measure proximity on graphs with side information joint work by hanghang tong, huiming qu, hani...
Post on 21-Dec-2015
216 views
TRANSCRIPT

Measure Proximity on Graphs with Side Information
Joint Work by
Hanghang Tong, Huiming Qu, Hani Jamjoom
Speaker: Mary McGlohon
1ICDM 2008, Pisa, Italy15-19 December, 2009
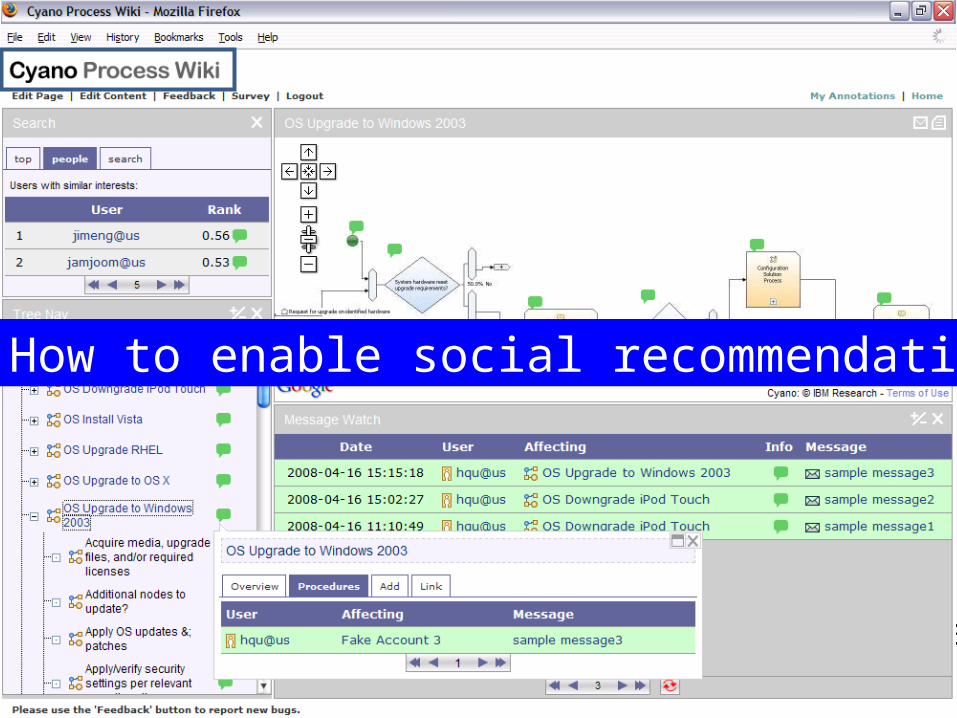
Cyano: Process Collaboration Wiki
2
Q: How to enable social recommendation in Cyano?
Q: How to enable social recommendation?

Scoop: current recommendation system[Qu+ SCC 2008]
• Given a node in a graph (e.g., given a user node in a user-to-process graph),
• Find– 1. [Ranking List] a list of recommended nodes,
which are most related to the query node – 2. [Connection Subgraph] a connection subgraph,
which can best interpret the relationship between the query node and the recommended node(s)
3
Proximity is the core of scoop!
What to recommend
Why to recommend

Challenges in Scoop• How to incorporate users’ feedback (like/dislike)?
4
How to automatically adjust the rankingfor the query node 1?
1
4
2
5
310
Current subgraph between 1 and 10
How to modify our subgraph to weaken the links between 1 and 10 that involve node 5?
Q: How to incorporate such side information in measuring
node proximity on graphs?
Feedback on ranking list Feedback on conn-graph

Isomorphic Settings of Scoop• Proximity is the Main Tool for
– Neighborhood search– Anomaly detection– Pattern matching– Image captioning
– …• Source of Side Information is Rich
– Ratings in recommendation system– Opinion/sentiment in blog analysis– Clickthrough data– …
5

Roadmap
• Motivations• Proximity w/o Side Information• Proximity w/ Side Information
– ProSIN: Method– Fast-ProSIN: Fast Solution
• Experimental Results• Conclusion
6

Proximity on Graph: What?
A BH1 1
D1 1
E
F
G1 11
I J1
1 1
a.k.a Relevance, Closeness, ‘Similarity’…7

What is a ``good’’ Proximity?
A BH1 1
D1 1
E
F
G1 11
I J1
1 1
• Multiple Connections
• Quality of connection
•Direct & In-direct conns
•Length, Degree, Weight…
…
8

Sol: Random walk with restart [Pan+ KDD 2004]
Node 4
Node 1Node 2Node 3Node 4Node 5Node 6Node 7Node 8Node 9Node 10Node 11Node 12
0.130.100.130.220.130.050.050.080.040.030.040.02
1
4
3
2
56
7
910
811
120.13
0.10
0.13
0.13
0.05
0.05
0.08
0.04
0.02
0.04
0.03
Ranking vector More red, more relevant
Nearby nodes, higher scores
4r
9

2c 3c ...W 2W 3WQ I c
Why is RWR a good score?
all paths from i to j with length 1
all paths from i to j with length 2
all paths from i to j with length 3
W : adjacency matrix. c: damping factor
1( )Q I cW ,( , ) i jQ i j r
i
j
10

Proximity in Current Scoop
11
U1
U2
U3
U4
P1
P2
P3
P4
P5
User Process
Initial result: P2 P3 P1
1
4
2
5
3
6
8
7
9
10
1
4
2
5
310
Ranking List Conn-Subgraph

Roadmap
• Motivations• Proximity w/o Side Information• Proximity w/ Side Information
– ProSIN: Method– Fast-ProSIN: Fast Solution
• Experimental Results• Conclusion
12
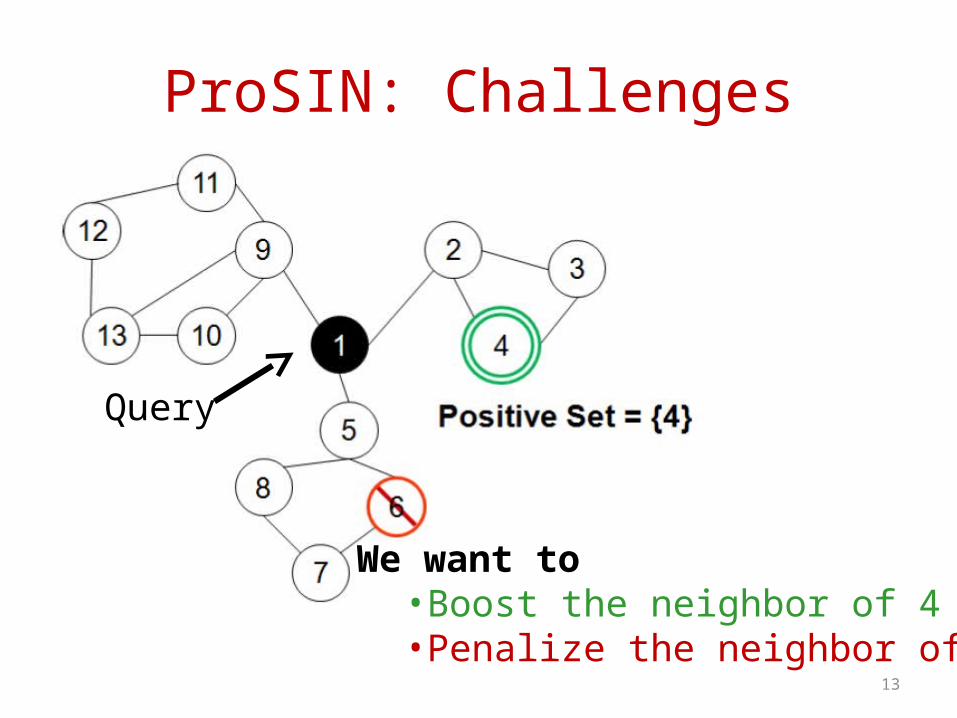
ProSIN: Challenges
13
Query
We want to•Boost the neighbor of 4•Penalize the neighbor of 6

ProSIN: How to
Use Side Information to refine the graph!14
Query

ProSIN: Detailed Algorithm• Input:
– A weighted directed graph A– Source node s and target t– Side information: positive net P and the negative set N
• Output: – Proximity score from the source to target
• Method:1. Add a link from the source node to each of the positive nodes x2. Introduce the sink node into the graph3. For each of the negative nodes y,
find its neighboring nodes Add a link from node y to the sink Add a link from each neighboring node of node y to the sink
4. Perform random walk with restart for the source node s on the refined graph
5. Output the proximity score as the steady state probability that the random particle will finally stay at the target node t
15Skip

Process management
16
Given a user-process graph, `U2’ is the query,Which are the top 3 most related processes?
Initial result (no feedback): P2 P3 P1Updated result (`no’ to `P2’) : P3 P4 P5
U1
U2
U3
U4
P1
P2
P3
P4
P5
User Process

Roadmap
• Motivations• Proximity w/o Side Information• Proximity w/ Side Information
– ProSIN: Method– Fast-ProSIN: Fast Solution
• Experimental Results• Conclusion
17

Computing RWR
1
4
3
2
56
7
910
811
12
0.13 0 1/3 1/3 1/3 0 0 0 0 0 0 0 0
0.10 1/3 0 1/3 0 0 0 0 1/4 0 0 0
0.13
0.22
0.13
0.050.9
0.05
0.08
0.04
0.03
0.04
0.02
0
1/3 1/3 0 1/3 0 0 0 0 0 0 0 0
1/3 0 1/3 0 1/4 0 0 0 0 0 0 0
0 0 0 1/3 0 1/2 1/2 1/4 0 0 0 0
0 0 0 0 1/4 0 1/2 0 0 0 0 0
0 0 0 0 1/4 1/2 0 0 0 0 0 0
0 1/3 0 0 1/4 0 0 0 1/2 0 1/3 0
0 0 0 0 0 0 0 1/4 0 1/3 0 0
0 0 0 0 0 0 0 0 1/2 0 1/3 1/2
0 0 0 0 0 0 0 1/4 0 1/3 0 1/2
0 0 0 0 0 0 0 0 0 1/3 1/3 0
0.13 0
0.10 0
0.13 0
0.22
0.13 0
0.05 00.1
0.05 0
0.08 0
0.04 0
0.03 0
0.04 0
2 0
1
0.0
n x n n x 1n x 1
Ranking vector Starting vectorAdjacency matrix
1
(1 )i i ir cWr c e
Restart p
18

0 1/3 1/3 1/3 0 0 0 0 0 0 0 0
1/3 0 1/3 0 0 0 0 1/4 0 0 0 0
1/3 1/3 0 1/3 0 0 0 0 0 0 0 0
1/3 0 1/3 0 1/4
0.9
0 0 0 0 0 0 0
0 0 0 1/3 0 1/2 1/2 1/4 0 0 0 0
0 0 0 0 1/4 0 1/2 0 0 0 0 0
0 0 0 0 1/4 1/2 0 0 0 0 0 0
0 1/3 0 0 1/4 0 0 0 1/2 0 1/3 0
0 0 0 0 0 0 0 1/4 0 1/3 0 0
0 0 0 0 0 0 0 0 1/2 0 1/3 1/2
0 0 0 0 0
0
0
0
0
00.1
0
0
0
0
0 0 1/4 0 1/3 0 1/2 0
0 0 0 0 0 0 0 0 0 1/3 1/3
1
0 0
Q: Given query i, how to solve it?
??
Adjacency matrix Starting vectorRanking vectorRanking vector
Query
19

OntheFly: 0 1/3 1/3 1/3 0 0 0 0 0 0 0 0
1/3 0 1/3 0 0 0 0 1/4 0 0 0 0
1/3 1/3 0 1/3 0 0 0 0 0 0 0 0
1/3 0 1/3 0 1/4
0.9
0 0 0 0 0 0 0
0 0 0 1/3 0 1/2 1/2 1/4 0 0 0 0
0 0 0 0 1/4 0 1/2 0 0 0 0 0
0 0 0 0 1/4 1/2 0 0 0 0 0 0
0 1/3 0 0 1/4 0 0 0 1/2 0 1/3 0
0 0 0 0 0 0 0 1/4 0 1/3 0 0
0 0 0 0 0 0 0 0 1/2 0 1/3 1/2
0 0 0 0 0
0
0
0
0
00.1
0
0
0
0
0 0 1/4 0 1/3 0 1/2 0
0 0 0 0 0 0 0 0 0 1/3 1/3
1
0 0
1
4
3
2
5 6
7
9 10
811
12
ir
ir
20
??

OntheFly: 0 1/3 1/3 1/3 0 0 0 0 0 0 0 0
1/3 0 1/3 0 0 0 0 1/4 0 0 0 0
1/3 1/3 0 1/3 0 0 0 0 0 0 0 0
1/3 0 1/3 0 1/4
0.9
0 0 0 0 0 0 0
0 0 0 1/3 0 1/2 1/2 1/4 0 0 0 0
0 0 0 0 1/4 0 1/2 0 0 0 0 0
0 0 0 0 1/4 1/2 0 0 0 0 0 0
0 1/3 0 0 1/4 0 0 0 1/2 0 1/3 0
0 0 0 0 0 0 0 1/4 0 1/3 0 0
0 0 0 0 0 0 0 0 1/2 0 1/3 1/2
0 0 0 0 0
0
0
0
0
00.1
0
0
0
0
0 0 1/4 0 1/3 0 1/2 0
0 0 0 0 0 0 0 0 0 1/3 1/3
1
0 0
0
0
0
1
0
0
0
0
0
0
0
0
0.13
0.10
0.13
0.22
0.13
0.05
0.05
0.08
0.04
0.03
0.04
0.02
1
4
3
2
5 6
7
9 10
811
12
0.3
0
0.3
0.1
0.3
0
0
0
0
0
0
0
0.12
0.18
0.12
0.35
0.03
0.07
0.07
0.07
0
0
0
0
0.19
0.09
0.19
0.18
0.18
0.04
0.04
0.06
0.02
0
0.02
0
0.14
0.13
0.14
0.26
0.10
0.06
0.06
0.08
0.01
0.01
0.01
0
0.16
0.10
0.16
0.21
0.15
0.05
0.05
0.07
0.02
0.01
0.02
0.01
0.13
0.10
0.13
0.22
0.13
0.05
0.05
0.08
0.04
0.03
0.04
0.02
No pre-computation / light storage
Slow on-line response O(mE)
ir
ir
21
1
43
2
5 6
7
9 10
811
120.130.10
0.13
0.13
0.05
0.05
0.08
0.04
0.02
0.04
0.03

NB_Lin [Tong+ ICDM06]
• Pre-Compute Stage
– Step 1:
– Step 2:
• On-Line Stage– 2 matrix-vector multiplications
22
1
4
3
2
5 6
7
9 10
811
12
4
1
2
3
5
6
7
8
9
10
11
12
C1
C2
C3
1 1( )S cVU
Fast response if …
The desired graph is un-known
W ~~ ~ U
S VX X

How to rescue: Fast-ProSIN
23
Before
After
A lot of Overlap!- Pre-Compute on original graph- Update in on-line stage

Roadmap
• Motivations• Proximity wo/ Side Information• Proximity w/ Side Information
– ProSIN: Method– Fast-ProSIN: Fast Solution
• Experimental Results• Conclusion
24

Experimental Setup
• Data Sets– DBLP-AC
• Author-Conference bipartite graph; 400K authors; 3.5K conferences; 1M edges
– DBLP-ML• Co-authorship graph from ICML and NIPS; 4.5K nodes, 20K edges
– Coral• Image-Region-Keyword graph, 52K nodes, 350K edges
• We want to check– The effectiveness of ProSIN– The efficiency of Fast-ProSIN
25

Initial Results No to `ICML’ Yes to `SIGIR’
'ICDM' 'ICML' 'SDM' 'VLDB' 'ICDE'
'SIGMOD' 'NIPS''PKDD''IJCAI'
'PAKDD'
'ICDM' 'SDM''PKDD''ICDE''VLDB'
'SIGMOD''PAKDD''CIKM''SIGIR'
'WWW'
'SIGIR''TREC''CIKM''ECIR''CLEF''ICDM''JCDL''VLDB''ACL''ICDE'
two main sub-communities in KDD: DBs (green) vs. Stat (Red)
Negative feedback on ICML will exclude other stats confs (NIPS, IJCAI)
Positive feedback on SIGIR will bring more IR (brown) conferences.
What are most related conferences wrt KDD? (DBLP author-conference bipartite graph) 26
Interactive Neighborhood Search

Initial Results No to `ICML’ Yes to `SIGIR’
'ICDM' 'ICML' 'SDM' 'VLDB' 'ICDE'
'SIGMOD' 'NIPS''PKDD''IJCAI'
'PAKDD'
'ICDM' 'SDM''PKDD''ICDE''VLDB'
'SIGMOD''PAKDD''CIKM''SIGIR'
'WWW'
'SIGIR''TREC''CIKM''ECIR''CLEF''ICDM''JCDL''VLDB''ACL''ICDE'
two main sub-communities in KDD: DBs (green) vs. Stat (Red)
Negative feedback on ICML will exclude other stats confs (NIPS, IJCAI)
Positive feedback on SIGIR will bring more IR (brown) conferences.
What are most related conferences wrt KDD?(DBLP author-conference bipartite graph) 27
Interactive Neighborhood Search

Initial Results No to `ICML’ Yes to `SIGIR’
'ICDM' 'ICML' 'SDM' 'VLDB' 'ICDE'
'SIGMOD' 'NIPS''PKDD''IJCAI'
'PAKDD'
'ICDM' 'SDM''PKDD''ICDE''VLDB'
'SIGMOD''PAKDD''CIKM''SIGIR'
'WWW'
'SIGIR''TREC''CIKM''ECIR''CLEF''ICDM''JCDL''VLDB''ACL''ICDE'
two main sub-communities in KDD: DBs (green) vs. Stat (Red)
Negative feedback on ICML will exclude other stats confs (NIPS, IJCAI)
Positive feedback on SIGIR will bring more IR (brown) conferences.
what are most related conferences wrt KDD?(DBLP author-conference bipartite graph) 28
Interactive Neighborhood Search

AndrewMcCallum
YimingYang
Tom M. Mitchell
Seán Slattery
Rayid Ghani
XueruiWang
Rebecca Hutchinson
Jian Zhang
ZoubinGhahramani
John D.Laffterty
21
22
4
1
11
1
1
1
1
2
1
Text Mining
Information Retrieval
Statistics
Connection Subgraph: Initial Result (between “Andrew Mccallum” and “Yiming Yang”)
There are two main connections between “McCallum” and “Yang” 29

AndrewMcCallum
YimingYang
Michael I.Jordan
XiaojinZhu
RongJin
AndrewNg
Jian Zhang
ZoubinGhahramani
John D.Laffterty
2
1 162
7
FernandoC.N. Pereira
2
4
2
21
4
2
2
3
Connection Subgraph: After Feedback
(between “Andrew Mccallum” and “Yiming Yang”, but avoid “Tom M. Mitchell”)
The feedback guides to avoid the entire ‘Text’ connection, and brings more connections on ‘Statistics’
30

Test Image
Sea Sun Sky Wave Cat Forest Tiger Grass
Image
Keyword
Region
Automatic Image Caption
Q: How to assign keywords to the test image?31

Semi-automatic image caption (precision)
32
Our method
Baseline
Linear Combination
Remove Negative Nodes
5 keywords that are most relevant to the test image are returned for users’ yes/no confirmation
Predict Length

Semi-automatic image caption (recall)
33
Our method Baseline
Linear Combination
Remove Negative Nodes
Predict Length

Fast-ProSIN: Quality-Speed Trade-off
34
Precision Recall Time
93.0%+ quality preservingUp to 49x speed-up

Conclusion• Goal: Incorporate Users’ Feedback (Like/Dis-like) in Proximity
Measurement on Graphs
• Q: How to customize Tom‘s applications?• A: ProSIN
– Basic Idea: Bias Random Walk
– Wide Applicability, Easy to Use
• Q: How to reflect Tom’s real-time interest?• A: Fast-ProSIN
– Basic Idea: Explore smoothness– Significant speedup (minutes to seconds)
35
