“metatron” enterprise big data 처리를 위한 혁신
TRANSCRIPT

“metatron”Enterprise Big Data 처리를 위한 혁신
SKT Metatron/Big Data사업팀
김기남 매니저

Big Data에 대한 오해
우리나라 기업에서 Big Data는...
metatron
Ready to Enterprise

Big Data에 대한 오해Big Data 철학부터 알자

Big Data에 대한 오해
Big Data는 가공할 수록 가치가 높아진다…??가공 후 저장한 Data에 대한 분석보다 Raw 데이터에 대한 저장과 분석이 더 큰 가치를 지닌다.
CRM
SCM
MES
...
Sensor
DataAnalysis Insight and
Action
DataStore & Processing
Big Data Generate... value
* Source: McKinsey Digital
Value leakage
Value leakage Value leakage
TCO &
Computational Power
40% ~*

Big Data에 대한 오해
Better algorithms beat more data...??
분석가들 사이에서도 갑론을박이 있지만 현재는 More data beats better algorithms !!
DATA
ALGORITHM

● Rule based Programming (연역법)
알고리즘
추정
측정
일반화
Big Data에 대한 오해
Let the data do the work instead!
Data driven 으로의 패러다임 shift
Data Output
Algorithm
● Machine Learning (귀납법)
Computer
Data
패턴
잠정적 추정
알고리즘
Data
Computer
Output
Algorithm

우리나라 기업에서는 Big Data는...Big Data 도입하려는

우리나라 기업에서의 Big Data는…
“우리회사는 기존 BI 시스템에 R과 Visual Discovery Tool 도입을 통해 Big Data 시스템을 구축했다.”
RIn-memory
BI
Visual discovery
CRM Data
Operations Data
Finance Data
More DataMore DataMore DataMore DataMore DataMore DataMore Data
알고리즘 변경과 + 화려하고 빠른 Visualization = Big Data Value?

우리나라 기업에서의 Big Data는…
“우리회사에 저장된 DW 데이터는 10T도 안되기 때문에 우리회사는 빅데이터 시스템이 필요 없다.”
CRM Data
Operations Data
Finance Data
More DataMore DataMore DataMore DataMore DataMore DataMore Data
현재 수집된 데이터는 BI 리포팅 목적을 위해 Mart로 요약된 데이터인데… Raw 데이터 수집 분석에 취약
Data

우리나라 기업에서의 Big Data는…
Hadoop을 활용한 분산 Computing은 기존 Data Base system 대비 많이 저렴함
“생산 공정에서 센싱되는 Log를 모으기 위해 대량의 Storage가 필요한데, ROI가 나올지...”
기존 Computing Hadoop 분산 Computing
구조 CPU
Storage
▪ 단위 CPU로 Storage 활용
▪ 1개의 파일은 1개 Storage에만 저장
파일크기 개별 Storage 크기 이하 Storage 크기 X n개 (제약 없음)
높음
고급 high end 장비 필요(대당 수억 원)
낮음
저가 low end 장비로 가능(대당 수백만 원)
▪ 다수 서버 CPU와 Storage 동시 활용
▪ 1개의 파일을 다수 Storage에 분산
투자비

우리나라 기업에서의 Big Data는…
Raw data에 대한 Machine learning의 value를 가져가기 어려움
RDBMS (MPP) Analytics
?“Hadoop에 저장은 했으나, 분석을 하기 위해 RDBMS로 이관해 기존 분석 Tool 로 분석”
Storage

metatronIntroduction of

metatron
Core differentiations
No Limits on Data Size
Ready to Machine Learning
No Coding
metatron
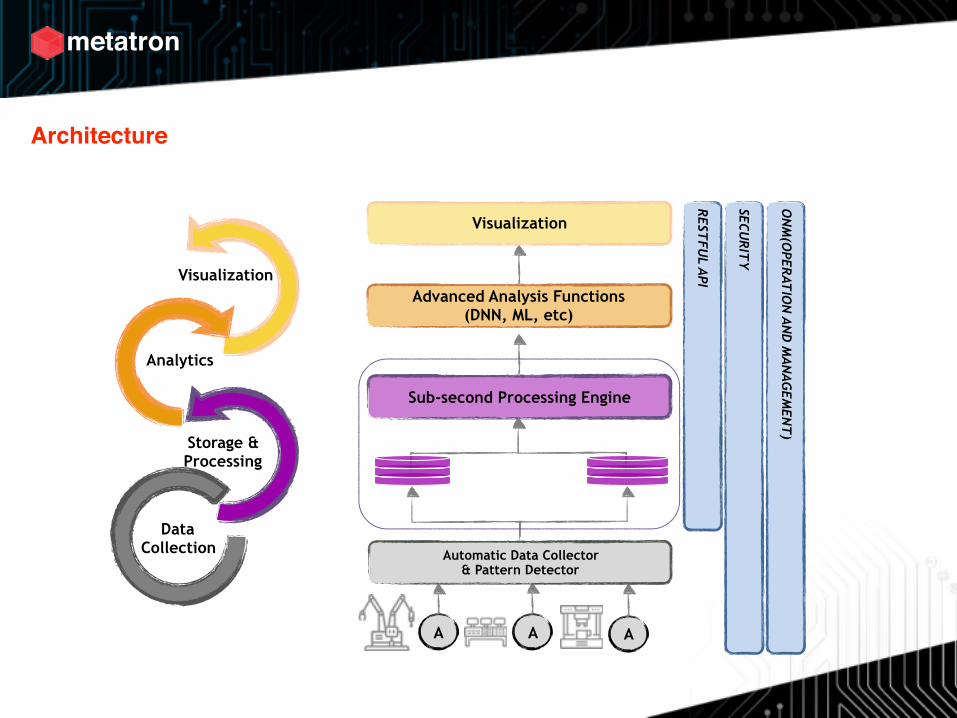
Architecture
Sub-second Processing Engine
Advanced Analysis Functions (DNN, ML, etc)
Visualization
AAA
Big data Storage
Automatic Data Collector & Pattern Detector
REST
FUL API
SECUR
ITY
ON
M(O
PERAT
ION
AND
MAN
AGEM
ENT
)
Data Collection
Storage & Processing
Analytics
Visualization

metatron
Focuses on Easy-to-use Data Preparation Process
Automatic Data Collector
✓ Forwarder: 다양한 OS와 Data type 지원
✓ Pattern Matcher: 소스타입 인식 및 패턴 매칭 (디멘전과 매저를 자동 분류)
✓ Colletor API: 데이타 수집상태 모니터링 visualization
✓ Queue: 실시간 데이터 수집 시 데이터 유실 방지
✓ Drag & Drop 으로 Look-up Join
✓ 10,000 events/sec per core
Forwarder
Forwarder
Forwarder
Aggregator
Aggregator
Aggregator
Collector
API
Queue
Pattern Matcher
Data Processing
Visualization
Real-time Ingestion

metatron
Processes time-series data in almost real-time without a size limit
Sub-second processing engine
✓ Time-series Data에 대한 index 기반 저장 및 실시간 Search 시원
✓ 저장 시 Aggregation 연산을 동시 진행 (Sum, Average, Min, and Max)
✓ In-memory를 활용한 실시간 처리 엔진과 Historical data 처리 엔진이 분리되어 동시에 Processing이 가능
✓ HDFS를 Storage로 사용
✓ Time-series에 Data에 대한 Aggregation query 응답 성능:1천만 rows/sec/8 core
Hadoop Distributed StorageMeta-store
Real-time indexer
Historical Engine
Query Engine
Queue
Advanced Analytics
Histor
ical
Engin
e
Real-time Engine

metatron
Provide Machine Learning and Statistical Analysis in distributed environment
Advanced Analysis Functions
✓ Spark ML Lib 지원
✓ Spark ML 외 자체 ML 기능도 제공
✓ 분산 기반 일반통계 알고리즘 제공
✓ 필요 시 커스텀한 분산 알고리즘 개발 지원
✓ 유저 편의를 위한 알고리즘 Model Selection 기능 제공
Distributed Machine Learning
Distributed Statistical Analysis
Supervised Learning ✓ Classification ✓ Regression ✓ Feature Selection
Unsupervised Learning ✓ Clustering ✓ Latent variable Models ✓ Signal Decomposition
✓ Time series and trend analysis
✓ Multivariate Analysis ✓ Anomaly detection ✓ Probability density
Estimation

metatron
Fast visualize for massive data base on in-memory grids
Visualization
✓ In-memory Grid를 사용해 Massive Data visual 최적화
✓ 100만건 Data 0.3초 내 그리기
✓ 다양한 차트, 그래프, Map(구글맵, Flash Map) 지원
✓ Drill-down visual 분석 지원
✓ 분석 Report 공유 및 Dashboard 기능 제공
UI Component In-memory Grid (Buffered layer) Data Repository
Fast UI Component

EnterpriseReady to

Ready to Enterprise
For Enterprise Architecture

Thank you