model order reduction via matlab parallel computing toolbox · model order reduction via matlab...
TRANSCRIPT

Model Order Reduction via Matlab Parallel ComputingToolbox
E. Fatih Yetkin & Hasan Dag
Istanbul Technical UniversityComputational Science & Engineering Department
September 21, 2009
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 1 / 40

1 Parallel ComputationWhy We Need Parallelism in MOR?What is Parallelism?Parallel Architectures
2 Tools of ParallelizationProgramming ModelsParallel Matlab
3 Parallel Version of Rational Krylov MethodsRational Krylov MethodsH2 optimality and Rational Krylov methodsAn Example SystemParallelization of the AlgorithmResults
4 Conclusions
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 2 / 40

Why We Need Parallelism in MOR?Computational Complexity
Model reduction methods aim to build a model, which is easy tohandle. However, for some type of methods such as balancedtruncation or rational Krylov reduction process takes lots of time fordense problems.
Computational Complexity of Rational Krylov Methods
Complexity of the process decomposition of (A− σiE ) for k points isO(N3)
Therefore, especially in dense problems parallelism is an obligation.
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 3 / 40

What is Parallelism?Sequential Programming
A single CPU (core) is available
Problem is composed of series of commands
Each command is executed one after another
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 4 / 40
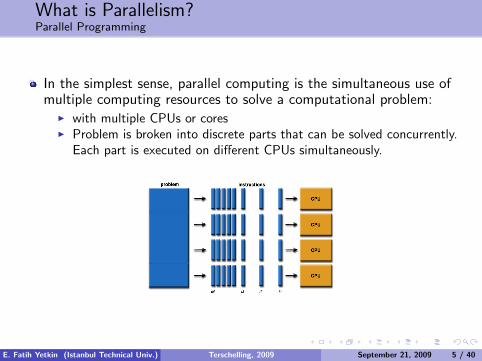
What is Parallelism?Parallel Programming
In the simplest sense, parallel computing is the simultaneous use ofmultiple computing resources to solve a computational problem:
I with multiple CPUs or coresI Problem is broken into discrete parts that can be solved concurrently.
Each part is executed on different CPUs simultaneously.
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 5 / 40
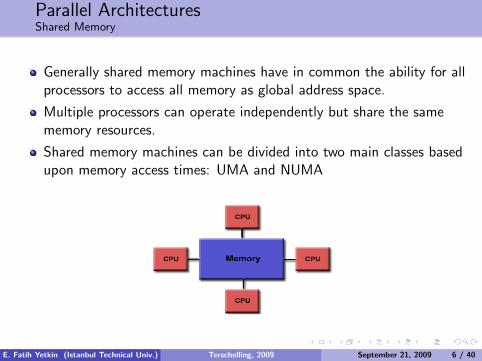
Parallel ArchitecturesShared Memory
Generally shared memory machines have in common the ability for allprocessors to access all memory as global address space.
Multiple processors can operate independently but share the samememory resources.
Shared memory machines can be divided into two main classes basedupon memory access times: UMA and NUMA
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 6 / 40
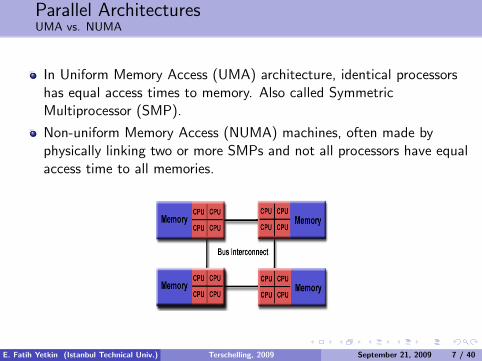
Parallel ArchitecturesUMA vs. NUMA
In Uniform Memory Access (UMA) architecture, identical processorshas equal access times to memory. Also called SymmetricMultiprocessor (SMP).
Non-uniform Memory Access (NUMA) machines, often made byphysically linking two or more SMPs and not all processors have equalaccess time to all memories.
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 7 / 40

Parallel ArchitecturesDistributed Memory
Processors have their own local memory. Memory addresses in oneprocessor do not map to another processor, so there is no concept ofglobal address space across all processors.
When a processor needs access to data in another processor, it isusually the task of the programmer to explicitly define how and whendata is communicated. Synchronization between tasks is likewise theprogrammer’s responsibility.
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 8 / 40
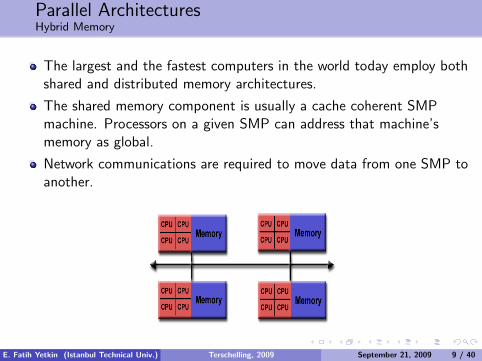
Parallel ArchitecturesHybrid Memory
The largest and the fastest computers in the world today employ bothshared and distributed memory architectures.
The shared memory component is usually a cache coherent SMPmachine. Processors on a given SMP can address that machine’smemory as global.
Network communications are required to move data from one SMP toanother.
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 9 / 40

Parallel Programming Models: ThreadsPOSIX Threads & OpenMP
In the threads model of parallel programming, a single process canhave multiple, concurrent execution paths.
Threads can come and go, but a.out remains present to provide thenecessary shared resources until the application is completed.
Unrelated standardization efforts have resulted in two very differentimplementations of threads: POSIX Threads and OpenMP.
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 10 / 40
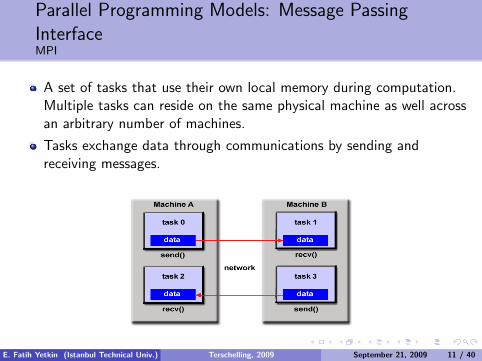
Parallel Programming Models: Message PassingInterfaceMPI
A set of tasks that use their own local memory during computation.Multiple tasks can reside on the same physical machine as well acrossan arbitrary number of machines.
Tasks exchange data through communications by sending andreceiving messages.
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 11 / 40

Matlab Distributed Computing ToolboxDistributed or Parallel
From the view of Matlab terminology parallel jobs run on the internalworkers such as cores and distributed jobs run on the cluster nodes.
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 12 / 40

Basics of Parallel Computing Toolboxparfor
In Matlab you can use parfor to make a parallel loop.
Message passing or some low level communication issues handled byMatlab itself.
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 13 / 40

Basics of Parallel Computing Toolboxwhen we can use parfor?
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 14 / 40

Basics of Parallel Computing Toolboxwhen we can not use parfor?
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 15 / 40

Basics of Parallel Computing Toolboxsingle process multiple data (spmd)
In Matlab you can use spmd blocks to run a process on different datasets.
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 16 / 40

Basics of Parallel Computing Toolboxsingle process multiple data (spmd)
Master processor has a right to access for all workers’ data
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 17 / 40

Basics of Parallel Computing Toolboxdistributed arrays
It is possible to distribute any array to workers.
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 18 / 40

Basics of Parallel Computing Toolboxdistributed arrays
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 19 / 40
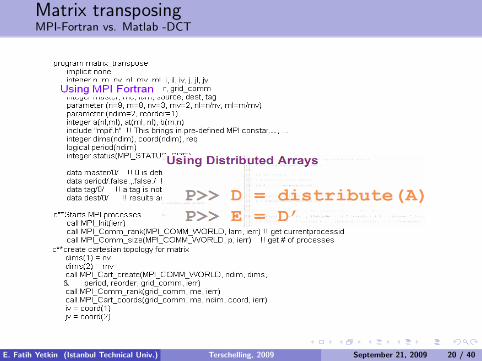
Matrix transposingMPI-Fortran vs. Matlab -DCT
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 20 / 40

Rational Krylov Methods
If D selected as zero system triple can be selected as Σ = (A,B,C ) for
x = Ax + Bu
y = CT x + Du
Two matrices V ∈ Rnxk and W ∈ Rnxk can be defined whereW ∗V = Ik and k � n
With these two matrices reduced order system can be found as
A = W ∗AV B = W ∗B C = CV (1)
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 21 / 40

Rational Krylov Method
There are lots of ways to build the projection matrices.
One way is using rational Krylov subspace bases.
Assume that k distinct points in complex plane are selected forinterpolation.
Then interpolation matrices, V and W can be built as shown below.
V = [(s1I − A)−1B . . . (sk I − A)−1B]
W = [(s1I − AT )−1C . . . (sk I − AT 1)−1C ] (2)
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 22 / 40

Rational Krylov Projectors
Assuming that det(W ∗V ) 6= 0, the projected reduced system can bebuilt as,
A = W TAV , B = W TB, C = CV (3)
where W = W (V ∗W )−1 to ensure W ∗V = Ik .
The basic problem is to find a strategy to select the interpolationpoints.
As the worst case, the interpolation points can be selected asrandomly from the operating frequency of the system.
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 23 / 40

Rational Krylov Projectors
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 24 / 40

H2 norm of a system
This approach is not optimal. To improve this approach severalmethods can be used. In this work we use the iterative rational Krylovapproach to achieve H2 norm optimal reduced model.
H2 norm of a system is defined as below,
||G ||2 :=
[ ∫ +∞
−∞|G (jω)|2dω
]1/2
(4)
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 25 / 40

H2 optimality
Reduced order system Gr (s) is H2 optimal if it minimizes the
Gr (s) = argmindeg(G)=r ||G (s)− G (s)||H2 (5)
And there are two important theorems to obtain an H2 optimalreduced model given by Meier (1967) and Grimme (1997).
Antoulas et.al. combine these two important results to achieve anIterative Rational Krylov Algorithm (IRKA) to obtain H2 optimalreduced order model
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 26 / 40

Iterative Rational Krylov Algorithm (IRKA)
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 27 / 40

Example RLC network
We use a ladder RLC network as benchmark example for thenumerical implementation of the Alg.1 and Alg.2.
Minimal realization of the circuit is given in Fig.1. For this circuitorder of the system n = 5. On the other hand, system matrices ofthis circuit can easily be extended
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 28 / 40
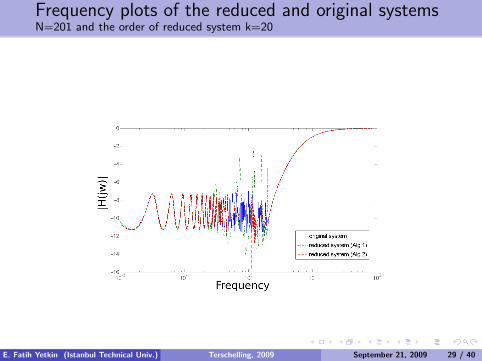
Frequency plots of the reduced and original systemsN=201 and the order of reduced system k=20
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 29 / 40

Computational Cost of Methods
Computational cost of the rational Krylov methods can be given asO(N3) for dense problems
In IRKA rational Krylov methods are used iteratively and thecomputational complexity has to be multiplied by the iterationnumber r .
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 30 / 40

Parallel Parts of Algorithms
Although both algorithms have k times factorization to compute(si I − A)−1B, these factorizations can be computed on differentprocessors independently.
The matrix-matrix and matrix-vector multiplications in the algorithmsare amenable to parallel processing.
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 31 / 40

Parallel Version of Alg. 1
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 32 / 40
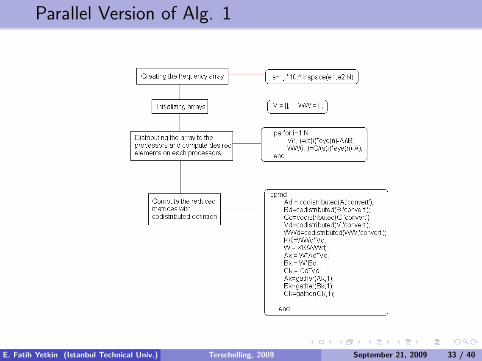
Parallel Version of Alg. 1
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 33 / 40
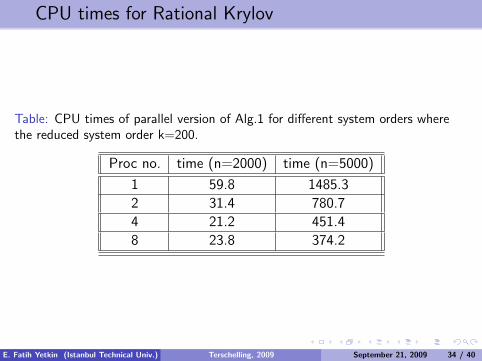
CPU times for Rational Krylov
Table: CPU times of parallel version of Alg.1 for different system orders wherethe reduced system order k=200.
Proc no. time (n=2000) time (n=5000)
1 59.8 1485.3
2 31.4 780.7
4 21.2 451.4
8 23.8 374.2
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 34 / 40

CPU times for IRKA
Table: CPU times of parallel version of Alg.2 for different system orders wherethe reduced system order k=200.
Proc no. time (n=2000) time (n=5000)
1 512.6 2486.2
2 410.7 1605.9
4 203.9 810.8
8 176.1 648.4
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 35 / 40

Speedup graph for RK
Speedup of a parallel algorithm is defined as
Sp =T1
Tp(6)
where T1 is the CPU time for one processor and Tp is the CPU time for Pprocessor.
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 36 / 40
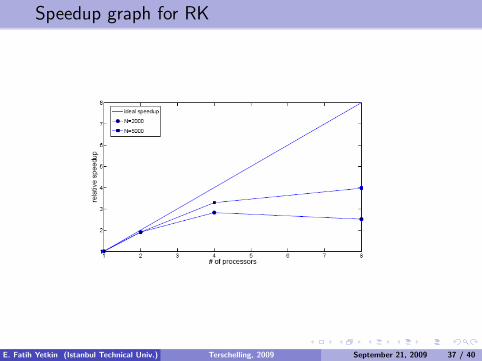
Speedup graph for RK
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 37 / 40
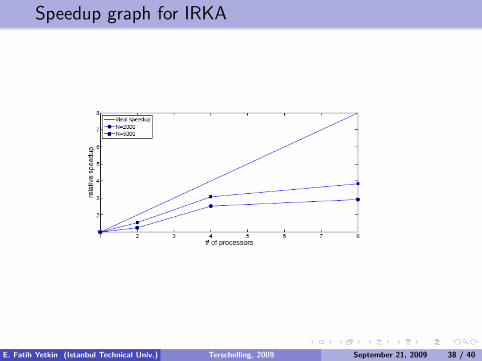
Speedup graph for IRKA
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 38 / 40

continued
It can easily be seen from the figures, when we increase the numberof processors processing time decreases appreciably upto some point,after which it starts to increase.
This is due to communication times becoming dominant overcomputation time. But in both algorithm, when the size of thesystem matrices are getting larger better speedups are obtained.
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 39 / 40

Conclusions
In this work, iterative rational Krylov method based optimal H2 normmodel reduction methods are parallelized.
These methods require huge computation but the algorithmthemselves are suitable for parallel processing.
Therefore, computational time decreases when the number ofprocessors is increased.
Due to communication needs of the processors, communication timedominates the overall process time when the system order is small.
But in larger orders, parallel algorithm has better speedup values.
E. Fatih Yetkin (Istanbul Technical Univ.) Terschelling, 2009 September 21, 2009 40 / 40