molecular genetics - auburn university of genomic biology page 4 these astute observations allowed...
TRANSCRIPT

Chapter 3. The Beginnings of Genomic Biology –
Molecular Genetics
Contents
3. The beginnings of Genomic Biology – molecular genetics 3.1. DNA is the Genetic Material 3.2. Watson & Crick – The structure of DNA 3.3. Chromosome structure
3.3.1. Prokaryotic chromosome structure 3.3.2. Eukaryotic chromosome structure 3.3.3. Heterochromatin & Euchromatin
3.4. DNA Replication 3.4.1. DNA replication is semiconservative 3.4.2. DNA polymerases 3.4.3. Initiation of replication 3.4.4. DNA replication is semidiscontinuous 3.4.5. DNA replication in Eukaryotes. 3.4.6. Replicating ends of chromosomes
3.5. Transcription 3.5.1. Cellular RNAs are transcribed from DNA 3.5.2. RNA polymerases catalyze transcription 3.5.3. Transcription in Prokaryotes 3.5.4. Transcription in Prokaryotes - Polycistronic mRNAs are
produced from operons 3.5.5. Beyond Operons – Modification of expression in
Prokaryotes 3.5.6. Transcriptions in Eukaryotes 3.5.7. Processing primary transcripts into mature mRNA
3.6. Translation
3.6.1. The Nature of Proteins
3.6.2. The Genetic Code
3.6.3. tRNA – The decoding molecule
3.6.4. Peptides are synthesized on Ribosomes
3.6.5. Translation initiation, elongation, and termnation
3.6.6. Protein Sorting in Eukaryotes
3.7. Regulation of Eukaryotic Gene Expression
3.7.1. Transcriptional Control
3.7.2. Pre-mRNA Processing Control
3.7.3. mRNA Transport from the Nucleus 3.7.4. Translational Control 3.7.5. Protein Processing Control 3.7.6. Degradation of mRNA Control 3.7.7. Protein Degradation Control
3.8. Signaling and Signal Transduction 3.8.1. Types of Cellular Signals 3.8.2. Signal Recognition – Sensing the Environment 3.8.3. Signal transduction – Responding to the Environment

CONCEPTS OF GENOMIC BIOLOGY Page 1
As the development of classical genetics proceeded from Mendel in 1866 through the early part of the 20th century the understanding that Mendel’s factors that produced traits were carried on chromosomes, and that there were infinite ways that the genetic information from 2 parents could assort in each generation to produce the genetic variety demanded by Darwin’s theories on “origin of species” on which natural selection acted. This gave rise to the study of gene behavior of more complex traits and an understanding of genes in populations.
At the same time a quest for the material inside a cell, perhaps a subcomponent of a chromosome, that carried the genetic instructions to make organisms what they are was ongoing.
In 1928, a British scientist, Frederick Griffith, published his work showing that live, rough, avirulent bacteria could be transformed by a “principle” found in dead, smooth, virulent bacteria into smooth, virulent bacteria. This meant that the bacterial traits of rough versus smooth and avirulence versus virulence were controlled by a substance that could carry the phenotype from dead to live cells.
Griffith’s observations on Pneumococcus were controversial to say the least, and inspired a spirited debate and much experimentation directed at proving whether the “transforming principle” was protein or nucleic acid, the two main components of chromosomes identified early in the 20th century, well before Griffith’s experiments. This
debate continued until Oswald Avery and his colleagues, Colin MacLeod, and Maclyn McCarty published their work in 1944 unequivocally showing that DNA was, in fact, Griffith’s transforming principle. This completely
CHAPTER 3. THE BEGINNINGS OF GENOMIC
BIOLOGY – MOLECULAR GENETICS (RETURN)
Frederick Griffith (1879-1941)
3.1. DNA IS THE GENETIC MATERIAL. (RETURN)

CONCEPTS OF GENOMIC BIOLOGY Page 2
revolutionized genetics and is considered the founding observation of molecular genetics.
Oswald T. Avery Colin MacLeod Maclyn McCarty
In 1953, more evidence supporting DNA being the genetic material resulted from the work of Alfred Hershey and Martha Chase on E. coli infected with bacteriophage T2. In their experiment, T2 proteins were labeled with the 35S radioisotope, and T2 DNA was labeled with was labeled with the 32P radioisotope. Then the labeled viruses were mixed separately with the E. coli host, and after a short time, phage attachment was disrupted with a kitchen blender, and the location of the label determined. The 35S-labeled protein was found outside the infected cells, while the 32P-labeled DNA was inside the E. coli, indicating that DNA carried the information needed for viral infection.
Once it was established that DNA was the genetic material carrying the instructions for life so to speak, attention turned to the question of “How could a molecule carry genetic information?” The key to that became obvious with a detailed understanding of the structure of the DNA molecule, which was developed by two scientists a Cambridge University, James Watson and Francis Crick.
Figure 3.1. An electron micrograph of bacteriophage T2 (left), and a sketch showing the structures present in the virus (right). The head consists of a DNA molecule surrounded by proteins, while the core, sheath, and tail fibers are all made of protein. Only the DNA molecule enters the cell.

CONCEPTS OF GENOMIC BIOLOGY Page 3
The basic laboratory observations that lead to the formulation of a structure for DNA did not involve biologists. Rather Irwin Chargaff, an analytical, organic chemist, and physicists, Rosalind Franklin and Maurice Wilkins made the laboratory observations that led to the solution of the structure of DNA.
Chargaff determined that there were 4 different nitrogen bases found in DNA molecules; the purines, adenine (A) and guanine G), and the pyrimidines, cytosine (C) and thymine (T), and he purified DNA from a number of different sources so he could examine the quantitative relationships of A, T, G, and C. He con-cluded that in all DNA molecules, the mole-percentage of A was nearly equal to the mole-percentage of T, while the mole-percentage of G was nearly equal to the mole-percentage of C. Alternatively, you could state this as the mole-percentage of pyri-midine bases equaled the mole-percentage of purine bases. These observations became known as Chargaff’s rules.
Rosalind Franklin a young x-ray crystallographer working in the laboratory of Maurice Wilkins at Cambridge University used a technique known as x-ray diffraction to generate images of DNA molecules that showed that DNA had a helical structure with repeating structural elements every 0.34 nm and every 3.4 nm along the axis of the molecule.
Rosalind Franklin Maurice Wilkins
Figure 3.2. X-ray diffraction image of DNA molecule showing helical structure with repeat structural elements.
3.2. WASON & CRICK – THE STRUCTURE OF DNA. (RETURN)

CONCEPTS OF GENOMIC BIOLOGY Page 4
These astute observations allowed Watson and Crick to synthesize together a 3-dimentional structure of a DNA molecule with all of these essential features. This structure was published in 1953, and immediately generated much excitement, culminating in a Nobel Prize in Physiology and Medicine, in 1962 awarded to Franklin, Wilkins, Watson, and Crick.
The key elements of this structure are:
Double helical structure – each helix is made from the alternating deoxyribose sugar and phosphate groups derived from deoxynuclotides, which are the monomeric units that are used to make up polymeric nucleic acid molecules. Each nucleotide in each chain consists of a nitrogen base of either the purine type (adenine or guanine) or the pyrimidine type (cytosine or thymidine) attached to the 1’-position of 2’-deoxyribose sugar, and a phosphate group, esterified by a phospho-ester bond to the 5’-position of the sugar.
Figure 3.3. Watson & Crick’s DNA structure. Their model consisted of a double helicical structure with the sugars and phosphates making the two hlices on the outside of the structure. The sugars were held together by 3’-5’-phosphodiester bonds. The bases pair on the inside of the molecule with A always pairing with T, and G always pairing with C. This pairing leads to Chargaff’s observations about bases in DNA.
Figure 3.4. Structures of purine and pyrimidine bases in DNA, and structure of 2’-deoxyribose sugar.
CONCEPTS OF GENOMIC BIOLOGY Page 5
Each of the 2 polynucleotide chains of the double helix are held together by hydrogen bonds beween the adenosines in one strand and the thymidines in the other strand, and between the guanosines in one strand hydrogen bonded to the cytosines in the other strand.
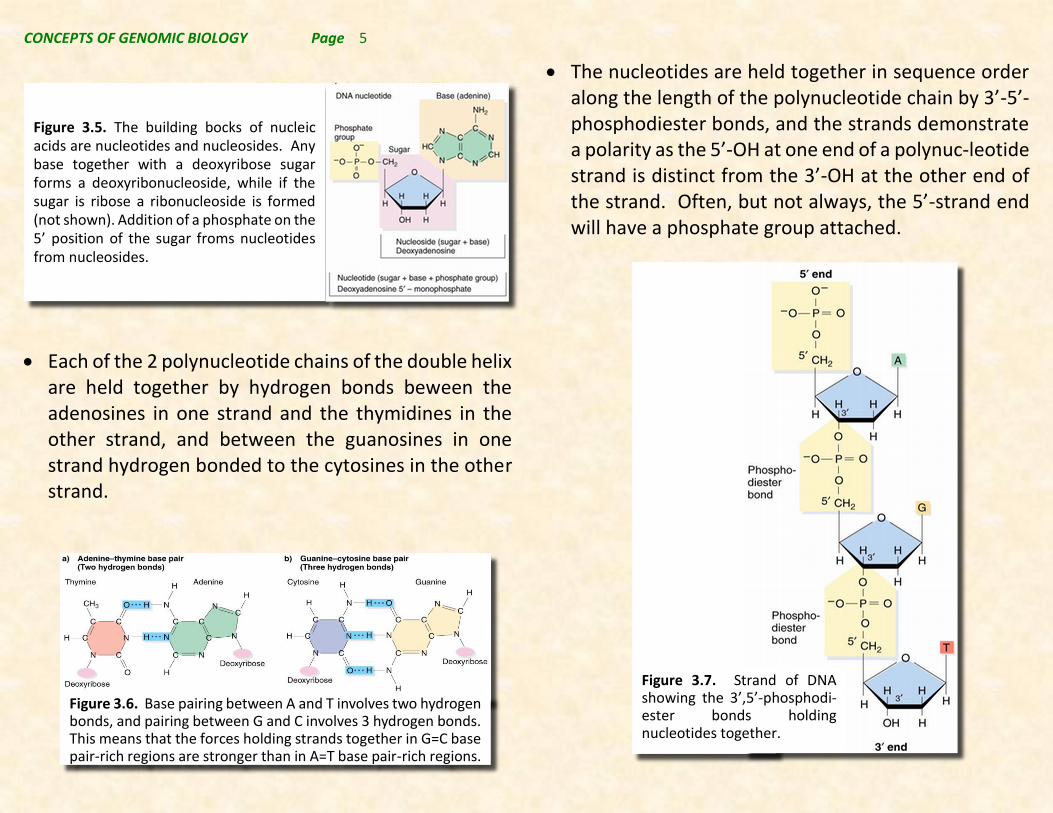
The nucleotides are held together in sequence order along the length of the polynucleotide chain by 3’-5’-phosphodiester bonds, and the strands demonstrate a polarity as the 5’-OH at one end of a polynuc-leotide strand is distinct from the 3’-OH at the other end of the strand. Often, but not always, the 5’-strand end will have a phosphate group attached.
Figure 3.5. The building bocks of nucleic acids are nucleotides and nucleosides. Any base together with a deoxyribose sugar forms a deoxyribonucleoside, while if the sugar is ribose a ribonucleoside is formed (not shown). Addition of a phosphate on the 5’ position of the sugar froms nucleotides from nucleosides.
Figure 3.6. Base pairing between A and T involves two hydrogen bonds, and pairing between G and C involves 3 hydrogen bonds. This means that the forces holding strands together in G=C base pair-rich regions are stronger than in A=T base pair-rich regions.
Figure 3.7. Strand of DNA showing the 3’,5’-phosphodi-ester bonds holding nucleotides together.

CONCEPTS OF GENOMIC BIOLOGY Page 6
In order to get a uniform diameter for the molecule and have proper alignment of the nucleotide pairs in the middle of the strands, the strands must be orient-ed in antiparallel fashion, i.e. with the strand polarity of each strand of the double helix going in the opposite direction (one strand is 3’-> 5’ whie the other is 5’ -> 3’).
The truly elegant aspect of this solution to DNA structure produces a spacing of exactly 0.34 nm between nucleotide base pairs in the molecule, and there are 10 base-pairs per complete turn of the helix. This corresponds precisely with Rosalind Franklin’s x-ray diffraction measurements of repeating units of 0.34 nm and 3.4 nm, and with her measurements of 2 nm for the diameter of the double helix.
It is also noteworthy that Watson and Crick suggested that the structure they proposed produced a clear method for the two strands of the DNA molecule to duplicate and maintain the fidelity of the sequence of bases along each chain as DNA was synthesized inside a cell. Thus, providing a mechanism for the fidelity of information transfer from cell generation to cell generation.

CONCEPTS OF GENOMIC BIOLOGY Page 7
The DNA inside a cell seldom exists as a simple, “naked” DNA molecule. Because DNA molecules are long linear molecules with an overall negative charge deriving from the phosphate groups making up the helices, positively charged ionic species within cells are attracted to these molecules. These positively charged molecules can be small ions such as K+ and Mg++, or they can be larger positively charged proteins, and/or other larger molecular species. These ionic interactions play an important role producing the folding and packaging that is required to keep the large linear molecule packaged inside the microscopic cell.
In the case of proteins it is clear that the positively charged proteins can interact both by general ionic interactions, but they can also ingeract in sequence specific ways; i.e. specific proteins only bind to specific sequences of bases in the DNA strand. Thus, the types of molecular interactions that ionic substances, particularly proteins, have with DNA molecules play important roles in determining the expression of information that is carried in the DNA molecule. It will be obvious as we proceed through our study of genomic biology, that such DNA-protein interactions are as critical to describing “genetic information” as are the base sequences of the
DNA molecules themselves. This was obvious well before we btained the first genomic DNA sequences, but has become even more apparent and significant now that we have the DNA sequences of many genomes. Thus, genomic biology is not merely the study of DNA nucleotide sequences, but involves the study of the structure of the genetic material such as chromosomes and chromatin.
3.3.1. Prokaryotic chromosome structure (return)
Most Prokaryotes (e.g. bacteria) have a single, circular chromosome although some have more than one chromosome, and some have linear chromosomes rather than circular chromosomes. Certainly, the most well studied bacteria, e.g. Escherichia coli, has a single circular chromosome that can exist in either a relaxed or supercoiled state.
Supercoiling involves breaking one of the 2 circular helical strands and then rotating the broken ends either in the direction of the helix (+ supercoil) or in the opposite direction of the helix (- supercoil). As supercoiling is added to the DNA molecule it becomes “tightly” coiled (see Figure 3.8.), and therefore can be compacted more easily. This permits the packaging of the large DNA molecule into the relatively small cells in which it must exist and function.
3.3. CHROMOSOME STRUCTURE. (RETURN)

CONCEPTS OF GENOMIC BIOLOGY Page 8
Additional packaging results from the supercoiled DNA being carefully looped onto a scaffold of proteins leading to an organized intracellular structure that can be easily accessible but also keep DNA from twisting and being damaged du-ring normal cellular processes.
3.3.2. Eukaryotic chromosome structure (return)
In general Eukaryotes have much larger genomes than do Archea and other Prokaryotes. This difference in relative genome size compared to the complexity of the organism does not appear to be as true for species within
the
Eukaryota. This lack of correlation between organismal complexity and genome size (called the C-vlaue) is referred to as the C-value paradox (Table 3.1) The C-value paradox results from great variation in the nature of DNA in different Eukaryotes. Some eukaryotes contain substantial amounts of DNA that appears to have limited or at have a gene density in their genomes resembling the Prokaryotes (e.g. the yeasts and malarial parasite in the table above). The majority of Eukaryotes fall somewhere in between these extremes, but are highly variable in their DNA contents. For now we need to appreciate that this variation in DNA content and type appears to have a relationship to chromosome structure.
Figure 3.9. Diagram of DNA organizational structure in prokaryotes. Supercoiled DNA is looped and attached to scaffold proteins.
Figure 3.8. An E. coli cell lysed open showing the expanse of its DNA molecule (left). Note that this entire molecule must be folded and packaged inside the cell in the picture. On the right are two electron micrographs showing circular DNA molecules either in a relaxed (top) or supercoiled (bottom) state.
CONCEPTS OF GENOMIC BIOLOGY Page 9
But the nature of this relationship will be considered further once we learn more about DNA sequencing and examine fully sequenced genomes.
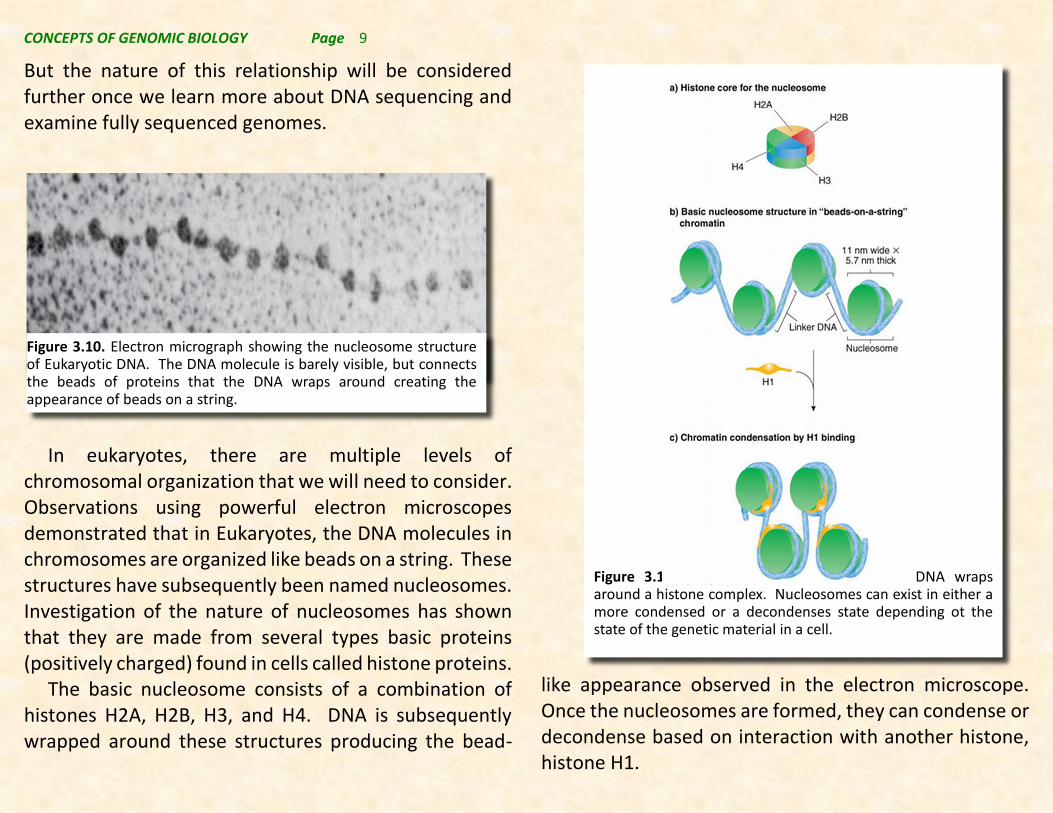
In eukaryotes, there are multiple levels of chromosomal organization that we will need to consider. Observations using powerful electron microscopes demonstrated that in Eukaryotes, the DNA molecules in chromosomes are organized like beads on a string. These structures have subsequently been named nucleosomes. Investigation of the nature of nucleosomes has shown that they are made from several types basic proteins (positively charged) found in cells called histone proteins.
The basic nucleosome consists of a combination of histones H2A, H2B, H3, and H4. DNA is subsequently wrapped around these structures producing the bead-
like appearance observed in the electron microscope. Once the nucleosomes are formed, they can condense or decondense based on interaction with another histone, histone H1.
Figure 3.10. Electron micrograph showing the nucleosome structure of Eukaryotic DNA. The DNA molecule is barely visible, but connects the beads of proteins that the DNA wraps around creating the appearance of beads on a string.
Figure 3.11. Nucleosomes are formed when DNA wraps around a histone complex. Nucleosomes can exist in either a more condensed or a decondenses state depending ot the state of the genetic material in a cell.

CONCEPTS OF GENOMIC BIOLOGY Page 10
During prophase of mitosis or meiosis, the nucleosome structure of chromatin further condenses into a so-called solenoid structure, which is approxim-ately 30 nm in diameter. This solenoid from is not visible in a light microscope but can be viewed in an electron microscope. This appears to be the form DNA assumes when chromosomes condense during during mitosis, but the DNA is not as accessible for use in the cell as it is during interphase, when the chromatin is decondensed.
The solenoid structures are subsequently looped and fastened to chromosome scaffold proteins generating a structure that is visible in a light microscope that we know as a chromosome.
While this may seem like an elaborate structure involving several sets of structural proteins, such a
structure appears to be required to allow for the appropriate assembly and assortment of the genetic material during the cell cycle in mitosis. Without this structural organization, it
is likely that cellular DNA would become a hopeless tangle, and cellular reproduction would be severely hampered, and would likely require too much time and effort to ultimately be successful.
Figure 3.13. Loop-folding of the 30 nm solenoid structure yields a packaged DNA that is visible in a ligh microscope in each Eukaryotic chromosome.
Figure 3.12. Condensation of chromatin leads to the careful packaging of DNA into so called solenoid sturctures. These structures ultimately form chromosomes.

CONCEPTS OF GENOMIC BIOLOGY Page 11
3.3.3. Heterochromatin & Euchromatin. (return)
The cell cycle affects DNA packing into chromatin with chromatin condensing for mitosis and meiosis and then decondensing during interphase while being most dispersed at S-phase. However, cytogeneticists have observed that there can be two differently staining forms of chromatin, called Euchromatin and heterochromatin. Euchromatin condenses and decondenses with the cell cycle. Euchromatin accounts for most of the active genome in dividing cells and bears most of the protein-coding DNA sequences. Heterochromatin remains condensed throughout the cell cycle and is believed to be relatively inactive. There are two types of heterochromatin based on activity, ie. constitutive heterochromatin that is tightly condensed in virtually all cell types and facultative heterochromatin which varies between cell types and/or developmental stages.
Other methods of characterizing types of DNA suggest that there are sequences of DNA that can occur in may copies in the genome. These types of sequences can be repeated only once in the genome or they can occur 10’s of thousans of times or more in genomes. Sequences can be categorized into:
• Unique-sequence DNA, present in one or a few copies per genome.
• Moderately repetitive DNA, present in a few to 105 copies per genome
• Highly repetitive DNA, present in about 105–107 copies per genome
Observations about repetitive DNA sequences as described above have been known for decades, and initially it was shown that Prokaryotic DNA was mostly unique-sequence DNA, and Prokaryotes had little or no repetitive sequences. However, Eukaryotes have a mix of unique and repetitive sequence types of DNA.
• Unique-sequence DNA includes most of the genes that encode proteins, and Euchromatin is rich in unique-sequence DNA.
• Repetitive-sequence DNA includes the moderately and highly repeated sequences. They may be dispersed throughout the genome or clustered in tandem repeats. Heterochromatin is rich in moderate and highly repetitive DNA.
• Human DNA contains about 65% unique sequences while unque sequence DNA makes up a much lower percentage of the genome of organisms that have unexpectedly large genomes (C-values) that were discussed earlier in this section.

CONCEPTS OF GENOMIC BIOLOGY Page 12
As Watson and Crick were solving the structure of DNA, they realized the general mechanism by which the molecule could be copied and maintain fidelity in copying the DNA molecule. From that beginning, interest in understanding the duplication of the DNA molecules of a cell became a subject of investigation, and led to a number of Nobel Prize awards. However, understanding DNA replication was critical to the development of the technologies needed for molecular genetics and ultimately genomic biology research.
3.4.1. DNA Replication is semiconservative. (return)
Among the earliest experiments concerning the nature of how DNA replicates were the studies of Mathew Meselson and Frank Stahl. Meselson, while a Ph.D. student designed an experiment that utilized so called “heavy” isotopes nitrogen. Elemental isotopes consist of atoms having the same number of proton, but with more than the average number of neutrons. For example, nitrogen normally has 7 protons, and 7 neutrons, giving it an atomic mass of 14 (written 14N) but it is possible to find atoms with 7 protons, and 8
neutrons, having an atomic mass of 15 (written as 15N). It turns out that if you grew bacterial cells on a nitrogen source enriched in a 15N enriched nitrogen source, the DNA molecules purified from such cells have a greater density (they are heavier). By synchronizing cells and purifying DNA after each round of DNA replication and then determining the density of the newly made DNA molecules using density gradient centrifugation, Meselson and Stahl were able to show that the first round of DNA synthesis produced molecules having a hybrid density between light and heavy DNA. While after a subsequent round of DNA replication they produced light and hybrid molecules. Such a pattern of 15N labeling
3.4. DNA REPLICATION. (RETURN)
Figure 3.14. Diagram showing the predicted outcome of conservative, semiconservative, and dispersive DNA replication. Original strands are shown in red while newly made DNA is shown in blue.

CONCEPTS OF GENOMIC BIOLOGY Page 13
was consistent only with the semiconservative replication of DNA.
3.4.2. DNA Polymerases. (return)
The enzyme that replicates the DNA double helix is called DNA polymerase. The enzyme is difficult to work with because there are but a few copies of it needed per cell, and then they are required only in S-phase of the cell cycle. In spite of these limitations, Arthur Kornberg, won the Nobel Prize in 1959 for the first purification and characterization of an enzyme that makes DNA. Kornberg’s enzyme was purified from the bacterium E. coli, and beside the enzyme 4 additional components were required to make DNA in a test tube. These factors included a template DNA (Kornberg used E. coli DNA), the four deoxy nucleotide triponosphates (dNTP), i.e. dATP, dGTP, dCTP, and dTTP. Note that these are the deoxy NTP, and not the ribose containing NTP’s. The remaining requirements for DNA polymerase are magnesium ion (Mg++) and a primer single strand of DNA. This primer requirement involves a single strand of DNA that will form a short double-stranded region of DNA. DNA polymerase then adds nucleotides to the free 3’-end of this primer, but without the primer DNA polymerase is unable to make a DNA strand. As the nucleotides are added they are added from the 5’-end to the growing 3’-end of the strand according to the sequence of the
corresponding strand being copied. This copied strand is referred to as the template strand.
All DNA polymerases studied to date make DNA using the general principles established for Kornberg’s enzyme, but there are significant differences between
Figure 3.15. Note that the template strand is read from it’s 3’-end to its 5’-end while the antiparallel, new DNA strand is made from the 5’-end to the 3’-end.

CONCEPTS OF GENOMIC BIOLOGY Page 14
them in other respects. For example, in E. coli there are five different DNA polymerases. Kornberg’s enzyme is now known as DNA polymerase I, but there are also DNA polymerases II, III, IV, and V. DNA polymerases II, IV, and V are not involved in the DNA replication process, and they have specialized functions in repairing damaged DNA under specific circumstances. DNA polymerases I and III are the DNA polymerases involved in the replication of cellular DNA. Both of these DNA polymerases contain a 3’ -> 5’ exonuclease activity that is involved in proof-reading the recently made DNA strand and removing any mistakes that are made. Only DNA polymerase I has a 5’ -> 3’ exonuclease activity and we will visit this function again below when the role of DNA polymerase I in DNA replication is considered.
3.4.3. Initiation of replication. (return)
Replication initiates at a specific sequence in the genome that is often called an origin of replication. E. coli has one origin, called oriC, where replication starts when the strands of the helix are forced apart to expose the bases, creating a replication bubble with two replication forks. Replication is usually bidirectional from the origin using the two forks to enlarge the bubble in both directions. E. coli has one origin, oriC, with the following properties:
A minimal sequence of about 245 bp required for initiation.
Three copies of a 13-bp AT-rich sequence.
Four copies of a 9-bp sequence.
Figure 3.16. Initiation of DNA replication in E. coli. at oriC. Noote the 9 and 13 bp repeats where DNA helicase binds and activates replicatlion throught the action of DNA primase.

CONCEPTS OF GENOMIC BIOLOGY Page 15
From a series of in vitro studies it has been shown in E. coli that the following steps are involved in initiating replication:
1) Initiator proteins attach to oriC (E. coli’s initiator protein is the DnaA protein derived from the dnaA gene.
2) DNA helicase (from dnaB gene) binds initiator proteins on the DNA and denatures the AT-rich 13-bp region using ATP as an energy source.
3) DNA primase (from the dnaG gene) binds helicase to form a primosome, which synthesizes a short (5–10 nt) RNA primer.
3.4.4. DNA Replication is Semidiscontinuous (return)
When DNA denatures (strands separate) at the ori, replication forks are formed. DNA replication is usually bidirectional, but we will consider events at just one replication fork, but don’t forget that a similar set of events are occurring at the other replication fork in the bubble. The events occurring at each fork are:
1) Single-strand DNA-binding proteins (SSBs) bind the ssDNA formed by helicase, preventing reannealing.
2) Primase synthesizes a primer on each template strand.
3) DNA polymerase III adds nucleotides to the 3’-end of the primer, synthesizing a new strand complementary to the template and displacing the SSBs. DNA is made in opposite directions (at each fork) on the two template strands since DNA polymerase only adds nuclotides to the free 3’-end.
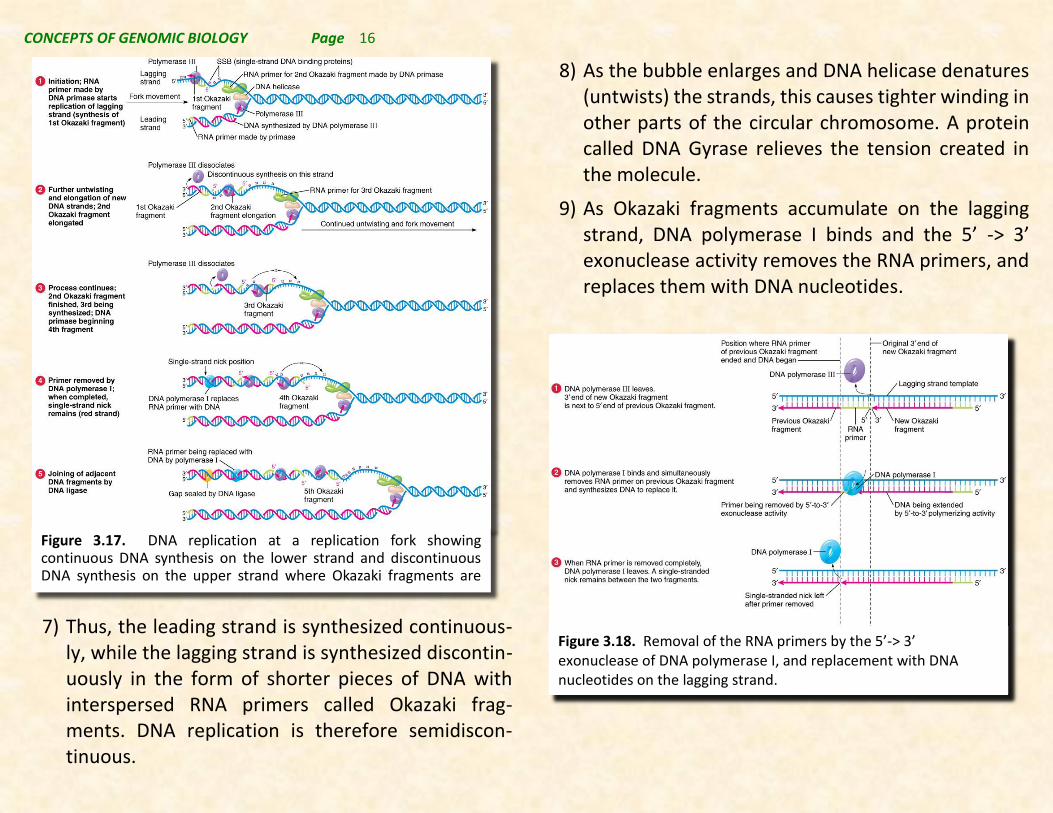
4) The new strand made 5’-to-3’ in the same direction as movement of the replication fork, i.e. DNA polymerase III is continuously moving toward the fork on one strand of the bubble at each fork. This defines the “leading strand”. On the other strand the new strand must be made in the opposite direction as it must be made 5’ -> 3’.
5) This means that on this “lagging strand” primase must add the RNA primer very close to the replication fork, and the DNA polymerase III moves away from the fork rather than toward the fork like it was on the leading strand.
6) The Leading strand needs only one primer and continuously makes the new DNA strand, while on the lagging strand a series of RNA primers are required and only a limited number of DNA nucleotides are added by DNA polymerase III before the previously made fragment is encountered.
CONCEPTS OF GENOMIC BIOLOGY Page 16
7) Thus, the leading strand is synthesized continuous-ly, while the lagging strand is synthesized discontin-uously in the form of shorter pieces of DNA with interspersed RNA primers called Okazaki frag-ments. DNA replication is therefore semidiscon-tinuous.
8) As the bubble enlarges and DNA helicase denatures (untwists) the strands, this causes tighter winding in other parts of the circular chromosome. A protein called DNA Gyrase relieves the tension created in the molecule.
9) As Okazaki fragments accumulate on the lagging strand, DNA polymerase I binds and the 5’ -> 3’ exonuclease activity removes the RNA primers, and replaces them with DNA nucleotides.
Figure 3.17. DNA replication at a replication fork showing continuous DNA synthesis on the lower strand and discontinuous DNA synthesis on the upper strand where Okazaki fragments are produced.
Figure 3.18. Removal of the RNA primers by the 5’-> 3’ exonuclease of DNA polymerase I, and replacement with DNA nucleotides on the lagging strand.

CONCEPTS OF GENOMIC BIOLOGY Page 17
10) The DNA fragments lacking RNA primers are now fastened together using an enzyme called DNA ligase that closes the remaining gaps on the lagging strand.
3.4.5. DNA replication in Eukaryotes. (return)
Enzymes of eukaryotic DNA replication are not as well characterized as their prokaryotic counterparts. Fifteen DNA polymerases are known in mammalian cells, for example. Three DNA polymerases are used to replicate nuclear DNA. Pol_ extends the 10-nt RNA primer by about 30 nt. Pol_ and Pol_ extend the RNA/DNA primers, one the leading strand and the other on the lagging stand, but it is not clear which synthesizes which.
Primer removal differs from that in prokaryotes. Pol_ continues extension of the newer Okazaki fragment, displacing the RNA and producing a flap that is removed
by nucleases, thus allowing the Okazaki fragments to be joined by DNA ligase.
Other DNA polymerases replicate mitochondrial or chloroplast DNA, or they are used in DNA repair. These are all similar to the prokaryotic system described in detail above.
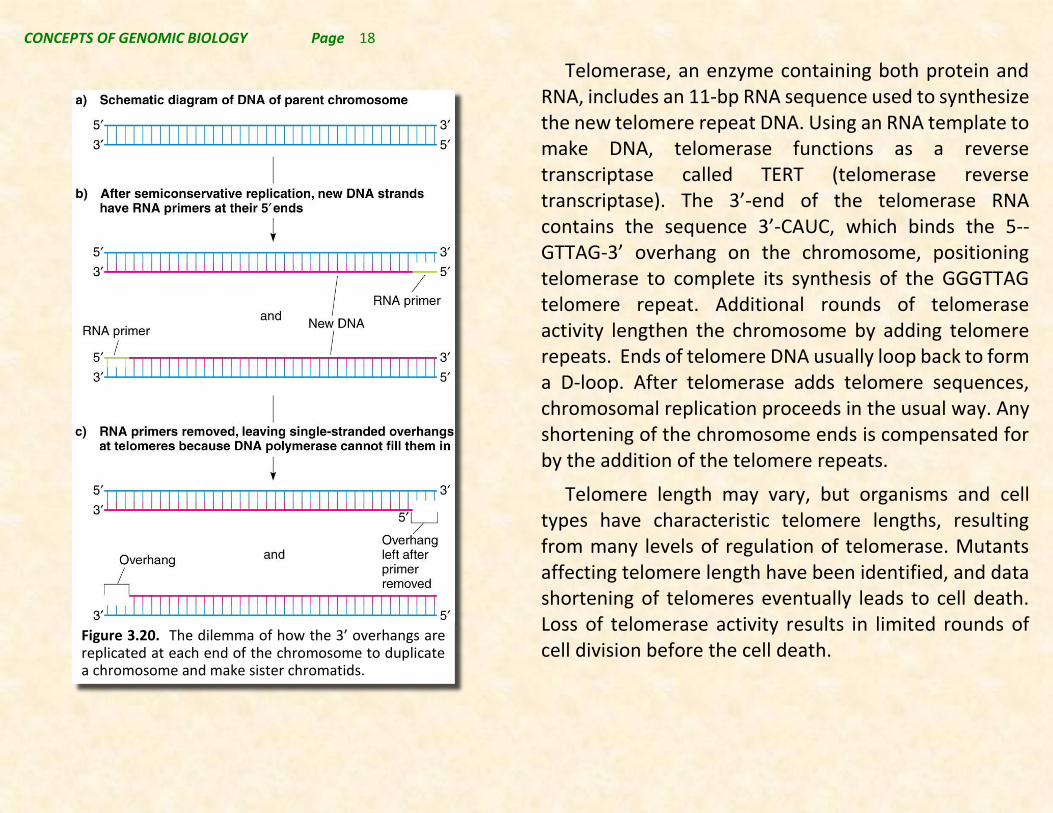
3.4.6. Replicating ends of chromosomes. (return)
Replicating the ends of chromosomes in organisms without circular chromosomes presents unique problems. Removal of primers at the 5’-end of the newly made strand will produce shorter strands that cannot be extended with existing DNA polymerases, and if the gap is not addressed chromosomes would become shorter each time DNA replicates. Thus a new mechanism for the completion of the ends of the chromosome is required. This is accomplished using the telomerase system.
Most eukaryotic chromosomes have short, species-specific sequences tandemly repeated at their telomeres. It has been shown that chromosome lengths are maintained by telomerase, which adds telomere repeats without using the cell’s regular replication machinery. In humans, the telomere repeat sequence is 5’-TTAGGG-3’.
Figure 3.19. DNA ligase joins an opening in a DNA strand remaking acomplete phosphodiester-linked polynucleotide chain.
CONCEPTS OF GENOMIC BIOLOGY Page 18
Telomerase, an enzyme containing both protein and RNA, includes an 11-bp RNA sequence used to synthesize the new telomere repeat DNA. Using an RNA template to make DNA, telomerase functions as a reverse transcriptase called TERT (telomerase reverse transcriptase). The 3’-end of the telomerase RNA contains the sequence 3’-CAUC, which binds the 5--GTTAG-3’ overhang on the chromosome, positioning telomerase to complete its synthesis of the GGGTTAG telomere repeat. Additional rounds of telomerase activity lengthen the chromosome by adding telomere repeats. Ends of telomere DNA usually loop back to form a D-loop. After telomerase adds telomere sequences, chromosomal replication proceeds in the usual way. Any shortening of the chromosome ends is compensated for by the addition of the telomere repeats.
Telomere length may vary, but organisms and cell types have characteristic telomere lengths, resulting from many levels of regulation of telomerase. Mutants affecting telomere length have been identified, and data shortening of telomeres eventually leads to cell death. Loss of telomerase activity results in limited rounds of cell division before the cell death.
Figure 3.20. The dilemma of how the 3’ overhangs are replicated at each end of the chromosome to duplicate a chromosome and make sister chromatids.

CONCEPTS OF GENOMIC BIOLOGY Page 19
Figure 3.21. Replication of chromosome ends using telomerase.

CONCEPTS OF GENOMIC BIOLOGY Page 20
In cells the genetic information carried in the DNA nucleotide sequence becomes functional information that gives characteristics to cells ultimately specifying traits. This conversion of DNA sequence information into functional information begins with the creation of cellular RNAs from one of the two strands of DNA sequence. This process is called transcription. The mechanism by which these cellular RNAs are transcribed from DNAs will be presented in this section while the regulation of these processes will be covered later.
3.5.1. Cellular RNAs are transcribed from DNA (return)
Ribosomal RNAs (return 3.6.4.)
The most abundant type of RNA in most cells is a structural component of the cellular particle that is involved in the synthesis of proteins called a ribosome. Since ribosomes have 2 subunits, a large subunit and a small subunit, they also have two major types of ribosomal RNA. These are described in detail in Table 3.2. In addition to the largest ribosomal RNAs there are additional smaller ribosomal RNAs as well. Note that the size and nature of all of these ribosomal RNAs is different in Prokaryotes and Eukaryotes.
3.5. TRANSCRIPTION. (RETURN) RNAtype Size Species C-value(bp)Prokaryota
RibosomalRNAs(rRNA)
16S 1542nt 30Sribosomalsmallsubunit
23S 2906nt 50Sribosomallargesubunit
5S 120nt 50Sribosomallargesubunit
TransferRNAs(tRNA)
Sizevaries~90nt Locatedaroundthegenome
MessengerRNAs(mRNA)
SizevariesforeachmRNA-proteincodingRNA
Eukaryota
RibosomalRNAs(rRNA)
18s 1869nt 40Sribosomalsmallsubunit
28S 5070nt 60Sribosomalsmallsubunit
5.8S 156nt 60Sribosomalsmallsubunit
5S 121nt 60Sribosomalsmallsubunit
Mitochondria-mammalian
12S 954nt mitochondrialsmallribomalsubunit
16S 1558nt mitochondriallargeribosomalsubunit
Mitochondria-plants
16S 1934nt mitochondrialsmallribomalsubunit
26S 2567nt mitochondriallargeribosomalsubunit
5S 117nt mitochondriallargeribosomalsubunit
Chloroplast-greenplant
16S 1490nt chloroplastsmallribosomalsubunit
23S 2809nt chloroplastlargeribosomalsubunit
5S 120nt chloroplastlargeribosomalsubunit
TransferRNAs(tRNA)
Sizevaries~90nt Nuclear,chloroplast,&mitochondrialgenomes
MessengerRNAs(mRNA)
SizevariesforeachmRNA-proteincodingRNA
SmallNuclearRNA(snRNA)
~150nt Functionsinposttranscriptionalprocessing
SmallnucleolarRNA(snoRNA)
35-150nt VariousfunctionsassociatedwithrRNAs
SmallregulatoryRNAs(miRNA,siRNA,piwiRNA,etal)
20-30nt
-transcriptionallyandposttranscriptionally
TABLE3.2.
TranscribedRNAsfromProkaryotesandEukaryotes
Variousregulatoryfunctions-

CONCEPTS OF GENOMIC BIOLOGY Page 21
In prokaryotes a small 30S ribosomal subunit contains the 16S ribosomal RNA. The large 50S ribosomal subunit contains two rRNA species (the 5S and 23S ribosomal RNAs). Bacterial 16S ribosomal RNA, 23S ribosomal RNA, and 5S rRNA genes are typically organized as a co-transcribed unit (operon). There may be one or more copies of the operon dispersed in the genome (for example, Escherichia coli has seven). Archaea contains either a single rDNA operon or multiple copies of the operon.
In Eukaryotes, the cytoplasmic small ribosomal subunit (40S) contains an 18S rRNA while the large ribosomal subunit (60S contains a 28S, 5S, and 5.8S rRNA. As in Prokaryotes these rRNAs are structural components of ribosomes where they perform essential function. In mammals, the 28S, 5.8S, and 18S rRNAs are encoded by a single nuclear transcription unit (45S). Two internally transcribed spacers separate the 3 rRNA species in the 45S transcript. Generally, there are many copies of the 45S rDNAs organized clusters throughout the nuclear genome. In humans, for example, each cluster has 300-400 repeats. 5S rDNA is not made as part of the 45S transcript, but occurs in tandem arrays (~200-300 5S genes) interspersed in the mammalian genome independently of the 45S rDNA genes.
Mammalian mitochondria have only two mitochondrial rRNA molecules (12S and 16S) but do not contain 5S rRNA. The ribosomal RNAs are transcribed from the mitochondrial genome. This is also the case for plant mitochondrial rRNAs although plants contain a more prokaryotic like ribosomal RNAs, i.e. a 16S, a 26S, and a 5S rRNA. Plants also contain chloroplast ribosomal RNAs (16S, 23S, and 5S) produced by transcription from the chloroplast genome.
Messenger RNAs – mRNAs
All organisms (and mitochondria and chloroplasts) produce a type of RNA that codes for the amino acid sequence of proteins. This RNA is a copy of the DNA sequence of the gene and is transcribed from one of the two DNA strands of each gene. By reproducing the DNA sequence as an mRNA copy the sequence information for the gene is faithfully maintained allowing the generation of many gene “copies” that can be used to produce even more protein copies from each gene.
Transfer RNAs - tRNA (return 3.6.3.)
Transfer RNAs (tRNAs) are smaller (~90 nt) RNA molecules that are transcribed from genes scattered throughout both Prokaryotic and Eukaryotic genomes, including mitochondrial and chloroplast genomes. These molecules are the “decoding” molecules that determine which amino acids are put in proteins in the order

CONCEPTS OF GENOMIC BIOLOGY Page 22
specified by the nucleotide sequence in the mRNA. They are highly structured RNA molecules, and there is at least one, often several, tRNA for each of the twenty protein-contained amino acids. Each tRNA is processed from a transcribed precursor-tRNA molecule coded for by specific tRNA genes, and typically there is but one tRNA produced per tRNA gene.
In Eukaryotes tRNA are scattered across all chromosomes, and there are separate sets of tRNA genes in each of the organelle genomes present in eukaryotes.
Other Non-protein-coding Transcribed RNAs
More recently additional types of RNAs that perform vital functions in cells have been described. Most of these have been described in Eukaryotes once we described and characterized genomes of Eukaryotes.
Small nuclear RNAs (snRNA) are smaller RNAs (typically ~ 150 nt) transcribed from nuclear DNA in eukaryotic cells. snRNAs are structurally part of small nuclear ribonucleoprotein particles (snRNPs) that are involved in processing mRNAs in the nucleus of cells. Typically there are but a handful of different snRNAs made in each species and these are highly conserved among eukaryotes.
Small nucleolar RNAs (snoRNAs) are a class of small RNA molecules that function to guide modification of other types of RNA, mostly rRNA, tRNA, and snRNA. One
of the main functions of snoRNAs involves modification of the 45S ribosomal precursor so that it can be futher processes to generate the 18S, 5.8S, and 28S rRNAs.
Small regulatory RNAs are found in prokaryotes where they are involved in the regulation of gene expression, but mostly they are known for the role they play in transcriptional, posttranscriptional and translational control of gene expression in Eukaryotes. These molecules are an array of 20-30 nt RNAs transcribed in various ways from genes in the genomes of organisms. Note that although there are primarily 2 types of srRNAs, microRNAs (miRNA) and short interfering RNA (siRNA) these types are specific to certain organisms and there are likely thousands of genes transcribed for such srRNAs.
3.5.2. RNA polymerases catalyze transcription (return)
RNA polymerase is the enzyme responsible for copying a DNA sequence into an RNA sequence, during the process of transcription. As complex molecule composed of protein subunits, RNA polymerase controls the process of transcription, during which the information stored in a molecule of DNA is copied into a molecule of cellular RNA.
The detailed mechanism of how RNA polymerase works is shown in Figure 3.22.

CONCEPTS OF GENOMIC BIOLOGY Page 23
Multisubunit RNA polymerases exist in all species, but the number and composition of these proteins vary across taxa. For instance, bacteria contain a single type of RNA polymerase that transcribes mRNA, tRNA, and all rRNAs. Eukaryotes contain three (animals and fungi) to five (plants) distinct types of RNA polymerases. Each of
these RNA polymerases transcribes different species of RNA as shown in Table 3.3.
In spite of these differences, there are striking similarities among transcriptional mechanisms for all
RNAtype RNAPolymerasetypeRibosomalRNAs(rRNA)
18s RNApolymeraseI
28S RNApolymeraseI
5.8S RNApolymeraseI
5S RNApolymeraseIII
Mitochondria-mammalian
12S mitochondrialRNApolymerase
16S mitochondrialRNApolymerase
Chloroplast-greenplant
16S chloroplastRNApolymerase
23S chloroplastRNApolymerase
5S chloroplastRNApolymerase
TransferRNAs(tRNA)
All RNApolymeraseIII
MessengerRNAs(mRNA)
Nuclear RNApolymeraseII
SmallNuclearRNA(snRNA)
Most RNApolymeraseII
Remainder RNApolymeraseIII
SmallnucleolarRNA(snoRNA)
RNApolymeraseIII
SmallregulatoryRNAs(miRNA,siRNA,piwiRNA,etal)
miRNA RNApolymeraseII
siRNA plantRNApolymeraseIV/V
Mammals-RNAPolymeraseII
TABLE3.3.
RNAstranscribedbyEukaryoticRNApolymerases
Figure 3.22. The chemical reaction catalyzed by RNA polymerases showing both the reactants and products and the specificity of base pair addition. Note the antiparallel nature of the RNA strand to the DNA strand being transcribed. RNA polymerase makes a phosphodiester bond between the 5’-phosphate group closest to the ribose sugar and the 3’-OH on the 3’-end of the growing strand of RNA.

CONCEPTS OF GENOMIC BIOLOGY Page 24
RNA polymerases. For example, transcription is divided into three steps for both bacteria and eukaryotes. They are initiation, elongation, and termination. The process of elongation is highly conserved between bacteria and eukaryotes, but initiation and termination are somewhat different.
All species require a mechanism by which transcription can be regulated in order to achieve spatial and temporal changes in gene expression. Proteins that interact with the core RNA polymerase, and that recognize specific sequences in the DNA mediate these initial regulatory steps during transcription initiation. However the types and nature of these interacting proteins are quite distinct in Prokaryotes compared to Eukaryotes. This leads to a discussion of how transcription initiation at each gene locus takes place in both Prokaryotes and Eukaryotes.
3.5.3. Transcription in Prokaryotes (return)
For a model of Prokaryotic gene regulation, the bacterium, Escherichia coli, will be used as a model. This model is similar to nearly all Prokaryotes.
A prokaryotic gene is a DNA sequence in the chromosome. The gene has three regions, each with a function in transcription (see Figure 3.23.). These are:
1) A promoter sequence that attracts RNA polymerase to begin transcription at a site specified by the promoter. Some genes use one strand of DNA as the template; other genes use the other strand.
2) The transcribed sequence, called the RNA-coding sequence. The sequence of this DNA corresponds with the RNA sequence of the transcript.
3) A terminator region that specifies where trans-cription will stop.
The process of transcription initiation in E. coli is shown in Figure 3.24. The process involves two DNA sequences centered at -35 bp and -10 bp upstream
Figure 3.23. Prokaryotic genes all have promoter regions upstream (toward the 5’-end of the mRNA) of the protein coding gene and terminator regions downstream (toward the 3’-end of the mRNA). These regions are located at the 3’-end (promoter) and the 5’-end (terminator) of the template strand of DNA. Typically the nucleotide where RNA polymerase begins transcribing is designaed the +1 nucleotide position, and sequences in the promoter are designated as (-) nt positions.

CONCEPTS OF GENOMIC BIOLOGY Page 25
from the +1 start site of transcription in the promoter region of the gene. These two consensus sequences (in E. coli) are 5’-TTGACA-3’ at the -35 nt region and 5’-TATAAT-3’ at the -10 region (previously known as a Pribnow box, but they can vary according to the organism and gene within the organism.
Transcription initiation requires the RNA polymerase holoenzyme (only one type is found in bacteria) to bind to the promoter DNA sequence. Holoenzyme consists of:
1) Core enzyme of RNA polymerase, containing five polypeptides (two alpha, one beta, one beta’ and
an omega; written as 2’).
2) One of several sigma factors (-factor) that binds the core enzyme and confers ability to recognize specific gene promoters.
RNA polymerase holoenzyme binds promoter in two steps (Figure 3.24) that involve the sigma factor. First, it loosely binds to the -35 sequence of dsDNA closed promoter complex (Figure 3.24a). Second, it binds tightly to the -10 sequence (Figure 3.24b), untwisting about 17 bp of DNA at the site. At this point RNA polymerase is in position to begin transcription (open promoter complex).
Promoters often deviate from consensus the consensus sequences at -35 and -10, and the associated genes will show different levels of transcription,
corresponding with -factor’s ability to recognize their
a)
b)
c)
d)
Figure 3.24. Prokaryotic (E. coli) transcription initiation. a) RNA Polymerase holoenzyme is “recruited to the promoter by a specific -factor (sigma factor); b) strands of the DNA are separated exposing the sense strand for copying; d) nucleotides are polymerized as RNA polymerase moves down the strand, and -factor leaves the complex as; d) elongation continues, the newly made mRNA exits the enzyme, and the transcription “bubble” moves further down the DNA template.

CONCEPTS OF GENOMIC BIOLOGY Page 26
sequences. E. coli has several sigma factors with important roles in gene regulation. Each sigma can bind a molecule of core RNA polymerase and guide its choice of genes to transcribe, but has different affinity for specific promoters.
Most E. coli genes have a 70 promoter, and 70 is
usually the most abundant -factor in the cell. 70 recognizes the sequence TTGACA at -35, and TATAAT at -10. Other sigma factors may be produced in response to changing conditions, and each can bind the core RNA polymerase, enabling holoenzyme to recognize different
promoters. An example is 32, which arises in response to heat shock and other forms of stress and recognizes a sequence at -39 bp and -15 bp. E. coli has additional sigma factors with various roles (Table 3.4), and other bacterial species also have multiple similar and additional sigma factors.
Many bacterial genes are controlled by regulatory proteins that interact with regulatory sequences near the promoter. There are two classes of regulatory proteins, i.e. activators that stimulate transcription by facilitating RNA polymerase activity, and repressors that inhibit transcription by decreasing RNA polymerase binding or elongation of RNA.
Once initiation is completed, RNA synthesis begins, and the sigma factor is released and reused for other
TABLE 3.4.
E. coli -factors and their function s-factors Function
_70 (rpoD) = _A the "housekeeping" sigma factor or also called as primary sigma factor, transcribes most genes in growing cells. Every cell has a “housekeeping” sigma
_19 (fecI) the ferric citrate sigma factor, regulates the fec gene for iron transport
_24 (rpoE) the extracytoplasmic/extreme heat stress sigma factor
_28 (rpoF) the flagellar sigma factor _32 (rpoH) the heat shock sigma factor; it is turned
on when the bacteria are exposed to heat. Due to the higher expression, the factor will bind with a high probability to the polymerase-core-enzyme. Doing so, other heatshock proteins are expressed, which enable the cell to survive higher temperatures. Some of the enzymes that are expressed upon activation of _32 are chaperones, proteases and DNA-repair enzymes.
_38 (rpoS) the starvation/stationary phase sigma factor
_54 (rpoN) the nitrogen-limitation sigma factor

CONCEPTS OF GENOMIC BIOLOGY Page 27
initiations (Figure 3.24c). Core enzyme completes the transcript. Core enzyme untwists DNA helix locally, allowing a small region to denature. Newly synthesized RNA forms an RNA–DNA hybrid, but most of the transcript is displaced as the DNA helix reforms (Figure 3.24d).
Terminator sequences are used to end transcription. In E. coli there are two types of transcript termination:
1) Rho-independent (-independent) or type I terminators (Figure 3.25, upper) have twofold symmetry that would allow a hairpin loop to form (Figure 3.25). The palindrome is followed by 4–8 U residues in the transcript, and when these sequences are transcribed, they form a stem-loop structure and cause chain termination.
2) Rho-dependent (-dependent) or type II terminators (Figure 3.25, lower) require the protein
for termination. Rho binds to the C-rich sequence in the RNA upsteam of the termination site and moves with the transcript until encountering a stalled polymerase. It then acts as a helicase, using ATP hydrolysis for energy to move along the transcript and destabilize the RNA–DNA hybrid at the termination region, terminating transcription.
3.5.4. Transcription in Prokaryotes – polycistronic mRNAs from operons (return)
While we have considered the structure of a prokaryotic gene as having a promoter, a coding region, and a termination region (see Figure 3.23), in most cases multiple protein-coding regions are under the control of a single promoter. This genetic structure is referred to as an operon, and the mRNA transcribed from each operon is in fact an RNA capable of producing multiple peptides. This type of mRNA, typical of prokaryotes, and Eukaryotic mitochondria and chloroplasts, is referred to as a
Figure 3.25. Simplified schematics of the mechanisms of prokaryotic transcriptional termination. In Rho-independent termination, a terminating hairpin forms on the nascent mRNA interacting with the NusA protein to stimulate release of the transcript from the RNA polymerase complex (top). In Rho-dependent termination, the Rho protein binds at the upstream rut site, translocates down the mRNA, and interacts with the RNA polymerase complex to stimulate release of the transcript.

CONCEPTS OF GENOMIC BIOLOGY Page 28
polycistronic mRNA. Thus, the proteins binding to promoter and regulatory regions of genomes that regulate gene expression in prokaryotes regulate the production of multiple peptides simultaneously. Typically, these peptides are functionally related, e.g. the proteins required to catabolize lactose as a carbon source [lac operon] (see Figure 3.26.), or the proteins required to make the amino acid tryptophan [trp operon] (see Figure 3.27.).
The lac operon is an example of an inducible (positively regulated) operon. The repressor protein does not bind to the operator and stop transcription in the presence of the effector (lactose), while the tryptophan operon is an example of a repressible (netatively regulated) operon. The repressor protein only binds to the operator in the presence of the effector molecule (tryptophan). Thus, using the similar types of regulatory proteins and genes, and similar operon structure almost any type of gene regulation can be obtained.
Additionally, it should be noted that the proteins for related critical cellular functions can be coordinately regulated as a consequence of the production of polycistronic mRNAs.
Figure 3.26. The lac operon in E. coli. Three lactose metabolism genes (lacZ, lacY, and lacA) are organized together in a cluster called the lac operon. The coordinated transcription and translation of the lac operon structural genes is controlled by a shared promoter, operator, and terminator. A lac regulator gene (lacI) with its separate promoter is found just outside the lac operon. The lacI gene produces a regulatory protein, the lac repressor protein that binds to the “inducer”, which is lactose (or a derivative, allolactose) when it is present in a cell. The lacI protein also can bind to a region of the operon between the lac promoter and the structural genes referred to as the lac operator (lacO). In the absence of lactose (allolactose) the lacI protein tightly binds to the operator and prevents RNA polymerase from transcribing the polycistronic mRNA. When lactose binds to the lacI protein, the lacI protein cannot bind to the lacO gene, and RNA polymerase proceeds to produce the polycistronic mRNA corresponding to the lacZ, lacY, and lacA genes. © 2013 Nature Education Adapted from Pierce, Benjamin. Genetics: A Conceptual Approach, 2nd
ed. All rights reserved.
CONCEPTS OF GENOMIC BIOLOGY Page 29
3.5.5. Beyond Operons - Modification of expression of prokaryotic genes (return)
Additional regulation of operons is often used to produce further fine-tuning of transcription. This can vary with each operon in Prokaryotic genomes. A common type of additional regulation has been shown for the lac operon and many other catabolic operons. Glucose is the preferred carbon source in E. coli. In the presence of glucose, lactose will not be utilized. This means that if an abundant supply of glucose and lactose are both available, the lac operon will not be induced until the glucose is used up. This phenomenon is often referred to as catabolite repression, and the critical components of catabolite repression in the lac operon are shown in Figure 3.28.
When the concentration of intracellular glucose is low (Figure 3.28, upper panel) the levels of the signal molecule cAMP are high, and cAMP binds to CAP protein. The association between RNA polymerase and promoter DNA is enhanced when the CAP-cAMP complex is present. Enhanced RNA polymerase binding leads to a high rate of transcription (provided that the operator is free) and translation of the lac operon polycistronic mRNA. The resulting mRNA transcripts are translated into the enzymes beta-galactosidase, permease, and transacetylase, and these enzymes are
A
B
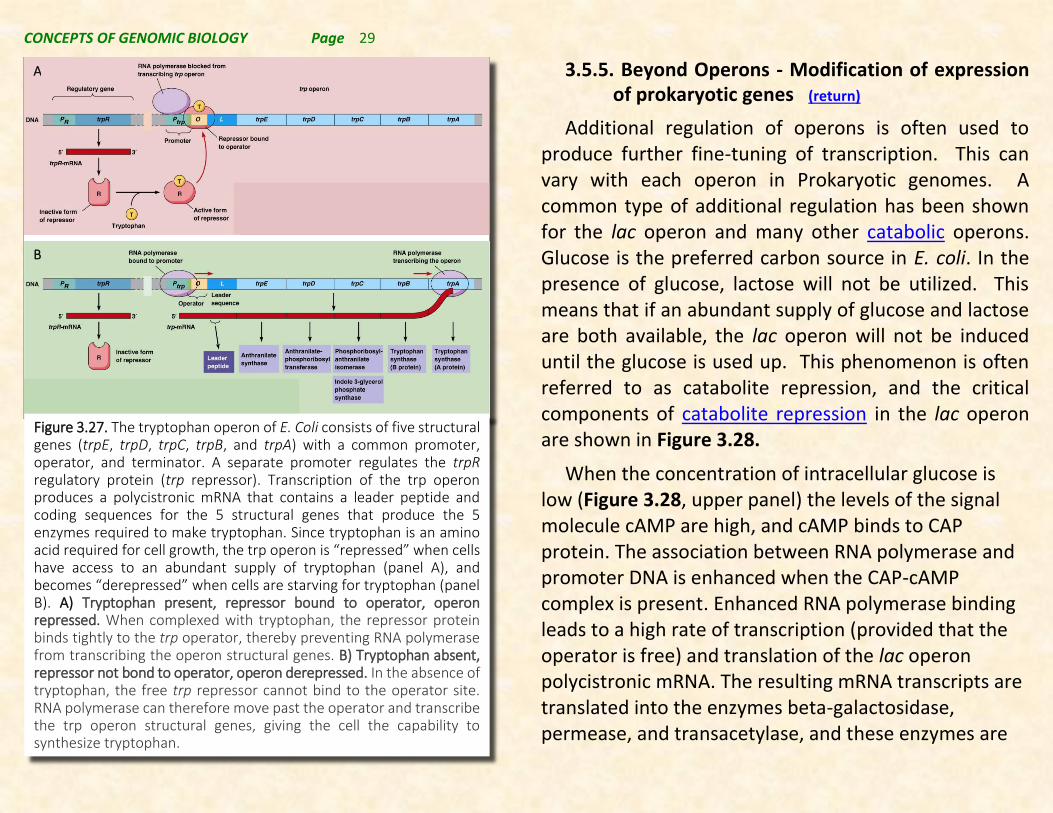
Figure 3.27. The tryptophan operon of E. Coli consists of five structural genes (trpE, trpD, trpC, trpB, and trpA) with a common promoter, operator, and terminator. A separate promoter regulates the trpR regulatory protein (trp repressor). Transcription of the trp operon produces a polycistronic mRNA that contains a leader peptide and coding sequences for the 5 structural genes that produce the 5 enzymes required to make tryptophan. Since tryptophan is an amino acid required for cell growth, the trp operon is “repressed” when cells have access to an abundant supply of tryptophan (panel A), and becomes “derepressed” when cells are starving for tryptophan (panel B). A) Tryptophan present, repressor bound to operator, operon repressed. When complexed with tryptophan, the repressor protein binds tightly to the trp operator, thereby preventing RNA polymerase from transcribing the operon structural genes. B) Tryptophan absent, repressor not bond to operator, operon derepressed. In the absence of tryptophan, the free trp repressor cannot bind to the operator site. RNA polymerase can therefore move past the operator and transcribe the trp operon structural genes, giving the cell the capability to synthesize tryptophan.

CONCEPTS OF GENOMIC BIOLOGY Page 30
used to break down lactose into glucose and Galactose. The latter can subsequently be converted into glucose.
When the glucose concentration in the cell is high (Figure 3.28, lower panel), low concentrations of cAMP result in decreased binding of cAMP to CAP. Therefore, the cAMP-CAP complex is not bound to the bacterial DNA, and as a result, neither is RNA polymerase. This lowers the rate of transcription and polycistronic mRNA production is decreased for the lacZ, lacY, and lacA genes. The absence of these proteins reduces glucose production from lactose, leading to the use of the available glucose prior to the use of any lactose.
The interaction of CAP with DNA and with cAMP directly regulates the production of mRNA. Some type of interaction of proteins with regulatory regions in the DNA mediates the phenomenon of catabolite repression in operons associated with carbon source utilization in prokaryotes.
In anabolic operons (typical of amino acid synthesis), a phenomenon of additional regultation referred to as attenuation has been documented. The example most commonly considered involves the trp operon discussed above.
The leader sequence in the polycistronic mRNA of the trp operon contains several trp codons, and can form 3 different stem-loop structures. Depending on the
Figure 3.28. Diagram showing the major effects of low glucose (upper panel) and high glucose (lower panel) on the expression of lac operon genes. © 2013 Nature Education Adapted from Pierce, Benjamin. Genetics: A Conceptual Approach, 2nd ed. (New York: W. H. Freeman and Company), 446. All rights reserved.

CONCEPTS OF GENOMIC BIOLOGY Page 31
amount of available tryptophan, one of two structures can be produced (Figure 3.29) One structure leads to termination of transcription in the leader sequence when
trp is abundant. While the other structure does not terminate transcription, and the polycistronic mRNA is produced.
Several amino acid synthetic operons (e.g. phenyl-alanine, histidine, leucine, threonine, and isoleucine-valine) demonstrate this same type of attenuation. Consequently, this mechanism is relatively widespread as a means of modulating and fine-tuning pathways for amino acid biosynthesis.
3.5.6. Transcription in Eukaryotes (return)
Although transcription in Eukaryotes follows the general principles outlined above for Prokaryotes, there are many specific details that are different. Recall that there are as many as five Eukaryotic RNA polymerases. While each of these transcribes different types of RNA, they are all Multisubunit RNA polymerases that function in related ways. The mechanism of the important RNA polymerase II that produces mRNAs will be described here, but each of the 5 has similar mechanisms for initiation, elongation, and termination of transcription.
Eukaryotic mRNAs are nearly always monocistronic mRNAs with a general structure as shown in Figure 3.30. The key transcribed features are a 5’-UTR (untranslated region), a coding region, and 3’-UTR. Other non-trans-cribed features that are typical of mRNAs in
Figure 3.29. Attenuation of the trp operon. The diagram at the center shows the general folding of the leader sequence of the trp polycistronic mRNA and labeling of strands. The mRNA is folded in four parallel strands connected at the bottom by two small hairpin loops between strands 1 and 2 and strands 3 and 4 and by one large hairpin loop at the top between strands 2 and 3. In the structure on the left, strands 1 and 2 and strands 3 and 4 are stabilized by base pairing. This structure terminates transcription of the trp operon in the presence of high tryptophan. In contrast, strands 2 and 3 are stabilized by base pairing in the structure on the right, which allows transcription of the trp operon to continue in the presence of low tryptophan. © 1981 Nature Publishing Group Yanofsky, C. Attenuation in the control of expression of bacterial operons. Nature 289, 753 (1981). All rights reserved.

CONCEPTS OF GENOMIC BIOLOGY Page 32
Eukaryotic cells include a 5’-Cap structure and a poly-A tail that will be described in more detail below.
Promoters in many Eukaryotes have been analyzed either by the use of directed mutations within promoter sequences or by comparative analysis of multiple genes from different organisms. These studies have revealed that there are two types of elements found in Eukaryotic promoters, core promoter elements and promoter proximal elements.
Core promoter elements are located near the transcription start site and specify where transcription begins. Examples include:
1) The initiator element (Inr), a pyrimidine-rich A that spans the transcription start site;
2) The TATA box (also known as a TATA element or Goldberg–Hogness box) at -30 nt (full sequence is TATAAAA). This element aids in local DNA denaturation and sets the start point for transcription.
Promoter-proximal elements are required for high levels of transcription. They are further upstream from the start site, at positions between -50 and -200. These elements generally function in either orientation. Examples include:
1) The CAAT box, located at about -75. 2) The GC box, consensus sequence GGGCGG, located
at about -90.
Various combinations of core and proximal elements are found near different genes. Promoter-proximal elements are key to understanding the rate at which transcription initiation occurs and thus the level of gene expression.
Eukaryotic Transcription initiation requires assembly of RNA polymerase II and binding of general transcription factors (GTFs) on the core promoter at the TATA box (see
AAAAAA
G7-Me
AAAAAA
G7-Me
AAAAAA
5’ 3’
upstream Enhancers Promoter
TATA box 5’ UTR 3’ UTR
DNA
Coding Region
Exon 1 Exon 2 Exon 3
Intron 1 Intron 2
5’ Cap 3’ Poly-A tail
Primary Transcript
Pre-mRNA
Final mRNA
Gene Transcription by RNA Polymerase II
Nuclear Processing – 5’ Capping & poly-A tail addition
Nuclear Processing – Intron removal & transport to the cytoplasm
5’ UTR 3’ UTR Protein Coding Region 5’ Cap 3’ Poly-A tail
Figure 3.30. Diagram showing the elements and structure of a typical eukaryotic mRNA-producing gene. Note that a primary transcript is produced which is subsequently modified by the addition of a 7-methyl guanosine (Cap), and the poly-A tail. Subsequently, introns are spiced from the transcript to make a finished mRNA ready to exit the nucleus.
CONCEPTS OF GENOMIC BIOLOGY Page 33
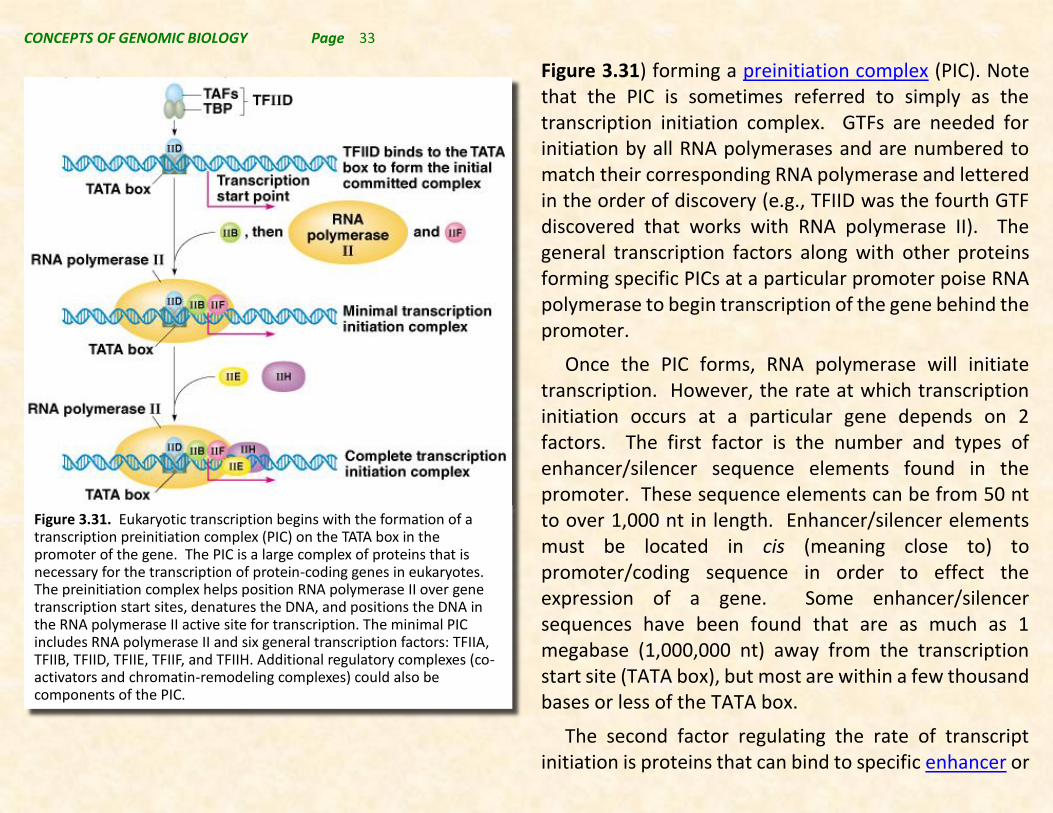
Figure 3.31) forming a preinitiation complex (PIC). Note that the PIC is sometimes referred to simply as the transcription initiation complex. GTFs are needed for initiation by all RNA polymerases and are numbered to match their corresponding RNA polymerase and lettered in the order of discovery (e.g., TFIID was the fourth GTF discovered that works with RNA polymerase II). The general transcription factors along with other proteins forming specific PICs at a particular promoter poise RNA polymerase to begin transcription of the gene behind the promoter.
Once the PIC forms, RNA polymerase will initiate transcription. However, the rate at which transcription initiation occurs at a particular gene depends on 2 factors. The first factor is the number and types of enhancer/silencer sequence elements found in the promoter. These sequence elements can be from 50 nt to over 1,000 nt in length. Enhancer/silencer elements must be located in cis (meaning close to) to promoter/coding sequence in order to effect the expression of a gene. Some enhancer/silencer sequences have been found that are as much as 1 megabase (1,000,000 nt) away from the transcription start site (TATA box), but most are within a few thousand bases or less of the TATA box.
The second factor regulating the rate of transcript initiation is proteins that can bind to specific enhancer or
Figure 3.31. Eukaryotic transcription begins with the formation of a transcription preinitiation complex (PIC) on the TATA box in the promoter of the gene. The PIC is a large complex of proteins that is necessary for the transcription of protein-coding genes in eukaryotes. The preinitiation complex helps position RNA polymerase II over gene transcription start sites, denatures the DNA, and positions the DNA in the RNA polymerase II active site for transcription. The minimal PIC includes RNA polymerase II and six general transcription factors: TFIIA, TFIIB, TFIID, TFIIE, TFIIF, and TFIIH. Additional regulatory complexes (co-activators and chromatin-remodeling complexes) could also be components of the PIC.

CONCEPTS OF GENOMIC BIOLOGY Page 34
silencer sequence elements. Activators are proteins that bind to enhancer sequences. Activator proteins also contain protein-protein interaction domains that allow them to bind to and affect the behavior of other proteins. These other proteins could be RNA polymer- ase itself; other general transcription factors in the PIC; or other adapter proteins that interact with the PIC (see Figure 3.32).
Repressor proteins can either bind to silencer or enhancer sequence elements in the promoter. In so
doing they reverse the effect of activator proteins by either interfering with the critical protein-protein interactions of activators or by binding tightly to enhancer sequences keeping activators from binding.
Thus, activator and repressor proteins are important in transcription regulation. They are recognized by promoter-proximal elements and other enhancer/ silencer sequence elements found upstream of the promoter, and they are specific for groups of similarly regulated genes. These proteins mediate the rate of transcription initiation for genes that contain recognized sequence elements. The presence or absence of specific activator and repressor sequences in a specific cell either because of cell type or because of environmental factors can mediate the initiation of transcription. For example, housekeeping genes (used in all cell types for basic cellular functions) have common promoter-proximal elements and are recognized by activator proteins found in all cells. Examples of genes with housekeeping functions include: actin, hexokinase, and Glucose-6-phosphate dehydrogenase.
Genes expressed only in some cell types or at particular times have promoter-proximal elements recognized by activator proteins found only in specific cell types or times. Enhancers are another cis-acting element. They are required for maximal transcription of a gene.
Figure 3.32. An activator protein binding to a promoter-proximal enhancer seuqence, interacting with an adapter protein, and the PIC to enhance transcription initiation.

CONCEPTS OF GENOMIC BIOLOGY Page 35
Enhancers/silencers are usually upstream of the transcription initiation site but may also be downstream. They may modulate from a distance of thousands of base pairs away from the initiation site.
Because there are similar enhancer and silencer sequences in front of several genes that are coordinately regulated, and each gene promoter has its own unique spectrum of such sequences, Eukaryotic cells can avoid the necessity of contiguous organization of genes into operons as is common in prokaryotes. Additionally, each
tissue produces a set of tissue-specific and general activator and repressor proteins, and the spectrum of these proteins can be influenced by environmental factors such as cellular surroundings, temperature, chemical environment, etc. This affords the ability of each cell to “customize” the expression of genes depending on the protein functions that are required in each cell based on cell type and cellular environment. This phenomenon is referred to as combinatorial gene regulation and is illustrated in Figure 3.33.
Once transcription initiation has occurred, the RNA polymerase moves away from the TATA box as the transcript is elongated. This is fundamentally the work of RNA polymerase, and the other proteins of the PIC now leave the complex to be recycled to form new PICs while RNA polymerase elongates the primary transcript nucleotide chain to complete the formation of the primary transcript.
3.5.7. Processing the primary transcript into a mature mRNA (return)
As shown in Figure 3.30, the primary transcript must be processed in 3 significant ways to become a mature mRNA. This processing all takes place in the nucleus of the cell and prepares the mRNA for transport to the cytosol of the cell where it will subsequently be translated to produce a protein.
Figure 3.33. Combinatorial gene regulation leads to the coordinate regulation of batteries of genes in Eukaryotes. The types of enhancer and silencer sequences in front of each gene determine the level of transcription of each gene based on the activator and repressor proteins present in each cell/tissue type and the environment surrounding each cell.

CONCEPTS OF GENOMIC BIOLOGY Page 36
First, the primary transcript must acquire a cap at its 5’- end. The cap prepares the transcript for transport from the nucleus, provides stability to attack by exonucleases in the cytoplasm, and aids in the initiation of the translation process. Structurally, a cap consists of a 7-methyl guanosine attached by 3 phosphate groups to the 5’-end of the transcript. Note that the cap is reversed compared to the RNA strand, i.e. it is attached 5’ to 5’ not 5’ to 3’ as are the other nucleotides in the transcript. The cap can be attached to the transcript during transcription before completion of the primary transcript, but it is critical to efficient transport of the mRNA from the nucleus so it must be attached in the nucleus.
The second processing step occurs at the 3’-end of the transcript (Figure 3.35), and is involved in transcript termination of elongation by RNA polymerase II. Note that other eukaryotic RNA polymerases may have other mechanisms of transcript termination since they do not produce poly adenylated transcripts.
The process for addition of the poly-A tail involves a complex of proteins that assembles at a poly-A addition consensus sequence (AAUAAA). The proteins involved in the cleavage step of the termination process include:
1) CPSF (cleavage and polyadenylation specificity factor).
2) CstF (cleavage stimulation factor).
3) Two cleavage factor proteins (CFI and CFII).
Following cleavage, the enzyme poly(A) polymerase (PAP) adds A nucleotides to the 3’ end of the cleaved transcript RNA, using ATP as a substrate. PAP is bound to CPSF during this process. Typically, about 200-250 A’s are added. PABII (poly-A binding protein II) binds the poly-A tail as it is produced. Upon completion of the poly-A tail, further transcription is terminated with the release of the pre-mRNA transcript from the protein complex.
Figure 3.34. Structure of the 5’-Cap added to Eukaryotic primary RNA transcripts. The cap consists of a 7-methyl guanosine residueattached 5’ to 5’ at the 5’ end of the transcript by 3 phosphate groups (a phosphotetraester).

CONCEPTS OF GENOMIC BIOLOGY Page 37
The third step in the process of producing a mature mRNA from a pre-mRNA involves removal of sequences that are found in the DNA coding sequence and pre-mRNA that are absent from the mature mRNA that is found in the cytoplasm of the cell. These removed sequences are called introns. The parts of the pre-mRNA that remain in the mature mRNA are called exons (see Figure 3.30).
The removal of introns from the primary transcript to is a process referred to as splicing, and it typically involves a protein RNP particle referred to as a spliceosome.
Spliceosomes are small nuclear ribonucleoprotein particles (snRNPs) associated with pre-mRNAs. snRNAs that were previously discussed are structural parts of spliceosome RNPs. The principal snRNAs involved are U1, U2, U4, U5, and U6. Each of these snRNAs is associated with several proteins; e.g. U4 and U6 are part of the same snRNP. Others are in their own snRNPs. Each snRNP type is abundant (~105 copies per nucleus) consistent with the critical role that these snRNPs play in nuclear processes.
The steps of RNA splicing are outlined in Figure 3.36:
1) U1 snRNP binds the 5’ splice junction of the intron, as a result of base-pairing of the U1 snRNA to the intron RNA.

CONCEPTS OF GENOMIC BIOLOGY Page 38
2) U2 snRNP binds by base pairing to the branch-point sequence upstream of the 3’ splice junction.
3) U4/U6 and U5 snRNPs interact and then bind the U1 and U2 snRNPs, creating a loop in the intron.
4) U4 snRNP dissociates from the complex, forming the active spliceosome.
5) The spliceosome cleaves the intron at the 5’ splice junction, freeing it from exon 1. The free 5’ end of the intron bonds to a specific nucleotide (usually A) in the branch-point sequence to form an RNA lariat.
6) The spliceosome cleaves the intron at the 3’ junction, liberating the intron lariat. Exons 1 and 2 are ligated, and the snRNPs are released.
One of the most interesting aspects of intron splicing is that there can be different transcripts created based on how introns are spliced. This is referred to as alternative splicing can be used to produce different polypeptides from the same gene as shown in Figures 3.37 and 3.38.
Figure 3.36. The process of intron spicing conducted by U2-dependent spiceosomes. Note that there are other types of spiceosomes, and that there are a few introns that are spliced independent of spliceosomes. The binding of at least 5 RNP complexes containing snRNAs and proteins ultimately produce a structure that holds the transcript cleaved ends together while the intron is spliced out producing a “lariat” structure. The exon ends of the transcript are then ligated together producing a mature mRNA with the intron removed from the sequence.

CONCEPTS OF GENOMIC BIOLOGY Page 39
From the above discussion it is clear that processing of a mature mRNA from the primary RNA transcript, and the transport of the mature mRNA from the nucleus to the cytoplasm are steps that can influence the amount of translatable mRNA for a particular protein that exists in a cell. The details of the steps we have discussed have emerged from a series of original molecular genetic studies, and have been greatly embellished more recently by functional genomic studies that we will investigate further in subsequent chapters.
Figure 3.37. A schematic representation of alternative splicing. The figure illustrates different types of alternative splicing: exon inclusion or skipping, alternative splice-site selection, mutually exclusive exons, and intron retention. For an individual pre-mRNA, different alternative exons often show different types of alternative-splicing patterns. © 2002 Nature Publishing Group Cartegni, L., Chew, S. L., & Krainer, A. R. Listening to silence and understanding nonsense: exonic mutations that affect splicing. Nature Reviews Genetics 3, 285–298 (2002). All rights reserved.
ProteinA ProteinB ProteinC
DNA
RNA
Transla on
mRNA
Exon1cc
Exon1 Exon2 Exon3 Exon4 Exon5
Exon1 Exon2 Exon3 Exon4 Exon5
Transla on Transla on
12345 1245 1235
Alterna veSplicing
Figure 3.38 Alternative splicing of 1 primary transcript to produce 3 different proteins.
CONCEPTS OF GENOMIC BIOLOGY Page 40
Following transcription, the genetic information carried in nucleotide sequence of mRNA is translated into an amino acid sequence of a polypeptide or protein. This
section concerns the process by which this translation of genetic information takes place.
3.6.1. The Nature of Proteins (return)
Amino acids are the monomeric building blocks used
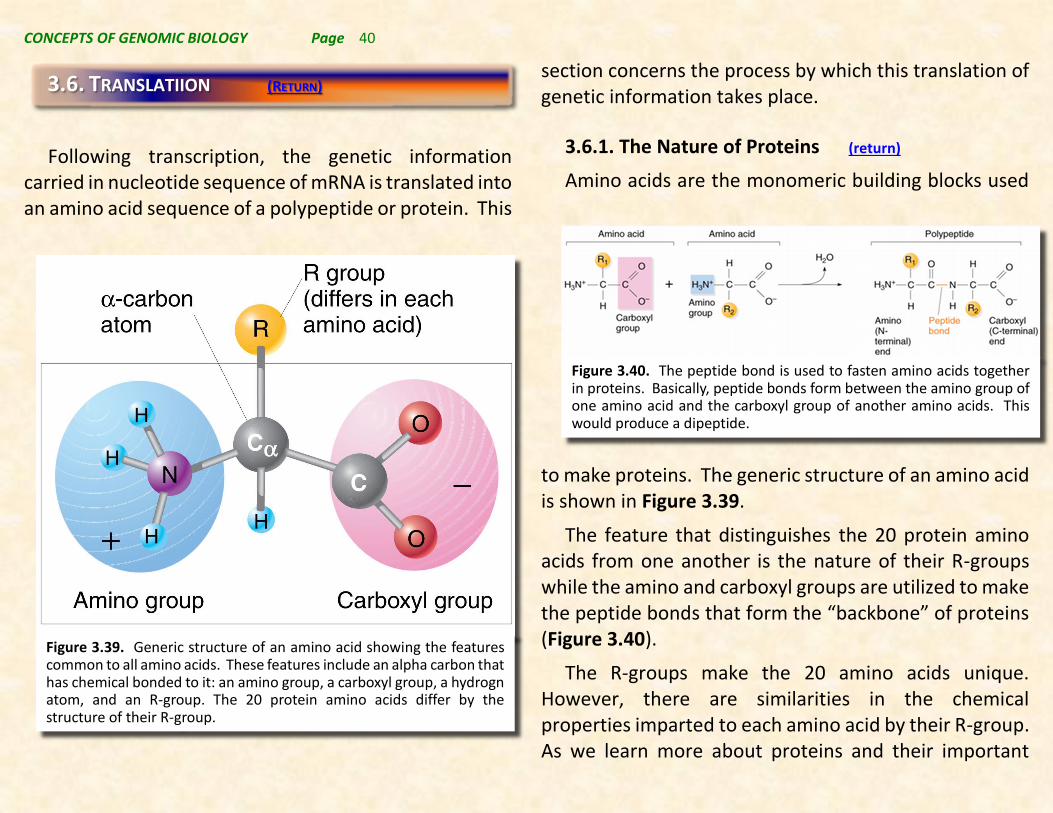
to make proteins. The generic structure of an amino acid is shown in Figure 3.39.
The feature that distinguishes the 20 protein amino acids from one another is the nature of their R-groups while the amino and carboxyl groups are utilized to make the peptide bonds that form the “backbone” of proteins (Figure 3.40).
The R-groups make the 20 amino acids unique. However, there are similarities in the chemical properties imparted to each amino acid by their R-group. As we learn more about proteins and their important
3.6. TRANSLATIION (RETURN)
Figure 3.39. Generic structure of an amino acid showing the features common to all amino acids. These features include an alpha carbon that has chemical bonded to it: an amino group, a carboxyl group, a hydrogn atom, and an R-group. The 20 protein amino acids differ by the structure of their R-group.
Figure 3.40. The peptide bond is used to fasten amino acids together in proteins. Basically, peptide bonds form between the amino group of one amino acid and the carboxyl group of another amino acids. This would produce a dipeptide.
CONCEPTS OF GENOMIC BIOLOGY Page 41
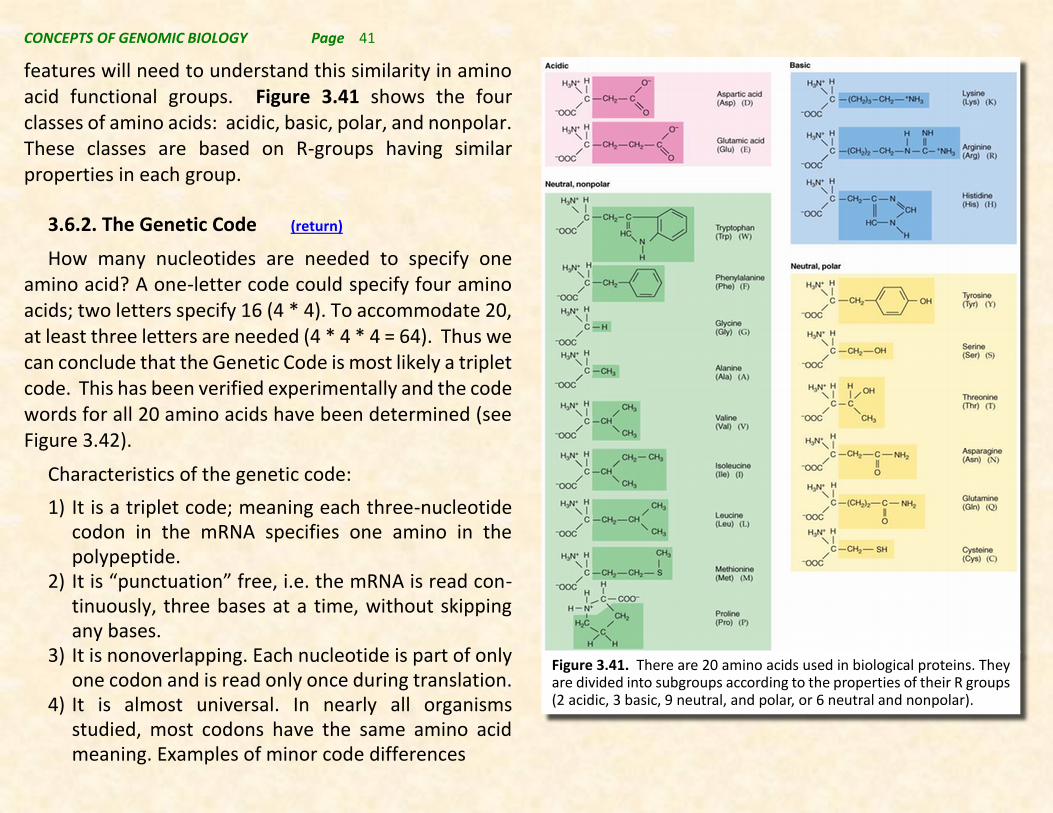
features will need to understand this similarity in amino acid functional groups. Figure 3.41 shows the four classes of amino acids: acidic, basic, polar, and nonpolar. These classes are based on R-groups having similar properties in each group.
3.6.2. The Genetic Code (return)
How many nucleotides are needed to specify one amino acid? A one-letter code could specify four amino acids; two letters specify 16 (4 * 4). To accommodate 20, at least three letters are needed (4 * 4 * 4 = 64). Thus we can conclude that the Genetic Code is most likely a triplet code. This has been verified experimentally and the code words for all 20 amino acids have been determined (see Figure 3.42).
Characteristics of the genetic code:
1) It is a triplet code; meaning each three-nucleotide codon in the mRNA specifies one amino in the polypeptide.
2) It is “punctuation” free, i.e. the mRNA is read con-tinuously, three bases at a time, without skipping any bases.
3) It is nonoverlapping. Each nucleotide is part of only one codon and is read only once during translation.
4) It is almost universal. In nearly all organisms studied, most codons have the same amino acid meaning. Examples of minor code differences
Figure 3.41. There are 20 amino acids used in biological proteins. They are divided into subgroups according to the properties of their R groups (2 acidic, 3 basic, 9 neutral, and polar, or 6 neutral and nonpolar).
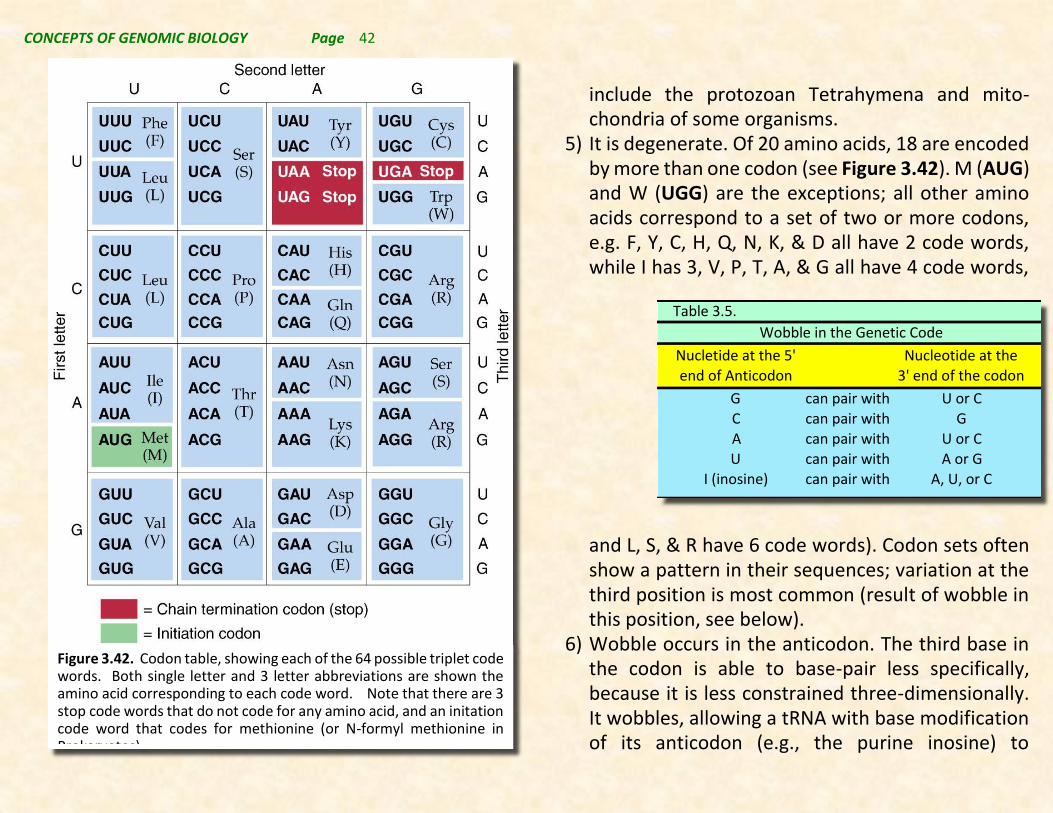
CONCEPTS OF GENOMIC BIOLOGY Page 42
include the protozoan Tetrahymena and mito-chondria of some organisms.
5) It is degenerate. Of 20 amino acids, 18 are encoded by more than one codon (see Figure 3.42). M (AUG) and W (UGG) are the exceptions; all other amino acids correspond to a set of two or more codons, e.g. F, Y, C, H, Q, N, K, & D all have 2 code words, while I has 3, V, P, T, A, & G all have 4 code words,
and L, S, & R have 6 code words). Codon sets often show a pattern in their sequences; variation at the third position is most common (result of wobble in this position, see below).
6) Wobble occurs in the anticodon. The third base in the codon is able to base-pair less specifically, because it is less constrained three-dimensionally. It wobbles, allowing a tRNA with base modification of its anticodon (e.g., the purine inosine) to
Table3.5.
Nucletideatthe5'
endofAnticodon
Nucleotideatthe
3'endofthecodon
G canpairwith UorC
C canpairwith GA canpairwith UorC
U canpairwith AorGI(inosine) canpairwith A,U,orC
WobbleintheGeneticCode
Figure 3.42. Codon table, showing each of the 64 possible triplet code words. Both single letter and 3 letter abbreviations are shown the amino acid corresponding to each code word. Note that there are 3 stop code words that do not code for any amino acid, and an initation code word that codes for methionine (or N-formyl methionine in Prokaryotes).

CONCEPTS OF GENOMIC BIOLOGY Page 43
recognize up to three different codons (Figure 3.43 and Table 3.5).
7) The code has start and stop signals. AUG is the usual start signal for protein synthesis and defines the open reading frame. Stop signals are codons with no corresponding tRNA, the nonsense or chain-terminating codons. There are generally three stop codons: UAG (amber), UAA (ochre), and UGA (opal).
3.6.3. tRNA the decoding molecule (return)
As described earlier in Section 3.5.1. transfer RNA (tRNA) are a type of transcribed RNA produced from a set
of tRNA genes scattered throughout the genomes of eukaryotes, mitochondria, and chloroplasts. A genome would have to have at least 1 transfer RNA for each of the 20 amino acids, but in fact because of multiple code words and the inability of wobble to make it possible for 1 tRNA to code for even 4 code words, there must be substantially more than 20 tRNAs in each genome. Typical Eukaryotic genomes contain around 100 tRNA genes, and multiple tRNAs for each amino acid.
Structurally, tRNAs have a highly organized, folded structure, and because they must all bind to the same sites on ribosomes, the overall general structure of each tRNA are quite similar. In 2-dimensions tRNAs are typically written showing a cloverleaf structure (Figure 3.44, upper left). Because of base pairing the 3’ end and the 5’ end form a stem, and there are 3 separate loops making up each of the leaves of the “clover”. The loop opposite from the stem contains the anticodon sequenc,, while the other two loops help the tRNA fold into a proper 3-dimensional structure (Figure 3.44, upper right). This 3-dimensional structure is an L-shaped molecule that fits into sites on the ribosome during the translation process. The amino acid is attached to the free 3’-OH group at the 3’ end of the tRNA sequence via an ester bond (acid function of the amino acid to the hydroxyl function on the ribose sugar. This 3’-terminal OH is always on an adenosine
Figure 3.43. Schematic showing normal and Wobble base pairing at the 5’ end of the anticodon in the tRNA with the 3’ end of the codon in the mRNA.

CONCEPTS OF GENOMIC BIOLOGY Page 44
nucleoside, which is preceded by two cytosines. These 3
nucleotide residues are not transcribed, but are posttranscriptionally added during processing of the primary transcript. Note all tRNAs share this 3’ feature.
The enzyme that adds the amino acids to the tRNA, called an amino acyl tRNA synthetase (note for a particular amino acid attachment, amino acyl would be replaced by the name of the amino acid, e.g. for the amino acid, glycine, a glycyl tRNA synthetase attaches glycine to the 3’-OH on the adenosine at the 3’-terminus). There must be at least 1 amino acyl tRNA synthetase for the tRNAs coding for each amino acid, but there may be multiple tRNA synthetases if there are multiple tRNAs.
tRNA synthetases recognize the proper amino acid to be fastened to each tRNA based on the shape of the amino acid, and they also recognize the tRNA to which the amino acid should be fastened based on the detailed shape of the tRNA. Note that tRNAs do not recognize anticodon sequence, but rather overall shape characteristics of the tRNAs. Although all tRNAs have a relatively similar shape so that they fit into ribosomes, they have enough uniqueness to their shape that only the properly shaped tRNAs are recognized by the corresponding tRNA synthetases and thus shape recognition assures that the proper amino acid gets attached to a tRNA with the appropriate anticodon for that amino acid.
Figure 3.44. Characteristics and structure of tRNAs. Upper left shows a 2-D “cloverleaf” structure typical of most tRNAs. However, this structure has additional secondary structure producing a 3-D structure similar to that shown in the upper right. An atomic space-filling model of this 3-D structure is shown in the lower left, and the detailed 3’-end of all tRNAs showing the CCA where the amino acid is attached that is posttranscriptionally added to all tRNAs is shown in the lower right.

CONCEPTS OF GENOMIC BIOLOGY Page 45
The attachment of the amino acid to the tRNA molecule carried out by the an amino acyl tRNA synthetase is described in Figure 3.45. This reaction requires that the amino acid be energized by ATP forming an amino acyl AMP enzyme bound complex and releasing
pyrophosphate (PPi). The amino acid is then transferred to a tRNA forming an ester bond, and the aminoacylated tRNA and AMP are then released from the enzyme.
Functionally, amino acids are inserted into the polypeptide in the proper sequence due to the decoding function of the tRNA. This involves specific binding of each amino acid to its cognate (appropriate) tRNA, and specific base pairing between the mRNA codon and tRNA anticodon. Thus, the fidelity of the transfer of genetic information from the DNA of the gene to the amino acid sequence of the protein relies as much on the fidelity of the “coding” done by the tRNA molecules as on the fidelity of the transcription process creating the mRNA.
3.6.4. Peptides Are Synthesized On Ribosomes In Both Prokaryotes and Eukaryotes (return)
Ribosomes are RNA-protein complexes that are so small that they cannot be seen with a light microscope. Although both Prokaryotes and Eukaryotes have ribosomes, there are key differences between both the RNA species and proteins found in ribosomes in the two groups of organisms. It should also be noted that mitochondria and chloroplasts in Eukaryotic cells produce Prokaryote-like ribosomes that produce proteins in each or these organelles.
Figure 3.45. The catalytic cycle of an amino acyl tRNA synthetase. The enzyme binds an amino acid and ATP (top); ATP is hydrolyzed producing pyrophosphate and aminoacyl-AMP bound to the enxyme. This if followed by the appropriate tRNA binding to the aa-tRNA synthetase, and subsequently the formation of the amino acylated tRNA (referred to as a charged tRNA), with the subsequent liberation of the tRNA and AMP.

CONCEPTS OF GENOMIC BIOLOGY Page 46
The details of ribosomal structure in Prokaryotes and Eukaryotes are shown in Figure 3.46; you may need to refer back to section 3.5.1 and Table 3.2 for more details. Bacterial 70S ribosomes are composed of a 50S large
subunit and a 30S small subunit. Each of these contains the rRNAs and proteins shown in Figure 3.46. Note that Eukaryotic mitochondria and chloroplasts contain a genome that codes for bacteria-like rRNAs and and ribosomal proteins, and thus, the prokaryotic versions of ribosomes are found in these intracellular compartments in Eukaryotes.
Eukaryotic ribosomes are significantly larger than their prokaryotic counterparts. The 80S ribosome is composed of a 60S large ribosomal subunit and a 40S small ribosomal subunit. Both of these are made up of larger rRNAs and more proteins than their prokaryotic counterparts.
The important structural features of ribosomes are created by the assembly of the large and small subunits into a functional ribosome (Figure 3.47). There are 3 tRNA binding sites created on the surface of the fully assembled ribosome. One of these sites is for the entering aminoacyl-tRNA (A-site), a second is for the tRNA containing the growing peptide chain (P-site), and the last site is used for the tRNA to exit the ribosome after it has lost its amino acid.
Figure 3.46. The structure and composition of (a) Prokaryotic and (b) Eukaryotic ribosomes. Both are composed of a large ribosomal subunit and a small ribosomal subunit although these are different sizes. The rRNAs and proteins that are a part of each of the subunits are also shown.
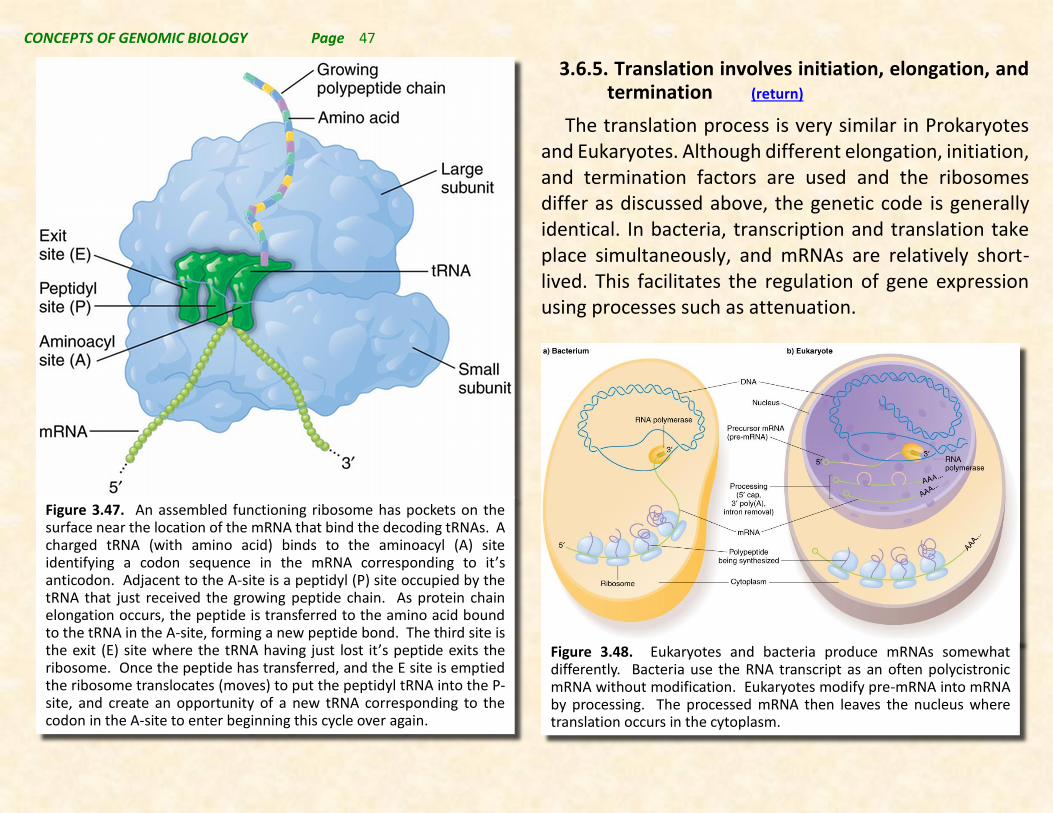
CONCEPTS OF GENOMIC BIOLOGY Page 47
3.6.5. Translation involves initiation, elongation, and termination (return)
The translation process is very similar in Prokaryotes and Eukaryotes. Although different elongation, initiation, and termination factors are used and the ribosomes differ as discussed above, the genetic code is generally identical. In bacteria, transcription and translation take place simultaneously, and mRNAs are relatively short-lived. This facilitates the regulation of gene expression using processes such as attenuation.
Figure 3.47. An assembled functioning ribosome has pockets on the surface near the location of the mRNA that bind the decoding tRNAs. A charged tRNA (with amino acid) binds to the aminoacyl (A) site identifying a codon sequence in the mRNA corresponding to it’s anticodon. Adjacent to the A-site is a peptidyl (P) site occupied by the tRNA that just received the growing peptide chain. As protein chain elongation occurs, the peptide is transferred to the amino acid bound to the tRNA in the A-site, forming a new peptide bond. The third site is the exit (E) site where the tRNA having just lost it’s peptide exits the ribosome. Once the peptide has transferred, and the E site is emptied the ribosome translocates (moves) to put the peptidyl tRNA into the P-site, and create an opportunity of a new tRNA corresponding to the codon in the A-site to enter beginning this cycle over again.
Figure 3.48. Eukaryotes and bacteria produce mRNAs somewhat differently. Bacteria use the RNA transcript as an often polycistronic mRNA without modification. Eukaryotes modify pre-mRNA into mRNA by processing. The processed mRNA then leaves the nucleus where translation occurs in the cytoplasm.

CONCEPTS OF GENOMIC BIOLOGY Page 48
By comparison, in eukaryotes mRNAs can have more variable half-lives from short to long-lived, are subject to a series of modifications, and must exit the nucleus to be translated. These multiple steps offer additional opportunities to regulate levels of protein production, and thereby fine-tune gene expression.
Initiation of translation
The process of initiation of translation involves the formation of a functional ribosome at the AUG start code word on the mRNA. In both Prokaryotes and Eukaryotes, this process involves the small ribosomal subunit interacting with the mRNA at a translation start site (Figure 3.49). The initiator tRNA with methionine (N-formyl-methionine in Prokaryotes) then locates the AUG code word, and provides the opportunity for assembly of a completed ribosome with the addition of the large ribosomal subunit.
This simple process of initiation is substantially more complex in Eukaryotes, and relatively simple in Prokaryotes. The details of Prokaryotic translation initiation are shown in Figure 3.50, and the details of Eukaryotic translation initiation are shown in Figure 3.51. Figure 3.49. The process of initiation in both Porkaryotes and
Eukaryotes is fundamentally similar. The small ribosomal subunit interacts with the mRNA and an initiator tRNA is located at the AUG start code word. The large subunit then completes initiation by aligning to the complex and froming an active ribosome.
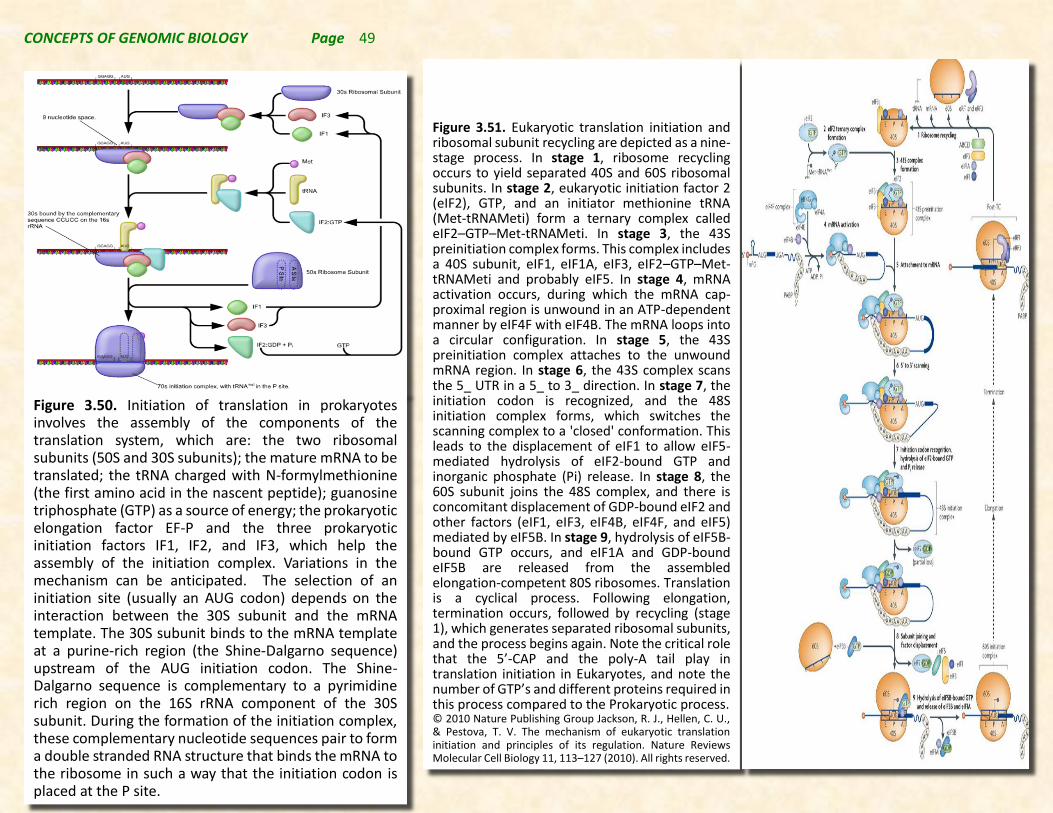
CONCEPTS OF GENOMIC BIOLOGY Page 49
Figure 3.51. Eukaryotic translation initiation and ribosomal subunit recycling are depicted as a nine-stage process. In stage 1, ribosome recycling occurs to yield separated 40S and 60S ribosomal subunits. In stage 2, eukaryotic initiation factor 2 (eIF2), GTP, and an initiator methionine tRNA (Met-tRNAMeti) form a ternary complex called eIF2–GTP–Met-tRNAMeti. In stage 3, the 43S preinitiation complex forms. This complex includes a 40S subunit, eIF1, eIF1A, eIF3, eIF2–GTP–Met-tRNAMeti and probably eIF5. In stage 4, mRNA activation occurs, during which the mRNA cap-proximal region is unwound in an ATP-dependent manner by eIF4F with eIF4B. The mRNA loops into a circular configuration. In stage 5, the 43S preinitiation complex attaches to the unwound mRNA region. In stage 6, the 43S complex scans the 5_ UTR in a 5_ to 3_ direction. In stage 7, the initiation codon is recognized, and the 48S initiation complex forms, which switches the scanning complex to a 'closed' conformation. This leads to the displacement of eIF1 to allow eIF5-mediated hydrolysis of eIF2-bound GTP and inorganic phosphate (Pi) release. In stage 8, the 60S subunit joins the 48S complex, and there is concomitant displacement of GDP-bound eIF2 and other factors (eIF1, eIF3, eIF4B, eIF4F, and eIF5) mediated by eIF5B. In stage 9, hydrolysis of eIF5B-bound GTP occurs, and eIF1A and GDP-bound eIF5B are released from the assembled elongation-competent 80S ribosomes. Translation is a cyclical process. Following elongation, termination occurs, followed by recycling (stage 1), which generates separated ribosomal subunits, and the process begins again. Note the critical role that the 5’-CAP and the poly-A tail play in translation initiation in Eukaryotes, and note the number of GTP’s and different proteins required in this process compared to the Prokaryotic process. © 2010 Nature Publishing Group Jackson, R. J., Hellen, C. U., & Pestova, T. V. The mechanism of eukaryotic translation initiation and principles of its regulation. Nature Reviews Molecular Cell Biology 11, 113–127 (2010). All rights reserved.
Figure 3.50. Initiation of translation in prokaryotes involves the assembly of the components of the translation system, which are: the two ribosomal subunits (50S and 30S subunits); the mature mRNA to be translated; the tRNA charged with N-formylmethionine (the first amino acid in the nascent peptide); guanosine triphosphate (GTP) as a source of energy; the prokaryotic elongation factor EF-P and the three prokaryotic initiation factors IF1, IF2, and IF3, which help the assembly of the initiation complex. Variations in the mechanism can be anticipated. The selection of an initiation site (usually an AUG codon) depends on the interaction between the 30S subunit and the mRNA template. The 30S subunit binds to the mRNA template at a purine-rich region (the Shine-Dalgarno sequence) upstream of the AUG initiation codon. The Shine-Dalgarno sequence is complementary to a pyrimidine rich region on the 16S rRNA component of the 30S subunit. During the formation of the initiation complex, these complementary nucleotide sequences pair to form a double stranded RNA structure that binds the mRNA to the ribosome in such a way that the initiation codon is placed at the P site.
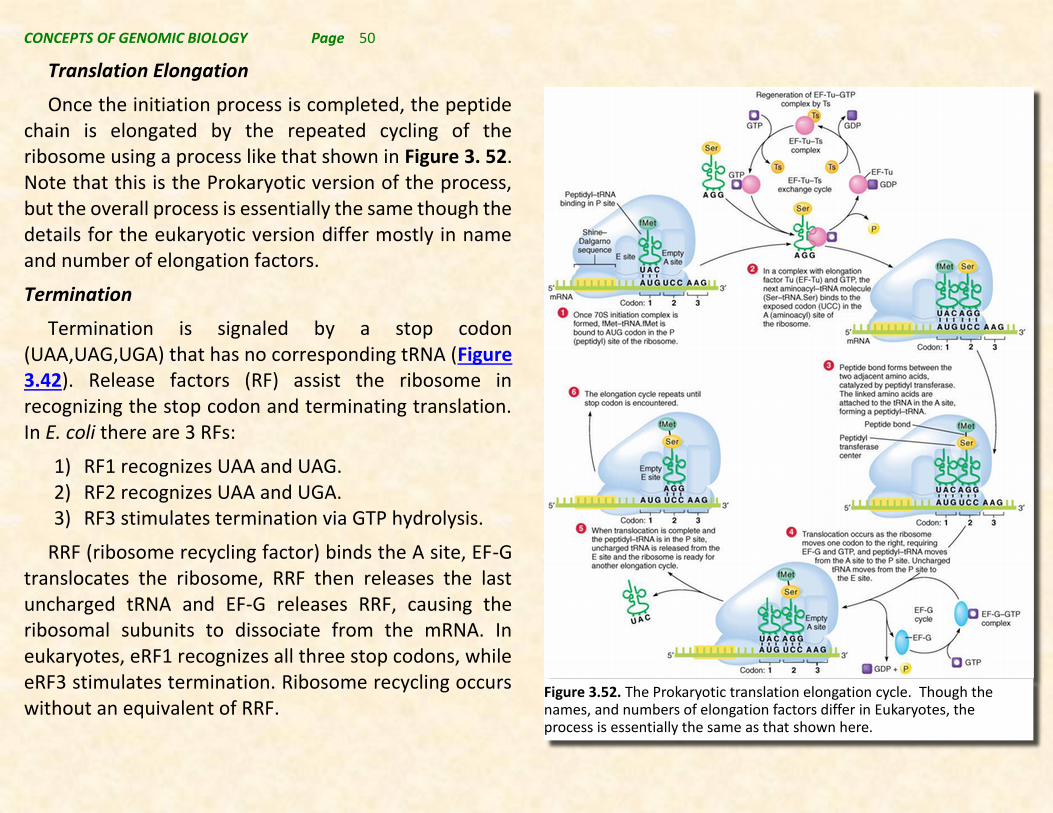
CONCEPTS OF GENOMIC BIOLOGY Page 50
Figure 3.52. The Prokaryotic translation elongation cycle. Though the names, and numbers of elongation factors differ in Eukaryotes, the process is essentially the same as that shown here.
Translation Elongation
Once the initiation process is completed, the peptide chain is elongated by the repeated cycling of the ribosome using a process like that shown in Figure 3. 52. Note that this is the Prokaryotic version of the process, but the overall process is essentially the same though the details for the eukaryotic version differ mostly in name and number of elongation factors.
Termination
Termination is signaled by a stop codon (UAA,UAG,UGA) that has no corresponding tRNA (Figure 3.42). Release factors (RF) assist the ribosome in recognizing the stop codon and terminating translation. In E. coli there are 3 RFs:
1) RF1 recognizes UAA and UAG. 2) RF2 recognizes UAA and UGA. 3) RF3 stimulates termination via GTP hydrolysis.
RRF (ribosome recycling factor) binds the A site, EF-G translocates the ribosome, RRF then releases the last uncharged tRNA and EF-G releases RRF, causing the ribosomal subunits to dissociate from the mRNA. In eukaryotes, eRF1 recognizes all three stop codons, while eRF3 stimulates termination. Ribosome recycling occurs without an equivalent of RRF.
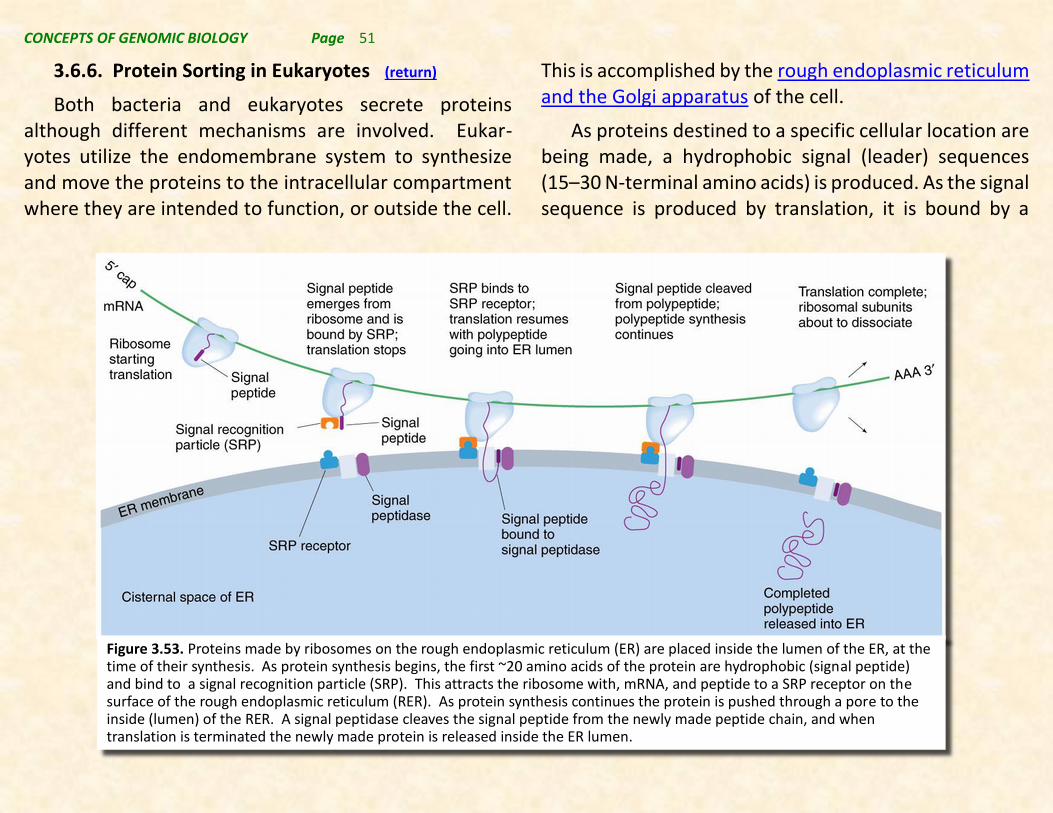
CONCEPTS OF GENOMIC BIOLOGY Page 51
3.6.6. Protein Sorting in Eukaryotes (return)
Both bacteria and eukaryotes secrete proteins although different mechanisms are involved. Eukar-yotes utilize the endomembrane system to synthesize and move the proteins to the intracellular compartment where they are intended to function, or outside the cell.
This is accomplished by the rough endoplasmic reticulum and the Golgi apparatus of the cell.
As proteins destined to a specific cellular location are being made, a hydrophobic signal (leader) sequences (15–30 N-terminal amino acids) is produced. As the signal sequence is produced by translation, it is bound by a
Figure 3.53. Proteins made by ribosomes on the rough endoplasmic reticulum (ER) are placed inside the lumen of the ER, at the time of their synthesis. As protein synthesis begins, the first ~20 amino acids of the protein are hydrophobic (signal peptide) and bind to a signal recognition particle (SRP). This attracts the ribosome with, mRNA, and peptide to a SRP receptor on the surface of the rough endoplasmic reticulum (RER). As protein synthesis continues the protein is pushed through a pore to the inside (lumen) of the RER. A signal peptidase cleaves the signal peptide from the newly made peptide chain, and when translation is terminated the newly made protein is released inside the ER lumen.

CONCEPTS OF GENOMIC BIOLOGY Page 52
signal recognition particle (SRP) composed of RNA and protein (Figure 3.53). The SRP suspends translation until the complex (containing nascent protein, ribosome, mRNA, and SRP) binds a docking protein (SRP receptor) on the ER membrane. When the complex binds the docking protein, the signal sequence is inserted into the membrane through a specifically designed pore complex, SRP is released, and translation resumes.
The growing polypeptide is inserted through the membrane into the ER, in an example of cotranslational transport. In the ER cisternal space, the signal sequence is removed by signal peptidase. The protein is usually glycosylated and then transferred to the Golgi for sorting.
In eukaryotes, proteins synthesized on the rough ER (endoplasmic reticulum) are glycosylated and then transported in vesicles to the Golgi apparatus. In the Golgi proteins are sorted based on other sequence signals, and then they are packaged in membrane vesicles for transport via the sends them to their destinations.
Fundamentally, the central dogma of molecular biology that dates back to Francis Crick, states that
genetic information is transferred through an RNA intermediate to the amino acid sequence of proteins. Thus, proteins are critical to the function of genes that leads to the phenotype we observe for each gene. Clearly the amount of each type of protein made in a cell determines the phenotype of the cell. The proteins that are expressed in specific quantities and in specific cellular locations in multicellular organisms is referred to understanding the expression of a gene.
We have seen that gene expression in prokaryotes is regulated primarily at the transcriptional level, and involves factors that mediate changes in mRNA levels in cells in response to environmental and intracellular factors (refer back to section 3.5.5).
However, we also understand that the processes of transcription and translation in Eukaryotes are more complex involving not just basic transcription and translation, but also involving compartmentation of both transcription and translation into nuclear as well as several cytoplasmic membrane-bound compartments. This establishes a basis for investigating the additional levels of complexity of these processes in Eukaryotes.
The points of control that regulate gene expression for protein-coding genes in eukaryotes are shown in Figure 3.54. Details of each step are given below.
3.7. REGULATION OF EUKARYOTIC GENE EXPRESSION (RETURN)

CONCEPTS OF GENOMIC BIOLOGY Page 53
Figure 3.54. Showing the control points for the accumulation of proteins as a result of gene expression.
3.7.1. Transcriptional Control (RETURN)
Transcriptional control relates to the production of the pre-mRNA from the coding region of a protein-coding gene. Some of the factors regulating transcriptional control have been discussed above in section 3.5.6. and involve the transcription factors regulating the formation of the preinitiation complex (PIC) or derive from models of combinatorial gene regulation involving enhancer and silencer sequences in promoters and trans-acting activator and repressor proteins that interact with these sequences.
However there are additional aspects of transcriptional control that also impact gene expression. These include:
Chromatin Remodeling –
In eukaryotes, the binding of DNA with histones to form chromatin generally represses gene expression and is part of gene regulation. Chromatin remodeling is the dynamic modification of chromatin architecture to allow access of condensed genomic DNA to the transcriptional regulatory machinery (proteins), and thereby control gene expression.
Activation of eukaryotic genes requires alteration of the chromatin structure near the core promoter. Two classes of protein complexes cause chromatin remodeling (see Figure 3.55):
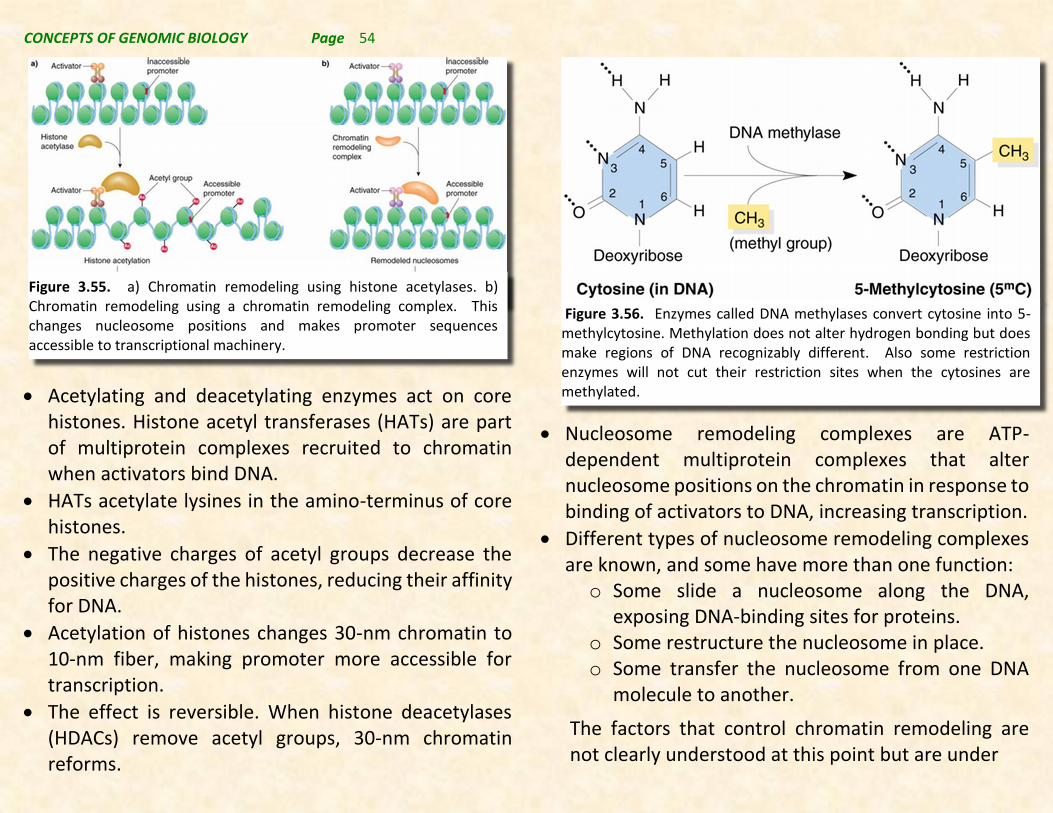
CONCEPTS OF GENOMIC BIOLOGY Page 54
Acetylating and deacetylating enzymes act on core histones. Histone acetyl transferases (HATs) are part of multiprotein complexes recruited to chromatin when activators bind DNA.
HATs acetylate lysines in the amino-terminus of core histones.
The negative charges of acetyl groups decrease the positive charges of the histones, reducing their affinity for DNA.
Acetylation of histones changes 30-nm chromatin to 10-nm fiber, making promoter more accessible for transcription.
The effect is reversible. When histone deacetylases (HDACs) remove acetyl groups, 30-nm chromatin reforms.
Nucleosome remodeling complexes are ATP-dependent multiprotein complexes that alter nucleosome positions on the chromatin in response to binding of activators to DNA, increasing transcription.
Different types of nucleosome remodeling complexes are known, and some have more than one function: o Some slide a nucleosome along the DNA,
exposing DNA-binding sites for proteins. o Some restructure the nucleosome in place. o Some transfer the nucleosome from one DNA
molecule to another.
The factors that control chromatin remodeling are not clearly understood at this point but are under
Figure 3.56. Enzymes called DNA methylases convert cytosine into 5-methylcytosine. Methylation does not alter hydrogen bonding but does make regions of DNA recognizably different. Also some restriction enzymes will not cut their restriction sites when the cytosines are methylated.
Figure 3.55. a) Chromatin remodeling using histone acetylases. b) Chromatin remodeling using a chromatin remodeling complex. This changes nucleosome positions and makes promoter sequences accessible to transcriptional machinery.

CONCEPTS OF GENOMIC BIOLOGY Page 55
investigation.
DNA methylation –
DNA methylation of particular DNA sequences can also silence transcription in many eukaryotes. DNA methylase alters cytosine to 5-methylcytosine (5mC) (Figure 3.56).
Higher eukaryotes such as mammals have about 3% of their cytosines modified to 5mC, while lower eukaryotes have virtually 0%.
5mC is nonrandomly distributed, with most found in the symmetrical sequence CpG. This allows patterns of methylation to be studied by using restriction enzymes that contain the CG sequence in their recognition sites. For example: o HpaII cuts at 5’-CCGG-3’, but only if the cytosines
are unmethylated. o MspI also cuts at 5’-CCGG-3’, regardless of
methylation o Differences in the array of DNA fragments
produced by these enzymes on Southern blotting allow methylation patterns to be inferred.
CpG dinucleotides are found in clusters called CpG islands in specific regions of the genome.
Human CpG islands often occur in the promoters of protein-coding genes.
Generally the CpG islands are unmethylated, and transcription occurs.
Methylation of the CpG sequence represses transcription by binding of specific proteins to the methylated CpG that recruit histone deacetylases that cause chromatin remodeling, making promoters inaccessible.
An example of methylation affecting gene expression is fragile X syndrome (OMIM 309550). Expansion of a triplet repeat and abnormal methylation in the FMR-1 gene silences its expression.
3.7.2. Pre-mRNA Processing Control (RETURN)
The primary mRNA transcript (pre-mRNA) is processed into an mRNA in the nucleus of a cell as described in section 3.5.7. This processing involves 3 steps: 1) the capping of the pre-mRNA at the 5’-end; 2) the addition of the polyA-tail at the 3’-end; and 3) the splicing of introns out of the pre-mRNA to complete the synthesis of the mature mRNA. The efficiency of each of these steps determines the rate of production of mature mRNAs and therefore amount of mRNA that will be available for translation. Additionally, steps 1 and 2 affect the stability of the mature mRNA once it is transported to the cytoplasm, and this also affects the amount of mature mRNA.

CONCEPTS OF GENOMIC BIOLOGY Page 56
Beyond the influence of processing on quantity of mRNA, intron splicing can regulate the specific introns that are found in each mRNA. In the extreme RNA splicing can produce completely different transcritps from the same pre-mRNA. An example of this is shown in Figure 3.57.
3.7.3. mRNA Transport from the Nucleus (RETURN)
The transport of RNA molecules from the nucleus to the cytoplasm is critical to Eukaryotic gene expression. The different RNA species that are produced in the nucleus are exported through the nuclear pore complexes via large protein complexes that form a nuclear pore called mobile export receptors.
Small RNAs (such as tRNAs and microRNAs) follow relatively simple export routes by binding directly to export receptors while large RNAs (such as ribosomal RNAs and mRNAs) assemble into complicated ribonucleoprotein (RNP) particles and recruit their exporters via class-specific adaptor proteins.
Export of mRNAs is unique as it is extensively coupled to transcription and intron splicing. Understanding the mechanisms that connect RNP formation and RNA export from the nucleus is a major challenge in the gene expression field.
3.7.4. Translational Control (RETURN)
Once the RNA has reached the cytoplasm, many factors control the rate at which it will be translated. The control of gene expression at the level of translation can occur in many ways.
Ribosomal translational control, i.e. selecting specific mRNAs for translation, can also impact gene expression. Unfertilized eggs are an example, in which mRNAs show
Figure 3.57. Differential splicing of introns can produce two different proteins from the same pre-mRNA transcript. In Thyroid the calcitonin gene is polyadenylated after exon 4, and after intron spicing an mRNA is made, translated, and cleaved to produce calcitonin. In neuronal cells, a pre-mRNA containing 5 exons is produced, and this is polyadenylated after exon 5. Differential splicing in neuronal cells produces an mRNA lacking exon 4 but containing exon 5. This mRNA is translated and cleaved to produce CGRP a different peptide hormone.

CONCEPTS OF GENOMIC BIOLOGY Page 57
significant increases in translation after fertilization without new mRNA synthesis. Examples of this are shown in Table 3.6.
Stored mRNAs are associated with proteins that both protect them and inhibit their translation.
Poly(A) tails promote translation initiation, and stored mRNAs generally have shorter tails.
In some mRNAs of mouse and frog oocytes, a normal-length poly(A) tail is added and then trimmed enzymatically.
Particular mRNAs are marked for deadenylation by a region in the 3’ untranslated region, called the adenylate/uridylate (AU)-rich element (ARE), with the consensus sequence UUUUUAU.
Activation of the stored mRNA occurs when a cytoplasmic polyadenylation enzyme recognizes the ARE and adds about 150 A residues, making a full-length poly(A) tail.
3.7.5. Protein Processing Control (RETURN)
Once translated proteins are also processed. This processing depends on whether the proteins are made on the endoplasmic reticulum, or on cytosolic ribosomes. Refer to section 3.6.6 and Figure 3.53 for more
information. Proteins made on the ER are glycosylated, and this both controls their ultimate cellular destination and stability. Proteins associated with membranes can
Table 3.6.

CONCEPTS OF GENOMIC BIOLOGY Page 58
also have hydrophobic groups such as myristic acid groups attached to assist them in binding to membranes.
Numerousl other types of posttranslational modifications, such as phosphorylation, can dramatically affect enzymatic activity and thus regulate protein function. These effects will be summarized further in the Proteomics section of the course.
3.7.6. Degradation of mRNA Control (RETURN)
The control of mRNA degradation is a complex process. However, small regulatory RNAs (srRNA) have emerged as important ways that mRNA degradation is regulated. srRNAs can be either microRNAs (miRNA) that are typically 20-21 nt in length, or short interfering RNAs (siRNA) that are typically 23-24 nt in length.
Recall from section 3.5 that miRNAs are transcribed from miRNA genes by RNA polymerase II (see Figure 3.58a). They are formed from hairpin loop structures, and participate in RNA silencing complexes (RISC). These complexes target specific mRNAs for degradation which prevents their further translation into protein. miRNAs can also target mRNAs for storage inhibiting their translation until an appropriate signal brings these mRNAs out of storage by degrading the miRNA.
siRNAs are produced from larger double stranded precursors (see Figure 3.58b). An enzyme called dicer produces the siRNAs by cleavage of these larger
precursors. SiRNAs can also load into RISC particles where they target specific mRNA for degradation silencing their subsequent translation into proteins.
Figure 3.58. Small regulatory RNAs are produced by either the miRNA or the siRNA pathway. Both pathways produce RNAs that target specific mRNAs for degradation, thus controlling gene

CONCEPTS OF GENOMIC BIOLOGY Page 59
3.7.7. Protein Degradation Control (RETURN)
Regulation of protein degradation occurs in many ways:
A constitutively produced mRNA may be translated continuously, and so the protein degradation rate determines its level.
A short-lived mRNA may make a very stable protein, so that it persists for long periods in the cell.
Protein stability varies.
Proteolysis (protein degradation) in eukaryotes requires ubiquitin, a protein cofactor.
Protein stability is directly related to the amino acid at the N terminus of the protein (the N-end rule). In yeast, stability of the same protein was measured with different N-terminal amino acids.
The N-terminal amino acid directs the rate of ubiquitin binding, which in turn determines the half-life of the protein.

CONCEPTS OF GENOMIC BIOLOGY Page 60
We have investigated the ways in which the expression of genetic information is regulated, and
concluded that there are a number of levels at which such expression is mediated. Are summarized in Figure 3.59. While this figure clearly defines the control points in the regulatory process, it does not show us how each of the control levels is regulated.
At the cellular level, the expression of genes, and the overall regulation of the activities of each cell are regulated with input from the intracellular and extracellular environment of the cell. In this way cells regulate their intracellular activities including when, where, and how genes are expressed by receiving mostly chemical and physical signals from the environment, and responding to those signals with appropriate responses to ensure cellular proliferation and success. Cells respond to numerous signals simultaneously, and process this information to make an integrated response. In fact, some cellular signaling involves cells generating signals that other cells respond to.
3.8.1. Types of cellular signals (RETURN)
Lots of cellular signals, but not all, are chemical in nature. In unicellular organisms, including prokaryotes, nutrients are detected as signals so that these organisms can locate the riches food sources. In multicellular organisms a number of chemical signals are well documented, including, growth factors, hormones, neurotransmitters, and extracellular matrix components.
3.8. SIGNALING AND SIGNAL TRANSDUCTION (RETURN)
Figure 3.59. Regulation of gene expression at various levels insideEukaryotic cells. In the nucleus Translational control is exertedduring the production of a primary transcript. Processing controlinvolves control of intron/exon splicing, capping, and polyA tailaddition. Nuclear transport control is exhibited by factors thatcontrol the transport of the mature mRNA from the nucleus. In thecytosol control can be exerted at the level of mRNA degradation ortranslation. Once a protein is formed by translation, the activity ofthe protein can be modified by protein modification such asphosphorylation, acetylation, methylation, or in other ways, andthe rate at which proteins are degraded is also under cellularcontrol.

CONCEPTS OF GENOMIC BIOLOGY Page 61
Often signals can exert their effects locally, but they can also work at a distance from their site of synthesis. In fact the definition of a hormone is a substance produced in one cell that acts at a distance on another cell. Neurotransmitters are types of signaling molecules that act across the short distance between adjacent neurons or between neurons and muscle cells. The hormone insulin is an example of a signal that must a greater distance from its site of synthesis in the pancreas to act in liver, or adipose tissues.
Cells also respond to physical stimuli. For example, skin cells respond to the pressure of touch; yet similar cells in the ear react to the movement of sound waves. Specialized cells in the human vascular system monitor and respond to changes in blood pressure thus maintaining a consistent cardiac load. Numerous organisms sense and respond to temperature in various ways. And photoreceptors in our eyes respond to a light signal in specific ways depending on the nature of light perceived.
As you can see from this very partial list of signals, cells have evolved to respond to their environment in variety of ways. These responses prepare cells to change in response to changes in the cellular environment insuring their cellular success.
3.8.2. Signal Recognition – Sensing the Environment (RETURN)
The signaling response is initiated by specific proteins referred to as signal receptors. Typically, there are specific receptors for most signals that are perceived. For example, adrenaline binds to adrenaline receptors, insulin binds to insulin receptors, vitamin D binds to vitamin D receptors, Estrogen binds to estrogen receptors, etc. This means that there are literally hundreds of different receptors found in most cells, and each cell type can have a different population of receptors that specify the important signals to which they will respond.
Often receptors are proteins that sit in the plasma membrane surrounding the cell (cell surface receptors) and have a portion of the protein on the outside of the cell (usually where the chemical ligand they perceive binds) and a portion of the protein on the inside of the cell (the intracellular signal generating portion). The amino acid sequence of such proteins often crosses the membrane on or more times (membrane spanning domains), and the receptor may or may not transport a substance across the membrane. There are at least 5 classes of such receptors: 1) G-protein-coupled receptors; 2) ion channel receptors; 3) tyrosine-histidine kinase phosphorelay receptors; 4) toll-gate receptors; and 5) integrin receptors.

CONCEPTS OF GENOMIC BIOLOGY Page 62
Many cell surface receptors typically start a series of enzyme catalyzed reactions inside the cell (a signaling pathway or signaling cascade) that lead to a response or change inside the cell when the signal (usually a chemical signal called a ligand or agonist) is perceived outside the cell. Thus, it is not necessary for the signal to cross the membrane and enter the cell to effect change in the cell.
However, ion channel receptors work differently since they are proteins that literally form a hole in the membrane, a channel, through which ions can enter or leave the cell. The hole is usually ion-specific (e.g. only transmits potassium ion or calcium ion), and it is formed by membrane spanning domains of the channel (Figure 3.60). Some channels respond to chemical ligands, while others monitor the membrane voltage and open in response to membrane depolarization such as occurs in nerve action potential transmission. Note that the response generated by ion channel receptors is to alter the concentration of specific ions inside the cell that then becomes the signal which is subsequently amplified by the signal transduction pathway.
Not all receptors are cell surface receptors. Some are intracellular receptors, and these typically bind nonionic small molecules that can freely pass across the plasma membrane such as gasses like nitrous oxide or steroid hormones like estrogen or glucocorticoids. Since the signals easily enter cells they can be sensed by
intracellular sensors, that can mediate responses more directly inside the cell. Typically, such receptors have abbreviated signaling pathways. A generic example of a lipophilic messenger signaling pathway such as a steroid hormone or lipophilic vitamin such as vitamin D is given in Figure 3.61.
Figure 3.60 Ion channel receptors. Some ion channels respond to the voltage across the membrane while other types of channel receptors respond to the binding of a chemical ligand to the receptor. Membrane “stretching” as a result of pressure applied to the cell can also open tension-gated receptors. These types of channels transmit various ions, but most commonly either potassium or calcium are the ions transported. Voltage-gated channels are important in nerve cell function, but these channels can be found many if not all cell types.
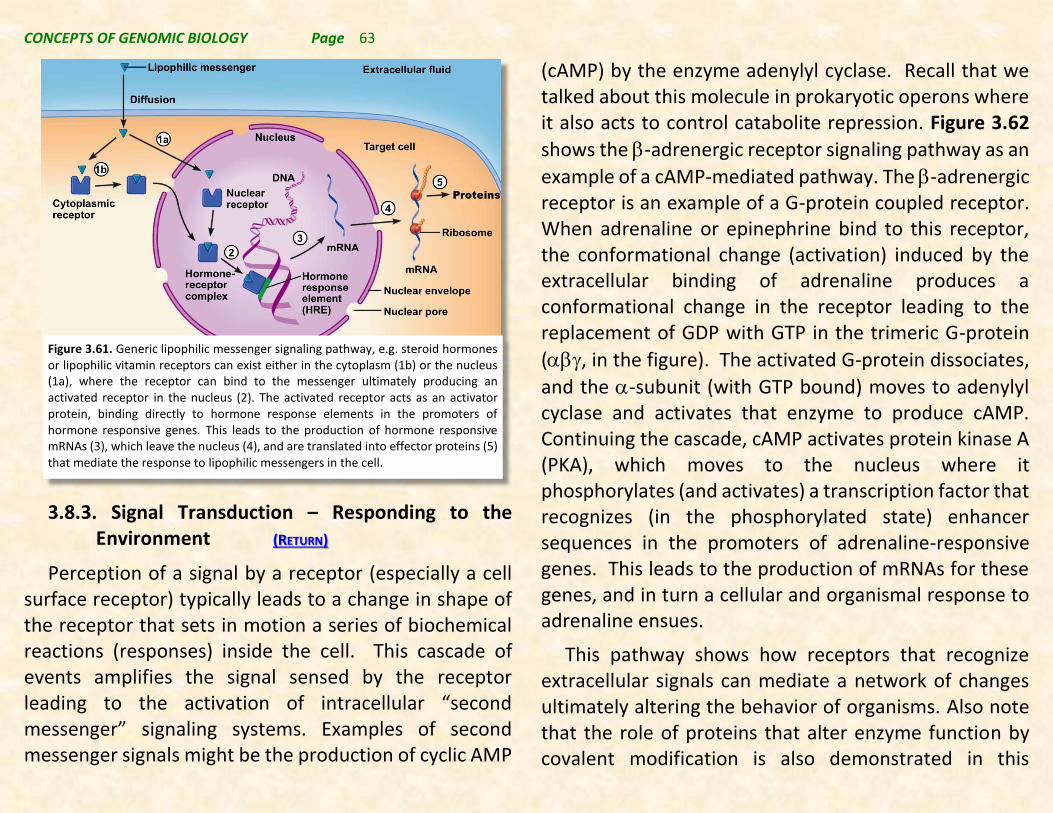
CONCEPTS OF GENOMIC BIOLOGY Page 63
3.8.3. Signal Transduction – Responding to the Environment (RETURN)
Perception of a signal by a receptor (especially a cell surface receptor) typically leads to a change in shape of the receptor that sets in motion a series of biochemical reactions (responses) inside the cell. This cascade of events amplifies the signal sensed by the receptor leading to the activation of intracellular “second messenger” signaling systems. Examples of second messenger signals might be the production of cyclic AMP
(cAMP) by the enzyme adenylyl cyclase. Recall that we talked about this molecule in prokaryotic operons where it also acts to control catabolite repression. Figure 3.62
shows the -adrenergic receptor signaling pathway as an
example of a cAMP-mediated pathway. The -adrenergic receptor is an example of a G-protein coupled receptor. When adrenaline or epinephrine bind to this receptor, the conformational change (activation) induced by the extracellular binding of adrenaline produces a conformational change in the receptor leading to the replacement of GDP with GTP in the trimeric G-protein
(, in the figure). The activated G-protein dissociates,
and the -subunit (with GTP bound) moves to adenylyl cyclase and activates that enzyme to produce cAMP. Continuing the cascade, cAMP activates protein kinase A (PKA), which moves to the nucleus where it phosphorylates (and activates) a transcription factor that recognizes (in the phosphorylated state) enhancer sequences in the promoters of adrenaline-responsive genes. This leads to the production of mRNAs for these genes, and in turn a cellular and organismal response to adrenaline ensues.
This pathway shows how receptors that recognize extracellular signals can mediate a network of changes ultimately altering the behavior of organisms. Also note that the role of proteins that alter enzyme function by covalent modification is also demonstrated in this
Figure 3.61. Generic lipophilic messenger signaling pathway, e.g. steroid hormones or lipophilic vitamin receptors can exist either in the cytoplasm (1b) or the nucleus (1a), where the receptor can bind to the messenger ultimately producing an activated receptor in the nucleus (2). The activated receptor acts as an activator protein, binding directly to hormone response elements in the promoters of hormone responsive genes. This leads to the production of hormone responsive mRNAs (3), which leave the nucleus (4), and are translated into effector proteins (5) that mediate the response to lipophilic messengers in the cell.
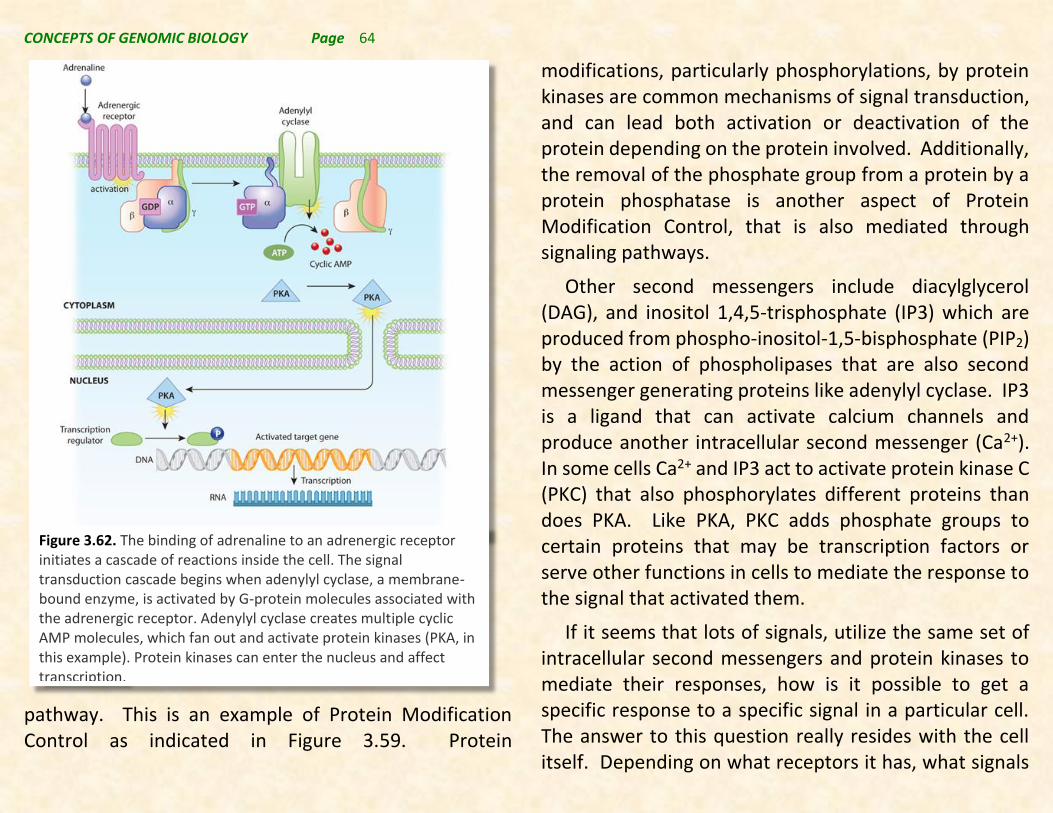
CONCEPTS OF GENOMIC BIOLOGY Page 64
pathway. This is an example of Protein Modification Control as indicated in Figure 3.59. Protein
modifications, particularly phosphorylations, by protein kinases are common mechanisms of signal transduction, and can lead both activation or deactivation of the protein depending on the protein involved. Additionally, the removal of the phosphate group from a protein by a protein phosphatase is another aspect of Protein Modification Control, that is also mediated through signaling pathways.
Other second messengers include diacylglycerol (DAG), and inositol 1,4,5-trisphosphate (IP3) which are produced from phospho-inositol-1,5-bisphosphate (PIP2) by the action of phospholipases that are also second messenger generating proteins like adenylyl cyclase. IP3 is a ligand that can activate calcium channels and produce another intracellular second messenger (Ca2+). In some cells Ca2+ and IP3 act to activate protein kinase C (PKC) that also phosphorylates different proteins than does PKA. Like PKA, PKC adds phosphate groups to certain proteins that may be transcription factors or serve other functions in cells to mediate the response to the signal that activated them.
If it seems that lots of signals, utilize the same set of intracellular second messengers and protein kinases to mediate their responses, how is it possible to get a specific response to a specific signal in a particular cell. The answer to this question really resides with the cell itself. Depending on what receptors it has, what signals
Figure 3.62. The binding of adrenaline to an adrenergic receptor initiates a cascade of reactions inside the cell. The signal transduction cascade begins when adenylyl cyclase, a membrane- bound enzyme, is activated by G-protein molecules associated with the adrenergic receptor. Adenylyl cyclase creates multiple cyclic AMP molecules, which fan out and activate protein kinases (PKA, in this example). Protein kinases can enter the nucleus and affect transcription.

CONCEPTS OF GENOMIC BIOLOGY Page 65
it is receiving, what second messenger systems it has, and what response proteins are available different signaling pathways can interact or “crosstalk” to produce a specific, though complicated response to the total environmental input to each cell. At the same time two different cells or tissues may produce very different responses to the same environmental signals. This makes our job of understanding such signaling difficult indeed, but that is how biology has chosen to integrate this complex and complicated set of information to produce the “right” level of gene expression in each cell and tissue of the organism.