modeling the internet and the web: modeling and understanding human behavior on the web
DESCRIPTION
Modeling the Internet and the Web: Modeling and Understanding Human Behavior on the Web. Outline. Introduction Web Data and Measurement Issues Empirical Client-Side Studies of Browsing Behavior Probabilistic Models of Browsing Behavior Modeling and Understanding Search Engine Querying. - PowerPoint PPT PresentationTRANSCRIPT

Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Modeling the Internet and the Web:
Modeling and Understanding Human Behavior on the Web

2Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Outline
• Introduction
• Web Data and Measurement Issues
• Empirical Client-Side Studies of Browsing Behavior
• Probabilistic Models of Browsing Behavior
• Modeling and Understanding Search Engine Querying

3Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Introduction
• Useful to study human digital behavior, e.g. search engine data can be used for– Exploration e.g. # of queries per session?– Modeling e.g. any time of day dependence?– Prediction e.g. which pages are relevant?
• Helps– Understand social implications of Web usage– Better design tools for information access– In networking, e-commerce etc

4Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Web data and measurement issues
Background:• Important to understand how data is collected• Web data is collected automatically via software
logging tools– Advantage:
• No manual supervision required
– Disadvantage:• Data can be skewed (e.g. due to the presence of robot traffic)
• Important to identify robots (also known as crawlers, spiders)

5Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
A time-series plot of Web requests
Number of page requests per hour as a function of time from page requests in the www.ics.uci.edu Web server logs during the first week of April 2002.
6Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Robot / human identification
• Robot requests identified by classifying page requests using a variety of heuristics– e.g. some robots self-identify themselves in
the server logs (robots.txt)– Robots explore the entire website in breadth
first fashion– Humans access web-pages in depth first
fashion
• Tan and Kumar (2002) discuss more techniques

7Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Robot / human identification
• Robot traffic consists of two components– Periodic Spikes (can overload a server)
• Requests by “bad” robots
– Lower-level constant stream of requests• Requests by “good” robots
• Human traffic has – Daily pattern: Monday to Friday – Hourly pattern: peak around midday & low
traffic from midnight to early morning

8Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Server-side data
Data logging at Web servers• Web server sends requested pages to the
requester browser• It can be configured to archive these
requests in a log file recording– URL of the page requested– Time and date of the request– IP address of the requester– Requester browser information (agent)

9Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Data logging at Web servers
– Status of the request– Referrer page URL if applicable
• Server-side log files – provide a wealth of information– require considerable care in interpretation
• More information in Cooley et al. (1999), Mena (1999) and Shahabi et al. (2001)

10Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Page requests, caching, and proxy servers
• In theory, requester browser requests a page from a Web server and the request is processed
• In practice, there are– Other users– Browser caching– Dynamic addressing in local network– Proxy Server caching

11Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Page requests, caching, and proxy servers
A graphical summary of how page requests from an individual user can be masked at various stages between the user’s local computer and the Web server.

12Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Page requests, caching, and proxy servers
• Web server logs are therefore not so ideal in terms of a complete and faithful representation of individual page views
• There are heuristics to try to infer the true actions of the user: -– Path completion (Cooley et al. 1999)
• e.g. If known B -> F and not C -> F, then session ABCF can be interpreted as ABCBF
• Anderson et al. 2001 for more heuristics
• In general case, hard to know what user viewed

13Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Identifying individual users from Web server logs
• Useful to associate specific page requests to specific individual users
• IP address most frequently used• Disadvantages
– One IP address can belong to several users– Dynamic allocation of IP address
• Better to use cookies– Information in the cookie can be accessed by the
Web server to identify an individual user over time– Actions by the same user during different sessions
can be linked together

14Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Identifying individual users from Web server logs
• Commercial websites use cookies extensively• 90% of users have cookies enabled permanently
on their browsers• However …
– There are privacy issues – need implicit user cooperation
– Cookies can be deleted / disabled
• Another option is to enforce user registration– High reliability– Can discourage potential visitors

15Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Client-side data
• Advantages of collecting data at the client side:– Direct recording of page requests (eliminates ‘masking’ due to
caching)– Recording of all browser-related actions by a user (including
visits to multiple websites)– More-reliable identification of individual users (e.g. by login ID for
multiple users on a single computer)
• Preferred mode of data collection for studies of navigation behavior on the Web
• Companies like comScore and Nielsen use client-side software to track home computer users
• Zhu, Greiner and Häubl (2003) used client-side data

16Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Client-side data
• Statistics like ‘Time per session’ and ‘Page-view duration’ are more reliable in client-side data
• Some limitations– Still some statistics like ‘Page-view duration’ cannot
be totally reliable e.g. user might go to fetch coffee– Need explicit user cooperation– Typically recorded on home computers – may not
reflect a complete picture of Web browsing behavior• Web surfing data can be collected at
intermediate points like ISPs, proxy servers– Can be used to create user profile and target
advertise

17Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Handling massive Web server logs
• Web server logs can be very large– Small university department website gets a million
requests per month– Amazon, Google can get tens of millions of requests
each day• Exceed main memory capacities, stored on
disks• Time-costs to data access place significant
constraints on types of analysis• In practice
– Analysis of subset of data– Filtering out events and fields of no direct interest

18Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Empirical client-side studies of browsing behavior
• Data for client-side studies are collected at the client-side over a period of time– Reliable page revisitation patterns can be gathered– Explicit user permission is required– Typically conducted at universities– Number of individuals is small– Can introduce bias because of the nature of the
population being studied– Caution must be exercised when generalizing
observations• Nevertheless, provide good data for studying
human behavior

19Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Early studies from 1995 to 1997
• Earliest studies on client-side data are Catledge and Pitkow (1995) and Tauscher and Greenberg (1997)
• In both studies, data was collected by logging Web browser commands
• Population consisted of faculty, staff and students
• Both studies found – clicking on the hypertext anchors as the most
common action– using ‘back button’ was the second common action

20Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Early studies from 1995 to 1997
– high probability of page revisitation (~0.58-0.61)• Lower bound because the page requests prior to the start of
the studies are not accounted for• Humans are creatures of habit?• Content of the pages changed over time?
– strong recency (page that is revisited is usually the page that was visited in the recent past) effect
• Correlates with the ‘back button’ usage
• Similar repetitive actions are found in telephone number dialing etc

21Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
The Cockburn and McKenzie study from 2002
• Previous studies are relatively old• Web has changed dramatically in the past few
years• Cockburn and McKenzie (2002) provides a more
up-to-date analysis– Analyzed the daily history.dat files produced by the
Netscape browser for 17 users for about 4 months– Population studied consisted of faculty, staff and
graduate students• Study found revisitation rates higher than past
94 and 95 studies (~0.81)– Time-window is three times that of past studies

22Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
The Cockburn and McKenzie study from 2002
• Revisitation rate less biased than the previous studies?• Human behavior changed from an exploratory mode to a
utilitarian mode?
– The more pages user visits, the more are the requests for new pages
– The most frequently requested page for each user can account for a relatively large fraction of his/her page requests
• Useful to see the scatter plot of the distinct number of pages requested per user versus the total pages requested
• Log-log plot also informative
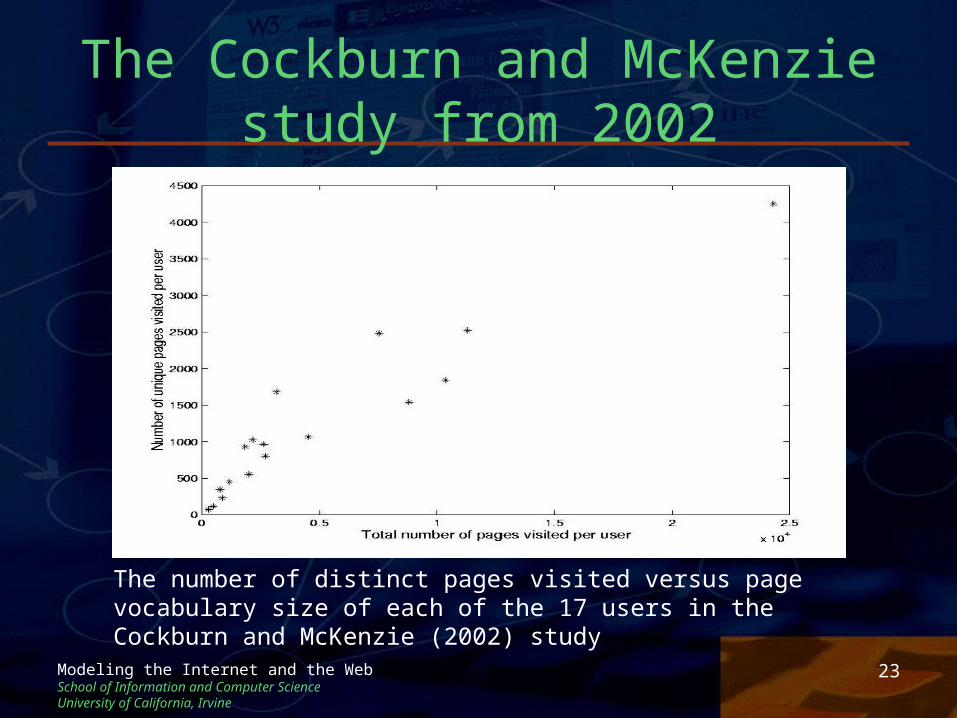
23Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
The Cockburn and McKenzie study from 2002
The number of distinct pages visited versus page vocabulary size of each of the 17 users in the Cockburn and McKenzie (2002) study

24Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
The Cockburn and McKenzie study from 2002
The number of distinct pages visited versus page vocabulary size of each of the 17 users in the Cockburn and McKenzie (2002) study (log-log plot)

25Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
The Cockburn and McKenzie study from 2002
Bar chart of the ratio of the number of page requests for the most frequent page divided by the total number of page requests, for 17 users in the Cockburn McKenzie (2002) study

26Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Video-based analysis of Web usage
• Byrne et al. (1999) analyzed video-taped recordings of eight different users over a period of 15 min to 1 hour
• Audio descriptions of the users was combined with the video recordings of their screen for analysis
• Study found – users spent a considerable amount of time scrolling
Web pages– users spent a considerable amount of time waiting for
pages to load (~15% of time)

27Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Probabilistic models of browsing behavior
• Useful to build models that describe the browsing behavior of users
• Can generate insight into how we use Web
• Provide mechanism for making predictions
• Can help in pre-fetching and personalization

28Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Markov models for page prediction
• General approach is to use a finite-state Markov chain– Each state can be a specific Web page or a category
of Web pages– If only interested in the order of visits (and not in
time), each new request can be modeled as a transition of states
• Issues– Self-transition– Time-independence

29Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Markov models for page prediction
• For simplicity, consider order-dependent, time-independent finite-state Markov chain with M states
• Let s be a sequence of observed states of length L. e.g. s = ABBCAABBCCBBAA with three states A, B and C. st is state at position t (1<=t<=L). In general,
• Under a first-order Markov assumption, we have
• This provides a simple generative model to produce sequential data
L
ttt sssPsPsP
2111 ),...,|()()(
L
ttt ssPsPsP
211 )|()()(

30Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Markov models for page prediction
• If we denote Tij = P(st = j|st-1 = i), we can define a M x M transition matrix
• Properties– Strong first-order assumption– Simple way to capture sequential dependence
• If each page is a state and if W pages, O(W2), W can be of the order 105 to 106 for a CS dept. of a university
• To alleviate, we can cluster W pages into M clusters, each assigned a state in the Markov model
• Clustering can be done manually, based on directory structure on the Web server, or automatic clustering using clustering techniques

31Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Markov models for page prediction
• Tij = P(st = j|st-1 = i) now represent the probability that an individual user’s next request will be from category j, given they were in category i
• We can add E, an end-state to the model• E.g. for three categories with end state: -
• E denotes the end of a sequence, and start of a new sequence
0)|3()|2()|1(
)3|()3|3()3|2()3|1(
)2|()2|3()2|2()2|1(
)1|(_)1|3()1|2()1|1(
EPEPEP
EPPPP
EPPPP
EPPPP
T

32Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Markov models for page prediction
• First-order Markov model assumes that the next state is based only on the current state
• Limitations– Doesn’t consider ‘long-term memory’
• We can try to capture more memory with kth-order Markov chain
• Limitations– Inordinate amount of training data O(Mk+1)
),..,|(),..,|( 111 kttttt sssPsssP

33Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Fitting Markov models to observed page-request data
• Assume that we collected data in the form of N sessions from server-side logs, where ith session si, 1<= i <= N, consists of a sequence of Li page requests, categorized into M – 1 states and terminating in E. Therefore, data D = {s1, …, sN}
• Let denote the set of parameters of the Markov model, consists of M2 -1 entries in T
• Let denote the estimated probability of transitioning from state i to j.
ij

34Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Fitting Markov models to observed page-request data
• The likelihood function would be
• This assumes conditional independence of sessions.• Under Markov assumptions, likelihood is
• where nij is the number of times we see a transition from state i to state j in the observed data D.
N
iisPDPL
1
)|()|()(
MjiL ijn
ij ,1,)(

35Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Fitting Markov models to observed page-request data
• For convenience, we use log-likelihood
• We can maximize the expression by taking partial derivatives wrt each parameter and incorporating the constraint (via Lagrange multipliers) that the sum of transition probabilities out of any state must sum to one
• The maximum likelihood (ML) solution is
ij
ijijnLl log)(log)(
j
ij 1
i
ijML
ij n
n

36Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Bayesian parameter estimation for Markov models
• In practice, M is large (~102-103), we end up estimating M2 probabilities
• D may contain potentially millions of sequences, so some nij = 0
• Better way would be to incorporate prior knowledge – prior probability distribution and then maximize , the posterior distribution on given the data (rather than )
• Prior distribution reflects our prior belief about the parameter set
• The posterior reflects our posterior belief in the parameter set now informed by the data D
)|( DP
)(P
)|( DP

37Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Bayesian parameter estimation for Markov models
• For Markov transition matrices, it is common to put a distribution on each row of T and assume that each of these priors are independent
where • Consider the set of parameters for the ith row in T, a
useful prior distribution on these parameters is the Dirichlet distribution defined as
• where , and C is a normalizing constant
i
iMiPP }),...,({)( 1
j
ij 1
M
j
q
ijqiMiij
iCDP
1
)1(
1 }),...,({
j
ijij qq 1,0,

38Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Bayesian parameter estimation for Markov models
• The MP posterior parameter estimates are
• If nij = 0 for some transition (i, j) then instead of having a parameter estimate of 0 (ML), we will have allowing prior knowledge to be incorporated
• If nij > 0, we get a smooth combination of the data-driven information (nij) and the prior
i
ijijMP
ij n
qn
)/( iij nq

39Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Bayesian parameter estimation for Markov models
• One simple way to set prior parameter is– Consider alpha as the effective sample size– Partition the states into two sets, set 1 containing all
states directly linked to state i and the remaining in set 2
– Assign uniform probability e/K to all states in set 2 (all set 2 states are equally likely)
– The remaining (1-e) can be either uniformly assigned among set 1 elements or weighted by some measure
– Prior probabilities in and out of E can be set based on our prior knowledge of how likely we think a user is to exit the site from a particular state
40Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Predicting page requests with Markov models
• Many flavors of Markov models proposed for next page and future page prediction
• Useful in pre-fetching, caching and personalization of Web page
• For a typical website, the number of pages is large – Clustering is useful in this case
• First-order Markov models are found to be inferior to other types of Markov models
• kth-order is an obvious extension– Limitation: O(Mk+1) parameters (combinatorial
explosion)

41Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Predicting page requests with Markov models
• Deshpande and Karypis (2001) propose schemes to prune kth-order Markov state space– Provide systematic but modest improvements
• Another way is to use empirical smoothing techniques that combine different models from order 1 to order k (Chen and Goodman 1996)
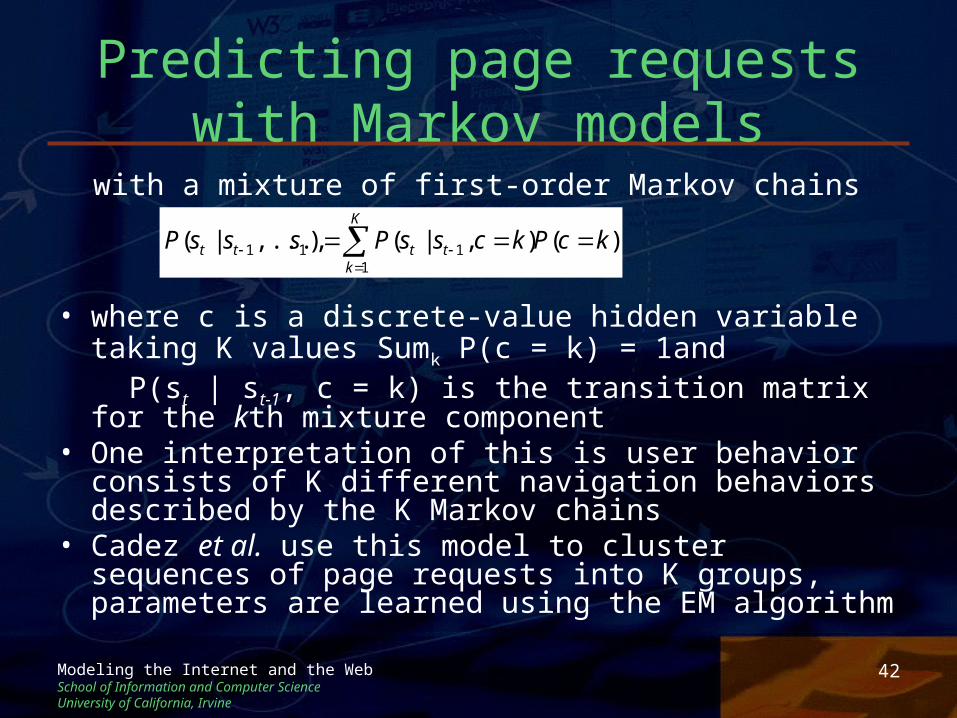
• Cadez et al. (2003) and Sen and Hansen (2003) propose mixtures of Markov chains, where we replace the first-order Markov chain:
)|(),...,|( 111 tttt ssPsssP
42Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Predicting page requests with Markov models
with a mixture of first-order Markov chains
• where c is a discrete-value hidden variable taking K values Sumk P(c = k) = 1and
P(st | st-1, c = k) is the transition matrix for the kth mixture component
• One interpretation of this is user behavior consists of K different navigation behaviors described by the K Markov chains
• Cadez et al. use this model to cluster sequences of page requests into K groups, parameters are learned using the EM algorithm
)(),|(),...,|(1
111 kcPkcssPsssPK
ktttt

43Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Predicting page requests with Markov models
• Consider the problem of predicting the next state, given some number of states t
• Let s[1,t] = {s1,…, st} denote the sequence of t states• The predictive distribution for a mixture of K Markov
models is
• The last line is obtained if we assume conditioned on component c = k, the next state st+1 depends only on st
K
ktttt skcsPssP
1],1[1],1[1 )|,()|(
K
kttt skcPkcssP
1],1[],1[1 )|(),|(
K
kttt skcPkcssP
1],1[1 )|(),|(

44Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Predicting page requests with Markov models
• Weight based on observed history is
where • Intuitively, these membership weights ‘evolve’ as
we see more data from the user• In practice,
– Sequences are short– Not realistic to assume that observed data is
generated by a mixture of K first-order Markov chains• Still, mixture model is a useful approximation
KkjcPjcsP
kcPkcsPskcP
jt
tt
1,)()|(
)()|()|(
],1[
],1[],1[
L
tttt kcssPkcsPkcsP
21],1[ ),|()|1()|(

45Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Predicting page requests with Markov models
• K can be chosen by evaluating the out-of-sample predictive performance based on– Accuracy of prediction– Log probability score– Entropy
• Other variations of Markov models– Sen and Hansen 2003– Position-dependent Markov models (Anderson et al.
2001, 2002)– Zukerman et al. 1999
46Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Search Engine Querying
• How users issue queries to search engines– Tracking search query logs
timestamp, text string, user ID etc.
– Collecting query datasets from different distributionJansen et al (1998), Silverstein et al (1998)Lau and Horvitz (1999), Spink et al (2002)Xie and O’Hallaron (2002)
e.g.Xie and O’Hallaron (2002)
• Checked how many queries were coming• Checked “user’s” IP address• Reported 111,000 queries (2.7%) originating from AOL

47Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Analysis of Search Engine Query Logs
# of Sample Query Source SE Time Period
Lau & Horvitz 4690 of 1 Million Excite Sep 1997
Silverstein et al 1 Billion AltaVista 6 weeks in Aug & Sep 1998
Spink et al (series of studies)
1Million for each time period
Excite Sep 1997Dec 1999May 2001
Xie & O’Hallaron
110,000 Vivisimo 35 days Jan & Feb 2001
1.9 Million Excite 8 hrs in a day, Dec 1999

48Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Main Results• Average number of terms in a query is ranging
from a low of 2.2 to a high of 2.6• The most common number of terms in a query is
2• The majority of users don’t refine their query
– The number of users who viewed only a single page increase 29% (1997) to 51% (2001) (Excite)
– 85% of users viewed only first page of search results (AltaVista)
• 45% (2001) of queries is about Commerce, Travel, Economy, People (was 20%1997)– The queries about adult or entertainment decreased
from 20% (1997) to around 7% (2001)
49Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Main Results
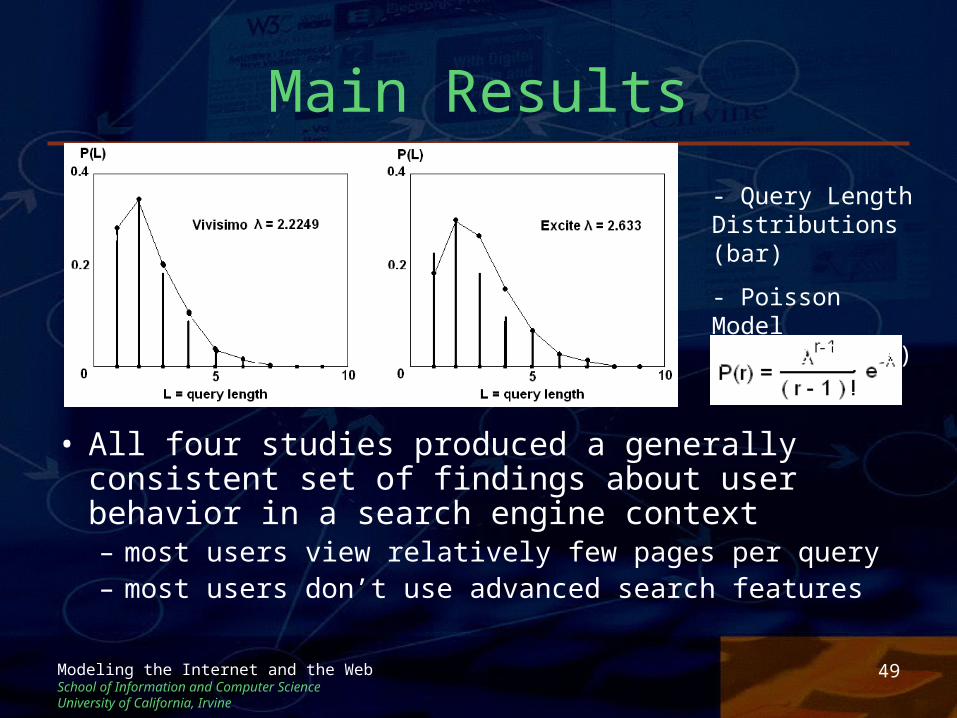
• All four studies produced a generally consistent set of findings about user behavior in a search engine context– most users view relatively few pages per query– most users don’t use advanced search features
- Query Length Distributions (bar)
- Poisson Model(dots & lines)

50Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Advanced Search Tips• Useful operators for searching (Google)
+ Include stop word (common words)+where +is Irvine
- Excludeoperating system -Microsoft
~ Synonyms~computer
“…“ Phrase search“modeling the internet”
or Either A Or Bvacation London or Paris
site: Domain searchadmission site:www.uci.edu
51Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Power-law Characteristics
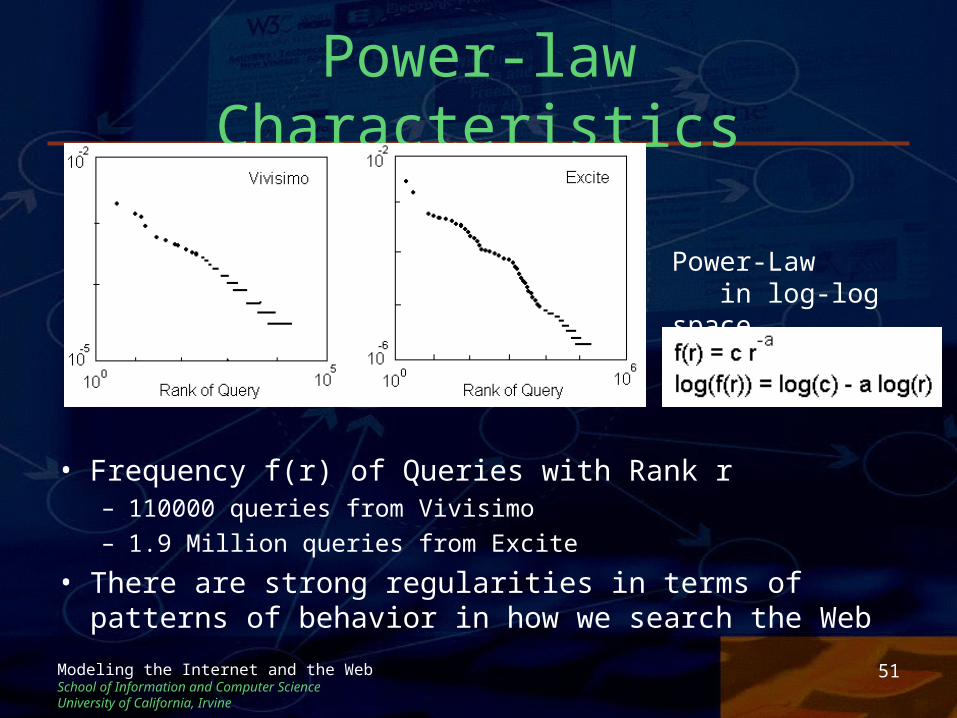
• Frequency f(r) of Queries with Rank r– 110000 queries from Vivisimo– 1.9 Million queries from Excite
• There are strong regularities in terms of patterns of behavior in how we search the Web
Power-Law in log-log space

52Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Models for Search Strategies
• It is significant to know the process by which a typical user navigates through search space when looking for information using a search engine
• The inference of user’s search actions could be used for marketing purposes such as real-time targeted advertising

53Modeling the Internet and the WebSchool of Information and Computer ScienceUniversity of California, Irvine
Graphical Representation
• Lar & Horvitz(1999)– Model of user’s search query actions over time– Simple Bayesian network
1) Current search action
2) Time interval
3) Next search action
4) Informational goals
– Track ‘Search Trajectory’ of individual users
– Provide more relevant feedback to users