL evaluation as MT evaluation– F-measureBased scores– weights tunedby confusion Matrix on dev

Experimental settings
• Exp settings 4 – Evaluation of evaluation– WMT and NIST MetricsMaTr (2010)– Kendall’s τ rank correlation coefficient• evaluate the correlation of the proposed metric with
human judgments on translation adequacy ranking. • A higher value for τ indicates more similarity to the ranking
by the evaluation metric to the human judgment. • The range of possible values of correlation coefficient is [-
1,1], where 1 means the systems are ranked

Observations
• HMEANT vs other metric

Observations
• HMEANT on CV data

Observations
• HMEANT annotated via Mono vs Bi-lingual
Error analysis: annotators drop parts of the meaning in the translation when trying to align them to the source input

Observations
• HMEANT vs MEANT (automatic SRL)– SRL tool: ASSERT, 87% (Pradhan et al. 2004)
80 %
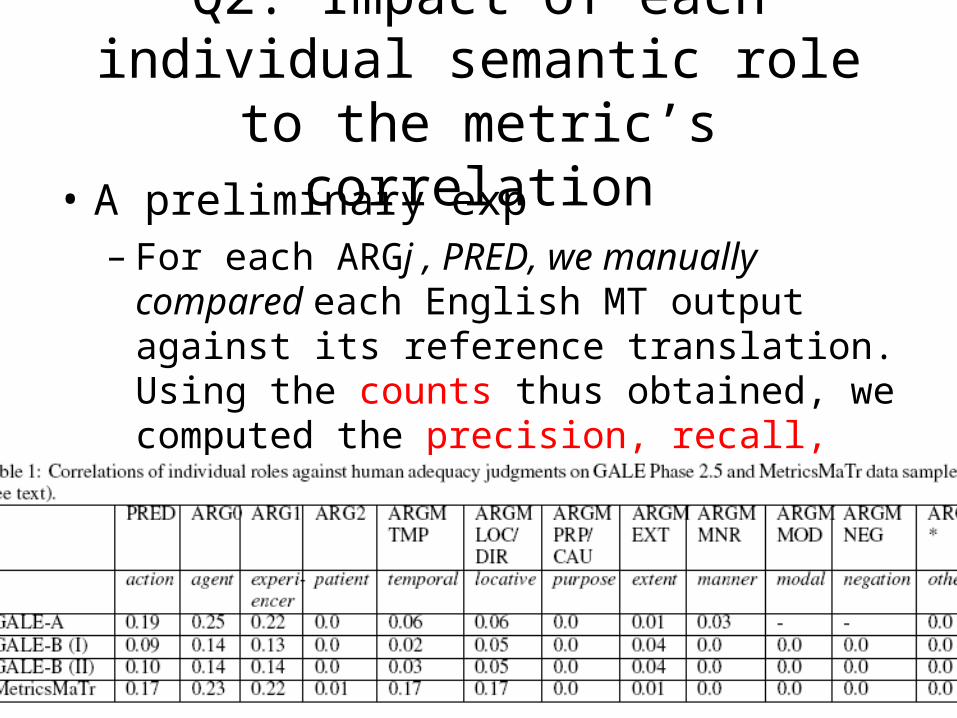
Q2: Impact of each individual semantic role to the metric’s correlation
• A preliminary exp– For each ARGj , PRED, we manually compared
each English MT output against its reference translation. Using the counts thus obtained, we computed the precision, recall, and f-score for PRED and each ARGj type.

IJCAI 11: evaluation the individual impact
• The preliminary exp suggest effectiveness– Propose metrics for evaluating individual impact

IJCAI 11: evaluation the individual impact
• The preliminary exp suggest effectiveness

IJCAI 11: evaluation the individual impact
• Results

IJCAI 11: evaluation the individual impact
• Results2AutomaticSRL tool
76-93%

Q: Can be Even more Accurate?
• SSST11...

Conclusion
• ACL11– Bring MEANT, HMEANT– HMEANT correlates well to human judges, as well as
more expensive HTER– Automatic SRL yields 80% correlations
• IJCAI11– Study impact of each individual semantic roles
• SSST11– Propose Length based weighting scheme to evaluate
contribution of each semantic frame

END