measuring system performance in cultural heritage systems
TRANSCRIPT

Measuring System Performance in Cultural Heritage Information Systems
Toine Bogers
Aalborg University Copenhagen, Denmark
‘Evaluating Cultural Heritage Information Systems’ workshopiConference 2015, Newport BeachMarch 24, 2015

Outline
• Types of cultural heritage (CH) information systems
- Definition
- Common evaluation practice
• Challenges
• Case study: Social Book Search track
2

Types of cultural heritage information systems
• Large variety in the types of cultural heritage collections → many different ways of unlocking this material
• Four main types of cultural heritage information systems
- Search
- Browsing
- Recommendation
- Enrichment
3

Search (Definition)
• Search engines provide direct access to the collection
- Search engine indexes representations of the collection objects (occasionally full-text)
- User interacts by actively submitting queries describing their information need(s)
- Search engine ranks the collection documents by (topical) relevance for the query
• Examples
- Making museum collection metadata accessible (Koolen et al., 2009)
- Searching through war-time radio broadcasts (Heeren et al., 2007)
- Unlocking television broadcast archives (Hollink et al., 2009) 4
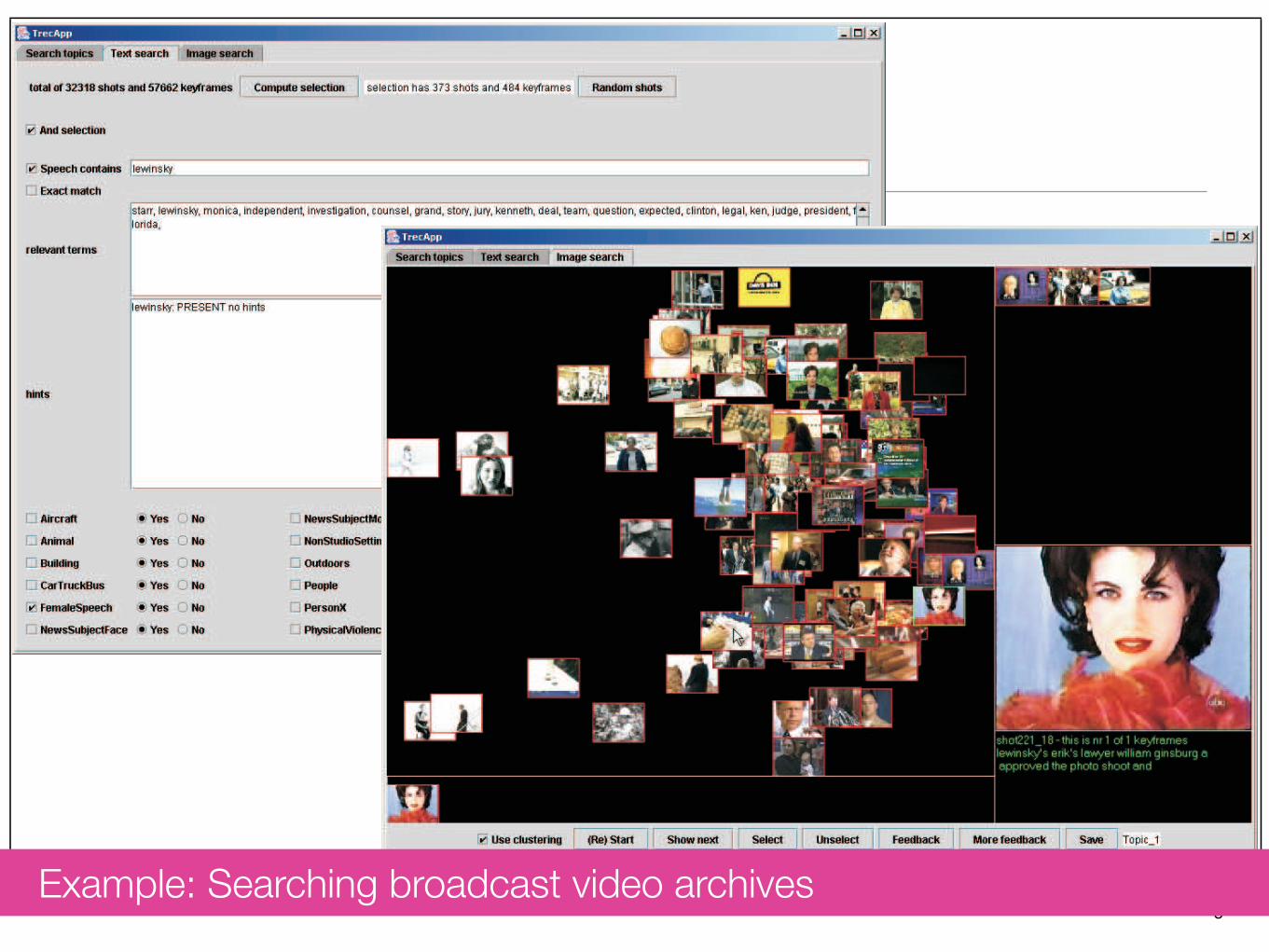
5Fig. 2. Screendump of the GUI used for the system. Top left the high-level concept search part and right the browsing andranking part.
2.4. Ranking
When the user has selected a set of suitable images, theuser can perform a ranking through query by example us-ing again the Lab histograms with Euclidean distance. Inthe result the closest matches within the filtered set of 2000shots are computed, where the system alternates betweenthe different examples selected.
An illustration of the user interface used is presented infigure 2.
3. EXPERIMENTAL SETUP
3.1. Search protocol
For the TRECVID 24 topics have to be found in a datasetconsisting of 60 hours of video from ABC, CNN, and C-SPAN. For the experiments total search is limited to 15 min-utes per topic to assure that e.g. sequential scanning of allcandidates was not an option.
The following is the list of topics, ordered according totheir general class:
• General setting: a crowd in urban environment (1),aerial view of buildings (2), road with vehicles (3),snow-covered mountains (4), flames (5).
• Specific object and/or events: the mercedes logo (6),the white house (7), tomb of the unknown soldier atArlington (8), the sphinx (9).
• Generic objects and/or events: airplane taking off (10),tank (1), cup of coffee (12), locomotive approachingyou (13), basketball passing down a hoop (14), cats(15), helicopter (16), rocket taking off (17).
• Specific persons: Pope John Paul II (18), Yassar Arafat(19), Morgan Freeman (20), Osama bin Laden (21),Mark Souder (22).
• Generic people and/or events: person diving into wa-ter (23), view from behind cather while pitcher is throw-ing the ball (24).
The system has been evaluated by having 44 studentsperform the interactive search task in groups of two. Beforethe start of the experiment they were asked to fill in a ques-tionnaire about their prior experiences with searching forinformation in general and searching for multimedia items.In summary, the overall experience with searching is high.All students search for information at least once a week and92% have been searching for information for two years ormore. All students search for multimedia items at least oncea year, and 65% does this once a week or more. 88% of thestudents have been searching for multimedia for at least twoyears [6].
3.2. Evaluation criteria
Traditional evaluation measures from the field of informa-tion retrieval are precision and recall. For evaluation within
Example: Searching broadcast video archives

Search (Evaluation practice)
• What do we need?
- Realistic collection of objects with textual representations
- Representative set of real-world information needs → for reliable evaluation we typically need ≥50 topics
- Relevance judgments → (semi-)complete list of correct answers for each of these topics, preferably from the original users
• How do we evaluate?
- Unranked → Precision (what did we get right?) & Recall (what did we miss?)
- Ranked → MRR (where is the first relevant result?), MAP (are the relevant results all near the top?), and nDCG (are the most relevant results returned before the less relevant ones?)
6
‘test collection’

Browsing (Definition)
• Browsing supports free to semi-guided exploration of collections
- Object metadata allows for links between objects → clicking on a link shows all other objects that share that property
- Exploration can also take place along other dimensions (e.g., temporal or geographical)
- Taxonomies & ontologies can be used to link objects in different ways
- Users can explore with or without an direct information need
• Examples
- Exploring digital cultural heritage spaces in PATHS (Hall et al., 2012)
- Semantic portals for cultural heritage (Hyvönen, 2009)7

8
Example: Providing multiple paths through collection using PATHS

Browsing (Evaluation practice)
• What do we need?- System-based evaluation of performance is hard to do → browsing is the
most user-focused of the four system types
- If historical interaction logs are available, then these could be used to identify potential browsing ‘shortcuts’
• How do we evaluate?- Known-item evaluation → Shortest path lengths to randomly selected
items can provide a hint about best possible outcome
‣ Needs to be complemented with user-based studies of actual browsing behavior!
- ‘Novel’ information need → User-based evaluation is required to draw any meaningful conclusions (about satisfaction, effectiveness, and efficiency)
9

Recommendation (Definition)
• Recommender systems provide suggestions for new content
- Non-personalized → “More like this” functionality
- Personalized → Suggestions for new content based on past interactions
‣ System records implicit (or explicit) evidence of user interest (e.g., views, bookmarks, prints, ...)
‣ Find interesting, related content based on content-based and/or social similarity & generate a personalized ranking of the related content by training a model of the users and item space
‣ User’s role is passive: interactions are recorded & suggestions are pushed on the user
• Examples
- Personalized museum tours (Ardissono et al, 2012; Bohnert et al., 2008; De Gemmis et al., 2008; Wang et al., 2009) 10
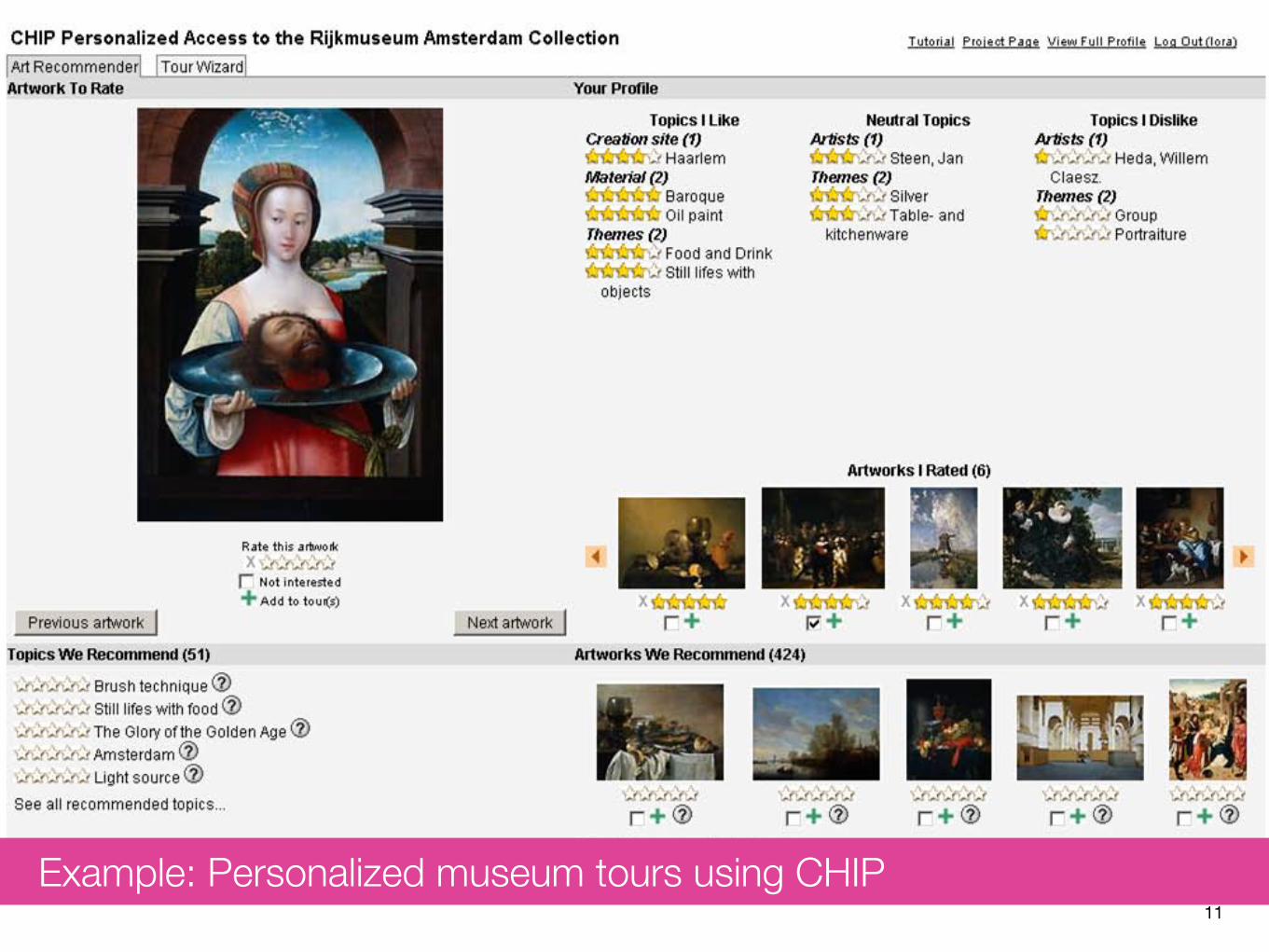
11
CHIP Demonstrator 883
further recommendations or not, by using the checkbox Not interested in. Ratedartworks checked as not interested in will not influence the recommendations.The user can continue the process of rating artworks as long as she is satisfiedwith the state of the user profile shown on the right, or as long as the set ofrecommended artworks shown in the lower right part of the screen seem relevant.The user can skip rating artworks by pressing the Next artwork button. Thereis no avarage number of artworks the user needs to rate. In order to kick off therecommendations the user needs to give at least one positive (3, 4 or 5 stars)rating. The system would not be able to recommend artworks and topics basedonly on negative (1 or 2 stars) ratings.
Important here is that we recommend not only artworks but also topics (basedon the semantic description of each artwork you have already rated). The user canprovide her positive or negative feedback to each recommendation (both topicsand artworks) by rating the empty set of stars associated with it. This wouldbe recorded then in the user profile in order to increase the level of certainty forrelated properties and artworks.
Fig. 4. Screenshot of the CHIP Recommender
If the user is logged with a FOAF profile in the option to view the full userprofile (right top) will show the user’s personal and social network data. In thefull profile we also store the history interaction data about tours that this userhas created and/or followed both on the Web and in the museum with the PDA-based mobile tour. Current investigations focus on including also social filtering
Example: Personalized museum tours using CHIP

Recommendation (Evaluation practice)
• What do we need?- User profiles for each user, containing a sufficiently large number (≥20) of
user preferences (views, plays, bookmarks, prints, ratings, etc.)
- Problematic in the start-up phase of a system, leading to the cold-start problem
‣ Possible solution → combining multiple algorithms to provide recommendations until we have collected enough information
• How do we evaluate?- Backtesting (combination of information retrieval & machine learning evaluation)
‣ We hide a small number (e.g., 10) of a user’s preferences, train our algorithm and check whether we can successfully predict interest in the ‘missing’ items
- Evaluation metrics are similar to search engine evaluation12

Enrichment (Definition)
• Enrichment covers all approaches that add extra layers of information to collection objects
- Many different types of ‘added information’: entities, events, errors/corrections, geo-tagging, clustering, etc.
- Typically use machine learning to predict additional information relevant for an object
‣ Supervised learning uses labeled examples to learn patterns
‣ Unsupervised learning attempts to find patterns without examples
• Examples
- Automatically correcting database entry errors (Van den Bosch et al., 2009)
- Historical event detection in text (Cybulska & Vossen, 2011)13

14
62 www.computer.org/intelligent IEEE INTELLIGENT SYSTEMS
A I A N D C U L T U R A L H E R I T A G E
cell values would aid the consistency of databases considerably.
Over time we also gathered skepti-cal remarks, notably by researchers of cultural heritage data expressing disbelief that a machine could auto-matically spot errors, as it does not possess domain knowledge. Coun-terarguments that it does possess at least some knowledge implicitly by its capacity to mine the mutual predict-ability of columns in the database are usually unconvincing. Therefore, in addition to the semiautomatic pre-sentation of errors to users, we are in-vestigating whether it would help to make the implicit expertise of our sys-tem explicit, to counter the skepticism. Our k-NN classifier does not have the capacity to explain why it makes cer-tain decisions, but it can show the nearest neighbors it found to come to a prediction—this may help a human expert understand why Timpute sug-gested a correction.
Another often-heard remark is that domain experts (curators and re-searchers alike) stress the importance of never deleting any information, even if it is incorrect. Original cell values that are flagged and corrected should always be retained; in addition, flags should be labeled as unchecked or checked by a human expert. Also, if the suggested correction is associ-ated with a confidence, either from the
machine learner or from the expert la-beler who inspected the flagged out-liers, this should be stored, too. This calls for the application of proper ver-sion control on top of the use of da-tabase management systems, offering the possibility to always roll back to earlier versions of the database.
The data-cleaning approach pre-sented here offers a functional-
ity that is broadly recognized as much-needed and vital for quality control of digitized cultural heritage data. Our approach is generic, in the sense that practitioners can apply it to any do-main that has a substantially large da-tabase in need of cleaning (containing, as illustrated, at least several hundred items), but does not require the avail-ability of external digital resources such as normalized lists of object names or classifications. The system reduces the workload on domain experts when cor-recting errors, by zooming in on the er-rors, with high estimated recall.
Our basic knowledge-free system can be expanded quite easily by other, more specific, correction methods and by domain-specific knowledge. For in-stance, for detecting and correcting spelling errors, we intend to add an initial spell-check phase that will use standard resources where available
(such as taxonomies, dictionaries, and domain-specific lists of names).
Currently, the system is limited to handling flat databases; future ver-sions will have the ability to deal with relational databases. We also found that for the prediction of certain col-umns, Timpute relies heavily on cer-tain other columns. Errors in these columns will tend to cause Timpute to generate erroneous predictions as well; therefore, we will investigate an incre-mental version, taking corrections to other columns into account. Finally, we aim to develop an online version of Timpute, running in the background while information is added to data-bases, to notify users immediately of possibly erroneous values as they are entered. We will further develop and test the mBase search and correction prototype at Naturalis, after which we intend to integrate it with the mu-seum’s existing information architec-ture. Testing will involve contrastive processing-time measurements, to pro-vide estimates of actual time savings offered by Timpute.
In sum, we see a rising awareness in the necessity of digital data quality control in the cultural heritage field. We believe cleaning digital data should constitute a standard first step in infor-mation processing at cultural heritage institutions. Furthermore, it is vital to keep the human experts in the loop; it is in their own interest that their data is improved, and our approach allows them to take this hurdle that has so far been a humanly infeasible task.
AcknowledgmentsWe thank Tijn Porcelijn and Steve Hunt for their programming assistance. We are grate-ful to the donators of the four data sets: Guus Lange and Pim Arntzen, who both provided us with expert feedback, Luit Ga-zendam, Hennie Brugman, Frans Wiering, and Maarten van der Peet. This research was funded by the Netherlands Organiza-tion for Scientific Research, under the Con-tinuous Access to Cultural Heritage (Catch) program.
Figure 3. Details of an animal specimen database entry result returned by mBase. A snake has been incorrectly classified as belonging to the taxonomic class “Amphibia.” This error, found by Timpute, is colored, and Timpute’s suggestion and confidence indication are displayed.
Authorized licensed use limited to: University of Southern California. Downloaded on May 7, 2009 at 16:59 from IEEE Xplore. Restrictions apply.
Example: Automatic error correction in databases

15
Back to theme page
Slachtoffers gemaakt door de Nederlandse troepen op wegnaar Jogyakarta. Kinderschilderij van de inname van Jogyakartatijdens de tweede politionele actie, december 1948.NG-1998-7-10
Slachtoffers gemaakt door de Nederlandse troepen op weg naar Jogyakarta (Object) Associated EventsDepictsEvent: Tweede politionele actie
biographical aspectsCreator:Toha Adimidjojo, Mohammed (4) Date:1948-12-19 (3) 1949-06-30 (3) 20e eeuw (18) tweede kwart 20e eeuw (17)material aspectsType: aquarel (3) tekening (3)Technique: aquarelleren (3)Material: hardboard (4)
semiotic aspectsSubject: Jogyakarta (4)Tweede politionele actie (7)
1948-12-19 (4) 1949-06-31 (1)militaire geschiedenis (12)
Associated Objects (25) < prev 1 2 3 4 5 next >
Your Navigation Path < prev 1 next >
Navigation Path Details
President Soekarno g...Associated Press
Sinkin panjang met s...Anonymous
Indonesië vrij!Hatta, Mohammad
Schild van een AtjeherAnonymous
Aankomst van Van Spi...Anonymous
Het kasteel van Bata...Beeckman, Andries
Figure 1: Screenshot of object page in the Agora Event Browsing Demonstrator
4. THE AGORA DEMONSTRATORThe automatically generated event thesaurus is applied in
a new historical event browser called Agora2 which providesan integrated access route to museum objects and audio-visual material from RMA and S&V respectively. It is a firststep towards a platform to investigate the added value of his-torical events and narratives for the exploration of integratedcollections. For each event and object there is an automat-ically generated page that shows (1) all associated objects,e.g., museum and audio-visual objects; (2) all associatedevents and the type of their relationship, e.g., previous-in-time event, sub-event; (3a) the event descriptive metadata,e.g., actors, place, period; or (3b) object descriptive meta-data organized in three groups, e.g., biographical, materialand semiotic dimensions – see figure 1 for a screenshot –and finally (4) the navigation path. The current version ofthe event thesaurus will be extended further to accommo-date searching for relations between events such as temporalinclusion, causality and meronymy.
5. DISCUSSIONIn this paper, we presented a modular pipeline for cap-
turing knowledge about historical events from Dutch texts.Compared with previous approaches (i.e., [5]), it relies ona minimum of manual annotation and can be repurposedfor other languages. To the best of our knowledge, this isthe first work to extract events from unstructured Dutchtext. Although our results are promising, more sophisticatedtechniques are necessary to obtain more fine-grained extrac-tions and define measures for the historic relevance of theextracted events. Additionally, we also aim to find and rep-resent relations between events such as causality, meronymyand correlation.
6. ACKNOWLEDGEMENTSThis research was funded by the CAMeRA Institute of the
VU University Amsterdam and by the CATCH programme,NWO grant 640.004.801.
2http://agora.cs.vu.nl/eventdemo
7. ADDITIONAL AUTHORSLora Aroyo (VU University Amsterdam), Guus Schreiber
(VU University Amsterdam) and Bob Wielinga (VU Univer-sity Amsterdam), Jacco van Ossenbruggen (CWI and VUUniversity Amsterdam), Johan Oomen (Netherlands Insti-tute for Sound and Vision), Geertje Jacobs (RijksmuseumAmsterdam).
8. REFERENCES[1] R. Cilibrasi and P. Vitanyi. The google similarity
distance. IEEE Trans. Knowledge and Data
Engineering, 19(3):370–383, 2007.[2] J. R. Finkel, T. Grenager, and C. Manning.
Incorporating non-local information into informationextraction systems by gibbs sampling. In Proceedings of
the 43nd Annual Meeting of the Association for
Computational Linguistics (ACL 2005), 2005.[3] G. Geleijnse, J. Korst, and V. de Boer. Instance
classification using co-occurrences on the web. InProceedings of the ISWC 2006 workshop on Web
Content Mining (WebConMine), Athens, GA, USA,November 2006.
[4] N. Gkalelis, V. Mezaris, and I. Kompatsiaris.Automatic event-based indexing of multimedia contentusing a joint content-event model. In ACM Events in
MultiMedia Workshop (EiMM10), Oct 2010.[5] N. Ide and D. Woolner. Exploiting semantic web
technologies for intelligent access to historicaldocuments. In Proceedings of the Fourth Language
Resources and Evaluation Conference (LREC), pages2177–2180, Lisbon, Portugal, 2004.
[6] E. Rilo↵ and R. Jones. Learning dictionaries forinformation extraction by multi-level bootstrapping. InProceedings of AAAI ’99, pages 474–479, 1999.
[7] R. Shaw, R. Troncy, and L. Hardman. Lode: Linkingopen descriptions of events. In 4th Annual Asian
Semantic Web Conference (ASWC’09), 2009.[8] W. R. van Hage, V. Malaise, G. de Vries, G. Schreiber,
and M. van Someren. Abstracting and reasoning overship trajectories and web data with the Simple EventModel (SEM). Multimedia Tools and Applications, 2011.
162
Example: Historical event extraction from text

Enrichment (Evaluation practice)
• What do we need?- Most enrichment approaches use machine learning algorithms to predict
which annotations to add to an object
- Data set with a large number (>1000) of labeled examples, each of which contain different features about this object and the actual output label
- Including humans in a feedback loop can reduce the number of examples needed for good performance, but results in a longer training phase
• How do we evaluate?- Metrics from machine learning are commonly used
‣ Precision (what did we get right?) & Recall (what did we miss?)
‣ F-score (harmonic mean of Precision & Recall)
16

Challenges
• Propagation of errors
- Unlocking cultural heritage is inherently a multi-stage process
‣ Digitization → correction → enrichment → access
- Errors will propagate and influence all subsequent stages → difficult to tease apart what caused errors at the later stage
‣ Only possible with additional manual labor!
• Language
- Historical spelling variants need to be detected and incorporated
- Multilinguality → many collections contain content in multiple languages, which present problems for both algorithms and evaluation
17

Challenges
• Measuring system performance still requires user input!
- Queries, relevance judgments, user preferences, pre-classified examples, ...
• Different groups provide different input affecting the performance → how do we reach them and how do we strike a balance?
- Experts
‣ Interviews, observation
- Amateurs & enthusiasts
‣ Dedicated websites & online communities
- General public
‣ Search logs18

Challenges
• Scaling up from cases to databases
- Can we scale up small-scale user-based evaluation to large-scale system-based evaluation?
- Which evaluation aspects can we measure reliably?
- How much should the human be in the loop?
• No two cultural heritage systems are the same!
- Means evaluation needs to be tailored to each situation (in collaboration with end users)
19

Case study: Social Book Search
• The Social Book Search track (2011-2015) is a search challenge focused on book search & discovery
- Originally at INEX (2011-2014), now at CLEF (2015- )
• What do we need to investigate book search & discovery?
- Collection of book records
‣ Amazon/LibraryThing collection containing 2.8 million book metadata records
‣ Mix of metadata from Amazon and Librarything
‣ Controlled metadata from Library of Congress (LoC) and British Library (BL)
- Representative set of book requests & information needs
- Relevance judgments (preferably graded)20

Challenge: Information needs & relevance judgments
• Getting a large, varied & representative set of book information needs and relevance judgment is far from trivial!
- Each method has its own pros and cons in terms of realism and size
21
Information needs
Relevance judgments Size
Interview ✓ ✓ ✗
Surveys ✓ ✗ ✓Search engine logs ✗ ✗ ✓
Web mining ✓ ✓ ✓

Solution: Mining the LibraryThing fora
• Book discussion fora contain discussions on many different topics
- Analyses of single or related books
- Author discussions & comparisons
- Reading behavior discussions
- Requests for new books to read & discover
- Re-finding known but forgotten books
• Example: LibraryThing fora
22
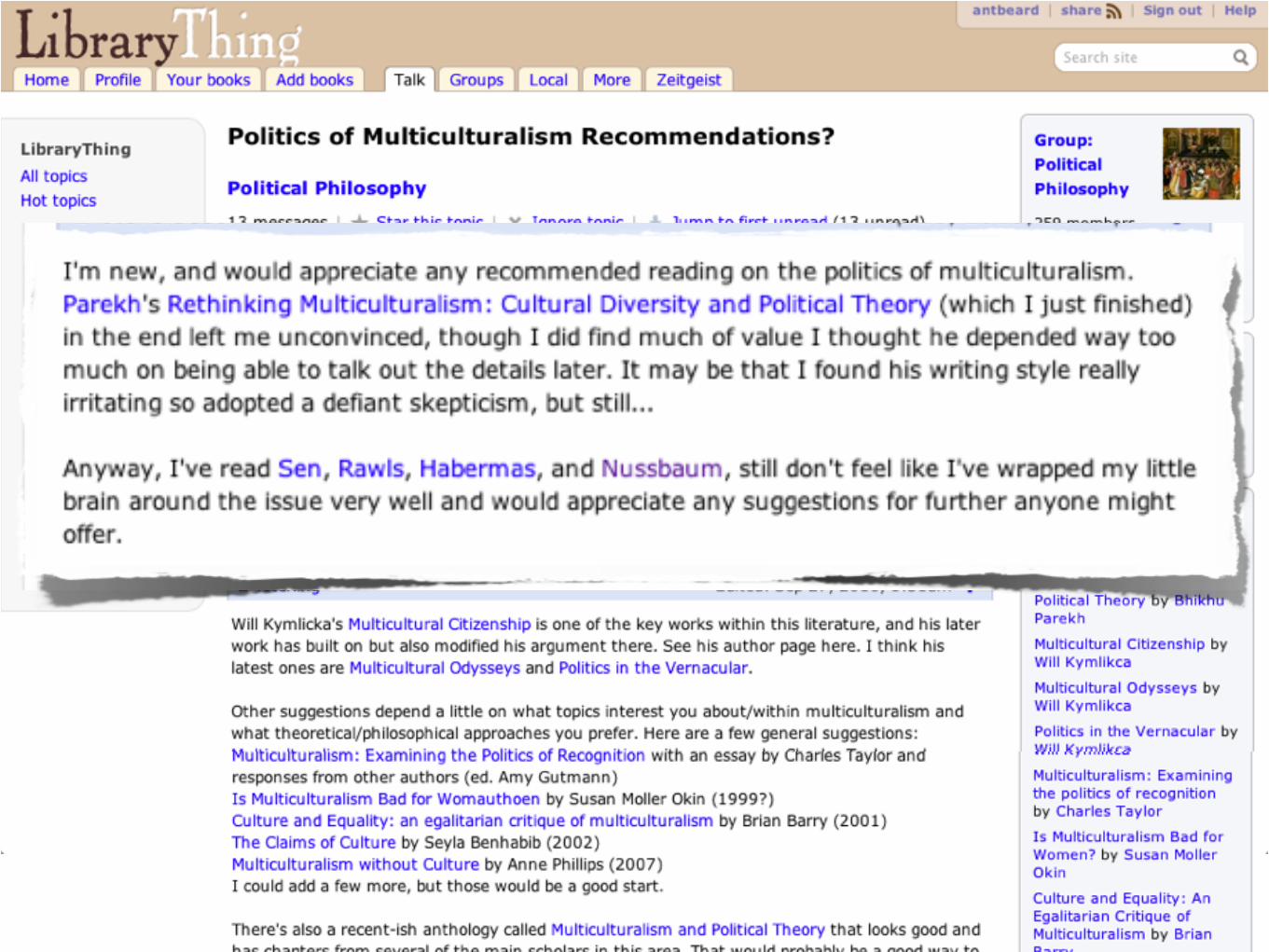
Annotated LT topic
23

Annotated LT topic
24
Group name
Topic title
Narrative
Recommended books

Solution: Mining the LibraryThing fora
• LibraryThing fora provided us with 10,000+ rich, realistic, representative information needs captured in discussion threads
- Annotated 1000+ threads with additional aspects of the information needs
- Graded relevance judgments based on
‣ Number of mentions by other LibraryThing users
‣ Interest by original requester
25

Catalog additions
26
Forums suggestions added after the topic was posted
Not just true for the book domain!
27

Relevance for designing CH information systems
• Benefits
- Better understanding of the needs of amateurs, enthusiasts, and the general public
- Easy & cheap way of collecting many examples of information needs
- Should not be seen as a substitute, but as an addition
• Caveat
- Example needs might not be available on the Web for every domain...
28

Conclusions
• Different types of systems require different evaluation approaches
• Many challenges exist that can influence performance
• Some of these challenges can be addressed by leveraging the power and the breadth of the Web
29
Want to hear more about what we can learn from the Social
Book Search track? Come to our Tagging vs. Controlled
Vocabulary: Which is More Helpful for Book Search? talk
in the ”Extracting, Comparing and Creating Book and Journal
Data” session (Wednesday, 10:30-12:00, Salon D)
Questions? Comments? Suggestions?
30