modern technologies in data science
TRANSCRIPT

Chu-Cheng Hsieh
Modern technologies in data science

www.linkedin.com/in/chucheng

3
Task: Find “Error” in /var/log/system.log
Interview

4
/*Java*/BufferedReader br = new BufferedReader(
new FileReader(”system.log")); try { StringBuilder sb = new StringBuilder(); String line = br.readLine();
while (line != null) { if (line.contains(“Error”) { System.out.println(line); } String everything = sb.toString(); } finally { br.close();}
Worst!

5
# Python
with open(”system.log", "r") as ins: for line in ins:
if “Error” in line:print line[:-1]
Bad!

6
# Bash
grep "Error" system.log
# !! Best !!grep –B 3 –A 2 "Error" system.log|less
Good!

7
Task: Find “Error” in /var/log/system.log
What if,
system.log > 1TB? 10TB? … 1PB?
Interview

8
More CPUsMore Data

9credit: http://www.cse.wustl.edu/~jain/

10
(1)Multi-thread coding is really really painful.
(2)Max # of cores in a machines in limited

11

12
$US 390 billion

Map Reduce
13 13

14
An easy way of “multi-core” programming.

Map
15 15

16
Q. How to eat a pizza in 1 minute?

17
Ans.

18
Map = “things can be divide-and-conquer”

Reduce
19 19

20
Reduce =
“merge pieces to make result meaningful”

21
“Word Count”4 Nodes

22
“map”

23
“reduce”

24
Map-reduce - an easy way to
“collaborate”.

25
UCLAimport java.io.IOException;import java.util.*;import org.apache.hadoop.fs.Path;import org.apache.hadoop.conf.*;import org.apache.hadoop.io.*;import org.apache.hadoop.mapred.*;import org.apache.hadoop.util.*;
public class WordCount {//////////// MAPPER function //////////////
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text,IntWritable> {
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output,Reporter reporter) throws IOException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); Text word = new Text(); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, new IntWritable(1)); } } }
//////////// REDUCER function ///////////// public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text,IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text,IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { /////////// JOB description /////////// JobConf conf = new JobConf(WordCount.class); conf.setJobName("wordcount"); conf.setMapperClass(Map.class); conf.setReducerClass(Reduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); JobClient.runJob(conf); }}

26
a = load ’input.txt';#mapb = foreach a generate flatten(TOKENIZE((chararray)$0)) as word;
#reducec = group b by word;d = foreach c generate COUNT(b), group;
store d into ‘wordcount.txt';
PIG

27
What’s wrong with PIG?

28
Word count + “case insensitive”

29
REGISTER lib.jar;a = load ’input.txt';#mapb = foreach a generate flatten(TOKENIZE((chararray)$0)) as word;b2 = foreach b generate lib.UPPER(word)
#reducec = group b2 by word;d = foreach c generate COUNT(b), group;
store d into ‘wordcount.txt';
Case In sensitive

30
package myudfs;import java.io.IOException;import org.apache.pig.EvalFunc;import org.apache.pig.data.Tuple;
public class UPPER extends EvalFunc<String>{ public String exec(Tuple input) throws IOException { if (input == null || input.size() == 0 || input.get(0) == null) return null; try{ String str = (String)input.get(0); return str.toUpperCase(); }catch(Exception e){ throw new IOException(”Error in input row ", e); } }}
UDF

31

32 https://spark.apache.org/

33
chsieh@dev-sfear01:~$ spark-shell --master local[4]
Spark assembly has been built with Hive, including Datanucleus jars on classpath15/03/26 14:32:12 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableWelcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 1.3.0 /_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_76)Type in expressions to have them evaluated.Type :help for more information.Spark context available as sc.SQL context available as sqlContext.
scala>

34
chsieh@dev-sfear01:~/SparkTutorial$ cat wc.txt onetwo twothree three threefour four four fourfive five five five five

35
// RDD[String] = MapPartitionsRDDval file = sc.textFile("wc.txt")
val counts = file.flatMap(line => line.split(" ")) // RDD[String] =
MapPartitionsRDD .map(word => (word, 1))
// RDD[(String, Int)] = MapPartitionsRDD .reduceByKey( (l, r) => l + r)
// RDD[(String, Int)] = ShuffledRDD
counts.collect()// Array[(String, Int)] = // Array((two,2), (one,1), (three,2), (five,5), (four,4))
counts.saveAsTextFile(”file:///path/to/wc_result")// Use hdfs:// for hadoop file system

36
mapFlat( … )
map( … ) and then flatten( )
scala> List(List(1, 2), Set(3, 4)).flattenres0: List[Int] = List(1, 2, 3, 4)// create an empty list// travel each item once
val l = List(List(1,2), List(3,4,List(4, 5))).flattenl: List[Any] = List(1, 2, 3, 4, List(4, 5))

37
// ReduceByKey
(”two”, 1) (”two”, 1)^^^^^ ^^^^^ key key
l r
(”two”, 2)

38
Why Spark?

39
It’s super fast !!

40
How can it so fast?

41
RDD (Resilient Distributed Datasets)

42
How to create an RDD?

43
Method #1 (Parallelized)
scala> val data = Array(1, 2, 3, 4, 5)data: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val distData = sc.parallelize(data)distData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize

44
Method #2 (External Dataset)
scala> val distFile = sc.textFile("data.txt")distFile: RDD[String] = MappedRDD@1d4cee08
Local Path Amazon S3 => s3n:// Hadoop => hdfs:// etc. URI

45
Desired Properties for map-reduce
Distributed
Lazy (Optimize as much as you can)
Persistence (Caching)

46
Input(disk)
Tuples(disk)
Tuples(disk)
Tuples(disk)
Output(disk)
MR1
MR2
MR3
MR4
Input(disk)
RDD1(in memory)
RDD2(in disk)
RDD3(in memory)
Output(disk)
t1 t2 t3 t4

47
We have RDD, than how to “operate” it?

48
# Transformation (can wait)RDD1 => “map” => RDD2
# Action (cannot wait)RDD1 => “reduce” => ??

49
scala> val data = Array(1, 2, 3, 4, 5)data: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val distData = sc.parallelize(data)distData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[5] at parallelize at <console>:23
scala> val addone = distData.map(x => x + 1) // Transformationaddone: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[6] at map at <console>:25
scala> val back = addone.map(x => x - 1) // Transformationback: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[7] at map at <console>:27
scala> val sum = back.reduce( (l, r) => l + r) // Actionsum: Int = 15

50
Passing functions
Object Util {def addOne(x:Int) = {
x + 1}
}
val addone_v1 = distData.map(x => x + 1)
// or
val addone_v2 = distData.map(Util.addOne)

51
Popular Transformations
map(func): run func(x)
filter(func)return x if func(x) is true
sample(withReplacement, fraction, seed)
union(otherDataset)
intersection(otherDataset)

52
Popular Transformations (cont.)
Assuming RDD[(K, V)]
groupByKey([numTasks])return a dataset of (K, Iterable<V>) pairs.
reduceByKey(func, [numTasks])groupByKey and then reduce by “func”
join(otherDataset, [numTasks])(K, V) join (K, W) => (K, (V, W))

53
Popular Actions
reduce(func): (left, right) => func(left, right)
collect()force computing transformations
count()
first()
take(n)
persist()
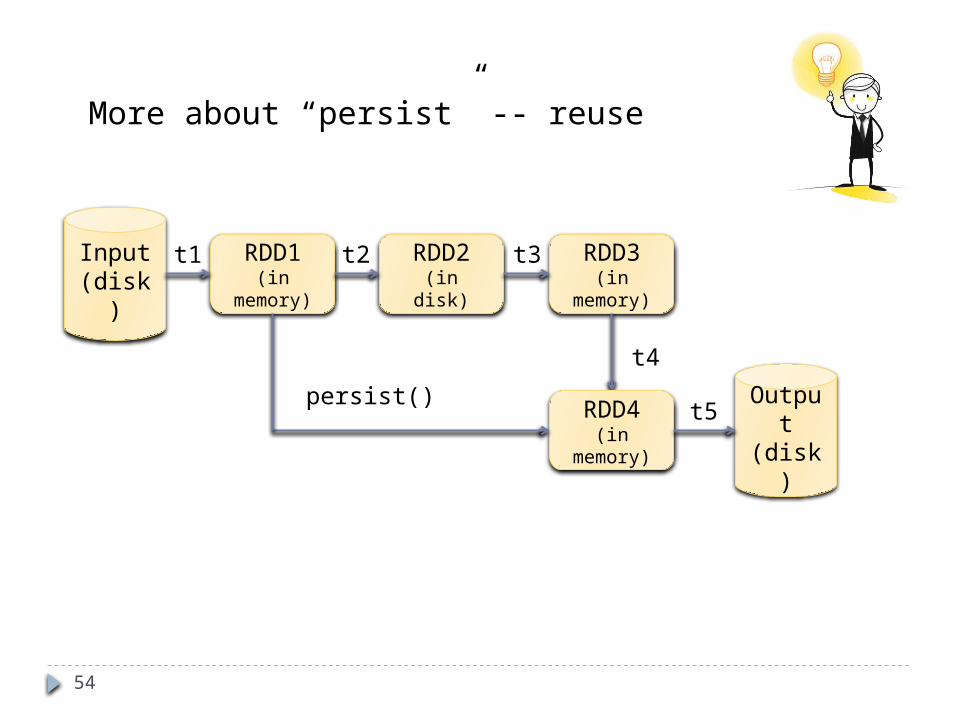
54
More about “persist” -- reuse
Input(disk)
RDD1(in memory)
RDD2(in disk)
RDD3(in memory)
Output(disk)
t1 t2 t3
t4
RDD4(in memory)
persist()t5

55
You are master now.

Journey Continue
56 56

57

58
val file = sc.textFile("wc.txt")val counts = file.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey( (l, r) => l + r)
// Using SQL syntax is possible
import sqlContext.implicits._val sq = new org.apache.spark.sql.SQLContext(sc)
case class WC(word: String, count: Int) val wordcount = counts.map(col => WC(col._1, col._2)) val df = wordcount.toDF()df.registerTempTable("tbl")
val avg = sq.sql("SELECT AVG(count) FROM tbl")

59
Why Spark SQL?

60
Guess what I’m doing here?
// row: (country, city, profit)data .filter( _._1 == “us”)
.map ( (a, b, c) => (b, c))
.groupBy( _._1 )
.mapValues( v =>v.reduce( (a, b) => (a._1, a._2+b._2))
).values.sortBy (x => x._2, false).take(3)

61
sq.sql(”SELECT city, SUM(profit) as pFROM dataWHERE country=‘us’GROUP BY cityORDER BY p DESCLIMIT 3
")
//(country, city, profit)data .filter( _._1 == “us”)
.map ( (a, b, c) => (b, c))
.groupBy( _._1 )
.mapValues( v =>v.reduce( (a, b) =>
(a._1, a._2+b._2))
).values.sortBy (x => x._2,
false).take(3)
Find top 3 cities in US with highest profit
Readability

62
Next

63

64
chsieh@dev-sfear01:~/SparkTutorial$ cat kmeans_data.txt
0.0 0.0 0.00.1 0.1 0.10.5 0.5 0.8
9.0 9.0 9.09.1 9.1 9.19.2 9.2 9.2

65
import org.apache.spark.mllib.clustering.KMeansimport org.apache.spark.mllib.linalg.Vectors
// Load and parse the dataval data = sc.textFile("kmeans_data.txt")val parsedData = data.map(s => Vectors.dense(s.split(' ')
.map(_.toDouble))).cache()
// Cluster the data into two classes using KMeansval numClusters = 2val numIterations = 20val clusters = KMeans.train(
parsedData, numClusters, numIterations)
// Show resultsscala> clusters.clusterCentersres0: Array[org.apache.spark.mllib.linalg.Vector] = Array([9.099999999999998,9.099999999999998,9.099999999999998], [0.19999999999999998,0.19999999999999998,0.3])

66

67

68

PageRank: Random Surfer ModelThe probability of a Web surfer to reach a page after many clicks, following random links
Random Click

70 Credit: http://en.wikipedia.org/wiki/PageRank

PageRank
PR(p) = PR(p1)/c1 + … + PR(pk)/ck
pi : page pointing to p, ci : number of links in pi
One equation for every page N equations, N unknown variables
Credit: Prof. John Cho / CS144 (UCLA)

Users.txt1,BarackObama,Barack Obama2,ladygaga,Goddess of Love3,jeresig,John Resig4,justinbieber,Justin Bieber6,matei_zaharia,Matei Zaharia7,odersky,Martin Odersky8,anonsys
72

followers.txt2 14 11 26 37 37 66 73 7
73

74
// Load the edges as a graphval graph = GraphLoader.edgeListFile(sc, "followers.txt")
// Run PageRankval ranks = graph.pageRank(0.0001).vertices // id, rank
// Join the ranks with the usernamesval users = sc.textFile("users.txt")
.map { line => val fields = line.split(",")
(fields(0).toLong, fields(1)) // id, username
}val ranksByUsername = users.join(ranks).map { case (id, (username, rank)) => (username, rank)}
// Print the resultprintln(ranksByUsername.collect().mkString("\n"))

75