meetup #1. building a cnn in kaggle data science bowl
TRANSCRIPT

Subway plankton solutions


http://www.kaggle.com/c/datasciencebowl

Задача
Определить принадлежность планктона к одному из 121 класса по фотографии.



Negative log-likelihood
4.8 0.56
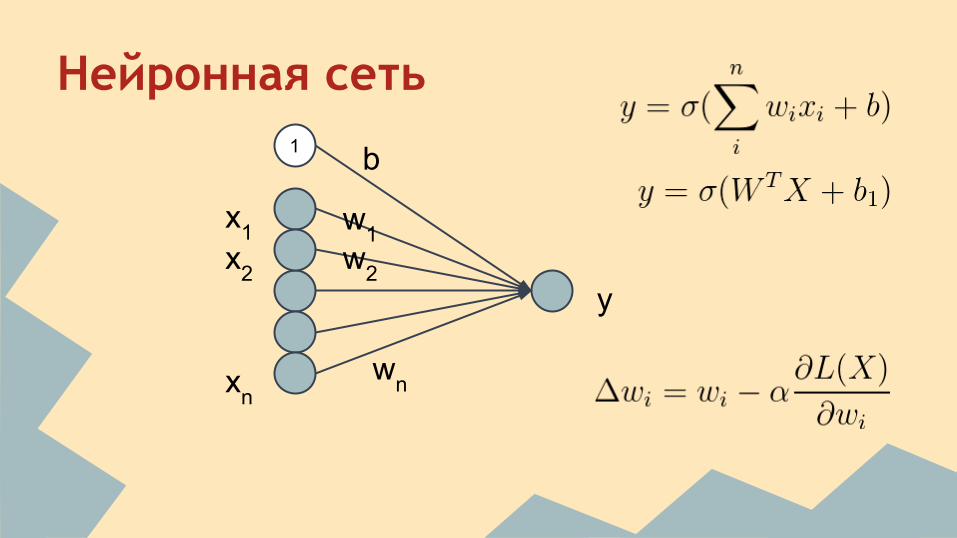
Нейронная сеть
x1x2
xn
w1w2
wn
y
1 b
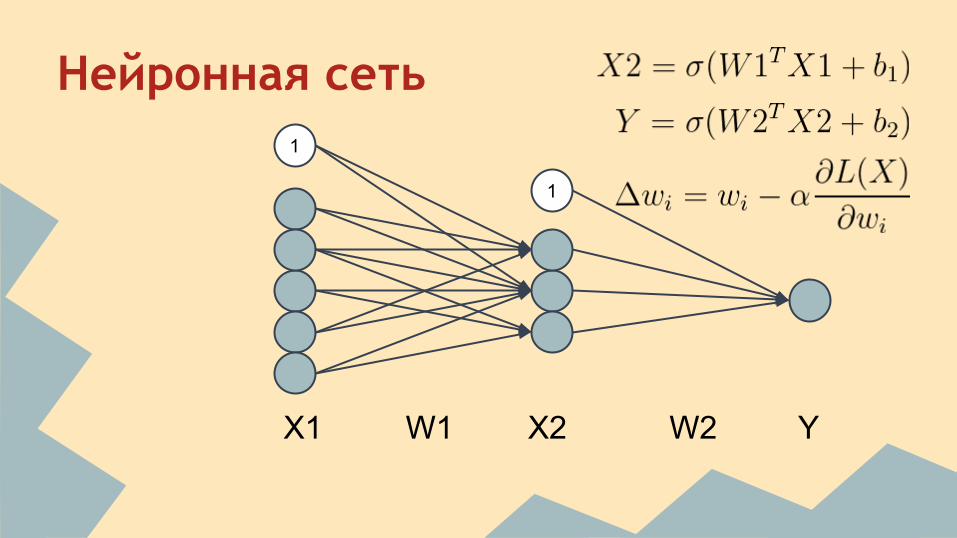
Нейронная сеть1
1
X1 W1 X2 W2 Y

Скрытый слой1
1
X1 W1 X2 W2 Y

http://deeplearning.net/tutorial/http://deeplearning.stanford.edu/tutorial/

http://yaroslavvb.blogspot.ru/http://stats.stackexchange.com/questions/126097/convolutional-neural-network-using-absolute-of-tanh-on-convolution-output


● convolutional (conv)● maxpool (pool)● fully connected (fc)● softmax

Размерность свёрточного слоя
каналы x ширина x высотатрёхмерная свёртка!
ПримерыВходной цветной слой: 3x7x7
Входной черно-белый: 1x7x7

Pooling
Уменьшение картинкиViewpoint invariance
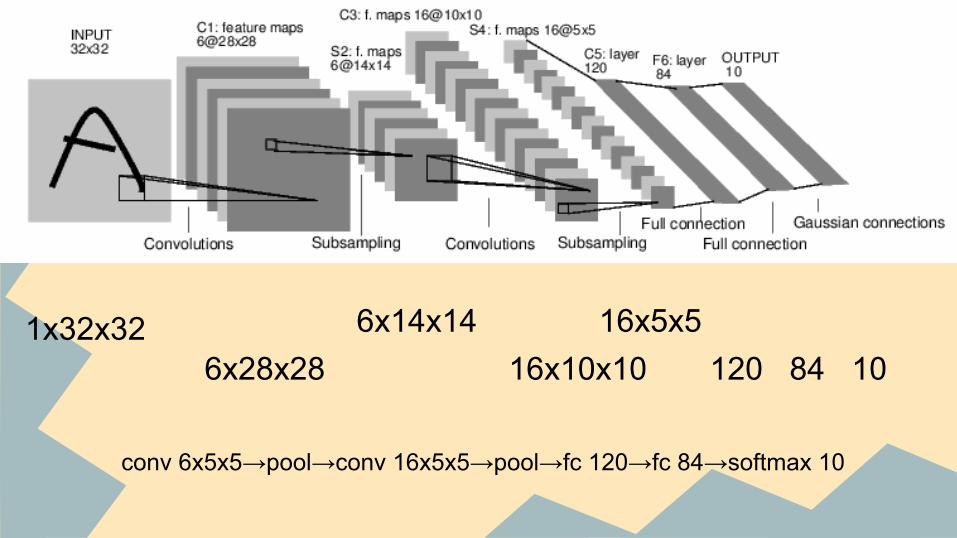
1x32x326x28x28
6x14x1416x10x10
16x5x5120 84 10
conv 6x5x5→pool→conv 16x5x5→pool→fc 120→fc 84→softmax 10

Технологии
CaffeCXXNETTorchTheano
PyLearn2Lasagne

Инструменты
● Python 2.7 (Anaconda)● PyCharm 4 Community Edition● git @ bitbucket.org● CUDA toolkit 6.5● PyLearn2 → Theano+cudnn● Ubuntu● 16gb RAM● NVIDIA GTX770 (4gb RAM)

Задача 1 Baseline
Получить хоть какую-то модель● преобразовать картинки в матрицу чисел● ошибка уменьшается по эпохам● результат лучше, чем рандом● генерировать правильный формат output
для Kaggle и получить errorkaggle=errorvalid
4.8 0.562.0

Инфраструктура (2 недели)
● Генерация матрицы из картинок (разные алгоритмы сведения к одному размеру)
● Перекрёстное тестирование (6-Fold CV)● Логирование● Удобное описание нейросети и параметров обучения● Сохранение и загрузка моделей● Загрузка результатов в Kaggle● Data Augmentation● Усреднение результатов● Дообучение глубокой сети
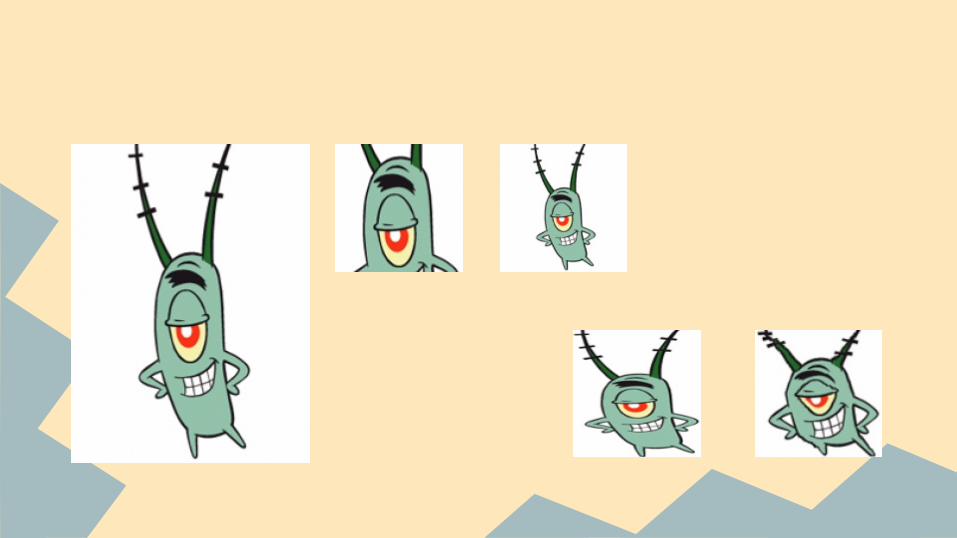

Data Augmentation
OffsetScale RotationFlip
4.8 0.56
1.5
1.2
0.85

Лучшая сеть на PyLearn2
conv 32x5x5conv 64x3x3
2 * conv 128x3x34 * conv 128x3x3
2 * fc 1000softmax
4.8 0.560.82
1.5
1.2
0.85

Theano
● Операции не выполняются сразу● Строится граф вычислений● Автовычисление производныхY = T.softmax(T.dot(W.T, X) + b)error = nll(Y_true, Y)W = W - lr * T.grad(error, W)b = b - lr * T.grad(error, b)

Месяц экспериментов на Theano
● CNN (conv, maxpool, dense) (1 неделя)● batch normalization (Ioffe, Szegedy, 2015)● weight initialization (He etc, 2015)● Nesterov momentum● adaptive optimization (adadelta, adagrad,
rmsprop)● padding conv layer (2 недели)

● Weight Initialization — возможность обучать глубокую нейросеть, существенное уменьшение ошибки с первых эпох!
● Adadelta — не нужно подбирать lr вручную, нужно меньше эпох!
● Batch Normalization — нужно в 3 раза меньше эпох, конечный результат значительно лучше!


Сработали
только weight init имомент Нестерова...
буль...

Не помогло
WhiteningАнализ ошибок (misclass table)Batch NormalizationAdadelta, adagrad, rmspropsoft targetingshandcrafted features (parallel)

Расколбас!
изображения 0–255 к 1.0–0.0tanh лучше sigmoidweight initialization

Batch Normalization
Работает на глубоких сетяхЗамедляет обучение на 30-100% (по времени на эпоху)

Как в прошлый раз, но ● жирнее ● инициализация весов● увеличили размер картинки (82x82)● Gaussian Dropout
●4.8 0.560.8
0.82

amazon_train2.py
Размер 100x100 (resize)PReLUGaussian DropoutPolishingLeap of Faith
4.8 0.560.8
0.82
0.73

Подробнее про
PolishingLeap of Faith

conv 16x3x3 poolconv 32x3x3 poolconv 64x3x3conv 96x3x3 poolconv 128x3x3conv 192x3x3conv 256x3x3 pool
4.8 0.560.8
0.82
0.73

amazon_train1.py
Размер 100x100 (shrink)PReLUGaussian Dropout
4.8 0.560.8
0.82 0.73
0.7

Усреднение
двух предыдущих моделей
4.8 0.560.8
0.82 0.73
0.7 0.68

amazon_train_1_2_igipop_40_averaged
+ fc layer- меньше gaussian dropout
4.8 0.560.8
0.82 0.73
0.7 0.68

vedr.py + усреднение
conv 16 32 pool 48 64 80 pool 96 112 128 144 pool 160 176 192 poolfc 2000 2000 2000image size=165x165
4.8 0.560.8
0.82 0.73
0.7 0.68
0.66

Amazon EC2
$0.65/час ‘On Demand’$0.065/час ‘Spot’ = 100� в сутки$23 за 3 дня вычислений на 5 компьютерахЗа электричество заплатили 1500� за 2 месяца
Instance→Setup→Snapshot→ *Instance→ComputeНе забывайте terminate!

Разное
CNN плохо абстрагируют размерPReLU плохо считался на AWSфильтры 3х3 хороши

Что у победителей
Fractional Max-Pooling (Graham, 2015)Spatial Pyramid Pooling [7]Entropy Regularization [8]Обратные кластеры слоёв

Литература[1] http://deeplearning.net/tutorial/
[2] Zeiler, Fergus. Visualizing and Understanding Convolutional Networks (2013)
[3] He, Zhang, Ren, Sun. Delving Deep into Rectifiers: Surpassing Human-Level Perfomance on ImageNet Classification (2015)
[4] Ioffe, Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (2015)
[5] Graham. Fractional Max-Pooling (2015)
[6] Simonyan, Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition (2015)
[7] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition (2014)
[8] Dong-Hyun Lee. Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks (2013)