measurement and metrics for test managers
TRANSCRIPT

MG AM Tutorial
10/13/2014 8:30:00 AM
"Measurement and Metrics for Test
Managers"
Presented by:
Rick Craig
Software Quality Engineering
Brought to you by:
340 Corporate Way, Suite 300, Orange Park, FL 32073
888-268-8770 ∙ 904-278-0524 ∙ [email protected] ∙ www.sqe.com

Rick Craig
Software Quality Engineering A consultant, lecturer, author, and test manager, Rick Craig has led numerous teams of testers on both large and small projects. In his thirty years of consulting worldwide, Rick has advised and supported a diverse group of organizations on many testing and test management issues. From large insurance providers and telecommunications companies to smaller software services companies, he has mentored senior software managers and helped test teams improve their effectiveness. Rick is coauthor of Systematic Software Testingand is a frequent speaker at testing conferences, including every STAR conference since its inception in 1992.

1© 2014 SQE Training V3.3

2© 2014 SQE Training V3.3

Notice of Rights
Entire contents © 2014 by SQE Training, unless otherwise noted on specific items. All
rights reserved. No material in this publication may be reproduced in any form without
the express written permission of SQE Training
Home Office
SQE Training
330 Corporate Way, Suite 300
Orange Park, FL 32073 U.S.A.
(904) 278-0524
(904) 278-4380 fax
www.sqetraining.com
Notice of Liability
The information provided in this book is distributed on an “as is” basis, without
warranty. Neither the author nor SQE Training shall have any liability to any person or
entity with respect to any loss or damage caused or alleged to have been caused
directly or indirectly by the content provided in this course.
3© 2014 SQE Training V3.3

Please set any pagers or cellular phones to mute.
4© 2014 SQE Training V3.3

5© 2014 SQE Training V3.3

6© 2014 SQE Training V3.3

7© 2014 SQE Training V3.3

8© 2014 SQE Training V3.3

Lord Kelvin was apparently a virtual sound-bite machine. There are entire Web sites devoted to him and to his quotes. are entire Web sites devoted to him and to his quotes.
9© 2014 SQE Training V3.3

10© 2014 SQE Training V3.3

11© 2014 SQE Training V3.3

12© 2014 SQE Training V3.3

Measure: a quantified observation about any aspect of software
Metric: a measure used to compare two or more products, processes, or
projects
Meter: a metric that acts as a trigger or threshold. That is, if some threshold
is met, then an action is warranted (e.g., exit criteria)
Meta-measure: a measure of a measure. Usually used to measure the
effectiveness of a measure (e.g., number of defects discovered per hour of
test)
13© 2014 SQE Training V3.3

Simple: a metric that does not include complicated formulas, is intuitive, and easy
to understand. Number of severe bugs is relatively simple (if the severity categories to understand. Number of severe bugs is relatively simple (if the severity categories
are defined). Defect Age (PhAge) is not as simple.
Objective: a metric that is measured multiple times with the same result or by
different engineers with the same result. The number of test cases executed is
more objective than customer satisfaction.
Easily collected: metrics that are automatic (LOC is the only one I can think of) or
done as a by-product of a task we must do anyway. For example, we collect
information about defects so that we can fix them; therefore, it is relatively simple to
analyze the trends and patterns of the defects from the defect reporting system.
Robust: metrics that can be used to compare across multiple projects and/or
organizations. There are no perfectly robust metrics, but some are more robust than
others. For example, the number of engineers on a project is much more robust
than “quality.”
Valid: Not all metrics are valid. In fact, some are totally incorrect, and others may be
“off” just a little. We test a metric’s validity by comparing it to another metric. For
example, for test effectiveness we may measure coverage and DDP. If the
coverage is high but the DDP is low, we may suspect the validity (or at least the
value) of the coverage metric or the DDP.
14© 2014 SQE Training V3.3

Characteristics of metrics and their use:
•Broadly applicable
•Highly visible
•Consistently applied
•Management supported
•Organizational acceptance
•Not undermined by politics
•Clear identification of responsibility
•Historical data available
•Must relate to current practices
•Facilitate process improvement
•Limit the number of metrics
•Easily calculated
•Readily available
•Precisely defined
•Tool support
Adapted from Dan Paulish and K. H. Moller, Software Metrics. IEEE Press, 1993
15© 2014 SQE Training V3.3

16© 2014 SQE Training V3.3

17© 2014 SQE Training V3.3

Have you ever had to collect or submit a metric or report that you knew no
one would ever see? Did you (or at least were you tempted) to put down just
any old value so you could get back to doing something important?
Congratulations, you too, have falsified a metric.
Similarly, have you ever been asked to do something that you thought was a
waste of time and so you procrastinated in the hope that it would just go
away (and sometimes it does!)? This is an example of lack of buy-in. When
Bill Hetzel and Rick Craig conducted metrics research in the 1990s, they
learned that one of the main reasons for failure of metrics programs was lack
of buy-in by the people asked to collect the metrics. Later Bill went on to
develop the “practitioner paradigm of software metrics” based upon the
premise that the practitioners themselves should decide what metrics to
collect. Interestingly enough, in most teams, the practitioners volunteered to
collect most of the metrics that the project or test manager wanted—and
since it was their idea, buy-in was not an issue.
18© 2014 SQE Training V3.3

19© 2014 SQE Training V3.3

Unless you’re blessed with a “silver tongue,” buy-in is far from easy and
training helps. Metrics can be a powerful force in obtaining buy-in. If an
industry metric shows that 90% of the “best” projects in your industry use
inspections*, but they are not used in your organization, that is a powerful
incentive to implement inspections. Presenting this information to upper
management will almost always command their attention and assistance in
obtaining buy-in.
* 90% is obviously not really a meaningful value, just an example.
20© 2014 SQE Training V3.3

21© 2014 SQE Training V3.3

One of the biggest problems with metrics is buy-in. If practitioners feel that the metrics
are not being used—or worse, are being used as a “grade card”—they will often refuse
to collect the data and/or even falsify the results!
22© 2014 SQE Training V3.3

The Hawthorne Studies were conducted by Harvard Business School
professor Elton Mayo from 1927 to 1932 at the Western Electric Hawthorne
Works in Chicago IL.
Originally, the researchers were interested in determining what (if any) affect
light had on worker productivity. After their initial experiments indicated that
there was no clear connection between productivity and the amount of
illumination, the researchers began to wonder what other factors might
increase productivity.
The researchers found that their concern for the workers made the workers
feel that they were part of a team and subsequently productivity improved.
Please let us offer an alternate “Hawthorne Effect”: When you collect
metrics that involve people, it will change the way they behave—but not
always for the better. What do you think would happen if you “graded” the
testers on the number of test cases written?
Read more about the Hawthorne effect:
http://www.techwell.com/2014/07/are-your-metrics-causing-unintended-
consequences
23© 2014 SQE Training V3.3

24© 2014 SQE Training V3.3

25© 2014 SQE Training V3.3

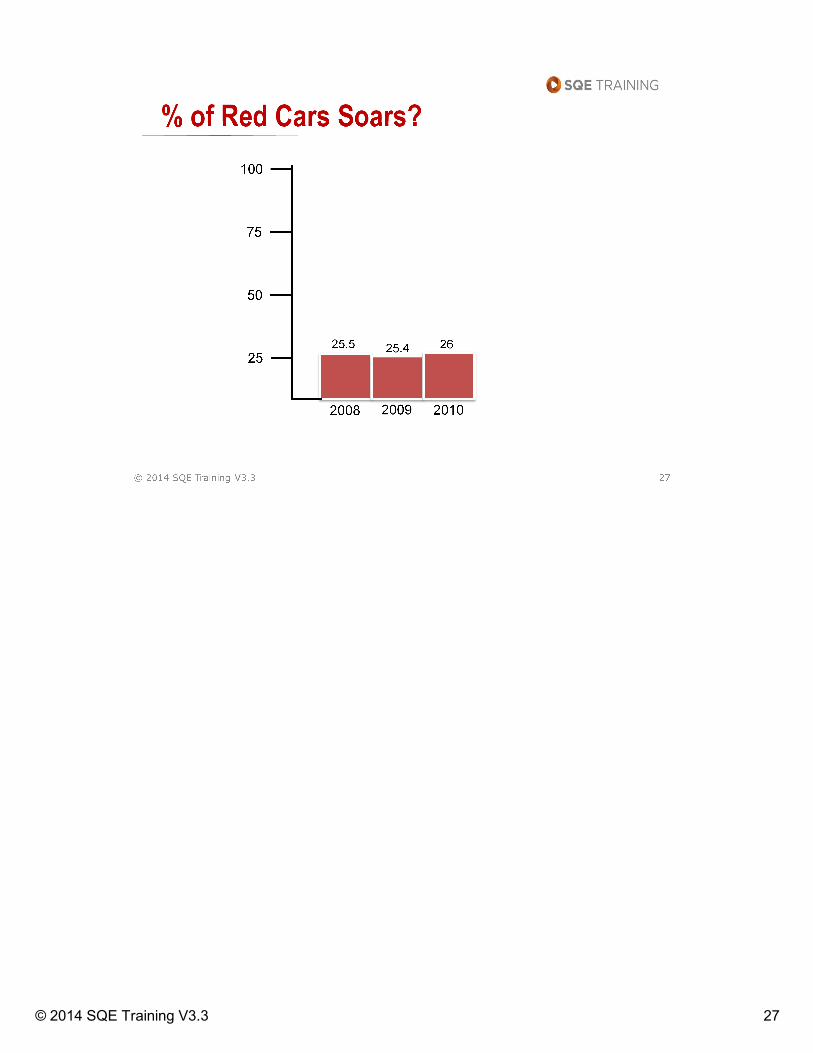
The numbers on the graph above were made up so please don’t Google
them. I do remember seeing a chart something like this in the USA Today a
few years ago (you know the little charts on each section of the paper). The
scale was skewed to make a point. Take a look at the next slide.
Note: Everyone taking this class should read How to Lie with Statistics by
Darrell Huff. W.W. Norton, Co. 1954 (enjoyable read)
Another good reference is The Visual Display of Quantitative Information by
Edward R. Tufte.
26© 2014 SQE Training V3.3
27© 2014 SQE Training V3.3

28© 2014 SQE Training V3.3

Use a metric to validate a metric: Virtually anything that is important to
measure should have two or more metrics. For example, to measure test
effectiveness you might choose to use a coverage metric and DDP. If the
two metrics agree, you have some confidence in the measurements. If they
don’t, you have some more research to do.
Consistency sometimes trumps accuracy: All metrics are flawed, but
some are useful anyway. For example, suppose your speedometer
consistently registers 10 MPH faster than you are actually traveling; as long
as you know this, you still can use your speedometer to measure your
speed.
29© 2014 SQE Training V3.3

More is not always better/All metrics are not forever: We have visited
companies that have entire teams that collect, slice, and dice hundreds of
metrics. But no one looks at them. Just because you can measure
something doesn’t mean it is worth the effort. Once or twice a year, all
metrics should be reviewed to see if they are still valid and useful. It is
demoralizing to collect metrics that are never used.
30© 2014 SQE Training V3.3

This page left blank
31© 2014 SQE Training V3.3

32© 2014 SQE Training V3.3

The well-designed dashboard of a 1958 Corvette
33© 2014 SQE Training V3.3

Fun fact: The business dashboard originated at General Electric many years
ago.
— Greg Brue, Six Sigma for Managers, Briefcase Books, 1976
An “instrument” refers to a topic such as Quality of product e.g. the
dashboard above has 5 instruments.
A note to Mobile testers: Even though we are really just getting our act
together with metrics for testing mobile apps, one thing is becoming clear:
there is a greater focus on non-functional quality attributes. Therefore, you
might consider breaking the “instrument” above called Quality of the Product
into two instruments: Quality of the Product-Functional and Quality of the
Product-nonfunctional
“Computing software quality metrics for mobile applications is similar to
desktop applications but there are specific issuesO”
--Dr. Paul Pocatilu
34© 2014 SQE Training V3.3

35© 2014 SQE Training V3.3

Quality is the totality of features and characteristics of a product or service
that bear on its ability to satisfy stated or implied needs.
—ISO 8402
36© 2014 SQE Training V3.3

These quality characteristics are sometimes called the “-ility” factors. These
factors are very appealing on first blush, but it is often problematic to come
up with practical ways to measure them.
37© 2014 SQE Training V3.3

What does the chart above say about the relative risk of each module??
One of the ISTQB principles of test is called defect clustering. Modules that
have had a lot of defects in earlier releases or in previous levels of test are
more likely to have defects in the future. If you have ever been a
maintenance programmer, you have no doubt marveled that the same
function, module, program, etc., always seems to be same one that breaks.
38© 2014 SQE Training V3.3

Defect Density: a metric that compares the number of defects to a measure
of size (e.g., defects per KLOC)
— Rick Craig and Stefan Jaskiel, Systematic Software Testing. Artech
House, 2002
39© 2014 SQE Training V3.3

As the complexity of a product increases, so too does the probability of
shipping defects.
40© 2014 SQE Training V3.3

41© 2014 SQE Training V3.3

42© 2014 SQE Training V3.3

43© 2014 SQE Training V3.3

44© 2014 SQE Training V3.3

Just because you’ve run 90% of the test cases (raw data) doesn’t mean that
you are 90% done vs. risk, coverage, execution effort or time to execute.
45© 2014 SQE Training V3.3

Does a report like this help?
46© 2014 SQE Training V3.3

47© 2014 SQE Training V3.3

48© 2014 SQE Training V3.3

Many organizations use the “defect arrival rate” as an impartial measure to
assist them in predicting when a product will be ready to release. When the
defect arrival rate begins to drop, it is often assumed (sometimes correctly)
that the software is ready to be released. While a declining arrival rate is
typically a good sign, remember that other forces (less effort, no new test
cases, etc.) may cause the arrival rate to dip. This is why it is normally a
good idea to base important decisions on more than one supporting metric.
NOTE: The defects may need to be “weighted.”
49© 2014 SQE Training V3.3

“The defect that is prevented doesn’t need repair, examination, or
explanation. The first step is to examine and adopt the attitude of defect
prevention. This attitude is called, symbolically, Zero Defects.”
— Philip Crosby: Quality is Free (1979).
The cost to correct production bugs is many times more than bugs
discovered earlier in the lifecycle. In some systems the factor may be 10; in
others it may be 1,000 or more. A landmark study done by TRW, IBM, and
Rockwell in 1974 showed that a requirements bug found in production cost
on average 100+ times more than one discovered at the beginning of the
lifecycle. Interestingly enough, the graph above was created 20 years later
with almost the same result.
50© 2014 SQE Training V3.3

51© 2014 SQE Training V3.3

The purpose of the Test Summary Report is for the test manager to report on
the results of the testing. An added benefit, though, can be its collection and
analysis of metrics.
52© 2014 SQE Training V3.3

53© 2014 SQE Training V3.3

54© 2014 SQE Training V3.3

55© 2014 SQE Training V3.3

IBM/Techwell Study 2014
56© 2014 SQE Training V3.3

57© 2014 SQE Training V3.3

58© 2014 SQE Training V3.3

59© 2014 SQE Training V3.3

This is an experience Rick Craig had at his restaurant many years ago:
My head server decided to create a customer satisfaction survey (on her
own initiative). You have to love employees like that! The survey had two
sections: one rated the quality of the food as Outstanding, Excellent, Above
Average, Average, and Below Average; and the other section rated service
on a scale of Outstanding, Excellent, and Above Average. I asked the server
who created the survey about the missing Average and Below Average
categories, and she assured me that as long as she was in charge, no one
would ever get average or below average service! I realized that the survey
designer’s personal bias can (and will) significantly influence the survey
results!
60© 2014 SQE Training V3.3

61© 2014 SQE Training V3.3

62© 2014 SQE Training V3.3

Bug drawing by Catherine Sabourin. From I am a Bug by Rob Sabourin.
Some of the problems associated with counting defects:
•When should you start counting defects?
•Start of development
•Completion of the work product
•Formal configuration management
•Start of test
•Which activities are considered “defect finding”?
•Inspections
•Test executions
•Test design and development
•Informal review
•Special analysis
•What about omissions?
•Forgotten requirements
•Omitted features
•How should you treat severity and impact?
•How should you treat confusion and dissatisfaction?
TIP: Identifying defect clusters by programmer name can be politically dangerous; a safer approach is to associate defects with team.
63© 2014 SQE Training V3.3

Defect Removal Efficiency (DRE) is a metric similar to DDP. DDP counts the
bugs found (whether fixed or not). DRE only counts the bugs that are found
and removed.
64© 2014 SQE Training V3.3

65© 2014 SQE Training V3.3

This graph is just an example. The actual hours required to fix a bug will vary
widely from company to company due to complexity of the software, maturity
of the organization, automation, etc.
66© 2014 SQE Training V3.3

Typically, the longer a defect exists before discovery, the more it costs to fix.
One metric often collected for a defect is called the Phase Age (or PhAge).
EXAMPLE: A requirement defect discovered during a high-level design
review would be assigned a PhAge of 1. Had this defect not been found until
the pilot, it would have been assigned a PhAge of 8.
67© 2014 SQE Training V3.3

Latent defect: an existing defect that has not yet caused a failure because
the exact set of conditions has not been met
Masked defect: an existing defect that has not yet caused a failure because
another defect has prevented that part of the code from being executed
68© 2014 SQE Training V3.3

69© 2014 SQE Training V3.3

70© 2014 SQE Training V3.3

Most test methodologies require (at a minimum) a measure of requirements
coverage. A requirements traceability matrix ensures that every requirement
has been addressed. It does not ensure, however, that each requirement
has been fully tested. It also is only as good as the underlying requirements
and design documents.
NOTE: One test case may address multiple requirements. The same
philosophy (and even the same matrix) can show coverage of the design
attributes.
71© 2014 SQE Training V3.3

72© 2014 SQE Training V3.3

You can certainly use requirements traceability when testing mobile apps.
Due to extreme environmental variables in mobile apps, some have
advocated using some of the above attributes in a coverage matrix.
73© 2014 SQE Training V3.3

The table above is a conceptual model of the output of a code coverage tool.
These tools can measure statement, decision, or path coverage.
NOTE: A high level of code coverage does not necessarily ensure that a
system has been well tested because the code may not address all of the
requirements and the uncovered code may be the most risky.
74© 2014 SQE Training V3.3

It is our opinion that code coverage is a metric that is most useful at the
developmental test level(s)—unit and/or integration. Code coverage tools
have been available for decades but are enjoying a resurgence do to the
increasing popularity of agile methods.
75© 2014 SQE Training V3.3

76© 2014 SQE Training V3.3

77© 2014 SQE Training V3.3

78© 2014 SQE Training V3.3

79© 2014 SQE Training V3.3

80© 2014 SQE Training V3.3

81© 2014 SQE Training V3.3

82© 2014 SQE Training V3.3

Please note that Product Quality is a development metric that is normally
measured by the testers. The other instruments are test metrics.
Some testers color code the instruments:
Red: In trouble
Yellow: Keep an eye on it
Green: Good to go
We have seen dashboards adorned with thermometers (showing status),
stoplights, and smiley faces.
83© 2014 SQE Training V3.3

84© 2014 SQE Training V3.3

85© 2014 SQE Training V3.3

86© 2014 SQE Training V3.3

This page left blank
87© 2014 SQE Training V3.3

88© 2014 SQE Training V3.3

Brooks’s Law: “Adding manpower to a late software project makes it later”
According to Brooks himself, the law is an "outrageous oversimplification", but it captures the general rule. Brooks points to two main factors that explain why it works this way:
It takes some time for the people added to a project to become productive. Brooks calls this the “ramp up” time. Software projects are complex engineering endeavors, and new workers on the project must first become educated about the work that has preceded them; this education requires diverting resources already working on the project, temporarily diminishing their productivity while the new workers are not yet contributing meaningfully. Each new worker also needs to integrate with a team composed of multiple engineers who must educate the new worker in their area of expertise in the code base, day by day. In addition to reducing the contribution of experienced workers (because of the need to train), new workers may even have negative contributions – for example, possibly introducing bugs that move the project further from completion.
Communication overheads increase as the number of people increases. The number of different communication channels increases along with the square of the number of people; doubling the number of people results in four times as many different conversations. Everyone working on the same task needs to keep in sync, so as more people are added they spend more time trying to find out what everyone else is doing.
Frederick P. Brooks, Jr., The Mythical Man-Month: Essays on Software Engineering. Addison-Wesley, 1995
89© 2014 SQE Training V3.3

The above information comes from the ISTQB.
If you are going to gain credibility in the software development arena, you must be
able to accurately estimate time and resources.
It’s important that the schedule reflect how the estimates for the milestones are
determined. For example, when the time schedule is very aggressive, estimating
becomes even more critical, so that the planning risks, contingencies, and test
priorities can be specified. Recording schedules based on estimates also provide the
test manager with an audit trail of how the estimates did—and did not—come to pass
and forms the basis for better estimating in the future.
Test estimation should include all activities involved in the test process:
• Test planning and control
• Test analysis and design
• Test implementation and execution
• Test evaluation and reporting
• Test closure activities
A common practice is also to estimate the number of test cases required.
Assumptions made during estimation should always be documented as part of the
estimation.
90© 2014 SQE Training V3.3

The above information comes from the ISTQB.
Other factors:
Complexity of the process, technology, and organization
Significant ramp up, training, and orientation needs
Assimilation or development of new tools, techniques, custom
hardware, number of testware
Requirements for a high degree of detailed test specification
Complex timing of component arrival
Fragile test data
91© 2014 SQE Training V3.3

The above information comes from the ISTQB.
A common practice is also to estimate the number of test cases required.
Assumptions made during estimation should always be documented as part
of the estimation.
In most cases, the estimate, once prepared must be delivered to
management, along with a justification. Frequently, some negotiation
ensues, often resulting in a rework of the estimate. Ideally, the final estimate
represents the best-possible balance of organizational and project goals in
the areas of quality, schedule budget, and features (scope).
92© 2014 SQE Training V3.3

These figures (both on the slide and in the notes) are for the software
industry as a whole, not specifically testing, but I think it would be
reasonable to assume that testers face similar challenges.
93© 2014 SQE Training V3.3

Estimation of software and system engineering has long been known to be
fraught with difficulties, both technical and political, though project
management best practices for estimation are well established. Test
estimation is the application of these best practices to the testing activities
associated with a project or operation.
94© 2014 SQE Training V3.3

John McGarry, David Card, Cheryl Jones, Beth Layman, Elizabeth Clark,
Joseph Dean, Fred Hall.
Practical Software Measurement. Addison-Wesley, 2001
In 1986, Professors S. D. Conte, H. E. Dunsmore, and V. Y. Shen (Conte
Dunsmore, Shen 1986 Software Engineering Metrics and Models) proposed
that a good estimate approach should provide estimates that are within 25%
of the actual results 75% of the time. This evaluation standard is the most
common standard used to evaluate estimation accuracy (Richard Stuzke,
Estimating Software-Intensive Systems., Addison-Wesley, 2005)
95© 2014 SQE Training V3.3

96© 2014 SQE Training V3.3

The cone of uncertainty helps explain why some of our early estimates are
so bad. Using the diagram above, you can see that at project inception our
estimates could be off by a factor of 4 above or a factor of 4 below the
estimate. As the project progresses, we are learning more about the project
and can refine the estimate based on our newly gained knowledge.
This is why one of Rick Craig’s estimation tips is not to spend a ton of time
on an estimate. Spending more time deliberating with the same information
nets more or less the same estimate. With this in mind, another tip is to
constantly re-estimate as our knowledge of the project improves and to use
planning risks and contingencies to agree on what to do if the estimate is
particularly bad.
Note: The Cone of Uncertainly was first defined by Barry Boehm more than
twenty-five years ago.
97© 2014 SQE Training V3.3

98© 2014 SQE Training V3.3

Anecdote by Rick Craig: I confess that I misunderstood the “cone of uncertainty” for
years. Perhaps because I live in Florida, whenever I heard the term cone of years. Perhaps because I live in Florida, whenever I heard the term cone of
uncertainty, I immediately thought of the forecast cones used by meteorologists to
describe the potential path of a hurricane. The forecaster can easily predict where
the hurricane will be in the next few hours, but the farther they project into the
future, the greater potential there is for error in the forecast.
Similarly in the chart above, the upper line shows how a project progresses if
everything is nearly perfect (remember this is an anecdote). The middle line
represents the estimated path, and the bottom line indicates what happens (all too
often) when everything goes wrong. Amusingly enough, this graph which I will
jokingly call the “testing” track forecast cone (after the NHS track forecast cone) still
makes the same point: estimates that are made early in the project and are not
refined can be off by a factor of x (OK, I’m much less precise than Mr. Boehm)
above or below the projected track, and the inaccuracy will increase the farther the
projection is made into the future.
Another way to look at it is to compare it to the path of a bullet (now my Marine
Corps roots are showing). If the tip of a gun barrel is off by even a fraction of an
inch, the bullet will miss its target by many inches or feet when it lands down range
. The longer the range the greater the potential error.
99© 2014 SQE Training V3.3

Manager: When will you be done testing?
Tester: Oh, in about four weeks.
Manager: Any chance it might take five weeks?
Tester: Sure, it might take that long.
Manager: Any chance it might actually take eight weeks?
Tester: (getting very irritated) Well, I suppose if we get another crappy
build like the last one it might.
Manager: You’re obviously not a very good estimator. First, you told me it
would take four weeks; now you admit it might take up to double that. Any
chance you missed it on the downside? Can you deliver it in
three weeks?
Tester: That is so like you. I said four weeks, and now you want it in
three.
We call this the fantasy factor. Our managers are always saying “give me
your best estimate.” They don’t mean the most accurate O they mean if
everything were perfect—and in our desire to please, we acquiesce.
100© 2014 SQE Training V3.3

There are a number of factors that can affect a schedule; however, they can
all be characterized in one of four categories:
•Time
•Scope or size
•Resources
•Quality or risk
A change to one of these categories typically requires a counterbalance
change to be made to at least one of the others. Unfortunately, many test
managers focus on time and do not always consider the other possibilities.
101© 2014 SQE Training V3.3

Most of us have been there. You have estimated that you can test a product
in six weeks with four testers. The manager offers to double your staff but
insists that you complete the task in three weeks (half the time). This
happens, of course, because of pressure to get the product out the door.
The problem is exacerbated because time and effort are often measured in
the same units (e.g., hours or days). We know that there is a relationship
between the schedule and the resources applied. For example, in most
cases, ten people can get a task done more quickly than five (although you
can probably come up with some examples where ten people actually take
longer—like reaching a consensus). Generally as project size grows,
productivity drops but not necessarily in a linear fashion.
This drop in productivity can be caused by increased complexity,
management overhead, Brooks’s Law, etc.
102© 2014 SQE Training V3.3

The list in the slide above was adapted from the ISTQB Advanced Syllabus
for Test Management.
Organizational history and metrics includes metrics-derived models that
estimate the number of defects, the number of test cycles, the number of
test cases, each test’s average effort, and the number of regression cycles
involved.
Industry averages and predictive models include techniques such as:
• Test points
• Function points
• Lines of code
• Estimated development effort
• Other project parameters
103© 2014 SQE Training V3.3

Read Karl’s entire article “Estimation Safety Tips” at www.stickyminds.com
104© 2014 SQE Training V3.3

* This is tongue in cheek. We are suggesting you not use the words pad or
fudge or whatever—but rather “normalize” the value.
The more “distant” the knowledge/data used to create an estimate, the less
valuable that information is likely to be.
Metrics captured from the same project are more valuable than O metrics
captured from the same department which are more valuable than O
metrics captured from the same company which are more valuable than O
metrics captured from the same business sector which are more valuable
than O metrics captured from the same country which are more valuable
than ... global metrics.
TIP: The tighter the time scale, the more important the risk assessment.
TIP: Remember that it is sometimes necessary to measure resources, size,
or quality rather than time.
105© 2014 SQE Training V3.3